Расчет показателей тесноты связи
Контрольная работа
по предмету
«Эконометрика»
Челябинск 2008 г.
1. Расчет показателей тесноты связи между двумя
экономическими показателями из статистических данных
Таблица 1. Исходные статистические данные
|
№п/п
|
Квартал, год
|
Чистая прибыль,
млн. долл. США
|
ARPU, доллары
США
|
Средний
ежемесячный трафик на одного абонента
|
Общее число
абонентов на конец периода, млн. чел.
|
|
1
|
4 кв, 2002
|
85,2
|
21,2
|
175
|
6,64
|
|
2
|
1 кв, 2003
|
80,2
|
18,5
|
148
|
9,42
|
|
3
|
2 кв, 2003
|
128,5
|
18,7
|
162
|
11,34
|
|
4
|
3 кв, 2003
|
155,7
|
18,8
|
159
|
13,89
|
|
5
|
4 кв, 2003
|
152,7
|
16,3
|
140
|
16,72
|
|
6
|
1 кв, 2004
|
207,8
|
14,1
|
147
|
19,19
|
|
7
|
2 кв, 2004
|
267,5
|
14,1
|
160
|
22,78
|
|
8
|
3 кв, 2004
|
338,3
|
14,0
|
168
|
26,63
|
|
9
|
4 кв, 2004
|
209,1
|
11,2
|
164
|
34,22
|
|
10
|
1 кв, 2005
|
232,5
|
9,1
|
138
|
38,69
|
|
11
|
2 кв, 2005
|
303,9
|
9,3
|
134
|
44,07
|
|
12
|
3 кв, 2005
|
347,4
|
8,9
|
130
|
50,36
|
|
13
|
4 кв, 2005
|
242,6
|
7,3
|
123
|
58,19
|
|
14
|
1 кв, 2006
|
184,4
|
6,2
|
118
|
61,05
|
|
15
|
2 кв, 2006
|
294,7
|
7,1
|
128
|
64,10
|
|
16
|
3 кв, 2006
|
486,3
|
7,8
|
135
|
67,59
|
|
17
|
4 кв, 2006
|
280,3
|
8,3
|
133
|
72,86
|
|
18
|
1 кв, 2007
|
448,6
|
8,2
|
134
|
74,16
|
|
19
|
2 кв, 2007
|
507,9
|
9,2
|
151
|
74,67
|
|
20
|
3 кв, 2007
|
654,7
|
10,0
|
167
|
77,97
|
|
|
|
|
|
|
|
сумма
|
5608,3238,32914844,54
|
|
|
|
|
среднее
|
280,4211,92145,742,23
|
|
|
|

Рисунок 1
Построение
описательной экономической модели.
Данная работа будет посвящена анализу связи между количеством
абонентов в сети, средней ежемесячной выручкой от продажи услуг в расчете на
одного абонента (ARPU) и чистой прибылью оператора связи на конец отчетного
периода.
Исходя из сделанного предположения строим эконометрическую
модель, которая относится к классу факторных статических моделей:
y=f(x1, x2)
где x1 - количество абонентов в сети (объясняющая
переменная)
x2 - средняя ежемесячная выручка от продажи услуг в
расчете на одного абонента (ARPU) (объясняющая переменная)
y - чистая прибыль (зависимая переменная)
Чтобы убедиться в том, что выбор объясняющих переменных
оправдан, оценим связь между признаками количественно, для этого заполним
матрицу корреляций:
Таблица 2. Матрица корреляций между исходными статистическими
признаками
|
x1
|
x2
|
y
|
|
x1
|
1
|
-0,97
|
0,72
|
|
x2
|
-0,97
|
1
|
-0,71
|
|
y
|
0,72
|
-0,71
|
1
|
Анализируя матрицу корреляций, можем сделать вывод о наличии
сильной положительной связи между количеством абонентов и чистой прибылью
оператора. В то же время также существует сильная отрицательная связь ARPU и чистой прибылью.
Для дальнейшего исследования модифицируем модель к виду
парной регрессии: y=f(x1).
Для выбора функциональной формы модели проанализируем
корреляционное поле:

Рисунок 2. Корреляционное поле (x1 - кол-во
абонентов в сети, млн. чел.; y - чистая
прибыль оператора
Визуальный анализ показывает, что для построения модели
вполне подойдет степенная функция:
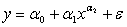
Для дальнейшего исследования приведем наше уравнение к
линейному виду. То есть:
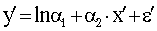 ,
,
где  .
.
Таким образом, все дальнейшие исследования будем проводить с этим
уравнением.
Оценка
параметров модели.
Проведем оценку параметров модели при помощи различных
способов.
Метод
средних.
Предположим, что изменение чистой прибыли обусловлено только
изменением количества абонентов (т.е. α0 = 0). Тогда оценка a1 и a2 неизвестного параметра α1 и α2 определится по формулам:
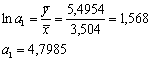
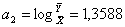
Тогда модель принимает вид: y=4,7985×x1,35881+e.
Метод
выбранных точек.
Проанализируем корреляционное поле и выберем точки, которые
ближе всех лежат в предполагаемой прямой линии, описывающей модель. Это будут
точки 4 кв. 2004 г. (209,1; 34,22) и 2 кв. 2007 г. (507,9; 74,67).
Рассчитаем параметры модели:
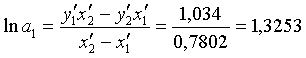
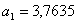
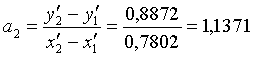
уравнение регрессии выглядит следующим образом:
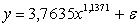
Метод
наименьших квадратов.
Для применения этого метода составим вспомогательную таблицу:
Таблица 3
|
№ п/п
|
Квартал, год
|
Чистая прибыль,
млн. долл. США y
|
Общее число
абонентов на конец периода, млн. чел. x
|
x2
|
xy
|
|
1
|
4 кв, 2002
|
4,445001
|
1,893112
|
3,5838738,414885
|
|
|
2
|
1 кв, 2003
|
4,384524
|
2,242835
|
5,0303099,833764
|
|
|
3
|
2 кв, 2003
|
4,855929
|
2,428336
|
5,89681611,791827
|
|
|
4
|
3 кв, 2003
|
5,047931
|
2,631169
|
6,9230513,28196
|
|
|
5
|
4 кв, 2003
|
5,028475
|
2,816606
|
7,93326914,163233
|
|
|
6
|
1 кв, 2004
|
5,336576
|
2,954389
|
8,72841415,766321
|
|
|
7
|
2 кв, 2004
|
5,58912
|
3,125883
|
9,77114517,470935
|
|
|
8
|
3 кв, 2004
|
5,823933
|
3,282038
|
10,77177319,114369
|
|
|
9
|
4 кв, 2004
|
5,342813
|
3,53281
|
12,4807518,875143
|
|
|
10
|
1 кв, 2005
|
5,44889
|
3,655581
|
13,36327219,918859
|
|
|
11
|
2 кв, 2005
|
5,716699
|
3,785779
|
14,33212321,642159
|
|
|
12
|
3 кв, 2005
|
5,850477
|
3,919197
|
15,36010522,929172
|
|
|
13
|
4 кв, 2005
|
5,491414
|
4,063714
|
16,51377122,315536
|
|
|
14
|
1 кв, 2006
|
5,217107
|
4,111693
|
16,90601921,451142
|
|
|
15
|
2 кв, 2006
|
5,685958
|
4,160444
|
17,30929423,65611
|
|
|
16
|
3 кв, 2006
|
6,186826
|
4,21346
|
17,7532526,067944
|
|
|
17
|
4 кв, 2006
|
5,63586
|
4,28854
|
18,3915824,16961
|
|
|
18
|
1 кв, 2007
|
6,106132
|
4,306225
|
18,54357426,294378
|
|
|
19
|
2 кв, 2007
|
6,230285
|
4,313078
|
18,60264226,871705
|
|
|
20
|
3 кв, 2007
|
6,484177
|
4,356324
|
18,97755928,247176
|
|
|
|
|
|
|
|
|
сумма
|
109,90812770,081213257,172588392,276228
|
|
|
|
|
среднее
|
5,4954063,50406112,85862919,613811
|
|
|
|
Составим систему для расчета значений параметров на основе
следующей системы уравнений:
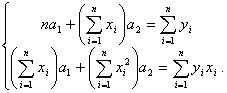
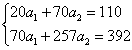
Решив эту систему, получаем значения
a1 = 31,766
a2 = 0,5833
Линия регрессии описывается уравнением:
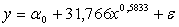 .
.
Таблица 4. Уравнения регрессий, полученные при помощи разных
методов
|
№п/п
|
Метод расчета
|
Уравнение
регрессии
|
|
1.
|
Метод средних
|
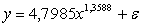
|
|
2.
|
Метод выбранных
точек
|
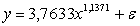
|
|
3.
|
Метод
наименьших квадратов
|
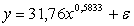
|
Покажем на графике различие между полученными линиями
регрессии:
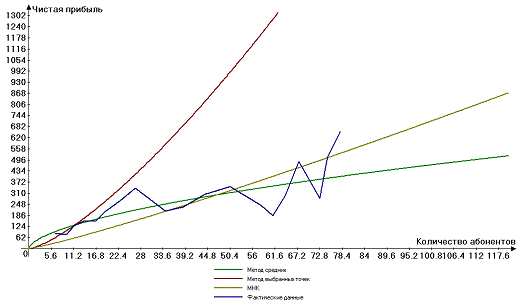
Рисунок 3. Линии регрессии, полученные при помощи различных
методов
теснота
корреляция регрессионный зависимость
2. Определение и графическое изображение
регрессионной зависимости между рассматриваемыми показателями по методу
выбранных точек и МНК линейная модель и любая на выбор (квадратичная,
логарифмическая). Оценка адекватности построенной модели
Проверка
качества построенной модели.
Выполним оценку качества поэтапно.
Оценим адекватность модели в целом, для каждой из выбранных
моделей. Так как выбранная нами модель является нелинейной, то приведем
исследуемые модели к линейному виду.
Таблица 5. Уравнения регрессий, приведенных к линейному виду
|
№п/п
|
Метод расчета
|
Уравнение
регрессии
|
|
1.
|
Метод средних
|
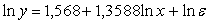
|
|
2.
|
Метод выбранных
точек
|
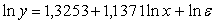
|
|
3.
|
Метод
наименьших квадратов
|
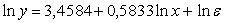
|
Таблица 6. Предварительные расчеты для вычисления дисперсий
случайных отклонений
|
№ п/п
|
x1
|
y
|
 e2 e2
|
|
|
|
|
МС
|
МВТ
|
МНК
|
МС
|
МВТ
|
МНК
|
|
1
|
1,89
|
4,45
|
3,4780
|
4,5627
|
0,0928
|
0,9352
|
0,0138
|
|
2
|
2,24
|
4,38
|
4,6156
|
3,8756
|
4,7666
|
0,0534
|
0,2590
|
0,1460
|
|
3
|
2,43
|
4,86
|
4,8676
|
4,0866
|
4,8748
|
0,0001
|
0,5919
|
0,0004
|
|
4
|
2,63
|
5,05
|
5,1432
|
4,3172
|
4,9932
|
0,0091
|
0,5340
|
0,0030
|
|
5
|
2,82
|
5,03
|
5,3952
|
4,5281
|
5,1013
|
0,1345
|
0,2504
|
0,0053
|
|
6
|
2,95
|
5,34
|
5,5824
|
4,6847
|
5,1817
|
0,0604
|
0,4249
|
0,0240
|
|
7
|
3,13
|
5,59
|
5,8154
|
4,8797
|
5,2817
|
0,0512
|
0,5032
|
0,0945
|
|
8
|
3,28
|
5,82
|
6,0276
|
5,0573
|
5,3728
|
0,0415
|
0,5877
|
0,2035
|
|
9
|
3,53
|
5,34
|
6,3684
|
5,3425
|
5,5191
|
1,0518
|
0,0000
|
0,0311
|
|
10
|
3,66
|
5,45
|
6,5352
|
5,4821
|
5,5907
|
1,1801
|
0,0011
|
0,0201
|
|
11
|
3,79
|
5,72
|
6,7121
|
5,6301
|
5,6666
|
0,9909
|
0,0075
|
0,0025
|
|
12
|
3,92
|
5,85
|
6,8934
|
5,7818
|
5,7445
|
1,0877
|
0,0047
|
0,0112
|
|
13
|
4,06
|
5,49
|
7,0898
|
5,9461
|
5,8288
|
2,5548
|
0,2068
|
0,1138
|
|
14
|
4,11
|
5,22
|
7,1550
|
6,0007
|
5,8568
|
3,7553
|
0,6140
|
0,4091
|
|
15
|
4,16
|
5,69
|
7,2212
|
6,0561
|
5,8852
|
2,3570
|
0,1370
|
0,0397
|
|
16
|
4,21
|
6,19
|
7,2932
|
6,1164
|
5,9161
|
1,2242
|
0,0050
|
0,0733
|
|
17
|
4,29
|
5,64
|
7,3953
|
6,2018
|
5,9599
|
3,0955
|
0,3203
|
0,1050
|
|
18
|
4,31
|
6,11
|
7,4193
|
6,2219
|
5,9702
|
1,7244
|
0,0134
|
0,0185
|
|
19
|
4,31
|
6,23
|
7,4286
|
6,2297
|
5,9742
|
1,4360
|
0,0000
|
0,0656
|
|
20
|
4,36
|
6,48
|
7,4874
|
6,2789
|
5,9994
|
1,0064
|
0,0421
|
0,2350
|
|
|
|
|
|
|
|
|
|
|
сум.
|
70,08109,93126,5863106,1953110,046321,90715,43821,6154
|
|
|
|
|
|
|
|
|
ср.
|
3,55,56,32935,30985,50231,09540,27190,0808
|
|
|
|
|
|
|
|
Примечание:
МС - метод средних
МВТ - метод выбранных точек
МНК - метод наименьших квадратов
На основе таблицы для каждой модели рассчитаем значение
дисперсий случайного остатка
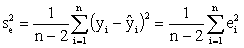 ,
,
и значения коэффициента детерминации
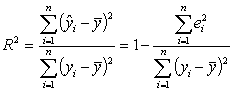 .
.
Результат запишем в таблицу:
Таблица 7. Оценка адекватности моделей парной регрессии
|
№п/п
|
Метод расчета
|
Дисперсия
случайного остатка (s2e)
|
Коэффициент
детерминации (R2)
|
|
1.
|
Метод средних
|
1,2171-2,6455
|
|
|
2.
|
Метод выбранных
точек
|
0,30210,095
|
|
|
3.
|
Метод
наименьших квадратов
|
0,08970,7312
|
|
Как видно из таблицы, наилучшее качество имеет модель, построенная
по методу наименьших квадратов.
Следующие этапы оценки качества проведем только для этой
модели.
Для нее расчетное значение F-критерия равно:
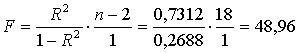 ,
,
а соответствующее критическое значение - F0,05;1;18 = 4,41. Поскольку расчетное значение
больше критического, то модель признается статистически значимой.
Вычислим дисперсии оценок коэффициентов регрессии. Для
этого воспользуемся формулами:

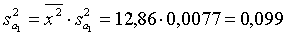
Стандартные ошибки коэффициентов регрессии будут равны:
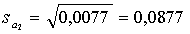
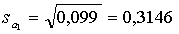
Оценим статистическую значимость коэффициентов регрессии.
Для этого рассчитаем t-статистику для каждого коэффициента:
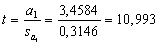
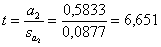
Сравним с критическими значениями, взятыми из таблицы
(#"516395.files/image032.gif">
|
1.
|
0,1
|
1.7341
|
|
2.
|
0,05
|
2.1009
|
|
3.
|
0,01
|
2.8784
|
Можно сделать вывод, что коэффициенты регрессии статистически
значимы при 1%-м уровне значимости.
Оценим доверительные интервалы для коэффициентов регрессии
при разных уровнях значимости. Для этого воспользуемся формулами
для α1 - 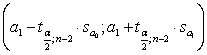
для α2 - 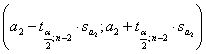
Доверительный интервал определяет границы, в которых будет
находиться значение теоретического коэффициента регрессии с уровнем значимости α.
Уровень значимости α определяется исходя из
требуемой точности. Обычно - 0.1, 0.05 или 0.01.
Результат расчета занесем в таблицу:
Таблица 9. Доверительные интервалы для коэффициентов регрессии при
различных уровнях значимости
|
№п/п
|
Уровень
значимости
|
Коэффициент
|
Доверительный
интервал
|
|
1.
|
0,1
|
a1
|
2,9128
|
4,0039
|
|
2.
|
|
a2
|
0,4312
|
0,7353
|
|
3.
|
0,05
|
a1
|
2,7974
|
4,1193
|
|
4.
|
|
a2
|
0,399
|
0,7675
|
|
5.
|
0,01
|
a1
|
2,5529
|
4,3639
|
|
6.
|
|
a2
|
0,3308
|
0,8357
|
Рассчитаем доверительные интервалы для зависимой переменной.
Для этого воспользуемся формулами
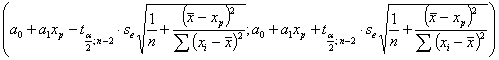
для расчета доверительного интервала для среднего значения и
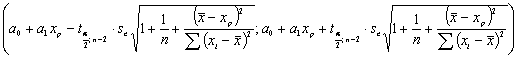
для расчета доверительного интервала для индивидуальных значений.
Результаты расчета для 5%-го уровня значимости представлены в таблице и на
графиках:
Таблица 10. Доверительные интервалы для зависимой переменной
(уровень значимости - 5%)
|
№п/п
|
x
|
y
|
 доверительный интервал доверительный интервал
|
|
|
|
|
|
для среднего
значения
|
для
индивидуального значения
|
|
|
|
|
нижний предел
|
верхний предел
|
нижний предел
|
верхний предел
|
|
1
|
1,89
|
4,45
|
4,5627
|
0,8327
|
4,8343
|
0,3944
|
5,2725
|
|
2
|
2,24
|
4,38
|
4,7666
|
1,0837
|
4,9912
|
0,6229
|
5,4520
|
|
3
|
2,43
|
4,86
|
4,8748
|
1,2155
|
5,0757
|
0,7420
|
5,5493
|
|
4
|
2,63
|
5,05
|
4,9932
|
1,3582
|
5,1697
|
0,8704
|
5,6576
|
|
5
|
2,82
|
5,03
|
5,1013
|
1,4865
|
5,2577
|
0,9860
|
5,7583
|
|
6
|
2,95
|
5,34
|
5,1817
|
1,5801
|
5,3249
|
1,0708
|
5,8342
|
|
7
|
3,13
|
5,59
|
5,2817
|
1,6937
|
5,4113
|
1,1750
|
5,9300
|
|
8
|
3,28
|
5,82
|
5,3728
|
1,7935
|
5,4937
|
1,2686
|
6,0187
|
|
9
|
3,53
|
5,34
|
5,5191
|
5,6353
|
1,4161
|
6,1637
|
|
10
|
3,66
|
5,45
|
5,5907
|
2,0139
|
5,7091
|
1,4872
|
6,2359
|
|
11
|
3,79
|
5,72
|
5,6666
|
2,0845
|
5,7904
|
1,5616
|
6,3133
|
|
12
|
3,92
|
5,85
|
5,7445
|
2,1539
|
5,8767
|
1,6370
|
6,3936
|
|
13
|
4,06
|
5,49
|
5,8288
|
2,2263
|
5,9728
|
1,7176
|
6,4815
|
|
14
|
4,11
|
5,22
|
5,8568
|
2,2498
|
6,0053
|
1,7441
|
6,5110
|
|
15
|
4,16
|
5,69
|
5,8852
|
2,2735
|
6,0384
|
1,7709
|
6,5410
|
|
16
|
4,21
|
6,19
|
5,9161
|
2,2991
|
6,0748
|
1,8000
|
6,5738
|
|
17
|
4,29
|
5,64
|
5,9599
|
2,3349
|
6,1266
|
1,8409
|
6,6205
|
|
18
|
4,31
|
6,11
|
5,9702
|
2,3432
|
6,1388
|
1,8505
|
6,6316
|
|
19
|
4,31
|
6,23
|
5,9742
|
2,3465
|
6,1436
|
1,8542
|
6,6358
|
|
20
|
4,36
|
6,48
|
5,9994
|
2,3668
|
6,1737
|
1,8776
|
6,6629
|
|
|
|
|
|
|
|
|
|
сред.
|
3,55,54,85
|
|
|
|
|
|
|
|
сумм.
|
70,08109,9397,03
|
|
|
|
|
|
|
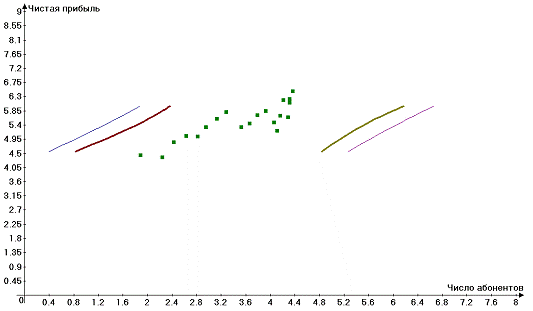
Рисунок 4. Доверительные интервалы для среднего и индивидуального
значений зависимой переменной. Уровень значимости - 5%
Определение
коэффициента детерминации R2.
Коэффициент детерминации R2 достаточно высок (0,73),
расчетное значение F-статистики для R2 (48,93) более чем в 10 раза больше критического
(4,41), следовательно может использоваться на практике. В то же время
существование необъясненной дисперсии предполагает возможность улучшить
качество модели путем введения еще одной переменной.
Список
литературы
1.
В.П. Носко, Эконометрика для начинающих: Основные понятия, элементарные методы,
границы применимости, интерпретация результатов, Москва 2000. - 240 стр.
.
Бархатов В.И. Плетнев Д.А. Эконометрика // Учебно-методическое пособие