Автоматизация документооборота в учебных заведениях
Содержание
Введение
. Общая часть
.1 Цель и назначение разработки проекта
.2 Анализ существующих технологий
.3 Выбор средств и технологий
. Практическая часть
.1 Руководство пользователя
. Описание и расчет трудоемкости работ и затрат на разработку
Заключение
Список используемых источников
Приложение А
Введение
Целью данной выпускной квалификационной работы является разработка и
создание информационной системы, которая позволит работать с данными учащихся
по успеваемости, которая предназначена для преподавателей и администрации
Хабаровского машиностроительного техникума. Программный продукт сможет
обеспечить просмотр информации, своевременное и корректное внесение изменений,
быстрый и удобный поиск необходимых сведений в базе данных.
В выпускной квалификационной работе необходимо разработать:
- техническое задание;
- информационную базу данных;
- интерфейс программы;
- запросы пользователя;
- программный продукт;
- программную документацию;
- пояснительную записку.
В соответствии с целью были сформулирован следующий ряд задач:
- выполнить анализ требований и определить степень функциональности
разрабатываемой системы;
- выполнить обзор и провести анализ существующих систем
обработки и визуализации данных;
- определить задачи, технологию и программные средства
разработки;
- спроектировать и разработать информационную систему для
учебного заведения;
В первом разделе описаны некоторые из имеющихся на рынке технологий и
программных решений, предназначенных для обработки данных, сделан анализ их
преимуществ и недостатков, которые способствовали выбору конкретного
технического решения, рассматривается средства и технологии, язык
программирования, программные решения для создания БД.
Во втором разделе описывается процесс поэтапной разработки информационной
системы.
В третьем разделе сделан расчет затрат на разработку определение
трудоемкости работ по реализации проекта.
Заключение включает в себя подведение итогов, результаты проведенной
работы по разработке информационной системы.
1. Общая часть
Разработка программного продукта - информационная система "База
данных "Успеваемость студентов КГБОУ "СПО "ХМТ" выполняется
в соответствии с заданием на выпускную квалификационную работу по специальности
230111 по дисциплине "Компьютерные сети".
.1 Цель и
назначение разработки проекта
Программное решение, разрабатываемое в данной работе, предназначено для
осуществления частичной автоматизации документооборота внутри учебного
заведения - контроля успеваемости учащихся. Актуальность разработки обусловлена
тем, что на данный момент значительно усложнен процесс анализа успеваемости
студентов в связи большим количеством дисциплин и, как следствие, изучением
большого количества документации: зачетных книжек, журналов успеваемости по
предметам и т.п. В связи с данными условиями существует потребность в
разработке и внедрении в учебный процесс специализированных
программно-технических средств, способных оптимизировать и повысить уровень
оперативности процесса контроля успеваемости студентов.
На данный момент для документооборота в учебных заведениях, в основном,
используются программные средства прикладных программ очень обобщенного и
универсального характера, не учитывающие специфику конкретного учебного
заведения, либо обладающие избыточной функциональностью для решения данной задачи,
в связи с чем их использование представляется не вполне рациональным.
Вследствие этого, на осуществление контроля и анализа уровня успеваемости
учащихся затрачивается большое количество рабочего времени. При помощи
разрабатываемого в настоящей работе программного продукта, ориентированного на
работу в конкретной предметной области, появится возможность оптимизировать
процесс контроля успеваемости студентов техникума.
Использование базы данных успеваемости студентов позволит освободить от
трудоемкого процесса изучения большого количества информации, списка студентов
техникума и их результатов учебы, обеспечит оперативный и качественный контроль
успеваемости, чем поспособствует повышению эффективности учебного процесса.
Описание
технологического процесса
Перед каждой сессией составляется реестр успеваемости студентов. В
соответствии с этим реестром, составляется список студентов, имеющих
задолженности по предметам, либо пропуски занятий. В ходе составления списков и
реестров используется информация из журналов успеваемости групп и зачетных
книжек студентов. Если данную информацию вносить в реестр оперативно, то это
позволит в любой момент иметь актуальную информацию о неуспевающих студентах и
позволит избежать трудоемкого рутинного процесса накануне сессий или
контрольных срезов.
Исходя из выше описанной последовательности процесса, можно выделить
следующие задачи пользователей программного продукта:
. Внесение и, при необходимости, модификация информации об успеваемости в
базу данных.
. Отбор и группировка данных о неуспевающих студентах с визуализацией и
конкретизацией информации.
Требования
к программной реализации системы
Программный продукт должен выполнять следующие функции: хранение
информации, возможность просмотра списка всех неуспевающих студентов, а также
выполнить поиск по фамилии студента, сортировку.
Требования к функциональным характеристикам
"Базы данных "Успеваемость студентов КГБОУ "СПО
"ХМТ" должна выполнять следующие функции:
хранение информации об успеваемости студентов;
просмотр информации;
добавление данных в имеющийся список;
поиск информации;
удаление информации;
редактирование данных;
сортировка списка.
Требования надежности и условий эксплуатации. Требования к
параметрам и составу технических средств
Требования надежности. Для обеспечения надежного использования и
функционирования базы данных необходимо применение следующих методов:
- контроль со стороны базы данных, за корректностью информации вводимой
пользователем;
- восстановление работоспособности базы данных в случае возникновения
сбоев.
Требования к условиям эксплуатации. Для эксплуатации данного программного
продукта предъявляются следующие требования к уровню подготовки пользователей:
пользователь должен обладать общим представлением о работе на
персональной ЭВМ типа IBM PC;
База данных успеваемости студентов техникума основана на применении
типовых программных средств и может быть освоена в кратчайшие сроки в процессе
ее использования.
Для проведения периодических определенных сервисных работ по обслуживанию
программы требуются услуги программиста по сопровождению, удовлетворяющего
следующим требованиям:
знание аппаратного-технического состава компьютера;
навыки и опыт администрирования ОС MicrosoftWindowsME/NT/2000/ 2003/XP/7;
знание особенностей работы с пакетом MicrosoftOffice, в частности с
MSAccess 2003.
Требования к составу и параметрам технических средств. Для обеспечения
эффективной работы программы необходимо оборудование, требования к
характеристике которого представлены в Таблице 1.
Таблица 1.Системные требования, предъявляемые к рабочей станции
программного продукта
|
Требования
|
Конфигурация технических
средств программного комплекса
|
|
Windows ХР
|
Windows 7
|
MS Office 2003
|
|
Минимальная частота
процессораMHz
|
1400
|
2800
|
2400
|
|
Рекомендуемая частота
процессора MHz
|
2000
|
3400
|
3400
|
|
Минимальный объем
оперативной памяти, Mb
|
512
|
1500
|
1500
|
|
Рекомендуемый объем
оперативной памяти, Mb
|
2000
|
4000
|
4000
|
|
Пространство на диске, Gb
|
20
|
100
|
60
|
Рабочие станции могут работать под управлением таких операционных систем
MicroSoftWindows (определяется требованиями MicroSoftОffice 2003) как:
- MicroSoft Windows 2000 Professional;
Microsoft Windows XP (Home/Professional)
- MicrosoftWindows 7;
Для хранения БД потребуется приблизительно 50 Мb дисковой памяти.
.2 Анализ
существующих технологий
Информационной системой называется совокупность программных и технических
средств, выполняющих хранение, группировку и анализ большого количества
информации. [5]
Информационные системы бывают электронными и не электронными.
Неэлектронными информационными системами могут считаться:
картотека в библиотеке;
реестры регистратуры в больнице;
и т.п.
Электронными информационными системами можно назвать:
базу данных в отделе кадров;
книжку кон 6тактов в моб. телефоне;
ресурсы сети Интернет.
Информационные системы подразделяются на две группы:
. Системы с индивидуальным целевым назначением и областью применения.
. Системы, которые являются частью какой-нибудь автоматизированной
системы управления. Они могут являться важнейшим компонентом систем
автоматизированного проектирования, интеллектуальных систем научных
исследований.
К информационным системам с индивидуальным назначением относятся
информационные поисковые и информационно-справочные системы.[7]
В задачи информационно-справочных систем входит обеспечение пользователя
входной и результирующей информацией в привычном для него виде - решение задач
планирования, управления, разработки и подготовки проектов производства и
научных исследовательских работ по их постановке и имеющимся исходным данных,
не зависимо от степени сложности в режиме диалога с ЭВМ, с использованием
профессионального опыта и с принятием решений одновременно по нескольким
критериям.
Системы 2-й группы, делятся на три отдельных класса:
расчетно-логические (системы принятия решения),
интеллектуальные - диалоговые (вопрос/ответ),
экспертные системы.
Первый класс - системы принятия решения представляют собой системы,
которые используются программой, реализующей модели принятия решения для
конкретных задач, возникающих в профессиональной деятельности людей. Сущность
задачи заключается в выборе некоторого подмножества среди имеющегося множества
альтернатив или в упорядочивании и систематизации этих альтернатив.[4]
Интеллектуально-диалоговые системы используются при поиске методов
решения задач интеллектуального типа с применением достижений в сфере
информационных технологий относительно использования баз данных и баз знаний.
Экспертной системой считается система способная выполнять функции
эксперта для решения определенных задач.
По степени автоматизации системы подразделяют на:
информационные, информационно советующие;
управляющие;
самонастраивающиеся управляющие системы.[9]
Другими словами, можно констатировать существование трех видов
информационных систем:
База данных - система, применяемая для хранения большого количества
структурированной информации определённого типа. К базам данных справедливо
можно отнести следующие примеры информационных систем:
каталог книг в библиотеке;
регистратура в больниц;
книга контактов в мобильном телефоне;
база данных сотрудников в отделе кадров.
Базой знаний считают систему, используемую для хранения больших объемов
неструктурированной разнотипной информации.[5] К базам знаний относят такие
информационные системы, как:
книги в библиотеке;
информация в сети Интернет.
Под информационно-аналитической системой понимают систему,
предназначенную как для хранения, так и для анализа и обработки хранимой
информации:
- Exсel;
Access;
STATISTICA;
SPSS;
1С бухгалтерия и др.
В рамках информационной системы находится вся необходимая информация для
выработки и принятия решений без воздействия на само существо решений, т.е.
после проведение анализа принятие решения осуществляется человеком.[9]
Электронные информационные системы подразделяются на два класса в
зависимости от способа хранения информации:
несетевые информационные системы, которые работают в соответствии с
технологией файл-сервер. Реализация работы данных систем ограничена одним
отдельно стоящим компьютером, который не подключен к компьютерной сети (SPSS,
STATISTICA, Excel);
сетевые информационные системы, реализованные по технологии
клиент-сервер. Подобные системы работают на подключённом к сети (локальной или
Интернет) компьютере.
Для технологии "клиент-сервер" является характерным разделение
функций приложения на три функциональных группы:
группа ввода и отображения данных (организация взаимодействие с
пользователем);
группа прикладных функций, необходимых для данной предметной области;
группа функций управления ресурсами (базой данных, файловой системой и
т.д.);
Поэтому, любое приложение включает следующий набор компонентов:
компонент представления данных;
прикладной компонент;
компонент для управления ресурсом;
Установление связи между компонентами реализуется по строго определенным
правилам, которые называют "протоколом взаимодействия".[7]
Самым значимым отличием технологии клиент-сервер от файл-серверной
технологии является способ хранения информации. Суть файл-серверной технологии
заключается в том, что интерфейс системы и данные, которые она обрабатывает,
хранятся на одном компьютере.[4]
При клиент-серверной технологии клиентами сети являются компьютеры
пользователей, которые к этой сети подключены. Доступ к серверу клиенты
получают через сеть.
Сервер сети - это основной компьютер, управляющий данной сетью. Все
ресурсы, которыми располагает сервер, доступны клиентам сети, и любое изменение
данных на сервере сразу видят все клиенты сети.
В информационной системе, построенной по клиент-серверной технологии,
информация хранится на сервере, а на клиентских компьютерах хранится интерфейс
информационной системы, через который пользователи информационной системы имеют
возможность получать доступ к данным.
Таблица 2 - Сравнение свойств технологий файл-сервер и
клиент-сервер
|
Преимущества и недостатки
технологии Файл-Сервер:
|
Преимущества и недостатки
технологии Клиент-Сервер:
|
|
+
|
простота разработки;
|
+
|
простота синхронизации
данных;
|
|
+
|
независимость компьютера от
сети;
|
+
|
небольшая цена аппаратного
обеспечения (мощным/дорогим должен быть только сервер);
|
|
+
|
высокая защищенность от
несанкционированного доступа;
|
+
|
возможность оперативного
изменения структуры данных;
|
|
-
|
неоперативное обновление
данных на нескольких компьютерах;
|
-
|
низкая защищенность от
несанкционированного доступа;
|
|
-
|
высокая стоимость
компьютеров;
|
-
|
зависимость от компьютерной
сети;
|
|
-
|
Сложность и трудоемкость
изменения структуры данных.
|
-
|
общая высокая стоимость.
|
С точки зрения разработки и использования, любая из информационных систем
или баз данных обладает тремя основными компонентами:
файл данных - расположенный на сервере или локальном компьютере файл, в
котором содержится структура данных. Структурой данных считаются таблицы,
фильтры, запросы, а также пользовательские функции, сохраненные процедуры,
триггеры и диаграммы;
объект связи - компонент, принадлежащий языку программирования, который
связывает файл данных с интерфейсной частью информационной системы или базы
данных;
интерфейс информационной системы - это комплекс функциональных средств,
организовывающий взаимодействие системы с конечным пользователем или другой
системой. Он может использоваться как на сервере, так и на клиентском
компьютере. [5]
Понятие и
виды баз данных
База данных представляет собой комплекс организованных специальным
образом данных, которые находятся на хранении в памяти вычислительной системы и
характеризуют состояние объектов и виды их взаимосвязей в отдельной предметной
области применения.
Банк данных - это система специальным образом организованных данных (баз
данных), технических, языковых, программных, организационно-методических
средств и методов, предназначенных для централизованного накопления с
последующим коллективным многоцелевым использованием данных.[4]
Как правило, базы данных создаются не с целью решения какой-либо
конкретной задачи одного пользователя, а для многократного и многоцелевого
использования. Необходимо стремиться, чтобы весь спектр информации, описывающей
предметную область, вносилась в базу данных однократно, накапливалась и
содержалась в актуальном состоянии централизовано, а все пользователи, которым
необходима эта информация, должны иметь к ней доступ и возможность с ней
работать.
Базы данных - это организованные по определенным правилам данные, или
системы взаимосвязанных данных, целостность которых организовывается и
поддерживается при помощи специальных программных средств.
Для функционирования банка данных необходимо использование специальных
языковых и наличие программных средств (называемых СУБД), призванных облегчить
пользователю выполнение всех операций, по организации хранения данных, доступа
к ним и их корректировки.[9]
База данных выступает основной компонентой банка данных, и преобладающая
часть классификационных признаков зависят именно от нее.
По форме представления информации системы делятся на аудио и визуальные,
а также мультимедиа системы. Эта классификация характеризует вид, в котором
информация хранится в базе данных и выдается из нее пользователям: в форме
звука, изображения, или существует возможность использовать разные формы
отображения данных. Понятие "изображение" здесь понимается в широком
смысле - в этом качестве может быть представлен как символьный текст, так и
неподвижное графическое изображение (чертежи, рисунки, фотографии,
географические карты и т.п.).
В зависимости от характера организации данных, БД могут быть
неструктурированными, частично структурированными и структурированными. Эта
классификация относится к информации, которая представлена в символьном виде.
Примером неструктурированной БД могут быть базы, организованные в виде
семантических сетей. К частично структурированным базам можно отнести БД в виде
текста или цифровой информации, а также гипертекстовые системы. Для
структурированных БД требуется предварительное проектирование и описание
структуры БД. Только после выполнения этих процедур такие базы данных могут
заполняться данными для обработки и хранения. [8]
Структурированные БД, в зависимости от типа используемой модели, могут
быть:
иерархическими,
сетевыми,
реляционными,
смешанными,
мультимодельными.
Данная классификация по типу модели справедлива не только для баз данных,
но и для СУБД. [5]
Для структурированных БД характерным является наличие нескольких уровней
информационных единиц, которые входят одна в другую. В большинстве
структурированных систем поддерживаются уровни поля, записи и файла.
Наименьшей семантической единице информации соответствует поле;
совокупность полей или/и других, более сложных информационных единиц,
используемых в конкретной СУБД, образуют запись, а из множества однотипных
записей создается файл базы данных. Большинство современных СУБД способны в явном
виде поддерживать также и уровень базы данных, реализованных как совокупность
взаимосвязанных файлов БД.[7]
Иерархические и сетевые модели отличаются тем, что между информационными
единицами (записями, размещенными в разных файлах) могут формироваться
определенные связи.
По способу организации хранения данных и характеру обращения к ним, базы
данных могут быть локальными (персональными), общими (интегрированными,
централизованными) и распределенными.
Персональная (локальная) база данных - это БД, которая предназначена для
локального использования одним пользователем. Такие БД могут создаваться
самостоятельно каждым пользователем, а могут быть извлечены из общей БД.
Для интегрированных и распределенных БД характерно наличие возможности
одновременного обращения к одной и той же информации нескольких пользователей
(параллельный/многопользовательский, режим доступа).[6]
Кроме этого, распределенные БД обладают характерными особенностями,
связанными с тем, что разные части БД физически могут храниться на разных ЭВМ,
а логически, для пользователя, они представляют собой единый информационный
массив.
Реляционная модель данных конкретной предметной области - это набор
отношений, которые могут изменяться во времени. При формировании информационной
системы, с помощью совокупности отношений можно организовывать хранение данных
об объектах предметной области и осуществлять моделирование связей между ними.
Важнейшим понятием является отношение, которое представляет собой
двумерную таблицу с некоторыми данными.
Сущность - это любой объект, данные о котором находятся в базе данных.
Данные о сущности находятся в отношении.[5]
Свойства, характеризующие сущность, представлены в атрибутах. Каждый
атрибут в структуре таблицы именуется и ему соответствует заголовок столбца
таблицы.
Для реляционной модели характерна ориентация на организацию данных
посредством двумерных таблиц. Каждая из таких реляционных таблиц представляет
собой двумерный массив и имеет следующие свойства:
Каждый элемент таблицы - это одним элемент данных.
Каждый столбец имеет свое уникальное имя.
В таблице отсутствуют одинаковые строки.
Все столбцы в таблице являются однородными, то есть в столбце все
элементы имеют одинаковый тип.
Порядок расположения столбцов и строк может быть произвольным.
Между различными таблицами, в зависимости от структуры БД, может быть
установлено отношение "один ко многим", которое обозначает, что
каждой записи в одной таблице соответствует несколько записей из другой
таблицы, или отношение "многие ко многим", в соответствии с которым
одной записи в первой таблице соответствует много записей из второй и наоборот.
Тип отношения "многие ко многим" реализуется с помощью двух и более
отношений "один ко многим".[9]
СУБД реляционного типа, которые ориентированы на создание систем
операционной обработки данных, являются менее эффективными при выполнении задач
аналитической обработки информации, чем многомерные базы данных. Причин этому
несколько: во-первых, это наличие достаточно жестких ограничений, которые
накладывает существующая реализация языка SQL. В качестве пример такого реально
существующего ограничения можно привести предположение о том, что в реляционной
базе данные неупорядочены (или точнее сказать, упорядочены случайным образом).
При этом, для их упорядочивания при каждом обращении к базе данных необходимы
дополнительные затраты времени на проведение сортировки. В аналитических
системах занесение и выборка данных происходит большими порциями. Но данные,
после того как они занесены в базу данных, в течение длительного периода времени
остаются неизменными.[2] И здесь более эффективным и рациональным оказывается
хранение данных в виде частично денормализованных таблиц, когда для увеличения
скорости и производительности могут сохраняться не только детализированные
значения, но предварительно вычисленные и агрегированные. А для навигации и
выборки могут применяться специализированные методы индексации и адресации,
которые основаны на предположении о малоподвижности и малой изменчивости данных
в базе данных. Иногда такой способ организации данных, называют
предвычисленным, указывая тем самым, на то, что он отличается от
нормализованного реляционного подхода, в котором предполагается динамическое
вычисление каких-либо итогов (агрегация) и установление между реквизитами из
разных таблиц определенных связей (операции соединения).[7]
Одной из важнейших задач при проектировании и эксплуатации систем
обработки данных (СОД), является обеспечение целостности данных. Проблема
целостности заключается в обеспечении поддержания правильности данных, содержащихся
в базе данных в любой момент времени. Понятие целостности можно сформулировать
как непротиворечивость и актуальность информации, ее защищенность от
несанкционированного изменения и разрушения.
Целостность входит в ряд аспектов информационной безопасности вместе с
доступностью и возможностью получить необходимую информационную услугу, и
конфиденциальностью - организацией защиты от несанкционированного прочтения или
извлечения.[5]
Целостность данных реализуется путем описания набора специальных предложений,
которые называются "ограничения целостности". Ограничения целостности
представляют собой формулирование допустимых значениях для отдельных
информационных единиц и связей между ними. Определяются эти ограничения, как
правило, в зависимости от особенностей предметной области. Выполнение
ограничений целостности выполняется при осуществлении операций над БД.
Пользователей БД можно разделить на 3 категории: администрация БД,
прикладные программисты БД и конечные пользователи. Каждая группа пользователей
имеет свой взгляд на БД и использует свою терминологию при выражении своих
информационных потребностей и решении задач.
Для обеспечения адекватного способа восприятия БД каждой из категорий ее
пользователей и с целью удовлетворения их информационных потребностей было
решено ввести иерархию пользовательских представлений или, другими словами,
уровни абстракции данных. К числу важнейших функций СУБД, также, относится
поддержание всех этих уровней абстракции данных. Таким образом, архитектура
СУБД является многоуровневой. Для реализации каждого из уровней абстракции
данных используется соответствующая функциональная компонента СУБД. Из этого
следует, что архитектура СУБД представляет собой совокупность ее функциональных
компонент, а также комплекс средств по обеспечению их взаимодействия как друг с
другом, так и с пользователями БД.[9]
В 1975 г. Американским национальным институтом стандартизации (ANSI) была
предложена 3-х уровневая модель архитектуры СУБД с поддержкой 3-х
соответствующих уровней абстракции данных - концептуального, внутреннего и
внешнего. Данную модель можно считать универсальной в том смысле, что под ее
описание подходит архитектура практически любой СУБД. [4]
Каждый из уровней архитектуры СУБД предполагает поддержку соответствующей
модели БД, отражающей интересы и потребности всех категорий пользователей в
одной и той же БД.
Таким образом, совокупность моделей БД, которые соответствуют уровням
абстракции данных определенной предметной области, и называется архитектурой
БД.
Так, концептуальный уровень архитектуры СУБД служит для поддержания
единой точки зрения на БД всеми категориями пользователей и общей для всех ее
приложений, то есть, независимо от них. Именно на среду концептуального уровня
и происходит отображение инфологической модели предметной области
использования. Схемой БД или концептуальной моделью БД называется представление
БД на концептуальном уровне. Она реализует интегрированное представление о
конкретной предметной области.
Для описания концептуальной модели в СУБД служит язык описания данных
(ЯОД). Поскольку концептуальный уровень архитектуры СУБД демонстрирует
логическую структуру БД, то схема БД также называется логической моделью БД.[7]
Внутренний уровень архитектуры СУБД необходим для поддержания
представления БД в среде хранения (на внешних запоминающих устройствах). Этот
уровень также называют физическим, поскольку именно на этом уровне
осуществляется представление базы данных полностью в
"материализованном" виде. Для описания БД на этом уровне используется
язык описания хранения данных (ЯОХД) СУБД и носит называние внутренней модели
БД. В этой модели включено описание размещения БД на внешнем ЗУ, а также методы
доступа к данным. Многие современные СУБД имеют объединенное описание
логической и физической моделей БД.
.3 Выбор средств
и технологий
Программные
решения для создания и работы баз данных
Система управления базами данных (СУБД) представляет собой
специализированный комплекс языковых и программных средств, назначением
которого является создание, ведение и организация совместного использования БД
одновременно несколькими пользователями. Традиционно СУБД различают по тому,
какая используется модель данных. Так, СУБД, работающие с реляционной моделью
данных, называют реляционными СУБД.[5]
В зависимости от языков общения, различают открытые, замкнутые и
смешанные системы управления БД.
В Открытых системах для обращения к БД применяется один из универсальных
языков программирования. Системы замкнутого типа обладают собственными языками
коммуникации с пользователями БнД.
Исходя из числа уровней в архитектуре, бывают одно-, двух- и
трехуровневые системы.
Архитектурным уровнем СУБД считают некий функциональный компонент,
механизмы которого используются для поддержки одного из уровней абстракции
данных (логического и физического уровня, а также внешний уровень -
"взгляд" пользователя).
В зависимости от функций, на выполнение которых ориентирована СУБД,
разделяют информационные и операционные системы. Информационные СУБД
обеспечивают организацию хранения информации и реализуют доступ к ней. Если
необходимо выполнять более сложную обработку, то для этого нужно создавать
специальные программы. [9]
В операционных СУБД выполняется достаточно сложная обработка, например,
организовывается автоматическое получение агрегированных показателей, не
хранящихся непосредственно в базе данных, возможно изменение алгоритмов
обработки и другие функции.
По сфере применения СУБД классифицируются на универсальные и
специализированные, или проблемно-ориентированные системы.
По показателю "мощность" СУБД выделяют "настольные" и
"корпоративные". Для настольных СУБД характерными чертами являются
относительно невысокие технические и аппаратные требования, невысокая
стоимость, ориентация на конечного пользователя. [5]
Корпоративные СУБД призваны обеспечивать работу в распределенной среде,
поддерживать высокую производительность, использовать коллективную работу при
проектировании систем. Системы данного класса обеспечены развитыми средствами
администрирования и обладают более широкими возможностями в задачах поддержания
целостности.
Среди широко известных среди корпоративных СУБД можно назвать Oracle,
Informix, Sybase, MS SQL Server, MSAccess, Progress и некоторые другие.
С помощью средств СУБД пользователи могут создать файлы БД, просматривать
их, вносить изменения, осуществлять поиск, создавать отчеты необходимой
произвольной формы. Также, поскольку запись структуры файлов БД на диске
осуществляется в его начале, есть возможность открытия, просмотра, выбора
данных и из чужого файла, который был кем-то создан программно или с помощью
средств СУБД. На сегодня создано уже много различных СУБД, обладающих
приблизительно одинаковыми возможностями.[9]
СУБД выполняют целый ряд важнейших функций, процесс исполнения которых
незаметен для конечного пользователя.
Рассмотрим некоторые наиболее важные их них.
). Организация и управление хранением данных.
Назначением данной функции является предоставление пользователям
возможности по осуществлению сохранения, извлечения и обновления информации. А
также подготовка необходимых массивов внешней памяти как для хранения данных,
которые непосредственно входят в БД, так и для дополнительных служебных
операций, как, например, ускорение доступа к данным.[8]
). Управление работой буферов оперативной памяти.
Как правило, СУБД оперируют БД, имеющими значительный размер; зачастую
этот размер может существенно превышать доступный объем оперативной памяти.
Если при обращении системы к элементу данных будет осуществляться обмен с
внешней памятью, то скорость работы всей системы будет эквивалентна скорости
работы устройства внешней памяти. Реальным способом увеличения этой скорости
будет буферизация данных в ресурсах оперативной памяти. В высокоэффективных
СУБД существует поддержка собственного набора буферов оперативной памяти с
наличием собственной дисциплины замены буферов. При осуществлении управления
буферами основной памяти появляется необходимость разработки и применения
согласованных алгоритмов буферизации, синхронизации и журнализации. Однако,
есть отдельное направление СУБД, которые ориентированы на постоянное
расположение всей БД в оперативной памяти.
). Управление словарями данных.
В своей работе СУБД пользуются специальным системным каталогом, который
еще называют словарем данных, предназначенным для поиска необходимых структур
данных вместе с их отношениями, помогая тем самым избежать кодирования в каждой
программе сложных взаимосвязей, поскольку любые программы доступ к данным
получают посредством СУБД.[5]
В словаре данных хранится информация, которая описывает данные в базе
данных. Каталог является доступным как для пользователей, так и для функций
СУБД. Обычно словарь данных содержит следующую информацию: имена, типы и
размеры элементов данных; имена связей; имена пользователей, которые имеют
права доступа к данным; ограничения поддержки целостности, накладываемые на
данные; концептуальная, внешняя и внутренняя схемы отображения между ними;
статистические данные, такие, как частота транзакций и значения счетчиков
обращений к объектам базы данных.[5]
В итоге, в СУБД обеспечивается абстракция данных, тем самым устраняется в
системе структурная зависимость и зависимость по данным.
) Журнализация.
Одним из основных требований, выдвигаемых к СУБД является обеспечение
надежного хранения данных в ресурсах внешней памяти. Надежность хранения заключается
в том, что СУБД должна обладать средствами и возможностью для восстановления
последнего согласованного состояния БД после любого программного или
аппаратного сбоя.
Чаще всего рассматриваются два варианта возможных аппаратных сбоев:
мягкие сбои, под которыми понимается внезапная остановка работы компьютера
(например, внезапное выключение питания), и так называемые жесткие сбои, для
которых характерна потеря информации на внешних носителях памяти.[9]
Для обеспечения возможности надежного хранения данных в БД требуется
избыточность хранения данных, при этом та часть информации, которая будет
использована при восстановлении, должна быть сохранена с особой надежностью.
Наиболее распространенным методом реализации такой избыточности информации
выступает ведение журнала изменений БД.
В данном случае журнал является особой частью БД, которая недоступна для
пользователей СУБД и которая обеспечена особо тщательной поддержкой (иногда
используется поддержка двух копий журнала, которые расположены на разных физических
носителях), в которой регистрируются все изменения в основной части БД.
На практике применяется стратегия "упреждающей" записи в журнал
(по протоколу WriteAheadLog - WAL). При этом способе запись о факте изменения
любого объекта БД должна быть записана во внешней памяти журнала раньше, чем
объект, подвергшийся изменению будет записан во внешней памяти основной части
БД. Если в СУБД при работе корректно соблюдаются процедуры протокола WAL, то с
помощью информации из журнала можно восстановить БД после любого сбоя или
критической ошибки. [6]
). Управление транзакциями.
Транзакция - это определенная последовательность операций или действий
над БД, являющихся с точки зрения СУБД как единое целое. Если транзакция
выполняется успешно, то СУБД фиксирует изменения БД во внешней памяти, в
противном случае ни одно из этих изменений никак не будет отражено в состоянии
БД. Использование понятия транзакции необходимо в целях поддержания логической
целостности БД.
В качестве примеров простых транзакций можно привести операции
добавления, обновления или удаления сведений о некоем объекте в базе данных.
Сложная же транзакция формируется тогда, когда требуется внести в базу данных
сразу несколько изменений. Вызов инициализации транзакции может быть
инициирован как отдельным пользователем, так и прикладной программой.
Понятие транзакции является обязательным условием даже для
однопользовательских СУБД, хотя более существенным предстает в
многопользовательских СУБД. [7]
). Управление безопасностью.
В процессе работы СУБД создается система безопасности, которая должна
обеспечивать защиту и конфиденциальность данных в рамках БД. Правилами
безопасности устанавливается, кто из пользователей может получить доступ к БД,
к каким из элементов данных пользователю предоставлен доступ, какие операции с
данными пользователь может совершать. Данная функция в многопользовательских
системах имеет большое значение, поскольку в них несколько пользователей сразу
могут одновременно получать доступ к данным. [3]
). Поддержка языков баз данных.
При работе с базами данных необходимо использование специальных языков,
называемых языками баз данных. В СУБД, созданных в последнее время, как
правило, поддерживается единый интегрированный язык, который содержит в себе
все средства, необходимые для работы с БД, начиная от работы по ее созданию, и
заканчивая базовым пользовательским интерфейсом коммуникации с базами данных.
Для наиболее распространенных сегодня реляционных СУБД стандартным языком
является язык SQL (StructuredQueryLanguage - язык структурированных запросов).
В состав SQL включены два основных компонента: язык определения данных (DDL) и
язык манипулирования данными (DML). SQL предоставляет возможность определять
схему реляционной БД и осуществлять манипулирование данными.- одна из свободных
систем управления базами данных(СУБД). MySQL принадлежит компании
OracleCorporation, которую она получила вместе с поглощённой SunMicrosystems,
занимавшейся разработкой и поддержкой приложения. Распространяется под GNU
GeneralPublicLicense или под собственной коммерческой лицензией. Кроме этого
разработчики могут создавать необходимую функциональность по заказам
лицензионных пользователей, именно благодаря таким заказам почти с самых ранних
версий в данной СУБД появился механизм репликации. [9]
СУБД MySQL является подходящим решением для использования в малых и
средних приложениях. Она присутствует в составе серверов LAMP, WAMP, AppServ и
в портативных сборках серверов XAMPP, Денвер. MySQL традиционно используется в
качестве сервера, который предоставляет доступ локальным или удалённым
клиентам, однако в дистрибутиве имеется библиотека внутреннего сервера, которая
позволяет включать MySQL также и в состав автономных программ. [7]
Благодаря поддержке многих типов таблиц обеспечивается хорошая гибкость
СУБД MySQL: пользователи имеют возможность выбирать как таблицы типа MyISAM,
так и таблицы с поддержкой транзакций на уровне отдельных записей InnoDB. К
тому же, в состав поставки СУБД MySQL входит специальный тип таблиц EXAMPLE,
которые декларируют принципы создания новых типов таблиц. Открытая архитектура
и GPL-лицензирование СУБД MySQL способствуют постоянному появлению новых типов
таблиц.
На сегодня имеется несколько разработанных версий системы, в каждую из
которых включен целый ряд продуктов, например Oracle 8, Oracle 9i, Oracle 10g.
Каждая линейка продуктов включает помимо самой СУБД (например,
OracleDatabase 10g, OracleDatabase 11g), также обладает средствами разработки и
анализа данных.предлагает готовые пакетируемые решения, в стоимость которых
автоматически включена база данных, интеграционная платформа, сервер
приложений, инструменты для проведения аналитики неструктурированных данных и
управления ими. Масштабируемость и гибкость бизнес-приложений Oracle позволяет
им легко интегрироваться с ИТ-инфраструктурой предприятия, не теряя при этом
уже вложенные в IT инвестиции. [9]
СУБД OracleDatabase 11g обладает улучшенными характеристиками благодаря
автоматизации задач в администрировании и обеспечения самых лучших возможностей
по безопасности и соответствию требованиям нормативно-правовых актов в сфере
защиты информации. Появилось больше автоматизированных функций, режимов
управления и самодиагностики. В перечне характеристик системы следует отметить
возможность управления большими объемами данных с использованием компрессии и
распределенных таблиц, высокую эффективность защиты данных, наличие возможности
полного восстановления данных, механизмы интеграции в бизнес-процесс
геофизических данных и медиа-данных и т.д.[7]
Одной из основных достоинств в характеристике СУБД Oracle можно назвать
возможность функционирования системы на большинстве существующих платформ. В
том числе на персональных компьютерах, больших ЭВМ, UNIX-серверах и т. д.
Отличительной особенностью сервера Oracle является хранение и обработка
данных, имеющих различные типы. Данный раздел функциональности интегрирован в
ядро СУБД, его поддержку осуществляет модуль interMedia, входящий в состав
OracleDatabase. Ним обеспечивается работа с текстовыми документами с
использованием различных видов поиска, контекстного в том числе; работа с более
20-тью форматами графических образов; работа с аудио и видео-контеном.
СУБД Oracle, кроме предоставления расширенного набора встроенных типов
данных, благодаря использованию ObjectOption, позволяет прибегать к созданию
новых типов данных и спецификации методов доступа к этим данным. Фактически это
означает, что разработчикам предоставлен инструмент, с помощью которого можно
создавать собственные структурированные типы данных, наиболее точно
отображающие объекты предметной области. [9]Access
На сегодняшний день MicrosoftAccess занимает место в числе самых
популярных среди программных систем управления базами данных для настольных
(персональных) реализаций. В числе причин такой популярности можно назвать:
высокий уровень универсальности и продуманности и удобства интерфейса для
визуального программирования, который ориентирован на пользователей самой
различной степени подготовки. В частности, здесь реализована удобная и
несложная система управления объектами базы данных, с помощью которой можно
оперативно и гибко переключаться из режима разработки в режим их
непосредственного использования;
наличие высоко развитых возможностей для интеграции с другими
программными продуктами, которые входят в состав MicrosoftOffice, либо с любыми
другими программными продуктами, способными поддерживать технологию OLE;
наличие богатого набора визуальных средств и механизмов разработки. [6]
В процессе разработки данного продукта на рынке появлялись его разные
версии. Среди наиболее известны (в некотором смысле этапных) можно назвать
Access 2.0, Access 7.0 (он первый был включен в программный комплекс MS Office
95). Несколька позже увидели свет версии Access 97 (в MS Office 97) и Access
2000 (в MS Office 2000). Самой последней версией является MS Access 2013,
которая также входит в состав комплекта MS Office.
Перечислим некоторые из механизмов MicrosoftAccess, которые существенно
упрощающие процесс разработки приложений. [10]
. Наличие процедур обработки событий и модулей форм и отчетов. На языке
VBA, который встроен в систему, можно создавать процедуры обработки событий,
которые возникают в отчетах и формах. Конкретные процедуры по обработке событий
сохраняются в модулях, которые связанны с конкретными отчетами и формами, в
результате чего сам код является частью макета отчета или формы. Кроме того,
имеется возможность вызова функции VBA посредством свойства события.
. Свойства, которые определяются в процессе выполнения программы. С
помощью процедуры обработки событий или макроса можно определить практически
любое из свойств отчета или формы при выполнении в ответ на возникновение
события в отчете или форме.
. Использование модели событий. Модель событий, подобная используемой в
языке MicrosoftVisualBasic, при возникновении различных событий, позволяет
приложениям реагировать, например, на перемещение мыши, нажатие клавиши на
клавиатуре или окончание определенного интервала времени.
. Обработка данных с помощью средств VBA. Используя язык VBA можно
определять и осуществлять обработку различных объектов, в том числе, таблиц,
запросов, полей, индексов, связей, отчетов, форм и элементов управления.
. Наличие построителя меню. Данный механизм предназначен для облегчения
процесса создания специальных меню в приложениях. Вместе с этим, в специальных
меню могут содержаться подменю.
. Наличие улучшенных средств отладки кода. Помимо пошагового выполнения
программ и установки точек прерывания на языке VBA, на экран можно вывести
список всех активных в данный момент процедур.
. Использование процедуры обработки ошибок. Кроме применения традиционных
методов обработки ошибок, есть возможность использования процедуры обработки
события Error для осуществления перехвата ошибок в процессе выполнения макросов
и программ.
. Улучшенный интерфейс защиты. С помощью команды и окна диалога защиты
значительно упрощается процедура защиты и смены владельца объекта.
. Наличие программной поддержки механизма OLE. Использование механизма
OLE дает возможность осуществлять обработку объектов из других приложений.
. Создание программ-надстроек. Используя средства VBA, существует
возможность создания программы-надстройки, например нестандартного мастера и
построителя. Мастер представляет собой средство MicrosoftAccess, которое на
основе задаваемых пользователю вопросов, в соответствии с его указаниями
создает объект (таблицу, запрос, отчет, форму и т.д.).[6]
Использование диспетчера надстроек процедура установки программ-надстроек
в MicrosoftAccess существенно упрощается.
Языки
программирования для работы с базами данных
Данная программа должна быть реализована с помощью языка высокого уровня.
Сравним достоинства и недостатки некоторых из языков данного класса.
В числе самых распространенных языков запросов можно считать язык SQL
(StructureQueryLanguage). Разработан он был в середине 1970-х гг. (фирма IBM).
Система Oracle стала первой коммерческой системой с реализацией этого языка
(1979 г.). В дальнейшем его реализация появилась в целом ряде широко популярных
СУБД, предназначенных для использования на ЭВМ и операционных системах различных
типов. В некоторых СУБД, таких, как MS SQL-сервер, Oracle, INGRES и др., именно
язык SQL является основным. В реде систем, например СУБД семейства Access,
ADABAS, dBase и других, язык SQL применяется только как альтернативный. [2]
Предшественником языка SQL был язык SEQUEL (Structured
EnglishQueryLanguage).
При использовании возможностей языка, которые реализованы в большинстве
систем, значительно упрощает процесс создания гетерогенных систем, а также
позволяет избежать дополнительных проблем при необходимости перевода ИС в
другую среду иной СУБД. [11]
Язык SQL очень приближен к классу языков с реляционным исчислением
кортежей и в основном используется в реляционных СУБД.
Этот язык имеет развитые возможности и может использоваться как конечными
пользователями при формулировке несложных запросов, так и квалифицированными
специалистами в области обработки данных. Развитие SQL приводит к его
усложнению.
В языке баз данных SQL содержатся два языка: язык манипулирования данными
(SQL-DML) и язык определения схемы (SQL-DDL). Язык DML ориентирован на
возможности по созданию поисковых и корректирующих запросов к базе данных. Его
операторы могут применяться как самостоятельно (автономный или интерактивный
SQL), так и вместе с другими языками манипулирования данными (встроенный SQL).
С помощью языка DDL описываются и создаются такие объекты базы данных, как
представления, таблицы, индексы и др.
Данный язык обладает двумя типами встроенных SQL-операторов: динамический
SQL и статический SQL. Особенностью статического SQL является то, что он
ссылается на SQL-операторы, известные еще до момента запуска программы и в
дальнейшем они не подвергаются изменениям. Динамические же SQL-операторы могут
определяться только при выполнении программы. [5]
Иногда, помимо DDL и DML, выделяют в качестве самостоятельного
подмножества язык управления данными (DCL - DataControlLanguage). Обычно,
операторы DCL используются с целью создания объектов, которые имеют отношение к
управлению правами доступа пользователей к базе данных, для определения
соответствующих уровней привилегий доступа пользователям.относится к категории
языков высокого уровня. Пользователю при его использовании не нужно помнить о
необходимости открытия и закрытия различных таблиц, искать наиболее эффективный
и рациональный способ реализации запроса, об активизации индексов и т.п.
Система все это осуществляет автоматически. Многие современные СУБД обладают
построителями запросов SQL. В этом качестве, как правило, выступают языки,
подобные QBE. [7]можно считать языком, который используется как для изучения,
так и использования. С его помощью можно осуществлять разработку не только
простых приложений с графическим интерфейсом, но и разрабатывать довольно
сложные прикладные программы. Программирование в VB сочетает в себе визуальные
компоненты и контролы, описание атрибутов и определение действий для
компонентов, возможность написания дополнительного кода, чтобы расширить
функциональные возможности. Использование определенных по умолчанию значений и
действий для компонентов позволяет легко создать простую программу без
необходимости написания кода программистом. В ранних версиях VisualBasic имело
место наличие определенных проблем с производительностью программ, но при
использовании современных компьютеров и возможностью компиляции собственного
кода эта проблема стала не такой значимой.
Возможность компиляции программного кода была введена в VisualBasic 5. И
все же, исполняемые программы до сих пор для запуска требуют наличия
определенных библиотек. До появления Windows 2000 они должны біли поставляться
вместе с программой. Сейчас эти библиотеки входят в состав Windows. [11]
Создание форм в VB осуществляется с помощью технологии "перетащи и
брось" (drag and drop). Необходимо просто разместить на форме элементы
управления (например, поля ввода, переключатели, кнопки и т.д.). Элементов
управления обладают индивидуальными атрибутами и обработчиками событий. Многие
из атрибутов можно изменять во время работы программы, что дает возможность
создания программ, динамически реагирующих на определенные действия
пользователя. [4]
При помощи VisualBasic можно реализовывать исполняемые программы (EXE
файлы), библиотеки DLL, элементы управления ActiveX, но, прежде всего, его
использую для разработки приложений под Windows. Диалоговые окна с ограниченным
функционалом можно использовать для предоставления подсказок. При помощи
элементов управления обеспечивается реализация основных возможностей
приложения, а программисту при помощи обработчиков событий дана возможность
расширять логику программы. Например, в выпадающем списке автоматически
отображается список и дает возможность пользователю выбрать нужный элемент.
Вызов обработчика событий осуществляется для выполнения дополнительного кода в
зависимости от того, какой выбран элемент.
Язык для сбора мусора использует справочную информацию, имеется большая
библиотека сервисных объектов, возможность объектно-ориентированной разработки.
VisualBasic не зависим от регистра. При сравнении строк регистра учитывается,
но сравнение может быть выполнено без его учета. [9]
Компилятор VisualBasic поставляется вместе с другими языками VisualStudio
(C, C++), но наличие ограничений в интегрированной среде разработки не дает
возможности создавать некоторые виды приложений.
Система разработки MicrosoftVisual C++ представляет собой реализацию
среды программирования для одного из наиболее распространенных языков
системного программирования C++, разработанную компанией Microsoft. Эта система
в настоящее время реализована как интегрированная среда разработки, в которую
включены все необходимые средства и механизмы для разработки конечных программ,
ориентированных на работу под управлением ОС типа Microsoft Windows. В основе
системы программирования MicrosoftVisual C++ лежит библиотека классов MFC
(MicrosoftFoundationClasses). В этой библиотеке в виде классов C++ реализованы
все основные компоненты управления и интерфейса ОС. В ее составе также имеются
классы для обеспечения разработки приложений под архитектуру клиент-сервер и
трехуровневую архитектуру (в современных версиях библиотеки). Возможности
системы программирования MicrosoftVisual C++ позволяют осуществлять разработку
любых приложений, выполняющихся в среде ОС типа MicrosoftWindows, в том числе
клиентских или серверных результирующих программ, взаимодействующих между собой
по протоколам одной из указанных выше архитектур.[11]- это продукт разработки
компании BorlandInternational для быстрого и эффективного создания приложений.
Он является высокопроизводительным инструментом визуального построения
приложений, в котором имеется настоящий компилятор кода. Данная система
предоставляет средства и механизмы визуального программирования, во многом
похожие на те, которыми обладает MicrosoftVisualBasic или другие инструменты
визуального проектирования. Основой Delphi является язык ObjectPascal, который
выступает как расширение объектно-ориентированного языка Pascal. В составе
Delphi также есть локальный SQL-сервер, библиотеки визуальных компонентов,
генераторы отчетов и много прочих инструментов, необходимых для
профессиональной разработки информационных систем или прикладных программ для
Windows-среды.[1]
Стоит отметить, что Delphi предназначен для разработчиков разного уровня
подготовки, желающих быстро и эффективно разрабатывать приложения под
архитектуру клиент-сервер. Delphi может производить небольшие по размерам (до
20-50 Кбайт) высокоэффективные и быстрые исполняемые модули (.dll и.exe),
поэтому в Delphi может быть интересен, прежде всего, для тех, кто разрабатывает
продукты для продажи. С другой стороны реализация небольших по размерам и
быстро исполняемых модулей означает, что требования, предъявляемые к клиентским
рабочим местам, значительно снижаются - это играет немаловажную роль и для
конечных пользователей. [2]
В языке программирования Delphi собрана комбинация таких технологий, как:
объектно-ориентированная модель компонент;
высокопроизводительный компилятор в машинный код;
средства визуального построения приложений;
средство для создания баз данных;
средства для реализации сетевых технологий.7 Studio можно считать полным
решением для разработки корпоративных приложений, начиная от проектирования до
окончательного развертывания по архитектуре с управлением моделью (MDA),
благодаря которому сюда интегрировано моделирование, разработка и развертывание
приложений для платформы Windows. [3]7 Studio обладает развитыми библиотеками и
инструментами для создания приложений и веб-сервисов, может полностью
интегрировать соответствующие технологии и эффективно повышать
производительность разработчиков, поскольку предоставляет все необходимые
механизмы для исследования вопросов по переходу на Microsoft .NET. При помощи
Kylix 3 для Delphi, включенного в комплект поставки, разработчикам
предоставлена возможность переносить свои приложения на платформу Linux,
расширяя перечень платформ, доступных для их приложений. С интеграцией ведущих
приложений разработки в рамках единого и легкого в использовании пакета, Delphi
7 Studio помогает сократить жизненный цикл разработки приложений, тем самым
ускоряя вывод создаваемых с его помощью программ.
Обоснование
выбора программных средств для реализации проекта
Для разработки интерфейсной части информационной системы "База
данных "Успеваемость студентов КГБОУ "СПО "ХМТ" была
выбрана интегрированная среда программирования Delphi 7-й версии для разработки
и программирования приложений ОС Windows.[1]
Среди преимуществ Delphi по сравнению с однотипными программными
продуктами, можно выделить:
быстроту проектирования и разработки приложений;
высокую производительность готового приложения;
низкие требования конечного продукта к ресурсам компьютера;
возможность наращивания за счет внедрения новых инструментов и компонент
в среду Delphi;
возможность модернизации имеющихся и создания новых инструментов и
компонент собственными средствами Delphi;
хорошая проработка иерархии объектов и модулей.
Система программирования Delphi ориентирована на разработку приложений
различной направленности и предоставляет для этого большое количество
компонентов.[3]
Основными достоинствами этого программного продукта для разработчиков
является:
- Компилятор высокой производительности, позволяющий перевести код на
исходном языке в машинный;
- Внедрение объектно-ориентированной модели программирования;
- Высокая скорость создания приложений, благодаря большому
количеству стандартных модулей;
- Большое количество сервисов и средств для создания баз
данных;
Встроенный компилятор до сих пор является самым быстрым, он производит
компиляцию со скоростью, превышающей 120 000 строк/мин. Его высокая
производительность позволяет создавать качественные прикладные программы
клиент-серверной архитектуры. [11] Процесс построения становится очень удобным
благодаря наличию большого числа готовых компонент, которые можно легко
вставить в тело программы, переведя их на поле проекта. Разработчик еще до компиляции
может увидеть то, как будет выглядеть готовая программа и внести необходимые
коррективы.
Еще одним важным достоинством 7 версии Делфи является то, что код можно
использовать максимальное количество раз, то есть помимо стандартных 270
базовых классов, пользователь может создавать и использовать сам. Это очень
полезная особенность при создании решении сложной и специфической проблемы. [3]
В Делфи 7 предусмотрена возможность подключения к различным корпоративным
базам данных. Связь с БД основана на таблицах и SQL-запросах. В составе
программного продукта Делфи 7 присутствуют такие сервисы, как DatabaseEngine и
SQL Link. Еще одни плюсом является поддержка локального сервера Interbase.
Для создания базы данных выбор сделан в пользу СУБД Access (фирма Microsoft)
поскольку она обладает достаточно высокими характеристиками по скорости и
входит в состав очень популярного пакета программ MicrosoftOffice. Набор
функций и команд, которые предлагаются в распоряжение разработчиков программных
продуктов в среде Access, по функциональной гибкости и возможностям
соответствует большинству современных требований, предъявляемых к обработке и
представлению данных. В Access существует поддержка разнообразных всплывающих и
многоуровневых меню, возможность работы с мышью и окнами, реализован набор
функций низкоуровневого доступа к файлам, по управлению цветами, настройками
периферийных устройств, по представлению данных в виде электронных таблиц и
т.д. В системе, также, присутствуют средства для быстрой генерации экранов, меню
и отчетов, поддержка языка формирования и управления запросами SQL, встроенный
язык Visual Basic for Applications (VBA), имеет хорошие показатели работы в
сети. В СУБД Access позволяется использование других компонентов пакета
MicrosoftOffice, таких как текстовый редактор WordforWindows, электронные
таблицы Excel и т.д.[10]
Среди важных преимуществ СУБД Access стоит выделить и то, что в ней можно
разрабатывать системы и приложения, которые способны обрабатывать БД как на
локальном компьютере, так и в локальной сети или в Internet с использованием
режима обработки данных "клиент-сервер".
Немаловажным является и то, что Access предоставляет много средств и
возможностей по созданию приложений, направленных на обработку БД. При этом
разработчику не обязательно обладать квалификацией программиста высокого
класса, а вполне достаточно владеть представлением о разработке событийных
приложений в среде Windows, и немного владеть навыками написания кода на языке
VisualBasic. [10] Это поможет разработчику достаточно быстро приобрести навыки
по созданию приложений в Access, что позволит автоматизировать как много
простых, так и достаточно сложных и трудоемких задач, ориентированных на
обработку данных.
К тому же, база данных MS Access - это один файл. Сколько бы таблиц и индексов
она не содержала, все это хранится в одном единственном файле. А значит, такую
базу данных легче обслуживать - переносить на новое место, делать резервные
копии и так далее. Еще один плюс - имена полей в такой БД можно давать русскими
буквами.
Перечисленные факторы определили выбор СУБД Access в качестве среды для
практического применения при проектировании базы данных в данной работе.
Описание существующего оборудования
Для использования программы необходимо стандартное оборудование ввода и
вывода.
В качестве устройства вывода требуется монитор с цветовой палитрой High
Color 16-бита или True Color 24-бита, расширение монитора требуется со
значением 1024х 768 точек. Данное расширение позволяет программе правильно
отображать информацию на экране.
Устройствами ввода служат клавиатура и мышь.
Для стабильного и надежного функционирования программы на жестком диске
желательно иметь до 100 Мбайт свободного пространства.
Работа программы осуществляется на основе программного обеспечения фирмы
Microsoft. Необходимыми средствами являются операционная система Windows
XP/Vista/7 и пакет программ MicrosoftOffice 2003/XP, в частности
MicrosoftAccess.
Технические требования к компьютеру для максимально эффективного и
комфортного использования информационной системы "База данных
"Успеваемость студентов КГБОУ "СПО "ХМТ":
- процессор - тактовая частота не менее 1.3 GHz;
- оперативная память - не менее 1 Gb;
- место на жестком диске - не менее 1,5 Gb;
- разрешение экрана компьютера не ниже 1024х 768 пикселей;
- привод DVD-ROM (для установки программы);
- операционная система - Windows XP SP3;
- работающий USB-порт;
- наличие сетевой карты;
- наличие принтера для оформления отчетов.
2. Практическая часть
Разработка
программы
Структуру данного программного пакета можно разделить на две части:
информационная база, содержащая данные о студентах, дисциплинах,
преподавателях и количестве пропуcков, реализованная средствами MSAccess 2007;
Основным назначением информационной базы является накопление и хранение
информации в виде таблиц данных. Также, здесь возможны непосредственный ввод,
редактирование и удаление информации прямо в таблицах.
Интерфейсная часть предназначена для отображения и вывода информационных
данных с возможностью поиска и детализации необходимой информации.
Интерфейсная часть извлекает информацию из таблиц базы данных,
организовывает необходимые инфологические связи между таблицами, структурирует
их и осуществляет вывод.
Структурная схема программы показана на рисунке 1.
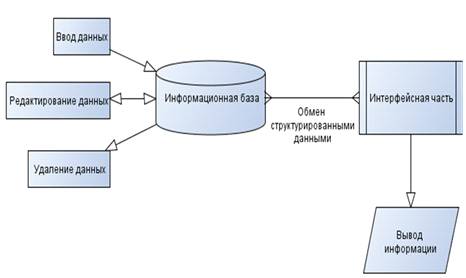
Рисунок 1 - Структурная схема программы
Описание информационной базы
Перед началом созданием системы автоматизированной обработки информации
необходимо сформировать понятия о предметах, фактах и событиях, которыми будет
оперировать данная система. Для этого было необходимо сформулировать их
информационное представление. Среди инструментов унифицированного представления
данных одним из наиболее удобных, независимого от программного обеспечения для
реализации, является модель "сущность-связь". [5]
Данная модель опирается на некую важную семантическую информацию о
реальном мире и предназначена для логического представления данных. В ней
значения данных определяются в контексте их взаимосвязи с другими данными.
Важно, что из модели "сущность-связь" могут быть порождены все
существующие модели данных (иерархическая, сетевая, реляционная, объектная),
поэтому она является наиболее общей.
Модель "сущность-связь" не является моделью данных в строгом
смысле, поскольку не определяет операций над данными и ограничивается описанием
только их логической структуры.
Любой фрагмент предметной области может быть представлен как множество сущностей,
между которыми существует некоторое множество связей. [9]
Сущность (entity) - это объект, который может быть идентифицирован неким
способом, отличающим его от других объектов.
Выбор сущностей (entityset) - множество сущностей одного типа (обладающих
одинаковыми свойствами).
Сущность фактически представляет из себя множество атрибутов, которые
описывают свойства всех членов данного набора сущностей. [7]
Спецификация сущностей представлена в таблице 2. В первом столбце таблицы
указано наименование сущности. Во втором столбце описательные атрибуты.
Таблица 3 - Спецификация сущностей
|
Сущность
|
Описательные атрибуты
|
|
Студенты
|
Код, фамилия, имя,
отчество, курс, № группы
|
|
Предметы
|
Код, предмет, ФИО
преподавателя
|
|
Пропуски
|
Код студента, код предмета,
количество пропусков
|
Атрибут представляет собой свойство сущности. Это понятие аналогично
понятию атрибута в отношении.
Ключ сущности - атрибут или набор атрибутов, используемый для
идентификации экземпляра сущности.[5]
Спецификация атрибутов сущностей представлена в таблице 4. В первом
столбце таблицы указано название сущности. Во втором - наименование атрибута. В
третьем столбце указывается тип атрибута.
Таблица 4 - Спецификация атрибутов
|
Сущность
|
Атрибут
|
Тип
|
|
Студенты
|
Код
|
Счетчик
|
|
Фамилия
|
Текстовый
|
|
Имя
|
Текстовый
|
|
Отчество
|
Текстовый
|
|
Курс
|
Числовой
|
|
№ группы
|
Текстовый
|
|
Предметы
|
Код
|
Счетчик
|
|
Предмет
|
Текстовый
|
|
ФИО преподавателя
|
Текстовый
|
|
Пропуски
|
Код студента
|
Числовой
|
|
Код предмета
|
Числовой
|
|
Количество пропусков
|
Числовой
|
Спецификация связей между сущностями представлена в таблице 5. В первом
столбце указан тип связи, где буква M означает "многие". Во втором
столбце указано название первой сущности связи, в третьем - название второй
сущности связи.
Таблица 5 - Спецификация связей
|
Тип связи
|
Первая сущность
|
Вторая сущность
|
Поля связи
|
|
1:М
|
Пропуски
|
Студенты
|
Код студента
|
|
1:М
|
Пропуски
|
Предметы
|
Код предмета
|
Таким образом, информационная база данных состоит из трех таблиц.
Таблица "Студенты" содержит основные данные о студентах.
Ключевым полем этой таблицы является поле "Код" (рисунок 2).
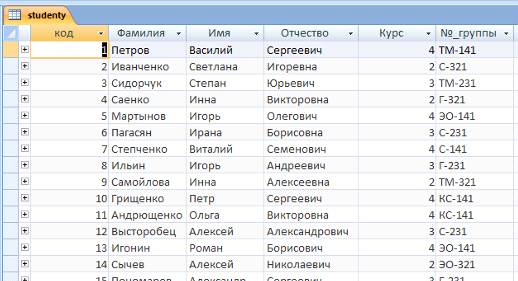
Рисунок 2 - Таблица "Студенты"
В таблице "Предметы" содержится перечень дисциплин и
преподавателей, которые ведут эти дисциплины. Ключевым полем этой таблицы
является поле "Код" (рисунок 3).
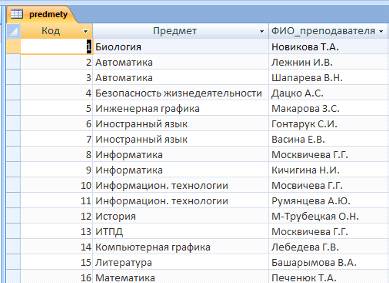
Рисунок 3- Таблица "Предметы"
Основной информационной таблицей является таблица "Пропуски", в
которой содержатся данные о количестве пропусков каждого студента в разрезе
предметов. Ключевого поля таблица не имеет. В качестве данных в таблицу
заносится закодированная информация о студентах и количестве пропусков по
предметам (рисунок 4).
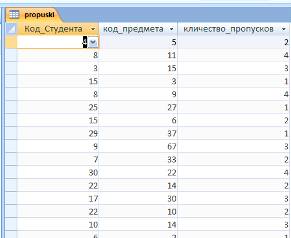
Рисунок 4 - Таблица "Пропуски"
Описание алгоритмов
Алгоритмическая последовательность работы программы состоит в следующем:
) занесение, корректировка и удаление данных производятся
непосредственно таблицы базы данных в Access; никакая обработка информации
здесь больше не осуществляется;
2) связь базы данных с интерфейсом осуществляется при помощи
встроенного в Delphiмеханизма ADOConnection, предназначенного для подключения
информационной базы;
) группировка и структуризация данных осуществляется с помощью
механизма ADOQuery посредством SQL запроса, на основании которого делается
выборка и передается в механизм DataSourse;
) визуализация данных осуществляется через форму с помощью
визуальных компонентов Delphi, источником данных которой является выходная
информация механизма ADOQuery.
ADO - это пользовательский интерфейс доступа к произвольным типам данных,
включая реляционные и нереляционные БД, электронную почту, системные, текстовые
и графические файлы. Связь с данными посредством технологии OLE DB. [1]
Использование ADO является альтернативой BorlandDataBase, обеспечивая
более эффективную работу с данными.
Для работы с ADO предусмотрены компоненты, расположенные внутри
библиотеки - ADO. Они инкапсулируют такие объекты ADO, как и RecordSet. Это
обеспечивается, соответственно, новыми компонентами Delphi: ADOConnection,
ADCommand и ADODataSet.
Связь с БД в технологии ADO осуществляется через набор данных (компонент
DataSource), компоненты визуализации данных (DBGrid,DBEdit и т.д.). Отличие
заключается в том, что вместо компонентов, располагающихся на странице
DataAccess используются компоненты, расположенные на странице ADO.
Технология ADO (ActiveXDataObjects) во многом похожа на BDE. Обе эти
технологии проектировались для решения схожих проблем, обе технологии
поддерживают навигацию по наборам данных, оперирование с наборами данных. ADO -
более новая технология. [3] Существенно, что ADO позволяет получить доступ к
данным форматов Microsoft (MDAC), например, к базам данных СУБД
MicrosoftAccess. Это одна из существенных причин создания в Delphi баз данных,
основанных не на BDE, которая хотя и используется, но не развивается, а
технологии ADO.
Основным достоинством технологии ADO является ее естественная ориентация
на создание "облегченного" клиента. В рамках этой технологии на
машине разработчика БД устанавливаются базовые объекты MSADO и соответствующие
компоненты Delphi, обеспечивающие использование технологии ADO (эти установки
осуществляются автоматически при развертывании Delphi). На машине сервера
данных (это может быть файловый сервер в рамках файл-серверной технологии или
машина с сервером данных - в технологии клиент-сервер) устанавливается так
называемый провайдер данных - некоторая надстройка над специальной технологией
OLEDB, "понимающая" запросы объектов ADO и "умеющая"
переводить эти запросы в нужные действия с данными. Взаимодействие компонентов
ADO и провайдера осуществляется на основе универсальной для Windows технологии
ActiveX, причем провайдер реализуется как СОМ-сервер, а ADO-компоненты - как
СОМ-клиенты.[2]
Для работы с запросами в Delphi по технологии ADO используется компонент
ADOQuery. Что касается подключения компонента, работа с ним подобна работе с
ADOTable. Ему так же необходимо указать ADOConnection, подключенный к БД (можно
так же настроить свойство подключения к БД ConnectionString). Для отображения
на форме данных ему так же нужен компонент DataSource, подключаемый к
компонентам отображения и управления данными из закладки палитры DataControls
(DBGrid, DBEdit и другие).
Компонент TADOQuery обеспечивает применение запросов SQL при работе с
данными через ADO. Это могут быть запросы просмотра данных SELECT и запросы
изменения данных INSERT, DELETE, UPDATE, ALTER TABLE, CREATE TABLE. Могут также
выполняться хранимые процедуры. По своей функциональности он подобен
стандартному компоненту запроса TQuery. В отличие от TADOCommand, этот
компонент преимущественно предназначен для получения набора записей из одной
или нескольких таблиц БД. Также как TQuery, TADOQuery имеет свойство
DataSource, позволяющее передать параметры запроса от одного компонента
другому. [2]
Основное свойство компонента - SQL, содержащее запрос. Запрос SELECT
выполняется методом Open или заданием значения true свойству Active. Выполнение
запросов, не возвращающих множество данных (INSERT, DELETE, UPDATE, ALTER
TABLE, CREATE TABLE), осуществляется методом ExecSQL.
Любое изменение текста SQL во время выполнения приводит к разрыву
соединения компонента с базой данных. Так что после задания нового значения SQL
соединение надо восстанавливать методом Open или заданием true свойству Active.
При этом если связь с базой данных осуществляется через компонент
ADOConnection, надо учитывать указанную в описании этого компонента взаимосвязь
свойства Active компонента ADOQuery и свойства Connected компонента
ADOConnection.
В отличие от ADOTable, запрос не содержит свойств для выбора таблицы,
которую он будет отображать. Вместо этого он имеет поле SQL, которое должно
содержать текст SQL-запроса к БД для выбора необходимых данных. [3]
Для получения содержимого таблицы следует указать следующие поля
ADOQuery:- выбрать из списка настроенное подключение к БД.- ввести текст любого
SQL-запроса, например, "SELECT * FROM mytable". Active - присвоить
значение True.
Если при присвоении свойству Active, сведений об ошибках не было
выведено, значит все выполнено правильно и далее можно пользоваться ADOQuery,
как обычной таблицей для вывода его данных (вывод осуществляется аналогично
таблице через компонент DataSourcе, например, в DBGrid). [3]
Плюс запроса в том, что в нем можно сформировать нужную выборку сразу из
нескольких таблиц. Здесь можно так же применить сортировку и группировку
данных. [5]
В нашей программе для выбора и группировки данных применен следующий
SQL-запрос:studenty.№_группы, studenty.Фамилия, studenty.Имя,
studenty.Отчество, predmety.Предмет, predmety.ФИО_преподавателя, propuski.кличество_пропусковFROMstudentyINNERJOIN
(predmetyINNERJOINpropuskiONpredmety.Код = propuski.код_предмета)
ONstudenty.код = propuski.Код_Студента;
Данный запрос реализует следующие связи между таблицами (рисунок 5):
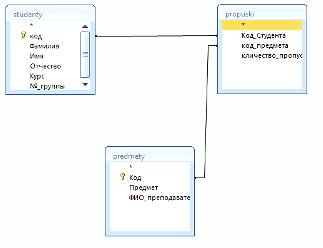
Рисунок 5 - Связи между таблицами базы данных
Невизуальный компонент DataSource в Delphi представляет собой источник
данных, который обеспечивает связь между набором данных и компонентами
отображения и редактирования данных.[1]
Все наборы данных должны быть связаны с компонентом источника данных,
если требуется редактирование данных. Основное свойство источника данных -
DataSet. Оно указывает на компонент набора данных (Table, Query и др.), с
которыми связан источник. Свойство State дает информацию о текущем состоянии
набора данных: находится ли он в состоянии редактирования, вставки данных и так
далее. [3]
Для организации связи таблиц базы данных с визуальным интерфейсом в
программе реализован модуль данных DM, включающий в себя вышеперечисленные
элементы (рисунок 6).
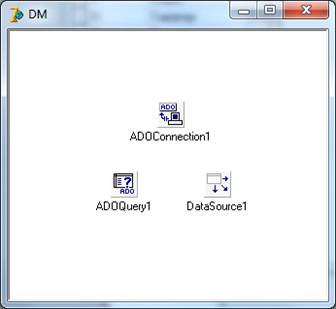
Рисунок 6 - Модуль данных Dtlphi 7
Программный код модуля данных приведен в Приложении А.
Организация интерфейса пользователя
Интерфейс программы организован с помощью стандартной формы Delphi 7, на
которой размещены следующие компоненты:
DBGrid - предназначен для отображения в виде таблицы и редактирования
связанной с БД информации, источником данных для этого компонента является
компонент DataSourсe1 из модуля данных DM;
DBNavigator - предназначен для навигации по записям отображаемой таблицы;
поле Edit и кнопка BitBtn - компоненты для реализации функции поиска
строк в таблице по фамилии студента - в поле Edit вводится фамилия и нажимается
кнопка "Найти", если совпадения найдены, то они выводятся в таблице,
для возврата к полной таблице необходимо очистить поле Edit и нажать кнопку
"Найти". Форма интерфейса программы приведена на рисунке 7.
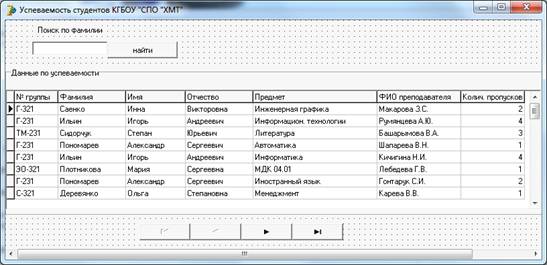
Рисунок 7 - Форма интерфейса программы
Программный код реализации формы интерфейса приведен в Приложении А.
2.1 Руководство пользователя
автоматизация документооборот трудоемкость затраты
Ввод информации в базу данных осуществляется в MSAccess. Данные заносятся
непосредственно в таблицу "propuski". Справочная информация о кодах
студентов и предметов берется соответственно из таблиц "studenty" и
"predmety". Файл с таблицами базы данных "uspevaemost.mdb"
находится в рабочей папке программы "stud".
Для входа в интерфейсную часть программы необходимо запустить файл
Project1.exe, который находится в рабочей папке программы.
При входе в программу система запросит имя пользователя и пароль - ничего
вводить не нужно. При необходимости, для ограничения доступа, в программу можно
внести изменения и задать необходимые имя доступа и пароль. После нажатия
кнопки "Ок" откроется окно с интерфейсом информационной системы.
В окне интерфейса сразу отображается таблица с данными о пропусках
студентов. Перемещение по строкам таблицы возможно при помощи панели навигации,
расположенной в нижней части окна, либо при помощи клавиатуры: кнопки
"вверх" и "вниз", либо при помощи элемента скролл-бар,
расположенного по правую сторону таблицы. Перемещение по полям таблицы
осуществляется при помощи клавиатуры кнопками "влево" и "вправо".
Поиск в таблице осуществляется по фамилии студента с помощью панели
поиска, расположенной над таблицей. Для поиска нужно в поле ввести фамилию
студента и нажать кнопку "найти".
Для возврата к полному списку необходимо очистить поле поиска и снова
нажать кнопку "найти".
В программе реализована возможность сортировки списка по любому из
столбцов путем нажатия мышкой на его заголовке.
3. Описание и расчет трудоемкости работ и затрат на
разработку
Базовый показатель для определения составляющих затрат труда вычисляется
по формуле:
= q * c, (1)
где Q - условное число команд; q - коэффициент, учитывающий условное
число команд в зависимости от типа задачи; с - коэффициент, учитывающий новизну
и сложность программы.
Выбираем значение коэффициента q из таблицы 5, равное 1500.
Таблица 6 -Значения коэффициента q
|
Тип задачи
|
Пределы изменений
коэффициента
|
|
Задачи учета
|
от 1400 до 1500
|
|
Задачи оперативного
управления
|
от 1500 до 1700
|
|
Задачи планирования
|
от 3000 до 3500
|
|
Многовариантные задачи
|
от 4500 до 5000
|
|
Комплексные задачи
|
от 5000 до 5500
|
Программные продукты по степени новизны может быть отнесены к одной из
4-х групп:
группа А - разработка принципиально новых задач;
группа Б - разработка оригинальных программ;
группа В - разработка программ с использованием типовых решений;
группа Г - разовая типовая задача.
Коэффициент С определяем из таблицы 7, на пересечении групп сложности и
степени новизны, равный 1.15.
Таблица 7 - Коэффициенты расчета трудоемкости
|
Язык программирования
|
Группа сложности
|
Степень новизны
|
Коэффициент B
|
|
|
А
|
Б
|
В
|
Г
|
|
|
Высокого уровня
|
1
|
1,38
|
1,26
|
1,15
|
0,69
|
1,2
|
|
2
|
1,30
|
1,19
|
1,08
|
0,65
|
1,35
|
|
3
|
1,20
|
1,10
|
1,00
|
0,60
|
1,5
|
|
Низкого уровня
|
1
|
1,58
|
1,45
|
1,32
|
0,79
|
1,2
|
|
2
|
1,49
|
1,37
|
1,24
|
0,74
|
1,35
|
|
3
|
1,38
|
1,26
|
1,15
|
0,69
|
1,5
|
Теперь, исходя из формулы 1 можно определить условное число команд Q:
= q * c=1500*1.15=1725.
Далее необходимо рассчитать время на создание программного продукта.
Общее время на создание программы складывается из различных компонентов.
Структура общего времени на создание программного продукта представлена в таблице
8.
Таблица 8 - Структура общего времени на создание программного продукта
|
№ этапа
|
Обозначение времени данного
этапа
|
Содержание этапа
|
|
1
|
Тпо
|
Подготовка описания задачи.
|
|
2
|
То
|
Описание задачи.
|
|
3
|
Та
|
Разработка алгоритма.
|
|
4
|
Тбс
|
Разработка блок-схемы алгоритма.
|
|
5
|
Тн
|
Написание программы на
языке...
|
|
6
|
Тп
|
Набивка программы.
|
|
7
|
Тот
|
Отладка и тестирование
программы.
|
|
8
|
Тд
|
Оформление документации,
инструкции пользователю, пояснительной записки.
|
Время рассчитывается в человеко-часах, причем Тпо берется по фактически
отработанному времени, а время остальных этапов определяется расчетно, по
условному числу команд Q.
Определяем время, затраченное на каждый этап создания программного
продукта:
Тпо (время на подготовку описания задачи), берется по факту и составляет
(от 3-х до 5-ти дней по 8 часов):24чел-час.
То (время на описание задачи) определяется по формуле:
То = Q * B / (50 *K), (2)
где В - коэффициент учета изменений задачи, коэффициент В в зависимости
от сложности задачи и числа изменений выбирается в интервале от 1.2 до 1.5
(таблица 4), равный 1.2; К - коэффициент, учитывающий квалификацию
программиста.
Выбираем значение коэффициента К из таблицы 9, равный 1.
Таблица 9 - Коэффициенты квалификации программиста
|
Опыт работы
|
Коэффициент квалификации
|
|
До двух лет
|
0.8
|
|
2-3 года
|
1
|
|
3-5 лет
|
1.1 - 1.2
|
|
5-7 лет
|
1.3 - 1.4
|
|
более 7 лет
|
1.5 - 1.6
|
Применяя формулу 2 подсчитываем время на описание задачи:
То = Q * B / (50 *K)= 1725*1.2/(50*1)=41,4 чел-час.
Та (время на разработку алгоритма) рассчитываем по формуле:
Та = Q / (50 * K), (3)
Тогда применяя формулу 3, получаем:
Та = Q / (50 * K)=1725/(50*1)=34,5чел-час.
Тбс (время на разработку блок - схемы) определяется аналогично Та по
формуле 3 и составляет 34,5 чел-час.
Тн (время написания программы на языке программирования) определяется по
формуле:
Тн = Q * 1.5 / (50 * K), (4)
Применяя формулу 4, подсчитываем Тн:
Тн = Q * 1.5 / (50 * K)= 1725*1.5/(50*1)=51,7 чел-час.
Тп (время набивки программы) определяется по формуле:
Тп = Q / 50, (5)
Тогда рассчитывая Тп по формуле 5, получаем:
Тп = Q / 50= 1725/50= 34,5 чел-час.
Тот (время отладки и тестирования программы) определяется по формуле:
Тот = Q * 4.2/(50*К), (6)
Тогда,
Тот = Q * 4.2/(50*К)=1725*4.2/(50*1)=144,9 чел-час.
Тд (время на оформление документации), берется по факту и составляет (от
3-х до 5-ти дней по 8 часов):
Тд = 24 чел / час.
Суммарные затраты труда рассчитываются как сумма составных затрат труда
по формуле 7:
Т = Тпо + То + Та + Тбс + Тн + Тп + Тот + Тд, (7)
Теперь, зная время, затраченное на каждом этапе, можно подсчитать Т по
формуле 7:
Т =24+41,4+34,5+34,5+51,7+34,5+144,9+24=398,5 чел-час.
Затраты на разработку программного обеспечения включают в себя расходы по
заработной плате, начислений на заработную плату, амортизацию и прочие расходы
и определяются по формуле:
Спп = ФОТ+Сн + А + СЭЭ +СМиК + СТО+Спр + Снакл, (8)
где ФОТ - фонд оплаты труда;
Сн - социальный налог;
А - амортизационные отчисления;
СЭЭ- затраты на электроэнергию;
СМиК- затраты на материалы и комплектующие;
СТО - затраты на техническое обслуживание;
Спр - прочие расходы; Снакл- накладные расходы;
Заработная плата складывается из двух составляющих: основной заработной
платы и дополнительной. Суммарная заработная плата (или фонд оплаты труда, ФОТ)
вычисляется как сумма основной и дополнительной заработных плат по формуле:
ФОТ= Зосн +Здоп, тг. (9)
где: Зосн.- основная заработная плата;
Здоп. - дополнительная заработная плата.
Основная заработная плата рассчитывается по формуле:
Зосн= Т*ТС/(tср*8), руб. (10)
где Т (tΣ)- суммарные затраты труда, вычисляемые по формуле (7);ср -
среднее число дней в месяце, равно 21 дню, умножается на количество часов в
рабочем дне - 8;
ТС - тарифная ставка.
Зосн= Т*ТС/(tср*8)=398,5 *18660/(21*8)=44262 руб.
Дополнительная заработная плата составляет 20% от основной заработной
платы, рассчитывается по формуле:
Здоп= 0,2*Зосн, руб (11)
По формуле 11 дополнительная заработная плата равна:
Здоп= 0,2*Зосн, =0,2*44262 =8852,4 руб.
По формуле 9 фонд оплаты труда равен,
ФОТ= Зосн +Здоп=44262 + 8852,4 = 53114,4 руб.
Социальный налог составляет 26% от дохода работника, и рассчитывается по
формуле:
Сн =(ФОТ-ПО) *26%, (12)
где ПО - пенсионные отчисления, которые составляют 22% отФОТ и социальным
налогом не облагаются:
ПО = ФОТ*22% (13)
ПО=53114,4*0,22=11685,17 руб.
Сн =(ФОТ-ПО) *0,26=(53114,4 -11685,17)*0,26=10771,6 руб.
Заключение
В данной выпускной квалификационной работе была разработана и реализована
программа контроля успеваемости студентов КГБОУ "СПО "ХМТ".
Данная программа обеспечивает следующие основные функции: соединение с базой
данных и визуализацию информации с возможность поиска по фамилии студента.
Реализация системы проводилась в соответствии с требованиями задания на
дипломную работу. Выбор СУБД и среды программирования был обусловлен
функциональностью и простотой использования. При разработке программы
использовались BorlandDelphi 7.0 и MSAccess 2003. В процессе написания
программы большое внимание было уделено удобству работы пользователя и
построению дружественного интерфейса. В результате этого удалось создать
функциональное оконное приложение с открытым кодом, что позволит в дальнейшем,
при необходимости модернизировать его путем добавления нужных функций.
Введение программы обеспечит ведение автоматизированногоконтроля за
состоянием успеваемости учащихся, а именно за количеством пропусков по
различным дисциплинам, что предоставит возможность преподавательскому составу
оперативно реагировать на недостатки студентов в процессе обучения и принимать
соответствующие меры.
При необходимости функциональность программы может быть расширена.
Так же, в работе сделан расчет трудоемкости затрат на разработку данного
программного продукта, что позволит оценить эффективность его внедрения.
Ввиду вышеизложенного можно считать, что задание на выпускную
квалификационную работу выполнено и поставленная цель достигнута.
Список используемых источников
1. Delphi 7. Основы программирования. Решение
типовых задач. Самоучитель: Л.М. Климова - Москва, КУДИЦ-Образ, 2006 г.- 480 с.
2. Delphi в задачах и примерах (+ CD-ROM): Никита
Культин - Москва, БХВ-Петербург, 2008 г.- 288 с.
. Delphi. Профессиональное программирование: Дмитрий
Осипов - Санкт-Петербург, Символ-Плюс, 2006 г.- 1056 с.
. Андреев А.М. Березкин Д.В. Кантонистов Ю.А. Объектные
СУБД на российских просторах [Электронный ресурс]. - "Компьютерная
хроника", 1997 г., N11.
. Бураков П.В., Петров В.Ю. Введение в системы баз
данных: Учебное пособ. - Изд-во: СПбГУ ИТМО, 2010. - 129 с.
. Вейскас Д., Эффективная работа с MicrosoftAccess
2000, СПб: Питер, 2001.
. Гришков В.И. Исследование возможностей объектного
представления данных в прикладных системах // Труды СПИИРАН. Вып.1, т.3. - СПб:
СПИИРАН, 2003.
. Основы программирования в интегрированной среде
Delphi. Практикум: А. Желонкин - Санкт-Петербург, Бином. Лаборатория знаний,
2006 г.- 240 с.
. Роб П., Коронел К. Системы баз данных:
проектирование, реализация и управление. - 5-е изд., перераб. и доп. - СПб.:
БХВ-Петербург, 2004. - 1040 с.
. Харитонова И.И. Самоучитель по MicrosoftAccess 2000.
СПб: Питер, 2001.
Приложение А. Листинг программы
(DatMod.pas);, Classes, DB, ADODB;= class(TDataModule):
TADOConnection;: TADOQuery;: TDataSource;_: TWideStringField;DSDesigner:
TWideStringField;DSDesigner2: TWideStringField;DSDesigner3: TWideStringField;DSDesigner4:
TWideStringField;_2: TWideStringField;_3: TIntegerField;
{ Private declarations }
{ Public declarations } ;: TDM;
{$R *.dfm}.
***************************************************
(Unit1.pas)Unit1;, Messages, SysUtils, Variants, Classes,
Graphics, Controls, Forms,, Grids, DBGrids, DB, ADODB, StdCtrls, Buttons,
ExtCtrls, DBCtrls,;= class(TForm): TGroupBox;: TDBNavigator;: TDBGrid;: TEdit;:
TBitBtn;: TLabel;BitBtn1Click(Sender: TObject);DBGrid2TitleClick(Column:
TColumn);
{ Private declarations }
{ Public declarations };: TForm1;;
{$R *.dfm}
//процедурапоискапонажатиюкнопкиTForm1.BitBtn1Click(Sender:
TObject);trim(Edit1.Text)=''
then.ADOQuery1.Filtered:=false;begin.ADOQuery1.Filter:='Фамилия='+chr(39)+trim(Edit1.Text)+chr(39);.ADOQuery1.Filtered:=true;;
end;
//сортировка столбцов по нажатию названия столбца
procedure TForm1.DBGrid2TitleClick(Column:
TColumn);.ADOQuery1.sort:=Column.FieldName;;.
**************************************************Project1;,in
'Unit1.dpr' {Form1},in 'DatMod.pas' {DM: TDataModule};
{$R *.res}
Application.Initialize;
Application.CreateForm(TForm1, Form1);.CreateForm(TDM,
DM);.Run;.