Интеллектуальные информационные системы. Базы знаний
Интеллектуальные
информационные системы. Базы знаний
Содержание
Введение
. Построение баз знаний для семантической сети
.1 Цели создания онтологий
.2 Semantic Web
.3 Метаданные
.4 Язык представления онтологий: OWL
.5 Методология создания онтологической базы знаний
.6 Процесс построения онтологической базы знаний
.6.1 Постановка задачи
.6.2 Построение базы знаний в редакторе Protégé-OWL
.6.3 Перспективы использования онтологических баз знания
. Многоагентные системы
.1 Структура исследований в области многоагентных систем
.2 Агентно-ориентированный подход в программировании
.3 Классификация агентов
.4 Архитектура агента
.5 Кооперация агентов
.6 Платформа для разработки мультиагентных систем JADE
.7 Создание прототипа интеллектуального агента
. Технико-экономическое обоснование разработки базы знаний
.1 Характеристика программного продукта
.2 Расчет затрат и отпускной цены программного средства
.3 Расчет стоимостной оценки результата
.3.1 Расчет прироста чистой прибыли
.3.2. Расчет прироста амортизационных отчислений
.4 Расчет показателей эффективности использования программного
продукта
. Охрана труда тема: безопасная организация трудового процесса
пользователей и разработчиков интеллектуальных информационных систем
Заключение
Литература
Приложение А. Общая методология создания онтологий
Приложение Б. Исходные коды интеллектуального агента
Приложение В. Диаграмма классов интеллектуального агента
Введение
Онтология (от др.-греч. онтос -
сущее, логос - учение, понятие) - термин, определяющий учение о бытии, о сущем,
в отличие от гносеологии - учения о познании. Уже у X. Вольфа (1679-1754),
автора самого термина «онтология», учение о бытии было отделено от учения о
познании. Введен же термин в философскую литературу немецким философом Р.
Гоклениусом (1547-1628). При этом онтология являлась частью метафизики, наукой
самостоятельной, независимой и не связанной с логикой, с «практической
философией», с науками о природе. Ее предмет составляет изучение абстрактных и
общих философских категорий, таких как бытие, субстанция, причина, действие,
явление и т. д., а сама онтология как наука претендовала на полное объяснение
причин всех явлений.
В настоящее время понимание термина
«онтология» различно, в зависимости от контекста и целей его использования.
Приведем ряд основных определений онтологии.
Онтология - философская дисциплина,
которая изучает наиболее общие характеристики бытия и сущностей.
Онтология - это формальная теория,
ограничивающая возможные концептуализации мира. [Никола Гуарино].
Онтология - это точная спецификация
концептуализации, где в качестве концептуализации выступает описание множества
объектов предметной области и связей между ними. [Томас Грубер]
Онтология - это формальная
спецификация согласованной концептуализации. Под согласованной концептуализацией
подразумевается, что данная концептуализация не есть частное мнение, а является
общей для некоторой группы людей.
Онтология - это формально
представленные на базе концептуализации знания. Формально онтология состоит из
терминов, организованных в таксономию, их определений и атрибутов, а также
связанных с ними аксиом и правил вывода.
Онтология - набор базовых понятий и
отношений между ними.
Онтология - это иерархически
структурированное множество терминов, описывающих предметную область, которое
может быть использовано как исходная структура для базы знаний.
В середине 80х гг. XX века
происходит переоткрытие понятия "онтология". Отчасти это случилось в
связи с проектом CYC - проектом базы так называемых "общеизвестных"
знаний. Появилось понимание того факта, что взаимодействие разных
исследовательских сообществ невозможно без наличия "слоя-посредника",
в котором должен определяться словарь предметной области. Таким посредником и
выступили онтологии предметных областей.
На первых порах, в сфере
информационных технологий часто противопоставляли два определения онтологии:
более философское (определение Николы Гуарино) и более практическое
(определение Томаса Грубера).
В философском контексте, онтология -
система категорий, используемая для рассмотрения с учетом конкретного видения
мира.
В контексте информационных систем,
онтология - формализованное описание общепринятого понимания некоторой
предметной области, с помощью которого могут общаться люди, компьютерные
системы.
На самом деле, вопрос в отличии двух
определений сводится к разным требованиям к "слою-посреднику": в
одном случае нужна строгая формальная теория, формальный язык (например, язык
исчисления предикатов 1-го порядка), в другом - достаточно списка терминов
предметной области (онтологии - словари).
В рамках данной работы нас будут
интересовать следующие подходы к определению онтологии.
В известном проекте Ontolingila,
который ведется в Стэндфордском университете, предполагается, что онтология -
это эксплицитная спецификация определенной темы.
В разработках системы стандартов на
мульти-агентные системы международным сообществом FIPA (Foundation for
Intelligent Physical Agents) утверждается, что в философском смысле можно
ссылаться на онтологию как на определенную систему категорий, являющихся
следствием определенного взгляда на мир.
Базы знаний, которые используют
онтологии, называют базами онтологических знаний или онтологическими базами
знаний.
Понятно, что любая онтология имеет
под собой концептуализацию, но одна концептуализация может быть основой разных
онтологий, а две разные базы знаний могут отражать одну онтологию.
1. Построение баз знаний для
семантической сети
.1 Цели создания онтологий
Вот некоторые причины создания
онтологий:
для совместного использования людьми
или программными агентами общего понимания структуры информации;
для возможности повторного
использования знаний в предметной области;
для того чтобы сделать допущения в
предметной области явными;
для отделения знаний в предметной
области от оперативных знаний;
для анализа знаний в предметной
области.
Часто онтология предметной области
сама по себе не является целью. Разработка онтологии сродни определению набора
данных и их структуры для использования другими программами.
Доменно-независимые приложения и программные агенты используют в качестве
данных онтологии и базы знаний, построенные на основе этих онтологий.
.2 Semantic Web
Идея Семантической Сети (Semantic
Web) впервые была провозглашена в 2001 году Тимом Бернерсом-Ли (создателем
World Wide Web). Однако она не является новой ни для автора, ни для
web-сообщества в целом. Суть ее состоит в автоматизации, то есть обработкой
информации и её обменом должны заниматься не люди, а специальные
интеллектуальные агенты (программы, размещенные в Сети). Но для того, чтобы
взаимодействовать между собой, агенты должны иметь общее (разделяемое всеми)
формальное представление значения для любого ресурса. Именно для цели
представления общей, явной и формальной спецификации значения в Semantic Web
используются онтологии.
Работа над средствами описания
семантики в Сети началась задолго до публикации 2001 года. В 1997 году
консорциум W3C определил спецификацию RDF (Resource Description Framework). RDF
предоставляет простой, но мощный язык описания ресурсов, основанный на триплетах
(triple-based) "Субъект-Предикат-Объект" и спецификации URI. В 1999
году RDF получает статус рекомендации. Этот шаг в направлении улучшения
функциональности и обеспечения интероперабельности (т.е. возможности
обмениваться данными несмотря на их разнородность) в Сети считается одним из
важнейших. Концептуально RDF дает минимальный уровень для представления знаний
в Сети. Спецификация RDF опирается на ранние стандарты, лежащие в основе Web:
Unicode служит для представления
символов алфавитов различных языков,
URI используется для определения
уникальных идентификаторов ресурсов,
XML и XML Schema - для
структурирования и обмена информацией и для хранения RDF (XML синтаксис RDF).
Кроме RDF был разработан язык
описания структурированных словарей для RDF - RDF Schema (RDFS). Он
предоставляет минимальный набор средств для спецификации онтологий. RDFS
получил статус рекомендации W3C в 2004 году. Однако препятствием для Semantic
Web стало то, что документов, написанных на языке RDF/RDFS, было относительно
мало. В период с 2001 по 2004 годы шла интенсивная работа по созданию
программных средств для обработки и автоматической генерации RDF-документов.
Результатом в 2004 году стал язык
GRDDL (Gleaning Resource Descriptions form Dialects of Languages). Его
назначение состоит в предоставлении средств для извлечения RDF-триплетов из XML
и XHTML данных (в особенности это относится к документам, автоматически
генерируемым из закрытых баз данных). Развивалось и программное обеспечение для
Semantic Web. В области создания библиотек классов и построения логических
выводов над RDF-графами была создана библиотека Jena Framework, в области
создания модулей расширения для браузеров - Simile для Firefox. В области
создания визуальных сред редактирования большое число редакторов онтологий
стали поддерживать RDF.
В 2004 году статус рекомендации
получил язык OWL (Web Ontology Language). Он имеет 3 диалекта (3 множества
структурных единиц), используемых в зависимости от требуемой выразительной
мощности. OWL фактически является надстройкой над RDF/RDFS и поддерживает
эффективное представление онтологий в терминах классов и свойств, обеспечение
простых логических проверок целостности онтологии и связывание онтологий друг с
другом (импорт внешних определений). Многие формализмы описания знаний могут
быть отображены на формализм OWL (два из его диалектов - OWL Lite и OWL DL -
соответствуют двум дескриптивным логикам, имеющим разную выразительную силу).
Большое число создаваемых в настоящее время онтологий кодируются на OWL; уже
существующие онтологии транслируются в него.
На этом работа по обеспечению
Semantic Web необходимыми стандартами не остановилась. В 2005 году началась
работа над форматом обмена правилами - RIF (Rule Interchange Format). Его
назначение - соединить в одном стандарте несколько формализмов для описания
правил (по которым может осуществляться нетривиальный логический вывод): логику
клауз Хорна, логики высших порядков, продукционные модели и т.п.
Язык SPARQL - язык запросов к
RDF-хранилищам - в январе 2008 года приобрел статус официальной рекомендации
Консорциума W3C. Синтаксически он очень похож на SQL. Он уже широко
используется разработчиками информационных систем.
На рис. 1.3.1 представлена
диаграмма, называемая иногда стеком (или даже "слоеным пирогом")
Semantic Web.
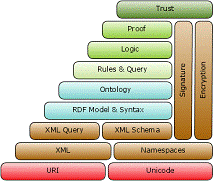
Рисунок 1.2.1 - Диаграмма Semantic
Web
Все основные уровни диаграммы были
описаны выше. Уровням "Ontology vocabulary" и "Logic"
соответствуют OWL и RIF. Уровень "Trust" на данный момент остается
незатронутым никакими стандартами. Здесь и возникает одно из существенных
препятствий к реализации всей идеи: поддержка автоматической проверки
корректности и правдивости информации. В самом деле, у многих поставщиков
семантических описаний может возникнуть соблазн "обмануть"
программу-агента, предоставив информацию, не соответствующую действительности,
либо навязчивую рекламу, как это в настоящее время проделывается с поисковыми
машинами, спам-фильтрами и т.п.
Еще одним камнем преткновения для
создания Semantic Web является фактическое отсутствие работающих
интеллектуальных агентов. [2]
.3 Метаданные
Неотъемлемой характеристикой любого
ресурса Сети является сопровождающая его информация. Эту
"сверхинформацию", или информацию об информации (о ресурсе), принято
называть метаданными.
Под метаданными будем понимать
машинопонятную информацию о веб-ресурсах и других сущностях.
Термин "машинопонятная"
является ключевым. Речь идет о понимании информации программными агентами.
Причем "понимании" с одной целью - использовать информацию для
решения задач, возложенных на них (агентов) пользователем.
Метаданные должны иметь хорошо
определенную ясную структуру и семантику.
Приведем два постулата (А1 и А2), на
которых основана архитектура метаданных Сети.
А1. Метаданные - это данные (другими
словами, информация об информации - это тоже информация).
Поскольку метаданные - это данные,
то они могут храниться в ресурсе (могут быть представлены как ресурс). То есть
любой ресурс Сети может хранить как данные, так и метаданные о себе или о
других ресурсах. Метаданные могут храниться внутри самого документа, внутри
другого документа либо передаваться вместе с документом средствами протокола
HTTP. Метаданные состоят из высказываний о данных и при представлении имеют
форму имени (или типа высказывания) и набора параметров.
А2. Архитектура, представляемая
метаданными, является набором независимых высказываний (утверждений).
Как следствие, при группировке двух
и более высказываний об одном ресурсе они объединятся логическим "И".
Альтернативные высказывания являются независимыми, а их наборы представляют
собой неупорядоченные множества.
Наиболее распространенной формой
высказывания является следующая модель:
Ресурс - атрибут - значение
Здесь ресурс - это объект, о котором
фиксируется высказывание, атрибут - некоторое свойство или параметр объекта,
значение представляет некоторое значение из области значений атрибута (или
диапазона значений атрибута данного объекта).- язык представления информации о
ресурсах WWW. Базовой структурной единицей RDF является коллекция троек (или
триплетов), каждая из которых состоит из субъекта, предиката и объекта (S,P,O).
Набор триплетов называется RDF-графом. В качестве вершин графа выступают
субъекты и объекты, в качестве дуг - предикаты (или свойства). Направление
дуги, соответствующей предикату в данной тройке (S,P,O), всегда выбирается так,
чтобы дуга вела от субъекта к объекту.

Рисунок 1.3.1 - RDF-тройка
Каждая тройка представляет некоторое
высказывание, увязывающее S, P и O.
Первые два элемента RDF-тройки
(субъект и предикат) идентифицируются при помощи URI. Объектом же может быть
как ресурс, идентифицируемый при помощи URI, так и RDF-литерал (значение).
.4 Язык представления онтологий: OWL
Распространение онтологического
подхода к представлению знаний оказало содействие при создании разнообразных
языков представления онтологии и инструментальных средств, предназначенных для
их редактирования и анализа. Существуют традиционные языки спецификации
онтологий: Ontolingua, CycL, языки, основанные на дескриптивных логиках (такие
как LOOM), языки, основанные на фреймах (OKBC, OCML, F-Logic). Более поздние
языки основаны на Web-стандартах (XOL, SHOE, UPML). Специально для обмена
онтологиями через Web были созданы языки RDF, RDFS, DAML+OIL, OWL.
Язык, о котором пойдет речь в данном
разделе, является одним из основных языков так называемой Семантической Сети
(Semantic Web). О Semantic Web упоминалось ранее. На сегодняшний день
наблюдается разрыв между способами представления метаданных (языками их
определения) и теми интеллектуальными агентами, которые должны ими
пользоваться. Языки описания метаданных и онтологий в Web развиты очень хорошо,
языки запросов и языки описания правил доведены до стадии технологических
стандартов в данной области. Однако узким местом всё еще являются механизмы
взаимодействия агентов на основе онтологий.
Многие популярные редакторы
онтологий, используют в качестве основного формализма дескриптивную логику (DL)
и предоставляют средства для создания OWL-онтологий.(Web Ontology Language, в
аббревиатуре буквы намеренно переставлены местами, чтобы получилось английское
слово "сова") - язык представления онтологий в Web. Фактически это
словарь, расширяющий набор терминов, определенных RDFS. OWL-онтологии могут
содержать описания классов, свойств и их экземпляров. Создание OWL - это ответ
на необходимость представления знаний в Сети в едином формате. Исторически
предшественником OWL был язык DAML+OIL, объединивший две инициативы: проект
DAML (DARPA Agent Markup Language) и проект OIL (Ontology Inference Layer).
Наиболее ранним проектом представления онтологий в Web был SHOE (Simlpe HTML
Ontology Extensions). Ветви развития языков описания онтологий для Web показаны
на рис. 1.4.1. Верхний уровень: OIL, DAML+OIL и OWL продолжают развиваться, но
наибольшей популярностью пользуется OWL.с 2004 года является рекомендацией W3C
и объединяет лучшие черты своих предшественников.
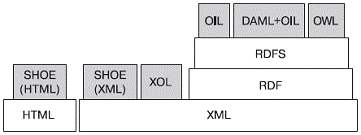
Рисунок 1.4.1 - Основные ветви
развития языков описания онтологий для Web
Язык OWL имеет три диалекта: OWL
Lite, OWL DL, OWL Full. Каждый из этих диалектов (кроме OWL Lite) является
расширением предыдущего. Как следствие, любая OWL Lite онтология является OWL
DL онтологией, а любая OWL DL онтология является OWL Full онтологией.
Рассмотрим структуру OWL-онтологии.
Любая онтология имеет заголовок и тело. В заголовке содержится информация о
самой онтологии (версия, примечания), об импортируемых онтологиях. За
заголовком следует тело онтологии, содержащее описания классов, свойств и
экземпляров.
Базовый элемент в OWL - это класс
(owl:Class).
Для организации классов в иерархию
используется свойство rdfs:subClassOf. Особое место занимают два
взаимодополняющих класса - owl:Thing и owl:Nothing. Первый из них является
надклассом любого класса OWL, второй - подклассом любого класса OWL. Экземпляр
любого класса OWL входит в экстенсионал класса owl:Thing. Экстенсионал класса
owl:Nothing является пустым множеством.класс может быть описан шестью
способами:
) идентификатором класса (URI);
) перечислением всех экземпляров
класса;
) ограничением на значение свойства;
) пересечением 2-х и более
определений классов;
) объединением 2-х и более
определений классов;
) дополнением (логическим
отрицанием) определения класса.
Только первый способ определяет
именованный класс OWL. Все оставшиеся определяют анонимный класс через
ограничение его экстенсионала. Способ 2 явно перечисляет экземпляры класса,
способ 3 ограничивает экстенсионал только теми экземплярами, которые
удовлетворяют данному свойству. Способы 4-6 используют теоретико-множественные
операции (объединение, пересечение и дополнение) над экстенсионалами
соответствующих классов, чтобы определить экстенсионал нового класса.
Описания класса являются
строительными блоками для определения классов посредством аксиом.
В OWL определены еще 3 конструкции,
комбинируя которые, можно определять более сложные аксиомы классов:
rdfs:subClassOf говорит о том, что
экстенсионал одного класса (подкласса) полностью входит в экстенсионал другого
(надкласса);
owl:equivalentClass говорит о том,
что экстенсионалы двух классов совпадают;
owl:disjointWith говорит о том, что
экстенсионалы двух классов не пересекаются. Иногда говорят, что таким образом
определяются дизъюнктивные классы.
В OWL выделяют две категории
свойств: свойства-объекты (или объектные свойства) и свойства-значения. Первые
связывают между собой индивиды (экземпляры классов). Вторые связывают индивиды
со значениями данных. Оба класса свойств являются подклассами класса
rdf:Property.
Для определения новых свойств как
экземпляров owl:ObjectProperty или owl:DatatypeProperty используются аксиомы
свойств.
Кроме того, OWL поддерживает
следующие конструкции для построения аксиом свойств:
Конструкции RDFS: rdfs:subPropertyOf
(определяет подсвойство данного свойства), rdfs:domain (определяет домен
свойства) и rdfs:range (определяет диапазон свойства)
Отношения между свойствами:
owl:equivalentProperty (определяет эквивалентное свойство) и owl:inverseOf
(определяет обратное свойство).
Ограничения глобальной
кардинальности: owl:FunctionalProperty (определяет однозначное свойство -
однозначное отображение домена свойства на диапазон) и
owl:InverseFunctionalProperty (обратно функциональное свойство, т.е.
определяет, что свойство, обратное данному свойству, является однозначным).
Логические характеристики свойства:
owl:SymmetricProperty (определяет свойство как симметричное) и
owl:TransitiveProperty (определяет транзитивное свойство).
Индивиды (экземпляры классов)
определяются при помощи аксиом индивидов (т.н. фактов). Рассмотрим два вида
фактов:
факты членства индивидов в классах и
факты о значениях свойств индивидов;
факты идентичности/различности
индивидов.
Аксиомы второго вида необходимы для
суждения об идентичности индивидов. Дело в том, что в OWL не делается никаких
предположений ни о различии, ни о совпадении двух индивидов, имеющих различные
идентификаторы URI. Подобные утверждения выражаются аксиомами идентичности с
помощью следующих конструкций:
owl:sameAs постулирует, что две
ссылки URI ссылаются на один и тот же индивид;
owl:differentFrom постулирует, что
две ссылки URI ссылаются на разные индивиды;
owl:AllDifferent предоставляет
средство для определения списка попарно различных индивидов. [2]
Итак, базовыми элементами OWL
являются классы, свойства и индивиды.
Вероятно, сами по себе языки
представления онтологий не были бы так сильно востребованы, если бы не
возникало необходимости автоматически обрабатывать онтологии, наполнять их
содержимым и выполнять к ним запросы. Наиболее популярными среди языков
запросов к RDF-хранилищам на сегодняшний день являются языки RDQL и SPARQL.
Рассмотрим несколько упрощенный
синтаксис SPARQL-запроса:
<список_переменных> <URI_онтологии> {
<список_шаблонов>.<фильтр>
}
Где: список_переменных - список имен
переменных; URI_онтологии - URI-ссылка на онтологию; список_шаблонов - список
шаблонов; фильтр - ограничения на значения переменных.
.5 Методология создания
онтологической базы знаний
Под знаниями в Semantic Web, как
правило, понимается формализованная информация, известная тому или иному
пользователю, приложению или агенту. Распространенным способом представления
знаний являются логические формулы (или аксиомы в терминологии OWL), смысл
которых четко определяется семантикой используемого языка. [3]
Разработчики систем, основанных на
знаниях, сталкиваются с проблемой приобретения знаний. Подобная проблема
существует и при создании онтологий. Кроме того, в настоящее время существует
лишь несколько предметно-независимых методологий, ориентированных на построение
онтологий.
Следует сразу отметить, что эти
подходы и методологии базируются на следующих принципах проектирования и
реализации онтологий, предложенных Томасом Грубером:
Ясность - онтология должна
эффективно передавать смысл введенных терминов. Определения должны быть
объективными, хотя мотивация введения терминов может определяться ситуацией или
требованиями вычислительной эффективности. Для объективизации определений должен
использоваться четко фиксированный формализм, при этом целесообразно задавать
определения в виде логических аксиом.
Согласованность - означает, что, по
крайней мере, все определения должны быть логически непротиворечивы, а все
утверждения, выводимые в онтологии, не должны противоречить аксиомам.
Расширяемость - онтология должна
быть спроектирована так, чтобы обеспечивать использование разделяемых словарей
терминов, допускающих возможность монотонного расширения и/или специализации
без необходимости ревизии уже существующих понятий.
Минимум влияния кодирования -
концептуализация, лежащая в основе создаваемой онтологии, должна быть
специфицирована на уровне представления, а не символьного кодирования. Этот
принцип связан с тем, что агенты, разделяющие онтологию, могут быть реализованы
в различных системах представления знаний.
Минимум онтологических обязательств
- онтология должна содержать только наиболее существенные предположения о
моделируемом мире, чтобы оставлять свободу расширения и специализации.
Рассмотрим подход, в котором
выделяются следующие процедуры «жизненного цикла» создания онтологии:
управление проектом, собственно разработка и поддержка разработки.
Процедуры управления проектом
включают планирование, контроль и гарантии качества. Планирование определяет,
какие задачи должны быть выполнены, как они организуются, как много времени и
какие ресурсы нужны для их выполнения. Контроль гарантирует, что
запланированные задачи выполнены и именно так, как это предполагалось. Гарантии
качества нужны для того, чтобы быть уверенным в том, что компоненты и продукт в
целом находятся на заданном уровне.
Собственно разработка включает
спецификацию, концептуализацию, формализацию и реализацию. Спецификация
определяет цели создания онтологии, ее предполагаемое использование и
потенциальных пользователей. Концептуализация - это структура реальности,
рассматриваемая независимо от словаря предметной области и конкретной ситуации.
Формализация трансформирует концептуальную модель в формальную или
«вычислительную». Наконец, в процессе реализации вычислительная модель
программируется на соответствующем языке представления знаний.
Процедуры поддержки включают
действия, выполняемые одновременно с разработкой, без которых онтология не
может быть построена. Они представлены процедурами приобретения знаний, оценки,
интеграции, документирования и управления конфигурациями. Приобретение знаний
аккумулирует знания в заданной предметной области. Оценка дает технические
решения по оценке онтологии, соответствующего программного обеспечения и
документации, как в процессе выполнения каждой фазы, так и между фазами.
Интеграция требуется, когда строится новая онтология с использованием уже
существующих. Документирование дает детальную, понятную и исчерпывающую
информацию о каждой фазе и продукте в целом. Управление конфигурациями
необходимо для архивации всех версий документации, программного обеспечения и
кода онтологии, а также для контроля за изменениями.
Общая схема создания онтологий
представлена в Приложении А.
В этой схеме, процесс построения
онтологии здесь распадается на серию параллельных подпроцессов по созданию
промежуточных представлений. Сначала строится глоссарий терминов, затем деревья
классификации концептов и диаграммы бинарных отношений. И только после этого -
остальные промежуточные представления. [1]
Практическая разработка онтологии
включает:
определение классов в онтологии;
расположение классов в
таксономическую иерархию;
создание базы знаний, определяя
отдельные экземпляры классов.
Выделим некоторые фундаментальные
правила разработки онтологии. Они выглядят довольно категоричными, но во многих
случаях помогут принять верные проектные решения.
Не существует единственно
правильного способа моделирования предметной области - всегда существуют
жизнеспособные альтернативы.
Разработка онтологии - это
обязательно итеративный процесс.
Понятия в онтологии должны быть
близки к объектам (физическим или логическим) и отношениям в интересующей
предметной области. Скорее всего, это существительные (объекты) или глаголы
(отношения) в предложениях, которые описывают предметную область.
Знание того, для чего предполагается
использовать онтологию, и того, насколько детальной или общей она будет, может
повлиять на многие решения, касающиеся моделирования. Нужно определить, какая
из альтернатив поможет лучше решить поставленную задачу и будет более
наглядной, более расширяемой и более простой в обслуживании. Следует помнить,
что онтология - это модель реального мира, и понятия в онтологии должны
отражать эту реальность.
Повторное использование существующих
онтологии может быть необходимым, если системе нужно взаимодействовать с
другими приложениями, которые уже вошли в отдельные онтологии или
контролируемые словари. Многие полезные онтологии уже доступны в электронном
виде и могут быть импортированы. Существуют библиотеки повторно используемых
онтологий, например, Ontolingua или DAML.
1.6 Процесс построения
онтологической базы знаний
.6.1 Постановка задачи
Предметной областью разработки
онтологической базы знаний дипломного проекта являются высшие учебные
заведения. Согласно методологии сначала строится глоссарий терминов, включающий
все термины (концепты и их экземпляры, атрибуты, действия и т. п.), важные для
предметной области, и их естественно-языковые описания. Фрагмент такого глоссария
представлен в табл. 1.6.1
Таблица 1.1 - Фрагмент глоссария
|
Термин
|
Описание термина
|
|
University
|
Один из типов высшего учебного заведения
|
|
Academic subjects
|
Учебный предмет, научная дисциплина
|
|
Administrative unit
|
Административная единица - факультет, кафедра, группа
|
|
Educational form
|
Форма образования - дневная, заочная
|
|
Functional roles
|
Роль которую играет человек в определенном сообществе
|
|
Academic rank
|
Академическое звание - доцент, доктор наук
|
|
Administrative post
|
Должность - декан, ректор
|
|
Speciality
|
Специальность, профессия
|
|
Sciens
|
Наука
|
.6.2 Построение базы знаний в
редакторе Protégé-OWLégé - Это свободно
распространяемая Java-программа, предназначенная для построения (создания,
редактирования и просмотра) онтологий той или иной прикладной области. Она
включает редактор онтологий, позволяющий проектировать онтологии, разворачивая
иерархическую структуру абстрактных и конкретных классов. На основе
сформированной онтологии Protégé
позволяет генерировать формы получения знаний для введения экземпляров классов
и подклассов.
Данный инструмент поддерживает
использование языка OWL и позволяет генерировать HTML-документы, отображающие
структуру онтологий.
Когда глоссарий терминов достигает
«существенного» объема, строятся деревья классификации концептов. Как правило,
при этом используются отношения типа subclass-of, is-a и некоторые другие
таксономические отношения. Для отображения деревьев классификации концептов
базы знаний “Университеты” можно использовать плагин Protégé - OWL Viz.
Следующим шагом является построение
диаграмм бинарных отношений, целью создания которых является фиксация отношений
между концептами одной или разных онтологий Для отображения диаграмм бинарных
отношений можно использовать плагин Protégé
- OntoGraph.
Как показывает анализ процедур
построения, выполняемых при создании онтологий в подходе все они хорошо
коррелируют с теми стадиями, которые выделены и используются при построении баз
знаний. И это не случайное совпадение, а закономерность, связанная с тем, что
онтология - это, по существу, база знаний специального вида. Поэтому, как и в
случае построения баз знаний, здесь используется концепция быстрого
прототипирования.
.6.3 Перспективы использования
онтологических баз знания
Исследования в области онтологий и
онтологических систем являются «горячими точками» не только в ИИ, но и в
работах по интеллектуализации информационного поиска, в первую очередь, в среде
Интернет; в работах по мультиагентным системам; в проектах по автоматическому
«извлечению» знаний из текстов на естественном языке; в проектах, ведущихся в
смежных областях.
Как показывает анализ литературы и
Интернет-ресурсов по данной тематике, в настоящее время:
эффективная обработка информации в
Web связывается, в первую очередь, с использованием ИИ-технологий;
основные подходы в этой области
ориентированы на решение проблемы извлечения из Web-pecypcoв эксплицитных
знаний на основе семантического маркирования таких ресурсов;
во всех исследовательских и многих
коммерческих проектах данного направления активно используются (или, по крайней
мере, декларируется использование) агентно-ориентированные вычисления и
технологии.
Учитывая вышесказанное, в следующей
главе пойдет речь о мультиагентных системах и системах интеллектуальных
агентов.
2. Многоагентные системы
.1 Структура исследований в области
многоагентных систем
В последнее десятилетие среди
различных направлений искусственного интеллекта на одно из ведущих мест все
больше претендуют исследования, объединяемые общим названием “многоагентные
системы” (MAC).
Многоагентные системы могут
строиться по принципам распределенного интеллекта как объединение отдельных
интеллектуальных систем, обладающих своими базами знаний и средствами
рассуждений.
Многоагентные системы - это особый
взгляд на программирование, расширяющий восприятие за пределы привычного
Объектно Ориентированного Программирования (ООП). Основная идея агентов - это
делегирование. Владелец или пользователь агента делегирует ему некоторую
задачу, и агент автономно исполняет эту задачу от имени пользователя. Агент
должен быть способен связаться с пользователем для получения инструкций и
обеспечения пользователя результатами. Наконец, агент должен быть способен
контролировать состояние своей окружающей среды и в случае необходимости
предпринимать действия направленные на выполнение делегированной ему задачи.
Такие агенты, например, могут выполнять заказ книг в электронном магазине,
поиск информации в базах данных, сети Интернет и т.д.
Можно предположить, что в основу
многоагентной идеи лёг принцип устройства социума, поскольку сама идея агентов
является естественной социальной системой. Общество образует некая совокупность
индивидов, каждый из которых преследует собственные цели. Для достижения этих
целей индивид производит какие-то операции над миром. Однако, как правило,
индивидуальные цели являются недостижимыми без помощи других членов сообщества,
поэтому для удовлетворения своих потребностей индивиды вынуждены сотрудничать.
Впрочем, их цели могут и конфликтовать, следовательно, зачастую агенты также вынуждены
и конкурировать друг с другом. Данная модель является достаточно полной
картиной любой человеческой группы, включая и всё общество в целом.
Многоагентная система представляет
собой программную систему, в которой несколько агентов сотрудничают, чтобы
достигнуть некоторой цели. Для каждого по отдельности агента, поставленная
перед системой задача была бы невыполнима, поэтому агенты должны решать ее
вместе. При решении задачи агенты, в пределах своего пространства, могут
обмениваться информацией, делегировать друг другу подзадачи. Хотя агентные
системы и являются новым, в некотором роде, более перспективным методом по
отношению к экспертным системам, тем не менее, они основаны, в первую очередь,
именно на них.
В настоящее время MAC
рассматривается как множество интеллектуальных агентов, распределенных по сети,
мигрирующих по ней в поисках релевантных данных, знаний и процедур, и
сотрудничающих в процессе выработки решений. По сути, возникла новая парадигма
сообщества “программных роботов”, цель которых - удовлетворение различных
информационных и вычислительных потребностей конечных пользователей.
Структура исследований в области MAC
очень широка и сравнима с широтой исследований в области ИИ. С некоторой долей
условности исследования в области MAC можно разделить на следующие основные
направления:
теория агентов, в которой
рассматриваются формализмы и математические методы для описания рассуждений об
агентах и для выражения желаемых свойств агентов;
методы кооперации агентов
(организации кооперативного поведения) в процессе совместного решения задач или
при каких-либо других вариантах взаимодействия;
архитектура агентов и многоагентных
систем - сфера исследований, в которой изучается, как построить компьютерную
систему, удовлетворяющую тем или иным свойствам, которые выражены средствами
теории агентов,
языки программирования агентов,
методы, языки и средства
коммуникации агентов,
методы и программные средства
поддержки мобильности агентов (миграции агентов по сети).
Особое место занимают исследования,
связанные с разработкой
приложений MAC и инструментальных
средств поддержки технологии их разработки.
.2 Агентно-ориентированный подход в
программировании
При определении понятия “агент”
удобно опираться на представления об объекте, развитом школой объектно-ориентированного
программирования (ООП). Тогда искусственный агент может пониматься как
метаобъект, наделенный некоторой долей субъектности, т.е. способный
манипулировать другими объектами, создавать и уничтожать их, а также имеющий
развитые средства взаимодействия со средой и себе подобными. Иными словами, это
“активный объект” или “искусственный деятель”, находящийся на заметно более
высоком уровне сложности по отношению к традиционным объектам в ООП и
использующий их для достижения своих целей путем управления, изменяющего их
состояния. Соответственно минимальный набор базовых характеристик произвольного
агента включает такие свойства как:
активность, способность к
организации и реализации действий;
автономность (полуавтономность),
относительная независимость от окружающей среды или наличие некоторой “свободы
воли”, связанное с хорошим ресурсным обеспечением его поведения;
общительность, вытекающая из
необходимости решать свои задачи совместно с другими агентами и обеспечиваемая
развитыми протоколами коммуникации;
целенаправленность, предполагающая
наличие собственных источников мотивации, а в более широком плане, специальных
интенциональных характеристик.
Соответственно, если рассмотреть
систему абстрактных полярных шкал типа “пассивный - активный”, “реактивный -
целенаправленный”, “зависимый - автономный” и поместить на них объекты и
агенты, то интуитивно ясно, что объекты будут находиться на левых полюсах, а
агенты должны быть расположены правее, ближе к полюсам “активный”,
“целенаправленный”, “автономный”. Сдвинутое к правым полюсам промежуточное
положение агентов на указанных шкалах показывает достигнутый уровень
субъектности в искусственной системе.
Агентно-ориентированный подход к
программированию - разновидность представления программ, или парадигма
программирования, в которой основополагающими концепциями являются понятия
агента и его ментальное поведение, которое зависит от среды, в которой он
находится.
Концепция агентов подразумевает
обращение к ряду новых для специалистов по ИИ понятий из психологии и
социологии, и, в первую очередь, понятий из теории деятельности и теории
коммуникации. При этом деятельность и интеллект понимаются как процессы,
рекурсивно зависящие друг от друга, что обеспечивает их порождение и
реализацию. Интеллект агента выступает как подсистема управления деятельностью,
позволяющая ему организовать и регулировать свои действия или действия другого
агента. В то же время, интеллект имеет коммуникативную природу и формируется в
процессах взаимодействия (коммуникации) агента с другими агентами, а
потребность в коммуникации связана с реализацией целенаправленной деятельности.
Под интеллектуальными агентами в
информатике и ИИ понимаются любые физические или виртуальные единицы:
способные действовать на объекты в
некоторой среде, на других агентов, а также на самих себя (действие);
способные общаться с другими
агентами (общение);
исходящие из некоторых потребностей
и способные к целеобразованию (потребностно-целевая основа);
обладающие набором интенциональных
характеристик (убеждения, желания, намерения и пр.);
несущие определенные обязанности и
предоставляющие ряд услуг (наличие обязательств);
обладающие собственными ресурсами,
обеспечивающими их автономию (автономия);
способные к восприятию среды
(восприятие с ограниченным разрешением);
способные строить частичное
представление этой среды на основе ее восприятия, т.е. перцептивных навыков и
умений (локальное представление среды);
способные к обучению, эволюции и
адаптации (эволюционный и адаптационный потенциал);
способные к самоорганизации и
самовоспроизведению (самосохранение). [1]
Точное определение агента на
сегодняшний день отсутствует. В основном используется определение, принятое на
конференции международной ассоциации по лингвистике FIRA (Federation of Intelligent
Physical Agents) в октябре 1996 года в Токио: "Агент - это сущность,
которая находится в некоторой среде, интерпретирует их и исполняет команды,
воздействующие на среду. Агент может содержать программные и аппаратные
компоненты.
Отсутствие четкого определения мира
агентов и присутствие большого количества атрибутов, с ним связанных, а также
существование большого разнообразия примеров агентов говорят о том, что агенты
- это достаточно общая технология, которая аккумулирует в себе несколько различных
областей". Агент - это программный модуль, способный выполнять
определенные ему функции или функции другого агента (человека, чьи функции он
воспроизводит).
.3 Классификация агентов
Фактически, используя понятие
"агент", каждый автор или сообщество определяют своего агента с
конкретным набором свойств в зависимости от целей разработки, решаемых задач,
техники реализации, критериев. Как следствие, в рамках данного направления
появилось множество типов агентов, например: автономные агенты, персональные
ассистенты, интеллектуальные агенты, социальные агенты и т.д. А в зависимости
от степени возможности внутреннего представления внешнего мира и способа
поведения агенты классифицируются как локальные, сетевые, мобильные,
интерфейсные, транслирующие, маршрутизации и т.д.
Таблица 2.1 Пример классификации
агентов
|
Характеристики
|
Простые агенты
|
Смышленые агенты
|
Интеллектуальные агенты
|
|
Автономное выполнение
|
+
|
|
+
|
|
Взаимодействие с другими агентами и/или пользователями
|
+
|
+
|
+
|
|
Слежение за окружением
|
+
|
+
|
+
|
|
Способность использования абстракций
|
|
+
|
+
|
|
Способность использования предметных знаний
|
|
+
|
+
|
|
Возможность адаптивного поведения для достижения целей
|
|
|
+
|
|
Обучение из окружения
|
|
|
+
|
Как следует из приведенной таблицы,
собственно целесообразное поведение появляется только на уровне
интеллектуальных агентов. Для него необходимо не только наличие целей
функционирования, но и возможность использования достаточно сложных знаний о
среде, партнерах и о себе. Можно предложить немало различных оснований для
построения классификаций агентов.
В целом, типология агентов тесно
связана с классической проблемой взаимодействия “субъект - объект”. Уровень
субъектности агента непосредственно зависит от того, наделен ли он символьными
представлениями, требующимися для организации рассуждений, или в
противоположность этому он работает только на уровне образов (субсимвольном),
связанных с сенсомоторной регуляцией. Соответствующую классификацию агентов
можно построить по степени развития внутреннего представления о внешнем мире.
По этому признаку, выделяются
интеллектуальные (когнитивные, рассудочные) и реактивные агенты.
Реактивные агенты, имеющие довольно
ограниченное внутреннее представление внешней среды (или не имеющие его вовсе),
обладают очень ограниченным диапазоном предвидения. Они практически не способны
планировать свои действия, поскольку реактивность в чистом виде означает такую
структуру обратной связи, которая не содержит механизмов прогноза. Реактивные
агенты, как это видно из самого их названия, работают в основном на уровне
стимульно-реактивных связей, обладая очень бедной индивидуальностью и сильной
зависимостью от внешней среды (сообщества агентов).
Когнитивные агенты обладают более
богатым представлением внешней среды, чем реактивные. Это достигается за счет
наличия у них базы знаний и механизма решения. Близкий термин “рассудочный”
агент служит для обозначения агента, который обладает символьной моделью
внешнего мира, а также возможностью принимать решения на основе символьных
рассуждений, например, метода сравнения по образцу. Когнитивные агенты,
благодаря развитым внутренним представлениям внешней среды и возможностям
рассуждений, могут запоминать и анализировать различные ситуации, предвидеть
возможные реакции на свои действия, делать из этого выводы, полезные для
дальнейших действий и, в результате, планировать свое поведение. Именно
интеллектуальные способности позволяют таким агентам строить виртуальные миры,
работая в которых они формируют планы действий. Когнитивные агенты имеют ярче
выраженную индивидуальность, будучи более автономными, чем реактивные, и
характеризуются развитым целесообразным поведением в сообществе агентов,
достаточно не зависимым от других агентов.
Когнитивные агенты, благодаря их
сложности, наличию знаний и способностей к рассуждениям о своем поведении и
внешней среде могут работать относительно независимо, демонстрируя достаточно
гибкое поведение. Но та же сложность автономных агентов, выливающаяся в
способность противиться внешним воздействиям, вызывает определенные трудности
при организации их эффективного взаимодействия. Поэтому в составе MAC,
построенной из интеллектуальных агентов, как правило, присутствует около 5 - 10
автономных единиц.
Наоборот, довольно простая структура
реактивных агентов, обусловливает их жесткую зависимость от среды.
Следовательно, их возможности сравнительно невелики, когда они функционируют в
одиночку и ограничены своими собственными ресурсами. Однако им легче образовать
группу или организацию, способную гибко адаптироваться к изменениям среды под
действием механизма естественного отбора. Поэтому реактивные агенты
представляют интерес не на индивидуальном, а на коллективном уровне, причем их
способности к адаптации и развитию возникают в результате локальных
взаимодействий. Таким образом, реактивные агенты, которые почти не имеют
индивидуальности, растворяются в общей массе, но за счет своего большого числа
и избыточности они могут решать сложные задачи. В пределе, соответствующие MAC
могут формироваться в результате взаимодействий без точного определения отдельных
агентов. Подобные “рои”, состоящие из значительного числа реактивных агентов,
можно сравнить с неким сверхорганизмом, взаимная адаптация и кооперация клеток
которого позволяет создать общую цепь обратной связи, обеспечивающую
гомеостазис всей системы.
Таблица 2.2 Сравнительный анализ
свойств когнитивных и реактивных агентов
|
Характеристики
|
Когнитивные агенты
|
Реактивные агенты
|
|
Внутренняя модель внешнего мира
|
Развитая
|
Примитивная
|
|
Рассуждения
|
Сложные и рефлексивные рассуждения
|
Простые одношаговые рассуждения
|
|
Мотивация
|
Развитая система мотивации, включающая убеждения, желания,
намерения
|
Простейшие побуждения, связанные с выживанием
|
|
Память
|
Есть
|
Нет
|
|
Реакция
|
Медленная
|
Быстрая
|
|
Адаптивность
|
Малая
|
Высокая
|
|
Модульная архитектура
|
Есть
|
Нет
|
|
Состав MAC
|
Небольшое число автономных агентов
|
Большое число зависимых друг от друга агентов
|
Из сопоставления характеристик
когнитивных и реактивных агентов видно, что синергетические автономные агенты
должны обладать гибридной архитектурой, сочетающей достоинства реактивных и
когнитивных агентов. В этом плане налицо тенденция построения интегрированных
архитектур агентов, аналогичная современным вариантам интеграции логических и
нейросетевых моделей в ИИ.
В сообществе специалистов по MAC как
одна из перспективных моделей рассматривается модель самообучающегося агента.
Однако при этом делаются ссылки на результаты в области извлечения знаний и
машинного обучения, полученные ранее в ИИ применительно к экспертным системам.
Очевидно, что применительно к MAC задача обучения имеет свои особенности,
которые пока не учитываются. Весьма специфична и задача обучения агентов
коллективному поведению, поскольку кооперативное решение проблем подразумевает
совместное использование знаний нескольких агентов.
.4 Архитектура агента
Архитектуры агентов классифицируются
в зависимости от вида структуры, наложенной на функциональные компоненты агента
и принятых методов организации взаимодействия его компонент в процессе работы.
Базовая классификация архитектур
агентов основывается на парадигме, лежащей в основе принятой архитектуры. По
этому признаку различают два основных класса архитектур:
архитектура, которая базируется на
принципах и методах классического ИИ, т.е. систем, основанных на знаниях
(“архитектура разумного агента”),
архитектура, основанная на поведении
или “реактивная архитектура”, которая исходит из реакций системы на события
внешнего мира.
Только самые простые приложения
агентов могут быть реализованы по одноуровневой схеме. Как правило, архитектура
агента организуется в виде нескольких уровней. Как правило, уровни представляют
различные функциональные характеристики агентов, такие, как восприятие внешних
событий и простые реакции на них; поведение, управляемое целями; координация
действий с поведением других агентов; обновление внутреннего состояния агента,
т.е. убеждений о внешнем мире; прогнозирование состояний внешнего мира;
определение своих действий на очередном шаге и др.
Наиболее часто в архитектуре агента
присутствуют уровни, ответственные за:
а) восприятие и исполнение действий;
б) реактивное поведение;
в) локальное планирование;
г) кооперативное поведение;
д) моделирование внешней среды;
е) формирование намерений;
ж) обучение агента.
.5 Кооперация агентов
Идея многоагентности предполагает
кооперацию агентов при коллективном решении задач. В MAC агент, который не
способен решить некоторую задачу самостоятельно, может обратиться к другим
агентам. Другой вариант, когда необходима кооперация - это использование
коллектива агентов для решения общей трудной задачи. При этом агенты могут
строить планы действий, основываясь уже не только на своих возможностях, но и
“думая” о планах и намерениях других агентов. Известно, что коллективы даже
простейших автоматов, в которых каждый автомат преследует только свои примитивные
цели, в целом способны решать очень сложные задачи. В качестве иллюстрации
можно взять, например, пчелиный улей или муравейник. Можно надеяться, что
система, в которой агенты могут учитывать планы и интересы других агентов,
будет являться во многих случаях еще более гибкой.
В настоящее время предложено
множество различных моделей коллективного поведения агентов. Как правило,
каждая из моделей концентрирует внимание на нескольких аспектах такого
поведения и рассматривает проблемы в соответствии с выбранной архитектурой
(моделью) самого агента. Для знаний, отвечающих за коллективное поведение, в
архитектуре агента обычно выделяют специальный уровень - уровень кооперации.
Существуют две основные модели
взаимодействия агентов:
Одноуровневая архитектура - агенты
не образуют иерархии и решают общую задачу в распределенной организационной
структуре.
Иерархическая архитектура -
координация распределенного функционирования агентов в той или иной мере
поддерживается специально выделенным агентом, который при этом понимается как
находящийся на метауровне по отношению к остальным агентам.
Рассмотрим простейший вариант
иерархической организации взаимодействия агентов, который предполагает
использование хотя бы одного агента “метауровня”, осуществляющего координацию
распределенного решения задач агентами.
Агент-Координатор может быть
привязан к конкретному серверу, и тогда он называется “местом встречи агентов”.
Таким образом, место встречи агентов (АМР -Agent Meeting Place) - это по сути
дела агент, играющий роль брокера между агентами, запрашивающими некоторые
требующиеся им ресурсы, и агентами, которые эти ресурсы могут предоставить.
Поэтому архитектура АМР есть архитектура обычного агента, дополненная
некоторыми вспомогательными компонентами, характеризующими функции координатора
взаимодействия других агентов. Вспомогательные компоненты должны, с одной
стороны, содержать единое описание множества доступных через АМР агентов и их
возможностей (ресурсов, функций и пр.) а, с другой стороны, организовать
унифицированный доступ к ним. Это обеспечивается следующими компонентами АМР:
Объекты базовых сервисов (в
частности, это могут быть удаленный вызов объектов, упорядочение объектов,
дублирование объектов и другие базовые возможности), которые обычно
поддерживаются той или иной платформой открытой распределенной обработки.
Связные порты, ответственные за
прием и отправку агентов в АМР с помощью соответствующих протоколов.
Компонента установления подлинности
агента по имени (опознание агента, “авторизация”).
Администратор, выполняющий функции
проверки полномочий поступающего агента, контроля наличия на АМР запрашиваемой
услуги, оказания помощи агенту в выборе дальнейшего маршрута перемещения и др.
Поверхностный маршрутизатор, который
выполняет функции интерфейса между агентами и компонентами АМР, которые сами по
себе регистрируются в этом маршрутизаторе; он поддерживает ограниченный словарь
для удовлетворения агентских запросов.
Глубинный маршрутизатор, который
используется при более специальных или сложных запросах.
Лингвистический журнал, который
представляет собой базу данных, помогающую агентам и АМР понимать друг друга в
процессе коммуникаций. В нем регистрируются словари и языки, но не описания
языков или смысл терминов, а лишь ссылки на них, т.е. журнал предоставляет
информацию о том, что может быть понято в АМР.
Менеджер ресурсов; он регистрирует
агентов на АМР и связанные с ними ресурсы, а также управляет ресурсами АМР.
Среда реализации агента, которая
регистрируется в АМР и управляет доступом к компонентам агента; она
интерпретирует сценарии, обеспечивает доступ к базовым возможностям и др.
Система доставки событий
(источниками событий могут быть локальные средства, резидентные агенты АМР и
др.); система регистрирует события и выполняет поиск агентов для соответствующего
типа событий, сообщений. [1]
.6 Платформа для разработки
мультиагентных систем JADE
- это платформа разработки
мультиагентных систем. Она удовлетворяет спецификациям FIPA. Jade включает в
себя:
Динамическую среду, где JADE агенты
могут "жить"; она должна быть активна на принимающем хосте до того,
как на нём будут запущены один или более агентов.
Библиотеку классов, которую
программисты могут использовать (прямо или опосредованно) для разработки своих
агентов.
Набор графических инструментов,
позволяющий управлять и следить за активностью запущенных агентов.
Каждая запущенная динамическая среда
JADE называется контейнером и может содержать несколько агентов. Набор активных
контейнеров называется платформой. Единственный специальный контейнер - главный
(Main) должен всегда быть активным на платформе: все остальные контейнеры
регистрируются и связываются с ним в момент запуска. Отсюда следует, что первым
контейнером при старте платформы должен быть главный, а все остальные
контейнеры должны быть "нормальными" (т.е. не главными) контейнерами
и должны заранее "знать", как найти (то есть иметь данные о хосте и
порте) главный контейнер (на котором они будут регистрироваться).
Помимо возможности приёма
регистраций от других контейнеров, главный контейнер отличается от обычного
контейнера тем, что содержит два специальных агента (AMS и DF).(система
управления агентами) обеспечивает службу именования (то есть гарантирует, что
каждый клиент на платформе обладает уникальным именем) и осуществляет управление
на платформе (например, можно создавать и ликвидировать агентов на удалённом
контейнере по запросу AMS). (Координатор каталога) предоставляет сервис
"Жёлтые страницы", с помощью которого агент может искать других
агентов, предоставляющих услуги, которые нужны данному агенту для достижения
целей. Сервис «Жёлтых страниц» позволяет агентам опубликовать данные об одном
или более сервисах, которые они предоставляют, так, что другие агенты могут
находить и успешно использовать эти сервисы.
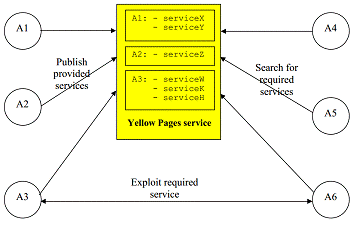
Рисунок 2.6.1 - Сервис «жёлтых
страниц» в JADE
точки зрения платформы, агент JADE -
обычный экземпляр определяемого пользователем Java-класса, который расширяет
класс Agent, реализованный в платформе. Из этого следует, что базовый набор действий
агента, необходимый для функционирования внутри платформы определен изначально.
Для отработки реакции на события
агент имеет поведения. Агент может отрабатывать несколько поведений
одновременно. Обработка поведений происходит не по приоритетам (как java
потоки), а совместно. Очередность исполнения отдельных простых поведений не
гарантируется, для этого нужно использовать поведения специальных типов или
синхронизацию. В Jade реализованы следующие типы поведений агента:
простое поведение:
единожды исполняемое поведение;
циклически исполняемое поведение;
сложное поведение:
последовательное поведение;
параллельное поведение.
Поведения, как и сам агент, являются
Java-классами, следовательно, в процессе разработки программист имеет возможность
комбинировать существующие типы поведений и наполнять их необходимым
функционалом.

Рисунок 2.6.2 - Модули агента Jade
Одной из наиболее важных
особенностей, которую JADE агенты представляют - это возможность коммуникации.
Коммуникационной парадигмой принято называть сообщение асинхронного
прохождения. Каждый агент имеет почтовый ящик (очередь сообщений агента), куда
среда выполнения JADE передает сообщения, отправленные другими агентами. Всякий
раз, когда сообщение поступает в очереди сообщений, получающий его агент
уведомляется. Однако процесс, когда агент на самом деле вынимает сообщения из
очереди сообщений, полностью лежит на плечах программиста.
Обмен сообщениями JADE агентами
имеет формат специфицированного языка ACL и определяется FIPA (The Foundation
for Intelligent Agent) как международный стандарт для взаимодействий агентов.
Этот формат включает в себя целый ряд пунктов, в частности:
Отправитель сообщения
Список получателей
Коммуникативные намерения, указывающие
на то, что отправитель намерен достичь отправкой сообщения.
Содержание, т.е. фактически
информация, содержащаяся в сообщении
Язык, т.е. синтаксис используемый
для передачи содержания (и отправитель, и получатель должны быть в состоянии
кодировать/разбирать выражения с этим синтаксисом, чтобы общение было
эффективным).
Онтология, т.е. словарь символов,
используемых в содержании и их значение (и отправитель, и получатель должны
приписывать символам одинаковый смысл, чтобы общение было эффективным).
Некоторые поля, используемые для
контроля над несколькими одновременными разговорами и указанный перерыв для
получения ответа. Например, conversation-id, reply-with, in-reply-to, reply-by.
Для обеспечения контроля за
разработко многоагентной системы могут быть использованы специальные системные
агенты:
Sniffer Agent - отслеживание потока
сообщений между агентами;
Dummy Agent - отправка сообщения
агенту;
Introspector Agent - мониторинг
жизненного цикла агента;
Remote Monitoring Agent - мониторинг
платформы. [3]
.7 Создание прототипа
интеллектуального агента
Используя платформу Jade создадим
прототип интеллектуального агента. Для этого используем следующий подход:
наделим простого Jade-агента возможностью работать с семантической базой знаний
в формате OWL. Для этой интеграции используем следующие два фреймворка:
OWL API;
Jena Semantic Web
Framework.
Для адекватной интеграции агента и
базы знаний, агент должен быть способен выполнять следующие простые операции:
получение сведений из базы знаний;
запись новых знаний в базу знаний;
выполнение запросов к базе знаний.
Рисунок 2.6.3 - Консоль управления
агентами Jade
Диаграмма классов прототипа
интеллектуального агента приведена в Приложении Б, а исходные коды когнитивного
агента находятся в Приложении В.
3. Технико-экономическое обоснование
разработки базы знаний
.1 Характеристика программного
продукта
Прототип многоагентной системы
взаимодействующей с базой знаний демонстрирует новую концепцию, известную как
семантическая паутина.
Разработка и внедрение онтологий
позволит:
программам-клиентам непосредственно
извлекать из всемирной сети факты и делать из них логические заключения, что
обеспечит качественно новый уровень обработки информации;
значительно повысит эффективность
автоматической обработки информации интеллектуальными агентами.
Экономическая целесообразность
инвестиций в разработку и использование программного продукта осуществляется на
основе расчета и оценки следующих показателей:
− чистая дисконтированная стоимость
(ЧДД);
− срок окупаемости инвестиций
(ТОК);
− рентабельность инвестиций
(РИ).
В результате разработки данного
программного продукта информация будет обрабатываться автоматически, что и
будет являться результатом от внедрения программного продукта.
.2 Расчет затрат и отпускной цены
программного средства
. Основная заработная плата
исполнителей проекта определяется по формуле
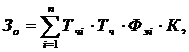
где n - количество
исполнителей, занятых разработкой ПС;Чi - часовая тарифная ставка i-го
исполнителя (руб.);
ФЭi - эффективный фонд
рабочего времени i-го исполнителя (дней)
ТЧ - количество часов
работы в день (ч);
К - коэффициент
премирования (1,5).
В настоящий момент
тарифная ставка 1-го разряда на предприятии составляет 700 000 руб.
Расчет основной
заработной платы представлен в табл. 4.1.
Таблица 3.1 - Расчет
основной заработной платы
|
Исполнитель
|
Раз-ряд
|
Тарифный коэф.
|
Месячная тарифная ставка, руб.
|
Часовая тарифная ставка, руб.
|
Плано-вый фонд рабочего времени, дн.
|
Заработная плата, руб.
|
|
Программист 2-й категории
|
10
|
2,84
|
1988000
|
11 694
|
180
|
25 259 294
|
|
Программист 1-ой категории
|
12
|
3,25
|
2275000
|
13 382
|
200
|
32 117 647
|
|
Ведущий программист
|
15
|
3,48
|
2436000
|
14 329
|
220
|
37 829 647
|
|
Начальник лаборатории
|
16
|
3,72
|
2604000
|
15 318
|
150
|
27 571 765
|
|
Основная заработная плата
|
|
|
|
|
|
122 778 353
|
. Дополнительная заработная плата
исполнителей проекта определяется по формуле
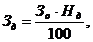
где НД - норматив
дополнительной заработной платы (20%)
Дополнительная
заработная плата составит:
ЗД = 122 778
353*20/100=24 555 671 руб.
. Отчисления в фонд
социальной защиты населения и на обязательное страхование (ЗС) определяются в
соответствии с действующими законодательными актами по формуле
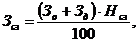
где НСЗ - норматив
отчислений в фонд социальной защиты населения и на обязательное страхование
(34% +0,6%).
ЗСЗ = (122 778 353+24
555 671) ·34,6/100=50 977 572 руб.
. Расходы по статье
«Машинное время» (РМ) включают оплату машинного времени, необходимого для
разработки и отладки ПС, и определяются по формуле:
РМ = ЦМ*ТЧ*СР
где ЦМ - цена одного
машино-часа;
ТЧ - количество часов
работы в день;
СР - длительность
проекта.
Стоимость машино-часа на
предприятии составляет 6 000 руб. Разработка проекта займет 220 дней Определим
затраты по статье “Машинное время”:
РМ = 6000·8·220=10 560
000 руб.
5. Затраты по статье
«Накладные расходы» (РН), связанные с необходимостью содержания аппарата
управления, вспомогательных хозяйств и опытных (экспериментальных) производств,
а также с расходами на общехозяйственные нужды (РН), определяются по формуле
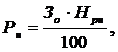
где НРН - норматив
накладных расходов (50%).
Накладные расходы
составят:
Рн = 122 778 353·0,5 =
61 389 176 руб.
Общая сумма расходов по
всем статьям сметы (СР) на ПО рассчитывается по формуле:
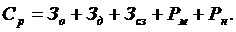
СР = 122 778 353 + 24
555 671 + 50 977 572 + 10 560 000 + 61 389 176 = 270 260 772 руб.
Кроме того,
организация-разработчик осуществляет затраты на сопровождение и адаптацию ПС
(РСА), которые определяются по нормативу (НРСА)
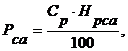
где НРАС - норматив
расходов на сопровождение и адаптацию (20%).
СР - смета расходов в
целом по организации без расходов на сопровождение и адаптацию (руб.).
РСА = 270 260 772 *
20/100= 54 052 154 руб.
Общая сумма расходов на
разработку (с затратами на сопровождение и адаптацию) как полная себестоимость
ПС (СП) определяется по формуле
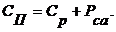
СП = 270 260 772 + 54
052 154 = 324 312 926 руб.
Прибыль ПС
рассчитывается по формуле
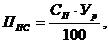
где ППС - прибыль от
реализации ПС заказчику (руб.);
УР - уровень
рентабельности ПС (25%);
СП - себестоимость ПС
(руб.).
ППС = 324 312 926*25/100
= 81 078 231 руб.
Прогнозируемая отпускная
цена ПС
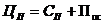 .
.
ЦП = 324 312 926 + 81
078 231 = 405 391 157 руб.
.3 Расчет стоимостной
оценки результата
Результатом (Р) в сфере
использования программного продукта является прирост чистой прибыли и
амортизационных отчислений.
3.3.1 Расчет прироста чистой
прибыли
Прирост прибыли за счет
экономии расходов на заработную плату в результате автоматического выполнения
работ машинами, ранее выполняемых автоматизированно с участием оператора.
. Экономия затрат на
заработную плату при использовании ПС в расчете на объем выполняемых работ
определяется по формуле:
ЭЗ = КПР *(tс • ТС - tн
• Тн) • NП • (1 + НД/100)*(1+ННО/100),
где NП - плановый объем
работ;, tH - трудоемкость выполнения работы до и после внедрения программного
продукта, нормо-час;
ТС, ТН - часовая
тарифная ставка, соответствующая разряду выполняемых работ до и после внедрения
программного продукта, руб./ч (8000 руб.);
КПР - коэффициент
премий, (1,5);
НД - норматив
дополнительной заработной платы, (20%);
ННО - ставка отчислений
от заработной платы, включаемых в себестоимость, (34,6%).
До внедрения
программного продукта трудоемкость работы операторов составляла 1,3
человека-часа, после внедрения системы - 0 человека-часа. Пусть в год система
проводит около 10 000 запросов-транзакций.
Экономия на заработной
плате и начисления на заработную плату составит
ЭЗ=1,5*(1,3*8000-0*8000)*10
000*(1,2)*1,346 = 251 971 200 руб.
Прирост чистой прибыли (ΔПЧ)
определяется по формуле:
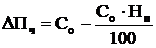 ,
,
где НП - ставка налога
на прибыль, (18%);- общая готовая экономия текущих затрат.
Таким образом, прирост
чистой прибыли составит
DПЧ = 251 971 200 - 251
971 200*18/100 = 206 616 384 руб.
.3.2. Расчет прироста
амортизационных отчислений
Расчет амортизационных
отчислений осуществляется по формуле:
А = НА* З/100
где З - затраты на
разработку программы, руб.;
НА - норма амортизации
программного продукта, (20%);
А = 324 312 926 *0,2 =
64 862 585 руб.
.4 Расчет показателей
эффективности использования программного продукта
Для расчета показателей
экономической эффективности использования программного продукта необходимо
полученные суммы результата (прироста чистой прибыли) и затрат (капитальных
вложений) по годам приводят к единому времени - расчетному году (за расчетный
год принят 2013 год) путем умножения результатов и затрат за каждый год на
коэффициент приведения (ALFAt), который рассчитывается по формуле:
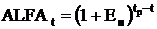 ,
,
где ЕН - норматив
приведения разновременных затрат и результатов;Р - расчетный год, tР = 1;- номер
года, результаты и затраты которого приводятся к расчетному (2013-1, 2014-2,
2015-3, 2016-4).
ЕН = 40%
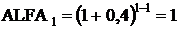 (2013 год);
(2013 год);
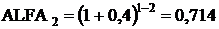 (2014 год);
(2014 год);
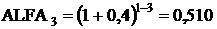 (2015 год);
(2015 год);
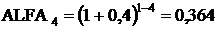 (2016 год);
(2016 год);
Результаты расчета
показателей эффективности приведены в таблице 3.2.
интеллектуальный база
знание онтология
Таблица 3.2 −
Расчет экономического эффекта от использования нового ПС
|
Наименование показателей
|
Ед. изм.
|
Усл. обозн.
|
По годам производства
|
|
|
|
1-й
|
2-й
|
3-й
|
4-й
|
|
Результат
|
|
|
|
|
|
|
|
1. Прирост чистой прибыли
|
руб.
|
∆ 206
616 384206 616 385206 616 386206 616 387 206
616 384206 616 385206 616 386206 616 387
|
|
|
|
|
|
2. Прирост амортизационных отчислений
|
руб.
|
∆А
|
64 862 585
|
64 862 585
|
64 862 585
|
64 862 585
|
|
2. Прирост результата
|
руб.
|
∆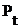 271
478 969271 478 970271 478 971271 478 972 271
478 969271 478 970271 478 971271 478 972
|
|
|
|
|
|
3.Коэффициент дисконтирования
|
руб.
|
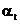 10,7140,5100,364 10,7140,5100,364
|
|
|
|
|
|
4. Результат с учетом фактора времени
|
руб.
|
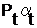 271
478 969193 835 985138 454 27598 818 346 271
478 969193 835 985138 454 27598 818 346
|
|
|
|
|
|
Затраты (инвестиции)
|
руб.
|
|
|
|
|
|
|
5. Инвестиции в разработку программного продукта
|
руб.
|
Иоб
|
405 391 157
|
|
|
|
|
6. Инвестиции с учетом фактора времени
|
руб.
|
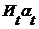 405
391 157 405
391 157
|
|
|
|
|
|
7. Чистый дисконтированный доход по годам (п.4 - п.6)
|
руб.
|
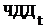 -133
912 188193 835 985138 454 27598 818 346 -133
912 188193 835 985138 454 27598 818 346
|
|
|
|
|
|
8. ЧДД нарастающим итогом
|
руб.
|
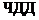 -133
912 18859 923 797198 378 072297 196 418 -133
912 18859 923 797198 378 072297 196 418
|
|
|
|
|
Рассчитаем рентабельность инвестиций
в разработку и внедрение программного продукта (РИ) по формуле
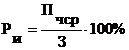 ,
,
где 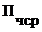 -
среднегодовая величина чистой прибыли за расчетный период, руб., которая
определяется по формуле
-
среднегодовая величина чистой прибыли за расчетный период, руб., которая
определяется по формуле
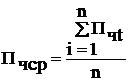 ,
,
где  -
чистая прибыль, полученная в году t, руб.
-
чистая прибыль, полученная в году t, руб.
ПЧСР = (826 465 536) /
4= 206 616 386 руб.
РИ = 206 616 386 / 405
391 157*100% = 50,96%
В результате
технико-экономического обоснования применения программного продукта были
получены следующие значения показателей их эффективности:
. Чистый дисконтированный
доход за четыре года работы системы составит 297 196 418 руб.
. Затраты на разработку
программного продукта окупятся на второй год его использования.
. Рентабельность
инвестиций составляет 50,96%.
Таким образом,
применение программного продукта является эффективным и инвестиции в его
разработку целесообразно осуществлять.
4. Охрана труда. Тема:
Безопасная организация трудового процесса пользователей и разработчиков
интеллектуальных информационных систем
Разрабатываемая
интеллектуальная информационная система предполагает интенсивное использование
умственного труда.
Умственный труд
объединяет работы, связанные с приемом и переработкой информации, требующей
преимущественно напряжения сенсорного аппарата, внимания, памяти, а также
активизации процессов мышления, эмоциональной сферы. Для данного вида труда
характерна гипокинезия, т. е. значительное снижение двигательной активности
человека, приводящее к ухудшению реактивности организма и повышению
эмоционального напряжения. Гипокинезия является одним из условий формирования
сердечно-сосудистой патологии у лиц умственного труда.
Напряженность
умственного труда характеризуется эмоциональной нагрузкой на организм.
Длительная умственная нагрузка оказывает угнетающее влияние на психическую
деятельность: ухудшаются функции внимания (объем, концентрация, переключение),
памяти (кратковременной и долговременной), восприятия (появляется большое число
ошибок). [6]
В связи с очень высокой
напряженностью умственного труда пользователей и разработчиков интеллектуальных
информационных систем следует обратить внимание на психические процессы,
свойства и состояния, влияющие на безопасность труда.
Чрезмерные, или
запредельные, формы психического напряжения вызывают нарушения нормального
психологического состояния человека, что приводит к снижению индивидуального,
свойственного человеку уровня психической работоспособности. В более выраженных
формах психического напряжения снижается скорость зрительных и двигательных
реакций человека, нарушается координация движений, могут появляться негативные
формы поведения и другие отрицательные явления. Запредельные формы психического
напряжения лежат в основе ошибочных действий операторов в сложной обстановке.
В зависимости от
преобладания возбудительного или тормозного процесса можно выделить два типа
запредельного психического напряжения - тормозной и возбудимый.
Тормозной тип -
характеризуется скованностью и замедленностью движений. Работник не способен с
прежней ловкостью и скоростью производить профессиональные действия. Снижается
скорость ответных реакций. Замедляется мыслительный процесс, ухудшается память,
появляется рассеянность и другие отрицательные признаки, не свойственные
данному человеку в спокойном состоянии.
Возбудимый тип -
проявляется в виде повышенной активности, многословности, нарушений координации
движений тела, дрожания голоса. Операторы совершают многочисленные, излишние,
ненужные действия. В общении с окружающими они обнаруживают раздражительность,
вспыльчивость, не свойственную им резкость, грубость, обидчивость.
Контроль психического
состояния персонала ответственных работ и принятие административных мер может
положительно влиять на сокращение травматизма и повышение надежности работ
сложных систем. [7]
На безопасность
трудового процесса особое влияние оказывает употребление лекарственных и
алкогольных веществ.
Прием легких
стимуляторов (чай, кофе) способствует повышению работоспособности, а прием
активных стимуляторов (первитин, фенамин) вызывает серьёзный отрицательный
эффект - ухудшение самочувствия, снижение скорости реакции и др.
Употребление
транквилизаторов типа седуксен или элениум оказывает выраженное успокоение и
предупреждение неврозов, одновременно снижая психическую активность, замедляет
реакцию, а также вызывает апатию и сонливость.
Употребление алкоголя
снижает работоспособность человека, при этом возрастает опасность несчастного
случая из-за действия алкоголя на физиологические и психические функции
человека. [8]
Рассмотрим основные
психологические причины травматизма и способы их профилактики.
Причинами возникновения
опасных ситуаций, связанных с травмами, могут являться нарушения правил и
инструкций по безопасности, а также нежелание или неспособность выполнять
требования безопасности. В основе этих причин травматизма лежат психологические
причины.
Психологические причины
возникновения опасных ситуаций можно подразделить на несколько типов:
. Нарушение
мотивационной части действий человека, которое проявляется в нежелании
действия, обеспечивающего безопасность. Эти нарушения возникают, если человек недооценивает
опасность, склонен к риску, критически относится к техническим рекомендациям,
обеспечивающим безопасность. Причины этих нарушений действуют, как правило, в
течение длительного времени или постоянно, если не принять специальных мер для
их устранения.
Нарушения мотивационной
части действий могут иметь временный характер, связанный, например, с
состоянием депрессии или алкогольного опьянения.
. Нарушение
ориентировочной части действий человека, которое проявляется в незнании норм и
способов обеспечения безопасности, правил эксплуатации оборудования.
. Нарушение
исполнительной части действий человека, которое проявляется в невыполнении
правил и инструкций по безопасности из-за несоответствия психофизических
возможностей человека требованиям данной работы.
Такое подразделение
психофизиологических (психофизических) причин позволяет наметить основные
способы их устранения.
Для устранения причин
нарушений мотивационной части необходимо следовать рекомендациям по обеспечению
мер безопасности.
Для устранения причин
ориентировочной части - обучение, выработка навыков и приемов соблюдения
безопасных действий.
Для устранения причин
исполнительной части - профессиональный отбор, периодические медицинские
освидетельствования, особенно для сложных, ответственных и опасных видов
трудовой деятельности.
Следует отметить, что
травматизм зависит от возраста работника. Наибольший уровень травматизма
наблюдается у молодых работников и у лиц, имеющих стаж более 15 - 20 лет.
Наивысший уровень
травматизма у молодых специалистов имеет место в первый год работы. Это связано
с профессиональной неопытностью, недостатком знаний, неумением правильно
диагностировать возникающие нарушения и опасную ситуацию, находить правильные
решения, отсутствием выработанных до автоматизма навыков и действий в опасной
ситуации. Часто психологической причиной повышенного травматизма являются
обстоятельства связанные с недооценкой опасности, повышенным риском,
необдуманными поступками.
Повышенный уровень
травматизма у опытных специалистов связан с возрастным снижением
психологических и физиологических функций организма (остроты зрения, быстроты
реакции, координации движений, памяти и т. д.), а также с привыканием к
опасности. Если человек в течение длительного времени не подвергался
воздействию опасного фактора, у него формируется представление о безопасности
процесса. В результате привыкания снижается уровень внимания и контроля за
работой оборудования.
Психологические причины
формирования опасных ситуаций и травматизма на производстве очень разнообразны
и в значительной степени зависят от типа нервной системы человека,
темперамента, образования, воспитания и т. п.
Отдельно перечислим
основные психологические причины осознанного нарушения правил безопасности,
такие как экономия времени и сил, безнаказанность, желание самоутвердиться,
стремление следовать групповым интересам и нормам, ориентация на плохие
примеры, привычка работать с нарушениями, переоценка собственного опыта,
склонность к риску и др.
Перечисленные
психологические причины травматизма должны учитываться при разработке
организационных мероприятий по повышению безопасности труда, при отборе лиц для
выполнения тех или иных видов трудовой деятельности, особенно, если она связана
с повышенной опасностью и ответственностью за жизнь и здоровье других людей.
Один из вероятных как
пользователей, так и разработчиков интеллектуальной информационной системы -
это инженер-программист. Инструкция, характеризующая его трудовой процесс,
включает нижеизложенные пункты.
Инженер-программист
должен знать:
. Руководящие и
нормативные материалы, регламентирующие методы разработки алгоритмов и программ
и использования вычислительной техники при обработке информации.
. Основные принципы
структурного программирования.
. Виды программного
обеспечения.
. Технико-эксплуатационные
характеристики, конструктивны особенности, назначение и режимы работы ЭВМ,
правила ее технической эксплуатации.
. Технологию
автоматической обработки информации и кодирования информации.
. Формализованные языки
программирования
. Действующие стандарты,
системы счислений, шифров и кодов.
. Порядок оформления
технической документации.
. Передовой
отечественный и зарубежный опыт программирования и использования вычислительной
техники.
. Основы экономики,
организации производства, труда и управления.
. Основы трудового
законодательства.
. Правила внутреннего
трудового распорядка.
. Правила и нормы охраны
труда.
Должностные обязанности
инженера-программиста:
. На основе анализа
математических моделей и алгоритмов решения задач разрабатывает программы, для
выполнения алгоритмов и решения поставленных задач средствами вычислительной
техники, проводит их тестирование и отладку.
. Разрабатывает
технологию решения задачи по всем этапам обработки информации.
. Осуществляет выбор
языка программирования для описания алгоритмов и структур данных.
. Определяет информацию,
подлежащую обработке средствами вычислительной техники, ее объемы, структуру,
макеты и схемы ввода, обработки, хранения и вывода, методы ее контроля.
. Выполняет работу по
подготовке программ к отладке и проводит отладку.
. Определяет объем и
содержание данных контрольных примеров, обеспечивающих наиболее полную проверку
соответствия программ их функциональному назначению.
. Осуществляет запуск
отлаженных программ и ввод исходных данных, определяемых условиями поставленных
задач.
. Проводит корректировку
разработанной программы на основе анализа выходных данных.
. Разрабатывает
инструкции по работе с программами, оформляет необходимую техническую
документацию.
. Определяет возможность
использования готовых программных продуктов.
. Осуществляет
сопровождение внедрения программ и программных средств.
. Разрабатывает и
внедряет системы автоматической проверки правильности программ, типовые и
стандартные программные средства, составляет технологию обработки информации.
Следует отметить, что
для обеспечения нормальных условий трудового процесса оператора ЭВМ, ему
следует выделять объем производственного помещения не менее 20 м3. Параметры
помещения рекомендуются следующие: высота зала до подвесного потолка 3-3,5
метра; расстояние между подвесным и основным потолком при этом 0,5 - 0,8 метра.
Площадь на одно рабочее место рекомендуется не менее 6 м2. Рабочие места с ЭВМ
желательно изолировать друг от друга вертикальными перегородками высотой 1,5-2
м. Помещения необходимо оборудовать системами отопления, кондиционирования
воздуха или эффективной приточно-вытяжной вентиляцией и поддерживать в них
следующие климатические условия: температура воздуха - +15 - +21 C0;
относительная влажность воздуха - 50 - 60% без конденсации; вибрация - 0,25 -
55Гц. Освещенность на поверхности стола должна быть 300-500 лк.
Заключение
В соответствии с
выбранной темой была разработана онтологическая база знаний. Затем была
проведена интеграция базы знаний с многоагентной системой. В итоге был получен
прототип интеллектуального агента.
В дипломном проекте были
подробно рассмотрены следующие темы:
Семантическая сеть;
Онтологические базы
знаний;
Многоагентные системы.
Был проведен расчет
экономической эффективности от внедрения многоагентной системы в контексте
полной автоматизации обработки информации в глобальной сети. По результатам
расчетов данная программная система окупается за короткий период времени,
поэтому можно судить о целесообразности его внедрения.
В процессе выполнения
дипломного проекта изучены основные принципы построения интеллектуальных
информационных систем, а также разобрана методология создания подобных систем.
Литература
[1] Гаврилова Т.А. Базы знаний интеллектуальных систем / Т. А.
Гаврилова, В. Ф. Хорошевский СПб.: Питер, 2000. - 382 с.
[2] Онтологии и тезаурусы: модели, инструменты, приложения:
[Электронный ресурс] - Соловьев В.Д., Добров Б.В., Иванов В.В., Лукашевич Н.В.,
- Режим доступа: #"651094.files/image033.gif">
Концептуализация, соответствующая
каждому классификационному дереву, состоит в построении
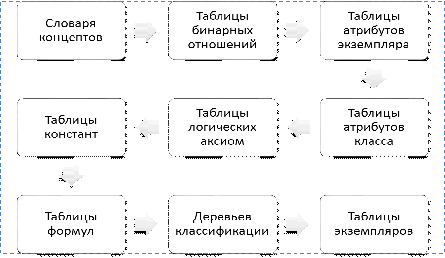
Рис. А.1 - Общая методология
создания онтологий
Приложение Б
(обязательное)
Исходные коды интеллектуального
агента
agentpack;jade.core.Agent;jade.core.behaviours.Behaviour;jade.core.behaviours.CyclicBehaviour;owlapitools.DemoOwlApi;
/**
*
* @author neutrino
*/class AgentReader extends Agent
{void setup() {.out.println("Agent "+getLocalName()+" started.");
// Add the CyclicBehaviour(new
CyclicBehaviour(this) {void action() {.out.println("Cycling");
}
});
// Add the generic behaviour(new
AgentReader.StepBehaviour());
} class StepBehaviour extends
Behaviour {int step = 1;void action() {(step) {1:
// Perform operation
1.out.println("Operation 1");.DemoReadOntToManchesterSyntax();;2:
// Perform operation
2.out.println("Operation 2");.DemoReadOntToXMLSyntax();;3:
// Perform operation
3.out.println("Operation 3");.DemoReadClassOntRef();;4:
// Perform operation
4.out.println("Operation 4");.DemoFindSuperclass();;
}++;
} boolean done() {step == 5;
} int onEnd()
{.doDelete();super.onEnd();
}
}
}agentpack;jade.core.Agent;jade.core.behaviours.Behaviour;jade.core.behaviours.CyclicBehaviour;owlapitools.DemoOwlApi;
/**
*
* @author neutrino
*/class AgentBuilder extends Agent
{void setup() {.out.println("Agent "+getLocalName()+"
started.");
// Add the CyclicBehaviour(new
CyclicBehaviour(this) {void action() {.out.println("Cycling");
}
});
// Add the generic behaviour(new
AgentBuilder.StepBehaviour());
} class StepBehaviour extends
Behaviour {int step = 1;void action() {(step) {1:
// Perform operation
1.out.println("Operation 1");.DemoCreateBaseClass();;2:
// Perform operation
2.out.println("Operation
2");.DemoCreateSubclass();.DemoCreateClassRestriction();;3:
// Perform operation
3.out.println("Operation
3");.DemoCreateIndividual();.DemoCreateIndividualRelation();;4:
// Perform operation
4.out.println("Operation 4");.DemoDeleteClass();.DemoDeleteIndividual();;
}++;
} boolean done() {step == 5;
} int onEnd()
{.doDelete();super.onEnd();
}
}
}agentpack;jade.core.Agent;jade.core.behaviours.Behaviour;jade.core.behaviours.CyclicBehaviour;jade.core.behaviours.OneShotBehaviour;
/**
* This example shows the basic usage
of JADE behaviours.<br>
* More in details this agent
executes a <code>CyclicBehaviour</code> that shows
* a printout at each round and a
generic behaviour that performs four successive
* "dummy" operations. The
second operation in particular involves adding a
*
<code>OneShotBehaviour</code>. When the generic behaviour completes
the
* agent terminates.
* @author Giovanni Caire - TILAB
*/class SimpleAgent extends Agent
{void setup() {.out.println("Agent "+getLocalName()+"
started.");
// Add the CyclicBehaviour(new
CyclicBehaviour(this) {void action() {.out.println("Cycling");
}
});
// Add the generic behaviour(new
FourStepBehaviour());
/**
* Inner class FourStepBehaviour
*/class FourStepBehaviour extends
Behaviour {int step = 1;void action() {(step) {1:
// Perform operation 1: print out a
message.out.println("Operation 1");;2:
// Perform operation 2: Add a
OneShotBehaviour.out.println("Operation 2. Adding one-shot
behaviour");.addBehaviour(new OneShotBehaviour(myAgent) {void action()
{.out.println("One-shot");
}
});;3:
// Perform operation 3: print out a
message.out.println("Operation 3");;4:
// Perform operation 3: print out a
message.out.println("Operation 4");.FirstRequest();;
}++;
} boolean done() {step == 5;
} int onEnd()
{.doDelete();super.onEnd();
}
} // END of inner class
FourStepBehaviour
}agentpack;com.hp.hpl.jena.ontology.OntModel;com.hp.hpl.jena.ontology.OntModelSpec;com.hp.hpl.jena.query.Query;com.hp.hpl.jena.query.QueryExecution;com.hp.hpl.jena.query.QueryExecutionFactory;com.hp.hpl.jena.query.QueryFactory;com.hp.hpl.jena.query.ResultSetFormatter;com.hp.hpl.jena.rdf.model.Model;com.hp.hpl.jena.rdf.model.ModelFactory;com.hp.hpl.jena.rdf.model.Resource;com.hp.hpl.jena.util.FileManager;java.io.FileInputStream;java.io.InputStream;org.apache.log4j.BasicConfigurator;org.apache.log4j.Logger;
/**
*
* @author neutrino
*/class ProtegeJena {rec =
null;Logger logger = Logger.getLogger(ProtegeJena.class);
/**
* @param args the command line
arguments
*/static void FirstRequest()
{.configure();.info("Entering
application.");inputFileName="./Education.owl";model =
ModelFactory.createOntologyModel(OntModelSpec.OWL_MEM_MICRO_RULE_INF);.get().readModel(model,
inputFileName);queryString =
" PREFIX rdf:
<#"651094.files/image035.gif">
Рис. В.1 - Интеллектуальный агент.
Диаграмма классов