Эконометрические исследования
Курсовой проект
Эконометрические исследования
Введение
Эконометрика - это наука, которая на
базе статистических данных дает количественную характеристику взаимозависимым
экономическим явлениям и процессам.
Слово «эконометрика» произошло от
двух слов: «экономика» и «метрика» (от греч. «метрон» - «правило определения
расстояния между двумя точками в пространстве», «метрия» - «измерение»).
Эконометрика - это наука об экономических измерениях.
Зарождение эконометрики является
следствием междисциплинарного подхода к изучению экономики. Эконометрика
представляет собой сочетание трех наук:
) экономической теории;
) математической и экономической
статистики;
) математики.
Эконометрика ставит своей
целью количественно охарактеризовать те экономические закономерности, которые
экономическая теория выявляет и определяет лишь в общем.
Анализ экономических процессов и
явлений в эконометрике осуществляется с помощью математических моделей,
построенных на эмпирических данных.
В данной курсовой работе мы будем
рассчитывать такие разделы как:
· Основные
описательные статистики
· Группировка данных
· Линейная регрессия
· Линейная регрессия
для сгруппированных данных
· Множественная
линейная регрессия
1. Вычисление по
исходным данным Xi основные описательные статистики
регрессия линейный статистический эконометрика
С помощью генератора случайных чисел
для дискретной случайной величины X создать выборку объема N=30.
|
Х
|
|
112
|
|
118
|
|
133
|
|
151
|
|
152
|
|
153
|
|
156
|
|
159
|
|
160
|
|
164
|
|
166
|
|
167
|
|
168
|
|
168
|
|
171
|
|
173
|
|
175
|
|
175
|
|
178
|
|
186
|
|
191
|
|
192
|
|
199
|
|
217
|
|
224
|
|
227
|
|
233
|
|
245
|
|
259
|
|
272
|
Для полученной выборки x1,…,
xN объема N =30 вычислить
1. Оценку
математического ожидания - выборочное среднее (функция СРЗНАЧ())
. Оценку дисперсии
(центральный момент второго порядка) - выборочную дисперсию s2,
несмещенную оценку дисперсии sx2 (функция ДИСП.В())
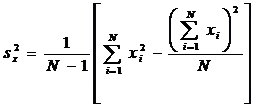
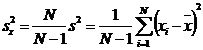
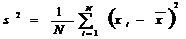
3. Среднее
квадратичное отклонение sx (функция СТАНДОТКЛОН.В())
. Стандартная ошибка среднего
. Выборочный центральный
момент 3-го порядка μ3* и несмещенную оценку μ3
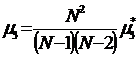
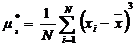
6. Выборочный центральный
момент 4-го порядка μ4*
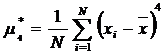
7. Коэффициент асимметрии
(функция СКОС())
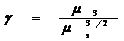
8. Коэффициент эксцесса
(функция ЭКСЦЕСС())
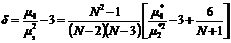
9. Размах выборки
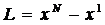
По проводимым
исследованиям получилось:
|
Выборочная оценка
|
Несмещенная оценка
|
Функция
|
|
Среднее значение
|
181,4666667
|
|
181,4667
|
|
Дисперсия
|
1446,382222
|
1496,257471
|
1496,257
|
|
Ср.кв. отклонение
|
|
|
38,68149
|
|
Размах выборки
|
160
|
|
|
|
Ср отклонение
|
0,948888889
|
|
29,92444
|
|
Отн отклонение
|
0,005228998
|
|
|
|
Мера точности
|
0,036560475
|
|
|
|
Вероятностное откл
|
26,07132254
|
|
|
|
Мера изменчивости
|
0,213160291
|
|
|
|
Станд. Ошибка среднего
|
|
7,062241078
|
|
|
µ3
|
-100,9216099
|
-111,8589272
|
|
|
Коэффициент ассиметрии
|
|
-0,001932685
|
0,629722
|
|
µ4
|
1096,274183
|
|
|
|
Коэффициент эксцесса
|
|
-3,33667844
|
0,156853
|
|
|
|
|
|
Медиана
|
172
|
|
172
|
|
Мода
|
|
|
168
|
Вычисление параметров распределения
с помощью Анализ данных\ Описательная статистика и сравнение с рассчитанными по
формулам
|
Х
|
|
|
|
Среднее
|
181,4666667
|
|
Стандартная ошибка
|
7,062241078
|
|
Медиана
|
172
|
|
Мода
|
168
|
|
Стандартное отклонение
|
38,68148745
|
|
Дисперсия выборки
|
1496,257471
|
|
Эксцесс
|
0,156853495
|
|
Асимметричность
|
0,629721919
|
|
Интервал
|
160
|
|
Минимум
|
112
|
|
Максимум
|
272
|
|
Сумма
|
5444
|
|
Счет
|
30
|
Мода - значение признака, имеющее
наибольшую частоту в статистическом ряду распределения
Медиана - это такое значение
признака, которое разделяет ранжированный ряд распределения на две части - со
значениями признака меньше медианы и со значениями признака больше медианы
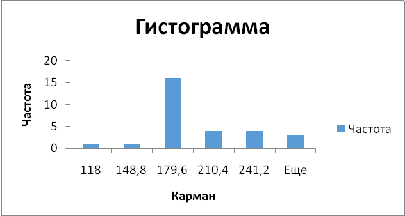
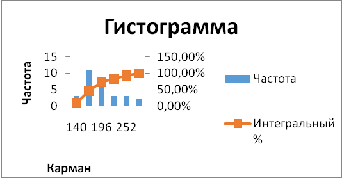
Построить гистограмму с помощью
Анализ данных\Гистограмма
|
Карман
|
Частота
|
|
118
|
1
|
|
148,8
|
1
|
|
179,6
|
16
|
|
210,4
|
4
|
|
241,2
|
4
|
|
Еще
|
3
|
После построения гистограммы нам
надо посчитать моду по формуле:
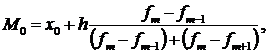
где M0 - значение моды,
x0 - нижняя граница
модального интервала,
h - величина интервала,
fm - частота модального интервала,
fm-1 - частота интервала,
предшествующего модальному,
fm+1 - частота интервала,
следующего за модальным.
Mo
= 195,9
По работе мода равна 195,9
Mode (Мода) - это значение, которое наиболее часто встречается в выборке.
Если одна и та же наибольшая частота встречается у нескольких значений, то
выбирается наименьшее из них.
. Сгруппированные данные
Сгруппировать полученные в
лабораторной работе №1 значения случайной величины X.
Вычислить
• Абсолютные
частоты ni (функция ЧАСТОТА. Относится к диапазону ячеек: выделить диапазон
для результата, ввести формулу, нажать Ctrl+Shift+Enter)
 Относительные частоты
Относительные частоты
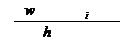
• Накопленные
частоты
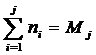
• Накопленные
относительные частоты
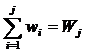
• Выборочную
функцию распределения вероятности
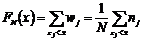
• Среднее
значение (для сгруппированных данных)
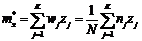
• Дисперсию
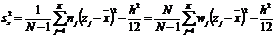
• Среднее
квадратичное отклонение sx
• Построить
интегральную и дифференциальную функции для нормального закона распределения с
полученными средним значением и дисперсией.
Вычислить с помощью функции
НОРМ.РАСП(), параметр Интегральная = 0 для дифференциального закона
распределения = 1 для интегрального закона распределения
• Вычислить
дифференциальную функцию распределения по формуле
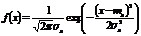
|
Интервал
|
|
X
|
абсолют. частоты
|
относ. част.
|
накопл. част
|
|
112
|
140
|
126
|
3
|
0,1
|
3
|
|
140
|
168
|
154
|
11
|
0,36666667
|
14
|
|
168
|
196
|
182
|
8
|
0,26666667
|
22
|
|
196
|
224
|
210
|
3
|
0,1
|
25
|
|
224
|
252
|
238
|
3
|
0,1
|
28
|
|
252
|
280
|
266
|
2
|
0,06666667
|
30
|
|
|
1176
|
30
|
1
|
|
|
накоп. относ. част
|
выбр. функ. расп.
|
распредел дифф по формуле (исправить)
|
|
0,1
|
0
|
0,003462
|
|
0,466667
|
0,1
|
0,016399
|
|
0,733333
|
0,466667
|
0,026243
|
|
0,833333
|
0,733333
|
0,01419
|
|
0,933333
|
0,833333
|
0,002592
|
|
1
|
0,933333
|
0,00016
|
|
1
|
|
|
норм. расп. диф. функ.
|
норм. расп. интегр. фун.
|
Wi/h
|
|
0,003807
|
0,077213
|
0,003571
|
|
0,008286
|
0,245889
|
0,013095
|
|
0,010482
|
0,519583
|
0,009524
|
|
0,007708
|
0,783977
|
0,003571
|
|
0,003294
|
0,936031
|
0,003571
|
|
0,000818
|
0,988054
|
0,002381
|
|
Карман
|
Частота
|
Интегральный%
|
|
140
|
3
|
10,00%
|
|
168
|
11
|
46,67%
|
|
196
|
8
|
73,33%
|
|
224
|
3
|
83,33%
|
|
252
|
3
|
93,33%
|
|
Еще
|
2
|
100,00%
|
|
140
|
3
|
10,00%
|
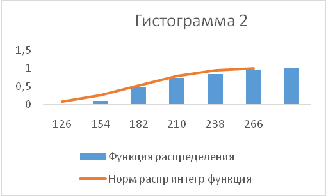
Построить гистограмму с помощью
Анализ данных\Гистограмма
Построить гистограммы Абсолютных и
относительных частот
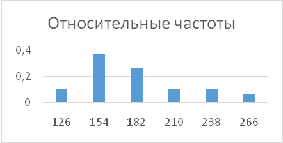
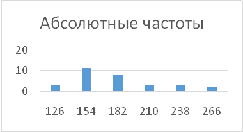
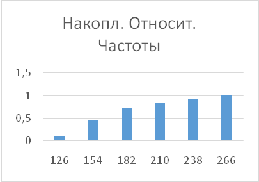
Кумулятивных и относительных
кумулятивных частот
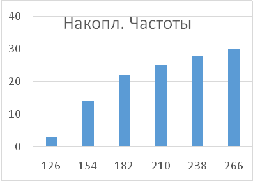
Построить гистограммы
• Эмпирический
дифференциальный и интегральный законы распределения
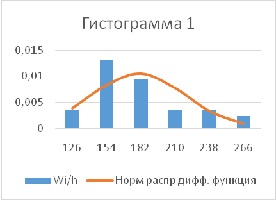
Интегральную и дифференциальную
функции для нормального закона распределения
· Основные
описательные статистики (лабораторная работа №1)
· При доверительной
вероятности γ = 0.95 (уровне значимости α = 0.05) найти
· Доверительный
интервал для среднего значения
· по формуле
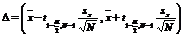
tα,N−1 определяется с помощью функции СТЬЮДЕНТ.ОБР()
· с помощью функции
ДОВЕРИТ.СТЬЮДЕНТ() - вычисляет
· «Анализ данных
\Описательная статистика» - поставить флажок Уровень надежности
· Доверительный
интервал для дисперсии
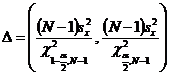
§ χα,N−1 определяется с
помощью функции ХИ2.ОБР()
· Доверительный
интервал для среднего квадратичного отклонения
|
Стьюдент
|
2,04522964
|
|
|
Доверит. Стьюдент
|
14,1943117
|
14,19431
|
|
Дов.инт. для дисп.
|
45,7222858
|
16,04707
|
|
165,939
|
194,3276
|
|
916,5071
|
2611,367
|
51,10154
|
|
Столбец1
|
|
|
|
|
Среднее
|
180,133333
|
|
Стандартная ошибка
|
7,09536571
|
|
Медиана
|
182
|
|
Мода
|
154
|
|
Стандартное отклонение
|
38,8629185
|
|
Дисперсия выборки
|
1510,32644
|
|
Эксцесс
|
-0,0710294
|
|
Асимметричность
|
0,79012192
|
|
Интервал
|
140
|
|
Минимум
|
126
|
|
Максимум
|
266
|
|
Сумма
|
5404
|
|
Счет
|
30
|
|
Уровень надежности (95,0%)
|
14,5116523
|
3. Вычисление тех же
статистик для сгруппированным данным
|
выбор. оценка
|
несмещ. оценка
|
|
Среднее значение
|
180,1333333
|
|
|
Дисперсия
|
1459,982222
|
1510,326
|
|
Ср.кв. отклонение
|
|
38,01306
|
|
Размах выборки
|
140
|
|
|
Ср отклонение
|
29,99111111
|
|
|
Отн отклонение
|
0,166493955
|
|
|
Мера точности
|
0,037203355
|
|
|
Вероятностное откл
|
25,62080575
|
|
|
Мера изменчивости
|
4,738721642
|
|
|
Станд. Ошибка среднего
|
|
6,940204
|
|
µ3
|
41842,13807
|
46376,75
|
|
Коэффициент ассиметрии
|
|
0,790122
|
|
µ4
|
5854766,861
|
|
|
Коэффициент эксцесса
|
|
-0,07103
|
Стандартное отклонение - степень
отклонения данных наблюдений или множеств от СРЕДНЕГО значения. Обозначается
буквами s или s. Небольшое стандартное отклонение указывает на то, что данные
группируются вокруг среднего значения, а значительное - что начальные данные
располагаются далеко от него. Стандартное отклонение равно квадратному корню
величины, называемой дисперсией. Она есть среднее число суммы возведенных в
квадрат разностей начальных данных, отклоняющихся от среднего значения.
Эксцесс характеризует относительную
остроконечность или сглаженность распределения
. Построить интегральную
и дифференциальную функции распределения для нормального закона распределения и
сравнить их с соответствующими эмпирическими законами распределения
Даны две выборки, состоящие из N значений случайных
величин X и Y, x1, x2, …, xN и y1, y2, …, yN. X − независимая переменная,
влияющая на Y. y = (y1, y2,…, yN) − отклик, x = (x1, x2, …, xN) − фактор, влияющий на отклик.
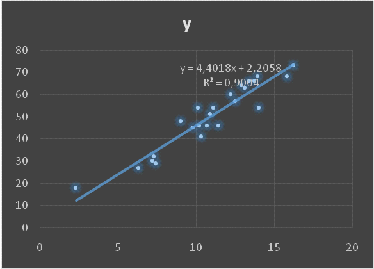
Построить уравнение регрессии
y= 4,4x+2,2
|
Наклон
|
а=
|
4,401821
|
|
Отрезок
|
b=
|
2,205791
|
Метод наименьших квадратов
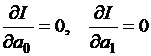
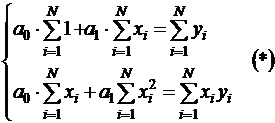
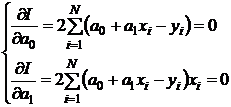
По системе 2 мы получили матрицу
|
x
|
y
|
yy
|
|
10,2
|
46
|
47,10436874
|
|
9,8
|
45
|
45,34364018
|
|
7,3
|
32
|
34,33908669
|
|
6,3
|
27
|
29,9372653
|
|
10,7
|
46
|
49,30527943
|
|
11,1
|
54
|
51,06600799
|
|
12,5
|
57
|
57,22855795
|
|
10,2
|
46
|
47,10436874
|
|
12,9
|
64
|
58,9892865
|
|
10,1
|
54
|
46,6641866
|
|
13,7
|
66
|
62,51074362
|
|
9
|
48
|
41,82218306
|
|
13,4
|
66
|
61,1901972
|
|
14
|
54
|
63,83129004
|
|
10,9
|
51
|
50,18564371
|
|
7,4
|
29
|
34,77926883
|
|
10,3
|
41
|
47,54455088
|
|
7,2
|
30
|
33,89890455
|
|
13,1
|
63
|
59,86965078
|
|
12,2
|
60
|
55,90801153
|
|
11,4
|
46
|
52,38655441
|
|
13,9
|
68
|
63,3911079
|
|
2,3
|
18
|
12,32997972
|
|
15,8
|
68
|
71,75456855
|
|
16,2
|
73
|
73,51529711
|
|
Регрессионная статистика
|
|
Множественный R
|
0,948879
|
|
R-квадрат
|
0,900372
|
|
Нормированный R-квадрат
|
0,89604
|
|
Стандартная ошибка
|
4,720319
|
|
Наблюдения
|
25
|
|
|
|
|
Значимость дисперсии и стандартных
ошибок в моделях множественной регрессии позволяет анализировать точность
оценок, строить доверительные интервалы для теоретических коэффициентов
уравнений, проверять соответствующие гипотезы.
Построение диаграммы и линии тренда
|
Дисперсионный анализ
|
|
|
|
|
df
|
SS
|
|
Регрессия
|
1
|
4631,368
|
|
Остаток
|
23
|
512,4724
|
|
Итого
|
24
|
5143,84
|
|
MS
|
F
|
Значимость F
|
|
4631,368
|
207,8579
|
5,23E-13
|
|
22,28141
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
|
Y-пересечение
|
2,205791
|
3,452207
|
|
x
|
4,401821
|
0,305316
|
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
Нижние 95,0%
|
Верхние 95,0%
|
|
0,638951
|
0,529167
|
-4,93564
|
9,347224
|
-4,93564
|
9,347224
|
|
14,41728
|
5,23E-13
|
3,770228
|
5,033415
|
3,770228
|
5,033415
|
При помощи проверки мы выяснили, что
коэффициенты регрессии совпадают.
5. Вычислить коэффициент
корреляции
Корреляция - статистическая взаимосвязь двух или нескольких случайных величин
(либо величин, которые можно с некоторой допустимой степенью точности считать
таковыми). При этом, изменения одной или нескольких из этих величин приводят к
систематическому изменению другой или других величин. Математической мерой
корреляции двух случайных величин служит коэффициент корреляции.
• Выборочная
ковариация (функция КОВАРИАЦИЯ.В())
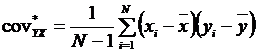
Cov = 43,8395
• Коэффициент
корреляции (функция КОРРЕЛ(), Анализ данных \ Корреляция)
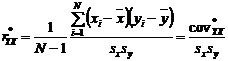
ryx =
0,948879141
|
N=
|
25
|
|
|
|
|
|
|
|
Средн. Х
|
10,876
|
Станд. Откл. Х
|
3,155851708
|
|
Средн. У
|
50,08
|
Станд. Откл. У
|
14,63989982
|
|
Формула
|
Функция
|
|
Ковариация
|
43,8395
|
43,8395
|
|
Коэффициент корреляции
|
0,948879141
|
0,948879
|
Коэффициент корреляции больше 0,7,
то есть связь между изучаемыми показателями сильная, можно проводить анализ
линейной модели
Оценить уровень значимости уравнения
регрессии:
• Коэффициент
детерминации
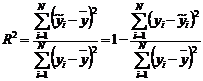
В случае одной
независимой переменной X
• F-статистика
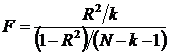
k
- количество факторов, включаемых в модель, (k
= 1)
(сравниваем с FРАСПОБР (α = 0,05; k = 1; N - k - 1 = 23) = 4,28
Коэф. детерминации
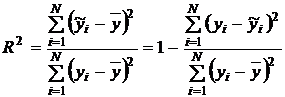
R2= 0,9, значит уравнение
регрессии объясняется 90% дисперсии результативного признака, а на долю прочих
факторов приходится 10% ее дисперсии (ее остаточной дисперсии).
Коэффициент детерминации
представляет собой квадрат корреляционного отношения - это отношение
межгрупповой дисперсии результативного признака, которая выражает влияние
различий группировочного факторного признака на среднюю величину
результативного признака, к общей дисперсии результативного признака, выражающей
влияние на него всех причин и условий.
F =
207,8579246
F - статистика
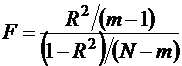
F=207,86 уравнение регрессии больше 4,28, уравнение значимо
Fтабличный - это максимальное значение критерия под влиянием
случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а - вероятность
не принять гипотезу при условии, что она верна. Как правило принимается равной
0,05.
Если Fтабл> Fфакт то признается
статистическая незначимость модели, ненадежность уравнения регрессии.
|
несмещенная оценка
|
|
22,28141
|
|
стандартная ошибка
|
|
4,720319
|
|
Sa
|
|
0,305316
|
|
Sb
|
|
3,452207
|
|
дов. интервал для сред. знач
|
1,302672
|
6,043054
|
|
дов. интервал для дисп.
|
39,36408
|
12,40115
|
|
интервал для Х
|
9,573328
|
12,17867
|
|
интервал для У
|
44,03695
|
56,12305
|
|
интервал для Х
|
6,072176
|
19,27447
|
|
интервал для У
|
130,6735
|
414,7873
|
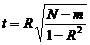
=
14,41727868
t=14,4 значимость коэффициента корреляции больше 2, 0687
следовательно уравнение значимо.
Вычислить:
• Сумма
квадратов, обусловленная регрессией (RSS)
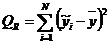
• Сумма
квадратов, обусловленная ошибкой (ESS)
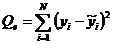
• Общая
сумма квадратов (TSS)
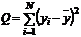
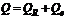
· Фактическая
дисперсия
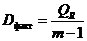
· Остаточная
дисперсия
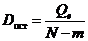
|
RSS=
|
1215,57127
|
|
|
|
|
|
273,0063857
|
218,4051085
|
0
|
0
|
0
|
|
0
|
70,03660175
|
40,85468435
|
0
|
0
|
|
0
|
0
|
4,330729115
|
0,928013382
|
0
|
|
0
|
0
|
0
|
82,04395857
|
92,29945339
|
|
0
|
0
|
0
|
0
|
433,666335
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ESS=
|
183,3887302
|
|
|
|
|
|
15,75021741
|
24,36023625
|
0
|
0
|
0
|
|
0
|
26,23289968
|
0
|
0
|
|
0
|
0
|
21,35328658
|
27,13763623
|
0
|
|
0
|
0
|
0
|
3,725578096
|
48,34058722
|
|
0
|
0
|
0
|
0
|
2,899582278
|
|
|
|
|
|
|
|
TSS=
|
1398,96
|
|
|
|
|
|
288,7566031
|
242,7653448
|
0
|
0
|
0
|
|
0
|
83,6253082
|
67,08758403
|
0
|
0
|
|
0
|
0
|
25,6840157
|
28,06564961
|
0
|
|
0
|
0
|
0
|
85,76953666
|
140,6400406
|
|
0
|
0
|
0
|
0
|
436,5659173
|
|
Факт
|
1215,57127
|
|
Ост
|
1,871313573
|
6. Множественная
линейная регрессия
Даны три выборки, состоящие из N значений случайных
величин X и Y и Z, x1, x2, …, xN; y1, y2, …, yN и z1, z2, …, zN.
Построить уравнение
регрессии 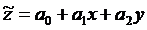
Ввести матрицу
коэффициентов и правую часть системы, найти значения коэффициентов регрессии
|
Решение системы линейных уравнений
|
|
|
|
25
|
555,3
|
272,3
|
5816
|
а0=
|
17,61815
|
|
555,3
|
12513,61
|
5999
|
130322,3
|
а1=
|
7,542868
|
|
272,3
|
5999
|
3136,43
|
63719,2
|
а2=
|
4,359133
|
Вычислить коэффициенты регрессии при
помощи функции ЛИНЕЙН()
|
Функция линейн
|
|
|
4,359133
|
7,542868
|
17,61815
|
|
0,356356
|
0,347553
|
9,610651
|
|
0,958769
|
4,464651
|
#Н/Д
|
|
255,7863
|
22
|
#Н/Д
|
Анализ данных/ Корреляция
|
|
x
|
y
|
z
|
|
x
|
1
|
|
|
|
y
|
-0,2821
|
1
|
|
|
z
|
0,823607
|
0,275716
|
1
|
Вычислить
|
RSS
|
10197,23
|
|
|
|
|
|
ESS
|
438,5283
|
|
|
|
|
|
TSS
|
10635,76
|
|
|
|
|
|
Dфакт
|
5098,616
|
|
|
|
|
|
Dост
|
19,93311
|
|
|
|
|
|
F
|
255,7863
|
|
|
|
|
|
R2
|
0,958769
|
|
|
|
|
|
R
|
0,979167
|
|
|
|
|
|
R2adg
|
0,963716
|
|
|
|
|
|
se
|
4,464651
|
|
|
|
|
|
s0
|
9,610651
|
s1
|
0,347553
|
s2
|
0,356356
|
|
t0
|
1,83319
|
t1
|
21,70278
|
t2
|
12,23253
|
F.ОБР.ПХ
(α = 0,05; k1
= m - 1; k2
= N - m = 22) = 3,44
СТЬЮДРАСПОБР (α = 0,05; N - m = 22) = 2,074
|
Fобр
|
3,443357
|
|
Ст распр
|
2,073873
|
Построим уравнение регрессии
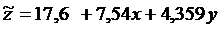
|
а0=
|
17,61815
|
|
а1=
|
7,542868
|
|
а2=
|
4,359133
|
Вычислили доверительные интервалы
для среднего значения, дисперсии и среднего квадратичного отклонения
Заключение
В данной курсовой работе мы
рассчитали такие разделы как:
· Основные
описательные статистики
· Группировка данных
· Линейная регрессия
· Линейная регрессия
для сгруппированных данных
· Множественная
линейная регрессия
Вычислили по исходным данным Xi основные
описательные статистики:
Нашли среднее значение =
181,4666667;
Дисперсию = 1446,382222,
Cреднее квадратичное отклонение (стандарт) = 38,68149
Размах выборки = 160реднее
отклонение = 38,68148745
Модуль =
Меру точности = 0,036560475
Вероятное отклонение = 26,07132254
Меру изменчивости (коэффициент
вариации) = 0,213160291
Стандартную ошибку среднего =
7,062241078
Коэффициенты асимметрии = 0,629722 и
эксцесса = 0,156853
Медиану = 172
Моду = 168
Сгруппировали данные:
Определили кумулятивные частоты =
1176 и абсолютные частоты = 30, относительные частоты, в сумме = 1;
Построили гистограммы абсолютных и
относительных частот, кумулятивных и относительных кумулятивных частот,
эмпирический дифференциальный и интегральный законы распределения;
Построили интегральную и
дифференциальную функции распределения для нормального закона распределения и
сравнили их с соответствующими эмпирическими законами распределения.
Вычислили доверительные интервалы
для среднего значения, дисперсии и среднего квадратичного отклонения.
Построили уравнение
регрессии
Вычислили коэффициент
корреляции = 0,948879,
Оценили уровень
значимости уравнения регрессии:
Коэф. Детерминации =
0,9, значит уравнение регрессии объясняется 90% дисперсии результативного
признакастатистика = 207,86, так как уравнение регрессии больше 4,28, то
уравнение значимо
Оценили значимость
коэфф. ур. Регрессии, так как уравнение регрессии больше 4,28, то уравнение
значимо
Коэф. Корреляции, t=14,4 значимость больше 2, 0687, следовательно уравнение значимо
Нашли:
Доверительный интервал для дисперсии
от 0,347553017 до 0,356355646
Доверительный интервал для среднего
от 12,232535 до 21,70278248
Список использованной
литературы
1. Презентация «Эконометрика»
2. Конспекты лекций
. http://univer-nn.ru/ekonometrika/koefficient-korrelyacii-srednyaya-oshibka-approksimacii-koefficient-elastichnosti/