Способы обработки данных
Министерство образования и науки
Российской Федерации
ГОУ ВПО Ижевский государственный
технический университет
Кафедра "вычислительной
техники"
Курсовая работа
на тему: "Способы обработки
данных"
по дисциплине "Языки
программирования"
Разработал: ст. гр.3-36-1
Приняла: ст. преп. каф. ВТ
Габитова Г.Н.
Ижевск 2010
Постановка
задачи
Общая формулировка: Дан текстовый файл,
содержащий последовательность чисел. Переписать числа в массив и обработать
соответственно заданию. Затем переписать числа из текстового файла в
типизированный файл и обработать файл, а затем создать список из текстового
файла и снова его обработать.
Задание: Просуммировать и удалить числа,
встречающиеся по одному разу. Затем сумму этих чисел добавить в конец.
алгоритм массив типизированный файл
Блок-схема
программы
fail
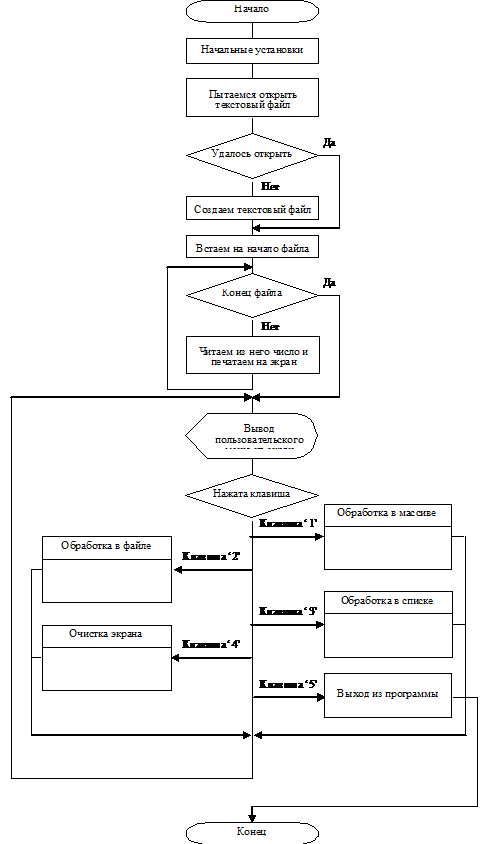
Текст
программы
program kurs;
uses crt;
const n=10; {максимальная длина массива}
type mas= array [1. n] of byte; {тип для массивов}= set of byte; {тип для множеств состоящих
из чисел}
fille= file of byte; {тип для типизированных
файлов состоящих из чисел}
din=^mode; {ссылочный тип}
mode=record {тип запись с полями}
x: byte; {для хранения числа}
adr: din; {и для хранения адреса следующего элемента}
end; {конец типа запись}
var i,v,ch: byte; {ch-хранит числа, необходима для создания текстового файла, если
исходный не был найден, i-количество записанных в текстовый файл чисел, v-используется как
логическая для определения какую процедуру вызвать и выхода из программы}
t: text; {исходный текстовый файл}
a: mas; {массив}
f: fille; {типизированный файл}
first,p1,p2: din; {first-голова списка, p1,p2-для перемещения по списку}
procedure delmass (k1: Integer; Var m: mas); {процедура удаления k1 элемента из массива m, путем сдвига всех
элементов массива, лежащих справа от удаляемого, на 1 позицию влево}
var i: byte; {счетчик цикла, он же номер элемента в массиве}
begin
for i: =k1 to n-1 do {перебираем элементы массива от удаляемого до предпоследнего}
m [i]: = m [i+1]; {i-му элементу присваиваем значение i+1-го элемента (на первом
шаге удаляемому присвоится значение элемента следующего за ним}
m [n]: =0; {последнему элементу массива присваиваем 0}
end;
procedure mass (var a: mas); {процедура
обрабатывающая переданный в нее массив a соответственно заданию}
var ch,sum,kol,j: byte; {ch-счетчик количества встреч i-го числа в массиве, sum-сумма чисел
встречающихся 1 раз, kol-количество чисел встречающихся 1 раз, j-счетчик цикла}
mn1,mnpos: mn; {mn1-множество чисел встречающихся 1 раз (которые
надо удалить), mnpos-множество номеров тех элементов массива которые встречаются 1
раз}
begin mn1: = []; {обновление множества чисел}
mnpos: = []; {и обновление множества номеров}
reset (t); {встаем на начало текстового файла}
for i: =1 to n do begin {видимо в файле всегда 10 чисел}
readln (t,ch); {читаем число из файла}
a [i]: =ch; {записываем прочитанное число в массив}
end;
close (t); {закрываем текстовый файл}
ch: =0; {обнуляем количество встреч}
sum: =0; {и обнуляем сумму чисел встречающихся 1 раз}
for i: =1 to n do begin {в этом цикле берется один элемент из массива}
ch: =0;
for j: =1 to n do begin {здесь другой элемент, таким образом происходит
сравнение каждого элемента с каждым, при этом рассматривается даже пара сам с
собой, т е когда i=j}
if (a [i] =a [j]) then {если i-ый элемент массива = j-му} (ch); {то увеличиваем
количество встреч i-числа}
end;
if ch=1 then {если количество встреч равно 1, т е число
совпало лишь само с собой - оно единственно}
mnpos: =mnpos+ [i]; {то его номер записываем в множество номеров}
if i in mnpos then begin {если номер попал в
множество,}
sum: =sum+a [i]; {то это число прибавляем к сумме}
inc (kol); {увеличиваем счетчик чисел, встречающихся 1
раз}
end;
end;
for i: =1 to n do {перебираем все номера элементов массива}
if i in mnpos then {если номер элемента массива входит в множество
номеров}
mn1: =mn1+ [a [i]]; {то значение элемента записываем в множество чисел
встречающихся 1 раз}
for i: =n downto 1 do {перебираем элементы массива с конца}
if a [i] in mn1 then {если элемент массива входит в множество,}
delmass (i,a); {то удаляем его из массива}
a [n-kol+1]: =sum; {в массиве после удаления останется n-kol элементов, тогда на n-kol+1 место записываем сумму
элементов встретившихся в массиве 1 раз}
{выводим получившийся массив}
for i: =1 to n-kol+1 do(a [i],' ');;;;fill (var
g: fille); ch,ch1,ch2,sum,kol,k,j: byte; {ch1, ch2 и k - вспомогательные
переменные для чтения и записи в типизированный файл}
mn1,mnpos: mn; {все остальные переменные имеют прежнее
назначение}
begin assign (f,'tipfile. txt'); {связываем файловую переменную f с файлом на диске по
имени что в кавычках}
reset (t); {встаем на начало текстового файла}
rewrite (f); {типизированный файл открываем на перезапись}
sum: =0; {обнуление суммы}
kol: =0; {обнуление количества}
mn1: = []; {обновление множества чисел
встречающихся 1 раз}
mnpos: = []; {обновление множества номеров чисел
встречающихся 1 раз}
while not eof (t) do begin {пока не конец
текстового файла}
readln (t,ch); {читаем из него число}
write (f,ch); {и записываем в типизированный файл}
end;
close (t); {закрываем текстовый файл}
reset (f); {встаем на начало типизированного файла}
{обработка алогична обработке в массиве}
for i: =0 to filesize (f) - 1 do begin {берем одно число из файла}: =0;
seek (f, i); {встали перед числом, которое хотим прочитать из файла}
read (f,ch1); {читаем его}
for j: =0 to filesize (f) - 1 do begin {берем другое число из файла}
seek (f,j); {встаем перед числом, которое хотим прочитать из файла}
read (f,k); {читаем его}
if ch1=k then {сравниваем два числа}
inc (ch); {если равны, то увеличиваем число встреч}
end;
if ch=1 then {если число встретилось лишь само с собой,}
mnpos: =mnpos+ [i]; {то записываем его номер в множество}
if i in mnpos then begin {если номер числа попал
в множество,}
seek (f, i); {то зачем-то еще раз его читаем,}
read (f,ch2); {но в др. переменную, хотя оно есть в ch1}
sum: =sum+ch2; {и прибавляем к сумме}
inc (kol); {увеличиваем количество чисел встретившихся 1
раз}
end;;i: =0 to filesize (f) - 1 do {перебираем все номера чисел в файле} i in mnpos then begin {если номер входит во
множество номеров,}
seek (f, i); {то находим число под этим номером}
read (f,j); {читаем его}
mn1: =mn1+ [j]; {и записываем в множество чисел встречающихся
1 раз}
end;
ch1: =0; {обнуляем}
reset (f); {встаем на начало файла}
for i: =filesize (f) - 2 downto 0 do begin {перебираем числа с конца файла} (f, i); {встаем перед
считываемым числом}
read (f,j); {читаем его в j}
if j in mn1 then {если прочитанное число входит в множество,}
for ch: =i to filesize (f) - 2 do begin {то удаляем его из файла} (f,ch+1); {встаем за ch-ым числом (на первом
шаге за удаляемым) }
read (f,j); {читаем число, которое за ch-ым}
seek (f,ch); {встаем перед ch-ым числом}
write (f,j); {записываем вместо ch-го, следующее за ним, которое было прочитано в j}
end;
end;
k: = filesize (f) - kol; {k-указывает на позицию последним числом в файле}
seek (f,k); {встаем на эту позицию}
write (f,sum); {записываем туда сумму чисел встретившихся 1 раз}
writeln ('posle');
reset (f); {встаем на начало файла}
for i: =0 to k do begin {и выводим из него k элементов}
read (f,j); {читаем из файла очередное число}
write (j,' '); {выводим его на экран с пробелом}
end;
close (f); {закрываем типизированный файл}
writeln;;;spisok; i,j,sum: byte; mn1: mn; {назначение переменных
такое же что и выше}
begin reset (t); {встаем на начало текстового файла}
first: =nil; {начало списка отсутствует}
while not eof (t) do begin {пока не конец файла} (p1); {создаем новый
элемент списка}
readln (t,p1^. x); {в его числовое поле читаем число из файла}
if first=nil then {если список не имеет начало,}
first: =p1 {то новый элемент будет началом}
else p2^. adr: =p1; {иначе подсоединяем его к концу}
p2: =p1; {оба указателя ставим на новый элемент, он же последний}
end;
p1^. adr: =nil; {список был создан, последний элемент списка
ссылаем в никуда}
p1: =first; {p1 встаем на начало списка}
ch: =0; {обнуляем число встреч}
sum: =0; {и сумму}
mn1: = []; {обновляем множество}
while p1<>nil do begin {пока p1 не встретила конец
списка делаем: }
ch: =0;
p2: =first; {p2 устанавливаем на начало списка}
while p2<>nil do begin {пока p2 не встретила конец
списка делаем: }
if p1^. x=p2^. x then {сравниваем числа в p1 и p2}
inc (ch); {если равны, то увеличиваем число встреч}
p2: =p2^. adr; {p2 устанавливаем на следующий элемент списка}
end;
if ch=1 then begin {если число в p1 одинаково лишь само с
собой,}
mn1: =mn1+ [p1^. x]; {то записываем его в множество чисел}
sum: =sum+p1^. x; {и добавляем его к сумме}
end;
p1: =p1^. adr; {p1 устанавливаем на следующий элемент в списке}
end;: =first; {p1 и p2}2: =p1; {устанавливаем на начало списка}
while (p1<>nil) do begin
if not (p1^. x in mn1) then begin {если число в p1 не входит в множество,}
p2: =p1; {то p2 ставим на место p1}
p1: =p1^. adr; {а p1 сдвигаем на следующий элемент списка}
end
else {иначе элемент надо удалить}
if p1=first then begin {если элемент первый в списке}
first: =p1^. adr; {то началом списка будет второй элемент}
dispose (p1); {а первый - бывшее начало, удаляем}
p1: =first; {p1 устанавливаем на новое начало списка}
end
else begin {иначе элемент не первый в списке и его надо
удалять по-другому}
p2^. adr: =p1^. adr; {p2 стоит перед удаляемым, в его адресное поле записываем адрес
элемента следующего за удаляемым}
p1^. adr: =nil; {удаляемый ссылаем в никуда}
dispose (p1); {и удаляем его}
p1: =p2^. adr; {p1 ставим на элемент который стоял за удаляемым}
end;;(p2); {создаем новый элемент}2^. adr: =nil; {ссылаем его в никуда,
т к он будет последним в списке}
p2^. x: =sum; {в его числовое поле записываем сумму}
p1: =first; {встаем на начало списка}
while p1^. adr<>nil do {находим}
p1: =p1^. adr; {последний элемент списка}^. adr: =p2; {и
последний ссылаем на новый созданный элемент}
writeln ('posle ');
p1: =first; {встаем на начало списка}
while p1<>nil do begin {пока не конец списка}
write (p1^. x,' '); {выводим число элемента списка на экран}
p1: =p1^. adr; {переходим на следующий элемент }
end;;;;clrscr; randomize; (t,'text. txt'); {связывание файловой
переменной t
с файлом на диске под именем что в кавычках}
{$i-} reset (t); {$i+} {пытаемся открыть текстовый файл, при отключенной ошибке ввода
вывода}
if ioresult <> 0 then begin {если файл не удалось
открыть, т е его нет}
rewrite (t); {создаем его}
for i: =1 to n do begin {n=10, значит в файл запишется 10 чисел}
ch: = random (10); {генерируем число}
writeln (t,ch); {записываем в файл}
end;
close (t); {закрываем файл, т е ставим отметку о конце файла}
end;
reset (t); {открываем его заново}
writeln ('ishodnie chisla'); {и}not seekeof (t) do begin
{выводим}(t,ch); {на}(ch,' '); {экран};;;; {ожидание нажатия клавиши} {повторять пока не
нажата клавиша 5}
writeln ('1: massiv'); {вывод}
writeln ('2: file'); {пользовательского}
writeln ('3: spisok'); {меню}
writeln ('4: clrscr'); {на}
writeln ('5: exit'); {экран}
readln (v); {чтение клавиши}
case v of
: mass (a); {если нажата клавиша 1, то вызов процедуры с массивом}
: fill (f); {2 - с файлом}
: spisok; {3 - со списком}
: clrscr; {4 - очистка экрана}
end;v=5; {если была нажата клавиша 5, то выход из
программы}.
Вывод
Не трудно заметить, что как при работе с массивом, так и с
типизированным файлом и с динамическим списком использовался один и тот же
алгоритм обработки. Но также видны и некоторые различия, связанные со
спецификой работы в той или иной среде. Поскольку массив целиком хранится в
памяти, то чтобы выбрать пару элементов из массива нужно лишь знать их номера
внутри массива. Если же это типизированный файл, то мало просто знать номера
компонент, необходимо сначала поочерёдно найти их в файле, используя процедуру seek, считать их в
переменные, т.е. записать в память, и только потом работать с ними. При работе
с динамическим списком сами элементы никаких порядковых номеров не имеют, как в
массиве или типизированном файле.
Из выше сказанного следует, что для массивов и для
типизированных файлов применима произвольная адресация элементов, а для
динамических списков последовательная адресация.