Модели множественной линейной регрессии
КУРСОВАЯ РАБОТА
Модели
множественной линейной регрессии
Введение
Множественная регрессия используется
в решении проблем спроса, доходности акций, при изучении функции издержек
производства, в макроэкономических расчетах и целом ряде других вопросов
эконометрики. Множественная регрессия является одним из наиболее
распространенных методов в эконометрике. Основной целью множественной регрессии
является построение модели с большим числом факторов, при этом определив
влияние каждого из них в отдельности, а также совокупное их воздействие на
моделируемый показатель.
Цель курсовой работы:
Исследовать зависимость заработной платы (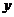 , тыс. руб.) от возраста
(
, тыс. руб.) от возраста
(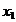 ,
лет) и стажа по данной специальности (
,
лет) и стажа по данной специальности (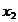 , лет), используя данные
наблюдений, приведенные в таблице 2.1. Построить регрессионную модель
, лет), используя данные
наблюдений, приведенные в таблице 2.1. Построить регрессионную модель 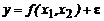 .
Рассчитать значение заработной платы для работника в возрасте 35 лет со стажем
работы по данной специальности 10 лет.
.
Рассчитать значение заработной платы для работника в возрасте 35 лет со стажем
работы по данной специальности 10 лет.
Задачи:
1. Определить наличие
зависимости показателя Заработная плата от Возраста и Стажа с использованием
корреляционной матрицы.
2. Найти оценки неизвестных
параметров модели.
. Оценить общее качество модели по
коэффициенту (индексу) детерминации и нормированному индексу детерминации.
. Проанализировать нормальность
распределения остатков по: гистограмме остатков, числовым характеристикам
асимметрии и эксцессу, критерию Пирсона.
. Проверить значимость коэффициентов
регрессии.
. Проверить статистических свойства
остатков (качества оценок коэффициентов регрессии):
. Проверить мультиколлинеарность
факторов.
. Оценить влияние каждого
объясняющего фактора на результирующий фактор ЗП (эластичность)
. Определим степень влияния факторов
на результирующий фактор ЗП при устранении влияния других факторов.
Расчеты для данной курсовой работы
производились c помощью приложения MS Excel.
1. Модели множественной
линейной регрессии
Построение уравнения множественной
регрессии начинается с решения вопроса о спецификации модели, который в свою
очередь включает 2 круга вопросов: отбор факторов и выбор уравнения регрессии.
Отбор факторов обычно осуществляется в два этапа:
) теоретический анализ взаимосвязи
результата и круга факторов, которые оказывают на него существенное влияние;
) количественная оценка взаимосвязи
факторов с результатом. При линейной форме связи между признаками данный этап
сводится к анализу корреляционной матрицы (матрицы парных линейных
коэффициентов корреляции):
ry, y ry, x1 ryx2…. ry,
xm1, y rx1, x2 rx2x 2…. rx 2, xm
……, y rxm, x1 rxm, x2…. rxm, xm
где ry, xj - линейный парный
коэффициент корреляции, измеряющий тесноту связи между признаками y и хj j=1;
m, m - число факторов., xk - линейный парный коэффициент корреляции, измеряющий
тесноту связи между признаками хj и хk j, k =1; m.
Факторы, включаемые во множественную
регрессию, должны отвечать следующим требованиям:
. Они должны быть количественно
измеримы. Если необходимо включить в модель качественный фактор, не имеющий
количественного измерения, то ему нужно придать количественную определенность
(например, в модели урожайности качество почвы задается в виде баллов).
. Каждый фактор должен быть
достаточно тесно связан с результатом (т.е. коэффициент парной линейной
корреляции между фактором и результатом должен быть существенным).
. Факторы не должны быть сильно
коррелированы друг с другом, тем более находиться в строгой функциональной
связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности
факторов является мультиколлинеарность - тесная линейная связь между факторами.
Мультиколлинеарность может привести
к нежелательным последствиям:
) оценки параметров становятся
ненадежными. Они обнаруживают большие стандартные ошибки. С изменением объема
наблюдений оценки меняются (не только по величине, но и по знаку), что делает
модель непригодной для анализа и прогнозирования.
) затрудняется интерпретация
параметров множественной регрессии как характеристик действия факторов в
«чистом» виде, ибо факторы коррелированны; параметры линейной регрессии теряют
экономический смысл;
) становится невозможным определить
изолированное влияние факторов на результативный показатель.
Мультиколлинеарность имеет место,
если определитель матрицы межфакторной корреляции близок к нулю:
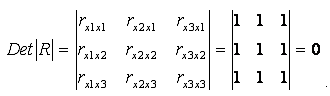
Если же определитель матрицы
межфакторной корреляции близок к единице, то мультколлинеарности нет.
Существуют различные подходы преодоления сильной межфакторной корреляции.
Простейший из них - исключение из модели фактора (или факторов), в наибольшей
степени ответственных за мультиколлинеарность при условии, что качество модели
при этом пострадает несущественно (а именно, теоретический коэффициент
детерминации - R2y (x1…xm) снизится несущественно).
Определение факторов, ответственных
за мультиколлинеарность, может быть основано на анализе матрицы межфакторной
корреляции. При этом определяют пару признаков-факторов, которые сильнее всего
связаны между собой (коэффициент линейной парной корреляции максимален по
модулю). Из этой пары в наибольшей степени ответственным за
мультиколлинеарность будет тот признак, который теснее связан с другими
факторами модели (имеет более высокие по модулю значения коэффициентов парной
линейной корреляции).
Еще один способ определения факторов,
ответственных за мультиколлинеарность основан на вычислении коэффициентов
множественной детерминации (R2xj (x1,…, xj-1, xj+1,…, xm)), показывающего
зависимость фактора xj от других факторов модели x1,…, xj-1, x j+1,…, xm. Чем
ближе значение коэффициента множественной детерминации к единице, тем больше
ответственность за мультиколлинеарность фактора, выступающего в роли зависимой
переменной. Сравнивая между собой коэффициенты множественной детерминации для
различных факторов можно проранжировать переменные по степени ответственности
за мультиколлинеарность.
При выборе формы уравнения
множественной регрессии предпочтение отдается линейной функции:
yi =a+b1·x1i+ b2·x2i+ …
+ bm·xmi+ui
в виду четкой интерпретации
параметров.
Данное уравнение регрессии называют
уравнением регрессии в естественном (натуральном) масштабе. Коэффициент
регрессии bj при факторе хj называют условно-чистым коэффициентом регрессии. Он
измеряет среднее по совокупности отклонение признака-результата от его средней
величины при отклонении признака-фактора хj на единицу, при условии, что все
прочие факторы модели не изменяются (зафиксированы на своих средних уровнях).
Если не делать предположения о
значениях прочих факторов, входящих в модель, то это означало бы, что каждый из
них при изменении х j также изменялся бы (так как факторы связаны между собой),
и своими изменениями оказывали бы влияние на признак-результат.
Расчет параметров
уравнения линейной множественной регрессии
Параметры уравнения множественной
регрессии можно оценить методом наименьших квадратов, составив и решив систему
нормальных линейных уравнений.
Кроме того, для линейной
множественной регрессии существует другой способ реализации МНК при оценке
параметров - через b - коэффициенты (через параметры уравнения регрессии в стандартных
масштабах).
Модель регрессии в стандартном
масштабе предполагает, что все значения исследуемых признаков переводятся в
стандарты (стандартизованные значения) по формулам:
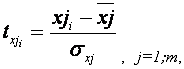
где х ji - значение переменной хj i
в i-ом наблюдении.
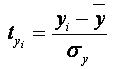
Таким образом, начало отсчета каждой
стандартизованной переменной совмещается с ее средним значением, а в качестве
единицы изменения принимается ее среднее квадратическое отклонение s. Если
связь между переменными в естественном масштабе линейная, то изменение начала
отсчета и единицы измерения этого свойства не нарушат, так что и
стандартизованные переменные будут связаны линейным соотношением:
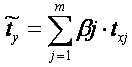
Для оценки b-коэффциентов применим
МНК. При этом система нормальных уравнений будет иметь вид:
1 y=b 1+rx1 x2∙ b2+ … + rx 1
xm∙b m2 y= rx 2 x1∙ b1+b 2+ … + rx2 xm∙b m
…= rxmx 1∙b 1+rxmx2∙ b
2+ … + bm
Найденные из данной системы
b-коэффициенты позволяют определить значения коэффициентов в регрессии в
естественном масштабе по формулам:
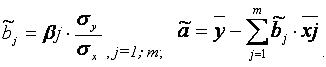
Показатели тесноты связи факторов с
результатом.
Если факторные признаки различны по
своей сущности и (или) имеют различные единицы измерения, то коэффициенты
регрессии bj при разных факторах являются несопоставимыми. Поэтому уравнение
регрессии дополняют соизмеримыми показателями тесноты связи фактора с
результатом, позволяющими ранжировать факторы по силе влияния на результат. К
таким показателям тесноты связи относят: частные коэффициенты эластичности, b -
коэффициенты, частные коэффициенты корреляции.
Частные коэффициенты эластичности Э
j рассчитываются по формуле:
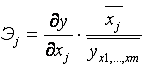
Частный коэффициент эластичности
показывают, на сколько процентов в среднем изменяется признак-результат y с
изменением признака-фактора х j на один процент от своего среднего уровня при
фиксированном положении других факторов модели. В случае линейной зависимости Э
j рассчитываются по формуле:
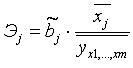
Где 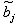 - оценка коэффициента регрессии при j-ом факторе.
- оценка коэффициента регрессии при j-ом факторе.
Стандартизированные частные
коэффициенты регрессии - b - коэффициенты (b j) показывают, на какую часть
своего среднего квадратического отклонения s у изменится признак-результат y с
изменением соответствующего фактора х j на величину своего среднего
квадратического отклонения (s х j) при неизменном влиянии прочих факторов
(входящих в уравнение).
По коэффициентам эластичности и b -
коэффициентам могут быть сделаны противоположные выводы. Причины этого: а)
вариация одного фактора очень велика; б) разнонаправленное воздействие факторов
на результат.
Коэффициент bj может также
интерпретироваться как показатель прямого (непосредственного) влияния j-ого
фактора (xj) на результат (y). Во множественной регрессии j-ый фактор оказывает
не только прямое, но и косвенное (опосредованное) влияние на результат (т.е.
влияние через другие факторы модели). Косвенное влияние измеряется величиной:
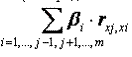
где m - число факторов в модели.
Полное влияние j-ого фактора на результат равное сумме прямого и косвенного
влияний измеряет коэффициент линейной парной корреляции данного фактора и
результата - rxj, y.
Коэффициент частной корреляции
измеряет «чистое» влияние фактора на результат при устранении воздействия
прочих факторов модели.
Для расчета частных коэффициентов
корреляции могут быть использованы парные коэффициенты корреляции.
Для случая зависимости y от двух
факторов можно вычислить 2 коэффициента частной корреляции:
(фактор х2 фиксирован).
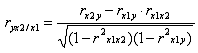
(фактор х1 фиксирован).
Это коэффициенты частной корреляции
1-ого порядка (порядок определяется числом факторов, влияние которых
устраняется).
Частные коэффициенты корреляции,
рассчитанные по таким формулам изменяются от -1 до +1. Они используются не
только для ранжирования факторов модели по степени влияния на результат, но и
также для отсева факторов. При малых значениях ryxm / x1, x 2… xm -1 нет смысла
вводить в уравнение m-ый фактор, т.к. его чистое влияние на результат
несущественно.
Коэффициенты множественной
детерминации и корреляции характеризуют совместное влияние всех факторов на
результат.
По аналогии с парной регрессией
можно определить долю вариации результата, объясненной вариацией включенных в
модель факторов (d 2), в его общей вариации (s 2 y). Ее количественная
характеристика - теоретический множественный коэффициент детерминации (R 2 y (x
1,…, xm)). Для линейного уравнения регрессии данный показатель может быть
рассчитан через b-коэффициенты, как:
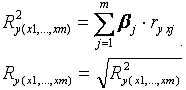 -
коэффициент множественной корреляции.
-
коэффициент множественной корреляции.
Он принимает значения от 0 до 1 (в
отличии от парного коэффициента корреляции, который может принимать
отрицательные значения). Поэтому R не может быть использован для интерпретации
направления связи. Чем плотнее фактические значения yi располагаются
относительно линии регрессии, тем меньше остаточная дисперсия и, следовательно,
больше величина Ry (x 1,…, xm). Таким образом, при значении R близком к 1,
уравнение регрессии лучше описывает фактические данные и факторы сильнее влияют
на результат. При значении R близком к 0 уравнение регрессии плохо описывает
фактические данные и факторы оказывают слабое воздействие на результат.
Оценка значимости полученного
уравнения множественной регрессии.
Оценка значимости уравнения
множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю
коэффициент детерминации рассчитанного по данным генеральной совокупности: 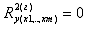 или
или 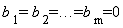 гипотеза
о незначимости уравнения регрессии, рассчитанного по данным генеральной
совокупности).
гипотеза
о незначимости уравнения регрессии, рассчитанного по данным генеральной
совокупности).
Для ее проверки используют
F-критерий Фишера.
При этом вычисляют фактическое
(наблюдаемое) значение F-критерия, через коэффициент детерминации R2y (x1,…,
xm), рассчитанный по данным конкретного наблюдения:
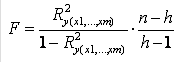
Где n-число наблюдений; h - число
оцениваемых параметров (в случае двухфакторной линейной регрессии h=3).
По таблицам распределения
Фишера-Снедоккора находят критическое значение F-критерия (Fкр). Для этого
задаются уровнем значимости a (обычно его берут равным 0,05) и двумя числами
степеней свободы k1=h-1 и k2=n-h.
Сравнивают фактическое значение
F-критерия (Fнабл) с табличным Fкр (a; k1; k2). Если Fнабл<Fкр (a; k1; k2),
то гипотезу о незначимости уравнения регрессии не отвергают. Если Fнабл>Fкр
(a; k1; k2), то выдвинутую гипотезу отвергают и принимают альтернативную
гипотезу о статистической значимости уравнения регрессии.
2. Модели множественной
линейной регрессии
Постановка задачи
Исследовать зависимость
заработной платы (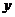 ,
тыс. руб.) от возраста (
,
тыс. руб.) от возраста (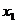 ,
лет) и стажа по данной специальности (
,
лет) и стажа по данной специальности (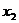 , лет), используя данные
наблюдений, приведенные в таблице 2.1. Построить регрессионную модель
, лет), используя данные
наблюдений, приведенные в таблице 2.1. Построить регрессионную модель 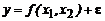 .
Рассчитать значение заработной платы для работника в возрасте 35 лет со стажем
работы по данной специальности 10 лет.
.
Рассчитать значение заработной платы для работника в возрасте 35 лет со стажем
работы по данной специальности 10 лет.
Таблица 2.1 - Данные
наблюдений
|
ЗП
|
возраст
|
стаж
|
|
984,48
|
28
|
10
|
|
974,45
|
26
|
8
|
|
1029,62
|
30
|
14
|
|
1048,86
|
35
|
15
|
|
1061,44
|
41
|
16
|
|
1073,42
|
45
|
17
|
|
928,07
|
27
|
3
|
|
1031,84
|
35
|
13
|
|
998,81
|
30
|
10
|
|
945,92
|
23
|
5
|
|
964,64
|
29
|
7
|
|
1011,18
|
33
|
11
|
|
1098,07
|
40
|
20
|
|
1133,82
|
41
|
24
|
|
967,97
|
41
|
6
|
|
907,61
|
2
|
|
1011,76
|
32
|
12
|
|
1028,62
|
37
|
13
|
|
966,15
|
31
|
7
|
|
983,7
|
30
|
9
|
После ввода исходных данных в Excel, рассчитываются
корреляционная матрица и значимость коэффициентов корреляции.
|
Корреляционная матрица
|
|
|
|
|
|
ЗП
|
возраст
|
стаж
|
|
ЗП
|
1
|
|
|
|
возраст
|
0,794825
|
1
|
0,747928
|
|
стаж
|
0,995338
|
0,747928
|
1
|
|
Значимость коэффициентов корреляции
|
|
|
tЗП, В набл.
|
5,556924
|
|
|
|
tЗП, С набл.
|
43,7846
|
|
|
|
tкр
|
2,100922
|
|
|
После спецификации модели
производится параметризация.
При помощи команды Сервис →
Анализ данных → Регрессия создается еще один лист Excel c соответствующим
именем.
Далее производится верификация
модели, в частности общее качество уравнения. Для этого вычисляется критическое
значение.
Далее находим нормальность
распределения остатков с помощью пакета анализа данных.
|
ВЫВОД ОСТАТКА
|
|
|
|
|
|
|
Наблюдение
|
Предсказанное ЗП
|
Остатки
|
|
1
|
992,3248
|
-7,8448
|
|
2
|
971,7141
|
2,73588
|
|
3
|
1031,487
|
-1,86704
|
|
4
|
1045,911
|
2,949402
|
|
5
|
1061,364
|
0,076288
|
|
6
|
1074,758
|
-1,33771
|
|
7
|
926,3648
|
1,705242
|
|
8
|
1027,359
|
4,480968
|
994,3839
|
4,426093
|
|
10
|
940,7981
|
5,121895
|
|
11
|
965,527
|
-0,887
|
|
12
|
1006,748
|
4,431645
|
|
13
|
1097,437
|
0,63271
|
|
14
|
1135,57
|
-1,74998
|
|
15
|
968,6059
|
-0,63588
|
|
16
|
912,9708
|
-5,36075
|
|
17
|
1014,995
|
-3,23458
|
|
18
|
1029,418
|
-0,79814
|
|
19
|
967,5861
|
-1,43611
|
|
20
|
985,1081
|
-1,40812
|
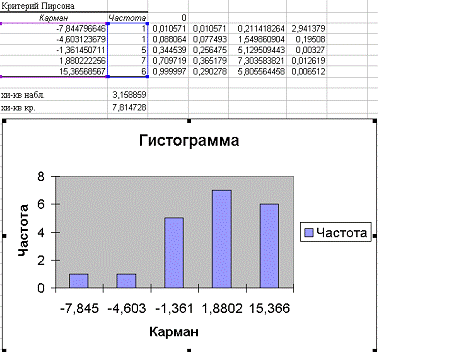
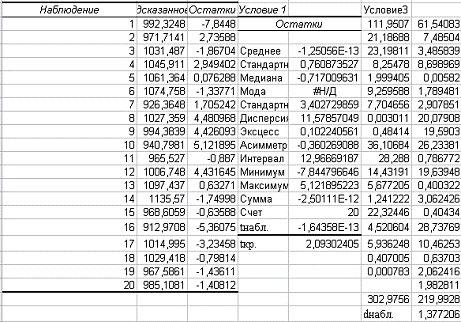
Расчет критерия Пирсона производится
с помощью пакета анализа. Также выводим график.
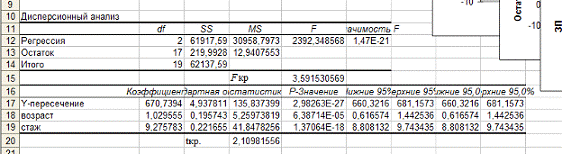
Рассмотрим значимость коэффициентов
регрессии, вычислим критическое значение.
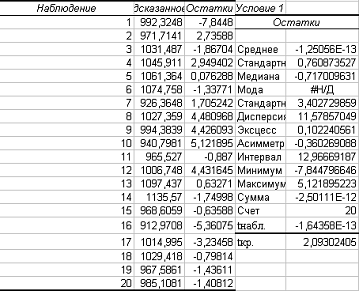
Проведем центрирование остатков на
том же листе «Регрессия».
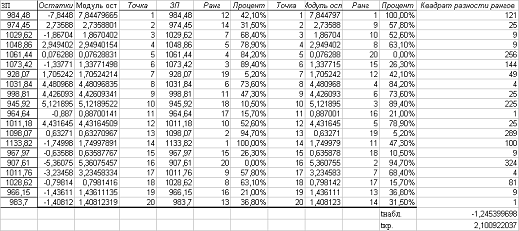
Гомоскедастичность
(гетероскедастичность) остатков рассчитывается на отедльном листе «Усорвие2» с
помощью формул массива и пакета анализа.
Автокорреляция остатков производится
на листе «Регрессия», Условие3.
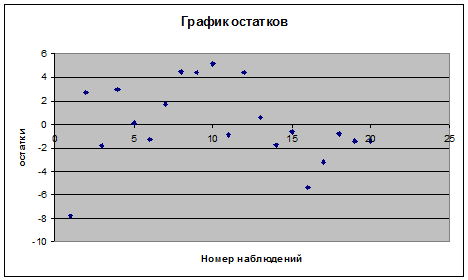
Если критерии Дарбина-Уотсона не
дает ответа о наличии автокорреляции, то можно воспользоваться визуальным
способом анализа графика зависимости остатков от номера наблюдения,
построенного с помощью диаграммы.
Для проведения анализа свойств
модели рассмотрим мультиколлинеарность факторов: выявление зависимости
объясняющих факторов.
Для проверки гипотезы об
отсутствии мультиколлинеарности используется статистика хи-квадрат с 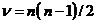 степенями
свободы, наблюдаемое значение которой определяется по формуле
степенями
свободы, наблюдаемое значение которой определяется по формуле 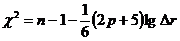 ,
где
,
где 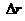 -
определитель матрицы парных коэффициентов корреляции между факторами, n -
количество наблюдений, p - число независимых переменных. Расссеты производятся
на листе «Исходные данные».
-
определитель матрицы парных коэффициентов корреляции между факторами, n -
количество наблюдений, p - число независимых переменных. Расссеты производятся
на листе «Исходные данные».
|
Мультиколлинеарность
|
|
|
Определитель
|
0,440604
|
|
хи-кв набл.
|
19,53393
|
|
хи-кв кр.
|
223,1602
|
Рассчитываем показатели
эластичности. Для этого капируем коэффициенты стажа и возраста из листа
«Регрессия».
|
Эластичность
|
|
|
|
ЗП_ср
|
Возраст_ср
|
Стаж_ср
|
|
1007,5215
|
32,85
|
11,1
|
|
Коэф. Возраст.
|
1,029554971
|
|
|
Эластичность по фактору возраст.
|
0,033568396
|
|
|
Коэф. Стаж.
|
9,275783402
|
0,102192554
|
|
Частные коэффициенты корреляции
рассчитываются на том же листе «Исходные данные»
|
Частные коэф. корр.
|
|
|
rЗП, В-С
|
0,787012
|
|
rЗП, С-В
|
0,995181
|
Для прогнозирования рассчитаем на
листе «Регрессия» точечный прогноз для расчеты точечной оценки заработной платы
при возрасте работника 35 лет и стаже работы 10 лет из условия задачи»

На новом листе
«Интервальный_прогноз» произведем вычисления интервальной оценки прогноза,
используя формулы ТАНСП(), МУМНОЖ(), МОБР().

Эконометрический анализ
построения модели множественной регрессии
Постановочный этап. Из
экономической теории известно, что заработная плата зависит от многих факторов,
например, от возраста, квалификации, стажа по данной специальности, общего
стажа работы, производительности труда и т.д. Выделим два фактора - возраст и
стаж по данной специальности, которые являются объясняющими факторами для
результативного (объясняемого) фактора - заработная плата (ЗП). Поэтому
возникает задача количественного описания зависимости указанных экономических
показателей уравнением множественной регрессии 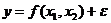 на основе 20 наблюдений
экономических показателей.
на основе 20 наблюдений
экономических показателей.
Определим наличие
зависимости показателя Заработная плата от Возраста и Стажа, а также форму этой
зависимости.
На листе «Исходные данные» получена
таблица корреляционной матрицы.
|
Корреляционная матрица
|
|
|
|
|
|
ЗП
|
возраст
|
стаж
|
|
ЗП
|
1
|
|
|
|
возраст
|
0,794825
|
1
|
0,747928
|
|
стаж
|
0,995338
|
0,747928
|
1
|
Коэффициент корреляции ЗП и возраст
равен 0,795 > 0, поэтому зависимость между ними прямая и высокая.
Коэффициент корреляции ЗП и стаж равен 0,995 > 0, поэтому зависимость между
ними прямая и весьма высокая.
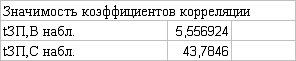
Проверим на значимость коэффициенты
парной корреляции. На листе «Исходные данные» вычислены наблюдаемые и
критическое значения t-статистики.
|
Корреляционная матрица
|
|
|
|
|
|
ЗП
|
возраст
|
стаж
|
|
ЗП
|
1
|
|
|
|
возраст
|
0,794825
|
1
|
0,747928
|
|
стаж
|
0,995338
|
0,747928
|
1
|
|
Значимость коэффициентов корреляции
|
|
|
tЗП, В набл.
|
5,556924
|
|
|
|
tЗП, С набл.
|
43,7846
|
|
|
|
tкр
|
2,100922
|
|
|
Так как |tЗП, В набл| = 5,56 > tкр = 2,1, то коэффициент корреляции значим
(значительно отличается от нуля). Поэтому подтверждается наличие линейной
зависимости между факторами ЗП и возраст.
Так как |tЗП, С набл| = 43,78 >
tкр = 2,1, то коэффициент корреляции значим. Поэтому также подтверждается
наличие линейной зависимости между факторами ЗП и стаж.
Исходя из проведенного
анализа можно выдвинуть предположение о том, что зависимость заработной платы от
возраста ()
и стажа ()
по данной специальности описывается линейной регрессионной моделью 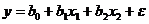 ,
где
,
где 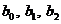 -
неизвестные параметры модели,
-
неизвестные параметры модели, 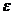 - случайный член,
который включает в себя суммарное влияние всех неучтенных в модели факторов,
ошибки измерений.
- случайный член,
который включает в себя суммарное влияние всех неучтенных в модели факторов,
ошибки измерений.
Найдем оценки
неизвестных параметров модели.
В результате проведения регрессионного
анализа на листе «Регрессия» получены точечные и интервальные оценки
неизвестных параметров модели.

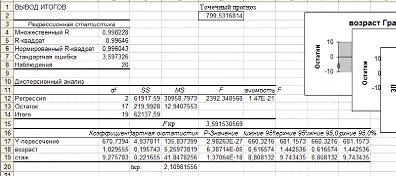
Точечная оценка
параметра 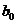 (Y-пересечение)
равна 870,74, ее интервальная оценка равна (860,32; 881,16).
(Y-пересечение)
равна 870,74, ее интервальная оценка равна (860,32; 881,16).
Точечная оценка
параметра 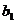 при
переменной возраст
равна 1,03, ее интервальная оценка равна (0,62; 1,44).
при
переменной возраст
равна 1,03, ее интервальная оценка равна (0,62; 1,44).
Точечная оценка
параметра 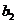 при
переменной равна
9,28, ее интервальная оценка равна (8,81; 9,74).
при
переменной равна
9,28, ее интервальная оценка равна (8,81; 9,74).
Таким образом, уравнение
регрессии имеет вид:
= 870,74 + 1,03 +
9,26 .
Так как любое значение
из доверительного интервала может служить оценкой параметра, то уравнение
регрессии также может иметь вид: y = 873 + 0,9 + 9.
Перейдем к верификации модели,
общему качеству уравнения. Оценим общее качество модели по коэффициенту
(индексу) детерминации и нормированному индексу детерминации.
Проанализируем показатели в таблице
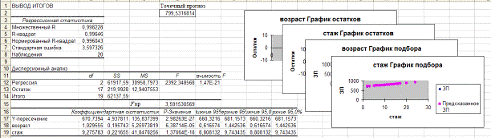
Регрессионная статистика листа «Регрессия»

Коэффициент множественной
детерминации R-квадрат равен 0,9964. Так как он близок к 1, то уравнение имеет
высокое качество. Этот факт подтверждает также нормированный индекс
множественной детерминации, равный 0,996.

Так как наблюдаемое значение Fнабл
=2392,35 > Fкр = 3,59, то R-квадрат значим, что еще раз подтверждает высокое
качество построенного уравнения линейной множественной регрессии.
Нормальность распределения остатков.
Проанализируем нормальность распределения остатков по: 1) гистограмме остатков,
2) числовым характеристикам асимметрии и эксцессу, 3) критерию Пирсона.
) На построенной гистограмме остатков,
соединим середины верхних сторон прямоугольников гистограммы и получим полигон
распределения, по которому визуально можно предположить закон распределения.
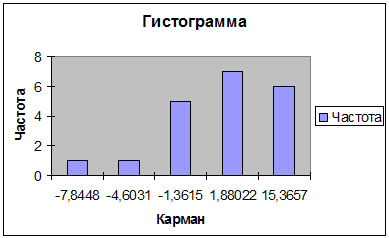
Так как ломаная линия на
рисунке 2.21 близка к кривой нормального распределения, заданной уравнением 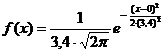 ,
то по визуальному анализу гистограммы можно предположить нормальность
распределения остатков.
,
то по визуальному анализу гистограммы можно предположить нормальность
распределения остатков.
2) Асимметричность равна -0,36,
эксцесс равен 0,1, то есть характеристики плотности распределения
асимметричность и эксцесс незначительно отличаются от нуля, поэтому можно
считать распределение нормальным.
) Подтвердим нормальность
распределения с помощью критерия Пирсона.
На листе «Регрессия» найдены
наблюдаемое и критическое значения статистики хи-квадрат
|
хи-кв набл.
|
3,158859311
|
|
хи-кв кр.
|
7,814727764
|
Наблюдаемое значение, равное 3,16,
меньше хи-квадрат критического, равного 7,81, поэтому остатки распределены по
нормальному закону.
Проверим значимость коэффициентов
регрессии.
Значимость коэффициентов
регрессии оценивается с помощью 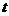 -статистики, значения
которой получены на листе «Регрессия».
-статистики, значения
которой получены на листе «Регрессия».
Наблюдаемое значение
статистики для коэффициента tнабл = 135,8 (оно
равно отношению точечной оценки коэффициента к его стандартной
ошибке). Критическое значение tкр = 2,1. Так как |tнабл| = 135,8 > tкр =
2,1, то коэффициент значим.
Аналогично, для
коэффициента имеем
tнабл = 5,26, tкр = 2,1, Так как |tнабл| =5,26 > tкр = 2,1, поэтому
коэффициент значим.
Для коэффициента имеем
|tнабл| =41,85 > tкр = 2,1, поэтому коэффициент значим.
Значимость коэффициентов
регрессии подтверждает выдвинутое на этапе спецификации предположение о
линейной форме зависимости факторов.
Проверка статистических
свойств остатков (качества оценок коэффициентов регрессии). Центрированность
остатков. Проверим выполнение условия 1 о равенстве математического ожидания
случайной переменной нулю.
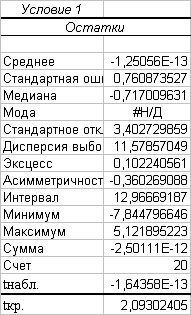
Среднее из числовых характеристик
остатков рассчитано на листе «Регрессия» в таблице Остатки
Среднее равно -1,25056. Оно
достаточно близко к нулю, поэтому можно предположить выполнимость условия 1
Гаусса-Маркова. Проверим значение среднего на значимость, то есть гипотезу о
равенстве нулю математического ожидания случайной переменной.
Сравним рассчитанные наблюдаемое и
критическое значения статистики (таблица 2.8). Так как |tнабл| = 1,64358 <
tкр = 2,09, то среднее незначимо (то есть не значительно отличается от нуля).
Следовательно, условие 1 Гаусса-Маркова выполняется.
Гомоскедастичность
(гетероскедастичность) остатков. Проверим выполнение условия 2 о постоянстве и
конечности дисперсии остатков, т.е. гомоскедастичность остатков.
На листе «Условие 2» рассчитаны
наблюдаемое и критическое значения t-статистики

Так как |tнабл| = 1,644 < tкр =
2,1, то гетероскедастичность присутствует. Следовательно, условие 2
Гаусса-Маркова выполняется, а значит, МНК-оценки параметров регрессии будут
эффективными. Поэтому модель можно использовать при точечном и интервальном
прогнозировании.
Автокорреляция остатков. Проверим
выполнение условия 3 о независимости случайного члена в любом наблюдении от его
значений во всех других наблюдениях.
На листе «Исходные
данные» найдены парные коэффициенты корреляции и определитель матрицы парных
коэффициентов корреляции объясняющих факторов Возраст и Стаж. Так как парный
коэффициент корреляции 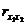 =0,75
< 0,8, то зависимость между факторами существует, но она незначительная.
Докажем это предположение проверкой гипотезы об отсутствии мультиколлинеарности
с помощью статистики хи-квадрат, наблюдаемое и критическое значения которой
найдены на листе «Регрессия»
=0,75
< 0,8, то зависимость между факторами существует, но она незначительная.
Докажем это предположение проверкой гипотезы об отсутствии мультиколлинеарности
с помощью статистики хи-квадрат, наблюдаемое и критическое значения которой
найдены на листе «Регрессия»

Так как хи-квадрат наблюдаемое равно
19,53 и меньше хи-квадрат критического, равного 223,16, то мультиколлинеарность
факторов отсутствует.
Эластичность. Оценим влияние каждого
объясняющего фактора на результирующий фактор ЗП.
На листе «Исходные данные» найдены
коэффициенты эластичности факторов
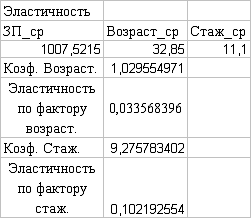
С изменением значения фактора
Возраст на 1% при фиксированном значении фактора Стаж значение фактора ЗП
увеличивается на 0,05%. Аналогично, с изменением значения фактора стаж на 1%
при фиксированном значении фактора возраст значение фактора ЗП увеличивается на
0,15%. Значит, влияние фактора Стаж больше чем фактора Возраст.
Частные коэффициенты корреляции:
целесообразность включения в модель факторов. Определим степень влияния
факторов на результирующий фактор ЗП при устранении влияния других факторов.
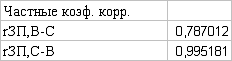
Так как 0,78 < 0,99, то из двух
факторов большее влияние оказывает фактор стаж.
Оба частных коэффициента корреляции
значимы: |tнаблЗП, В-С| = 5,4 > tкр = 2,1, |tнаблЗП, С-В| = 43,06 > tкр =
2,1.
Вывод: по результатам этапа
верификации: так как выполняются все условия верификации, то модель является
качественной. Таким образом, прогноз, выполненный по ней, является
качественным: несмещенным, состоятельным и эффективным.
Прогнозирование.
Так как выполняются все условия
верификации, то модель является качественной, следовательно, прогноз,
выполненный по ней, является качественным: несмещенным, состоятельным и
эффективным. На листе «Регрессия» рассчитан точечный прогноз заработной платы,
который равен 799,53, на листе «Интервальный_прогноз» получен интервальный
прогноз (797,38; 801,68), который означает, что с вероятностью 0,95 любое
значение из этого интервала является оценкой заработной платы.
Заключение
С помощью модели множественной
линейной регрессии можно определить наличие зависимости показателя Заработная
плата от Возраста и Стажа с использованием корреляционной матрицы, а так же
найти оценки неизвестных параметров модели. Она позволяет оценить общее
качество модели по коэффициенту (индексу) детерминации и нормированному индексу
детерминации. Используя модель линейной регрессии, можно проанализировать
нормальность распределения остатков по: гистограмме остатков, числовым
характеристикам асимметрии и эксцессу, критерию Пирсона. Можно проверить
значимость коэффициентов регрессии, статистических свойства остатков (качества
оценок коэффициентов регрессии), проверить мультиколлинеарность факторов и
оценить влияние каждого объясняющего фактора на результирующий фактор ЗП
(эластичность).
Список использованных
источников
корреляционный
матрица пирсон эксцесс
1. Костевич Л.С.
Математическое программирование: учеб-практ. пособие, Мн: БГЭУ, 2003
. Гарнаев А.Ю.
Использование MS Excel и VBA в экономике и финансах. СПб., 1999
. Курицкий Б.Я. Поиск
оптимальных решений средствами Excel 7.0. СПб.:BHV, 1997
. Сакович В.А.
Исследование операций Мн.:» ВШ», 1984
. Сборник задач и
упражнений по высшей математике. Математическое программирование. Под ред. А.В.
Кузнецова Мн.:1995
. Л.С. Костевич
Информационные технологии оптимальных решений: Учебное пособие. - Мн.: Академия
управления при Президенте Республики Беларусь, 1999.