Экономико-математический анализ данных
СОДЕРЖАНИЕ
Задание на выполнение контрольной
работы
Исходные данные
. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ ИСХОДНЫХ
ДАННЫХ
а) Рассчитать матрицу парных
коэффициентов корреляции
b) Оценить
значимость коэффициентов корреляции
. УРАВНЕНИЕ РЕГРЕССИИ
. ТОЧЕЧНЫЙ И ИНТЕРВАЛЬНЫЙ
ПРОГНОЗ ЗНАЧЕНИЯ Y
. ФАКТОРНЫЙ АНАЛИЗ
а) Произвести вычисления и
проанализировать полученные результаты
b)
Интерпретировать полученные факторы
с) Упорядочить субъекты РФ в порядке
убывания рейтинга по значениям факторов
. КЛАСТЕРНЫЙ АНАЛИЗ
Список литературы
ЗАДАНИЕ НА ВЫПОЛНЕНИЕ КОНТРОЛЬНОЙ РАБОТЫ
1. Выбрать и запустить программный пакет для
выполнения контрольной работы (VSTAT
или СтатЭксперт).
2. Из таблицы настоящих методических
указаний извлечь исходные данные своего варианта на лист Excel.
. Выполнить корреляционный анализ
исходных данных:
a. Рассчитать матрицу парных коэффициентов
корреляции;
b. Оценить значимость коэффициентов
корреляции;
4. Построить уравнение регрессии (в качестве
отклика y взять моделируемую
величину) в зависимости от всех значимо связанных с откликом факторов,
последовательно удаляя факторы, коэффициенты при которых незначимы по критерию
Стьюдента.
5. Сделать точечный и интервальный прогноз
значения y, приняв для
оставшихся в уравнении факторов значения на 10% больше их максимальных
значений.
. Выполнить факторный анализ:
a. Произвести вычисления и проанализировать
полученные результаты;
b. Интерпретировать полученные факторы;. Упорядочить
субъекты РФ в порядке убывания рейтинга по значениям факторов.
7. Выполнить кластерный анализ методом к -
средних для к = 2, 3. используя 2 показателя из исходных данных.
8. Оформить контрольную работу.
ИСХОДНЫЕ ДАННЫЕ
В таблице 1 приведены исходные данные моего
варианта контрольной работы (порядковый номер - 14, ФИО - Ярмиев Р.Г., моделируемая
величина - x16, факторы,
влияющие на моделируемую величину - x1,
x2, x4,
x7, x13,
x15).
Таблица 1.
|
|
Оборот
розничной торговли, млн. руб.
|
Площадь
территории, тыс. км2
|
Численность
населения на 1 января 2011 г, тыс. человек
|
Среднедушевые
денежные доходы (в месяц), руб.
|
Валовой
региональный продукт в 2009 г., млн. руб.
|
в
том числе растениеводства
|
Ввод
в действие общей площади жилых домов, тыс. м2.
|
|
|
(X16)
|
1
|
2
|
4
|
7
|
5
|
7
|
|
|
Y
|
X1
|
X2
|
X4
|
X7
|
X13
|
X15
|
|
1
|
Республика
Башкортостан
|
512129
|
142,9
|
4071,9
|
17677
|
645526,3
|
32317
|
2007
|
|
2
|
Республика
Марий Эл
|
43626
|
23,4
|
695,4
|
10195
|
68768
|
6639
|
303,6
|
|
3
|
Республика
Мордовия
|
48410
|
26,1
|
833,3
|
11055
|
92855,1
|
6875
|
289
|
|
4
|
Республика
Татарстан
|
454394
|
67,8
|
3787,4
|
18158
|
884232,9
|
31626
|
2027,3
|
|
5
|
Удмуртская
Республика
|
110263
|
42,1
|
1521,7
|
12423
|
229369,1
|
11193
|
482
|
|
6
|
Чувашская
Республика
|
82240
|
18,3
|
1250,5
|
10885
|
139481,8
|
6816
|
874,7
|
|
7
|
Пермский
край
|
316149
|
160,2
|
2634,1
|
19422
|
544541,3
|
11810
|
761,4
|
|
8
|
Кировская
область
|
95622
|
120,4
|
1338,7
|
13385
|
144989,1
|
7851
|
378,3
|
|
9
|
Нижегородская
область
|
350748
|
76,6
|
3307,6
|
16358
|
545940,1
|
16403
|
1453,4
|
|
10
|
Оренбургская
область
|
157682
|
123,7
|
2031,3
|
13398
|
414537,2
|
16468
|
586,6
|
|
11
|
Пензенская
область
|
113519
|
43,4
|
1384
|
12700
|
150851
|
10234
|
624,8
|
|
12
|
Самарская
область
|
423534
|
53,6
|
3215,5
|
20279
|
579023,2
|
14627
|
1041,1
|
|
13
|
Саратовская
область
|
183984
|
101,2
|
2519,1
|
11961
|
327181,1
|
21910
|
1144,3
|
|
14
|
Ульяновская
область
|
103684
|
37,2
|
1289,9
|
12905
|
152627,4
|
6865
|
466,8
|
|
|
Модели-
руемая величина
|
Факторы,
влияющие на моделируемую величину
|
|
|
|
|
В своей контрольной работе в качестве Y
я использовал моделируемую величину - X16
(Оборот розничной торговли), поэтому для упрощения в таблице 1 переименовал X16
на Y.
матрица
корреляция регрессия уравнение
1. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ ИСХОДНЫХ ДАННЫХ
а) Расчет матрицы парных коэффициентов корреляции
Основная задача корреляционного анализа
заключается в выявлении взаимосвязи между случайными переменными путём оценки
коэффициентов корреляции и детерминации, а также проверки значимости полученных
значений. [1, стр. 172]
С помощью программного пакета VSTAT
рассчитаем матрицу парных коэффициентов корреляции.
Выделяем область для анализа: VSTAT
→
Корреляционный анализ (Рис.1)
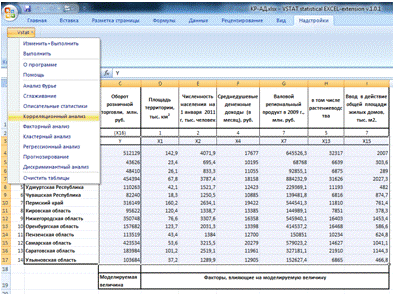
Рис.1 Корреляционный анализ
Получаем несколько таблиц корреляционного
анализа. Одна из которых - матрица парных корреляций (Таблица 2.1).
Таблица 2.1
|
Матрица
парных корреляций
|
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
0,8570
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
Анализ матрицы парных коэффициентов корреляции
показывает, что зависимая переменная Y
(«Оборот розничной торговли») имеет весьма высокую связь с:
X2 «Численностью населения»
(ryx2)=0,9758;
X4 «Среднедушевыми
денежными доходами» (ryx4)=0,9026;
X7 «Валовым
региональным продуктом» (ryx7)=0,9438;
X13 «Продукцией
растениеводства» (ryx13)=0,8184
X15 «Вводом в
действие общей площади жилых домов» (ryx15)=0,8807.
Однако, обнаруживается наличие
мультиколлинеарности.
В качестве критерия мультиколлинеарности может
быть принято соблюдение следующих неравенств: ryxi > rxixk, ryxk > rxixk,
rxixk < 0,8.
Анализ показывает, что многие коэффициенты тесно
связаны между собой: rx2x4=0.8384, rx2x7=0.9501, rx2x13=0.8781, rx2x15=0.9163,
rx4x7=0.8640, rx7x13=0.84207, rx7x15=0.8569, rx13x15=0.91275. Что нарушает
вышеприведенные неравенства и свидетельствует о наличии мультиколлениарности
между ними (Таблица 2.2).
Таблица 2.2
|
Матрица
парных корреляций
|
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
0,8570
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
|
|
X2 следует
исключить, так как он более сильно связан с другими иксами, несмотря на то, что
он сильнее связан с Y:
Таблица 2.3
|
Матрица
парных корреляций
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
0,8570
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
|
|
Следующим по тесноте связи является rх13х15.
Исключаем X13, так как переменная
X15 сильнее связана
с Y:
Таблица 2.4
|
Матрица
парных корреляций
|
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
0,8570
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
Переменная X7
тесно связана с X4 и X15,
но так как у фактора X4
сильнее связь с Y, то
исключаем X7:
Таблица 2.5
|
Матрица
парных корреляций
|
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
0,8570
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
В результате осталось три фактора - X1,
X4, X15.
b) Оценка значимости
коэффициентов корреляции
Для оценки статистической значимости полученного
значения линейного коэффициента корреляции rxy используется t-критерий
Стьюдента, согласно которому значение rxy считается статистически значимым,
если выполняется условие:
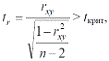 (1)
(1)
где n - количество наблюдений; tкрит = t1-α,n-2
представляет собой табличное значение t-критерия Стьюдента при уровне
значимости α и числе степеней
свободы k = n-2. [3, стр.10]
В нашем случае α=0,05; k=14-2=12.
Чтобы вычислить tкрит.,
в программе Excel необходимо использовать функцию «СТЬЮДРАСПОБР(α;k)».
Следовательно, подставляя значения в функцию «СТЬЮДРАСПОБР(0,05;12)», получаем tкрит.=2,1788
(Рис.2)
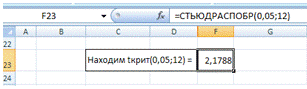
Рис.2 Вычисление tкрит.
Находим tрасч , используя формулу (1).
Преобразуем ее для ввода в Excel
- «=КОРЕНЬ(rxy ^2*(14-2)/(1- rxy ^2))»:
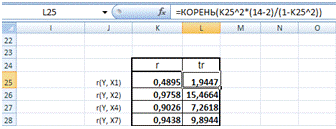
Рис.3 Вычисление tрасч
Для каждого коэффициента r(Y,Xj) вычислим t -
статистику с помощью программы Excel
и преобразованной формулой. Получим:
Таблица 3.1
|
r
|
tрасч
|
|
r(Y,
X1)
|
0,4895
|
1,9447
|
|
r(Y,
X2)
|
0,9758
|
15,4664
|
|
r(Y,
X4)
|
0,9026
|
7,2618
|
|
r(Y,
X7)
|
0,9438
|
9,8944
|
|
r(Y,
X13)
|
0,8184
|
4,9329
|
|
r(Y,
X15)
|
0,8807
|
6,4401
|
|
r(X1,
X2)
|
0,5415
|
2,2315
|
|
r(X1,
X4)
|
0,5291
|
2,1600
|
|
r(X1,
X7)
|
0,5015
|
2,0082
|
|
r(X1,
X13)
|
0,4811
|
1,9010
|
|
r(X1,
X15)
|
0,3366
|
1,2384
|
|
r(X2,
X4)
|
0,8384
|
5,3284
|
|
r(X2,
X7)
|
0,9502
|
10,5612
|
|
r(X2,
X13)
|
0,8781
|
6,3578
|
|
r(X2,
X15)
|
0,9163
|
7,9283
|
|
r(X4,
X7)
|
0,8640
|
5,9455
|
|
r(X4,
X13)
|
0,5538
|
2,3037
|
|
r(X4,
X15)
|
0,6233
|
2,7612
|
|
r(X7,
X13)
|
0,8421
|
5,4082
|
|
r(X7,
X15)
|
0,8570
|
5,7598
|
|
r(X13,X15)
|
0,9127
|
7,7397
|
Чтобы найти значимые коэффициенты сравним tрасч
и tкрит (2,1788).
Если tрасч > 2,1788, то r значим.
В таблице 3.1 выделены серым цветом
коэффициенты: r(Y,
X1), r(X1,
X4), r(X1,
X7), r(X1,
X13), r(X1,
X15) - их значения
меньше tкрит.,
следовательно они не значимы. А так как во всех коэффициентах присутствует
переменная X1, то можно сделать
вывод, что X1 («Площадь
территории») наименее значима и связана с Y
(«Оборот розничной торговли»). Поэтому исключаем её из модели:
Таблица 3.2
|
Матрица
парных корреляций
|
|
|
|
|
|
|
Переменная
|
1.Y
|
2.X1
|
3.X2
|
4.X4
|
5.X7
|
6.X13
|
7.X15
|
|
1.Y
|
1,0000
|
0,4895
|
0,9758
|
0,9026
|
0,9438
|
0,8184
|
0,8807
|
|
2.X1
не значим
|
0,4895
|
1,0000
|
0,5415
|
0,5291
|
0,5015
|
0,4811
|
0,3366
|
|
3.X2
|
0,9758
|
0,5415
|
1,0000
|
0,8384
|
0,9502
|
0,8781
|
0,9163
|
|
4.X4
|
0,9026
|
0,5291
|
0,8384
|
1,0000
|
0,8640
|
0,5538
|
0,6233
|
|
5.X7
|
0,9438
|
0,5015
|
0,9502
|
0,8640
|
1,0000
|
0,8421
|
|
6.X13
|
0,8184
|
0,4811
|
0,8781
|
0,5538
|
0,8421
|
1,0000
|
0,9127
|
|
7.X15
|
0,8807
|
0,3366
|
0,9163
|
0,6233
|
0,8570
|
0,9127
|
1,0000
|
|
Критическое
значение на уровне 95% при 2 степенях свободы = +0.4585
|
|
В результате анализа и проверки на значимость
коэффициентов корреляции остались две переменные - X4
и X15.
Сделаем вывод: корреляционный анализ данных
показал, что оборот розничной торговли тесно связан со среднедушевыми денежными
доходами и в том числе растениеводства.
.
УРАВНЕНИЕ РЕГРЕССИИ
Из задания следует: «Построить уравнение
регрессии (в качестве отклика y
взять моделируемую величину - X16)
в зависимости от всех значимо связанных с откликом факторов, последовательно
удаляя факторы, коэффициенты при которых незначимы по критерию Стьюдента».
Парной регрессией называется уравнение связи
двух переменных у и х вида y= f(x), где у - зависимая переменная
(результативный признак),
х -независимая, объясняющая переменная
(признак-фактор).
Парная регрессия применяется, если имеется
доминирующий фактор, который и используется в качестве объясняющей переменной.
Различают линейные и нелинейные относительно фактора x регрессии.
По количеству включенных в модель факторов X
модели делятся на однофакторные (парная модель регрессии) и многофакторные
(модель множественной регрессии), а по виду функции f(X1,
X2…Xk)
- на линейные и нелинейные. [3, стр.17]
Для построения уравнения нам подходит формула
линейной регрессии
= a+b*X.
С помощью программного пакета VSTAT
произведем регрессионный анализ. Выделяем область для анализа: VSTAT
→
Регрессионный анализ данных (Рис.4).
Рис.4 Регрессионный анализ данных
В результате получаем несколько таблиц
регрессионного анализа, одна из которых - «Оценки коэффициентов» (Таблица 4.1).
Таблица 4.1
|
Оценки
коэффициентов линейной регрессии
|
|
|
|
|
Переменная
|
Коэффициент
|
Среднекв.
отклонение
|
t-
значение
|
Нижняя
оценка
|
Верхняя
оценка
|
|
Y
|
-346625,29
|
65583,70
|
-5,29
|
-416881,43
|
-276369,14
|
|
X1
|
-262,66
|
193,74
|
-1,36
|
-470,20
|
-55,12
|
|
X2
|
53,60
|
33,95
|
1,58
|
17,24
|
89,97
|
|
X4
|
28,59
|
6,64
|
4,30
|
21,47
|
35,71
|
|
X7
|
-0,15
|
0,10
|
-1,50
|
-0,26
|
-0,04
|
|
X13
|
3,97
|
2,57
|
1,54
|
1,21
|
6,73
|
|
X15
|
58,25
|
42,67
|
1,37
|
12,54
|
103,96
|
В этой таблице нас интересует столбец
«Коэффициенты» для построения уравнения регрессии.
Строим уравнение линейной регрессии по формуле
Yt = a+b*X, получаем:
= -346625,29 - 262,66X1 + 53,60X2 + 28,59X4 -
0,15X7 + 3,97X13 + 58,25X15
Исходя из поставленной задачи, нам необходимо
последовательно удалять факторы, коэффициенты которых не значимы по критерию
Стьюдента.
Проверим значимость найденных коэффициентов,
используя критерий Стъюдента. Для этого воспользуемся функцией «СТЬЮДРАСПОБР»
(Рис.5) и вычислим tкр: «СТЬЮДРАСПОБР(0,05;14-p-1)» = 2,3646, где p=6 - число
параметров при факторных переменных.
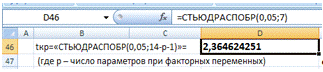
Рис.5 Критерий Стъюдента
Исключаем переменную X7, так как её значение в
столбце "t-статистика" (Таблица 4.1) наименьшее по отношению к
tкр=2,3646.
Аналогичным методом построим уравнение регрессии
(Рис.6), без фактора X7
(«Валовой региональный продукт в 2009г.»).
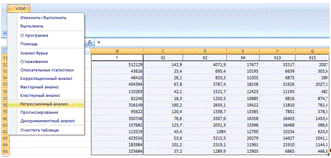
Рис.6 Регрессионный анализ данных без фактора X7
Результат регрессионного анализа:
Таблица 4.2
|
Оценки
коэффициентов линейной регрессии
|
|
|
|
|
Переменная
|
Коэффициент
|
Среднекв.
отклонение
|
t-
значение
|
Нижняя
оценка
|
Верхняя
оценка
|
|
Y
|
-278151,67
|
50540,52
|
-5,50
|
-331786,18
|
-224517,16
|
|
X1
|
-202,03
|
203,65
|
-0,99
|
-418,15
|
14,08
|
|
X2
|
48,89
|
36,33
|
1,35
|
10,34
|
87,45
|
|
X4
|
22,53
|
5,67
|
3,98
|
16,52
|
28,55
|
|
X13
|
1,99
|
2,37
|
0,84
|
-0,53
|
4,51
|
|
X15
|
57,28
|
45,86
|
1,25
|
8,61
|
105,95
|
|
Кpитическое
значения t-pаспpеделения пpи 8 степенях свободы (p=84%) = +1.061
|
|
Построим уравнение линейной регрессии:
= -278151,67 - 202,03X1 + 48,89X2 + 22,53X4 +
1,99X13 + 57,28X15
Проверим значимость найденных коэффициентов,
используя критерий Стъюдента. Вычислим tкр: «СТЬЮДРАСПОБР(0,05;8)» = 2,306.
Исключаем переменную X1,
так как ее t- значение не только меньше 2,306, но и является наименьшим среди
других переменных.
Построим уравнение регрессии, исключив X1
(«Площадь территории») аналогичным образом.
Таблица 4.3
|
Оценки
коэффициентов линейной регрессии
|
|
|
|
|
Переменная
|
Коэффициент
|
Среднекв.
отклонение
|
t-
значение
|
Нижняя
оценка
|
Верхняя
оценка
|
|
Y
|
-281733,86
|
50367,10
|
-5,59
|
-334797,05
|
-228670,67
|
|
X2
|
37,04
|
34,28
|
1,08
|
0,93
|
73,16
|
|
X4
|
22,72
|
5,66
|
4,02
|
16,76
|
28,68
|
|
X13
|
1,23
|
2,25
|
0,55
|
-1,13
|
3,60
|
|
X15
|
82,21
|
38,33
|
2,14
|
41,83
|
122,59
|
|
Кpитическое
значения t-pаспpеделения пpи 9 степенях свободы (p=84%) = +1.054
|
|
Уравнение линейной регрессии:
= -281733,86 + 37,04X2 + 22,72X4 + 1,23X13 +
82,21X15
Вычислим критерий Стъюдента tкр:
«СТЬЮДРАСПОБР(0,05;9)» = 2,2621.
Исключаем переменную X13, так как её t-значение
в Таблице 4.3 наименьшее по отношению к tкр=2,2621.
Строим уравнение регрессии, исключив X13
(«Растениеводство»).
Таблица 4.4
|
Оценки
коэффициентов линейной регрессии
|
|
|
|
|
Переменная
|
Коэффициент
|
Среднекв.
отклонение
|
t-
значение
|
Нижняя
оценка
|
Верхняя
оценка
|
|
Y
|
-266835,98
|
40905,55
|
-6,52
|
-309682,32
|
-223989,64
|
|
X2
|
47,72
|
27,21
|
1,75
|
19,22
|
76,22
|
|
X4
|
21,09
|
4,64
|
4,54
|
16,23
|
25,95
|
|
X15
|
86,13
|
36,32
|
2,37
|
48,09
|
124,17
|
|
Кpитическое
значения t-pаспpеделения пpи 10 степенях свободы (p=84%) = +1.047
|
|
Уравнение линейной регрессии:
= -266835,98 + 47,72X2 + 21,09X4 + 86,13X15
Вычислим критерий Стъюдента tкр:
«СТЬЮДРАСПОБР(0,05;10)» = 2,2281.
Исключаем переменную X2, так как её t-значение
< tкр=2,2281(Таблица 4.4).
Построим уравнение регрессии, исключив X2
(«Численность населения») аналогичным образом.
Таблица 4.5
|
ВЫВОД
ИТОГОВ
|
|
|
|
|
Регрессионная
статистика
|
|
Множественный
R
|
0,990004222
|
|
R-квадрат
|
0,98010836
|
|
Нормированный
R-квадрат
|
0,976491698
|
|
Стандартная
ошибка
|
24964,09744
|
|
Наблюдения
|
14
|
Таблица 4.6
|
Оценки
коэффициентов линейной регрессии
|
|
|
|
|
Переменная
|
Коэффициент
|
Среднекв.
отклонение
|
t-
значение
|
Нижняя
оценка
|
Верхняя
оценка
|
|
Y
|
-316892,12
|
31946,68
|
-9,92
|
-350196,97
|
-283587,26
|
|
X4
|
28,03
|
2,64
|
10,63
|
25,28
|
30,78
|
|
X15
|
144,97
|
15,15
|
9,57
|
129,17
|
160,77
|
|
Кpитическое
значения t-pаспpеделения пpи 11 степенях свободы (p=84%) = +1.043
|
|
Уравнение линейной регрессии:
= - 316892,12 + 28,03X4 + 144,97X15
Вычислим критерий Стъюдента tкр:
«СТЬЮДРАСПОБР(0,05;11)» = 2,201.
Исходя из данных расчета линейной регрессии,
можно сделать вывод о том, что расчетное значение t-статистики Стьюдента для
коэффициента переменной X4
выше табличного (2,18<10,63) также и для переменной X15
(2,18<9,57). Это означает, что коэффициенты при X4(28,03)
и X15(144,97) -
статистически значимы, а значит уравнение регрессии примет вид:
Y = -
316892,12 + 28,03X4 + 144,97X15.
3.
ТОЧЕЧНЫЙ И ИНТЕРВАЛЬНЫЙ ПРОГНОЗ ЗНАЧЕНИЯ Y
Задание: сделать точечный и интервальный прогноз
значения y, приняв для
оставшихся в уравнении факторов значения на 10% больше их максимальных
значений.
Исходя из задания, найдем максимальные значения
оставшихся факторов уравнения и увеличим их на 10%.
Факторы уравнения Y
= - 316892,12 + 28,03X4 + 144,97X15:
X4 «Среднедушевой
денежный доход (в месяц)». Его максимальное значение 20279 руб. (Самарская
область);
X15 «Ввод в действие
общей площади жилых домов». Максимальное значение 2027,3 тыс. м2 (Республика
Татарстан).
Увеличим максимальные значения факторов X4
и X15 на 10%:
X4 = 20279 + 10% =
22307
X15 = 2027,3 + 10% =
2230,03
Точечный прогноз заключается в получении
прогнозного значения Yp,
которое определяется путем подстановки в уравнение регрессии Yp=a+b*Xp
соответствующего (прогнозного) значения Xp.
[3, стр.22]
Подставим X4
и X15 в уравнение Y
= -316892,12 + 28,03X4 + 144,97X15.
Точечный прогноз:
Y1 =
-316892,12+28,03*22307 + 144,97*2230,03 =
= -316892,12+ 625265,21+323287,45 = 631660,54
Интервальный прогноз заключается в построении
доверительного интервала прогноза, т. е. нижней и верхней границ Ypmin,
Ypmax интервала,
содержащего точную величину для прогнозного значения Yp
(Ypmin < Yp
< Ypmin) с заданной
вероятностью. [3, стр.22]
Так как в уравнении у нас присутствуют две
переменные, то стандартным методом сделать интервальный прогноз не получится.
Для линейной модели регрессии доверительный
интервал рассчитывается следующим образом. Оценивается величина отклонения от
линии регрессии (обозначим её U)
[1, стр.221]:
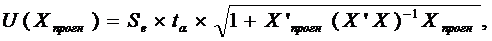
где: X’прогн=(1, X1 прогн, X2 прогн, …, Xk прогн).
U - величина
отклонения от линии регрессии;
tα - табличное
значение t-критерия
Стьюдента.
Se = (1/(n-k-1) * Σei^2)^(1/2);
U(Xпрогн) = Se*ta * (1+X'прогн*(X'X)^(-1)*Xпрогн)^(1/2).
Доверительный интервал для
индивидуального значения прогноза Y1
определяется соотношением:
Y1 - U(Xпрогн) <=
Y1 <= Y1 + U(Xпрогн)
где величина t1-α, n-2
представляет собой табличное значение t-критерия
Стьюдента на уровне значимости α при числе степеней свободы n-2. [3,
стр.22]
Проведем ряд дополнительных
расчетов:
Таблица 5.1
|
Y
|
X4
|
X15
|
Y1
|
ei=Y-Y1
|
ei^2
|
|
512129
|
17677
|
2007,0
|
469584,34
|
42544,66
|
1810048179,60
|
|
43626
|
10195
|
303,6
|
12907,02
|
30718,98
|
943655916,55
|
|
48410
|
11055
|
289,0
|
34897,98
|
13512,03
|
182574819,60
|
|
454394
|
18158
|
2230,0
|
515396,04
|
-61002,04
|
3721249006,17
|
|
110263
|
12423
|
482,0
|
101224,96
|
9038,04
|
81686148,97
|
|
82240
|
874,7
|
115041,46
|
-32801,46
|
1075936040,54
|
|
316149
|
19422
|
761,4
|
337925,55
|
-21776,55
|
474217999,24
|
|
95622
|
13385
|
378,3
|
113158,36
|
-17536,36
|
307523781,76
|
|
350748
|
16358
|
1453,0
|
352296,75
|
-1548,75
|
2398629,66
|
|
157682
|
13398
|
586,6
|
143720,02
|
13961,98
|
194936801,75
|
|
113519
|
12700
|
624,8
|
129691,54
|
-16172,54
|
261551082,40
|
|
423534
|
20279
|
1041,0
|
402482,58
|
21051,42
|
443162157,71
|
|
183984
|
11961
|
1144,0
|
184244,32
|
-260,32
|
67764,94
|
|
103684
|
12905
|
466,8
|
112532,84
|
-8848,84
|
78301987,04
|
|
|
Сумма
|
9577310316
|
Подставим значения в Se
= (1/(n-k-1)
* Σei^2)^(1/2), получим:
Se =
(1/(11)*9577310316)^(1/2) = 29507.
Для того чтобы найти величину отклонения от
линии регрессии
произведем некоторые вычисления над
значениями переменных X4, X15, чтобы
подставить их в формулу для расчета доверительного интервала.
Таблица 5.2
|
X
|
|
|
|
1,0
|
17677,0
|
2007,0
|
|
1,0
|
10195,0
|
303,6
|
|
1,0
|
11055,0
|
289,0
|
|
1,0
|
18158,0
|
2027,3
|
|
1,0
|
12423,0
|
482,0
|
|
1,0
|
10885,0
|
874,7
|
|
1,0
|
19422,0
|
761,4
|
|
1,0
|
13385,0
|
378,3
|
|
1,0
|
16358,0
|
1453,4
|
|
1,0
|
13398,0
|
586,6
|
|
1,0
|
12700,0
|
624,8
|
|
1,0
|
20279,0
|
1041,1
|
|
1,0
|
11961,0
|
1144,3
|
|
1,0
|
12905,0
|
466,8
|
Найдем транспонированную матрицу X` из таблицы
5.2, используя функцию «=ТРАНСП(массив)» в Excel:
Таблица 5.3
|
X`
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
1,0
|
|
|
17677,0
|
10195,0
|
11055,0
|
18158,0
|
12423,0
|
10885,0
|
19422,0
|
13385,0
|
16358,0
|
13398,0
|
12700,0
|
20279,0
|
11961,0
|
12905,0
|
|
|
2007,0
|
303,6
|
289,0
|
2027,3
|
482,0
|
874,7
|
761,4
|
378,3
|
1453,4
|
586,6
|
624,8
|
1041,1
|
1144,3
|
466,8
|
Теперь необходимо перемножить матрицы с помощью
функции «=МУМНОЖ(массив1,массив2)»:
Таблица 5.4
|
X'*X
|
14,0
|
200801,0
|
12440,3
|
|
200801,0
|
3026749761,0
|
194332438,4
|
|
12440,3
|
194332438,4
|
15492013,3
|
Вычислим обратную матрицу от X'*X функцией
«=МОБР(массив)»:
Таблица 5.5
|
X'X^(-1)
|
1,637645
|
-0,000124413
|
0,00024559
|
|
-0,00012
|
1,11494E-08
|
-3,9953E-08
|
|
0,000246
|
-3,99533E-08
|
3,6852E-07
|
Внесем прогнозные значения X4
и X15, транспонируем
их:
Таблица 5.6
|
Xпрогн
|
1
|
|
X'прогн
|
1
|
22307
|
2230,03
|
|
|
22307
|
|
|
|
|
|
|
|
2230,03
|
|
|
|
|
|
Умножим X'прогн на X'X^(-1) функцией
«=МУМНОЖ(массив1,массив2)»:
Таблица 5.7
|
X'прогнX'X^(-1)
|
-0,58996
|
3,51997E-05
|
0,00017615
|
Расчитаем X'прогн * X'X^(-1) * Xпрогн = 0,588.
Вычислим табличное значение t-критерия
Стьюдента на уровне значимости α при
числе степеней свободы n-2
функцией « =СТЬЮДРАСПОБР(0,05;12)»: tα
= 2,1788
Таким образом мы имеем все расчеты для того,
чтобы вычислить U(Xпрогн):
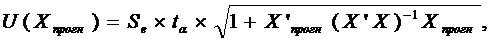
Подставим значения в формулу,
получим:
U(Xпрогн)=
29507*2,1788*((1+0,588)^(1/2)) = 81017,4
Доверительный интервал для Yпрогн.: Y1 - U(Xпрогн) <=
Y1 <= Y1 + U(Xпрогн)
,54 - 81017,4 <= 631660,54 <=
631660,54 + 81017,4
<= 631660,54 <= 712678
Вывод:
) точечный прогноз для уравнения регрессии
Y= -316892,12 +
28,03*X4 + 144,97*X15 = 631660,54
) границы прогнозного интервала:
нижняя: 550643;
верхняя: 712678.
.
ФАКТОРНЫЙ АНАЛИЗ
) Произвести вычисления и проанализировать
полученные результаты
Основные цели факторного анализа:
· сокращение
числа переменных (редукция данных);
· определение
структуры взаимосвязей между переменными (классификация переменных);
· косвенные
оценки признаков, неподдающихся непосредственному измерению;
· преобразование
исходных переменных к более удобному для интерпретации виду.
Если кратко охарактеризовать факторный анализ,
то наиболее важными являются следующие моменты:
) в противоположность контролируемому
эксперименту факторный анализ опирается в основном на наблюдения над
естественным варьированием переменных;
2) при использовании факторного анализа
совокупность переменных, изучаемых с точки зрения связей между ними, не
выбирается произвольно: сам метод позволит выявить основные факторы,
оказывающие существенное влияние в данной области;
) факторный анализ не требует
предварительных гипотез, наоборот, он сам может служить методом выдвижения
гипотез, а так же выступать критерием гипотез, опирающихся на данные,
полученные другими методами;
) факторный анализ не требует априорных
предположении относительно того, какие переменные независимы, а какие зависимы,
метод не преувеличивает причинно-следственные связи и решает вопрос об их мере
в процессе дальнейших исследований. [5,
стр.154]
Задача факторного анализа - представить
наблюдаемые параметры в виде линейных комбинаций факторов и, может быть,
некоторых дополнительных "несущественных" величин - помех.
Произведем вычисления факторного анализа и
проанализируем результаты. Выделяем область для анализа. VSTAT
→
Факторный анализ (Рис.7)
Рис.7 Факторный анализ VSTAT
Таблица 6.1
|
Оценки
собственных значений
|
|
|
Фактор
|
Собств.
значение
|
Накопленное
отношение
|
|
1
|
5,57
|
0,80
|
|
2
|
0,77
|
0,91
|
|
3
|
0,51
|
0,98
|
|
4
|
0,08
|
0,99
|
|
5
|
0,04
|
1,00
|
|
6
|
0,02
|
1,00
|
|
7
|
0,01
|
1,00
|
|
Отобрано
факторов 1, количество итераций = 1, уровень отбора = +1.000
|
Из таблицы 6.1 видно, что только один фактор
имеет собственное значение больше 1,00 (критерий Кайзера), это означает, что
следует рассматривать только один фактор (одну главную компоненту).
Таблица 6.2
|
Матрица
повернутых факторных нагрузок
|
|
Переменная
|
1
|
|
Y
|
0,98
|
|
X1
|
0,59
|
|
X2
|
0,99
|
|
X4
|
0,86
|
|
X7
|
0,97
|
|
X13
|
0,89
|
|
X15
|
0,91
|
Анализируя матрицу повернутых нагрузок (Таблица
6.2) делаем вывод, что почти все наблюдения связаны с некоторой скрытой
компонентой (меньше всех X1).
На языке модели факторного анализа доля
дисперсии отдельной переменной, принадлежащая общим факторам (и разделяемая с
другими переменными) называется общностью.
Таблица 6.3
|
Оценки
общностей
|
|
Переменная
|
Общность
|
|
Y
|
0,96
|
|
X1
|
0,35
|
|
X2
|
0,98
|
|
X4
|
0,74
|
|
X7
|
0,94
|
|
X13
|
0,79
|
|
X15
|
0,82
|
Как видно из таблицы 6.3 почти все факторы,
кроме X1, обладают достаточно высокой долей общности.) Интерпретировать
полученные факторы
Экономическая интерпретация:
Таблица 6.4
|
Фактор
|
Расшифровка
|
|
Y
|
Оборот
розничной торговли, млн. руб.
|
|
X1
|
Площадь
территории, тыс. км2
|
|
X2
|
Численность
населения на 1 января 2011 г, тыс. человек
|
|
X4
|
Среднедушевые
денежные доходы (в месяц), руб.
|
|
X7
|
Валовой
региональный продукт в 2009 г,, млн, руб.
|
|
X13
|
Продукция
растеневодства, млн, руб,
|
|
X15
|
Ввод
в действие общей площади жилых домов, тыс, м2,
|
Анализируя вышесказанное и вспоминая расшифровку
исходных данных можно сделать вывод, что обнаруженный фактор X1
является одним из экономических показателей Приволжского федерального округа.
Возможно это прибыльность или рентабельность.
) Упорядочить субъекты РФ в порядке убывания
рейтинга по значениям факторов
Из предыдущих вычислений факторного анализа с
помощью пакета VSTAT
возьмем значения факторов:
Таблица 6.5
|
Значения
факторов
|
|
Наблюдение
|
1
|
|
1
|
1,84
|
|
2
|
-1,26
|
|
3
|
-1,17
|
|
4
|
1,75
|
|
5
|
-0,65
|
|
6
|
-0,89
|
|
7
|
0,69
|
|
8
|
-0,62
|
|
9
|
0,79
|
|
10
|
-0,01
|
|
11
|
-0,68
|
|
12
|
0,86
|
|
13
|
0,18
|
|
14
|
-0,82
|
Упорядочим субъекты РФ в порядке убывания
рейтинга по значениям факторов используя функцию «Сортировка» в программе Excel:
Таблица 6.5
|
Значения
факторов
|
1
|
|
2
|
-1,26
|
|
3
|
-1,17
|
|
6
|
-0,89
|
|
14
|
-0,82
|
|
11
|
-0,68
|
|
5
|
-0,65
|
|
8
|
-0,62
|
|
10
|
-0,01
|
|
13
|
0,18
|
|
7
|
0,69
|
|
9
|
0,79
|
|
12
|
0,86
|
|
4
|
1,75
|
|
1
|
1,84
|
В порядке убывания рейтинга по значениям
фактора: от наиболее эффективного экономического показателя к менее
эффективному, субъекты расположились следующим образом:
) Республика Марий Эл,
2) Республика Мордовия,
) Чувашская Республика,
) Ульяновская область,
) Пензенская область,
) Удмуртская Республика,
) Кировская область,
) Оренбургская область,
) Саратовская область,
10) Пермский край,
11) Нижегородская область,
) Самарская область,
) Республика Татарстан,
) Республика Башкортостан.
.
КЛАСТЕРНЫЙ АНАЛИЗ
Задание: выполнить кластерный анализ методом к -
средних для к = 2, 3. используя 2 показателя из исходных данных.
Главное назначение кластерного анализа -
разбиение множества исследуемых объектов, характеризуемых совокупностью
признаков (параметров x1,
x2,…, xk),
на однородные в соответствующем понимании группы (кластеры). Это означает, что
решается задача классификации данных и выявления соответствующей структуры в
ней. Иными словами, предполагается выделение компактных, удаленных друг от
друга групп объектов или отыскание «естественного» разбиения совокупности на
области скопления.
Выполним кластерный анализ субъектов
Приволжского федерального округа по двум признакам: Оборот розничной торговли,
млн. руб. (Y), Площадь
территории, тыс, км2 (X1)
методом k-средних для k=2,
где k - число кластеров.
Метод k
- средних (конечно k
£ n)
Идея алгоритма этого метода:
Для начала кластеризации выбираются k
случайно выбранных объектов, которые будут служить центрами кластеров. Номера
кластеров совпадут с номерами этих центров.
Далее, на первом шаге из оставшихся n-k
объектов извлекается объект и проверяется к какому из кластеров его
присоединить (по минимуму расстояния) и его присоединяем. "Центр"
заменяется новым, с учетом присоединенного объекта, и вес его (количество
объектов кластера) увеличивается на один.
На следующем шаге выбирается следующий объект Xi+1
и для него все повторяется. Таким образом, через n-k
шагов все объекты будут отнесены к k
кластерам.
Выделяем область для анализа. VSTAT
→
Кластерный анализ (Рис.12)
Рис.8 Выделение области для кластерного анализа.
Количество групп классификации к=2.
Результат выполнения кластерного анализа:
Таблица 7.1
|
Результат
кластеризации
|
|
|
|
|
|
Наблюдение
|
Кластер
|
Расстояние
от центра
|
Координата
X
|
Координата
Y
|
|
2
|
1,00
|
60710,68
|
-1,27
|
-0,02
|
|
3
|
1,00
|
55926,68
|
-1,22
|
0,01
|
|
5
|
1,00
|
5926,36
|
-0,79
|
-0,04
|
|
6
|
1,00
|
22096,71
|
-1,19
|
-0,38
|
|
8
|
1,00
|
8714,88
|
0,15
|
1,75
|
|
10
|
1,00
|
53345,37
|
0,42
|
1,43
|
|
11
|
1,00
|
9182,35
|
-0,76
|
-0,03
|
|
13
|
1,00
|
79647,34
|
0,23
|
0,78
|
|
14
|
1,00
|
653,05
|
-0,87
|
-0,10
|
|
4
|
2,00
|
43003,21
|
0,81
|
-1,65
|
|
7
|
2,00
|
95241,82
|
1,47
|
1,22
|
|
12
|
2,00
|
12143,29
|
0,51
|
-1,76
|
|
1
|
2,00
|
100738,21
|
1,97
|
-0,39
|
|
9
|
2,00
|
60642,80
|
0,54
|
-0,81
|
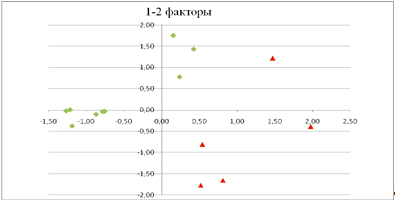
Рис.9 График координат кластеризации k=2
Можно заметить, что выделилось два класса: в
один вошли объекты под номерами 2, 3, 5, 6, 8, 10, 11, 13, 14 (Республика Марий
Эл, Республика Мордовия, Удмуртская Республика, Чувашская Республика, Кировская
область, Оренбургская область, Пензенская область, Саратовская область,
Ульяновская область), а в другой - 4, 7, 12, 1, 9 (Республика Татарстан,
Пермский край, Самарская область, Республика Башкортостан, Нижегородская
область). Отделимость классов оценивается сравнением внутрикластерных и
межкластерных расстояний на качественном уровне.
Также можно отметить, что в первом кластере
минимальное расстояние от центра у номера 14 (Ульяновская область),
максимальное - у номера 13 (Саратовская область). Во втором кластере
минимальное расстояние от центра у номера 12 (Самарская область), максимальное
- 1 (Республика Башкортостан).
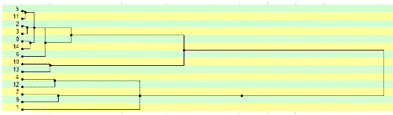
Рис.10 Дендрограмма
Дендрограмма визуально показывает процесс
объединения наблюдений в кластеры. Они отображаются на рисунке горизонтальными
линиями.
Таблица 7.1
|
Центры
кластеров
|
|
|
|
Кластер
|
Y
|
X1
|
|
1
|
104336,67
|
59,53
|
|
2
|
411390,80
|
100,22
|
В первый кластер объединились факторы с
наименьшим оборотом розничной торговли и наименьшей площадью территории.
Соответственно, во второй кластер объединились факторы с наибольшим оборотом
розничной торговли и наибольшей площадью территории.
Изменим количество групп классификации к=3
(Рис.11)
Результат выполнения кластерного анализа:
Таблица 7.2
|
Результат
кластеризации
|
|
|
|
|
|
Наблюдение
|
Кластер
|
Расстояние
от центра
|
Координата
X
|
Координата
Y
|
|
2
|
1,00
|
60710,68
|
-1,27
|
-0,02
|
|
3
|
1,00
|
55926,68
|
-1,22
|
0,01
|
|
5
|
1,00
|
5926,36
|
-0,79
|
-0,04
|
|
6
|
1,00
|
22096,71
|
-1,19
|
-0,38
|
|
8
|
1,00
|
8714,88
|
0,15
|
1,75
|
|
10
|
1,00
|
53345,37
|
0,42
|
1,43
|
|
11
|
1,00
|
9182,35
|
-0,76
|
-0,03
|
|
13
|
1,00
|
79647,34
|
0,23
|
0,78
|
|
14
|
1,00
|
653,05
|
-0,87
|
-0,10
|
|
7
|
2,00
|
17299,55
|
1,47
|
1,22
|
|
9
|
2,00
|
17299,55
|
0,54
|
-0,81
|
|
12
|
3,00
|
39818,35
|
0,51
|
-1,76
|
|
1
|
3,00
|
48776,70
|
1,97
|
-0,39
|
|
4
|
3,00
|
8958,36
|
0,81
|
-1,65
|
Рис.11 Количество групп классификации
Выделились три класса: в первый кластер вошли
объекты под номерами 2, 3, 5, 6, 8, 10, 11, 13, 14 (Республика Марий Эл,
Республика Мордовия, Удмуртская Республика, Чувашская Республика, Кировская
область, Оренбургская область, Пензенская область, Саратовская область,
Ульяновская область), во второй - 7, 9 (Пермский край, Нижегородская область),
в третий - 12, 1, 4 (Самарская область, Республика Башкортостан, Республика
Башкортостан). Отделимость классов оценивается сравнением внутрикластерных и
межкластерных расстояний на качественном уровне.
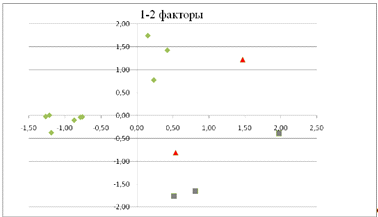
Рис.13 График координат кластеризации k=3
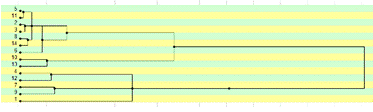
Рис.14
Дендрограмма
Таблица 7.3
|
Центры
кластеров
|
|
|
|
Кластер
|
Y
|
X1
|
|
1
|
104336,67
|
59,53
|
|
2
|
333448,50
|
118,40
|
|
3
|
463352,33
|
88,10
|
Информация о кластерных центрах:
Первый кластер - наименьший оборот розничной
торговли и наименьшая площадь территории.
Второй кластер - средний оборот розничной
торговли и наибольшая площадь территории.
Третий кластер - наибольший оборот розничной
торговли и средняя площадь территории.
СПИСОК ЛИТЕРАТУРЫ
. Экономико-математические
методы и модели. Компьютерное моделирование. Орлова И.В. -2007. -365 с.
2. Эконометрика.
Методические указания по изучению дисциплины и выполнению контрольной работы и
аудиторной работы на ПЭВМ под ред. Орловой И.В. / ВЗФЭИ. - М.: ВЗФЭИ, 2005. -
79 с.
. Эконометрика.
Лабораторный практикум: Учеб. пособие для студентов высших учебных заведений,
обучающихся по специальности и направлению «Прикладная информатика (в
экономике)» Шанченко Н.И. - 2011. - 118 с.
. Сахабетдинов
М.А. Курс лекций по эконометрике: Учеб. пособие для студентов первого и второго
образования ВЗФЭИ, обучающихся по специальностям "Финансы и кредит",
"Бухгалтерский учет, анализ и аудит" - 2008. - 126 с.
. Многомерный
статистический анализ в экономических задачах: компьютерное моделирование в
SPSS: Учеб. пособие / Под ред. И.В. Орловой. - М.: Вузовский учебник, 2011. -310
с.
Базы данных, информационно-справочные и
поисковые системы:
- Интернет-репозиторий
образовательных ресурсов ВЗФЭИ. - URL: http://repository.vzfei.ru. Доступ по
логину и паролю.
Поисковые системы Yandex, Google.
Доступ свободный.
Электронные ресурсы:
VSTAT - Программа статистического
анализа данных.