Статистически оптимальный генератор псевдослучайных последовательностей
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ
АГЕНСТВО ПО ОБРАЗОВАНИЮ
Государственное
образовательное учреждение высшего профессионального образования
<<Московский
государственный институт электронной техники
(технический
университет)>>
Факультет
микроприборов и технической кибернетики
КАФЕДРА
ВЫСШЕЙ МАТЕМАТИКИ № 1
ДИПЛОМНАЯ
РАБОТА
на тему: "Статистически оптимальный генератор псевдослучайных
последовательностей"
Содержание
Введение
. Теоретическая часть
.1 Свойства равномерно распределенной псевдослучайной
последовательности (РРПП)
1.2 Генераторы ПСП
.2.1 Линейный конгруэнтный генератор
.2.2 Квадратичный конгруэнтный генератор
.2.3 RSA-алгоритм
генерации псевдослучайных последовательностей
.2.4 Линейный сдвиговый регистр с обратной
связью
.2.5 Самоуправляемый 2-линейный регистр сдвига
.3 Тестирование ПСП
.3.1 Универсальный алгоритм статистического тестирования
1.3.2 Статистический набор тестов НИСТ
.3.3 Тест n-серий
.3.4 Универсальный статистический тест Маурера
.3.5 Критерий серий
1.4 Задачи многокритериальной оптимизации
. Практическая часть
.1 Реализация линейного конгруэнтного генератора
.2 Реализация квадратичного
конгруэнтного генератора
.3 Реализация RSA-
алгоритма генерирования псевдослучайных последовательностей
2.4 Реализация генерации псевдослучайных последовательностей
с помощью сдвигового регистра
.5 Реализация генерации псевдослучайных последовательностей с
помощью самоуправляемого 2-линейного регистра сдвига
.6 Тестирование генераторов ПСП
Выводы и заключение
Приложение. Коды программ
Список использованной литературы
линейный конгруэнтный генератор алгоритм
Введение
Случайные числа играют важную роль в криптографии и ее различных
приложениях. Двумя основными требованиями к последовательности случайных чисел
являются случайность и непредсказуемость. Рассмотрим по порядку.
. Случайность.
Обычно при создании последовательности псевдослучайных чисел
предполагается, что данная последовательность чисел должна быть случайной в
некотором определенном статистическом смысле. Для доказательства того, что
данная последовательность является случайной, используются 2 критерия:
Однородное распределение: распределение чисел в последовательности должно
быть однородным; это означает, что частота появления каждого числа должна быть
приблизительно одинаковой.
Независимость: ни одно значение в последовательности не должно зависеть
от других.
Хотя существуют тесты, показывающие, что последовательность чисел
соответствует некоторому распределению, такому как однородное распределение,
теста для "доказательства" независимости нет. Тем не менее, можно
подобрать набор тестов для доказательства того, что последовательность является
зависимой. Общая стратегия предполагает применение набора таких тестов до тех
пор, пока не будет уверенности, что независимость существует.
. Непредсказуемость.
При "правильной" случайной последовательности каждое число
статистически не зависит от остальных чисел и, следовательно, непредсказуемо.
То есть невозможно, зная предыдущие элементы последовательности и алгоритм,
предугадать следующий элемент.
Последовательность называется по-настоящему случайной, если ее нельзя
воспроизвести. Это означает, что если запустить генератор по-настоящему
случайных последовательностей дважды при одном и том же входе, то на его выходе
получатся разные случайные последовательности.
Источники таких случайных чисел найти трудно. Физические генераторы
шумов, такие как детекторы событий ионизирующей радиации, газовые разрядные
трубки и имеющий течь конденсатор могут быть такими источниками. Однако
применение этих устройств в криптографии ограниченно. Проблемы также вызывают
грубые атаки на такие устройства. Альтернативным решением является создание
набора из большого числа случайных чисел и опубликование его в некоторой книге.
Тем не менее, и такие наборы обеспечивают очень ограниченный источник чисел по
сравнению с тем количеством, которое требуется. Более того, хотя наборы из этих
книг действительно обеспечивает статистическую случайность, они предсказуемы,
так как легко можно получить их копию.
Таким образом, шифрующие приложения используют для создания случайных
чисел специальные алгоритмы. Эти алгоритмы детерминированы и, следовательно,
создают последовательность чисел, которая не является статистически случайной.
Тем не менее, если алгоритм хороший, полученная последовательность будет
проходить много тестов на случайность. Такие числа часто называют
псевдослучайными числами.
Созданию хороших генераторов псевдослучайных последовательностей
уделяется достаточно большое внимание в математике. Проблема в том, что все
генераторы псевдослучайных последовательностей при определенных условиях дают
предсказуемые результаты и корреляционные зависимости.
Случайные числа и их генераторы являются неотъемлемыми элементами
современных криптосистем. Приведем конкретные примеры использования случайных
чисел в криптографии:
. сеансовые и другие ключи для симметричных криптосистем, таких
как DES, ГОСТ 28147-89, Blowfish.
. стартовые значения для программ генерации ряда математических
величин в ассиметричных криптосистемах, например RSA, ELGamal.
. случайные слова, комбинируемые с парольными словами для
нарушения "атаки угадывания" пароля криптоаналитиком.
. вектор инициализации для блочных криптосистем, работающих в
режиме обратной связи.
. случайные значения параметров для многих систем электронной
цифровой подписи, например DSA
или СТБ 1176.2-99.
. случайные выборы в протоколах аутентификации, например в
протоколе Цербер.
. случайные параметры протоколов для обеспечения уникальности
различных реализаций одного и того же протокола, например в протоколах SET и SSL.
Целью данной дипломной работы является написание пакета программ,
осуществляющих генерацию и тестирование псевдослучайных последовательностей, и
выбор оптимального генератора.
В данной работе приведены:
теоретические основы и описания генераторов псевдослучайных
последовательностей и тестов для них;
описание работы программ и экспериментальные результаты;
1.
Теоретическая часть
Прежде чем начать описывать алгоритмы построения и алгоритмы тестирования
псевдослучайных последовательностей, введем основные понятия и определения. Последовательность - функция x одного натурального переменного, обладающая следующим
свойством: каково бы ни было принадлежащее
области определения функции x
натуральное число n, любое
удовлетворяющее условию m<n натуральное число m также принадлежит области
определения функции x. Областью
значений функции x может при этом
быть произвольное множество X.
Значение x(n) обычно называют членом последовательности x, имеющим номер n. Псевдослучайная
последовательность (ПСП) - последовательность чисел, которая была вычислена по
некоторому определённому арифметическому правилу, но имеет все свойства
случайной последовательности чисел в рамках решаемой задачи. Генератор псевдослучайных чисел (ГПСЧ) - алгоритм,
генерирующий последовательность чисел, элементы которой почти независимы друг
от друга и подчиняются заданному распределению. Равномерно распределенная псевдослучайная последовательность(РРПП) - это
случайная последовательность x1,x2,…,xt,xt+1,… со значениями в дискретном
множестве A = {0,1,…,N-1}, определенная на вероятностном пространстве (Ω,
F, P) и удовлетворяющая двум свойствам С1 и С2.
1.1 Свойства
равномерно распределенной псевдослучайной последовательности
Свойство
С1. Для любого 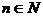 и произвольных значений индексов 1≤t1<…<tn случайные величины
и произвольных значений индексов 1≤t1<…<tn случайные величины 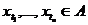 независимы в совокупности.
независимы в совокупности.
Свойство
С2. Для любого номера 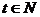 случайная величина xt
имеет дискретное равномерное на А распределение вероятностей:
случайная величина xt
имеет дискретное равномерное на А распределение вероятностей:
P{ xt = i} = 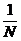 ,
,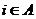 .
.
Из
базовых свойств С1, С2 вытекают следующие дополнительные свойства, используемые
при генерации случайных чисел. Свойство С3. Если {xt} -
РРСП, то для любого и любой фиксированной последовательности индексов 1≤t1<…<tn n-мерное
дискретное распределение вероятностей вектора(слова) (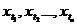 ) является равномерным:
) является равномерным:
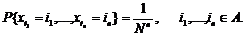
Свойство
С4. Если xt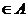 - элемент РРСП, то
- элемент РРСП, то 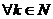 справедливы
следующие выражения его начального и центрального моментов k-ого
порядка:
справедливы
следующие выражения его начального и центрального моментов k-ого
порядка:
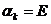 {
{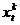 } =
} = 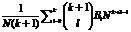 ;
;
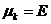 {
{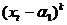 } =
} = 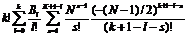 ,
,
где
{Bl} - числа Бернулли.
Свойство
С5. Для ковариационной функции и спектральной плотности РРСП {xt} справедливы следующие выражения:
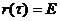 {
{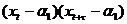 } =
} = 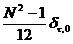 , τ
, τ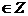
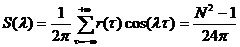 , λ
, λ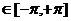 .
.
Свойство
С6. (воспроизводимость при прореживании). Для любой фиксированной
последовательности моментов времени 1≤t1<…<tn<tn+1<…
при "прореживании " РРСП {xt} возникает
подпоследовательность
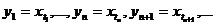 ,
,
которая
так же является РРСП. Свойство С7. (воспроизводимость при суммировании).
Если {xt} - РРСП, а 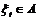 -
произвольная неслучайная либо случайная последовательность, не зависящая от {xt}, то случайная последовательность
-
произвольная неслучайная либо случайная последовательность, не зависящая от {xt}, то случайная последовательность
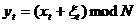
так
же является РРСП. Свойство С8. Если {xt} -
РРСП, то 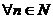 количество информации по Шеннону, содержащейся в
отрезке последовательности
количество информации по Шеннону, содержащейся в
отрезке последовательности 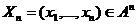 , о
будущем элементе
, о
будущем элементе 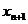 равно нулю:
равно нулю:
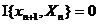
Поэтому
для любого алгоритма прогнозирования 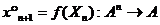 вероятность
ошибки прогнозирования не может быть меньше, чем для "угадывания по
жребию":
вероятность
ошибки прогнозирования не может быть меньше, чем для "угадывания по
жребию":
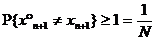 .
.
Свойство
С9. Если {xt} - РРСП, то для любого 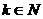 и
произвольной борелевской функции k переменных
и
произвольной борелевской функции k переменных 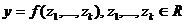 при
при 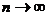 имеет место сходимость "почти наверное":
имеет место сходимость "почти наверное":
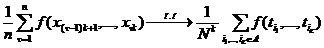 .
.
1.2
Генераторы псевдослучайных последовательностей
Современная
информатика широко использует псевдослучайные числа в самых разных приложениях
- от метода Монте-Карло и имитационного моделирования до криптографии. При этом
от качества используемых генераторов псевдослучайных чисел (ГПСЧ) напрямую
зависит качество получаемых результатов. Любой ГПСЧ с ограниченными ресурсами рано или поздно
зацикливается, то есть начинает повторять одну и ту же последовательность
чисел. Длина циклов ГПСЧ зависит от самого генератора и в среднем составляет
около 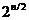 , где n - размер внутреннего состояния в битах, хотя
линейные конгруэнтные генераторы и генераторы на основе сдвиговых регистров
обладают максимальными циклами порядка 2n. Если ГПСЧ сходится к
слишком коротким циклам, такой ГПСЧ становится предсказуемым и является
непригодным. Большинство простых арифметических генераторов хотя и
обладают большой скоростью, но страдают от многих серьёзных недостатков:
, где n - размер внутреннего состояния в битах, хотя
линейные конгруэнтные генераторы и генераторы на основе сдвиговых регистров
обладают максимальными циклами порядка 2n. Если ГПСЧ сходится к
слишком коротким циклам, такой ГПСЧ становится предсказуемым и является
непригодным. Большинство простых арифметических генераторов хотя и
обладают большой скоростью, но страдают от многих серьёзных недостатков:
1. Слишком короткий период/периоды.
. Последовательные значения не являются независимыми.
. Некоторые биты "менее случайны", чем другие.
. Неравномерное одномерное распределение.
. Обратимость.
Генераторы псевдослучайных последовательностей бывают аппаратными (на
основе сдвиговых регистров) и программными (детерминированные генераторы,
генераторы с источником энтропии).
Классификация генераторов псевдослучайных последовательностей наглядно
представлена на следующем рисунке[1]:
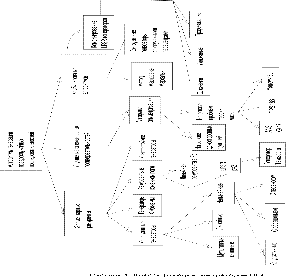
В этой работе будут рассмотрены следующие генераторы псевдослучайных
последовательностей: линейный конгруэнтный генератор, квадратичный конгруэнтный
генератор, RSA генератор ПСП, сдвиговый регистр как
генератор ПСП и самоуправляемый 2-линейный регистр сдвига.
1.2.1
Линейный конгруэнтный генератор (ЛКГ)[6].
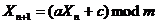 (1)
(1)
Где m - модуль, m>0;
a -
множитель, 0≤a<m;
c -
приращение, 0≤c<m;
X0 - начальное значение, 0≤X0<m;
Последовательность, полученная по формуле (1) называется линейной
конгруэнтной последовательностью. Конгруэнтная последовательность всегда
образует циклы. Это свойство является общим для всех последовательностей вида Xk = f(Xk-1), где f преобразует конечное множество само в себя. Повторяющиеся
циклы называются периодами.
Формулу (1) можно обобщить следующим образом, где (n+k)-ый член
последовательности выражается непосредственно через n -ый:
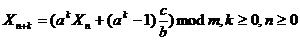
b = a - 1;
1.2.1.1 Выбор
модуля, множителя и приращения.[6]
При выборе модуля m
необходимо учитывать 2 фактора:
число m должно быть достаточно большим, так
как период последовательности не может быть больше, чем m.
нужно подобрать значение m так,
чтобы (aXn + c)modm вычислялось
быстро.
Теорема 1.
Линейная конгруэнтная последовательность, определенная числами m,a,c, и X0, имеет период максимальной длины m, тогда и только тогда, когда:
) Число c и m взаимно простые.
2) b = a - 1 кратно p для каждого простого p, являющегося делителем m.
3) b кратно 4, если m
кратно 4.
Чтобы доказать теорему рассмотрим вспомогательные теоретико-числовые
результаты.
Лемма 1.
Пусть p - простое число, а e - положительное целое число, такое
что, pe > 2. Если
 ,
,
 , то
, то (2)
(2)
 ,
, (3)
(3)
Лемма
2.
Пусть
число m допускает разложение на простые множители в виде
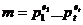
Длина
λ
линейной конгруэнтной последовательности,
определенной параметрами (X0,a,c,m),
является наименьшим общим кратным длин λj периодов
линейных конгруэнтных последовательностей
( ,
,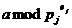 ,
,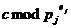 ,
,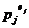 ), 1≤j≤t
), 1≤j≤t
Теперь
мы можем доказать теорему 1. Из леммы 2 следует, что теорему достаточно
доказать для случая, когда m является степенью простого числа, поскольку
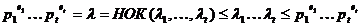
выполняется
тогда и только тогда, когда λj = для 1≤j≤t.
Предположим,
поэтому, что 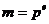 , где p - простое число, а е - целое положительное число. Так
как утверждение теоремы 1 очевидно при a = 1, то можно
считать, что a > 1. Период может иметь длину m
тогда и только тогда, когда каждое целое число x , такое что
0<x<m, встречается в этом периоде. Действительно, никакое
значение x не может встретиться в периоде более одного раза.
Таким образом, период последовательности имеет длину m тогда и только
тогда, когда период последовательности с начальным значением X0 = 0 имеет период длинной m. Поэтому
достаточно доказать теорему, когда X0 = 0. Справедлива
следующая формула:
, где p - простое число, а е - целое положительное число. Так
как утверждение теоремы 1 очевидно при a = 1, то можно
считать, что a > 1. Период может иметь длину m
тогда и только тогда, когда каждое целое число x , такое что
0<x<m, встречается в этом периоде. Действительно, никакое
значение x не может встретиться в периоде более одного раза.
Таким образом, период последовательности имеет длину m тогда и только
тогда, когда период последовательности с начальным значением X0 = 0 имеет период длинной m. Поэтому
достаточно доказать теорему, когда X0 = 0. Справедлива
следующая формула:
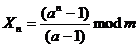 .(4)
.(4)
Если
c и m не взаимно простые числа, то значение Xn никогда не может быть равно 1. Следовательно, условие 1 теоремы
необходимо. Период имеет длину m тогда и только тогда, когда наименьшее положительное
значение n, для которого Xn=X0 = 0, равняется n=m. Из
(4) и условия 1 теоремы следует, что для доказательства теоремы необходимо
доказательства следующего утверждения.
Лемма
3.
Предположим, что 1<a<pe, где p - простое число. Если λ - наименьшее целое положительное число,
для которого (aλ - 1)/(a-1) ≡ 0(mod pe), то
λ = pe тогда и
только тогда, когда 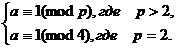

Доказательство:
Предположим,
что λ
= pe. Если a 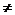 1(mod p), то (an - 1)/(a-1) ≡ 0(mod pe) тогда и только тогда, когда (an -
1) ≡ 0(mod pe). Значит условие
1(mod p), то (an - 1)/(a-1) ≡ 0(mod pe) тогда и только тогда, когда (an -
1) ≡ 0(mod pe). Значит условие 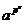 - 1≡ 0(mod pe) влечет равенство ≡
1 (mod p), но = a(mod p). Таким образом, предположение, что a 1(mod p), приводит к противоречию. Если
p = 2, a = 3 (mod 4), то
- 1≡ 0(mod pe) влечет равенство ≡
1 (mod p), но = a(mod p). Таким образом, предположение, что a 1(mod p), приводит к противоречию. Если
p = 2, a = 3 (mod 4), то
(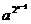 - 1)/(a-1) ≡ 0(mod 2e).
- 1)/(a-1) ≡ 0(mod 2e).
Эти
рассуждения показывают, что в большинстве случаев необходимо, чтобы a =
1+ qpf, где pf >
2 и q не кратны p, когда λ = pe.
Докажем
достаточность. По лемме 1, для всех g > 0:
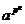 ≡
1(mod pf+g), 1(mod
pf+g+1),
≡
1(mod pf+g), 1(mod
pf+g+1),
следовательно
( - 1)/(a-1) ≡
0(mod pg)
( - 1)/(a-1) 0 (mod pg+1)(5)
В
частности, ( - 1)/(a-1) ≡
0(mod pe). Тогда для конгруэнтной последовательности,
определяемой параметрами (0,a,1,pe) Xn, справедливо Xn =
(an -
1)/(a-1) ≡ 0(mod pe). Значит, ее период равен λ, то есть Xn = 0 тогда и только тогда, когда n
кратно λ . Следовательно, pe
кратно λ. Это возможно только, если λ = pg для некоторый g и соотношения (5) означают, что λ = pe.
Теорема
1 доказана.
1.2.2
Квадратичный конгруэнтный генератор
Этот
алгоритм генерации псевдослучайной последовательности 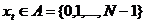 определяется квадратичным рекуррентным соотношением:
определяется квадратичным рекуррентным соотношением:
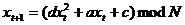 , t
=0,1,…,(6)
, t
=0,1,…,(6)
Где
x0,a,c,d - параметры генератора. Выбор этих параметров
осуществляется на основе следующих 2ух свойств последовательности (6).
Свойство
С1. Квадратичная конгруэнтная последовательность (6) имеет наибольший период 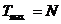 тогда и только тогда, когда выполнены следующие
условия:
тогда и только тогда, когда выполнены следующие
условия:
1) c,N - взаимно простые числа;
2) d,a-1 - кратны p, где p -
любой нечетный простой делитель N.
3) d - четное число, причем
d = 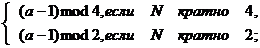
4) если
N кратно 9, то 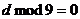 , либо
, либо 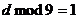 и
и 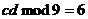
Свойство
С2. Если 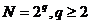 , то наибольший период
, то наибольший период 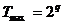 тогда и
только тогда, когда c - нечетно, d - четно, a -
нечетное число, удовлетворяющее соотношению
тогда и
только тогда, когда c - нечетно, d - четно, a -
нечетное число, удовлетворяющее соотношению
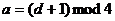
1.2.3 RSA-алгоритм генерации псевдослучайных
последовательностей
Этот
алгоритм основывается на том факте, что в настоящее время в криптоанализ RSA
не может быть осуществлен с полиномиальной сложностью. RSA-алгоритм
генерации двоичной псевдослучайной последовательности 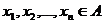 состоит из шести шагов.
состоит из шести шагов.
) Сгенерировать
достаточно большие простые различные числа p,q и
вычислить числа 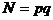 ,
, 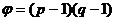 .
Выбирать случайное целое число k,
.
Выбирать случайное целое число k, 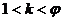 , взаимно
простое с φ,
так, что НОД(k, φ) = 1.
, взаимно
простое с φ,
так, что НОД(k, φ) = 1.
) Выбрать
случайное целое - стартовое значение - 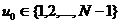 .
.
) Для
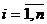 выполнить шаги 4,5.
выполнить шаги 4,5.
) Вычислить
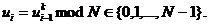
) Вычислить
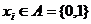 - самый младший бит числа
- самый младший бит числа 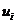 в двоичном представлении.
в двоичном представлении.
) Сформировать
выходную последовательность 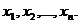
Недостатком RSA - алгоритма
является его невысокое быстродействие при реализации на универсальных
компьютерах, вызванное большими затратами машинного времени при выполнении
модулярного умножения на шаге 4.
1.2.4
Линейный сдвиговый регистр с обратной связью (LFSR).
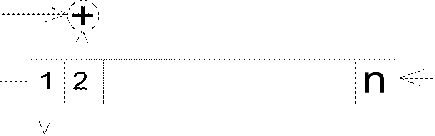
Регистры сдвига или сдвиговые регистры (англ. shift register)
представляют собой последовательно соединенную цепочку триггеров. Основной
режим их работы - это сдвиг разрядов кода, записанного в эти триггеры. То есть
по тактовому сигналу содержимое каждого предыдущего триггера переписывается в
следующий по порядку в цепочке триггеров. Код, хранящийся в регистре, с каждым
тактом сдвигается на один разряд в сторону старших разрядов или в сторону
младших разрядов.
Сдвиговый
регистр с обратной связью состоит из двух частей: сдвигового регистра и функции
обратной связи. Длина сдвигового регистра - количество битов. Когда нужно
извлечь бит, все биты сдвигового регистра сдвигаются вправо или влево на одну
позицию. Новый крайний слева бит определяется функцией остальных битов
регистра. На выходе сдвигового регистра оказывается один, обычно младший,
значащий бит. Период сдвигового регистра - длина получаемой последовательности
до начала ее повторения. Для LFSR функция обратной связи представляет собой
сумму по модулю 2 (xor) некоторых битов регистра (эти биты называются отводной
последовательностью). LFSR может находиться в 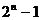 внутренних
состояниях, где n - длина сдвигового регистра. Если сдвиговый регистр заполнен
нулями, то такое состояние будет порождать на выходе только нули (так как в
качестве функции обратной связи используется xor), поэтому такое состояние
бесполезно. Теоретически LFSR может генерировать последовательность с длиной
бит, так как длина последовательности совпадает с
количеством внутренних состояний. LFSR будет проходить все внутренние состояния
(иметь максимальный период) только при определённых отводных
последовательностях - если многочлен, образованный из отводной
последовательности и константы 1, является примитивным по модулю 2. Степень
многочлена - длина сдвигового регистра. Примитивный многочлен степени n - это
неприводимый многочлен, который является делителем
внутренних
состояниях, где n - длина сдвигового регистра. Если сдвиговый регистр заполнен
нулями, то такое состояние будет порождать на выходе только нули (так как в
качестве функции обратной связи используется xor), поэтому такое состояние
бесполезно. Теоретически LFSR может генерировать последовательность с длиной
бит, так как длина последовательности совпадает с
количеством внутренних состояний. LFSR будет проходить все внутренние состояния
(иметь максимальный период) только при определённых отводных
последовательностях - если многочлен, образованный из отводной
последовательности и константы 1, является примитивным по модулю 2. Степень
многочлена - длина сдвигового регистра. Примитивный многочлен степени n - это
неприводимый многочлен, который является делителем 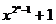 , но не является делителем
, но не является делителем 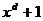 для всех d, делящих .
для всех d, делящих .
Преимущества генератора ПСП, основанного на сдвиговом регистре:
эффективная аппаратная реализация;
быстродействие.
Недостатки:
генераторы на основе регистров образуют только циклические
последовательности чисел. Для получения нециклических последовательностей
необходимо использовать дополнительный комбинационный преобразователь кодов,
включаемый на выходе генератора. Но при этом основные параметры генератора -
быстродействие, мощность, площадь кристалла - ухудшаются.
1.2.5 Самоуправляемый 2-линейный регистр сдвига
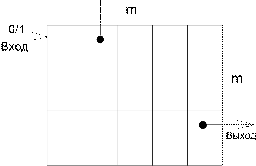
Возьмем
2 неприводимых многочлена 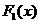 и
и 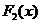 , причем
, причем 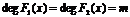 , и составим соответствующую матрицу размером m*m.
, и составим соответствующую матрицу размером m*m.
На
вход генератора подается либо "0", либо "1".
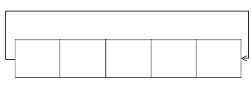
Если
на вход генератора подается "0", то все строки генератора
преобразуются в соответствии с заданным законом рекурсии .
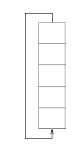
Если
на вход генератора подается "1", то все столбцы матрицы преобразуются
в соответствии с законом рекурсии .
Начальное
заполнение генератора - любое, кроме нулевого.
1.3
Тестирование
1.3.1
Универсальный алгоритм статистического тестирования случайных и псевдослучайных
последовательностей
В
современных криптосистемах интенсивно используются равномерно распределенные
случайные последовательности или имитирующие их псевдослучайные
последовательности. Стойкость криптосистем существенно зависит от того,
насколько точно соответствует модели РРСП используемая последовательность xt 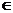 A(t = 1,2…). Проверка близости {xt} к
модели РРСП осуществляется методами статистического тестирования и состоит в
проверке выполнения гипотез базовых свойств С1,С2 РРСП. Иногда вместо базовых
свойств С1 и С2 проверяют выполнение свойств С3-С10 РРСП, следующих из С1 и С2. Сформулируем
универсальный алгоритм статистического тестирования случайных и псевдослучайных
последовательностей. Пусть имеется программный (физический или табличный)
генератор, порождающий псевдослучайную (случайную) последовательность:
A(t = 1,2…). Проверка близости {xt} к
модели РРСП осуществляется методами статистического тестирования и состоит в
проверке выполнения гипотез базовых свойств С1,С2 РРСП. Иногда вместо базовых
свойств С1 и С2 проверяют выполнение свойств С3-С10 РРСП, следующих из С1 и С2. Сформулируем
универсальный алгоритм статистического тестирования случайных и псевдослучайных
последовательностей. Пусть имеется программный (физический или табличный)
генератор, порождающий псевдослучайную (случайную) последовательность:
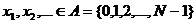
необходимой
длины. Пусть определены 2 гипотезы: 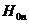 - о том,
что наблюдаемая последовательность
- о том,
что наблюдаемая последовательность 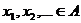 заданной
длины является РРСП и имеет место n-мерное
дискретное равномерное распределение вероятностей;
заданной
длины является РРСП и имеет место n-мерное
дискретное равномерное распределение вероятностей; 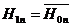 - альтернатива общего вида, утверждающая, что свойство
С3 нарушено и {xt} не соответствует модели РРСП. Согласно принятой в
математической статистике классификации, гипотеза является простой, а
- альтернатива общего вида, утверждающая, что свойство
С3 нарушено и {xt} не соответствует модели РРСП. Согласно принятой в
математической статистике классификации, гипотеза является простой, а 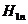 -
сложной.
-
сложной.
Пусть
для 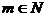 построена некоторая m-мерная
векторная статистика
построена некоторая m-мерная
векторная статистика
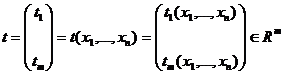 ,(7)
,(7)
удовлетворяющая
2ум условиям:
1) Найдено дискретное распределение вероятностей
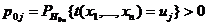 ,
, 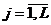 (8)
(8)
статистики
(7) при верной гипотезе , где 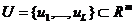 -
конечное множество L упорядоченных возможных значений статистики (7).
-
конечное множество L упорядоченных возможных значений статистики (7).
) При
верной альтернативе дискретное распределение вероятностей
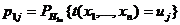 , (9)
, (9)
статистики
(7) отличается от распределения (8).
Универсальный
алгоритм тестирования основан на выявлении различия дискретных вероятностных
распределений (8) и (9) по наблюдаемой выборке с помощью 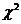 -критерия согласия Пирсона и состоит из пяти этапов.
-критерия согласия Пирсона и состоит из пяти этапов.
. Генерируем
подпоследовательность длиной 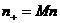 и
разбиваем ее на M фрагментов:
и
разбиваем ее на M фрагментов:
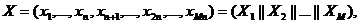
где
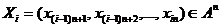 - i-ый фрагмент
- i-ый фрагмент 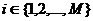 длиной n;
длиной n;
M - количество
фрагментов.
. Для
i-го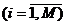 фрагмента
фрагмента 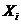 вычисляем значение m-мерной
статистики (7):
вычисляем значение m-мерной
статистики (7):
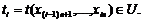
3. По сформированной таким образом выборке объема M вычисляем частоту встречаемости всех
возможных значений статистики t(.):
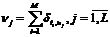 ,(10)
,(10)
где
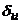 - символ Кронекера.
- символ Кронекера.
4. Вычисляем
-статистику Пирсона:
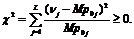 (11)
(11)
5. Выносим решение по правилу:
Принимается
гипотеза 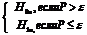 (12)
(12)
где
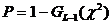 - так называемое P-значение для
статистики (11);
- так называемое P-значение для
статистики (11);
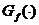 -
функция - распределения с f степенями
свободы;
-
функция - распределения с f степенями
свободы; 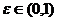 - задаваемый уровень значимости теста.
- задаваемый уровень значимости теста.
Уровень
значимости теста - это традиционное понятие проверки гипотез в частотной
статистике. Он определяется как вероятность принять решение отклонить
нуль-гипотезу, если на самом деле нуль-гипотеза верна (решение известное как
ошибка первого рода, или ложноположительное решение.) Уровень значимости
обыкновенно обозначают греческой буквой α (альфа). Популярными уровнями значимости являются 5%, 1%, и 0.1%.
Различные значения α-уровня имеют свои достоинства и недостатки. Меньшие α-уровни дают бо́льшую уверенность в том, что уже установленная альтернативная гипотеза значима,
но при этом есть больший риск не отвергнуть ложную нуль-гипотезу (ошибка
второго рода, или "ложноотрицательное решение"), и таким образом
меньшая статистическая мощность. Выбор α-уровня неизбежно требует компромисса между значимостью и мощностью, и
следовательно между вероятностями ошибок первого и второго рода.
Замечание
1.
При
увеличении количества фрагментов 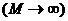 асимптотический
размер теста (10)-(12), то есть вероятность ошибки первого рода, совпадает с
заданным уровнем значимости
асимптотический
размер теста (10)-(12), то есть вероятность ошибки первого рода, совпадает с
заданным уровнем значимости 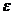 :
:
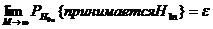 ,
,
и
тест является состоятельным, то есть его мощность стремится к единице
(вероятность ошибки второго рода стремится к нулю):
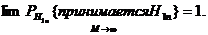
Замечание
2.
Для
практического применения теста (10)-(12) необходимо выбирать количество
фрагментов M так, чтобы 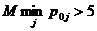 .
.
1.3.2
Статистический набор тестов НИСТ
В 1999 году разработчиками НИСТ(Национальный институт стандартизации и
технологий США) в рамках проекта AES(Advanced Encryption Standard) был
представлен статистический набор тестов НИСТ (NIST Statistical Test Suite) и
предложена методика проведения статистического тестирования шифров и
генераторов случайных чисел.
Для принятия решения, достаточно ли случайна последовательность значений,
вырабатываемая шифром или генератором псевдослучайных чисел, используется
несколько подходов:
−
первый и самый простой из них - это принятие положительного решения о
случайности выхода шифра в зависимости от заданного порогового уровня
случайности. Для этого вычисляют специальную статистическую характеристику 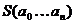 от последовательности выхода
от последовательности выхода 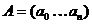 шифра и сравнивают ее с заранее заготовленными
эталонными значениями. При этом считается, что двоичная последовательность A не
проходит статистический тест всякий раз, когда статистика теста S принимает
значение меньшее, чем пороговый уровень Srange.;
шифра и сравнивают ее с заранее заготовленными
эталонными значениями. При этом считается, что двоичная последовательность A не
проходит статистический тест всякий раз, когда статистика теста S принимает
значение меньшее, чем пороговый уровень Srange.;
−
следующий критерий - принятие решения на основе задания доверительного интервала.
В этом случае двоичная последовательность A не проходит статистический тест,
если значение статистики теста S находится вне пределов доверительного
интервала значений статистики, вычисленного для заданного уровня значимости 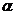 . Критерий на основе доверительного интервала намного
более надежен по сравнению с предыдущим;
. Критерий на основе доверительного интервала намного
более надежен по сравнению с предыдущим;
−
еще один способ определения решения заключается в вычислении для некоторой
статистической функции S значения соответствующей ей и последовательности A
вероятности Р. В этом случае статистика теста рассматривается как реализация
случайной величины, которая подчиняется определенному закону распределения.
Обычно статистическую функцию строят таким образом, чтобы всплески ее значений
указывали на наличие неслучайных дефектов в представляемой на рассмотрение
случайной последовательности чисел. Вероятность P означает вероятность того,
что статистика примет значения большие, чем это возможно для случайной
последовательности. Обратно, малые значения этой вероятности говорят о
прохождении последовательностью A тестов на случайность.
Пакет
НИСТ включает в себя 16 статистических тестов, которые разработаны для проверки
гипотезы о случайности представляемой двоичной последовательности любой длины.
В таблице 1 даны общие характеристики каждого статистического теста НИСТ.
|
Табл.1 Статистические тесты
НИСТ
|
|
Статистический тест
|
Определяемый дефект
|
|
1. Частотный тест
|
Слишком много нулей или
единиц
|
|
2. Проверка кумулятивных
сумм
|
Слишком много нулей или
единиц в начале последовательности
|
|
3. Проверка
"дырок" в подпоследовательностях
|
Отклонения в распределении
подпоследовательностей единиц
|
|
4. Проверка
"дырок"
|
Большое (малое) число
подпоследовательностей нулей и единиц свидетельствует, что колебание потока
бит слишком быстрое (медленное)
|
|
5. Проверка рангов матриц
|
Отклонение распределения
рангов матриц от соответствующего распределения для истинно случайной
последовательности, связанное с периодичностью подпоследовательностей
|
|
6. Спектральный тест
|
Периодические свойства
последовательности
|
|
7. Проверка
непересекающихся шаблонов
|
Непериодические шаблоны
встречаются слишком часто
|
|
8. Проверка пересекающихся
шаблонов
|
Слишком часто встречаются
m-битные последовательности единиц
|
|
9. Универсальный статистический
тест Маурера
|
Сжимаемость (регулярность)
последовательности
|
|
10. Проверка случайных
отклонений
|
Отклонение от распределения
числа появлений случайных отклонений определенного значения
|
|
11. Разновидность проверки
случайных отклонений
|
Отклонение от распределения
общего числа появлений (среди множества случайных отклонений) конкретного
состояния
|
|
12. Проверка
аппроксимированной энтропии
|
Неравномерность
распределения m-битных слов. Малые значения означают высокую повторяемость
|
|
13. Сжатие при помощи
алгоритма Лемпела-Зива
|
Большую сжимаемость, чем
истинно случайная последовательность
|
|
14. Линейная сложность
|
Отклонение от распределения
линейной сложности для конечной длины подстроки
|
В данной работе реализованы следующие тесты:
тест n-серий;
универсальный статистический тест Маурера;
критерий серий;
1.3.3 Тест n-серий
Тест n-серий является классическим тестом n-мерной равномерности. Он является
частным случаем универсального алгоритма тестирования (10)-(12), описанного в
1.3.1:
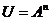 ,
, 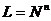 ;
; 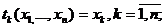
m=n; 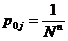 ,
, 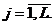 (13)
(13)
При
этом вычисляемая статистика 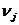 - это
частота встречаемости j-й возможной n-серии
- это
частота встречаемости j-й возможной n-серии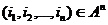 :
:
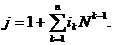
Серии,
отличающиеся только перестановкой символов, считаются различными, поэтому общее
количество серий 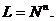
С
учетом (13) и замечания 2 для применения теста требуется, чтобы количество M
фрагментов исследуемой последовательности 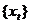 было не
менее критической величины
было не
менее критической величины
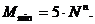
Таким
образом, при увеличении исследуемого порядка равномерности n
требуемое количество фрагментов растет экспоненциально быстро. В этом
заключается главный недостаток теста n-серий.
1.3.4
Универсальный статистический тест Маурера
Универсальный статистический тест Маурера основан на следующей идее:
последовательность случайна, когда ее невозможно значительно упаковать или
сжать. Для этого вводится мера, которая оценивает степень сжимаемости.
Пусть
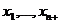 - наблюдаемая последовательность над алгоритмом
- наблюдаемая последовательность над алгоритмом 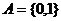 ,
, 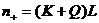 , где K,Q и L -
фиксированные натуральные числа. Параметр L-длина
фрагмента, Q - количество начальных данных теста, K -
количество основных шагов теста. Пусть
, где K,Q и L -
фиксированные натуральные числа. Параметр L-длина
фрагмента, Q - количество начальных данных теста, K -
количество основных шагов теста. Пусть 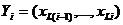 -
фрагмент (слово) длиной L и
-
фрагмент (слово) длиной L и 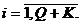
Для
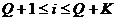 определим величину
определим величину
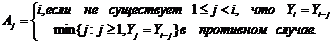 (14)
(14)
Универсальный
статистический тест Маурера основан на следующей статистике (мере сжимаемости):
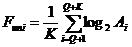 (15)
(15)
Теорема
2.(Маурер) Если выполняется гипотеза 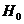 и
и 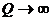 , то для статистик (14) и (15) моменты имеют вид
, то для статистик (14) и (15) моменты имеют вид
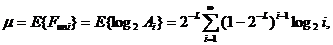 (16)
(16)
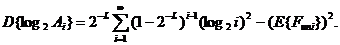 (17)
(17)
Дисперсия
статистики 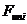 вычисляется по формуле
вычисляется по формуле
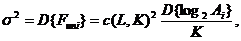 (18)
(18)
где
для 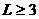
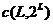 близко к 0.8, и если
близко к 0.8, и если 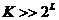 , то c(L,K)
близко к 0.5,0.6 и 0.65 соответственно для L=4, L=8 и
L=12. Для
, то c(L,K)
близко к 0.5,0.6 и 0.65 соответственно для L=4, L=8 и
L=12. Для 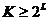 достаточна
точна аппроксимация:
достаточна
точна аппроксимация:
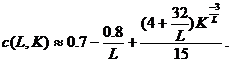 (19)
(19)
На
практике L рекомендуется выбирать от 6 до 16, 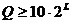 и K "как можно больше"(например,
и K "как можно больше"(например, 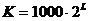 ).
).
Универсальный
статистический тест Маурера, таким образом, имеет вид.
. Выбираются
параметры Q,K,L и регистрируется последовательность 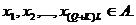
. На
основании последовательности 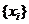 строится
статистика .
строится
статистика .
. Принимается
гипотеза
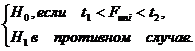 (20)
(20)
где
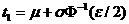 и
и 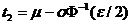 ; ε - уровень значимости критерия;
; ε - уровень значимости критерия; 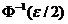 - квантиль уровня ε/2 стандартного нормального распределения.
- квантиль уровня ε/2 стандартного нормального распределения.
1.3.5
Критерий серий
Критерий
серий применяется для проверки гипотезы H0, утверждающей, что элементы выборки получены
случайным образом и независимы. Пусть 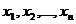 -
выборка результатов наблюдений, а
-
выборка результатов наблюдений, а 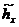 -
выборочная медиана, определенная по этим данным. Каждому элементу выборки ставим
в соответствие "+" или "-" в зависимости от того, больше
или меньше медианы его значение(нулевые значения не учитываются). Тем самым
всей выборке поставлен в соответствие набор знаков. Обозначим n1 число знаков "+", n2 - "-" в полученном наборе знаков. Серией в
этом наборе называется всякая последовательность, состоящая из одинаковых
знаков и ограниченная противоположенными знаками, либо находящаяся в конце или
в начале набора. Статистика критерия - число серий N.
Критическая область определяется неравенствами
-
выборочная медиана, определенная по этим данным. Каждому элементу выборки ставим
в соответствие "+" или "-" в зависимости от того, больше
или меньше медианы его значение(нулевые значения не учитываются). Тем самым
всей выборке поставлен в соответствие набор знаков. Обозначим n1 число знаков "+", n2 - "-" в полученном наборе знаков. Серией в
этом наборе называется всякая последовательность, состоящая из одинаковых
знаков и ограниченная противоположенными знаками, либо находящаяся в конце или
в начале набора. Статистика критерия - число серий N.
Критическая область определяется неравенствами 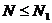 и
и 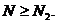 При больших объемах выборки, когда n1, либо n2, либо
оба значения больше 20, для проверки гипотезы H0 можно использовать статистику Z,
выборочное значение которой вычисляется по формуле:
При больших объемах выборки, когда n1, либо n2, либо
оба значения больше 20, для проверки гипотезы H0 можно использовать статистику Z,
выборочное значение которой вычисляется по формуле:
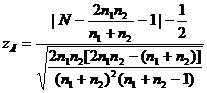 ,(21)
,(21)
При
условии, что верна гипотеза H0,
статистика Z имеет приблизительно нормальное распределение N(0,1).
В этом случае критическая область определяется неравенствами:
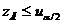 или
или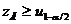 .
.
Замечание:
Критерий серий применяется для проверки случайности любой выборки, элементами
которой являются два различных символа, например: 1 и 0, A и B,
"+" и "-".
1.4 Задачи
многокритериальной оптимизации
Многие практические задачи приводят к необходимости решения так
называемых задач многокритериальной оптимизации. Эти задачи возникают в тех
случаях, когда необходимо с помощью одного акта принятия решений добиться
наилучшего выполнения нескольких возможно противоречивых целей. С
математической точки зрения задачи многокритериальной оптимизации являются
естественным обобщением обычных задач оптимизации.
Пусть
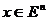 есть n-мерный вектор конструктивных параметров создаваемого
изделия и задано допустимое множество X, которому должны принадлежать
вектора x. Качество изделия оценивается набором критериев
есть n-мерный вектор конструктивных параметров создаваемого
изделия и задано допустимое множество X, которому должны принадлежать
вектора x. Качество изделия оценивается набором критериев 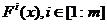 . Этот набор объединим единым символом
. Этот набор объединим единым символом 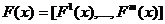 , называемым векторным критерием.
, называемым векторным критерием.
Наша
задача подобрать такую допустимую точку 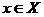 , чтобы
все компоненты вектора
, чтобы
все компоненты вектора 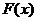 принимали возможно меньшие значения. Это условие
обычно бывает невыполнимо: минимизация какой-нибудь одной компоненты F
приводит к увеличению других компонент.
принимали возможно меньшие значения. Это условие
обычно бывает невыполнимо: минимизация какой-нибудь одной компоненты F
приводит к увеличению других компонент.
Задачу
многокритериальной минимизации на
множестве X будем обозначать
 (22)
(22)
Определим
множество
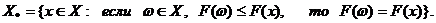
(Векторное
неравенство 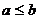 , где
, где 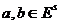 означает,
что выполнены покомпонентные неравенства
означает,
что выполнены покомпонентные неравенства 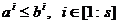 , или,
что то же самое, выполнено любое из неравенств:
, или,
что то же самое, выполнено любое из неравенств:
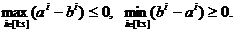 )
)
Введем
образы множеств X и  при
отображении
при
отображении 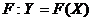 ,
, 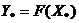 . Задачу
(22) перепишем в виде
. Задачу
(22) перепишем в виде
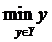 .(23)
.(23)
Множество
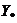 можно определить условием
можно определить условием
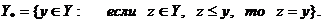
Пространство
n-мерных векторов будем
называть пространством параметров. Пространство m-мерных
векторов 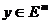 назовем пространством критериев. Множество называется множеством Парето в пространстве
критериев, множество - множеством Парето в пространстве параметров.
назовем пространством критериев. Множество называется множеством Парето в пространстве
критериев, множество - множеством Парето в пространстве параметров.
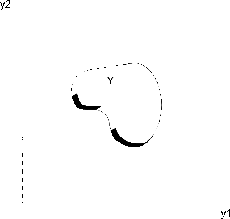
Рисунок
2. Множество Парето.
На
рисунке 2 для двухкритериальной задачи (m=2) показаны
множества Парето в пространстве критериев (жирная линия), множество
достижимых критериев Y (лежит внутри и на границе области, ограниченной
сплошной линией). С каждой точкой 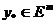 можно
связать отрицательный и положительный ортанты:
можно
связать отрицательный и положительный ортанты: 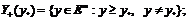
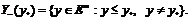 Можно сказать, что
Можно сказать, что 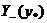 -
совокупность точек, лучших, чем
-
совокупность точек, лучших, чем 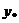 , а
, а 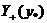 - худших, чем . Точки,
принадлежащие множеству Парето в пространстве критериев, таковы, что для каждой
точки
- худших, чем . Точки,
принадлежащие множеству Парето в пространстве критериев, таковы, что для каждой
точки 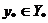 множество лучших точек не
содержит ни одной точки из множества Y. Можно множество назвать юго-западом точки , а множество -
северо-востоком. Тогда для каждой точки из множества Парето в пространстве
критериев пересечение ее юго-запада с множеством допустимых критериев Y
пусто.
множество лучших точек не
содержит ни одной точки из множества Y. Можно множество назвать юго-западом точки , а множество -
северо-востоком. Тогда для каждой точки из множества Парето в пространстве
критериев пересечение ее юго-запада с множеством допустимых критериев Y
пусто.
Понятия
"лучший", "худший" можно перенести из пространства
критериев в пространство параметров. Будем говорить, что точка лучше точки  (или z
хуже, чем x), если
(или z
хуже, чем x), если 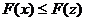 ,
, 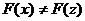 . Множество , таким
образом, представляет собой объединение таких точек, что для каждой из них
. Множество , таким
образом, представляет собой объединение таких точек, что для каждой из них 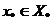 нет ни одной точки из X, лучшей, чем
нет ни одной точки из X, лучшей, чем 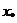 . Эта идея отражена в определении множества . Под точным решением задачи многокритериальной
оптимизации (22) или эквивалентной ей задачи (23) мы понимаем нахождение
множества Парето в пространстве параметров , которое
в дальнейшем будем называть множеством оптимальных решений задачи (22).
Структура множества даже для простейших задач оказывается сложной. Ее
описание с помощью аппроксимационных формул трудно реализуемо, поэтому введем
понятие ε
- оптимального решения. Далее считаем,
что множество X не пусто, каждая компонента вектор-функции F(x)
удовлетворяет на X условию Липшица с одной и той же константой Липшица L,
т.е. для любых x и z из X выполнены условия
. Эта идея отражена в определении множества . Под точным решением задачи многокритериальной
оптимизации (22) или эквивалентной ей задачи (23) мы понимаем нахождение
множества Парето в пространстве параметров , которое
в дальнейшем будем называть множеством оптимальных решений задачи (22).
Структура множества даже для простейших задач оказывается сложной. Ее
описание с помощью аппроксимационных формул трудно реализуемо, поэтому введем
понятие ε
- оптимального решения. Далее считаем,
что множество X не пусто, каждая компонента вектор-функции F(x)
удовлетворяет на X условию Липшица с одной и той же константой Липшица L,
т.е. для любых x и z из X выполнены условия 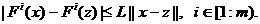 Отсюда
следует векторной условие
Отсюда
следует векторной условие
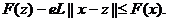 (24)
(24)
(e -
единичный m-мерный вектор).
Определение: Множество 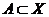 называется ε-оптимальным решением задачи (22), если:
называется ε-оптимальным решением задачи (22), если:
) Для
каждой точки найдется такая точка 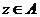 , что
, что
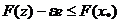 (25)
(25)
2) В
множестве A нет таких двух различных точек x и z,
что 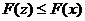 . Векторное неравенство (25) эквивалентно выполнению
любого из следующих двух скалярных неравенств:
. Векторное неравенство (25) эквивалентно выполнению
любого из следующих двух скалярных неравенств:
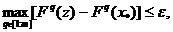
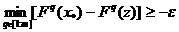 .(26)
.(26)
Второе
условие ε-оптимальности можно переформулировать так: для любых
разных точек x и z из A выполнены эквивалентные между собой неравенства:
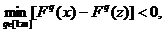
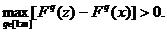
Другими
словами, у вектора 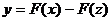 наименьшая компонента строго отрицательная,
наибольшая - строго положительная. Тем самым ни об одной точке из A
нельзя сказать, что она лучше или хуже любой другой точки из A.
Нет среди них точек, имеющих один и тот же образ, т.е.
наименьшая компонента строго отрицательная,
наибольшая - строго положительная. Тем самым ни об одной точке из A
нельзя сказать, что она лучше или хуже любой другой точки из A.
Нет среди них точек, имеющих один и тот же образ, т.е. 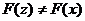 для всех точек z и x из A.
для всех точек z и x из A.
Зададим
набор точек 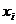 из допустимого множества X и обозначим
эту совокупность
из допустимого множества X и обозначим
эту совокупность 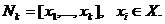 В каждой точке
В каждой точке 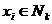 вычислим
векторный критерий. Количество точек в наборе
вычислим
векторный критерий. Количество точек в наборе 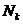 будем
увеличивать специальным образом, определяя при этом последовательность
множества
будем
увеличивать специальным образом, определяя при этом последовательность
множества 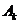 таким образом, чтобы в конце расчетов множество оказалось ε-оптимальным решением задачи (22).
таким образом, чтобы в конце расчетов множество оказалось ε-оптимальным решением задачи (22).
Правило
построения множества .
Множество
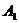 состоит из одной точки
состоит из одной точки 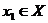 . Пусть
известны
. Пусть
известны 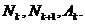 В допустимой
точке
В допустимой
точке 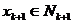 вычислим вектор
вычислим вектор 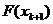 .
.
Возможны
3 случая:
) Если
оказалось, что среди элементов 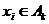 есть
такие, что
есть
такие, что 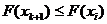 ,
, 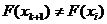 , то все
они удаляются из ; точка
, то все
они удаляются из ; точка 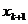 включается
в множество . Полученное множество обозначается через
включается
в множество . Полученное множество обозначается через 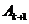 .
.
) Если
оказалось, что существует хотя бы один такой элемент , что 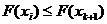 , то не включается в .
Множество обозначается через .
, то не включается в .
Множество обозначается через .
) Если
не выполнены условия предыдущих двух случаев, то точка включается в множество , которое
обозначается далее .
2. Практическая
часть
В данной работе были реализованы и протестированы следующие виды
генераторов ПСП:
Линейный конгруэнтный генератор(ЛКГ);
Квадратичный конгруэнтный генератор(ККГ);
RSA -
генератор;
Генератор ПСП на основе сдвигового регистра;
Генератор ПСП на основе самоуправляемого 2-линейного регистра сдвига.
2.1
Реализация линейного конгруэнтного генератора
Напомним формулу для получения последовательности с помощью линейного
конгруэнтного генератора:
Программа,
реализующая линейный конгруэнтный генератор, носит название LKG.
При запуске программы необходимо ввести длину последовательности. Выходная
последовательность записывается в 2 файла: SQ_linear.txt - в десятичном виде,
SQ_linear_b.txt - в двоичном виде. При переводе из десятичной записи числа в
двоичную оставляем значение старшего разряда.
Пример
1.
Для
корректной работы программы необходимо задать параметры линейного конгруэнтного
генератора. Для примера возьмем следующие параметры:
a = 61, c =
7, m = 10000000, x0 = 625.
Выбор
именно таких параметров удовлетворяет заданным условиям, необходимым для
достижения максимального периода:
1) Число c и m взаимно простые.
2) b = a - 1 кратно p для каждого простого p, являющегося делителем m.
3) b кратно 4, если m
кратно 4.
Результат работы программы можно представить в виде диаграммы:
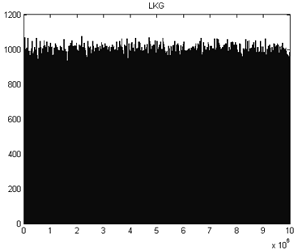
По диаграмме видно, что полученная последовательность имеет равномерное
распределение, но диаграммы не достаточно для проверки случайности
последовательности.
2.2
Реализация конгруэнтного квадратичного генератора
Программа,
реализующая квадратичный конгруэнтный генератор, называется KKG.
При запуске программы необходимо ввести длину выходной последовательности.
Выходная последовательность записывается в десятичном и двоичном виде в файлы
SQ_kvadrat.txt и SQ_kvadrat_b.txt соответственно.
Пример
2.
Для
корректной работы программы были выбраны следующие значения параметров
конгруэнтного квадратичного генератора:
=
3, d = 22, c = 7, N = 231 , x0 = 258.
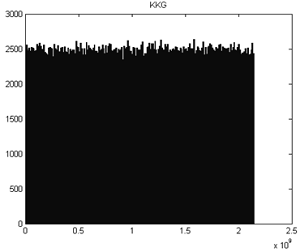
По
диаграмме можно предположить, что полученная последовательность имеет
равномерное распределение.
2.3
Реализация RSA - алгоритма генерации
псевдослучайных последовательностей
В соответствии с алгоритмом необходимо сгенерировать два различных
достаточно больших простых числа p и q.
В качестве таких чисел взяты следующие:
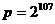 ,
, 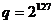
Для
работы с большими числами был реализован специальный класс. Недостатком RSA-алгоритма
является его невысокое быстродействие при выполнении модулярного умножения 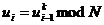 . Достоинство RSA-алгоритма -
его криптостойкость.
. Достоинство RSA-алгоритма -
его криптостойкость.
Выходная
последовательность хранится в файле SQ_rsa.txt
Пример
3. Последовательность, полученная в результате работы алгоритма.
01100001100111111011000101110000101100111100111011000110101001000010111100011101001001101101100011100001101110011110000111010101110001001101000111011100101001111
2.4
Реализация сдвигового регистра
Сдвиговый
регистр реализован в виде динамического массива. Размер регистра - 29 .
Максимальный период для выходной последовательности равен 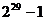 . Что касается начального заполнения регистра, то
возьмем его равным (0,0,0,...,0,1). Тогда минимальный многочлен полученной ЛРП
будет равен характеристическому многочлену, и период будет максимально
возможным для данной функции обратной связи. Для получения корректных
результатов необходимо пропустить некоторое количество циклов работы регистра.
В данной программе выходная последовательность начинает формироваться после
того, как регистр пропустит 20 000 циклов.
. Что касается начального заполнения регистра, то
возьмем его равным (0,0,0,...,0,1). Тогда минимальный многочлен полученной ЛРП
будет равен характеристическому многочлену, и период будет максимально
возможным для данной функции обратной связи. Для получения корректных
результатов необходимо пропустить некоторое количество циклов работы регистра.
В данной программе выходная последовательность начинает формироваться после
того, как регистр пропустит 20 000 циклов.
Пример
4. Последовательность, полученная в результате работы сдвигового регистра.
1
0 1 1 0 0 1 0 0 0 0 0 1 1 1 0 1 0 1 1 1 0 1 0 0 1 0 0 1 0 1 1 0 1 0 1 1 0 0 0 0
1 0 0 1 1 1 1 0 0
2.5
Реализация 2-линейного самоуправляемого регистра сдвига
Регистр
реализован в виде двумерного динамического массива. Размер массива 31x31.
Соответствующие характеристические многочлены 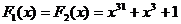 .
Регистр реализован над
.
Регистр реализован над 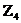 . Любое число
. Любое число 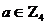 может
быть представлено в следующем виде:
может
быть представлено в следующем виде:  ,
, 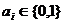 . Будем считать, что регистр управляется младшим
разрядом числа a (a0), а на
выход идет старший разряд (a1).
Начальное заполнение регистра выберем произвольным. Максимальный период
выходной последовательности -
. Будем считать, что регистр управляется младшим
разрядом числа a (a0), а на
выход идет старший разряд (a1).
Начальное заполнение регистра выберем произвольным. Максимальный период
выходной последовательности - 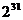 -1.
-1.
Пример
5. Последовательность, полученная в результате работы 2-линейного
самоуправляемого регистра сдвига.
1
1 1 1 1 1 0 1 0 0 1 1 0 0 0 1 0 1 1 1 1 1 0 1 1 1 0 0 1 1 1 1 0 1 0 0 1 0 0 0 1
1 1 0 1 1 0 1 0 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 0 1 0 1 1 1 1 1 0 0 0 0 1 0 0
2.6
Тестирование генераторов ПСП
Качественный генератор псевдослучайной последовательности (ПСП),
ориентированный на использование в системах защиты информации, должен
удовлетворять следующим требованиям:
1. криптографическая стойкость;
2. хорошие статистические свойства, ПСП по своим статистическим
свойствам не должна существенно отличаться от истинно случайной
последовательности;
. большой период формируемой последовательности
. эффективная аппаратная и программная реализация;
. быстродействие.
Проверка близости полученной последовательности к равномерности
распределения, ее случайности и независимости проводится методами
статистического тестирования.
1. Тест n-серий. В данном
тесте проверяется, насколько близка полученная последовательность к
равномерному распределению.
Последовательность,
полученная в результате работы генератора, разбивается на пары. Далее по всей
последовательности считается число совпадения этих пар с парами чисел 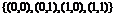 -
- 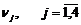 , и
вычисляется статистика теста
, и
вычисляется статистика теста 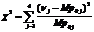 .
Необходимый размер последовательности для работы данного теста
.
Необходимый размер последовательности для работы данного теста 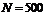 ,
, 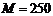 ,
, 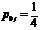 . Уровень значимости теста
. Уровень значимости теста 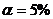 .
.
. Обобщенный
статистический тест Маурера. Этот тест показывает, насколько полученная
последовательность случайна. Для упрощения вычислений при реализации теста, а
именно вычисления параметра теста 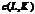 , взяты
следующие табличные значения для параметров L,K и Q:
, взяты
следующие табличные значения для параметров L,K и Q:
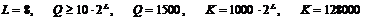
Тогда
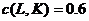 . Из-за такого выбора параметров для корректной работы
теста необходимо сгенерировать последовательность достаточно большой длины:
. Из-за такого выбора параметров для корректной работы
теста необходимо сгенерировать последовательность достаточно большой длины: 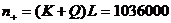 .
.
3. Критерий серий. В данном тесте проверяется случайность и
независимость полученной последовательности. Серией в данной реализации теста
будем называть всякую последовательность нулей или единиц, ограниченную
противоположенными цифрами или находящуюся в конце или начале набора.
Будем проводить сравнение генераторов по следующим параметрам:
1. t - время работы генератора.
2. K = 1/T - где T - период полученной последовательности;
3.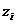 характеристика i-ого теста =
характеристика i-ого теста = 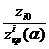 , где
, где 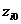 -
значение вычисленной статистики, а
-
значение вычисленной статистики, а 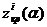 -
значение границы критической области соответствующего критерия на данном уровне
значимости.
-
значение границы критической области соответствующего критерия на данном уровне
значимости.
Первые
два параметра понятны, что касается третьего, то он показывает насколько хорошо
тот или иной генератор проходит данный статистический тест. Чем меньше значение
zi тем
дальше значение статистики выборки располагается от критической области, то
есть тем надежнее генератор.
Результаты
тестирования генераторов на блоке тестов представлены в таблице 2. На
пересечении строк (статистических тестов) и столбцов (различных генераторов
ПСП) в таблице находится значение Чем
меньше значение , тем дальше выборочное значение статистики лежит от
критической области на данном уровне значимости .
Следовательно, можно сказать, что чем меньше значение , тем лучше генератор проходит статистический тест.
Прочерки в таблице означают, что получившееся значение 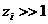 , для таких значений будем
считать, что генератор не проходит статистический тест.
, для таких значений будем
считать, что генератор не проходит статистический тест.
Таблица
2. Результаты тестирования генераторов.
|
ЛКГ
|
ККГ
|
RSA
|
Сдвиг.рег.
|
2-лин. рег.
|
|
Тест n-серий
|
0,468
|
0,069
|
0,1142
|
0,0211
|
0,3451
|
|
Тест Маурера
|
-
|
1,021
|
1,011
|
0,9987
|
0,9988
|
|
Критерий серий
|
-
|
0,9438
|
0,0348
|
0,0511
|
0,5139
|
Из таблицы 2 видно, что при дальнейшем сравнении можно исключить Линейный
конгруэнтный генератор(ЛКГ), так как он не проходит два теста из трех.
Последовательность, полученная в результате работы ЛКГ, равномерно
распределена, но не обладает другими двумя необходимыми свойствами -
случайностью и независимостью. Для остальных генераторов включим в таблицу
новые параметры - время и период полученной последовательности.
Таблица 3. Сравнение генераторов.
|
ККГ
|
RSA
|
Сдвиг.рег.
|
2-лин.рег.
|
|
Тест n-серий
|
0,468
|
0,069
|
0,1142
|
0,0211
|
|
Тест Маурера
|
1,021
|
1,011
|
0,9987
|
0,9988
|
|
Критерий серий
|
0,9438
|
0,0348
|
0,0511
|
0,5139
|
|
Время работы
|
0,031
|
0,09
|
0,047
|
0,06
|
|
MAX период
|
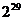 -1 -1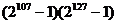 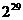 -1-1 -1-1
|
|
|
|
Для того, чтобы выбрать из всех генераторов оптимальный необходимо решить
задачу многокритериальной оптимизации.
Постановка
задачи: на множестве генераторов 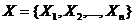 необходимо
найти такой, что
необходимо
найти такой, что 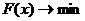 , где
, где 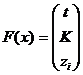 - вектор
параметров.
- вектор
параметров. 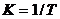 , T -максимальный период полученной
последовательности. Выбрать генератор минимальный по всем трем параметрам не
представляется возможным, поэтому поступим следующим образом. По каждому
критерию каждому генератору присвоим ранг, в зависимости от того насколько
хорошо генератор проходит тот или иной критерий. Ранги обозначим цифрами от 1
до 5, где 1 - генератор проходит критерий наилучшим образом, 5 - генератор
проходит критерий наихудшим образом. Получим соответствующую таблицу рангов для
генераторов.
, T -максимальный период полученной
последовательности. Выбрать генератор минимальный по всем трем параметрам не
представляется возможным, поэтому поступим следующим образом. По каждому
критерию каждому генератору присвоим ранг, в зависимости от того насколько
хорошо генератор проходит тот или иной критерий. Ранги обозначим цифрами от 1
до 5, где 1 - генератор проходит критерий наилучшим образом, 5 - генератор
проходит критерий наихудшим образом. Получим соответствующую таблицу рангов для
генераторов.
Таблица
4. Ранги генераторов.
|
ЛКГ
|
ККГ
|
RSA
|
Сдвиг.рег.
|
2-лин.рег
|
|
Тест n-серий
|
5
|
2
|
3
|
1
|
4
|
|
Тест Маурера
|
5
|
4
|
3
|
1
|
2
|
|
Критерий серий
|
5
|
4
|
1
|
2
|
3
|
|
Время работы
|
1
|
2
|
5
|
3
|
4
|
|
1/T
|
4
|
3
|
1
|
3
|
2
|
Просуммируем ранги каждого генератора.
Таблица 5. Суммы рангов.
|
Генератор
|
Сумма рангов.
|
|
ЛКГ
|
21
|
|
ККГ
|
17
|
|
RSA
|
13
|
|
Сдвиговый регистр
|
10
|
|
2-линейный регистр сдвига
|
15
|
Из
таблицы видно, что оптимальным генератором ПСП на уровне значимости является сдвиговый регистр.
Выводы и
заключение.
В данной работе:
. Реализованы алгоритмы генерации псевдослучайных последовательностей. В
том числе реализован генератор псевдослучайных последовательностей, который не
относится к классическим генераторам, - самоуправляемый 2-линейный регистр
сдвига.
. Разработан блок статистических тестов, позволяющий проверить
соответствие полученной последовательности равномерному распределению, а так же
ее случайность и независимость.
. Проведено сравнение работы генераторов псевдослучайных
последовательностей с помощью разработанного блока тестов.
. Выбран оптимальный генератор псевдослучайных последовательностей.
Оптимальность генератора оценивалась по совокупности характеристик:
успешное прохождение блока статистических тестов, эффективная аппаратная
реализация, максимально возможная длина последовательности . Из рассмотренных 5
генераторов ПСП оптимальным по данным характеристикам был выбран генератор ПСП
на основе сдвигового регистра.
Приложение. Коды программ
Линейный конгруэнтный генератор
int main()
{
int i,k;
int x0 = 625;a = 61;c = 7;N =
10000000;rem,s,count;*
sq;start,finish;tmp;file_opn;file_opn_b;_opn.open("SQ_linear.txt");_opn_b.open("SQ_linear_b.txt");<<"Input
k: ";>> k;= new int[k];= clock();[0] = x0;(i=1; i<k+1; i++)
{[i] = a*sq[i-1] + c;(sq[i]>N)[i] = sq[i]%N;
}= clock();
for(i=0; i<k; i++)
{_opn<<sq[i]<<" ";
}(i=0; i<k; i++)
{= 0;(sq[i]>0)
{++;= sq[i]%2;(rem == 1)
{= sq[i]*0.5 - 0.5;((s == 0)||(s == 1))
{(count < 23)
{= 0;;
};
}[i] = s;
}
{= sq[i]/2;((s == 0)||(s == 1))
{(count < 23)
{= 0;;
};
}[i] = s;
}
}_opn_b<<s<<" ";
}
tmp = (double)(finish - start)/100;("Time =\t%1.5f
(sec)\n", tmp/CLOCKS_PER_SEC);
return 0;
}
Квадратичный конгруэнтный генератор
int main()
{i,k;x0 = 258;a = 3;d = 22;c = 7;N;// =
32768;count;iNext;iPrev,rem,s;file_opn;file_opn_b;_opn.open("SQ_kvadrat.txt");_opn_b.open("SQ_kvadrat_b.txt");<<"Input
k: ";>> k;.setpow(2,31);= x0;(i=1; i<k+1; i++)
{
iNext.setpow(iPrev,2);.setadd(iNext,iPrev);.setadd(iNext,c);.setmod(iNext,N);=
iNext;_opn<<iNext<<" ";
}0;
}
RSA - генератор
cBigNumber setabs(const cBigNumber a)
{(a < 0)(-1)*a;a;
}NOD(cBigNumber a, cBigNumber b)
{result;= setabs(a);= setabs(b);( b>a )
{= b%a;(b == 0)= a;
else= NOD(a, b);
}
{= a%b;(a == 0)
result = b;
else= NOD(a, b);
}result;
}main()
{p,q,N,fi;k,u0,n,i;start,finish;
double tmp;iNod;
cBigNumber iNext, iPrev,
bit;file_opn;_opn.open("SQ_rsa.txt");=
clock();.setpow(2,107);.setpow(2,127);
p--;-;
finish = clock();= (double)(finish - start)/100;("Time1
=\t%1.5f (sec)\n", tmp/CLOCKS_PER_SEC);= clock();.setmul(p,q);= clock();=
(double)(finish - start)/100;("Time2 =\t%1.5f (sec)\n",
tmp/CLOCKS_PER_SEC);-;-;= clock();.setmul(p, q);= clock();= (double)(finish -
start)/100;("Time3 =\t%1.5f (sec)\n", tmp/CLOCKS_PER_SEC);= clock();(
; ; )
{= rand();= NOD(k,fi);(iNod == 1);
}= clock();= (double)(finish - start)/100;("Time4
=\t%1.5f (sec)\n", tmp/CLOCKS_PER_SEC);= rand();<<"INput n:
";>> n;= clock();= u0;(i=0; i<n; i++)
{.setpowmod(iPrev,k,N);= iNext;%=
2;_opn<<iNext<<" ";
}= clock();= (double)(finish - start)/100;("Time5
=\t%1.5f (sec)\n", tmp/CLOCKS_PER_SEC);
return 0;
}
Сдвиговый регистр
int plusmod2(int a, int b)
{res;(((a == 0)&&(b == 1))||((a == 1)&&(b ==
0)))= 1;= 0;res;
}main()
{*reg;*out;iTemp;i,n,j,k=20000;razr = 29;count0 = 0;count1 =
0;file_opn;_opn.open("SQ_shift.txt");<<" Input num of
sq(n>20000): ";>>n;= new int[razr];
out = new int[n];
for(i=0; i<razr; i++)
{(i == (razr-1))[i] = 1;
else
reg[i] = 0;
}(i=0; i<n; i++)
{[i] = reg[0];= plusmod2(reg[0],reg[1]);(j=0; j<razr;
j++)[j] = reg[j+1];[razr] = iTemp;
}(i=k; i<n; i++)
{_opn<<out[i]<<" ";
}(i=0; i<n; i++)
{(out[i] == 0)++;++;
}<<"\n";<<"Num of 0:
"<<count0;<<"Num of 1: "<<count1;
return 0;
}
Самоуправляемый 2-линейный регистр сдвига.
int main()
{i,j,k,in,out,num,tmp;m =
31;sq[31][31];file_opn;_opn.open("SQ_2shift.txt");(time(NULL));
for(i=0; i<m; i++)
{(j=0; j<m; j++)[i][j] = rand()%4;
}
cout<<"Input length of sq: ";>>num;(k=0;
k<num; k++)
{(sq[0][2] == 0)= 0;(sq[0][2] == 1)= 1;(sq[0][2] == 2)=
0;(sq[0][2] == 3)= 1;(in == 0)
{(i=0; i<m-1; i++)
{= sq[i][30];[i][30] = sq[i][0];(j=0; j<m-1; j++)
{(j == 29)[i][j] = tmp;[i][j] = sq[i][j+1];
}
}
}
{(j=0; j<m-1; j++)
{= sq[30][j];[30][j] = sq[0][j];(i=0; i<m-1; i++)
{(i == 29)[i][j] = tmp;[i][j] = sq[i+1][j];
}
}
}(sq[29][28] == 0)= 0;(sq[29][28] == 1)= 0;(sq[29][28] == 2)=
1;(sq[29][28] == 3)= 1;_opn<<out<<" ";
}0;
}
Тест n-серий
const double table_hi[2][15] ={{0.01,0.025,0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,0.975,0.99},
{0.1148,0.2158,0.3518,0.5844,1.0052,1.4237,1.8692,2.3660,2.9462,3.6649,4.6416,6.2514,7.8147,9.3484,11.3449}};main()
{N = 500;
int M = N/2;i,j,k=0;
int len=0;n = 4; //число степеней свободы
int iV[4];p0j;*sq;
int **sqi;**V; // частота попадания*Vk;
int pairs[2][4];hi_kv = 0;itmp;alfa = 0.05; //уровень значимости (5%, 1%, 0.1%);= new int*[2];[0] = new int[M];[1] = new int[M];= new
int*[2];
V[0] = new int[M];
V[1] = new int[M];= new int[N];= new int[N];[0][0] = 0;[1][0]
= 0;[0][1] = 0;[1][1] = 1;[0][2] = 1;[1][2] = 0;
pairs[0][3] = 1;
pairs[1][3] = 1;* file_name =
"SQ_2shift.txt";*in;=fopen(file_name,"r");(in==NULL
)("\nIncorrect input file\n");(i=0; i<N; i++)
{(in,"%d",&sq[i]);
len++;
}(i=0; i<N; i++)<<sq[i]<<" ";
// сам тестj = 1/(pow(N,2)); // вероятность появления пары чисел, квадрат
- тк они могут местами меняться.
for(i=0; i<M; i++)
{(j=0; j<2; j++)
{[j][i] = sq[k];++;
}
}
for(i=0; i<4; i++)
iV[i] = 0;
for(i=0; i<M; i++)
{(j=0; j<4; j++)
{((sqi[0][i] == pairs[0][j])&&(sqi[1][i] ==
pairs[1][j]))
iV[j]++;
}
}
cout<<"Chislo sovpadenii par:
"<<"\n";(i=0; i<4; i++)
{<<iV[i]<<"\n";
}
// вычисляем хи-квадрат статистику= (double)M/n;
for(j=0; j<4; j++)_kv = hi_kv + pow((iV[j] -
itmp),2)/itmp;<<"Statistika hi-kvadrat :
"<<hi_kv<<" ";(i=0; i<15; i++)
{(table_hi[0][i] == (1-alfa))
{(table_hi[1][i] > hi_kv)<<"\nPrinimaem
gipotezy o raspredelenii na yrovne znachimossti alfa =
5%\n";<<"\nOtvergaem gipotezy o raspredelenii\n";
}
}0;
}
Обобщенный статистический тест Маурера.
int main()
{L = 8;Q = 1500;K = 128000;N;i,j,k,count;*sq,*A,**y;
//int y[129500][8];
double eps = 0.05; // уровень значимости теста 5%
double Feps = 1.960; // квантиль уровня eps/2t1,
t2;Funi,mt_t,mt,C,D,D_t,sigma;* file_name = "SQ_rsa.txt";*in;=fopen(file_name,"r");(in==NULL
)("\nIncorrect input file\n");= (Q+K)*L;= new int[N];
for(i=0; i<N; i++)
fscanf(in,"%d",&sq[i]);
// Вычисляем Ai= 0;= new int*[8];[0] =
new int[K+Q];[1] = new int[K+Q];[2] = new int[K+Q];[3] = new int[K+Q];[4] = new
int[K+Q];[5] = new int[K+Q];[6] = new int[K+Q];[7] = new int[K+Q];(i=0;
i<Q+K; i++)
{(j=0; j<8; j++)
{
y[j][i] = sq[k];++;
}
}= new int[N];(i=Q+1; i<Q+K+1; i++)
{(j=i-1; j>=0; j--)
{= 0;
for(k=0; k<8; k++)
{(y[k][j] == y[k][i])++;(count == 8)[i] = i-j;[i] = i;
}(count == 8);
}
}
// Вычисляем статистику= 0;
for(i = Q+1; i<Q+K+1; i++)= Funi +
log(A[i])/(K*log(2));<<"Statistica(mera sgimaemosti):
"<<Funi;
// Мат. ожидание_t = 0;= 0;
for(i=1; i<Q+1; i++)
{_t = pow((1 - pow(2,(-1)*L)),(i-1))*log(i)/log(2);
mt = mt + mt_t;
}
mt = mt*pow(2,(-1)*L);<<"\nMatematicheskoe
ogidanie: "<<mt;
//Дисперсия= 0.6; // для K>>2^L С близко к 0,6 для L = 8;
D = 0;_t = 0;(i=1; i<Q+1; i++)_t = D_t +
pow((1-pow(2,(-1)*L)),(i-1))*pow(log(i)/log(2),2);_t = D_t*pow(2,(-1)*L);= D_t
- pow(mt,2);= sqrt(D/K)*C;<<"\nSrednekvadraticheskoe otklonenie:
"<<sigma;= mt + sigma*Feps;= mt - sigma*Feps;((Funi >
t2)&&(Funi < t1))<<"\nPrinimaem gipotezy o raspredelenii
na yrovne znachimosti 5%.\n";<<"\n Otvergaem gipotezy.
";<<"\nInterval [t2
t1]"<<"["<<t2<<"
"<<t1<<"]";
return 0;
}
Критерий серий
int main()
{i,iSeries,n1,n2;
int N=500; // размер последовательности*sq;eps = 0.05;Up = 1.960;
double Zv,tmp,tmp2,tmp3;
sq = new int[N];
char* file_name = "SQ_2shift.txt";*in;=fopen(file_name,"r");(in==NULL
)("\nIncorrect input file\n");(i=0; i<N; i++)
{(in,"%d",&sq[i]);
}<<"SQ: ";(i=0; i<N;
i++)<<sq[i]<<" ";= 0;(i=1; i<N+1; i++)
{(sq[i] == sq[i-1]);++;
}= 0;= 0;(i=0; i<N; i++)
{(sq[i] == 0)++;++;
}<<"\nKolichestvo serii: "<<iSeries;<<"\n";<<"\n
kolichestvo 0: "<<n1;<<"\n";<<"\n
kolichestvo 1: "<<n2;<<"\n";=
2*n1*n2/pow((n1+n2),2);= (double)iSeries - (double)2*n1*n2/(n1+n2) - 1;(tmp2 >
0)= tmp2;= tmp2*(-1);= (tmp3 - 0.5)/sqrt((tmp*((double)2*n1*n2 - (double)(n1 +
n2))/(n1+n2-1)));<<"Statistica test: "<<Zv;(Zv <
Up)<<"\nPrinimaem gipotezy o
raspredelenii.\n";<<"Otvergaem gipotezy\n";
return 0;
}
Список
использованной литературы
1. Харин Ю.С., Берник В.И., Матвеев Г.В., Агиевич С.В.
"Математические и компьютерные основы криптологии" - Мн.: Новое
знание, 2003
2. Евтушенко Ю.Г., Мазурик В.П. "Программное
обеспечение систем оптимизации" - М.: Знание, 1989
. Белов А.А., Баллод Б.А., Елизарова Н.Н. "Теория
вероятностей и математическая статистика" - Ростов н/Д: Феникс, 2008.
. Нечаев А.А. "Мультирегистры сдвига и сложность
мультипоследовательностей",Труды по дискретной математике - М: Физматлит,
2003 - Т.6.
. Ефимов А.В., Поспелов А.С., Земсков В.Н
"Сборник задач по математике для ВТУЗОВ", ч.4 - М: Физматлит, 2004
. Кнут Д.Э. "Искусство программирования",
т.2 - М.: "Вильямс", 2007
. Лидл Р., Нидеррайтер Г. "Конечные поля" -
М.: Мир, 1988.
. Ивченко Г.И., Медведев Ю.И. "Математическая
статистика", - М: "Высшая школа", 1984