|
Значение
статистики DW
|
Вывод
|
|
4-dL<DW<4
|
Гипотеза Н0
отвергается, есть отрицательная корреляция
|
|
4-du<DW<4-dL
|
Неопределенность
|
|
du<DW<4-du
|
Гипотеза Н0
не отвергается
|
|
dL<DW<du
|
Неопределенность
|
|
0<DW<dL
|
Гипотеза Н0
отвергается, есть положительная корреляция
|
DW - значение статистики Дарбина-Уотсона
dl - нижняя граница критерия
Дарбина-Уотсона
du - верхняя граница критерия Дарбина-Уотсона
Значения dl и du берем из таблицы при уровне значимости равном
0,05, учитывая число наблюдений n и число объясняющих переменных p. В моем случае n = 10 и p = 6.
· Mean dependent var - среднее арифметическое
значение зависимой переменной.
· S.D. Dependent var - стандартное среднее
квадратическое отклонение зависимой переменной.
· Akaike info criterion - информационный
критерий Акаике, AIC.
Критерий является попыткой свести в один показатель два
требования: уменьшение числа параметров модели и качество подгонки модели.
Согласно этому критерию из двух моделей следует выбрать модель с меньшим
значением AIC.
· Schwarz criterion - критерий Шварца. Его
отличие от AIC состоит в большем штрафе за количество параметров.
· F-Statistic - F-статистика. Значение
F-статистики служит для проверки модели на адекватность. Для проверки модели на
адекватность с помощью F - статистики Фишера используют значение вероятности Prob
(F-Statistic). Выдвигается нулевая гипотеза о равенстве нулю всех коэффициентов
регрессии. Если значение вероятности меньше принятого значения α, то нулевая гипотеза отвергается. Обратите внимание на то, что
F-тест - это суммарный тест. Поэтому может возникнуть ситуация когда все
t-статистики являются незначимыми, а F-статистика показывает адекватность
модели.
Чтобы показать уравнение с коэффициентами и уравнение с уже
подставленными значениями коэффициентов воспользуемся View/Representations:

Рис. 11
Уравнение регрессии имеет вид:
Y =-4217.196572*X1 - 3.777026419*X2 + 0.03634073978*X3 +
4.883264939*X4 - 7.337717306*X5 + 0.361023724*X6 + 150509.8134
Уравнение регрессии позволяет понять, как формируется
рассматриваемая переменная «Численность населения РФ»:
1. При увеличении возрастного коэффициента рождаемости на 1
численность населения уменьшается на 4217,17 тыс. человек
2. При увеличении естественного прироста населения на 1
тыс. численность населения уменьшается на 3,77 тыс. человек
. При возрастании численности вынужденных переселенцев
и беженцев на 1 тыс. численность населения увеличивается на 36 человек
4. При увеличении количества разводов на 1 тыс. численность
населения увеличивается на 4,88 тыс. человек
. При увеличении количества браков на 1 тыс. численность
населения уменьшается на 7,33 тыс. человек
6. При возрастании международной миграции на 1 тыс.
численность населения увеличивается на 361 человек
При равенстве нулю всех факторов модели, Y = 150509,8134 тыс.
человек.
Оценим статистическую значимость прогнозного уравнения:
· Коэффициент детерминации R2=0,998548>0,7 говорит
о том, что доля влияния независимых переменных на зависимую значительна (99%).
· Адекватность регрессии опытным данным
можно проверить с помощью критерия Фишера F-statistic и вероятности Prob (F-statistic). Выдвигается нулевая
гипотеза H0 о статистической незначимости линейного уравнения регрессии в
целом и отсутствии связи между зависимой и независимыми переменными (bi = 0 и ryxi = 0). Если Prob (F-statistic) > a=0,05,
то H0 принимаем.
Будем проводить проверку с помощью Prob (F-statistic).
Т.к. Prob (F-statistic)= 0,000242 > 0,05, то отвергаем гипотезу H0 о незначимости
регрессии.
Получение стандартизованного уравнения регрессии.
В исследуемой задаче число экзогенных переменных больше двух
(равно 6). В этом случае рекомендуется преобразовать эндогенную и экзогенные
переменные одним из способов нормирования (выберем один из таких способов -
стандартизацию). В этом случае исходные данные преобразуются по формулам:
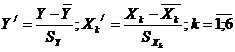
 .
.
Стандартизованное уравнение регрессии удобно тем, что коэффициенты
в этом уравнении безразмерны. и в уравнении отсутствует свободный член.
Стандартизованное уравнение регрессии в среде EViews можно получить в 3 этапа: сначала находим
для Y и Xk,  значения среднего и среднеквадратического отклонения, т.е. для
каждой серии группы данных находим значения Mean и Std. Dev (воспользуемся для этого таблицей на рис. 8).
значения среднего и среднеквадратического отклонения, т.е. для
каждой серии группы данных находим значения Mean и Std. Dev (воспользуемся для этого таблицей на рис. 8).
Следующим этапом является стандартизация исходных данных по
указанным выше формулам. В окне группы выделяем каждый столбец, а затем
набираем формулу, используя значения Mean и Std. Dev., указанные на рис. 8. Таким образом, получаются значения Y/ и X/ (рис. 12):
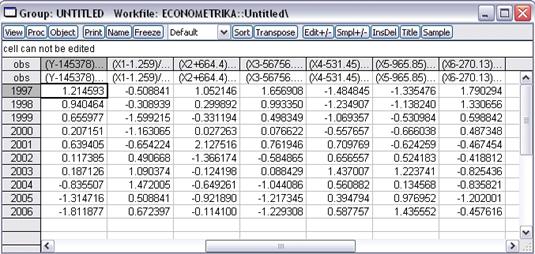
Рис. 12
Заключительным этапом является получение стандартизованного
уравнения регрессии. В меню окна стандартизованных данных выбираем Procs/Make Equation. Перед нами появится диалоговое окно (рис. 13):
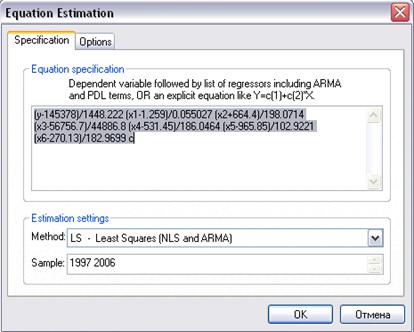
Рис. 13
В окне (рис. 13) перечисляем стандартизованные переменные, входящие
в уравнение регрессии (на первом месте - зависимая переменная (Y), затем - независимые переменные, которые включены в
уравнение (X1, X2, X3, X4, X5, X6); C - это свободный член уравнения регрессии.
В строке Method выбираем LS - Least Squares (NLS and ARMA) - метод наименьших квадратов. Нажав ОК, получаем результат
(рис. 14):
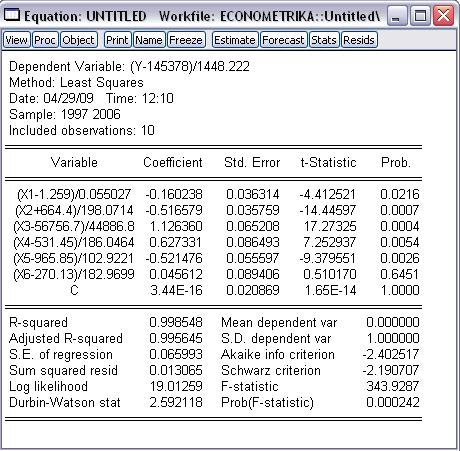
Рис. 14
Для просмотра полной записи уравнения необходимо выбрать View/Representations (рис. 15): Коэффициенты стандартизованного
уравнения регрессии показывают скорость изменения среднего значения Y для соответствующего значения Xk, .
Стандартизованное уравнение регрессии позволяет отметить, что
наибольшее влияние на Y (численность
населения РФ) оказывает Х3 (численность вынужденных переселенцев и беженцев),
т. к. коэффициент при Х3 самый большой (1,126360129).
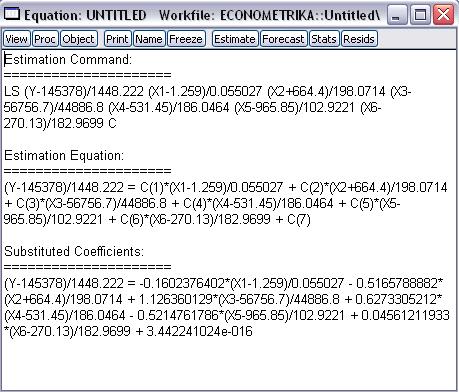
Рис. 15
Параметры стандартизованного уравнения регрессии определяют,
что с возрастанием численности вынужденных переселенцев и беженцев на величину
стандартного отклонения при постоянных значениях Х1, Х2, Х4, Х5 и Х6
численность населения возрастет на величину, равную стандартному отклонению Y, умноженному на
1,126360129.
Коэффициент при Х6 мал (0,045612), что говорит о том, что при
большом изменении фактора Х6, Y изменится незначительно.
Расчёт коэффициентов эластичности.
Эффективность воздействия факторов на зависимую переменную
можно оценивать не только с помощью коэффициента корреляции, но и с помощью
коэффициента эластичности.
Коэффициент эластичности определяет изменение Y при изменении Xk на 1%.
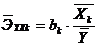 ,
,
где 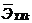 - коэффициент эластичности;
- коэффициент эластичности; 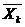 - среднее значение Xk;
- среднее значение Xk; 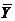 - среднее значение Y;
- среднее значение Y; 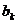 - коэффициент при Xk в стандартизованном уравнении регрессии.
- коэффициент при Xk в стандартизованном уравнении регрессии.
Рассчитаем коэффициенты эластичности для всех Xk, входящих в уравнение регрессии:
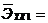 -1,39*10-6;
-1,39*10-6; 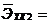 0,00236;
0,00236; 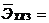 0,44;
0,44; 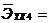 0,0023;
0,0023; 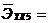 -0,0035;
-0,0035; 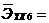 0,000085.
0,000085.
Опираясь на эти данные, можно сделать вывод, что наибольшее
влияние на Y оказывает фактор Х3, а наименьшее -
фактор Х1.
Исследование уравнения регрессии
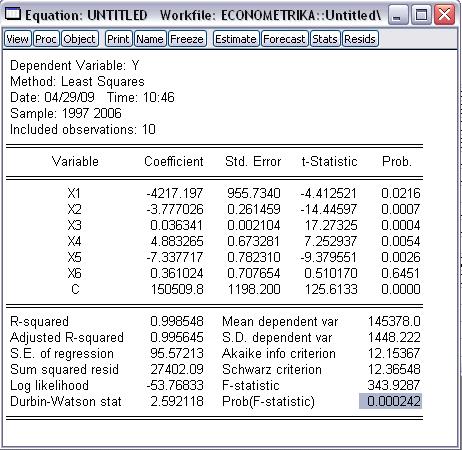
Рис. 16
Коэффициент
детерминации.
Мерой качества уравнения регрессии, характеристикой
прогностической силы анализируемой регрессионной модели является коэффициент
детерминации (R-squared). Он показывает, какая
часть вариации зависимой переменной обусловлена вариацией объясняющей
переменной. Чем ближе коэффициент детерминации к единице, тем лучше регрессия
аппроксимирует эмпирические данные.
В нашем случае коэффициент детерминации равен 0,998548. Это
значит, что изменение численности населения на 99,85% объясняется изменением
факторов Х1 - Х6.
Проверка
значимости коэффициентов регрессии.
Для проверки значимости уравнения регрессии используем
критерий Фишера.
F-критерий обозначается F-statistic=343,93.
Выдвинем нулевую гипотезу Н0: не существует
статистической зависимости между эндогенной и экзогенными переменными и
параметры регрессии не значимы. Также выберем устраивающую нас вероятность
ошибки I
рода α=0,05.
Вероятность Prob (F-statistic) = 0.000242<0,05, значит, с
вероятностью ошибки I рода α=0,05 нам следует отвергнуть
нулевую гипотезу и решить, что существует статистическая зависимость между
эндогенной и экзогенными переменными и параметры регрессии значимы.
Средняя ошибка аппроксимации
Стандартная ошибка аппроксимации S.E. of regression = 0,0659, или, другими
словами, построенная регрессия на 6,59% отклоняется от опытных данных.
Проверка
значимости оценок параметров регрессии.
Для проверки значимости оценок параметров регрессии
используется критерий Стъюдента.
Выдвинем нулевую гипотезу Н0: оценки параметров
регрессии и истинные значения параметров βk в генеральной
совокупности существенно различаются, т.е. фактор X не влияет на Y. Также выберем
устраивающую нас вероятность ошибки I рода α=0,05.
Вероятности для t-статистики параметров регрессии указаны в
столбце Prob: рХ1=0.0216, рХ2=0.0007, рХ3=0.0004,
рХ4=0.0054, рХ5=0.002, рХ6 = 0.6451, рс
= 0.0001. Сравнив их с α = 0.05, можно сделать вывод:
коэффициенты при X1, X2, X3, X4, X5 значимы, а при X6 - незначим. Продолжим исследование и попытаемся улучшить
модель.
Построение корреляционной матрицы
Мы выдвигаем гипотезу о наличии линейной связи между Y и Xk,  . При этом предположении мы можем
исследовать интенсивность связи между переменными с помощью корреляционного
анализа.
. При этом предположении мы можем
исследовать интенсивность связи между переменными с помощью корреляционного
анализа.
Корреляционный анализ исследует силу стохастической связи между
переменными. Теснота этой связи количественно выражается величиной коэффициента
корреляции r є [-1: +1].
Принято считать, что существует сильная связь между двумя
переменными, если модуль коэффициента корреляции больше либо равен 0,7. Причём,
если коэффициент корреляции отрицательный, то связь между переменными обратная,
если положительный - прямая; равный же 0 коэффициент корреляции позволяет
говорить об отсутствии линейной зависимости между переменными.
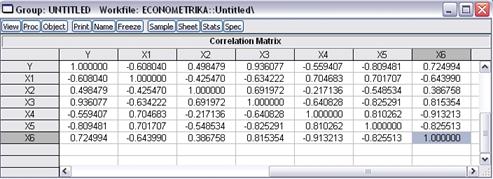
Рис. 17
Проанализируем полученные данные: коэффициент корреляции между Y и X3, X5, X6 больше 0,7,
т.е. можно говорить о наличии сильной зависимости между этими переменными.
Проверка на мультиколлинеарность.
При выборе объясняющих переменных может возникнуть явление высокой
взаимной коррелированности экзогенных переменных (мультиколлинеарность).
Мультиколлинерность приводит к уменьшению точности оценки
параметров или невозможности получения объективных оценок из-за связи
независимых переменных между собой.
Для выявления связи между независимыми переменнми проводится
анализ корреляционной матрицы между экзогенными переменными и выявляются пары
переменных, имеющих высокие коэффициенты корреляции (больше 0,4). Если такие
переменные существуют, то говорят о явлении мультиколлинеарности между ними.
Как видим, коэффициент корреляции больше 0,4 для следующих
пар переменных: (X1, X2), (X1, X3), (X1, X4), (X1, X5), (X1, X6), (X2, X3), (X2, X5), (X3, X4), (X3, X5), (X3, X6), (X4, X5), (X4, X6), (X5, X6).
Мы столкнулись с явлением мультиколлинеарности.
Воспользуемся методом исключения переменных: по парной
корреляции наибольшая связь между зависимыми переменными у X4 и X6. Теперь чтобы исключить
какой-либо фактор воспользуемся коэффициентами частной корреляции.
Частная корреляция.
Частная корреляция оценивает силу связи между зависимой
переменной и одной из независимых переменных при исключении влияния остальных,
то есть связь оценивается в чистом виде.
С помощью частного коэффициента корреляции определяют, какая
из экзогенных переменных наиболее сильно связана с эндогенной переменной.
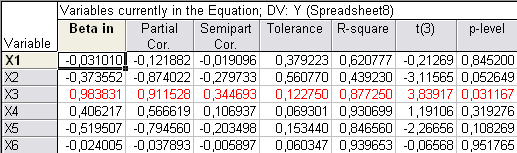
Рис. 18
Коэффициенты частной корреляции X4 и X6 соответственно равны
0,566619 и -0,037893, следовательно наибольшее влияние на Y оказывает X4, поэтому фактор X6 можно исключить из
модели.
Так как мы исключили фактор X6, нужно опять строить
модель множественной регрессии, но только для факторов Xk, k=1,2,3,4,5.
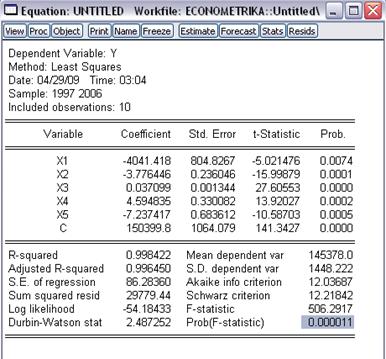
Рис. 19
Оценим статистическую значимость прогнозного уравнения:
Коэффициент детерминации R2=0.998422>0,7, что
говорит о том, что доля влияния независимых переменных на зависимую
значительна.
Адекватность регрессии опытным данным
Т.к. Prob (F-statistic)= 0,000011 < 0,05, то отвергаем гипотезу H0 о незначимости
регрессии.
Значимость оценок регрессии:
Продолжим исследование.
Оценим наличие мультиколлинеарности:
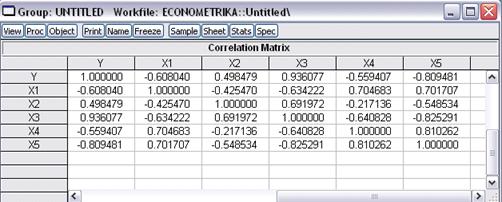
Рис. 20
Мы столкнулись с явлением мультиколлинеарности. Снова
применяем метод исключения переменных: воспользуемся коэффициентом частной
корреляции.
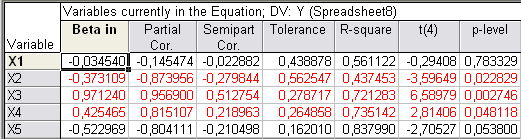
Рис. 21
Для X3 и X5 они соответственно равны: 0,95690 и -0,804111,
следовательно наибольшее влияние на Y оказывает X3, поэтому фактор X5 можно исключить из
модели.
Так как мы исключили фактор X5, нужно опять строить
модель множественной регрессии, но только для факторов Xk, k=1,2,3,4.
econometric модель регрессионный eviews
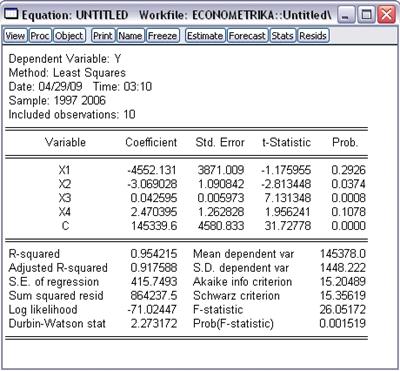
Рис. 22
Оценим статистическую значимость прогнозного уравнения:
Коэффициент детерминации R2=0.954215>0,7, что
говорит о том, что доля влияния независимых переменных на зависимую значительна
(95%).
Адекватность регрессии опытным данным
Т.к. Prob (F-statistic)= 0,0015 < 0,05, то отвергаем гипотезу H0 о незначимости
регрессии.
Значимость оценок регрессии
В исследовании оказывается, что Prob для X1, X4> 0,05 это говорит о
статистической незначимости коэффициентов при X1, X4.
Продолжим исследование и попытаемся улучшить модель.
Оценим наличие мультиколлинеарности:
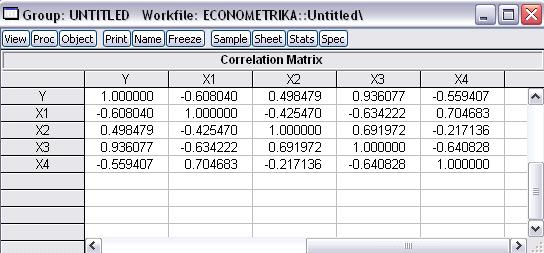
Рис. 23
Мы столкнулись с явлением мультиколлинеарности. Снова
применяем метод исключения переменных: воспользуемся коэффициентом частной
корреляции:
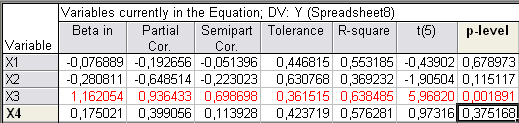
Рис. 24
Для X1 и X4 они соответственно равны: -0,192656 и 0,399056, значит X4 больше влияет на Y, чем X1. Поэтому фактор X1 можно исключить из
модели.
При увеличении числа беженцев и вынужденных переселенцев на 1
тыс. человек, численность населения РФ увеличивается в среднем на 30,201486
человек.
Список литературы
1.
Молчанов И.Н., Герасимова И.А, «Компьютерный практикум по начальному
курсу эконометрики (реализация на Eviews)», Ростов-н/Д., - 2001.
.
И.И. Елисеева, «Эконометрика», Москва - 2007 г.
.
Сайт Федеральной служба государственной статистики: www. gks.ru