Обработка случайных выборок
Содержание
Введение
. Обработка одномерной случайной выборки
.1 Нахождение точечных оценок для не сгруппированной выборки
.2 Нахождение точечных оценок для сгруппированной выборки
.3 Построения гистограммы функций распределения
.4 Расчёт критерия Пирсона
.5 Расчёт критерия Колмогорова
. Обработка двумерной случайной выборки
.1 Построение поля рассеивания, гипотеза о виде корреляционной
зависимости
.2 Построение корреляционной таблицы
.3 Расчёт коэффициентов уравнения прямой регрессии
.4 Нахождение выборочного коэффициента корреляции
.5 Расчёт коэффициентов уравнения криволинейной регрессии
.6 Нахождение корреляционного отношения
.7 Расчёт критерия Фишера
Заключение
Литература
Приложения
Введение
Теория вероятностей является одним
из классических разделов математики. Вероятностные и статистические методы в
настоящее время глубоко проникли в приложения. Они используются в физике,
технике, экономке, биологии и медицине. Особенно возросла их роль в связи с
развитием вычислительной техники.
Например, для изучения физических
явлений производят наблюдения или опыты. Их результаты обычно регистрируют в
виде значений некоторых наблюдаемых величин. При повторении опытов мы
обнаруживаем разброс их результатов. Например, повторяя измерения одной и той
же величины одним и тем же прибором при сохранении определенных условий
(температура, влажность и т.п.), мы получаем результаты, которые хоть немного,
но все же отличаются друг от друга. Даже многократные измерения не дают
возможности точно предсказать результат следующего измерения. В этом смысле
говорят, что результат измерения есть величина случайная. Еще более наглядным
примером случайной величины может служить номер выигрышного билета в лотерее.
Можно привести много других примеров случайных величин. Все же и в мире случайностей
обнаруживаются определенные закономерности. Математический аппарат для изучения
таких закономерностей и дает теория вероятностей. Таким образом, теория
вероятностей занимается математическим анализом случайных событий и связанных с
ними случайных величин.
1 Обработка одномерной случайной
выборки
.1 Нахождение точечных оценок для не
сгруппированной выборки
Математи́ческое ожида́ние - среднее значение
случайной величины, распределение вероятностей случайной величины. Для
несгруппированной выборки находится по формуле:
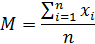
где 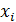 - значение из выборки,
- значение из выборки, 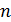 - величина выборки.
- величина выборки.
Дисперсия - мера
разброса данной случайной величины, то есть её отклонения от математического
ожидания. Выборочная дисперсия равна:
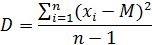
Среднеквадратичное
отклонение (СКО) - показатель рассеивания значений случайной величины
относительно её математического ожидания.
Ассиметрия - величина,
характеризующая асимметрию распределения данной случайной величины. Коэффициент
асимметрии A статистического распределения определяется по формуле:
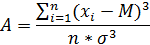
Коэффициент эксцесса -
мера остроты пика распределения случайной величины. Эксцесс E статистического
распределения определяется по формуле:
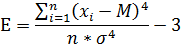
.2 Нахождение точечных
оценок для сгруппированной выборки
Изначально вся выборка
упорядочивается по убыванию.
Количество интервалов,
на которые необходимо разбить полученную выборку определяется по формуле: k =
(1 + 3.32 * log10 (n));
Данные о выборке Х:
Выборка: 100
Величина: 0,475
Минимум = 0,0191
Максимум =
3,82Количество интервалов: 8
Интервалы: 1) - 12; 2) -
24; 3) - 28; 4) - 23; 5) - 6; 6) - 4; 7) - 2; 8) - 0;
О выборке У:
Выборка: 100
Величина: 0,406
Минимум = -0,076
Максимум = 3,17
Количество интервалов: 8
Интервалы: 1) - 2; 2) -
2; 3) - 5; 4) - 13; 5) - 32; 6) - 28; 7) - 9; 8) - 8;
Математическое ожидание
для сгруппированной выборки:
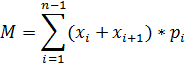
где где , 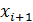 - границы интервала,
- границы интервала, 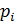 - вероятность попадания
в этот интервал.
- вероятность попадания
в этот интервал.
Дисперсия:
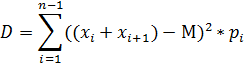
Среднеквадратическое
отклонение: 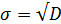
Ассиметрия:
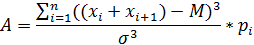
Эксцесс:
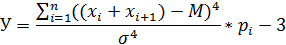
Погрешностью является
разность значений точечных оценок, полученных для обоих выборок, взятая по
модулю:
ΔМ=
|Мнс - Мс|, ΔD= |Dнс
- Dс|, Δ ϭ = | ϭ нс - ϭ с|, ΔA= |Aнс
- Aс|, ΔE= |Eнс
- Eс|.
Таблица со значениями
расчётов представлены на рисунке 1.1. и рисунке 1.2.
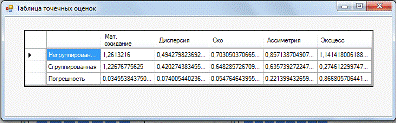
Рисунок 1.1 Таблица
расчета точечных оценок для выборки Х

Рисунок 1.2 Таблица
расчета точечных оценок для выборки У
Проанализируем полученные
данные. Маленькая погрешность расчётов свидетельствует о правильности
вычислений как не сгруппированной, так и в сгруппированной выборках.
.3 Построения
гистограммы функций распределения
Гистограмму используют для
изображения интервальных рядов. Для построения гистограммы по данным
вариационного ряда с равными интервалами, на оси абсцисс откладывают значения
величин интервалов, на которые разбита выборка, а на оси ординат - значения
частот или относительных частот. Далее строят прямоугольники, основаниями
которых служат отрезки оси абсцисс, длины которых равны длинам интервалов, а
высотами - отрезки, длины которых вычисляются делением вероятности попадания в
данный интервал на длину этого интервала. Самое большое значение на оси У
принимает значение 1, т.к. площадь значений должна равняться единице и
превышать это значение не может, а самое маленькое равно 0, так как площадь
отрицательной быть не может. На оси Х, минимальное значение - значение минимума
выборки, максимальное - максимума.
Для проверки гистограммы,
использовались следующие законы распределения.
Гауссовский нормальный:
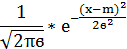
где параметр m - среднее значение
(математическое ожидание) случайной величины и указывает координату максимума
кривой плотности распределения, а σ² - дисперсия.
Гаусовское стандартное
распределение:
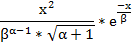
Экспоненциальный:
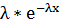
Сдвинутый экспоненциальный:
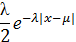
Вейбула:
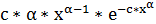
Релея:
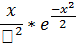
Равномерный:
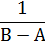
Нормированный равномерный:
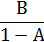
Проанализируем результаты,
построенных гистограмм.
Выборка Х.
Из всех законов распределения нам
подходят Гауссовский нормальный, Гауссовский стандартный, Сдвинутый
экспоненциальный.

Рисунок 1.3 Гауссовский нормальный
закон распределения для выборки Х
На рисунке 1.3. Гауссовский
нормальный закон распределения для выборки Х продемонстрировано наложение
графика Гауссовский нормального распределения на гистограмму, график идеально
подходит под распределение.
Следующим будет проверяться
гауссовский стандартный закон.
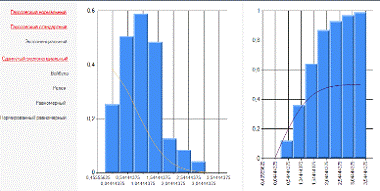
Рисунок 1.3 Гауссовский стандартный
закон распределения для выборки Х
Из рисунка (рисунок 1.3. Гауссовский
стандартный закон распределения) видно, что данный закон распределения не
подходит.
И последнее подходящее распределение
- это сдвинутое экспоненциальное.
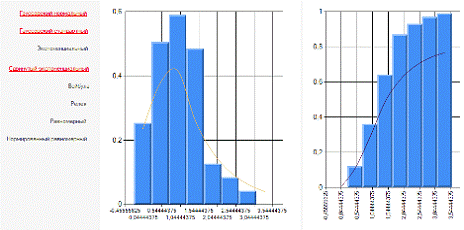
Рисунок 1.3 Сдвинутый
экспоненциальный закон распределения для выборки Х
График (рисунок 1.3. Сдвинутый
экспоненциальный закон распределения для выборки Х) не совсем точно
накладывается на гистограмму.
Из этого можно сделать вывод, что
это гауссовский нормальный закон распределения.
Выборка У.
Как и в выборке Х подходят
Гауссовский нормальный, Гауссовский стандартный, Сдвинутый экспоненциальный
законы распределения.
Рассмотрим гауссовский нормальный
закон.
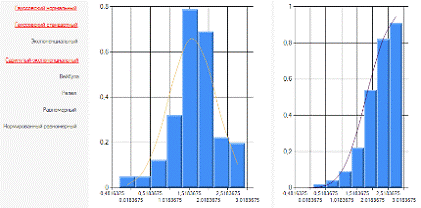
Рисунок 1.3 Гауссовский нормальный
закон распределения для выборки У
График распределения на рисунке 1.3.
Гауссовский нормальный закон распределения для выборки У почти совпадает с
гистограммой.
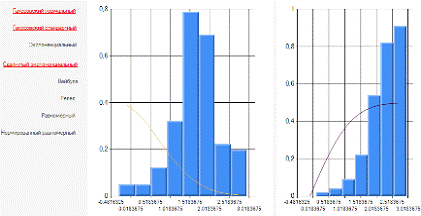
Рисунок 1.3 Гауссовский стандартный
закон распределения для выборки У
Как видим из рисунка 1.3.
Гауссовский стандартный закон распределения для выборки У гауссовский
стандартный не подходит, как и в предыдущей выборке.
Рассмотрим сдвинутый
экспоненциальный закон.
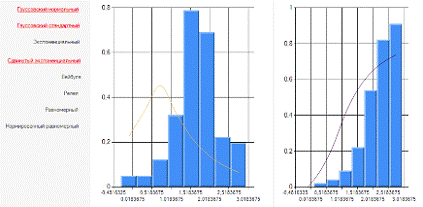
Рисунок 1.3 Сдвинутый
экспоненциальный закон распределения для выборки У
Этот график (рисунок 1.3 Сдвинутый
экспоненциальный закон распределения для выборки У) также не подходит под
исходную диаграмму, следовательно, снова наша выборка подчиняется гауссовскому
нормальному закону распределения.
.4 Расчёт критерия Пирсона
Критерий согласия К.
Пирсона 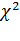 , который можно
представить как сумму отношений квадратов расхождений между f' и f к
теоретическим частотам:
, который можно
представить как сумму отношений квадратов расхождений между f' и f к
теоретическим частотам:
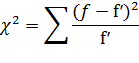
Вычисленное значение
критерия расч необходимо
сравнить с табличным (критическим) значением табл.
Табличное значение определяется по специальной таблице, оно зависит от принятой
вероятности Р и числа степеней свободы k (при этом k = m - 3, где m - число
групп в ряду распределения для нормального распределения). При расчете критерия
согласия Пирсона должно соблюдаться следующее условие: достаточно большим
должно быть число наблюдений (n 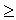 50), при этом если в
некоторых интервалах теоретические частоты < 5, то интервалы объединяют для
условия > 5.
50), при этом если в
некоторых интервалах теоретические частоты < 5, то интервалы объединяют для
условия > 5.
Если расч 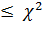 табл,
то расхождения между эмпирическими и теоретическими частотами распределения
могут быть случайными и предположение о близости эмпирического распределения к
нормальному не может быть отвергнуто.
табл,
то расхождения между эмпирическими и теоретическими частотами распределения
могут быть случайными и предположение о близости эмпирического распределения к
нормальному не может быть отвергнуто.
В том случае, если
отсутствуют таблицы для оценки случайности расхождения теоретических и
эмпирических частот, можно использовать критерий согласия В.И. Романовского КРом,
который, используя величину , предложил оценивать
близость эмпирического распределения кривой нормального распределения при
помощи отношения
КРом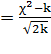 ,
,
где m - число групп; k =
(m - 3) - число степеней свободы при исчислении частот нормального
распределения.
Если вышеуказанное
отношение < 3, то расхождения эмпирических и теоретических частот можно
считать случайными, а эмпирическое распределение - соответствующим нормальному.
Если отношение > 3, то расхождения могут быть достаточно существенными и
гипотезу о нормальном распределении следует отвергнуть.
.5 Расчёт критерия
Колмогорова
Критерий согласия А.Н.
Колмогорова 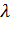 используется при
определении максимального расхождения между частотами эмпирического и
теоретического распределения, вычисляется по формуле
используется при
определении максимального расхождения между частотами эмпирического и
теоретического распределения, вычисляется по формуле
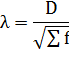
где D - максимальное
значение разности между накопленными эмпирическими и теоретическими частотами; 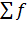 - сумма эмпирических
частот.
- сумма эмпирических
частот.
По таблицам значений вероятностей
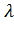 -критерия можно найти
величину
-критерия можно найти
величину 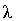 ,
соответствующую вероятности Р. Если величина вероятности Р значительна по
отношению к найденной величине , то можно предположить,
что расхождения между теоретическим и эмпирическим распределениями
несущественны.
,
соответствующую вероятности Р. Если величина вероятности Р значительна по
отношению к найденной величине , то можно предположить,
что расхождения между теоретическим и эмпирическим распределениями
несущественны.
Необходимым условием при
использовании критерия согласия Колмогорова является достаточно большое число
наблюдений (не меньше ста).
Расчёт критериев Пирсона
и Колмогорова выборки Х:
Критерий Пирсона: 6,24
Критерий Колмагорова:
0,0894
Расчёт критериев Пирсона
и Колмогорова выборки У:
Критерий Пирсона: 183
Критерий Колмагорова:
0,344
Вся информация о выборках также
приведена на рисунке 1.5.Обработка однмерной выборки Х в приложении Б и рисунке
Рисунок 1.5. Обработка однмерной выборки У в приложении В.
2. Обработка двумерной случайной
выборки
.1 Построение поля рассеивания,
гипотеза о виде корреляционной зависимости
Корреляционный анализ, как и другие
статистические методы, основан на использовании вероятностных моделей,
описывающих поведение исследуемых признаков в некоторой генеральной
совокупности, из которой получены экспериментальные значения xi
и yi.
Когда исследуется корреляция между
количественными признаками, значения которых можно точно измерить в единицах
метрических шкал (метры, секунды, килограммы и т.д.), то очень часто
принимается модель двумерной нормально распределенной генеральной совокупности.
Такая модель отображает зависимость между переменными величинами xi
и yi графически в виде геометрического места точек в
системе прямоугольных координат. Эту графическую зависимость называются также
диаграммой рассеивания или корреляционным полем.
Данная модель двумерного нормального
распределения (корреляционное поле) позволяет дать наглядную графическую
интерпретацию коэффициента корреляции, т.к. распределение в совокупности
зависит от пяти параметров:- средние значения (математические ожидания); -
стандартные отклонения случайных величин Х и Y и р -
коэффициент корреляции, который является мерой связи между случайными
величинами Х и Y.
Если р = 0, то значения, xi,
yi, полученные из двумерной нормальной совокупности,
располагаются на графике в координатах х, у в пределах области,
ограниченной окружностью (рисунок 2.1. Виды зависимости а). В этом случае между
случайными величинами Х и Y отсутствует корреляция и они
называются некоррелированными. Для двумерного нормального распределения
некоррелированность означает одновременно и независимость случайных величин
Х и Y.
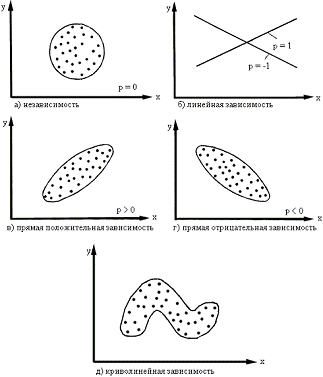
Рисунок 2.1 Виды зависимости
Если р = 1 или р = -1, то между
случайными величинами Х и Y существует линейная функциональная
зависимость (Y = c + dX). В этом случае говорят о полной корреляции. При
р = 1 значения xi, yi определяют точки, лежащие на
прямой линии, имеющей положительный наклон (с увеличением xi
значения yi также увеличиваются), при р = -1 прямая имеет
отрицательный наклон (рисунок 2.1. Виды зависимости б).
В промежуточных случаях (-1 <
p < 1) точки, соответствующие значениям xi, yi,
попадают в область, ограниченную некоторым эллипсом (рисунок 2.1. Виды
зависимости в, рисунок 2.1. Виды зависимости г), причем при p > 0
имеет место положительная корреляция (с увеличением xi
значения yi имеют тенденцию к возрастанию), при p < 0
корреляция отрицательная. Чем ближе р к ±1, тем уже эллипс и тем теснее
экспериментальные значения группируются около прямой линии.
Здесь же следует обратить внимание
на то, что линия, вдоль которой группируются точки, может быть не только
прямой, а иметь любую другую форму: парабола, гипербола и т. д. В этих случаях
мы рассматривали бы так называемую, нелинейную (или криволинейную) корреляцию
(рисунок 2.1. Виды зависимости д). Таким образом, визуальный анализ корреляционного
поля помогает выявить не только наличия статистической зависимости (линейную
или нелинейную) между исследуемыми признаками, но и ее тесноту и форму. Это
имеет существенное значение для следующего шага в анализе ѕ выбора и вычисления
соответствующего коэффициента корреляции.
Модель корреляционного поля,
полученного для данной двумерной выборки представлено на рисунке
2.1.Корреляционное поле.
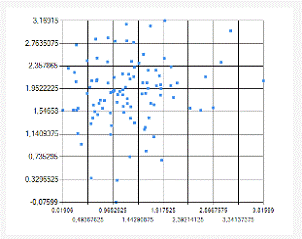
.1 Корреляционное поле
Т.к. коэффициент корреляции для
данной двумерной выборки равен +0,15, т.е. корреляционная зависимость очень
слабая. Чему соответствует вид поля - широкий эллипс, почти круг, имеющий
слабую тенденцию возрастания.
.2 Построение корреляционной таблицы
На практике в результате независимых
наблюдений над величинами X и Y, как правило, имеют дело не со всей
совокупностью всех возможных пар значений этих величин, а лишь с ограниченной
выборкой из генеральной совокупности.
Первоочередной задачей
статистической обработки экспериментального материала является систематизация
полученных данных и выяснение формы соответствующей генеральной совокупности.
Таблицу с группированными данными
называют корреляционной. В первой строке основной части таблицы в порядке
возрастания перечисляются все промежутки, на которые разбита выборка X. В
первом столбце также промежутки, на которые разбита выборка Y. На пересечении
соответствующих строк и столбцов указываются количество точек, которые попадают
в этот участок. Последний столбец и последняя строка содержат суммы соответствующих
строк и столбцов.
Корреляционная таблица
y/x
|0,019-0,49|0,49-0,97|0,97- 1,4| 1,4- 1,9| 1,9- 2,4| 2,4- 2,9| 2,9- 3,3| 3,3-
3,8|Ny
,076-0,33|
0| 0| 1| 1| 5|
3| 2| 0| 12| 0,33-0,74 |
0| 1| 1| 6| 7|
5| 2| 2| 24| 0,74- 1,1 |
2| 0| 1| 3| 10|
7| 1| 4| 28| 1,1- 1,5 |
0| 1| 2| 3| 6| 8|
2| 1| 23| 1,5- 2 | 0|
0| 0| 0| 1| 3| 1|
0| 5| 2- 2,4 | 0| 0| 0|
0| 3| 1| 0| 0| 4| 2,4-
2,8 | 0| 0| 0| 0|
0| 0| 1| 1| 2| 2,8- 3,2
| 0| 0| 0| 0|
0| 0| 0| 0| 0| Nx
| 2| 2| 5| 13| 32|
27| 9| 8|
.3 Расчёт коэффициентов уравнения
прямой регрессии
Выбрав вид функции регрессии, т.е.
вид рассматриваемой модели зависимости Y от Х (или Х от У), например, линейную
модель yx=a+bx, необходимо определить конкретные значения
коэффициентов модели.
При различных значениях а и b можно
построить бесконечное число зависимостей вида yx=a+bx т.е на
координатной плоскости имеется бесконечное количество прямых, нам же необходима
такая зависимость, которая соответствует наблюдаемым значениям наилучшим
образом. Таким образом, задача сводится к подбору наилучших коэффициентов.
Линейную функцию a+bx ищем, исходя
лишь из некоторого количества имеющихся наблюдений. Для нахождения функции с
наилучшим соответствием наблюдаемым значениям используем метод наименьших
квадратов.
Обозначим: Yi - значение,
вычисленное по уравнению Yi=a+bxi. yi -
измеренное значение, εi=yi-Yi
- разность между измеренными и вычисленными по уравнению значениям, εi=yi-a-bxi.
В методе наименьших квадратов
требуется, чтобы εi, разность между
измеренными yi и вычисленными по уравнению значениям Yi,
была минимальной. Следовательно, находим коэффициенты а и b так, чтобы сумма
квадратов отклонений наблюдаемых значений от значений на прямой линии регрессии
оказалась наименьшей:
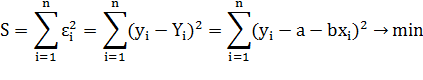
Исследуя на экстремум эту функцию
аргументов а и с помощью производных, можно доказать, что функция принимает
минимальное значение, если коэффициенты а и b являются решениями системы:
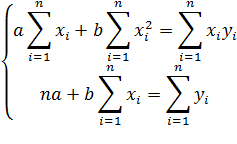
Если разделить обе части нормальных
уравнений на n, то получим:
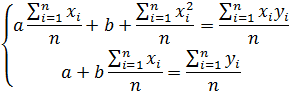
Учитывая, что
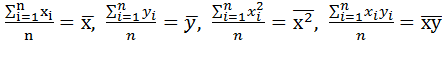
Получим 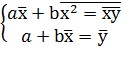 , отсюда
, отсюда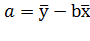 , подставляя значение a
в первое уравнение, получим:
, подставляя значение a
в первое уравнение, получим:
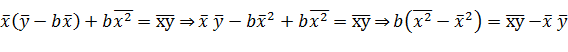
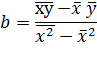
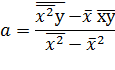
При этом b называют
коэффициентом регрессии; a называют свободным членом уравнения регрессии.
.4 Нахождение выборочного
коэффициента корреляции
Понятие корреляции является одним из
основных понятий теории вероятностей и математической статистики, оно было
введено Гальтоном и Пирсоном.
Закон природы или общественного
развития может быть представлен описанием совокупности взаимосвязей. Если эти
зависимости стохастичны, а анализ осуществляется по выборке из генеральной
совокупности, то данная область исследования относится к задачам
стохастического исследования зависимостей, которые включают в себя
корреляционный, регрессионный, дисперсионный и ковариационный анализы. В данном
разделе рассмотрена теснота статистической связи между анализируемыми
переменными, т.е. задачи корреляционного анализа.
В качестве измерителей степени
тесноты парных связей между количественными переменными используются
коэффициент корреляции (или то же самое "коэффициент корреляции
Пирсона") и корреляционное отношение.
Пусть при проведении некоторого
опыта наблюдаются две случайные величины X и Y, причем одно и то же значение x
встречается nx раз, y - ny раз, одна и та же пара чисел
(x,y) наблюдается nxy раз. Все данные записываются в виде таблицы,
которую называют корреляционной.
Выборочная ковариация k(X,Y) величин
X и Y определяется формулой
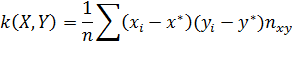
где 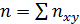 а x*, y*-
выборочные средние величин X и Y
а x*, y*-
выборочные средние величин X и Y
Выборочный коэффициент корреляции
находится по формуле:
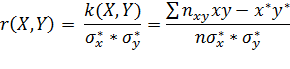
где 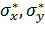 - выборочные средние
квадратические отклонения величин X и Y.
- выборочные средние
квадратические отклонения величин X и Y.
Выборочный коэффициент
корреляции r(X,Y) показывает тесноту линейной связи между X и Y: чем ближе
r(X,Y) к единице, тем сильнее линейная связь между X и Y.
2.5 Расчёт коэффициентов уравнения
криволинейной регрессии
Это уравнение вида Y = b0
+b1X1 + b2X2;
) Найтин еизвестные b0, b1,b2
можно, решим систему трехлинейных уравнений с тремя неизвестными b0,b1,b2:
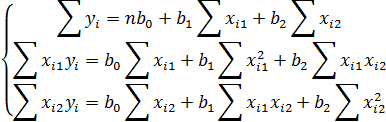
Для решения системы можете
воспользоваться решение системы методом Крамера
) Или использовав формулы^
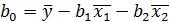
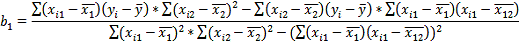
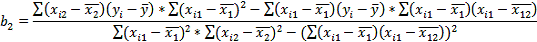
Выборочные дисперсии эмпирических
коэффициентов множественной регрессии можно определить следующим образом:
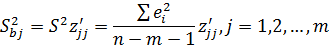
Здесь z'jj - j-тый
диагональный элемент матрицы Z-1 =(XTX)-1.
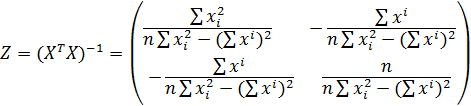
При этом:

где m - количество объясняющих
переменных модели.
.6 Нахождение корреляционного
отношения
Корреляционное отношение в
криволинейной регрессии играет ту же роль, что и коэффициент корреляции в
линейной, показывая тесноту группировки данных вокруг линии регрессии. Именно
по этой причине анализ силы связи по 0 называют корреляционным, какова бы ни
была изучаемая регрессия.
Эмпирическое корреляционное
отношение определяется по формуле:
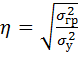 , где
, где
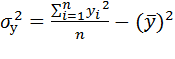 - общая дисперсия.
- общая дисперсия.
2.7 Расчёт критерия Фишера
Критерием Фишера (F-критерием, φ*-критерием) - называют
любой статистический критерий, тестовая статистика которого при выполнении
нулевой гипотезы имеет распределение Фишера (F-распределение).
Статистика теста так или иначе
сводится к отношению выборочных дисперсий (сумм квадратов, деленных на
"степени свободы"). Чтобы статистика имела распределение Фишера
необходимо, чтобы числитель и знаменатель были независимыми случайными
величинами и соответствующие суммы квадратов имели распределение Хи-квадрат.
Для этого требуется, чтобы данные имели нормальное распределение. Кроме того,
предполагается, что дисперсия случайных величин, квадраты которых суммируются,
одинакова.
Тест проводится путем
сравнения значения статистики с критическим значением соответствующего
распределения Фишера при заданном уровне значимости. Известно, что если 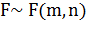 , то
, то 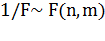 ,. Кроме того, квантили
распределения Фишера обладают свойством F1-α=1/Fα.
Поэтому обычно на практике в числителе участвует потенциально большая величина,
в знаменателе - меньшая и сравнение осуществляется с "правой"
квантилью распределения. Тем не менее тест может быть и двусторонним и
односторонним. В первом случае при уровне значимости
,. Кроме того, квантили
распределения Фишера обладают свойством F1-α=1/Fα.
Поэтому обычно на практике в числителе участвует потенциально большая величина,
в знаменателе - меньшая и сравнение осуществляется с "правой"
квантилью распределения. Тем не менее тест может быть и двусторонним и
односторонним. В первом случае при уровне значимости 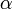 используется
квантиль Fα/2, а при одностороннем тесте Fα.
используется
квантиль Fα/2, а при одностороннем тесте Fα.
Более удобный способ
проверки гипотез - с помощью p-значения p(F) - вероятностью того, что случайная
величина с данным распределением Фишера превысит данное значение статистики.
Если p(F) (для двустороннего теста - 2p(F) меньше уровня значимости α,
то нулевая гипотеза отвергается, в противном случае принимается.
Статистика теста для
двумерной выборки будет вычисляться по формуле:
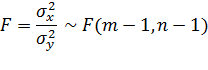
Если статистика больше
критического, то дисперсии не одинаковы, в противном случае дисперсии выборок
одинаковы.
Все значения,
рассчитанные в данном разделе:
Линейное уравнение
прямой регрессии: y=1,94-0,00267*x
Коэффициент корреляции:
0,151
Корреляционное
отношение: 2,5
Критерий Фишера: 1,41
Также вся информация о двумерной
выборке приведена на рисунке 2.7. Обработка двумерной выборки.
Заключение
В данной курсовой работе была
смоделирована и решена задача по обработке одномерной и двумерной случайной
выборки при помощи вычислительной техники в приложении Microsoft Visual Studio
на языке программирования C#. Результаты машинних экспериментов были наглядно
проиллюстрированы графиками различных распределений для одномерной выборки и
корреляционным полем для двумерной.
Компьютерная техника позволяет
наиболее просто и наглядно продемонстрировать случайные процессы происходящие в
природе. Также при помощи программ очень удобно вычислять значения величин и
критериев теории вероятности и математической статистики, из полученных в
результате эксперимента данных.
Литература
случайная выборка корреляционный
1. Вентцель Е.С. Теория вероятностей. - М.: Наука, 1969. - 576с.
2. Гмурман В.Е. Теория вероятностей и математическая
статистика. - М.: Высш.школа, 1992. - 368с.
. Гмурман В.Е. Руководство к решению задач по теории
вероятностей и математической статистики. - М.: Высш.школа, 1979. - 400с.
. Гурский Е.И. Теория вероятностей с элементами
математической статистики. - М.: Высш.школа, 1991. - 328с.
Приложение А
Программный код
.System;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;kurs
{partial class Form1: Form
{Form1()
{();= "= Теория Вероятности
=";Menu = new MenuStrip();p1 = new
ToolStripMenuItem("Одномерная");.Items.Add(p1);x = new
ToolStripMenuItem("Выборка x");.DropDownItems.Add(x);y = new
ToolStripMenuItem("Выборка y");.DropDownItems.Add(y);p2 = new
ToolStripMenuItem("Двумерная");.Items.Add(p2);p3 = new ToolStripMenuItem("Выход:)");.Items.Add(p3);.Click
+= X;.Click += Y;.Click += D;.Click += Close;.Add(Menu);= Menu;
}void Form1_Load(object sender,
EventArgs e)
{
}X(object who, EventArgs e)
{f = new
Form2("X.txt");.Show();
}Y(object who, EventArgs e)
{f = new Form2("Y.txt");.Show();
}D(object who, EventArgs e)
{f = new Form6();.Show();
}Close(object who, EventArgs e)
{result = MessageBox.Show("Вы
хотите выйти?", "Выход:)", MessageBoxButtons.YesNo);(result ==
DialogResult.Yes) Application.Exit();
}int s { get; set; }
}
}.System;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;System.IO;kurs
{partial class Form2: Form
{kol;k;h;xmax,xmin;name;[] pogr =
new double[5];[] Et = new double[5];[] Pr = new double[5];[] prak;[] y;[] Em;[]
zn;[] Points;void proverka()
{(xmin < 0 || xmin > 0)
linkLabel3.Enabled = linkLabel5.Enabled = linkLabel6.Enabled =
linkLabel7.Enabled = linkLabel8.Enabled=false;(xmin > 0 &&
xmax<1||xmin==0 || xmax==1) linkLabel1.Enabled = linkLabel2.Enabled =
linkLabel4.Enabled = linkLabel8.Enabled = false;
}file(string s) { name = s;
}Form2(string s)
{();= "Одномерная
выборка";(s);
}void Form2_Load(object sender,
EventArgs e)
{[] lines =
File.ReadAllLines(name);i;[] X = new double[lines.Length];= X.Length;.Text =
"Выборка: " + X.Length;(i = 0; i < kol; i++)
{[i] = Convert.ToDouble(lines[i]);
}= Convert.ToInt32(1 + 3.32 *
Math.Log10(Convert.ToDouble(kol)));= new double[k];= new double[k];= new
double[k];= new double[k];= new double[k+1];t = xmin;K = k;(ref X);(ref X);(i =
0; i < Points.Length; i++)
{[i] = t;+= h;
}(i = 1, zn[0] = xmin; i < k;
i++)[i] = zn[i - 1] + h;(i = 0; i < 5; i++)[i] = Math.Abs(Et[i] - Pr[i]);=
0;(i = 0; i < k; i++)
{[i] = prak[i] / h;[i] = K;+=
prak[i];
}.Series[0].Points.DataBindXY(zn,
y);.Series[0].Points.DataBindXY(zn, Em);();
}
void button1_Click(object sender,
EventArgs e)
{f = new Form5();.Show();.Table(Et,
Pr, pogr);
}delegate double F(double x, double
m, double sko);double square (double a, double b, double m, double sko, F f)
{hh = b - a, S1, S2, x;= f(a, m,
sko) * hh;
{= hh / 2;= S2;= 0;= a;(x < b -
hh / 2)
{+= f(x, m, sko);+= hh;
}*= hh;
}(Math.Abs(S2 - S1) > 0.0001);S2;
}void krit(double m, double sko, F
f)
{pr = 0, kl = 0;[] Y = new
double[k];[] teor = new double [k];[] R = new double[k];P = 0;i;(i = 0; i <
k; i++)
{[i] = square(Points[i], Points[i +
1], m, sko, f);+= Math.Pow((prak[i] - Y[i]), 2) / Y[i];[i] = P;[i] =
Math.Abs(teor[i] - Em[i]);+= Y[i];[i] = Y[i] / h;
}*= kol;.Sort(R);= R[R.Length - 1] /
Math.Sqrt(Em[Em.Length - 1]);.Text = "Критерий Пирсона: " + pr;.Text
= "Критерий Колмагорова: " + kl;.Series[1].Points.DataBindXY(zn,
Y);.Series[1].Points.DataBindXY(zn, teor);
}void clear()
}double f1(double x, double m,
double sko)
{(1 / (sko * (Math.Sqrt(2 *
Math.PI)))) * Math.Exp(-((Math.Pow(x - m, 2) / (2 * Math.Pow(sko / 1, 2)))));
}double f3(double x, double m,
double sko)
{Math.Sqrt(1 / Math.Pow(sko, 2)) *
Math.Exp(-Math.Sqrt(1 / Math.Pow(sko, 2)) * x);
}double f4(double x, double l,
double c)
{(l / 2) * Math.Exp(-l * Math.Abs(x
- c));
}double f5(double x, double l,
double c)
{c * l * Math.Pow(x, l - 1) *
Math.Exp(-c * Math.Pow(x, l));
}double f6(double x, double m,
double sko)
{(x / Math.Pow(sko, 2)) *
(Math.Exp(-Math.Pow(x, 2) / (2 * Math.Pow(sko, 2))));
}double f7(double x, double m,
double sko)
{1 / (xmax - xmin);;
}double f8(double x, double m,
double sko)
{xmax / (1 - xmin);
}void linkLabel1_LinkClicked(object
sender, LinkLabelLinkClickedEventArgs e)
{(Et[0], Et[2], f1);
}void linkLabel2_LinkClicked(object
sender, LinkLabelLinkClickedEventArgs e)
{(0, 1, f1);
}void
linkLabel3_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(Et[0], Et[2], f3);
}void
linkLabel4_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(1, 1, f4);
}void
linkLabel5_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(1, 1, f5);
}void
linkLabel6_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(Et[0], Et[2], f6);
}void
linkLabel7_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(Et[0], Et[2], f7);
}void
linkLabel8_LinkClicked_1(object sender, LinkLabelLinkClickedEventArgs e)
{(Et[0], Et[2], f8);
}unsort(ref double [] X)
{i;M = 0, D = 0, SKO = 0, A = 0, E =
0;(i = 0; i < kol; i++)+= X[i];= M / (double)kol;(i = 0; i < kol; i++)
{+= Math.Pow((X[i] - M), 2);+=
Math.Pow((X[i] - M), 3);+= Math.Pow((X[i] - M), 4);
}= D / (kol - 1);= Math.Sqrt(D);= A
/ kol / Math.Pow(SKO, 3);= E / kol / Math.Pow(SKO, 4) - 3;[0] = M; Et[1] = D;
Et[2] = SKO; Et[3] = A; Et[4] = E;
}sort(ref double [] X)
{i,j;M_=0,D_=0,SKO=0,t,H,A_=0,E_=0;(i=0;i<kol-1;i++)(j=0;j<kol-1;j++)(X[j+1]>X[j])
{=X[j];[j]=X[j+1];[j+1]=t;
}[] KOL=new double [k];[] M=new
double [k];[] D=new double [k];[] A=new double [k];[] E=new double
[k];(i=0,xmin=X[0],xmax=X[0];i<kol;i++)
{(xmin>X[i]) =X[i];(xmax<X[i])
=X[i];
}=(xmax-xmin)/(double)k;.Text =
"Величина: " + h;.Text = "Диапазон: xmin = " + xmin +
" xmax = " + xmax;.Text = "Количество интервалов: " +
k;(i=0,H=xmin;i<k;i++,H+=h)(j=0;j<kol;j++)(X[j]>=H&&X[j]<=H+h)[i]++;.Text
= "Интервалы: ";(i = 0; i < k; i++).Text += (i + 1) + ") -
" + KOL[i] + "; ";(i=0,H=xmin;i<k;i++,H+=h)_+=M[i]=(H+H+h)/2*KOL[i]/(double)kol;(i
= 0, H = xmin; i < k; i++, H += h)
{_+=D[i]=Math.Pow(((H+H+h)/2-M_),2)*KOL[i]/(double)kol;_+=A[i]=Math.Pow(((H+H+h)/2-M_),3)*KOL[i]/(double)kol;_+=E[i]=Math.Pow(((H+H+h)/2-M_),4)*KOL[i]/(double)kol;=Math.Sqrt(D[i]);[i]=KOL[i]/(double)kol;
}[0]=M_;[1]=D_;[2]=SKO=Math.Sqrt(D_);
[3]=A_=A_/Math.Pow(SKO,3); [4]=E_=E_/Math.Pow(SKO,4)-3;
}
}
}.System;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;System.IO;System.Windows.Forms.DataVisualization.Charting;kurs
{partial class Form4: Form
{Form4()
{();= "Корреляционное
поле";
}void Form4_Load(object sender,
EventArgs e)
{[] vib =
File.ReadAllLines("X.txt");[] vib2 =
File.ReadAllLines("Y.txt");kol = vib.Length,i;[] X = new
double[kol];[] Y = new double[kol];(i = 0; i < kol; i++)
{[i] = Convert.ToDouble(vib[i]);[i]
= Convert.ToDouble(vib2[i]);
}(i = 0; i < kol; i++)
{.Series[0].Points.AddXY(X[i],Y[i]);
}
}void chart1_Click(object sender,
EventArgs e)
{
}
}
}.System;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;kurs
{partial class Form5: Form
{Form5()
{();= "Таблица точечных
оценок";
}void Form5_Load(object sender,
EventArgs e)
{
}void Table(double[] Et, double[]
Pr, double[] pogr)
{.AllowUserToAddRows = false;row =
new DataGridViewRow();Cell0 = new DataGridViewTextBoxCell(); Cell0.Value =
"Негруппированная";Cell1 = new DataGridViewTextBoxCell(); Cell1.Value
= Convert.ToString(Et[0]);Cell2 = new DataGridViewTextBoxCell(); Cell2.Value =
Convert.ToString(Et[1]);Cell3 = new DataGridViewTextBoxCell(); Cell3.Value =
Convert.ToString(Et[2]);Cell4 = new DataGridViewTextBoxCell(); Cell4.Value =
Convert.ToString(Et[3]);Cell5 = new DataGridViewTextBoxCell(); Cell5.Value =
Convert.ToString(Et[4]);.Cells.AddRange(Cell0, Cell1, Cell2, Cell3, Cell4,
Cell5);.Rows.Add(row);row1 = new DataGridViewRow();Cell0a = new
DataGridViewTextBoxCell(); Cell0a.Value = "Cгруппированная";Cell1a =
new DataGridViewTextBoxCell(); Cell1a.Value = Convert.ToString(Pr[0]);Cell2a =
new DataGridViewTextBoxCell(); Cell2a.Value = Convert.ToString(Pr[1]);Cell3a =
new DataGridViewTextBoxCell(); Cell3a.Value = Convert.ToString(Pr[2]);Cell4a =
new DataGridViewTextBoxCell(); Cell4a.Value = Convert.ToString(Pr[3]);Cell5a =
new DataGridViewTextBoxCell(); Cell5a.Value =
Convert.ToString(Pr[4]);.Cells.AddRange(Cell0a, Cell1a, Cell2a, Cell3a, Cell4a,
Cell5a);.Rows.Add(row1);row2 = new DataGridViewRow();Cell0b = new
DataGridViewTextBoxCell(); Cell0b.Value = "Погрешность";Cell1b = new
DataGridViewTextBoxCell(); Cell1b.Value = Convert.ToString(pogr[0]);Cell2b =
new DataGridViewTextBoxCell(); Cell2b.Value = Convert.ToString(pogr[1]);Cell3b
= new DataGridViewTextBoxCell(); Cell3b.Value = Convert.ToString(pogr[2]);Cell4b
= new DataGridViewTextBoxCell(); Cell4b.Value =
Convert.ToString(pogr[3]);Cell5b = new DataGridViewTextBoxCell(); Cell5b.Value
= Convert.ToString(pogr[4]);.Cells.AddRange(Cell0b, Cell1b, Cell2b, Cell3b,
Cell4b, Cell5b);.Rows.Add(row2);
}
}
}.System;System.Collections.Generic;System.ComponentModel;System.Data;System.Drawing;System.Linq;System.Text;System.Windows.Forms;System.IO;kurs
{partial class Form6: Form
{i, j, l, sum=0;xmin1, xmax1, h,
hh;(i = 0, xmin1 = X[0], xmax1 = X[0]; i < kol1; i++)
{(xmin1 > X[i])= X[i];(xmax1 <
X[i])= X[i];
}(i = 0, xmin2 = Y[0], xmax2 = Y[0];
i < kol2; i++)
{(xmin2 > Y[i])= Y[i];(xmax2 <
Y[i])= Y[i];
}= Convert.ToInt32(1 + 3.32 *
Math.Log10(Convert.ToDouble(kol1)));= Convert.ToInt32(1 + 3.32 *
Math.Log10(Convert.ToDouble(kol2)));= (xmax1 - xmin1) / k1;= (xmax2 - xmin2) /
k2;[,] Mas = new int[k1, k2];[] Sum = new int[k1];(i = 0; i < k1; i++)
{(j = 0; j < k2; j++)[i, j] =
0;[i] = 0;
}(l = 0; l < kol1; l++)(i = 0, h
= xmin1; i < k1; i++, h += h1)(X[l] <= (h + h1) && X[l] >=
h-0.0001)(j = 0, hh = xmin2; j < k2; j++, hh += h2)(Y[l] <= (hh + h2)
&& Y[l] >= hh)[i, j]++;=xmin1;Column0 =new DataGridViewTextBoxColumn();.HeaderText
= "y/x";Column1 =new DataGridViewTextBoxColumn();.HeaderText =
Convert.ToString(h) + "-" + Convert.ToString(h + h1); h += h1;Column2
=new DataGridViewTextBoxColumn();.HeaderText = Convert.ToString(h) + "-"
+ Convert.ToString(h + h1); h += h1;Column3 =new
DataGridViewTextBoxColumn();.HeaderText = Convert.ToString(h) + "-" +
Convert.ToString(h + h1); h += h1;Column4 =new
DataGridViewTextBoxColumn();.HeaderText = Convert.ToString(h) + "-" +
Convert.ToString(h + h1); h += h1;Column5 =new DataGridViewTextBoxColumn();.HeaderText
= Convert.ToString(h) + "-" + Convert.ToString(h + h1); h +=
h1;Column6 =new DataGridViewTextBoxColumn();.HeaderText = Convert.ToString(h) +
"-" + Convert.ToString(h + h1); h += h1;Column7 =new DataGridViewTextBoxColumn();.HeaderText
= Convert.ToString(h) + "-" + Convert.ToString(h + h1); h +=
h1;Column8 = new DataGridViewTextBoxColumn();.HeaderText = Convert.ToString(h)
+ "-" + Convert.ToString(h + h1); h += h1; Column9 =new
DataGridViewTextBoxColumn();.HeaderText = "Ny";.Columns.Add(Column0);.Columns.Add(Column1);.Columns.Add(Column2);.Columns.Add(Column3);.Columns.Add(Column4);.Columns.Add(Column5);.Columns.Add(Column6);.Columns.Add(Column7);
.Columns.Add(Column8);.Columns.Add(Column9);(i = 0,h=xmin2; i <k2; i++, sum
= 0,h+=h2)
{Cell0 = new
DataGridViewTextBoxCell();Cell1 = new DataGridViewTextBoxCell();Cell2 = new
DataGridViewTextBoxCell();Cell3 = new DataGridViewTextBoxCell();Cell4 = new
DataGridViewTextBoxCell();Cell5 = new DataGridViewTextBoxCell();Cell6 = new
DataGridViewTextBoxCell();Cell7 = new DataGridViewTextBoxCell();Cell8 = new
DataGridViewTextBoxCell();Cell9 = new DataGridViewTextBoxCell();row = new
DataGridViewRow();.Value = Convert.ToString(h) + "-" +
Convert.ToString(h+h2);.Value = Convert.ToString(Mas[i, 0]); sum += Mas[i, 0];
Sum[0] += Mas[i, 0];.Value = Convert.ToString(Mas[i, 1]); sum += Mas[i, 1];
Sum[1] += Mas[i, 1];.Value = Convert.ToString(Mas[i, 2]); sum += Mas[i, 2];
Sum[2] += Mas[i, 2];.Value = Convert.ToString(Mas[i, 3]); sum += Mas[i, 3]; Sum[3]
+= Mas[i, 3];.Value = Convert.ToString(Mas[i, 4]); sum += Mas[i, 4]; Sum[4] +=
Mas[i, 4];.Value = Convert.ToString(Mas[i, 5]); sum += Mas[i, 5]; Sum[5] +=
Mas[i, 5];.Value = Convert.ToString(Mas[i, 6]); sum += Mas[i, 6]; Sum[6] +=
Mas[i, 6];.Value = Convert.ToString(Mas[i, 7]); sum += Mas[i, 7]; Sum[7] +=
Mas[i, 7];.Value = Convert.ToString(sum);.Cells.AddRange(Cell0, Cell1, Cell2,
Cell3, Cell4, Cell5, Cell6, Cell7, Cell8,Cell9);.dataGridView1.Rows.Add(row);
}Cell00 = new
DataGridViewTextBoxCell();Cell01 = new DataGridViewTextBoxCell();Cell02 = new
DataGridViewTextBoxCell();Cell03 = new DataGridViewTextBoxCell();Cell04 = new
DataGridViewTextBoxCell();Cell05 = new DataGridViewTextBoxCell();Cell06 = new
DataGridViewTextBoxCell();Cell07 = new DataGridViewTextBoxCell();Cell08 = new
DataGridViewTextBoxCell();Cell09 = new DataGridViewTextBoxCell();row_ = new
DataGridViewRow();.Value = "Ny";.Value =
Convert.ToString(Sum[0]);.Value = Convert.ToString(Sum[1]);.Value =
Convert.ToString(Sum[2]);.Value = Convert.ToString(Sum[3]);.Value =
Convert.ToString(Sum[4]);.Value = Convert.ToString(Sum[5]);.Value =
Convert.ToString(Sum[6]);.Value = Convert.ToString(Sum[7]);.Value = "
";_.Cells.AddRange(Cell00, Cell01, Cell02, Cell03, Cell04, Cell05, Cell06,
Cell07, Cell08, Cell09);.dataGridView1.Rows.Add(row_);
}void ur_pr(double[] X, double[] Y,
int kol1,out double a,out double b)
{i;Xi = 0, Yi = 0, XiYi = 0, Xi2 =
0;(i = 0; i < kol1; i++)
{+= X[i];+= X[i] * X[i];= Y[i];+=
X[i] * Y[i];
}= (XiYi - Xi * Yi) / (Xi2 - Xi *
Xi);= (Xi2 * Yi - Xi * XiYi) / (Xi2 - Xi * Xi);
}void koef_kor(double[] X, double[]
Y, int kol1, int kol2, out double Dx, out double Dy, out double Y_, out double
r)
{i;_ = 0; Dx = 0; Dy = 0;X_ = 0, k =
0, SKOx, SKOy;(i = 0; i < kol1; i++)
{_ += X[i];_ = Y_ + Y[i];
}_ /= kol1;_ = Y_ / kol2;(i = 0; i
< kol1; i++)
{+= (X[i] - X_) * (Y[i] - Y_);= Dx +
Math.Pow((X[i] - X_), 2);= Dy + Math.Pow((Y[i] - Y_), 2);
}/= kol1;= Dx / (kol1 - 1);= Dy /
(kol1 - 1);= Math.Sqrt(Dx);= Math.Sqrt(Dy);= k / (SKOx * SKOy);
}void ur_kt(double[] X, double[] Y)
{i;o,a,b,c;sx=0,sy=0,sxy=0,ss=0,s2=0,s3=0,s4=0;(i=0;i<k1;i++)
{+=X[i];+=Y[i];+=X[i]*Y[i];+=Math.Pow(X[i],2)*Y[i];+=Math.Pow(X[i],2);+=Math.Pow(X[i],3);+=Math.Pow(X[i],4);
}=k1*s2*s4+sx*s3*s2+s2*sx*s3-s2*s2*s2-sx*sx*s4-k1*s3*s3;=sy*s2*s4+sx*s3*ss+s2*sxy*s3-s2*s2*ss-sxy*sx*s4-s3*s3*sy;=k1*sxy*s4+sy*s3*s2+sx*ss*s2-s2*sxy*s2-sx*sy*s4-s3*ss*k1;=k1*s2*ss+sx*sxy*s2+sx*s3*sy-sy*s2*s2-sx*sx*ss-s3*sxy*k1;=a/o;=b/o;=c/o;.Text="y="+a+b+"x+"+c+"x^2";
}void kor_otn(double[] X, double[]
Y, int kol2, double xmin, double xmax, double Dy, double Y_,out double N)
{i, j;h, Dy_gr = 0;[] kol_gr = new
double[k2];[] sr_gr = new double[k2];(i = 0; i < k2; i++)
{_gr[i] = 0;_gr[i] = 0;
}(i = 0; i < kol2; i++)(j = 0, h
= xmin; j < k2; j++, h += h2)(Y[i] <= (h + h2) && Y[i] >= h)
{_gr[j]++;_gr[j] += Y[i];
}(i = 0; i < k2; i++)_gr[i] /=
kol_gr[i];(i = 0; i < k2; i++)_gr += Math.Pow((sr_gr[i] - Y_), 2) *
kol_gr[i] / kol2;= Math.Sqrt(Dy_gr / Dy);
}void fisher(double Dx, double
Dy,out double F)
{(Dx > Dy)= Dx / Dy;= Dy / Dx;
}Form6()
{();
}void Form6_Load(object sender,
EventArgs e)
{i;Dx, Dy, xmin, xmax, Y_, a, b, r,
N, F;[] lines1 = File.ReadAllLines("X.txt");[] X = new
double[lines1.Length]; (i = 0; i < X.Length; i++)
{[i] = Convert.ToDouble(lines1[i]);
}[] lines2 =
File.ReadAllLines("Y.txt");[] Y = new double[lines2.Length];(i = 0; i
< Y.Length; i++)
{[i] = Convert.ToDouble(lines2[i]);
}kol1 = X.Length;kol2 =
Y.Length;(X,Y,kol1,kol2,out xmin,out xmax);_pr(X, Y, kol1, out a, out b);.Text
= "Линейное уранение прямой регрессии: y=" + a + b +
"*x";_kor(X, Y, kol1, kol2,out Dx,out Dy,out Y_,out r);.Text =
"Коэффициент корреляции: " + r;_kt(X,Y);_otn(X, Y, kol2, xmin, xmax,
Dy, Dx,out N);.Text = "Корреляционное отношение: " + N;(Dx, Dy,out
F);.Text = "Критерий Фишера: " + F;
} void button2_Click(object sender,
EventArgs e)
{f = new Form4();.Show();
}
}
}