Исследование статистической зависимости давления идеального газа от его температуры при изохорном процессе
Исследование
статистической зависимости давления идеального газа от его температуры при
изохорном процессе
1. Теоретическая часть
В данной работе исследуется зависимость давления идеального
газа от его температуры при изохорном процессе с помощью методов математической
статистики.
Идеальный газ - математическая модель газа, в которой
предполагается, что потенциальной энергией молекул можно пренебречь по
сравнению с их кинетической энергией. Между молекулами не действуют силы
притяжения или отталкивания, соударения частиц между собой и со стенками сосуда
абсолютно упруги, а время взаимодействия между молекулами пренебрежимо мало по
сравнению со средним временем между столкновениями.
Давление газа на стенку сосуда - суммарный импульс,
переданный за единицу времени отдельными частицами при столкновениях со
стенкой.
Температура - физическая величина, характеризующая
тепловое состояние системы и связанная со средней кинетической энергией
молекул.
Давление газа и температура зависят от нескольких факторов,
обе величины связаны с движением частиц (молекул газа), следовательно,
зависимость статистическая. Количество молекул очень велико, скорости и
направления движения молекул совершенно хаотичны. Целесообразно рассматривать
связь со средними значениями скоростей, что значит принять между величинами X и
Y корреляционную зависимость.
Обычно в любой области науки при изучении двух величин
проводятся эксперименты, и задача состоит в том, чтобы на основании
экспериментальных точек выявить функциональную зависимость.
Так как зависимость корреляционная, задача состоит в том,
чтобы приближённо свести корреляционную связь к функциональной с помощью
подбора такой функции, которая максимально возможно была бы близка к
экспериментальным точкам. Такая функция называется функцией регрессии.
Обычно вид самой функции угадывается, но она зависит от
некоторых параметров. Задача статистического и корреляционного анализа состоит
в нахождении этих параметров. Для этого и используется метод наименьших
квадратов.
Приведем основные определения и понятия из курса теории
вероятностей и математической статистики, которые будут задействованы и
использованы в данной работе.
Математическая статистика - наука, которая
занимается обработкой данных. Во многих своих разделах математическая
статистика опирается на теорию вероятностей, позволяющую оценить надежность и
точность выводов, делаемых на основании ограниченного статистического материала
(выборки).
Статистика - это наука, которая занимается получением,
обработкой, а также анализом данных и публикацией информации, характеризующей
количественные закономерности жизни общества в неразрывной связи с их
качественным содержанием. В более узком смысле статистика - это совокупность
данных о каком-либо процессе или явлении. Задача математической статистики
состоит в создании методов сбора и обработки статистических данных для
получения научных и практических выводов. Установление закономерностей, которым
подчинены массовые случайные явления, основано на изучении методами теории
вероятностей статистических данных - результатов наблюдений.
Выборочной совокупностью (выборкой)
называют совокупность случайно отобранных объектов.
Генеральной совокупностью называют совокупность
объектов, из которых производится выборка.
Для того чтобы по данным выборки можно было судить об
изучаемом признаке генеральной совокупности, необходимо, чтобы объекты выборки
правильно его представляли; т.е. выборка должна быть репрезентативной
(представительной). В силу закона больших чисел можно утверждать, что выборка
будет репрезентативной, если ее осуществлять случайно: каждый объект выборки
отобран случайно из генеральной совокупности, если все объекты имеют одинаковую
вероятность попасть в выборку.
Репрезентативность - главное свойство
выборки, состоящее в близости ее характеристик (состава, средних величин и
т.д.) к соответствующим характеристикам генеральной совокупности, из которой
отобрана выборка.
Таким образом, статистическими методами пользуются для
выявления закономерностей наблюдений и для проверки соответствия построенных
теорий реальных явлений с их фактическим протеканием.
Как уже было сказано выше, существует тесная связь между
математической статистикой и теорией вероятностей.
Объемом совокупности называют число объектов
этой совокупности.
Теория вероятностей - раздел математики, в
котором по данным вероятностям одних случайных событий находят вероятности
других событий, связанных каким-либо образом с первыми. Теория вероятностей
изучает также случайные величины и случайные процессы. Одна из основных задач
теории вероятностей состоит в выяснении закономерностей, возникающих при
взаимодействии случайных факторов.
У нас имеется выборка случайных значений, объем которой равен 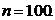
Случайной
называют величину, которая в результате испытания примет одно и только
одно возможное значение, наперед не известное и зависящее от случайных причин,
которые заранее не могут быть учтены. Случайные величины бывают двух видов:
дискретные и непрерывные.
Дискретной называют случайную величину, возможные
значения которой есть отдельные изолированные числа, которые эта величина
принимает с определенными вероятностями.
Наблюдаемые значения случайной величины называются вариантами. Частотой
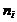 называется число, которое показывает,
сколько раз встречается данный вариант. Относительной частотой w называется отношение частоты к объему выборки n.
называется число, которое показывает,
сколько раз встречается данный вариант. Относительной частотой w называется отношение частоты к объему выборки n.
Математическим ожиданием M(X) дискретной случайной
величины называют сумму произведений всех ее возможных значений на их
вероятности. Если дискретная случайная величина принимает счетное множество
возможных значений, то:
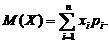
Дисперсией 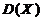 дискретной случайной величины называют
математическое ожидание квадрата отклонения случайной величины от ее
математического ожидания:
дискретной случайной величины называют
математическое ожидание квадрата отклонения случайной величины от ее
математического ожидания:
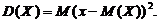
Средним квадратичным отклонением
случайной величины X называют квадратный корень из дисперсии:
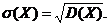
Модой 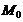 называют варианту, которая имеет наибольшую
частоту.
называют варианту, которая имеет наибольшую
частоту.
Медианой 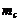 называют варианту, которая делит
вариационный ряд на две части, равные по числу вариант.
называют варианту, которая делит
вариационный ряд на две части, равные по числу вариант.
Начальным моментом порядка k случайной величины X
называют математическое ожидание величины Xk:
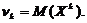
В частности, начальный момент первого порядка равен
математическому ожиданию:
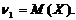
Центральным моментом порядка k случайной величины X называют математическое ожидание
величины 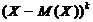 :
:
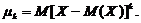
В частности, центральный момент первого порядка равен нулю:
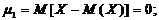
центральный момент второго порядка равен дисперсии:
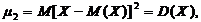
центральный момент третьего порядка равен:
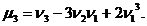
Исправленной выборочной дисперсией называют произведение выборочной
дисперсии на исправитель:
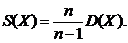
Выборочным исправленным средним квадратичным отклонением называют квадратный корень от исправленной
выборочной дисперсии:
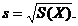
Корреляционное поле и корреляционная таблица являются вспомогательными средствами при
анализе выборочных данных. При нанесении на координатную плоскость двумерных
выборочных точек получают корреляционное поле. Для численной обработки
результатов обычно группируют и представляют в форме корреляционной таблицы. В
каждой клетке корреляционной таблицы приводятся численности 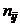 тех пар (X, Y), компоненты которых
попадают в соответствующие интервалы группировки по каждой переменной.
тех пар (X, Y), компоненты которых
попадают в соответствующие интервалы группировки по каждой переменной.
Корреляция -
вероятностная (статистическая) зависимость между величинами, не имеющая, вообще
говоря, строго функционального характера.
Корреляционным моментом 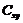 случайных величин X и Y называют
математическое ожидание произведения отклонений этих величин
случайных величин X и Y называют
математическое ожидание произведения отклонений этих величин
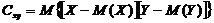 .
.
Для вычисления корреляционного момента используют формулу:
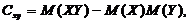

Две случайные величины Y и X называются коррелированными,
если их корреляционный момент отличен от 0; Y и X называются некоррелированными
величинами, если их корреляционный момент равен 0.
Коэффициентом корреляции  случайных величин X и Y называют
отношение корреляционного момента к произведению средних квадратических
отклонений этих величин
случайных величин X и Y называют
отношение корреляционного момента к произведению средних квадратических
отклонений этих величин
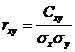 .
.
Гистограммой частот называется столбчатая диаграмма, состоящая из прямоугольников,
основаниями которых служат частичные интервалы длиной h, а высоты равны
отношению 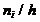 (плотность частоты).
(плотность частоты).
Гистограммой нормированных относительных частот называется диаграмма, на
которой изображены столбцы, при этом ось Х - это интервалы, а ось Y - это
относительная частота встречаемости:
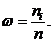
Полигоном частот называется ломаная, отрезки которой соединяют точки 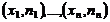 . Для построения полигона на оси абсцисс
откладывают варианты
. Для построения полигона на оси абсцисс
откладывают варианты 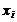 , а на оси ординат - соответствующие им
частоты .
, а на оси ординат - соответствующие им
частоты .
Полигоном относительных частот называют ломаную, отрезки которой соединяют точки 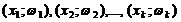 . Для построения полигона на оси абсцисс
откладывают варианты , а на оси ординат - соответствующие им
относительные частоты
. Для построения полигона на оси абсцисс
откладывают варианты , а на оси ординат - соответствующие им
относительные частоты 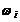 .
.
Функцией распределения называют функцию,
определяющую вероятность того, что случайная величина Х в результате испытания
примет значение, меньшее х:
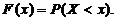
Функцией распределения выборки является эмпирическая функция
распределения.
Эмпирической функцией распределения называют функцию 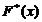 , определяющую для каждого значения х относительную частоту
события Х < х:
, определяющую для каждого значения х относительную частоту
события Х < х:
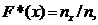
где 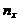 - число вариант, меньших х; n - объем
выборки.
- число вариант, меньших х; n - объем
выборки.
2. Регрессионный анализ
Регрессия - зависимость среднего значения какой-либо
величины Y
от другой величины X. Понятие регрессии в некотором смысле обобщает понятие функциональной
зависимости y
= f(x). Только в случае
регрессии одному и тому же значению x в различных случаях соответствуют различные
значения у.
Регрессионный анализ заключается в определении аналитического
выражения связи, в которой изменение одной величины (называемой зависимой или
результативным признаком) обусловлено влиянием одной или нескольких независимых
величин (факторов).
По форме зависимости различают:
1. линейную регрессию, которая выражается уравнением
прямой:
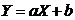
2. нелинейную (параболическую):
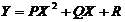
Исследование линейной регрессии:
Определим коэффициенты линейной функции методом наименьших квадратов. Для этого
составим сумму
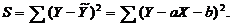
Для того чтобы эта сумма была минимальной, необходимо, чтобы
ее частные производные по параметрам A и B были равны нулю
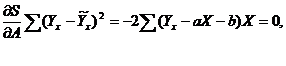
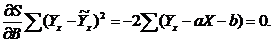
Раскрыв скобки, мы получим
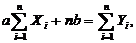
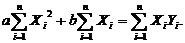
Выразим a и b
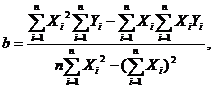
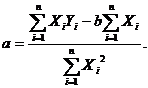
Одним из важнейших методов определения зависимости между X и Y
является метод наименьших квадратов. Видя общее расположение точек, можно
предположить, что эта зависимость линейная. Количество прямых, проходящих через
заданную совокупность точек, бесконечно. Выберем оптимальную из них. Для этого
суммарное отклонение между теоретическими и экспериментальными точками должно
быть минимальным. Это отклонение мы найдем с помощью функции
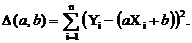
Метод нахождения минимального отклонения и есть метод
наименьших квадратов. Это суммарное отклонение зависит от коэффициентов а и
b функции Y, поэтому эти коэффициенты должны быть минимальными, то есть
производная функции 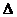 в этих точках равны нулю:
в этих точках равны нулю:
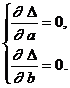
Найдя частные производные и приравняв их нулю, получим следующую
систему уравнений
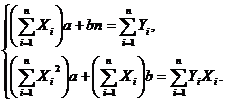
Решив эту систему, мы найдем наилучший набор этих параметров. Эта
теоретическая кривая с параметрами, которые определяются методом наименьших
квадратов, и будет искомой линией - линией линейной регрессии.
Исследование параболической регрессии:
В этом случае уравнение регрессии Y на X имеет вид:
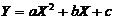 ,
,
где a, b и c - неизвестные параметры.
Найдем такие p, q, r, при которых парабола наименее уклоняется от точек (Xi, Yi). Сделаем это методом
наименьших квадратов. Для того чтобы сумма квадратов отклонений
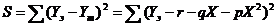
была наименьшей, необходимо, чтобы выполнялись три условия
(по числу неизвестных коэффициентов)
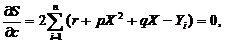
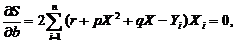
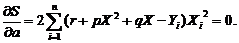
После преобразований уравнения примут следующий вид:
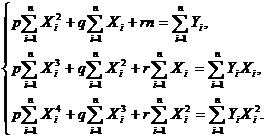
Подставив соответствующие значения в полученные формулы, и
решив систему уравнений, мы получим искомую функцию параболической регрессии
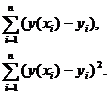
Эти формулы используются для линейной и параболической регрессий,
затем сравнивают полученные результаты и находят наименьшие среди полученных
результатов. Та регрессия, у которой будут наименьшие оценки, более точно
отражает распределение точек на диаграмме рассеивания.
3.
Обработка исходных данных
Дана выборка (объема n=100) зависимости числа (Y) от числа (X).
Табл. 1. Исходные данные
|
X
|
Y
|
X
|
Y
|
X
|
Y
|
X
|
Y
|
X
|
Y
|
|
15,000
|
40,500
|
4,780
|
15,300
|
13,500
|
46,400
|
15,700
|
47,400
|
19,200
|
61,200
|
|
0,212
|
8,010
|
1,360
|
16,000
|
6,620
|
24,900
|
13,500
|
36,700
|
3,540
|
6,660
|
|
17,900
|
74,100
|
4,940
|
26,800
|
18,400
|
56,000
|
16,600
|
48,200
|
4,640
|
13,600
|
|
7,680
|
31,600
|
12,300
|
41,500
|
1,760
|
8,970
|
12,100
|
30,900
|
9,600
|
29,200
|
|
18,000
|
54,200
|
4,640
|
17,000
|
12,400
|
55,500
|
15,000
|
49,700
|
7,480
|
22,100
|
|
14,900
|
45,000
|
5,180
|
15,000
|
11,200
|
41,700
|
12,200
|
28,000
|
6,540
|
27,100
|
|
13,400
|
40,600
|
1,870
|
3,160
|
14,600
|
53,400
|
8,060
|
34,200
|
1,100
|
1,920
|
|
0,358
|
2,840
|
6,620
|
20,900
|
1,440
|
2,820
|
17,600
|
68,300
|
19,400
|
61,100
|
|
0,994
|
-4,620
|
8,060
|
28,600
|
11,000
|
32,200
|
19,700
|
57,600
|
4,520
|
19,100
|
|
9,780
|
40,000
|
8,160
|
23,700
|
17,800
|
60,000
|
9,980
|
34,300
|
8,780
|
27,500
|
|
5,000
|
19,400
|
6,760
|
31,600
|
8,980
|
35,900
|
16,400
|
46,200
|
3,540
|
27,500
|
|
6,680
|
36,300
|
13,800
|
56,900
|
10,600
|
36,600
|
17,800
|
57,600
|
16,700
|
52,700
|
|
17,700
|
55,700
|
3,140
|
19,800
|
16,800
|
61,400
|
5,420
|
34,300
|
9,700
|
37,700
|
|
1,990
|
8,180
|
6,260
|
22,400
|
2,700
|
9,400
|
6,980
|
12,400
|
1,970
|
6,150
|
|
19,700
|
64,400
|
10,800
|
27,700
|
7,580
|
12,400
|
5,980
|
26,700
|
17,100
|
49,200
|
|
7,160
|
20,400
|
6,280
|
25,700
|
12,300
|
37,700
|
4,220
|
13,600
|
6,140
|
25,800
|
|
10,800
|
35,100
|
7,540
|
22,200
|
4,060
|
18,900
|
1,060
|
19,500
|
3,240
|
9,660
|
|
0,652
|
12,900
|
3,980
|
13,800
|
0,244
|
13,500
|
9,920
|
37,200
|
8,040
|
38,900
|
|
9,720
|
40,900
|
14,300
|
45,200
|
4,860
|
12,300
|
17,100
|
58,000
|
6,700
|
25,800
|
|
12,600
|
40,500
|
10,000
|
37,300
|
9,480
|
35,000
|
9,340
|
22,100
|
9,560
|
39,200
|
Основные характеристики выборки
Числовые характеристики X:
1) M*(x) =9,19470;
2) D*(x) = 30,1964;
3) S2(x) = 30,50141;
4) σ*(x) = 5,49512
5) s*(x) = 5,52281;
6) 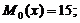
7) 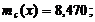
8) начальные и центральные моменты первого, второго и
третьего порядков:
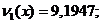
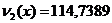
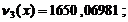
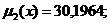
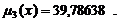
Числовые характеристики Y:
1) M*(y) = 31,6405;
2) D*(y) =305,57007;
3) S2(y) =308,65664;
) σ*(y) = 17,48056;
5) s*(y) = 17,56863;
) начальные и центральные моменты первого, второго и
третьего порядков:
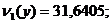
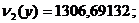
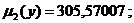
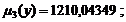
Корреляционный момент и коэффициент корреляции :
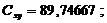
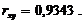
Из Полученного значения коэффициента корреляции следует прямая
связь между исследуемыми величинами, т. к. оно положительно. Так как 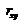 принимает значение близкое к (1), то X и Y зависимы. При
увеличении X увеличивается Y.
принимает значение близкое к (1), то X и Y зависимы. При
увеличении X увеличивается Y.
Построим диаграмму рассеивания для данных значений X и Y:
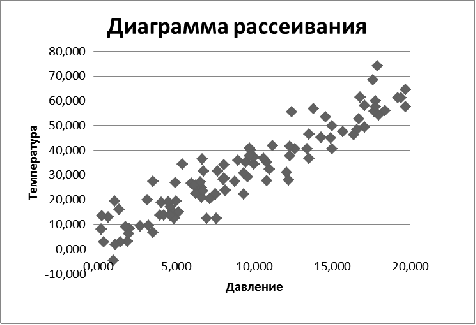
Рис. 1. Диаграмма рассеивания
4.
Корреляционный анализ
Для корреляционного анализа данные удобнее представить в виде корреляционной
таблицы. Область попадания точек разбиваем на 7 интервалов по X и 7 по Y. В
первой строке таблицы укажем средние значения интервалов для Y, а в первом столбце - средние значения интервалов по X. На пересечении строк и столбцов находятся частоты 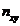 наблюдаемых пар значений признаков.
наблюдаемых пар значений признаков.
Табл. 2. Корреляционная таблица
|
X Y
|
1,00286
|
12,2486
|
23,4943
|
34,74
|
45,986
|
57,231
|
68,477
|
nx/n
|
|
1,604
|
6
|
7
|
1
|
0
|
0
|
0
|
0
|
0,14
|
|
4,388
|
0
|
9
|
7
|
0
|
0
|
0
|
0
|
0,16
|
|
7,172
|
0
|
2
|
13
|
5
|
0
|
0
|
0
|
0,20
|
|
9,956
|
0
|
0
|
3
|
14
|
0
|
0
|
0
|
0,17
|
|
12,74
|
0
|
0
|
1
|
3
|
4
|
2
|
0
|
0,10
|
|
15,524
|
0
|
0
|
0
|
0
|
7
|
3
|
0
|
0,10
|
|
18,308
|
0
|
0
|
0
|
0
|
1
|
9
|
3
|
0,13
|
|
ny/n
|
0,06
|
0,18
|
0,25
|
0,22
|
0,12
|
0,14
|
0,03
|
1
|
С помощью корреляционной таблицы мы сможем найти оценки для X:
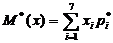 , где
, где 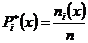 ,
, 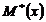 = 9, 260;
= 9, 260;
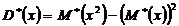 ,
, 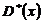 =28,73556;
=28,73556;
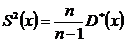 ,
, 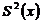 = 33,52482;
= 33,52482;
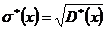 ,
, 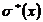 =5,36056;
=5,36056;
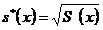 ,
, 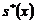 =5,79006.
=5,79006.
С помощью корреляционной таблицы найдем числовые
характеристики Y:
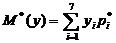 , где
, где 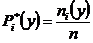 ,
, 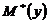 =31,36626;
=31,36626;
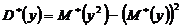 ,
, 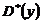 = 299,72195;
= 299,72195;
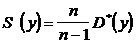 ,
, 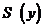 = 349,675608;
= 349,675608;
 ,
, 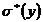 = 17,31248;
= 17,31248;
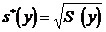 ,
, 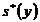 = 18,69962.
= 18,69962.
Используя данные корреляционной таблицы, построим
гистограммы, полигоны и графики эмпирических функций распределения для X
и Y (см. рис. 2 - рис. 7):
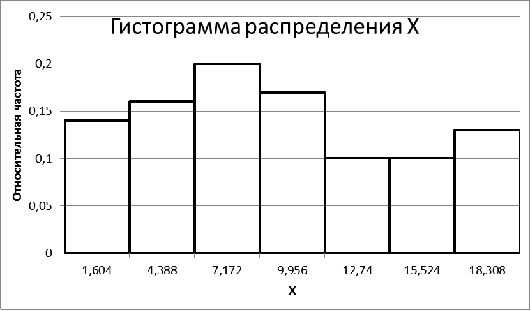
Рис. 2. Гистограмма относительных частот по X
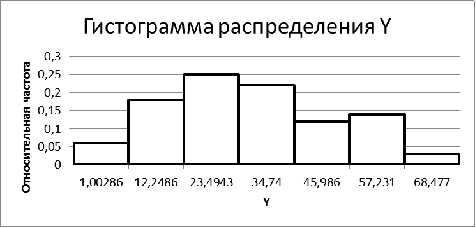
Рис. 3. Гистограмма относительных частот по Y
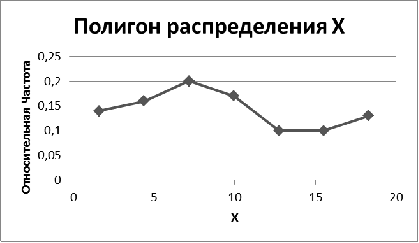
Рис. 4. Полигон относительных частот по X
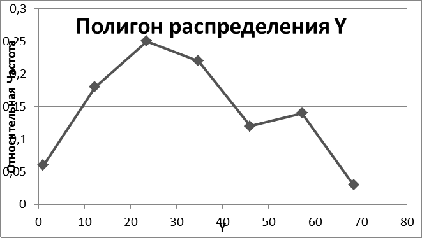
Рис. 5. Полигон относительных частот по Y
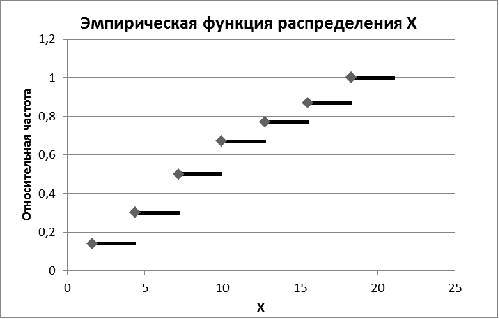
Рис. 6. Эмпирическая функция распределения по X
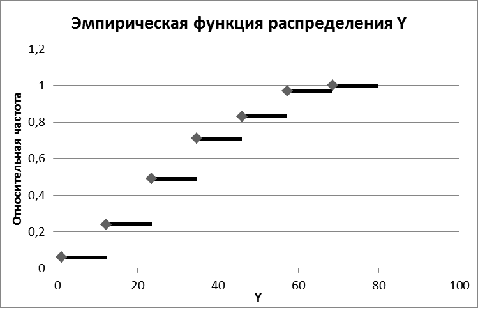
Рис. 7. Эмпирическая функция распределения по Y
5.
Регрессионный анализ
Линейная
регрессия
Для нахождения коэффициентов a и b методом наименьших
квадратов были посчитаны следующие необходимые параметры:
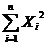 = 11473,98048;
= 11473,98048;
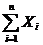 = 919,47;
= 919,47;
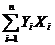 =38067,15706;
=38067,15706;
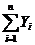 = 3164,05.
= 3164,05.
В нашем случае коэффициенты а и b соответственно равны:
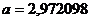 ,
, 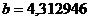 .
.
Следовательно, первое уравнение линейной регрессии для нашей
выборки имеет вид:
y = 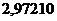 x
x 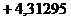 .
.
Для нахождения коэффициентов с и d методом наименьших
квадратов были посчитаны следующие необходимые параметры:
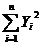 = 130669,13150;
= 130669,13150;
= 919,47;
= 38067,15706;
= 3164,05.
В нашем случае коэффициенты c и d соответственно равны:
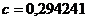 ,
, 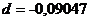 .
.
Следовательно, второе уравнение линейной регрессии для нашей
выборки (см. рис. 8) имеет вид:
x = 0,29424y - 0,09047.
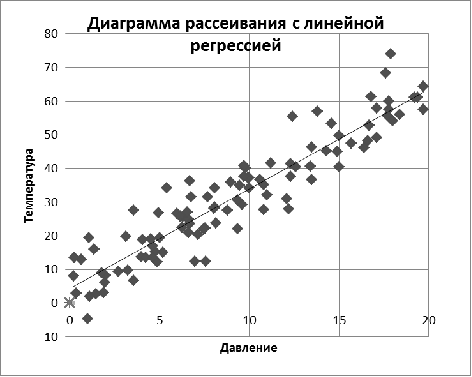
Рис. 8. Линейная регрессия
Параболическая
регрессия
Для нахождения коэффициентов p, q и r методом наименьших
квадратов были посчитаны следующие необходимые параметры:
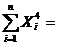 2575510,37568;
2575510,37568;
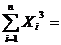 165006,98099;
165006,98099;
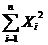 = 11473,98048;
= 11473,98048;
 538674,01185;
538674,01185;
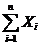 = 919,47;
= 919,47;
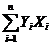 = 38067,15706;
= 38067,15706;
= 3164,05.
В нашем случае коэффициенты p, q и r соответственно равны:
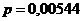 ,
, 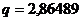 ,
, 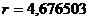 .
.
Следовательно, уравнение параболической регрессии для нашей
выборки (см. рис. 9) имеет вид:
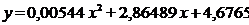 .
.
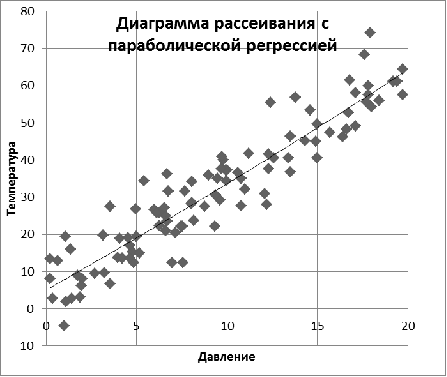
Рис. 9. Параболическая регрессия
Таким образом, мы выяснили, что:
. Зависимость между X и Y близка к линейной.
. Зависимость между X и Y близка к квадратичной.
. При этом обе кривые - прямая и парабола -
практически не отклоняются от точек выборки (X, Y), но все-таки точнее
выборку описывает параболическая регрессия.
Теоретически утверждалось, а теперь подтвердилось на
практике, что чем больше степень уравнения регрессии, тем точнее график. Это
легко заметить на рисунках. Но трудность вычислений возрастает неимоверно;
если, чтобы найти уравнение линейной регрессии приходилось решать систему из
двух уравнений, включающих неприятные суммы, то для параболической - уже из
трех, для кубической - из четырех.
Для данной выборки существует закономерность; в уравнениях
регрессий, по мере возрастания степени уравнений n, коэффициенты перед
переменными в этой степени стремятся к нулю. Это позволяет сделать вывод, что
построение регрессий высших степеней не дало бы нам ощутимого улучшения
результата.
Рассмотрим статистику 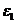 , которая показывает отклонение значений
, которая показывает отклонение значений 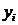 от
от 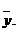
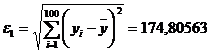 .
.
Проверим гипотезы 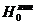 и
и 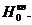 Значения, вычисленные с использованием
соответствующих статистик
Значения, вычисленные с использованием
соответствующих статистик 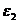 и
и 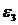 должны быть меньше значения . Статистика используется для проверки гипотезы о
линейной зависимости, и показывает, насколько величины отклоняются от линии регрессии
должны быть меньше значения . Статистика используется для проверки гипотезы о
линейной зависимости, и показывает, насколько величины отклоняются от линии регрессии 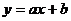 . Вычисляем
. Вычисляем
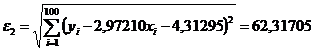 .
.
Аналогично для гипотезы 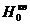 используем статистику , которая, соответственно, показывает отклонение от квадратной регрессии
используем статистику , которая, соответственно, показывает отклонение от квадратной регрессии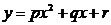 . Видим
. Видим
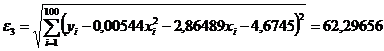 .
.
Из того, что и меньше следует, что гипотезы верны.
Проверим гипотезу о нормальном распределении признака Х. Для этого
будем сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в
предположении нормального распределения) частоты. При уровне значимости α=0,05 требуется проверить нулевую гипотезу 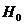 : генеральная совокупность распределена
нормально.
: генеральная совокупность распределена
нормально.
В качестве критерия проверки нулевой гипотезы примем случайную
величину
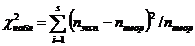
По таблице критических точек распределения χ2 по заданному уровню значимости α и числу степеней свободы k = s - 3 ищем
критическую точку 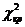 (α; k)
(α; k)
Если 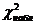 < - нет оснований отвергнуть нулевую гипотезу.
< - нет оснований отвергнуть нулевую гипотезу.
Если > - нулевую гипотезу отвергают.
Для нахождения теоретических частот разделим выборку на s=7 частичных интервалов, как это было сделано для
корреляционной таблицы, нормируем случайную величину Х, вычисляем теоретические
вероятности Рi попадания Х в интервал (xi; xi+1) по функции Лапласа и, наконец, найдем теоретические
частоты nтеор.
Табл. 3. Вычисление теоретических частот нормального
распределения X
|
nэксп
|
Xi
|
Xi+1
|
Zi
|
Zi+1
|
Фi
|
Фi+1
|
Pi
|
nтеор
|
χ2
|
|
14
|
0,212
|
2,996
|
-1,68788
|
-1,16853
|
-0,5
|
-0,379
|
0,121
|
12,1
|
0,29835
|
|
16
|
2,996
|
5,78
|
-1,16853
|
-0,64919
|
-0,379
|
-0,2422
|
0,1368
|
13,68
|
0,39345
|
|
20
|
5,78
|
8,564
|
-0,64919
|
-0,12984
|
-0,2422
|
-0,0517
|
0,1905
|
19,05
|
0,04738
|
|
17
|
8,564
|
11,348
|
-0,12984
|
0,389512
|
-0,0517
|
0,1517
|
0,2034
|
20,34
|
0,54846
|
|
10
|
11,348
|
14,132
|
0,389512
|
0,90886
|
0,1517
|
0,3186
|
0,1669
|
16,69
|
2,68161
|
|
10
|
14,132
|
16,916
|
0,90886
|
1,428209
|
0,3186
|
0,4236
|
0,105
|
10,5
|
0,02381
|
|
13
|
16,916
|
19,7
|
1,428209
|
1,947558
|
0,4236
|
0,5
|
0,0764
|
7,64
|
3,76042
|
|
100
|
Σ
|
1
|
100
|
7,75347
|
Наблюдаемое значение = 7,75347. Критическое значение (0,05; 4) = 9,5. Выполняется < , следовательно, нет оснований отвергнуть
нулевую гипотезу.
6.
Доверительные интервалы
Рассмотренные ранее 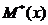 ,
, 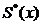 ,
, 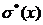 ,
, 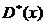 ,
, 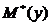 ,
, 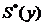 ,
, 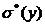 ,
, 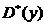 являются точечными оценками, но наряду с
ними при изучении выборки используются интервальные оценки, так как полезно не
только построить оценку, но и охарактеризовать величину возможной при её
использовании ошибки.
являются точечными оценками, но наряду с
ними при изучении выборки используются интервальные оценки, так как полезно не
только построить оценку, но и охарактеризовать величину возможной при её
использовании ошибки.
Интервальной называют оценку, которая определяется двумя числами -
концами интервала. Интервальные оценки позволяют установить точность и
надежность оценок.
Величина 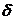 характеризует точность оценки, если
выполняется неравенство
характеризует точность оценки, если
выполняется неравенство 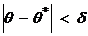 , где
, где 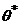 - оценка некоторого параметра
- оценка некоторого параметра 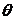 генеральной совокупности. Надежностью (доверительной
вероятностью) оценки по называют вероятность
генеральной совокупности. Надежностью (доверительной
вероятностью) оценки по называют вероятность 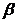 , c которой осуществляется неравенство . Наиболее часто задают надежность, равную
0,95; 0,9; 0,999.
, c которой осуществляется неравенство . Наиболее часто задают надежность, равную
0,95; 0,9; 0,999.
Доверительным называют интервал 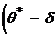 ,
, 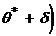 , который покрывает известный параметр с
заданной надежностью .
, который покрывает известный параметр с
заданной надежностью .
Рассмотрим доверительный интервал для математического ожидания
генеральной совокупности. Известен объем выборки n = 100; 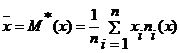 = 9,1947,
= 9,1947, 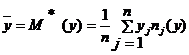 = 31,6405, исправленное выборочное среднеквадратичное отклонение
= 31,6405, исправленное выборочное среднеквадратичное отклонение 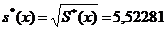 ,
, 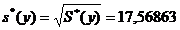 .
.
Найдем доверительный интервал для оценки неизвестного
математического ожидания по X и Y с надежностями 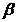 = 0,95; 0,99; 0,999.
= 0,95; 0,99; 0,999.
Если наблюдаемая случайная величина имеет нормальное
распределение, но ее среднеквадратичное отклонение нам неизвестно, то мы можем
построить доверительный интервал по распределению Стьюдента с 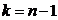 степенями свободы, то есть должно быть
справедливо неравенство:
степенями свободы, то есть должно быть
справедливо неравенство:
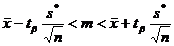 ;
;
где 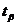 определим по заданным и
определим по заданным и 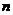 . Это соотношение выражает доверительный интервал для
. Это соотношение выражает доверительный интервал для 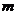 , определяемый с помощью распределения
Стьюдента.
, определяемый с помощью распределения
Стьюдента.
Найдем доверительные интервалы для математического ожидания X.
При 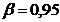 ;
; 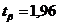 : 8,11223 < < 10,27517.
: 8,11223 < < 10,27517.
При 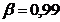 ;
; 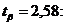 7,76982 < < 10,61959.
7,76982 < < 10,61959.
При 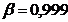 ;
; 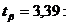 7,32247 < < 11,06693.
7,32247 < < 11,06693.
Заключение
диаграмма регрессия давление газ
В курсовой работе был проведен статистический анализ зависимости 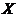 в 100 экспериментах от
в 100 экспериментах от 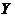 . Производя этот анализ, мы использовали
не только аналитические функции, но и графические данные.
. Производя этот анализ, мы использовали
не только аналитические функции, но и графические данные.
В результате было научно доказано, что при изохорном процессе
с увеличением температуры увеличивается давление.
Зависимость давления от температуры при изохорном процессе близка
к линейной и к квадратичной. Однако видно, что разница между значениями
статистик 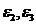 небольшая. С практической точки зрения
удобнее приближать точки выборки
небольшая. С практической точки зрения
удобнее приближать точки выборки 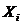 и
и 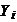 к прямой
к прямой 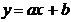 . Тем самым, был доказан закон Шарля, частный случай уравнения
идеального газа Менделеева - Клапейрона, одного из фундаментальных понятий в
термодинамике.
. Тем самым, был доказан закон Шарля, частный случай уравнения
идеального газа Менделеева - Клапейрона, одного из фундаментальных понятий в
термодинамике.
Список литературы
1 Гмурман,
В.Е. Теория вероятностей и математическая статистика. Учебное пособие для
вузов. - М.: Высшая школа, 2001.
2 Гмурман,
В.Е. Руководство по решению задач по теории вероятностей и математической
статистике. Учебное пособие для вузов. - М.: Высшая школа, 1979.
Баврин,
И.И. Теория вероятностей и математическая статистика - М.: Высшая школа, 2005.
Кремер,
Н.Ш. Теория вероятностей и математическая статистика - Учебник для втузов. -
2-е изд. - М.: ЮНИТИ - ДАНА, 2004.
Сивухин,
Д.В. Общий курс физики. Том II. Термодинамика и молекулярная физика. 5-е изд.,
испр. - М.: Физматлит, 2005.