Статистическая обработка данных
Курсовой
проект
по
дисциплине «Статистика»
на
тему: Статистическая обработка данных
Содержание
Введение
1.
Постановка задачи. Цель работы. Исходные данные
.
Вычисление основных выборочных характеристик по заданной выборке
.
Результаты вычисления интервальных оценок для математического ожидания и
дисперсии
.
Результаты ранжирования выборочных данных и вычисление моды и медианы
.
Параметрическая оценка функции плотности распределения
.
Проверка гипотезы о нормальном распределении случайной величины по критерию
Пирсона
Заключение
Список
использованной литературы
интервальный дисперсия
выборочный данные
Введение
Целью данной курсовой работы является изучение
и, как в следствии, расширение знаний о математической статистике, ознакомление
с методами обработки экспериментального материала, с целью получения надежных
выводов, ознакомление с методикой применения статистических критериев для
проверки гипотез.
. Постановка задачи. Цель работы. Исходные
данные
1) Задача:
По выборке объёма N
провести статистическую обработку результатов эксперимента.
) Цель работы:
Изучить и усвоить основные понятия
математической статистики. Овладеть методикой статистического оценивания
числовых характеристик случайной величины и нормального закона распределения. Ознакомиться
с методикой применения статистических критериев для проверки гипотез.
) Исходные данные.
Проведен эксперимент, в результате которого была
получена выборка N = 60,
которая соответствует случайной величине, распределённой по нормальному закону.
Данная выборка представлена в таблице 1.1
Таблица 1.1
|
10.2836
|
10.7148
|
9.4963
|
12.8971
|
10.9190
|
12.8067
|
|
14.0510
|
7.3201
|
7.9052
|
15.2359
|
10.6512
|
9.6341
|
|
11.0156
|
12.4240
|
8.9727
|
12.1429
|
13.1025
|
11.9252
|
|
11.8667
|
8.3636
|
10.2223
|
9.1232
|
12.2658
|
11.1741
|
|
10.8028
|
10.4434
|
11.2314
|
9.6948
|
11.0725
|
8.3374
|
|
12.4564
|
9.5759
|
8.7116
|
14.2939
|
9.5319
|
13.1150
|
|
11.8891
|
17.3345
|
6.9275
|
13.3734
|
13.4795
|
13.8429
|
|
12.1071
|
11.7579
|
14.8285
|
9.5450
|
12.1039
|
|
12.9304
|
7.3669
|
12.4592
|
12.3466
|
11.8461
|
11.5607
|
|
10.7288
|
15.9654
|
16.1488
|
9.8759
|
12.9522
|
12.5015
|
2. Вычисление основных выборочных характеристик
по заданной выборке среднее арифметическое случайной величины Х (N
= 60)
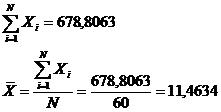
) среднее
линейное отклонение

) дисперсия
случайной величины Х
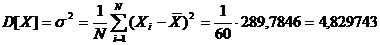
)
несмещенная оценка дисперсии
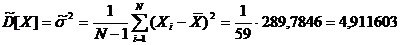
5) среднеквадратическое отклонение
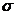 =
=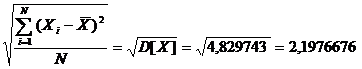
6) несмещенная выборочная оценка для
среднеквадратического отклонения
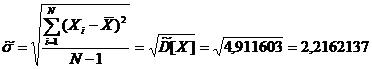
7)
коэффициент вариации
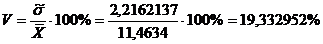
)
коэффициент асимметрии случайной величины Х
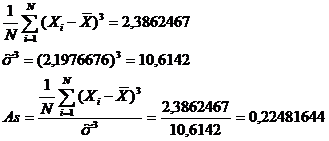
9) коэффициент эксцесса случайной
величины Х
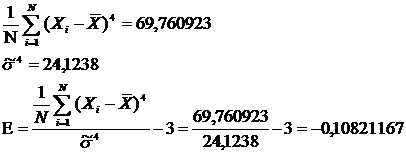
10) вариационный размах
= Xmax - Xmin = 17,3345-
6,9275= 10,407
На основании полученных вычислений
можно сделать следующие выводы:
Выполняется необходимое условие для
того, чтобы выборка имела нормальный закон распределения, т.к. для коэффициента
вариации V выполняется
неравенство:
V = 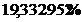 < 33%
< 33%
Отсюда следует, что не все
выборочные значения случайной величины Х положительны, что мы и видим в
исходных данных.
Для нормального распределения
коэффициенты асимметрии и эксцесса должны быть равны нулю, т.е. As = E = 0.
По результатам вычисления асимметрия
близка к нулю и составляет As = 0,22481644
В нашем случае асимметрия
положительна, это значит, что «длинная часть» кривой расположена справа от
математического ожидания.
Коэффициент эксцесса так же как и
коэффициент асимметрии близок к нулю, так как Е = 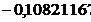 . Он
отрицательный, значит, кривая имеет более низкую и «плоскую» вершину, чем
нормальная кривая.
. Он
отрицательный, значит, кривая имеет более низкую и «плоскую» вершину, чем
нормальная кривая.
В связи с этим необходимы
дополнительные исследования для выяснения степени близости распределения
выборки к нормальному распределению.
3.Результаты вычисления интервальных
оценок для математического ожидания и дисперсии
Для вычисления интервальной оценки
математического ожидания воспользуемся формулой:

Где а = М[X]
- математическое ожидание
N - 1 = V
= 59 - число степеней свободы
tv;p - величина,
численно равная половине интервала, в который может попасть случайная величина  , имеющая
определенный закон распределения при заданной доверительной вероятности Р и
заданном числе степеней свободы V.
, имеющая
определенный закон распределения при заданной доверительной вероятности Р и
заданном числе степеней свободы V.
Подставляем в формулу вычисленные
ранее значения , 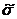 и N.
и N.
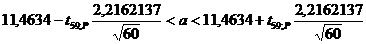
Задаемся доверительной вероятностью:
Р1 = 0,95 Р2 = 0,99
Для каждого значения Рi (i=1,2)
находим по таблице значения t59;p и вычисляем
два варианта интервальных оценок для математического ожидания.
При Р1 = 0,95 t59;0,95 = 2

При Р2 = 0,99 t59;0,95 =
2,66
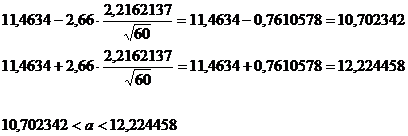
Для интервальной оценки дисперсии
существуют неравенства:
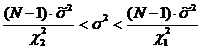
Поставляем в неравенство известные
значения и N, получим
неравенство, в котором неизвестны 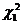 и
и 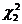 .
.

Задаваясь доверительной вероятностью
Рi (или
уровнем значимости а) вычисляем значения 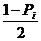 и
и 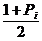 . Используем эти два значения и
степень свободы V = N - 1 = 59,
по таблице находим и .
. Используем эти два значения и
степень свободы V = N - 1 = 59,
по таблице находим и .
= 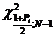 =
= 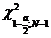 =
= 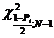 =
= 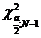
и - это границы интервала, в который
попадает случайная величина Х, имеющая 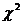 (хи-квадрат) распределение
вероятности Рi и заданной
степени свободы V (V=59).
(хи-квадрат) распределение
вероятности Рi и заданной
степени свободы V (V=59).
Для Р1 = 0,95 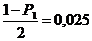 и
и 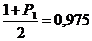
находим по таблице: = 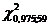 = 40,4817
= 40,4817
= 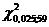 = 83,2976
= 83,2976
Подставляя в неравенства и и,
вычисляя, получим интервальную оценку.
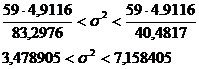
При Р2 = 0,99 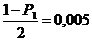 и
и 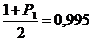
= 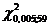 = 91,9517
= 91,9517
Поставляя в неравенства и , и
вычисляя, получим интервальную оценку.

Для интервальной оценки среднеквадратического
отклонения имеем:
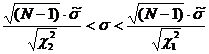
При Р1 =
0,95
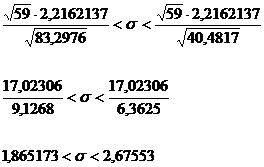
При Р2 = 0,99
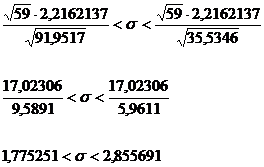
4. Результаты ранжирования
выборочных данных и вычисление моды и медианы
Используя исходные данные,
записываем все заданные значения выборки в виде неубывающей последовательности
значений случайной величины Х, которые представлены в таблице 4.1.
Таблица 4.1
Ранжированный
ряд
|
6,9275
|
9,5319
|
10,6512
|
11,7579
|
12,4240
|
13,3734
|
|
7,3201
|
9,5450
|
10,7148
|
11,8461
|
12,4564
|
13,4795
|
|
7,3669
|
9,5759
|
10,7288
|
11,8667
|
12,4592
|
13,8429
|
|
7,9052
|
9,6341
|
10,8028
|
11,8891
|
12,5015
|
14,0510
|
|
8,3374
|
9,6948
|
10,9190
|
11,9252
|
12,8067
|
14,2939
|
|
8,3636
|
9,8759
|
11,0156
|
12,1039
|
12,8971
|
14,8285
|
|
8,7116
|
10,1539
|
11,0725
|
12,1071
|
12,9304
|
15,2359
|
|
8,9727
|
10,2223
|
11,1741
|
12,1429
|
12,9522
|
15,9654
|
|
9,1232
|
10,2836
|
11,2314
|
12,2658
|
13,1025
|
16,1488
|
|
9,4963
|
10,4434
|
11,5607
|
13,1150
|
17,3345
|
Интервал [6,9275; 17,3345], содержащий все
элементы выборки, разбиваем на частичные интервалы, используя при этом формулу
Стерджеса для определения оптимальной длины и границ этих частичных интервалов.
По формуле Стерджеса длина частичного интервала
равна:
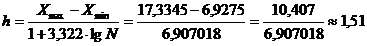
Для удобства и простоты расчетов
выбираем h = 1,5 и
вычисляем последовательно границы интервалов.
За начало первого интервала
принимаем значение:
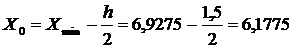
Далее вычисляем границы интервалов.
 = 6,1775 + 1,5 = 7,6775
= 6,1775 + 1,5 = 7,6775
 = 7,6775 + 1,5 = 9,1775
= 7,6775 + 1,5 = 9,1775
 = 9,1775+ 1,5 = 10,6775
= 9,1775+ 1,5 = 10,6775
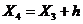 = 10,1775+ 1,5 = 12,1775
= 10,1775+ 1,5 = 12,1775
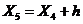 = 12,1775+ 1,5 = 13,6775
= 12,1775+ 1,5 = 13,6775
 = 13,6775+ 1,5 = 15,1775
= 13,6775+ 1,5 = 15,1775
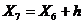 = 15,1775+ 1,5 = 16,6775
= 15,1775+ 1,5 = 16,6775
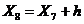 = 16,6775+ 1,5 = 18,1775
= 16,6775+ 1,5 = 18,1775
Вычисление границ заканчивается, как
только выполняется неравенство Xn > Xmax, то есть X8 =
18,1775> Xmax = 17,3345.
По результатам вычислений составляем
таблицу. В первой графе таблицы помещаем частичные интервалы, во второй графе -
середины интервалов, в третьей графе записано количество элементов выборки,
попавших в каждый интервал - частоты, в четвертой графе записаны относительные частоты
и в пятой графе записаны значения плотности относительных частот или значения
выборочной, экспериментальной функции плотности. Данная информация представлена
в таблице 4.2.
Таблица 4.2
Значение выборочной функции и
плотности
|
h
|
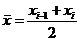 ni ni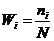  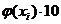 3 3
|
|
|
|
|
|
[6,1775; 7,6775)
|
6,9275
|
3
|
0,05
|
0,033
|
33
|
|
[7,6775; 9,1775)
|
8,4275
|
6
|
0,1
|
0,067
|
67
|
|
[9,1775; 10,6775)
|
9,9275
|
12
|
0,2
|
0,133
|
133
|
|
[10,6775; 12,1775)
|
11,4275
|
17
|
0,283
|
0,189
|
189
|
|
[12,1775; 13,6775)
|
12,9275
|
14
|
0,233
|
0,156
|
156
|
|
[13,6775; 15,1775)
|
14,4275
|
4
|
0,067
|
0,044
|
44
|
|
[15,1775; 16,6775)
|
15,9275
|
3
|
0,05
|
0,033
|
33
|
|
[16,6775; 18,1775)
|
17,4275
|
1
|
0,016
|
0,011
|
По результатам вычислений функции плотности,
представленной в таблице 4.2., можно сделать вывод, что мода имеет один
локальный максимум в окрестности точки х = 11,4275 и с частотой по n
= 17.
Оценку медианы находим, используя вариационный
ряд:
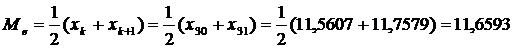
Так как N = 2k, k = N / 2 = 60 /
2 = 30
Сравнение оценок медианы 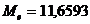 и оценки
математического ожидания
и оценки
математического ожидания 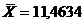 показывает,
что они отличаются на 1,34 %.
показывает,
что они отличаются на 1,34 %.
. Параметрическая оценка функции
плотности распределения
Исходя из гипотезы, что заданная
выборка имеет нормальный закон распределения, найдем параметрическую оценку
функции плотности, используя формулу для плотности распределения вероятности
нормального закона:
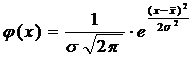
Где и известны - они вычисляются по
выборке.
= 2,1976676 = 11,4634
Значения этой функции вычисляются
для середины частичных интервалов вариационного ряда, т.е. при х = 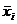 . На
практике для упрощения вычислений функции
. На
практике для упрощения вычислений функции 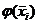 , где i = 1,2,…, k, пользуются
таблицами значений функции плотности стандартной нормальной величины.
, где i = 1,2,…, k, пользуются
таблицами значений функции плотности стандартной нормальной величины.

Для этого вычисляем значения 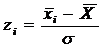 для i = 1,2,…, k, затем по
таблице значений функций плотности стандартной нормальной величины находим значение
для i = 1,2,…, k, затем по
таблице значений функций плотности стандартной нормальной величины находим значение
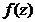 .
.
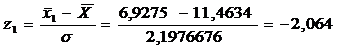
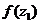 =0,0478
=0,0478
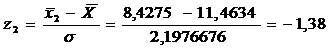
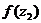 =0,1539
=0,1539
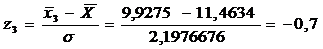
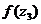 =0,3123
=0,3123
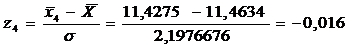
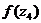 =0,3989
=0,3989
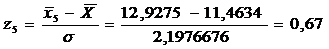
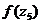 =0,3187
=0,3187
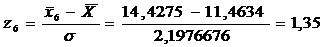
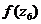 =0,1604
=0,1604
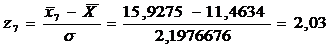
 =0,0508
=0,0508
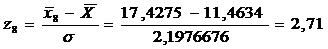
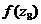 =0,0101
=0,0101
Переходим к
вычислению функции: 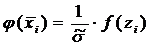
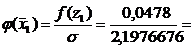 0,022
0,022 
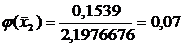
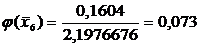

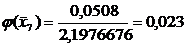
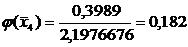
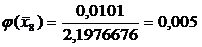
Функция 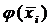 ,
вычисленная при заданных параметрах и в середине частичного интервала,
фактически является теоретической относительной частотой, отнесенной к середине
частичного интервала.
,
вычисленная при заданных параметрах и в середине частичного интервала,
фактически является теоретической относительной частотой, отнесенной к середине
частичного интервала.
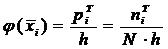
Поэтому для определения
теоретической частоты 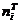 ,
распределенной по всей ширине интервала, эту функцию необходимо умножить на
,
распределенной по всей ширине интервала, эту функцию необходимо умножить на 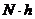 .
.
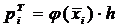 где h = 1,5
где h = 1,5

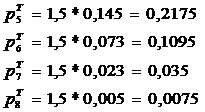
 где N = 60
где N = 60
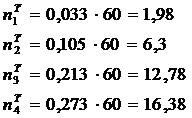
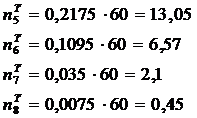
Результаты вычислений вероятностей и
соответствующих частот приведены в таблице 5.2.
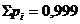
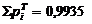
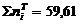
Из полученных результатов проведенных вычислений
следует, что сумма вероятностей в интервале [6,1775; 18,1775) почти равна
единице, а сумма всех частот равна 59,61. Данные результаты объясняются тем,
что мы вычисляем вероятности в интервале, где заданы экспериментальные данные.
Сравнение экспериментальных и
теоретических частот по критерию Пирсона с целью проверки гипотезы о нормальном
распределении возможно только в том случае, если для каждого частичного
интервала выполняется условие 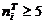 . Представленные в таблице 5.2
результаты вычислений показывают, что это условие выполняется не всегда. Поэтому
все те частичные интервалы, для которых частоты
. Представленные в таблице 5.2
результаты вычислений показывают, что это условие выполняется не всегда. Поэтому
все те частичные интервалы, для которых частоты 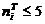 , объединяем с соседними. Соответственно
объединяем и экспериментальные частоты
, объединяем с соседними. Соответственно
объединяем и экспериментальные частоты 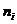 .
.
Таблица 5.1
|
 0,0330,0670,1330,1890,1560,0440,0330,011 0,0330,0670,1330,1890,1560,0440,0330,011
|
|
|
|
|
|
|
|
|
|
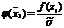 0,0220,070,1420,1820,1450,0730,0230,005 0,0220,070,1420,1820,1450,0730,0230,005
|
|
|
|
|
|
|
|
|
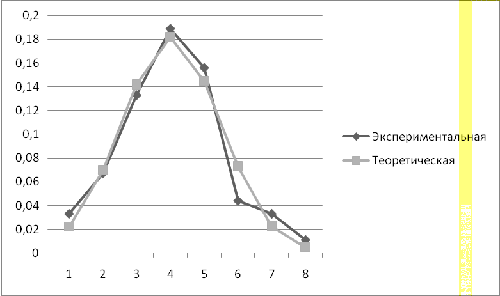
Рис. 1. График. Теоретическая и
экспериментальная плотности вероятности.
Таблица 5.2
Результаты вычисления экспериментальных и
теоретических вероятностей и частот
|
[xi-1; xi)
|
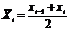 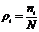 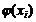 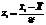 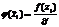 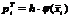  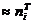
|
|
|
|
|
|
|
|
|
|
[6,1775; 7,6775)
|
3
|
6,9275
|
0,05
|
0,033
|
-2,064
|
0,022
|
0,033
|
1,98
|
2
|
|
[7,6775; 9,1775)
|
6
|
8,4275
|
0,1
|
0,067
|
-1,38
|
0,07
|
0,105
|
6,3
|
6
|
|
[9,1775; 10,6775)
|
12
|
9,9275
|
0,2
|
-0,7
|
0,142
|
0,213
|
12,78
|
13
|
|
[10,6775; 12,1775)
|
17
|
11,4275
|
0,283
|
0,189
|
-0,016
|
0,182
|
0,273
|
16,38
|
16
|
|
[12,1775; 13,6775)
|
14
|
12,9275
|
0,233
|
0,156
|
0,67
|
0,145
|
0,2175
|
13,05
|
13
|
|
[13,6775; 15,1775)
|
4
|
14,4275
|
0,067
|
0,044
|
1,35
|
0,073
|
0,1095
|
6,57
|
7
|
|
[15,1775; 16,6775)
|
3
|
15,9275
|
0,05
|
0,033
|
2,03
|
0,023
|
0,035
|
2,1
|
2
|
|
[16,6775; 18,1775)
|
1
|
17,4275
|
0,016
|
0,011
|
2,71
|
0,005
|
0,0075
|
0,45
|
1
|
|
Σ
|
|
|
0,999
|
|
|
|
0,9935
|
59,61
|
|
. Проверка гипотезы о нормальном распределении
случайной величины по критерию Пирсона
Для проверки гипотезы о нормальном распределении
случайной величины Х сравнивают между собой экспериментальные и теоретические
частоты по критерию Пирсона:
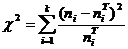
Статистика 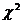 имеет
распределение с V = k - r - 1
степенями свободы, где k - число интервалов эмпирического
распределения, r - число параметров теоретического
распределения, вычисленных по экспериментальным данным. Для нормального распределения
число степеней свободы равно:
имеет
распределение с V = k - r - 1
степенями свободы, где k - число интервалов эмпирического
распределения, r - число параметров теоретического
распределения, вычисленных по экспериментальным данным. Для нормального распределения
число степеней свободы равно:
V=k -3
В теории математической статистики
доказывается, что проверку гипотезы о модели закона распределения по критерию
Пирсона можно делать только в том случае, если выполняются следующие
неравенства:
N ≥ 50 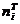 ≥ 5
где i = 1,2,3…
≥ 5
где i = 1,2,3…
Из результатов вычислений,
приведенных в таблице 1.5.1, следует, что необходимое условие для применения
критерия согласия Пирсона не выполнены, т.к. в некоторых группах < 5.
Поэтому те группы вариационного ряда, для которых необходимое условие не
выполняется, объединяют с соседними и, соответственно, уменьшают число групп,
при этом частоты объединенных групп суммируются. Так объединяют все группы с
частотами < 5 до
тех пор, пока для каждой новой группы будет выполняться условие ≥ 5.
При уменьшении числа групп для
теоретических частот соответственно уменьшают и число групп для эмпирических
частот. После объединения групп в формуле для числа степеней свободы V=k-3 в
качестве k принимают
новое число групп, полученное после объединения частот.
Результаты объединения интервалов и
теоретических частот для таблицы 5.2 приведены соответственно в таблице 6.1.
Результаты вычислений из таблицы 6.1
можно использовать для проверки гипотезы о нормальном распределении с помощью
критерия Пирсона.
Задаются уровнем значимости а =0,05
или одним из следующих значений: а1 = 0,01; а2 = 0,1; а3 = 0,005.
Вычисляют наблюдаемые значения
критерия, используя экспериментальные и теоретические частоты из таблицы 6.1.
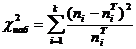
Для выборочного уровня значимости а
= 0,05 по таблице распределения находят критические значения 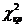 при числе
степеней свободы V= k-3, где k - число
групп эмпирического распределения.
при числе
степеней свободы V= k-3, где k - число
групп эмпирического распределения.
Сравниваем фактически наблюдаемое  с
критическим , найденным
по таблице, и принимаем решение:
с
критическим , найденным
по таблице, и принимаем решение:
если > , то выдвинутая гипотезы о
теоретическом законе распределения отвергается при заданном уровне значимости.
Если < , то выдвинутая гипотеза о
теоретическом законе распределения не противоречит выборке наблюдений при
заданном уровне значимости, т.е. нет оснований отвергать гипотезу о нормальном
распределении, т.к. эмпирические и теоретические частоты различаются
незначительно (случайно).
Таблица 6.1
Результаты объединения интервалов и
теоретических частот
|
    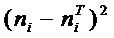 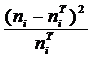
|
|
|
|
|
|
|
[6,1775; 9,1775)
|
0,138
|
8,28
|
9
|
0,5184
|
0,0626
|
|
[9,1775; 10,6775)
|
0,213
|
12,78
|
12
|
0,6084
|
0,0476
|
|
[10,6775; 12,1775)
|
0,273
|
16,38
|
17
|
0,3844
|
0,0235
|
|
[12,1775; 13,6775)
|
0,2175
|
13,05
|
14
|
0,9025
|
0,0692
|
|
[13,6775; 18,1775)
|
0,152
|
9,12
|
8
|
1,2544
|
0,1375
|
|
Σ
|
0,9935
|
59,61
|
600,3404
|
|
|
При выбранном уровне значимости а = 0,05 и числе
групп k = 5, число
степеней свободы V = 2.
По таблице для а = 0,05 и V = 2 находим
= 5,99147.
В результате получаем:
Для 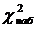 = 0,3404, найденного по результатам
вычислений приведенных в таблице 6.1, имеем:
= 0,3404, найденного по результатам
вычислений приведенных в таблице 6.1, имеем:
= 0,3404< = 5,99147
Из этого следует, что нет оснований
отвергать гипотезу о нормальном распределении случайной величины Х.
Заключение
Статистические методы (методы,
основанные на использовании математической статистики), являются эффективным
инструментом сбора и анализа информации о качестве. Применение этих методов, не
требует больших затрат и позволяет с заданной степенью точности и
достоверностью судить о состоянии исследуемых явлений (объектов, процессов) в
системе качества, прогнозировать и регулировать проблемы на всех этапах
жизненного цикла продукции и на основе этого вырабатывать оптимальные
управленческие решения.
Статистические методы контроля
производства и качества продукции имеют ряд преимуществ перед другими методами:
- являются профилактическими;
- позволяют во многих случаях
обоснованно перейти к выборочному контролю и тем самым снизить трудоемкость
контрольных операций;
- создают условия для наглядного
изображения динамики изменения качества продукции и настроенности процесса
производства, что позволяет своевременно принимать меры к предупреждению брака
не только контролерам, но и работникам цеха - рабочим, бригадирам, технологам,
наладчикам, мастерам.
Список использованной литературы
1)
Статистическая обработка результатов выборочного контроля: Метод.рек./Сост.: Ю.
Г. Сильвестров: СибГИУ.- Новокузнецк, 2010 -41 с.
)
Статистическое управление процессами при помощи контрольных карт: Метод.рек.
/Сост.: Ю. Г. Сильвестров: ГОУ ВПО «СибГИУ». - Новокузнецк, 2014 - 17 с.
)
ГОСТ Р 50779.42-99. Статистические методы. Контрольные карты Шухарта [Текст]. -
: Издательство стандартов, 2007. - 36 с.