Правила потребительского поведения на автомобильном рынке
Оглавление
Введение
Глава 1. Основые идеи анализа потребительской корзины
Глава 2. Критический обзор основных методов выявления ассоциативных
правил
2.1 Классический подход. Измерители поддержки и достоверности
правил
2.2 Тест Хи-квадрат на независимость переменных
2.3 Логлинейный анализ зависимости переменных
Глава 3. Описание данных
Глава 4. Выявление интересных ассоциативных правил
4.1 Подготовка данных и суммарная статистика
4.2 Применение измерителей "поддержка" и
"достоверность"
4.3 Применение Хи-квадрат теста на независимость
4.4 Применение точного теста Фишера
Глава 5. Эконометрический анализ выбора марки автомобиля
5.1 Результаты по моделям бинарного выбора
5.2 Предельные эффекты моделей бинарного выбора
5.3 Связь анализа ассоциативных правил с эконометрическим анализом
выбора бренда
Заключение
Список литературы
Приложения
Введение
Поведение потребителей на автомобильном рынке является одной
из наиболее интересных и менее изученных областей для исследователей из сфер
экономики, маркетинга и менеджмента. Мировые тенденции показывают стабильный
рост продаж на рынке автомобилей, однако четких представлений о предпочтениях
потребителей не сформировано. На сегодняшний день, большое количество людей
воспринимают автомобили исключительно как средство передвижения, обращая свое
внимание на функциональность и практичность. Однако для других людей автомобиль
является не просто средством для передвижения, но и показателем социального
статуса человека. Помимо всего этого, размеры автомобильного рынка достаточно
велики, что подтверждается существованием автомобильных брендов различных
классов и категорий. Такое разнообразие брендов на рынке, а также
неопределенность в предпочтениях покупателей создают проблему для продавцов
автомобилей, желающих увеличить объемы продаж. Зная, что владельцы автомобилей
марки "А" часто меняют свой автомобиль на автомобиль марки
"В", продавцы на рынке автомобилей могли бы формировать определенные
маркетинговые стратегии, которые позволили бы им увеличить продажи.
Такого рода проблемы определяют актуальность исследования,
которое заключается в обнаружении различных зависимостей между автомобильными
брендами. Целью данного исследования является выявление определенных правил
потребительского поведения на автомобильном рынке. Для выполнения поставленной
цели необходимо выполнить следующие задачи:
) подробно изучить существующую литературу по
соответствующей тематике
2) Найти подходящий источник данных
) Собрать данные
) Определить методы анализа данных
) Применить наиболее подходящие методы
) Сделать выводы по полученным результатам
Для данного исследования используются различные подходы
анализа ассоциативных правил, которые являются основой анализа рыночной
корзины, а также применяется эконометрический подход для определения
зависимости выбора определенного бренда.
Остальная часть работы построена следующим образом: в первой
главе представлены основные идеи анализа потребительского поведения, во второй
главе обсуждаются достоинства и недостатки различных методов выявления
интересных правил, описание собранных данных представлено в третьей главе, в
четвертой главе подробно описан процесс определения ассоциативных правил,
эконометрический анализ описан в пятой главе, в последней главе сделаны выводы
по проведенному исследованию.
Глава 1. Основые
идеи анализа потребительской корзины
Исследователи в сфере экономики и маркетинга давно
заинтересованы в выявлении определенных моделей в поведении потребителей.
Многим известно, что кофе и сахар являются дополняющими друг друга товарами, в
то время как кофе и чай являются заменяющими друг друга. Знание таких связей
действительно важно, так как снижение цен на один товар может увеличить спрос
не только на сам товар, но и на продукцию, которая его дополняет. Поэтому, если
два товара являются комплементами друг для друга, их спросы будут иметь
положительную взаимосвязь. С другой стороны, если два товара заменяют друг
друга, то мы, скорее всего, будем наблюдать отрицательную корреляцию, так как
снижение спроса на один товар увеличивает спрос на другой, заменяющий его
товар. [8]
Практикующие менеджеры и маркетологи также заинтересованы в
нахождении взаимосвязей между брендами, надеясь на основании полученных
ассоциаций определять различные маркетинговые стратегии. Для многих таких
менеджеров и маркетологов вышеописанная взаимосвязь между сахаром и кофе
является очевидной в силу здравого смысла и имеющегося опыта. Однако в нашем
случае, изучая автомобильный рынок, нет определенного логического обоснования
тому, что владельцы автомобиля марки "А" имеют высокую вероятность
приобрести автомобиль марки "В”, кроме как анализ данных владельцев
автомобилей. Возможно, наиболее знаменитой ассоциацией, выявленной в таком виде
анализа данных, является взаимосвязь между детскими подгузниками и пивом. Не
смотря на причины данной взаимосвязи, ассоциация пива и подгузников не была
такой явной для маркетологов. Выявление именно таких правил потребительского
поведения является основной причиной применения анализа рыночной корзины в
изучении автомобильного рынка. [8]
В качестве исходных данных для анализа рыночной корзины
используется информация только о составе транзакции покупателей, то есть нет
необходимости иметь индивидуальные характеристики самого потребителя. Например,
в анализе покупок автомобилей используются данные покупателя о том, какими
автомобилями покупатель когда-либо обладал, и для обнаружения ассоциативных
правил нам не нужно знать возраст, пол, стаж и другие индивидуальные
характеристики покупателя. Основным фокусом исследования является набор покупок
пользователей для каждой транзакции. Из этих строк в виде набора покупок
выявляются серии ассоциативных правил, которые позволяют видеть совместно
потребляемые товары. Каждое ассоциативное правило состоит из
"условия" и "следствия". Предположим следующее ассоциативное
правило: Если потребитель приобретает товар А, то он или она, скорее всего,
приобретет товар Б. В таком правиле А является условным товаром, а Б -
следственным. Стоит отметить, что возможно существование набора условных и
набора следственных товаров. [8]
С другой стороны, связь между брендами можно определить,
анализируя не только ассоциативные правила, но и с помощью выявления
зависимостей в эконометрических моделях. Для данного исследования наиболее
подходящими являются модели бинарного выбора. Модели бинарного выбора
применяются, когда зависимая переменная принимает значения либо 1, либо 0, а
объясняющие переменные определяют вероятность выбора бренда. В исследовании
автомобильных брендов можно рассмотреть зависимость наличия определенной марки
автомобиля в настоящем от марок автомобилей, которые были в прошлом. [8; 12]
автомобильный рынок потребительское поведение
Глава
2. Критический обзор основных методов выявления ассоциативных правил
Можно выявить большое количество ассоциативных правил из
собранных данных об автомобилях, но суть анализа рыночной корзины заключается в
том, чтобы определить наиболее интересных из них. Тяжело подобрать какой-то
конкретный измеритель интересности правила, однако существуют наиболее часто
применимые в литературе способы, которые подробно анализируется, а также
применяются в данном анализе. [11]
2.1
Классический подход. Измерители поддержки и достоверности правил
Проблема нахождения ассоциативных правил А⇒ В впервые была изучена в 1993 году, как задача сбора данных для
нахождения часто вместе встречающихся предметов в Булевых транзакционных
данных. В классическом подходе решения данной проблемы ассоциативное правило
можно назвать интересным, если значения "поддержки" (support) и
"достоверности" (confidence) превышает определенное исследователем
минимальное значение. Значение поддержки (1) определяется как процент
транзакций, которые содержат определенные комбинации продукций, относительно
общего числа транзакций. Достоверность (2) показывает, насколько следствие
правила зависит от условия, то есть достоверность отображает условную
вероятность существования следственного предмета, имея условный. [1]
= P (BA) (1)= P (B| A) (2)
Одним из ограничений подхода поддержки и достоверности
является то, что высокое значение достоверности должно согласовываться с
высоким значением корреляции. Предположим, продукт "А" имеет высокую
положительную корреляцию с продуктом "В" и негативную корреляцию с
продуктом "С". Если значение достоверности и поддержки для правила А⇒В ниже, чем для А⇒C, то мы будем наблюдать
противоречие значений корреляций с значениями достоверности и поддержки. Такого
рода недостатки, выявленные в литературе по ассоциативным правила, заставляют
использовать альтернативные способы определения интересности правил. [3; 4; 6]
Через несколько лет после появления ассоциативных правил
исследователи начали осознавать недостатки значения достоверности. [3; 10]
Поэтому в скором времени был представлен другой измеритель под названием
"интерес" (lift/interest), который можно получить следующим образом:
= P (B|A) /P (B) (3)
Интерес является измерителем, который позволяет преодолеть
проблемы, возникающие у достоверности и поддержки. Рассмотрим следующее
ассоциативное правило "А⇒В". Значение
интереса можно определить, как P (B|A) /P (B) или P (AB) / [P (A) P (B)]. Как
мы можем видеть из предыдущей формулы, в отличие от достоверности интерес
представляет собой симметричный показатель, то есть правило "А⇒В"можно записать в виде "В⇒А".
Интерес принимает значения на промежутке от 0 до бесконечности
и интерпретируется следующим образом:
· Если Интерес<1, тогда А и В появляются
в данных вместе реже, чем ожидалось предположениями условной зависимости. А и В
отрицательно зависят друг от друга.
· Если Интерес=1, тогда А и В появляются в
данных вместе так же часто, как и предполагалось условной зависимостью. А и В
не зависят друг от друга.
· Если Интерес>1, тогда А и В появляются
в данных вместе чаще, чем ожидалось предположениями условной зависимости. А и В
положительно зависят друг от друга
Однако существует два важных ограничения для измерителя
"интерес". Первое связано с вариативностью выборки, которая означает,
что для низких абсолютных значений поддержки значение интереса может сильно
колебаться при малейшем изменении значения поддержки. Второе связано с тем, что
значение интереса не следует применять для сравнения наборов продукций разных
размеров, так как интерес увеличивается с увеличением набора продукции.
Причиной этому является более резкое снижение показателей в знаменателе формулы
интереса, чем в числителе, при увеличении набора продукции. Поэтому
"lift”, как правило, переоценивает интересность крупных наборов продукции.
[6; 7]
2.2 Тест
Хи-квадрат на независимость переменных
Естественным способом определения зависимостей между условием
и следствием в ассоциативном правиле А⇒В является тест
Хи-квадрат на независимость. [10]
Рассмотрим следующий пример: Покупатели приобретают продукты
А и В, суммарное количество которых составляет 2700 и 2200 штук соответственно.
|
Покупает А
|
Не покупает А
|
сумма
|
|
Покупает В
|
1500
|
700
|
2200
|
|
Не покупает В
|
1200
|
500
|
1700
|
|
сумма
|
2700
|
1200
|
3900
|
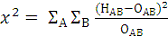 (4)
(4)
Количество степеней свободы в данном случае равно 1, а из формулы
(4) мы получаем значение хи-квадрат, равное 2,6. Критическое значение для одной
степени свободы и значения "p-value" 0.05 будет равно 3.84, что
превышает полученное значение хи-квадрат и указывает на независимость продуктов
А и В.
Как мы можем видеть, тест Хи-квадрат на независимость представляет
собой интересный способ для определения взаимосвязи или, как в примере выше, ее
отсутствия между продуктами. Однако данный метод имеет важные ограничения,
связанные с большими наборами данных. [5]
Во-первых, тест хи-квадрат основывается на нормальной сходимости к
биномиальному распределению. Такая аппроксимация нарушается, когда значения
ожидаемых частот достаточно мала. Тест хи-квадрат следует применять только
тогда, когда каждая ячейка таблицы сопряжённости имеет значения ожидаемых
частот более 1 и значения большинства этих ячеек должно быть не менее 5. В
случае применения анализа рыночной корзины, однако, эти ограничения очень часто
нарушаются.
Во-вторых, как правило, при применении ассоциативных правил
значения в ячейках таблицы сопряженности не сбалансированы. Такая
несбалансированность связана с отсутствием в комбинациях следствий и условий
наборов каких-либо продукций, размеры которых превышают наборы, присутствующие
в комбинациях следствий и условий.
Последнее ограничение указывает на то, что хи-квадрат тест выдает
большие значения, когда набор данных стремится к бесконечности. Поэтому
значимая взаимозависимость различных продуктов будет расти с увеличением набора
данных. Причиной этому является зависимость хи-квадрата от общего количества
транзакций, в то время как критической значение зависит только от количества
степеней свободы и уровня значимости. Перечисленные выше условия снижают
вероятность применения данного метода в нашем анализе, однако существует
возможность использования альтернативных вычислителей взаимозависимости, в
качестве которых выступает тест Фишера. С другой стороны, преимущество
хи-квадрат теста перед измеритель интереса "lift” заключается в том, что
хи-квадрат учитывает всю возможную информацию о наличии и отсутствии в наборе
какого-либо продукта, когда интерес учитывает только наличие ассоциаций.
2.3
Логлинейный анализ зависимости переменных
После хи-квадрат теста стоит рассмотреть логлинейный анализ.
Логлинейный анализ подходит для измерения взаимозависимостей между таблицами
сопряженности с тремя и более переменными, когда мы не заинтересованы в
нахождении связи между условием и следствием ассоциативного правила, а хотим
рассмотреть взаимосвязь между отдельными продуктами в рамках набора. [2]
Важно понимать, что в логлинейном анализе нет конкретного
разделения переменных на зависимые или независимые, все переменные
рассматриваются одинаково. В определенном плане ограничения для хи-квадрат
теста, описанные в предыдущей части также накладываются и на логлинейный
анализ. Наблюдения должны быть независимы, не более 20% ячеек ожидаемых частот
могут иметь значения ниже 5, и абсолютно все ячейки ожидаемых частот должны
быть больше единицы. Нарушение хотя бы одно из этих ограничений может повлиять
на потерю статистической значимости различных логлинейных моделей.
В данной главе были представлены основные подходы выявления
интересных правил. Для анализа рыночной корзины наиболее подходящими
измерителями являются "поддержка", "достоверность" и
"интерес", так как они не имеют столь строгих ограничений, связанных
с большими наборами данных, как у хи-квадрат теста или логлинейного анализа.
Однако в данном исследовании будут применены все перечисленные способы, а уже
потом выявлены наиболее подходящие из них, так как нет конкретных рекомендаций
в существующей литературе для выбора того или иного метода для выявления
ассоциативных правил для автомобильного рынка.
Глава 3.
Описание данных
В качестве основного источника данных для данного анализа был
выбран сайт для автолюбителей avtomarket.ru. Данный ресурс представляет собой
ценный источник данных, так как является единственным сайтом, содержащим
информацию не только об автомобилях, но и об их владельцах. Данные содержат
информацию об отзыве на один из автомобилей пользователя, информацию о самом
пользователе, а также информацию о наборе из автомобилей, которыми пользователь
сайта когда-либо обладал.
В первую очередь, на сайте avtomarket.ru рассматривались все
отзывы на автомобили, расположенные по дате обновления. На странице отзыва на
автомобиль можно было найти информацию о дате отзыва, пробеге автомобиля, годе
выпуска автомобиля, примерной стоимости автомобиля, а также оценку автомобиля,
выставленную самим пользователем. В конечной таблице данных отмечалось название
марки автомобиля, на который был написан отзыв. Далее необходимо было перейти
на страницу автора отзыва, чтобы собрать индивидуальную информацию о владельце
автомобиля. На этой же странице существует раздел "машины",
информация которого позволяет собрать данные о когда-либо существовавших
автомобилях у владельца данной страницы.
В таблице №1 представлено подробное описание каждой
переменной. Для данного исследования было собрано 299 наблюдений по
пользователям сайта avtomarket.ru.
Для проведения анализа ассоциативных правил используется
последняя строка из таблицы 1, отображающая автомобили пользователей. Остальные
переменные используются для нахождения зависимостей в эконометрическом анализе.
Таблица 1
|
Название переменной
|
Описание
|
Вид переменной
|
|
Pontiac-Hyundai
|
Название марки автомобиля, на который написан
отзыв
|
бинарная
|
|
Price_from
|
"Цена от" на автомобиль в отзыве.
Формируется сайтом avtomarket.ru
|
количественная
|
|
Price_to
|
"Цена до" на автомобиль в отзыве.
Формируется сайтом avtomarket.ru
|
количественная
|
|
Mileage
|
Пробег автомобиля из отзыва (км).
|
количественная
|
|
Year
|
Возраст автомобиля из отзыва, начиная с даты
выпуска
|
количественная
|
|
Mark
|
Оценка автомобиля из отзыва. Среднее значение
по 5 характеристикам.
|
количественная
|
|
Gender
|
Пол владельца автомобиля
|
бинарная
|
|
Age
|
Возраст владельца автомобиля
|
количественная
|
|
rating
|
Место владельца автомобиля в рейтинге сайта
|
количественная
|
|
experience
|
Стаж владельца автомобиля
|
количественная
|
|
Auto1-Auto17
|
Название марок и моделей автомобилей, которыми
пользователь сайта когда-либо обладал
|
качественная
|
Глава 4.
Выявление интересных ассоциативных правил
4.1
Подготовка данных и суммарная статистика
Анализ рыночной корзины в данном исследовании проводится в
программе "R" с применением пакета "arules", который
позволяет применять команды, связанные с выявлением ассоциативных правил.
Для начала анализа рыночной корзины в "R"
необходимо правильно оформить данные. Как было отмечено в прошлой главе, для
определения ассоциативных правил используются данные об автомобилях, которыми
пользователь обладал в прошлом. Предположим, все прошлые автомобили одного
пользователя представляют собой одну транзакцию, а каждый отдельный автомобиль
является предметом транзакции. Так как пакет "arules" определяет
правила между уникальными продуктами, необходимо удалить из имеющихся
транзакций повторяющиеся предметы. Причиной этому является ограничение название
автомобиля названием марки, которое можно объяснить имеющимся количеством
наблюдений. Таким образом, данные, подготовленные для пакета "arules"
представляют собой транзакции с уникальными марками автомобилей.
После импортирования данных в "R" имеет смысл
рассмотреть суммарную статистику по ним. Как можно увидеть в таблице 2,
собранные данные содержат 27 уникальных марок, и имеют плотность 0.07.
Показатель "плотность" представляет собой отношение числа заполненных
ячеек к общему числу ячеек. Ниже в таблице представлены наиболее часто
встречаемые марки в транзакциях. Автомобиль марки "ВАЗ" с большим
отрывом опережает другие марки по популярности, за ним следуют автомобили марок
"Ford", "Nissan", "Volkswagen" и
"Audi". В таблице 3 можно увидеть, сколько транзакций приходится на
определенное количество уникальных марок. Самая крупная транзакция включает в
себя автомобили 11 марок, таких транзакций в собранных данных всего две.
Некоторые описательные статистики приведены в таблице 4.
Таблица 2
|
27 columns (items) and
a density of 0.06897837
|
|
Most frequent items:
|
|
vaz
|
fo
|
ni
|
vw
|
au
|
(other)
|
|
91
|
32
|
32
|
32
|
29
|
339
|
Таблица 3
|
element
(itemset/transaction) length distribution: sizes
|
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
9
|
11
|
|
106
|
65
|
35
|
32
|
25
|
15
|
5
|
10
|
3
|
2
|
Таблица 4
|
Min.
|
1st Qu.
|
Median
|
Mean
|
3rd Qu.
|
Max
|
|
0.000
|
0.000
|
1.000
|
1.862
|
3.000
|
11.000
|
4.2
Применение измерителей "поддержка" и "достоверность"
Переходя от описательных статистик к ассоциативным правилам,
в первую очередь, стоит рассмотреть такие показатели, как "поддержка"
и достоверность".
В анализе рыночной корзины "поддержка" показывает,
как часто конкретный продукт появляется в данных, или в нашем случае, как часто
автомобиль определенной марки появляется у пользователей. Сначала были
определены названия марок, которые появляются хотя бы в 10% транзакций (рис.
1), а затем уже определялась частота появления в транзакциях всех марок,
названия которых можно увидеть на рисунке 2 в порядке убывания. В данном
анализе наиболее высоким значением показателя поддержки обладает автомобиль
марки "ВАЗ", а самым малым - "Lexus".
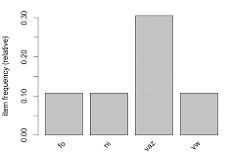
Рис. 1
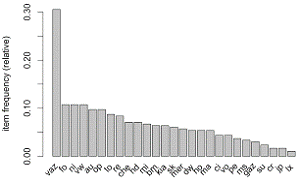
Рис. 2
Для выявления закономерностей строится модель с показателями
"достоверность" и "поддержка". Достоверность в данном
анализе показывает долю транзакций, в которых наличие одной марки или
комбинации марок ведет к наличию другой марки или комбинации марок. В первой
модели оба показателя принимают значения, которые по умолчанию устанавливаются
в "R" (support=0.1, confidence=0.8). Такая модель не выявляет никаких
правил, поэтому необходимо самостоятельно обозначить минимальные значения
"поддержки" и "достоверности" так, чтобы они
соответствовали имеющимся данным. Установив минимальные значения поддержки и
достоверности на уровне 0.01 и 0.25 соответственно, получаем вторую модель с
895 закономерностями. Из таблицы 5 можно увидеть распределение ассоциативных
правил по их размерам. Максимальное количество правил содержат три марки
автомобилей, меньше всего ассоциативных правил с 7 марками автомобилей. Стоит
отметить, что правила, в которых более двух марок, могут иметь 1 и более марок
как в условии правила, так и в его следствии. В таблице 6 представлены
описательные статистики индикаторов качества модели.
Таблица 5
|
Rule length
distribution (lhs + rhs): sizes
|
|
2
|
3
|
4
|
5
|
6
|
7
|
|
89
|
369
|
268
|
120
|
42
|
7
|
Таблица 6
|
support
|
confidence
|
lift
|
|
Min.
|
0.01007
|
Min.
|
0.2500
|
Min.
|
1.023
|
|
1st Qu.
|
0.01007
|
1st Qu.
|
0.4702
|
1st Qu.
|
3.438
|
|
Median
|
0.01342
|
Median
|
0.8000
|
Median
|
7.842
|
|
Mean
|
0.01400
|
Mean
|
0.7433
|
Mean
|
8.575
|
|
3rd Qu.
|
0.01342
|
3rd Qu.
|
1.0000
|
3rd Qu.
|
11.920
|
|
Max.
|
0.06711
|
Max.
|
1.0000
|
Max.
|
29.800
|
Теперь можно перейти к просмотру закономерностей, полученных
из второй модели. Как было отмечено в предыдущих главах, показатели "поддержка"
и "достоверность" имеют свои определенные недостатки, поэтому правила
были отсортированы в "R" по показателю "интерес". На
рисунке 3 изображены первые 20 правил. Из них видно, что правила с самым высоки
показателем "интерес" имеют 3 и более марок.
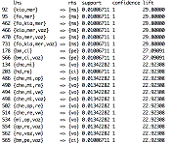
Рис. 3
Большинство правил с самым высоким "интересом"
содержат в следствии марки "Москвич" и "Volvo". Так как в
условиях правил часто присутствует автомобиль марки "ВАЗ" и правила с
4 и более марками не так соответствуют реальности, как правила с тремя и двумя
марками, имеет смысл поставить ограничение в "R" на длину правил до 3
марок. На рисунке 4 представлены первые 20 ассоциативных правил,
отсортированных по значению "интерес" длиной в 3 марки автомобилей.
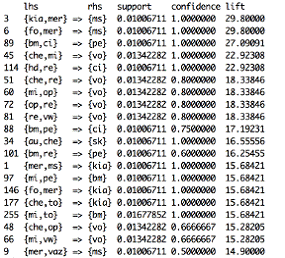
Рис. 4
Из данных правил хотелось бы выделить наиболее интересные из
них. Автомобиль марки "BMW" встречается как в условии, так и
следствии четырех ассоциативных правил вместе с французскими марками
"Citroen", "Peugeot" и "Renault". В следствии
пяти ассоциативных правил встречается автомобиль марки "Volvo",
который связан с марками "Opel" и "Chevrolet" находящихся в
условиях правил. А также в 5 правилах пересекаются такие марки, как
"Mercedes", "Kia" и "Москвич".
Последними были изучены закономерности, состоящие из двух
марок. На рисунке 5 изображены 30 ассоциативных правил, отсортированных по
показателю "интерес".
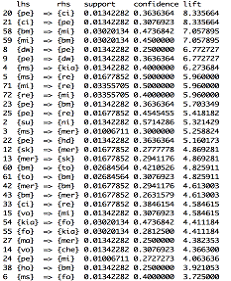
Рис. 5
Несколько интересных фактов можно отметить и из этих правил.
Как и на предыдущем рисунке, можно увидеть взаимозависимость между французскими
марками. Это видно по ассоциациям Peugeot-Citroen,Renault-Citroen,
Renault-Peugeot. Также сохранилась взаимосвязь Peugeot-BMW, Mitsubishi-BMW,
Volvo-Chevrolet, которые наблюдаются в ассоциативных правилах с тремя марками.
Выявленные выше ассоциативные правила являются важными для
данного исследования, так как по ним можно уже сделать определенные выводы.
Высокие показатели достоверности и интереса отражают то, насколько эти правила
интересны, однако существуют альтернативные методы, определяющие
взаимозависимость марок автомобилей, которые необходимо применить.
4.3
Применение Хи-квадрат теста на независимость
Одним из таких альтернативных методов является хи-квадрат
тест на независимость. С помощью данного теста также, как и в предыдущем
способе, можно посмотреть, есть ли взаимосвязь между двумя или более
переменными. В данном анализе критерий хи-квадрат будет иметь нулевую гипотезу,
утверждающую отсутствие взаимосвязи между марками. Для проверки гипотезы
необходимо построить таблицу ассоциаций между брендами, представленную в виде
матрицы совместных частот. Такие матрицы также называются таблицами
сопряженности. В рассматриваемом случае получена матрица размерности 27x27,
каждая строка и колонка которой представляет собой название марки автомобиля.
После построения таблицы наблюдаемых частот, нужно знать, что было бы, если
марки не имели бы какой-либо связи, то есть необходимо построить таблицу
ожидаемых частот.
Значения в таблице с ожидаемыми частотами заметно отличаются от
значений в таблице с наблюдаемыми частотами, что может свидетельствовать о
зависимости марок. Для проверки данного факта используется критерий согласия
Пирсона 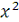 :
:
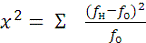 (4)
(4)
Критерий вычисляется для каждой ячейки таблицы сопряженности, а за тем
суммируется. Отклонить нулевую гипотезу можно только тогда, когда превышает критическое значение. Критическое значение определяется
по имеющимся степеням свободы и выбранному уровню значимости. Так как в данном
анализе слишком большое число степеней свободы, удобнее провести тест в
программе "R".

Рис. 6
На рисунке 6 изображены результаты хи-квадрат теста на
независимость марок. Полученное значение "p-value" позволяет
отвергнуть нулевую гипотезу, подтверждая наличие зависимости брендов друг от
друга.
Однако во второй главе были отмечены важные ограничения по
применению данного теста, связанные с большими наборами данных. В полученной
таблице ожидаемых частот достаточно большое количество ячеек имеют значения
ниже 1, и большинство этих же ячеек имеют значения ниже 5. Таким образом, были
нарушены два ограничения, что делает результаты хи-квадрат теста незначимыми.
Во второй главе также было отмечено, что есть другой способ решения этой
проблемы, который включает в себя применение теста Фишера.
4.4
Применение точного теста Фишера
Точный тест Фишера в основном применяется для малых выборок и
для малых таблиц сопряженности, когда значения в ячейках ожидаемых частот ниже
5. Данный метод в этом анализе применяется для тестирования уже полученных
зависимостей марок с помощью измерителей "достоверность",
"поддержка" и "интерес". Нулевая гипотеза, как и в
хи-квадрат тесте, утверждает отсутствие зависимости марок. Данный тест был
проведен в программе "R".
|
Fisher's exact
|
|
Правила
|
p-value
|
|
Peugeot ⇒ Citroen
|
0.000
|
|
BMW ⇒ Mitsubishi
|
0.000
|
|
Daewoo ⇒ Peugeot
|
0.001
|
|
Москвич⇒ Kia
|
0.003
|
|
Москвич⇒ Renault
|
0.000
|
|
Mitsubishi ⇒ Renault
|
0.000
|
|
Peugeot ⇒ BMW
|
0.001
|
|
Peugeot ⇒ Renault
|
0.001
|
|
Suzuki ⇒ Nissan
|
0.003
|
|
Москвич⇒ Mercedes
|
0.002
|
|
Peugeot ⇒ Hyundai
|
0.003
|
|
Skoda⇒ Mercedes
|
0.000
|
|
BMW ⇒ Toyota
|
0.000
|
|
Mercedes ⇒ BMW
|
0.002
|
|
Citroen ⇒ Renault
|
0.000
|
В таблице 7 приведены 15 правил, состоящих из двух марок, с
самым высоким показателем "интерес". Как видно из таблицы, во всех
p-value позволяет отвергнуть нулевую гипотезу о независимости марок, что
подтверждает результаты, полученные в анализе рыночной корзины.
Что касается логлинейного анализа, как уже отмечалось в
прошлой главе, ограничения для хи-квадрат теста и логлинейного анализа
идентичны, поэтому для данного исследования применение данного метода выявления
зависимостей между марками не имеет смысла.
Глава 5.
Эконометрический анализ выбора марки автомобиля
Для проведения эконометрического анализа зависимости марки
автомобиля от другой марки были использованы данные по автомобиля, на которые
пользователи сайта avtomarket.ru написали отзыв, и данные по автомобилям,
которые пользователи сайта имели в прошлом. Также использовались данные по
характеристикам автомобиля, на который был написан отзыв, и данные по
индивидуальным характеристика самих пользователей.
В данном исследовании эконометрический анализ можно провести,
использовав модели бинарного выбора, так как в качестве зависимой переменой в
моделях выступает наличие марки, на которую был написан отзыв. Для определения
таких зависимых переменных проводилось суммирование по строкам с целью
определения марок, на которые было написано больше всего отзывов. В результате
в нашем анализе в роли зависимых переменных выступают бренды "ВАЗ",
"Volkswagen", "Toyota" и "Nissan".
5.1
Результаты по моделям бинарного выбора
Из таблицы 8 можно сделать определенные выводы по влиянию
марок друг на друга. Как известно, величины коэффициентов интерпретировать
нельзя, однако по знаку коэффициентов можно сказать, что пользователи, у
которых были автомобили марок либо "Daewoo", либо "Suzuki",
либо "ГАЗ" имеют больше вероятности купить автомобиль марки
"ВАЗ", чем другие. Данные результаты отражены в обычной МНК
регрессии, для логистической модели статистически значимо только влияние марки
"Daewoo", которое тоже является положительным.
Для автомобиля марки "Toyota" коэффициенты марок
"Honda" и "Mazda" положительные, но в обоих моделях все
коэффициенты статистически незначимы.
Таблица 8
|
VAZ
|
OLS coefficients
|
Logit coefficients
|
|
Daewoo
|
0.1881* (0.085)
|
3.0206* (1.419)
|
|
Suzuki
|
0.2785* (0.117)
|
2.0558 (1.389)
|
|
GAZ
|
0.2637* (0.119)
|
3.1478 (1.669)
|
|
experience
|
-0.0049 (0.004)
|
-0.1218 (0.163)
|
|
mark
|
-0.2922* (0.056)
|
-3.4897* (1.151)
|
|
age
|
-0.0017 (0.004)
|
-0.0670 (0.165)
|
|
cons
|
1.5530 (0.269)
|
15.9969* (5.466)
|
* показывает значимость на 5% уровне
Таблица 9
|
Toyota
|
OLS coefficients
|
Logit coefficients
|
|
Honda
|
0.1919 (0.104)
|
1.4780 (0.840)
|
|
Mazda
|
0.1008 (0.146)
|
0.9027 (1.188)
|
|
Experience
|
0.0064 (0.006)
|
0.0673 (0.066)
|
|
Age
|
-0.0026 (0.005)
|
-0.0283 (0.063)
|
|
Mark
|
-0.0159 (0.071)
|
-0.2066 (0.766)
|
|
cons
|
0.1478 (0.330)
|
-1.5485 (3.545)
|
* показывает значимость на 5% уровне
В моделях с зависимой переменной "Volkswagen"
статистически значимое влияние имеет только автомобиль марки "Opel".
Автолюбители, у которых в прошлом был "Opel" имеют вероятность купить
"Volkswagen" выше, чем другие автолюбители. Данные результаты
отображены как в обычной МНК регрессии, так и в логистической.
Таблица 10
|
VolkswagenOLS coefficientsLogit coefficients
|
|
|
|
Opel
|
2.1109* (0.910)
|
|
Mitsubishi
|
0.1453 (0.111)
|
1.5774 (1.092)
|
|
Mark
|
0.1761* (0.071)
|
2.3984* (0.993)
|
|
Age
|
-0.0035 (0.005)
|
-0.0754 (0.088)
|
|
Experience
|
-0.0056 (0.006)
|
-0.0552 (0.080)
|
|
cons
|
-0.4731 (0.335)
|
-9.9303* (4.646)
|
* показывает значимость на 5% уровне
В таблице 11 представлены коэффициенты моделей с зависимой
переменной "Nissan". Как видно из таблицы, пользователи, у которых в
прошлом был автомобиль марки "Nissan", имеют вероятность купить
автомобиль марки "Nissan" выше, чем те, у кого не было автомобиля
марки "Nissan". Это подтверждено обычной МНК регрессией и
логистической моделью.
Таблица 11
|
Nissan
|
OLS coefficients
|
Logit coefficients
|
|
Peugeot
|
0.1063 (0.075)
|
1.0932 (0.858)
|
|
Nissan
|
0.1669* (0.45)
|
1.6730* (0.517)
|
|
cons
|
0.0451* (0.015)
|
-3.0320* (0.293)
|
* показывает значимость на 5% уровне
5.2
Предельные эффекты моделей бинарного выбора
Для того чтобы проинтерпретировать величину эффектов,
необходимо использовать коэффициенты предельных эффектов. Для обычной МНК регрессии
коэффициенты предельных эффектов имеют абсолютно такие же величины как и в
предыдущих таблицах, однако для логистической модели величины отличаются.
В таблице 12 представлены предельные эффекты для обычной МНК
регрессии, предельные эффекты для логистической модели при среднем и средние
предельные эффекты для логистической модели, в которых зависимой переменной
является автомобиль марки "ВАЗ". Предельные эффекты МНК показывают,
что наличие в прошлом марок "Daewoo", "Suzuki" и
"ГАЗ" увеличивают вероятность приобретения "ВАЗ" на 19%,
27% и 26% соответственно. Средние предельные эффекты для логистической модели
показывают, что наличие "Daewoo" и "ГАЗ" в прошлом по
отдельности увеличивают вероятность приобретения "ВАЗ" на 15%.
Предельные эффекты при среднем для логистической модели сравнительно малы и
статистически незначимы.
Таблица 12
|
AZ
|
OLS marginal effects
|
Logit marginal effects
at the mean
|
Logit average maginal effects
|
|
Daewoo
|
0.1881* (0.085)
|
0.0470 (0.036)
|
0.1469* (0.064)
|
|
Suzuki
|
0.2785* (0.117)
|
0.0320 (0.033)
|
0.0999 (0.062)
|
|
GAZ
|
0.2637* (0.119)
|
0.0490 (0.040)
|
0.1530* (0.076)
|
|
experience
|
-0.0049 (0.004)
|
-0.0018 (0.002)
|
-0.0059 (0.007)
|
|
mark
|
-0.2922* (0.056)
|
-0.0543 (0.039)
|
-0.1697 (0.047)
|
|
age
|
-0.0017 (0.004)
|
-0.0010 (0.002)
|
-0.0032 (0.008)
|
В таблице 13 представлены предельные эффекты для моделей с
зависимой переменной "Toyota". Коэффициенты, как и в предыдущей
таблице для автомобиля "Toyota" остаются статистически незначимыми.
Таблица 13
|
Toyota
|
OLS marginal effects
|
Logit marginal effects
at the mean
|
Logit average maginal effects
|
|
Honda
|
0.1919 (0.104)
|
0.13332 (0.073)
|
0.1412 (0.080)
|
|
Mazda
|
0.1008 (0.146)
|
0.0813 (0.106)
|
0.0862 (0.113)
|
|
Experience
|
0.0064 (0.006)
|
0.0060 (0.005)
|
0.0064 (0.006)
|
|
Age
|
-0.0026 (0.005)
|
-0.0025 (0.005)
|
-0.0027 (0.006)
|
|
Mark
|
-0.0159 (0.071)
|
-0.0186 (0.068)
|
-0.0197 (0.073)
|
В моделях с зависимой переменной "Volkswagen"
коэффициенты предельных эффектов так же остаются значимыми для марки
"Opel". Для МНК регрессии наличие в прошлом "Opel"
увеличивает вероятность приобретения "Volkswagen" на 22%. Для
логистической модели предельные эффекты при среднем показывают, что наличие в
прошлом "Opel" увеличивает вероятность приобретения
"Volkswagen" на 15%, а средние предельные эффекты для логистической
модели показывают увеличение вероятности приобретения "Volkswagen" на
20% при наличии в прошлом автомобиля "Opel".
Таблица 14
|
Volkswagen
|
OLS marginal effects
|
Logit marginal effects
at the mean
|
Logit average maginal effects
|
|
Opel
|
0.2248* (0.107)
|
0.1520* (0.065)
|
0.2067* (0.085)
|
|
Mitsubishi
|
0.1453 (0.111)
|
0.1135 (0.78)
|
0.1544 (0.104)
|
|
Mark
|
0.1761* (0.071)
|
0.1727* (0.063)
|
0.2349* (0.094)
|
|
Age
|
-0.0035 (0.005)
|
-0.0054 (0.006)
|
-0.0073 (0.008)
|
|
Experience
|
-0.0056 (0.006)
|
-0.0039 (0.005)
|
-0.0054 (0.007)
|
В таблице 15 представлены предельные эффекты для моделей с
зависимой переменной "Nissan". Предельные эффекты МНК регрессии,
предельные эффекты при среднем для логистической модели и средние предельные
эффекты для логистической модели показывают увеличение вероятности приобретения
автомобиля марки "Nissan" на 17%, 9% и 10% соответственно при наличии
в прошлом марки "Nissan".
Таблица 15
|
Nissan
|
OLS marginal effects
|
Logit marginal effects
at the mean
|
Logit average maginal effects
|
|
Peugeot
|
0.1063 (0.075)
|
0.0584 (0.045)
|
0.0646 (0.051)
|
|
Nissan
|
0.1669* (0.45)
|
0.0893* (0.027)
|
0.0989* (0.032)
|
5.3 Связь
анализа ассоциативных правил с эконометрическим анализом выбора бренда
Наиболее интересные факты из проведенного исследования
наблюдаются при совместном рассмотрении результатов анализа ассоциативных
правил и эконометрического анализа. Если рассмотреть все ассоциативные правила
длиной в две марки, то в них можно найти комбинаций, соответствующие полученным
моделям.
Таблица 16
|
правило
|
поддержка
|
достоверность
|
интерес
|
|
Honda⇒Toyota
|
0.0167
|
0.3125
|
3.5817
|
|
Opel⇒Volkswagen
|
0.0369
|
0.3793
|
3.5323
|
|
Daewoo⇒ВАЗ
|
0.0302
|
0.5625
|
1.8420
|
|
ГАЗ⇒ВАЗ
|
0.0100
|
0.3333
|
1.0915
|
Ассоциативные правила, соответствующие моделям из
эконометрического анализа, представлены в таблице 16. Наиболее высоким
показателем интерес из этих правил обладают "Honda⇒Toyota" и "Opel⇒Volkswagen". В
моделях бинарного выбора влияния автомобиля марки "Honda" на
вероятность приобретения "Toyota" значимо на 10% уровне, а влияние
марки "Opel" на вероятность приобретения "Volkswagen"
значимо на 5% уровне.
Заключение
Используя различные методы для выявления ассоциативных
правил, а также данные сайта avtomarket.ru, в данном анализе было выявлено
множество интересных взаимосвязей между автомобильными брендами. Помимо анализа
рыночной корзины, данное исследование состояло из эконометрического анализа, в
котором были определены марки автомобилей, наличие которых влияет на
приобретение другой марки.
Во второй главе были представлены преимущества и недостатки
наиболее популярных способов определения ассоциативных правил. Самым
эффективным в применении оказался метод, состоящий из измерителей
"поддержка", "достоверность" и "интерес".
Благодаря данным показателям было выявлено 895 ассоциативных правил, 89 из
которых являются правилами из двух марок. Хи-квадрат тест и логлинейный анализ
менее пригодны для анализа рыночной корзины из-за строгих ограничений для
значений ячеек в таблице ожидаемых частот. Однако такие ограничения отсутствуют
для точного теста Фишера, который был проведен для правил длиной в две марки и
подтвердил значимое наличие взаимосвязей.
Что касается самих результатов по анализу рыночной корзины,
можно сказать, что наиболее интересные взаимозависимости можно наблюдать среди
французских марок "Citroen", "Peugeot" и
"Renault", с этими же марками связан автомобиль марки
"BMW". Бренд "Volvo" имеет взаимосвязь с
"Chevrolet" и "Opel", а "Mercedes" с
"Kia" и "Москвичом".
Эконометрический анализа показал, что вероятность
приобретения автомобиля марки "Volkswagen" выше при наличии в прошлом
автомобиля марки "Opel", вероятность приобретения "ВАЗ"
выше при наличии в прошлом "Daewoo" или "ГАЗ", а
вероятность приобретения "Nissan" выше, если в прошлом у владельца
был тоже "Nissan". Интересным фактом является то, что некоторые из
таких зависимостей найдены в полученных ассоциативных правилах.
Развитие данного анализа возможно и его осуществлению может
помочь сбор большего количества данных. Набрав больше данных, можно найти
ассоциативные правила не только среди марок, но и среди моделей внутри одного
бренда. Такая информация также будет очень важна для менеджеров и маркетологов
автомобильного сектора, так как они будут знать, какой автомобиль нужен их
покупателю, с точностью до названия модели.
Список литературы
1. Agrawal R., Imieliсski T., Swami A. Mining association rules
between sets of items in large databases // ACM SIGMOD Record. - 1993. - Т.22. - №.2. - С. 207-216.
. Agresti A. Categorical data analysis. - New York: John Wiley
& Sons, 1996. - Т.996.
. Aggarwal C. C., Yu P. S. A new framework for itemset generation
// Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on
Principles of database systems. - ACM, 1998. - С.18-24.
. Agrawal R. et al. Fast algorithms for mining association rules
// Proc. 20th int. conf. very large data bases, VLDB. - 1994. - Т.1215. - С.487-499.
. Brin S., Motwani R., Silverstein C. Beyond market baskets:
Generalizing association rules to correlations // ACM SIGMOD Record. - ACM,
1997. - Т.26. - №.2. - С.265-276.
. DuMouchel W. Bayesian data mining in large frequency tables,
with an application to the FDA spontaneous reporting system // The American
Statistician. - 1999. - Т.53. - №.3. - С.177-190.
. DuMouchel W., Pregibon D. Empirical bayes screening for multi-item
associations // Proceedings of the seventh ACM SIGKDD international conference
on Knowledge discovery and data mining. - ACM, 2001. - С.67-76.
. Giudici P., Figini S. Market basket analysis // Applied Data
Mining for Business and Industry, Second Edition. - 2009. - С.175-191.
. McFadden D. Econometric models for probabilistic choice among
products // Journal of Business. - 1980. - С. S13-S29.
. Silverstein C., Brin S., Motwani R. Beyond market baskets:
generalizing association rules to dependence rules // Data mining and knowledge
discovery. - 1998. - Т.2. - №.1. - С.39-68.
. Tan P. N., Kumar V., Srivastava J. Selecting the right
interestingness measure for association patterns // Proceedings of the eighth
ACM SIGKDD international conference on Knowledge discovery and data mining. -
ACM, 2002. - С.32-41.
. Train K. Qualitative choice analysis: Theory, econometrics, and
an application to automobile demand. - MIT press, 1986. - Т.10.
Приложения

Рис 1. (Ассоциативные правила с двумя марками)
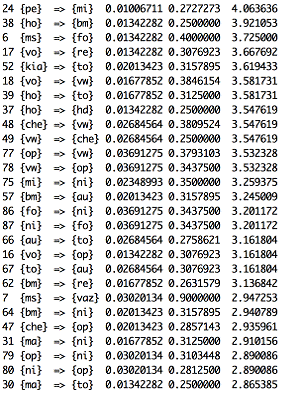
Рис 2. (Ассоциативные правила с двумя марками)

Рис 3. (Ассоциативные правила с двумя марками)
Рис 4. (Ассоциативные правила с двумя марками)
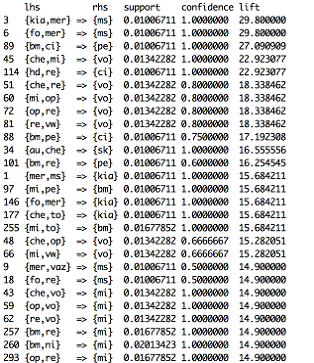
Рис 5. (Ассоциативные правила с тремя марками)
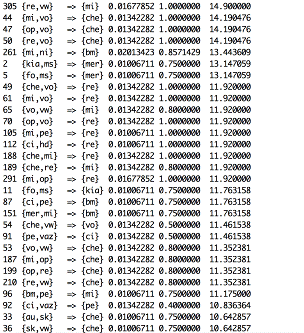
Рис 6. (Ассоциативные правила с тремя марками)

Рис 7. (Ассоциативные правила с тремя марками)
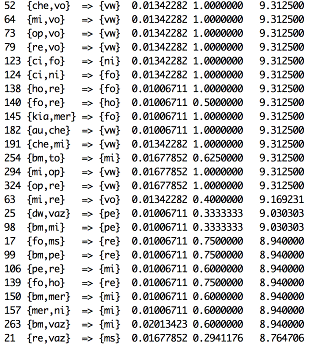
Рис 8. (Ассоциативные правила с тремя марками)
Скрипт из
"R":(arules)< - read. transactions ("~/Desktop/marki.
csv", sep =",")(md)(md [1: 3])(md [,1: 27])(md, support=0.1)(md,
topN=27)< - apriori (md)< - apriori (md, parameter=list (support=0.01,
confidence=0.25, minlen=2))(m1)(sort (m1, by="lift") [1: 200])(sort
(m1, by="lift") [400: 600])< - apriori (md, parameter=list
(support=0.01, confidence=0.25, minlen=3, maxlen=3))(sort (m1,
by="lift") [1: 20])< - apriori (md, parameter=list (support=0.01,
confidence=0.25, minlen=2, maxlen=2))(sort (m1, by="lift") [1:
89])(sort (m1, by="lift") [1: 200])(sort (m1, by="lift")
[1: 100])< - apriori (md, parameter=list (support=0.01, confidence=0.25,
minlen=2, maxlen=2))(sort (m1, by="lift") [1: 89])< - apriori (md,
parameter=list (support=0.01, confidence=0.25, minlen=3, maxlen=3))(sort (m1,
by="lift") [1: 100])