Разработка лабораторного комплекса 'Кластерные технологии'
ДИПЛОМНАЯ
РАБОТА
Разработка
лабораторного комплекса «Кластерные технологии» в рамках дисциплины
«Высокопроизводительные вычислительные системы» для обучения студентов кафедры
АСУ
Оглавление
1. Ввведение
.1 Вводная часть
.2 Анализ кластерных технологий в
контексте лабораторного практикума
.2.1 Типы кластеров
.2.2 Показатели эффективности
параллельного алгоритма
.2.3 Средства разработки и поддержки
параллельных приложений
.2.4 Принципы работы среды MPICH
.2.5 Кластер МИИТ Т-4700
.3 Обоснование целесообразности
разработки
.4 Требования разработке
.4.1 Требования к кластерной системе
.4.2 Требования к методическому
обеспечению
.4.3 Требования к документации
.4.4 Требования к техническому
обеспечению
.4.5 Требования к рабочим станциям
.4.6 Требования к разрабатываемому
ПО
.4.7 Требования к показателям
назначения
.5 Анализ исходных данных
. РАЗРАБОТКА ЛАБОРАТОРНОГО КОМПЛЕКСА
«КЛАСТЕРНЫЕ СИСТЕМЫ»
.1 Разработка методического
обеспечения для лабораторного комплекса
.2 Содержание лабораторных работ
.2.1 Рабочее задание для
лабораторной работы №1
.2.2 Рабочее задание для
лабораторной работы №2
.2.3 Рабочее задание для
лабораторной работы №3
.3 Разработка программного
обеспечения для лабораторного комплекса
.4 Подготовка рабочих мест и
описание хода выполнения лабораторных работ
.4.1 Лабораторная работа №1
.4.1.1 Подготовка рабочего места для
выполнения лабораторной работы №1
.4.1.2 Описание хода лабораторной
работы №1
.4.2 Лабораторная работа №2
.4.2.1 Подготовка рабочего места для
выполнения лабораторной работы №2
.4.2.2 Описание хода лабораторной
работы №2
. СИСТЕМОТЕХНИЧЕСКИЙ РАСЧЁТ: РАСЧЁТ
ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ ВЫЧИСЛЕНИЙ
.1 Описание показателей
эффективности параллельных вычислений
.2 Описание хода лабораторной работы
№3
. АНАЛИЗ ЧЕЛОВЕКО-МАШИННОГО
ВЗАИМОДЕЙСТВИЯ
.1 Обзор теории тестовых заданий
(Item response theory)
.2 Процедура расчёта
.3 Построение характеристических
кривых для заданий
.4 Обсуждение результатов и
дальнейших действий
.5 Вывод
. ЭКОНОМИЧЕСКАЯ ЧАСТЬ
.1 Постановка экономической задачи
.2 Расчет затрат, связанных с
разработкой лабораторного комплекса
.3 Экономическая эффективность
.3.1 Расчёт показателей
эффективности
.3.2 Расчет затрат по эксплуатации
лабораторного комплекса
.3.3 Расчёт эффективности разработки
ЗАКЛЮЧЕНИЕ
СПИСОК ИСТОЧНИКОВ
ПРИЛОЖЕНИЯ
Приложение 1. Листинг разработанного
ПО
Приложение 2. Инструкция по
написанию и запуску заданий на кластере МИИТ Т-4700
1. Введение
1.1 Вводная часть
Цель дипломного проекта - Разработка лабораторного комплекса
«Кластерные технологии» в рамках дисциплины «Высокопроизводительные
вычислительные системы» для обучения студентов кафедры АСУ.
Кроме того в ходе дипломного проектирования будет
разработано программное обеспечение, которое будет представлять собой
интерфейс, позволяющий запускать параллельные программы, балансируя нагрузку
между узлами кластера. Поставляемый интерфейс MPICH2 этого не позволяет.
1.2 Анализ кластерных технологий в контексте лабораторного
практикума
1.2.1 Типы кластеров
Кластер - группа компьютеров, объединённых высокоскоростными каналами
связи и представляющая с точки зрения пользователя единый аппаратный ресурс.
Один из первых архитекторов кластерной технологии Gregory F. Pfister
[Грегори Пфистер] дал кластеру следующее определение: «Кластер - это
разновидность параллельной или распределённой системы, которая:
· состоит из нескольких связанных между собой компьютеров;
· используется как единый, унифицированный компьютерный
ресурс».
Обычно различают следующие основные виды кластеров:
· отказоустойчивые кластеры (High-availability clusters, HA,
кластеры высокой доступности)
· кластеры с балансировкой нагрузки (Load balancing clusters)
· вычислительные кластеры (Computing clusters)
· grid-системы.
Кластеры
высокой доступности
Обозначаются аббревиатурой HA (англ. High Availability - высокая
доступность). Создаются для обеспечения высокой доступности сервиса,
предоставляемого кластером. Избыточное число узлов, входящих в кластер,
гарантирует предоставление сервиса в случае отказа одного или нескольких
серверов. Типичное число узлов - два, это минимальное количество, приводящее к
повышению доступности. Создано множество программных решений для построения
такого рода кластеров.
Отказоустойчивые кластеры и системы вообще строятся по трем основным
принципам:
· с холодным резервом или активный/пассивный. Активный узел
выполняет запросы, а пассивный ждет его отказа и включается в работу, когда
таковой произойдет. Пример - резервные сетевые соединения, в частности,
Алгоритм связующего дерева. Например, связка DRBD и HeartBeat.
· с горячим резервом или активный/активный. Все узлы выполняют
запросы, в случае отказа одного нагрузка перераспределяется между оставшимися.
То есть кластер распределения нагрузки с поддержкой перераспределения запросов
при отказе. Примеры - практически все кластерные технологии, например,
Microsoft Cluster Server. OpenSource проект OpenMosix.
· с модульной избыточностью. Применяется только в случае, когда
простой системы совершенно недопустим. Все узлы одновременно выполняют один и
тот же запрос (либо части его, но так, что результат достижим и при отказе
любого узла), из результатов берется любой. Необходимо гарантировать, что
результаты разных узлов всегда будут одинаковы (либо различия гарантированно не
повлияют на дальнейшую работу). Примеры - RAID и Triple modular redundancy.
Конкретная технология может сочетать данные принципы в любой комбинации.
Например, Linux-HA поддерживает режим обоюдной поглощающей конфигурации (англ.
takeover), в котором критические запросы выполняются всеми узлами вместе, прочие
же равномерно распределяются между ними.
Кластеры
распределения нагрузки
Принцип их действия строится на распределении запросов через один или
несколько входных узлов, которые перенаправляют их на обработку в остальные,
вычислительные узлы. Первоначальная цель такого кластера - производительность,
однако, в них часто используются также и методы, повышающие надёжность.
Подобные конструкции называются серверными фермами. Программное обеспечение
(ПО) может быть как коммерческим (OpenVMS, MOSIX, Platform LSF HPC, Solaris
Cluster Moab Cluster Suite, Maui Cluster Scheduler), так и бесплатным
(OpenMosix, Sun Grid Engine, Linux Virtual Server).
Вычислительные
кластеры
Кластеры используются в вычислительных целях, в частности в научных
исследованиях. Для вычислительных кластеров существенными показателями являются
высокая производительность процессора в операциях над числами с плавающей
точкой (flops) и низкая латентность объединяющей сети, и менее существенными -
скорость операций ввода-вывода, которая в большей степени важна для баз данных
и web-сервисов. Вычислительные кластеры позволяют уменьшить время расчетов, по
сравнению с одиночным компьютером, разбивая задание на параллельно
выполняющиеся ветки, которые обмениваются данными по связывающей сети. Одна из
типичных конфигураций - набор компьютеров, собранных из общедоступных
компонентов, с установленной на них операционной системой Linux, и связанных
сетью Ethernet, Myrinet, InfiniBand или другими относительно недорогими сетями.
Такую систему принято называть кластером Beowulf. Специально выделяют
высокопроизводительные кластеры (Обозначаются англ. аббревиатурой HPC Cluster -
High-performance computing cluster). Список самых мощных высокопроизводительных
компьютеров (также может обозначаться англ. аббревиатурой HPC) можно найти в
мировом рейтинге TOP500. В России ведется рейтинг самых мощных компьютеров СНГ.
Системы
распределенных вычислений (grid)
Такие системы не принято считать кластерами, но их принципы в
значительной степени сходны с кластерной технологией. Их также называют
grid-системами. Главное отличие - низкая доступность каждого узла, то есть
невозможность гарантировать его работу в заданный момент времени (узлы
подключаются и отключаются в процессе работы), поэтому задача должна быть
разбита на ряд независимых друг от друга процессов. Такая система, в отличие от
кластеров, не похожа на единый компьютер, а служит упрощённым средством
распределения вычислений. Нестабильность конфигурации, в таком случае,
компенсируется больши́м числом узлов.[1]
1.2.2 Показатели эффективности параллельного алгоритма
Ускорение ( speedup ), получаемое при использовании параллельного
алгоритма для p процессоров, по сравнению с последовательным вариантом
выполнения вычислений определяется величиной
Sp(n)=T1(n)/Tp(n),
т.е. как отношение времени решения задач на скалярной ЭВМ к времени
выполнения параллельного алгоритма (величина n применяется для параметризации
вычислительной сложности решаемой задачи и может пониматься, например, как
количество входных данных задачи).
Эффективность ( efficiency ) использования параллельным алгоритмом
процессоров при решении задачи определяется соотношением
Ep(n)=T1(n)/(pTp(n))=Sp(n)/p
(величина эффективности определяет среднюю долю времени выполнения
алгоритма, в течение которой процессоры реально задействованы для решения
задачи).
Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p
и Ep(n)=1. При практическом применении данных показателей для оценки
эффективности параллельных вычислений следует учитывать два важных момента:
При выборе надлежащего параллельного способа решения задачи может
оказаться полезной оценка стоимости (cost) вычислений, определяемой как
произведение времени параллельного решения задачи и числа используемых
процессоров
Cp=pTp.
В связи с этим можно определить понятие стоимостно-оптимального
(cost-optimal) параллельного алгоритма как метода, стоимость которого
является пропорциональной времени выполнения наилучшего последовательного
алгоритма.[2]
1.2.3 Средства разработки и поддержки параллельных приложений
Message Passing Interface(MPI)- программный интерфейс (API) для передачи
информации, который позволяет обмениваться сообщениями между процессами,
выполняющими одну задачу. Разработан Уильямом Гроуппом, Эвином Ласком и
другими.является наиболее распространённым стандартом интерфейса обмена данными
в параллельном программировании, существуют его реализации для большого числа
компьютерных платформ. Используется при разработке программ для кластеров и
суперкомпьютеров. Основным средством коммуникации между процессами в MPI
является передача сообщений друг другу. Стандартизацией MPI занимается MPI
Forum. В стандарте MPI описан интерфейс передачи сообщений, который должен
поддерживаться как на платформе, так и в приложениях пользователя. В настоящее
время существует большое количество бесплатных и коммерческих реализаций MPI.
Существуют реализации для языков Фортран 77/90, Си и Си++.
В первую очередь MPI ориентирован на системы с распределенной памятью, то
есть когда затраты на передачу данных велики, в то время как OpenMP
ориентирован на системы с общей памятью (многоядерные с общим кэшем). Обе
технологии могут использоваться совместно, дабы оптимально использовать в
кластере многоядерные системы.- самая распространённая бесплатная реализация,
созданная в Арагонской национальной лаборатории (США). Существуют версии этой
библиотеки для всех популярных операционных систем. К тому же, она бесплатна.
Перечисленные факторы делают MPICH идеальным вариантом для того, чтобы начать
практическое освоение MPI. MPICH2 соответствует стандарту MPI 2.0, отсюда и
название.[3]
1.2.4 Принципы работы среды MPICH
MPICH для Windows состоит из следующих компонентов:
· Менеджер процессов smpd.exe, который
представляет собой системную службу (сервисное приложение). Менеджер процессов
ведёт список вычислительных узлов системы, и запускает на этих узлах
MPI-программы, предоставляя им необходимую информацию для работы и обмена
сообщениями.
· Заголовочные файлы (.h) и библиотеки
стадии компиляции (.lib), необходимые для разработки MPI-программ.
· Библиотеки времени выполнения (.dll),
необходимые для работы MPI-программ.
· Дополнительные утилиты (.exe),
необходимые для настройки MPICH и запуска MPI-программ.
Существует мнение, что smpd.exe является не менеджером
процессов, а просто средством для их запуска. Это мнение обосновано тем, что
полноценный менеджер процессов должен составлять расписание запуска процессов,
осуществлять мониторинг и балансировку загрузки узлов. Однако в терминологии
Арагонской лаборатории, smpd.exe называется «Process manager service for MPICH2
applications»
Все компоненты, кроме библиотек времени выполнения, устанавливаются по
умолчанию в папку C:\Program Files\MPICH2; dll-библиотеки устанавливаются в
C:\Windows\System32.
Менеджер процессов является основным компонентом,
который должен быть установлен и настроен на всех компьютерах сети (библиотеки
времени выполнения можно, в крайнем случае, копировать вместе с
MPI-программой). Остальные файлы требуются для разработки MPI-программ и
настройки некоторого «головного» компьютера, с которого будет производиться их
запуск.
Менеджер работает в фоновом режиме и ждёт запросов к
нему из сети со стороны «головного» менеджера процессов (по умолчанию
используется сетевой порт 8676). Чтобы как-то обезопасить себя от хакеров и вирусов,
менеджер требует пароль при обращении к нему. Когда один менеджер процессов
обращается к другому менеджеру процессов, он передаёт ему свой пароль. Отсюда
следует, что нужно указывать один и тот же пароль при установке MPICH на
компьютеры сети.
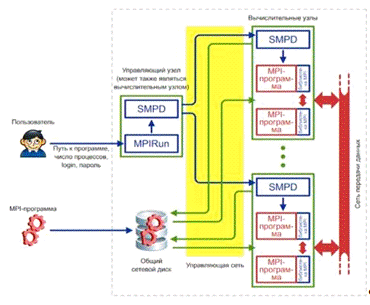
Рисунок 1.1 Схема работы MPICH на кластере
В современных кластерах сеть передачи данных обычно
отделяется от управляющей сети
Запуск MPI-программы производится следующим образом
(смотрите рисунок 1.1):
1. Пользователь с помощью программы Mpirun (или
Mpiexec, при использовании MPICH2 под Windows) указывает имя исполняемого файла
MPI-программы и требуемое число процессов. Кроме того, можно указать имя
пользователя и пароль: процессы MPI-программы будут запускаться от имени этого
пользователя.
2. Mpirun передаёт сведения о запуске локальному
менеджеру процессов, у которого имеется список доступных вычислительных узлов.
. Менеджер процессов обращается к
вычислительным узлам по списку, передавая запущенным на них менеджерам процессов
указания по запуску MPI-программы.
. Менеджеры процессов запускают на
вычислительных узлах несколько копий MPI-программы (возможно, по несколько
копий на каждом узле), передавая программам необходимую информацию для связи
друг с другом.
Очень важным моментом здесь является то, что перед
запуском MPI-программа не копируется автоматически на вычислительные узлы
кластера. Вместо этого менеджер процессов передаёт узлам путь к
исполняемому файлу программы точно в том виде, в котором пользователь указал
этот путь программе Mpirun. Это означает, что если вы, например, запускаете
программу C:\proga.exe, то все менеджеры процессов на вычислительных узлах
будут пытаться запустить файл C:\proga.exe. Если хотя бы на одном из узлов
такого файла не окажется, произойдёт ошибка запуска MPI-программы.
Чтобы каждый раз не копировать вручную программу и все
необходимые для её работы файлы на вычислительные узлы кластера, обычно
используют общий сетевой ресурс. В этом случае пользователь копирует
программу и дополнительные файлы на сетевой ресурс, видимый всеми узлами
кластера, и указывает путь к файлу программы на этом ресурсе. Дополнительным
удобством такого подхода является то, что при наличии возможности записи на
общий сетевой ресурс запущенные копии программы могут записывать туда
результаты своей работы.
Работа MPI-программы происходит следующим образом:
1. Программа запускается и инициализирует
библиотеку времени выполнения MPICH путём вызова функции MPI_Init.
2. Библиотека получает от менеджера процессов
информацию о количестве и местоположении других процессов программы, и
устанавливает с ними связь.
. После этого запущенные копии программы могут
обмениваться друг с другом информацией посредством библиотеки MPICH. С точки
зрения операционной системы библиотека является частью программы (работает в
том же процессе), поэтому можно считать, что запущенные копии MPI-программы
обмениваются данными напрямую друг с другом, как любые другие приложения,
передающие данные по сети.
. Консольный ввод-вывод всех процессов MPI-программы
перенаправляется на консоль, на которой запущена Mpirun. Перенаправлением
ввода-вывода занимаются менеджеры процессов, так как именно они запустили копии
MPI-программы, и поэтому могут получить доступ к потокам ввода-вывода программ.
. Перед завершением все процессы вызывают
функцию MPI_Finalize, которая корректно завершает передачу и приём всех
сообщений, и отключает MPICH.
Все описанные выше принципы действуют, даже если вы
запускаете MPI-программу на одном компьютере.[4]
1.2.5 Кластер МИИТ Т-4700
Для решения ресурсоемких вычислительных задач при промышленном
проектировании, стоящих перед исследователями университета, МИИТ приобрел
суперкомпьютерный комплекс «Т_Платформы» МИИТ Т-4700.
МИИТ Т-4700 на момент открытия стал самым мощным в России суперкомпьютером
на базе процессоров AMD Opteron™ 2356 (Barcelona).
Вычислительный кластер на базе 64-х двухпроцессорных узлов Discus с
четырехъядерными процессорами AMD Opteron™ (Barcelona) обеспечивает пиковую
производительность 4,7 триллионов операций в секунду (Тфлопс).
Реальная производительность кластера на тесте Linpack составила 3,89
Тфлопс (83% от пиковой). В качестве интерконнекта решение использует наиболее
производительную сетевую технологию InfiniBand, объединяющую суперкомпьютер с
системой хранения данных и оборудованием корпоративного портала МИИТа.
Благодаря объединению всех аппаратных компонентов комплекса в единую
высокоскоростную сеть университет сможет организовать удобный доступ к
вычислительным ресурсам системы МИИТ Т-4700 непосредственно через корпоративный
портал, что существенно упростит внедрение новых технологий в процесс
исследований и разработок.
Суперкомпьютер МИИТа укомплектован набором свободно распространяемых
средств управления и мониторинга, а также специализированными средствами разработки
и отладки приложений PGI Server от компании Portland Group. В комплект поставки
также вошли предустановленные прикладные продукты компании MSC Software Corp.
Для прочностных, гидро и газодинамических расчетов, пакет для промышленного
моделирования SolidWorks, а также пакеты для моделирования и оптимизации
транспортных потоков PTV Vision®. [5]
На кластере так же установлена реализация MPI, разработанная NetworkBased
Computing Laboratory (NBCL), которая носит название MVAPICH2, что позволит
задействовать его ресурсы для обучения студентов в рамках разрабатываемого
курса.
1.3 Обоснование целесообразности разработки
Современные технологии позволяют сделать из множества
персональных компьютеров вычислительный кластер. В учебном плане кафедры АСУ
есть лекционный курс «Высокопроизводительные Вычислительные Системы». Кафедра
также располагает всеми необходимыми аппаратными средствами для создания
вычислительного кластера. Кроме того, в университете имеется мощный кластер
МИИТ Т-4700(подробнее в п. 1.2.5). В рамках дипломного проекта требуется
разработать лабораторный комплекс и соответствующее методическое и программное
обеспечение, которые обеспечат овладение описанными выше технологиями и
возможность применения их на практике.
Для специалистов, выпускаемых кафедрой АСУ, такие
навыки очень полезны и могут повысить востребованность выпускников при поиске
места работы. При этом следует учитывать, что кластерные технологии широко
используются в основной профессиональной отрасли для выпускников кафедры - на железнодорожном
транспорте, а также в других сферах промышленности, энергетики, медицине и др.
1.4 Требования разработке
1.4.1 Требования к кластерной системе
Для лабораторного комплекса должны быть задействованы
два кластера:
· кластер, организованный посредством
программной реализации MPI MPICH2 на базе вычислительных средств кафедры;
· кластер МИИТ Т-4700.
Требования
к информационному обеспечению
Исходные
данные
Исходные данные для функционирования программы запуска параллельных
программ описаны подробно в пункте 6.
Выходные
данные
На основании исходных данных, разрабатываемая программа формирует команду
запуска параллельной программы в виде текста, которая впоследствии выполняется.
1.4.2 Требования к методическому обеспечению
В результате дипломной работы должно быть сформировано методическое
обеспечение, позволяющее студенту ознакомиться с кластерными технологиями и
затрагивающее следующие темы:
· библиотека MPI(Message Passing Interface): функции,
реализации;
· компиляция и запуск параллельных программ на вычислительном
кластере;
· программное обеспечение для реализации кластера из
персональных компьютеров, объединённых ЛВС: обзор, установка;
· компиляция и запуск параллельных программ на кластере из
персональных компьютеров, объединённых ЛВС;
· вычисление показателей эффективности параллельных алгоритмов
на кластерах разных конфигураций, сравнение вычисленных показателей и
извлечение выводов.
1.4.3 Требования к документации
В ходе дипломного проектирования должны быть разработаны:
· методические материалы для выполнения всех лабораторных
работ;
· инструкция пользователя для разрабатываемой программы
1.4.4 Требования к техническому обеспечению
· Кластер устанавливается на имеющуюся
в учебном классе операционную систему
· Вычислительные узлы кластера должны
загружаться в автоматическом режиме, без участия пользователя
· Подключение к кластеру дополнительных
вычислительных узлов должно происходить без перенастройки системы
· Кластер должен быть представлен
пользователю как единый ресурс
· Управление процессами осуществляется
через терминал
· Должна быть предусмотрена возможность
подключения различных по производительности узлов и решена задача балансировки
нагрузки между вычислительными узлами.
Для выполнения работы необходима, сеть из нескольких
компьютеров.
1.4.5 Требования к рабочим станциям
Аппаратные:
· ЦП вычислительного узла с тактовой
частотой не менее 900 MHz
· 256 Мб ОЗУ на всех вычислительных
узлах
· Вычислительные узлы должны быть
связаны в вычислительную сеть Fast Ethernet (для обучения допустимы
Ethernet/Wi-Fi).
Операционная система:
· Windows Server 2003
· Windows XP
· Windows Vista
· Windows 7
Программное обеспечение:
· В качестве среды разработки будет
использоваться Visual Studio 2008 или 2010 (возможно использование бесплатной
версии Express).
· Программное обеспечение MPICH2.
1.4.6 Требования к разрабатываемому ПО
Комплект MPICH2 включает пользовательский интерфейс для запуска
параллельных программ wmpiexec.exe. Программа, на основании данных, введённых
пользователем, генерирует команду запуска и выполняет её. Данный интерфейс
имеет следующий недостаток: команды, генерируемые им, распределяют нагрузку
между узлами равномерно, без балансировки.
Необходимо разработать аналог интерфейса, предоставляемого в комплекте
MPICH2, который позволит на основании данных, описанных в п.6, сгенерировать
команду для запуска параллельной программы, распределяющую нагрузку с учётом
производительности узлов, которые должны быть задействованы по желанию
пользователя для решения конкретной задачи.
1.4.7 Требования к показателям назначения
В рамках лабораторного практикума необходимо
предусмотреть возможность расчёта показателей эффективности параллельных
алгоритмов:
· Ускорение
· Эффективность
· Стоимость
Подробнее о показателях эффективности параллельных алгоритмов написано в
пункте 1.2.2.
1.5 Анализ исходных данных
Исходные данные необходимые для функционирования разрабатываемой
программы для запуска параллельных программ поступают от трёх источников:
· Пользователь
· Вычислительные узлы
· Конфигурационный файл
Таблица 1.1 Источники данных
|
Источники данных
|
Исходные данные
|
|
Пользователь
|
Путь к mpiexec.exe Путь и название исполняемого файла
параллельной программы Число и имена узлов для выполнения задачи Выбор
равномерного, навязанного или сбалансированного распределения нагрузки с
учётом производительности узлов
|
|
Вычислительные узлы
|
Величина, характеризующая производительность узла
|
|
Конфигурационный файл
|
Константы величин используемых для запуска параллельных
программ Настройки запуска, сохранённые пользователем
|
2.
2. РАЗРАБОТКА ЛАБОРАТОРНОГО КОМПЛЕКСА «КЛАСТЕРНЫЕ СИСТЕМЫ»
2.1 Разработка методического обеспечения для лабораторного
комплекса
Лабораторный комплекс «Кластерные системы» состоит из 3-х лабораторных
работ. В ходе каждой из них студенту предлагается ознакомиться с новым
материалом, а затем приступить к выполнению работы.
Лабораторная работа №1 знакомит студента с распределёнными вычислениями
на примере технологии MPI и её реализации MPICH2 для Windows. Студенту
предлагается освоить следующие процессы:
· связывание нескольких компьютеров в один аппаратный ресурс;
· настройка службы менеджера процессов MPICH2;
· адаптация среды разработки под компиляцию MPI-программ;
· написание и компиляция программ MPI-программ;
· запуск MPI-программ на нескольких узлах;
· анализ результатов работы программы.
К лабораторной работе №1 разработано ПО, устраняющее один из недостатков
пакета MPICH2 - отсутствие возможности балансировки нагрузки в случае
консолидации разных по производительности узлов(см. раздел Разработка
программного обеспечения для лабораторного комплекса). Этим ПО, представляющем
собой пользовательский интерфейс для утилиты mpiexec.exe и рекомендуется
пользоваться для запуска MPI-программ в условиях объединения различных по
производительности вычислительных узлов.
В ходе выполнения лабораторной работы №2 студент осваивает:
· работу с кластером МИИТ Т-4700 через протокол SSH;
· работу с менеджером распределённых ресурсов Torque.
Как и в первой лабораторной работе, студенту предстоит освоить написание,
компиляцию и запуск программ, но уже на linux-кластере и в пакетном режиме и
проанализировать результаты выполнения.
Третья работа посвящена, показателям эффективности параллельных
алгоритмов. В ней студент, используя данные, полученные в первых двух
лабораторных работах, должен рассчитать следующие показатели: ускорение,
эффективность и стоимость параллельных вычислений.
Каждая работа для наглядности сопровождается построением графиков.
2.2 Содержание лабораторных работ
2.2.1 Рабочее задание для лабораторной работы №1
· Средствами MPICH2 организовать кластер из настольных
компьютеров. Для этого установить и настроить MPICH2 на каждом компьютере,
который будет использоваться в качестве вычислительного или управляющего узла
кластера.
· Написать и откомпилировать параллельную программу для запуска
в интерактивном режиме на реализованном кластере. Для этого требуется
установить среду разработки, например Visual C++, добавить в неё библиотеку
MPICH2 и откомпилировать написанную программу.
· Произвести многократный запуск программы с занесением
выходных данных о времени выполнения данных в таблицу. Для запуска параллельных
программ используется программа, входящая в пакет MPICH2 mpiexec.exe, которую
нужно запустить из командной строки с передачей таких параметров как путь к
параллельной программе, кол-во вычислительных узлов, их IP-адреса или имена,
число процессов параллельной программы и т.д. Ввиду сложности такой команды
предусмотрен пользовательский интерфейс для генерации такой команды на
основании исходных данных, вводимых пользователем. На основании предложенного
варианта необходимо выполнить параллельную программу несколько раз и занести
данные в Таблицу 2.1.
Таблица 2.1 Лабораторная работа №1. Результаты выполнения MPI-программ
|
Вычислительные узлы
|
Сложность задачи (Число итераций )
|
Время выполнения
|
|
|
Равномерно распределённая нагрузка
|
Сбалансировано распределенная нагрузка
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
· Построить зависимости времени выполнения программы от
сложности задачи для равномерно и сбалансировано распределенной нагрузки на
основании данных таблицы.
2.2.2 Рабочее задание для лабораторной работы №2
· Написать и откомпилировать параллельную программу для запуска
в пакетном режиме на кластере МИИТ Т-4700. Для этого необходимо получить доступ
к linux-кластеру через протокол SSH (воспользовавшись, например, PuTTy или
WinSCP) и откомпилировать написанную программу с помощью программы-компилятора,
входящей в состав mvapch2.
· Составить скрипт задания менеджера распределённых ресурсов
TORQUE, выполняющую параллельную программу в пакетном режиме, в котором
необходимо описать выходной файл, путь и название и прочие опции выполнения
программы.
· Программа и скрипт должны содержать шапку в виде комментария
с указанием номера и названия лабораторной работы, фамилии студента и номера
группы.
· Произвести многократный запуск программы с занесением
приведённых ниже показателей в таблицу. На основании предложенного варианта
необходимо выполнить параллельную программу с помощью mpiexec несколько раз и
занести данные в Таблицу 2.2.
Таблица 2.2 Лабораторная работа №2. Результаты выполнения MPI-программ
|
Опции запуска MPI-программы
|
Сложность задачи
|
Время выполнения
|
|
Число узлов
|
Число ядер
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
· Построить зависимости времени выполнения программы от
сложности задачи и числа вычислительных узлов и ядер на основании данных
таблицы.
2.2.3 Рабочее задание для лабораторной работы №3
· Рассчитать показатели эффективности использования кластеров
(ускорение, эффективность, стоимость (данные показатели описаны подробнее в п.
1.2.2.)), на основании данных, полученных в Лабораторных работах №1 и №2.
Таблица 2.3 Расчёт показателей эффективности кластера на базе MPICH2
|
Вычислительные узлы
|
Сложность задачи
|
Время выполнения при сбалансировано распределенной нагрузке
|
Ускорение Sp(n)= T1(n)/Tp(n)
|
Эффективность Ep(n) =Sp(n)/p
|
Стоимость Cp=pTp
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2.4 Расчёт показателей эффективности кластера МИИТ Т-4700
|
Опции запуска MPI-программы
|
Сложность задачи
|
Время выполнения при сбалансировано распределенной нагрузке
|
Ускорение Sp(n)= T1(n)/Tp(n)
|
Эффективность Ep(n) =Sp(n)/p
|
Стоимость Cp=pTp
|
|
Число узлов
|
Число ядер
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
· Построить зависимости показателей эффективности параллельных
алгоритмов от сложности задачи и конфигурации кластера на основании данных
таблицы.
· Проанализировать результат и сделать вывод.
2.3 Разработка программного обеспечения для лабораторного
комплекса
Как было заключено на этапе предпроектного анализа, комплект MPICH2
включает пользовательский интерфейс для запуска параллельных программ
wmpiexec.exe. Программа, на основании данных, введённых пользователем,
генерирует команду запуска и выполняет её. Данный интерфейс имеет следующий
недостаток: команды, генерируемые им, распределяют нагрузку между узлами
равномерно, без балансировки.
Разработанная программа - Интерфейс для MPICH - устраняет недостаток,
описанный выше, т.е. позволяет на основании данных, описанных в требованиях к
исходным данным (п.1.4.5) , сгенерировать команду для запуска параллельной
программы, распределяющую нагрузку по желанию пользователя или сбалансировав
нагрузку в автоматическом режиме с учётом производительности узлов, которые
должны быть задействованы для решения конкретной задачи. Кроме того для
удобства пользователя предусмотрены возможности сохранения и загрузки настроек.
Внешний вид интерфейса представлен на рисунке 2.1.
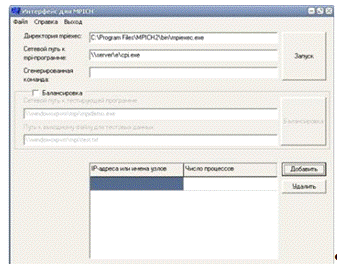
Рисунок 2.1 Внешний вид программы Интерфейс для MPICH
диаграмма вариантов использования разработанного обеспечения представлена
на рисунке 2.2.
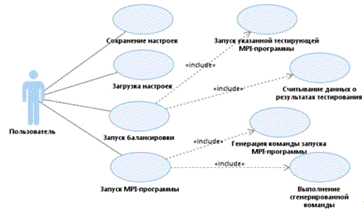
Рисунок 2.2 UML-Диаграмма вариантов использования Интерфейса для MPICH
Запуск балансировки и запуск MPI-программ рассмотрен подробнее с помощью
диаграмм активности(Рис. 2.3 и 2.4).
Для балансировки пользователь вводит необходимые исходные данные: сетевые
имена узлов, сетевое имя тестирующей программы и сетевое имя файла для
выходного файла. Далее Интерфейс для MPICH генерирует и выполняет команду,
запускающую тестирующую MPI-программу. Принципы работы MPICH2 описаны подробно
в п. 1.2.4. Тестирующей MPI-программой может стать любая программа, которая
равномерно распределяет нагрузку между вычислительными узлами кластера, после
чего помещает в выходной файл целые величины, которые пропорциональны скорости
вычислений каждого узла. В данной работе для тестирования используется
программа вычисления числа Пи. Интерфейс считывает выходные данные тестирующей
MPI-программы и помещает в столбец таблицы «Число процессов» напротив каждого
вычислительного узла.
Запуск балансировки главным образом это запуск тестирующей специфической
MPI-программы, который по сути мало чем отличается от Запуска
MPI-программы(Рис. 2.4).
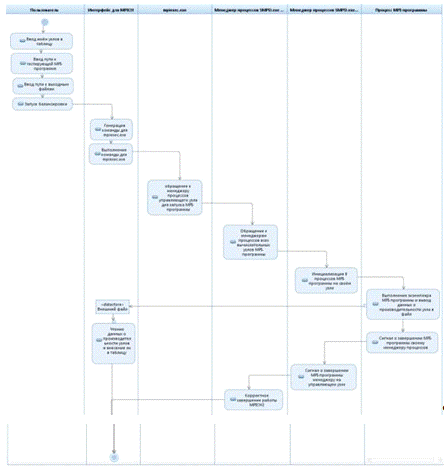
Рисунок 2.3 UML-диаграмма деятельности запуска балансировки
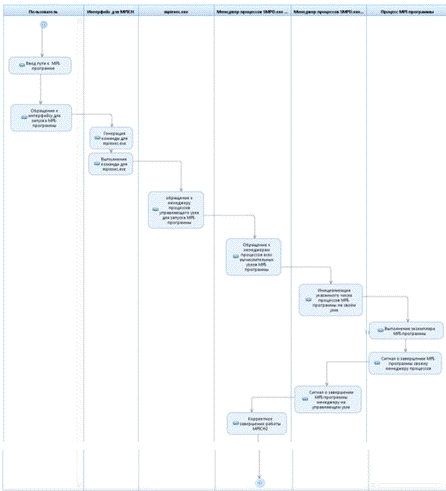
Рисунок 2.4 UML-диаграмма деятельности запуска MPI-программы
Листинг программы Интерфейс для MPICH и используемой ей тестирующей
программы представлен в приложении 1.
кластерный технология лабораторный программный
2.4 Подготовка рабочих мест и описание хода
выполнения лабораторных работ
2.3.1 Лабораторная работа №1
2.3.1.1 Подготовка рабочего места для выполнения лабораторной
работы №1
Установка
ПО
Перед тем как приступить к выполнению лабораторной
работы №1 необходимо загрузить последнюю версию MPICH2 с официального сайта
разработчика: #"868476.files/image006.gif">
Рисунок 2.5 Указание пароля для доступа к менеджеру
процессов
В окне указания пути установки рекомендуется оставить
каталог по умолчанию. Кроме того, поставить точку в пункте «Everyone»(Рис.
2.6):
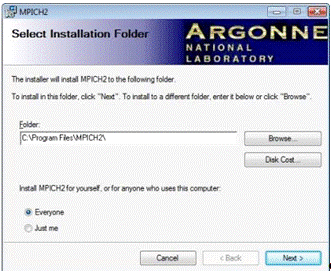
Рисунок 2.6 Указание пути установки
Если Windows спросит, разрешить ли доступ в сеть
программе smpd.exe, то нажмите «Разрешить».
Прежде чем переходить к настройке, обязательно следует
проверить:
· запущена ли служба «MPICH2 Process
Manager»,
· разрешён ли этой службе доступ в
сеть.
Необходимо зайти в службы: Пуск → Настройка →
Панель управления → Администрирование → Службы. Служба «MPICH2 Process
Manager» должна быть в списке служб (Рис. 2.7) и должна работать.

Рисунок 2.7 Служба «MPICH2 Process Manager» в списке
служб
Далее следует зайти в настройки брэндмауэра Windows:
Пуск → Настройка → Панель управления → Брандмауэр Windows и
добавить программы «Process launcher for MPICH2 applications» и «Process
manager service for MPICH2 applications» в список исключений.
Настройка
MPICH2
Необходимо создать на каждом компьютере пользователя с одинаковым именем
и паролем. От имени этого пользователя будут запускаться MPI-программы.
Любое действие система MPICH выполняет от указанного имени пользователя.
Для того, чтобы спрашивать имя пользователя и пароль, используется программа
Wmpiregister. Проблема в том, что имя пользователя и пароль спрашиваются
достаточно часто, что может вызывать раздражение. Для того, чтобы этого
избежать, Wmpiregister может сохранять имя пользователя и пароль в реестре
Windows. Для этого необходимо:
· запустить программу wmpiregister,
· ввести имя пользователя в поле Account,
· ввести пароль в поле password,
· нажать кнопку Register
· нажать кнопку OK
Теперь при обращении к mpiexec, задания будут выполняться на всех узлах
от имени этого пользователя, и вводить пароль повторно пользователю mpich2 не
придётся.
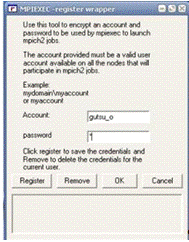
Рис. 2.8 Скриншот программы wmpiregister
Создание
общего сетевого ресурса
Для удобного запуска MPI-программ следует создать на одном из компьютеров
общий сетевой ресурс. Для этого требуется в свойствах папки на вкладке
«Доступ» (в нерусифицированной версии Windows - «Sharing») открыть доступ к
папке. В этой папке будут храниться MPI-программы и выходные данные тестирующих
программ.
2.3.1.2 Описание хода лабораторной работы №1
Создание
MPI-программы в Visual Studio
Необходимо добавить файлы библиотеки MPICH2 в среду разработки.(Рис. 2.9,
2.10)
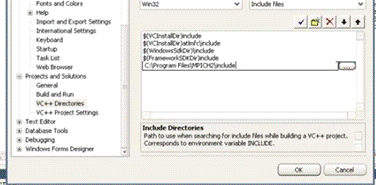
Рис. 2.9 Добавление заголовочных файлов mpich2 в среду разработки Visual
C++
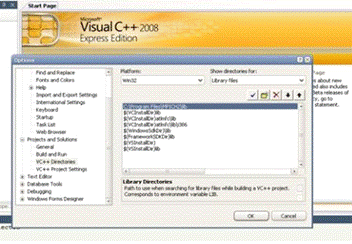
Рис. 2.10 Добавление библиотечных файлов mpich2 в среду разработки Visual
C++
Также необходимо добавить библиотеку mpi.lib в проект, отредактировав
свойства проекта (Рис. 2.11).
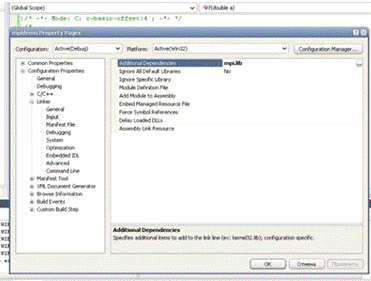
Рис. 2.11 Добавление библиотеки mpi.lib в проект Visual C++
Любой участок кода, который может быть выполнен отдельно независимо от
других, можно выполнять параллельно в отдельном потоке или процессе. Для
демонстрации воспользуемся программой вычисляющей число Пи. Метод нахождения
числа Пи заключается в численном решении интеграла:
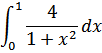
Вычисление такого интеграла по методу прямоугольников сводится к
дискретизации подынтегральной функции и суммированию площадей прямоугольников
под функцией (Рис. 2.12):
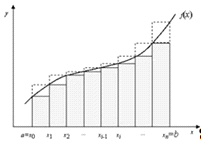
Рисунок 2.12 Подынтегральная функция
Чем выше частота дискретизации, тем точнее результат.
В нашей задаче выполнение суммирования(в листинге этот участок кода
помечен бледным цветом) можно распараллелить, т.к. итерации не зависят друг от
друга, а затем посчитать общую сумму результатов всех процессов.
Программа при запуске запрашивает у пользователя в интерактивном режиме
число интервалов для суммирования - это и есть частота дискретизации(n).
Листинг
программы MPI-программы
// Подключение необходимых заголовков
#include <stdio.h>
#include <math.h>
// Подключение заголовочного файла MPI
#include "mpi.h"
// Функция для промежуточных вычисленийf(double a)
{(4.0 / (1.0+ a*a));
}
// Главная функция программыmain(int argc, char **argv)
{
// Объявление переменныхdone = 0, n, myid, numprocs, i;PI25DT =
3.141592653589793238462643;mypi, pi, h, sum, x;startwtime = 0.0,
endwtime;namelen;processor_name[MPI_MAX_PROCESSOR_NAME];
// Инициализация подсистемы MPI_Init(&argc, &argv);
// Получить размер коммуникатора MPI_COMM_WORLD
// (общее число процессов в рамках
задачи)_Comm_size(MPI_COMM_WORLD,&numprocs);
// Получить номер текущего процесса в рамках
// коммуникатора
MPI_COMM_WORLD_Comm_rank(MPI_COMM_WORLD,&myid);_Get_processor_name(processor_name,&namelen);
// Вывод номера потока в общем пуле(stdout, "Process %d of %d is on
%s\n", myid,numprocs,processor_name);(stdout);
(!done)
{
// количество интервалов(myid==0)
{(stdout, "Enter the number of intervals: (0 quits)
");(stdout);(scanf("%d",&n) != 1)
{(stdout, "No number entered; quitting\n");= 0;
}= MPI_Wtime();
}
// Рассылка количества интервалов всем процессам (в том числе и
себе)_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);(n==0)= 1;
{= 1.0 / (double) n;= 0.0;
// Обсчитывание точки, закрепленной за процессом
for(i = myid + 1 ; (i <= n) ; i += numprocs)
{= h * ((double)i - 0.5);+= f(x);
}= h * sum;
// Сброс результатов со всех процессов и сложение_Reduce(&mypi,
&pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
// Если это главный процесс, вывод полученного результата(myid==0)
{("PI is approximately %.16f, Error is %.16f\n", pi, fabs(pi -
PI25DT));= MPI_Wtime();("wall clock time = %f\n",
endwtime-startwtime);(stdout);
}
}
}
// Освобождение подсистемы MPI_Finalize();0;
}
Запуск
MPI-программ
Для запуска MPI-программ в комплект MPICH2 входит программа с графическим
интерфейсом Wmpiexec, которая представляет собой оболочку вокруг соответствующей
утилиты командной строки Mpiexec. Однако Wmpiexec не обладает функцией
балансировки нагрузки между узлами с разной производительностью. Поэтому для
запуска предлагается воспользоваться программой Интерфейс для MPICH(Рис. 2.13).
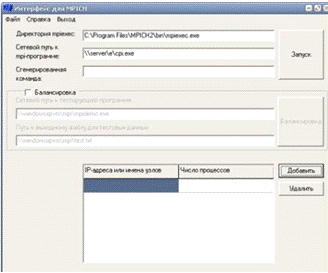
Рис. 2.13 Скриншот программы Интерфейс для MPICH
Балансировка
Для балансировки нагрузки, необходимо:
· Внести данные в таблицу(имя компьютера или IP-адрес).
· Указать сетевой путь к тестирующей программе, и сетевой путь
к выходному файлу.
· Нажать кнопку «Балансировка».
В результате успешного завершения балансировки значения в столбце число
процессов установятся на рекомендованные.
Для запуска программы, необходимо, чтобы таблица узлов была полностью
заполнена. При этом пользователь может изменить рекомендованные программой
значения. Также должен быть указан путь к mpiexec.exe и сетевой путь к
MPI-программе. После введения данных нужно нажать «Запуск».
Результаты
выполнения MPI-программы
В ходе дальнейшего выполнения лабораторной работы необходимо выполнить
MPI-программу несколько раз и занести данные о времени выполнения программы в
таблицу №1. В столбце Вычислительные узлы нужно перечислить узлы, на
которых выполняется задание. Сложность задачи это параметр, который
определяет объем вычислений для решения проблемы. В общем случае это может быть
заданная точность вычислений, объём входных данных и т.д. В нашем случае это
число итераций вычисления интеграла. После выполнения MPI-программы с заданными
(согласно варианту) сложностью и конфигурацией кластера, необходимо внести
время выполнения программы в секундах в таблицу. Если задача решается
нескольких узлах то необходимо произвести запуск в 2-х режимах: с равномерно
распределённой нагрузкой и сбалансировано распределённой.
В данном примере запуск MPI-программы производится на следующих
конфигурациях:
· 2 узла с двухядерными процессорами(Рис 2.14);
· 1 узел с одним ядром(если назначить 1 узлу только один
процесс, то он будет выполняться на одном ядре, т.е. последовательно);
· 1 узел с числом процессов, назначенных ему, растущим как 2x
,где x - номер опыта (т.е. 1, 2, 4, 8, 16, 32, 64), для демонстрации влияния
накладных расходов распараллеливания задачи на общее время выполнения
программы.
Естественно, о сбалансированном режиме в случае работы одного узла,
говорить не имеет смысла, поэтому в соответствующей ячейке стоит прочерк.

Рисунок. 2.14 Схема кластера из 2-х узлов
Таблица №2.5 Результаты выполнения MPI-программ на кластере на базе
MPICH2
|
Вычислительные узлы
|
Сложность задачи
|
Время выполнения
|
|
|
Равномерно распределённая нагрузка
|
Сбалансировано распределенная нагрузка
|
|
Узел 1 Узел 2
|
0.137732
|
0.010345
|
|
1000
|
0.003373
|
0.003709
|
|
1000000
|
0.010750
|
0.006647
|
|
10000000
|
0.061743
|
0.150230
|
|
100000000
|
0.536879
|
0.428189
|
|
500000000
|
2.368173
|
1.638354
|
|
1000000000
|
4.806102
|
3.204190
|
|
2000000000
|
9.413170
|
6.402070
|
|
Узел 1 последовательное выполнение
|
1
|
0.000311
|
-
|
|
1000
|
0.000274
|
-
|
|
1000000
|
0.008735
|
-
|
|
10000000
|
0.088661
|
-
|
|
100000000
|
0.885291
|
-
|
|
500000000
|
4.463532
|
-
|
|
1000000000
|
8.913408
|
-
|
|
2000000000
|
17.874241
|
-
|
|
Узел 1:1 процесс
|
1000000
|
0.008860
|
-
|
|
Узел 1:2 процесса
|
1000000
|
0.004488
|
-
|
|
Узел 1:4 процесса
|
1000000
|
0.004782
|
-
|
|
Узел 1:8 процессов
|
1000000
|
0.005014
|
-
|
|
Узел 1:16 процессов
|
1000000
|
0.006190
|
-
|
|
Узел 1:32 процесса
|
1000000
|
0.007988
|
-
|
|
Узел 1:64 процесса
|
1000000
|
0.013651
|
-
|
Построение
графиков
По данным из таблицы требуется построить зависимости времени выполнения
от сложности задачи для равномерно и сбалансировано распределенной нагрузки.

Рисунок 2.15 График времени выполнения вычислений
Полученные данные и построенные на их основании графики наглядно
демонстрируют эффект от применения распараллеливания. Также видно, что в связи
с тем, что один из узлов намного производительнее другого, балансировка смогла
существенно улучшить временные показатели вычислений.
На следующем графике (Рисунок 2.16) показана зависимость времени
вычисления от числа параллельных процессов при одинаковой сложности задачи.
Очевидно, что когда число процессов превышает число ядер, накладные расходы на
обмен данными между процессами ухудшают временные показатели. При определённых
условиях увеличение числа процессов может сделать параллельный алгоритм по
скорости хуже последовательного.

Рисунок 2.16 Время выполнения программы сложностью 1М итераций
2.3.2 Лабораторная работа №2
2.3.2.1 Подготовка рабочего места для выполнения лабораторной
работы №2
Перед выполнением лабораторной работы №2 требуется получить доступ к
кластеру, запросив его у администратора. Возможно выполнение лабораторной
работы всей группой от имени одного пользователя. После получения имени и
пароля для доступа через протокол SSH и загрузки свободно распространяемых
программ PuTTY, WinSCP, не требующих установки на рабочей станции, можно
приступить к работе.
2.3.2.2 Описание хода лабораторной работы №2
Подключение
к кластеру МИИТ Т-4700
Доступ к кластеру осуществляется через протоколы SSH, SFTP. Для этого
можно воспользоваться PuTTY, WinSCP и другими клиентами. В данном описании
будет использоваться WinSCP. Требуется запустить WinSCP.exe и создать новую
сессию. В открывшемся окне ввести данные о подключении: название хоста, номер
порта, имя пользователя и пароль, как показано на рисунке 2.17.
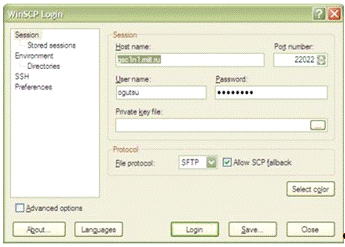
Рисунок 2.17 Скриншот программы WinSCP
Компиляция
программы
Для компиляции mpi-программы на linux-кластере используется
программа-компилятор. В mpich есть компиляторы для языков C, C++, Fortran.
Чтобы откомпилировать программу написанную на языке C++, требуется, после того
как файл с исходником перенесён в папку пользователя с помощью WinSCP, послать
через терминал команду общего вида:
<утилита-компилятор> -o <исполняемый файл MPI-программы>
<исходный файл MPI-программы>
В нашем случае необходимо выполнить следующую команду:@gsc1n1:~>
/share/mpi/mvapich2-1.2p1-pgi/bin/mpicxx -o /mnt/scratch/home/ogutsu/cpi.mpi
/mnt/scratch/home/ogutsu/pi.c
Где, mpicxx - утилита-компилятор для C++, после ключа -o следует путь к
исполняемому файлу /mnt/scratch/home/ogutsu/cpi.mpi, который будет сформирован
в результате компиляции, и после пробела указан путь к исходному коду
MPI-программы /mnt/scratch/home/ogutsu/pi.c.
Листинг
программы MPI-программы
#include "mpi.h"
#include <stdio.h>
#include <math.h>
f(double);
f(double a)
{(4.0 / (1.0 + a*a));
}
main(int argc,char *argv[])
{done = 0, n=1000000000, myid, numprocs, i;PI25DT =
3.141592653589793238462643;mypi, pi, h, sum, x;startwtime = 0.0,
endwtime;namelen;processor_name[MPI_MAX_PROCESSOR_NAME];
_Init(&argc,&argv);_Comm_size(MPI_COMM_WORLD,&numprocs);_Comm_rank(MPI_COMM_WORLD,&myid);_Get_processor_name(processor_name,&namelen);
(myid == 0) {
fflush(stdout);(n==0) {
fprintf( stdout, "No number entered;
quitting\n" );
n = 0;
}
startwtime = MPI_Wtime();
}_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);(n == 0)= 1;{= 1.0 /
(double) n;= 0.0;(i = myid + 1; i <= n; i += numprocs) {= h * ((double)i -
0.5);+= f(x);
}= h * sum;_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
(myid == 0) {("pi is approximately %.16f, Error is %.16f\n",,
fabs(pi - PI25DT));
endwtime = MPI_Wtime();
printf("wall clock time = %f\n",
endwtime-startwtime);
fflush( stdout );
}
}
_Finalize();0;
}
Составление
скрипта задания
После компиляции по указанному пути появится исполняемый файл программы.
Для её запуска требуется написать задание, выполнение управление которым на
linux-кластере осуществляет менеджер распределённых ресурсов Torque. Задание
запуска программы полученной выше для менеджера ресурсов Torque представляет
собой скрипт следующего содержания:
#!/bin/bash
#PBS -o /mnt/scratch/home/ogutsu/mylogstart
/share/mpiexec-0.83/mpiexec /mnt/scratch/home/ogutsu/cpi.mpiend
Данный определяет путь к файлу стандартного вывода /mnt/scratch/home/ogutsu/mylog,
запускает утилиту /share/mpiexec-0.83/mpiexec, которая выполняет mpi-программы,
в данном случае нашу /mnt/scratch/home/ogutsu/cpi.mpi. Написание и запуск
заданий для менеджера распределённых ресурсов Torque описано подробнее в
приложении 2.
Запуск
заданий
Общая схема кластера под управлением менеджера ресурсов Torque изображена
на рисунке 2.18.
Команда-l nodes=20 f1.pbs
помещает задание f1.pbs, которое нужно выполнить на 20 узлах кластера, в
очередь. Если задание первое в очереди, то оно выполняется. Задание выполняет
программу в пакетном режиме, помещая вывод в файл, указанный в скрипте задания.
Его содержимое можно легко посмотреть.
Содержимое /mnt/scratch/home/ogutsu/mylog:is approximately
3.1415926535899708, Error is 0.0000000000001776clock time = 8.752536
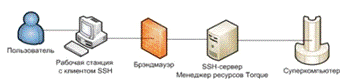
Рисунок 2.18 Схема кластера, управляемого менеджеров ресурсов Torque
Занесение
данных в таблицу
Результаты многократного запуска программы следует занести в таблицу №2.
В столбце Опции запуска MPI-программы нужно написать число узлов и
ядер, на которых выполняется задание. О запуске заданий менеджера
распределённых ресурсов Torque написано подробнее в приложении 2. В качестве сложности
задачи снова выступает число итераций вычисления интеграла. Т.к.MPI-
программа выполняется на кластере в пакетном режиме, варьировать этот параметр
нужно в самой программе или передавая программе параметр при запуске. После
выполнения MPI-программы с заданными (согласно варианту) сложностью и числом
вычислительных узлов, необходимо внести время выполнения программы в секундах в
таблицу 2.6. В последней серии опытов число ядер меняется по закону 2n-1, где n
номер опыта, а сложность задачи меняется пропорционально числу ядер, начиная с
числа 16777216, т.е. 223+n.
Таблица №2.6 Результат выполнения вычислений на кластере МИИТ Т-4700
|
Опции запуска MPI-программы
|
Сложность задачи
|
Время выполнения
|
|
Число узлов
|
Число ядер
|
|
|
|
1
|
8
|
1000000000
|
1.264005
|
|
2
|
8
|
1000000000
|
0.702406
|
|
3
|
8
|
1000000000
|
0.567381
|
|
4
|
8
|
1000000000
|
0.447176
|
|
5
|
8
|
1000000000
|
0.412220
|
|
6
|
8
|
1000000000
|
0.366205
|
|
7
|
8
|
1000000000
|
0.298248
|
|
8
|
8
|
1000000000
|
0.241296
|
|
9
|
8
|
1000000000
|
0.214650
|
|
10
|
8
|
1000000000
|
0.163198
|
|
1
|
1
|
1000000
|
0.017913
|
|
2
|
1000000
|
0.009362
|
|
4
|
1000000
|
0.004605
|
|
8
|
1000000
|
0.002418
|
|
2
|
8
|
1000000
|
0.001659
|
|
4
|
8
|
1000000
|
0.000832
|
|
8
|
8
|
1000000
|
0.000616
|
|
16
|
8
|
1000000
|
0.000605
|
|
1
|
1
|
16777216
|
0.199176
|
|
2
|
33554432
|
0.210453
|
|
4
|
67108864
|
0.231804
|
|
8
|
134217728
|
0.224581
|
|
2
|
8
|
268435456
|
0.221952
|
|
4
|
8
|
536870912
|
0.264089
|
|
8
|
8
|
1073741824
|
0.272010
|
3. СИСТЕМОТЕХНИЧЕСКИЙ
РАСЧЁТ: РАСЧЁТ ПОКАЗАТЕЛЕЙ ЭФФЕКТИВНОСТИ ВЫЧИСЛЕНИЙ
3.1 Описание показателей эффективности параллельных вычислений
Содержание лабораторной работы №3 связано с оценкой показателей
эффективности вычислительного процесса на базе кластерных технологий. К таким
показателям относятся ускорение, эффективность алгоритма и стоимость
вычислений.
Ускорение (speedup), получаемое при использовании параллельного
алгоритма для p процессоров, по сравнению с последовательным вариантом
выполнения вычислений определяется величиной
Sp(n)=T1(n)/Tp(n),
т.е. как отношение времени решения задач на скалярной ЭВМ к времени
выполнения параллельного алгоритма (величина n применяется для параметризации
вычислительной сложности решаемой задачи и может пониматься, например, как
количество входных данных задачи).
Эффективность (efficiency) использования параллельным алгоритмом
процессоров при решении задачи определяется соотношением
Ep(n)=T1(n)/(pTp(n))=Sp(n)/p
(величина эффективности определяет среднюю долю времени выполнения
алгоритма, в течение которой процессоры реально задействованы для решения
задачи).
Из приведенных соотношений можно показать, что в наилучшем случае Sp(n)=p
и Ep(n)=1. При практическом применении данных показателей для оценки
эффективности параллельных вычислений следует учитывать два важных момента:
При выборе надлежащего параллельного способа решения задачи может
оказаться полезной оценка стоимости (cost) вычислений, определяемой как
произведение времени параллельного решения задачи и числа используемых
процессоров
Cp=pTp.
В связи с этим можно определить понятие стоимостно-оптимального
(cost-optimal) параллельного алгоритма как метода, стоимость которого
является пропорциональной времени выполнения наилучшего последовательного
алгоритма.
Оценка показателей производится по результатам измерений, полученным при
выполнении первых двух лабораторных работ и сведены в таблицы 3.1 и 3.2.
3.2 Описание хода лабораторной работы №3
Рассчитать показатели эффективности алгоритмов (ускорение, эффективность,
стоимость), на основании данных, полученных в Лабораторных №1 и №2.
Таблица 3.1 Расчёт показателей эффективности вычислений кластера на базе
MPICH2
|
Вычислительные узлы
|
Сложность задачи
|
Время выполнения
|
Ускорение Sp(n) = T1(n)/Tp(n)
|
Эффективность Ep(n) = Sp(n)/p
|
Стоимость Cp = pTp
|
|
Узел 1 Узел 2
|
1
|
0.010345
|
0.03006283
|
0.00751571
|
0.04138
|
|
1000
|
0.003709
|
0.07387436
|
0.01846859
|
0.01484
|
|
1000000
|
0.006647
|
1.31412667
|
0.32853167
|
0.02659
|
|
10000000
|
0.150230
|
0.59016841
|
0.1475421
|
0.60092
|
|
100000000
|
0.428189
|
2.06752392
|
0.51688098
|
1.71276
|
|
500000000
|
1.638354
|
2.72440022
|
0.68110006
|
6.55342
|
|
1000000000
|
3.204190
|
2.78179758
|
0.6954494
|
12.8168
|
|
2000000000
|
6.402070
|
2.79194714
|
0.69798678
|
25.6083
|
|
Узел 1:1 процесс
|
1000000
|
0.008860
|
1
|
1
|
0.00886
|
|
Узел 1:2 процесса
|
1000000
|
0.004488
|
1.974153298
|
0.987076649
|
0.008976
|
|
Узел 1:4 процесса
|
1000000
|
0.004782
|
1.852781263
|
0.463195316
|
0.019128
|
|
Узел 1:8 процессов
|
1000000
|
0.005014
|
1.767052254
|
0.220881532
|
0.040112
|
|
Узел 1:16 процессов
|
1000000
|
0.006190
|
1.431340872
|
0.089458805
|
0.09904
|
|
Узел 1:32 процесса
|
1000000
|
0.007988
|
1.109163746
|
0.034661367
|
0.255616
|
|
Узел 1:64 процесса
|
1000000
|
0.013651
|
0.649036701
|
0.010141198
|
0.873664
|
Показатели, рассчитанные в Таблице 3.1 и ломанные на рисунке 3.1 численно
и наглядно должны подтверждать выводы, сделанные в ходе лабораторной работы №1.
При неоправданно большом числе параллельных процессов, накладные расходы
на синхронизацию этих процессов превышают выигрыш от распараллеливания.
Таблица 3.2 Расчёт показателей эффективности вычислений кластера МИИТ
Т-4700
|
Опции запуска MPI-программы
|
Сложность задачи
|
Время выполнения
|
Ускорение Sp(n)= T1(n)/Tp(n)
|
Эффектив-ность Ep(n) = Sp(n)/p
|
Стоимость Cp= pTp
|
|
Число узлов
|
Число ядер
|
|
|
|
|
|
|
1
|
8
|
1000000000
|
1.264005
|
8.8517854
|
1.10647317
|
|
2
|
8
|
1000000000
|
0.702406
|
15.929108
|
0.99556925
|
11.2385
|
|
3
|
8
|
1000000000
|
0.567381
|
19.7199078
|
0.82166282
|
13.6171
|
|
4
|
8
|
1000000000
|
0.447176
|
25.0207994
|
0.78189998
|
14.3096
|
|
5
|
8
|
1000000000
|
0.412220
|
27.1425477
|
0.67856369
|
16.4888
|
|
6
|
8
|
1000000000
|
0.366205
|
30.5531082
|
0.63652309
|
17.5778
|
|
7
|
8
|
1000000000
|
0.298248
|
37.5147562
|
0.66990636
|
16.7019
|
|
8
|
8
|
1000000000
|
0.241296
|
46.3691939
|
0.72451865
|
15.4429
|
|
9
|
8
|
1000000000
|
0.214650
|
52.1253249
|
0.72396285
|
15.4548
|
|
10
|
8
|
1000000000
|
0.163198
|
68.5590571
|
0.85698821
|
13.0558
|
|
1
|
1
|
1000000
|
0.017913
|
1
|
1
|
0.01791
|
|
2
|
1000000
|
0.009362
|
1.91337321
|
0.95668661
|
0.01872
|
|
4
|
1000000
|
0.004605
|
3.88990228
|
0.97247557
|
0.01842
|
|
8
|
1000000
|
0.002418
|
7.40818859
|
0.92602357
|
0.01934
|
|
2
|
8
|
1000000
|
0.001659
|
10.7974684
|
0.67484177
|
0.02654
|
|
4
|
8
|
1000000
|
0.000832
|
21.5300481
|
0.672814
|
0.02662
|
|
8
|
8
|
1000000
|
0.000616
|
29.0795455
|
0.4543679
|
0.03942
|
|
16
|
8
|
1000000
|
0.000605
|
29.6082645
|
0.23131457
|
0.07744
|
На кластере МИИТ Т-4700, рост накладных расходов при решении задачи
низкой сложности делает сильное распараллеливание всё менее эффективным в отличие
от случая с большой сложностью задачи, о чём свидетельствуют убывающий графики
ускорения и эффективности(рис 3.2 и 3.3).
4. АНАЛИЗ
ЧЕЛОВЕКО-МАШИННОГО ВЗАИМОДЕЙСТВИЯ
В данном разделе речь пойдёт о разработке метода оценки для определения
готовности студента к обучению с использованием разрабатываемого лабораторного
комплекса «Кластерные системы». В основе разработки теста лежит теория тестовых
заданий (IRT).
4.1 Обзор теории тестовых заданий (Item response theory)
создана в рамках направления «Data Mining» (которое во
время создания IRT не называлось ещё никак) для выявления скрытых параметров, в
данном случае определяющих успешность учащихся и информативность
контрольно-измерительных материалов (так в современной литературе по обучающим
технологиям называются задания для контрольных работ, промежуточных испытаний,
экзаменов и т.п., мы же для краткости будем вести речь об экзаменах).
Достоинством IRT считается возможность сравнения по
одной шкале результатов экзаменов как по оцениваемым, так и по заданиям.
Фактически протокол экзаменов, записанный в виде таблицы (экзаменационную
ведомость) можно единообразно читать как по строкам (результаты студента по
многим экзаменам), так и по столбцам (результаты экзамена по группе студентов)
и, следовательно, единообразно оценивать успеваемость студентов и
информативность экзаменов в смысле критериальной валидности.решает ещё одну
важную задачу - в большинстве случаев оценки за результаты экзаменов
выставляются в баллах, вследствие чего математически корректная обработка таких
оценок возможна только в терминах порядковых статистик. IRT переводит шкалу
баллов в логиты, в результате получается возможность использования
математического аппарата, созданного для метрических шкал.
Основоположник IRT датский математик Г. Раш (G. Rasch)
ввел две меры: «логит уровня знаний» и «логит уровня трудности задания». Первую
он определил как логарифм отношения доли правильных ответов испытуемого на все
задания теста, к доле неправильных ответов, а вторую - как логарифм доли неправильных
ответов на задание теста к доле правильных ответов на тоже задание. Фактически
предлагается перейти от самих оценок на экзамене к логарифмам оценок
вероятностей успеха на экзамене для студента и вероятностей выполнения заданий
для экзаменов и, соответственно, к статистикам по множеству испытуемых. В
современных технологиях методы построения IRT-оценок не требуют больших затрат
времени и вычислительных ресурсов.
Содержательно интерпретация IRT позволяет в
статистическом смысле сравнить достижения разных студентов по разным учебным
дисциплинам и строить соответствующие рейтинги.
Отсюда же получается возможность построения оценок, не
зависящих от конкретного подбора заданий, и построение поправок в оценках на
сложность самих заданий, т.е. получается инструмент калибровки экзаменов, если
считать экзамен измерительной процедурой. Тем самым получается метод решения
принципиальной методической проблемы построения оценок на экзамене - даже по
математике невозможно в параллельных версиях экзамена подобрать задачи
одинаковой или хотя бы сравнимой трудности, по другим областям знаний это ещё
сложнее. В IRT поправка на трудность или сложность получается сдвигом
соответствующей характеристической кривой.
В литературе известно мнение об общей устойчивости
IRT-оценок в смысле test-retest-, crosstest- и test-subtest-валидностей, но,
вообще говоря, в каждом конкретном случае эту устойчивость надо доказывать
отдельно.
В IRT вводится основное предположение о существовании
некоторой взаимосвязи между наблюдаемыми результатами и латентными качествами
испытуемых. Предполагается, что каждому испытуемому ставится в соответствие
только одно значение латентного параметра. Элементы первого множества - это
уровни знаний N испытуемых θi, где i = 1,...,N.
Второе множество образуют значения латентного параметра δj, j = 1,…,K, равные
трудностям k заданий. На практике решается задача по ответам испытуемых
на задания оценить значения латентных параметров θ и δ.
4.2 Процедура расчёта
Чтобы разработать тест для определения готовности студента к обучению с
использованием разрабатываемого лабораторного комплекса «Кластерные системы»,
десяти испытуемым были предложены 12 заданий. В дихотомической матрице (Таблица
4.1) ответы характеризуется двумя символами 0 и 1. Нулю соответствует неверный ответ,
единице - верный ответ.
Таблица 4.1 Бинарная матрица результатов тестирования
|
Вопросы
|
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
|
Испытуемые
|
1
|
1
|
1
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
1
|
1
|
1
|
|
2
|
1
|
1
|
0
|
1
|
1
|
0
|
0
|
1
|
1
|
0
|
1
|
1
|
|
3
|
0
|
1
|
0
|
0
|
0
|
1
|
1
|
0
|
0
|
0
|
0
|
1
|
|
4
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
5
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
1
|
|
6
|
1
|
1
|
0
|
1
|
1
|
1
|
1
|
1
|
1
|
0
|
1
|
1
|
|
7
|
1
|
1
|
0
|
0
|
0
|
1
|
1
|
1
|
0
|
0
|
1
|
0
|
|
8
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
9
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
10
|
0
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
Вот список заданий, которые были предложены испытуемым:
. В чём разница между C и C++?
. Что такое Microsoft Visual C++?
3. Найдите
ошибки во фрагменте кода C.#include
<#"868476.files/image021.gif">
Далее вычисляем начальные значения уровня подготовленности испытуемых по
формуле:
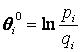
Здесь j пробегает значения от 1 до M, где M -количество испытуемых.
Величины pj и qj рассчитаны нами ранее и приведены в таблице 4.2.
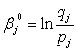
Таблица 4.4 Таблица расчёта сложности заданий
|
j
|
r
|
p
|
q
|
Β0
|
(β0)2
|
|
2
|
5
|
0.833
|
0.167
|
-1.609
|
2.590
|
|
11
|
5
|
0.833
|
0.167
|
-1.609
|
2.590
|
|
12
|
5
|
0.833
|
0.167
|
-1.609
|
2.590
|
|
1
|
4
|
0.667
|
0.333
|
-0.693
|
0.480
|
|
6
|
4
|
0.667
|
0.333
|
-0.693
|
0.480
|
|
7
|
4
|
0.667
|
0.333
|
-0.693
|
0.480
|
|
8
|
4
|
0.667
|
0.333
|
-0.693
|
0.480
|
|
4
|
3
|
0.500
|
0.500
|
0.000
|
0.000
|
|
5
|
2
|
0.333
|
0.667
|
0.693
|
0.480
|
|
9
|
2
|
0.333
|
0.667
|
0.693
|
0.480
|
|
3
|
1
|
0.167
|
0.833
|
2.590
|
|
10
|
1
|
0.167
|
0.833
|
1.609
|
2.590
|
|
|
|
|
-2.996
|
15.834
|
В таблицах 4.3. и 4.4 мы имеем значения параметров на разных интервальных
шкалах. Нам надо свести их в единую шкалу стандартных оценок. Для этого
необходимо вычислить дисперсии Sθ и Sβ, используя данные из таблиц.

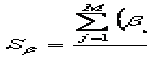
Далее вычисляем угловые коэффициенты
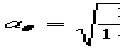
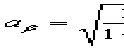
Наконец, мы можем записать оценки параметров θ и β на единой интервальной шкале.
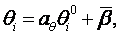
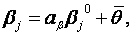
Результаты сведены в таблицы 4.5 и 4.6 (второй столбец).
Таблица 4.5 Сложность заданий
|
j
|
βn
|
|
2
|
-2.465
|
|
11
|
-2.465
|
|
12
|
-2.465
|
|
1
|
-0.82851
|
|
6
|
-0.82851
|
|
7
|
-0.82851
|
|
8
|
-0.82851
|
|
4
|
0.409456
|
|
5
|
1.647417
|
|
9
|
1.647417
|
|
3
|
3.283913
|
|
10
|
3.283913
|
Таблица 4.6 Подготовленность испытуемых
|
i
|
θn
|
|
10
|
3.552311
|
|
1
|
2.302181
|
|
6
|
2.302181
|
|
2
|
0.849367
|
|
7
|
0.283845
|
|
3
|
-1.34866
|
|
5
|
-1.99154
|
|
9
|
-4.0516
|
4.3 Построение характеристических кривых для заданий
По полученным данным можем построить характеристические кривые для
заданий. Характеристическая кривая описывается следующим уравнением:
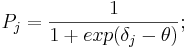
В принципе, вместо логистической функции можно использовать любую функцию
со смыслом функции распределения вероятностей, проверив обычными методами
статистическую гипотезу о соответствии теоретического и наблюдаемого
распределений, использование логистической функции связано отчасти с
историческими причинами, отчасти с простотой вычислений. Например, известна
модель Фергюссона, в которой вместо логистической функции строится функция
нормального распределения и вводится поправочный коэффициент в показателе
экспоненты для согласования моделей Раша и Фергюссона.
Характеристические кривые заданий показывают вероятность успеха в
зависимости от уровня его подготовленности. Чем выше уровень подготовленности θ испытуемого, тем выше вероятность
успеха в том или ином задании. Отметим, что в точках, где θ = β вероятность правильного ответа
должна быть равной 0,5. То есть, если трудность задания равна уровню
подготовленности (ability) испытуемого, то он с равной вероятностью может
справиться или не справиться с этим заданием.[8]
Сами кривые для нашего теста представлены на рисунке 4.1.

Рисунок 4.1 Характеристические кривые сложности заданий(сложность 1M
итераций)
1. 4.4 Обсуждение результатов и дальнейших действий
Построенные характеристические кривые должны помочь сделать вывод об
уровне подготовленности испытуемых и об эффективности диагностических
материалов, что необходимо для адекватной оценки знаний. Для этого можно
руководствоваться разными соображениями. С одной стороны, большее количество
заданий, даже если задания повторяют характеристические кривые друг друга,
повышает точность оценивания уровня знаний испытуемого. С другой стороны,
задания с близкими характеристическими кривыми в смысле измерительной ценности
неразличимы и поэтому ведут к ненужным затратам времени и других ресурсов.
Поэтому характеристические кривые заданий должны равномерно покрыть шкалу
потенциально возможных уровней знаний испытуемых. При измерении уровня знаний
по классической модели для каждого обучаемого формируется экзамен определенной
длины из выбранных случайным образом заданий. При этом экзамены отличаются по сложности,
и итоговая оценка формируется по статистике правильных ответов с учетом весовых
коэффициентов заданий. Недостатком такого метода может быть появление ситуаций,
когда слабому студенту попадается сложное задание и как следствие этого -
практическое отсутствие ответов. А сильный студент может получить легкий
экзамен и не проявить свои способности. Для обеспечения максимальной
информативности результатов контроля необходимо, чтобы средняя сложность
предъявляемого обучаемому задания соответствовала его гипотетическому уровню
готовности.
Практически это можно осуществить с помощью адаптивного тестирования.
Под адаптивным тестовым контролем понимают компьютеризованную систему
научно обоснованной проверки и оценки результатов обучения, настраиваемую под
когнитивные и прочие возможности каждого конкретного студента. Эффективность
контрольно-оценочных процедур повышается при использовании многошаговой
стратегии отбора и предъявления заданий, основанной на алгоритмах с полной
контекстной зависимостью, в которых очередной шаг совершается только после
оценки результатов выполнения предыдущего шага. После выполнения испытуемым
очередного задания каждый раз возникает потребность в принятии решения о
подборе трудности следующего задания в зависимости от того, верным или неверным
был предыдущий ответ. Алгоритм отбора и предъявления заданий строится по
принципу обратной связи, когда при правильном ответе испытуемого очередное
задание выбирается более трудным, а неверный ответ влечет за собой предъявление
последующего более легкого задания, чем то, на которое испытуемым был дан
неверный ответ. Также есть возможность задания дополнительных вопросов по
темам, которые обучаемый знает не очень хорошо для более тонкого выяснения
уровня знаний в данных областях. Таким образом, можно сказать, что адаптивная
модель напоминает преподавателя на экзамене - если обучаемый отвечает на
задаваемые вопросы уверенно и правильно, преподаватель достаточно быстро ставит
ему положительную оценку. Если обучаемый начинает «плавать», то преподаватель
задает ему дополнительные или наводящие вопросы того же уровня сложности или по
той же теме, и в зависимости от ответов повышает или понижает уровень сложности
заданий. И, наконец, если обучаемый с самого начала отвечает плохо, оценку
преподаватель тоже ставит достаточно быстро, но отрицательную.
К непременным условиям реализации таких алгоритмов следует отнести:
· наличие банка калиброванных заданий с устойчивыми оценками их
параметров, позволяющими прогнозировать успех или неуспех испытуемого при подборе
очередного задания адаптивного теста;
· использование программно-инструментальных средств и
компьютерных программ для индивидуализации алгоритмов подбора заданий,
основанных, как правило, на оценке вероятности правильного выполнения учебных
заданий;
· использование параметрических моделей Item Response
Theory.[7]
Тестирование можно начать с задания средней сложности, т.е. с задания со
сложностью равной 0 логитов. А следующее задание будет зависеть от правильности
ответа испытуемого. Если испытуемый решит задание верно, то следующий вопрос
будет сложнее, иначе будет предложен вопрос легче.
Тестирование заканчивается, когда обучаемый выходит на некоторый
постоянный уровень сложности, например, отвечает подряд на некоторое
критическое количество вопросов одного уровня сложности.
Достоинства:
· Выявляет темы, которые обучаемый знает плохо и позволяет
задать по ним ряд дополнительных вопросов.
Недостатки:
· Заранее неизвестно, сколько вопросов необходимо задать
обучаемому, чтобы определить его уровень знаний. Если вопросов, заложенных в
систему тестирования, оказывается недостаточно, можно прервать тестирование и
оценивать результат по тому количеству вопросов, на которое ответил обучаемый;
В таких случаях нужны поправки на динамику работоспособности и утомления
испытуемого. Этой поправки нет в известных моделях, следовательно, необходимо
исправить модель, что бы в ней она учитывалась.[8]
4.5 Вывод
Из таблицы 3.2.5 видно, что ∑βi=-0.44. Рекомендуется стремиться к тому,
чтобы ∑βi было близко к нулю. Чем ближе ∑βi
тем более
сбалансированным является тест. Однако если мы захотим оптимизировать тест и
сократить задания, которые обладают одинаковой характеристической кривой, то
тест в среднем станет труднее, т.к. в нашем случае сократить придётся именно
простые задания. С помощью такого теста адекватно оценить знания испытуемых с
невысоким уровнем подготовленности будет тяжело. Наиболее целесообразным
решением данной проблемы может стать применение адаптивного тестирования,
описанного ранее(п. 3.5.).
5. ЭКОНОМИЧЕСКАЯ
ЧАСТЬ
5.1 Постановка экономической задачи
Цель данной работы - Разработка лабораторного комплекса
«Кластерные технологии» в рамках дисциплины «Высокопроизводительные
вычислительные системы» для обучения студентов кафедры АСУ.
Кроме того в ходе дипломного проектирования будет разработано программное
обеспечение, которое будет представлять собой интерфейс, позволяющий запускать
параллельные программы, балансируя нагрузку между узлами кластера. Поставляемый
интерфейс MPICH2 этого не позволяет.
Настоящая разработка должна позволить:
· Повысить уровень подготовки студентов кафедры АСУ
· Оптимизировать временные затраты на организацию учебного
процесса
В результате дипломного проектирования будет разработан лабораторный
комплекс, для изучения и решения задач параллельного программирования с
использованием средств университета: кластера и стационарных компьютеров,
объединённых ЛВС.
Для оценки эффективности разработки выбран следующий показатель
социальной эффективности:
«Экономический уровень оплаты труда» (ЭУОТ), который отражает сумму
оплаты за выполнение сотрудником функций определённого уровня и позволяет
сделать выводы о том, насколько эффективно сотрудники располагают временем на
решение тех или иных функций.
В данном случае у сотрудников, участвующих в процессе подготовки
студентов кафедры АСУ по дисциплине «Высокопроизводительные вычислительные
системы», а именно у лектора и лаборанта, появится возможность более
эффективного распоряжения временем для выполнения их функций.
5.2 Расчет затрат, связанных с разработкой лабораторного
комплекса
Затраты, связанные с разработкой лабораторного комплекса определяются как
сумма затрат на техническое, программное обеспечение и разработку методического
и программного обеспечения.
Стоимость вычислительной техники, необходимой выполнения лабораторных
работ может быть представлена в виде таблицы:
Таблица 5.1 Стоимость вычислительной техники
|
Наименование элемента ТО
|
Количество
|
Назначение
|
Цена, руб.
|
SЦ
|
|
Настольный компьютер(включая периферийные устройства)
|
14
|
Рабочие станции для студентов в ауд.1313
|
40 000
|
560 000
|
|
Кластер МИИТ Т-4700 (полная стоимость проекта, монтаж,
аппаратное и программное обеспечение)
|
1
|
решения ресурсоемких вычислительных задач при промышленном
проектировании
|
80 000 000
|
80 000 000
|
|
Коммутатор
|
1
|
Коммутатор в ауд. 1313
|
10 000
|
10 000
|
В данном случае выполнение лабораторных работ реализуется на имеющемся
оборудовании, которое не закупается специально, а затрачивает часть свободного
ресурса , поэтому рассчитаем удельную стоимость технического обеспечения по
формуле:
Куд=Ц*t/Tгод
где Ц-стоимость первоначальная, используемого оборудования;
Ц1 =570 000 руб.
Ц2= 80 000 000 руб.
Для обучения студентов потребуется 3 часа работы на кластере МИИТ Т-4700
и 24 часа работы в аудитории в год1= 24 ч;=3 ч.
Т1год ,Т2год - временной ресурс имеющегося оборудования за год:
Т1год= 8*22*12 = 2 112 ч;
Т2год= 24*30*12 = 8640 ч.
Ц2 следует умножить на 20/64, т.к. для учебных нужд есть возможность
задействовать не все узлы кластера 20 из них достаточно.
Куд1= (570 000 х 24)/2112 = 6470 руб.
Куд2= (80 000 000 х 20/64 х 3)/8640 = 8680 руб.
Затраты на реконструкцию и строительство в случае кластера МИИТ Т-4700
уже учтены, а в аудитории 1313 не требуются, поэтому дополнительных расчётов
стоимости строительства и реконструкции не потребуется.
Стоимость периферийных устройств так же учтена в цене кластера и
настольного компьютера.
Таблица 5.2 Стоимость лицензий на программное обеспечение
|
Наименование элемента ПО
|
Количество
|
Назначение
|
Цена, руб.
|
SЦ
|
|
MS Windows XP Professional
|
14
|
Операционная система рабочей станции в ауд. 1313
|
5 500
|
77 000
|
Остальное используемое программное обеспечение распространяется свободно.
ЦПО=77 000 руб.
Как и в случае с техническим обеспечением должна быть рассчитана удельная
стоимость на программное обеспечение
Куд3= (77 000 х 24)/2112 = 875 руб.
Куд=Куд1+Куд2+Куд3=16 025 руб.
Процесс проектирования методического обеспечения лабораторного комплекса
и программного обеспечения «Интерфейс для MPICH» состоит из следующих работ:
. Получение задания на проектирование и постановка задачи;
. Изучение задания;
. Сбор и изучение научно-технической литературы;
. Составление аналитического обзора состояния вопроса;
. Разработка программного обеспечения;
.1. Описание требований к ПО;
.2. Построение диаграмм;
.3. Кодирование;
.4. Отладка;
.5. Анализ полученных результатов;
.6. Корректировка программы;
. Разработка методического обеспечения лабораторного комплекса;
.1. Разработка содержания лабораторных работ;
.2. Разработка рабочих заданий;
.3. Описание подготовки рабочих мест;
.4. Описание хода выполнения лабораторных работ;
.5. Описание хода выполнения лабораторных работ с участием кластера;
Таблица 5.3. Расчёт затрат на разработку.
|
Этап проектирования
|
Трудоемкость в ч/часах
|
Исполнитель
|
ЗП + ед.соц.налог в час
|
Эл.энерго и амортизация в час
|
Накладные расходы в час
|
∑затраты
|
|
|
Должность
|
Количество
|
Оклад
|
|
|
|
|
|
1
|
8
|
Дипломник
|
1
|
1700
|
10
|
3,62
|
0
|
108.96
|
|
2
|
16
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
217.92
|
|
3
|
40
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
544.8
|
|
4
|
40
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
544.8
|
|
5.1
|
4
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
68.96
|
|
5.2
|
4
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
68.96
|
|
5.3
|
24
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
413.76
|
|
5.4
|
24
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
413.76
|
|
5.5
|
4
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
68.96
|
|
5.6
|
8
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
137.92
|
|
6.1
|
8
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
108.96
|
|
6.2
|
8
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
108.96
|
|
6.3
|
8
|
Дипл.
|
1
|
1700
|
10
|
3,62
|
0
|
108.96
|
|
6.4
|
160
|
Дипл.
|
1
|
1700
|
10
|
7,24
|
0
|
2758.4
|
|
6.5
|
4
|
Дипл
|
1
|
1700
|
10
|
199,24
|
0
|
836.96
|
|
|
|
|
|
|
|
|
6511.04
|
При расчете стоимости электроэнергии, потребляемой в час в процессе
проектирования считалось, что 1 компьтер потребляет ≈ 0,6 кВт/час, а цену
принять равной 1,5 руб/кВт.
Кластер потребляет ≈ 60 кВт, что обходится в 150руб./ч., но так как
мы не используем весь кластер, как и раньше будем учитывать потребление
электроэнергии только 20/64 кластера.
Часовая амортизация зависит от цены компьютера и режима его работы. Для
режима работы ПК, соответствующего наличию выходных и праздничных дней, и 8-ми
часовому рабочему дню, можно считать часовую амортизацию по формуле:
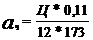 ,
,
Где
Ц- цена ЭВМ,
,11-
норма амортизации в год;
-
норма работы часов в месяц.
При
использовании одного компьютера
ач=2.12
руб./ч
Для
расчёта амортизации кластера МИИТ Т-4700 формула аналогичная
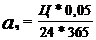
ач=142
руб./ч
Итого
затраты на разработку и внедрение лабораторного комплекса составят:
Куд+∑затраты=
16025 + 6511=22536 руб.
5.3 Экономическая эффективность
5.3.1 Расчёт показателей эффективности
Рассчитаем экономическую эффективность разработки лабораторного
комплекса.
С точки зрения расчёта экономического эффекта задача является прямой.
Выводы об экономической эффективности будут сделаны на основании показателя
«Экономический уровень оплаты труда» (ЭУОТ).
Таблица 5.4 Расчёт ЭУОТ
|
Исходная доля времени на выполнение функции
соответствующего уровня
|
Уровень оплаты труда в год
|
|
Уровень сотрудника
|
1
|
2
|
3
|
|
|
1
|
|
|
|
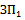
|
|
2
|
0
|
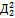
|
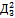
|
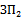
|
|
3
|
0
|
0
|
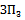
|
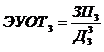
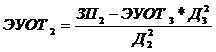
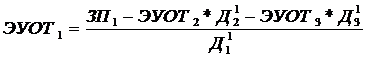
«Экономический
уровень оплаты труда» (ЭУОТ) отражает сумму оплаты за выполнение сотрудником
функций определённого уровня и позволяет сделать выводы о том, насколько
эффективно сотрудники располагают временем на решение тех или иных функций.
В
нашем случае у сотрудников, участвующих в процессе подготовки студентов кафедры
АСУ по дисциплине «Высокопроизводительные вычислительные системы», а именно у
лектора и лаборанта, появится возможность более эффективного распоряжения
временем для выполнения их функций.
Таблица
5.5 Годовые заработные платы сотрудников
|
Сотрудник
|
Заработная плата в год
|
|
Лектор(доцент)
|
180000
|
|
Лаборант
|
60000
|
Таблица 5.6 Оценка ЭУОТ на текущий момент
|
Исходная доля времени на выполнение функций
соответствующего уровня
|
ЭУОТ
|
|
Задачи уровня лектора
|
Задачи уровня лаборанта
|
|
|
Лектор
|
0.7
|
0.3
|
220 408
|
|
Лаборант
|
0
|
0.7
|
85 714
|
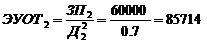
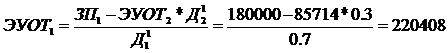
Таблица
5.7 Оценка ЭУОТ при применении лабораторного комплекса
|
Исходная доля времени на выполнение функций
соответствующего уровня
|
ЭУОТ
|
|
Задачи уровня лектора
|
Задачи уровня лаборанта
|
|
|
Лектор
|
0.9
|
0.1
|
193 333
|
|
Лаборант
|
0
|
1
|
60 000
|
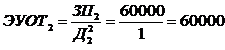
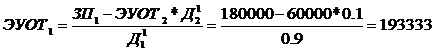
Таблица
5.8 Расчёт эффекта
|
Уровень оплаты труда в год
|
«Экономический уровень оплаты труда» до внедрения ИТ
|
«Экономический уровень оплаты труда» после внедрения ИТ
|
Эффект
|
|
Лектор
|
180000
|
220 408
|
193 333
|
27075
|
|
Лаборант
|
60000
|
85 714
|
60 000
|
25714
|
|
|
|
Суммарный эффект
|
52789
|
5.3.2 Расчет затрат по эксплуатации лабораторного комплекса
При использовании компьютерного класса из 14 компьютеров 24 часа в год,
расходы на электроэнергию составят:
.62*14*24=1216 руб./год
При использовании части узлов кластера МИИТ Т-4700 3 часа в год получим:
*3=428 руб./год
Итого затраты на электроэнергию 1644 руб./год.
5.3.3 Расчёт эффективности разработки
Следует учесть, что рассчитанный показатель ЭУОТ является далеко не
главным показателем эффективности данной разработки. Самое главное в
лабораторном комплексе это то, что он повысит уровень подготовки студентов
кафедры АСУ, поможет выпускникам быть более востребованными и конкурентоспособными
на рынке труда. Этот показатель представить в денежном выражении не
представляется возможным.
Рассчитаем эффективность разработки:
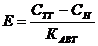 , где
, где
СТТ
- текущие затраты при традиционной
технологии,
СН - текущие затраты при новой технологии,
КАВТ - затраты на автоматизацию (разработку проекта).
СТТ
-СН, рассчитан в пункте 3.1. =52 789
руб.
КАВТ=22536 руб. + 1644 руб. за первый год эксплуатации.
Е=52
789 / 24180=2.19
ЗАКЛЮЧЕНИЕ
Вычислительные кластеры используются в вычислительных
целях, в частности в научных исследованиях. Для вычислительных кластеров
существенными показателями являются высокая производительность процессора в
операциях над числами с плавающей точкой (flops) и низкая латентность
объединяющей сети, и менее существенными - скорость операций ввода-вывода,
которая в большей степени важна для баз данных и web-сервисов. Вычислительные
кластеры позволяют уменьшить время расчетов, по сравнению с одиночным
компьютером, разбивая задание на параллельно выполняющиеся ветки, которые
обмениваются данными по связывающей сети.[1]
Один из разделов учебной дисциплины ВВС посвящен
изучению кластерных технологий, однако в настоящее время отсутствует
лабораторная поддержка данного направления. Представляется целесообразным
включить в учебный процесс лабораторную работу, в рамках которой студенты могли
бы отрабатывать практические навыки построения, использования и анализа
кластеров различного типа.
СПИСОК
ИСТОЧНИКОВ
1. Статья «Кластер» |
Wikipedia://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80_(%D0%B3%D1%80%D1%83%D0%BF%D0%BF%D0%B0_%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82%D0%B5%D1%80%D0%BE%D0%B2)
. В.П. Гергель. «Высокопроизводительные вычисления для
многоядерных многопроцессорных систем». Нижний Новгород - 2012.
. Статья «MPI» |
Wikipedia://ru.wikipedia.org/wiki/Message_Passing_Interface
. Статья «MPICH и Windows» | Image
Processing://iproc.ru/programming/mpich-windows/
. Статья «Суперкомпьютер МИИТ
Т-4700»://miit.ru/content/130385.pdf?id_wm=130385
. Сайт загрузок MPICH2 Аргоннской Национальной
Лаборатоории://www.mcs.anl.gov/research/projects/mpich2/downloads/index.php?s=downloads
7. Центр загрузок Microsoft
Corp.://www.microsoft.com/en-us/download/default.aspx
8. В.С. КИМ. «Тестирование учебных достижений».
Монография. Уссурийск - 2010. Глава 5.
. Статья «Использование Теории тестовых заданий (Item
Response Theory) в адаптивном
тестировании»://www.wikiznanie.ru/ru-wz/index.php/%D0%98%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D0%B8_%D1%82%D0%B5%D1%81%D1%82%D0%BE%D0%B2%D1%8B%D1%85_%D0%B7%D0%B0%D0%B4%D0%B0%D0%BD%D0%B8%D0%B9_(Item_Response_Theory)_%D0%B2_%D0%B0%D0%B4%D0%B0%D0%BF%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D0%BC_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B8
. «Система пакетной обработки заданий Torque.
Руководство пользователя.» Т-Платформы - 2014
. З.А. Крепкая. «CASE-Средства проектирования
информационных систем на железнодорожном транспорте на основе структуроного и
объектно-ориентированного подходов. Часть 2. Унифицированный язык моделирования
UML. CASE-средства объектно-ориентированного проектирования IBM Rational Rose»
. Москва - 2008.
ПРИЛОЖЕНИЯ
Приложение 1. Листинг разработанного ПО
Листинг
программы Интерфейс для MPICH
Project1.cpp
//---------------------------------------------------------------------------
#include <vcl.h>
#pragma hdrstop
//---------------------------------------------------------------------------("Unit1.cpp",
Form1);
//---------------------------------------------------------------------------WinMain(HINSTANCE,
HINSTANCE, LPSTR, int)
{
{>Initialize();>CreateForm(__classid(TForm1),
&Form1);>Run();
}(Exception &exception)
{>ShowException(&exception);
}(...)
{
{Exception("");
}(Exception &exception)
{>ShowException(&exception);
}
}0;
}
//---------------------------------------------------------------------------
.h
//---------------------------------------------------------------------------
#ifndef Unit1H
#define Unit1H
//---------------------------------------------------------------------------
#include <Classes.hpp>
#include <Controls.hpp>
#include <StdCtrls.hpp>
#include <Forms.hpp>
#include <Grids.hpp>
#include <ExtCtrls.hpp>
#include <Menus.hpp>
#include <Dialogs.hpp>
//---------------------------------------------------------------------------TForm1
: public TForm
{
__published: // IDE-managed
Components*Button1;*Button2;*Button3;*StringGrid1;*Button4;*Edit1;*Edit2;*Edit3;*Edit4;*Edit5;*GroupBox1;*CheckBox1;*Label1;*Label2;*Label3;*Label4;*Label5;*Label6;*Label7;*MainMenu1;*N1;*N2;*N3;*N4;*N5;*SaveDialog1;*OpenDialog1;__fastcall
Button3Click(TObject *Sender);__fastcall Button1Click(TObject
*Sender);__fastcall Button2Click(TObject *Sender);__fastcall
Button4Click(TObject *Sender);__fastcall FormCreate(TObject *Sender);__fastcall
CheckBox1MouseUp(TObject *Sender,Button, TShiftState Shift, int X, int
Y);__fastcall N5Click(TObject *Sender);__fastcall N4Click(TObject
*Sender);__fastcall N3Click(TObject *Sender);__fastcall N2Click(TObject
*Sender);: // User declarations: // User declarations
__fastcall TForm1(TComponent* Owner);
};
//---------------------------------------------------------------------------PACKAGE
TForm1 *Form1;
//---------------------------------------------------------------------------
#endif
Unit.cpp
//---------------------------------------------------------------------------
#pragma hdrstop
#include "Unit1.h"
#include <vcl.h>
#include <fstream.h>
#include <string.h>
#include <math.h>
//---------------------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"*Form1;
//---------------------------------------------------------------------------
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
}
//---------------------------------------------------------------------------
__fastcall TForm1::Button3Click(TObject *Sender)
{command;
//command= "
";="\""+Edit1->Text+"\" -hosts "
+(StringGrid1->RowCount-1)+" ";(int
i=1;i<StringGrid1->RowCount;i++){
command=command+ StringGrid1->Cells[0][i]+" ";
command=command+ "8 ";
}=command+" -noprompt "+ Edit4->Text+"
"+Edit5->Text;
(command.c_str());
f(Edit5->Text.c_str());str[5];(int
i=1;i<StringGrid1->RowCount;i++)
{.getline(str,100);->Cells[1][i]=str;
}.close();
}
//---------------------------------------------------------------------------__fastcall
TForm1::Button1Click(TObject *Sender)
{->RowCount++;
}
//---------------------------------------------------------------------------__fastcall
TForm1::Button2Click(TObject *Sender)
{(StringGrid1->Row==0)StringGrid1->Row++;(StringGrid1->RowCount>2){(int
i=StringGrid1->Row;i<StringGrid1->RowCount-1;i++)->Rows[i]=
StringGrid1->Rows[i+1];->RowCount--;}
}
//---------------------------------------------------------------------------__fastcall
TForm1::Button4Click(TObject *Sender)
{->Text="";->Text="\""+Edit1->Text+"\"
-hosts " +(StringGrid1->RowCount-1)+" ";(int
i=1;i<StringGrid1->RowCount;i++){
Edit3->Text=Edit3->Text+
StringGrid1->Cells[0][i]+" ";
Edit3->Text=Edit3->Text+
StringGrid1->Cells[1][i]+" ";
}->Text=Edit3->Text+"-noprompt "+
Edit2->Text;(Edit3->Text.c_str());
}
//---------------------------------------------------------------------------__fastcall
TForm1::FormCreate(TObject *Sender)
{->Cells[0][0]="IP-адреса или имена
узлов";->Cells[1][0]="Число процессов";
}
//---------------------------------------------------------------------------
__fastcall TForm1::CheckBox1MouseUp(TObject *Sender,Button, TShiftState
Shift, int X, int Y)
{(CheckBox1->State==cbUnchecked)
{->Enabled=false;->Enabled=false;->Enabled=false;->Enabled=false;->Enabled=false;
}else
{->Enabled=true;->Enabled=true;->Enabled=true;->Enabled=true;->Enabled=true;
}
}
//---------------------------------------------------------------------------
__fastcall TForm1::N5Click(TObject *Sender)
{->Execute();(SaveDialog1->FileName!="")
{s( SaveDialog1->FileName.c_str());
<<Edit1->Text.c_str()<<"\n";<<Edit2->Text.c_str()<<"\n";<<Edit3->Text.c_str()<<"\n";<<Edit4->Text.c_str()<<"\n";<<Edit5->Text.c_str()<<"\n";<<StringGrid1->RowCount<<"\n";(int
i=1;i<StringGrid1->RowCount;i++)
{<<StringGrid1->Cells[0][i].c_str()<<"\n";<<StringGrid1->Cells[1][i].c_str()<<"\n";
}.close();
}
}
//---------------------------------------------------------------------------
__fastcall TForm1::N4Click(TObject *Sender)
{->Execute();(OpenDialog1->FileName!="")
{
o( OpenDialog1->FileName.c_str());str[100];
.getline(str,100);->Text=str;.getline(str,100);->Text=str;.getline(str,100);->Text=str;.getline(str,100);->Text=str;.getline(str,100);->Text=str;
.getline(str,100);->RowCount=StrToInt(str);
(int i=1;i<StringGrid1->RowCount;i++)
{.getline(str,100);->Cells[0][i]=str;.getline(str,100);->Cells[1][i]=str;
}
.close();
}
}
//---------------------------------------------------------------------------
__fastcall TForm1::N3Click(TObject *Sender)
{->Close();
}
//---------------------------------------------------------------------------
__fastcall TForm1::N2Click(TObject *Sender)
{(NULL,"Программа Интерфейс для MPICH\n для запуска
MPI-программ","О прогамме",MB_OK);
}
//---------------------------------------------------------------------------
Листинг
тестирующей MPI-программы
#include <stdio.h>
#include <math.h>
#include <conio.h>
#include "mpi.h"
f(double a)
{(4.0 / (1.0+ a*a));
}
main(int argc, char **argv)
{done = 0, n, myid, numprocs, i;PI25DT = 3.141592653589793238462643;
double mypi[160], pi[160], perf[20], h, sum, x, maxtime=0;startwtime
= 0.0, endwtime;namelen;processor_name[MPI_MAX_PROCESSOR_NAME];
_Init(&argc,
&argv);_Comm_size(MPI_COMM_WORLD,&numprocs);_Comm_rank(MPI_COMM_WORLD,&myid);_Get_processor_name(processor_name,&namelen);
(stdout, "Process %d of %d is on %s\n", myid,numprocs,processor_name);(stdout);
(myid==0)
{(stdout);=10000000*numprocs;= MPI_Wtime();
}_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
double procstime=MPI_Wtime();(n==0)= 1;
{= 1.0 / (double) n;= 0.0;(i = myid + 1 ; (i <= n) ; i += numprocs)
{= h * ((double)i - 0.5);+= f(x);
}
double procetime=MPI_Wtime();
for(i=0;i<numprocs;i++)mypi[i]=0;
mypi[myid] = procetime -
procstime;_Reduce(mypi, pi, numprocs, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);(myid==0)
{
for(int j=0;j<numprocs;j++){
printf("%.9f\n", pi[j]);
}
for(int
j=0;j<numprocs;j=j+8){[j/8]=(pi[j]+pi[j+1]+pi[j+2]+pi[j+3]+pi[j+4]+pi[j+5]+pi[j+6]+pi[j+7])/8;
if(maxtime<perf[j/8])maxtime=perf[j/8];
printf("%.9f\n",
perf[j/8]);
}
int numhosts=numprocs/8;
FILE *of;
of=fopen(argv[1],"w");
for(int j=0;j<numhosts;j++){
int
p=floor(maxtime/perf[j]*8+0.8);
printf("%d\n", p);
fprintf(of,"%d\n", p);
}
fclose(of);
= MPI_Wtime();("wall clock time = %f\n",
endwtime-startwtime);(stdout);
}
}_Finalize();0;
}
Приложение 2. Инструкция по написанию и запуску
заданий на кластере МИИТ Т-4700
Для запуска задач на вычислительном кластере МИИТ Т-4700 необходимо
пользоваться менеджером распределённых ресурсов Torque. Пользователь готовит
файл задания для Torque и ставит его в очередь командой qsub. При этом
пользователь запрашивает необходимые для этой задачи ресурсы: число узлов
кластера, число процессоров на каждом из них, необходимое количество
оперативной памяти и время выполнения задачи.
Если запрошенные ресурсы не противоречат имеющимся настройкам кластера и
очереди (т.е., не было запрошено, например, больше процессоров, чем их
физически есть), задание будет поставлено в очередь. После этого, как только
образуются свободные ресурсы на кластере, соответствующие запрашиваемым, Torque
запустит задание.
Файл задания представляет собой командный файл, который настраивает
нужные переменные среды (пути, расположение временных каталогов, файлов с
данными и выходных файлов) и запускает программу пользователя.
Спецификация необходимых ресурсов может быть осуществлена в команде qsub
с помощью ключей командной строки.
· -l nodes=1:ppn=2 Число узлов=1, число
ядер=2
· -l mem=100mb Объём выделенной на задание памяти
= 100mb
· -l walltime=1:30:00 Время выполнения задания
· -q single Название очереди для задания
· -o sleep.out Название файла для стандартного вывода
· -e sleep.err Название файла для вывода ошибок
Например, чтобы поставить в очередь под названием single задачу sleep.job
на один процессор, на полтора часа, используя сто мегабайт памяти, нужно
выполнить такую команду:
qsub -l nodes=1:ppn=1,mem=100mb,walltime=1:30:00 -q single sleep.job
Еще одна возможность задания ресурсов - это указание их внутри самого
командного файла, в строках-комментариях начинающихся с #PBS. Например, файл
sleep.job, который описывает задание, похожее на приведённое выше, может
выглядеть следующим образом:
#!/bin/bash
#PBS -q single
#PBS -l nodes=1:ppn=1,mem=100mb,walltime=1:30:00
#PBS -S /bin/bash
#PBS -o sleep.out
#PBS -e sleep.err
#PBS -N sleep
" Start date:`date`"10" End date:`date`"
В таком случае задание запускается просто как qsub sleep.job. В отличие
предыдущего задания, у этого будет sleep, а стандартный вывод и вывод ошибок
будут помещены в файлы sleep.out и sleep.err соответственно. С помощью
оператора echo можно также поместить в выходной файл желаемые данные. В нашем
примере после выполнения задания в sleep.out будет выведено:date:<текущая
дата>date:<текущая дата>
Полный список параметров и ресурсов для qsub можно найти c помощью man
qsub и man pbs_resources.
После того, как задание успешно поставлено в очередь, ему присваивается
уникальный идентификатор задачи (Job ID). Используя этот номер, можно
манипулировать заданием в очереди:
· - qstat Посмотреть состояние очереди;
· - qdel Удалить задание из очереди;
· - qalter Изменить параметры уже запущенного задания;
· - qrerun Перезапустить задание, если это возможно;
· - qhold Приостановить задание;
· - qrls Запустить приостановленное задание.
Каждая из этих команд имеет множество параметров, ознакомиться с которыми
пользователь может при помощи команды man <имя команды>, например man
qstat.
Если задание было успешно поставлено в очередь, qstat по умолчанию
выведет на экран таблицу, столбцы которой имеют следующие значения:
· Job id - уникальный идентификатор задания;
· Name - имя исполняемого задания;
· User - имя владельца задания;
· Time Use - общее процессорное время, использованное заданием
на данный момент
· S - состояние задачи (Q - находится в очереди, R -
вычисляется, E - произошла ошибка при выполнении или задание завершает
выполнение);
· Queue - название очереди, в которой запущена задание.
Пример запуска команды qstat:id Name User Time
Use S Queue
------------------ ---------------- --------------- -------- - -----
.master PCGAMESS davydovk 00:00:00 R single
.master cpi-mpirun kruchin 00:00:00 R para
.master dl chepasov 0 Q para