[1] <#"655942.files/image008.gif">
Описание
алгоритма
информация шифр криптографический алгоритм
Термины и обозначения.
Описание стандарта шифрования Российской Федерации содержится в очень
интересном документе, озаглавленном «Алгоритм криптографического преобразования
ГОСТ 28147-89» [1]. То, что в его названии вместо термина «шифрование»
фигурирует более общее понятие « криптографическое преобразование »,
вовсе не случайно. Помимо нескольких тесно связанных между собой процедур шифрования,
в документе описан один построенный на общих принципах с ними алгоритм
выработки имитовставки. Последняя является не чем иным,
как криптографической контрольной комбинацией, то есть кодом, вырабатываемым из
исходных данных с использованием секретного ключа с целью имитозащиты,
или защиты данных от внесения в них несанкционированных изменений.
На различных шагах алгоритмов ГОСТа данные, которыми они оперируют,
интерпретируются и используются различным образом. В некоторых случаях элементы
данных обрабатываются как массивы независимых битов, в других случаях - как
целое число без знака, в третьих - как имеющий структуру сложный элемент,
состоящий из нескольких более простых элементов. Поэтому во избежание путаницы
следует договориться об используемых обозначениях.
Элементы данных в данной статье обозначаются заглавными латинскими
буквами с наклонным начертанием (например, X). Через |X|
обозначается размер элемента данных X в битах. Таким образом, если
интерпретировать элемент данных X как целое неотрицательное число, можно
записать следующее неравенство: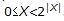 .
.
Если элемент данных состоит из нескольких элементов меньшего размера, то
этот факт обозначается следующим образом: X=(X 0,X
1,…,Xn -1)=X 0||X
1||…||Xn -1. Процедура объединения
нескольких элементов данных в один называется конкатенацией данных
и обозначается символом «||». Естественно, для размеров элементов данных должно
выполняться следующее соотношение: |X|=|X 0|+|X
1|+…+|Xn -1|. При задании сложных
элементов данных и операции конкатенации составляющие элементы данных
перечисляются в порядке возрастания старшинства. Иными словами, если
интерпретировать составной элемент и все входящие в него элементы данных как
целые числа без знака, то можно записать следующее равенство:
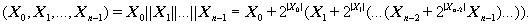
В алгоритме элемент данных может интерпретироваться как массив отдельных
битов, в этом случае биты обозначаем той же самой буквой, что и массив, но в
строчном варианте, как показано на следующем примере:
X=(x 0,x 1,…,xn -1)=x
0+21·x 1+…+2 n-1·xn
-1.
Таким образом, если вы обратили внимание, для ГОСТа принята т.н.
«little-endian» нумерация разрядов, т.е. внутри многоразрядных слов данных
отдельные двоичные разряды и их группы с меньшими номерами являются менее
значимыми. Об этом прямо говорится в пункте 1.3 стандарта: «При сложении и
циклическом сдвиге двоичных векторов старшими разрядами считаются разряды
накопителей с большими номерами». Далее, пункты стандарта 1.4, 2.1.1 и другие
предписывают начинать заполнение данными регистров-накопителей виртуального
шифрующего устройства с младших, т.е. менее значимых разрядов. Точно такой же
порядок нумерации принят в микропроцессорной архитектуре Intel x86, именно
поэтому при программной реализации шифра на данной архитектуре никаких
дополнительных перестановок разрядов внутри слов данных не требуется.
Если над элементами данных выполняется некоторая операция, имеющая
логический смысл, то предполагается, что данная операция выполняется над
соответствующими битами элементов. Иными словами A•B=(a 0•b
0,a 1•b 1,…,an -1•bn
-1), где n=|A|=|B|, а символом «•»
обозначается произвольная бинарная логическая операция; как правило, имеется в
виду операция исключающего или, она же - операция
суммирования по модулю2:
Логика построения шифра и структура ключевой информации
ГОСТа.
Если внимательно изучить оригинал ГОСТ 28147-89, можно заметить, что в
нем содержится описание алгоритмов нескольких уровней. На самом верхнем
находятся практические алгоритмы, предназначенные для шифрования массивов
данных и выработки для них имитовставки. Все они опираются на три алгоритма
низшего уровня, называемые в тексте ГОСТа циклами. Эти
фундаментальные алгоритмы упоминаются в данной статье как базовые циклы,
чтобы отличать их от всех прочих циклов. Они имеют следующие названия и
обозначения, последние приведены в скобках и смысл их будет объяснен позже:
§ цикл зашифрования (32-З);
§ цикл расшифрования (32-Р);
§ цикл выработки имитовставки (16-З).
В свою очередь, каждый из базовых циклов представляет собой многократное
повторение одной единственной процедуры, называемой для определенности далее в
настоящей работе основным шагом криптопреобразования.
Таким образом, чтобы разобраться в ГОСТе, надо понять три следующие вещи:
§ что такое основной шаг криптопреобразования;
§ как из основных шагов складываются базовые циклы;
§ как из трех базовых циклов складываются
все практические алгоритмы ГОСТа.
Прежде чем перейти к изучению этих вопросов, следует поговорить о
ключевой информации, используемой алгоритмами ГОСТа. В соответствии с принципом
Кирхгофа, которому удовлетворяют все современные известные широкой
общественности шифры, именно ее секретность обеспечивает секретность
зашифрованного сообщения. В ГОСТе ключевая информация состоит из двух структур
данных. Помимо собственно ключа, необходимого для всех
шифров, она содержит еще и таблицу замен. Ниже приведены
основные характеристики ключевых структур ГОСТа.
§ Ключ является
массивом из восьми 32-битовых элементов кода, далее в настоящей работе он
обозначается символом K: В ГОСТе элементы ключа используются как
32-разрядные целые числа без знака: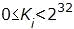 . Таким образом, размер ключа
составляет 32·8=256 бит или 32 байта.
. Таким образом, размер ключа
составляет 32·8=256 бит или 32 байта.
§ Таблица замен является
вектором, содержащим восемь узлов замены. Каждый узел
замены, в свою очередь, является вектором, содержащим шестнадцать 4-битовых
элементов замены, которые можно представить в виде целых чисел от 0 до 15, все
элементы одного узла замены обязаны быть различными. Таким образом, таблица
замен может быть представлена в виде матрицы размера 8x16 или 16x8, содержащей
4-битовые заменяющие значения. Для языков программирования, в которых двумерные
массивы расположены в оперативной памяти по строкам, естественным является
первый вариант (8x16), его-то мы и возьмем за основу. Тогда узлы замены будут
строками таблицы замен. В настоящей статье таблица замен обозначается символом H:.
Таким образом, общий объем таблицы замен равен: 8 узлов x 16 элементов/узел x 4
бита/элемент = 512 бит = 64 байта.
Основной шаг криптопреобразования.
Основной шаг криптопреобразования по своей сути является оператором,
определяющим преобразование 64-битового блока данных. Дополнительным параметром
этого оператора является 32-битовый блок, в качестве которого используется
какой-либо элемент ключа. Схема алгоритма основного шага приведена на рисунке
1.
Шаг 0
Определяет исходные данные для основного шага криптопреобразования:
§ N
- преобразуемый 64-битовый блок данных, в ходе выполнения шага его младшая (N
1) и старшая (N 2) части обрабатываются как
отдельные 32-битовые целые числа без знака. Таким образом, можно записать N=(N1,N2).
§ X
- 32-битовый элемент ключа;
Шаг 1
Сложение с ключом. Младшая половина преобразуемого блока складывается по
модулю 232 с используемым на шаге элементом ключа, результат
передается на следующий шаг;
Шаг 2
Поблочная замена. 32-битовое значение, полученное на предыдущем шаге,
интерпретируется как массив из восьми 4-битовых блоков кода: S=(S
0, S 1, S 2, S 3,
S 4, S 5, S 6, S 7),
причем S 0содержит 4 самых младших, а S 7 -
4 самых старших бита S.
Далее значение каждого из восьми блоков заменяется новым, которое
выбирается по таблице замен следующим образом: значение блока Si меняется
на Si-тый по порядку элемент (нумерация с нуля) i-того
узла замены (т.е. i-той строки таблицы замен, нумерация также с нуля).
Другими словами, в качестве замены для значения блока выбирается элемент из
таблицы замен с номером строки, равным номеру заменяемого блока, и номером
столбца, равным значению заменяемого блока как 4-битового целого
неотрицательного числа. Отсюда становится понятным размер таблицы замен: число
строк в ней равно числу 4-битовых элементов в 32-битовом блоке данных, то есть
восьми, а число столбцов равно числу различных значений 4-битового блока
данных, равному как известно 24, шестнадцати.
Шаг 3
Циклический сдвиг на 11 бит влево. Результат предыдущего шага сдвигается
циклически на 11 бит в сторону старших разрядов и передается на следующий шаг.
На схеме алгоритма символом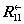 обозначена функция циклического сдвига своего аргумента на
11 бит влево, т.е. в сторону старших разрядов.
обозначена функция циклического сдвига своего аргумента на
11 бит влево, т.е. в сторону старших разрядов.
Шаг 4
Побитовое сложение: значение, полученное на шаге 3, побитно складывается
по модулю 2 со старшей половиной преобразуемого блока.
Шаг 5
Сдвиг по цепочке: младшая часть преобразуемого блока сдвигается на место
старшей, а на ее место помещается результат выполнения предыдущего шага.
Шаг 6
Полученное значение преобразуемого блока возвращается как результат
выполнения алгоритма основного шага криптопреобразования.
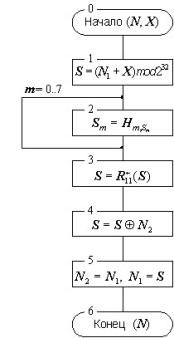
Рис. 1.
Базовые циклы криптографических преобразований.
Как отмечено в начале настоящей статьи, ГОСТ относится к классу блочных
шифров, то есть единицей обработки информации в нем является блок данных.
Следовательно, вполне логично ожидать, что в нем будут определены алгоритмы для
криптографических преобразований, то есть для зашифрования, расшифрования и
«учета» в контрольной комбинации одного блока данных. Именно эти алгоритмы и
называются базовыми циклами ГОСТа, что подчеркивает их
фундаментальное значение для построения этого шифра.
Базовые циклы построены из основных шагов криптографического
преобразования, рассмотренного в предыдущем разделе. В процессе выполнения
основного шага используется только один 32-битовый элемент ключа, в то время
как ключ ГОСТа содержит восемь таких элементов. Следовательно, чтобы ключ был
использован полностью, каждый из базовых циклов должен многократно выполнять
основной шаг с различными его элементами. Вместе с тем кажется вполне
естественным, что в каждом базовом цикле все элементы ключа должны быть
использованы одинаковое число раз, по соображениям стойкости шифра это число
должно быть больше одного.
Все сделанные выше предположения, опирающиеся просто на здравый смысл,
оказались верными. Базовые циклы заключаются в многократном выполнении основного
шага с использованием разных элементов ключа и отличаются друг
от друга только числом повторения шага и порядком использования ключевых
элементов. Ниже приведен этот порядок для различных циклов.
Цикл зашифрования 32-З:
0,K 1,K 2,K 3,K
4,K 5,K 6,K 7,K
0,K 1,K 2,K 3,K
4,K 5,K 6,K 7,K
0,K 1,K 2,K 3,K
4,K 5,K 6,K 7,K
7,K 6,K 5,K 4,K
3,K 2,K 1,K 0.
Цикл расшифрования 32-Р:
0,K 1,K 2,K 3,K
4,K 5,K 6,K 7,K
7,K 6,K 5,K 4,K
3,K 2,K 1,K 0,K
7,K 6,K 5,K 4,K
3,K 2,K 1,K 0,K
7,K 6,K 5,K 4,K
3,K 2,K 1,K 0.
Зашифрование в данном режиме заключается в применении цикла 32-З к блокам
открытых данных, расшифрование - цикла 32-Р к блокам зашифрованных данных. Это
наиболее простой из режимов, 64-битовые блоки данных обрабатываются в нем
независимо друг от друга. Схемы алгоритмов зашифрования и расшифрования в
режиме простой замены приведены на рисунках 3а и б соответственно, они
тривиальны и не нуждаются в комментариях.
Размер массива открытых или зашифрованных данных, подвергающийся
соответственно зашифрованию или расшифрованию, должен быть кратен 64 битам: |
T о|=| T ш|=64· n,
после выполнения операции размер полученного массива данных не изменяется.
Режим шифрования простой заменой имеет следующие особенности:
§ Так как блоки данных шифруются независимо друг от друга и от
их позиции в массиве данных, при зашифровании двух одинаковых блоков открытого
текста получаются одинаковые блоки шифртекста и наоборот. Отмеченное свойство
позволит криптоаналитику сделать заключение о тождественности блоков исходных
данных, если в массиве зашифрованных данных ему встретились идентичные блоки,
что является недопустимым для серьезного шифра.
§ Если длина шифруемого массива данных не кратна 8 байтам или
64 битам, возникает проблема, чем и как дополнять последний неполный блок
данных массива до полных 64 бит. Эта задача не так проста, как кажется на
первый взгляд. Очевидные решения типа «дополнить неполный блок нулевыми битами»
или, более обще, «дополнить неполный блок фиксированной комбинацией нулевых и
единичных битов» могут при определенных условиях дать в руки криптоаналитика
возможность методами перебора определить содержимое этого самого неполного
блока, и этот факт означает снижение стойкости шифра. Кроме того, длина
шифртекста при этом изменится, увеличившись до ближайшего целого, кратного 64
битам, что часто бывает нежелательным.
На первый взгляд, перечисленные выше особенности делают практически
невозможным использование режима простой замены, ведь он может применяться
только для шифрования массивов данных с размером кратным 64 битам, не
содержащим повторяющихся 64-битовых блоков. Кажется, что для любых реальных
данных гарантировать выполнение указанных условий невозможно. Это почти так, но
есть одно очень важное исключение: вспомните, что размер ключа составляет 32
байта, а размер таблицы замен - 64 байта. Кроме того, наличие повторяющихся
8-байтовых блоков в ключе или таблице замен будет говорить об их весьма плохом
качестве, поэтому в реальных ключевых элементах такого повторения быть не
может. Таким образом, мы выяснили, что режим простой замены вполне подходит для
шифрования ключевой информации, тем более, что прочие режимы для этой цели
менее удобны, поскольку требуют наличия дополнительного синхронизирующего
элемента данных - синхропосылки (см. следующий раздел). Наша догадка верна,
ГОСТ предписывает использовать режим простой замены исключительно для
шифрования ключевых данных.
Реализация
Класс BytesChopper, применяющийся для расщепления
байтовых и строковых последовательностей на блоки по 64 бита:
public class BytesChopper
{byte[] _bytesToChop;byte[][]
_outerBytesContainer;int BlocksCount
{;set;
}BytesChopper(string innerString)
{
_bytesToChop = Encoding.Default.GetBytes(innerString);();
}BytesChopper(byte[] bytes)
{
_bytesToChop = bytes;();
}byte[] Get(int packageNumber)
{_outerBytesContainer[packageNumber];
}void MakeChopping()
{(_bytesToChop.Length%8!=0) throw new
ArgumentException("Wrong inner line length,%64!=0");partitions =
Convert.ToInt32(Math.Ceiling((double)_bytesToChop. Count() / 8));
_outerBytesContainer = new
byte[partitions][];(int i = 0; i < partitions; i++)
{
_outerBytesContainer[i] = ChopBytes(i);
}= partitions;
}byte[] ChopBytes(int numOfChunk)
{[] buf = new byte[8];length =
(byte)Math.Min(8, _bytesToChop.Length - numOfChunk * 8);i;(i = 0; i <
length; i++)
{[i] = _bytesToChop[numOfChunk * 8 + i];
}
return buf;
}
}
Класс BitWorker для работы с битами внутри байтов и
уинтов:
public static class BitWorker
{
///<summary>
/// Возвращает бит в num байте val
///</summary>
///<param name="val">Входной байт</param>
///<param name="num">Номер
бита, начиная с 0</param>
///<returns>true-бит равен 1,
false- бит равен
0</returns>static bool GetBit(byte val, int num)
{
if ((num > 7) || (num < 0))//Проверка
входных данных
{
throw new ArgumentException();
}
return ((val >> num) & 1) >
0;//собственно все вычисления
}static bool GetBit(uint val, int num)
{((num > 31) || (num < 0))//Проверка входных
данных
{
throw new ArgumentException();
}
return ((val >> num) & 1) >
0;//собственно все вычисления
}
///<summary>
/// Устанавливает значение определенного бита в байте
///</summary>
///<param name="val">Входной байт</param>
///<param name="num">Номер бита</param>
///<param name="bit">Значение бита: true-бит равен 1,
false- бит равен 0
</param>
///<returns>Байт, с измененным значением
бита</returns>
public static byte SetBit(byte val, int num,
bool bit)
{((num > 7) || (num < 0))//Проверка входных данных
{new ArgumentException();
}tmpval = 1;
tmpval = (byte)(tmpval << num);//устанавливаем
нужный бит в единицу= (byte)(val & (~tmpval));//сбрасываем в 0 нужный
бит(bit)// если бит требуется установить в 1
{= (byte)(val | (tmpval));//то устанавливаем нужный бит
в 1
}val;
}static uint SetBit(uint val, int num, bool
bit)
{((num > 31) || (num < 0))//Проверка входных
данных
{new ArgumentException();
}tmpval = 1;
tmpval = (uint)(tmpval << num);//устанавливаем
нужный бит в единицу= (uint)(val & (~tmpval));//сбрасываем в 0 нужный бит(bit)//
если бит требуется установить в 1
{= (uint)(val | (tmpval));//то устанавливаем нужный бит
в 1
}val;
}
///<summary>
/// Изменяет порядок битов на обратный
///</summary>
///<param name="val">Входнойбайт</param>
///<returns>Байт с обратным порядком
битов</returns>
public static byte Reverse(byte val)
{i = 0;rez = 0;(i = 0; i < 8; i++)
{= (byte)(rez << 1);(((val >> i)
& 1) > 0)
{= (byte)(rez | 1);
}
}rez;
}static uint Reverse(uint val)
{i = 0;rez = 0;(i = 0; i < 32; i++)
{= rez << 1;(((val >> i) &
1) > 0)
{= rez | 1;
}
}rez;
}
}
Класс Key для хранения ключа.
public class Key
{readonly byte[] KeyBytes;readonly string
KeyString;
// ReSharper disable once
UnassignedReadonlyFieldreadonly uint[] KeyUints;Key(string key)
{(key.Length!=64) throw new
ArgumentException("Wrong key string length, key must have 64 letters, its
32 bytes, its 256 bits");= key;= new byte[32];= new uint[8];[] buf =
MathBlock.FromHex(key);(int i = 0; i < buf.Length; i++)
{[i] = buf[i];
}();
}
// ReSharper disable once
RedundantAssignmentvoid FillKeyUints()
{[0] =
MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[31]),
BitWorker.Reverse(KeyBytes[30]), BitWorker.Reverse (KeyBytes[29]),
BitWorker.Reverse(KeyBytes[28]));[1] = MathBlock.FourBytesToUint(BitWorker.Reverse
(KeyBytes[27]), BitWorker.Reverse(KeyBytes[26]), BitWorker.Reverse
(KeyBytes[25]), BitWorker.Reverse(KeyBytes[24]));[2] =
MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[23]),
BitWorker.Reverse(KeyBytes[22]), BitWorker.Reverse (KeyBytes[21]),
BitWorker.Reverse(KeyBytes[20]));[3] =
MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[19]),
BitWorker.Reverse(KeyBytes[18]), BitWorker.Reverse (KeyBytes[17]),
BitWorker.Reverse(KeyBytes[16]));[4] = MathBlock.FourBytesToUint(BitWorker.Reverse
(KeyBytes[15]), BitWorker.Reverse(KeyBytes[14]), BitWorker.Reverse
(KeyBytes[13]), BitWorker.Reverse(KeyBytes[12]));[5] =
MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[11]),
BitWorker.Reverse(KeyBytes[10]), BitWorker.Reverse (KeyBytes[9]), BitWorker.Reverse(KeyBytes[8]));[6]
= MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[7]),
BitWorker.Reverse(KeyBytes[6]), BitWorker.Reverse (KeyBytes[5]),
BitWorker.Reverse(KeyBytes[4]));[7] =
MathBlock.FourBytesToUint(BitWorker.Reverse (KeyBytes[3]), BitWorker.Reverse(KeyBytes[2]),
BitWorker.Reverse (KeyBytes[1]), BitWorker.Reverse(KeyBytes[0]));
}
}
Класс MathBlock для математических операций:
public static class MathBlock
{static uint FourBytesToUint(byte first,
byte second, byte third, byte fourth)
{ShiftLeft(first, 24) + ShiftLeft(second,
16) + ShiftLeft(third, 8) + fourth;
}static byte[] UintToByteArray(uint
innerUint)
{BitConverter.GetBytes(innerUint);
}static uint RotateLeft(uint value, int
count)
{bitsize = sizeof(uint) * 8;
// Вырезаем старшие n битhi =
(uint)((value >> (bitsize - count)) & ((1 << count) - 1));
// Сдвигаем аргумент на n бит влево, при этом младшая
часть заполнится
// нулями, а потому or'ом записываем туда вырезанную
старшую часть
return (value << count) | hi;
}static byte RotateLeft(byte value, int
count)
{bitsize = sizeof(byte) * 8;
// Вырезаем старшие n битhi =
(byte)((value >> (bitsize - count)) & ((1 << count) - 1));
// Сдвигаем аргумент на n бит влево, при этом младшая
часть заполнится
// нулями, а потому or'ом записываем туда вырезанную
старшую часть
return (byte)((value << count) | hi);
}static uint ShiftLeft(uint innerUint, int
position)
{innerUint << position;
}static uint ShiftLeft(byte byteToShift, int
position)
{(uint)(byteToShift) << position;
}static uint AddMod(uint firstUint, uint
secondUint, int pow)
{Mod((firstUint + secondUint), pow);
}static uint Xor(uint firstUint, uint
secondUint)
{firstUint ^ secondUint;
}static uint Mod(uint innerUint, int pow)
{(uint)(innerUint% (long)Math.Pow(2, pow));
}static string ToHex(byte[] input)
{hexOutput = "";(byte letter in
input)
{value = Convert.ToInt32(letter);+=
string.Format("{0:X}", value);(value == 0) hexOutput +=
string.Format("{0:X}", value);
}hexOutput.ToLower();
}static byte[] FromHex(string input)
{= input.ToLower();(input.Length%2 != 0)
input = '0' + input;length = input.Length / 2;[] answer = new
byte[length];buf;(int i = 0; i < length; i++)
{= input.Substring(i * 2, 2);value =
Convert.ToByte(buf, 16);[i] = value;
}answer;
}
}
Класс SBlock для хранения таблицы замен:
public class SBlock
{
//[Stroka, stolbec]readonly static byte[,]
Bytes =
{
{4, 10, 9, 2, 13, 8, 0, 14, 6, 11, 1, 12, 7,
15, 5, 3},
{14,11, 4, 12, 6, 13, 15, 10, 2, 3, 8, 1, 0,
7, 5, 9},
{5, 8, 1, 13, 10, 3, 4, 2, 14, 15, 12, 7, 6,
0, 9, 11},
{7, 13, 10, 1, 0, 8, 9, 15, 14, 4, 6, 12,
11, 2, 5, 3},
{6, 12, 7, 1, 5, 15, 13, 8, 4, 10, 9, 14, 0,
3, 11, 2},
{4, 11, 10, 0, 7, 2, 1, 13, 3, 6, 8, 5, 9,
12, 15, 14},
{13,11, 4, 1, 3, 15, 5, 9, 0, 10, 14, 7, 6,
8, 2, 12},
};
}
Абстрактный класс EncryptionTemplateMethod и его реализации Encoder и
Decoder, выполняющие основную работу по шифрации-дешифрации. Использован паттерн TemplateMethod для метода PrepareKeys(string key):
internal abstract class
EncryptionTemplateMethod
{uint[] N;uint[] Keys;uint
OperationsBuffer;uint[] State
{{ return N; }
}EncryptionTemplateMethod(string key)
{= new uint[2];= new uint[32];(key);
}
//Template method will be implemented in
Encoder and Decoder realisationabstract void PrepareKeys(string key);void
PrepareRegisters(byte[] innerBytes)
{(innerBytes.Length != 8) throw new
ArgumentException("Partition must be 8 bytes long");[0] =
MathBlock.FourBytesToUint(innerBytes[3], innerBytes[2], innerBytes[1],
innerBytes[0]);[1] = MathBlock.FourBytesToUint(innerBytes[7], innerBytes[6],
innerBytes[5], innerBytes[4]);
}void Process(byte[] innerBytes)
{(innerBytes);
for (int i = 0; i < 32; i++)
{(i);
}
}void Round(int number)
{(Keys[number]);();();();(number);.WriteLine(number+
": "+N[0]+ " | " + N[1]);
}
//step 1void AddKey(uint key)
{= MathBlock.AddMod(N[0], key, 32);
}
//step 2void SwapBlocks()
{[] block =
SplitUintToFourBitsArray(OperationsBuffer);(block);= AgglutinateBytes(block);
}byte[] SplitUintToFourBitsArray(uint
innerUint)
{i, j;[] buffer = new byte[8];(i = 0; i <
8; i++)
{(j = 0; j < 4; j++)
{.SetBit(buffer[i], j,
BitWorker.GetBit(innerUint, i * 4 + j));
}
}buffer;
}byte[] SwapBytes(byte[] innerBytes)
{i;length = innerBytes.Length;(i = 0; i <
length; i++)
{[i] = SBlock.Bytes[i, innerBytes[i]];
}innerBytes;
}uint AgglutinateBytes(byte[] innerBytes)
{buf = 0;i, j;bit;(i = 0; i < 8; i++)
{(j = 0; j < 4; j++)
{= BitWorker.GetBit(innerBytes[i], j);
buf = BitWorker.SetBit(buf, j + i * 4, bit);
}
}buf;
}
//step 3void RotateBufferLeft()
{= MathBlock.RotateLeft(OperationsBuffer,
11);
}
//step 4void XOROperation()
{= MathBlock.Xor(OperationsBuffer, N[1]);
}
//step 5void ExchangeRegisters(int number)
{(number < 31)
{[1] = N[0];[0] = OperationsBuffer;
}
{[1] = OperationsBuffer;
}
}
}
internal class Encoder :
EncryptionTemplateMethod
{Encoder(string key) : base(key)
{
}override void PrepareKeys(string key)
{k = new Key(key);[0] = k.KeyUints[0];[1] =
k.KeyUints[1];[2] = k.KeyUints[2];[3] = k.KeyUints[3];[4] = k.KeyUints[4];[5] =
k.KeyUints[5];[6] = k.KeyUints[6];[7] = k.KeyUints[7];[8] = k.KeyUints[0];[9] =
k.KeyUints[1];[10] = k.KeyUints[2];[11] = k.KeyUints[3];[12] =
k.KeyUints[4];[13] = k.KeyUints[5];[14] = k.KeyUints[6];[15] = k.KeyUints[7];[16]
= k.KeyUints[0];[17] = k.KeyUints[1];[18] = k.KeyUints[2];[19] =
k.KeyUints[3];[20] = k.KeyUints[4];[21] = k.KeyUints[5];[22] =
k.KeyUints[6];[23] = k.KeyUints[7];[24] = k.KeyUints[7];[25] =
k.KeyUints[6];[26] = k.KeyUints[5];[27] = k.KeyUints[4];[28] =
k.KeyUints[3];[29] = k.KeyUints[2];[30] = k.KeyUints[1];[31] = k.KeyUints[0];
}
}
internal class Decoder :
EncryptionTemplateMethod
{Decoder(string key) : base(key)
{
}override void PrepareKeys(string key)
{k = new Key(key);[0] = k.KeyUints[0];[1] =
k.KeyUints[1];[2] = k.KeyUints[2];[3] = k.KeyUints[3];[4] = k.KeyUints[4];[5] =
k.KeyUints[5];[6] = k.KeyUints[6];[7] = k.KeyUints[7];[8] = k.KeyUints[7];[9] =
k.KeyUints[6];[10] = k.KeyUints[5];[11] = k.KeyUints[4];[12] = k.KeyUints[3];[13]
= k.KeyUints[2];[14] = k.KeyUints[1];[15] = k.KeyUints[0];[16] =
k.KeyUints[7];[17] = k.KeyUints[6];[18] = k.KeyUints[5];[19] =
k.KeyUints[4];[20] = k.KeyUints[3];[21] = k.KeyUints[2];[22] =
k.KeyUints[1];[23] = k.KeyUints[0];[24] = k.KeyUints[7];[25] =
k.KeyUints[6];[26] = k.KeyUints[5];[27] = k.KeyUints[4];[28] =
k.KeyUints[3];[29] = k.KeyUints[2];[30] = k.KeyUints[1];[31] = k.KeyUints[0];
}
}
Статический класс GostEncoder - обертка для наших классов энкодера и декодера:
public static class GostEncoder
{static byte[] resultBytes;static byte[]
Encode(string line, string key)
{chopper = new BytesChopper(line);encoder =
new Encoder(key);i, count = chopper.BlocksCount;= new byte[count * 8];[]
innerBytes;(i = 0; i < count; i++)
{= chopper.Get(i);.Process(innerBytes);[]
encodedbytes = GetEncodedBytes(encoder);(encodedbytes, i);
}resultBytes;
}void AddToResult(byte[] bytes, int
chunkNumber)
{i, count = bytes.Length;(i = 0; i <
count; i++)
{[chunkNumber*8 + i] = bytes[i];
}
}byte[] GetEncodedBytes(EncryptionTemplateMethod
encoderdecoder)
{[] N0 =
MathBlock.UintToByteArray(BitWorker.Reverse (encoderdecoder.State[0]));[] N1 =
MathBlock.UintToByteArray(BitWorker.Reverse (encoderdecoder.State[1]));
byte[] resultBytes = new byte[8];i;(i = 0; i
< 4; i++)
{[i] = N0[i];
resultBytes[4 + i] = N1[i];
}resultBytes;
}static string Decode(byte[] encryptedBytes,
string key)
{chopper = new
BytesChopper(encryptedBytes);decoder = new Decoder(key);i, count =
chopper.BlocksCount;= new byte[count * 8];[] innerBytes;(i = 0; i < count;
i++)
{= chopper.Get(i);.Process(innerBytes);[]
encodedBytes = GetEncodedBytes(decoder);(encodedBytes, i);
}Encoding.Default.GetString(resultBytes);
}
}
Класс тестов:
[TestClass]class UnitTest1
{
[TestMethod]void BytesChopperTest()
{[] buf = { 100, 100, 200, 200, 100, 100,
200, 200, 100, 100, 200, 200, 100, 100, 200, 200 };chopper = new
BytesChopper(buf);.AreEqual(chopper.BlocksCount, Math.Ceiling((double)
buf.Count()/8));
foreach (var b in chopper.Get(0))
{.WriteLine(b);
}(var b in chopper.Get(1))
{.WriteLine(b);
}
}
[TestMethod]void BytesChopperExceptionTest()
{[] buf = { 100, 100, 200, 200, 100, 100,
200, 200, 100, 100, 200, 200, 100, 100, 200};
{chopper = new BytesChopper(buf);
}(Exception e)
{.AreEqual(e.GetType(),
typeof(ArgumentException));
}
}
[TestMethod]void FromHex()
{[] stringsBuffer = { "AAFF",
"FFA", "0FFA", "FFA0"};(string line in
stringsBuffer)
{[] bytes = MathBlock.FromHex(line);(int i =
0; i < bytes.Length; i++)
{.Write(bytes[i]+ " ");
}.Write("\n");
}
}
[TestMethod]void ToHex()
{[] A = { 100, 100, 200, 200};[] B = { 100,
200, 200 };[] C = { 0, 100, 200, 200 };.WriteLine(MathBlock.ToHex(A));
Debug.WriteLine(MathBlock.ToHex(B));.WriteLine(MathBlock.ToHex(C));
}
[TestMethod]void Xor()
{A = uint.MaxValue;
uint B = uint.MaxValue;C = uint.MaxValue/2;
Debug.WriteLine(A);.WriteLine(MathBlock.Xor(A,
B));.WriteLine(MathBlock.Xor(A, C));
Debug.WriteLine(MathBlock.Xor(B, C));
Assert.AreEqual((uint)173,
MathBlock.Xor(101, 200));
}
[TestMethod]void AddMod()
{.AreEqual(MathBlock.AddMod(120, 200, 5),
(uint)0);.AreEqual(MathBlock.AddMod(400, 240, 6),
(uint)0);.AreEqual(MathBlock.AddMod(400, 241, 6), (uint)1);
}
[TestMethod]void ShiftLeft()
{.AreEqual(MathBlock.ShiftLeft((byte)10, 2),
(uint)40);.AreEqual(MathBlock.ShiftLeft(uint.MaxValue / 2, 1), (uint.MaxValue/
2) * 2);
}
[TestMethod]void RotateLeft()
{.AreEqual(MathBlock.RotateLeft(MathBlock.ShiftLeft((uint)1,
31), 1), (uint)1);.AreEqual(MathBlock.RotateLeft(MathBlock.ShiftLeft((uint)1,
31)+1, 1),
(uint)3);.AreEqual(MathBlock.RotateLeft((byte)MathBlock.ShiftLeft((byte)1, 7),
1), (byte)1);.AreEqual(MathBlock.RotateLeft((byte)129, 1), (byte)3);
}
[TestMethod]void FourBytesToUint()
{.AreEqual(MathBlock.FourBytesToUint(1, 1, 1,
1), (uint)16843009);.AreEqual(MathBlock.FourBytesToUint(3, 3, 3, 3),
(uint)50529027);.AreEqual(MathBlock.FourBytesToUint(170, 170, 170, 170),
(uint)2863311530);
}
[TestMethod]void FourBytesReverse()
{buffer =
BitWorker.Reverse(MathBlock.FourBytesToUint(170, 171, 172, 173));mustBe =
MathBlock.FourBytesToUint(BitWorker.Reverse(173),
BitWorker.Reverse(172),.Reverse(171), BitWorker.Reverse(170));.AreEqual(buffer,
mustBe);
}
[TestMethod]void UintToByteArray()
{[] arrayBytes = {170, 170, 170,
170};.AreEqual(MathBlock.UintToByteArray(2863311530)[0],
arrayBytes[0]);.AreEqual(MathBlock.UintToByteArray(2863311530)[1],
arrayBytes[1]);.AreEqual(MathBlock.UintToByteArray(2863311530)[2],
arrayBytes[2]);.AreEqual(MathBlock.UintToByteArray(2863311530)[3],
arrayBytes[3]);.AreEqual(MathBlock.UintToByteArray(2863311530).Length,
arrayBytes.Length);[] arrayBytes1 = { 1, 1, 1, 1
};.AreEqual(MathBlock.UintToByteArray(16843009)[0],
arrayBytes1[0]);.AreEqual(MathBlock.UintToByteArray(16843009)[1],
arrayBytes1[1]);.AreEqual(MathBlock.UintToByteArray(16843009)[2],
arrayBytes1[2]);.AreEqual(MathBlock.UintToByteArray(16843009)[3],
arrayBytes1[3]);.AreEqual(MathBlock.UintToByteArray(16843009).Length,
arrayBytes1.Length);
}
[TestMethod]void GetBitSetBit()
{.AreEqual(BitWorker.GetBit(1, 0),
BitWorker.GetBit((uint) 1000000001, 0));.AreEqual(BitWorker.SetBit(1, 1, true),
3);.AreEqual(BitWorker.SetBit(1000000001, 1, true), (uint) 1000000003);
}
[TestMethod]void Reverse()
{.AreEqual(BitWorker.Reverse(128),
(byte)1);.AreEqual(BitWorker.Reverse(2147483648), (uint)1);
}
[TestMethod]void KeyTest()
{key0 = new
Key("AABBAAFFAACCAADDAABBAADD
AACCAAFFaabbaaffaaccaaddaabbaaddaaccaaff");key1 = new
Key("aabbaaffaaccaaddaabbaaddaaccaaff AABBAAFFAACCAADDAABBAA
DDAACCAAFF");(int i = 0; i < 8; i++)
{.AreEqual(key0.KeyUints[i],
key1.KeyUints[i]);.WriteLine(key0.KeyUints[i]);
}
}
[TestMethod]void EncoderTest()
{testKey =
"AABBAAFFAACCAADDAABBAADDAACCAAFF
aabbaaffaaccaaddaabbaaddaaccaaff";testData = "asdasdas";[]
testBytes = GostEncoder.Encode(testData, testKey);
foreach (var testByte in testBytes)
{.Write(testByte + " ");
}.Write("\n");testString =
GostEncoder.Decode(testBytes, testKey);.Write(testString);
Assert.AreEqual(testData, testString);
}
[TestMethod]void EncoderTest2()
{testKey =
"46745674574747aff43353453454568F0012323534
5474846645645645646454";testData = "BLABLABL";[] testBytes =
GostEncoder.Encode(testData, testKey);
foreach (var testByte in testBytes)
{.Write(testByte + " ");
}.Write("\n");testString =
GostEncoder.Decode(testBytes, testKey);.Write(testString);
Assert.AreEqual(testData, testString);
}
[TestMethod]void EncoderTest3()
{testKey =
"46745674574747aff43353453454568F0012323
5345474846645645645646454";testData = "Hello World!xDxD";[]
testBytes = GostEncoder.Encode(testData, testKey);(var testByte in testBytes)
{.Write(testByte + " ");
}.Write("\n");testString =
GostEncoder.Decode(testBytes, testKey);.Write(testString);.AreEqual(testData,
testString);
}
[TestMethod]void EncoderShortTest()
{testKey = "AABBAAFFAACCAADDAABBAADDAACCAAFF
aabbaaffaaccaaddaabbaaddaaccaaff";testData = "asda";
{[] testBytes = GostEncoder.Encode(testData,
testKey);
}(Exception e)
{.AreEqual(e.GetType(),
typeof(ArgumentException));
}
}
[TestMethod]void EncoderBigTest()
{testKey = "AABBAAFFAACCAADDAABBAADDAACCAAFF
aabbaaffaaccaaddaabbaaddaaccaaff";testData =
"asdasdasdasdasdasdasdasd";[] testBytes =
GostEncoder.Encode(testData, testKey);
foreach (var testByte in testBytes)
{.Write(testByte+" ");
}testString = GostEncoder.Decode(testBytes,
testKey);.Write("\n");.WriteLine(testData+"\n");.WriteLine(testString);.AreEqual(testData,
testString);
}
[TestMethod]void EncoderBigNotFullTest()
{testKey =
"AABBAAFFAACCAADDAABBAADDAACCAAFF
aabbaaffaaccaaddaabbaaddaaccaaff";testData = "asdasdasdasdasdasdasd";
{[] testBytes = GostEncoder.Encode(testData,
testKey);
}(Exception e)
{.AreEqual(e.GetType(),
typeof(ArgumentException));
}
}
}
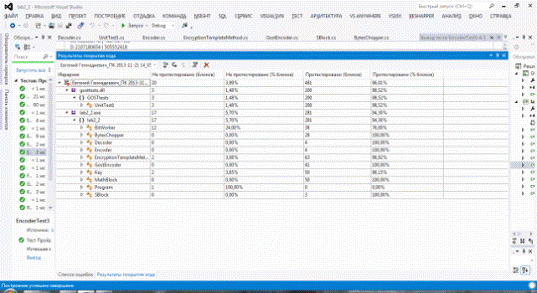
Результаты
тестирования программы
Программа реализована методами TDD на C# под Visual Studio 2012.
Строка «asdasdas»:
Строка «Hello
world!xDxD»
Анализ покрытия кода тестами (не протестированы тривиальные случаи):