Изучение моделей регрессии
Введение
Из всего многообразия методов моделирования
структурно-сложных экономических систем можно выделить два основных
«работающих» класса:
• эконометрика;
• имитационное моделирование.
В отличие от систем физических или
биологических, которые достаточно хорошо изучены, точность предсказания
будущего поведения экономических объектов (рынок, отрасль, регион, предприятие,
банк) относительно не высока. Возможно, именно сложность объекта привлекает
исследователей: количество научных работ растет почти экспоненциально.
Изучение моделей множественного выбора в
настоящее время является очень актуальным вопросом, так как они применяются в
социологических, социально-экономических и медицинских выборочных
обследованиях. Это даёт возможность проводить более грамотную экономическую
политику и как следствие приносит большую прибыль предприятиям.
Методы эконометрики используются для поиска и
проверки общих закономерностей, связывающих траекторные переменные системы и
переменные внешней среды. А поскольку измерение любых величин, в особенности
экономических, связано со случайными ошибками, то применение аппарата
математической статистики для анализа вероятностных свойств этих величин
неизбежно. Использование эконометрических моделей предполагает представление
объекта в виде «черного ящика» и формальное исследование зависимостей между
переменными, например, на основе системы одновременных уравнений.
Целью написания работы является изучение моделей
регрессии.
Объектом исследования является модель
лог-регрессии.
Предмет исследования -‒
использование модели лог-регрессии в эконометрических исследованиях.
Для изучения темы использовалась тематическая
литература таких авторов как: Магнус Л.Р, Тихомиров Н.П., Дорохина Е.Ю., а так
же труды ведущих отечественных экономистов: В.Н. Афанасьева, И.И. Елисеевой,
А.К. Шалабанова. Так же в работе использованы интернет источники.
В работе были использованы ряд статистических
методов, таких как: метод массового статистического наблюдения, анализ и синтез
данных, а также эконометрические методы: метод наименьших квадратов и
конфлюэнтный анализ.
Работа состоит из введения, двух глав
(теоретической и практической), выводов (заключения), списка использованных
источников.
1. Теоретическая часть
.1 Функциональные преобразования переменных в
линейной регрессии
В линейной регрессии иногда переменные выражены
в нелинейном виде или они имеют разные размерности. В этих случаях требуется
преобразование данных. Применяют чаще всего два вида преобразований:
· логарифмирование данных;
· переход к безразмерным величинам
путем деления на некоторые известные величины, той же размерности, что и
исходные данные.
Покажем на примере линеаризации нелинейных
моделей регрессии как проводят подобные преобразования.
При нелинейной зависимости признаков, приводимых
к линейному виду, параметры множественной регрессии определяются по МНК,
который используется не к исходной информации, а к преобразованным данным. Так,
рассматривая степенную функцию
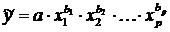 ,
,
преобразовываем ее в линейный вид:
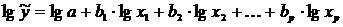 ,
,
где переменные выражены в логарифмах.
Далее обработка МНК такая же: строится система
нормальных уравнений и определяются неизвестные параметры. Потенцируя значение 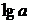 ,
находим параметр a и
соответственно общий вид уравнения степенной функции. Оценка нелинейной
регрессии по включенным переменным определяется МНК или его модификациями, как
и в линейной регрессии. Так, в двухфакторном уравнении нелинейной регрессии
,
находим параметр a и
соответственно общий вид уравнения степенной функции. Оценка нелинейной
регрессии по включенным переменным определяется МНК или его модификациями, как
и в линейной регрессии. Так, в двухфакторном уравнении нелинейной регрессии
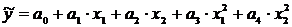
может быть проведена линеаризация, введением в
него новых переменных 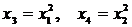 . В результате
получается четырехфакторное уравнение линейной регрессии
. В результате
получается четырехфакторное уравнение линейной регрессии
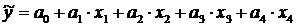 .
.
Если между экономическими явлениями существуют
нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных
функций.
Различают два класса нелинейных регрессий:
1. Регрессии, нелинейные относительно
включенных в анализ объясняющих переменных, но линейные по оцениваемым
параметрам, например
- полиномы различных степеней 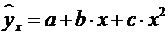 ,
,
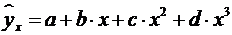 ;
;
равносторонняя гипербола 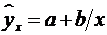 ;
;
полулогарифмическая функция 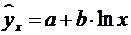 .
.
2. Регрессии, нелинейные по оцениваемым
параметрам, например
- степенная 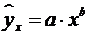 ;
;
показательная 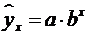 ;
;
экспоненциальная 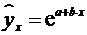 .
.
Регрессии нелинейные по включенным переменным
приводятся к линейному виду простой заменой переменных, а дальнейшая оценка
параметров производится с помощью метода наименьших квадратов. Рассмотрим
некоторые функции.
Парабола второй степени приводится
к линейному виду с помощью замены: 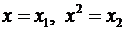 .
В результате приходим к двухфакторному уравнению
.
В результате приходим к двухфакторному уравнению 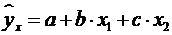 ,
оценка параметров которого при помощи МНК.
,
оценка параметров которого при помощи МНК.
Парабола второй степени обычно применяется в
случаях, когда для определенного интервала значений фактора меняется характер
связи рассматриваемых признаков: прямая связь меняется на обратную или обратная
на прямую.
Равносторонняя гипербола может
быть использована для характеристики обратной связи между факторами (например,
удельных расходов сырья, материалов, топлива от объема выпускаемой продукции,
времени обращения товаров от величины товарооборота, процента прироста
заработной платы от уровня безработицы, расходов на непродовольственные товары
от доходов или общей суммы расходов). Гипербола приводится к линейному
уравнению простой заменой: 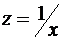 .
.
Аналогичным образом приводятся к линейному виду
зависимости , 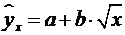 и
другие.
и
другие.
Среди нелинейных моделей наиболее часто
используется степенная функция 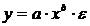 , которая
приводится к линейному виду логарифмированием:
, которая
приводится к линейному виду логарифмированием:
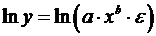 ;
;
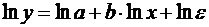 ;
;
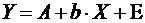 ,
,
где 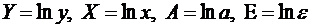 .
Т.е. МНК применяется для преобразованных данных:
.
Т.е. МНК применяется для преобразованных данных:
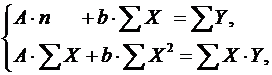
а затем потенцированием находим искомое
уравнение.
Для определения неизвестных коэффициентов
линеаризованной формы показательной функции методом наименьших квадратов
необходимо минимизировать сумму квадратов отклонений логарифмов наблюдаемых
значений результативной переменной У от теоретических значений Ỹ
(значений, рассчитанных на основании модели регрессии), т. е. минимизировать
функционал МНК вида:
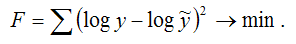
Оценки неизвестных коэффициентов А и В
линеаризованной формы показательной функции находятся при решении системы
нормальных уравнений вида:
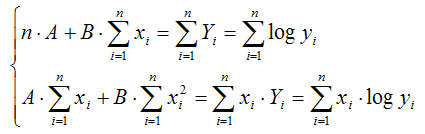
Данная система является системой нормальных
уравнений относительно коэффициентов А и В для функции вида Yi=A+Bхi+E.
Однако основным недостатком полученных
МНК-оценок неизвестных коэффициентов моделей регрессии, сводимых к линейному виду,
является их смещённость.
.2 Лог-линейная регрессия, как модель с
постоянной эластичностью
Регрессия, линейная в логарифмах, именуется
лог-линейной регрессией.
Тесноту связи изучаемых явлений оценивает
линейный коэффициент парной корреляции 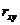 для
линейной регрессии (-1 ≤ ≤ 1):
для
линейной регрессии (-1 ≤ ≤ 1):
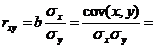
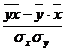 ,
,
где 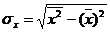 -
среднее квадратическое отклонение в ряду x,
-
среднее квадратическое отклонение в ряду x,
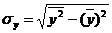 - среднее
квадратическое отклонение в ряду y.
- среднее
квадратическое отклонение в ряду y.
Линейный коэффициент корреляции как измеритель
тесноты линейной связи признаков связан не только с коэффициентом регрессии b,
но и с коэффициентом эластичности, который является показателем силы связи,
выраженным в процентах.
Коэффициент эластичности отражает, на сколько
процентов изменится значение y
при изменение значения фактора на 1%. Коэффициент эластичности рассчитывается
как 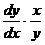 .
.
Обобщающий (средний) коэффициент эластичности
рассчитывается для среднего значения 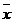 :
:
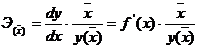
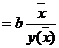
и показывает, на сколько процентов изменится y
относительно своего среднего уровня при росте x
на 1% относительно своего среднего уровня.
Точечный коэффициент эластичности рассчитывается
для конкретного значения x=x0:
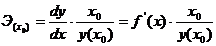
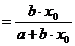
и показывает, на сколько процентов изменится y
относительно своего уровня y(x0)
при увеличении 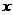 на 1% от уровня x0.
на 1% от уровня x0.
Степенная функция является примером нелинейной
по параметрам регрессии. Данная модель нелинейна относительно оцениваемых
параметров, т.к. включает параметры a
и b неаддитивно.
Однако ее можно считать внутренне линейной, так как логарифмирование приводит
ее к линейному виду: 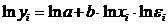 .
.
При исследовании взаимосвязей среди функций,
использующих ln
y, в эконометрике
преобладают степенные зависимости - это кривые спроса и предложения, кривые
освоения для характеристики связи между трудоемкостью продукции и масштабами
производства в период освоения выпуска нового вида изделий, а также зависимость
валового национального дохода от уровня занятости.
Для оценки параметров степенной функции 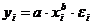 применяется
МНК к линеаризованному уравнению ,
т.е. решается система нормальных уравнений:
применяется
МНК к линеаризованному уравнению ,
т.е. решается система нормальных уравнений:
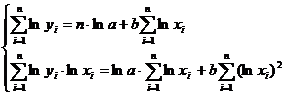
Параметр b
определяется непосредственно из системы, а параметр a
- косвенным путем после потенцирования величины ln
a.
Так как в виде степенной функции изучается не
только эластичность спроса, но и предложения, то обычно параметром b<0
характеризуется эластичность спроса, а параметром b>0
- эластичность предложения.
Если же модель представить в виде:
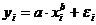 ,
,
то она становится внутренне нелинейной, так как
ее невозможно превратить в линейный вид, то же относится к моделям вида:
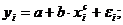
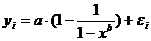 ,
,
так как эти уравнения не могут быть
преобразованы в уравнения, линейные по коэффициентам.
Ниже представлены формулы расчета коэффициентов
эластичности (табл. 1).
Широкое использование степенной функции связано
с тем, что параметр 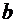 в ней имеет четкое
экономическое истолкование - он является коэффициентом эластичности.
Коэффициент эластичности фактора - результата Y
по фактору X показывает, на
сколько процентов изменится в среднем результат Y,
если фактор X изменится на 1%.
в ней имеет четкое
экономическое истолкование - он является коэффициентом эластичности.
Коэффициент эластичности фактора - результата Y
по фактору X показывает, на
сколько процентов изменится в среднем результат Y,
если фактор X изменится на 1%.
Таблица 1. Формулы коэффициентов точечной
эластичности и средних коэффициентов эластичности
|
Вид
функции 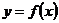
|
Точечный
коэффициент эластичности
|
Средний
коэффициент эластичности
|
|
Линейная
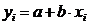
|
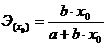
|
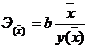
|
|
Парабола
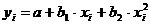
|
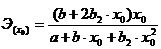
|
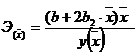
|
|
Равносторонняя
гипербола 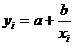
|
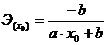
|

|
|
Степенная
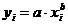
|
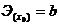
|
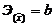
|
|
Показательная
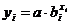
|
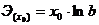
|
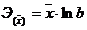
|
Формула для расчета коэффициента эластичности
имеет вид:
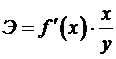 .
.
Так как для остальных функций коэффициент
эластичности не является постоянной величиной, а зависит от соответствующего
значения фактора X, то обычно
рассчитывается средний коэффициент эластичности:
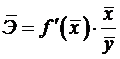 .
.
Приведем дополнительные формулы расчета средних
коэффициентов эластичности для наиболее часто используемых типов уравнений
регрессии (табл.2)
Возможны случаи, когда расчет коэффициента
эластичности не имеет смысла. Это происходит тогда, когда для рассматриваемых
признаков бессмысленно определение изменения в процентах.
В двухфакторном регрессионном анализе найти
уравнение регрессии в стандартизированном масштабе 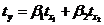 можно
через формулы:
можно
через формулы:
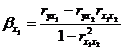 ,
, 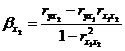 .
.
На основе линейного уравнения множественной
регрессии:
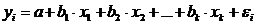
могут быть найдены частные уравнения регрессии:
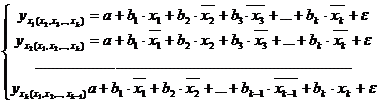
В отличие от парной регрессии частные уравнения
регрессии характеризуют изолированное влияние фактора на результат, ибо другие
факторы закреплены на неизменном среднем уровне. Это позволяет на основе
частных уравнений регрессии определять частные коэффициенты эластичности:
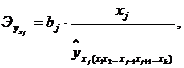
где bj
- коэффициент регрессии при j-ом
факторе;
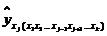 ‒ частное
уравнение регрессии.
‒ частное
уравнение регрессии.
Для того чтобы оценить сравнительную силу
влияния факторов, по каждому фактору рассчитывают средние коэффициенты
эластичности.
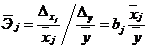 ,
,
где 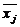 -
среднее значение j-го
факторного признака;
-
среднее значение j-го
факторного признака;
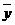 - среднее значение
результативного признака;
- среднее значение
результативного признака;
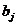 - коэффициент
регрессии при j-м факторном
признаке.
- коэффициент
регрессии при j-м факторном
признаке.
Расчет коэффициента эластичности дополняет
экономический анализ. Данный коэффициент показывает, на сколько процентов
следует ожидать изменения результативного показателя при изменении фактора на
1% и неизменном значении других факторов.
2. Практическая часть
.1 Характеристика экзогенных и эндогенных
переменных. Построение двухфакторного уравнения регрессии. Построение
однофакторных уравнений линейной регрессии. Прогнозирование значения
результативного признака
Список переменных, используемых в модели
У - индекс человеческого развития (ИЧР) -
безразмерная величина;
Х1 - ВВП 1997 г., % к 1990 г. - безразмерная
величина;
Х6 - ожидаемая продолжительность жизни при
рождении в 1997 г., число лет дожития
Эндогенной переменной в модели Y=F(X1,
X6) является У (ее
значение будет определятся в модели), соответственно, Х1, Х6 - это экзогенные
переменные (их значения задаются извне).
Таблица 2. Исходные значения переменных
|
Страна
|
У
|
Х1
|
Х6
|
|
Австрия
|
0,904
|
115
|
77
|
|
Австралия
|
0,922
|
123
|
78,2
|
|
Белоруссия
|
0,763
|
74
|
68
|
|
Бельгия
|
0,923
|
111
|
77,2
|
|
Великобритания
|
0,918
|
113
|
77,2
|
|
Германия
|
0,906
|
110
|
77,2
|
|
Дания
|
0,905
|
119
|
75,7
|
|
Индия
|
0,545
|
146
|
62,6
|
|
Испания
|
0,894
|
113
|
78
|
|
Италия
|
0,9
|
108
|
78,2
|
|
Канада
|
0,932
|
113
|
79
|
|
Казахстан
|
0,74
|
71
|
67,6
|
|
Китай
|
0,701
|
210
|
69,8
|
|
Латвия
|
0,744
|
94
|
68,4
|
|
Нидерланды
|
0,921
|
118
|
77,9
|
|
Норвегия
|
0,927
|
130
|
78,1
|
|
Польша
|
0,802
|
127
|
72,5
|
|
Россия
|
0,747
|
61
|
66,6
|
|
США
|
0,927
|
117
|
76,7
|
|
Украина
|
0,721
|
46
|
68,8
|
|
Финляндия
|
0,913
|
107
|
76,8
|
|
Франция
|
0,918
|
110
|
78,1
|
|
Чехи
|
0,833
|
99,2
|
73,9
|
|
Швейцария
|
0,914
|
101
|
78,6
|
|
Швеция
|
0,923
|
105
|
78,5
|
Подготовим данные к обработке - проранжируем их,
проследим, какие связи между ними. Поле рассеяния Х1, Х6 на У показано на
рис.1. На графике видно, что наличествует прямая линейная зависимость Х6 от У.
Для Х1 не прослеживается определенная зависимость результирующего признака У от
фактора Х6. График распадается на 2 части: в диапазоне У от 0,55 до 0,7 связь
прямая и линейная, затем слом уровня Х6 в 5 раз и опять проступает
повышательный тренд в диапазоне 0,7 до 1. Эти графические наблюдения
показывают, что для линейной регрессии У от Х6 мало оснований.
Строим многофакторную линейную регрессию для
модели
=a+b1*X1+b2*X6
Применив МНК, получаем такое эмпирическое
уравнение регрессии (полные результаты приведены в Прил.1)
= -0,63377-0,000552*X1 + 0,020747*X6
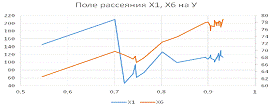
Рис.1
Примечание: из-за разной масштабности Х1 и Х6
данные по Х6 отложены на правой шкале.
Множественный коэффициент корреляции (Индекс
множественной корреляции).
Тесноту совместного влияния факторов на
результат оценивает индекс множественной корреляции. В отличии от парного
коэффициента корреляции, который может принимать отрицательные значения, он
принимает значения от 0 до 1. Поэтому R не может быть использован для
интерпретации направления связи. Чем плотнее фактические значения Yi
располагаются относительно линии регрессии, тем меньше остаточная дисперсия и,
следовательно, больше величина Ry(x1,...,xm).
Таким образом, при значении R близком к 1,
уравнение регрессии лучше описывает фактические данные и факторы сильнее влияют
на результат. При значении R близком к 0 уравнение регрессии плохо описывает
фактические данные и факторы оказывают слабое воздействие на результат.
Аналогичный результат получим при
использовании других формул:
Связь между признаком Y и факторами
Xi очень высокая.
Расчёт коэффициента корреляции
выполним, используя известные значения линейных коэффициентов парной корреляции
и в-коэффициентов.
Коэффициент детерминации, 2=
0,9762 = 0,952. Эта величина показывает, что 95,2 % колебаний У
объяснено этим уравнением, оставшиеся 4,8% относятся на ошибки спецификации и
случайную ошибку. Коэффициент детерминации также равен доле факторной дисперсии
в общей дисперсии. Такое высокое значение - хороший результат.
Проверка общего качества уравнения
множественной регрессии.
Оценка значимости уравнения
множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю
коэффициент детерминации рассчитанного по данным генеральной совокупности: R2
или b1 = b2 =... = bm = 0 (гипотеза о незначимости
уравнения регрессии, рассчитанного по данным генеральной совокупности).
Для ее проверки используют
F-критерий Фишера.
При этом вычисляют фактическое
(наблюдаемое) значение F-критерия, через коэффициент детерминации R2,
рассчитанный по данным конкретного наблюдения.
По таблицам распределения
Фишера-Снедоккора находят критическое значение F-критерия (Fкр). Для этого
задаются уровнем значимости б (0,05) и двумя числами степеней свободы k1=m
и k2=n-m-1. статистика. Критерий Фишера.
Чем ближе этот коэффициент к
единице, тем больше уравнение регрессии объясняет поведение Y.
Более объективной оценкой является
скорректированный коэффициент детерминации:
Добавление в модель новых
объясняющих переменных осуществляется до тех пор, пока растет скорректированный
коэффициент детерминации.
Проверим гипотезу об общей
значимости - гипотезу об одновременном равенстве нулю всех коэффициентов
регрессии при объясняющих переменных:
0: R2
= 0; в1 = в2 = ... = вm = 0. 1: R2
≠ 0.
Проверка этой гипотезы осуществляется
с помощью F-статистики распределения Фишера (правосторонняя проверка). =
Если F < Fkp = Fб
; n-m-1, то нет оснований для отклонения гипотезы H0.
Табличное значение при степенях
свободы k1 = 2 и k2 = n-m-1 = 25 - 2 - 1 = 22, Fkp(2;22)
= 3,44
Отметим значения на числовой оси.
Таблица 3
|
Принятие
H0
|
Отклонение
H0, принятие H1
|
|
95%
|
5%
|
|
3,44
|
219,61
|
Поскольку фактическое значение F=219,61 > Fkp
=3,44, нулевую гипотезу принимаем, соответственно, коэффициент детерминации
статистически значим и уравнение регрессии статистически надежно.
Оценка значимости дополнительного включения
фактора (частный F-критерий).
Необходимость такой оценки связана с тем, что не
каждый фактор, вошедший в модель, может существенно увеличить долю объясненной
вариации результативного признака. Это может быть связано с последовательностью
вводимых факторов (т. к. существует корреляция между самими факторами).
Мерой оценки значимости улучшения качества
модели, после включения в нее фактора хj, служит частный F-критерий
- Fxj:
где m - число оцениваемых
параметров.
В числителе - прирост доли вариации
у за счет дополнительно включенного в модель фактора хj.
Если наблюдаемое значение Fxj
больше Fkp, то дополнительное введение фактора xj в
модель статистически оправдано.
Частный F-критерий оценивает
значимость коэффициентов «чистой» регрессии (bj). Существует
взаимосвязь между частным F-критерием - Fxj и t-критерием,
используемым для оценки значимости коэффициента регрессии при j-м факторе:
Оценим с помощью частного F-критерия:
) целесообразность включения в
модель регрессии факторов х1 после введения хj (Fx1).
Определим наблюдаемое значение
частного F-критерия:
R2(X6,xn
= r2(X6) = 0,9622 = 0,926 kp(k1=1;k2=22) = 4,3
Сравним наблюдаемое значение
частного F-критерия с критическим: x1>4,3, следовательно, фактор
Х1 целесообразно включать в модель после введения факторов Хj.
) целесообразность включения в
модель регрессии факторов Х6 после введения хj (FX6).
Определим наблюдаемое значение
частного F-критерия:
2(x1,xn
= r2(x1) = -0,004342 = 1,9E-5
Сравним наблюдаемое значение
частного F-критерия с критическим: X6>4,3, следовательно, фактор
х6 целесообразно включать в модель после введения факторов хj.
Таким образом, по уравнению множественной
регрессии можно сделать вывод о его статистической надежности.
Теперь вычислим оценки парных регрессий.
Y=a+b*X1
Y=a+b*X6
Для регрессии У на Х1 получаем такие оценки (см.
Прил.2)
Y = -0,000014451*X1 + 0,8513
Видно, что оценка при Х1 настолько близка к 0,
что этот фактор практически не работает в уравнении.
Линейный коэффициент корреляции рассчитывается
по формуле:
Линейный коэффициент корреляции
принимает значения от -1 до +1.
Связи между признаками могут быть
слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
,1 < rxy < 0,3:
слабая;
,3 < rxy < 0,5:
умеренная;
,5 < rxy < 0,7:
заметная;
,7 < rxy < 0,9:
высокая;
,9 < rxy < 1:
весьма высокая;
В нашем примере связь между
признаком Y фактором X1 слабая и обратная.
Коэффициент эластичности.
Коэффициенты регрессии нежелательно
использовать для непосредственной оценки влияния факторов на результативный
признак в том случае, если существует различие единиц измерения результативного
показателя у и факторного признака Х, как это имеет место в данном случае. Для
этих целей вычисляются коэффициенты эластичности и бета - коэффициенты.
Средний коэффициент эластичности E
показывает, на сколько процентов в среднем по совокупности изменится результат
У от своей средней величины при изменении фактора X1 на 1% от своего среднего
значения.
Коэффициент эластичности находится
по формуле:
Коэффициент эластичности меньше 1.
Следовательно, при изменении Х1 на 1%, Y изменится менее чем на 1%. Другими
словами - влияние Х1 на Y не существенно.
Бета - коэффициент показывает, на
какую часть величины своего среднего квадратичного отклонения изменится в
среднем значение результативного признака при изменении факторного признака на
величину его среднеквадратического отклонения при фиксированном на постоянном
уровне значении остальных независимых переменных:
Т.е. увеличение x на величину
среднеквадратического отклонения Sx приведет к уменьшению среднего
значения Y на 0,43% среднеквадратичного отклонения Sy.
Для линейной регрессии индекс корреляции равен
коэффициенту корреляции rx1y = -0.00434. Полученная величина rx1y
свидетельствует о том, что фактор x1 никак не влияет на Y
Значимость коэффициента корреляции.
Выдвигаем гипотезы: 0: rxy
= 0, нет линейной взаимосвязи между переменными; 1: rxy ≠
0, есть линейная взаимосвязь между переменными;
Для того чтобы при уровне значимости б проверить
нулевую гипотезу о равенстве нулю генерального коэффициента корреляции
нормальной двумерной случайной величины при конкурирующей гипотезе H1
≠ 0, надо вычислить наблюдаемое значение критерия (величина случайной
ошибки)
и по таблице критических точек
распределения Стьюдента, по заданному уровню значимости б и числу степеней
свободы k = n - 2 найти критическую точку tкрит двусторонней
критической области. Если tнабл < tкрит оснований
отвергнуть нулевую гипотезу. Если |tнабл| > tкрит -
нулевую гипотезу отвергают.
По таблице Стьюдента с уровнем
значимости б=0,05 и степенями свободы k=23 находим
крит: tкрит
(n-m-1;б/2) = (23;0,025) = 2,069
где m = 1 - количество объясняющих
переменных.
Если |tнабл| > tкритич,
то полученное значение коэффициента корреляции признается значимым (нулевая
гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку |tнабл| < tкрит,
то принимаем гипотезу о равенстве 0 коэффициента корреляции. Другими словами,
коэффициент корреляции статистически незначим
Отметим значения на числовой оси.
Таблица 4
|
Принятие
H0
|
Отклонение
H0, принятие H1
|
|
95%
|
5%
|
|
0,0208
|
2,069
|
Нулевую гипотезу отвергаем.
Результаты регрессии У на Х6.
Y = 0,02018*X6 -0,6521
Линейный коэффициент корреляции считаем по
формуле:
В нашем примере связь между
признаком Y фактором X6 весьма высокая и прямая.
Смысл оценок параметров регрессии:
коэффициент регрессии b = 0,0202 показывает
среднее изменение результативного показателя (в единицах измерения У) с
повышением или понижением величины фактора Х6 на единицу его измерения. В
данном примере с увеличением на 1 единицу Y повышается в среднем на 0,0202.
Коэффициент a = -0,65 формально показывает
прогнозируемый уровень У, но только в том случае, если х6=0 находится близко с
выборочными значениями.
Но если х6=0 находится далеко от выборочных
значений х6, то буквальная интерпретация может привести к неверным результатам,
и даже если линия регрессии довольно точно описывает значения наблюдаемой
выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие
значения х6, можно определить выровненные (предсказанные) значения
результативного показателя y(x6) для каждого наблюдения.
Связь между У и Х определяет знак коэффициента
регрессии b (если > 0 - прямая связь, иначе - обратная). В нашем примере
связь прямая.
Коэффициент эластичности.
Коэффициент эластичности находится по формуле:
В нашем примере коэффициент
эластичности больше 1. Следовательно, при изменении Х6 на 1%, Y изменится более
чем на 1%. Другими словами, Х6 существенно влияет на Y.
Бета - коэффициент показывает, на
какую часть величины своего среднего квадратичного отклонения изменится в
среднем значение результативного признака при изменении факторного признака на
величину его среднеквадратического отклонения при фиксированном на постоянном
уровне значении остальных независимых переменных:
Т.е. увеличение x6 на величину
среднеквадратического отклонения Sx6 приведет к увеличению среднего
значения Y на 96,2% среднеквадратичного отклонения Sy.
Квадрат (множественного)
коэффициента корреляции называется коэффициентом детерминации, который
показывает долю вариации результативного признака, объясненную вариацией
факторного признака. 2= 0,9622 = 0,9255
т,е. в 92,55 % случаев изменения Х6
приводят к изменению Y. Соответственно, точность подбора уравнения регрессии
высокая. Остальные 7,45 % изменения Y объясняются факторами, не учтенными в
модели (а также ошибками спецификации).
Анализ данных этой таблицы показывает, что
регрессия для Х1 не может быть принята для дальнейшего использования - она
статистически ненадежна. Сравнение многофакторной регрессии и парной регрессии
У на Х6 показывает, что многофакторная регрессия лучше, но из-за того, что в
ней оценки фактора Х1 ненадежны (t
набл = -3,512859127 при уровне критическом в 2,073873068 с 95% вероятностью
незначима), этот фактор следует удалить.
|
Показатель
|
Y=F(X1,X6) Y=-0,633774523-0,000552295*Х1
+0,020746702*Х6
|
Y=F(X1)
Y=0,851304526-0,000014451*Х1
|
Y=F(X6) Y=-0,652063486+
0,020178753*Х6
|
|
R-квадрат
(коэффициент детерминации)
|
0,952276652
|
1,88287E-05
|
0,925507804
|
|
Нормированный
R-квадрат
|
0,947938166
|
-0,043458614
|
0,922269013
|
|
F-статистика
|
219,4951453
|
0,000433068
|
285,7571736
|
|
Значимость
F
|
2,92442E-15
|
0,983576471
|
1,82412E-14
|
|
Эластичность
|
|
|
|
|
Х1
|
-0,071268188
|
-0,001864763
|
|
|
Х6
|
1,817130969
|
|
1,767386299
|
|
В-коэффициент
|
|
|
|
|
Х1
|
-0,165837354
|
-0,004339206
|
|
|
Х6
|
0,989110446
|
|
0,962033161
|
|
Средняя
ошибка аппроксимации
|
2,148463212
|
10,8769876
|
2,659652795
|
|
Статистика
Дарбина-Уотсона (крит. значение = 2,064)
|
1,753086257
|
0,130093972
|
0,965789921
|
|
Прогноз
по средним значениям факторов (Усреднее = 0,84972)
|
0,849719984
|
0,852889049
|
0,849720027
|
Поэтому для применения наилучшим образом
подходит уравнение парной регрессии
Y= Y = 0,02018*X6
-0,6521
Покажем эти различия на графике (см. рис.2), на
котором видно, что регрессия У на Х1 ничего не предсказывает, кроме среднего
значения У. Множественная и парная регрессии, почти совпадая по оценкам
параметров, дают расчетные значения очень близкие и соответственно их графики
накладываются друг на друга и достаточно хорошо аппроксимируют фактические значения
У.
Таким образом, проанализировав колебания
значений переменных У - индекс человеческого развития; Х1 - ВВП 1997г., % к
1990 г.; Х6 - ожидаемая продолжительность жизни при рождении в 1997 г., число
лет дожития получили результат, что для предсказания изменения индекса
человеческого развития по 25 странам Европы достаточно собрать информацию об
ожидаемой продолжительности жизни для поколения рождения в 1997 г. С
надежностью в 92,5% будет предсказано значение У для данных 25 стран со средней
ошибкой в 2,7%.
Распространять эти результаты на более широкую
выборку стран и иной период наблюдения некорректно.
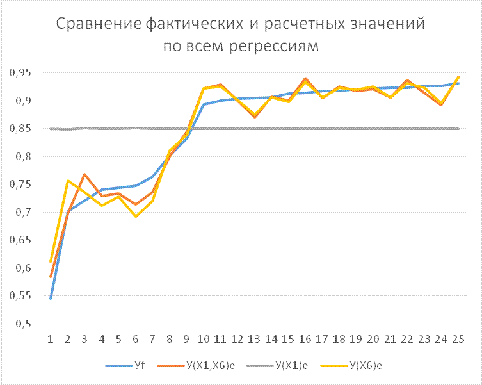
Рис.2 Сравнение фактических и расчетных значений
по всем регрессиям
Заключение
Связь между (y и xx1 ), (y и xx6
) является несущественной.
Непосредственное влияние фактора X1
на результат Y в уравнении регрессии измеряется вj и составляет
-0,166; косвенное (опосредованное) влияние данного фактора на результат
определяется как: rx1X6в2 = 0,163 * 0,989 = 0,1615.
Регрессия для Х1 не может быть принята для
дальнейшего использования - она статистически ненадежна. Сравнение
многофакторной регрессии и парной регрессии У на Х6 показывает, что
многофакторная регрессия лучше, но из-за того, что в ней оценки фактора Х1
ненадежны (t набл =
-3,512859127 при уровне критическом в 2,073873068 с 95% вероятностью
незначима), этот фактор следует удалить. Поэтому для применения наилучшим
образом подходит уравнение парной регрессии
Y= Y = 0,02018*X6
-0,6521
Проанализировав колебания значений переменных У
- индекс человеческого развития; Х1 - ВВП 1997г., % к 1990 г.; Х6 - ожидаемая
продолжительность жизни при рождении в 1997 г., число лет дожития получили
результат, что для предсказания изменения индекса человеческого развития по 25
странам Европы достаточно собрать информацию об ожидаемой продолжительности
жизни для поколения рождения в 1997 г. С надежностью в 92,5% будет предсказано
значение У для данных 25 стран со средней ошибкой в 2,7%.
регрессия эластичность эндогенный
Основная литература
1. Эконометрика: Учебник / И.И.
Елисеева, С.В. Курышева, Т.В. Костеева и др. Ї М.: Финансы и статистика, 2014.
- 244 с.
2. Эконометрика: Учебник для
вузов / Под ред. проф. Кремера Н.Ш. Ї М.: ЮНИТИ-ДАНА, 2005. - 311 с.
Дополнительная литература
. Айвазян С.А., Мхитарян В.С.
Прикладная статистика и основы эконометрики. - М.: ЮНИТИ, 1998. - 1022 с.
2. Магнус Я.Р., Катышев П.К.,
Пересецкий А.А. Эконометрика. Начальный курс: Учебник. - М.: Дело, 2001. - 400
с.
3. Катышев П.К., Магнус Я.Р.,
Пересецкий А.А. Сборник задач к начальному курсу эконометрики. - М.: Дело,
2002. - 208 с.
4. Тюрин Ю.Н., Макаров А.А.
Статистический анализ данных на компьютерах /Под ред. В.Э. Фигурнова. - М
Инфра-М, 1998.
Приложение 1
Таблица 1 Многофакторная линейная регрессия
|
ВЫВОД
ИТОГОВ
|
Регрессионная
статистика
|
|
|
|
|
|
|
Множественный
R
|
0,9758
|
|
|
|
|
|
|
|
|
R-квадрат
|
0,9523
|
|
|
|
|
|
|
|
|
Нормированный
R-квадрат
|
0,9479
|
|
|
|
|
|
|
|
|
Стандартная
ошибка
|
0,0231
|
|
|
|
|
|
|
|
|
Наблюдения
|
25
|
|
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
|
|
|
Регрессия
|
2
|
0,2345
|
0,1173
|
219,5
|
3E-15
|
|
|
|
|
Остаток
|
22
|
0,0118
|
0,0005
|
|
|
|
|
|
|
Итого
|
24
|
0,2463
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
Нижние
95%
|
Верхние
95%
|
Нижние
95,0%
|
Верхние
95,0%
|
|
Y-пересечение
|
-0,634
|
0,073
|
-8,677
|
1E-08
|
-0,785
|
-0,482
|
-0,785
|
-0,482
|
|
Х1
|
-6E-04
|
0,0002
|
-3,513
|
0,002
|
-9E-04
|
-2E-04
|
-9E-04
|
-2E-04
|
|
Х6
|
0,0207
|
0,001
|
20,952
|
5E-16
|
0,0187
|
0,0228
|
0,0187
|
0,0228
|
|
Среднее
|
Эл
|
СКО
|
В-коэф
|
|
|
|
|
|
|
0,8497
|
|
0,1013
|
|
|
|
|
|
|
|
109,65
|
-0,071
|
30,416
|
-0,166
|
|
|
|
|
|
|
74,424
|
1,8171
|
4,8294
|
0,9891
|
|
|
|
|
|
|
ВЫВОД
ОСТАТКА
|
|
|
|
ВЫВОД
ВЕРОЯТНОСТИ
|
|
|
Наблюдение
|
Предсказанное
У
|
Остатки
|
Стандартные
остатки
|
|
Персентиль
|
У
|
A
|
|
|
1
|
0,5843
|
-0,039
|
-1,777
|
|
2
|
0,545
|
0,0722
|
|
|
2
|
0,6984
|
0,0026
|
0,1191
|
|
6
|
0,701
|
0,0038
|
|
|
3
|
0,7682
|
-0,047
|
-2,133
|
|
10
|
0,721
|
0,0655
|
|
|
4
|
0,7295
|
0,0105
|
0,475
|
|
14
|
0,74
|
0,0142
|
|
|
5
|
0,7334
|
0,0106
|
0,4797
|
|
18
|
0,744
|
0,0143
|
|
|
6
|
0,7143
|
0,0327
|
1,4793
|
|
22
|
0,747
|
0,0438
|
|
|
7
|
0,7361
|
0,0269
|
1,2142
|
|
26
|
0,763
|
0,0352
|
|
|
8
|
0,8002
|
0,0018
|
0,0804
|
|
30
|
0,802
|
0,0022
|
|
|
9
|
0,8446
|
-0,012
|
-0,525
|
|
34
|
0,833
|
0,0139
|
|
|
10
|
0,9221
|
-0,028
|
-1,268
|
|
38
|
0,894
|
0,0314
|
|
|
11
|
0,929
|
-0,029
|
-1,309
|
|
42
|
0,9
|
0,0322
|
|
|
12
|
0,9002
|
0,0038
|
0,1714
|
|
46
|
0,904
|
0,0042
|
|
|
13
|
0,871
|
0,034
|
1,5352
|
|
50
|
0,905
|
0,0375
|
|
|
14
|
0,9071
|
-0,001
|
-0,051
|
|
54
|
0,906
|
0,0012
|
|
|
15
|
0,9005
|
0,0125
|
0,5659
|
|
58
|
0,913
|
0,0137
|
|
|
16
|
0,9411
|
-0,027
|
-1,226
|
|
62
|
0,914
|
0,0297
|
|
|
17
|
0,9055
|
0,0125
|
0,5666
|
|
66
|
0,918
|
0,0137
|
|
|
18
|
0,9258
|
-0,008
|
-0,352
|
|
70
|
0,918
|
0,0085
|
|
|
19
|
0,9172
|
0,0038
|
0,1707
|
|
74
|
0,921
|
0,0041
|
|
|
20
|
0,9207
|
0,0013
|
0,0594
|
|
78
|
0,922
|
0,0014
|
|
|
21
|
0,9066
|
0,0164
|
0,7426
|
|
82
|
0,923
|
0,0178
|
|
|
22
|
0,9369
|
-0,014
|
-0,626
|
|
86
|
0,923
|
0,015
|
|
|
23
|
0,9147
|
0,0123
|
0,5538
|
|
90
|
0,927
|
0,0132
|
|
|
24
|
0,8929
|
0,0341
|
1,5419
|
|
94
|
0,927
|
0,0368
|
|
|
25
|
0,9428
|
-0,011
|
-0,488
|
|
98
|
0,932
|
0,0116
|
|
|
DW
|
1,7531
|
|
|
|
|
2,1485
|
|
|
RS
|
0,2883
|
|
|
|
|
|
|
|
Стьюдент.
обр. 2Х
|
2,0639
|
|
|
|
|
|
|
Рис. 1 График остатков Х1
Рис. 2 График остатков
Х6
Рис. 3 График подбора Х1
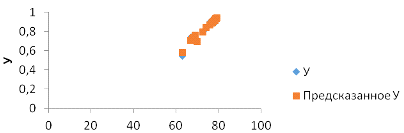
Рис. 3 График подбора Х6
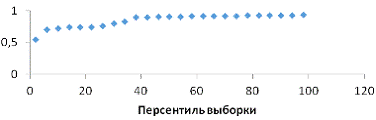
Рис. 5 График нормального распределения
Таблица 2
|
Признаки
X и Y
|
|
|
|
|
|
Для Y и X1
|
888,142
|
0,00985
|
29,802
|
0,0992
|
|
Для Y и X6
|
22,39
|
0,00985
|
4,732
|
0,0992
|
|
Для X1 и X6
|
22,39
|
888,142
|
4,732
|
29,802
|
Таблица 3 Матрица парных коэффициентов
корреляции R:
|
-
|
y
|
x1
|
X6
|
|
y
|
1
|
-0,00434
|
0,962
|
|
x1
|
-0,00434
|
1
|
0,163
|
|
X6
|
0,962
|
0,163
|
1
|
Приложение 2
Таблица 1 Парная регрессия У на Х1
|
ВЫВОД
ИТОГОВ
|
Регрессионная
статистика
|
|
|
|
|
|
Множественный
R
|
0,004339
|
|
|
|
|
|
|
|
|
R-квадрат
|
1,88E-05
|
|
|
|
|
|
|
|
|
Нормированный
R-квадрат
|
-0,04346
|
|
|
|
|
|
|
|
|
Стандартная
ошибка
|
0,103474
|
|
|
|
|
|
|
|
|
Наблюдения
|
25
|
|
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
|
|
|
Регрессия
|
1
|
4,64E-06
|
4,64E-06
|
0,000433
|
0,983576
|
|
|
|
|
Остаток
|
23
|
0,246258
|
0,010707
|
|
|
|
|
|
|
Итого
|
24
|
0,246263
|
|
|
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
Нижние
95%
|
Верхние
95%
|
Нижние
95,0%
|
Верхние
95,0%
|
|
Y-пересечение
|
0,851305
|
0,078904
|
10,78916
|
1,79E-10
|
0,68808
|
1,014529
|
0,68808
|
1,014529
|
|
Х1
|
-1,4E-05
|
0,000694
|
-0,02081
|
0,983576
|
-0,00145
|
0,001422
|
-0,00145
|
0,001422
|
|
Среднее
|
Эл
|
Сто
|
В-коэф
|
|
|
|
|
|
|
0,84972
|
|
0,101296
|
|
|
|
|
|
|
|
109,648
|
-0,00186
|
30,41624
|
-0,00434
|
|
|
|
|
|
|
ВЫВОД
ОСТАТКА
|
|
|
|
ВЫВОД
ВЕРОЯТНОСТИ
|
|
|
Наблюдение
|
Предсказанное
У
|
Остатки
|
Стандартные
остатки
|
|
Персентиль
|
У
|
A
|
|
|
1
|
0,849195
|
-0,30419
|
-3,00304
|
|
2
|
0,545
|
0,558155
|
|
|
2
|
0,84827
|
-0,14727
|
-1,45386
|
|
6
|
0,701
|
0,210085
|
|
|
3
|
0,85064
|
-0,12964
|
-1,27982
|
|
10
|
0,721
|
0,179806
|
|
|
4
|
0,850279
|
-0,11028
|
-1,08868
|
|
14
|
0,74
|
0,149025
|
|
|
5
|
0,849946
|
-0,10595
|
-1,04591
|
|
18
|
0,744
|
0,142401
|
|
|
6
|
0,850423
|
-0,10342
|
-1,021
|
|
22
|
0,747
|
0,138451
|
|
|
7
|
0,850235
|
-0,08724
|
-0,8612
|
|
26
|
0,763
|
0,114332
|
|
|
8
|
0,849469
|
-0,04747
|
-0,46862
|
|
30
|
0,802
|
0,059189
|
|
|
9
|
0,849871
|
-0,01687
|
-0,16655
|
|
34
|
0,833
|
0,020253
|
|
|
10
|
0,849672
|
0,044328
|
0,437615
|
|
38
|
0,894
|
0,049584
|
|
|
11
|
0,849744
|
0,050256
|
0,496135
|
|
42
|
0,9
|
0,05584
|
|
|
12
|
0,849643
|
0,054357
|
0,536622
|
|
46
|
0,904
|
0,06013
|
|
|
13
|
0,849585
|
0,055415
|
0,547065
|
|
50
|
0,905
|
0,061232
|
|
|
14
|
0,849715
|
0,056285
|
0,555653
|
|
54
|
0,906
|
0,062125
|
|
|
15
|
0,849758
|
0,063242
|
0,62433
|
|
58
|
0,913
|
0,069268
|
|
|
16
|
0,849845
|
0,064155
|
0,633346
|
|
62
|
0,914
|
0,070191
|
|
|
17
|
0,849672
|
0,068328
|
0,674546
|
|
66
|
0,918
|
0,074432
|
|
|
18
|
0,849715
|
0,068285
|
0,674118
|
|
70
|
0,918
|
0,074385
|
|
|
19
|
0,849599
|
0,071401
|
0,704876
|
|
74
|
0,921
|
0,077525
|
|
|
20
|
0,849527
|
0,072473
|
0,715461
|
|
78
|
0,922
|
0,078604
|
|
|
21
|
0,8497
|
0,0733
|
0,723621
|
|
82
|
0,923
|
0,079414
|
|
|
22
|
0,849787
|
0,073213
|
0,722765
|
|
86
|
0,923
|
0,079321
|
|
|
23
|
0,849426
|
0,077574
|
0,76582
|
|
90
|
0,927
|
0,083683
|
|
|
24
|
0,849614
|
0,077386
|
0,763966
|
|
94
|
0,927
|
0,08348
|
|
|
25
|
0,849672
|
0,082328
|
0,812756
|
|
98
|
0,932
|
0,088335
|
|
|
DW
|
0,130094
|
|
|
|
|
10,87699
|
|
|
RS
|
0,065399
|
|
|
|
|
|
|
|
Стьюдент.Обр.2Х
|
2,063899
|
|
|
|
|
|
|
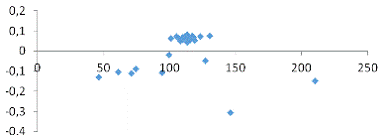
Рис. 1 График остатков Х1
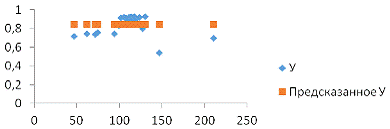
Рис. 2 График подбора Х1
Рис. 3 График нормального распределения
Приложение 3
Таблица 1 Парная регрессия У на Х6
|
ВЫВОД
ИТОГОВ
|
|
Регрессионная
статистика
|
|
|
|
|
Множественный
R
|
0,962033
|
|
|
|
|
|
|
|
|
R-квадрат
|
0,925508
|
|
|
|
|
|
|
|
|
Нормированный
R-квадрат
|
0,922269
|
|
|
|
|
|
|
|
|
Стандартная
ошибка
|
0,028242
|
|
|
|
|
|
|
|
|
Наблюдения
|
25
|
|
|
|
|
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
|
|
|
Регрессия
|
1
|
0,227918
|
0,227918
|
285,7572
|
1,82E-14
|
|
|
|
|
Остаток
|
23
|
0,018345
|
0,000798
|
|
|
|
|
|
|
Итого
|
24
|
0,246263
|
|
|
|
|
|
|
|
|
Коэффициенты
|
t-статистика
|
P-Значение
|
Нижние
95%
|
Верхние
95%
|
Нижние
95,0%
|
Верхние
95,0%
|
|
Y-пересечение
|
-0,65206
|
0,089019
|
-7,32496
|
1,88E-07
|
-0,83621
|
-0,46791
|
-0,83621
|
-0,46791
|
|
Х6
|
0,020179
|
0,001194
|
16,90435
|
1,82E-14
|
0,017709
|
0,022648
|
0,017709
|
0,022648
|
|
Среднее
|
Эл
|
СКО
|
В-коэф
|
|
|
|
|
|
|
0,84972
|
|
0,101296
|
|
|
|
|
|
|
|
74,424
|
1,767386
|
4,829362
|
0,962033
|
|
|
|
|
|
|
ВЫВОД
ОСТАТКА
|
|
|
|
ВЫВОД
ВЕРОЯТНОСТИ
|
|
|
Наблюдение
|
Предсказанное
У
|
Остатки
|
Стандартные
остатки
|
|
Персентиль
|
У
|
A
|
|
|
1
|
0,611126
|
-0,06613
|
-2,3918
|
|
2
|
0,545
|
0,121333
|
|
|
2
|
0,756413
|
-0,05541
|
-2,00431
|
|
6
|
0,701
|
0,079049
|
|
|
3
|
0,736235
|
-0,01523
|
-0,55104
|
|
10
|
0,721
|
0,02113
|
|
|
4
|
0,71202
|
0,02798
|
1,012035
|
|
14
|
0,74
|
0,037811
|
|
|
5
|
0,728163
|
0,015837
|
0,57282
|
|
18
|
0,744
|
0,021286
|
|
|
6
|
0,691841
|
0,055159
|
1,995095
|
|
22
|
0,747
|
0,07384
|
|
|
7
|
0,720092
|
0,042908
|
1,552001
|
|
26
|
0,763
|
0,056236
|
|
|
8
|
0,810896
|
-0,0089
|
-0,32177
|
|
30
|
0,802
|
0,011092
|
|
|
9
|
0,839146
|
-0,00615
|
-0,22231
|
|
34
|
0,833
|
0,007379
|
|
|
10
|
0,921879
|
-0,02788
|
-1,0084
|
|
38
|
0,894
|
0,031185
|
|
|
11
|
0,925915
|
-0,02591
|
-0,93735
|
|
42
|
0,9
|
0,028794
|
|
|
12
|
0,9017
|
0,0023
|
0,083175
|
|
46
|
0,904
|
0,002544
|
|
|
13
|
0,875468
|
0,029532
|
1,068174
|
|
50
|
0,905
|
0,032632
|
|
|
14
|
0,905736
|
0,000264
|
0,009541
|
|
54
|
0,906
|
0,000291
|
|
|
15
|
0,897665
|
0,015335
|
0,55468
|
|
58
|
0,913
|
0,016797
|
|
|
16
|
0,933986
|
-0,01999
|
-0,72291
|
|
62
|
0,914
|
0,021867
|
|
|
17
|
0,905736
|
0,012264
|
0,443583
|
|
66
|
0,918
|
0,013359
|
|
|
18
|
0,923897
|
-0,0059
|
-0,2133
|
|
70
|
0,918
|
0,006424
|
|
|
19
|
0,919861
|
0,001139
|
0,041185
|
|
74
|
0,921
|
0,001236
|
|
|
20
|
0,925915
|
-0,00391
|
-0,14161
|
|
78
|
0,922
|
0,004246
|
|
|
21
|
0,905736
|
0,017264
|
0,624434
|
|
82
|
0,923
|
0,018704
|
|
|
22
|
0,931969
|
-0,00897
|
-0,3244
|
|
86
|
0,923
|
0,009717
|
|
|
23
|
0,923897
|
0,003103
|
0,112233
|
|
90
|
0,927
|
0,003347
|
|
|
24
|
0,895647
|
0,031353
|
1,134049
|
|
94
|
0,927
|
0,033822
|
|
|
25
|
0,942058
|
-0,01006
|
-0,3638
|
|
98
|
0,932
|
0,010792
|
|
|
DW
|
0,96579
|
|
|
|
|
2,659653
|
|
|
RS
|
0,275477
|
|
|
|
|
|
|
|
СТЬЮДЕНТ.ОБР.2Х
|
2,063899
|
|
|
|
|
|
|
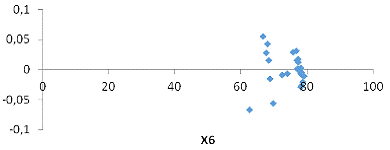
Рис. 1 График остатков
Х6
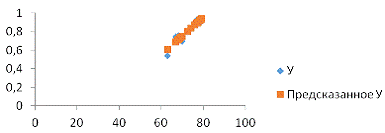
Рис. 2 График подбора Х6
Рис. 3 График нормального распределения