Построение модели множественной линейной регрессии
Задание
Имеются данные о деятельности крупнейших
компаний США - чистом доходе (Y,
млрд. долл.), численности служащих (Х1, тыс. чел.) и
использованном капитале (Х2, млрд. долл.):
Задание:
1. Оцените распределение переменной Х1:
·
определите
вид переменной по типу измерения;
·
постройте
статистический ряд и гистограмму, опишите закон распределения переменной;
·
определите
ожидаемое значение переменной и средний разброс ее значений;
·
сделайте
вывод об ожидаемом значении данного показателя в генеральной совокупности с
95%-ной вероятностью;
·
определите,
можно ли признать имеющийся набор данных нормально распределенным; укажите, как
можно устранить существующие проблемы в наборе данных.
2. Исследуйте корреляционную зависимость
между переменными У и Х1 (переменная Y
подчиняется нормальному распределению):
·
выберите
и рассчитайте числовой показатель взаимосвязи между переменными, сделайте вывод
о силе и направлении связи между ними;
·
проверьте
сделанные выводы с помощью поля корреляции;
·
предложите
одну или несколько математических функций, наиболее соответствующих зависимости
между переменными.
3. Произведите моделирование взаимосвязи
между переменными У и Х1 с помощью линейной функции:
·
постройте
с помощью метода наименьших квадратов линейное уравнение регрессии Ŷ =
b0 + b1 · X1;
·
приведите
интерпретацию каждого из коэффициентов регрессии;
·
проверьте
качество построенной модели при уровне значимости 0,05;
·
проверьте
наличие автокорреляции остатков графическим методом и с помощью критерия
Дарбина-Уотсона при уровне значимости 0,01;
·
проверьте
наличие гетероскедастичности графическим методом и с помощью теста ранговой
корреляции при уровне значимости 0,1;
·
сделайте
вывод, можно ли использовать линейную модель для прогнозирования. Совпадают ли
ваши выводы с предположениями, сделанными в п. 2?
4. Произведите моделирование взаимосвязи
между переменными с помощью множественной линейной регрессии Ŷ =
b0 + b1 Х1 + b2 Х2.
5. Проверьте качество новой модели при том
же уровне значимости, а также наличие автокорреляции остатков. Как можно
объяснить изменения показателей?
. Если необходима дальнейшая
корректировка модели, внесите предложения по изменению спецификации.
. Сравните качество построенных моделей.
Какая из моделей, на ваш взгляд, предпочтительнее для выражения исследуемой
зависимости и почему?
Рассчитайте 99%-ные доверительные интервалы для
теоретических коэффициентов наилучшей регрессии. Сделайте выводы.
8. По наилучшей регрессионной модели
рассчитайте точечный прогноз среднего значения чистого дохода при значениях
численности служащих 100 тыс. чел. и стоимости использованного капитала 30
млрд. долл.
Содержание
1. Оценка распределения переменной
Х1
2. Исследование корреляционной
зависимости между переменными Х1 и У
. Моделирование взаимосвязи между
переменными У и Х1 с помощью линейной функции
. Моделирование взаимосвязи между
переменными с помощью множественной линейной регрессии
. Проверка качества модели,
построенной с помощью множественной регрессии
. Сравнение качества моделей,
построенных с помощью линейной регрессии и множественной регрессии
7. Расчет точечного прогноза по
заданным значениям
Список литературы
Приложение
1. Оценка распределения переменной Х1
переменная линейный регрессия
прогноз
В набор данных в данной задаче входит две
переменных Х1 (численность служащих, тыс. чел.) и Х2 (использованный капитал,
млрд.руб.), поэтому данный набор данных является двумерным массивом. Так как
последовательность записи наблюдаемых значений не важна, то набор данных
является перекрестным набором. Переменные в наборе принимают числовые
показатели, поэтому являются количественными дискретными переменными.
Для того чтобы найти закон распределения случайной
величины и построить гистограмму, произведем группировку значений случайной
величины по интервалам, найдем частоту попадания величин с эти интервалы, а
далее - определим середину каждого из интервалов и вероятность попадания в
указанные нами интервалы. Данные действия необходимы, так как при построении
гистограммы по оси абсцисс откладываются средние значения в интервалах, по оси
ординат - вероятности попадания в интервал. Построив график, мы найдем закон
распределения переменной. Количество интервалов и их ширину подберем
самостоятельно таким образом, чтобы построенная на основе закона распределения
гистограмма была наглядной.
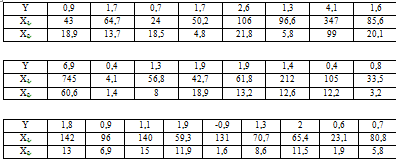
Исходные данные

Упорядочим значения численности служащих (Х1,
тыс.чел.) по возрастанию.

Из данных видно, что минимальное значение
численности служащих равно 4,1 тыс.чел., максимальное - 745 тыс.чел. Ширина
равных интервалов группировки рассчитывается по формуле:
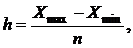 (1)
(1)
где: Xmax -
максимальное значение переменной; Xmin -
минимальное значение переменной; n - число групп.
Количество интервалов примем равным
6. Границы интервалов определяются путем прибавления величины шага к значению
предыдущей границы. Рассчитаем ширину равных интервалов группировки:
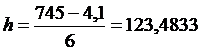 тыс.чел.
тыс.чел.
Частота попадания значений случайной
величины в соответствующие интервалы определяется с помощью встроенной функции MS Excel ЧСТРОК,
т.к. ее удобно использовать для подсчета частоты попадания значений в
определенный интервал: ЧСТРОК (диапазон ячеек)
Построим закон распределения
случайной величины Х1 (численность служащих). Рассчитаем вероятность попадания
каждого значения в интервал.
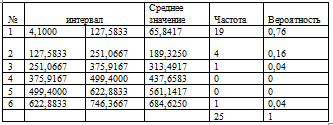
Для наглядности расчеты сведем в таблицу 1.
Таблица 1. Расчет вероятности
попадания каждого значения в интервал.
Строим гистограмму с помощью Мастера диаграмм MS
Excel (закон
распределения случайной величины), при этом по оси абсцисс откладываем средние
значения в интервале, по оси ординат - вероятность попадания в интервал
(рис.1).
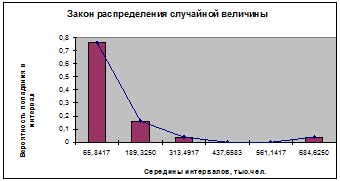
Рисунок 1 - Закон распределения случайной
величины
Определим ожидаемое значение переменной и
средний разброс ее значений. Для определения ожидаемого значения переменной
найдем ее математическое ожидание.
Математическое ожидание -
некоторое число, которое характеризует типичное значение случайной величины.
Оно рассчитывается по формуле:
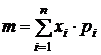 (2)
(2)
Математическое ожидание можно
рассчитать с помощью встроенной функции Excel - СРЗНАЧ
(диапазон ячеек).
m= 115,4520
тыс.чел.
Для определения среднего разброса
значения переменной найдем ее среднее квадратичное отклонение.
Среднее квадратичное отклонение - некоторое
число, которое показывает, на сколько в среднем конкретные значения случайной
величины отличаются от математического ожидания. Оно рассчитывается по формуле:
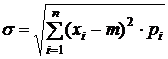 (3)
(3)
Среднее квадратичное отклонение
можно рассчитать с помощью встроенной функции Excel -
СТАНДОТКЛОН (диапазон ячеек).
σ= 148,7732 тыс.чел..
Сделаем вывод о наиболее типичном значении
данного показателя в генеральной совокупности с 95%-ной уверенностью.
Имея информацию о выборке, можно приблизительно
оценить, чему может быть равна ошибка оценивания - разность между выборочным
средним и математическим ожиданием генеральной совокупности. Такой оценкой
является стандартная ошибка, которая рассчитывается по формуле:
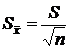 (4)
(4)
где: S
- выборочное среднее квадратичное отклонение; n
- объем выборки.
Рассчитаем стандартную ошибку:
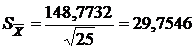 тыс.чел.
тыс.чел.
По таблице распределения Стьюдента
определим значение критический точки. В таблице распределения Стьюдента
используется величина α
= 1 - γ, которая
называется уровнем значимости и показывает, каков процент ошибки, т.е. процент
того, что значение параметра генеральной совокупности окажется за пределами
доверительного интервала.
В нашем случае уровень значимости α=1-0,95=0,05 при ν=n-1=25-1=24.
Встроенная формула Excel для нахождения критической точки: =СТЬЮДРАСПОБР(0,05;24)
tкр= 2,0639
Доверительный интервал - интервал вокруг
математического ожидания случайной величины, имеющей нормальное распределение и
ширину 4 средних квадратичных отклонения. Границы доверительного интервала
находятся по формуле: от (m - tкр · Sх) до (m + tкр · Sх) (5)
Тогда нижняя граница доверительного интервала:
,4520 - 2,0639 . 29,7546 = 54,0414
тыс.чел.
верхняя граница доверительного интервала:
,4520 + 2,0639 . 29,7546 = 176,8626
тыс.чел.
Вывод: можно быть на 95% уверенными, что
значение средней численности служащих лежит в пределах от 54,0414 тыс.чел. до
176,8626 тыс.чел.
Определим, можно ли признать имеющийся набор
данных нормально распределенным. Построенная гистограмма не соответствует
нормальному распределению, т.к. по определению нормальное распределение - это
непрерывное распределение, имеющее графическое представление в виде
симметричной колоколообразной кривой. Форма кривой нормального распределения
зависит от значений числовых характеристик распределения - математического
ожидания и среднего квадратичного отклонения.
Значение математического ожидания влияет на
сдвиг кривой вдоль оси: вершина кривой всегда расположена над математическим
ожиданием. Значение среднего квадратичного отклонения влияет на степень
растяжения кривой вверх и в стороны. Наш набор данных имеет асимметрическое
распределение. Чтобы привести данные к нормальному виду, можно применить
логарифмирование или увеличить количество данных.
. Исследование корреляционной зависимости между
переменными Х1 и У
Так как переменная Х1 не подчиняется
нормальному закону распределения, то для характеристики взаимосвязи будем
использовать коэффициент ранговой корреляции. Построим
поле корреляции.
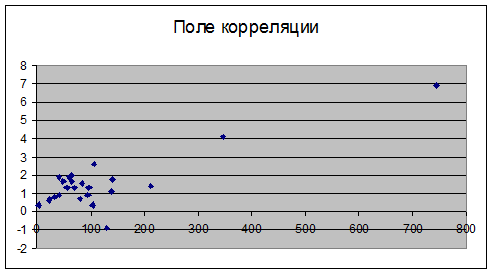
Рисунок 2 - Поле корреляции
На поле корреляции заметна положительная
корреляционная зависимость (с увеличением Х увеличивается Y).
Точки на поле корреляции сгруппированы вокруг линии, направленной вверх и
вправо, но имеют значительный разброс, следовательно, можно сделать
предварительный вывод: между переменными Х и Y
наблюдается слабая линейная зависимость.
Определим вид переменных Х и Y
по типу измерения:
численность служащих (Х) - количественная
дискретная переменная;
чистый доход (Y)
- количественная дискретная переменная.
Так как обе переменные являются количественными,
но одна из переменных (Х) не подчиняется нормальному распределению исходя из
выводов, сделанных выше, для оценки силы корреляционной зависимости используем
коэффициент ранговой корреляции Спирмена:
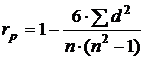 (6)
(6)
гдеd - разность между рангами значений переменных Х и Y;
n
- объем выборки (число наблюдаемых пар значений в наборе данных).
Рангом (R) называется
порядковый номер, который присваивается каждому наблюдаемому значению
переменной после упорядочивания. Расчеты сведем в таблицу 2.
Таблица 2. Расчет
коэффициента ранговой корреляции
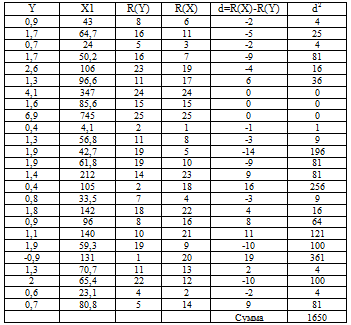
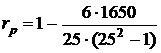 = 0,36538462
= 0,36538462
По таблице 3 дадим
интерпретацию полученному коэффициенту ранговой корреляции.
Таблица 3 -
Интерпретация коэффициента ранговой корреляции
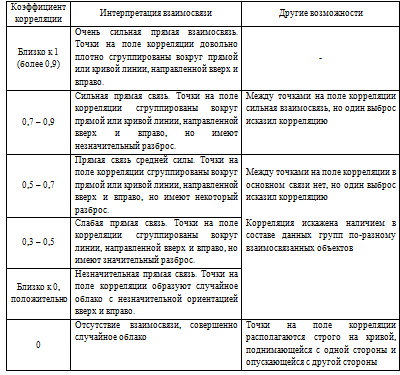
Коэффициент корреляции равен 0,365, что по
таблице 3 можно интерпретировать следующим образом: прямая связь средней силы.
Точки на поле корреляции сгруппированы вокруг прямой или кривой линии,
направленной вверх и вправо, но имеют некоторый разброс, что соответствует
выводу, сделанному по полу корреляции.
Для проверки гипотезы о значимости коэффициента
ранговой корреляции используется критерий:
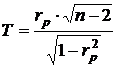 (7)
(7)
который подчинен распределению Стьюдента
с числом степеней свободы n
= n-2.
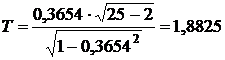
По таблице распределения Стьюдента
необходимо определим критическую точку для двустороннего уровня значимости α:
α = 0,05n = 10-2 = 23кр(α ; n) = tкр(0,05;
23)= 2,06866.
Так как Т=1,8825< tкр=2,06866,
то критерий Т попадает область принятия гипотезы, значит,
принимается нулевая гипотеза, т.е. коэффициент корреляции в генеральной
совокупности незначим.
. Моделирование взаимосвязи между
переменными У и Х1 с помощью линейной функции
Произведем моделирование взаимосвязи
между переменными У и Х1 с помощью линейной функции.
Линейный
регрессионный анализ позволяет предсказывать одну переменную на основании
другой с использованием прямой линии, характеризующей взаимосвязь между этими
переменными: Ŷ = b0 + b1 · X
Переменную,
поведение которой прогнозируют, называют результирующей переменной (Y); переменную, которая используется
для прогнозирования, - фактором (Х1). Коэффициенты b0 и b1 называются
коэффициентами регрессии.
Угловой коэффициент
b1 показывает наклон линии регрессии, или изменение результирующего
показателя Y при изменении фактора Х на единицу. Свободный член b0 показывает сдвиг линии регрессии по вертикальной оси, т.е.
определяет значение результирующего показателя Y при нулевом значении фактора Х.
С помощью метода
наименьших квадратов строится уравнение регрессии, которое характеризуется
наименьшей суммой квадратов отклонений реальных точек наблюдений от линии
регрессии.
Метод наименьших
квадратов использует следующие формулы для расчета коэффициентов регрессии:
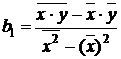 (6)
(6)
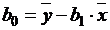 (7)
(7)
Все необходимые промежуточные расчеты сведем в
таблицу 4.
Также для расчета коэффициентов
уравнения линейной линейной регрессии и показателей его качества может
использоваться режим работы "Регрессия". Результаты, полученные с
помощью данного режима, представлены в приложении А.
Таблица 4. Промежуточные расчеты для вычисления
коэффициентов регрессии
|
№
п/п
|
x
|
y
|
x*y
|
х2
|
|
1
|
43
|
0,9
|
38,7
|
1849
|
|
2
|
64,7
|
1,7
|
109,99
|
4186,09
|
|
3
|
24
|
0,7
|
16,8
|
576
|
|
4
|
50,2
|
1,7
|
85,34
|
2520,04
|
|
5
|
106
|
2,6
|
275,6
|
11236
|
|
6
|
96,6
|
1,3
|
125,58
|
9331,56
|
|
7
|
347
|
4,1
|
1422,7
|
120409
|
|
8
|
85,6
|
1,6
|
136,96
|
7327,36
|
|
9
|
745
|
6,9
|
5140,5
|
555025
|
|
10
|
4,1
|
0,4
|
1,64
|
16,81
|
|
11
|
56,8
|
1,3
|
73,84
|
3226,24
|
|
12
|
42,7
|
1,9
|
81,13
|
1823,29
|
|
13
|
61,8
|
1,9
|
117,42
|
3819,24
|
|
14
|
212
|
1,4
|
296,8
|
44944
|
|
15
|
105
|
0,4
|
42
|
11025
|
|
16
|
33,5
|
0,8
|
26,8
|
1122,25
|
|
17
|
142
|
1,8
|
255,6
|
20164
|
|
18
|
96
|
0,9
|
86,4
|
9216
|
|
19
|
140
|
1,1
|
154
|
19600
|
|
20
|
59,3
|
1,9
|
112,67
|
3516,49
|
|
21
|
131
|
-0,9
|
-117,9
|
17161
|
|
22
|
70,7
|
1,3
|
91,91
|
4998,49
|
|
23
|
65,4
|
2
|
130,8
|
4277,16
|
|
24
|
23,1
|
0,6
|
13,86
|
533,61
|
|
25
|
80,8
|
0,7
|
56,56
|
6528,64
|
|
Среднее
значение:
|
115,4520
|
1,56
|
351,028
|
34577,2908
|
|
s
|
148,7732
|
1,4393
|
|
|
|
s2
|
22133,4751
|
2,0717
|
|
|
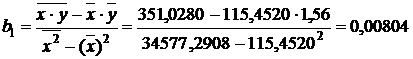
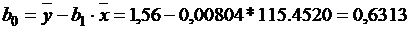
Тогда линейное уравнение
регрессии будет иметь вид:
Ŷ = 0,6313 +
0,00804 · X1
Приведем интерпретацию
каждого из коэффициентов уравнения регрессии. Угловой коэффициент регрессии
(коэффициент наклона) показывает, что если Х1 увеличивается на одну единицу, то
У возрастает на 0,00804 единицы, т.е. при возрастании численности служащих на 1
тыс.чел., чистый доход У увеличивается на 0,00804 млрд.долл.
Свободный член уравнения
регрессии показывает усредненное влияние на результативный признак неучтенных
(не выделенных для исследования) факторов. Свободный член регрессии дает
прогнозируемое значение У, если Х1 равен 0. То есть при численности служащих в
0 чел., чистый доход составит 0,6313 млрд.руб.
Проверим качество
построенной модели при уровне значимости 0,05. Если существует значимая
линейная взаимосвязь между фактором и результирующим показателем, построенное
уравнение регрессии будет адекватно данным генеральной совокупности. Таким
образом, проверка адекватности уравнения сводится к проверке значимости
линейной взаимосвязи между переменными.
Проверить значимость линейной
взаимосвязи можно несколькими способами:
1) проверить значимость углового
коэффициента регрессии;
2) проверить значимость коэффициента
детерминации.
Оба способа основаны на методе проверки
статистических гипотез.
Для проверки углового коэффициента
используется критерий Стьюдента:
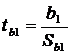 (8)
(8)
гдеb1 - эмпирический угловой коэффициент регрессии;
Sb1 - стандартная ошибка
углового коэффициента регрессии, которая
определяется по формуле:
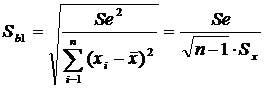 (9)
(9)
гдеSе2 и Sе
- остаточная дисперсия и стандартная ошибка регрессии соответственно;
Sх
- среднее квадратичное отклонение переменной Х.
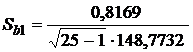 =0,00112
=0,00112
Критерий tb1
имеет распределение Стьюдента с числом степеней свободы n
= n - 2 = 25 - 2 =23
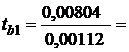 7,1774
7,1774
Найдем табличный критерий Стьюдента
для уровня значимости 0,05. Для этого используем функцию =СТЬЮДРАСПОБР(0,05;23)
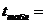 2,06866
2,06866
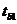 = 7,1774 > 2,06866,
= 7,1774 > 2,06866,
то есть значение критерия tb1 попадает в
одну из критических областей. Вывод:
1) угловой коэффициент признается значимым;
2) существует значимая линейная связь между
фактором и результирующим показателем;
) построенное уравнение адекватно данным
генеральной совокупности.
Проверим значимость свободного члена регрессии.
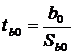 (10)
(10)
где b0 - эмпирический свободный член регрессии;
Sb0 - стандартная ошибка
свободного члена регрессии, которая определяется по формуле:
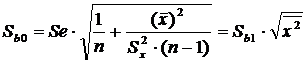 (11)
(11)
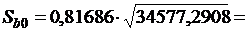 0,20841
0,20841
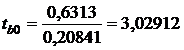
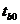 = 3,02912 > 2,06866, то
есть значение критерия tb0 попадает в
одну из критических областей, то есть значение
свободного члена генеральной совокупности значимо.
= 3,02912 > 2,06866, то
есть значение критерия tb0 попадает в
одну из критических областей, то есть значение
свободного члена генеральной совокупности значимо.
Определим коэффициент детерминации
по формуле:
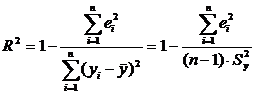 (12)
(12)
где Sy2
- дисперсия переменной Y.
Sy2
= 2,071667
Коэффициент детерминации
показывает, какую долю вариации (разброса) результирующего показателя Y можно объяснить с помощью фактора Х. Он может принимать значения
от 0 до 1. Чем ближе коэффициент детерминации к 1, тем большая доля вариации
результирующего показателя объясняется действием фактора Х, т.е. тем точнее
осуществляется предсказание по уравнению регрессии. Промежуточные расчеты
сведем в таблицу 5.
Таблица 5. Промежуточные
расчеты для вычисления коэффициента детерминации
|
№
|
x
|
y
|
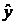 e=-yе2 e=-yе2
|
|
|
|
1
|
43
|
0,9
|
0,97701
|
0,07701
|
0,00593054
|
|
2
|
64,7
|
1,7
|
1,151478
|
-0,548522
|
0,30087638
|
|
3
|
24
|
0,7
|
0,82425
|
0,12425
|
0,01543806
|
|
4
|
50,2
|
1,7
|
1,034898
|
-0,665102
|
0,44236067
|
|
5
|
106
|
2,6
|
1,48353
|
-1,11647
|
1,24650526
|
|
6
|
96,6
|
1,3
|
1,407954
|
0,107954
|
0,01165407
|
|
7
|
4,1
|
3,42117
|
-0,67883
|
0,46081017
|
|
8
|
85,6
|
1,6
|
1,319514
|
-0,280486
|
0,0786724
|
|
9
|
745
|
6,9
|
6,62109
|
-0,27891
|
0,07779079
|
|
10
|
4,1
|
0,4
|
0,664254
|
0,264254
|
0,06983018
|
|
11
|
56,8
|
1,3
|
1,087962
|
-0,212038
|
0,04496011
|
|
12
|
42,7
|
1,9
|
0,974598
|
-0,925402
|
0,85636886
|
|
13
|
61,8
|
1,9
|
1,128162
|
-0,771838
|
0,5957339
|
|
14
|
212
|
1,4
|
2,33577
|
0,93577
|
0,87566549
|
|
15
|
105
|
0,4
|
1,47549
|
1,07549
|
1,15667874
|
|
16
|
33,5
|
0,8
|
0,90063
|
0,10063
|
0,0101264
|
|
17
|
142
|
1,8
|
1,77297
|
-0,02703
|
0,00073062
|
|
18
|
96
|
0,9
|
1,40313
|
0,50313
|
0,2531398
|
|
19
|
140
|
1,1
|
1,75689
|
0,65689
|
0,43150447
|
|
20
|
59,3
|
1,9
|
1,108062
|
-0,791938
|
0,6271658
|
|
21
|
131
|
-0,9
|
1,68453
|
2,58453
|
6,67979532
|
|
22
|
70,7
|
1,3
|
1,199718
|
-0,100282
|
0,01005648
|
|
23
|
65,4
|
2
|
1,157106
|
-0,842894
|
0,7104703
|
|
24
|
23,1
|
0,6
|
0,817014
|
0,217014
|
0,04709508
|
|
25
|
80,8
|
0,7
|
1,280922
|
0,580922
|
0,33747037
|
|
|
|
|
Сумма
|
15,3468302
|
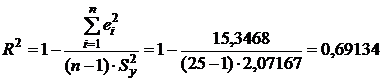
Значение коэффициента
детерминации R2 = 0,69134 показывает, что 69% вариации результирующего показателя
объясняется с помощью уравнения регрессии (действием фактора Х), а 31% -
случайностью.
Проверим статистическую значимость уравнения с
помощью критерия Фишера.
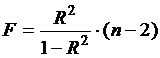 (13)
(13)
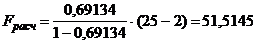
Табличное значение
критерия рассчитаем как =FРАСПОБР(0,05;1;23).
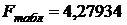
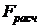 >
> 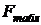 , значение критерия F попадает в
критическую область, выводы оказываются следующими:
, значение критерия F попадает в
критическую область, выводы оказываются следующими:
1) коэффициент детерминации признается
значимым;
2) существует значимая линейная связь между
фактором и результирующим показателем;
) построенное уравнение адекватно данным
генеральной совокупности.
Построим линию регрессии на поле
корреляции (рис.4).
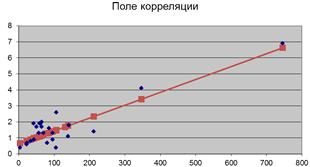
Рисунок 4 - Линия регрессии на поле корреляции
Проверим наличие автокорреляции остатков
графическим методом и с помощью критерия Дарбина-Уотсона при уровне значимости
0,01.
Одной из предпосылок МНК является
независимость между собой значений случайных отклонений. Если присутствует
корреляция между ними, то говорят о наличии автокорреляции остатков.
Автокорреляцией остатков называется зависимость между значениями случайных
отклонений, упорядоченными по значениям фактора Х.
Наиболее наглядный способ проверки
состоит в построении диагностической диаграммы: поля корреляции между
случайными отклонениями (ошибками прогнозирования) еi и прогнозируемыми
значениями результирующего показателя ŷi.Значения случайного
отклонения откладываются по вертикальной оси, прогнозируемые значения
результирующего показателя - по горизонтальной оси (рис.5).
При анализе диагностической диаграммы можно
сделать следующий вывод: между точками на поле взаимосвязи не наблюдается,
диаграмма представляет собой облако из точек, расположенных хаотично и
неупорядоченно, следовательно, автокорреляция остатков отсутствует, значит,
предпосылки МНК выполняются.
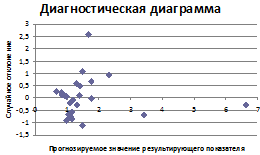
Рисунок 5 - Диагностическая диаграмма к
определению автокорреляции.
Проверим наличие автокорреляции с помощью
критерия Дарбина-Уотсона при уровне значимости 0,01. Упорядочим случайные
отклонения по возрастанию значений фактора Х и составим вспомогательную таблицу
6.
Таблица 6. Промежуточные расчеты критерия
Дарбина-Уотсона
|
x
|
y
|
y1
|
ei
|
ei2
|
ei-1
|
ei-
ei-1
|
(ei
- ei-1)2
|
|
4,1
|
0,4
|
0,664269
|
-0,264269
|
0,069838131
|
|
|
|
|
23,1
|
0,6
|
0,817108
|
-0,217108
|
0,047135748
|
-0,264269
|
0,0471614
|
0,00222419
|
|
24
|
0,7
|
0,824347
|
-0,124347
|
0,015462279
|
-0,2171077
|
0,0927603
|
0,00860447
|
|
33,5
|
0,8
|
0,900767
|
-0,100767
|
0,010153934
|
-0,1243474
|
0,0235807
|
0,00055605
|
|
42,7
|
1,9
|
0,974773
|
0,925227
|
0,856045353
|
-0,1007667
|
1,0259939
|
1,05266353
|
|
43
|
0,9
|
0,977186
|
-0,077186
|
0,005957687
|
0,9252272
|
-1,002413
|
1,00483231
|
|
50,2
|
1,7
|
1,035104
|
0,664896
|
0,442086889
|
-0,0771861
|
0,7420822
|
0,55068599
|
|
56,8
|
1,3
|
1,088195
|
0,211805
|
0,044861287
|
0,6648961
|
-0,453091
|
0,20529174
|
|
59,3
|
1,9
|
1,108306
|
0,791694
|
0,626780158
|
0,2118048
|
0,5798897
|
0,33627201
|
|
61,8
|
1,9
|
1,128416
|
0,771584
|
0,595342082
|
0,7916945
|
-0,02011
|
0,00040443
|
|
64,7
|
1,7
|
1,151744
|
0,548256
|
0,30058479
|
0,7715841
|
-0,223328
|
0,0498754
|
|
65,4
|
2
|
1,157375
|
0,842625
|
0,710017292
|
0,5482561
|
0,2943691
|
0,08665317
|
|
70,7
|
1,3
|
1,200009
|
0,099991
|
0,009998261
|
0,8426252
|
-0,742634
|
0,55150516
|
|
80,8
|
0,7
|
1,281255
|
-0,581255
|
0,337856794
|
0,0999913
|
-0,681246
|
0,46409584
|
|
85,6
|
1,6
|
1,319866
|
0,280134
|
0,078474852
|
-0,5812545
|
0,8613881
|
0,74198952
|
|
96
|
0,9
|
1,403525
|
-0,503525
|
0,253537839
|
0,2801336
|
-0,783659
|
0,6141215
|
|
96,6
|
1,3
|
1,408352
|
-0,108352
|
0,011740133
|
-0,5035254
|
0,3951735
|
0,15616211
|
|
105
|
0,4
|
1,475923
|
-1,075923
|
1,157609572
|
-0,1083519
|
-0,967571
|
0,93619319
|
|
106
|
2,6
|
1,483967
|
1,116033
|
1,245530105
|
-1,0759227
|
2,1919559
|
4,8046705
|
|
131
|
-0,9
|
1,68507
|
-2,58507
|
6,682588306
|
1,1160332
|
-3,701103
|
13,6981669
|
|
140
|
1,1
|
1,757468
|
-0,657468
|
0,432263541
|
-2,5850703
|
1,9276028
|
3,71565236
|
|
142
|
1,8
|
1,773556
|
0,026444
|
0,000699296
|
-0,6574675
|
0,6839117
|
0,46773524
|
|
212
|
1,4
|
2,336646
|
-0,936646
|
0,877304827
|
0,0264442
|
-0,96309
|
0,92754181
|
|
347
|
4,1
|
3,422604
|
0,677396
|
0,458864983
|
-0,9366455
|
1,6140413
|
2,60512917
|
|
745
|
6,9
|
6,624172
|
0,275828
|
0,076081345
|
0,6773957
|
-0,401567
|
0,16125627
|
|
|
|
|
|
15,34681548
|
|
33,1422829
|
Критерий Дарбина - Уотсона рассчитывается по
формуле:
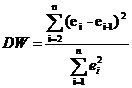 (14)
(14)
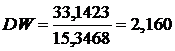
Для определения критических точек воспользуемся
таблицей критических точек Дарбина-Уотсона: при уровне значимости a
= 0,01, одной независимой переменной m=1,
и числе наблюдений n=25, dl
= 1,033 и du
= 1,211.
Так как du
< DW < 4 - du
(1,033 < 2,160 < 2,789), то можно сделать вывод, что автокорреляция
отсутствует.
Проверим наличие гетероскедастичности
графическим методом и с помощью теста ранговой корреляции при уровне значимости
0,1 (рис.6).
На диагностической диаграмме заметно
увеличение дисперсии при увеличении значений фактора, т. е. можно сделать вывод
о наличии гетероскедастичности в построенной регрессионной модели.
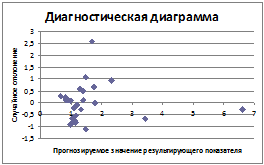
Рисунок 6 - Диагностическая диаграмма к
определению гетероскедастичности.
Проверим наличие гетероскедастичности в
регрессионной модели с помощью теста ранговой корреляции Спирмена. Суть теста ранговой корреляции сводится к оценке
коэффициента корреляции между рангами переменной Х и модуля случайных
отклонений е.
Ранг - это место данного числового
значения среди упорядоченных значений анализируемого показателя.
Коэффициент ранговой корреляции
находится по формуле:
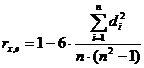 (15)
(15)
Вспомогательные расчеты оформим в виде таблицы
7.
Проверка правильности составления
матрицы на основе исчисления контрольной суммы:
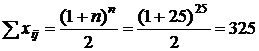
Сумма по столбцам
матрицы равны между собой и контрольной суммы, значит, матрица составлена
правильно.
Рассчитаем коэффициент ранговой
корреляции:
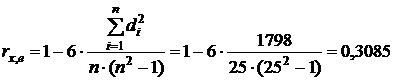
Вывод: между фактором Х и
случайными отклонениями е имеется взаимосвязь слабой силы.
Таблица 7. Вспомогательные расчеты к тесту
ранговой корреляции
|
x
|
y
|
R(xi)
|
ei
|
|
R(ei)
|
di
|
di2
|
|
43
|
0,9
|
6
|
-0,077186
|
0,0771861
|
2
|
4
|
16
|
|
64,7
|
1,7
|
11
|
0,5482561
|
0,5482561
|
13
|
-2
|
4
|
|
24
|
0,7
|
3
|
-0,124347
|
0,1243474
|
6
|
-3
|
9
|
|
50,2
|
1,7
|
7
|
0,6648961
|
0,6648961
|
16
|
-9
|
81
|
|
106
|
2,6
|
19
|
1,1160332
|
1,1160332
|
24
|
-5
|
25
|
|
96,6
|
1,3
|
17
|
-0,108352
|
0,1083519
|
5
|
12
|
144
|
|
347
|
4,1
|
24
|
0,6773957
|
0,6773957
|
17
|
7
|
49
|
|
85,6
|
1,6
|
15
|
0,2801336
|
0,2801336
|
11
|
4
|
16
|
|
745
|
6,9
|
25
|
0,2758285
|
0,2758285
|
10
|
15
|
225
|
|
4,1
|
0,4
|
1
|
-0,264269
|
0,264269
|
9
|
-8
|
64
|
|
56,8
|
1,3
|
8
|
0,2118048
|
0,2118048
|
7
|
1
|
1
|
|
42,7
|
1,9
|
5
|
0,9252272
|
0,9252272
|
21
|
-16
|
256
|
|
61,8
|
1,9
|
10
|
0,7715841
|
0,7715841
|
18
|
-8
|
64
|
|
212
|
1,4
|
23
|
-0,936646
|
0,9366455
|
22
|
1
|
1
|
|
105
|
0,4
|
18
|
-1,075923
|
1,0759227
|
23
|
-5
|
25
|
|
33,5
|
0,8
|
4
|
-0,100767
|
0,1007667
|
4
|
0
|
0
|
|
142
|
1,8
|
22
|
0,0264442
|
0,0264442
|
1
|
21
|
441
|
|
96
|
0,9
|
16
|
-0,503525
|
0,5035254
|
12
|
4
|
16
|
|
140
|
1,1
|
21
|
-0,657468
|
0,6574675
|
15
|
6
|
36
|
|
59,3
|
1,9
|
9
|
0,7916945
|
0,7916945
|
19
|
-10
|
100
|
|
131
|
-0,9
|
20
|
-2,58507
|
2,5850703
|
25
|
-5
|
25
|
|
70,7
|
1,3
|
13
|
0,0999913
|
0,0999913
|
3
|
10
|
100
|
|
65,4
|
2
|
12
|
0,8426252
|
0,8426252
|
20
|
-8
|
64
|
|
23,1
|
0,6
|
2
|
-0,217108
|
0,2171077
|
8
|
-6
|
36
|
|
80,8
|
0,7
|
14
|
-0,581255
|
0,5812545
|
14
|
0
|
0
|
|
|
|
325
|
|
|
325
|
0
|
1798
|
Проверим значимость коэффициента
ранговой корреляции при уровне значимости 0,01:
Н0: rx,e = 0 - коэффициент
ранговой корреляции незначим,
Н1: rx,e ≠ 0 - коэффициент ранговой корреляции значим.
Рассчитаем наблюдаемое значение
критерия Стьюдента.
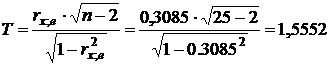
Критическое значение критерия
Стьюдента при уровне значимости a
= 0,1 и числе степеней свободы ν = n - 2 =25 - 2
=23, 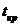 = 1,7139.
Коэффициент ранговой корреляции признается незначимым, так как наблюдаемое
значение Т = 1,5552 меньше чем критическое значение = 1,7139.
Зависимость между фактором Х и случайными отклонениями е
отсутствует, т.е. наблюдается гомоскедастичность.
= 1,7139.
Коэффициент ранговой корреляции признается незначимым, так как наблюдаемое
значение Т = 1,5552 меньше чем критическое значение = 1,7139.
Зависимость между фактором Х и случайными отклонениями е
отсутствует, т.е. наблюдается гомоскедастичность.
4. Моделирование взаимосвязи между
переменными с помощью множественной линейной регрессии
Прогнозирование одной переменной Y на
основании нескольких факторов Х1, Х2 и т.д. называется
множественной регрессией. Уравнение множественной линейной регрессии для данной
задачи выглядит следующим образом:
Ŷ = b0 + b1 · X1 + b2 · X2 (16)
Угловые
коэффициенты b1, b2 для каждого фактора показывают изменение результирующего
показателя Y при изменении данного фактора Х на единицу при условии, что все
остальные факторы остаются неизменными. Свободный член b0 показывает значение результирующего показателя Y при нулевых значениях всех
факторов.
Чаще всего для
определения коэффициентов уравнения регрессии используется метод наименьших
квадратов, который минимизирует сумму квадратов отклонений реальных точек
наблюдений от линии регрессии. Вычисление коэффициентов
множественной регрессии произведем с помощью функции ЛИНЕЙН, которая дает
параметры линейного приближения по методу наименьших квадратов.
ЛИНЕЙН (известные_значения_у;
известные_значения_х; константа; статистика)
Результат:
Рассчитывает массив данных, описывающих
уравнение линейной регрессии на основе метода наименьших квадратов.
Аргументы:
- известные_значения_у: диапазон значений
результирующего показателя Y;
известные_значения_х:
диапазон значений факторов (одновременно выделяются все столбцы, содержащие
значения факторов);
константа:
логическое значение: если оно равно 0, свободный член b0 равен 0;
если оно равно 1, то b0 вычисляется
обычным образом.
статистика:
логическое значение:
если оно равно 0, то функция рассчитывает только
коэффициенты регрессии;
если оно равно 1, то функция рассчитывает
дополнительную регрессионную статистику.
Полученный результат представлен в таблице 8.
Таблица 8. Результат расчета с помощью функции
ЛИНЕЙН
|
b0
|
0,51383517
|
Sb0
|
0,1982011
|
|
b1
|
0,00565112
|
Sb1
|
0,0014665
|
|
b2
|
0,02407261
|
Sb2
|
0,0105045
|
|
R2
|
0,75081808
|
Se
|
0,750434
|
|
F
|
33,1444541
|
n
|
22
|
|
ssоб
|
37,3306747
|
ssост
|
12,389325
|
Уравнение регрессии будет иметь вид:
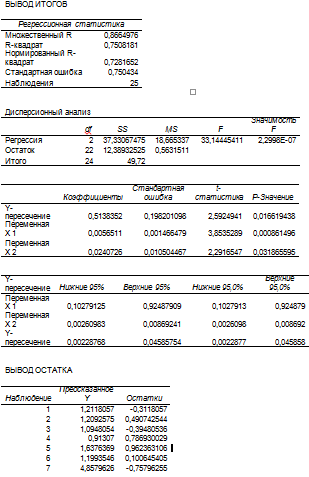
Ŷ = 0,51384 +
0,00565 · X1 + 0,02407 · X2
Также для расчета коэффициентов
уравнения множественной линейной регрессии и показателей его качества может
использоваться режим работы "Регрессия". Результаты, полученные с
помощью данного режима, представлены в приложении Б.
Дадим словесную интерпретацию коэффициентов
уравнения регрессии. b0
- свободный член. Показывает, что при нулевых значениях X1 и X2 значение
результирующего показателя будет равно 0,51384. Коэффициент b1
показывает, что при увеличении численности на 1 тыс.чел. чистый доход
увеличится на 1 млрд.долл. при постоянном объеме использованного капитала,
коэффициент b2 показывает, что при увеличении использованного
капитала на 1 млрд.долл. чистый доход увеличится на 1 млрд.долл. при постоянной
численности служащих.
5. Проверка качества модели, построенной с
помощью множественной регрессии
Рассчитаем стандартную ошибку регрессии, которая
для многомерных данных определяется следующим образом:
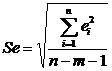 (17)
(17)
где m - число
факторов Х.
Стандартная ошибка регрессии
показывает величину, на которую в среднем отклоняются реальные наблюдаемые
значения yi от
прогнозируемых по уравнению регрессии ŷi.
Чем меньше величина стандартной ошибки регрессии, тем более точными окажутся
прогнозы, выполненные на основании уравнения регрессии.
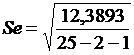 = 0,75043
= 0,75043
Рассчитаем
коэффициент детерминации. В случае множественной регрессии коэффициент
детерминации показывает, какую долю разброса результирующего показателя Y можно объяснить с помощью
используемых в уравнении регрессии m факторов. С увеличением коэффициента детерминации, точность
прогнозирования по уравнению регрессии возрастает.
(18)
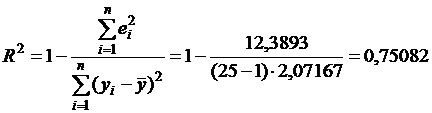
Это означает, что 75%
вариации результирующего показателя объясняется с помощью уравнения
регрессии(действием факторов х1 и х2), а 25% - случайностью.
Выводы, сделанные на
основе стандартной ошибки регрессии или коэффициента детерминации, относятся
лишь к эмпирическим данным. Каким бы качественным не было построенное уравнение
по отношению к эмпирическим данным, может оказаться, что в генеральной
совокупности связь между переменными отсутствует вовсе, и выявленная сильная
линейная связь - просто случайность, основанная на случайно отобранной выборке.
Проверка адекватности
эмпирического уравнения регрессии данным генеральной совокупности
осуществляется с помощью проверки значимости коэффициента детерминации. Цель
этой проверки заключается в том, чтобы выяснить, объясняет ли совместное
влияние всех m факторов значительную долю разброса переменной Y.
Нулевая и альтернативная
гипотезы формулируются следующим образом:
Н0: R2 = 0 - значение коэффициента детерминации незначимо, совместное
влияние m факторов объясняет незначительную долю разброса переменной Y.
Н1: R2 > 0 - значение коэффициента детерминации значимо, совместное
влияние m факторов объясняет значительную долю разброса переменной Y.
Для проверки используется критерий
Фишера:
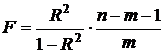 (19)
(19)
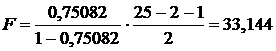 4
4
Критерий F имеет
распределение Фишера с числами степеней свободы n1 = m=2 и n2 = n-m-1=22.
Найдем табличное значение критерия Фишера.
Для этого воспользуемся функцией =FРАСПОБР(0,05;2;22). Fтабл =
3,4433568.
Так как Fрасч = 33,1444
> Fтабл =
3,4433568, то значение критерия попадает в критическую область, т.е. мы
отказываемся от нулевой гипотезы и принимаем альтернативную. Отсюда следуют
выводы:
) коэффициент детерминации
признается значимым;
) существует значимая линейная связь
между факторами и результирующими показателями;
) построенное уравнение адекватно
данным генеральной совокупности.
Поскольку регрессия
оказалась значимой, то можно продолжить проверку качества уравнения регрессии,
используя гипотезы о значимости коэффициентов регрессии.
Значимость
коэффициента детерминации (значимость регрессии) показывает, что один или
несколько (может быть и все) из используемых в уравнении m факторов вместе значимо
влияют на результирующий показатель Y. При этом неизвестно, какие из факторов действительно влияют на
результат, а какие нет.
Если выяснить,
какие из используемых факторов не влияют на результат, их можно исключить из
уравнения регрессии без снижения его качества. При этом уравнение может
значительно упроститься, что существенно для его использования. Проверка
значимости каждого из коэффициентов регрессии bj показывает,
насколько значимым является влияние соответствующего фактора Хj на Y при условии, что все остальные
факторы остаются неизменными.
Проверку значимости
коэффициентов регрессии осуществим с помощью критерия Стьюдента. Проверка
гипотезы о значимости любого из коэффициентов регрессии осуществляется
следующим образом:
Н0: bj = 0 - значение
теоретического коэффициента регрессии незначимо, фактор Xj не влияет на
результирующий показатель.
Н1: bj ≠ 0 - значение теоретического коэффициента регрессии
значимо, фактор Xj влияет на результирующий показатель.
Для проверки используется критерий
Стьюдента:
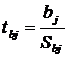 (20)
(20)
Критерий tbj имеет распределение Стьюдента с
числом степеней свободы n = n-m-1.
) свободный член
регрессии b0 = 0,51383517.
Стандартная ошибка регрессии Sb0 = 0,1982011. Фактическое
значение критерия Стьюдента
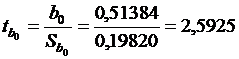
Найдем табличный критерий Стьюдента
для уровня значимости 0,05. Для этого используем функцию =СТЬЮДРАСПОБР(0,05;22)
2,07387
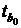 = 2,5925 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что свободный член регрессии
признается значимым.
= 2,5925 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что свободный член регрессии
признается значимым.
) коэффициент регрессии b1 = 0,00565.
Стандартная ошибка регрессии Sb1 = 0,00147. Фактическое значение
критерия Стьюдента
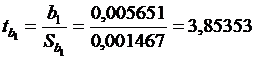
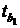 = 3,85353 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что коэффициент регрессии b1 признается
значимым.
= 3,85353 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что коэффициент регрессии b1 признается
значимым.
) коэффициент регрессии b2 = 0,024073.
Стандартная ошибка регрессии Sb2 = 0,010504. Фактическое значение
критерия Стьюдента
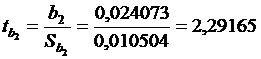
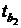 = 2,29165 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что коэффициент регрессии b2 признается
значимым.
= 2,29165 > 2,07387, то
есть значение критерия попадает в
одну из критических областей. Отсюда делаем вывод, что коэффициент регрессии b2 признается
значимым.
Чтобы сравнить влияние различных
факторов на результирующий показатель, следует сравнить коэффициенты корреляции
между каждым из этих факторов и результирующим показателем rXj,Y. Для этого
воспользуемся функцией =КОРРЕЛ(массив1;массив2).
Влияние фактора 1: коэффициент
корреляции rX1,Y = 0,8314657
Влияние фактора 2: коэффициент
корреляции rX2,Y = 0,7695045.
Для фактора Х1 коэффициент корреляции больше rX1,Y = 0,8314657
> rX2,Y = 0,7695045, поэтому фактор 1 (численность
служащих) сильнее влияет на результирующий показатель (чистый доход).
Статистические
выводы о качестве уравнения регрессии будут обоснованными только в том случае,
если выполняются определенные условия относительно свойств случайного
отклонения, называемые предпосылками метода наименьших квадратов (МНК). Если
предпосылки МНК не выполняются, могут быть существенные проблемы с
интерпретацией полученных выводов. Поэтому, построив уравнение регрессии,
необходимо проверить выполнение этих условий.
Наиболее наглядный
способ проверки состоит в построении диагностической диаграммы: поля корреляции
между случайными отклонениями (ошибками прогнозирования) еi и прогнозируемыми
значениями результирующего показателя ŷi. Значения случайного
отклонения откладываются по вертикальной оси, прогнозируемые значения
результирующего показателя - по горизонтальной оси (рис.7).
Возможные варианты
интерпретации структуры диагностической диаграммы приведены в таблице 9.
Таблица 9.
Интерпретация диагностической диаграммы
|
Структура диагностической диаграммы
|
Интерпретация
|
|
Явная взаимосвязь отсутствует
|
Никаких проблем не обнаружено
|
|
Заметна линейная или нелинейная взаимосвязь - присутствует
автокорреляция остатков, при этом одно или несколько значений могут резко
отклоняться
|
По-видимому, данные связаны нелинейной связью. Качество
уравнения можно повысить, воспользовавшись нелинейной регрессией или добавив
в уравнение новую переменную
|
|
Дисперсия случайных отклонений различается для разных значений ŷi - присутствует гетероскедастичность
|
Прогнозы, сделанные на основании этого уравнения, недостаточно
точны. Для улучшения качества уравнения необходимо устранить
гетероскедастичность
|
По виду диагностической диаграммы можно сделать
вывод: точки расположены хаотично, явная взаимосвязь отсутствует, поэтому
никаких проблем не обнаружено.
Проверим наличие автокорреляции с помощью
критерия Дарбина-Уотсона при уровне значимости 0,01. Упорядочим случайные
отклонения по возрастанию значений фактора Х и составим вспомогательную таблицу
(табл.10).
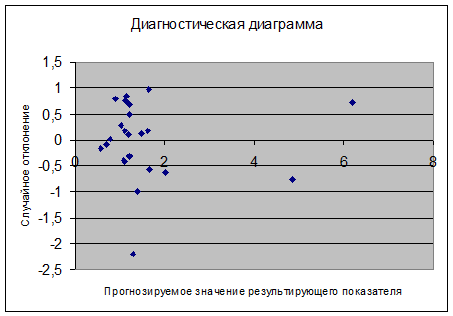
Критерий Дарбина - Уотсона рассчитывается по
формуле:
(14)
Для определения критических точек воспользуемся
таблицей критических точек Дарбина-Уотсона: при уровне значимости a
= 0,01, двух независимых переменных m=2,
и числе наблюдений n=25, dl
= 0,981 и du
= 1,303.
Так как du
< DW < 4 - du
(0,981 < 1,253 < 2,697), то можно сделать вывод, что автокорреляция
отсутствует.
Таблица 10. Вспомогательные расчеты к вычислению
критерия Дарбина-Уотсона
|
x1
|
х2
|
у
|
ei
|
ei2
|
ei-1
|
ei- ei-1
|
(ei
-
ei-1)2
|
|
|
4,1
|
1,4
|
0,9
|
0,5707064
|
0,32929358
|
0,10843426
|
|
|
|
|
23,1
|
1,9
|
1,7
|
0,690114
|
1,009885977
|
1,01986969
|
0,32929358
|
0,6805924
|
0,463206
|
|
24
|
18,5
|
0,7
|
1,0948054
|
-0,39480536
|
0,15587127
|
1,00988598
|
-1,404691
|
1,973158
|
|
33,5
|
3,2
|
1,7
|
0,7801801
|
0,919819925
|
0,8460687
|
-0,3948054
|
1,3146253
|
1,72824
|
|
42,7
|
18,9
|
2,6
|
1,2101104
|
1,389889633
|
1,93179319
|
0,91981993
|
0,4700697
|
0,220966
|
|
43
|
18,9
|
1,3
|
1,2118057
|
0,088194297
|
0,00777823
|
1,38988963
|
-1,301695
|
1,694411
|
|
50,2
|
4,8
|
4,1
|
0,91307
|
3,186930029
|
10,156523
|
0,0881943
|
3,0987357
|
9,602163
|
|
56,8
|
8
|
1,6
|
1,0273997
|
0,572600278
|
0,32787108
|
3,18693003
|
-2,61433
|
6,83472
|
|
59,3
|
11,9
|
6,9
|
1,1354107
|
5,764589296
|
33,2304898
|
0,57260028
|
5,191989
|
26,95675
|
|
61,8
|
13,2
|
0,4
|
1,1808329
|
-0,7808329
|
0,60970002
|
5,7645893
|
-6,545422
|
42,84255
|
|
64,7
|
13,7
|
1,3
|
1,2092575
|
0,090742544
|
0,00823421
|
-0,7808329
|
0,8715754
|
0,759644
|
|
65,4
|
11,5
|
1,9
|
1,1602535
|
0,739746502
|
0,54722489
|
0,09074254
|
0,649004
|
0,421206
|
|
70,7
|
8,6
|
1,9
|
1,1203939
|
0,77960613
|
0,60778572
|
0,7397465
|
0,0398596
|
0,001589
|
|
80,8
|
5,8
|
1,4
|
1,1100669
|
0,289933117
|
0,08406121
|
0,77960613
|
-0,489673
|
0,23978
|
|
85,6
|
20,1
|
0,4
|
1,4814306
|
-1,081430589
|
1,16949212
|
0,28993312
|
-1,371364
|
1,880638
|
|
96
|
6,9
|
0,8
|
1,2224438
|
-0,422443793
|
0,17845876
|
-1,0814306
|
0,6589868
|
0,434264
|
|
96,6
|
5,8
|
1,8
|
1,1993546
|
0,600645405
|
0,3607749
|
-0,4224438
|
1,0230892
|
1,046712
|
|
105
|
12,2
|
0,9
|
1,4008887
|
-0,500888716
|
0,25088951
|
0,60064541
|
-1,101534
|
1,213377
|
|
106
|
21,8
|
1,1
|
1,6376369
|
-0,537636894
|
0,28905343
|
-0,5008887
|
-0,036748
|
0,00135
|
|
131
|
1,6
|
1,9
|
1,2926482
|
0,607351806
|
0,36887622
|
-0,5376369
|
1,1449887
|
1,310999
|
|
140
|
15
|
-0,9
|
1,6660813
|
-2,566081258
|
6,58477302
|
0,60735181
|
-3,173433
|
10,07068
|
|
142
|
13
|
1,3
|
1,6292383
|
-0,32923828
|
0,10839785
|
-2,5660813
|
2,236843
|
5,003467
|
|
212
|
12,6
|
2
|
2,0151877
|
-0,015187705
|
0,00023067
|
-0,3292383
|
0,3140506
|
0,098628
|
|
347
|
99
|
0,6
|
4,8579626
|
-4,257962553
|
18,1302451
|
-0,0151877
|
-4,242775
|
18,00114
|
|
745
|
60,6
|
0,7
|
6,1827205
|
-5,482720473
|
30,0602238
|
-4,2579626
|
-1,224758
|
1,500032
|
|
|
|
|
|
|
107,143121
|
|
|
134,2997
|
6. Сравнение качества моделей, построенных с
помощью линейной регрессии и множественной регрессии
Линейное уравнение регрессии имеет
вид: Ŷ = 0,6313 + 0,00804 · X1. Здесь не учитывается влияние на результирующий показатель
фактора Х2. Путем проверки качества построенной модели можно сделать следующие
выводы:
) оба коэффициента
уравнения регрессии значимы;
) существует значимая линейная связь между
фактором и результирующим показателем;
) значение коэффициента детерминации признается
значимым;
) построенное уравнение адекватно данным
генеральной совокупности;
) в модели отсутствует автокорреляция остатков и
присутствует гомоскедастичность.
6) Значение
коэффициента детерминации R2 = 0,69134 показывает,
что 69% вариации результирующего показателя объясняется с помощью уравнения
регрессии (действием фактора Х), а 31% - случайностью.
Уравнение множественной
регрессии имеет вид:
Ŷ = 0,51384 +
0,00565 · X1 +0,02407 · X2
В данной модели учитывается влияние
на результат обеих факторов.
Путем проверки качества построенной
модели можно сделать следующие выводы:
) все коэффициенты
уравнения регрессии значимы;
) значение коэффициента детерминации признается
значимым;
) построенное уравнение адекватно данным
генеральной совокупности;
) в модели отсутствует автокорреляция остатков.
5) Для фактора Х1 коэффициент
корреляции больше rX1,Y = 0,8314657 > rX2,Y = 0,7695045,
поэтому фактор 1 (численность служащих) сильнее влияет на результирующий
показатель (чистый доход).
Значение
коэффициента детерминации R2 = 0,75082 показывает,
что 75% вариации результирующего показателя объясняется с помощью уравнения
регрессии(действием факторов х1 и х2), а 25% - случайностью.
Коэффициент
детерминации показывает, какую долю вариации (разброса) результирующего
показателя Y можно объяснить с помощью фактора Х. Он может принимать значения
от 0 до 1. Чем ближе коэффициент детерминации к 1, тем большая доля вариации
результирующего показателя объясняется действием фактора Х, т.е. тем точнее
осуществляется предсказание по уравнению регрессии. Если сравнивать
коэффициенты детерминации построенных моделей, то для модели множественной
регрессии коэффициент детерминации больше.
2 множ= 0,75082 > R2 лин= 0,69134,
поэтому точнее осуществляется
предсказание результирующего показателя по уравнению множественной регрессии.
Рассчитаем 99%-ные доверительные интервалы для
теоретических коэффициентов множественной регрессии.
Для любого из
коэффициентов доверительный интервал строится следующим образом:
(b - tкр · Sb; b + tкр · Sb) (15)
гдеb - эмпирический коэффициент
регрессии
Sb - стандартная ошибка соответствующего коэффициента;
tкр - критическое (табличное) значение коэффициента Стьюдента,
рассчитанное при числе степеней свободы n = n-2.
1) свободный член регрессии b0
=
0,5138. Стандартная ошибка регрессии Sb0 = 0,1982. Найдем
табличный критерий Стьюдента для уровня значимости 0,01. Для этого используем
функцию =СТЬЮДРАСПОБР(0,01;22)
2,8073. Доверительный интервал
нижняя граница 0,5138 - 2,8073 ·
0,1982=-0,04258
верхняя граница 0,5138 + 2,8073 ·
0,1982=1,070252
) коэффициент регрессии b1 = 0,00565.
Стандартная ошибка регрессии Sb1 = 0,00147. Доверительный интервал
нижняя граница 0,00565 - 2,8073 ·
0,00147=0,001534
верхняя граница 0,00565 + 2,8073 ·
0,00147=0,009768
) коэффициент регрессии b2 = 0,02407.
Стандартная ошибка регрессии Sb2 = 0,0105. Доверительный интервал
нижняя граница 0,02407 - 2,8073 ·
0,0105=
-0,00542
верхняя граница 0,02407 + 2,8073 ·
0,0105=
0,053562
7. Расчет точечного прогноза по заданным
значениям
По уравнению множественной
регрессии
Ŷ = 0,51384 +
0,00565 · X1 +0,02407 · X2
как наилучшей модели, рассчитаем точечный
прогноз среднего значения чистого дохода при значениях численности служащих 100
тыс. чел. и стоимости использованного капитала 30 млрд. долл.
Ŷ = 0,51384 +
0,00565 · 100 +0,02407 · 30
Ŷ = 1,8011
млрд.долл.
Список литературы
1. Е.Д.Саяпина. Задания и
методические указания по выполнению курсовой работы по курсу "Эконометрика",
Новомосковск, 2013
. Эконометрика. Книги 1 и 2. (Учебник) Носко
В.П. (2011, 672с. и 576с.)
. Эконометрика. (Учебник) Под ред.
Уткина В.Б. (2012, 564с.)
4. Эконометрика. (Учебно-метод. пособие) Шалабанов А.К., Роганов
Д.А. (КазГУ; 2008, 198с.) <#"880379.files/image066.gif">
Приложение Б
Коэффициенты уравнения множественной
регрессии и показателей его качества полученные с помощью режим работы
"Регрессия"