Эксплуатация услуг как этап жизненного цикла услуг
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«УФИМСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ЭКОНОМИКИ И СЕРВИСА»
КУРСОВАЯ РАБОТА
По дисциплине «Управление
ИТ-сервисами и контентом»
На тему: «Эксплуатация услуг как этап
жизненного цикла услуг»
Выполнил:
студент заочного факультета
группы БИЗк2
Вагапов Д.О.
Проверил: Исхаков З.Ф
Уфа 2014
Содержание
Введение
1. Управление событиями
. Управление инцидентами
Заключение
Список литературы
эксплуатация услуга
управление инцидент
Введение
В данной работе мы познакомимся с основными процессами этапа эксплуатации
услуг. Разберем более детально всю тему, а так же рассмотрим входы, выходы,
основную деятельность, ключевые показатели производительности для каждого из
них. Рассмотрим как происходят управление процесса событиями. Изучим
предупреждения, отклонения и информационное событие. Узнаем что такое инциденты
и как им управлять, все его этапы.
.
Управление событиями
Управление событиями (Event Management) - процесс,ответственный за
управление событиями в течение жизненного цикла. Управление событиями одна из
главных деятельностей операционного управления ИТ.
Событие (Event) - изменение состояния, которое имеет значение для
управления конфигурационной единицей или услугой.
Для того чтобы быть эффективным, операционное управление должно знать
состояние инфраструктуры и ее компонентов, а также отслеживать любые отклонения
от нормальной работы. Управление событиями реализовывается с помощью систем
мониторинга и контроля, которые основаны на двух типах инструментов.
Инструменты активного мониторинга - опрашивают ключевые конфигурационные
единицы с целью выяснения их статуса и доступности. Любое отклонение вызовет
алерт (предупреждение), который перенаправляется необходимой команде или
инструменту для принятия необходимых действий.
Приведем определение из глоссария ITIL:
Активный мониторинг (Active Monitoring) - мониторинг конфигурационных
единиц или услуг, использующий автоматизированные регулярные проверки для
отслеживания текущего статуса объекта мониторинга.
Инструменты пассивного мониторинга - обнаруживают и собирают алерты, без
принятия каких-либо ответных действий.
Пассивный мониторинг (Passive Monitoring) - мониторинг конфигурационной
единицы, услуги или процесса, который основывается на предупреждениях или
уведомлениях о текущем состоянии объекта мониторинга.
Из определений, данных в глоссарии, не совсем очевидна разница двух видов
мониторинга. Основным отличием является принятие ответных действий в случае
алерта при активном мониторинге и их полное отсутствие при пассивном.
Необходимо сразу отметить разницу между мониторингом и Управлением
событиями. Эти процессы очень похожи, но, тем не менее, имеют отличия.
Управление событиями сфокусировано на обнаружении значимых событий, касающихся
статусов услуг и инфраструктуры. Мониторинг же следит за всеми событиями, и ,
по сути, имеет более широкий охват. Например, мониторинг может отслеживать
состояние устройства, чтобы удостовериться, что оно функционирует в
установленных рамках, даже если устройство не генерирует никаких событий. Таким
образом, Управление событиями является частью системы мониторинга.
Фактически, Управление событиями может контролировать любой аспект
сервис-менеджмента. Объектами Управления событиями могут быть:
· конфигурационные единицы;
· условия среды (пожар или обнаружение дыма);
· мониторинг использования лицензий на программное обеспечение;
· безопасность;
· нормальная активность (например, использование приложений или
производительность сервера).
Ценность Управления событиями для бизнеса косвенная. Тем не менее, можно
выделить следующие преимущества, которые дает Управление событиями бизнесу.
Предоставляет механизмы для раннего обнаружения инцидентов. Во многих
случаях Управление событиям позволяет обнаружить инцидент и принять
соответствующие действия до того, как он значительно повлияет на услугу в
целом.
При интеграции с другими процессами сервис-менеджмента может повысить их
эффективность. Он может сообщить об изменениях или отклонениях статусов, что
позволит соответствующей команде своевременно предпринять необходимые действия.
Раннее оповещение о необходимости обновления процедур или ресурсов;
Управление событиями основано на автоматизированных операциях, что
увеличивает эффективность и позволяет задействовать персонал на более
"креативные" работы, в частности, проектирование новых услуг и поиск
путей по улучшению существующих.
Управление событиями работает со следующими типами событий:
· события, сигнализирующие о регулярной операции, например:
· уведомления о том, что работы в соответствии с графиком
выполнены;
· аутентификация пользователя для использования приложения;
· e-mail достиг получателя;
· события, отмеченные как отклонения, например:
· попытка входа в приложение с использованием некорректного
пароля;
· нестандартная ситуация в работе бизнес-процесса, которая
может потребовать дальнейших действий;
· использование CPU выше установленной нормы;
· установка неизвестных приложений.
События, отмеченные как нестандартные, но при этом не являющиеся
отклонениями. При обнаружении подобных событий необходим более детальный
мониторинг.
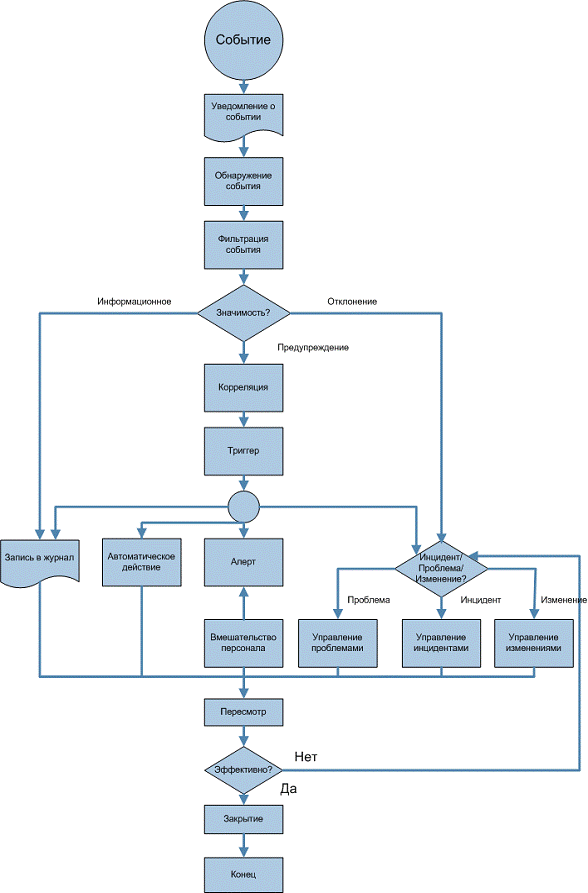
Рис. 1. процесс Управления событиями
Разного рода события возникают постоянно, но при этом не все события
нужно регистрировать и обнаруживать. Важно, чтобы люди, участвующие в
проектировании, разработке, развертывании и поддержке услуг, четко понимали,
какие именно события необходимо отслеживать.
Конфигурационные единицы в большинстве случаев выдают предупреждения в
случае выполнения определенных условий. Возможность формировать эти
предупреждения должна быть спроектирована и встроена в конфигурационные
единицы. Многие конфигурационные единицы генерируют предупреждения с
использованием открытого стандарта SNMP.
В идеальном случае на этапе Проектирования формируется стандартный набор
событий, которые необходимо отслеживать в отношении конкретных конфигурационных
единиц. В рамках этапа Внедрения этот набор тестируется и настраивается.
После того, как предупреждение сформировано, специальный агент в системе
обнаруживает его, "читает" и анализирует значимость события.
Следующий шаг - фильтрация событий. На этом этапе выносится решение о том,
будет ли данное событие проигнорировано или его необходимо передать менеджменту
для осуществления необходимых ответных действий. Если событие игнорируется, оно
просто записывается в журнал событий (лог). Никаких других действий не
выполняется. Фильтрация является первым шагом к классификации событий. Этап
фильтрации, по сути, является необязательным.
Каждая организация имеет свои критерии для оценки значимости события, но
ITIL рекомендует использовать как минимум три категории событий:
информационное событие - относится к событию, которое не требует никаких
действий и не является отклонением. Такие события просто записываются в логи и
используются для слежения за работой системы и ее компонентов, или контроля
выполнения каких-то операций. Они также могут использоваться для сбора статистики
и дальнейших исследований. Примерами информационных событий могут быть вход
пользователя в систему или успешное завершение транзакции.
предупреждение - этот тип события формируется тогда, когда услуга или
устройство приближается к пороговым значениям. Предупреждения предназначены для
того, чтобы соответствующий сотрудник, процесс или инструмент проверили
ситуацию более детально и приняли необходимые меры для предотвращения
отклонения. Примерами предупреждений могут быть использование памяти сервера более
75% или увеличение количества коллизий в сети.
отклонение - этот тип событий сигнализирует о том, что услуга или
устройство функционируют неправильно (за пределами нормы). Это значит, что
нарушаются SLA и OLA, что, как следствие, приводит к негативному влиянию на
бизнес в целом. Примерами отклонений могут послужить:
выход из строя сервера;
больше, чем n пользователей подключились одновременно к приложению N;
сегмент сети не отвечает на запросы.
Если событие отмечено как значительное, необходимо определить точно его
значимость и необходимые ответные действия - это этап корреляции. Корреляция
обычно выполняется частью средства управления под названием "Correlation
Engine", которая применяет к событию набор правил и критериев в
определенном порядке. Основная идея в том, что событие может повлиять на
бизнес, а правила помогут определить степень и тип этого влияния. В механизме
корреляции событий прописывается способ реагирования на событие, например: что
делаем при первом, втором и последующих проявлениях данного предупреждающего
события, при сочетании или последовательности ряда событий - отклонений,
одиночном, но имеющем очень серьезные для заказчика последствия, отклонении.
Примеры того, что может использовать Correlation Engine для оценки:
· количество похожих событий ( например, большое количество
попыток неправильного ввода пароля может свидетельствовать о попытке взлома
устройства);
· сопровождают ли событие какие-либо специфичные действия с
данными или кодом;
· является ли событие отклонением;
· категория события;
· назначение приоритета событию и т.п.
Механизм, который инициирует ответные действия, называется триггером.
Существует множество типов триггеров, каждый из которых спроектирован для
инициализации конкретных действий. Например:
· Триггеры инцидентов, которые формируют запись в Системе
управления инцидентами и, соответственно, запускают процесс Управления
инцидентами;
· Триггеры изменений, которые формируют RFC и инициируют
процесс Управления изменениями;
· Скрипты, которые выполняют определенные действия, например,
перезагрузку устройства;
· Триггеры баз данных, которые ограничивают доступ
пользователей к определенным областям базы или удаляют/создают записи в ней.
Следующий этап - выбор ответных действий. Существует множество вариантов
ответных действий, которые при этом могут комбинироваться.
Ниже приведены примеры вариантов ответных действий.
Вне зависимости от того, какое ответное действие будет выбрано, хорошей
практикой является формирование записи о событии в логе. Должна быть
стандартная процедура для операционного персонала, предусматривающая
периодический анализ логов, а также четкие инструкции о том, как использовать
конкретный лог. Также необходимо помнить о том, что информация в логах может не
иметь значения до возникновения инцидента. В рамках Управления событиями нужно
определить период хранения логов перед тем, как они будут заархивированы или
удалены.
Для регулярных и "понятных" событий можно разработать
автоматические ответные действия. Триггер запустит их и затем проверит
результат выполнения. Если что-то пошло не так, будет сформирована запись о
проблеме или инциденте. Примерами автоматических ответных действий могут быть:
· перезагрузка устройства;
· повторный запуск услуги;
· изменение параметра устройства;
· блокировка приложения для предотвращения несанкционированного
доступа и т.п.
Алерт (предупреждение) и вмешательство людей. Алерт служит для
уведомления о событии людей, которые имеют необходимые навыки и знания для его
разрешения. При этом алерт должен содержать как можно более полную информацию о
событии, на основании которой человек сможет принять правильное решение.
Создание Запроса на изменение (RFC). В Управлении событиями есть две
точки, где могут быть созданы RFC:
при возникновении отклонения. Например, проверка компьютера показала, что
на нем установлено три неавторизованных приложения. В этом случае необходимо
сформировать RFC, который поможет процессу Управления изменениями устранить
отклонение.
на этапе корреляции была определена необходимость изменения. В данном
случае на этапе корреляции определяется, что наиболее подходящим ответным
действием будет изменение чего-то.
Создание записи об инциденте. Если Correlation Engine определяет то, что
определенный набор событий является инцидентом, создается запись об инциденте.
Запись об инциденте должна быть максимально полной и отражать связи со всеми
событиями, относящимися к инциденту.
Создание записи о Проблеме или формирование связи с уже имеющейся записью.
Инциденты обычно связаны с определенными записями о проблемах. При
возникновении инцидента важно связать его с соответствующей записью о проблеме,
а если такой нет - создать ее.
Особые типы инцидентов. В некоторых случаях событие может являться
отклонением, но при этом не влиять непосредственно на услуги. Такие инциденты
не включаются в расчет времени простоя и относятся скорее с проблемам
операционного характера. Информация о них должна быть записана в
соответствующий лог и передана персоналу, который разбирается с инцидентами
этого типа.
Каждый день может происходить десятки и сотни событий и зачастую
невозможно детально рассматривать каждое событие. Обзорные действия
предназначены для проверки того, как были отработаны инциденты, не пропущены ли
какие-то события, сбора статистических данных и т.п. При этом обзорные действия
не должны повторять то, что было сделано до этого.
Метрики, которые можно использовать для измерения эффективности
Управления событиями:
· количество событий по категориям;
· количество событий по значимости;
· количество событий, которые потребовали участия персонала;
· количество инцидентов, вызванных известными ошибками и
проблемами;
· количество одинаковых инцидентов (или повторяющихся);
· количество инцидентов, связанных с проблемами
производительности;
· количество инцидентов, свидетельствующих о наличии
потенциальных проблем с доступностью и т.п.
Основными сложностями и рисками для Управления событиями являются
недостаточное финансирование, выбор оптимального уровня фильтрации событий и
упущение момента для своевременного развертывания агентов в рамках
инфраструктуры.
Для того чтобы Управление событиями было эффективным, его механизмы
должны быть разработаны на этапе Проектирования услуг в рамках процессов
Управления доступностью и Управления мощностями. Но при этом Управление
событиями не является статичным - в ходе эксплуатации услуг могут появляться
новые требования и события, которые необходимо отслеживать. Проектирование
Управления событиями должно включать следующее.
Инструментарий - что может быть отслежено в отношении конфигурационных
единиц и как можно воздействовать на них. Другими словами это точное
определение и проектирование того, как контролировать и мониторить
инфраструктуру и услуги. В рамках определения инструментария необходимо
ответить на следующие вопросы:
· что необходимо мониторить?
· какой тип мониторинга необходим?
· когда необходимо формировать событие?
· какая информация должна содержаться в событии?
· для кого предназначены сообщения о событиях?
Сообщения об ошибках должны отображать критичные ошибки,
свидетельствующие о сбое или вероятности его возникновения.
Механизмы обнаружения событий и формирования алертов. Проектирование этих
механизмов требует:
· знания взаимосвязей всех бизнес-процессов, которые контролируются
с помощью Управления событиями;
· знания SLA для каждой услуги, поддерживаемой конфигурационной
единицей;
· знания того, кто поддерживает конфигурационную единицу;
· знания того, какие значения параметров конфигурационной
единицы являются нормальными, а какие нет;
· понимание того, что именно нужно знать для эффективного
управления конфигурационной единицей;
· знания информации, которая может помочь эффективной поддержке
конфигурационной единицы;
· осознания важности совокупности одинаковых или похожих
событий;
· понимание взаимосвязей конфигурационных единиц;
· доступности информации об известных ошибках, полученной от
вендоров или из предыдущего опыта.
Определение пороговых значений для каждой конфигурационной единицы. При
этом значения могут изменяться в зависимости от многих обстоятельств. Например,
максимальное количество пользователей, получающих доступ к серверу, зависит от
того, какие именно работы они на нем выполняют.
. Управление инцидентами
Управление инцидентами (Incident Management) - процесс, отвечающий за
управление жизненным циклом всех инцидентов. Основная цель Управления
инцидентами - скорейшее восстановление услуги для пользователей.
Инцидент (Incident) - незапланированное прерывание услуги или снижение
качества услуги. Сбой конфигурационной единицы, который еще не повлиял на
услугу, также является инцидентом. Например, сбой одного диска из массива
зеркалирования.
Как видно из определения процесса, Управление инцидентами предназначено
для максимально быстрого восстановления нормальной эксплуатации услуги и
минимизации неблагоприятного влияния на бизнес в случае возникновения
инцидента. Под "нормальной эксплуатацией услуги" здесь понимается
эксплуатация в соответствии с SLA. Процесс рассматривает все события, которые
нарушают или могут нарушить нормальную эксплуатацию услуги. Информация о таких
событиях может поступать из разных источников, основными из которых являются
звонки пользователей и технического персонала в сервис-деск и процесс
Управления событиями.
Ценность Управления инцидентами для бизнеса более очевидна, чем у других
процессов этапа Внедрения. Часто именно этот процесс является основой для
формирования обоснования бизнесу о необходимости остальных процессов этапа
Внедрения. В частности, Управление инцидентами помогает бизнесу тем, что:
· быстро находит и разрешает инциденты, в результате чего
снижается время простоя услуг, что в целом увеличивает показатели доступности
услуг;
· выравнивает деятельности IT в соответствии с приоритетами
бизнеса;
· увеличивает способность выявления возможностей для улучшения
услуг в результате расследования инцидентов;
· сервис-деск, разрешая инциденты, определяет дополнительные
требования IT и бизнеса к услугам и обучению.
Время разрешения инцидента обычно формализовано в рамках SLA, OLA и
других базовых соглашений. Команды поддержки должны быть готовы к соблюдению
временных ограничений.вводит также понятие Модель инцидентов, которая включает
в себя:
· шаги, которые необходимо предпринять для того, чтобы
разрешить инцидент;
· хронологический порядок шагов;
· распределение ответственностей - кто и что делает;
· временные рамки и пороговые величины для завершения каждого
действия;
· вопросы того, с кем необходимо связать и на каком этапе;
Таким образом, Модель инцидентов описывает последовательность действий
при возникновении определенного типа инцидентов. Использование моделей
инцидентов позволяет стандартизовать процесс Управления инцидентами и ускорить
его. Этот подход применим в отношении часто возникающих "стандартных"
инцидентов. "Нестандартные" случаи обрабатываются отдельно, например,
инциденты, связанные с информационной безопасностью. В отдельную категорию
выделяются "значительные инциденты", которые должны разрешаться
максимально быстро. Значительный инцидент (Major Incident) наивысшая категория
влияния для инцидента. Значительный инцидент означает значительные потери для
бизнеса. То, какие инциденты будут считаться значительными, каждая организация
решает индивидуально.
Для того чтобы разрешить инцидент, его необходимо сначала обнаружить, то
есть идентифицировать. С точки зрения непрерывности бизнеса неприемлемо ждать
обращений пользователей или технического персонала в сервис-деск. Все ключевые
компоненты должны контролироваться, чтобы своевременно обнаруживать сбои или
возможности их возникновения.
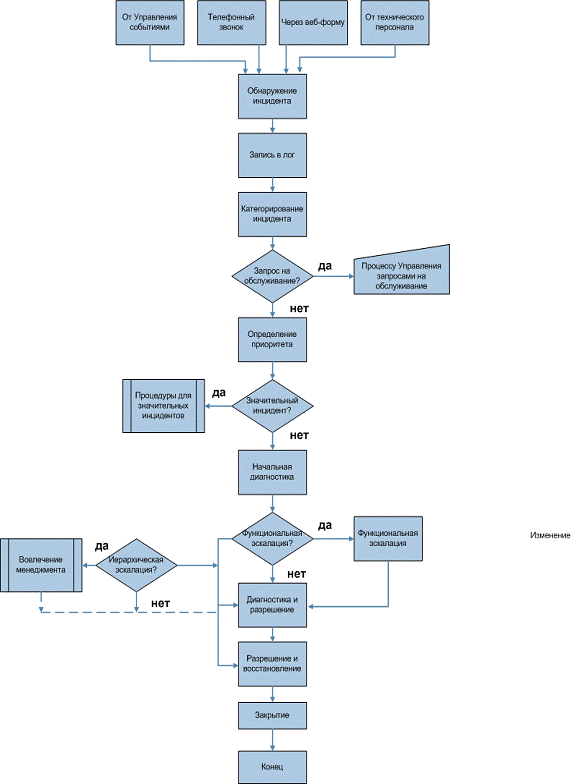
Рис. 2. Процесс Управления инцидентами
Запись об инциденте должна включать:
· уникальный идентификатор инцидента;
· категорию инцидента;
· срочность инцидента. Срочность (Urgency) - мера того,
насколько быстро с момента своего появления инцидент, проблема или изменение
приобретет существенное влияние на бизнес. Например, инцидент с высоким уровнем
влияния может иметь низкую срочность до тех пор, пока это влияние не
затрагивает бизнес в период закрытия финансового года. Влияние и срочность
используются для назначения приоритета.
· влияние инцидента;
· приоритет инцидента;
· дата и время записи;
· Имя/ID человека или группы, сделавшей запись об инциденте;
· метод уведомления;
· имя/отдел/номер/расположение пользователя;
· метод обратной связи;
· описание симптомов;
· статус инцидента;
· связанные конфигурационные единицы;
· группа поддержки/сотрудник, к кому переадресован инцидент;
· связанная с инцидентом проблема/известная ошибка;
· деятельности, осуществленные для разрешения инцидента;
· время и дата разрешения инцидента;
· категория закрытия;
· время и дата закрытия.
Следующий этап разрешения инцидента - категорирование. Оно необходимо для
дальнейших работ, в частности, поиска известных ошибок и проблем, которые могли
послужить причиной для возникновения инцидента. Обычно используется три-четыре
уровня категорирования (рис. 3).
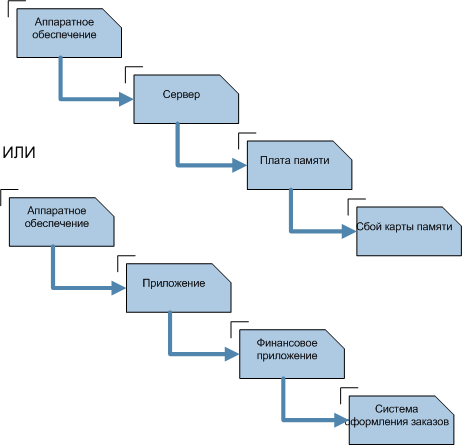
Рис. 3. Варианты категорирования инцидентов
Нет стандартных методов для категорирования инцидентов, каждая
организация сама определяет, какие категории будет использовать.
Приоритет инцидента определяется исходя из двух понятий - срочности и
влияния. Влияние в отношении инцидентов чаще всего определяется на основе
количества пользователей, которые он затронул. Тем не менее, этот показатель не
всегда является объективным. В некоторых случаях влияние инцидента даже на
одного единственного пользователя может оказать значительное негативное влияние
на бизнес в целом.
Другие факторы, которые можно использовать для оценки влияния:
· риск для жизни или сегмента;
· количество услуг, которые затрагивает инцидент;
· уровень финансовых потерь;
· влияние на бизнес-репутацию;
· возникновение нарушений законодательства и требований
регуляторов.
В таблицах 1 и 2 приведен пример матриц для определения приоритета
инцидента и времени, в течение которого его необходимо разрешить.
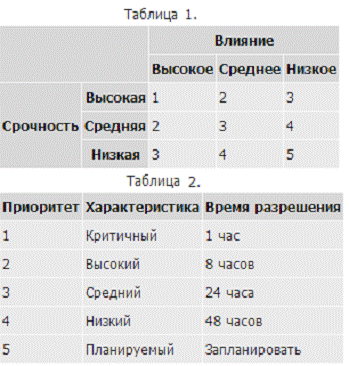
Для персонала поддержки необходимо разработать четкие инструкции
определения приоритета инцидента на основе срочности и влияния на бизнес.
Необходимо отметить, что приоритет инцидента может меняться в зависимости от
изменения окружающих условий и требований бизнеса.
Далее следует этап начальной диагностики. В первую очередь он относится к
инцидентам, поступившим в сервис-деск. Специалист службы сервис-деск должен
попытаться найти причину, вызвавшую инцидент, понять, что именно работает
некорректно и выявить максимальное количество характеристик инцидента во время
связи с пользователем, например, по телефону. Другими словами, специалист
должен попытаться решить инцидент и закрыть его. Если это невозможно, он
сообщает пользователю идентификационный номер инцидента.
Если сервис-деск не может разрешить инцидент или сроки первой ступени
разрешения инцидентов истекли, инцидент должен быть немедленно передан дальше.
Эскалация (Escalation) - деятельность, направленная на получение
дополнительных ресурсов, когда это необходимо для достижения Целевых
показателей уровня услуги или ожиданий заказчиков. Эскалация может
потребоваться в рамках любого процесса Управления услугами, но наиболее часто
ассоциируется с Управлением инцидентами, Управлением проблемами и управлением
жалобами заказчика. Существует два типа эскалации: функциональная эскалация и
Иерархическая эскалация.
Функциональная эскалация. Функциональная эскалация подразумевает передачу
инцидента в группу поддержки с более высокой квалификацией и компетенцией. При
этом если очевидно, что второй уровень поддержки не сможет разрешить инцидент,
его можно сразу передать на третий уровень поддержки. Третий уровень поддержки
может включать в себя не только сотрудников организации, но и поставщиков,
вендоров и т.п. При этом ответственность за уведомление пользователя о ходе
разрешения инцидента остается на сервис-деске, вне зависимости от того, где
инцидент рассматривается на данный момент.
Иерархическая эскалация. Иерархическая эскалация подразумевает вовлечение
или просто информирование руководителей более высокого уровня о возникновении
инцидента. Она способствует своевременному принятию решений относительно
выделения дополнительных ресурсов и вовлечения внешних организаций в процесс
разрешения инцидента.
Следующий этап разрешения инцидентов называется исследование и
диагностика. В случаях, когда пользователи обращаются только для поиска
информации, сервис-деск должен предоставить ее в минимальные сроки. Но если
сообщается о наличии сбоя, это требует определенных действий по исследованию и
диагностике инцидента. При этом все предпринятые действия должны быть
отображены в записи об инциденте. Действия чаще всего включают в себя:
· установление того, что именно не работает или что именно ищет
пользователь;
· определение хронологии событий;
· оценка влияния инцидента, в том числе количества
пользователей, которых он затронул;
· поиск в базе знаний аналогичных случаев в прошлом.
Когда потенциальное разрешение инцидента определено, необходимо провести
тестирование того, что действия по восстановлению завершены, и услуга полностью
восстановлена для пользователей. Группа, разрешившая инцидент, должна передать
его на закрытие сервис-деску.
Сервис-деск, в свою очередь проверяет, что все действия, необходимые для
разрешения инцидента, выполнены, пользователи удовлетворены и согласны закрыть
инцидент. Это включает в себя следующее:
· закрытие категорирования - производится проверка корректности
изначально установленной категории инцидента. Если она оказалось неправильной,
ее исправление и занесение изменений в запись об инциденте;
· опрос удовлетворенности пользователей - - осуществляется
по звонку или электронной почте для статистики и отображения эффективности работы
сервис-деска;
· проверка полноты записи об инциденте;
· определение того, какая проблема вызвала инцидент, является
она постоянной или периодически повторяющейся. Сюда относится также определение
проактивных действий по предотвращению инцидентов этого типа в дальнейшем и
формирование записи о проблеме, если она новая;
· формальное закрытие инцидента - формальное закрытие записи об
инциденте.
В некоторых случаях инцидент может быть повторно открыт даже после
формального закрытия. Правильным будет заранее определить правила о том, как,
когда и при каких условиях инцидент может быть повторно открыт. Это
используется, в частности, когда в один и тот же день возникают одинаковые
инциденты. Для нового инцидента, тем не менее, необходимо сформировать новую
запись со ссылкой на предыдущий инцидент. Запись о предыдущем инциденте может
быть использована для разрешения нового.
Метриками эффективности процесса Управления инцидентами могут быть:
· общее количество инцидентов;
· количество инцидентов, находящихся на разных стадиях -
закрыт, в работе, передан и т.п.
· размер текущего лога об инцидентах;
· количество значительных инцидентов;
· среднее время разрешения инцидентов;
· процент инцидентов, разрешенных в согласованное время
разрешения инцидентов;
· средние затраты на инцидент;
· количество повторно открытых инцидентов и их процентное
соотношение к общему количеству инцидентов;
· количество инцидентов, неправильно назначенных в команды
поддержки;
· количество инцидентов, для которых были неправильно
определены категории;
· количество удаленно разрешенных инцидентов ( без
персонального присутствия);
· количество инцидентов, разрешенных с использованием каждой
Модели инцидентов;
· количество инцидентов в разрезе определенных интервалов дня.
Для эффективного Управления инцидентами необходимо обеспечить следующее:
· способность обнаруживать инциденты как можно раньше. Это
включает в себя обучение пользователей немедленно сообщать об инцидентах и
конфигурирование инструментов Управления событиями;
· доступность информации об известных проблемах и ошибках. Это
позволит персоналу использовать опыт предыдущих инцидентов;
· взаимодействие с CMS для определения взаимосвязей
конфигурационных еиниц и обращения к их истории для поддержки первого уровня;
· взаимодействие с SLM для корректной оценки инцидентов,
расстановки приоритетов и выполнения процедур Эскалации. SLM в свою очередь
может использовать информацию от Управления инцидентами для определения того,
что целевые уровни производительности реалистичны и могут быть достигнуты.
Основные риски для процесса Управления инцидентами:
· большое количество инцидентов, которые не могут быть
разрешены в установленные сроки в связи с недостатком ресурсов или их недостаточной
подготовкой;
· приостановка разрешения инцидентов из-за некорректной работы
поддерживающих инструментов;
· недостаточность или несвоевременность информации из-за
некорректной работы поддерживающих инструментов или плохой взаимосвязи с
другими процессами;
· несоответствия с основными контрактами и соглашениями,
которые возникают вследствие их плохой проработки и нереалистичности
согласованных целевых показателей.
Заключение
В данной работе мы познакомились с основными процессами этапа эксплуатации
услуг. Разобрали более детально всю тему, а так же рассмотрели входы, выходы, в
основную деятельность, ключевые показатели производительности для каждого из
них. Рассмотрели как происходят управление процессами событиями. Изучили
предупреждения, отклонения и информационное события. Узнали что такое инциденты
и как ими управлять, все его этапы.
Список литературы
) Д.А.
Скрипник Электронная книга. ITIL. IT Service Management по стандартам V.3.1.
2) Панкрухин
А.П. Маркетинг: Учебник. - М.: Институт международного права и экономики имени
А.С. Грибоедова, 2010. - 398 с.
3) Маркетинг:
Учебник для вузов. / Н.Д. Эриашвили, К. Ховард, Ю.А. Цыпкин и др.; Под ред.
Н.Д. Эриашвили. - 3-е изд., перераб. и доп. - М.: ЮНИТИ-ДАНА, 2011. - 631 с.
) http://www.dis.ru/manag/arhiv/2001/6/4.html
«Модели конфликтов», Фогмин Г. П. №6 2010 г.
5) http://www.miks.ru/articles/27679.html
) Гембл
П., Стоун М., Вудкок Н. Маркетинг взаимоотношений с потребителями. - Пер. с
англ. В.Егорова. - М.: ФАИР-ПРЕСС, 2010. - 512с