Особливості використання системи Google Translator Toolkit сучасним перекладачем
МІНІСТЕРСТВО
ОСВІТИ І НАУКИ УКРАЇНИ
СХІДНОЄВРОПЕЙСЬКИЙ
УНІВЕРСИТЕТ ІМЕНІ ЛЕСІ УКРАЇНКИ
Кафедра
прикладної лінгвістики
ДИПЛОМНА
РОБОТА
ОСОБЛИВОСТІ
ВИКОРИСТАННЯ СИСТЕМИ GOOGLE TRANSLATOR TOOLKIT СУЧАСНИМ ПЕРЕКЛАДАЧЕМ
Виконав студент 55
групи
інституту іноземної
філології
спеціальності
“прикладна лінгвістика”
Кобак Микола
Васильович
ЛУЦЬК
2013
ЗМІСТ
ВСТУП
РОЗДІЛ I. РОЛЬ МАШИННОГО ПЕРЕКЛАДУ В
СУЧАСНОМУ СВІТІ
1.1 Причини та історія виникнення
машинного перекладу
1.2 Критерії класифікації систем
машинного перекладу
РОЗДІЛ II. ОСНОВНІ ПІДХОДИ ДО
АВТОМАТИЧНОГО ПЕРЕКЛАДУ
2.1 Системи прямого машинного
перекладу
2.2 Системи з використанням
трансферу (Tranfer-based MT)
2.3 Системи з використанням
проміжної мета-мови (Interlingua)
2.4 Переклад на основі зразків
(EBMT)
2.5 Статистичний машинний переклад
(SMT)
РОЗДІЛ III. АВТОМАТИЗОВАНИЙ ПЕРЕКЛАД
3.1 Основні поняття, що стосуються
автоматизованого перекладу
3.2 Системи на основі пам’яті
перекладів
РОЗДІЛ IV. GOOGLE TRANSLATOR TOOLKIT
ЯК ПОЄДНАННЯ СИСТЕМ ОБОХ ТИПІВ
4.1 Система Google Translate як
компонент Google Translator Toolkit
4.2 Порівняння системи Google
Translate з іншими онлайн-сервісами
4.3 Принцип роботи Google Translator
Toolkit
4.4 Порівняння системи Google
Translator Toolkit з його аналогами
ВИСНОВКИ
СПИСОК ВИКОРИСТАНИХ ДЖЕРЕЛ
ДОДАТКИ
ВСТУП
Ця робота присвячена дослідженню
систем автоматичного та автоматизованого перекладу, зокрема Google Translate та
Google Translator Toolkit.
Однією з тенденцй розвитку сучасного
суспільства є процес глобалізації, який призводить спрощення міжнародних
зв’язків. Розвиток Інтернету забезпечує майже всі необідні умови для
спілкування між людьми з різних держав. Однак мовний бар’єр дуже сповільнює
його розвиток. За допомогою традиційного перекладу його подолати немождиво,
тому що обсяг перекладів постійно зростає, і навіть збільшення кількості
кваліфікованих фахівців не зможе вирішити проблему.
Системи машинного перекладу в певній
мірі долають мовний бар’єр у спілкуванні. Хоча машинний переклад і не може замінити
традиційний, він допомагає фахівцям справитися в великою кількістю перекладів.
Отже, актуальність дослідження
полягає в необхідності виявлення особливостей роботи з програмами автоматичного
та автоматизованого перекладу.
Об’єктом дослідження є онлайн-сервіси
машинного перекладу: Google Translate, Google Translate Toolkit, Pragma Online,
Wordfast Pro, OmegaT, Bing Translator та інші, а предметом - особливості
використання системи Google
Translator
Toolkit.
Мета даного дослідження полягає у
вивчені особливостей роботи з системою Google Translator Toolkit,
проаналізувати її ефективність в порівнянні з іншими сервісами.
Мета дослідження передбачає
необхідність вирішення конкретних завдань:
· розглянути підходи
до реалізації перекладу у СМП;
· описати онлайн-сервіси
перекладу, їх фунції, можливості, переваги та недоліки;
· порівняти систему
Google Translate Toolkit з іншими системами машинного перекладу.
Матеріалом дослідження послужили
переклади газетної статті за допомогою систем машинного перекладу.
Новизна дослідження зумовлена
стрімким ростом потреби у перекладах, а також збільшенням кількості систем
автоматичного та автоматизованого перекладу, тому необхідне дослідження
особливості роботи та використання цих систем.
Для вирішення поставлених у роботі
завдань використовувалися наступні методи: емпіричний, елементарно-теоретичний,
метод системного аналізу та метод аналізу і порівняння.
Теоретична цінність роботи полягає у
її частковому внеску в дослідження систем машинного перекладу і особливостей
роботи з ними.
Практична цінність дослідження
полягає у можливості його використання при написанні дипломних та курсових
робіт. Вона також може слугувати як посібник при покупці перекладачем певного
програмного продукту.
Обсяг та структура дослідження.
Робота містить 53 сторінки, складається з вступу, чотирьох розділів і
висновків. В кінці роботи поданий список додатків.
РОЗДІЛ I.
РОЛЬ МАШИННОГО ПЕРЕКЛАДУ В СУЧАСНОМУ СВІТІ
.1 Причини та історія виникнення
машинного перекладу
Переклад різноманітних видів документації
з однієї мови на іншу є важливою частиною науково-технічного прогресу.
Кількість перекладів, що виконуються у промислово розвинених країнах продовжує
постійно зростати. В еру глобалізації першочерговим завданням постає переклад
рiзноманiтної технічної та комерційної документації на мови країн-iмпортерiв
продукції. Воно ускладнюється специфікою іноземних мов i жорсткими вимогами до
якості такого перекладу, що має в цих випадках міжнародне значення.
Все ще залишаючись двомовною
країною, Україна мусить вирішити декілька проблем у сфері перекладу iнформацiї:
переклад з іноземних мов на українську та російську і навпаки, а також
забезпечити якісний переклад між двома даними мовами.
Важко переоцінити актуальність i
складність цих проблем. Одним із першочергових завдань є переклад державного
патентного фонду України, який складається з мільйонів документів. Для
виконання даної роботи потрібно створити термiнологiчнi стандарти українською
мовою та двомовнi словники і зробити це потрібно якнайшвидше, інакше українська
мова матиме статус державної на свiтовому iнформацiйному ринку, а це одна з
причин, що ізолює нашу державу від світового співтовариства.
Одним з найуспішніших рішень
подолання мовного бар’єру стало утворення сфери машинного перекладу - галузі комп’ютерної
лiнгвiстики, що сформувалася з середини 50-х років у США i СРСР).
Машинний переклад (Machine
Translation, MT) - це спосіб перекладу текстів з однієї мови на іншу, з
використанням як апаратних, так і програмних комп’ютерних засобів.
Сфера машинного перекладу має такі
ознаки:
· постійне збільшення
кількості користувачів i виробників систем машинного перекладу (далі - СМП);
· великою кількістю
способів організації СМП;
· використанням
найновіших інформаційних засобів, в тому числі ПК, мережі Інтернет для
реалiзацiї СМП.
Чарльз Беббідж, один із засновників
комп'ютерних дисциплін, видатний математик XIX століття, намагався переконати
британський уряд у необхідності фінансувати його дослідження щодо розробки
"обчислювальної машини". За його задумом, колись ця машина зможе
здійснювати переклад з однієї на іншу мову, проте його проект залишився
нездійсненним.
Протягом XX століття відбувся
інформаційний бум - стрімко зросла кількість науково-технічної інформації. На
початку 50-х років XX ст. ідеї машинного перекладу (МП) чи автоматичного
перекладу (АП), тобто з мінімальною участю людини чи без неї, стали об'єктом
дослідження лінгвістики та прикладних математичних дисциплін, що було зумовлено
практичними потребами обміну інформацією. Причинами такої зацікавленості була
нестача кількості перекладачів для оперативного перекладу великої кількості
науково-технічної літератури. Важливою сферою використання обчислювальної
техніки МП так і не став, що було зумовлено її недостатнім розвитком, нестачею
комп’ютерів, їх невеликою обчислювальною потужністю, складністю створення
програм, малою кількістю кваліфікованих працівників, здатних ними
послуговуватися та колективним використанням його ресурсів. Ці обставини не
дозволяли проводити експериментальні дослідження та втрачалася оперативність
перекладу. Важливою причиною було недостатнє вивчення формальних аспектів
природних мов. Через це МП залишався в основному лише цікавою галуззю
досліджень.
Формально 1949 рік прийнято вважають
початком епохи машинного перекладу, коли відомий американський спеціаліст з
дешифрування Уоррен Уївер, директор відділення природничих наук Рокфелерівської
фундації написав листа Норберту Вінеру в березні того ж року і порівняв
завдання перекладу з процесом дешифрування текстів. В результаті нетривалої
наукової дискусії з'явився меморандум, який було розіслано двомстам
спеціалістам у галузі лінгвістики, дешифрування та теорії програмування, в
якому теоретично обґрунтувано принципову можливість створення систем машинного
перекладу.
У 1954 р. відбувся «Джорджтаунський
експеримент». Джорджтаунський університет спільно з IBM представили перший
електронний перекладач - російсько-англійську систему IBM Mark II, яка містила
словник з 250 одиниць і 6 граматичних правил. Хоча можливості цієї системи були
обмежені, вона послужила стимулом для подальшого розвитку галузі
[22, 4-8].
У 1966 році, приблизно через десять
років після проведення Джорджтаунського експерименту відбулося засідання
консультативного комітету з опрацювання природних мов (ALPAC) при Національній
академії наук США. Згідно з її доповіддю, жодна із запропонованих СМП не давала
якісного результату, не виправдовуючи тим самим затрат на їх розробку.
«Природний» переклад у ті часи не вимагав таких колосальних витрат і був
набагато якіснішим, тому, як наслідок, галузь машинного перекладу визнали
неперспективною і через це різко зменшилось фінансування розробки СМП у США та
Європі [ 6,
12].
У СРСР перші експерименти було
проведено в 1955 в Інституті прикладної математики при АН СРСР під керівництвом
О. С. Кулагіної та І. О. Мельчука. Було створено три системи АП - з французької
на російську, з англійської на російську та з французької на російську (у
новому варіанті).
Наприкінці 70-х років заняття МП
поновилися разом зі зростанням інтересу з боку проектувальників і дослідників
до лінгвістичним проблем штучного інтелекту та комп'ютерного пошуку інформації.
І тільки з початку 80-х років, коли
комп’ютери стали потужнішими, дешевшими та доступнішими, машинний переклад
нарешті став економічно вигідним. Хоча якість перекладу за допомогою СМП значно
покращилася, існують певні пробеми, які залишаються невирішеними і до сьогодні.
-і роки можна вважати справжньою
епохою відродження в розвитку МП, що пов'язано не лише з високим рівнем
можливостей персональних комп'ютерів, появою сканерів і програм OCR, але і з
поширенням глобальної мережі Інтернет, що зумовили реальний попит на CМП.
Він знову став привабливою областю
вкладення капіталів як для приватних інвесторів, так і для державних структур.
Наразі розроблено багато систем
машинного перекладу, які класифікуються за різними принципами. Щоб краще
розглянути СМП з точки зору здатності адекватності перекладу, потрібно поділити
їх за особливостями їх побудови. Для цього розглянемо критерії класифікації
СМП.
.2. Критерії класифікації систем
машинного перекладу
Багатоаспектність проблеми машинного
перекладу вимагає навести класифікацію СМП, для розуміння процесу перекладу,
який здійснює машина.
Основними критеріями класифікації:
а) За обсягом роботи, яку виконує
комп’ютер, системи поділяються на MAT (machine-aided translation) та MT
(machine translation). В MAT системах людина є головним учасником перекладу,
комп’ютер лише допомагає їй краще організувати процес, виконуючи такі функції
як пошук слів, заміну, тощо [7, 12].
Натомість, в MT системах за процес
перекладу відповідає саме машина, здійснюючи аналіз документів, пошук
еквівалентів та генерацію кінцевого перекладу. В даному випадку людині просто
відводиться роль керівника [19, 15-20].
б) Ще одним з критеріїв класифікації
СМП є кількість мов, які вона підтримує. Відповідно до даного аспекту системи
поділяються на двомовні та багатомовні.
До цього пунтку відноситься також
така характеристика як оборотність, тобто здатність СМП перекладати у
будь-якому напрямку, що складається з підтримуваних мовних пар.
в) Однією з важливих характеристик
програм є також тематика документів, на переклад яких орієнтована система.
Існують СМП, основна мета яких - переклад текстів з певних сфер, таких як
техніка, наука, інформатика, тощо. Їх протилежністю є універсальні програми,
однак при використанні спеціалізованих СМП якість перекладу дещо краща
[9, 83-87].
г) Залежно від підходу, на основі
якого створена СМП, вони поділяються на: статистичні (statistic) та системи,
які працюють завдяки використанням правил (rule-based)
[10, 42].
д) Лінгвістичний критерій, за яким
СМП на основі правил поділяють на:
· системи, що
реалiзують прямий переклад (direct translation);
· системи, якi
базуються на трансферi (transfer approach);
· системи з
мовою-посередником (interlingua approach).
У нашій роботі нас, перш за все,
цікавитимуть автоматичні та автоматизовані системи МП, їх переваги та недоліки,
способи покращення якості перекладу, тому в наступних розділах ми будемо
детальніше розглядати програми з точки зору лінгвістичних моделей, а також
системи пам’яті перекладів.
Висновки
до розділу І
Зростання обсягів перкладів зумовило
виникнення такої галузі комп’ютерної лінгвістики як машинний переклад. Хоча
дисципліна є відносно новою, за час її розвитку було розроблено багато підходів
та способів автоматизації перекладу. В наш час існує багато систем машинного
перекладу, однак жодна з них не може забезпечити користувача якісним
перекладом. Це пояснюється не поганою якістю програм, а складністю мови як
системи. Різні мови мають свої правила і винятки, і тому дуже важко створити
СМП, яка змогла б правильно перекладати між мовами, що належать до різних
гілок. Однак машинний переклад забезпечує користувачів чорновим перекладом, він
стає у нагоді при великій кількості однотипних документів, які потрібно
перекласти на кілька мов. Зараз багато міжнародних організацій використовують
СМП, тому що він допомагає заощаджувати час, зусилля та гроші.
РОЗДІЛ II.
ОСНОВНІ ПІДХОДИ ДО АВТОМАТИЧНОГО ПЕРЕКЛАДУ
.1 Системи прямого машинного
перекладу
Прямий машинний переклад є
найдавнішим і найпримітивнішим методом. Він є послівним і для реалізації
системи даного типу не потрібно створювати велику кількість правил. Переклад
створюється на основі двомовних словників, при цьому аналіз тексту джерела є
дуже поверхневим. Слова перекладаються окремо і в однаковій послідовності.
Після цього порядок слів та закінчення пристосовуються до відповідної мови.
Можливості таких систем визначалися доступними розмірами словників, які
залежними від обсягу пам'яті комп'ютера. Переклад тексту здійснювався окремими
реченнями, між якими нерідко втрачалися смислові зв'язки. Правила, які
застосовувалися під час перекладу були дуже простими (якщо - то) і їх створення
було громіздкою працею [6,
54]. Даний зразок демонструє правила для системи
прямого перекладу з англійської на російську мову і описує умови перекладу слів
much та many.preceding word is how return skol’koif preceding word is as return
stol’ko zheif word is muchpreceding word is very return nilif following word is
a noun retorn mnogo(word is many)preceding word is a preposition and following
word is noun return mnogiireturn mnogo [32].
Оскільки написання правил для всіх
нюансів мови - справа громіздка і невиправдана, науковці почали вдаватися до
інших методів машинного перекладу.
2.2 Системи з використанням
трансферу (Tranfer-based MT)
Для того, щоб зробити переклад,
необхідно мати певне представлення, яке показує значення речення-оригіналу. У
систем на основі методу Interlingua на цьому проміжному рівні знаходиться
власна метамова, яка не має нічого спільного з мовами, що використовуються при
перекладі, в той час як в системах на основі трансферу вона має певну
залежність від мовної пари, що беруть участь при перекладі. Способи, з
допомогою яких працюють transfer-based machine translation systems дещо
відрізняються, однак використовують загальну схему: вони застосовують набори
лінгвістичних правил, які визначаються як відповідність між структурою мови
оригіналу та мови перекладу. Перший етап включає в себе аналіз тексту-джерела,
його морфології і синтаксису (а іноді і семантики), щоб створити внутрішнє
представлення. Переклад генерується з цього представлення за допомогою
використання як двомовних словників так граматичних правил. Ця стратегія дає
змогу отримувати досить високу якість перекладу з точністю в приблизно 90%
(хоча даний показник дуже залежить від мови оригіналу та перекладу).
Система з використанням трансферу
спочатку аналізує морфологію і синтаксис тексту-джерела для того, щоб отримати
синтаксичне представлення. Його можна потім налаштувати, роблячи акцент на
відповідні частини для перекладу та ігноруючи інші види інформації. Процес
передачі потім перетворить це остаточне представлення (мовою оригіналу) до
представлення того ж рівня абстракції в цільової мови. Ці два подання називають
"проміжними" представленнями [16, 35].
Для отримання кінцевого результату
можуть бути використані різні методи аналізу та трансформації. Обрані методи і
вибір найважливішої інформації значній мірі залежать від побудови системи, тим
не менше, більшість систем включають, щонайменше, наступні стадії:
Морфологічний аналіз. Поверхневі
форми вхідного тексту, класифікуються як частини мови (наприклад, іменник,
дієслово, і т.д.) і підкатегорії (кількість, стать, час, і т.д.).
Лексична категоризація. У будь-якому
тексті деякі слова можуть мати більш ніж одне значення, що призводить до
неоднозначності в аналізі. Лексична категоризація бере до уваги контекст слова,
щоб спробувати вибрати правильне значення. Це може включати тегування за
частинами мови (PoS tagging) та уникнення лексичної багатозначності (word sense
disambiguation).
Лексичний трансфер. Це, в основному,
переклад за допомогою словників; Слову мовою оригіналу шукається відповідник у
двомовному словнику.
Структурний трансфер. У той час як
попередні етапи мали справу зі словами, цей етап має справу з великими
компонентами такі як фрази і уривки речень. На цій стадії узгоджуються роди і
числа, змінюється порядок слів або фраз.
Морфологічне генерування. Це
завершальний етап під час якого генерується власне перекладений текст
[2,
54].
Однією з головних даного типу систем
є фаза, що "передає" проміжне представлення тексту мовою оригіналу в
проміжне представлення тексту цільової мови. Вона знаходиться в одному з двох
рівнів лінгвістичного аналізу: Поверхневий трансфер (або синтаксичний). Цей
рівень характеризується передачею синтаксичних структур між оригіналом і
цільовою мовою. Підхід працює з мовами однієї сім’ї, наприклад, у романських
мовах між іспанською, каталонською, французькою, італійською і т.д.
Глибинний трансфер (або
семантичний). Цей рівень будує семантичне представлення, яке залежить від мови
оригіналу. Таке подання може складатися з ряду структур, що репрезентують собою
значення. Для повноцінного перекладу також потрібен і синтаксичний трансфер.
Цей рівень використовується для перекладу між віддаленими мовними сім’ями
(наприклад, іспанська - англійська) [12, 58].
.3 Системи з використанням проміжної
мета-мови (Interlingua)
Метод з використанням інтерлінгви є
одним з класичних підходів у галузі машинного перекладу. При такому підході
граматична інформація вихідного тексту спочатку виражається на нейтральній мові
“інтерлінгва”, з якої потім утворюється граматична інформація відповідної мови.
Він має великі переваги над попередниками. Переваги в тому, що система вимагає
меншої кількості компонентів для того, щоб пов'язати мовні пари, додати нову
мовну при даному підході не є надто проблематично, система може перефразовувати
вирази мови оригіналу, і підтримує мови, які сильно відрізняються один від
одного (наприклад, англійська та арабська). Ідеальний сфера застосування даного
типу систем - багатомовний переклад машини текстів окремої тематики
[20, 76-82].
При машинному перекладі, заснованому
на принципі Interlingua, переклад здійснюється через проміжну (семантичну)
модель тексту оригіналу. Interlingua являє собою незалежну від конкретної мови
модель, з якої може бути згенерований переклад на будь-яку мову. Принцип
Interlingua допускає можливість трансформації тексту мовою оригіналу в модель,
загальну для декількох мов. І вже з неї можуть бути зроблені тексти на інших
мовах. Таким чином, процес перекладу проходить дві стадії: з вихідного мови в
Interlingua і з Interlingua на цільову мову. Для здійснення принципу
Interlingua потрібно аналізатор для кожного вихідного мови та генеруюча
програма для кожної мови на виході. Для аналізу вихідного тексту необхідно
проведення глибокого семантичного розбору, який передбачає широке знання
лексики [21, 25-27].
2.4 Переклад на основі зразків
(EBMT)
Переклад на основі зразків є методом
машинного перекладу, що характеризується використанням двомовного корпусу
текстів в якості основної бази знань, під час виконання. В основі методу EBMT
полягає ідея перекладу за аналогією. Існує теорія, що люди не виконують
лінгвістичний аналіз при перекладі, а просто розбивають речення на певні фрази,
перекладають їх, а тоді формують із них речення на цільовій мові. Переклади
фраз виконуються за аналогією з попередніми перекладами (емпірично).
Ядро системи EBMT - блок пам`яті
перекладу, в якому зберігаються речення або фрази, які часто повторюються та їх
переклад. Система статистично вираховує (за допомогою методів інформаційного
пошуку), чи наявні перекладені записи схожі на відповідне речення вихідної
мови. Генерування перекладу відбувається таким чином, що речення, які найбільше
схожі одне на одне, перекладаються і в кінці комбінуються
[26].
Наприклад, маємо два речення в
двомовному корпусі:
. I’m very busy now, call me later.
- Зараз я дуже занятий, передзвони мені пізніше.
. I can’t help you with your
project. - Я не можу допомогти тобі з проектом.
Для того, щоб перекласти речення «Я
не можу допомогти тобі, передзвони пізніше.» система знайде в українському
варіанті корпусу частини речень, підбере їх англійські відповідники і складе їх
разом - I can’t help you, call me later.
При аналізі введеного в систему
речення для перекладу існує також таке поняття, як слова-винятки. Слова-винятки
- це слова, які можна опустити в тексті оригіналу (на початку і в кінці
знайдених блоків тексту) без втрати сенсу перекладу і для покращеної
підстановки (наприклад для англійської - "a", "the") [23,
11].
2.5 Статистичний машинний переклад
(SMT)
Статистичний машинний переклад
(Statistical machine translation - SMT) - різновид машинного перекладу, де
переклад генерується на основі статистичних моделей, параметри яких є похідними
від аналізу двомовних корпусів тексту. Статистичний машинний переклад має
властивість «навчання». Чим більше в розпорядженні є мовних пар і чим точніше
вони відповідають одна одній, тим кращим буде результат статистичного машинного
перекладу. Статистичний машинний переклад протиставляють системам машинного
перекладу, заснованим на правилах (Rule-Based Machine Translation) і на
прикладах (Example-Based MT). Перші ідеї статистичного машинного перекладу були
опубліковані Уорреном Уівером, в 1949 році. «Друга хвиля» - початок 1990-х,
IBM. «Третя хвиля» - Google, Microsoft, Language Weaver, Яндекс. Розробники
систем машинного перекладу для покращення якості вводять певні правила, тим
самим перетворюючи чисто статистичні системи в системи гібридного машинного
перекладу. Таке додавання дещо покращує якість перекладів, особливо при
недостатньому обсязі вхідних даних, що використовуються при побудові індексу
машинного перекладача [3, 79].
Ідея статистичного машинного
перекладу випливає з теорії інформації. Для систем статистичного перекладу
характерне використання масивів текстів, представлених одночасно двома мовними
версіями (так звані паралельні корпуси). Чим більший об'єм паралельного
корпусу, а також чим якісніший переклад текстів, що містяться в ньому, тим
краще перекладає статистична система. В якості теоретичної основи технології
статистичного машинного перекладу використовується модель, що базується на
теоремі Байеса. Дана модель надає можливості покращити переклад, використовуючи
найбільш частотні вживання слів на різних мовах, враховуючи потім відповідні
частоти при перекладі документа [4, 19].
Принцип роботи системи статистичного
машинного перекладу полягає в наступному: перед перекладом програма аналізує
великий корпус двомовних текстів. Цей процес забезпечує те, щоб слова і
граматичні форми, знаходились разом на обох мовах, залежно від частоти
використання та змістовної близькості. Таким чином, генерується словник та
граматичні правила і тексти перекладаються на цій основі. Метод SMT широко
розповсюджений, тому що він не ставить за передумову ніяких знань відповідної
мови. SMT охоче використовується, наприклад, міністерством оборони Америки,
коли йдеться про мови, які потрібно швидко перекласти за допомогою машинного
перекладу і не має часу на опрацювання текстів людиною
[8, 127-133].
Етапи створення систем статистичного
машинного перекладу.
· створення корпусу
паралельних документів;
· створення корпусу
паралельних речень;
· створення масивів
паралельних N-грам;
· створення індексних
файлів системи перекладу, що базуються на N-грамах;
· безпосереднє
створення модулів статистичного перекладача [36].
Якості джерела даних для створення
статистичних перекладачів використовують паралельні текстові корпуси, що
містять різні мовні версії однакових документів. При побудові паралельних
корпусів документів для забезпечення більшої точності використовуються
додаткові критерії, наприклад, підраховується кількість речень, цифр, імен
власних, довжини фрагментів текстів і т.п. Вирівнювання документальних корпусів
на рівні речень, тобто побудова паралельних корпусів речень, виконується на
основі головного постулату систем статистичного перекладу - принципу
монотонності. Цей принцип полягає в тому, що різні мовні версії одного і того ж
документа містять речення, розміщені в одному і тому ж порядку, тобто друге
речення знаходиться після першого, третє - після другого і т. д. Наступним
етапом формування бази даних статистичного перекладача є формування масиву
N-грам. N-грамою називається послідовність з N слів одного тексту, які слідують
одне за одним. При побудові баз даних сучасних статистичних систем перекладу
створюються масиви N-грам (найчастіше пентаграм). Для цих масивів у рамках
технологій статистичного машинного перекладу використовуються паралельні
двомовні корпусу речень. Для кожної пари речень будуються N-грами на одній
мові, яким відповідають (за місцем у відповідному реченні) N-грами на іншій
мові. Далі проводиться підрахунок кількості N-грам, які зустрічаються в
паралельному корпусі речень. Якщо на одній мові N-грамі відповідає кілька
N-грам на іншій мові, то вибирається найбільш частотна N-грама [23, 53-57].
Типова система статичного машинного
перекладу складається з:
· одномовного
корпусу;
· мовної моделі -
набору n-грам (послідовностей словоформ довжини n) з корпусу текстів;
· паралельного
корпусу;
· фразової таблиці -
таблиці відповідностей фраз вихідного корпусу і корпусу перекладів з
статистичними коефіцієнтами;
· статистичного
декодеру, який серед усіх можливих варіантів перекладу, вибирає найбільш
імовірний [35];
Головними перевагами SMT є швидка
настройка, легкість при додаванні нових напрямків перекладу, недоліками -
дефіцит паралельних корпусів, численні граматичні помилки, нестабільність
перекладу.
Висновки
до розділу ІІ
Існує багато критеріїв за якими
класифікуються СМП, але одним з найголовніших є підхід до її створення, згідно
якого програми поділяються на статистичні та ті, які працюють на основі правил
(rule-based).
Усі підходи систем машинного перекладу мають свої переваги та недоліки. Так,
для статистичних систем
характерна наявність дво- або багатомовного корпусу текстів, для створення
якого потрібні колосальні зусилля, однак не має необхідності задавати системі
велику кількість правил (як в системах rule-based).
Однак програми на основі правил не вимагають корпусів, можуть бути встановлені
на локальному комп’ютері та не використовують багато ресурсів. Найпершим та
найпростішим підходом в галузі МП є прямий переклад, який створював «підрядник»
тексту. Оскільки така якість не задовольняла нікого, вчені розробили складніші
підходи - на основі трансферу та проміжної мета-мови Інтерлінгва. Однак
найбільш перспективними системами є гібридні, тобто такі, що поєднують
статистичні та СМП на основі правил. Гібридна система є гнучкою при додаванні
мов, виборі еквівалентів, має здатність «навчатися», а також має точність СМП
на основі правил.
РОЗДІЛ III.
АВТОМАТИЗОВАНИЙ ПЕРЕКЛАД
За останні 10-15 років характер
роботи перекладача та вимоги до нього істотно змінилися. У першу чергу зміни
торкнулися перекладу науково-технічної, та офіційно-ділової документації.
Сьогодні вже недостатньо просто перекласти текст, користуючись комп'ютером як
друкарською машинкою. Замовник очікує від перекладача, що оформлення готового
документа буде відповідати зовнішньому вигляду оригіналу настільки точно,
наскільки це можливо, при цьому задовольняти прийнятим у певній країні
стандартам. Від перекладача потрібним є також уміння ефективно використовувати
раніше виконані замовлення на ту ж тему, а роботодавець, у свою чергу,
розраховує на помітну економію часу і коштів при перекладі повторюваних або
схожих фрагментах тексту. Ці жорсткі умови можна дотримати лише в тому випадку,
якщо перекладач не тільки досконало володіє рідною і іноземною мовою і глибоко
вивчив обрану ним предметну область, але й упевнено орієнтується в сучасних
комп'ютерних технологіях. Останнім часом стійко зростає обсяг перекладів,
пов'язаних з інформаційними технологіями, причому перекладацьким і комп'ютерним
компаніям доводиться мати справу не тільки з підготовкою документації, а й з
локалізацією програмного забезпечення, тобто з перекладом ресурсів, що
містяться в exe-і dll-файлах з подальшим тестуванням ПЗ.
.1 Основні поняття, що стосуються
автоматизованого перекладу
Автоматизований переклад (АП, англ.
Computer-Aided Translation (CAT)) - переклад текстів з використанням
комп'ютерних технологій. Від машинного перекладу (МП) він відрізняється тим, що
весь процес перекладу здійснюється людиною, комп'ютер лише допомагає їй
створити готовий текст або за менший час, або з кращою якістю.
Ідея АП з'явилася з моменту появи
комп'ютерів: перекладачі завжди виступали проти стандартної в ті роки концепції
МП, на яку було спрямовано більшість досліджень в області комп'ютерної
лінгвістики, але підтримували використання комп'ютерів для допомоги
перекладачам. У 1960-і роки Європейське об'єднання вугілля та почало створювати
термінологічні бази даних під загальною назвою Eurodicautom.
У сучасній формі ідея АП була
розвинена у статті Мартіна Кея 1980 року, який висунув наступну тезу: «by
taking over what is mechanical and routine, it (computer) frees human beings for
what is essentially human» (комп'ютер бере на себе рутинні операції і звільняє
людину для операцій, що вимагають людського мислення) [7, 287].
В даний час найпоширенішими
способами використання комп'ютерів при письмовому перекладі є робота із
словниками та глосаріями, окремими термінологічними базами, пам'яттю
перекладів, що містить приклади раніше перекладених текстів, а також
використання так званих корпусів - великих колекцій текстів однією або
декількома мовами, що дає стислий опис того, як слова і вирази реально
використовуються в мові в цілому або в конкретній сфері.
Автоматизований переклад це широке
поняття, що охоплює різні засоби та інструменти. Вони можуть включати:
· Програми для
перевірки правопису, що вбудовуються у текстові редактори або окремі програми;
· Програми для
перевірки розділових знаків, що також можуть бути вбудованими у текстові
редактори або додаткові програми;
· Програми для
управління термінологією, що дозволяють перекладачам управляти своєю власною
термінологічною базою в електронній формі. Це може бути створена у текстовому
редакторі звичайна таблиця, електронна таблиця, а також база даних, що
збудована у програмі FileMaker Pro. Для більш трудомістких (та більш дорогих)
рішень існує спеціальне програмне забезпечення: LogiTerm, MultiTerm, Termex та
ін.;
· Словники на
компакт-дисках, одномовні або багатомовні;
· Термінологічні бази
даних, що зберігаються на компакт-дисках або підключаються через мережу
Інтернет, наприклад The Open Terminology Forum або TERMIUM;
· Програми для
повнотекстового пошуку (або індексатори), що дозволяють користувачу робити
запити у раніше перекладених текстах або різних довідкових документах. Серед
перекладачів найбільш відомими є такі індексатори як Naturel, ISYS Search
Software, and dtSearch;
· Програми-конкорданси,
що дозволяють знаходити приклади слів або висловів у поширеному контексті в
одномовному, двомовному та багатомовному корпусах, як то бітекст або пам'ять
перекладів;
· Бітекст, що не є
дуже новим винаходом, являє собою наслідок злиття первинного тексту та його
перекладу, що може бути пізніше проаналізованим програмами для повнотекстового
пошуку або конкордансу;
· Програмне
забезпечення для управління проектами, що дозволяє мовознавцям структурувати
складні перекладацькі проекти, доручати різні завдання різним співробітникам, а
потім наглядати за процесом їх виконання;
· Менеджери пам'яті
перекладів (ТММ), що складаються з бази даних сегментів тексту на первинній
мові та їх перекладів на одну та більше цільових мов;
· Майже повністю
автоматичні системи, що нагадують машинний переклад, але дозволяють користувачу
вносити поправки у сумнівних випадках. Іноді такі програми називають машинним
перекладом за участю людини.
Таким чином, системи
автоматизованого перекладу працюють на основі накопичення і збереження знань,
які при потребі можуть бути використані повторно. Якщо текст для перекладу
повторюється чи є дуже схожим із іншими, програма автоматизованого перекладу
допомагає зберегти час і зусилля перекладача: наприклад, використання
клавіатури може бути зменшено на 70% з деякими текстами. Електронні словники забезпечують
користувачу швидкий доступ до лексичних даних а словники термінів допомагають,
без зусиль підібрати найпідходячий еквівалент для перекладу
[13, 127-134].
Системи автоматизованого перекладу
містять зазвичай додаткові модулі, які допомагають краще організувати роботу
перекладача - об’єднання декількох документів в проекти, підключення багатьох
баз даних пам’яті перекладів, інтеграція в текстові процесори, браузери, тощо.
.2 Системи на основі пам’яті
перекладів
Починаючи з появи перших систем основі
пам’яті перекладів на ринку, тисячі професіоналів освоїли дану технологію після
розуміння переваг, які вона може принести в плані продуктивності, економії часу
та зусиль і якісті перекладу. Сьогодні користувачам доступна велика
різноманітність програм, з новими інструментами, що з’являються на ринку майже
кожен місяць, посилюючи конкуренцію у сфері програм-перекладачів. Звичайно,
кожна система має певні унікальні особливості, які відрізняють її від інших, і
виконує певні завдання краще, ніж інші системи; тому потрібно вибирати програму
під певні критерії.
Пам'ять перекладів - база даних, що
містить набір перекладених раніше текстів. Один запис в такій базі даних
відповідає «одиниці перекладу» (англ. translation unit), яка зазвичай
відповідає одному реченню (рідше - частині складносурядного речення, або
абзацу). Якщо одиниця перекладу початкового тексту точно збігається з реченням,
що зберігається в базі (точна відповідність, англ. exact match), вона
автоматично підставляється у переклад. Нова одиниця може трохи відрізнятися від
тої, що зберігається у базі (неточна відповідність, англ. fuzzy match). Таке
речення може бути також підставлене у переклад, але перекладач буде повинен
внести необхідні зміни.
Крім прискорення процесу перекладу
фрагментів та періодичних змін, внесених до вже перекладених текстів, системи
ПП також забезпечують одноманітність перекладу термінології в однакових
фрагментах, що особливо важливо при технічному перекладі
[17, 57-62].
Зазвичай, програмним продуктам, що
використовують бази ТМ, притаманні спільні функціональні можливості.
. Імпорт - це перенесення текстового
файлу до пам'яті перекладів.
. Текстовий редактор, в якому власне
і здійснюється переклад. Всі програми мають два вікна - для оригіналу та
перекладу. Коли у вікно оригіналу вводиться текст, починається пошук
аналогічного фрагменту в базі даних. Якщо в пам’яті знаходиться аналогічний
фрагмент, він виводиться у вікно перекладу автоматично. Якщо точного збігу не
знайдено, у вікно виводиться найбільш схожий фрагмент, вказується відсоток
збігу. Можна встановлювати у процентах міру збігу між текстом для перекладу та
текстом в базі. Чим більший відсоток схожості, тим більша вірогідність
знаходження потрібного тексту. Встановлюючи менший відсоток, можна отримати
матеріал, який буде корисним, хоча б для довідки .
Перекладач самостійно редагує
запропонований фрагмент згідно з оригіналом, записує в пам'ять бази даних
переклад та переходить до наступного фрагменту. Якщо база знаходиться в мережі,
вона є доступною для усіх; поповнення бази здійснюється автоматично, кожним
працівником/перекладачем/користувачем.
. Текстовий розбір (англ. parsing) -
синтаксичний аналіз тексту. Важливо розрізнити пунктуацію, щоб, наприклад,
відрізнити кінець речення від абревіатури.
. Лінгвістичний розбір - підготовка
списків фразеологічних зворотів, термінів тощо.
. Сегментація - вибір найбільш
підходящих для перекладу сегментів тексту. Фрагменти, на які поділяються
тексти, називають сегментами. Сегментом вважається одне чи декілька речень,
частина речення чи словосполучення, лише в поодиноких випадках окреме слово.
. Виділення термінології -
скорочення обсягу ручного перекладу термінології.
. Експорт - перенесення тексту з
пам'яті перекладів до зовнішнього текстового файлу.
. Точний збіг - введена одиниця перекладу
повністю відповідає одиниці у базі. Під час перекладу речень це означає, що
сегмент був перекладений раніше. Такий збіг називають «100% match».
. Приблизний збіг. Якщо збіг був
неточний, він часто позначається у процентному співвідношенні від 0% до 100%.
. Конкорданс. Виділивши термін або
ідіому, можна знайти всі сегменти минулих перекладів що їх містять.
. Автоматичний переклад
Системи ПП часто надають можливість
повністю автоматизованого перекладу та заміни.
. Робота в мережі передбачає
співпрацю з іншими перекладачами.
. Термінологічний словник - звичайні
електронні словники, які можна імпортувати, поповнювати та редагувати.
. Централізована ПП - збережена на
центральному сервері ПП, яка співпрацює з кожною окремою ПП на кінцевих вузлах
мережі. Збільшується вірогідність виявлення збігів на 30-60% [24].
Першу програму, що використовувала
базу ПП, - Translation Manager - створила компанія IBM. Спочатку компанія
використовувала її виключно у власних цілях - для локалізації (адаптації на
іноземні мови) власних програмних продуктів. Потім програма була запропонована
ринку і довго була монополістом у галузі. Вона була швидкою та простою у
використанні і забезпечувала гарні можливості для індивідуальних налаштувань
користувача.
Програма SDLX, розроблена англійською
компанією SDL для своїх співробітників, мала недоліки пов’язані з незручностями
етапів перекладу. Текст неможливо безпосередньо імпортувати в редактор -
спочатку його потрібно видозмінити в SDL Edit - одній з 3 частин програми.
Програма Déjà
Vu користується у перекладачів в Європі
популярністю завдяки своїй гнучкості та адаптивності. Окрім зручності, вона
вирізняється співвідношенням ціна/якість. Відомо, що остання версія програми
тестувалась також і російськими перекладачами. Їхні статті й відгуки були
опубліковані в MultiLingual Computing & Technology.’s Workbench, або просто
Trados, швидко отримав визнання в Україні й Росії, спочатку серед
перекладацьких фірм, а потім й серед індивідуальних перекладачів. Великою
перевагою є те, що він інтегрується в такі відомі програмні продукти як Word та
інтернет-браузери. Trados є надзвичайно зручним для пересічного перекладача, що
не знайомий з програмуванням, він зрозуміліший ніж інші програми типу. Всі
елементи управління мають підказки. Цей продукт має всі корисні інструменти,
які в інших продуктах є лише в частковій наявності.
В кінці 2008 року з'явилася перша
вітчизняна система ПП AnyMem, розроблена київською компанією Advanced
International Translations.
Завдяки накопиченим перекладам в
базі ПП, перекладач може економити сили, час та гроші при перекладі нових
текстів схожих тематик, так як не потрібно знову перекладати повторювані
фрагменти й витрачати час на пошуки термінів, характерних для конкретної галузі
чи компанії. Інструкції, попереджувальні повідомлення, об’яви і т.п. можуть
бути перекладені один раз, а використані багаторазово.
За рахунок прискорення темпів
виконання перекладу збільшується продуктивність, отже, з’являється можливість
виконати більше замовлень. Також окрім швидкості перекладу, системи ПП надають
точність перекладу термінів, що особливо важливо для спеціалізованих текстів.
Оскільки технологія ПП широко
розповсюджена в Європі та США, де від перекладачів вимагають мати практичний
досвід користування сисемами автоматизованого перекладу. В Україні ця
технологія лише розвивається, але найбільші компанії вже прийняли використання
ПП за норму.
Однак поряд з перевагами існують
також і недоліки. Часто постає питання самої суті перекладу: донести основну
думку тексту, а не надати сухий переклад речень. Також є потенціальний ризик
відсутності смислових відношень окремого речення до сусідніх речень та тексту в
цілому. Якщо у базі перекладу існує помилка, вона пошириться на весь проект.
При зміні працевлаштування може
знадобитися опановувати новий програмний продукт.
Важливим також є фінансовий аспект.
Розмаїття програм створює таку проблему, якк несумісність баз ПП різних
виробників програмного забезпечення, форматів іпорту/експорту, кодування, тому
деколи виникає необхідність покупки іншої системи, а коштують вони від 200 до
2,5 тис доларів. У кожній конкретній системі ПП дані зберігаються в своєму
власному форматі (текстовий формат у Wordfast, база даних Access у Déjà
Vu), але існує міжнародний стандарт TMX (англ.
Translation Memory eXchange format), заснований на XML, який можуть створювати
практично усі системи ПП. Завдяки цьому результати роботи перекладачів можна
обмінювати між додатками; тобто перекладач, що працює з OmegaT, може
використовувати ПП, створену у Trados і навпаки.
До найпопулярніших систем
відносяться:
· Déjà Vu;
· OmegaT (безкоштовна
система, поширювана за ліцензією GNU);
· SDLX;
· Trados
(найпопулярніша програма, що довгий час була стандартом ПП);
· Star Transit;
· Wordfast (спочатку
була реалізована як набір макросів для MS Word, згодом для неї створили власний
інтерфейс);
· Lokalize (з
відкритим кодом, працює на GNU/Linux, Windows, Mac OS X);
· Transolution;
· Open Language
Tools;
· Інструменти
перекладу Google;
У кінці 2008 року з'явилася перша
вітчизняна система ПП AnyMem, розроблена київською компанією Advanced
International Translations.
Хоча системи автоматизованого
перекладу і не можуть забезпечити відразу якісний результат, однак при
достатньо довгому періоді їх використання, наявності обширної бази даних
перекладів, словників термінів, вони значно спрощують роботу професіонала,
особливо при роботі з текстами, у яких наявне обов'язкове стандартне
оформлення, стиль, певна лексика, тощо.
Висновки
до розділу ІІІ
Програми автоматизованого перекладу
забезпечують кращу організацію роботи професійного перекладача. Їх основною
функцією є накопичення перекладених сегментів (фраз, речень, абзаців), які при
можуть бути використані повторно (особливо при перекладі документів ділового
стилю, де існує багато зворотів, кліше, тощо). Системи АП розбивають тексти на
сегменти для кращого сприйняття тексту оригіналу людиною. Словники термінів
полегшують роботу перекладача з термінологією, допомагають підібрати правильні
еквіваленти. Багато програм автоматизованого перекладу мають функцію під’єднання
до онлайн-сервісів МП, що можуть надати чорновий переклад, який при потребі
можна редагувати. Хоча системи АП не звільняють перекладача від роботи, вони
значно спрощують сам процес, при достатньо великій ПП переклад стає справою
п’яти хвилин.
РОЗДІЛ IV.
GOOGLE TRANSLATOR
TOOLKIT ЯК
ПОЄДНАННЯ СИСТЕМ ОБОХ ТИПІВ
.1 Система Google Translate як
компонент Google Translator Toolkit
Translator Toolkit нє є цілісною
програмою, навпаки, даний веб-сервіс скаладається з багатьох компонентів і
служб, які взаємодіють виконанні роботи. Однією з головних є Google Translate -
система, яка виконує чорновий машинний переклад, а GTT надає можливість
подальшого редагування, запису в пам’ять перекладів, надання доступу іншим
користувачам, тощо.Translate - безкоштовний онлайн-сервіс машинного перекладу,
який дозволяє автоматично перекладати слова, тексти, електронні документи,
веб-сторінки багатьма мовами світу. Для певних мов користувачам система
пропонує варіанти перекладів, наприклад для термінів і багатозначних слів.
Спочатку GT використовував перекладач SYSTRAN, яким і зараз користуються такі
онлайн-сервіси як Babel Fish, AOL та Yahoo. Однак починаючи з жовтня 2007 року,
Google запустила власне програмне забезпечення. Переклад здійснюється з
використанням статистичного підходу до машинного перекладу, що дозволяє системі
«навчатися» і самовдосконалюватися: коли Google Translate створює переклад, він
шукає зразки в сотнях мільйонів документів, щоб надати найкращий переклад.
Знайшовши зразки в текстах, перекладених іншими людьми, Google Translate може
робити інтелектуальні припущення щодо правильного перекладу. Цей процес пошуку
зразків у великих обсягах тексту і називається "статистичним машинним
перекладом". Оскільки переклади генеруються машинами, не всі вони ідеальні.
Чим більше текстів певною мовою перекладають люди, а Google Translate їх
аналізує, тим кращою буде якість перекладу. Саме тому точність перекладу
різними мовами іноді відрізняється [31].
Наразі система підтримує 71 мову,
однак 19 з них є альфа-мовами, тобто знаходяться на стадії розробки і
тестування. Для покращення якості роботи програми з цими мовами програмі
необхідні корпуси паралельних текстів і колекції пам’яті перекладів. Google
Перекладач може виконувати оборотний переклад у будь якій мовній парі, що
підтримує система, але у більшості випадків реально виконує переклад через
англійську. Більш того, для української та білоруської мов, як правило,
використовується як проміжна ще й російська. Від цього дуже погіршується якість
перекладу. Наприклад, це добре помітно при перекладі з польської на українську,
що здійснюється через англійську та російську.Translate успішно інтегрується в
браузери, завдяки спеціальним розширенням, що встановлюються додатково. Для
Mozilla Firefox існує дуже багато плагінів, щодо Google Chrome, то дані
компоненти вже встановлені у нових версіях. Існує також спеціальний клієнт для
ОС Windows, що реалізований у безплатній та комерційній версії, яка
відрізняється кількома компонентами. Сервіс також працює з популярними зараз мобільними
операційними системами, такими як Android та iOS. Для мобільних пристроїв була
створена спеціальна функція голосового вводу, яка підтримує 15 мов
(української, на жаль, немає), а система може «прочитати» переклад на 23 мовах
за допомогою синтезу мовлення. Translate - перспективна система для перекладу,
тому що збільшення пам’яті перекладів і поповнення двомовних корпусів
забезпечує кращу якість перекладів. Її перевагою є також те, що вона може
самовдосконалюватися за рахунок збільшення баз даних. Однак статистичний метод
не є ідеальним, тому система такого типу не зможе надати повноцінного
перекладу.
4.2 Порівняння системи Google Translate
з іншими онлайн-сервісами
У даному розілі ми будемо
порівнювати якість перекладу онлайн-сервісів, які підтримують напрямок
«англійська - українська». Об’єктами оцінювання будуть відомі системи
онлайн-перекладу, такі як Google Translate,
Pragma Online, Перекладач Яндекс, Перекладач Мета, i.Ua Перекладач та Bing
Translator. Критеріями для оцінки будуть наступні:
· адекватність
перекладу (чи можна зрозуміти суть висловлювання);
· вживання правильних
еквівалентів слів;
· узгодження
закінчень;
· правильний порядок
слів;
Аналізуючи переклади першої статті
(додатки 1 - 6), почнемо з того, що чотири програми дали нам однаковий
результат - Pragma Online, Перекладач Яндекс, Перекладач Мета та i.Ua
Перекладач. Відрізняються вони лиш тим, що в Pragma Online та i.Ua Перекладачі
існує обмеження на переклад тексту в 1000 символів. В аналогічних сервісах
пошукових yandex.ua та meta.ua ці обмеження зняті. Оскільки на офіційному сайті
компанії Trident Software вказано, що дані сервіси - клієнти Trident Software
[34], можна припустити, що вони використовують програму Pragma у своїх
сервісах.
Щодо власне перекладу, то жодна з
програм не переклала правильно заголовок Yanukovych meets with Korean premier
in Seoul, однак переклад загалом можна зрозуміти. Оскільки це просте речення,
то порядок слів у перекладах правильний. Однак всі системи допустили помилки
при узгодженні прикметника з іменником (Korean premier).
Також зрозумілим є і речення № 2,
однак всі сервіси «помилилися» з вибором правильного еквіваленту до слова
premier і переклали його як прем'єр, хоча в даному контексті воно вжито в
значенні глава держави. Pragma Online та Bing Translator в даному випадку
переклали не всі власні імена, а просто скопіювали оригінал. Це можна пояснити
тим, що у них менший запас двомовних корпусів ніж в GT. Також у Pragma Online
існують проблеми з перекладом дієслів. В даному випадку система розпізнала has
met як модальне дієслово. В наступному реченні у всіх систем виникли проблеми з
порядком слів, однак загальний зміст можна зрозуміти.
Далі при перекладу фрази at the
meeting (речення № 4) GT скористався прийомом sense developement, переклавши її
як у ході зустрічі, Pragma Online не справилася з перекладом першої половини
речення, її значення повністю спотворено, а Bing Translator «заявив», що наш
президент новообраний. Наступне речення всі системи переклали майже без
проблем, загальний його зміст зрозуймілий, хоча Bing Translator зробив помилку
при керуванні but a long history of their friendship unites them - але довгу
історію їх дружбу об'єднує їх. Наступне речення програми переклали майже вдало,
загальне значення висловлювання є зрозумілим, однак Bing Translator, як завжди,
не узгодив закінчення: другом і партнера та Pragma Online переклала Ukrainian
people дослівно. При перекладі складних іменників GT та Pragma Online
справилися з завданням, а в перекладі за допомогою Bing Translator в даному
випадку присутні помилки - організації ядерної безпеки саміту. У реченні № 9 GT
та Bing Translator відносно справилися з завданням з мінімальним спотворенням
основного змісту, а Pragma Online неправильно вибрала значення для слова
contribution.
Оскільки Pragma Online має ліміт в
1000 символів, далі будемо користуватися системою Перекладач Мета, тому що вони
дають абсолютно однаковий результат.
У реченні № 10 всі системи
забезпечили відносно якісний переклад, головна думка збережена, однак існують
деякі неточності - Google Translate вжив лексему підвищення, яке не зовсім
підходить для данного контексту, Перекладач Мета переклав іменник hope як
дієслово сподіваються, а Bing Translator не узгодив закінчення. Починаючи з
цього місця і до кінця тексту GT виконав якісний переклад, однак потрібні ще
певні зміни в порядку слів. Перекладач Мета невірно сприйняв лексему concluded,
переклавши її як закінчуються, і в останньому реченні вжив слово дякував
замість аналога доконаного виду, допущено також помилки при перекладі керування
- за його увагу виконанню. Bing Translator допустив помилки у закінченнях слів.
При аналізі другої статті (додатки 7
- 11) бачимо схожі результати. При переекладі заголовка Refugees protest relocation
of an integration center адекватний результат надав лише Google Translate, хоча
і з помилкою у керуванні. Інші системи дуже сильно спотворили зміст
висловлювання і заголовок взагалі неможливо зрозуміти: Bing Translator -
Біженців протест переселення інтеграції центр, Pragma
Online -
Перерозподіл протесту біженців центру інтеграції. Ці дві системи дають похибки
при перекладі слів, які можуть виступати різними частинами мови, так Bing
Translator сприйняв protest як іменник, хоча тут потрібно було вжити дієслово.
В першому реченні статті Google
Translate показав найкращий результат, переклад був повністю адекватним, за
винятком прийменника в замість біля. З перекладу за допомогою системи Bing
Translator ми дізнаємося про суб’єктів та дію, однак інформація про інші
обставини спотворена і речення можна зрозуміти лише частково. Pragma
Online має інший
переклад, однак його також не можна вважати адекватним через велику кількість
помилок.
В наступному реченні слова they
say Bing Translator
сприйняв як вставне слово кажуть, хоча в даному випадку мова іде про
протестуючих. Google Translate переклав речення з певними помилками у
відмінках, однак саму суть речення вловити можна. Bing Translator допустив
помилки у відмінках слів та неправильно вибрав еквівалент словосполучення meet
rent payments - зустріти орендної плати. Таку ж помилку допустила і система Pragma
Online. Далі суть
речення зрозуміти можна однак системи допустили багато помилок, про які вже
згадувалося.
При перекладі наступного речення
система Google Translate допустила кілька неточностей при виборі правильного
еквіваленту (renovation - оновлення замість реконструкція; the move - рухатися
замість переїзд). Інші системи допустили такі ж помилки, однак зміст речення є
зрозумілим. Далі усі програми дали відносно зрозумілий переклад, помилки є
типовими для систем статистичного МП - узгодження словосполучень. При перекладі
власної назви Troeshchina Bing Translator та Pragma Online скопіювали оригінал,
однак Google Translate надав повноцінний переклад.
У наступних реченнях системи також
допустили дуже багато помилок при узгодженні словосполучень та виборі
правильних лексико-семантичних варіантів слів. Також потрібно зазначити, що ці
СМП поки що не здатні адекватно перекласти складні назви організацій, партій,
тощо. Це пояснюється тим, що статистичні системи не аналізують саму назву, як
це робить людина, а просто шукають варіанти перекладу у двомовному корпусі.
Як бачимо з перекладів, система
Google Translate найкраще справилася з завданням, тому що сервіси даної
компанії є найпопулярнішими в світі і дуже багато людей, виконуючи переклад,
тим самим допомагають сервісу покращити переклад. Найважливіша проблема Bing
Translator - типи зв’язку у словосполученнях, Pragma Online - вибір правильних
відповідників при перекладі. Всі три сервіси мають «властивість» помилятися при
перекладі власних назв. Порядок слів у складних реченнях є одним з викликів для
даних систем.
Оскільки всі три сервіси
використовують статистичний метод машинного перекладу, який має таку властивість
як самонавчання, є сподівання, що в майбутньому якість перекладу значно
покращиться. Наразі для СМП поки що важко «вловити» суть, основну думку
висловлювання, однак це пояснюється не програмними помилками чи збоями у
системах, а складністю природних мов, які є різними як з точки зору граматики і
синтаксису, так і в лінгвокультурному аспекті. Іноді для адекватного перекладу
професіоналові потрібно повністю зануритися в середовище носіїв мови оригіналу,
зрозуміти те, чого не можна пояснити словами, і навіть це не гарантує ідеальний
переклад. Однак, коли потрібно просто зрозуміти лише основну думку тексту,
заощадити час, гроші та зусилля - машинний переклад є ідеальним рішенням.
.3 Принцип роботи Google Translator
Toolkit
Ідея поєднати систему машинного
перекладу Google Translate і створити власну систему автоматизованого перекладу
з'явилася в розробників наприкінці серпня 2008 року. Цей проект спочатку
називався Google Translation Center, однак фахівці змінили назву на Translator
Toolkit. Система виявилась не такою амбіційною, як думали користувачі, однак
швидко завоювала популярність через простоту у використанні і тому, що вона є
безкоштовною. Насправді ідея поєднання машинного та автоматизованого перекладу
не є такою інноваційною. Вона з’явилася ще в 90-х роках минулого століття. В
науковій літературі вона відома як MT-assisted TM і була реалізована у вигляді
додаткових плагінів на CD в якості необов’язкових компонентів програм. В той
час професійні перекладачі не сприймали її серйозно і про ідею на деякий час
забули. Однак приблизно через десять років її почали використовувати такі
програмні засоби як SDL Trados 2007 Suite, який дозволяв використовувати
вбудовану систему машинного перекладу, OmegaT, яка також підтримує доступ до
онлайн перекладачів [5, 16].Translator Toolkit - безкоштовний онлайн-сервіс, що
дозволяє редагувати переклади документів, створених системою Google Translate.
Завдяки даній системі професіонали можуть краще організувати свою роботу,
надавати доступ до документів, словників термінів і пам’яті перекладів,
використовуючи сервіс Google Drive (колишній Google Docs).
За словами Майкла Гальса, члена
команди розробників GTT, основна мета цього сервісу - зробити інформацію
доступною кожній людині на Землі. Він пояснив, що система працює за наступною
схемою (рис. 4.1):
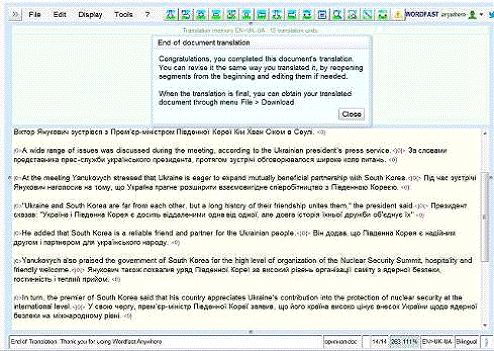
Рис. 4.1. Схема роботи Google
Translator Toolkit
«Найкраще те, що наша система
автоматичного перекладу постійно запам’ятовує переклади і враховує виправлення,
які зроблені перекладачами.
Таким чином, якість перекладу між
основними 47 мовами (а це 98% світової аудиторії мережі Інтернет) буде весь час
покращуватися», - заявив розробник [33].
Перелік основних фунцій
системиToolkit підтримує переклад документів наступних форматів:
· AdWords Editor
Archive (.aea)
· Android Resource
(.xml)
· Application
Resource Bundle (.arb)
· Chrome Extension
(.json)
· GNU gettext (.po)
· HTML
· Plain text (.txt)
· Microsoft Word
(.doc)
· Rich-text (.rtf)
· Open Office (.odt)
· Wikipedia™
Розмір файлу окремого документа не
повинен перевищувати 1 мегабайт. Розмір документів, з якими можна працювати
впродовж одного року становить 1 Гб.
Головним форматом для пам’яті
перекладів слугує Translation Memory eXchange (TMX), розмір файлу якої не
повинен перевищувати 50 Мб. Система надає можливість сворювати, редагувати і
зберігати пам’ять перекладів, користуватися TM, до яких було надано публічний
доступ.
Для роботи зі словниками термінів
також існують правила:
· кожен файл повинен
не перевищувати 1Мб;
· можна завантажувати
словники термінів у власному форматі;
· ліміт завантажень -
1 Гб на рік [27].
Автори і співавтори перекладів
Автором вважається користувач
системи GTT, який завантажив документ для перекладу, ПП чи словник термінів.
Вони можуть:
· редагувати переклади,
ПП і словники термінів;
· надавати доступ
іншим користувачам (співавторам) до даних об’єктів;
· видаляти файли, тим
самим забороняючи їх використання співавторами.
· В свою чергу
співавтори мають змогу:
· редагувати
переклади, ПП та словники термінів;
· здійснювати пошук у
ПП та словниках;
· завнтажувати копії
на локальні комп’ютери.
Для того, щоб надати доступ іншим
користувачам, потрібно надіслати їм запрошення. Для цього необхідно виділити
один або декілька файлів (перекладів, ПП чи словників), натиснути кнопку  (Share)
і в діалоговому вікні ввести e-mail адресу користувача(ів), яким потрібно
надати доступ [29].
(Share)
і в діалоговому вікні ввести e-mail адресу користувача(ів), яким потрібно
надати доступ [29].
Публікація
Оскільки GTT інтегрований з
сервісами Wikipedia та Knoll, це дозволяє здійснювати публікацію статтей
відразу після перекладу. Для цього потрібно натиснути кнопку «Завантажити»,
вибрати вкладку «стаття Вікіпедії» та ввести
посилання. Після перекладу виконати команду Файл - Опублікувати. Після цього у
новій вкладці з'явиться вікно з перекладеною статтею у Вікіпедії. Тут потрібно
ще раз підтвердити зберігання. Для того, щоб якість перекладу статтей була
високою, користувачам не дозволяється публікувати статті, де відсоток
перекладу, зроблений користувачем, складає менш ніж 50% [29].
Переклад відеороликів з YouTube
Для того, щоб перекласти відео, потрібно
виконати команду «Завантажити», перейти на вкладку «Відео YouTube» і вказати
посилання. Існують певні вимоги для перекладу роликів:
· Відео YouTube має бути доступне для
всіх або для тих, хто має посилання.
· Доріжка субтитрів у відео YouTube
має бути перекладена людиною, а не комп’ютером.
· Користувач повинен бути власником
відео YouTube, щоб отримувати та завантажувати його файл субтитрів для
перекладу.
Після завантаження в редактор програма матиме
наступний вигляд (рис. 4.2):
Рис. 4.2. Редактор субтитрів для відеороликів з Youtube
Відредагувавши файл субтитрів,
потрібно вибрати опцію «Файл - Процес - Опубліковано», або натиснути кнопку
«Опублікувати на YouTube». Після
цього перекладені субтитри будуть доступні всім користувачам цього сервісу.
Заповнювачі
Часто текст для перекладу містить
складні теги, що слугують для збереження оригінального форматування, які
небажано заміняти. Для того, щоб перекладач випадково не пошкодив їх вони
заміняються заповнювачами.
Наприклад, нам потрібно перекласти HTML
сторінку:<font
style="font-weight:bold" color="red">second</font>
word in this sentence is in bold and red.
У браузері вона виглядає так:second
word in this sentence is in bold and red.
При пошкодженні такого тега, формат,
а то і весь зміст речення буде спотворено, тому при використанні заповнювачів
текст буде виглядати наступним чином:{0}second{/0} word in this sentence is in
bold and red.
Існує два типи заповнювачів:
· окремі, які
відображаються у вигляді {n/},
де
n - порядковий номер
тега в сегменті.
· парні заповнювачі,
які складаються із відкриваючого {n}
та закриваючого {/n}.
Вони використовуються в основному для тегів HTML, наприклад при оформлені
посилань - <a href="#"656171.files/image004.gif">
Рис.
4.3. Вікно файлового менеджера Google Translator Toolkit.
У лівій частині вікна файлового
менеджера відображаються каталоги, у правій - їх вміст. Кнопка  дозволяє
виконати завантаження виділеного елемента, в нашому випадку це документ для
перекладу. В даному вікні можна керувати документами, налаштовувати умови
доступу для інших користувачів, тощо. Тут також є чат, за допомогою якого можна
зв’язатися з іншими людьми.
дозволяє
виконати завантаження виділеного елемента, в нашому випадку це документ для
перекладу. В даному вікні можна керувати документами, налаштовувати умови
доступу для інших користувачів, тощо. Тут також є чат, за допомогою якого можна
зв’язатися з іншими людьми.
Вікно текстового редактора
складається з робочого поля, поділеного на 2 частини - для тексту оригіналу та
перекладу, рядка меню та інструментів перекладача, які можна приховати. При
роботі користувач працює з одним сегментом, який виділений в обох частинах
робочого поля.
Рис. 4.4. Вікно текстового редактора
Google Translator Toolkit.
В інструментах показується
можливість вибору варіанту перекладу з ПП, або використання МП, причому
виводиться інформація про процент збігу, назву ПП, користувача та час
останнього редагування.
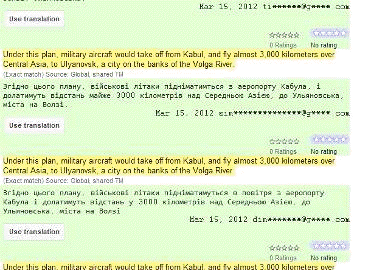
Рис. 4.5. Інструменти перекладу.
Для позначення сегментів сервіс
використовує такі кольори:
· зелений показує
переклад у контексті;
· синій позначає
сегменти зі 100% - м збігом;
· коричневий виділяє
сегменти з високим процентом збігу;
· червоний позначає
сегменти, які були перекладені за допомогою Google Translate;
· оранжевий демонструє відредагований
переклад;
· фіолетовий застосовується для
позначення сегментів з неправильними заповнювачами;
За бажанням кольори можна налаштовувати за
допомого меню «Вигляд».
Загалом інтерфейс системи Google
Translator Toolkit є простим у використанні, не вимагає спеціальних додаткових
знань для повноцінного використання, та забезпечує зручне та комфортне
Головними перевагами Google
Translator Toolkit є:
· доступ до системи з
будь-якого комп’ютера;
· простий та
зрозумілий інтерфейс;
· можливість
працювати у команді за рахунок надання доступу до документів, пам’яті
перекладів та словників термінів іншим користувачам;
· використовуючи
систему, користувачі допомагають розвиватися СМП Google Translate;
Недоліки системи проявляються у:
· неможливості
створювати проекти (GTT підтримує роботу лише з окремими документами);
· обмеженому використанні
ресурсу (розмір окремих документів не може перевищувати 1 Мб);
Розробники Google Translator Toolkit
стверджуюють, що головна мета проекту - зробити інформацію доступною для всіх
людей, використовуючи переклад. Система завоювала популярність серед людей, які
перекладають онлайн-енциклопедію Вікіпедія, для цього систему зробили сумісною
з Wiki-розміткою. Однак перекладачі-професіонали не поспішають відмовлятися від
використання платних систем АП. Це пояснюється тим, що GTT має меншу кількість
функцій, ніж його платні аналоги, не підтримує роботу з проектами, а також тим,
що однією з вимог прийняття на роботу в певній перекладацькій компанії є
володіння платною програмою автоматизованого перекладу.
.4 Порівняння системи Google
Translator Toolkit з його аналогами
Оскільки на ринку існує велика
кількість програмного забезпечення, яке здатне конкурувати з GTT, це дає нам
можливість для порівняння їх функцій, стабільності, тощо. В даному розділі ми
будемо порівнювати такі системи автоматизованого перекладу:
· Google Translator
Toolkit;
· OmegaT;
· Wordfast Pro та
його безкоштовну онлайн-версію Wordfast Anywhere;
· Déjà Vu
X2;
Критеріями оцінки даних програм
будуть:
· рівень простоти та
зручності при роботі з системою;
· стабільність роботи
програми;
· функціональність;
· інтеграція з іншими
програмними продуктами та сервісами;
· сумісність даних
для імпорту/експорту (ПП, проектів, словників термінів) з іншими програмами;
Оскільки інтерфейс програми Google
Translator Toolkit ми розглядали в попередньому розділі, не будемо на ньому
зациклюватися. Натомість проаналізуємо інші програми.
OmegaT
Головним завданням при використанні
OmegaT - створити проект і зберегти його в певний каталог. Всі файли: пам'ять
перекладів, термінологічна база, документи різними мовами - все зберігається в
одному проекті. Фактично у даній програмі немає поняття експорту/імпорту даних,
тому що для цього потрібно просто скопіювати файл з або в певну теку.
OmegaT
підтримує
наступні формати документів:
· Microsoft Office
2007 (.docx, .xlsx, .pptx)
· XHTML and HTML
· ODF
· PO
· IDML/TTX/XLIFF/TXML
На відміну від OmegaT, Wordfast має
більш логічно організований інтерфейс (додаток 14). На кожен компонент програми
існує місце в рядку меню, а в підменю розміщені операції, які можна виконувати
над даними об’єктами. Програма є досить простою у використанні, однак має дуже
багато функцій, які деколи важко знайти. Текстовий редактор можна налаштувати у
вигляді рядків з сегментами, розділеними спеціальними тегами, а також у вигляді
таблиці. Wordfast Anywhere є дуже схожою на попередні версії Wordfast, коли він
був реалізований у вигляді макросів для Microsoft Word (додаток 15).
Зовні Déjà
Vu X2 нагадує поєднання Wordfast Pro та OmegaT, однак
вона є трохи складнішою в організації роботи (додаток 13). Робоча область
складається з трьох частин - текстового редактора, провідника проекту та вікна
автопошуку фрагментів. Гарною особливістю
Déjà Vu X2 є те, що при
перекладі одиниць, що містяться в словнику термінів, програма «підказує» їх
користувачу. Ця програма дозволяє використовувати сервіси машинного перекладу
спрощення роботи користувача, однак необхідно мати ліцензійну версію.
Стабільність роботи систем
автоматизованого перекладу є запорукою успішної роботи перекладача. Google
Translator
Toolkit, Wordfast
Pro та Déjà Vu X2
мають гарні характеристики в цьому плані, однак при роботі з Wordfast Anywhere
можуть виникнути певні проблеми. Даний сервіс не використовує автоматичне
збереження документів як Google
Translator
Toolkit і часто
«підвисає», що може призвести до втрати даних. При роботі з OmegaT деколи
можуть буди неполадки з відображенням даних, чорні діалогові вікна (особливо з
операційною системою Windows 7 Ultimate x64). Wordfast
Pro також має певну
особливість: при повторному перекладі документа деякі сегменти можуть бути
відсутніми (рис. 4.6).
Рис. 4.6. Помилки при повторному
перекладі тексту у програмі Wordfast Pro
Усі системи в нашій вибірці мають
багатий функціонал. Розглянемо детальніше процес роботи з Google
Translator
Toolkit. Спочатку
для роботи потрібно завантажити документ, веб-сторінку, тощо. Далі система
використовує Google
Translatе для того,
щоб надати користувачу чорновий переклад, здійснений машиною. З цим перекладом
і працює людина, адаптуючи його під свої потреби. Програма автоматично зберігає
всі дані, які були змінені. Для роботи можна використовувати свою пам’ять
перекладів, словники, тощо. Google
Translator
Toolkit зберігає
перекладені сегменти на своїх серверах, тому при повторному перекладі тексту,
використовуючи інший обліковий запис, система дає результат 100% match. Після
збереження документа, переклад можна завантажити на жорсткий диск локального
комп’ютера, надати доступ іншим користувачам для перегляду чи редагування.
Корисною функцію даної системи є можливість додавання власних коментарів до
кожного сегменту перекладу, що дуже зручно при колективній роботі.
Однак сервіс Google
Translator
Toolkit не є
єдиним, що використовує машинний переклад як чорновий. В усіх інших програмах
також є можливість скористатися онлайн-системами МП. Зокрема, OmegaT та
Wordfast Pro дають можливість вибрати сервіс для перекладу, Déjà
Vu X2 використовує систему Google
Translate. Усі
програми з нашої вибірки мають багато функцій для кращої організації перекладу,
такі як пошук слів, автозаміна, пошук у словниках та базах перекладу, однак ці
функції не дуже часто використовуються.oogle
Translator
Toolkit
інтегрується багатьма іншими сервісами, такі як Google
Drive, що забезпечує
можливість співпраці з іншими користувачами, Wikipedia
та Google Knoll (наразі не працює), що дозволяє автоматично публікувати
перекладені статті, YouTube, що допомагає перекладати відеоролики на інші мови.
Серед програм з нашого списку жодна не має даної властивості.oogle
Translator
Toolkit підтримує
лише один формат пам’яті перекладів - *.tmx. Хоча даний формат є стандартним і
з яким найлегше працювати, інші програми не підтримують його. Взагалі, кожна
програма використовує лише власний формат пам’яті перекладів, тому імпортувати
ПП та глосарії між цими системами неможливо. Це пояснюється жорсткою
конкуренцією на ринку програмного забезпечення цього типу.
Висновки до розділу 4
Отже, щодо функціональності та
простоти роботи під час перекладу система Google Translator Toolkit не
поступається комерційним аналогам. Вона є зручною, стабільною та має
user-friendly інтерфейс. У цьому сервісі реалізовані як машинний, так і
автоматизований переклади. Система особлива тим, що вона інтегрована з іншими
відомими сервісами: Google Drive, Wikipedia,
Youtube. Це дозволяє виконувати переклад безпосередньо у «хмарі». До того ж,
система має глобальну ПП, яка містить двомовні сегменти, перекладені іншими
користувачами, що дозволяє суттєво спростити роботу. На жаль, сервіс не дуже
популярний серед професіоналів, його використовують переважно початківці та
ентузіасти, однак зараз існує тенденція переміщення програмного забезпечення з
локальних комп’ютерів в мережу, тому з часом кількість його користувачів
збільшиться.
ВИСНОВКИ
У період глобалізації суспільства в
iнформацiйнiй сфері сформувалася очевидна проблема збільшення попиту на
переклад науково-технічної, комерційної, ділової iнформацiї. Вiдповiддю на
соціальний запит подолання мовного бар’єру стало утворення галузі машинного
перекладу.
В основі підходу до вирішення
проблематики машинного перекладу має лежати певна класифiкацiя систем МП. Щодо
участі людини у процесі перекладу та обсягу роботи системи МП поділяються на
автоматизовані та автоматичні. В автоматизованих системах МП людина є
обов’язковим учасником процесу перекладу, в той час як в автоматичних системах
машина здійснює аналіз тексту оригіналу та синтез тексту перекладу, і сама
робить переклад у вигляді документу, котрий в певній мiрi може замінити
оригінал. Вiдповiдно до кiлькості мов, що їх “розуміє” система, розрізняють
двомовні та багатомовні системи. У залежності від підходу, на основі якого
виконується машинний переклад, СМП поділяються на статистичні (statistic)
та традиційні системи, які ґрунтуються на використанні лінгвістичних правил
(rule-based). У відповідності до лінгвістичного критерію СМП поділяються на
системи, що реалiзують прямий переклад (direct translation); системи, якi
базуються на трансферi (transfer approach); системи з мовою-посередником (interlingua
approach).
Системи прямого перекладу будуються
на використанні великих словників i порівняно простих алгоритмів
морфологiчно-синтаксичного аналізу тексту-оригіналу i синтезу текста-перекладу.
Ідея трансферу - впровадження в систему блока перетворення структури вхідного
тексту у вiдповiдностi з правилами і нормами мови перекладу. Головна ідея
систем з мовою-посередником - аналіз змісту тексту та його подання на
спецiальнiй мовi, яка не залежить від будь-якої природної мови.
На сьогоднішній день найбільш
відомими системами, які здатні перекладати тексти з англійської на українську
мову є Google Translate, Pragma Online,
Bing Translator.
Всі вони
використовують статистичний підхід до перекладу.
Поряд із системами машинного
перекладу також існують програми автоматизованого перекладу. Їхнє основне
завдання - допомагати користувачу організувати процес перекладу. Принцип їх
роботи базується на використанні попередніх перекладів, які зберігаються в
двомовній базі даних - пам’яті перекладів. Найвідомішими представниками програм
цього типу є Google Translator Toolkit, Wordfast Pro, SDL Trados, OmegaT та
інші. У нашій роботі ми займалися вивченням особливостей використання системи
Google Translator Toolkit і виявили, що попри свою простоту у використанні, сервіс
є досить потужним засобом перекладу, який підтримує всі основні файлові
формати, чорновий переклад за допомогою Google Translate, інтеграцію з відомими
онлайн сервісами, такими як Вікіпедія, Google
Knoll, YouTube,
AdWords. Система
забезпечує збереження та обмін документів, дозволяє використовувати глобальну
пам’ять перекладів, не потребує встановлення якихось додаткових компонентів. І
хоча зараз вона не є популярною серед професіоналів, з часом її використання
збільшиться.
автоматичний переклад
translator онлайн
СПИСОК ВИКОРИСТАНИХ ДЖЕРЕЛ
1. Ahmad K. and Kugler.
M. The Translator's Workbench: Tools & Terminology for Translation &
Text Preprocessing in Europe. 04/1996 Springer-Verlag
New York, Vol. 1. - 185p.
2. Basic translation/ E.
Miram, E., Daineko, Gon, A. et al. : N. Breshko, Ed. - Kyiv: Elga, 2006.
. Brown, P.F., Cocke, J.
, Della Pietra, S. A., Della Pietra, V. J., Jelinek, F. , Lafferty, J.D.,
Mercer, R.L., Roossin, P. S. A Statistical Approach to Machine Translation. //
Computational Linguistics. - 1990. - Vol. 16. - No. 2.
4. Farwell D. Wilks. Y. ULTRA:
A Multilingual Machine Translator. Proceedings of the
Machine Translation Summit III, 1991.
. Garcia, I.; Stevenson,
V. "Google Translator Toolkit. Free web-based translation memory for the
masses". Multilingual (September 2009).
- P.16-19.
. Hutchins, W.J.,
Somers, H. An Introduction to Machine Translation. - L.: Academic Press, 1992
7. Hutchins J., The
origins of the translator’s workstation. // Machine Translation, 13, 1998.
8. Koehn, P., Och, F.J.,
Marcu, D. Statistical phrase-based translation. // Proceedings of the Human
Language Technology and North American Association for Computational
Linguistics Conference. - Edmonton, 2003.
. Lawson V. Aslib
Proceedings 46(3), Aslib, March 1994 - No. 92.
. Nirenburg S., Raskin
V., Tucker A. "The Structure of Interlingua in TRANSLATOR" in Machine
Translation: Theoretical and Methodological Issues, Sergei Nirenburg, ed. NY:
Cambridge University Press. 1987.
12. Бельская, И.К. Язык человека
и машина / И.К. Бельская. - М.: Эксмо, 1969. - 135 с.
13. Беляева, Л.Н.,
Откупщикова М.И. Автоматический (машинный) перевод / Л.Н. Беляева, М.И.
Откупщикова. - СПб: Прикладное языкознание, 1996. - 334 c.
14. Блехман М.С. Машинный
перевод: история и реалии // Компьютерное обозрение. - 1996. - №5(29).
. Блехман М.С.
“Комп’ютерна лiнгвiстика”, монографія. - Харкiв:
ХГУ.
- 1997. - 153 с.
. Винокуров А.А.,
Чуканов
В. О.
Новый
метод оценки машинного перевода.// Информационные технологии и системы.
Hardware Software Security. Тенденции и перспективы - Сборник статей: М.,
Международная академия информатизации, 1997.
. Грабовский В. Н.
Технология Translation Memory // Мосты. Журнал переводчиков. 2004. № 2.
. Дарчук Н П.
Комп’ютерна лінгвістика: Підручник. - К. КНУ, 2008
. Кулагина О.С. О
современном состоянии машинного перевода // Математические вопросы кибернетики,
вып. 3, М.: Наука, 1991.
. Марчук, Ю.Н. Проблемы
машинного перевода/ Ю.Н. Марчук. - М.: изд-во, 1983. - 140 с.
. Нелюбин, Л.Л.
Компьютерная лингвистика и машинный перевод/ Л.Л. Нелюбин. - М.: изд-во, 1991.
. Ткачук В., Чумак Г.
Теорія і практика машинного перекладу: Навчальний посібник. - Тернопіль, 2006.
. Шахова, Н. Г. Что
могут программы машинного перевода? / Н. Г. Шахова // Мосты. - 2004. - № 4.
Інтернет-ресурси
24. Alan Wheatley. A Major
Breakthrough for Translator Training. - Режим доступу:. - Globalization Insider
XII/2.4, eCoLoRe (eContent Localization Resources for Translator Training)
25. Déjà Vu X2
Professional.
26. Finetext. The
Translation Company. Машинний переклад. - Режим
доступу: #"656171.files/image009.gif">
ДОДАТОК № 12
Головне вікно Google Translator
Toolkit.
Текстовий редактор в Google
Translator Toolkit
ДОДАТОК № 13
Головне вікно програми Déjà
Vu X2
ДОДАТОК № 14
Головне вікно програми Wordfast Pro
ДОДАТОК № 15
Робоча область
програми Wordfast Anywhere