Модуль реалізації алгоритмів на графах з візуалізацією етапів розробки
Модуль реалізації
алгоритмів на графах з візуалізацією етапів розробки
1. Призначення та область застосування
об’єкту проектування
1.1 Призначення та область застосування
«Модуль реалізації алгоритмів на графах з
візуалізацією етапів розробки» призначений для виконання таких функцій:
. Побудова алгоритму у вигляді графу.
. Аналіз графа, для виявлення помилок.
. Побудова псевдокоду із графу.
. Збереження графа у вигляді бінарного
файлу.
. Завантаження графа.
Програмний модуль може застосовуватись для
аналізу алгоритмів різної складності та виявленні в ньому помилок.
1.2 Огляд способів та засобів розробки
Процес розробки будь-яких алгоритмів
супроводжується зображенням його в схематичному вигляді: блок-схема, дерево
рішень, та інше. Останнім часом значно збільшилась кількість засобів, які
дозволяють суттєво полегшити процес схематичного зображення алгоритмів. Деякі з
них здатні не тільки зображати алгоритм в одному з перечислених вище виглядів,
а й генерувати вихідних код на одній з відомих мов високого рівня.
Цей процес не рідко може супроводжуватися
попереднім проведенням синтаксичного аналізу коду, для виявлення і виправлення
помилок. Також деякі із засобів дозволяють виконувати зворотну генерацію, тобто
програма отримує вихідний код, на деякій мові високого рівня, аналізує його і
дозволяє зобразити алгоритм у схематичному вигляді.
1.2.1 Побудова блок-схем алгоритмів програм
Алгоритм - це однозначна кінцева послідовність
точно визначених кроків або дій які забезпечують вирішення завдання при
наявності вихідних даних за кінцевий проміжок часу.
Основні властивості алгоритму:
1. Масовість - алгоритм повинен бути застосований для
цілого класу однотипних задач  ;
;
. Закінченість - алгоритм повинен складатися з кінцевого
числа кроків, кожен з яких виконується за кінцевий проміжок часу.
. Результативність - по закінченні роботи алгоритму повинен
бути отриманий певний результат.
. Однозначність - застосування алгоритму до одних і тих же
вихідних даних завжди повинно давати один і той же результат.
. Правильність - застосування алгоритму до правильних
вихідних даних або допустимих вихідних даних повинно приводити до отримання
необхідних результатів. Доказ правильності алгоритму - один із найбільш
складних етапів його створення. Найбільш поширена процедура правильності
алгоритму - це обґрунтування правомірності і перевірка правильності виконання
кожного з кроків на наборі тестів, підібраних так, щоб охопити всі допустимі
вхідні дані і всі допустимі вихідні дані.
. Ефективність - алгоритм повинен забезпечувати рішення
завдання за мінімальний проміжок часу з мінімальними витратами пам'яті. Для
оцінки алгоритмів існує багато критеріїв. Найчастіше оцінка алгоритму полягає в
оцінці часових витрат на вирішення завдання в залежності від «розміру» вихідних
даних. Використовується також термін, тимчасова здатність і «трудомісткість
алгоритму». Фактично ця оцінка зводиться до оцінки кількості основних операцій,
які виконуються алгоритмами, оскільки кожна конкретна операція виконується за
кінцевий заздалегідь відомий час.
Алгоритм вирішення задачі виходить більш ефективним, якщо
користуватися методами покрокової розробки, суть якого полягає в тому, що
алгоритм розробляється «зверху вниз». Спочатку визначається загальний підхід до
вирішення завдання, потім виділяються окремі самостійні частини, які виконують
якусь кінцеву обробку даних. Кожна із виділених частин у свою чергу може
розбиватися на окремі частини. Такий підхід дозволяє розбити алгоритм на
частини (модулі), кожна з яких вирішує самостійну підзадачу. Кожен з модулів
реалізується у вигляді окремої процедуру або функції. Тоді рішення задачі
складається з послідовного виклику процедур. Програма, що реалізує такий
алгоритм, називається структурованою програмою.
1.2.2 Правила побудови блок-схем
Блок-схема є формою представлення алгоритму за
допомогою графічних символів. Графічні символи, їх розміри, а також правила
побудови блок-схем визначені державними стандартами. Розглянемо часто вживані
графічні символи (повний список містить 42 символи).
Процес. Виконання операції або групи операцій, в
результаті чого змінюється значення, форма подання або розташування даних.
Всередині символу або ж у вигляді коментарю на природному мовою або у вигляді
формули записуються дії, які виробляються при виконанні операції або групи
операцій.
Розгалуження. Вибір напрямку
виконання алгоритму або програми в залежності від деяких змінних умов.
Символ використовується для зображення
уніфікованих структур:
Розгалуження ПОВНЕ
Розгалуження НЕПОВНЕ
ВИБІР
ЦИКЛ-ДО
ЦИКЛ-ПОКИ
Модифікація. Виконання операцій, які
змінюють команди або групу команд, що змінюють програму.
Символ використовується для зображення
уніфікованої структури ЦИКЛ з параметрами. Всередині символу записується
параметр циклу з зазначенням початкового та кінцевого значень, а також крок
зміни циклу, якщо він не дорівнює одиниці.
Процедура. Використання раніше
створених і окремо описаних алгоритмів або програм (процедур, функцій,
програмних модулів). Символ служить для вказівки звернення до процедур,
функцій, програмних модулів.
Ручне введення. Введення даних
оператором в процесі обробки за допомогою пристрою, що безпосередньо з’єднане з
комп’ютером (наприклад, клавіатура).
Дисплей. Введення - виведення
даних у разі, якщо безпосередньо підключений до процесору пристрій відтворює
дані та дозволяє оператору вносити зміни в процесі їх обробки.
Документ. Ввід - вивід даних,
носієм яких є папір.
Лінія потоку. Вказівка послідовності
зв'язків між символами.
Перелічимо деякі правила зображення ліній потоку:
) лінії потоку повинні бути паралельні лінії
зовнішньої рамки блок-схеми (кордонів аркуша, на якому зображена блок-схема);
) напрямок лінії потоку зверху вниз і зліва
направо приймається за основне і стрілками НЕ позначається, в інших випадках
напрямок лінії потоку позначається стрілками;
) зміна напряму лінії потоку здійснюється під
кутом 90 градусів.
З’єднувач. Введення зв’язку між
розділеними лініями потоку, що зв’язує символи. Якщо блок-схема складається з
декількох частин, розташованих на одній сторінці, то лінія потоку однієї
частини закінчується символом «з’єднувач», а лінія потоку на продовженні
блок-схеми починається з цього ж символу. Всередині символів «з’єднувачі»
ставляться однакові порядкові номери, що відповідають розірваний лінії потоку.
Міжсторінковий з’єднувач. Вказівка зв'язку
між роз’єднаними частинами схем алгоритмів і програм, розташованих на різних
листах. Даний символ служить для тих самих цілей, що й з'єднувач, але при
розташуванні частин блок-схеми на різних сторінках.
Початок - кінець. Початок, кінець,
переривання процесу обробки даних або виконання програми.
.2.3 Створення блок схем алгоритмів за допомогою
FCEditor
Відомо досить багато засобів схематичного
зображення алгоритмів, що підвищують швидкість та якість їх створення, дозволяють
уникнути рутинної роботи. Засоби схематичного зображення алгоритмів, що
випускаються різними виробниками, об’єднують в собі схожі функції, різних
можливості генерації коду, зручності роботи і аналізу.
Наприклад, один із таких засобів схематичного зображення
алгоритмів є FCEditor (див. рис. 1). Цей програмний продукт включає:
1. Вбудований редактор блок-схем.
2. Імпортування схеми із вихідного коду
програми.
. Побудова окремої схеми для кожної
процедури.
. Експорт схеми в графічний файл.
. Експорт схеми в код.
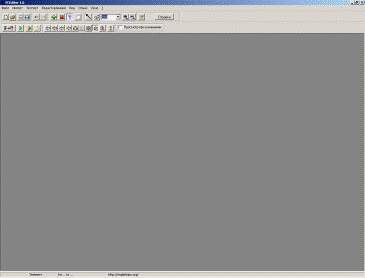
Рис. 1. Головне вікно FCEditor
FCEditor поширюється умовно безкоштовно, що дає
можливість ознайомитися з його перевагами та недоліками не купуючи його. Засіб
дозволяє легко освоїти основи розробки алгоритмів. Чому сприяє паралельна
генерація коду на мові високого рівня.
1.2.4 Огляд FCEDitorне потребує установки,
працює під керуванням ОС Microsoft Windows 9x/NT/2000/Vista. Як було зазначено,
FCEDitor дозволяє паралельно генерувати вихідний код алгоритму на мові
високого рівня за допомогою реалізованих в ньому синтаксичного та лексичного
аналізатора.
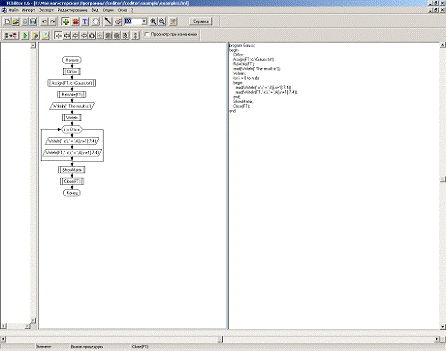
Рис. 2. FCEDitor в процесі побудови
алгоритму
Ключове вікно в FCEDitor є вікно відображення
блок-схеми, де відображається схематично побудований алгоритм та вихідний код
алгоритму на мові високого рівня (див. рис. 2). При відкриванні раніше
збереженого проекту алгоритму, відбувається генерація коду на вибраній мові
(доступні мови: Pascal та С++).
Перерахуємо деякі з можливостей FCEDitor:
1. Експорт блок-схеми в вихідний код, на
мові високого рівня.
2. Експорт блок-схеми в графічний файл.
. Імпорт блок-схеми із вихідного коду на
мові Pascal.
. Імпорт блок-схеми із вихідного коду на
мові C++.
. Повторна генерація блок-схеми після виправлення
коду.
.2.5 Створення нового проекту
Запустивши FCEDitor в меню «Файл» виберіть пункт
«Новый». Як показано на рис. 4, відкривається нове вікно, в якому зображено
початкову блок-схему та вихідний код, який відповідає цій блок-схемі. Ім'я
проекту вибирається по замовчування New_FlowChart_1, яке можна змінити при
збереженні проекту.
Засіб FCEDitor дає можливість змінити мову
генерації вихідного коду із блок-схеми. Виконати це можна за допомогою пункту
«Настройки» в меню «Опции» (рис. 4)
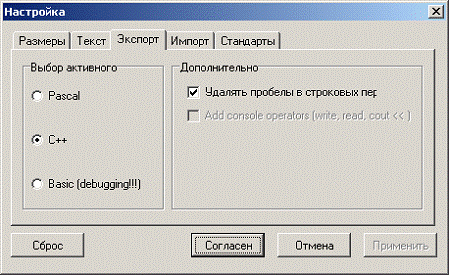
Рис. 4. Зміна мови генерації вихідного коду
Генерацію коду на мову вис корівня відбувається
паралельно з побудовою блок-схеми алгоритму.
1.2.6 Створення блок-схеми та генерація коду
Для побудови блок-схеми алгоритму необхідно
створити новий проект в FCEDitor, та виконати необхідні налаштування
програмного засобу. Створення блок-схеми алгоритму полягає в виборі блоків, які
необхідно додати до блок-схеми, та вибору місця, в яке його необхідно
помістити. Після вибору такого місця необхідно виконати подвійне клацання
мишкою на вибраному місці і необхідний елемент буде поміщено в нього.
Паралельно з додаванням елементу блок-схему буде виконана генерація коду, для
доданого елементу. Єдиною необхідною річчю, яка залишилась, буде редагування
цього коду згідно своїм потребам.
Зміна мови генерації коду відбувається шляхом
зміни налаштувань, як вже було зображено на рис. 5.
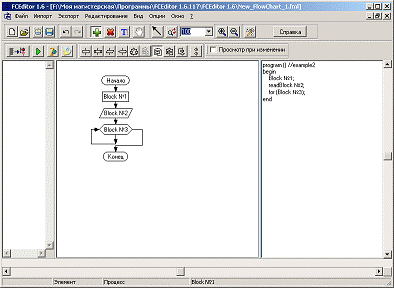
Рис. 5. Створення блок-схеми
1.2.7 Експорт блок схеми алгоритму
FCEDitor надає можливість виконувати експортувати
блок-схему безпосередньо в вихідний файл на мові високого рівня, який буде
збережений на жорсткому диску комп’ютера, або на іншому носію.
Експорт в вихідний файл виконується за допомогою
команди «Экспорт в код» меню «Экспорт» (рис 6.)
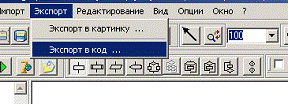
Рис. 6. Експорт блок-схеми в вихідний файл
Після успішного експорту буде створений вихідний
файл з кодом на мові високого рівня.
Експорт блок-схеми в файл зображення виконується
подібним чином. За допомогою команди «Экспорт в картинку» меню «Экспорт» (рис.
7.).
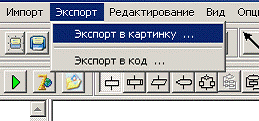
Рис. 7. Експорт блок-схеми в графічний файл
Серед доступних форматів збереження в графічний
файл доступний тільки формат BMP.
1.2.8 Імпорт блок схеми
FCEDitor дозволяє будувати блок-схему із вихідних
файлів на мові високого рівня (Pascal, С++).
Імпортування виконуюється за допомогою команди
«Импорт из…» меню «Импорт» (рис. 9), можна галочкою вказати мову, з якої
необхідно імпортувати блок-схему і потім вибрати «Импорт из…», або вибрати із
випадаючого списку (рис. 8).

Рис. 8. Імпорт блок-схеми з вихідного файлу на
мові високого рівня
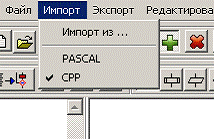
Рис. 9. Імпорт блок-схеми з вихідного файлу на
мові високого рівня
Результатом виконання імпорту, буде побудована
блок-схема (рис. 10), вихідний файл на мові високого рівня та згенерований код
з блок-схеми.
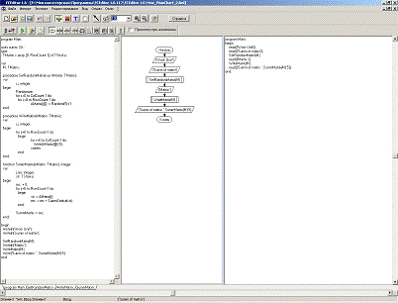
Рис. 10. Результат імпортування з вихідного файлу
на мові високого рівня
1.3 Огляд програмних та апаратних засобів
1.3.1 Псевдо код
Псевдокод - компактна (найчастіше неформальна)
мова опису алгоритмів, що використовує ключові слова мов програмування, але
опускає несуттєві деталі і специфічний синтаксис. Псевдокод зазвичай опускає
деталі, несуттєві для розуміння алгоритму людиною. Такими несуттєвих деталями
можуть бути описи змінних, системно-залежний код і підпрограми.
Головна мета використання псевдокоду -
забезпечити розуміння алгоритму людиною, зробити опис більш сприймаємим, ніж
вихідний код на мові програмування. Псевдокод широко використовується в
підручниках і науково-технічних публікаціях, а також на початкових стадіях
розробки комп'ютерних програм.
Блок-схеми можна розглядати як графічну
альтернативу псевдокоду. На відміну від стандартизації синтаксису мов
програмування, на синтаксис псевдокоду зазвичай не встановлюється стандартів,
так як останній безпосередньо не компілюють у виконувану програму. Тому можна
сказати, що зазвичай кожен варіант використання псевдокоду може бути відмінним
від попередньо відомих, однак щоб бути максимально зрозумілим, намагаються
використовувати більш-менш сталі форми його запису, як правило, запозичені з
будь-якої мови програмування. Найчастіше джерелом псевдокоду служать кілька
мов, і таким чином псевдокод часто не містить специфічних ознак кожної мови
програмування. Крім того, математичні вирази часто включаються в псевдокод в
тому вигляді, як їх прийнято записувати в математиці, а не в мовах
програмування, а деякі фрагменти псевдокоду можуть записуються фразами
природної мови (російської, англійської і т.д.). Однак при цьому конструкції
деяких мов програмування частіше використовуються для псевдокоду. Так,
наприклад, дуже часто використовується синтаксис, схожий на синтаксис мови
Pascal. Це пояснюється тим, що Pascal створювався як мова, орієнтована на
задачі навчання програмування, і тому синтаксис цієї мови особливо
пристосований для сприйняття людиною. Часто використовуються і інші мови: C,
Algol, Fortran та інші.
Відомі прогнози, які стверджують, що подальший
розвиток мов програмування піде по шляху їх зближення з псевдокодом, що в
кінцевому етапі дозволить здійснювати програмування на природних мовах.
У ряді випадків псевдокодом називають систему
команд абстрактної машини, наприклад, P-код, псевдокод вигаданої машини MIX і
т.д. На відміну від псевдокоду неформального характеру, такий псевдокод вже
суворо формалізований, важчий для розуміння людиною, але може транслювався в
працюючу програму за наявності програми-емулятора цієї гіпотетичної машини.
.3.2 Мови програмування високого рівня
Високорівнева мова програмування - мова
програмування, розроблена для швидкості і зручності використання програмістом.
Основна риса високорівневих мов - це абстракція, тобто введення смислових
конструкцій, що коротко описують такі структури даних і операції над ними,
опису яких на машинному коді (або іншій низкорівневій мові програмування) дуже
довгі і складні для розуміння.
Так, високорівневі мови прагнуть не тільки
полегшити розв’язання складних програмних завдань, але і спростити перенесення
програмного забезпечення. Використання різноманітних трансляторів та
інтерпретаторів забезпечує зв’язок програм, написаних за допомогою мов високого
рівня, з різними операційними системами та обладнанням, у той час як їх
вихідний код залишається, в ідеалі, незмінним.
Такого роду відірваність високорівневих мов від
апаратної реалізації комп’ютера крім безлічі плюсів має і мінуси. Зокрема, вона
не дозволяє створювати прості і точні інструкції до використовується
обладнання. Програми, написані на мовах високого рівня, простіше для розуміння
програмістом, але менш ефективні, ніж їх аналоги, які створюються за допомогою
низькорівневих мов. Одним з наслідків цього стало додавання підтримки того чи
іншого мови низького рівня (мова асемблер) в ряді сучасних професійних високорівневих
мов програмування.
Приклади: C++, Visual Basic, Java, Python, Ruby,
Perl, Delphi (Pascal), PHP. Мовам високого рівня властиве вміння працювати з
комплексними структурами даних. У більшість із них інтегрована підтримка
рядкових типів, об’єктів, операцій файлового вводу-виводу і т. п.
Першою мовою програмування високого рівня
вважається комп’ютерна мова Plankalkül розроблена
німецьким інженером Конрадом Цузе ще в період 1942-1946 рр. Однак, широке
застосування високорівневих мов почалося з виникненням ФОРТРАН і створенням
компілятора для цієї мови (1957).
2. Проектування модуля реалізації алгоритмів на графах з
візуалізацією етапів розробки
2.1 Поняття графа
У математичній теорії графів та інформатиці граф
- це сукупність об’єктів зі зв'язками між ними.
Об’єкти представляються як вершини, або вузли
графа, а зв’язки - як дуги, або ребра. Для різних областей застосування види
графів можуть різнитися спрямованістю, обмеженнями на кількість зв’язків та
додатковими даними про вершини або ребра.
Багато структур, що представляють практичний
інтерес для математики та інформатики, можуть бути представлені графами.
Граф (рис. 11) або неорієнтований граф G - це
впорядкована пара G: = (V, E), для якої виконуються наступні умови:
· V це безліч вершин або
вузлів,
· E це безліч
(невпорядкованих) пар різних вершин, що називаються ребрами.(а значить і E)
зазвичай вважаються кінцевими множинами. Багато хороших результатів, отриманих
для кінцевих графів, невірні (або будь-яким чином відрізняються) для
нескінченних графів. Це відбувається тому, що ряд міркувань стають помилковими
у разі нескінченних множин.
Вершини і ребра графа називаються також
елементами графа, число вершин у графі | V | - порядком, число ребер | E | -
розміром графа.
Вершини u і v називаються кінцевими вершинами
(або просто кінцями) ребра e = (u, v). Ребро, в свою чергу, з’єднує ці вершини.
Дві кінцеві вершини одного й того ж ребра називаються сусідніми.
Два ребра називаються суміжними, якщо вони мають
спільну кінцеву вершину.
Два ребра називаються кратним, якщо множина їх
кінцевих вершин збігаються.
Ребро називається петлею, якщо його кінці
збігаються, тобто e = (v, v).
Ступенем degV вершини V називають кількість
ребер, для яких вона є кінцевою (при цьому петлі рахуються двічі).
Вершина називається ізольованою, якщо вона не є
кінцем ні для одного ребра; висячою (або листом), якщо вона є кінцем рівно
одного ребра.
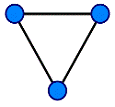
Рис. 11. Неорієнтований граф
.1.1 Орієнтований граф
Орієнтований граф (Рис. 12) (скорочено орграф) G
- це впорядкована пара G: = (V, A), для якої виконані наступні умови:
· V це множина вершин або
вузлів,
· A це множина
(впорядкованих) пар різних вершин, що називаються дугами або орієнтованими
ребрами.
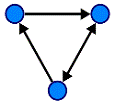
Рис. 12. Орієнтований грав
Дуга - це впорядкована пара вершин (v, w), де
вершину v називають початком, а w - кінцем дуги. Можна сказати, що дуга v 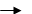 w веде від вершини v до
вершини w.
w веде від вершини v до
вершини w.
2.1.2 Змішаний граф
Змішаний граф G - це граф, в якому деякі ребра
можуть бути орієнтованими, а деякі - неоріентованими. Записується упорядкованою
трійкою G: = (V, E, A), де V, E і A визначені так само, як вище.
Зрозуміло, що орієнтований і неоріентований графи
є приватними випадками змішаного.
Шляхом (або ланцюгом) у графі називають кінцеву
послідовність вершин, в якій кожна вершина (крім останньої) сполучена з
наступною в послідовності вершин ребром.
Орієнтованим шляхом у орграфі називають кінцеву
послідовність вершин vi (i = 1, …, k), для якої всі пари (vi,
vi + 1) (i = 1, …, k-1) є (орієнтованими) ребрами.
Циклом називають шлях, у якому перша і остання
вершини збігаються. При цьому довжина шляху (або циклу) називають число
складових його ребер.
Зауважимо, що якщо вершини u і v є кінцями
деякого ребра, то згідно з даним визначенням, послідовність (u, v, u) є циклом.
Щоб уникнути таких «вироджених» випадків, вводять такі поняття.
· Кожен шлях, що з'єднує
дві вершини, містить елементарний шлях, що з'єднує ті ж дві вершини.
· Кожен простий
неелементарний шлях містить елементарний цикл.
· Кожен простий цикл, що
проходить через деяку вершину (або ребро), містить елементарний (під-) цикл, що
проходить через ту саму вершину (або ребро).
Бінарне відношення на множині вершин графа,
задане як «існує шлях з u у v», є відношенням еквівалентності, і, отже,
розбиває цю множину на класи еквівалентності, які називаються компонентами
зв’язності графа. Якщо у графі рівно одна компонента зв’язності, то граф
зв’язний. На компоненті зв’язності можна ввести поняття відстані між вершинами
як мінімальну довжину шляху, що з’єднує ці вершини.
Будь-який максимальний зв’язний підграф графа G
називається зв’язковою компонентою (або просто компонентою) графа G. Слово
«максимальний» означає максимальний щодо включення, тобто не міститься в
зв’язковому підграфі з великим числом елементів.
Ребро графа називається мостом, якщо його
видалення збільшує число компонент.
Виходячи з вище описаних типів графів, для
виконання поставленої задачі найбільш вдалим буде використання орієнтованого
графу, оскільки неорієнтований граф не дозволяє прослідковувати хід виконання
алгоритму, а використання змішаного графу призведе до того, що алгоритм
побудований на його основі не буде зрозумілим і наочним.
2.2 Цикли та умовний оператор IF
Послідовність інструкцій, призначена для
багаторазового виконання, називається тілом циклу. Одноразове виконання тіла
циклу називається ітерацією. Вираз, що визначає, буде в черговий раз
виконуватися ітерація, чи цикл завершиться, називається умовою виходу або
умовою закінчення циклу (або умовою продовження в залежності від того, як
інтерпретується його істинність - як ознака необхідності завершення чи
продовження циклу).
Змінна, що зберігає поточний номер ітерації,
називається лічильником ітерацій циклу або просто лічильником циклу. Цикл не
обов’язково містить лічильник, лічильник не обов’язково може бути один - умова
виходу з циклу може залежати від декількох змінюваних в циклі змінних, а може
визначатися зовнішніми умовами (наприклад, настанням певного часу), в
останньому випадку лічильник може взагалі не знадобитися.
Виконання будь-якого циклу включає початкову
ініціалізацію змінних циклу, перевірку умови виходу, виконання тіла циклу і
оновлення змінної циклу на кожній ітерації. Крім того, більшість мов
програмування надають засоби для дострокового завершення циклу, тобто виходу з
циклу незалежно від істинності умови виходу.
2.2.1 Безумовні цикли
Іноді в програмах використовуються цикли, вихід з
яких не передбачено логікою програми. Такі цикли називаються безумовними, або
нескінченними. Спеціальних синтаксичних засобів для створення нескінченних
циклів, з урахуванням їх нетиповості, мови програмування не передбачають, тому
такі цикли створюються за допомогою конструкцій, призначених для створення
звичайних (або умовних) циклів. Для забезпечення нескінченного повторення
перевірка умови в такому циклі або відсутня (якщо дозволяє синтаксис, як,
наприклад, у циклі LOOP… END LOOP мови Ада), або замінюється
константним значенням (while true do… в Паскаль).
2.2.2 Цикл з передумовою
Цикл з передумовою - цикл, що виконується поки
істинна деяка умова, зазначена перед його початком. Ця умова перевіряється до
виконання тіла циклу, тому тіло може бути не виконано жодного разу (якщо умова
з самого початку хибна). У більшості процедурних мов програмування реалізується
оператором while, звідси його друга назва - while-цикл.
2.2.3 Цикл з післяумовою
Цикл з післяумовою - цикл, в якому умова
перевіряється після виконання тіла циклу. Звідси випливає, що тіло завжди
виконується хоча б один раз. У мові Паскаль цей цикл реалізує оператор repeat.
until, у Сі - do… while.
У трактуванні умови циклу з післяумовою в різних
мовах є деякі розбіжності. У Паскаль і мовах, що пішли від нього, умова такого
циклу трактується як умова виходу (цикл завершується, коли умова істинна, «цикл
до»), а в Сі і його нащадках - як умова продовження (цикл завершується, коли умова
хибна, такі цикли іноді називають «цикл поки»).
2.2.4 Цикл з виходом із середини
Цикл з виходом із середини - найбільш загальна
форма умовного циклу. Синтаксично такий цикл оформляється за допомогою трьох
конструкцій: початку циклу, кінця циклу та команди виходу з циклу. Конструкція
початку відзначає точку програми, у якій починається тіло циклу, конструкція
кінця - точку, де тіло закінчується. Всередині тіла має бути команда виходу з
циклу, при виконанні якої цикл закінчується і керування передається на
оператор, що йде за конструкцією кінця циклу. Природно, щоб цикл виконався
більше одного разу, команда виходу повинна викликатися не безумовно, а тільки
при виконанні умови виходу з циклу.
Принциповою відмінністю такого виду циклу від
розглянутих вище є те, що частина тіла циклу, розташована після початку циклу і
до команди виходу, виконується завжди (навіть якщо умова виходу з циклу істинна
при першій ітерації), а частина тіла циклу, що знаходиться після команди
виходу, не виконується при останній ітерації.
Легко побачити, що за допомогою циклу з виходом
із середини можна легко змоделювати і цикл із передумовою (розмістивши команду
виходу в самому початку циклу), і цикл з післяумовою (розмістивши команду
виходу в кінці тіла циклу).
Частина мов програмування містять спеціальні
конструкції для організації циклу з виходом із середини. Так, в мові Ада для
цього використовується конструкція LOOP… END LOOP і команда виходу EXIT
або EXIT WHEN:
LOOP
… Частина тіла циклуWHEN <умова виходу>;
… Частина тіла циклу<умова вихода> THEN;;
… Частина тіла циклуLOOP:
Тут всередині циклу може бути будь-яка кількість
команд виходу обох типів. Самі команди виходу принципово не розрізняються,
звичайно EXIT WHEN застосовують, коли перевіряється тільки умова виходу,
а просто EXIT - коли вихід з циклу здійснюється в одному з варіантів
складного умовного оператора.
У тих мовах, де подібних конструкцій не
передбачено, цикл з виходом із середини може бути змодельовано за допомогою
будь-якого умовного циклу і оператора дострокового виходу з циклу (такого, як break
в Сі), або оператора безумовного переходу goto.
2.2.5 Цикл з лічильником
Цикл з лічильником - цикл, в якому деяка змінна
змінює своє значення від заданого початкового значення до кінцевого значення з
деяким кроком, і для кожного значення цієї змінної тіло циклу виконується один
раз. У більшості процедурних мов програмування реалізується оператором for, в
якому вказується лічильник (так звана «змінна циклу»), необхідна кількість
проходів (або граничне значення лічильника) і, можливо, крок, з яким змінюється
лічильник. Наприклад, в мові Оберон-2 такий цикл має вигляд:
v:= b TO e BY s DO
… тіло циклу
END
(тут v - лічильник, b - початкове значення
лічильника, e - граничне значення лічильника, s - крок).
Неоднозначне є питання про значення змінної по
завершенні циклу, в якому ця змінна використовувалася як лічильник. Наприклад,
якщо в програмі на мові Паскаль зустрінеться конструкція виду:
:= 100;i:= 0 to 9 do begin
… тіло циклу;:= i;
виникає питання: яке значення буде в підсумку
присвоєно змінної k: 9, 10, 100, може бути, яке-небудь інше? А якщо цикл
завершиться достроково? Відповідь залежать від того, чи збільшується значення
лічильника після останньої ітерації і чи не змінює транслятор це значення
додатково. Ще одне питання: що буде, якщо всередині циклу лічильнику буде явно
присвоєно нове значення? Різні мови програмування вирішують ці питання
по-різному. У деяких поведінка лічильника чітко регламентована. В інших,
наприклад, в тому ж Паскаль, стандарт мови не визначає ні кінцевого значення
лічильника, ні наслідків його явної зміни в циклі, але не рекомендує змінювати
лічильник явно і використовувати його по завершенні циклу без повторної
ініціалізації. Програма на Паскаль, що ігнорує цю рекомендацію, може давати
різні результати при виконанні на різних системах та використанні різних
трансляторів.
Радикально це питання вирішене в мові Ада:
лічильник вважається описаним в заголовку циклу, і поза ним просто не існує.
Навіть якщо ім’я лічильника у програмі вже використовується, всередині циклу в
якості лічильника використовується окрема змінна. Лічильнику заборонено явно
присвоювати які б то не було значення, він може змінюватися тільки внутрішнім
механізмом оператора циклу. В результаті конструкція
:= 100;i in (0..9) loop
… тіло циклуloop;:= i;
зовні аналогічна вищенаведеному циклу на Паскаль,
трактується однозначно: змінній k буде присвоєно значення 100, оскільки змінна
i, що використовується поза циклом, не має ніякого відношення до лічильника i,
який створюється і змінюється всередині циклу. Вважається, що подібне
відокремлення лічильника найбільш зручне і безпечне: не потрібен окремий опис
для нього і мінімальна ймовірність випадкових помилок, пов’язаних з випадковим
руйнуванням зовнішніх по відношенню до циклу змінних. Якщо програмісту потрібно
включити в готовий код цикл з лічильником, то він може не перевіряти, чи існує
змінна з ім’ям, яке він вибрав в якості лічильника, не додавати опис нового
лічильника в заголовок відповідної процедури, не намагатися використовувати
один з тих, що є, але в даний момент «вільних» лічильників.
Цикл з лічильником завжди можна записати як
умовний цикл, перед початком якого лічильнику присвоюється початкове значення,
а умовою виходу є досягнення лічильником кінцевого значення; до тіла циклу при
цьому додається оператор зміни лічильника на заданий крок. Однак спеціальні
оператори циклу з лічильником можуть ефективніше транслюватися, так як
формалізований вигляд такого циклу дозволяє використовувати спеціальні
процесорні команди організації циклів.
У деяких мовах, наприклад, Сі та інших, що пішли
від неї, цикл for, незважаючи на синтаксичну форму циклу з лічильником,
насправді є циклом з передумовою. Тобто в Сі конструкція циклу:
(i = 0; i < 10; ++i)
{
… тіло циклу
}
фактично являє собою іншу форму запису
конструкції:
i = 0;(i < 10)
{
… тіло циклу
++i;
}
Тобто в конструкції for спочатку пишеться
довільна ініціалізація циклу, а потім - умова продовження і, нарешті, деяка
операція, яка виконується після кожного тіла циклу (це не обов’язково має бути
зміна лічильника; це може бути правка покажчика або яка-небудь зовсім стороння
операція). Для мов такого виду вищеописана проблема вирішується дуже просто:
змінна-лічильник поводиться абсолютно передбачувано і по завершенні циклу
зберігає своє останнє значення.
2.2.6 Вкладені цикли
Існує можливість організувати цикл всередині
іншого циклу. Такий цикл буде називатися вкладених циклом. Вкладений цикл по
відношенню до циклу, в тіло якого він прикріплений буде називатися внутрішнім
циклом, і навпаки цикл, в тілі якого існує вкладений цикл буде називатися
зовнішнім по відношенню до вложеного. Всередині вкладеного циклу в свою чергу
може бути вкладений ще один цикл, утворюючи наступний рівень вкладеності і так
далі. Кількість рівнів вкладеності як правило не обмежується.
Повне число виконань тіла внутрішнього циклу не
перевищує добутку числа ітерацій внутрішнього і всіх зовнішніх циклів.
Наприклад взявши три вкладених один в одного цикли, кожен по 10 ітерацій,
отримаємо 10 виконань тіла для зовнішнього циклу, 100 для циклу другого рівня і
1000 в самому внутрішньому циклі.
Одна з проблем, пов’язаних з вкладеними циклами -
організація дострокового виходу з них. У багатьох мовах програмування є
оператор дострокового завершення циклу (break в Сі, exit в Турбо
Паскаль, last в Perl і т. п.), але він, як правило, забезпечує вихід
тільки з циклу того рівня, звідки викликаний. Виклик його з вкладеного циклу
призведе до завершення тільки цього внутрішнього циклу, зовнішній же цикл
продовжить виконуватися. Проблема може здатися надуманою, але вона дійсно іноді
виникає при програмуванні складної обробки даних, коли алгоритм вимагає
негайного переривання в певних умовах, наявність яких можна перевірити тільки в
глибоко вкладеному циклі.
Рішень проблеми виходу з вкладених циклів кілька.
· Найпростіший -
використовувати оператор безумовного переходу goto для виходу в точку програми,
безпосередньо наступної за вкладеним циклом. Цей варіант критикується
прихильниками структурного програмування, як і всі конструкції, що вимагають
використання goto. Деякі мови програмування, наприклад Modula-2, просто не
мають оператора безумовного переходу, і в них подібна конструкція неможлива.
· Альтернатива -
використовувати штатні засоби завершення циклів, у разі необхідності
встановлюючи спеціальні прапори, які потребують негайного завершення обробки.
Недолік - ускладнення коду, зниження продуктивності без будь-яких переваг, крім
теоретичної «правильності» із-за відмови від goto.
· Розміщення вкладеного
циклу в процедурі. Ідея полягає в тому, щоб вся дії, що можливо знадобитися
перервати достроково, оформлюється у вигляді окремої процедури, і для
дострокового завершення використовувати оператор виходу з процедури (якщо такий
є в мові програмування). У Сі, наприклад, можна побудувати функцію з вкладених
циклом, а вихід з неї організувати за допомогою оператора return. Недолік -
виділення фрагмента коду в процедуру не завжди логічно обґрунтовано, і не всі
мови мають штатні засоби дострокового завершення процедур.
· Скористатися механізмом
генерації та обробки виключень (виняткових ситуацій), який є зараз у більшості
мов високого рівня. У цьому випадку в нештатній ситуації код у вкладеному циклі
генерує виняток, а блок обробки виключень, в який поміщений весь вкладений
цикл, перехоплює і обробляє його. Недолік - реалізація механізму обробки
винятків у більшості випадків така, що швидкість роботи програми зменшується.
Правда, в сучасних умовах це не особливо важливо: практично втрата
продуктивності настільки мала, що має значення лише для дуже небагатьох додатків.
· Нарешті, існують
спеціальні мовні засоби для виходу з вкладених циклів. Так, в мові Ада
програміст може помітити цикл (верхній рівень вкладеного циклу) міткою, і в
команді дострокового завершення циклу вказати цю мітку. Вихід відбудеться не з
поточного циклу, а з усіх вкладених циклів до поміченого, включно.
2.2.7 Спільний цикл
Ще одним варіантом циклу є цикл, який задає
виконання певної операції для об’єктів з заданого множини, без явної вказівки
порядку перерахування цих об’єктів. Такі цикли називаються спільними (а також
циклами по колекції, циклами перегляду) і являють собою формальний запис
інструкції виду: «Виконати операцію X для всіх елементів, що входять в безліч
M». Спільний цикл, теоретично, ніяк не визначає, в якому порядку операція буде
застосовуватися до елементів множини, хоча певні мови програмування, зрозуміло,
можуть задавати конкретний порядок перебору елементів. Довільність дає
можливість оптимізації виконання циклу за рахунок організації доступу не в
заданому програмістом, а в найбільш вигідному порядку. При наявності можливості
паралельного виконання декількох операцій можливо навіть паралельне виконання
спільного циклу, коли одна й та сама операція одночасно виконується на різних
обчислювальних модулях для різних об’єктів, при тому що логічно програма
залишається послідовною.
Спільні цикли є в деяких мовах програмування (C
#, Java, JavaScript, Perl, Python, PHP, LISP, Tcl та ін) - вони дозволяють
виконувати цикл по всім елементам заданої колекції об’єктів. У визначенні
такого циклу потрібно вказати тільки колекцію об’єктів та змінну, якій в тілі
циклу буде присвоєно значення об’єкту, який в даний момент обробляється (або
посилання на нього). Синтаксис в різних мовах програмування синтаксис оператора
різний:
#:
{
// Використання item
}
Perl:
foreach (@set)
{
# Використання $_
}
Java:
for (type item: set)
{
// Використання item
}
JavaScript:
for (txtProperty in objObject)
{
/*
Використання:[txtProperty]
*/
}
PHP:
foreach ($arr as $item) {
/* Використання $item*/
}
2.2.8 Умовний оператор IF
Часто при написанні складних програм виникає
необхідність змінити напрямок виконання послідовності операцій, в залежності
від певної умови.
Оператори, які виконують роль розгалуження
програми на підставі якої-небудь умови, називаються операторами умовного
переходу.
Найпростішими операторами умовного переходу є
оператори If
У мові Pascal If має наступну структуру:
умова Then
оператори;;
оператори;;
Умовою завжди має бути логічний вираз (тобто
результат якого або true або false). Після ключового слова Then пишуться
оператори, які виконуються, якщо умова істинна, після ключового слова else
пишуться оператори, які виконуються, якщо умова хибна. Частина else є
необов’язковою, якщо вона відсутня, то якщо умова хибна, буде виконуватися
наступний за if оператор.
У мові С + + If має структуру
<умова>
{
<оператори>
}
{
<оператори>
}
2.3 Реалізація модуля побудови алгоритмів на
графах з візуалізацією процесу розробки
Практика програмування припускає, що по
завершенню процесу програмування програмний продукт повинен бути описаний у
відповідній формі, для того, щоб надалі він міг бути модифікований або
використаний у складі складнішої системи іншими розробниками. В результаті
розробник має справу з програмним продуктом, таким яким він поступає де-факто,
документацією для розробника, і описом програмного продукту.
В загальному виді структура роботи модуля
реалізаціях алгоритмів на графах має вигляд, наведений на рис. 13.

Рис. 13. Загальний вигляд роботі крос-компілятора
Для створення модуля реалізації алгоритмів на
графах потрібно вирішити ряд наступних підзадач, які являються складовими
частинами єдиної системи:
– Створити реєстр змінних з функцією
перевірки правильності введення.
– Створити внутрішнє представлення графу.
– На основі правил побудови графу алгоритму
створити блок перевірки відповідності графа цим правилам.
– Реалізувати блок генерації псевдокоду.
– Реалізувати блок форматування псевдокоду.
2.4 Реєстр змінних
Написання програми будь-якої складності полягає,
в кінцевому результаті, в описанні змінних, та виконання різних маніпуляцій над
ними, тому, що всі данні які використовує програма повинні десь зберігатися.
Будь-який аналізатор коду, чи алгоритму, повинен містити у своєму складі
динамічну таблицю змінних, у якій містяться змінні певної області видимості
алгоритму чи програми. Область видимості, або її ще називають зоною видимості,
являє собою певний код, в рамках якого змінна певного типу є видимою і може
використовуватися для різних операцій: математичних, рядкових, чи просто для
зберігання тимчасового результату виконання.
Область видимості може бути глобальною і
локальною. Локальна область видимості, як вже було написано вище - це певна
логічна структурна одиниця програми, в рамках якої певні змінні можуть бути
використані для математичних, рядкових, логічних чи інших операцій. Змінні, які
були описані в межах локальної області видимості не можуть бути використані за
її межами. Прикладом локальної області видимості може слугувати процедура, або
функція, також в якості локальної області видимості можна розглядати певний
модуль програми, або namespace - простір імен, який використовується в. Net для
об’єднання класів, змінних і констант.
Глобальною областю видимістю може бути вся
програма, або проект. В залежності від того, які атрибути (модифікатори)
використовувалися при описанні, змінна може використовуватися в локальній, або
глобальній області видимості. Прикладом змінних з глобальною областю видимості
може слугувати статична змінна (Visual C#), або глобальна змінна (Оbject
Pascal, C++).
В модулі реалізації алгоритмів на графах,
введений свій реєстри змінних, для використанні його в процесі генерації коду,
побудові алгоритму та перевірці правильності іменування змінних.
Правило іменування змінних полягає в тому, щоб
імена змінних були створені згідно певного алфавіту, а саме:
· символ підкреслення «_»,
· цифри 0,1,2,3,4,5,6,7,8,9
· латинські літери a…z, A…Z
Змінна може містити будь-яку кількість вище
вказаних символів, в будь-якій комбінації, крім того винятку, що ім’я змінної
повинно починатися або з символу підкреслення «_», або з літери латинського
алфавіту. Обмеження на довжину змінної складає 256 символів.
2.5 Алгоритм побудови псевдокоду
Основною метою побудови будь-якого алгоритму - є
вирішення певної задачі чи проблеми за допомогою нього. Для того щоб
застосувати алгоритм, необхідно реалізувати його на одній з мов програмування.
Зазвичай, основою для візуалізації алгоритму слугують блок-схеми, які є не
зовсім наглядними для того, щоб перевести її у програму, тому для таких цілей
використовують проміжні етапи реалізації алгоритмів, один з яких має назву
псевдокод.
Псевдокод дозволяє відобразити схематичне
зображення алгоритму використовуючи ключові слова мов програмування, але
опускаючи несуттєві деталі і специфічний синтаксис.
Одним із завдань у виконаній роботі було
створення модуля генерації псевдокоду виходячи з побудованого графу алгоритму,
до складу якого входить сам модуль побудови псевдокоду і модуль форматування псевдокоду,
задачею якого є форматування коду у відповідності з певними правилами.
Оскільки для схематичного відображення алгоритму
було вирішено використовувати граф, то процес генерації псевдокоду, відповідно,
полягає у реалізації алгоритму обходу графу з певними його модифікаціями.
2.5.1 Генерація псевдокоду лінійного алгоритму
Генерація псевдо коду графу лінійного алгоритму
не викликає яких-небудь складнощів, оскільки виконується звичайний обхід графу
з записом коду кожної вершини (рис. 15)
Рис. 15. Побудова псевдо коду лінійного алгоритму
Як видно з малюнку наведеного вище, елементарний
лінійний алгоритм дав можливість побудувати такий кою. Серед особливостей, які
слід відзначити, є такі:
) при генерації псевдокоду вершини
«Введення даних» буде виводиться текст «INPUT <variables list>», де
variables list - це список змінних, які були записані при додаванні вершини;
) при генерації псевдокоду вершини
«Виведення даних» буде виводиться текст «OUTPUT <variables list>», де
variables list - це список змінних, які були записані при додаванні вершини.
Таким чином алгоритм побудови псевдокоду
лінійного алгоритму складається з перебігу усіх вершин графу у прямому напряму
і запису коду вершин, з виконанням відповідних замін, які були наведенні вище.
Оскільки алгоритм обходу рекурсивний, то для уникання повторного запису коду
вершин, при виході з рекурсії використовується признак проходження вершини. При
відвідуванні вершини їй встановлюється статус checked - вершина вже було
розглянута і її код був записаний, з даного правила є виключення, яки буде
описане нижче.
Рис. 16. Алгоритм генерації коду лінійного
алгоритму
2.5.2 Генерація псевдокоду нелінійного алгоритму
Процес генерацій псевдокоду нелінійного алгоритму
в значній мірі відрізняється від попередньо описаних дій. Відмінності полягають
в процесі обходу графу та заміні коду вершин для кожного з виду підграфів.
Таких під графів є три:
) підграф вершини умовного оператора IF…
ELSE,
) підграф циклу WHILE…DO,
) підграф циклу DO…WHILE.
Кожен із таких підграфів має свій специфічний
алгоритм управління обходом і заміни коду вершин, при необхідності.
Генерація псевдокоду підграфу умовного оператора
IF… ELSE, має дві особливості. Однією з таких особливостей є виділення гілки
ELSE, при її наявності, тобто:
(умова) THEN
Оператор 1;
Оператор 2;
ELSE
Оператор 1;
Оператор 2;
END IF
Іншою особливістю є виділення вершини закінчення
оператора IF (рис. 17), тобто вершини, в якій сходяться шляхи виконання
алгоритму, після його розгалуження вершиною умовного оператора (END IF).
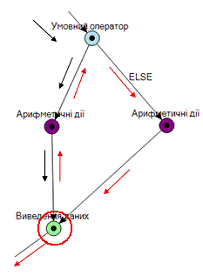
Рис. 17. Процес обходу графа при генерації
псевдокоду умовного оператора IF… ELSE
В загальному вигляді алгоритм генерації
псевдокоду підграфу умовного оператора полягає в обході гілки послідовності
операторів при виконанні умови (пряма гілка) і в обході гілки ELSE
(Else-гілка), при її наявності. Початок обходу під графу виконується з прямої
гілки і продовжується до тих пір, поки не досягне іншої вершини умовного
оператора, або буде досягнуто вершини закінчення умовного оператора. Признак,
по якому можна розпізнати вершину закінчення умовного оператора полягає в тому,
що вершина повинна мати обов’язково дві вхідні гілки, і одну, або дві (якщо це
вершина умовного оператора) вихідні гілки. При досягненні вершини закінчення
умовного оператора, на рис. 17 позначена червоним кружечком, напрямок обходу
змінюється, тобто виконується повернення до вершини умовного оператора, з
подальшим обходом по Else-гілці.
Підграф циклу WHILE…DO, являє собою подібний за
структурою підграф умовного оператора IF … ELSE за виключенням того, що код
вершини IF (умова) перетворюється в WHILE(умова), та в ньому відсутня вершина
закінчення розгалуження, оскільки «пряма гілка» передає наступний крок
виконання до вершини умовного оператора, з якого почала свій хід - утворюючи,
таким чином, цикл, який закінчиться в тому разі, коли умова перестане
виконуватись. Схематично напрямок обходу підграфу при генерації псевдокоду
зображено на рис. 18. Для уникнення зациклення алгоритму обходу графу і
правильної генерації псевдокоду, кожна вершина має атрибут cheked, який
вказує на те, була вершина вже розглянута, чи ні. При проходженні через кожну
вершину, атрибут cheked набуває значення true - що відповідає активному стану і
сигналізує про те, що вершина вже була розглянута алгоритмом обходу і її код
був записаний. При повторному проходженні через цю вершину, вона вже не буде
розглядатися і таким чином уникатиметься зациклення. Тобто, при повторному
проходженні через вершину умовного оператора, алгоритму не під в напрямку
«прямої гілки», а продовжить обхід графу через Else-гілку. Блок схема алгоритму
обходу підграфу WHILE…DO зображена на рис. 19.
Схематичне зображення алгоритму обходу підграфу
циклу WHILE…DO
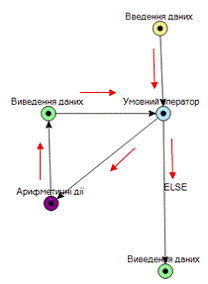
Останнім видом підграфу, який необхідно
розглянути є підграф циклу DO…WHILE, який також базується на вершині умовного
оператора IF. Алгоритм обходу даного підграфу подібний до вище описаного
алгоритму обходу підграфу циклу WHILE…DO. Відмінностями в цьому підграфі є те,
що його обхід починається не обов’язково вершини IF..ELSE, як у під графі циклу
WHILE…DO, а з будь-якої вершини, що вносить певні складнощі в побудову такого
алгоритму. Складність побудови алгоритму генерації псевдокоду підграфу циклу
DO…WHILE, полягає в тому, що необхідно, якимось чином відрізнити вершину
початку циклу (обведена кружечком на рис.) тому, що ця вершина по своїм
характеристикам (кількості вхідних і вихідних гілок) подібна до вершини
закінчення підграфу умовного оператора IF…ELSE. Ключова відмінність між цими
вершинами полягає в тому, з якої вершини в неї входять гілки. Тобто, для того
щоб однозначно визначити, що вершина є початком підграфу циклу DO…WHILE, нам
необхідно впевнитися в тому, що до вершини ведуть дві гілки, одна з яких,
безпосередньо, є «прямою гілкою» вершини умовного оператора IF…ELSE. Напрямок
обходу підграфу алгоритмом генерації псевдокоду зображено стрілочками, на рис.
Схематичне зображення алгоритму обходу підграфу
циклу DO…WHILE
.6 Форматування псевдокоду
Псевдокод є альтернативним записом алгоритму,
наближеним до реальної мови програмування, що полегшує його розгляд, та
подальшу модифікацію. Оскільки псевдокод відображає структурну побудову
алгоритму, доцільним є форматування коду у вигляді структурних блоків, тобто
необхідно візуально відокремити певні логічні структури алгоритму, такі як
цикли чи умовні оператори. Прикладом такого форматування може слугувати наступний
код:
Оператор1(умова1) THEN
Оператор2
Оператор3(умова2) THEN
Оператор4
Оператор5IF
Оператор6IF
Оператор7
Різними логічними структурами в даному випадку є
зовнішній і внутрішній оператори IF…THEN…ELSE. Для більш зрозумілого читання
коду використовуються відступи, щоб візуально їх виділити, та відобразити
приналежність операторів ОператорN до своїх логічних груп. Для прикладу той же
код можна зобразити без форматування, що логічно і синтаксично також буде
вірно, проте необхідно затратити певний час, для того, щоб зрозуміти, до яких
логічних груп відносяться різні оператори. Особливо складно відділити
оператори, які входять до вложених умовних операторів, та циклів, якщо степінь
вложеності більше 2.
Оператор1(умова1) THEN
Оператор2
Оператор3(умова2) THEN
Оператор4
Оператор5IF
Оператор6IF
Оператор7
Алгоритм форматування псевдокоду полягає в
порядковому розгляді псевдокоду. Тобто, алгоритм отримує на вхід рядок
псевдокоду перевіряє його за певними правилами, та повертає той же рядок,
тільки в певною кількістю відступів перед рядком. Ця кількість відступів
залежить від кількості відступів, які були додані до попереднього рядка, так
від того, яким службовим словом починається рядок, якщо цей рядок не містить
виключно код простого оператора. Так алгоритм працює за кількома простими
правилами, наведеними нижче:
· Починається з IF, WHILE,
DO:
) додати один символ табуляції, до
наступного рядка;
) для поточного рядка використати
попередню кількість символів табуляції;
· Починається з ELSE:
) зменшити на один символ табуляції, для
поточного рядка;
) для наступного рядка використати
попередню кількість символів табуляції;
· Починається з END IF, END
WHILE:
) зменшити на один символ табуляції для
поточного та наступного рядків;
· Оператор:
) використати попередню кількість символів
табуляції для поточного рядка
Згідно цих правил був реалізований модуль, який
виконує форматування псевдокоду, отриманого після відпрацювання алгоритмів
обходу графу.
2.7 Аналіз правильності побудови графу
Процес побудови алгоритму будь-якої складності
полягає у виконанні певних простих але, в той же час, важливих правил, без яких
алгоритм буде або не зрозумілим для сторонніх людей, або, в результаті,
призведе до не правильної реалізації цього алгоритму.
Так в процесі схематичного зображення алгоритму з
допомогою блок-схем повинні виконуватись певні правила побудови, наприклад: у
блок-схеми повинні бути блок початку і кінця алгоритму, неможливий вивід або
використання змінних, які раніше не були введені та ін. Невиконання цих простих
правил призведе до того, що алгоритм буде не правильним.
Побудова схематичного зображення з допомогою
графа полягає не тільки в виконанні вище описаних правил, а й у відповідності
певним обмеженням, які накладаються на алгоритм в зв’язку з використанням для
цих цілей графа.
Оскільки для побудови алгоритму буде
використовуватися орієнтований граф, то необхідно враховувати направленість
ребер графа.
Основні обмеження на побудову графа алгоритму
наведені нижче:
. Кожен граф алгоритму повинен містити
вершину «Введення даних» та «Виведення даних»
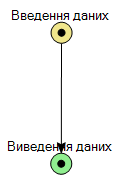
Вершина «Введення даних» відповідає аналогічному
блоку, який використовується в блок-схемах «Початок», відповідно вершина
«Виведення даних», якою обов’язково повинен закінчуватися алгоритм, є аналогом
блоку «Кінець» у блок-схемах.
. Кожна вершина повинна мати тільки одне
вихідне ребро, виключенням в цьому випадку є тільки вершина умовного оператора,
у якого одне вихідне ребро відповідає гілці, коли умова виконується, а інше
ребро відповідає гілці ELSE умовного оператора.
. Кожна вершина повинна мати одне або два
вхідні ребра, крім початкової вершини «Введення даних». Прикладом таких
ситуацій можуть бути:. Вершини закінчення оператора (IF. ELSE), коли
обидві гілки сходяться до одного оператора, наприклад, до «Виведення даних»,
. Вершина початку циклу DO…WHILE
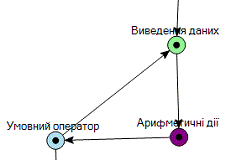
. Вершина початку циклу WHILE…DO
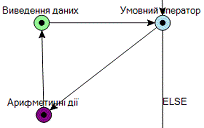
. Граф не повинен містити не закінчених
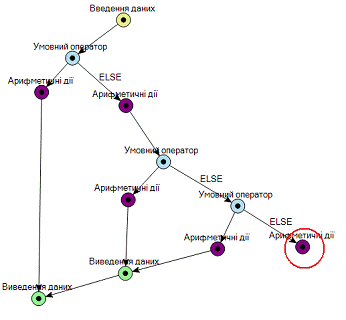
гілок, тобто у графа алгоритму повинен бути тільки один початок і один кінець,
недотримання цього правила не дасть змоги побудувати псевдокод алгоритму.
Прикладом незакінченої гілки може слугувати наступний малюнок, на якому вершина
незакінченої гілка обведена кружечком:
Так, як деякі з обмежень мають критичний
характер, для побудови псевдокоду, то вони реалізовані програмно. Одним з них,
є обмеження на можливість побудови графа з вершинами, що з’єднані одна з одною.
Дане обмеження було введено, виходячи з міркування нелогічності такого
зав’язку, тобто, такий зв’язок може бути розтлумачений як нескінченний цикл, що
не має ніякої доцільності у використанні його в схематичній побудові
алгоритмів.
Наступним обмеженням реалізованим програмно є
обмеження на кількість вхідних і вихідних ребер вершини. Оскільки для побудови
використовується граф, то виходячи з його визначення, кожна вершина може мати
n-1 ребро, де n - це кількість вершин у графі, тобто вершина може бути з’єднана
з усіма вершинами графа окрім самої себе. Але для поставленої задачі ця
властивість вершини графа була трохи модифікована, тому що в основній своїй
більшості, алгоритми є лінійними, або розгалуженими.
Виходячи з того, що кожна вершина графа
використовується для відображення елементарної операції і визначення лінійного
алгоритму, згідно якого всі дії виконуються тільки один раз і в строгій
послідовності, у вершини повинна містити тільки одне вхідне ребро і одне
вихідне.
В разі використання вершин умовного оператора
(IF. ELSE) в алгоритмах розгалуження на неї накладається обмеження згідно якого
тільки вершина умовного оператора може мати два вихідних ребра: гілка виконання
умови і гілка не виконання умов (гілка ELSE).
Обмеження на кількість вхідних ребер вершини може
мати виняток тільки у тому разі, коли вершина є складовою вершиною циклу
DO…WHILE, або вершиною закінчення оператора (IF. ELSE).
2.7.1 Алгоритм аналізу перевірки правильності
графу
Загальних процес побудову алгоритму з допомого
розробленого модуля складається з трьох основних етапів:
. Схематичного зображення алгоритму у
вигляді графу
. Аналіз графу на виконання обмежень
. Побудову псевдокоду алгоритму.
Аналіз графу виконується перед побудовою
псевдокоду, для можливості його побудову, в разі неуспішного аналізу, буде
видано повідомлення про помилку, яка виникла при аналізі і можливу причину її
виникнення.
Обмеження, які не реалізовані на рівні побудови
графу перевіряються на стадії аналізу графу, серед них: перевірка на наявність
початкової вершини «Введення даних» та кінцевої вершини «Виведення даних»,
перевірка графу на наявність незавершених гілок.
Алгоритм перевірки на наявність незавершених
гілок у графі, являє собою рекурсивний алгоритм обходу, в якому кожна вершина
перевіряється на кількість вихідних ребер, якщо цих ребер більше нуля і вершини
не вершиною виводу даних, то результат аналізу буде не успішним.
Нижче наведено код, який реалізує дану перевірку:
/// <summary>
/// Повертає признак наявності «висячих» вершин
/// </summary>
/// <param name= «startNode»>Початкова
вершина графа</param>
/// <returns>true - якщо такі вершини є,
інакше - false</returns>static bool HaveHangingNodes (GraphNode
startNode)
{result = false;. InnerEntrisCount++;(ILink link
in startNode. Port. DestinationLinks)
{node = (GraphNode) link. ToNode;(node. IsLoop)
continue;= HaveHangingNodes(node);(result) return true;
}(startNode. Port. DestinationLinksCount == 0)=!
(startNode is OutputDataNode);result;
}
Таким чином алгоритм аналізу графу можна
зобразити наступним чином:
Після успішного проходження кожного з етапів
перевірки графу, аналіз буде вважатися успішним, що зробить можливим подальшу
побудову псевдокоду алгоритму.
2.8 Вибір технології та мови програмування
Виходячи з поставлених вимог для розробки модуля
реалізації алгоритмів на графах з візуалізацією етапів розробки доцільно для
розробки використати Object-технологію - інтерфейс користувача розробити в
середовищі програмування Visual Studio 2008, використовуючи мову програмування
Visual C# 3.0.
Платформа Microsoft. NET надає:
· Стійке середовище
виконання CLR (Common Language Runtime), яке входить до складу даної платформи;
· Засоби розробки додатків
на будь-якій з багатьох мов програмування, що підтримуються платформою.NET;
· Величезну бібліотеку
класів NET Framework, що лежить в основі відкритої моделі програмування. Вони
доступні в будь-якій мові програмування, що підтримується платформою.NET;
· Підтримку мережевої
інфраструктури, побудованої на верхньому рівні стандартів Internet, внаслідок
чого забезпечується високий рівень взаємодії між додатками;
· Підтримку нового
промислового стандарту, а саме технології Web-служб. Технологія Web-служб надає
новий механізм створення розподілених додатків. По суті, вона є поширенням
технології створення додатків на базі компонентів і на сферу Internet;
· Модель безпеки, що
програмісти можуть легко використовувати у своїх програмах;
· Потужні інструментальні
засоби розробки.
3 Тестування системи
Тестування програмного забезпечення - це процес
аналізу або експлуатації програмного забезпечення з метою виявлення дефектів.
Тестування передбачає «аналіз» або «експлуатацію»
програмного продукту. Тестова діяльність, що пов’язана з аналізом результатів
розробки програмного забезпечення, називається статичним тестуванням.
Воно передбачає перевірку програмних кодів, контроль та перевірку програми без
запуску на комп'ютері. Тестова діяльність, що передбачає експлуатацію
програмного продукту, називається динамічним тестуванням. Динамічне та
статичне тестування доповнюють одне одного.
Тестування програмного забезпечення виконує дві
базові функції: верифікацію та атестацію. Верифікація забезпечує
відповідність результатів конкретної фази процесу розробки вимог даної та
попередньої стадії. Атестація є гарантією того, що програмний продукт
задовольняє системним вимогам.
Програмний продукт є якісним, коли:
· під час роботи
користувача з програмним продуктом виникає невелика кількість відмов;
· програмний продукт
надійний, а це означає, що його використання рідко викликало аварійні відмови;
· програмний продукт
задовольняє вимогам більшості користувачів.
Тестування проводилося на персональному
комп’ютері з наступними апаратними характеристиками:
– монітор 17» W;
– процесор Intel
Core 2 Duo T7250 (2.2 Ггц);
– ОЗУ 2048 Mb;
– жорсткий диск 320
Gb.
При тестуванні даного програмного комплексу було
використано максимально можлива кількість вбудованих функцій в модуль.
Тестування проводилось для генерації псевдо коду
із різних графів, один з графів наведено на рис.
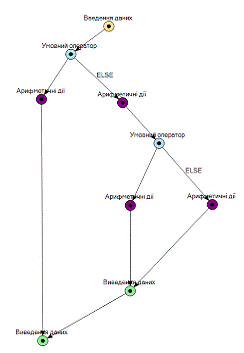
Граф простого алгоритму з розгалуженням
В результаті генерації, був отриманий псевдокод,
що відповідає зображеному на графі алгоритму:
a, b, c, d(a > b) THEN= a + 1= b + 1(b >
10) THEN= b + 10= b / 2IFbIFa, b
Тестування показало, що модуль виконує закладені
в нього функції, які були розроблені згідно технічного завдання. Тестування
аналізатора графа показало, що при побудові алгоритму виконуються всі
обмеження, на утворення зв’язку між вершинами, та закінченість побудови
алгоритму. Блок побудови псевдокоду відповідає покладеним на нього функціям,
тобто виконує генерацію коду і виконує правильне форматування коду.
Висновки
В результаті дослідження пробудови алгоритмів та
використання їх при написанні програм різного рівня складності на будь-якій
мові програмування, можна зробити висновок, що відображення його в звичному
вигляді (блок-схеми), в подальшому може доповнитися більш наглядними засобами,
в тому числі і за допомогою графів.
Використання псевдокоду для подальшої розробки
алгоритмів, можливо в недалекому майбутньому перейде на настільки високий
рівень, що програми будуть описуватися за допомогою природної мови - це зробить
аналіз алгоритмів, пошук помилок, та їх подальшу модернізацію настільки
простими, що дозволить значно підвищити швидкість процесу впровадження
алгоритму в життя.
Створений програмний модуль відповідає всім
вимогам побудови алгоритмів, та генерації псевдокоду. Надає можливість
редагувати псевдо код, сигналізує про наявні помилки при побудові графу, з
можливими причинами їх виникнення.
При створенні програмного продукту завдання було
розбито на дві частини: Створення модуля побудови графу алгоритму і модуля
аналізу та побудови і форматування псевдокоду.
Науковою новизною створеного програмного
комплексу є те, що для побудови алгоритму і схематичного його відображення було
використано орієнтовані графи, що на мою думку, дозволяє досить наочно
відобразити основні принципи алгоритму.
Список джерел
алгоритм програма мова оператор
1. Роббинс Джон. Отладка приложений для Microsoft.NET и
Microsoft Windows - М. Русская Редакция, 2004. - 736 с.
. Кристиан Гросс. C# 2008 и платформа.NET 3.5 Framework: от
новичка до профессионала, 2-е издание - Вильямс, 2009. - 897 с.
. Джозеф C. LINQ: язык интегрированных запросов в C# 2008
для профессионалов - Вильямс, 2008. - 560 с.
. Трей Нэш. C# 2008: ускоренный курс для профессионалов.
Язык программирования C# 3.0 для.NET 3.5 - Вильямс, 2008. - 576 с.
. Джимми Нильссон. Применение DDD и шаблонов
проектирования: проблемно-ориентированное проектирование приложений с примерами
на C# и.NET - Вильямс, 2007. - 429 с.
. Дон Бокс, Крис Селлз. Основы платформы.NET, том 1. Обще
языковая исполняющая среда. - Вильямс, 2003. - 288 с.
. Роберт Седжвик. Фундаметальные алгоритмы на С++. Часть 5.
Алгоритмы на графах - ДиаСофтЮП, 2002. - 496 с.
. Емеличев В.А., Мельников О.И., Сарванов В.И., Тышкевич
Р.И. Лекции по теории графов. Изд.2, испр. - 2009. 392 с.
. Харари Фрэнк. Теория графов - Едиториал УРСС, 2003. - 297
с.
. Кристофидес Н. Теория графов. Алгоритмический подход.
Перевод на русский язык. - Наука, 1989. 241 с.
. Камерон П. Теория графов. Теория кодирования и
блок-схемы. Перевод на русский язык. - Наука, 1980. 140 с.
. Акимов О.Е. Дискретная математика: логика, группы, графы,
фракталы. - Едиториал УРСС, 2005. - 655 с.
. Харари Ф. Теория графов: Перевод с английского. -
Едиториал УРСС, 2006. - 300 с.
. Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест,
Клиффорд Штайн. Алгоритмы: построение и анализ. 2-е издание. - Вильямс, 2008. -
1296 с.
. Скакунов Александр. Алгоритмы и структуры данных. -
Едиториал УРСС, 1996. 357 с.
. Уоррен Генри С. Алгоритмические трюки для программистов.
- Диалектика-Вильямс, 2003. - 288 с.