Основные подходы искусственного интеллекта
К множеству методов искусственного интеллекта принадлежит довольно
большой диапазон концептуально различных подходов. Далее подробнее рассмотрим
только те методы искусственного интеллекта, которые использовались в данной
работе.
Искусственные нейронные сети
Искусственные нейронные сети - одно из наиболее «старых» направлений
развития средств искусственного интеллекта. В истории развития искусственных
нейронных сетей был длительный период депрессии, связанный с невозможностью
опровергнуть «убийственный» антипример М. Минского. Он заметил, что основная на
то время конфигурация нейронных сетей - персептрон - неспособна обучиться
большому количеству задач, среди которых также простая функция исключающего
ИЛИ. Однако с открытием алгоритма обратного распространения развитие
искусственных нейронных сетей вновь оживилось и является на сегодняшний день
одной из основных технологий искусственного интеллекта. Нет недостатка и в
литературе, освещающей эту область. Читателям, желающим получить начальное
представление об искусственных нейронных сетях, можно посоветовать классическую
книжку Уоссермена [8], учебное пособие Заенцева [9] и вводный курс Калана [10].
В качестве фундаментальной энциклопедии по искусственным нейронным сетям
следует отметить книгу Хайкина [11].
Далее попытаемся кратко описать основные сведения об искусственных
нейронных сетях.
Безусловно, искусственные нейронные сети (ИНС) возникли как попытка
воспроизвести с помощью технических устройств нервную систему живых существ.
Тут же отметим, что для моделирования нейронных сетей используются не только
универсальные вычислительные устройства (компьютеры). Пожалуй, еще более
перспективными являются попытки воспроизвести высшую нервную систему с помощью
различных аппаратных примитивов. С широким наступлением миниатюрных
нанотехнологий это направление стало еще плодотворнее, но публикаций на эту
тему сравнительно немного, возможно из-за закрытого характера подобных
исследований.
Еще одно замечание - чью нервную систему полезнее имитировать. Наверное
наивысшего развития нервная система достигла и людей. Однако некоторые виды
животных демонстрируют феноменальные возможности, недоступные человеку и в
некоторых случаях имеет смысл присмотреться к тому, как действует в этих
случаях их нервная система.
Основные сведения о нервной системе высших животных
Центральная нервная система состоит из взаимосвязанных нервных клеток,
нейронов. Нейрон имеет следующие основные свойства:
Биологический нейрон содержит следующие структурные единицы (Рис.1.1)
Тело клетки - сома (1), заполненная цитоплазмой. Цитоплазма (2) -
внутренняя среда клетки. Отличается концентрацией ионов K+, Na+, Ca++ и других
веществ по сравнению с внеклеточной средой.
Дендриты (3) - входные волокна, собирают информацию от других нейронов.
Длина их обычно не больше 1 мм.
Мембрана (4) отделяет сому от внешней среды- поддерживает постоянный
состав цитоплазмы в теле клетки и определенную характеристику проведение
нервных импульсов.
Аксон (5) один у каждого нейрона - длинное, иногда больше метра, выходное
нервное волокно клетки. Импульс генерируется в начале аксона передается
воздействия на другие нейроны или мышечные волокна. Ближе к концу аксон часто
ветвится с помощью синапсов.
Синапс (6) - место контакта нервных волокон - передает возбуждение от
клетки к клетке. Хорошей проводимостью импульса аксон обязан шванновским
клеткам (7), почти целиком состоящие из миелина, органического изолирующего
вещества. Они плотно "обматывают" нервное волокно, изолируя его от
внешней среды.
Нейроны сильно связаны между собой. У нейрона может быть больше 1000
синапсов. Близкие по функциям клетки образуют скопления, шаровидные или
параллельные слоистые. В мозгу выделены сотни скоплений. Кора головного мозга -
наидолее известное такое скопление. Толщина коры - 2 мм, площадь - около
квадратного фута.
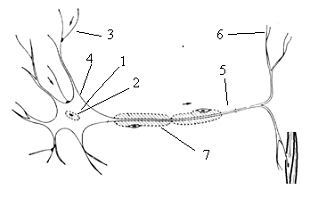
Рис.1.1. Биологический нейрон
Нервная система человека, построенная из элементов, называемых нейронами,
имеет ошеломляющую сложность. Около 1011 нейронов участвуют в
примерно 1015 передающих связях. Учитывая параллельность работы всех
нейронов можно понять, почему живые существа с легкостью решают задачи,
недоступные даже самым быстрым современным компьютерам.
Формальный нейрон
Естественной начальной задачей в моделировании нервной системы является
формализация основной ее структурной единицы. Следует понять, от каких деталей
функционирования биологического нейрона мы готовы отказаться, чтобы не потерять
в целом возможности сети. Как правило, не учитывают временные задержки,
характерные процессу распространения нервного импульса. Исходя из этого
формальный нейрон можно определить следующим образом:
Множество входных связей, определяемых как вектор W вещественных чисел - весов.
Сумматор, который «собирает» в нейрон все входные воздействия. Если
входные воздействия обозначить как вектор X той же размерности что и вектор W, то сумматор может вычислять скалярное произведение X на W
x1w1 + x2w2 + … + xnwn
В этом случае каждое слагаемое - это адекватный биологическому прототипу
вклад каждого дендрита в формирование общего импульса, передаваемого в тело
нейрона - здесь учитывается и сила входного сигнала xi и его проводимость в виде веса wi. Накопленную таким образом сумму
часто обозначают как NET.
Последний компонент формального нейрона - активационная функция, которая
преобразует накопленный сомой импульс в выходной импульс, передаваемый по
аксону. Такой выход нейрона часто обозначают как OUT. В результате, схематическое изображение формального
нейрона часто выглядит следующим образом (Рис.1.2.)
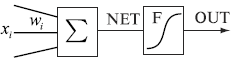
Рис.1.2. Формальный нейрон: xi - компоненты вектора входа, wi - компоненты вектора весов связей, å - сумматор, F -
активационная функция.
В теории ИНС используют различные активационные функции. Так, в начале
своего развития преобладали ИНС с пороговыми активационными
функциями.(Рис.1.3). Такие сети обычно называли персептронами. Зависимость,
определяемая пороговой функцией содержит порог - вещественный параметр q:
= 1, если NET >q,
= 0 в остальных случаях,
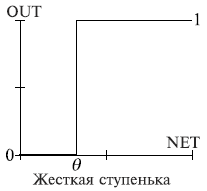
Рис. 1.3. Пороговая активационная функция (жесткая ступенька)
Пороговая функция неплохо воспроизводит характерную особенность нейрона,
имеющего порог насыщения - пока суммарный импульс не превышает заданного
порога, нейрон бездействует, при превышении этого порога нейрон достигает
критической точки возбуждения и выдает во внешнюю среду через аксон импульс.
Логистическая функция (сигмоид, Рис.1.4.) задается формулой
 :
:
Важное
отличие от разрывной пороговой функции - непрерывность, что позволяет
использовать ее в многослойных сетях, обучение которых основано на градиентном
или другом методе, использующем производную активационной функции (например,
метод обратного распространения ошибки). К тому же значение производной легко
выражается через саму функцию. Такой быстрый расчет производной ускоряет
обучение.
Другая
характерная особенность сигмоида - это сжимающая функция: аргумент может
принимать произвольные значения, а выход функции - в диапазоне [0, 1].
Благодаря этому удается избежать эффекта насыщения - безудержного роста
значений весов сети в процессе обучения.
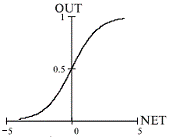
Рис.1.4. Логистическая функция (сигмоид)
Аналогичен сигмоиду, но имеет симметричную область значений [-1, 1]
гиперболический тангенс (Рис.1.5.).
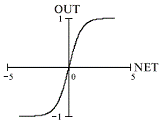
Рис.1.5. Гиперболический тангенс
Архитектура сети
Множество взаимосвязанных нейронов (нейронная сеть) может иметь различную
структуру, которая в существенной степени предопределяет характер решаемых
сетью задач. Чаще всего используются сети, состоящие из слоев. Слой - это
совокупность нейронов, использующих общий вход (Рис.1.5.).
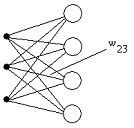
Рис.1.5. Слой из четырех нейронов с 3-х компонентным входом.
Определяющей характеристикой слоя является совокупность всех его весов,
которые можно естественно задать матрицей W. В большинстве случаев все нейроны слоя имеют одинаковую
активационную функцию.
Многослойная сеть прямого распространения состоит из нескольких
последовательно связанных слоев нейронов (Рис.1.6). В такой сети сигнал
распространяется от входа первого слоя (вход сети) к выходу последнего слоя
(выход сети)
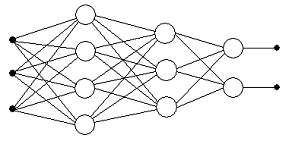
Рис. 1.6. Трехслойная нейронная сеть.
Таким образом, говоря о структуре многослойной сети, достаточно сказать:
. Сколько в ней слоев.
. Сколько нейронов в каждом слое.
. Каковы активационные функции слоев.
Значения весов связей не являются статической структурной характеристикой
и поэтому не водят в структуру сети, а определяются в процессе обучения.
Кроме такой архитектуры можно упомянуть о сетях с обратными связями.
Алгоритмы настройки таких сетей как правило сложнее и они встречаются в практических
приложениях сравнительно редко.
Обучение сети
Характерной особенностью большинства конфигураций нейронных сетей
является их способность обучаться решению требуемой задачи. Поскольку структура
сети в процессе обучения остается неизменной, то под обучением понимают
постепенный процесс настройки весов связей.
Обучение бывает двух типов: обучение с учителем и обучение без учителя.
Обучение с учителем характеризуется наличием обучающего множества. Обучающее
множество - это совокупность пар <вектор входа X - вектор выхода Y>. Каждая такая пара определяет, что сеть, получающая на вход первый
вектор обучающей пары, в идеале должна воспроизвести на своем выходе второй
вектор обучающей пары. К этому нужно стремиться для всех элементов обучающего
множества. В действительности обучение прекращается при достижении некоторого
приближения к этому состоянию, что измеряется функционалом ошибки сети.
Функционал ошибки обычно имеет следующий вид:
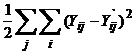
где
j - номер примера
(элемента обучающего множества), i - номер компоненты вектора выхода, Y -
вектор выхода, заданный в обучающем множестве, Y` - вектор,
который сети выдала на выходе, получив на вход вектор X из этого
примера в обучающем множестве.
Таким
образом, задача обучения сети формализуется как задача минимизации функционала
ошибки. Поскольку этот функционал является сложной (точнее, составной)
функцией, его нахождение можно производить на основе идеи градиентного метода.
Алгоритм, который реализует эту процедуру, называется алгоритмом обратного
распространения ошибки. Общеизвестны трудности, которые возникают при
выполнении этого алгоритма. Основной из них является проблема локального
минимума - алгоритм выбирает в качестве найденного решения один из локальных
минимумов и уже не может вырваться из его окрестности в поисках более точного
минимума.
Важнейшей практической задачей данной работы является попытка заменить
алгоритм обратного распространения на генетический алгоритм в надежде смягчить
проблему локального минимума.
Генетические алгоритмы
Генетический алгоримтм является основным в группе так называемых
эволюционных алгоритмов. Основоположником его принято считать Дж.
Холланда.[12]. Однако для начального ознакомления можно порекомендовать более
поздние и популярные источники [13] .
Ссылаясь на свободную энциклопедию «Википедия», определим ГА следующим
образом:
«Генетический алгоритм (англ. genetic algorithm) - это эвристический
алгоритм поиска, используемый для решения задач оптимизации и моделирования
путём случайного подбора, комбинирования и вариации искомых параметров с
использованием механизмов, напоминающих биологическую эволюцию». Комбинирование
и вариация искомых параметров достигаются путем применения в цикле алгоритма
известных даже из школьного курса биологии генетических операторов -
кроссинговера («скрещивания»), мутации и инверсии. Схематично алгоритм можно
представить следующим образом (Рис.1.7.)
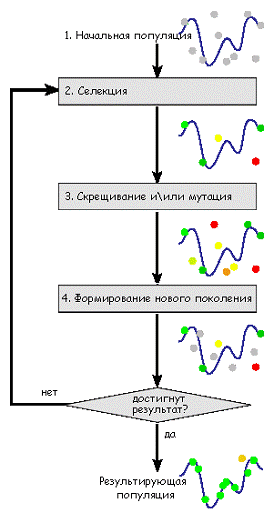
Рис.1.7. Схема генетического алгоритма.
Постановка задачи генетического алгоритма формально звучит очень просто -
это нахождение минимума (желательно глобального) для многомерной функции
F(x1,x2, . . ., xn).
Эту функцию в контексте генетического алгоритма называют функцией
приспособленности (fitness
function), а конкретный вектор-параметр, для
которого она вычисляется - особью. Точнее говоря, особь в классическом
генетическом алгоритме представлена своей «хромосомой» - бинарным
представлением, кодирующим вещественные компоненты вектора, характеризующего особь.
Вещественное представление особи еще называют фенотипом, а бинарное -
генотипом. Генетический алгоритм должен осуществлять как процесс кодирования
фенотипа в генотип, так и обратное декодирование.
. В генетическом алгоритме в начале генерируется начальная
популяция - множество особей (их хромосом). Первоначально значения параметров
фенотипа - произвольные случайные величины в допустимом диапазоне изменения.
. На фазе селекции в популяции выбираются две особи для
дальнейшего размножения путем скрещивания. При выборе двух особей генетический
алгоритм отдает предпочтение особям с большим значением функции
приспособленности, однако делает он это не строго детерминировано, а
вероятностно. Для выбора часто принято использовать достаточно известный «метод
рулетки», при котором вероятность остановки рулетки на некотором секторе
пропорциональна его площади (или угловой мере).
. На третьей фазе к выбранной паре применяют операцию скрещивания
(кроссовер), которая схематично выглядит следующим образом (Рис.1.8.):
Рис.1.8. Схема кроссовера.
Далее во многих модификациях из двух новых особей остается одна - с
наилучшей функцией приспособленности. Оставшаяся хромосома с заданной
вероятностью может быть дополнительно подвергнута операции мутации и инверсии.
Оператор мутации изменяет значение случайно выбранного гена в хромосоме
на противоположное (т.е. с 1 на 0 или наоборот).
Оператор инверсии изменяет значение всех генов в хромосоме на
противоположное (т.е. с 1 на 0 или наоборот).
. Стадия формирования нового поколения. Здесь нужно удалить одну
особь из популяции, чтобы сохранить постоянной величину популяции. И в этом
случае следует обратить внимание на одну особенность. Считается что удаление
должно отдавать предпочтение наихудшим особям. Однако достаточно эффективный
метод рулетки здесь не подходит. В литературе часто предлагают использовать
турнирный метод. Это напоминает соревнования по олимпийской системе, когда в
каждом туре из двух команд-соперниц остается только победитель. Однако такой
подход довольно трудоемкий при большом размере популяции.
В данной работе используется другой подход, который кажется интуитивно
правильным, хотя в литературе не найдены сведения о его использовании.
. Возможны различные условия остановки алгоритма: истечение
заданного количества шагов эволюции, стабилизация интегральной для популяции
величины приспособленности и их комбинация.
В конце концов, после завершения цикла алгоритма возникает популяция с
достаточно высокой функцией приспособленности ее особей. Наилучшая особь в
популяции может считаться решением задачи.
Удаление особи из популяции
Как уже было сказано, удаление турнирным методом - довольно
продолжительная по времени выполнения процедура.
Вспомним, что целью турнирной селекции является такой выбор особи для
удаления, чтобы вероятность удаления худшей особи была выше вероятности
удаления лучшей. Сохраняя это требование можно предложить более эффективные,
чем турнирный метод, способы. Поясним одну из таких схем на рисунке.
Здесь показана популяция из 8 хромосом и функция вероятности удаления той
или иной хромосомы из популяции. В нашей реализации мы храним популяцию в
упорядоченной (возрастающей по функции приспособленности) коллекции.
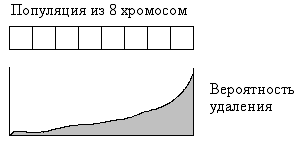
Рис.1.9. Нелинейная функция, определяющая вероятность удаления хромосомы
Очевидно, что требованиям удовлетворяет функция от номера хромосомы в
популяции, которая:
1. Возрастает в диапазоне номеров хромосом.
2. Суммарная вероятность удаления равна 1 (что соответствует равенству
1 интеграла данной функции на диапазоне номеров).
Для простоты и не теряя при этом существенно качественной картины, можно
использовать линейную функцию.

Рис.1.10. Линейная функция, определяющая вероятность удаления хромосомы
Таким образом, алгоритм удаления будет следующим:
Цикл прохода по хромосомам в списке в обратном порядке:
Если случайная величина оказывается меньше вероятности удаления текущей
хромосомы, то удалить эту хромосому и прекратить цикл.
Если цикл так и не удалил хромосому, удалить первую хромосому.
Генетические алгоритмы с вещественным кодированием
Авторы идеи вещественного кодирования ([Herrera, 1998], [Michalewich, 1995], [Wright,
1991]) отталкиваются от предположения, что двоичное представление хромосом
влечет за собой определенные трудности при выполнении поиска в непрерывных
пространствах, что, в свою очередь, приводит к большой размерности пространства
поиска.
Для кодирования признака, принимающего действительные значения в
некотором диапазоне, в битовую строку, используется специальный прием. Интервал
допустимых значений признака xi разбивают на участки с требуемой точностью. Для преобразования
целочисленного значения гена из множества в вещественное число из интервала
пользуются формулой:
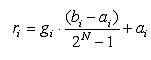 ,
,
где N - количество разрядов для
кодирования битовой строки. Чаще всего используются значения N = 8; 16; 32.
При увеличении N
пространство поиска расширяется и становится огромным. В иностранных источниках
по РГА часто приводится такой пример. Пусть для 100 переменных, изменяющихся в
интервале [-500; 500], требуется найти минимум с точностью до шестого знака
после запятой. В этом случае при использовании ГА с двоичным кодированием длина
строки составит 3000 элементов, а пространство поиска - около 10 в степени
1000.
Для преодоления таких количественных проблем предлагается использовать
вещественное представление признаков в хромосоме [14, 15, 16]. В этом случае
гены (признаки) напрямую представляются в виде вещественных чисел, т.е. генотип
объекта становится идентичным его фенотипу. Теперь точность искомого решения
потенциально ограничена не количеством битовых разрядов для кодирования, а
только точностью представления вещественных чисел компьютера, на котором
реализуется вещественный ГА. В результате, возникает предположение, что
вещественное кодирование в ГА позволит повысить точность найденных решений и
скорость нахождения оптимального решения (из-за отсутствия процессов
кодирования и декодирования хромосом на каждом шаге алгоритма). Для такого
подхода, естественно не подходят стандартные генетические операторы. По этой
причине были разработаны и исследованы специальные операторы. Наиболее полный
их обзор приведен в [14].
Пусть C1=(c11, c21, . . ., cn1)
и C2=(c12, c22, . . ., cn2)
- две хромосомы, выбранные оператором селекции для проведения кроссовера.
. Плоский кроссовер (flat crossover).
Потомок H=(h1, h2, . . ., hn), где hi - случайное число из интервала [ci1, ci2].
. Арифметический кроссовер (arithmetical crossover). Создаются два потомка H1=(h11,
h21, . . ., hn1)
и H2=(h12, h22, . . ., hn2):
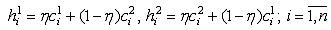 ,
, 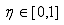
- константа.
. BLX-a кроссовер. Генерируется один потомок
H=(h1, h2, . . ., hn), где hi - случайное число из интервала [cmin - D×a, cmax + D×a], cmax =max(ci1,
ci2), cmin =min(ci1, ci2),
D= cmax - cmin,
. Линейный кроссовер (linear crossover).
Создаются три потомка, рассчитываемые по формулам:
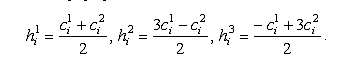
На этапе селекции в линейном кроссовере выбираются две особи с
наибольшими приспособленностями.
В качестве оператора мутации наибольшее распространение получили:
случайная и неравномерная мутация Михалевича.
При случайной мутации ген, подлежащий изменению, принимает случайное значение
из интервала своего изменения
В неравномерной мутации значение гена после оператора мутации
рассчитывается по формуле:
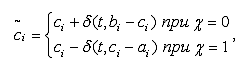
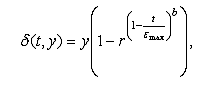
где - целое случайное число, принимающее значение 0 или 1; - случайное
вещественное число; - максимальное количество эпох алгоритма; b - параметр, задаваемый
исследователем.
Самым эффективным оператором скрещивания признан BLX-кроссовер с a=0,5. Особенность данного оператора в том, что при
скрещивании генов значения потомка могут лежать в некоторой области, выходящей
за границы значений этих генов на величину D×a.
В публикациях, посвященных РГА, высказывается сомнение в его
эффективности, по крайней мере для некоторых параметров его применения. Одной
из задач данной работы является проверка этих утверждений.
Гибридные методы
Идея использования удачных сочетаний различных подходов весьма
универсальна. Подобные сочетания можно считать «гибридными». В лучшем случае от
гибрида ожидается получение синергетического эффекта, то есть существенное
улучшение показателей.
В рамках широкого спектра методов искусственного интеллекта можно
представить весьма большое количество различных их сочетаний. В данной работе
сконцентрируемся на попытке проектирования и реализации гибридного подхода,
сочетающего два элемента искусственного интеллекта: ИНС и ГА. Такое сочетание
интенсивно изучается и обсуждается [17, 18]. Существует даже аббревиатура для
этой группы методов - Cogann
(Coombinations of genetic algorythm and neural nets). В [18] даже предлагается классификация таких
сочетаний:
. Независимое применение ГА и ИНС. ГА и ИНС самостоятельно применяют для
решения одинаковой задачи, а затем сравнивают решения.
. ИНС для поддержки ГА. Например, нейронная сеть может использоваться для
формирования начальной популяции.
. ГА для поддержки ИНС. Это основная группа подходов, в рамках которой
можно даже выделить подгруппы:
· применение ГА для подбора параметров либо преобразования
пространства параметров, используемых нейронной сетью для классификации;
· применение ГА для подбора правила обучения либо параметров,
управляющих обучением нейронной сети;
· применение ГА для анализа ИНС;
· ГА для выбора топологии нейронных сетей;
· применение ГА для обучения нейронных сетей;
· Адаптивные взаимодействующие системы.
В данной работе делается попытка осуществить предпоследний вариант
сочетания. Таким образом, ГА используется для глобальной настройки весов ИНС.
Особый интерес представляет последний вариант сочетания, являющийся,
по-видимому, наивысшей ступенью развития всех предлагаемых подходов - в рамках
единый системы все упомянутые подходы должны взаимно дополнять друг друга,
создавая синергетический эффект.
Использование ГА+ИНС для решения задачи прогнозирования
Каким образом можно применять гибрид ГА+ИНС в контексте задачи
прогнозирования временного ряда? Одним из интуитивно приемлемых вариантов
является «метод скользящего окна». При этом временной ряд разбивается на
фрагменты («окна»), состоящие из последовательности элементов заданной длины
(«ширина окна»). Каждое последующее окно располагается во временном ряду на
позицию правее (Рис.1.11 а). Такой подход воплощает идею сглаживания ВР. При
этом предполагается, что данные некоторого окна могут использоваться для
определения (прогноза) значения, непосредственно следующего за окном (Рис.1.11
б).
Рис. 1.11 а) три последовательных окна шириной 5: б) окно и определяемый
им результат прогноза.
Таким образом, временной ряд может служить источником вполне
естественного для ИНС обучающего множества. Пример, представленный на Рис.1.11 может
породить следующее (небольшое) обучающее множество:
Таблица
|
Входной вектор
|
Выходной вектор (цель
обучения)
|
t1 t2 t3 t4 t5
|
t6
|
|
2
|
t2 t3 t4 t5 t6
|
t7
|
|
3
|
t3 t4 t5 t6 t7
|
t8
|
|
4
|
t4 t5 t6 t7 t8
|
t9
|
Типовым приемом прогнозирования является разбиение исходного множества на
данные инициализации и на данные проверки. В методике использования
многослойных ИНС имеется аналогия - данные для обучения и данные для проверки
корректности обучения. Например, мы можем использовать 1-й и 2-й пример для
обучения, а 3-й и 4-й - для проверки качества прогноза. Есть также
предположение, что в силу специфики обучения и применения ИНС в нашем случае
тестовое множество можно не использовать - критерием качества может быть
классический MSE-критерий.
Описание программной системы, реализующей прогнозирующие нейронные сети
Программная реализация системы выполнялась на языке C# средствами Microsoft Visual Studio 2010. Диаграммы классов, используемые при
проектировании системы, созданы с помощью Model Maker 11 C# Edition.
Программные классы системы формируют несколько основных пространств имен:
· NeuroClasses - классы, реализующие функционирование ИНС;
· GeneticClasses - классы, реализующие функционирование ГА;
· NNetGATraining - классы, обеспечивающие гибридное
использование ГА и ИНС.
Кроме этого, имеются вспомогательные пространства имен Globals (для общих констант и генератора
случайных чисел) и FitnessFunctions
- для определения множества функций приспособленности.
И наконец, для тестирования возможностей классов разработано клиентское
оконное приложение в виде проекта Windows Forms - Client2.
Следует отметить, что в совокупности классов присутствуют классы, не
используемые в клиентском приложении. Однако их наличие принципиально для
возможного расширения функциональности системы.
Программная поддержка ИНС
Соответствующе классы находятся в пространстве имен NeuroClasses, схематично показанном на диаграмме
классов (Рис.2.1).
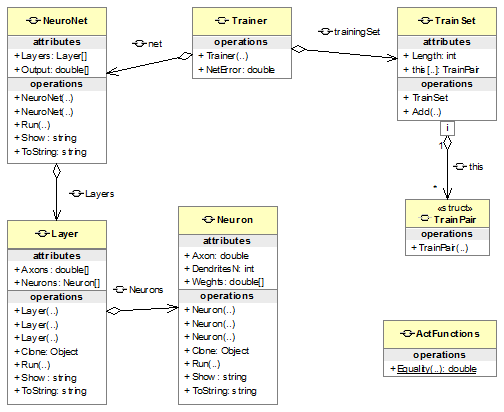
Рис.2.1. Диаграмма классов пространства имен NeuroClasses
Первичным классов в этом пространстве является класс Neuron, реализующий один нейрон ИНС. Этот
класс реализует стандартный интерфейс ICloneable, обеспечивая создание независимых копий нейрона. Это важно,
поскольку ссылочная природа переменных в C# может создать в нашем случае нежелательные побочные эффекты
модификации объектов нейросети со стороны внешних клиентов.
Для достижения лучших показателей производительности используется прием
«ленивой» инициализации значения выходного импульса нейрона - соответствующее свойство
Axon только получает доступ к закрытой
переменной output, изменение которой осуществляется
методом срабатывания нейрона Run.
Наличие трех разных конструкторов позволяет довольно удобно создавать
нейроны в различных клиентских ситуациях.
Класс Layer является реализацией слоя в
многослойной ИНС. Этот класс универсально реализует входной, скрытые и выходной
слой ИНС. Основной метод Run,
получая вектор водных импульсов, переадресует вычисление вектора выхода массиву
нейронов. Класс Layer реализует
интерфейс ICloneable по тем же причинам, что и класс Neuron.
Класс NeuroNet содержит в своем составе массив
слоев и основной метод Run,
который организует последовательность вызовов методов Run для слоев, постепенно преобразуя входной вектор сети
в выходной.
Хотя в данной работе не стояла задача обучения ИНС специфическими
нейросетевыми алгоритмами (например, обратное распространение ошибки), те менее
базовые функции обучения все же необходимы. Они реализованы Следующими
классами.
Класс TrainPair представляет один элемент обучающего
множество и хранит пару векторов: вектор входа и вектор желаемого выхода.
Класс TrainSet представляет все обучающее
множество, которое хранится как список объектов TrainPair. В классе определен метод добавления
Add и индексатор.
Класс Trainer содержит нейрону сеть и обучающее
множество и метод NetError, который
позволяет вычислить «ошибку» сети - упоминаемый ранее функционал ошибки сети на
данном обучающем множестве.
Реализация генетического алгоритма
Классы, имеющие отношение к реализации ГА в основном сосредоточены в
пространстве имен GeneticClasses,
схематически показанном на диаграмме классов (Рис.2.2.).
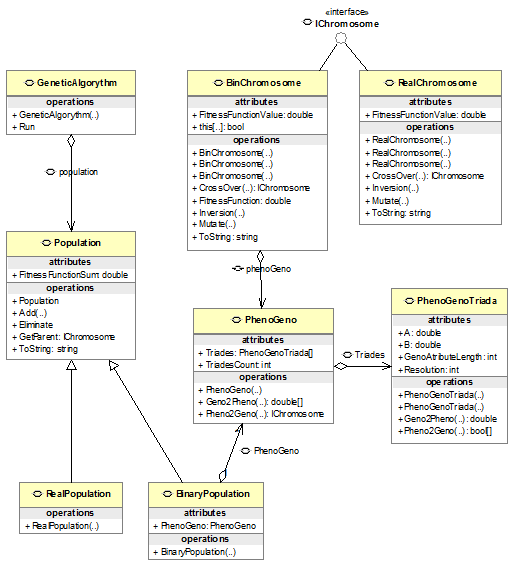
Рис.2.2. Диаграмма классов пространства имен GeneticClasses
Первичным типом этой диаграммы явдяется интерфейс IChromosome,
описывающий требования, накладываемые на программную реализацию хромосомы
любого типа:
public interface IChromosome
{FitnessFunctionValue{get;set;}CrossOver(IChromosome
chr);Mutate(double p); // p - вероятность мутацииInversion(double p); // p - вероятность инверсии
}
Вполне очевидны элементы этого интерфейса, соответствующие основным
терминам ГА.
Класс BinChromosome (реализует интерфейс IChromosome) реализует «классическую» хромосому,
использующую бинарное кодирование фенотипа. Закрытыми переменными этого класса
являются:
protected double fitnesFunctionValue;bool[] allels;PhenoGeno
phenoGeno;double[] phenoAtributes;
Следует отметить подход к определению значения функции приспособленности
(переменная fitnesFunctionValue). Исходя из теории ГА - это
«внешняя» по отношению к ГА функция из «реального мира». Для обеспечения
высокого уровня универсальности можно было бы передавать в класс BinChromosome
переменную функционального типа (делегат в C#). Однако это привело бы к некоторым потенциальным
проблемам: избыточность вычислений и сложность в определении универсальной
сигнатуры такой функции.
Вместо этого используется более простое решение - значение функции
приспособленности просто хранится в хромосоме в переменной fitnesFunctionValue. Это значение определяется в момент
создания хромосомы в ее конструкторе и в дальнейшем, как правило, даже не
должно изменяться.
Аналогичный подход работает и для остальных классов, реализующих другие
типы хромосом.
Переменная alleles представляет
бинарный массив - генотип хромосомы.
Для формирования этого массива в качестве первоисточника используется
вещественный массив phenoAtributes с
параметрами фенотипа. Для кодирования и декодирования хромосома содержит
специальный объект phenoGeno.
Это объект класса PhenoGeno, который содержит в себе массив объектов PhenoGenoTriada. Каждый такой объект содержит
диапазон и точность кодировании (переменные a, b, и resolution). Используя эти данные и входной
параметр-фенотип X метод Pheno2Geno
осуществляет его преобразование во фрагмент генотипа - бинарныймассив. Метод
Geno2Pheno осуществляет обратное преобразование.
Класс Geno2Pheno реализует стандартные генетические операторы кроссовера,
мутации и инверсии.
Класс BinChromosome реализует интерфейс IChromosome для поддержки хромосом с
вещественным кодированием. Переменные этого класса:
private string id; //идентификатор хромосомыdouble
fitnessFunctionValue;double[] phenoAttributes;double from;double to;double
alpha; //параметр BLX-кросовера
Для удобства наблюдения за ходом ГА в клиентских приложениях, в классе BinChromosome присутствует текстовый идентификатор
id хромосомы, который закрытая функция MakeID генерирует как строку с высокой
вероятностью уникальности.
Массив phenoAttributes соответствует фенотипу особи.
Переменные from и to определяют диапазон изменения всех
параметров фенотипа. Вместо индивидуального определения диапазона для каждого
параметра, общий диапазон используется, во-первых, для простоты, а во-вторых,
поскольку элементы фенотипа будут соответствовать индивидуальным весам сети,
для которых диапазон изменения значений не различим.
Переменная alpha - это
коэффициент, характеризующий реализацию кроссовера для РГА.
Генетические операторы реализованы в классе BinChromosome следующим образом (см. Глава 2,
стр.20-21)
кроссовер - BLX-a кроссовер;
мутация - случайная мутация Михалевича
Для обслуживания ГА удобно определить служебный класс Population, реализующий полезные функции
популяции в целом. Здесь важно отметить 2 факта:
класс содержит множество особей в отсортированном в порядке возрастания
функции приспособленности списке species;
класс поддерживает переменную fitnessSum, которая хранит суммарное
значение функций приспособленностей особей.
Соответственно этому метод Add
добавления особи в популяцию сохраняет отсортированное состояние списка species
и актуальное значение переменной fitnessSum.
Метод GetParent отбирает особь для скрещивания по методу рулетки. Таким
образом, двукратный вызов этого метода предоставит двух «родителей» для
скрещивания.
Метод Eliminate осуществляет удаление особи из
популяции методом, описанным в Главе 2, стр. 18-19.
Классы BinaryPopulation и RealPopulation переопределяют некоторые особенности
класса Population.
Вершиной этого небольшого «айсберга» является класс GeneticAlgorythm. Основная переменная этого класса -
популяция population (объект класса Population).
Выполнение ГА осуществляет простой метод Run:
public void Run()
double ffSum;
{ ffSum = population.FitnessFunctionSum;();++;
}(!Stop(curStep, ffSum));
}
Здесь хорошо видно, что это циклический алгоритм, на каждом шаге которого
выполняется основное действие - вызов метода RunStep - один шаг ГА. Наличие такого метода упрощает
выполнение клиентского приложения в пошаговом режиме.
Условие завершения (предикат Stop) учитывает 2 аспекта - исчерпание шагов эволюции и достижение требуемой
точности.
Метод RunStep является центральным, поэтому
приведен здесь полностью:
public void RunStep()
{
//Подготовка и выполнение кроссовера
IChromosome parent1, parent2, child;=
population.GetParent();= population.GetParent();=
parent1.CrossOver(parent2);(new GACrossoverEventArgs(parent1, parent2, child));
//Выполнение мутации=child.Mutate(pMutation);(new GAMutationEventArgs(child));
//Выполнение инверсии=child.Inversion(pInversion);(new
GAInversionEventArgs(child));
//добавление новой и удаление старой особи
population.Add(child);.Eliminate();
}
Заметим, что в класс GeneticAlgorythm включена поддержка механизма событий:
определены события, соответствующие выполнению генетических операций:
public event GACrossoverHandler GACrossoverEvent;event
GAMutationHandler GAMutationEvent;event GAInversionHandler GAInversionEvent;
- определены методы для корректного вызова событий:
public void OnGACrossover(GACrossoverEventArgs ea) { . .
.}void OnGAMutation(GAMutationEventArgs ea) { . . .}void
OnGAInversion(GAInversionEventArgs ea) { . . .}
- в коде метода RunStep
видно, как эти события вызываются.
Эти средства сделали удобной реализацию демонстрации хода ГА в клиентском
приложении.
Реализация гибридного сочетания ГА+ИНС
Реализация требуемого сочетания ГА+НС осуществляется с помощью классов
пространства имен NNetGATraining
(Рис.2.3.).
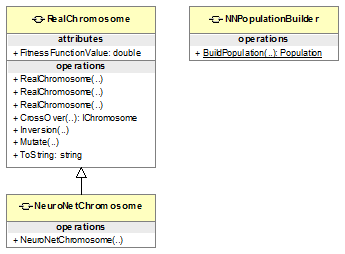
Рис.2.3. Диаграмма классов пространства имен NNetGATraining
Центральным классом здесь является класс NeuroNetChromosome, производный
от класса RealChromosome и реализующий необходимую дополнительную специфику.
Главной особенностью этого класса является его способность вычислять
функцию приспособленности как функционал ошибки нейронной сети на заданном
обучающем множестве.
Подробно рассмотрим, как создаются объекты этого класса:
public NeuroNetChromosome([] netStructure,[]
netWeights,pActFunction,alpha,trainingSet)
: base(netWeights, alpha)
{.netStructure = netStructure;.netWeights = netWeights;=
pActFunction;
net = MakeNet();
//вычисление функции приспособленности как ошибки сети на обучающем
множестве
Trainer trainer = new Trainer(net, trainingSet); = trainer.NetError();
}
Конструктор получает параметр netWeight - это массив вещественных чисел, который в этом классе
выполняет 2 функции:
· является фенотипом РГА-хромосомы (поэтому он передается в
базовый конструктор класса RealChromosome);
· является набором весов нейронной сети, которую представляет
данный объект NeuroNetChtomosome.
Конструктор на основании этого массива создает соответствующую сеть. Для
этого конструктор получает множество дополнительных параметров.
Целочисленный массив netStructure определяет топологию сети. Например, если он содержит элементы 4, 2 и 3,
то это значит, что сеть состоит из трех слоев: в первом - 4 нейрона, во втором
- 2, и в третьем -3.
Закрытый метод MakeNet
создает на основе этой топологии и других дополнительных параметров нейронную
сеть с заданными в netWeights весами.
Теперь остается только вычислить функцию приспособленности такой
хромосомы, как функционал ошибки сети (2 последние строчки конструктора).
Еще один специфический метод класса NeuroNetChtomosome - переопределяет генетическую
операцию скрещивания:
public IChromosome CrossOver(IChromosome chr)
{rChr= (RealChromosome)(base.CrossOver(chr));new
NeuroNetChromosome(,.PhenoAttributes,,,);
}
Класс NNPopulationBuilder создает первоначальную популяцию из
хромосом-нейросетей.
Описание функций клиентского приложения
Перед клиентским приложением стоит несколько задач:
1. Обеспечить ввод множества настроечных параметров для
создаваемых ИНС и ГА.
2. Обеспечить режим автоматического выполнение ГА для достижения
приемлемой цели.
. Обеспечить пошаговый режим выполнения ГА, для обеспечения
наглядности и контроллируемости работы ГА.
Первая задача решается благодаря множеству элементов управления,
расположенных в стартовом окне приложения (Рис.2.4.).
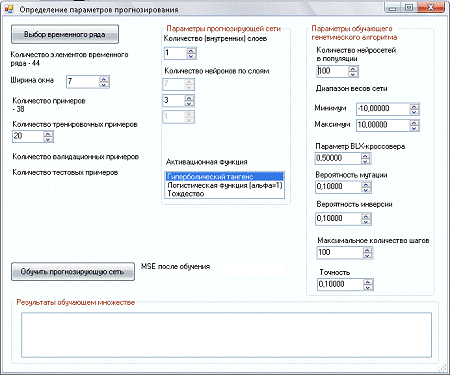
Рис.2.4. Стартовое окно клиентского приложения.
После ввода настроечных параметров следует нажать кнопку «Обучить
прогнозирующую сеть». В результате появится следующее окно (Рис.2.5.).
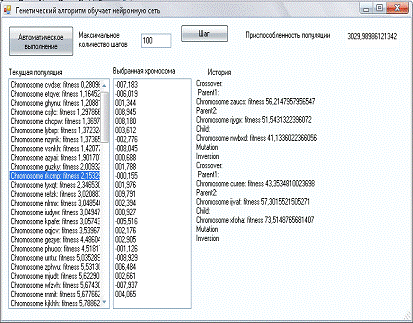
Рис.2.5. Окно выполнения генетического алгоритма.
В этом окне можно выполнять ГА в автоматическом режиме и в пошаговом
режиме. В пошаговом режиме можно наблюдать общее состояние популяции и
состояние каждой хромосомы. Кроме того, протоколируется история выполнения
генетического алгоритма.
После закрытия этого окна происходит возврат к начальному окну, в котором
отображаются результаты обучения (Рис.2.6.):
величина MSE - обобщающий
показатель качества обучения на всем обучающем множестве:
по каждому экземпляру скользящего окна можно увидеть реальный и
предсказанный последующий элемент ряда.
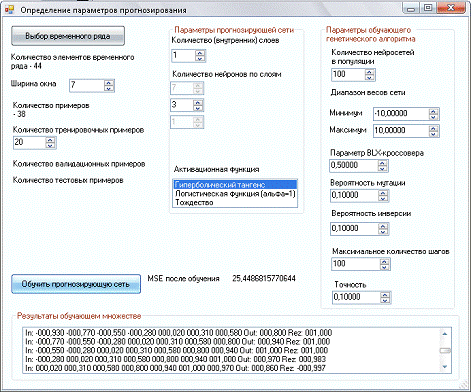
Рис.2.6. Результаты обучения прогнозирующей сети.
Возможности нейросетевого прогнозирования средствами Matlab
Для того, чтобы иметь возможность верификации полученных результатов,
полезно иметь другую реализацию подобной задачи. Оказалось, что задачу
прогнозирования в постановке, принятой в данной работе, можно довольно просто
решить с помощью стандартных средств универсальной системы математического
моделирования Matlab [20].
Matlab
включает в себя множество модулей, соответствующих тому или иному
математическому методу. Любой из модулей Matlab может быть вызван как функция в тексте программы,
написанном на встроенном в MATLAB
языке. Среди модулей MATLAB
имеется Neural Network Toolbox - модуль, позволяющий осуществлять весьма
разнообразные эксперименты с нейронными сетями.
Простое приложение в Matlab для прогнозирования
Рассмотрим пример приложения на Matlab, которое осуществляет основные
этапы прогнозирования временных рядов с помощью нейронных сетей. Приложение состоит из двух небольших функций, которые
рассмотрим подробно далее. Функция Client1
1 function Client1()
a = importdata('GNP.txt')
net = newff(b,c,15)
net = train(net,b,c)
p1={[23.1 42.4 49.1 52.7 55.1 60.4 57.5 55.9 62.6 61.3]'}
y=sim(net,p1)
8 end
Строка 1. Заголовок функции. Функция вызывается без параметров ().
Строка 2. С помощью функции Matlab «Importdata» производится считывание
из указанного текстового файла 'GNP.txt' временного ряда в матрицу ‘a’.
Строка3. С помощью написанной нами функции «TimeSeries2TrainingSet»
вектор a временного ряда преобразуется в обучающее множество нейронной сети в
виде матрицы b входных векторов и вектора выходных значений c. При этом нужно
указать ширину «скользящего окна» (10) и количество примеров обучающего
множества (20). Подробнее функция TimeSeries2TrainingSet будет рассмотрена
позже.
Строка 4. С помощью стандартной функции Matlab 'newff' производится
построение нейронной сети. В данном варианте вызова функции 'newff' некоторые
настроечные параметры не указываются явно и принимают стандартные значения.
Название 'newff' означает, что создается новая сеть прямого распространения
(Feed Forward). Такая сеть по умолчанию является двуслойной. При создании сети
указываются такие параметры, как обучающее множество b и c, и количество
нейронов в скрытом слое (15).
Строка 5. Построенная сеть обучается методом обратного распространения ошибки
(Back Propagation)с помощью встроенной функции ‘train'. Как известно, принцип
обратного распространения реализован с помощью нескольких конкретных методов. В
примере функция ‘train' использует по умолчанию один из наиболее быстрых
методов, метод Левенберга-Марквардта. Во время выполнения функции ‘train’
Matlab наглядно демонстрирует процесс и результаты обучения с помощью
следующего диалогового окна (Рис.4.1):
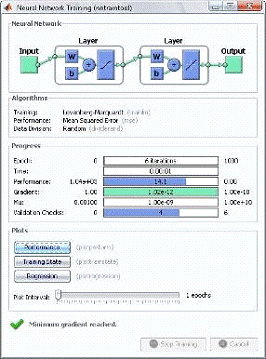
Рис. 4.1. Главное окно, отображающее ход обучения и результаты обучения
нейронной сети
Результатом данной функции является обученная сеть, т.е. сеть, в которой
веса связей настроены для наилучшего соответствия обучающего множества.
Наиболее важным показателем является точность обучения, оцениваемая с помощью MSE-критерия.
Строка 6. Формируется вектор p1, который на следующем шаге будет
подаваться на вход сети.
Строка 7. Функция 'sim' позволяет получить с помощью нейронной сети ее
выход при заданном входном векторе.
Функция TimeSeries2TrainingSet
[inputs outputs] = TimeSeries2TrainingSet(timeSeries,
winWidth, exampleCount)
% превращает временной ряд с заданной шириной окна winWidth
% в обучающее множество для нейронной сети, состоящее из exampleCount
элементов
in=[]=[]n = 1:exampleCount=timeSeries(n:n+winWidth-1)=[in
slice']=[out; timeSeries(1,n+winWidth)]=in=out'
Эта функция преобразовывает временной ряд в обучающее множество нейронной
сети, используя принцип «скользящего окна». Ее входом является вектор
‘timeSeries’, а выходом - обучающее множество (матрица inputs и вектор
outputs).
Заключение
В результате выполнения данной работы удалось получить ряд результатов, в
конечном счете позволяющих осуществлять прогнозирование временных рядов.
В первой части работы были рассмотрены основные положения теории прогнозирования.
Основной результат - классификация методов прогнозирования и постановка задачи
прогнозирования временных рядов. Критерий оценки качества - MSE-критерий.
Во второй части работы рассмотрены основные подходы ИИ, в частности ИНС и
ГА. В рамках данной работы в основном используются многослойные сети прямого
распространения. Обучение таких сетей предполагается осуществлять с помощью
генетического алгоритма с вещественным кодированием.
Рассмотрен классический генетический алгоритм и его модификация (РГА),
которая в большей степени подходит для достижения цели работы.
Разработана методика решения задачи прогнозирования временных сетей с
помощью сочетания ГА+ИНС, в котором ГА с вещественным кодированием параметров
используется как метод обучения многослойной ИНС.
Для практической реализации этой методики спроектированы реализованы
программные модули, соответствующие применяемым в рамках работы методам, а
также клиентское приложение, позволяющее осуществлять эксперименты с помощью
предлагаемой методики.
Для верификации результатов работы разработаны сценарии на языке MATLAB, позволяющие осуществлять сходные
эксперименты с помощью встроенных в MATLAB средств.
В ближайшей перспективе следовало бы провести достаточно представительное
множество экспериментов, которые позволили бы осуществить более полно
тестирование представленного программного обеспечения. Еще важнее, что в
результате таких экспериментов можно было бы выявить закономерности в поведении
создаваемых моделей в зависимости от входных параметров.
Список использованных источников
1. Ханк Д.Э.,
Уичерн Д.У., Райтс А.Дж. Бизнес-прогнозирование, 7-е издание.: Пер. с англ. -
М.: Издательский дом «Вильямс», 2003,. - 656 с.: ил.
. Бокс Дж.,
Дженкинс Г. Анализ временных рядов, прогноз и управление: Пер. с англ. // Под
ред. В.Ф. Писаренко. - М.: Мир, 1974, кн. 1. - 406 с.
. Лукашин
Ю.П. Адаптивные методы краткосрочного прогнозирования временных рядов. - М.:
Финансы и статистика, 2003. - 416с.: ил.
. Ивахненко
А.Г., Мюллер Й.А. Самоорганизация прогнозирующих моделей. - К.: Техника, 1985;
Берлин: ФЕБ Ферлаг Техник, 1984. - 223 с., ил.
. Лбов Г.С.,
Неделько В.М. Байесовский подход к решению задачи прогнозирования на основе
информации экспертов и таблицы данных. Доклады РАН Том 357. № 1. 1997. с.29-32
. Мандельброт
Бенуа - (Не)послушные рынки: фрактальная революция в финансах.: Пер. с англ. -
М.: Издательский дом «Вильямс», 2006. - 400с.: ил.
. Бэстенс
Д.-Э., ван ден Берг В.-М., Вуд Д. Нейронные сети и финансовые рынки: принятие
решений в торговых операциях. - Москва, ТВП, 1997. - 236 с.
. Уоссермен
Ф. Нейрокомпьютерная техника: Теория и практика. - М., Мир, Пер. с англ., 1992.
- 118 с.
. И. В.
Заенцев Нейронные сети: основные модели. Учебное пособие - Воронеж, 1999
. Каллан
Роберт Основные концепции нейронных сетей.: Пер. с англ. - М.: Издательский дом
«Вильямс», 2001. - 287 с.
. Хайкин
Саймон Нейронные сети: полный курс, 2-е издание.: Пер. с англ. - М.:
Издательский дом «Вильямс», 2006. - 1104 с.: ил.
12.
J. H. Holland. Adaptation in natural and artificial systems. University of
Michigan Press, Ann Arbor, 1975.
. Емельянов В.В., Курейчик В.В., Курейчик В.М. Теория и практика эволюционного моделирования. - М.: ФИЗМАТЛИТ, 2003. - 432 с.
.
Herrera F., Lozano M., Verdegay J.L. Tackling real-coded genetic algorithms: operators
and tools for the behaviour analysis // Artificial Intelligence Review, Vol.
12, No. 4, 1998. - P. 265-319.
.
Michalewicz Z. Genetic Algorithms, Numerical Optimization and Constraints,
Proceedings of the 6th International Conference on Genetic Algorithms,
Pittsburgh, July 15-19, 1995. - P. 151-158.
.
Wright A. Genetic algorithms for real parameter optimization // Foundations of
Genetic Algorithms, V. 1. - 1991. - P. 205-218.
17.
Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические
алгоритмы и нечеткие системы: Пер. с польск. И.Д.Рудинского. - М.: Горячая
линия - Телеком, 2006. - 452 с.: ил.
. Вороновский
Г.К., Махотило К.В., Петрашев С.Н., Сергеев С.А. Генетические алгоритмы,
искусственные нейронные сети и проблемы виртуальной реальности - Х.: ОСНОВА,
1997. - 112 с.
. Э.Е.
Тихонов. Методы прогнозирования в условиях рынка: учебное пособие. -
Невинномысск, 2006. - 221 с.
. Медведев
В.С., Потемкин В.Г. Нейронные сети. MATLAB 6. - М.: ДИАЛОГ-МИФИ, 2002. -496 с.
прогнозирование интеллект нейронный гибридный