Использование критериев согласия
Контрольная
работа
Использование
критериев согласия
Содержание
Введение
. Критерии согласия для средних
. Критерии согласия для дисперсий
. Критерии согласия относительно
долей
. Критерии для сравнения
распределений численностей
. Критерии для проверки случайности
и оценки резко выделяющихся наблюдений
Литература
Введение
В практике статистического анализа
экспериментальных данных основной интерес представляет не само по себе
вычисление тех или иных статистик, а ответы на вопросы такого типа.
Действительно ли среднее генеральной совокупности равно некоторому числу?
Значимо ли отличается от нуля коэффициент корреляции? Равны ли дисперсии двух
выборок? И таких вопросов в зависимости от конкретной исследовательской задачи
может возникать много. Соответственно разработано и множество критериев для
проверки выдвигаемых статистических гипотез. Некоторые наиболее употребительные
из них мы и рассмотрим. В основном они будут относиться к средним, дисперсиям,
коэффициентам корреляции и распределениям численностей.
Все критерии для проверки статистических гипотез
делятся на две большие группы: параметрические и непараметрические.
Параметрические критерии основаны на предположении о том, что выборочные данные
взяты из генеральной совокупности с известным распределением, и основная задача
состоит в оценке параметров этого распределения. Для непараметрических
критериев не требуется никаких предположений о характере распределения, за
исключением предположения о том, что оно непрерывно.
Первыми рассмотрим параметрические
критерии. Последовательность проверки будет включать формулирование
нуль-гипотезы 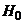 и
альтернативной гипотезы
и
альтернативной гипотезы 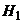 ,
формулирование делаемых допущений, определение выборочной статистики,
используемой при проверке и ,
образование выборочного распределения проверяемой статистики, определение
критических областей для выбранного критерия и построение доверительного
интервала для выборочной статистики.
,
формулирование делаемых допущений, определение выборочной статистики,
используемой при проверке и ,
образование выборочного распределения проверяемой статистики, определение
критических областей для выбранного критерия и построение доверительного
интервала для выборочной статистики.
1. Критерии согласия для средних
Пусть проверяемая гипотеза состоит в
том, что параметр генеральной совокупности 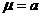 . Необходимость такой проверки может
возникнуть, например, в следующей ситуации. Предположим, что на основании
обширных исследований установлен диаметр раковины ископаемого моллюска в
отложениях из некоторого фиксированного места. Пусть также в нашем распоряжении
оказалось некоторое количество раковин, найденных в другом месте, а мы делаем
предположение, что конкретное место не оказывает влияния на диаметр раковины,
т.е. что среднее значение диаметра раковины для всей популяции моллюсков,
когда-то живших в новом месте, равно известному значению, полученному ранее при
изучении данного вида моллюсков в первом местообитании.
. Необходимость такой проверки может
возникнуть, например, в следующей ситуации. Предположим, что на основании
обширных исследований установлен диаметр раковины ископаемого моллюска в
отложениях из некоторого фиксированного места. Пусть также в нашем распоряжении
оказалось некоторое количество раковин, найденных в другом месте, а мы делаем
предположение, что конкретное место не оказывает влияния на диаметр раковины,
т.е. что среднее значение диаметра раковины для всей популяции моллюсков,
когда-то живших в новом месте, равно известному значению, полученному ранее при
изучении данного вида моллюсков в первом местообитании.
Если это известное значение равно 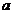 , то
нуль-гипотеза и
альтернативная гипотеза записываются
следующим образом:
, то
нуль-гипотеза и
альтернативная гипотеза записываются
следующим образом: 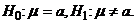 Примем, что
переменная x в рассматриваемой совокупности имеет нормальное распределение, а
величина дисперсии генеральной совокупности
Примем, что
переменная x в рассматриваемой совокупности имеет нормальное распределение, а
величина дисперсии генеральной совокупности 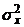 неизвестна.
неизвестна.
Будем проверять гипотезу с помощью
статистики:
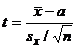 , (1)
, (1)
статистический критерий
дисперсия численность
где 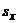 - выборочное стандартное отклонение.
- выборочное стандартное отклонение.
Было показано, что если 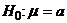 справедлива,
то t в выражении (1) имеет t-распределение Стьюдента с n-1 степенями свободы.
Если выбрать уровень значимости (вероятность отбросить правильную гипотезу)
равным
справедлива,
то t в выражении (1) имеет t-распределение Стьюдента с n-1 степенями свободы.
Если выбрать уровень значимости (вероятность отбросить правильную гипотезу)
равным 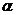 , то в
соответствии с тем, о чем шла речь в предыдущей главе, можно определить критические
значения для проверки =0.
, то в
соответствии с тем, о чем шла речь в предыдущей главе, можно определить критические
значения для проверки =0.
В данном случае, так как
распределение Стьюдента симметрично, то (1-) часть площади под кривой этого
распределения с n-1 степенями свободы будет заключена между точками 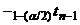 и
и 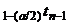 , которые
равны друг другу по абсолютной величине. Следовательно, все значения меньше
отрицательного и больше положительного значения для t-распределения с заданным
числом степеней свободы при выбранном уровне значимости будут составлять
критическую область. Попадание выборочного значения t в эту область приводит к
принятию альтернативной гипотезы.
, которые
равны друг другу по абсолютной величине. Следовательно, все значения меньше
отрицательного и больше положительного значения для t-распределения с заданным
числом степеней свободы при выбранном уровне значимости будут составлять
критическую область. Попадание выборочного значения t в эту область приводит к
принятию альтернативной гипотезы.
Доверительный интервал для 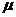 строится по
описанной ранее методике и определяется из следующего выражения
строится по
описанной ранее методике и определяется из следующего выражения
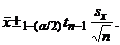 (2)
(2)
Итак, пусть в нашем случае известно,
что диаметр раковины ископаемого моллюска равен 18,2 мм. В нашем распоряжении
оказалась выборка из 50 вновь найденных раковин, для которых 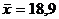 мм, а =2,18 мм.
Проверим : =18,2 против
мм, а =2,18 мм.
Проверим : =18,2 против
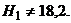 Имеем
Имеем
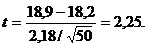
Если уровень значимости выбрать =0,05 то
критическое значение 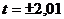 . Отсюда
следует, что можно
отклонить в пользу на уровне
значимости =0,05. Таким
образом, для нашего гипотетического примера можно утверждать (естественно, с
некоторой вероятностью), что диаметр раковины ископаемых моллюсков
определенного вида зависит от мест, в которых они обитали.
. Отсюда
следует, что можно
отклонить в пользу на уровне
значимости =0,05. Таким
образом, для нашего гипотетического примера можно утверждать (естественно, с
некоторой вероятностью), что диаметр раковины ископаемых моллюсков
определенного вида зависит от мест, в которых они обитали.
В связи с тем, что t-распределение
симметрично, приводятся только положительные значения t этого распределения при
выбранных уровнях значимости и числе степеней свободы. Причем учитывается не
только доля площади под кривой распределения справа от значения t, но и
одновременно слева от значения -t. Это связано с тем, что в большинстве случаев
при проверке гипотез нас интересует существенность отклонений сама по себе,
независимо от того, в большую или меньшую сторону эти отклонения, т.е. мы
проверяем против 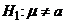 , а не
против : >a или : <a.
, а не
против : >a или : <a.
Вернемся теперь к нашему примеру.
Доверительный 100(1-)% интервал
для равен
,9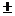 2,01
2,01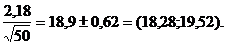
Рассмотрим теперь случай, когда
необходимо сравнить между собой средние двух генеральных совокупностей.
Проверяемая гипотеза выглядит так: : 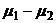 =0, :
=0, : 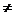 0. Предполагается также, что
0. Предполагается также, что 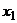 имеет
нормальное распределение со средним
имеет
нормальное распределение со средним 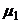 и дисперсией , а
и дисперсией , а 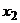 -
нормальное распределение со средним
-
нормальное распределение со средним 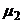 и той же дисперсией . Кроме
того, принимаем, что выборки, по которым оцениваются генеральные совокупности,
извлекаются независимо друг от друга и имеют объем соответственно
и той же дисперсией . Кроме
того, принимаем, что выборки, по которым оцениваются генеральные совокупности,
извлекаются независимо друг от друга и имеют объем соответственно 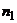 и
и 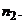 Из
независимости выборок следует, что если взять большее их число и для каждой пары
рассчитать средние значения, то множество этих пар средних будет полностью
некоррелированно.
Из
независимости выборок следует, что если взять большее их число и для каждой пары
рассчитать средние значения, то множество этих пар средних будет полностью
некоррелированно.
Проверка нулевой гипотезы проводится
с использованием статистики
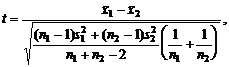 (3)
(3)
где 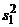 и
и 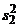 - оценки дисперсии для первой и
второй выборок соответственно. Нетрудно видеть, что (3) представляет собой
обобщение (1).
- оценки дисперсии для первой и
второй выборок соответственно. Нетрудно видеть, что (3) представляет собой
обобщение (1).
Было показано, что статистика (3)
имеет t-распределение Стьюдента с 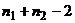 степенями свободы. При равенстве и
степенями свободы. При равенстве и 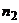 , т.е. = =
, т.е. = =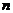 формула (3)
упрощается и имеет вид
формула (3)
упрощается и имеет вид
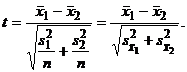 (4)
(4)
Рассмотрим пример. Пусть при
измерении стеблевых листьев одной и той же популяции растений в течение двух
сезонов получены следующие результаты: 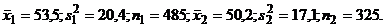 Будем считать, что условия для использования
критерия Стьюдента, т.е. нормальность генеральных совокупностей, из которых
взяты выборки, существование неизвестной, но одной и той же дисперсии для этих
совокупностей и независимость выборок выполнены. Оценим
Будем считать, что условия для использования
критерия Стьюдента, т.е. нормальность генеральных совокупностей, из которых
взяты выборки, существование неизвестной, но одной и той же дисперсии для этих
совокупностей и независимость выборок выполнены. Оценим 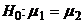 на уровне
значимости =0,01. Имеем
на уровне
значимости =0,01. Имеем
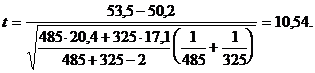
Табличное значение t = 2,58. Поэтому
гипотеза о равенстве
средних значений длин стеблевых листьев для популяции растений в течение двух
сезонов должна быть отвергнута на выбранном уровне значимости.
Внимание! В качестве нулевой
гипотезы в математической статистике выбирается гипотеза об отсутствии значимых
различий между сравниваемыми показателями, причем независимо от того, идет ли
речь о средних, дисперсиях или других статистиках. И во всех этих случаях, если
эмпирическое (вычисленное по формуле) значение критерия больше теоретического
(выбранного из таблиц), то отвергается. Если же эмпирическое
значение меньше табличного, то принимается.
Для того, чтобы построить
доверительный интервал для разности средних этих двух генеральных
совокупностей, обратим внимание на то, что критерий Стьюдента, как видно из
формулы (3), оценивает значимость разности между средними относительно
стандартной ошибки этой разности. В том, что знаменатель в (3) представляет
именно эту стандартную ошибку, нетрудно убедиться, используя уже рассмотренные
ранее соотношения и сделанные предположения. В самом деле, нам известно, что в
общем случае
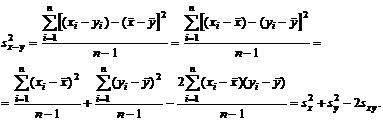
Если x и y независимы, то 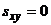 и
и 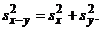
Взяв вместо x и y выборочные
значения 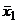 и
и 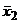 и припомнив
сделанное предположение о том, что обе генеральные совокупности имеют одну и ту
же дисперсию , получим
и припомнив
сделанное предположение о том, что обе генеральные совокупности имеют одну и ту
же дисперсию , получим
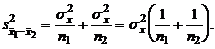 (5)
(5)
Оценка дисперсии может быть
получена из следующего соотношения
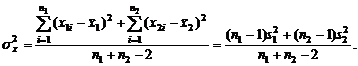 (6)
(6)
(Мы делим на , потому что
по выборкам оцениваются две величины и , и значит, число степеней свободы
должно быть уменьшено на два.)
Если теперь подставить (6) в (5) и
извлечь квадратный корень, то получится знаменатель в выражении (3).
После этого отступления вернемся к
построению доверительного интервала для через -.
Имеем
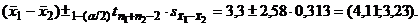
Сделаем некоторые замечания,
связанные с предположениями, используемыми при построении t-критерия. Прежде
всего было показано, что нарушения допущения о нормальности для 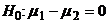 имеют
незначительное влияние на уровень значимости и мощность критерия для
имеют
незначительное влияние на уровень значимости и мощность критерия для 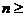 30.
Несущественно также и нарушение предположения об однородности дисперсий обоих
генеральных совокупностей, из которых берутся выборки, но тольков том случае,
когда объемы выборок равны. Если же
30.
Несущественно также и нарушение предположения об однородности дисперсий обоих
генеральных совокупностей, из которых берутся выборки, но тольков том случае,
когда объемы выборок равны. Если же 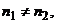 а дисперсии обеих совокупностей
отличаются друг от друга, то вероятности ошибок первого и второго рода будут
существенно отличаться от ожидаемых.
а дисперсии обеих совокупностей
отличаются друг от друга, то вероятности ошибок первого и второго рода будут
существенно отличаться от ожидаемых.
В этом случае для проверки следует
пользоваться критерием
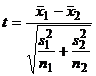 (7)
(7)
с числом степеней свободы
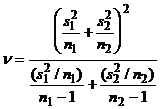 . (8)
. (8)
Как правило, 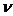 получается
дробным числом, поэтому при пользовании таблицами t-распределения необходимо
брать табличные значения для ближайших целых значений и проводить интерполяцию
для нахождения t, соответствующего полученному.
получается
дробным числом, поэтому при пользовании таблицами t-распределения необходимо
брать табличные значения для ближайших целых значений и проводить интерполяцию
для нахождения t, соответствующего полученному.
Рассмотрим пример. При изучении двух
подвидов озерной лягушки рассчитывалось отношение длины тела к длине голени.
Были взяты две выборки с объемами =49 и =27. Средние и дисперсии
интересующего нас отношения оказались равными соответственно =2,34; =2,08; =0,21; =0,35. Если
теперь проверять гипотезу с
использованием формулы (2), то получим, что
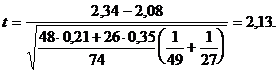
При уровне значимости =0,05 мы
должны отвергнуть нулевую гипотезу (табличное значение t=1,995) и считать, что
есть статистически достоверные на выбранном уровне значимости различия между
средними значениями измеряемых показателей для двух подвидов лягушки.
При использовании же формул (6) и
(7) имеем
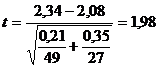 ,
, 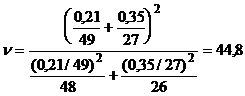 .
.
В данном случае для того же уровня
значимости =0,05
табличное значение t=2,015, и нулевая гипотеза принимается.
На этом примере достаточно ясно
видно, что пренебрежение условиями, принимаемыми при выводе того или иного
критерия, может привести к результатам, прямо противоположным тем, которые
имеют место на самом деле. Конечно же, в данном случае, имея выборки разного
объема в отсутствии заранее установленного факта о том, что дисперсии
измеряемого показателя в обеих популяциях статистически равны, следовало
пользоваться формулами (7) и (8), которые и показали отсутствие статистически
значимых различий.
Поэтому хочется повторить еще раз,
что проверка соблюдения всех предположений, сделанных при выводе того или иного
критерия, является совершенно необходимым условием для его корректного
использования.
Неизменным требованием в обоих
приведенных модификациях t-критерия было требование о независимости между собой
выборок. Однако на практике достаточно часто встречаются ситуации, когда это
требование не может быть выполнено по объективным причинам. Например,
измеряются некоторые показатели на одном и том же животном или участке
территории до и после действия внешнего фактора и т.д. И в этих случаях нас
может интересовать проверка гипотезы против 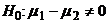 . Будем
по-прежнему предполагать, что обе выборки взяты из нормальных генеральных
совокупностей с одинаковой дисперсией.
. Будем
по-прежнему предполагать, что обе выборки взяты из нормальных генеральных
совокупностей с одинаковой дисперсией.
В этом случае можно воспользоваться
тем фактом, что разности между нормально распределенными величинами также имеют
нормальное распределение, и поэтому можно воспользоваться критерием Стьюдента в
форме (1). Таким образом, будет проверяться гипотеза о том что n разностей 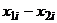 есть
выборка из нормально распределенной генеральной совокупности со средним , равным
нулю.
есть
выборка из нормально распределенной генеральной совокупности со средним , равным
нулю.
Обозначив i-ю разность через 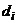 , имеем
, имеем
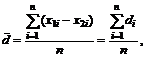 а
а
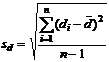 .
.
Рассмотрим пример. Пусть в нашем
распоряжении имеются данные о количестве импульсов отдельной нервной клетки за
определенный интервал времени до () и после () действия
раздражителя:
Отсюда 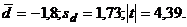 Имея в
виду, что (9) имеет t-распределение, и выбрав уровень значимости =0,01, из
соответствующей таблицы Приложения найдем, что критическое значение t для
n-1=10-1=9 степеней свободы равно 3,25. Сравнение теоретического и
эмпирического значений t-статистики показывает, что нулевая гипотеза об
отсутствии статистически значимых различий между частотой импульсации до и
после подачи стимула должна быть отвергнута. Можно сделать вывод о том, сто
используемый раздражитель статистически значимо меняет частоту импульсации.
Имея в
виду, что (9) имеет t-распределение, и выбрав уровень значимости =0,01, из
соответствующей таблицы Приложения найдем, что критическое значение t для
n-1=10-1=9 степеней свободы равно 3,25. Сравнение теоретического и
эмпирического значений t-статистики показывает, что нулевая гипотеза об
отсутствии статистически значимых различий между частотой импульсации до и
после подачи стимула должна быть отвергнута. Можно сделать вывод о том, сто
используемый раздражитель статистически значимо меняет частоту импульсации.
В экспериментальных исследованиях,
как упоминалось выше, зависимые выборки появляются достаточно часто. Тем не
менее этот факт иногда игнорируется и t-критерий некорректно используется в
форме (3).
В неправомерности этого можно
убедиться, рассматривая стандартные ошибки разности между некоррелированными и
коррелированными средними. В первом случае
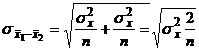 , а во втором
, а во втором
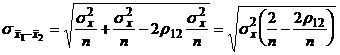 .
.
Стандартная ошибка разности d равна
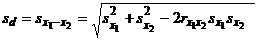 .
.
С учетом этого знаменатель в (9)
будет иметь вид
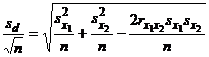 .
.
Теперь обратим внимание на то, что
числители выражений (4) и (9) совпадают:
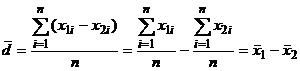 ,
,
следовательно, различие в величине t
в них зависит от знаменателей.
Таким образом, если в задаче с зависимыми
выборками будет использована формула (3), и при этом выборки будут иметь
положительную корреляцию, то получаемые значения t будут меньше, чем они должны
были бы быть при использовании формулы (9), и может возникнуть ситуация, что
будет принята нулевая гипотеза, в то время как она неверна. Обратная ситуация
может возникнуть, когда между выборками будет существовать отрицательная
корреляция, т.е. в этом случае значимыми будут признаваться такие различия,
которые на самом деле таковыми не являются.
Вернемся вновь к примеру с
импульсной активностью и вычислим для приведенных данных значение t по формуле
(3), не обращая внимания на то, что выборки связаны. Имеем: 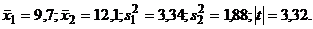 Для числа
степеней свободы, равного 18, и уровня значимости =0,01
табличное значение t=2,88 и, на первый взгляд, кажется, что ничего не
произошло, даже при использовании непригодной для данных условий формулы. И в
этом случае вычисленное значение t приводит к отбрасыванию нулевой гипотезы,
т.е. к тому же самому выводу, который был сделан с использованием правильной в
данной ситуации формулой (9).
Для числа
степеней свободы, равного 18, и уровня значимости =0,01
табличное значение t=2,88 и, на первый взгляд, кажется, что ничего не
произошло, даже при использовании непригодной для данных условий формулы. И в
этом случае вычисленное значение t приводит к отбрасыванию нулевой гипотезы,
т.е. к тому же самому выводу, который был сделан с использованием правильной в
данной ситуации формулой (9).
Однако давайте переформируем
имеющиеся данные и представим их в следующем виде (2):
Это те же самые значения, и они
вполне могли бы быть получены в каком-нибудь из опытов. Так как все значения в
обеих выборках сохранены, то использование критерия Стьюдента в формуле (3)
дает уже полученное ранее значение 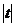 =3,32 и приводит к тому же самому
выводу, который уже был сделан.
=3,32 и приводит к тому же самому
выводу, который уже был сделан.
А теперь рассчитаем значение t по
формуле (9), которая и должна использоваться в данном случае. Имеем: 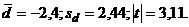 Критическое
значение t при выбранном уровне значимости и девяти степенях свободы равно
3,25. Следовательно, оснований отвергнуть нулевую гипотезу у нас нет, мы ее
принимаем, и оказывается, что этот вывод прямо противоположен тому, который был
сделан при использовании формулы (3).
Критическое
значение t при выбранном уровне значимости и девяти степенях свободы равно
3,25. Следовательно, оснований отвергнуть нулевую гипотезу у нас нет, мы ее
принимаем, и оказывается, что этот вывод прямо противоположен тому, который был
сделан при использовании формулы (3).
На этом примере мы вновь убедились в
том, как важно для получения правильных выводов при анализе экспериментальных
данных строго соблюдать все требования, которые были положены в основу
определения того или иного критерия.
Рассмотренные модификации критерия
Стьюдента предназначаются для проверки гипотез относительно средних двух
выборок. Однако возникают ситуации, когда появляется необходимость сделать
выводы относительно равенства одновременно k средних. Для этого случая тоже
разработана определенная статистическая процедура, которая будет рассмотрена в
дальнейшем при обсуждении вопросов, связанных с дисперсионным анализом.
. Критерии согласия для дисперсий
Проверка статистических гипотез
относительно дисперсий генеральных совокупностей проводится в той же
последовательности, что и для средних. Напомним вкратце эту последовательность.
. Формулируется нулевая гипотеза (об
отсутствии статистически значимых различий между сравниваемыми дисперсиями).
. Делаются некоторые предположения
относительно выборочного распределения статистики, с помощью которой
планируется оценивать параметр, входящий в гипотезу.
. Выбирается уровень значимости для
проверкигипотезы.
. Рассчитывается значение
интересующей нас статистики и принимается решение относительно истинности
нулевой гипотезы.
А теперь начнем с проверки гипотезы
о том, что дисперсия генеральной совокупности =a, т.е. 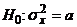 против
против 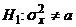 . Если
предположить, что переменная x имеет нормальное распределение, и что выборка
объема n извлекается из генеральной совокупности случайно, то для проверки
нулевой гипотезы используется
статистика
. Если
предположить, что переменная x имеет нормальное распределение, и что выборка
объема n извлекается из генеральной совокупности случайно, то для проверки
нулевой гипотезы используется
статистика
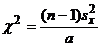 (10)
(10)
Вспомнив формулу для расчета
дисперсии, перепишем (10) так:
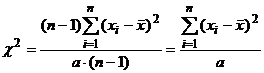 . (11)
. (11)
Из этого выражения видно, что
числитель представляет собой сумму квадратов отклонений нормально
распределенных величин от их среднего. Каждое из этих отклонений также
распределено нормально. Поэтому в соответствии с известным нам распределением
суммы квадратов нормально распределенных величин статистики (10) и (11) имеют 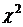 -распределение
с n-1 степенью свободы.
-распределение
с n-1 степенью свободы.
По аналогии с использованием
t-распределения при проверке для выбранного уровня значимости по таблице
распределения устанавливают
критические точки, соответствующие вероятностям принятия нулевой гипотезы 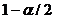 и
и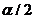 .
Доверительный интервал для при выбранном строится
следующим образом:
.
Доверительный интервал для при выбранном строится
следующим образом:
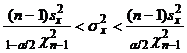 . (12)
. (12)
Рассмотрим пример. Пусть на
основании обширных экспериментальных исследований установлено, что дисперсия
содержания алкалоидов одного вида растений из определенного района равна 4,37
условных единиц. В распоряжение специалиста попадает выборка объемом n = 28
таких растений, предположительно из того же района. Проведенный анализ показал,
что для этой выборки 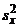 =5,01 и
нужно убедиться в том, что эта и известная ранее дисперсии статистически
неразличимы на уровне значимости =0,1.
=5,01 и
нужно убедиться в том, что эта и известная ранее дисперсии статистически
неразличимы на уровне значимости =0,1.
По формуле (10) имеем
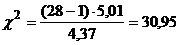 .
.
Полученную величину необходимо
сравнить с критическими значениями /2=0,05 и 1--/2=0,95. Из
таблицы Приложения для с 27
степенями свободы имеем соответственно 40,1 и 16,2, откуда следует, что нулевая
гипотеза может быть принята. Соответствующий доверительный интервал для равен
3,37<<8,35.
В отличии от проверки гипотез
относительно выборочных средних с использованием критерия Стьюдента, когда
ошибки первого и второго рода несущественно менялись при нарушении
предположения о нормальном распределении генеральных совокупностей, в случае
гипотез о дисперсиях при невыполнении условий нормальности ошибки меняются
существенно.
Рассмотренная выше задача о
равенстве дисперсии некоторому фиксированному значению представляет
ограниченный интерес, так как довольно редко встречаются ситуации, когда
известна дисперсия генеральной совокупности. Значительно больший интерес
представляет случай, когда нужно проверить, равны ли дисперсии двух
совокупностей, т.е. проверка гипотезы 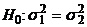 против альтернативы
против альтернативы 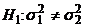 . При этом
предполагается, что выборки объемом и случайно извлекаются из генеральных
совокупностей с дисперсиями
. При этом
предполагается, что выборки объемом и случайно извлекаются из генеральных
совокупностей с дисперсиями 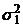 и
и 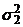 .
.
Для проверки нулевой гипотезы
используется критерий отношения дисперсий Фишера
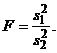 (13)
(13)
Так как суммы квадратов отклонений
нормально распределенных случайных величин от их средних значений имеют
распределение , то и
числитель и знаменатель (13) представляют собой величины с распределением , поделенные
соответственно на и , и
следовательно, их отношение имеет F-распределение с -1 и -1 степенями
свободы.
Общепринято - и так построены
таблицы F-распределения, - что в качестве числителя в (13) берется большая из
дисперсий, и поэтому определяется только одна критическая точка,
соответствующая выбранному уровню значимости.
Пусть в нашем распоряжении оказались
две выборки объемом =11 и =28 из
популяций обыкновенных и овальных прудовиков, для которых отношения высоты к
ширине имеют дисперсии =0,59 и =0,38.
Необходимо проверить гипотезу о равенстве этих дисперсий этих показателей для
изучаемых популяций при уровне значимости =0,05. Имеем
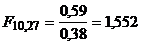 .
.
В литературе иногда можно встретить
утверждение о том, что проверке гипотезы о равенстве средних по критерию
Стьюдента должна предшествовать проверка гипотезы о равенстве дисперсий. Это
неправильная рекомендация. Более того, она может привести к ошибкам, которых
можно избежать, если ей не следовать.
В самом деле, результаты проверки
гипотезы о равенстве дисперсий с использованием критерия Фишера в значительной
мере зависят от предположения о том, что выборки взяты из совокупностей с
нормальным распределением. В то же время критерий Стьюдента малочувствителен к
нарушениям нормальности, и если удается получить выборки равного объема, то
предположение о равенстве дисперсий также не является существенным. В случае
неравных n следует пользоваться для проверки формулами (7) и (8).
При проверке гипотез о равенстве
дисперсий возникают некоторые особенности в расчетах, связанных с зависимыми
выборками. В этом случае для проверки гипотезы против альтернативы используется
статистика
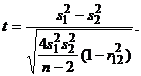 (14)
(14)
Если нулевая гипотеза справедлива,
то статистика (14) имеет t-распределение Стьюдента с n-2 степенями свободы.
При измерении блеска 35 образцов
покрытий была получена дисперсия =134,5. Повторные измерения через
две недели показали =199,1. При
этом коэффициент корреляции между парными измерениями оказался равным 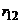 =0,876. Если
не обращать внимание на то, что выборки зависимы и воспользоваться критерием
Фишера для проверки гипотезы , то получим F=1,48. Если выбрать
уровень значимости =0,05, то
нулевая гипотеза будет принята, так как критическое значение F-распределения
для
=0,876. Если
не обращать внимание на то, что выборки зависимы и воспользоваться критерием
Фишера для проверки гипотезы , то получим F=1,48. Если выбрать
уровень значимости =0,05, то
нулевая гипотеза будет принята, так как критическое значение F-распределения
для 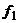 =35-1=34 и
=35-1=34 и 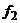 =35-1=34
степеней свободы равно 1,79.
=35-1=34
степеней свободы равно 1,79.
В то же время, если использовать
подходящую для данного случая формулу (14), то получим t=2,35, в то время как
критическое значение t для 33 степеней свободы и выбранного уровня значимости =0,05 равно 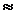 2,03.
Следовательно, нулевая гипотеза о равенстве дисперсий в этих двух выборках
должна быть отклонена. Таким образом, из этого примера видно, что, как и в
случае проверки гипотезы о равенстве средних, использование критерия, не
учитывающего специфику экспериментальных данных, приводит к ошибке.
2,03.
Следовательно, нулевая гипотеза о равенстве дисперсий в этих двух выборках
должна быть отклонена. Таким образом, из этого примера видно, что, как и в
случае проверки гипотезы о равенстве средних, использование критерия, не
учитывающего специфику экспериментальных данных, приводит к ошибке.
В рекомендуемой литературе можно
найти критерий Бартлетта, используемый при проверке гипотез об одновременном
равенстве k дисперсий. Кроме того, что вычисления статистики этого критерия
довольно трудоемки, основной недостаток этого критерия в том, что он необычайно
чувствителен к отклонениям от предположения о нормальности распределений
совокупностей из которых извлекаются выборки. Таким образом, при его
использовании никогда нельзя быть уверенным в том, что нулевая гипотеза
отклонена в самом деле из-за того, что статистически значимо различаются
дисперсии, а не из-за того, что выборки не имеют нормального распределения.
Поэтому в случае возникновения проблемы сравнения нескольких дисперсий
необходимо искать такую постановку задачи, когда можно будет использовать
критерий Фишера или его модификации.
3. Критерии согласия относительно
долей
Довольно часто приходится
анализировать совокупности, в которых объекты могут быть отнесены к одной из
двух категорий. Например, по принадлежности к полу в некоторой популяции, по
наличию некоторого микроэлемента в почве, по темной или светлой окраске яиц у
некоторых видов птиц и т.д.
Долю элементов, обладающих
определенным качеством, обозначим через P, где P представляет собой отношение
объектов с интересующим нас качеством ко всем объектам в совокупности.
Пусть проверяется гипотеза о том,
что в некоторой достаточно большой совокупности доля P равна некоторому числу a
(0<a<1), т.е. 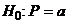 против
против 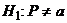 .
.
Для дихотомических (имеющих две
градации) переменных, как в нашем случае, P играет ту же роль, что и среднее
генеральной совокупности переменных, измеряемых количественно. С другой
стороны, ранее было указано, что стандартная ошибка доли P может быть
представлена в виде
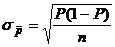 .
.
Тогда, если верна гипотеза , то
статистика
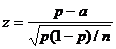 , (19)
, (19)
где p - выборочное значение P, имеет
единичное нормальное распределение. Сразу нужно оговориться, что такая
аппроксимация справедлива, если меньшее из произведений np или (1-p)n больше 5.
Пусть из литературных данных
известно, что в популяции озерной лягушки доля особей, имеющих продольную
полосу на спине составляет 62% или 0,62. В нашем распоряжении оказалась выборка
из 125 (n) особей, 93 (f) из которых имеют продольную полосу на спине.
Необходимо выяснить, соответствует ли доля особей с интересующим нас признаком
в популяции, из которой извлечена выборка, известным данным. Имеем:
p=f/n=93/125=0,744, a=0,62, n(1-p)=125(1-0,744)=32>5 и
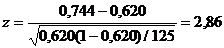 .
.
Следовательно, и для уровня
значимости = 0,05 и
для = 0,01
нулевая гипотеза должна быть отвергнута, так как критическое значение для = 0,05
равно 1,96, а для = 0,01 - 2,58.
Если существуют две большие
совокупности, в которых доли объектов с интересующих нас свойством составляют
соответственно 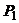 и
и 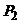 , то интерес
представляет проверка гипотезы : = против альтернативной :. Для проверки извлекаются случайно
и независимо две выборки объемами и . По этим выборкам оцениваются
, то интерес
представляет проверка гипотезы : = против альтернативной :. Для проверки извлекаются случайно
и независимо две выборки объемами и . По этим выборкам оцениваются 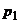 и
и 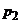 и
определяется статистика
и
определяется статистика
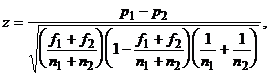 (20)
(20)
где и - число объектов, обладающих данным
признаком, соответственно в первой и второй выборках.
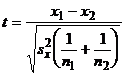 , так как
, так как 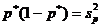 .
.
С другой стороны, стандартная ошибка
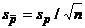 . Таким
образом, (20) может быть записано в виде
. Таким
образом, (20) может быть записано в виде
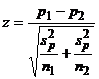 . (21)
. (21)
Единственное различие между этой
статистикой и статистикой, используемой при проверке гипотез о средних состоит
в том, что z имеет не t-, а единичное нормальное распределение.
Пусть изучение группы людей (=82)
показало, что доля лиц, у которых в электроэнцефалограмме обнаруживается -ритм,
составляет 0,84 или 84%. Исследование группы людей в другой местности (=51)
показало, что эта доля составляет 0,78. Для уровня значимости =0,05
необходимо проверить, что доли лиц, обладающих мозговой альфа-активностью в
генеральных совокупностях, из которых взяты выборки, одинаковы.
Прежде всего убедимся в том, что
имеющиеся экспериментальные данные позволяют пользоваться статистикой (20).
Имеем:
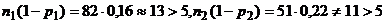 .
.
Далее рассчитаем
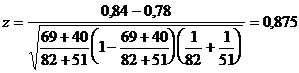 ,
,
и так как z имеет нормальное
распределение, для которого критической точкой при =0,05
является 1,96, то нулевая гипотеза принимается.
Рассмотренный критерий справедлив,
если выборки, для которых сравнивались доли объектов, обладающих интересующим
нас признаком, являются независимыми. Если это требование не выполняется,
например, когда совокупность рассматривается в последовательные интервалы
времени, то один и тот же объект может в этих интервалах обладать или не
обладать данным признаком.
Обозначим наличие у объекта
некоторого интересующего нас признака через 1, а его отсутствие - через 0.
Тогда мы приходим к таблице 3, где (a+c) - число объектов в первой выборке,
обладающих некоторым признаком, (a+c) - число объектов с этим признаком во
второй выборке, а n - общее число обследованных объектов. Очевидно, что это уже
известная четырехпольная таблица, взаимосвязь в которой оценивается с помощью
коэффициента
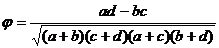 .
.
Для такой таблицы и малых (<10)
значений в каждой клетке Р.Фишером было найдено точное распределение для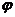 , которое
позволяет проверять гипотезу : =. Это распределение имеет довольно
сложный вид, и его критические точки приводятся в специальных таблицах. В
реальных ситуациях, как правило, значения в каждой клетке больше 10, и было
показано, что в этих случаях для проверки нулевой гипотезы можно использовать
статистику
, которое
позволяет проверять гипотезу : =. Это распределение имеет довольно
сложный вид, и его критические точки приводятся в специальных таблицах. В
реальных ситуациях, как правило, значения в каждой клетке больше 10, и было
показано, что в этих случаях для проверки нулевой гипотезы можно использовать
статистику
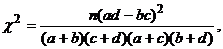 (22)
(22)
которая в случае, если нулевая
гипотеза верна, имеет распределение хи-квадрат с одной степенью свободы.
Рассмотрим пример. Пусть в течение
двух лет проверялась эффективность прививок от малярии, сделанных в разное
время года.. Проверяется гипотеза о том, что эффективность прививок не зависит
от времени года, когда они делаются. Имеем
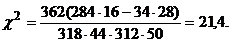
Табличное значение для =0,05 равно
3,84, а для =0,01 -
6,64. Следовательно, на любом из этих уровней значимости нулевая гипотеза
должна быть отвергнута, и в этом гипотетическом примере (впрочем имеющем
отношение к действительности) может быть сделан вывод о том, что пививки,
сделанные во второй половине года, значительно эффективней.
Естественным обобщением коэффициента
связи для четырехпольной таблицы является, как уже упоминалось ранее,
коэффициент взаимной сопряженности Чупрова. Для этого коэффициента неизвестно
точное распределение, поэтому о справедливости гипотезы 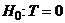 судят на
основании сравнения вычисленного значения и выбранного уровня значимости с
критическими точками для этого распределения. Число степеней свободы
определяется из выражения (r-1)(c-1), где r и c - число градаций по каждому из
признаков.
судят на
основании сравнения вычисленного значения и выбранного уровня значимости с
критическими точками для этого распределения. Число степеней свободы
определяется из выражения (r-1)(c-1), где r и c - число градаций по каждому из
признаков.
Напомним расчетные формулы
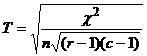 ,
, 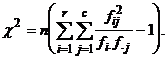
Приведены данные, полученные при
исследовании дальности зрения правым и левым глазом у людей, не имеющих
аномалий зрения. Условно эта дальность разбита на четыре категории, и нас
интересует достоверность связи между дальностью зрения левым и правым глазом.
Сначала найдем все слагаемые в двойной сумме. Для этого квадрат каждого
значения, приводимого в таблице, делится на сумму строки и столбца, к которым
принадлежит выбранное число. Имеем
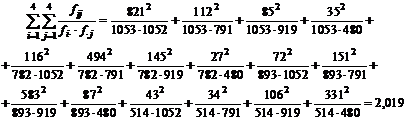
Используя это значение, получим =3303,6 и
T=0,714.
. Критерии для сравнения
распределений численностей
В классических экспериментах по
селекции гороха, знаменовавших начало генетики, Г.Мендель наблюдал частоты
различных видов семян, получаемых при скрещивании растений с круглыми желтыми
семенами и с морщинистыми зелеными семенами.
В данном и аналогично случаях
интерес представляет проверка нулевой гипотезы о равенстве функций
распределения генеральных совокупностей, из которых извлекаются выборки, т.е. 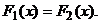 Теоретические
выкладки показали, что при решении такой задачи может быть использована
статистика
Теоретические
выкладки показали, что при решении такой задачи может быть использована
статистика
=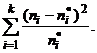 (23)
(23)
Критерий, использующий эту
статистику был предложен К.Пирсоном и носит его имя. Критерий Пирсона
применяется для группированных данных независимо от того, имеют ли они
непрерывное или дискретное распределение. В (23) k- число интервалов
группирования, 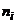 - эмпирические
численности, а
- эмпирические
численности, а 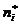 - ожидаемые
или теоретические численности (=
- ожидаемые
или теоретические численности (=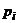 n). В случае справедливости нулевой
гипотезы статистика (23) имеет - распределение с k-1 степенями
свободы.
n). В случае справедливости нулевой
гипотезы статистика (23) имеет - распределение с k-1 степенями
свободы.
Критические точки -распределения
с 3 степенями свободы для =0,05 и =0,01 равны
соответственно 7,81 и 11,3. Следовательно нулевая гипотеза принимается и
делается вывод, что расщепление в потомстве достаточно хорошо соответствует
теоретическим закономерностям.
Для приведенных в таблице данных
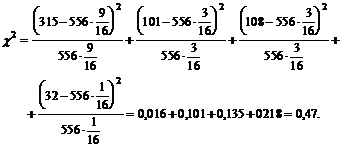
Рассмотрим еще один пример. В
колонии морских свинок получены в течение года следующие численности рождения
самцов по месяцам, начиная с января: 65, 64, 65, 41, 72, 80, 88, 114, 80, 129,
112, 99. Можно ли считать, что полученные данные соответствуют равномерному
распределению, т.е. распределению, в котором численность рождающихся в
отдельные месяцы самцов в среднем одинакова? Если принять такую гипотезу, то
ожидаемое среднее число рождающихся самцов будет равно 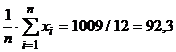 . Тогда
. Тогда
=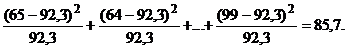
Критическое значение распределения с 11
степенями свободы и = 0,01 равно
24,7, поэтому на выбранном уровне значимости нулевая гипотеза отвергается.
Дальнейший анализ экспериментальных данных показывает, что вероятность рождения
самцов морских свинок во второй половине года повышается.
В случае, когда теоретическое
распределение предполагается равномерным, проблем с вычислением теоретических
численностей не возникает. В случае же других распределений расчеты усложняются.
Рассмотрим на примерах, как рассчитываются теоретические численности для
нормального и пуассоновского распределения, которые достаточно часто
встречаются в исследовательской практике.
Начнем с определения теоретических
численностей для нормального распределения. Идея состоит в том, чтобы
преобразовать наше эмпирическое распределение в распределение с нулевым средним
и единичной дисперсией. Естественно, что при этом границы класс-интервалов
будут выражаться в единицах стандартного отклонения, и тогда, помня о том, что
площадь под участком кривой, ограниченной верхним и нижним значением каждого
интервала, равна вероятности попадания в данный интервал, умножением этой
вероятности на общую численность выборки мы и получим искомую теоретическую
численность.
Пусть у нас есть эмпирическое
распределение для длины листьев дуба и необходимо проверить, можно ли считать с
уровнем значимости =0,05, что
это распределение незначимо отличается от нормального.
Поясним, как рассчитывались
значения, приводимые в таблице. Во-первых, по стандартной методике для
группированных данных были вычислены среднее и стандартное отклонение, которые
оказались равными 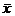 =10,3 и =2,67. По
этим значениям были найдены границы интервалов в единицах стандартного
отклонения, т.е. найдены стандартизованные величины
=10,3 и =2,67. По
этим значениям были найдены границы интервалов в единицах стандартного
отклонения, т.е. найдены стандартизованные величины 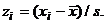 Например,
для границ интервала (4
Например,
для границ интервала (4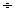 6) имеем:
(4-10,3)/2,67=-2,36; (6-10,3)/2,67=-1,61. Затем для каждого интервала была
вычислена вероятность попадания в него. Например, для интервала (-0,110,64) из
таблицы нормального распределения имеем, что слева от точки (-0,11) лежит 0,444
площади единичного нормального распределения, а слева от точки (0,64) - 0,739
этой площади. Таким образом, вероятность попадания в этот интервал равна
0,739-0,444=0,295. Остальные вычисления очевидны. Следует объяснить разницу
между n и
6) имеем:
(4-10,3)/2,67=-2,36; (6-10,3)/2,67=-1,61. Затем для каждого интервала была
вычислена вероятность попадания в него. Например, для интервала (-0,110,64) из
таблицы нормального распределения имеем, что слева от точки (-0,11) лежит 0,444
площади единичного нормального распределения, а слева от точки (0,64) - 0,739
этой площади. Таким образом, вероятность попадания в этот интервал равна
0,739-0,444=0,295. Остальные вычисления очевидны. Следует объяснить разницу
между n и 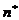 . Она
возникает за счет того, что теоретическое нормальное распределение можно
считать для практических целей сосредоточенным на интервале
. Она
возникает за счет того, что теоретическое нормальное распределение можно
считать для практических целей сосредоточенным на интервале 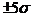 . В
эксперименте же значений, отклоняющихся больше, чем на
. В
эксперименте же значений, отклоняющихся больше, чем на 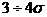 от среднего
не бывает. Поэтому площадь под кривой эмпирического распределения не равна
единице, за счет чего и возникает погрешность. Однако эта погрешность не вносит
существенных изменений в окончательные результаты.
от среднего
не бывает. Поэтому площадь под кривой эмпирического распределения не равна
единице, за счет чего и возникает погрешность. Однако эта погрешность не вносит
существенных изменений в окончательные результаты.
При сравнении эмпирического и
теоретического распределений число степеней свободы для -распределения
находится из сотношения f=m-1-l, где m - число класс-интервалов, а l - число
независимых параметров распределения, оцениваемых по выборке. Для нормального
распределения l=2, так как оно зависит от двух параметров: и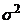 .
.
Число степеней свободы уменьшается
также на 1, так как для любого распределения существует условие, что 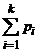 =1, и
следовательно, число независимо определяемых вероятностей равно k-1, а не k.
=1, и
следовательно, число независимо определяемых вероятностей равно k-1, а не k.
Для приведенного примера f = 8-2-1 =
5 и критическое значение при =0,05 для -распределения
с 5 степенями свободы равно 11,07. Следовательно, нулевая гипотеза принимается.
Технику сравнения эмпирического
распределения с распределением Пуассона рассмотрим на классическом примере о
числе смертей драгун за месяц в прусской армии от удара лошадиным копытом.
Данные относятся к XIX веку, а численности смертей 0, 1, 2 и т.д. характеризуют
эти печальные, но, к счастью происходившие сравнительно редко события в
прусской кавалерии почти за 20 лет наблюдений.
Как известно распределение Пуассона
имеет следующий вид:
 ,
,
где 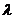 - параметр распределения, равный
среднему, k =0,1,2,...,n.
- параметр распределения, равный
среднему, k =0,1,2,...,n.
Так как распределение дискретное, то
интересующие нас вероятности находятся непосредственно по формуле.
Покажем, например, как определяется
теоретическая численность для k=3. Обычным способом находим, что среднее в этом
распределении равно 0,652. Имея это значение, найдем
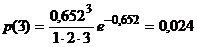 .
.
Отсюда 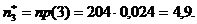
Если выбрать =0,05, то
критическое значение для -распределения
с двумя степенями свободы равно 5,99, и , следовательно, гипотеза о том, что
эмпирическое распределение на выбранном уровне значимости не отличается от
пуассоновского, принимается. Число степеней свободы в данном случае равно двум,
потому что распределение Пуассона зависит от одного параметра, и значит, в
соотношении f = m-1-l число параметров, оцениваемых по выборке l = 1, и f= 4-1-1 = 2.
Иногда на практике оказывается
важным знать, различаются ли между собой два распределения, даже если
затруднительно решить, каким теоретическим распределением они могут быть
аппроксимированы. Это особенно важно в тех случаях, когда, например, их средние
и/или дисперсии между собой статистически значимо не различаются. Обнаружение
существенных различий в характере распределения может помочь исследователю
сделать предположения относительно возможных факторов, которые приводят к этим
различиям.
В этом случае может быть
использована статистика (23), причем в качестве эмпирических численностей
используются значения одного распределения, а в качестве теоретического -
другого. Естественно, что в этом случае разбиение на класс интервалы должно
быть единым для обоих распределений. Это значит, что для всех данных из обоих
выборок выбираются минимальное и максимальное значение, независимо к какой
выборке они относятся, а затем в соответствии с выбранным числом
класс-интервалов определяется их ширина и подсчитывается число объектов,
попавших в отдельные интервалы, для каждой выборки отдельно.
При этом может оказаться, что в
некоторые классы не попадает или попадает мало (35) значений. Использование критерия
Пирсона дает удовлетворительные результаты, если в каждый интервал попадает не
менее 35 значений.
Поэтому, если это требование не выполняется, необходимо объединять соседние
интервалы. Конечно же, это делается для обоих распределений.
И, наконец, еще одно замечание,
касающееся сравнения вычисленного значения и критических точек для него по
выбранному уровню значимости. Нам уже известно, что если 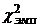 >
>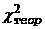 , то нулевая
гипотеза отвергается. Однако и значения , близкие к критической точке 1- справа,
должны вызывать у нас подозрения, потому что такое слишком хорошее совпадение
эмпирического и теоретического распределений или двух эмпирических
распределений (ведь в этом случае численности будут отличаться между собой
очень незначительно) вряд ли может встретиться для случайных распределений. В
этом случае возможны две альтернативных объяснения: либо мы имеем дело с
законом, и тогда получаемый результат неудивителен, либо экспериментальные
данные в силу каких-то причин “подогнаны” друг к другу, что требует их
повторной проверки.
, то нулевая
гипотеза отвергается. Однако и значения , близкие к критической точке 1- справа,
должны вызывать у нас подозрения, потому что такое слишком хорошее совпадение
эмпирического и теоретического распределений или двух эмпирических
распределений (ведь в этом случае численности будут отличаться между собой
очень незначительно) вряд ли может встретиться для случайных распределений. В
этом случае возможны две альтернативных объяснения: либо мы имеем дело с
законом, и тогда получаемый результат неудивителен, либо экспериментальные
данные в силу каких-то причин “подогнаны” друг к другу, что требует их
повторной проверки.
Кстати, в примере с горохом мы имеем
как раз первый случай, т.е. появление семян разной гладкости и окраски в
потомстве определяется законом, и поэтому неудивительно, что вычисленное
значение получилось
таким малым.
Теперь вернемся к проверке
статистической гипотезы об идентичности двух эмпирических распределений.
Приведены данные о распределении числа лепестков цветков анемона, взятых из
разных местообитаний.
Из табличных данных видно, что два
первых и два последних интервала должны быть объединены, так как число,
попадающих в них значений недостаточно для корректного использования критерия
Пирсона. Из этого примера видно также, что если бы анализировалось только
распределение из местообитания А, то класс-интервала, содержащего 4 лепестка,
вообще бы не было. Он появился в результате того, что рассматриваются два
распределения одновременно, а во втором распределении такой класс имеется.
Итак, проверим гипотезу, что два
этих распределения не отличаются друг от друга. Имеем
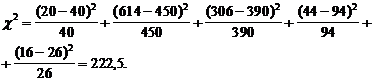
Для числа степеней свободы 4 и
уровня значимости даже равного 0,001, нулевая гипотеза отвергается.
Для сравнения двух выборочных
распределений можно использовать и непараметрический критерий, предложенный
Н.В.Смирновым и основанный на статистике, введенной ранее А.Н.Колмогоровым.
(Вот почему этот критерий иногда называют критерием Колмогорова-Смирнова.) Этот
критерий основан на сравнении рядов накопленных частот. Статистика этого
критерия находится как
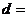 max
max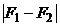 , (24)
, (24)
где 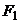 и
и 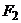 - кривые распределения накопленных
частот.
- кривые распределения накопленных
частот.
Критические точки для статистики
(24) находятся из соотношения
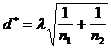 , (25)
, (25)
где и -объемы первой и второй выборок.
Критические значения для =0,1;=0,05; и =0,01 равны
соответственно 1,22; 1,36; 1,63. Проиллюстрируем использование критерия
Смирнова на группированных данных, и представляющих собой рост школьников
одинакового возраста из двух разных районов.
Максимальная разность между кривыми
накопленных частот равна 0,124. Если выбрать уровень значимости =0,05, то из
формулы (25) имеем
Таким образом, максимальная
эмпирическая разность больше теоретически ожидаемой, поэтому на принятом уровне
значимости нулевая гипотеза об идентичности двух рассматриваемых распределений
отвергается.
Критерий Смирнова может быть использован
и не для группированных данных, единственное требование состоит в том, что эти
данные должны быть извлечены из генеральных совокупностей с непрерывным
распределением. Желательно также, чтобы число значений в каждой из выборок было
не менее 40-50.
Для проверки нулевой гипотезы,
согласно которой двум независимым выборкам объемом n и m отвечают одинаковые
функции распределения, Ф. Вилкоксоном был предложен непараметрический критерий,
получивший обоснование в работах Г. Манна и Ф. Уитни. Поэтому в литературе этот
критерий называется, то критерием Вилкоксона, то критерием Манна-Уитни. Этот
критерий целесообразно использовать, когда объемы получаемых выборок малы, и
использование других критериев неправомерно.
Приводимые ниже выкладки
иллюстрируют подход к построению критериев, использующих статистики, связанные
не с самими выборочными значениями, а с их рангами.
Пусть в нашем распоряжении оказались
две выборки объема n и m значений. Построим из них общий вариационный ряд, и
каждому из этих значений сопоставим его ранг (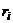 ), т.е. порядковый номер, который
оно занимает в ранжированном ряду. Если справедлива нулевая гипотеза, то любое
распределение рангов равновероятно, а общее число всевозможных комбинаций
рангов при заданных n и m равно числу сочетаний из N=n+m элементов по m.
), т.е. порядковый номер, который
оно занимает в ранжированном ряду. Если справедлива нулевая гипотеза, то любое
распределение рангов равновероятно, а общее число всевозможных комбинаций
рангов при заданных n и m равно числу сочетаний из N=n+m элементов по m.
Критерий Вилкоксона основан на
статистике
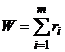 . (26)
. (26)
Формально для проверки нулевой
гипотезы необходимо подсчитать все возможные комбинации рангов, при которых
статистика W принимает значения равные или меньшие тому, которое получено для
конкретного ранжированного ряда, и найти отношение этого числа к общему числу
возможных комбинаций рангов по обоим выборкам. Сравнение полученного значения с
выбранным уровнем значимости позволит принять или отвергнуть нулевую гипотезу.
Разумность такого подхода состоит в том, что если одно распределение смещено
относительно другого, то это проявится в том, что маленькие ранги должны
соответствовать, в основном, одной выборке, а большие - другой. В зависимости
от этого соответствующие суммы рангов должны быть маленькими или большими в
зависимости от того, какая альтернатива имеет место.
Необходимо проверить гипотезу об
одинаковости функций распределения, характеризующих оба метода измерения, с
уровнем значимости =0,05.
В данном примере n = 3, m = 2, N = 2+3 = 5,
а сумма рангов, соответствующих измерениям по методу В равна 1+3 = 4.
Выпишем все 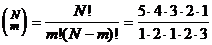 =10
возможных распределений рангов и их суммы:
=10
возможных распределений рангов и их суммы:
Ранги: 1,2 1,3 1,4 1,5 2,3 2,4 2,5
3,4 3,5 4,5
Суммы: 3 4 5 6 5 6 7 7 8 9
Отношение числа комбинаций рангов,
сумма которых не превосходит полученного значения 4 для метода В, к общему
числу возможных комбинаций рангов равно 2/10=0,2>0,05, так что для этого
примера нулевая гипотеза принимается.
При малых значениях n и m проверку
нулевой гипотезы можно осуществлять непосредственным подсчетом числа комбинаций
соответствующих сумм рангов. Однако для выборок большого объема это становится
практически невозможным, поэтому была получена аппроксимация для статистики W,
которая , как оказалось, асимптотически стремится к нормальному распределению с
соответствующими параметрами. Мы проведем расчет этих параметров, чтобы
проиллюстрировать подход к синтезу статистических критериев, основанных на
рангах. При этом мы воспользуемся результатами, приведенными в главе 37.
Пусть W -сумма рангов,
соответствующих одной из выборок, например, той, что имеет объем m. Пусть 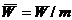 - среднее
арифметическое этих рангов. Математическое ожидание величины
- среднее
арифметическое этих рангов. Математическое ожидание величины 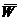 равно
равно
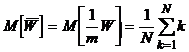 ,
,
так как при нулевой гипотезе ранги
элементов выборки объемом m представляют собой выборку из конечной совокупности
1, 2,...,N (N=n+m). Известно, что
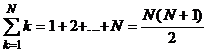 ,
,
поэтому 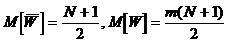 .
.
При вычислении дисперсии 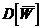 воспользуемся
тем фактом, что сумма квадратов рангов общего ранжированного ряда,
составленного из значений обоих выборок, равна
воспользуемся
тем фактом, что сумма квадратов рангов общего ранжированного ряда,
составленного из значений обоих выборок, равна
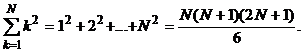
С учетом полученных ранее
соотношений для оценки дисперсий генеральных совокупностей и выборок имеем
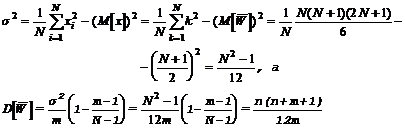
Отсюда следует, что
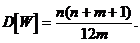
Было показано, что статистика
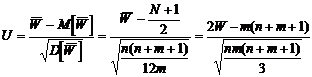 (27)
(27)
для больших n и m имеет
асимптотически единичное нормальное распределение.
Рассмотрим пример. Пусть для двух
возрастных групп получены данные о полярографической активности фильтрата
сыворотки крови. Необходимо с уровнем значимости =0,05 проверить гипотезу о том, что
выборки взяты из генеральных совокупностей, имеющих одинаковые функции
распределения. Сумма рангов для первой выборки равна 30, для второй - 90.
Проверкой правильности подсчета сумм рангов является выполнение условия 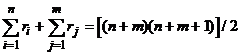 . В нашем
случае 30+90=(7+8)(7+8+1):2=120. По формуле (27), используя сумму рангов второй
выборки, имеем
. В нашем
случае 30+90=(7+8)(7+8+1):2=120. По формуле (27), используя сумму рангов второй
выборки, имеем
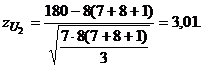
Если использовать сумму рангов для
первой выборки, то получим значение 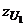 =-3,01. Так как вычисленная
статистика имеет единичное нормальное распределение, то, естественно, что и в
первом, и во втором случае нулевая гипотеза отвергается, так как критическое
значение для 5% уровня значимости равно по модулю 1,96.
=-3,01. Так как вычисленная
статистика имеет единичное нормальное распределение, то, естественно, что и в
первом, и во втором случае нулевая гипотеза отвергается, так как критическое
значение для 5% уровня значимости равно по модулю 1,96.
При использовании критерия
Вилкоксона определенные трудности возникают, когда в обоих выборках встречаются
одинаковые значения, так как при этом использование приведенной выше формулы
приводит к уменьшению мощности критерия, иногда очень существенному.
Чтобы для таких случаев свести
ошибки к минимуму целесообразно пользоваться следующим эмпирическим правилом.
Первый раз, когда встречаются одинаковые значения, принадлежащие разным
выборкам, то, какое из них в вариационном ряду поставить первым, определяется
случайно, например, подбрасыванием монеты. Если таких значений несколько, то,
определив случайно первое, остальные равные значения из обоих выборок чередуют
через одно. В тех же случаях, когда встречаются и другие равные значения,
поступают так. Если в первой группе равных значений первым случайно было
выбрано значение из одной какой-то выборки, то в следующей группе равных
значений первым выбирается значение из другой выборки и т.д.
. Критерии для проверки случайности
и оценки резко выделяющихся наблюдений
Довольно часто данные получают
сериями во времени или пространстве. Например, в процессе проведения
психофизиологических экспериментов, которые могут длиться несколько часов,
несколько десятков или сотен раз, измеряется латентный (скрытый период) реакции
на предъявляемый зрительный стимул, или в географических обследованиях, когда
на площадках, расположенных в определенных местах, например, вдоль опушки леса,
подсчитывается число растений некоторого вида и т.д. С другой стороны, при
вычислении различных статистик предполагается, что исходные данные независимы и
одинаково распределены. Поэтому интерес представляет проверка этого
предположений.
Сначала рассмотрим критерий для
проверки нулевой гипотезы о независимости одинаково нормально распределенных
величин. Таким образом, этот критерий является параметрическим. Он основан на
расчете среднего квадратов последовательных разностей
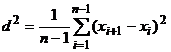 . (28)
. (28)
Если ввести новую статистику 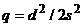 , то, как
известно из теории, при справедливости нулевой гипотезы статистика
, то, как
известно из теории, при справедливости нулевой гипотезы статистика
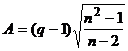 (29)
(29)
для n>10 распределена
асимптотически по стандартному нормальному распределению.
Рассмотрим пример. Приведены времена
реакции (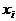 )
испытуемого в одном из психофизиологических экспериментов.
)
испытуемого в одном из психофизиологических экспериментов.
Имеем: 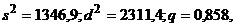 откуда
откуда
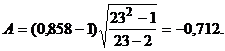
Так как для =0,05
критическое значение равно 1,96, нулевая гипотеза о
независимости полученного ряда принимается с выбранным уровнем значимости.
Другой вопрос, который часто
возникает при анализе экспериментальных данных состоит в том, что делать с
некоторыми наблюдениями, которые резко отличаются от основной массы наблюдений.
Такие резко выделяющиеся наблюдения могу возникнуть при методических ошибках,
ошибках вычислений и т.д. Во всех тех случаях, когда экспериментатору известно,
что в наблюдение вкралась ошибка, он должен исключать это значение независимо
от его величины. В других случаях существует только подозрение на ошибку, и
тогда необходимо использовать соответствующие критерии, с тем чтобы принять то
или иное решение, т.е. исключить или оставить резко выделяющиеся наблюдения.
В общем случае вопрос ставится так:
произведены ли наблюдения над одной и той же генеральной совокупностью или
некоторая часть или отдельные значения относятся к другой генеральной
совокупности?
Конечно, единственным надежным
способом для исключения отдельных наблюдений является тщательное изучение
условий, при которых эти наблюдения получены. Если по каким-то причинам условия
отличались от стандартных, то наблюдения должны быть исключены из дальнейшего
анализа. Но в определенных случаях имеющиеся критерии, хотя и несовершенные,
могут оказать существенную пользу.
Мы приведем здесь без доказательства
несколько соотношений, которые могут быть использованы для проверки гипотезы о
том, что наблюдения производятся случайно над одной и той же генеральной
совокупностью. Имеем
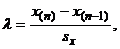 (30)
(30)
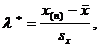 (31)
(31)
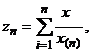 ( 32)
( 32)
где 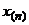 - подозреваемое на “выброс”
наблюдение. Если все значения ряда проранжировать, то в нем резко выделяющееся
наблюдение будет занимать n-е место.
- подозреваемое на “выброс”
наблюдение. Если все значения ряда проранжировать, то в нем резко выделяющееся
наблюдение будет занимать n-е место.
Для статистики (30) протабулирована
функция распределения. Приведены критические точки этого распределения для
некоторых n.
Критическими значениями для
статистики (31) в зависимости от n являются
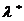 =4,0; 6<n<100.
=4,0; 6<n<100.
=4,5; 100<n<1000.
=5,0; n>1000.
В формуле (31) предполагается, что и вычисляются
без учета подозреваемого наблюдения.
Со статистикой (32) дело обстоит
сложнее. Для нее показано, что в случае, если 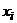 распределены равномерно, то
математическое ожидание и дисперсия
распределены равномерно, то
математическое ожидание и дисперсия 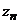 имеют вид:
имеют вид:
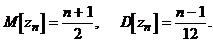
Критическую область образуют малые
значения , которые
соответствуют большим значениям . Если интересует проверка на
“выброс” наименьшего значения 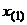 , то сначала преобразуют данные,
чтобы они имели равномерное распределение на интервале
, то сначала преобразуют данные,
чтобы они имели равномерное распределение на интервале 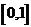 , а затем
берут дополнение этих равномерных величин до 1 и проверяют по формуле
(32).
, а затем
берут дополнение этих равномерных величин до 1 и проверяют по формуле
(32).
Рассмотрим использование приведенных
критериев для следующего проранжированного ряда наблюдений:
3,4,5,5,6,7,8,9,9,10,11,17. Необходимо решить, следует ли отвергнуть наибольшее
значение 17.
Имеем: 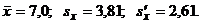 По формуле
(30) =(17-11)/3,81=1,57,
и нулевая гипотеза должна быть принята при =0,01. По формуле (31)
По формуле
(30) =(17-11)/3,81=1,57,
и нулевая гипотеза должна быть принята при =0,01. По формуле (31) 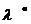 =(17-7,0)/2,61=3,83,
и нулевая гипотеза также должна быть принята. Для использования третьего
критерия найдем =5,53, тогда
=(17-7,0)/2,61=3,83,
и нулевая гипотеза также должна быть принята. Для использования третьего
критерия найдем =5,53, тогда
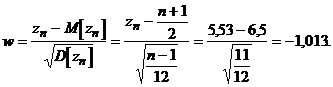
Статистика w распределена нормально
с нулевым средним и единичной дисперсией, и, следовательно нулевая гипотеза при
=0,05
принимается.
Сложность использования статистики
(32) состоит в необходимости иметь априорную информацию о законе распределения
выборочных значений, а затем аналитически преобразовать это распределение в
равномерное на интервале .
Литература
1. Елисеева И.И. Общая теория
статистики: учебник для вузов / И.И. Елисеева, М.М. Юзбашев; под ред. И.И.
Елисеевой. - М.: Финансы и статистика, 2009. - 656 с.
. Ефимова М.Р. Практикум по общей
теории статистики: учебное пособие для вузов / М.Р. Ефимова и др. - М.: Финансы
и статистика, 2007. - 368 с.
. Общая теория статистики:
Статистическая методология в изучении коммерческой деятельности: учебник для
вузов / О.Э. Башина и др.; под ред. О.Э. Башиной, А.А. Спирина. - М.: Финансы и
статистика, 2008. - 440 с.
. Салин В.Н. Курс теории статистики
для подготовки специалистов финансово-экономического профиля: учебник / В.Н.
Салин, Э.Ю. Чурилова. - М.: Финансы и статистика, 2007. - 480 с.
. Социально-экономическая
статистика: практикум: учебное пособие / В.Н. Салин и др.; под ред. В.Н.
Салина, Е.П. Шпаковской. - М.: Финансы и статистика, 2009. - 192 с.
. Статистика: учебное пособие / А.В.
Багат и др.; под ред. В.М. Симчеры. - М.: Финансы и статистика, 2007. - 368 с.
. Статистика: учебник / И.И.
Елисеева и др.; под ред. И.И. Елисеевой. - М.: Высшее образование, 2008. - 566
с.
. Теория статистики: учебник для
вузов / Р.А. Шмойлова и др.; под ред. Р.А. Шмойловой. - М.: Финансы и
статистика, 2007. - 656 с.
. Шмойлова Р.А. Практикум по теории
статистики: учебное пособие для вузов / Р.А. Шмойлова и др.; под ред. Р.А.
Шмойловой. - М.: Финансы и статистика, 2007. - 416 с.