Разработка АИС в складской логистике с применением ИТ
Введение
Информационная
технология - это совокупность методов,
производственных процессов и программно-технических средств, объединенных в
технологическую цепочку, обеспечивающую сбор, обработку, хранение,
распространение (транспортировку) и отображение информации с целью снижения
трудоемкости процессов использования информационного ресурса, а также повышения
их надежности и оперативности.
Цель курсовой работы: научиться
применять информационные технологии (ИТ) для разработки автоматизированной
системы средствами среды визуального проектирования BorlandDelphi 7.0 и системы
управления базами данных MicrosoftSQLServer.
Объектом исследования курсовой
работы являются ИТ, предметом - методы и средства, применяемые для создания
приложения автоматизированной системы.
В приложении выполняются такие
процессы как: хранение, обеспечение эффективного поиска и передачи информации
по соответствующим запросам для наиболее полного удовлетворения информационных
запросов большого числа пользователей. К основным требованиям автоматизации
информационных процессов относят: окупаемость, надежность, гибкость,
безопасность, дружественность, соответствие стандартам.
Курсовая забота состоит из 2-х
частей:
теоретическая часть;
практическая часть.
Теоретическая часть рассматривает принцип организации работы информационных технологий
в СУБД, хранимые процедуры в СУБД Microsoft SQLServer. Синтаксис применяемых
процедур.
Практическая часть включает:
1. Постановка задачи включает
формулировку задачи. Задачу для достижения поставленной цели. Решение задачи
осуществляется по средствам функции системы, пользователей системы.
2. Организационная структура
объекта управления. Концептуальная и логическая модели ИТ.
. Технологические
составляющие ИТ. Характеристики информационных потоков.
. Проектирование приложения и
интерфейс приложения в СУБД средствами интегрированной разработкой BorlandDelphi 7.0. - интерфейс
создается в соответствии с функциями БД.
В заключении приведены общие выводы по аналитической части, указаны результаты
работы программы, приведены её достоинства, недостатки и рекомендации по
улучшению, вместе с системными требованиями.
1. Теоретическая часть
1.1 Комплексы задач и
модели фазы планирования: перспективное, годовое, оперативное планирования
информационный база планирование
логический
Каждая фаза управления производством
включает ряд комплексов задач, описываемых соответствующими математическими
моделями. Решение этих задач дает необходимую для данной фазы результатную
информацию.
Фаза планирования (рис. 1). На этой
фазе управления в различных временных режимах решается несколько комплексов
функциональных задач планирования: перспективное планирование (на 3-5 лет),
годовое и оперативное (менее года).
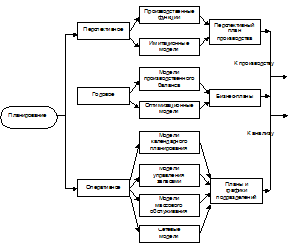
Рис. 1 Комплексы задач и модели фазы
планирования
Математические модели перспективного
планирования призваны описать состояние и стратегию развития производственного
предприятия через 3-5 лег. Естественно, такие планы являются
прогнозными, и для их создания привлекаются математические методы и модели,
позволяющие «проигрывать «поведение управляемого объекта при различных
прогнозируемых параметрах самого объекта и окружающей среды.
Вкачестве «внутренних» параметров
прогнозируются ресурсы производства, его организационная структура и т.д. На
разработку перспективного плана сильнейшее влияние оказывает прогноз состояния
внешней среды: спрос на производимую продукцию, рынки сбыта продукции,
состояние конкуренции, политическая и экономическая ситуация в регионе и
стране, изменение вкусов и обеспеченности потребителей и т.п. Точно
спрогнозировать значение внешних параметров на перспективу в 3-5 лет
невозможно, поэтому используются вероятностные методы и методы математической
статистики, позволяющие выявить, по крайней мере, предполагаемую тенденцию изменений
параметров внешней среды, влияющих на состояние предприятия. При этом широко
пользуются производственными функциями как аппаратом моделирования и
имитационными моделями.
Комплекс задач годового планирования
более конкретен, поэтому для моделирования «образа» производства предприятия
(т.е. плана) используются детерминированные модели, поскольку определить
значение производственных параметров и параметров внешней среды на ближайшую
перспективу можно с достаточной степенью точности для разработки годового плана
(фактически - концептуальной модели производства) используются модели
производственного баланса и оптимального программирования (как правило,
линейного).
Стратегической входной информацией
этого комплекса является перспективный план. Результатом решения комплекса
задач годового планирования является бизнес-план предприятия, в котором должны
быть представлены в сбалансированном виде ресурсные, производственные и
маркетинговые возможности предприятия, объединенные сквозной целью.
Если комплекс задач перспективного
планирования решается в основном для предприятия в целом и оперирует
агрегированной информацией, то комплекс задач годового планирования решается в
различных модификациях как для предприятия в целом, так и для его
производственных подразделений. На оперативном уровне планирования производства
используются модели календарного планирования, управления запасами, теории
массового обслуживания, сетевые модели, модели оптимального программирования.
Результатом решения задач этого комплекса являются планы и графики работ
производственных подразделений.
Информация фазы планирования
является ориентирующей входной информацией объекта управления (производства), и
в соответствии с ней организуется технологический производственный процесс.
Параметры производства, заданные в
фазе планирования, неизбежно испытывают возмущающее воздействие окружающей
среды и отклоняются от запланированных значений. Для того, чтобы возвратить
производство в очерченные планом рамки, необходимо его оперативное регулирование.
1.2 Репликация баз
данных
Репликация (replication) - это
процесс автоматического распределения копий данных и объектов БД между
экземплярами SQL Server с одновременной синхронизацией всей распространяемой
информации.
Почему необходимо
реплицировать данные
Существует достаточно много
оснований для репликации данных и хранимых процедур на разные серверы. Вот
некоторые из них.
· Снижение
сетевого трафика между удаленными офисами. Например, чтобы пользователи из
нью-йоркского отделения компании не запрашивали данные с лондонского сервера по
каналу с ограниченной пропускной способностью, можно реплицировать эти данные
на нью-йоркский сервер (в тот момент, когда не будет сильной нагрузки,
отрицательно отражающейся на пропускной способности канала связи) и обращаться
к ним локально.
· Отделение
OLTP-операций от функций средств поддержки принятия решений. Чтобы пользователи
системы поддержки принятия решений не выполняли запросы на занятом
OLTP-сервере, данные для запроса можно реплицировать на выделенный сервер поддержки
принятия решений.
· Объединение
данных, поступающих из различных мест. В каждом из нескольких региональных
отделений компании данные могут размещаться на локальном сервере SQL Server,
затем в процессе репликации перемещаться в центральное отделение и
автоматически объединяться.
· Реализация
избыточности данных. Данные могут быть реплицированы на резервный сервер,
который может использоваться для запросов, выполняемых с помощью средств
поддержки принятия решений, и предоставлять копию данных при отказе основного
сервера.
· Расширение
системы за пределы ЛВС. Данные, для доступа к которым используется Интернет,
могут быть реплицированы на различные серверы в разных географических регионах
для равномерного распределения нагрузки между серверами.
· Поддержка
мобильных пользователей. Данные могут быть реплицированы на портативные
компьютеры, где их можно обновлять в автономном режиме. При подключении к сети
измененные данные можно реплицировать в главную БД и осуществить их
синхронизацию.
Типы репликацииServer поддерживает три типа репликации (replicationtypes) -
моментальных снимков, транзакций и сведением. Репликация моментальных снимков
(snapshotreplication) - это периодическая репликация целостного набора данных,
зафиксированного по состоянию на определенный момент времени, с локального
сервера на удаленные. Лучше использовать этот тип репликации в БД, где
количество реплицируемых данных невелико, а источник данных статичен. Вы можете
предоставлять удаленным серверам ограниченную возможность обновления реплицированных
данных. Репликация транзакций (transactionalreplication) - это репликация
начального моментального снимка данных на удаленные серверы, а также репликация
отдельных транзакций, работающих на локальном сервере и выполняющих
последовательные изменения данных в начальном моментальном снимке.
Эти реплицированные транзакции
выполняются над реплицируемыми данными на каждом удаленном сервере для
синхронизации данных на удаленном сервере с данными локального сервера. Вы
можете использовать этот тип репликации, если вам необходимо постоянное
обновление данных на удаленных серверах. Вы можете предоставлять удаленным
серверам ограниченную возможность обновления реплицированных данных. Репликация
сведением (mergereplication) - это репликация начального моментального снимка
данных на удаленные серверы, а также репликация изменений, происходящих на
каком-либо удаленном сервере, обратно на локальный сервер с целью
синхронизации, разрешения конфликтов и повторной репликации на удаленные
серверы. Вы можете использовать репликацию сведением в случае, когда
многочисленным изменениям подвергаются одни и те же данные, либо когда
удаленные независимые компьютеры работают автономно, например, как в случае
автономного пользователя.
Терминология репликации
Средства репликации SQL Server
используют терминологию издательской деятельности для названий процессов и
компонентов репликации. Сервер, реплицирующий сохраненную информацию на другие
серверы, называется издателем (publisher). Реплицируемая информация состоит из
одной или нескольких публикаций (publications). Каждая публикация представляет
собой логически согласованный набор данных отдельной БД и состоит из одной или
нескольких статей (articles). Статья может быть одним или несколькими объектами
следующего типа:
· часть
или целая таблица (с фильтрацией по столбцам и / или по строкам);
· хранимая
процедура или определение представления;
· выполнение
хранимой процедуры;
· представление;
· индексированное
представление;
· пользовательская
функция.
В процессе репликации каждый
издатель взаимодействует с распространителем (distributor). Последний сохраняет
публикуемые БД, историю событий и метаданные. Роль распространителя зависит от
типа репликации. При этом распространитель может быть локальным (тот же
экземпляр SQL Server) или удаленным (отдельный экземпляр SQL Server).
Серверы, получающие реплицируемую
информацию, называются подписчиками (subscribers). Они получают избранные
публикации - подписки (subscriptions) - от одного или нескольких издателей. В
зависимости от типа репликации, подписчикам может быть разрешено изменять
реплицируемую информацию, а также реплицировать измененную информацию обратно
издателю. Подписчики могут быть авторизованы, или могут быть анонимными
(анонимная подписка используется при публикации данных в Интернете).
Для больших публикаций использование
анонимных серверов может повысить производительность системы.
Агенты репликации
(replicationagents) автоматизируют процесс репликации. Как правило, агент
репликации - это задание службы SQL ServerAgent, сконфигурированное
администратором для выполнения специфических задач по расписанию. Существует
некоторое число агентов репликации для различных задач репликации. Различные
типы репликации используют один или несколько таких агентов.
· Агент
Snapshot создает исходную мгновенную копию каждой реплицируемой публикации,
включая информацию о схеме. Его используют все типы репликации. Вы можете иметь
один такой агент на каждую публикацию.
· Агент
Distribution передает моментальный снимок данных и последующие изменения от
распространителя подписчикам. Этот агент используется при репликации
моментальных снимков и репликации транзакций. По умолчанию для всех подписок на
отдельную публикацию используется один агент Distribution. Такой агент
называется разделяемым (shared). Однако вы можете настроить систему так, чтобы
у каждого подписчика был личный, независимый (independent), агент Distribution.
· Агент
LogReader перемещает транзакции, помеченные для репликации, из журнала
транзакций с сервера-издателя на сервер-распространитель. Этот агент
используется при репликации транзакций. Каждая из помеченных для репликации БД
будет иметь один агент LogReader, запускающийся на распространителе и
подключающийся к издателю.
· Агент
QueueReader вносит в публикацию изменения, сделанные подписчиками в автономном
режиме. Репликация мгновенных снимков и репликация транзакций используют этот
агент в случае, если разрешена очередь обновлений. Агент запускается на
распространителе, и существует только один экземпляр такого агента, обслуживающий
всех издателей и публикации для конкретного распространителя.
· Агент
Merge передает моментальный снимок данных от распространителя подписчикам. Он
также перемещает и контролирует изменения в реплицируемых данных между
издателем и подписчиками. Этот агент дезактивирует подписки, информация которых
не обновлялась в течение максимального срока хранения публикации (по умолчанию
- 14 дней). Этот агент используется в случае репликации сведением. Каждая
подписка на объединенную публикацию имеет свой объединяющий агент, который
синхронизирует данные между сервером, публикующим данные, и
серверами-подписчиками.
· Агент
HistoryCleanUp удаляет журнал событий агента из БД распространения, и
используется для управления размером этой БД. Все типы репликации используют
этот агент. По умолчанию он запускается каждые 10 минут.
· Агент
DistributionCleanUp удаляет реплицированные транзакции из БД распространения, и
отключает неактивных подписчиков, данные которых не обновлялись в течение
максимального периода хранения распространяемых данных (по умолчанию - 72
часа). Если разрешены анонимные подписки, реплицированные транзакции не
удаляются до истечения максимального периода хранения. Репликация моментальных
снимков и репликация транзакций используют этот агент. По умолчанию он
запускается каждые 10 минут.
· Агент
ExpiredSubscriptionCleanUp выявляет и удаляет подписки с истекшим сроком
хранения. Все типы репликации используют этот агент. По умолчанию он
запускается один раз в день.
· Агент
ReinitializeSubscriptionsHavingDataValidationFailures повторно инициализирует
все подписки, имеющие ошибки при проверке согласованности данных. По умолчанию
этот агент запускается вручную.
· Агент
ReplicationAgentsCheckup выявляет неактивных агентов репликации и заносит
соответствующие записи в журнал приложений Windows. По умолчанию он запускается
каждые 10 минут.
Обзор типов репликации
Для внедрения репликации необходимо
знать, как работают все ее типы. Каждый тип репликации имеет свои преимущества
и недостатки.
Репликация моментальных
снимков
При репликации моментальных снимков
агент Snapshot периодически (по заданному расписанию) копирует все помеченные
для репликации данные с сервера-издателя в папку моментальных снимков
распространителя. Агент Distribution периодически копирует все данные из папки
моментальных снимков на каждый сервер-подписчик и, используя эти данные,
полностью обновляет на нем публикацию. Агент Snapshot выполняется на
распространителе, а агент Distribution может выполняться как на
распространителе, так и на каждом сервере-подписчике. Оба агента записывают
информацию журналов событий и журнала ошибок в БД распространения.
Репликация моментальных снимков
наиболее подходит для работы с не слишком интенсивно изменяемыми данными, для
небольших публикаций, которые могут обновляться полностью без существенного
увеличения нагрузки на сеть, а также для данных, которые не нужно постоянно
поддерживать в актуальном состоянии (допустим, архивные данные об объемах
продаж).
При репликации моментальных снимков
подписчикам можно разрешить обновлять реплицированную информацию немедленно
(ImmediateUpdating) и / или в порядке очереди (QueuedUpdating). Возможность
обновления подписки (UpdatableSubscription) полезна, когда подписчикам
требуется изредка изменять последнюю. Если же подписку изменяют часто, лучше
использовать репликацию сведением. Кроме того, в случае с обновляемыми
подписками все обновления являются частью транзакции. Это означает, что
обновление либо целиком подтверждается, либо откатывается, если происходит
конфликт. При репликации сведением конфликты разрешаются построчно.
Процесс репликации моментальных
снимков
Если используется немедленное
обновление подписки, при любой попытке подписчика обновить реплицированные
данные он сам или издатель инициируют транзакцию с двухэтапным подтверждением
(two/phasecommit, 2PC). 2PC/транзакция включает этап подготовки и этап
подтверждения, и выполняется под управлением службы MS DTC, запущенной на
подписчике и выступающей в качестве диспетчера транзакций. На подготовительном
этапе MS DTC координирует действия служб SQL Server, запущенных на издателе и
подписчике и играющих роль диспетчеров ресурсов, чтобы гарантировать успешное
выполнение транзакции в обеих БД. На этапе подтверждения MS DTC получает от
диспетчеров ресурсов уведомления об успешной подготовке, затем диспетчерам
передается команда подтверждения и транзакция подтверждается на
сервере-издателе и сервере-подписчике. Если на издателе имеется конфликт
(конфликтующее обновление еще не было тиражировано насервер-подписчик),
транзакция, инициированная подписчиком, завершается неудачно. 2PC/транзакция
гарантирует отсутствие конфликтов, поскольку издатель выявляет все конфликты до
подтверждения транзакции.
Если используется очередь обновлений
(QueuedUpdating), сделанные подписчиком изменения помещаются в очередь и
периодически передаются издателю. Изменения могут быть выполнены при отсутствии
соединения с издателем. Изменения, которые находятся в очереди, пересылаются на
данный сервер, когда устанавливается соединение. Так как обновления происходят
не в реальном времени, то конфликты могут происходить, если другой подписчик
или издатель изменили одни и те же данные. Конфликты разрешаются с
использованием стратегии разрешения конфликтов, определяемой в момент создания
публикации.
Если используются оба варианта
обновления подписок, очередь обновлений выступает в качестве страховки на
случай отказа немедленного обновления (например, из-за сбоев в работе сети).
Это полезно, когда между издателем и подписчиком существует постоянное
соединение, но при этом вы хотите убедиться, что подписчики могут совершать
обновления в случае, если соединение разорвано.
Репликация транзакций
При репликации транзакций агент
Snapshot создает исходный моментальный снимок данных, помеченных для
репликации, и копирует его с сервера-издателя в папку моментальных снимков
распространителя. Агент Distribution направляет полученный снимок каждому
подписчику. Агент LogReader следит за изменениями данных, участвующих в
репликации, и фиксирует каждое изменение журнала транзакций в БД
распространения на сервере-распространителе. Агент Distribution отправляет
каждое изменение всем подписчикам в первоначальном порядке выполнения этих
изменений. Если хранимая процедура используется для обновления большого
количества записей, можно реплицировать эту процедуру, а не каждую обновленную
строку. Все три этих агента репликации заносят информацию о событиях и ошибках
в БД распространения.
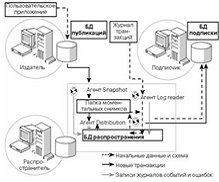
Процесс репликации транзакций
Агент Distribution может работать
постоянно, чтобы минимизировать задержку в обновлении данных между издателем и
подписчиками, или может выполняться по заданному расписанию. Подписчики при
наличии сетевого соединения с издателем могут получать изменения почти в
реальном времени. После того как все подписчики получат реплицированные
транзакции, агент DistributionCleanUp удаляет эти транзакции из БД
распространения. Если по окончании заданного периода хранения (по умолчанию -
72 часа) подписчик не получил реплицируемые транзакции, те удаляются из БД
распространения и подписка дезактивируется. Это позволяет предотвратить
чрезмерное увеличение размера БД распространения. Дезактивированная подписка
может быть повторно активирована, и тогда подписчику с целью обновления его
данных передается новый моментальный снимок.
Кроме того, репликацию транзакций,
по аналогии со снимочной репликацией, можно настроить для поддержки обновляемых
подписок.
Репликация сведением
При репликации сведением агент
Snapshot передает начальный моментальный снимок данных, участвующих в
репликации, от издателя в папку моментальных копий распространителя. Агент
Merge направляет полученный снимок каждому подписчику. Также он анализирует и
объединяет изменения реплицируемых данных, выполняемые издателем и
подписчиками. Если при объединении изменений происходит конфликт на издателе,
агент Merge разрешает его, используя указанный администратором способ. Вы
можете выбрать одно из существующих средств обнаружения конфликтов или
создавать свое собственное.
Оба агента заносят информацию о
событиях и ошибках в БД распространения (это единственная функция БД
распространения в случае репликации сведением).
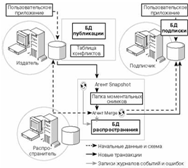
Процесс репликации сведением
Чтобы различать записи отдельных
копий реплицируемой таблицы и выявлять конфликты между записями, агент Merge
использует специальный уникальный столбец реплицируемых таблиц. Если такого
столбца нет, агент Snapshot добавляет его при создании публикации. Кроме того,
при создании публикации агент Snapshot создает на издателе триггеры.
Они ведут мониторинг реплицированных
записей и заносят информацию об изменениях в системные таблицы сведения. Агент
Merge также создает идентичные триггеры на каждом сервере-подписчике, когда
передает ему начальный моментальный снимок.
Агент Snapshot может работать
постоянно, чтобы минимизировать задержку в обновлении данных между издателем и
подписчиками, или может выполняться по заданному расписанию. Подписчики при
наличии сетевого соединения с издателем могут получать изменения почти в
реальном времени. Если по окончании заданного периода хранения (по умолчанию -
14 дней) подписчик не получил реплицируемые транзакции, подписка
дезактивируется. Дезактивированная подписка может быть повторно активирована, и
тогда подписчику с целью обновления его данных передается новый моментальный
снимок.
2. Практическая часть
.1 Постановка задачи и
описание предметной области
Применить информационные технологии
(ИТ) для разработки автоматизированной системы «Складская логистика» средствами
среды визуального проектирования BorlandDelphi 7.0 и системы управления базами данных MicrosoftSQLServer.
2.2 Проектирование АИТ
Описание предметной
области
Исходными данными, описывающими
предметную область являются таблицы:
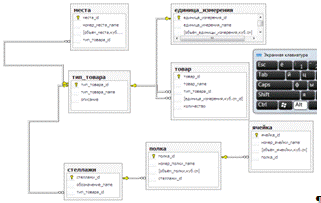
. Таблица «Товар», содержит
поля код, наименование товара, код типа товара, код единицы измерения,
количество;
. Таблица «Тип товара»,
содержащая поля код, тип товара, описание;
. Таблица «Единица измерения»
с полями: код, единица измерения, объем единицы измерения;
. Таблица «Стеллажи», имеющая
поля код, обозначение, код типа товара;
. Таблица «Места», имеющая
поля код места, № места, объем места, код типа товара;
. Таблица «Полки», с полями
код полки, № полки, объем полки, код стеллажа;
. Таблица «Ячейки», которая
содержит код ячейки, № ячейки, объем ячейки, код полки;
Приложение должно обеспечить работу
с таблицами:
1. Просмотр таблицы;
2. Редактирование таблицы
(добавление, удаление и корректировка записей, поиск, выборка);
. Вывод для просмотра результата
запроса.
Концептуальная и
логическая модели АИТ и АИС
Концептуальная модель
(КМ) обеспечивает интегрированное представление о предметной области и
имеет слабо формализованный характер, рисунок 1.
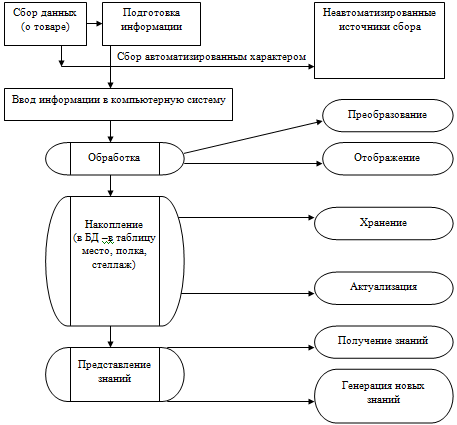
Рисунок 1 - Концептуальная модель
базовой ИТ
Сбор информации состоит в том, что поток осведомляющей информации,
поступающей от объекта управления, принимается человеком и переводится в
документальную форму (записывается на бумажный носитель информации).
Составляющими этого потока могут быть документы клиента, накладные, акты,
ордера, ведомости, журналы, описи и т.п.
Ввод информации при создании информационной технологии в
организационно-экономической системе в конечном итоге является ручным -
пользователь ЭВМ «набирает» информацию (алфавитно-цифровую) на клавиатуре,
визуально контролируя правильность вводимых символов по отображению на экране
дисплея.
Передача информации осуществляться может с помощью: телефона, электронной
почты и курьера.
Процесс обработки данных
связан с преобразованием значений и структур данных, а также их преобразованием
в форму, удобную для человеческого восприятия, т.е. отображением и
преобразованием. Отображенные данные - это уже информация. Процедуры
преобразования данных осуществляются по определенным алгоритмам и реализуются в
ЭВМ с помощью набора машинных операций. Процедуры отображения переводят данные
из цифровых кодов в изображение (текстовое или графическое).
Информационный процесс обмена предполагает
обмен данными между процессами информационной технологии. Это процедуры передачи
данных по каналам связи и сетевые процедуры, позволяющие осуществить
вычислительной сети. Процедуры передачи реализуются с помощью
операции кодирования - декодирования, модуляции - демодуляции, согласования и
усиление сигналов. Процедуры организации сети включают в себя в качестве
основных операции по коммутации и маршрутизации потоков данных (трафика) в
вычислительной сети. Процесс обмена позволяет, с одной стороны, передавать
данные между источником и получателем информации, а с другой -
объединять информацию многих ее источников.
Процесс накопления позволяет
так преобразовать информацию в форме данных, что удается ее длительное
время хранить, постоянно обновляя, и при необходимости оперативно
извлекать в заданном объеме и по заданным признакам. Процедуры процесса
накопления, таким образом, состоят в организации хранения и актуализации
данных. Для данной курсовой работы хранение информации происходит в
структурированной базе данных, как на ОЗУ, так и на ВЗУ. Под актуализацией понимается
поддержание хранимых данных на уровне, соответствующем информационным
потребностям решаемых задач в системе, где организована информационная
технология. Актуализация данных в данной курсовой работе осуществляется
с помощью операций добавления новых данных к уже хранимым, корректировки
(изменения значений или элементов структур) данных и их уничтожения, если
данные устарели и уже не могут быть использованы при решении функциональных задач
системы.
Процесс представления знаний включен
в базовую информационную технологию как один из основных, поскольку высшим
продуктом информационной технологии является знание. В этом
процессе объединяются процедуры формализации знаний, их накопления в формализованном
виде и формальной генерации (вывода) новых знаний на основе накопленных в
соответствии с поставленной задачей. Вывод нового знания - это эквивалент
решения задачи, которую не удается представить в формальном виде. Таким
образом, процесс представления знаний состоит из процедур получения
формализованных знаний и процедур генерации (вывода) новых знаний из
полученных.
Логический уровень информационной технологии представляется комплексом
взаимосвязанных моделей, формализующих преобразования информации и данных,
рисунок 2.
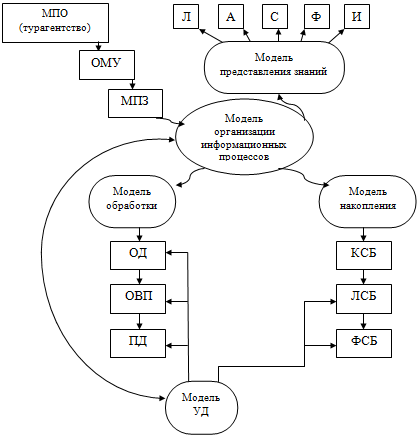
Рисунок 2 - Логическая модель
базовой ИТ
На основе модели предметной
области (МПО) - «Складская логистика», характеризующей объект управления,
создается общая модель управления (ОМУ) - товар, тип товара, условия
хранения, а из нее вытекают модели решаемых задач(МРЗ):
Административные функции:
- просмотр таблиц
разработанной базы данных;
- возможность
выполнения базовых действий над базой данных (добавление новых, а также
удаление и редактирование уже имеющихся записей);
- просмотр отчетов;
- выполнение,
конструирование SQL-запросов;
- выгрузка файлов в Microsoft Excel иMicrosoft Word, сохранение в
текстовый файл.
Так как решаемые задачи в
информационной технологии имеют в своей основе различные информационные
процессы, то на передний план выходит модель организации информационных
процессов (МОИП), призванная на логическом уровне увязать эти процессы при
решении задач управления.
При обработке данных формируются
четыре основных информационных процесса обработка, обмен, накопление и
представление знаний.
Модель обработки данных(МОД) включает в себя формализованное описание процедур
организации вычислительного процесса, преобразования данных и отображения
данных. Под организацией вычислительного процесса (ОВП) понимается
управление ресурсами компьютера (память, процессор, внешние устройства) при
решении задач обработки данных. Разработанная СУБД является работоспособным
приложением, эффективно работающим с данными. Обеспечивая с одной стороны выполнение
необходимых для данной предметной области операций над данными, приложение
имеет относительно небольшой объём, а следовательно не предъявляет высоких
требований к аппаратным ресурсам компьютера.
Процедуры преобразования данных
(ПД) на логическом уровне представляют собой алгоритмы и программы обработки
данных и их структур. В данной курсовой работе реализуются стандартные
процедуры, такие, как поиск, отчеты.
Моделями процедур отображения
данных (ОД) являются компьютерные программы преобразования данных,
представленных машинными кодами, в воспринимаемую человеком информацию, несущую
в себе смысловое содержание. Сбор и подготовка данных о товаре происходит по
большей части вручную администраторами. Ввод информации в систему
осуществляется с клавиатуры.
Последующая обработка данных
производится средствами машинных ресурсов ЭВМ под управлением операционной
системы. Данные преобразуются в текстовую информацию и отображаются через
компоненты среды Delphi: DBGreed, Label, Edit и другие аналогичные компоненты среды.
Модель накопления данных (МНД) формализует описание информационной базы, которая в
компьютерном виде представляется базой данных. Процесс перехода от
информационного (смыслового) уровня к физическому отличается трехуровневой
системой моделей представления информационной базы: концептуальной, логической
и физической схем.
Концептуальная схема
информационной базы (КСБ) обеспечивает
интегрированное представление о предметной области и имеет слабо
формализованный характер.
Создание таблиц реализуется на
основе логической модели, которая включает в себя процедуры сбора, передачи,
преобразования, хранения и обработку данных. Запросы создаются на основе
математических алгоритмов с помощью вычисления данных и определенным критерием
выбора данных.
Физическая модель АИТ и
АИС
Схема данных является графическим
отображением базы данных и используется SQL в процессе работы с
базой данной. Создание схемы данных позволяет упростить конструирование
многотабличных форм, запросов, а также обеспечить поддержание целостности
взаимосвязанных данных при корректировке таблиц, рисунок 4.
Функциональные задачи
информационных моделей управления
Происходит последовательное
преобразование управления: от общей математической модели управления до
алгоритмической модели решаемой функциональной задачи.
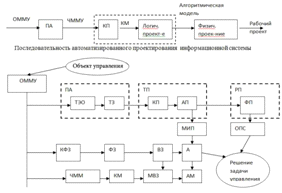
Рисунок 4 - Решение функциональных
задач в системе управления
АМ-алгоритмическая модель
ЧММ - частная математическая модель
МВЗ - модель вычислительной задачи
КФЗ - комплекс функциональных задач.
ВЗ - вычислительные задачи
ФЗ - функциональные задачи
МИП - модель информационных
процессов
А - алгоритм
Функциональные задачи формируются на
основе имеющейся общей математической модели, из которой формируется
первоначально комплекс функциональных задач, собственно функциональные задачи,
далее управление передаётся вычислительным задачам, которые используют
определённый алгоритм для решения функциональных задач.
Конкретные функциональные задачи,
сформулированные в данной курсовой работе:
- учёт
входящих данных, а также их хранение и обработка в информационной системе;
- работа
в режиме конструктора для разработки запросов в будущем на основе имеющихся
данных и отчётов;
- учёт
выходящих данных и анализа документов для составления отчётности;
Они преобразовываются с помощью
созданной АИС в вычислительные задачи, которые, в свою очередь, обрабатываются
написанным алгоритмом. После обработки, задачи являются решёнными.
Технологические
составляющие ИТ
Технологическими составляющими ИТ
являются информационное, лингвистическое, техническое, программное,
математическое, правовое, организационное и эргономическое обеспечения.
Информационное
обеспечение (ИО) представляет собой
совокупность проектных решений по объемам, размещению, формам организации
информации, циркулирующей в АИТ.
Объём информации зависит от вносимых
данных в существующую БД, размер БД не может превышать 1 гб.