Графы рынков
Введение
граф сетевой фондовый рынок
Актуальность исследования
Современные фондовые рынки генерируют огромные массивы
данных. Традиционно эти данные представляются в виде графиков, каждый из
которых отражает динамику соответствующей ценной бумаги. Такой способ
представления данных является ненаглядным, он не позволяет получить целостное
представление о происходящих на рынке процессах. С увеличением числа акций
процедура проведения анализа становится все более сложной.
Развитие информационных технологий способствовало тому, что
инвесторы сегодня имеют возможность совершать сделки на рынках разных стран.
При этом, несмотря на доступность услуг различного рода финансовых
консультантах, решение об инвестировании зачастую принимается человеком
самостоятельно. В этих условиях инвестору крайне необходимы модели, позволяющие
представлять информацию с рынка в удобном для анализа виде и быстро извлекать
полезную информацию.
Большое внимание в современной экономике уделяется анализу
фондовых рынков, выявлению на них закономерностей в периоды роста и кризиса.
Для этой цели также нужны модели, позволяющие компактно описать протекающие на
рынке процессы и быстро и извлечь информацию о существующих на них
зависимостях.
Помочь в решении этих проблем могут математические методы.
Сравнительно новым, но активно развивающимся направлением в математическом
моделировании является сетевой подход, основанный на представлении изучаемой
системы в виде графа. Существует ряд сетевых моделей фондового рынка, наиболее
распространенной из которых является так называемый рыночный граф (market graph), предложенный
Богинским, Бутенко и Пардалосом. В таком графе каждой вершине соответствует
ценная бумага, а ребро проводится тогда, когда корреляции между доходностями
соответствующих акций превышают некоторое пороговое значение. Совокупность
характеристик рыночного графа, может помочь инвестору оценить состояние рынка и
принять решение об изменении состава портфеля акций. Изучение этих
характеристик способствует более глубокому пониманию взаимосвязей между
доходностями ценных бумаг.
В то же время, использование корреляций Пирсона в качестве
меры близости при построении рыночного графа имеет целый ряд недостатков.
Главный из них заключается в том, что такая модель позволяет оценить лишь
степень согласованности в движении акций, что важно при управлении рисками и
формировании диверсифицированного портфеля, но не дает представления о реальной
доходности ценных бумаг. Таким образом, проблема поиска моделей для удобного
представления данных фондового рынка по сей день остается актуальной.
По нашему мнению, можно преодолеть недостатки модели
рыночного графа, используя альтернативную меру близости между акциями. Новая
мера рассчитывается как количество периодов (например, недель), когда две акции
одновременно были доходными с учетом инфляции. Модифицированная таким образом
модель рынка называется графов доходностей.
Объект и предмет исследования
Объектом исследования в данной работе являются
фондовые рынки (на примере рынков стран БРИК). Предметом исследования является
динамика структурных характеристик рассматриваемых рынков.
Цель и задачи
Целью работы заключается в том, чтобы исследовать
возможность применения альтернативной меры близости между акциями для
построения графа фондового рынка. Для реализации этой цели были поставлены
следующие задачи:
. Написать программные реализации алгоритмов для
построения сетевых моделей рынка и вычисления их характеристик.
. Построить модели графа доходностей для выбранных
фондовых рынков.
. Провести анализ характеристик полученных моделей,
дать результатам экономическую интерпретацию.
. Сравнить результаты, полученные для новой меры
близости с результатами для стандартных корреляций Пирсона.
Практическая значимость
Представленные в работе результаты позволяют сделать предположение
о полезности использованной модификации рыночного графа. Изучение характеристик
этой модели позволяет оценить состояние рынка, получить компактное и точное
описание протекающих на нем процессов и может помочь инвестору при принятии
решения.
Структура работы
Магистерская диссертация состоит из введения; основной части,
состоящей из трех глав; заключения (выводов), списка литературы и приложений.
Основная часть работы имеет следующую структуру.
В главе 1 «Обзор литературы» проведен анализ научной литературы
по теме исследования; освещен процесс развития сетевого подхода к моделированию
фондовых рынков; рассмотрены недостатки модели рыночного графа; приведено
описание модели графа доходностей, ее свойства и преимущества.
В главе 2 «Материалы и методы исследования» приведено
описание модельных данных и методика, использованная для построения и анализа
характеристик рыночных моделей.
В главе 3 «Результаты расчетов и их анализ» содержатся
результаты, полученные в ходе анализа; дана экономическая интерпретация
полученных данных; проведено сравнение результатов для новой меры близости и
стандартных корреляций Пирсона.
1.
Обзор литературы
1.1
Современное состояние международного фондового рынка
Фондовые рынки (рынки, на которых оборачиваются ценные бумаги)
имеют огромное значение для функционирования экономики. Они выполняют такие
важные функции, как привлечение инвестиций, привлечение средств для покрытия
дефицита бюджета. Показатели фондовых рынков, такие как биржевые индексы,
позволяют судить о состоянии экономики страны в целом [34].
Одним из основных направлений глобализации является
формирование международного рынка ценных бумаг (МРЦБ) [39]. Коренные изменения
в торговле ценными бумагами произошли благодаря развитию информационных
технологий: теперь инвесторы имеют возможность совершать сделки на рынках
различных стран. Системы, основанные на использовании современных
коммуникационных технологий, позволяют вести торговлю в автоматизированном
режиме, снижая роль финансовых посредников.
Наблюдается рост объемов ценных бумаг, обращающихся на рынке,
появляются новые виды инструментов. Примерами видов ценных бумаг являются акции
(обычные и привилегированные), облигации, векселя, а также их многочисленные
производные (деривативы) - опционы, варранты, фьючерсы. Сюда также относятся
различные чеки, депозитные сертификаты паи инвестиционных фондов и многие
другие.
Таким образом, современный рынок ценных бумаг представляет
собой очень сложную структуру. В условиях, когда число торгующихся акций
измеряется тысячами, даже сбор и обработка всей этой информации представляет
собой тяжелую задачу. Еще одной чертой фондовых рынков, затрудняющей анализ,
является их нестационарность: процессы, наблюдаемые в одном периоде, могут не
происходить в другом. Таким образом, построение компактной
экономико-математической модели сопряжено со значительными трудностями.
Самой распространенной и простой характеристикой, позволяющей
в компактной форме получить информацию о состоянии рынка ценных бумаг, является
значение индекса. Однако анализ рынка на основе индекса крайне неинформативен и
имеет целый ряд недостатков [40]. Во-первых, нужно учитывать, что при расчете
индекса включается только часть обращающихся на рынке акций. Во-вторых,
динамика индекса показывает только общую тенденцию изменения доходностей, но не
учитывает, насколько большое число бумаг придерживались этого тренда. Еще одним
недостатком является отсутствие прямой связи между ростом индекса и реальной, с
учетом инфляции, доходностью акций, в данный индекс входящих. В случае высокой
инфляции рост индекса может означать вовсе не доход инвестора, а его убыток.
Таким образом, проблема поиска моделей для удобного и
компактного представления данных рынка по сей день остается актуальной.
.2
Сетевой подход при моделировании сложных систем
В последние годы активно развивающимся направлением в
изучении сложных систем является сетевой анализ [38]. Каждый объект системы
может быть представлен узлом сети (графа), а взаимодействия между этими
объектами - соответствующими ребрами. Сетевые модели находят применение во
многих областях науки - биологии (генные сети, функциональные сети головного
мозга), социологии (сети взаимодействия между людьми, сети знакомств), технике
(сети сотовой связи, сети электроснабжения), компьютерных науках (World Wide Web, локальные сети) [19].
Проведенные исследования показывают, что многие из этих сетей имеют более
сложную структуру, чем обычные случайные графы с заданным числом узлов и
связей. Поэтому для обозначения таких моделей появился термин «сложные сети».
Считается, что активный интерес к исследованиям в области
сложных сетей появился благодаря работам, посвященным анализу сетей «тесного
мира» Уоттса-Строгатца [32] и «безмасштабных сетей» Барабаши-Альберт [2].
В 1967 г. американский социолог С. Милграм провел серию
экспериментов, целью которых был поиск среднего пути в сети, состоящей из людей
[18]. В ходе исследования жителям одного города раздали 296 писем, которые надо
было передать незнакомому человеку, жившему в другом, значительно удаленном городе.
Передавать письма можно было только через своих знакомых. В результате этого
эксперимента оказалось, среднем каждое письмо прошло через шесть человек.
Милгремом была выдвинута «теория шести рукопожатий», согласно которой любые два
человека на планете разделены в среднем лишь пятью уровнями общих знакомых.
Последующие исследования, в том числе с использованием электронной почты,
подтвердили полученные результаты, а наблюдаемый феномен получил название
«тесного мира», или «шесть ступеней разделения».
В работе [32] Д.Уоттс и С.Строгатц выделили особый класс
сложных сетей, обладающих феноменом «тесного мира». Основным свойством этих
сетей было то, что две вершины с большой долей вероятности не являются
смежными, но одна вершина достижима из другой посредством небольшого числа
переходов. Предложенная модель графа получила название сети «тесного мира»
(small-world network). Свойства сетей Уоттса-Строгатца были обнаружены во
многих объектах реального мира, таких как дорожные карты, метаболические сети,
социальные сети и т.д. [8, 30, 31].
Барабаши и Альберт [1, 2] изучали закон распределения узлов
по числу связей в ряде сетей реального мира. В результате исследования
выяснилось, что во многих реальных сетях это распределение подчиняется т.н.
степенному закону, т.е. несколько узлов-концентраторов содержит большое число
связей, а большинство узлов содержит лишь незначительное число связей. Эти сети
получили название безмасштабных (scale-free networks). Авторы предложили простую модель
возникновения таких сетей, включающую два условия - рост и предпочтительное
соединение.
Результаты этих исследований имеют большое теоретическое
значение и практические приложения в области физики, биологии, социологии, а
также экономики.
.3
Анализ фондовых рынков с помощью сетевого подхода
Одним из основных направлений современной финансовой науки
является анализ фондовых рынков, направленный на выявление на них различных
закономерностей в периоды роста и кризиса.
Впервые конкретные математические методы для анализа фондовых
рынков предложил американский экономист Г. Марковиц [16]. В своей работе,
ставшей впоследствии классической, Марковиц предложил модель формирования
оптимального портфеля и привел методы построения портфелей при определённых
условиях. Важным элементом этой модели является анализ совместного поведения
акций, основанный на вычислении их попарных корреляций.
Вместе с тем фондовый рынок можно рассматривать как сложную
сеть, вершины которой образованы ценными бумагами, а ребра обозначают связи
между ними.
Впервые сетевой подход для анализа рынка ценных бумаг
применил Р. Мантегна [14, 15]. Он предложил использовать матрицу корреляций для
вычисления «расстояний» между парами акций, а затем выбирать такие из них,
которые удовлетворяют критерию минимального остовного дерева. В получившемся
дереве «расстояния» между акциями представлены ребрами, а узлы - ценными
бумагами. Впоследствии многими авторами были исследованы похожие и изобретены
новые сетевые модели фондового рынка.
Онелла и соавторы [20] использовали метод, предложенный
Мантегной, для построения деревьев для ряда временных периодов. Получившиеся
модели представляли собой этапы развития одного «динамического дерева активов»
(dynamic asset tree). Авторами были
предложены различные характеристики этой системы, например, нормализованная
длина дерева (normalized tree length) и «средний культурный слой» (mean
occupation layer). В работе [22] была проиллюстрирована динамика этих
характеристик под влиянием «Черного понедельника» 1987 г. Дальнейшим развитием
этой методологии был «граф активов» (asset graph), дающий возможность включать
несколько компонент связности [20].
Туминелло и соавторы [25] предложили модель «максимально
отфильтрованного плоского графа» (planar maximally filtered graph), позволяющую
фильтровать сложные наборы данных, составляя подграф из значимых связей. Авторы
показали, что данный метод особенно эффективен для сетей, основанных на
корреляциях, и продемонстрировали его на примере фондового рынка.
Свойства сетей, основанных на корреляциях между ценными бумагами
были изучены в работах [21, 26, 27].
В 2003 г. Богинским и соавторами [6] была предложена модель
«рыночного графа» (market graph). В рамках данной модели фондовый рынок
рассматривается как сеть, в которой каждой ценной бумаге соответствует своя
вершина, а ребро между ними проводится в том случае, если коэффициент
корреляции между доходностями соответствующих акций превышает некоторое
пороговое значение. Модель графа рынка была впоследствии использована во многих
исследованиях. В частности, с использованием этой методологии были получены
интересные результаты для рынков США [5-7, 12], Китая [11], Швеции [12], России
[29, 35].
В работах [28, 36] был проведен сравнительный анализ стран
БРИК с использованием модели рыночного графа. Основным анализируемым шаблоном
были максимальные клики, как характеристики связности рынка. В результате
исследования был сделан вывод о том, что по своим структурным свойствам рынок
Китая отличается от остальных стран БРИК.
Общей чертой всех упомянутых выше моделей является использование
коэффициентов корреляции Пирсона в качестве меры близости между акциями. Это
наиболее естественный подход, но, несмотря на свою популярность, он имеет целый
ряд недостатков (см. раздел 1.5.2). Поэтому в отдельных случаях возникает
необходимость использования иной меры. Так, в работе [4] предложена
альтернативная мера близости, получившая название знаковой корреляции. Эта мера
основана на вероятности совпадения знака доходностей акций. Авторы показали,
что знаковые корреляции имеют простую, ясную интерпретацию, и в ряде случаев
позволяют положить более содержательные результаты.
Мерой близости, принципиально отличающейся от корреляций,
является мера, предложенная в работе [10]. Для каждой пары акций рассчитывается
количество периодов, когда доходности обеих бумаг были положительны с учетом
инфляции. Полученное число используется в качестве веса ребра между
соответствующими вершинами. Эта модель носит название графа доходностей.
.4
Некоторые основные понятия
Использование теории графов для моделирования фондовых рынков
позволяет предложить характеристики, в компактном и простом виде описывающие
протекающие на них процессы. В этом разделе приведены основные понятия,
относящиеся к теории графов [33, 41].
Неориентированным графом, или просто графом, называется
упорядоченная пара G(V, E), где V - множество вершин (или узлов), а E -
множество ребер (дуг). Количество вершин в графе обозначается как 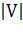 , количество ребер -
, количество ребер - 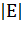 . В прикладных областях
графы часто называются сетями [37].
. В прикладных областях
графы часто называются сетями [37].
Пусть u и v - две вершины графа. Тогда соединяющее их ребро обозначается
как e
= (u, v). Говорят, что вершина u и ребро e инцидентны, вершина v также инцидентна ребру e. Если две вершины
инцидентны одному ребру, их называют смежными. По аналогично, два ребра,
имеющие общую вершину, называются смежными. Ребро, соединяющее вершину саму с
собой, называется петлей.
Степенью вершины в графе называется число ее связей с другими
вершинами. Распределение степеней вершин - это вероятностное распределение
степеней вершин в графе. Пусть 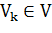 - подмножество узлов, имеющих степень k, тогда:
- подмножество узлов, имеющих степень k, тогда:
|
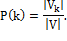
|
(1.1)
|
Одной из основных характеристик реальных сетевых моделей является
следование степенному закону [10, 13]. Согласно этому закону, вероятность, что
вершина графа имеет степень k, равна
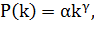 (1.2)
(1.2)
что эквивалентно:
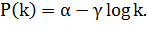 (1.3)
(1.3)
Плотность неориентированного графа G вычисляется по формуле:
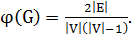 (1.4)
(1.4)
Максимальная плотность равна 1, если граф полный, минимальная
- 0 (если ребер в графе нет совсем).
Еще одной характеристикой сети является коэффициент
кластеризации. Если плотность ребер графа можно интерпретировать как
вероятность наличия ребра между любыми двумя узлами сети, то коэффициент
кластеризации - это вероятность того, что ребром будут соединены вершины,
имеющие общего соседа. Локальный коэффициент кластеризации рассчитывается по
формуле:
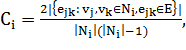 (1.5)
(1.5)
где 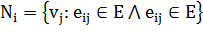 - множество соседей вершины
- множество соседей вершины 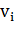 . Если все соседи узла
соединены друг с другом, то
. Если все соседи узла
соединены друг с другом, то 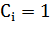 . Если между ними нет никаких связей, то
. Если между ними нет никаких связей, то 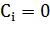 . Кластеризация всей сети
(глобальный коэффициент кластеризации) определяется как:
. Кластеризация всей сети
(глобальный коэффициент кластеризации) определяется как:
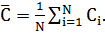 (1.6)
(1.6)
Высокое значение коэффициента кластеризации означает, что
граф плотно сгруппирован вокруг нескольких узлов; низкое значение - что связи в
графе распространены относительно равномерно.
Кликой называется подмножество вершин графа, в котором каждые
две вершины соединены друг с другом. Размер клики определяется количеством
образующих ее вершин. Задача о нахождении максимальной по размеру клики в графе
принадлежит к классу NP-полных [9].
Существует несколько общепринятых способов представления
графа в памяти компьютера: в виде списка ребер, в виде списка смежности, либо в
виде матрицы смежности [24]. При написании программ в данной работе были
использованы два из них. Матрицей смежности (adjacency matrix) называется матрица 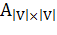 , в которой:
, в которой:
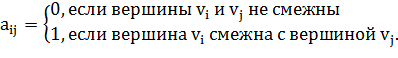 (1.7)
(1.7)
Использование матрицы смежности предпочтительно в случае
плотных графов, с большим числом ребер. Для разреженных ребер больше подходит
представление в виде списков смежности. Список смежности содержит для каждой
вершины v, список смежных с ней вершин. По отношению к памяти этот способ
менее требовательный, объем памяти, требуемый для хранения списка равен
O(|V|+|E|).
.5
Описание модели рыночного графа
Построение
модели
При построении рыночного графа мы пользуемся стандартными
характеристиками ценных бумаг [5-7]. Пусть 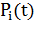 - цена закрытия акции i
(i = 1, …, N) в день t. Тогда логарифмическая доходность акции i за период
между
- цена закрытия акции i
(i = 1, …, N) в день t. Тогда логарифмическая доходность акции i за период
между 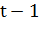 и
и 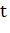 вычисляется следующим
образом:
вычисляется следующим
образом:
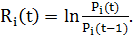 (1.8)
(1.8)
Далее мы формируем матрицу, элементами которой являются
коэффициенты корреляции, высчитываемые по формуле:
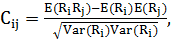 (1.9)
(1.9)
где:
· 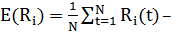 средняя доходность бумаги
i в течении N торговых дней,
средняя доходность бумаги
i в течении N торговых дней,
· 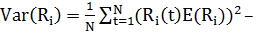 дисперсия доходности
ценной бумаги i в течении N дней.
дисперсия доходности
ценной бумаги i в течении N дней.
На основе полученной матрицы корреляций составляется матрица
смежности согласно следующему правилу:
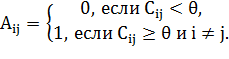 (1.10)
(1.10)
Иными словами, если коэффициент корреляции меньше заданного
порога, то ребро не проводится, и наоборот. Выбирая разные значения порога 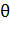 , мы в итоге получаем
различные графы.
, мы в итоге получаем
различные графы.
Недостатки
модели
Рассмотрим недостатки использования коэффициентов корреляции
Пирсона в качестве меры близости при построении графа фондового рынка [40].
. При использовании корреляций Пирсона клики в графе
могут образовывать акции, доходности которых изменялись согласованно, но не
были положительными. Так, в исследовании [23] было показано, что корреляции
наиболее сильны в периоды кризиса, когда акции падают. Инвесторов же в первую
очередь интересуют акции, приносящие доход. Корреляции позволяют оценить
возможности по формированию диверсифицированного портфеля, по управлению
рисками, но не включает информацию по итоговой доходности акций.
. При построении графов для каждой страны получается
свое среднее значение корреляций, что делает невозможным выбор «справедливого»
порога для перехода к невзвешенному графу - получается, что порог должен быть
разный для всех стран.
. С одной стороны, при изучении набора акций мы должны
учитывать не только корреляции между парами ценных бумаг, но и зависимости,
возникающие при анализе совокупности. Отсюда необходимость увеличивать число
наблюдений при включении в рассмотрение новых акций. В свою очередь, это делает
невозможным анализ всего рынка, на котором торгуются сотни или тысячи ценных
бумаг, для коротких промежутков времени. Поскольку рынок может меняться очень
интенсивно, анализ больших промежутков времени становится нецелесообразным. С
другой стороны, дневные колебания цен могут иметь большую волатильность, к тому
же инвестиции редко делают на срок в один день. Это вынуждает использовать
более крупные единичные отрезки времени, например, недели или декады, что
уменьшает количество наблюдений и ухудшает качество оценки корреляций.
. Проблемой, связанной с предыдущей, является
необходимость исключать из рассмотрения акции с низкой ликвидностью, так как
для оценки их корреляций недостаточно наблюдений. Альтернатива исключению акций
- использовать некую процедуру для «заполнения» недостающих цен, что
отрицательно сказывается на достоверности получаемых результатов.
С нашей точки зрения, для преодоления вышеприведенных
недостатков, можно использовать модель рыночного графа с измененной мерой
близости между акциями.
.6
Описание модели графа доходностей
Построение
модели
Для оценки потенциальной доходности фондового рынка мы
предлагаем использовать меру близости, отличную от корреляций Пирсона [10, 40].
Для каждой недели рассматриваемого промежутка времени высчитывается доходность
каждой бумаги и сравнивается со значением инфляции. Если доходность акции была
выше уровня инфляции, то она считается положительной в течение этой недели.
Затем для каждой пары акций высчитывается количество недель, когда их
доходности были одновременно положительны. Это значение используется в качестве
веса ребра между соответствующими вершинами. Более строго, пусть xi ∈ {0, 1} - индикатор того, что доходность акции x за неделю i, i = 1, …, N, положительна. Тогда
мера близости между акциями x и y для временного периода из N недель рассчитывается по
формуле:
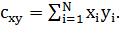 (1.11)
(1.11)
При построении графа, если акция не торговалась в течение
данной недели, она считалась недоходной. Таким образом, доходность ценной
бумаги была определена следующим образом. Акция является доходной тогда и
только тогда, когда она торговалась в данную неделю и ее доходность превысила
недельный уровень инфляции. Если торгов по акции в какую-то неделю не
совершалось, то ее доходность считалась равной нулю без каких-либо расчетов.
Вместо недели может быть взята другая единица времени,
например, день или месяц. С одной стороны, инфляция обычно подсчитывается по
месяцам; с другой стороны, цены акций фиксируются по дням. Таким образом,
неделя представляет собой разумный компромисс: примерное значение инфляции
можно рассчитывать как часть месячной, а цены в течение недели сильно не
меняются.
Свойства
новой меры близости
Представленная мера близости обладает следующими свойствами
[10]:
. Мера близости принимает фиксированный набор
значений, начиная с нуля и заканчивая числом недель в рассматриваемом периоде:
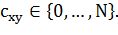 (1.12)
(1.12)
2. Если для каждой акции мы рассчитаем количество недель
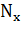 , когда ее доходность
была положительна, тогда вес ребра между двумя акциями ограничен минимальным из
двух значений:
, когда ее доходность
была положительна, тогда вес ребра между двумя акциями ограничен минимальным из
двух значений:
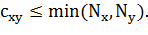 (1.13)
(1.13)
3. Если акции x и y не были одновременно положительно доходны ни в одну неделю,
то 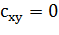 . Однако, обратное
утверждение неверно.
. Однако, обратное
утверждение неверно.
. Для промежутков времени, отличных от недель,
например, месяцев или дней, значение меры близости будет иным. Разница между
этими значениями не пропорциональна разнице между продолжительностью отрезков,
поскольку доходность за месяц не связана напрямую с доходностями недель в этом
месяце.
. Чтобы получить значение меры близости для ряда
последовательных непересекающихся периодов, необходимо найти сумму значений для
каждого из периодов.
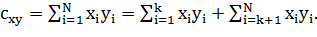 (1.14)
(1.14)
6. В общем случае, предложенная мера не обладает
свойством транзитивности, за исключением искусственного случая, когда все акции
доходны в одни и те же недели.
Свойства (1 - 3) следуют из определения меры близости.
Свойство (4) связано с возможностью выбора единичных промежутков времени,
отличных от недель (см. предыдущий раздел). Свойство (5) позволяет высчитывать
значение меры для различных промежутков времени. Используя свойство (6), мы
можем определить, насколько состояние реального рынка близко к тому
искусственному случаю, когда все акции приносят доход и убыток согласованно.
Преимущества
новой меры близости
Предложенная в модели графа доходностей мера близости
позволяет избавиться от всех вышеупомянутых недостатков корреляций Пирсона и
дает следующие преимущества [10].
. Возможность экономической интерпретации. Это
основное преимущество новой меры близости, которое делает ее более подходящей
для анализа фондового рынка, чем корреляции Пирсона. С экономической точки
зрения, значение меры характеризует возможности по получению дохода на рынке. Полученные
в ходе анализа результаты могут быть сравнены с другим индикатором - значением
индекса. Поскольку обе характеристики показывают доходность рынка, они должны
быть взаимосвязаны.
. Учет инфляции. При анализе фондового рынка очень
важно рассматривать значения с учетом уровня инфляции, поскольку если уровень
инфляции был высоким, положительная доходность на самом деле может означать
убыток инвестора.
. Использование точных значений. Использование точных
значений вместо выборочных коэффициентов корреляции дает возможность
рассчитывать значение меры для любого числа акций и любого числа периодов.
. Включение акций с низкой ликвидностью. Если акция не
торговалась в течение некоторого периода времени, ее доходность считается
равной нулю. Отсутствие доходности в этом случае объясняется низкой
ликвидностью бумаги, а не сравнением со значением инфляции.
Таким образом, анализ литературы по теме исследования показал
важность сетевого подхода в изучении сложных систем, в том числе фондовых
рынков. Наиболее распространенной моделью фондового рынка является модель
рыночного графа, основанная на анализе попарных корреляций между акциями.
Использование корреляций Пирсона в качестве меры близости между акциями
сопряжено с рядом трудностей, которые можно избежать, применяя альтернативную
меру близости.
В модели графа доходностей в качестве веса ребра используется
количество периодов, когда акции были одновременно доходными. Основные
преимущества этой модели: возможность интерпретации с экономической точки
зрения, учет инфляции, использование точных значений вместо выборочных
корреляций, включение акций с низкой ликвидностью. Таким образом, рассмотренная
модификация может быть применена для оценки возможностей по получению дохода на
рынке.
2.
Материалы и методы исследования
Первым шагом при выполнении работы был выбор модельных данных
и методики проведения сравнительного анализа моделей с новой мерой близости и
со стандартными корреляциями Пирсона. В разделе 2.1 содержится описание данных,
использовавшихся для моделирования. В разделе 2.2 приведен список
характеристик, которые анализировались в построенных моделях рынка. В разделе
2.3 описана методика сравнения этих характеристик в динамике.
.1
Описание модельных данных
В качестве модельных данных для проведения анализа были
выбраны данные фондовых рынков стран БРИК. Страны БРИК (Бразилия, Россия,
Индия, Китай) стремительно развиваются и становятся все более интегрированными
с развитыми экономиками. Вместе они занимают четверть от общей площади земной
суши, почти 40% от общего населения Земли и около 15% всего ВВП. По прогнозам
Goldman Sachs, тотальный вклад стран БРИК в мировой ВВП в 2050 году составит
128 триллионов долларов (для сравнения, прогнозируемый ВВП стран Большой
Семерки составит всего 66 триллионов долларов). Экономический рост стран БРИК
имеет большое влияние на капитализацию их фондовых рынков, а также
взаимозависимость с другими рынками. Согласно прогнозам, доля четырех стран
БРИК составит в 2030 году 41% от капитализации мирового фондового рынка. Ожидается,
что к тому времени Китай превысит по рыночной капитализации Соединенные Штаты
Америки и станет крупнейшим фондовым рынком в мире [17]. Таким образом, было бы
интересно проверить гипотез о схожести рынков стран БРИК и сравнить их с точки
зрения привлекательности для инвестора.
Данные по акциям Бразилии, Индии и Китая были получены с
помощью сервиса «Yahoo! Finance» - провайдера финансовой информации, принадлежащего компании
«Yahoo!». Для скачивания истории котировок при помощи Yahoo Finance API была
написана программа на языке Java. Исходный код этой программы приведен в
Приложении 1. Данные по акциям России были получены из другого открытого
источника - сайта компании «Финам»
(#"879905.files/image031.gif">
Рисунок 1. Распределение меры близости для рынка Бразилии для
периодов 1-4
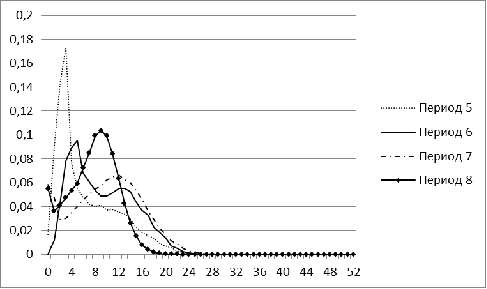
Рисунок 2. Распределение меры близости для рынка Бразилии для
периодов 5-8
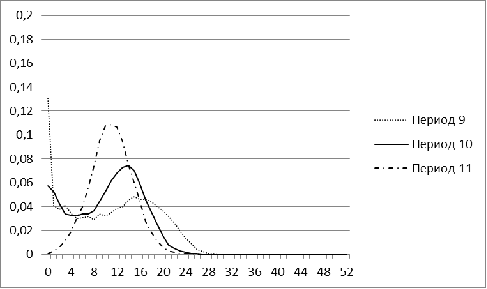
Рисунок 3. Распределение меры близости для рынка Бразилии для
периодов 9-11
В периоды с 1 по 5 распределение для рынка Бразилии имеет
явный перекос в сторону небольших значений, а начиная с 6 периода, у нее
появляется еще один пик. С течением времени второй пик постепенно
увеличивается. Для периода, соответствующего 2009 г, характерна большая
концентрация нулевых значений. Лишь в завершающем, 11 периоде, гистограмма
Бразилии напоминает нормальное распределение.
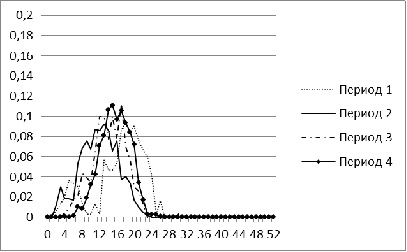
Рисунок 4. Распределение меры близости для рынка России для
периодов 1-4
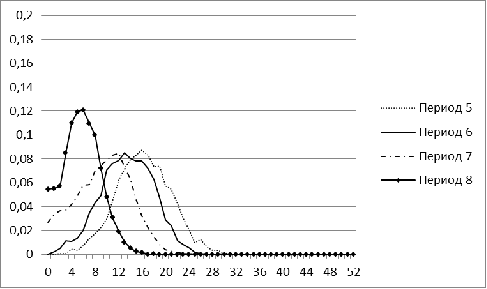
Рисунок 5. Распределение меры близости для рынка России для
периодов 5-8
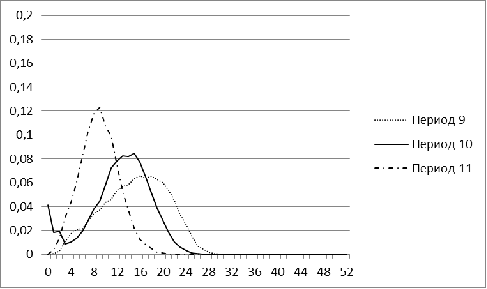
Рисунок 6. Распределение меры близости для рынка России для
периодов 9-11
Крайне нестабильную форму имеют распределения для рынка
России в периоды с 1 по 4. Это можно объяснить малым числом акций, попавших в
рассмотрение (менее 100). В последующие годы распределение для рынка России
становится больше похожим на нормальное. Наиболее резкое изменение форма
распределения претерпевает в период 8, соответствующий в нашей модели кризису
2008 г. Начиная с 2009 г., гистограмма вновь нормализуется, свидетельствуя о
том, что российский рынок восстанавливался.
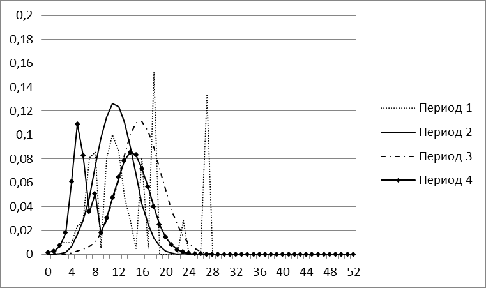
Рисунок 7. Распределение меры близости для рынка Индии для
периодов 1-4
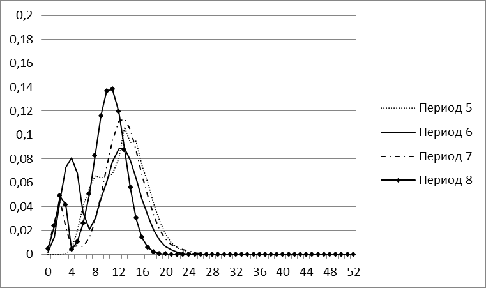
Рисунок 8. Распределение меры близости для рынка Индии для
периодов 5-8
В период 1, когда малое число акций попало в рассмотрение,
гистограмма для Индии имеет крайне нестабильную форму. В другие периоды
распределение больше похоже на нормальное. Как и в случае с Бразилией, распределение
рынка Индии имеет два пика в периоды с 6 по 10 - один в области больших, второй
в области малых значений. Аналогично наблюдается большая концентрация нулей в
2009 г.
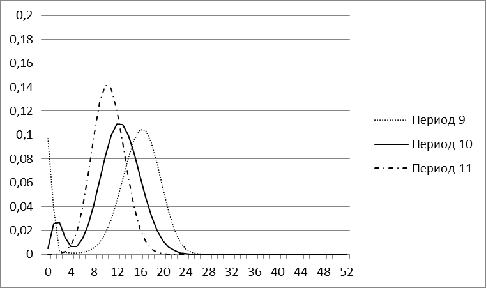
Рис. 9. Распределение меры близости для рынка Индии для
периодов 9-11
В отличие от остальных стран, гистограмма рынка Китая
наиболее стабильна и во все периоды по форме напоминает нормальное
распределение.
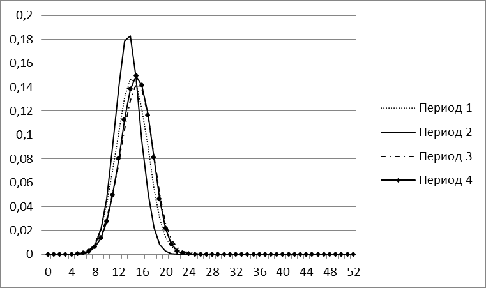
Рис. 10. Распределение меры близости для рынка Китая для
периодов 1-4
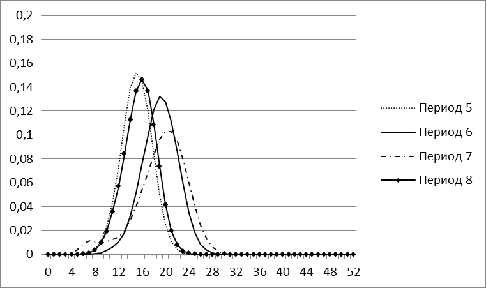
Рис. 11. Распределение меры близости для рынка Китая для
периодов 5-8
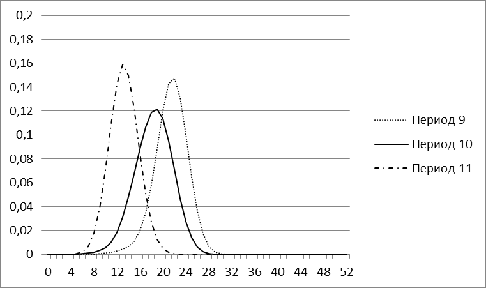
Рис. 12. Распределение меры близости для рынка Китая для
периодов 9-11
Анализ таблицы 3 показывает, что для рынков всех стран
характерно падение среднего значения в период 8, соответствующий в нашей модели
экономическому кризису 2008 г. За периодом кризиса следует сильный рост этой
характеристики, говорящий о восстановлении экономик стран БРИК. Для всех стран,
кроме Бразилии, еще одно падение наблюдется в 2011 г. - в большей степени на
рынках Китая и России, и в меньшей степени на рынке Индии.
Таблица 3/ Средние значения (μ)
и
стандартные отклонения (σ) меры близости графов
доходностей
|
Период
|
Бразилия
|
Россия
|
Индия
|
Китай
|
|
|
μ
|
σ
|
μ
|
σ
|
μ
|
σ
|
μ
|
σ
|
|
1
|
4,9
|
4,9
|
16,6
|
5,8
|
14,1
|
6,7
|
14,4
|
2,8
|
|
2
|
3,6
|
4,6
|
12,0
|
4,4
|
11,4
|
3,1
|
13,5
|
2,2
|
|
3
|
7,0
|
4,8
|
14,2
|
4,0
|
15,7
|
3,7
|
15,0
|
2,8
|
|
4
|
5,9
|
6,1
|
15,6
|
3,4
|
11,2
|
5,0
|
14,9
|
2,6
|
|
5
|
6,6
|
5,3
|
16,3
|
4,6
|
12,6
|
4,0
|
15,1
|
2,6
|
|
6
|
9,3
|
5,2
|
13,4
|
4,5
|
9,9
|
5,0
|
19,0
|
3,1
|
|
7
|
10,1
|
5,8
|
9,4
|
4,7
|
12,0
|
4,7
|
19,2
|
4,5
|
|
8
|
7,6
|
4,0
|
5,7
|
3,2
|
9,6
|
3,6
|
15,7
|
2,8
|
|
9
|
10,8
|
7,6
|
15,2
|
5,6
|
13,9
|
6,3
|
21,4
|
2,9
|
|
10
|
10,3
|
5,9
|
12,5
|
5,3
|
11,9
|
4,3
|
18,4
|
3,3
|
|
11
|
11,1
|
3,7
|
8,9
|
3,3
|
10,5
|
2,8
|
13,2
|
2,5
|
|
Ср.знач.
|
7,9
|
5,3
|
12,7
|
4,4
|
12,1
|
4,5
|
16,3
|
2,9
|
Наибольшие средние значения характерны для рынка Китая, даже
в годы кризиса они выше, чем у других стран. При этом среднеквадратичные
отклонения самые низкие, отсюда сделать вывод, что рынок Китая является
наиболее стабильным среди стран БРИК. Это говорит о том, что большее количество
акций приносили инвестору доход.
В целом средние значения по России и Индии сравнимы между
собой, но для России в годы кризиса они меньше, а в годы роста - выше
соответствующих значений Индии. Это говорит о меньшей стабильности фондового
рынка России, большей подверженности колебаниям. Среднеквадратичные отклонения
двух рынков также похожи.
Наконец, фондовый рынок Бразилии характеризуется самыми
низкими средними значениями меры, но наибольшими стандартными отклонениями.
Плотность
ребер
Первой характеристикой, зависящей от выбора порога, является
плотность ребер графа доходностей. Чем выше плотность ребер, тем больше акций
одновременно приносили инвесторам доход.
В таблицах 4-7 приведены результаты вычисления плотности для
порогов от 10 до 20 в графах Бразилии, России, Индии и Китая соответственно.
Естественно предположить, что чем выше средние значения, тем выше будет
плотность при переходе к невзвешенному графу.
Как было сказано ранее, для России периодов 1-4 и первого
периода Индии сравнивать плотности графов с плотностями других стран
некорректно ввиду очень малого количества акций. Выводы, приведенные ниже, были
сделаны без учета этих пяти периодов.
Таблица 4. Плотность графа доходностей рынка Бразилии для различных порогов
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,19
|
0,16
|
0,13
|
0,1
|
0,08
|
0,06
|
0,04
|
0,02
|
0,02
|
0,01
|
0,00
|
|
2
|
0,13
|
0,11
|
0,08
|
0,07
|
0,06
|
0,04
|
0,03
|
0,02
|
0,01
|
0,01
|
0,01
|
|
3
|
0,25
|
0,2
|
0,17
|
0,14
|
0,12
|
0,09
|
0,07
|
0,06
|
0,04
|
0,03
|
0,02
|
|
4
|
0,29
|
0,25
|
0,22
|
0,19
|
0,15
|
0,12
|
0,09
|
0,07
|
0,05
|
0,03
|
0,02
|
|
5
|
0,27
|
0,24
|
0,2
|
0,16
|
0,13
|
0,1
|
0,08
|
0,06
|
0,04
|
0,03
|
0,02
|
|
6
|
0,45
|
0,4
|
0,35
|
0,29
|
0,24
|
0,19
|
0,14
|
0,11
|
0,07
|
0,05
|
|
7
|
0,55
|
0,49
|
0,43
|
0,36
|
0,3
|
0,24
|
0,18
|
0,14
|
0,1
|
0,07
|
0,05
|
|
8
|
0,35
|
0,25
|
0,16
|
0,1
|
0,06
|
0,03
|
0,02
|
0,01
|
0,00
|
0,00
|
0,00
|
|
9
|
0,56
|
0,53
|
0,49
|
0,45
|
0,42
|
0,37
|
0,32
|
0,28
|
0,23
|
0,19
|
0,14
|
|
10
|
0,6
|
0,55
|
0,49
|
0,42
|
0,34
|
0,27
|
0,2
|
0,14
|
0,1
|
0,06
|
0,03
|
|
11
|
0,67
|
0,56
|
0,45
|
0,34
|
0,25
|
0,17
|
0,11
|
0,07
|
0,04
|
0,02
|
0,01
|
Таблица 5. Плотность графа доходностей рынка России для различных порогов
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,84
|
0,84
|
0,83
|
0,82
|
0,77
|
0,72
|
0,67
|
0,62
|
0,53
|
0,44
|
0,36
|
|
2
|
0,71
|
0,64
|
0,55
|
0,47
|
0,37
|
0,29
|
0,22
|
0,15
|
0,11
|
0,07
|
0,04
|
|
3
|
0,87
|
0,83
|
0,77
|
0,67
|
0,57
|
0,49
|
0,39
|
0,31
|
0,20
|
0,13
|
0,07
|
|
4
|
0,96
|
0,93
|
0,88
|
0,81
|
0,73
|
0,63
|
0,51
|
0,42
|
0,31
|
0,22
|
0,13
|
|
5
|
0,93
|
0,90
|
0,86
|
0,79
|
0,72
|
0,64
|
0,56
|
0,47
|
0,39
|
0,32
|
0,24
|
|
6
|
0,81
|
0,74
|
0,66
|
0,58
|
0,50
|
0,42
|
0,34
|
0,26
|
0,19
|
0,13
|
0,08
|
|
7
|
0,51
|
0,44
|
0,35
|
0,27
|
0,20
|
0,13
|
0,09
|
0,05
|
0,03
|
0,02
|
0,01
|
|
8
|
0,12
|
0,07
|
0,04
|
0,02
|
0,01
|
0,00
|
0,00
|
0,00
|
0,00
|
0,00
|
0,00
|
|
9
|
0,83
|
0,78
|
0,74
|
0,68
|
0,63
|
0,57
|
0,50
|
0,44
|
0,37
|
0,31
|
0,25
|
|
10
|
0,76
|
0,70
|
0,63
|
0,55
|
0,47
|
0,38
|
0,30
|
0,22
|
0,16
|
0,11
|
0,07
|
|
11
|
0,42
|
0,31
|
0,22
|
0,14
|
0,09
|
0,05
|
0,03
|
0,02
|
0,01
|
0,00
|
0,00
|
Таблица 6. Плотность графа доходностей рынка Индии для различных порогов
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,75
|
0,67
|
0,57
|
0,48
|
0,43
|
0,40
|
0,40
|
0,32
|
0,31
|
0,16
|
0,16
|
|
2
|
0,73
|
0,61
|
0,48
|
0,36
|
0,25
|
0,16
|
0,09
|
0,05
|
0,03
|
0,01
|
0,00
|
|
3
|
0,96
|
0,93
|
0,88
|
0,82
|
0,74
|
0,64
|
0,53
|
0,41
|
0,31
|
0,22
|
0,15
|
|
4
|
0,61
|
0,58
|
0,53
|
0,47
|
0,39
|
0,31
|
0,22
|
0,15
|
0,09
|
0,05
|
0,03
|
|
5
|
0,75
|
0,68
|
0,62
|
0,54
|
0,43
|
0,34
|
0,24
|
0,17
|
0,11
|
0,07
|
0,04
|
|
6
|
0,58
|
0,52
|
0,44
|
0,36
|
0,27
|
0,19
|
0,12
|
0,08
|
0,05
|
0,03
|
0,01
|
|
7
|
0,79
|
0,72
|
0,62
|
0,51
|
0,39
|
0,29
|
0,20
|
0,14
|
0,09
|
0,06
|
0,04
|
|
8
|
0,59
|
0,45
|
0,32
|
0,20
|
0,11
|
0,05
|
0,02
|
0,01
|
0,00
|
0,00
|
0,00
|
|
9
|
0,84
|
0,82
|
0,79
|
0,75
|
0,68
|
0,60
|
0,51
|
0,40
|
0,30
|
0,21
|
0,13
|
|
10
|
0,77
|
0,69
|
0,59
|
0,48
|
0,37
|
0,27
|
0,19
|
0,12
|
0,08
|
0,04
|
0,02
|
|
11
|
0,64
|
0,50
|
0,36
|
0,24
|
0,14
|
0,08
|
0,04
|
0,02
|
0,01
|
0,00
|
Таблица 7. Плотность графа доходностей рынка Китая для
различных порогов
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,96
|
0,92
|
0,85
|
0,75
|
0,62
|
0,47
|
0,33
|
0,21
|
0,12
|
0,06
|
0,03
|
|
2
|
0,97
|
0,92
|
0,83
|
0,69
|
0,51
|
0,33
|
0,18
|
0,09
|
0,03
|
0,01
|
0,00
|
|
3
|
0,97
|
0,94
|
0,89
|
0,81
|
0,71
|
0,58
|
0,44
|
0,30
|
0,18
|
0,10
|
0,05
|
|
4
|
0,98
|
0,95
|
0,90
|
0,82
|
0,71
|
0,57
|
0,42
|
0,28
|
0,16
|
0,08
|
0,03
|
|
5
|
0,98
|
0,96
|
0,91
|
0,84
|
0,73
|
0,59
|
0,44
|
0,29
|
0,17
|
0,09
|
0,04
|
|
6
|
1,00
|
0,99
|
0,99
|
0,98
|
0,96
|
0,93
|
0,88
|
0,80
|
0,70
|
0,58
|
0,45
|
|
7
|
0,95
|
0,94
|
0,93
|
0,92
|
0,90
|
0,87
|
0,83
|
0,77
|
0,71
|
0,62
|
0,53
|
|
8
|
0,99
|
0,97
|
0,93
|
0,87
|
0,79
|
0,68
|
0,54
|
0,39
|
0,26
|
0,15
|
0,07
|
|
9
|
1,00
|
1,00
|
1,00
|
0,99
|
0,99
|
0,98
|
0,97
|
0,95
|
0,92
|
0,86
|
0,77
|
|
10
|
0,99
|
0,99
|
0,98
|
0,96
|
0,93
|
0,88
|
0,81
|
0,72
|
0,62
|
0,50
|
0,38
|
|
11
|
0,93
|
0,86
|
0,75
|
0,61
|
0,45
|
0,30
|
0,18
|
0,10
|
0,05
|
0,02
|
0,01
|
Результаты расчета плотности в целом подтверждают выводы,
сделанные при анализе средних значений меры близости. Самая высокая плотность
при равных значениях порога характерна для рынка Китая, наименьшая - для рынка
Бразилии. Плотность рынков России и Индии в среднем примерно одинаковая, но для
рынка России характерны наибольшие колебания, что вновь говорит о его
нестабильности. Для всех рынков вновь наблюдается падение изучаемой
характеристики в период кризиса 2008 г., особенно сильное для России и Индии.
На рынке Китая тоже наблюдается падение, но не столь сильное. То есть даже в
период Кризиса возможности для получения дохода на рынке Китая оставались
сравнительно высокие.
Распределение
степеней вершин
Отдельный интерес представляет распределение степеней вершин
в модели графа доходностей.
Проведенные нами эксперименты показывают, что при малых
значениях порога (менее 15), гистограммы распределения не имеют какой-либо
ясной формы. Однако с увеличением порога и уменьшением плотности ребер, в
распределениях Индии и Китая все сильнее прослеживается следование степенному
закону. Рисунки 13-16 показывают распределение степеней вершин (на
логарифмической шкале) для ряда отдельных периодов Индии и Китая. Получающиеся
диаграммы могут быть аппроксимированы прямыми линиями, что означает присутствие
степенного закона. Диаграммы, построенные для других периодов и значений порога
(за исключением первого периода Индии, когда число акций очень мало) дают
схожие результаты.
К сожалению, проверить гипотезу о следовании степенному
закону для рынков Бразилии и России в нашем исследовании невозможно по причине
сравнительно малого количества вершин в графах этих стран.
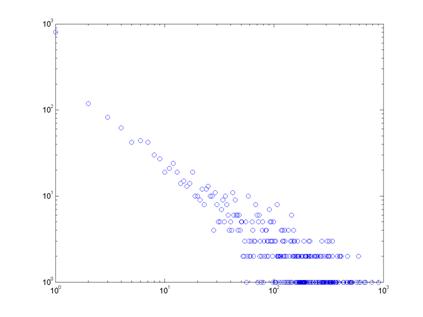
Рисунок 13. Распределение степеней вершин графа доходностей
Индии, период 5, порог 21
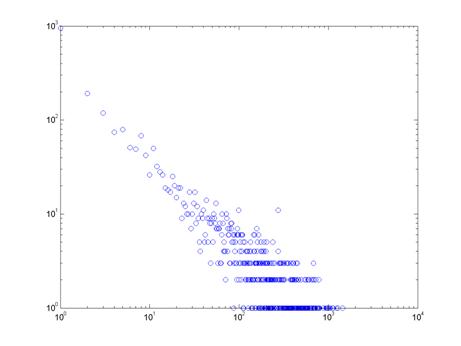
Рисунок 14. Распределение степеней вершин графа доходностей
Индии, период 10, порог 20
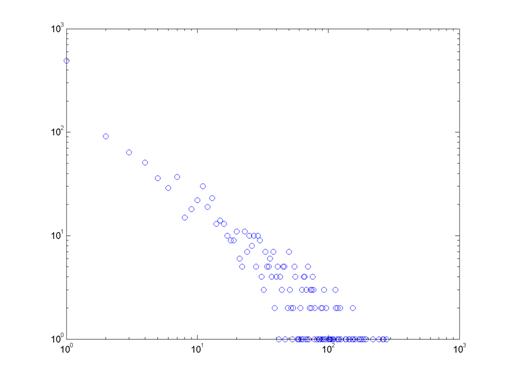
Рисунок 15. Распределение степеней вершин графа доходностей
Китая, период 4, порог 21
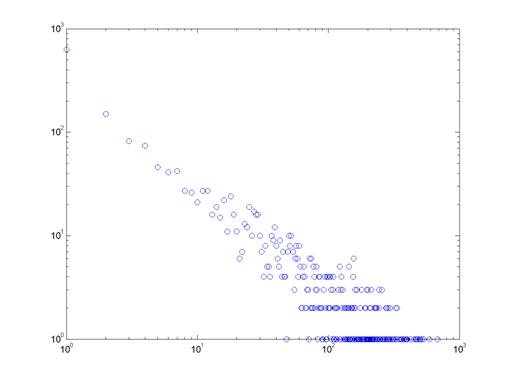
Рисунок 16. Распределение степеней вершин графа доходностей
Китая, период 11, порог 19
Коэффициенты
кластеризации
Коэффициент кластеризации в модели графа доходностей
характеризует тенденцию акций приносить доход одновременно. Для сравнительного
анализа рынков интерес представляют не только абсолютные значения
кластеризации, но и их отношение к плотности графа. В таблицах 8-11 приведены
результаты расчетов глобального коэффициента кластеризации при выбранных
значениях порога для четырех стран.
Анализ динамики абсолютных значений позволяет сделать
следующие выводы. Наибольшие средние показатели вновь характерны для рынка
Китая. Чуть меньше кластеризация у рынка Индии, на третьем месте рынок России.
Интересно, что для России коэффициенты кластеризации ниже, чем для Индии,
несмотря на то, что у двух стран примерно одинаковые плотности и средние
значения меры близости. Наконец, меньше всего значение коэффициента у рынка
Бразилии. Наиболее сильные колебания коэффициента кластеризации наблюдаются на
рынке России, говоря о его нестабильности.
Таблица 8. Коэффициент кластеризации графа доходностей рынка
Бразилии
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,52
|
0,47
|
0,46
|
0,42
|
0,39
|
0,35
|
0,29
|
0,27
|
0,24
|
0,21
|
0,15
|
|
2
|
0,44
|
0,42
|
0,40
|
0,37
|
0,36
|
0,31
|
0,29
|
0,26
|
0,22
|
0,18
|
0,15
|
|
3
|
0,62
|
0,58
|
0,55
|
0,51
|
0,46
|
0,45
|
0,41
|
0,39
|
0,36
|
0,31
|
0,29
|
|
4
|
0,61
|
0,57
|
0,55
|
0,52
|
0,47
|
0,43
|
0,42
|
0,41
|
0,35
|
0,33
|
0,26
|
|
5
|
0,61
|
0,56
|
0,53
|
0,51
|
0,49
|
0,46
|
0,41
|
0,39
|
0,34
|
0,28
|
0,25
|
|
6
|
0,74
|
0,70
|
0,66
|
0,61
|
0,57
|
0,55
|
0,53
|
0,50
|
0,45
|
0,40
|
0,36
|
|
7
|
0,82
|
0,77
|
0,74
|
0,73
|
0,69
|
0,66
|
0,63
|
0,58
|
0,54
|
0,51
|
0,45
|
|
8
|
0,69
|
0,64
|
0,61
|
0,58
|
0,53
|
0,48
|
0,36
|
0,29
|
0,25
|
0,20
|
0,14
|
|
9
|
0,78
|
0,76
|
0,74
|
0,72
|
0,71
|
0,67
|
0,64
|
0,62
|
0,61
|
0,59
|
0,56
|
|
10
|
0,81
|
0,79
|
0,75
|
0,71
|
0,68
|
0,65
|
0,63
|
0,60
|
0,58
|
0,53
|
0,49
|
|
11
|
0,85
|
0,82
|
0,79
|
0,76
|
0,74
|
0,70
|
0,65
|
0,60
|
0,52
|
0,44
|
0,32
|
Таблица 9. Коэффициент кластеризации графа доходностей рынка
России
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,92
|
0,85
|
0,92
|
0,97
|
0,97
|
0,90
|
0,78
|
0,49
|
0,93
|
0,88
|
0,76
|
|
2
|
0,92
|
0,83
|
0,89
|
0,96
|
0,94
|
0,88
|
0,75
|
0,41
|
0,91
|
0,85
|
0,72
|
|
3
|
0,90
|
0,78
|
0,86
|
0,94
|
0,86
|
0,68
|
0,27
|
0,88
|
0,83
|
0,68
|
|
4
|
0,90
|
0,76
|
0,82
|
0,90
|
0,90
|
0,84
|
0,61
|
0,20
|
0,86
|
0,80
|
0,60
|
|
5
|
0,86
|
0,73
|
0,83
|
0,88
|
0,87
|
0,79
|
0,56
|
0,11
|
0,84
|
0,78
|
0,51
|
|
6
|
0,84
|
0,66
|
0,78
|
0,87
|
0,86
|
0,75
|
0,52
|
0,06
|
0,80
|
0,76
|
0,42
|
|
7
|
0,83
|
0,58
|
0,70
|
0,78
|
0,84
|
0,71
|
0,51
|
0,04
|
0,78
|
0,70
|
0,32
|
|
8
|
0,78
|
0,41
|
0,61
|
0,72
|
0,81
|
0,60
|
0,44
|
0,00
|
0,76
|
0,64
|
0,24
|
|
9
|
0,76
|
0,36
|
0,54
|
0,63
|
0,79
|
0,55
|
0,33
|
0,00
|
0,70
|
0,59
|
0,13
|
|
10
|
0,73
|
0,24
|
0,35
|
0,56
|
0,74
|
0,48
|
0,22
|
0,00
|
0,65
|
0,54
|
0,06
|
|
11
|
0,63
|
0,17
|
0,19
|
0,37
|
0,62
|
0,39
|
0,12
|
0,00
|
0,61
|
0,45
|
0,03
|
Таблица 10. Коэффициент кластеризации графа доходностей рынка
Индии
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,87
|
0,80
|
0,77
|
0,70
|
0,70
|
0,61
|
0,62
|
0,57
|
0,57
|
0,57
|
0,57
|
|
2
|
0,87
|
0,84
|
0,81
|
0,77
|
0,74
|
0,65
|
0,59
|
0,52
|
0,35
|
0,24
|
0,13
|
|
3
|
0,98
|
0,96
|
0,93
|
0,90
|
0,88
|
0,85
|
0,82
|
0,80
|
0,78
|
0,75
|
0,72
|
|
4
|
0,78
|
0,76
|
0,73
|
0,69
|
0,66
|
0,64
|
0,62
|
0,60
|
0,58
|
0,54
|
0,48
|
|
5
|
0,92
|
0,91
|
0,90
|
0,87
|
0,79
|
0,77
|
0,66
|
0,65
|
0,63
|
0,59
|
0,52
|
|
6
|
0,75
|
0,72
|
0,69
|
0,66
|
0,64
|
0,63
|
0,63
|
0,61
|
0,58
|
0,50
|
0,40
|
|
7
|
0,87
|
0,84
|
0,80
|
0,77
|
0,74
|
0,73
|
0,72
|
0,71
|
0,69
|
0,65
|
0,59
|
|
8
|
0,79
|
0,75
|
0,72
|
0,69
|
0,66
|
0,59
|
0,49
|
0,36
|
0,22
|
0,11
|
0,05
|
|
9
|
0,91
|
0,90
|
0,88
|
0,86
|
0,84
|
0,81
|
0,79
|
0,76
|
0,74
|
0,71
|
0,67
|
|
10
|
0,87
|
0,84
|
0,81
|
0,79
|
0,77
|
0,76
|
0,74
|
0,72
|
0,67
|
0,60
|
0,51
|
|
11
|
0,83
|
0,80
|
0,77
|
0,74
|
0,71
|
0,66
|
0,58
|
0,48
|
0,33
|
0,20
|
0,11
|
Таблица 11. Коэффициент кластеризации графа доходностей рынка
Китая
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
0,97
|
0,95
|
0,92
|
0,89
|
0,84
|
0,81
|
0,77
|
0,74
|
0,69
|
0,61
|
0,49
|
|
2
|
0,98
|
0,95
|
0,91
|
0,86
|
0,80
|
0,76
|
0,71
|
0,66
|
0,55
|
0,39
|
0,22
|
|
3
|
0,98
|
0,96
|
0,94
|
0,91
|
0,87
|
0,83
|
0,79
|
0,75
|
0,72
|
0,65
|
0,56
|
|
4
|
0,98
|
0,97
|
0,94
|
0,91
|
0,86
|
0,82
|
0,77
|
0,73
|
0,67
|
0,60
|
0,49
|
|
5
|
0,99
|
0,97
|
0,95
|
0,91
|
0,87
|
0,82
|
0,78
|
0,74
|
0,70
|
0,64
|
0,53
|
|
6
|
1,00
|
1,00
|
0,99
|
0,99
|
0,98
|
0,96
|
0,93
|
0,90
|
0,87
|
0,83
|
0,80
|
|
7
|
0,98
|
0,97
|
0,97
|
0,96
|
0,95
|
0,93
|
0,92
|
0,90
|
0,87
|
0,85
|
0,82
|
|
8
|
0,99
|
0,98
|
0,96
|
0,90
|
0,87
|
0,83
|
0,79
|
0,75
|
0,70
|
0,62
|
|
9
|
1,00
|
1,00
|
1,00
|
1,00
|
0,99
|
0,99
|
0,99
|
0,97
|
0,96
|
0,93
|
0,89
|
|
10
|
1,00
|
0,99
|
0,99
|
0,98
|
0,96
|
0,94
|
0,91
|
0,89
|
0,86
|
0,83
|
0,79
|
|
11
|
0,95
|
0,92
|
0,87
|
0,83
|
0,79
|
0,76
|
0,73
|
0,68
|
0,59
|
0,44
|
0,29
|
Если сравнивать числа из таблиц 8-11 со значениями реберной
плотности (таблицы 4-7), то можно видеть, что они значительно выше. Это
справедливо для всех стран и всех периодов, следовательно, акции на фондовых
рынках имеют тенденцию образовывать «кластеры», доходности которых меняются
согласованно. Чем выше отношение коэффициента к плотности, тем сильнее эта
тенденция.
Размер
максимальной клики
Еще одним связанным с плотностью показателем является размер
максимальной клики, позволяющий судить о связности построенных графов.
Результаты расчетов для выбранных значений порога приведены в таблицах 12-15.
Как видно из таблиц, динамика максимальных клик в целом
повторяет динамику всех предыдущих характеристик. Так, в период, связанный с
кризисом 2008 г., происходит существенное падение размера клики. Это говорит о
том, что меньшее число акций приносили доход инвесторам. В период, следующий за
кризисом, вновь наблюдается сильный рост.
Сравнивать абсолютные значения размера максимальной клики для
разных стран представляется некорректным, поскольку число акций, торгующихся на
рынках, сильно различается.
Таблица 12. Размер максимальной клики графа доходностей рынка
Бразилии
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
79
|
66
|
56
|
47
|
41
|
32
|
26
|
22
|
18
|
12
|
6
|
|
2
|
72
|
66
|
58
|
51
|
43
|
35
|
27
|
25
|
19
|
18
|
13
|
|
3
|
110
|
100
|
90
|
84
|
74
|
67
|
52
|
43
|
40
|
30
|
26
|
|
4
|
127
|
115
|
100
|
87
|
73
|
62
|
52
|
46
|
35
|
27
|
23
|
|
5
|
121
|
108
|
93
|
86
|
79
|
66
|
59
|
46
|
38
|
30
|
26
|
|
6
|
182
|
155
|
133
|
118
|
103
|
86
|
74
|
62
|
47
|
42
|
29
|
|
7
|
228
|
201
|
180
|
150
|
136
|
118
|
105
|
86
|
74
|
61
|
44
|
|
8
|
139
|
106
|
80
|
56
|
41
|
29
|
20
|
16
|
10
|
10
|
10
|
|
9
|
355
|
335
|
312
|
288
|
269
|
245
|
218
|
199
|
173
|
142
|
114
|
|
10
|
338
|
284
|
243
|
205
|
165
|
130
|
106
|
82
|
68
|
50
|
38
|
|
11
|
228
|
186
|
155
|
123
|
95
|
74
|
61
|
43
|
37
|
31
|
24
|
Таблица 13. Размер максимальной клики графа доходностей рынка
России
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
23
|
22
|
21
|
21
|
18
|
17
|
17
|
15
|
14
|
12
|
10
|
|
2
|
21
|
20
|
19
|
17
|
15
|
12
|
11
|
7
|
7
|
5
|
4
|
|
3
|
17
|
16
|
15
|
13
|
13
|
11
|
8
|
7
|
6
|
5
|
3
|
|
4
|
42
|
39
|
36
|
33
|
29
|
27
|
24
|
20
|
16
|
12
|
9
|
|
5
|
55
|
52
|
48
|
44
|
42
|
40
|
37
|
30
|
27
|
23
|
19
|
|
6
|
65
|
62
|
54
|
48
|
44
|
36
|
30
|
23
|
19
|
17
|
11
|
|
7
|
64
|
50
|
41
|
32
|
26
|
23
|
18
|
16
|
12
|
10
|
8
|
|
8
|
17
|
15
|
12
|
9
|
7
|
5
|
3
|
2
|
2
|
2
|
1
|
|
9
|
131
|
125
|
113
|
110
|
105
|
92
|
82
|
71
|
65
|
57
|
44
|
|
10
|
134
|
123
|
108
|
94
|
79
|
68
|
55
|
45
|
35
|
29
|
21
|
|
11
|
55
|
43
|
33
|
26
|
21
|
15
|
12
|
10
|
8
|
6
|
4
|
Таблица 14. Размер максимальной клики графа доходностей рынка
Индии
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
19
|
20
|
|
1
|
16
|
15
|
13
|
13
|
13
|
12
|
12
|
12
|
12
|
8
|
8
|
|
2
|
159
|
126
|
101
|
79
|
58
|
43
|
29
|
22
|
15
|
10
|
8
|
|
3
|
728
|
647
|
563
|
485
|
408
|
343
|
284
|
227
|
180
|
137
|
111
|
|
4
|
790
|
673
|
542
|
433
|
331
|
254
|
191
|
138
|
102
|
68
|
53
|
|
5
|
1096
|
931
|
759
|
624
|
489
|
383
|
297
|
225
|
176
|
125
|
90
|
|
6
|
856
|
692
|
553
|
436
|
332
|
260
|
189
|
142
|
106
|
80
|
60
|
|
7
|
1271
|
1008
|
774
|
594
|
476
|
385
|
310
|
297
|
285
|
269
|
248
|
|
8
|
750
|
540
|
363
|
246
|
161
|
98
|
63
|
43
|
26
|
15
|
10
|
|
9
|
1770
|
1621
|
1455
|
1278
|
1081
|
891
|
721
|
567
|
417
|
299
|
200
|
|
10
|
1358
|
1129
|
917
|
729
|
578
|
438
|
327
|
240
|
176
|
128
|
91
|
|
11
|
811
|
596
|
426
|
300
|
198
|
125
|
75
|
47
|
29
|
18
|
12
|
Таблица 15. Размер максимальной клики графа доходностей рынка
Китая
|
#
|
Порог
|
|
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
|
1
|
824
|
709
|
599
|
498
|
381
|
273
|
190
|
140
|
104
|
97
|
91
|
|
2
|
878
|
725
|
563
|
404
|
270
|
170
|
101
|
63
|
37
|
23
|
14
|
|
3
|
974
|
877
|
759
|
630
|
499
|
382
|
268
|
172
|
120
|
87
|
61
|
|
4
|
1028
|
901
|
771
|
638
|
501
|
379
|
262
|
175
|
106
|
66
|
37
|
|
5
|
1100
|
950
|
812
|
655
|
493
|
352
|
248
|
155
|
99
|
60
|
37
|
|
6
|
1327
|
1282
|
1218
|
1137
|
1033
|
915
|
793
|
654
|
528
|
407
|
308
|
|
7
|
1344
|
1307
|
1263
|
1195
|
1128
|
1038
|
930
|
814
|
710
|
595
|
485
|
|
8
|
1375
|
1271
|
1129
|
975
|
811
|
639
|
479
|
337
|
233
|
159
|
97
|
|
9
|
1624
|
1614
|
1595
|
1565
|
1525
|
1453
|
1363
|
1233
|
1081
|
908
|
734
|
|
10
|
1616
|
1548
|
1467
|
1361
|
1251
|
1105
|
948
|
813
|
666
|
513
|
382
|
|
11
|
1217
|
985
|
747
|
554
|
401
|
277
|
196
|
126
|
77
|
50
|
32
|
3.2
Результаты анализа рыночного графа с использованием корреляций Пирсона
Интересно сравнить результаты, полученные с использованием
новой меры и стандартных корреляций Пирсона. Поэтому на следующем шаге было
произведено построение моделей рыночных графов для тех же данных и периодов и
расчет характеристик, аналогичных предыдущим.
Поскольку диапазоны значений для коэффициентов корреляции и
меры близости графа доходностей разные, при переходе к невзвешенному рыночному
графу были взяты свои пороги. Наиболее значимые результаты с нашей точки зрения
получаются для порогов 0.4, 0.5, 0.6 и 0.7.
Распределение
коэффициентов корреляции
По аналогии с графом доходностей, первой изучаемой
характеристикой было распределение значений меры близости. Гистограммы
корреляций для рынков Бразилии, России, Индии и Китая представлены на рисунках
17-28. В таблице 16 приведены соответствующие средние значения и стандартные
отклонения.
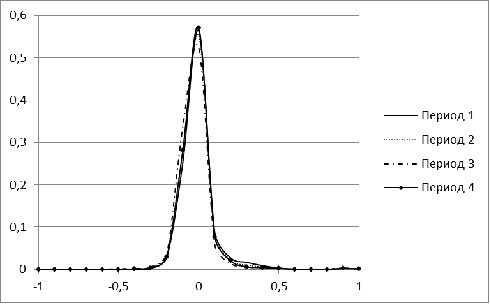
Рисунок 17. Распределение корреляций для рыночного графа
Бразилии, периоды 1-4
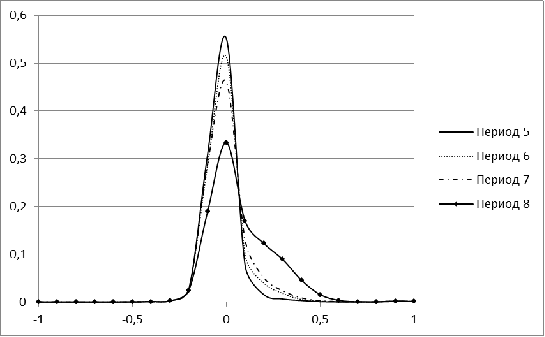
Рисунок 18. Распределение корреляций для рыночного графа
Бразилии, периоды 5-8
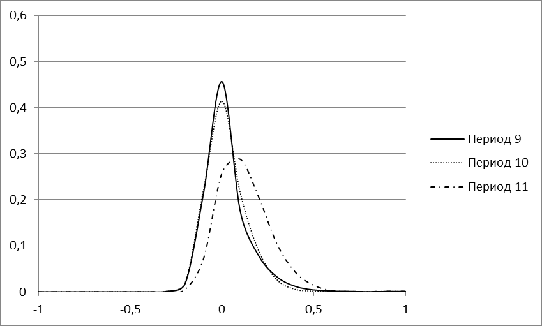
Рисунок 19. Распределение корреляций для рыночного графа
Бразилии, периоды 9-11
Гистограмма Бразилии на протяжении большинства периодов по
форе напоминает нормальное распределение. Лишь в периоде 8, соответствующем
кризису, увеличивается доля положительных корреляций.
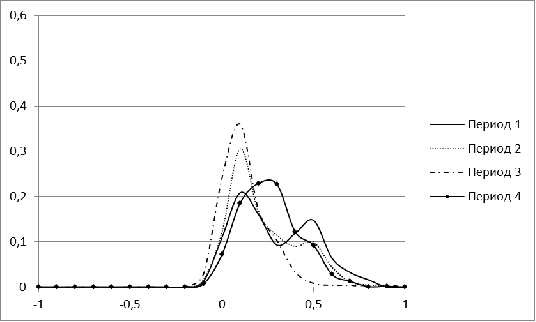
Рисунок 20. Распределение корреляций для рыночного графа
России, периоды 1-4
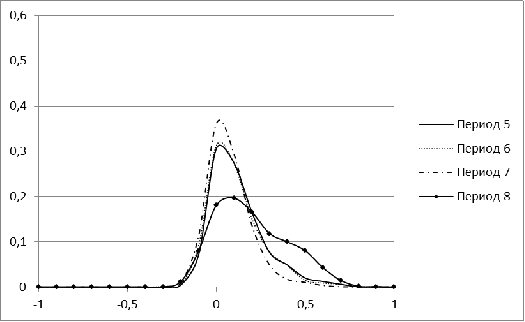
Рисунок 21. Распределение корреляций для рыночного графа
России, периоды 5-8
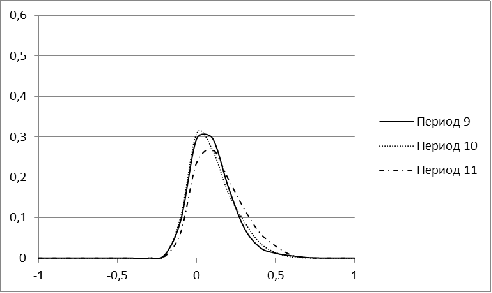
Рисунок 22. Распределение корреляций для рыночного графа
России, периоды 9-11
Для рынка России гистограмма расположена правее, что говорит
о большем количестве положительных корреляций, но немного скошена влево. Как и
в случае с Бразилией, в периоде 8 происходит изменение формы кривой.
Нестабильность кривой в первые 4 периода можно объяснить малым числом акций,
попавших в рассмотрение для рынка России.
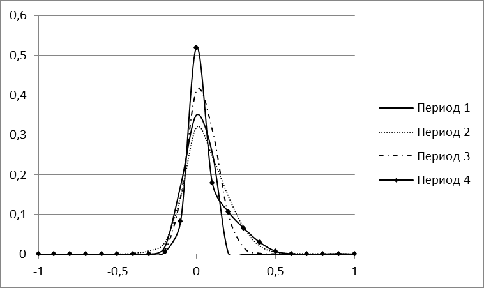
Рисунок 23. Распределение корреляций для рыночного графа
Индии, периоды 1-4
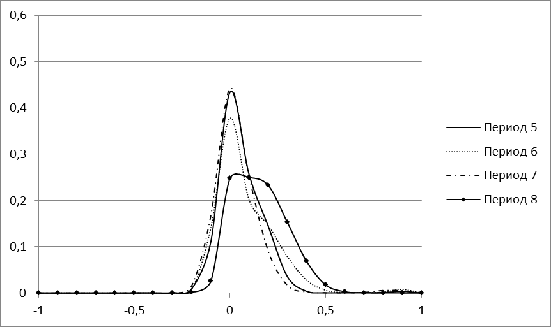
Рисунок 24. Распределение корреляций для рыночного графа
Индии, периоды 5-8
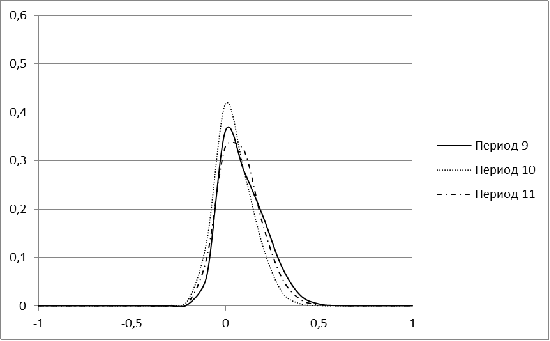
Рисунок 25. Распределение корреляций для рыночного графа
Индии, периоды 9-11
Гистограмма Индии в большинстве периодов скошена влево.
Наибольшие изменения ее форма претерпевает снова в период 8. Это выражается в
сдвиге центра гистограммы в сторону больших корреляций и более приплюснутой
форме.
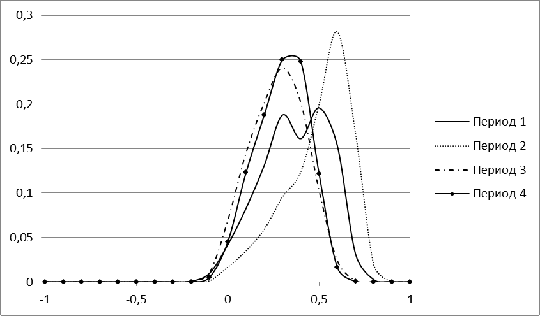
Рисунок 26. Распределение корреляций для рыночного графа
Китая, периоды 1-4
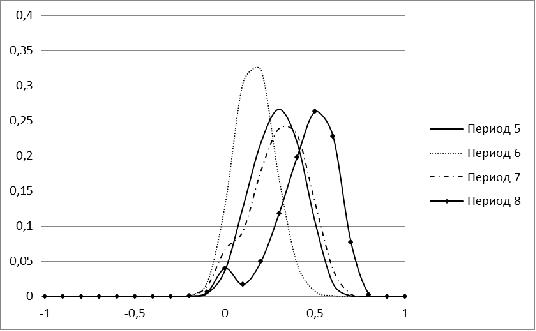
Рисунок 27. Распределение корреляций для рыночного графа
Китая, периоды 5-8
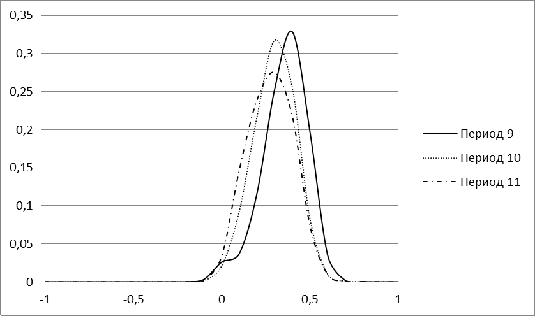
Рисунок 28. Распределение корреляций для рыночного графа Китая,
периоды 9-11
Распределение рынка Китая с течением времени меняется
сильнее, чем распределения других стран. В период номер 1 она имеет два пика, в
периоды с 4 она скошена в сторону больших корреляций. В период, соответствующий
кризису 2008 г., вновь наблюдается сдвиг в сторону больших значений.
Анализ таблицы 16 показывает, что наибольшее среднее значение
корреляций характерно для рынка Китая (0,38). Значительно меньше эта величина
для рынков России (0,21) и Индии (0,13). Наименьшей связностью обладает рынок
Бразилии (среднее значение - 0,06). Среднеквадратичные отклонения отличаются не
так сильно: наибольшее значение у России (0,16), затем идут Индия и Китай
(0,15). Наименьшее стандартное отклонение имеет рынок Бразилии (0,12).
Таблица 16. Средние значения (μ)
и
стандартные отклонения (σ) коэффициентов корреляции
рыночных графов
|
Период
|
Бразилия
|
Россия
|
Индия
|
Китай
|
|
|
μ
|
σ
|
μ
|
σ
|
μ
|
σ
|
μ
|
σ
|
|
1
|
0,03
|
0,12
|
0,34
|
0,21
|
0,21
|
0,36
|
0,42
|
0,18
|
|
2
|
0,03
|
0,11
|
0,28
|
0,19
|
0,11
|
0,15
|
0,55
|
0,18
|
|
3
|
0,02
|
0,11
|
0,18
|
0,14
|
0,09
|
0,32
|
0,15
|
|
4
|
0,02
|
0,10
|
0,31
|
0,16
|
0,10
|
0,14
|
0,35
|
0,14
|
|
5
|
0,02
|
0,10
|
0,17
|
0,16
|
0,10
|
0,12
|
0,34
|
0,14
|
|
6
|
0,04
|
0,11
|
0,16
|
0,15
|
0,13
|
0,16
|
0,22
|
0,11
|
|
7
|
0,05
|
0,12
|
0,12
|
0,13
|
0,08
|
0,13
|
0,35
|
0,16
|
|
8
|
0,12
|
0,16
|
0,25
|
0,20
|
0,20
|
0,14
|
0,50
|
0,17
|
|
9
|
0,07
|
0,13
|
0,15
|
0,13
|
0,14
|
0,12
|
0,40
|
0,13
|
|
10
|
0,07
|
0,12
|
0,15
|
0,14
|
0,09
|
0,10
|
0,35
|
0,12
|
|
11
|
0,17
|
0,14
|
0,19
|
0,15
|
0,13
|
0,11
|
0,33
|
0,13
|
|
Ср.знач.
|
0,06
|
0,12
|
0,21
|
0,16
|
0,13
|
0,15
|
0,38
|
0,15
|
Приведенные в таблице 16 характеристики имеют схожую динамику
для всех стран. Наибольший рост корреляций наблюдается в период кризиса 2008
г., что подтверждает гипотезу о том, что отрицательные доходности коррелируют
сильнее, нежели положительные. Для Бразилии, России и Индии рост корреляций
характерен и для периода 11. Стандартное отклонение растет и уменьшается
согласованно со средним значением. Таким образом, в годы кризиса связность
рынка возрастает: увеличивается как доля положительных корреляций, так и
степень связей.
Плотность
ребер
Результаты вычисления реберной плотности в рыночных графах
для выбранных значений порога приведены в таблицах 17-18.
Таблица 17. Плотность ребер для графов рынка Бразилии и
России
|
#
|
Бразилия
|
Россия
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
0,017
|
0,008
|
0,005
|
0,004
|
0,393
|
0,27
|
0,117
|
0,05
|
|
2
|
0,013
|
0,006
|
0,004
|
0,004
|
0,259
|
0,166
|
0,064
|
0,018
|
|
3
|
0,014
|
0,007
|
0,006
|
0,005
|
0,056
|
0,022
|
0,013
|
0,009
|
|
4
|
0,01
|
0,006
|
0,004
|
0,003
|
0,264
|
0,139
|
0,044
|
0,016
|
|
5
|
0,008
|
0,004
|
0,004
|
0,004
|
0,09
|
0,041
|
0,02
|
0,008
|
|
6
|
0,011
|
0,006
|
0,004
|
0,003
|
0,08
|
0,032
|
0,017
|
0,008
|
|
7
|
0,016
|
0,007
|
0,004
|
0,003
|
0,032
|
0,015
|
0,005
|
0,001
|
|
8
|
0,067
|
0,022
|
0,006
|
0,003
|
0,241
|
0,141
|
0,060
|
0,017
|
|
9
|
0,021
|
0,01
|
0,005
|
0,003
|
0,047
|
0,02
|
0,008
|
0,002
|
|
10
|
0,01
|
0,005
|
0,003
|
0,002
|
0,055
|
0,017
|
0,003
|
0,001
|
|
11
|
0,064
|
0,022
|
0,007
|
0,004
|
0,102
|
0,039
|
0,009
|
0,001
|
Таблица 18. Плотность ребер для графов рынка Индии и Китая
|
#
|
Индия
|
Китай
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
0,162
|
0,162
|
0,162
|
0,162
|
0,545
|
0,384
|
0,188
|
0,034
|
|
2
|
0,033
|
0,012
|
0,007
|
0,005
|
0,792
|
0,668
|
0,469
|
0,187
|
|
3
|
0,005
|
0,002
|
0,002
|
0,001
|
0,331
|
0,129
|
0,025
|
0,002
|
|
4
|
0,041
|
0,010
|
0,003
|
0,002
|
0,388
|
0,139
|
0,017
|
0,001
|
|
5
|
0,009
|
0,006
|
0,005
|
0,005
|
0,344
|
0,125
|
0,019
|
0,001
|
|
6
|
0,045
|
0,018
|
0,012
|
0,011
|
0,055
|
0,008
|
0,001
|
0,000
|
|
7
|
0,015
|
0,013
|
0,012
|
0,012
|
0,406
|
0,175
|
0,041
|
0,003
|
|
8
|
0,090
|
0,021
|
0,003
|
0,000
|
0,769
|
0,571
|
0,308
|
0,08
|
|
9
|
0,027
|
0,005
|
0,001
|
0,000
|
0,562
|
0,234
|
0,037
|
0,002
|
|
10
|
0,005
|
0,001
|
0,000
|
0,000
|
0,349
|
0,094
|
0,011
|
0,001
|
|
11
|
0,017
|
0,003
|
0,001
|
0,000
|
0,302
|
0,084
|
0,011
|
0,001
|
Анализ таблиц 17-18 подтверждает выводы, сделанные при
анализе средних значений. При одинаковых значениях порога значительно выше
плотность на рынке Китая, у Бразилии, России и Индии графы получаются
сравнительно разреженными. Для всех стран наблюдается рост реберной плотности в
период экономического кризиса 2008 г. и последующее ее снижение. В 2011 г. для
всех стран, кроме Китая, эта характеристика вновь увеличивается.
Коэффициент
кластеризации
Динамику плотности повторяет и связанная с ней характеристика
- коэффициент кластеризации (см. табл. 19-20).
Таблица 19. Коэффициент кластеризации для графов рынка
Бразилии и России
|
#
|
Бразилия
|
Россия
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
0,29
|
0,26
|
0,21
|
0,15
|
0,66
|
0,55
|
0,42
|
0,14
|
|
2
|
0,3
|
0,24
|
0,19
|
0,18
|
0,52
|
0,42
|
0,22
|
0,06
|
|
3
|
0,33
|
0,28
|
0,24
|
0,21
|
0,24
|
0
|
0
|
0
|
|
4
|
0,26
|
0,2
|
0,16
|
0,61
|
0,47
|
0,2
|
0,08
|
|
5
|
0,27
|
0,24
|
0,21
|
0,21
|
0,38
|
0,23
|
0,13
|
0,05
|
|
6
|
0,35
|
0,28
|
0,23
|
0,19
|
0,33
|
0,2
|
0,17
|
0,09
|
|
7
|
0,43
|
0,33
|
0,27
|
0,24
|
0,22
|
0,15
|
0,1
|
0,02
|
|
8
|
0,5
|
0,38
|
0,28
|
0,21
|
0,57
|
0,44
|
0,3
|
0,18
|
|
9
|
0,38
|
0,26
|
0,22
|
0,19
|
0,29
|
0,19
|
0,12
|
0,04
|
|
10
|
0,41
|
0,28
|
0,22
|
0,2
|
0,33
|
0,22
|
0,07
|
0,02
|
|
11
|
0,55
|
0,4
|
0,3
|
0,25
|
0,44
|
0,25
|
0,11
|
0,05
|
Таблица 20. Коэффициент кластеризации для графов рынка Индии
и Китая
|
#
|
Индия
|
Китай
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
0,57
|
0,57
|
0,57
|
0,57
|
0,85
|
0,81
|
0,67
|
0,45
|
|
2
|
0,41
|
0,26
|
0,21
|
0,17
|
0,93
|
0,88
|
0,77
|
0,64
|
|
3
|
0,26
|
0,18
|
0,12
|
0,09
|
0,74
|
0,61
|
0,42
|
0,13
|
|
4
|
0,38
|
0,25
|
0,14
|
0,09
|
0,79
|
0,62
|
0,37
|
0,1
|
|
5
|
0,25
|
0,14
|
0,11
|
0,1
|
0,76
|
0,62
|
0,36
|
0,07
|
|
6
|
0,47
|
0,3
|
0,19
|
0,15
|
0,59
|
0,43
|
0,21
|
0,05
|
|
7
|
0,27
|
0,2
|
0,16
|
0,14
|
0,78
|
0,65
|
0,45
|
0,17
|
|
8
|
0,52
|
0,34
|
0,17
|
0,08
|
0,91
|
0,86
|
0,75
|
0,59
|
|
9
|
0,36
|
0,18
|
0,08
|
0,04
|
0,84
|
0,72
|
0,5
|
0,19
|
|
10
|
0,25
|
0,12
|
0,07
|
0,05
|
0,76
|
0,62
|
0,38
|
0,16
|
|
11
|
0,35
|
0,16
|
0,09
|
0,05
|
0,79
|
0,69
|
0,5
|
0,24
|
Как и в случае графа доходностей, коэффициенты значительно
превышают соответствующие значения плотности. Это говорит о тенденции акций
образовывать кластеры, показывающие сходную динамику цен. Интересно, что для
рынка Бразилии, имеющего меньшую плотность, кластеризация в среднем выше, чем
на рынках России и Индии.
Максимальные
клики
Последней изученной характеристикой был размер максимальной
клики в графах (см. таблицы 21-22). Результаты, полученные при нахождении
максимальных клик для разных порогов, подтверждают выводы, сделанные ранее.
Наибольшие клики характерны для периодов, связанных с кризисом 2008 г. и 2011
г. для всех четырех стран БРИК. Это вновь подтверждает гипотезу о том, что в период
кризиса связность рынка увеличивается.
Таблица 21. Размер максимальной клики для графов рынка
Бразилии и России
|
#
|
Бразилия
|
Россия
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
24
|
8
|
4
|
4
|
14
|
9
|
6
|
4
|
|
2
|
20
|
10
|
8
|
4
|
15
|
11
|
6
|
3
|
|
3
|
24
|
18
|
17
|
15
|
4
|
2
|
2
|
2
|
|
4
|
21
|
13
|
4
|
4
|
18
|
11
|
7
|
4
|
|
5
|
13
|
8
|
8
|
8
|
13
|
10
|
7
|
4
|
|
6
|
20
|
14
|
8
|
8
|
18
|
12
|
9
|
6
|
|
7
|
30
|
19
|
12
|
8
|
19
|
12
|
7
|
4
|
|
8
|
71
|
39
|
24
|
8
|
47
|
31
|
18
|
9
|
|
9
|
50
|
36
|
28
|
18
|
21
|
15
|
8
|
4
|
|
10
|
24
|
15
|
10
|
6
|
25
|
13
|
6
|
3
|
|
11
|
68
|
42
|
20
|
18
|
39
|
21
|
9
|
5
|
Таблица 22. Размер максимальной клики графов рынка Индии и
Китая
|
#
|
Индия
|
Китай
|
|
|
0,4
|
0,5
|
0,6
|
0,7
|
0,4
|
0,5
|
0,6
|
0,7
|
|
1
|
8
|
8
|
8
|
8
|
605
|
420
|
206
|
60
|
|
2
|
22
|
20
|
17
|
14
|
857
|
692
|
455
|
223
|
|
3
|
23
|
22
|
19
|
13
|
314
|
146
|
44
|
8
|
|
4
|
116
|
59
|
57
|
57
|
340
|
143
|
24
|
6
|
|
5
|
144
|
138
|
129
|
122
|
362
|
152
|
44
|
7
|
233
|
224
|
212
|
202
|
79
|
28
|
9
|
5
|
|
7
|
295
|
290
|
279
|
259
|
475
|
252
|
96
|
21
|
|
8
|
227
|
103
|
45
|
23
|
1031
|
773
|
455
|
156
|
|
9
|
97
|
51
|
20
|
8
|
608
|
258
|
62
|
18
|
|
10
|
39
|
16
|
14
|
12
|
310
|
106
|
39
|
18
|
|
11
|
118
|
56
|
18
|
8
|
389
|
147
|
42
|
16
|
Таким образом, результаты, полученные при анализе графов
доходностей стран БРИК позволяют сделать следующие выводы. Модификация модели
рыночного графа, использованная в данной работе, позволяет оценить
потенциальную доходность, ситуацию на изучаемом рынке.
Выводы о падении и росте доходности вложений можно сделать и
по изменению биржевого индекса, но использованная модель позволяет сказать не
только о росте некоторых акций, но и учесть, насколько этот рост поддерживался
остальными акциями. Например, в нашей модели большой рост индекса не всегда
соответствует столь же большому росту среднего значения меры близости, а в ряде
случаев наоборот, сопровождается падением реальных возможностей для получения
дохода.
Анализ графов, построенных с применением новой меры близости,
показывает присутствие у этих моделей степенного закона. Т.е. характерно
присутствие узлов-концентраторов - акций, которые влияют на остальные сильнее
других.
Сравнительный анализ рынков БРИК с применением модели графа
доходностей позволяет сделать вывод о том, что рынок Китая имеет больше
возможностей для получения потенциального дохода инвестора, даже в годы
кризиса. На втором по привлекательности месте находятся рынки Индии и России,
на последнем месте - рынок Бразилии.
Анализ рыночных графов, построенных для тех же данных с
использованием стандартных корреляций Пирсона, позволяет сделать вывод о
высокой степени глобализации рынка Китая. Подтверждается гипотеза о том, что
отрицательные доходности коррелируют сильнее, нежели положительные. Это следует
из роста средних значений, плотности, коэффициента кластеризации и размера
максимальной клики в периоды, соответствующие кризису 2008 г.
Можно сделать вывод о том, что модель рыночного графа с
использованием стандартных корреляций Пирсона позволяет оценить возможности по
формированию диверсифицированного портфеля, по управлению рисками, но не
включает информацию по итоговой доходности акций. Модификация исходной модели с
использованием новой меры близости, позволяет преодолеть ее недостатки, и может
быть применена для оценки потенциальных возможностей по получению дохода
инвестором.
.3
Сравнение результатов
В таблицах 23-26 приведены основные характеристики обеих
моделей для Бразилии, России, Индии и Китая соответственно. В таблицу по каждой
стране включены следующие величины: средние значения меры близости, плотность,
коэффициент кластеризации и размер максимальной клики. Для моделей графа
доходностей приведены значения для порога в 15 недель; для рыночных графов со
стандартными коэффициентами корреляций выбрано значение порога 0,5.
Интересно также сравнить характеристики, рассмотренные выше,
с изменениями биржевых индексов в соответствующие периоды. Как и предложенная
мера близости, индекс характеризует состояние индекса, следовательно, их
динамика должна быть взаимосвязана. В таблицах 23-26, вместе с характеристиками
графов доходностей и рыночных графов, приведены данные о динамике основных
индексов тех бирж, акции которых попали в рассмотрение.
Ожидаемо, что и для графа доходностей, и для рыночного графа,
приведенные характеристики изменяются согласованно: с увеличением среднего
значения меры близости, увеличиваются также плотность ребер, коэффициент
корреляций, размер максимальной клики. Однако если характеристики одной модели
с соответствующими значениями другой модели, можно видеть противоположную
картину. В большинстве случаев увеличение корреляций Пирсона сопровождается
снижением значений меры близости для графа доходностей.
Таблица 23. Сводная таблица по результатам для рынка Бразилии
|
#
|
Граф доходностей
|
Динамика индекса IBOVESPA
|
|
Ср. знач.
|
Плотность (θ = 15)
|
Кластеризация (θ = 15)
|
Макс. клика (θ = 15)
|
|
|
1
|
4,9
|
0,06
|
0,35
|
32
|
-11,02%
|
|
2
|
3,6
|
0,04
|
0,31
|
35
|
-17,26%
|
|
3
|
7
|
0,09
|
0,45
|
67
|
94,12%
|
|
4
|
5,9
|
0,12
|
0,43
|
62
|
18,67%
|
|
5
|
6,6
|
0,1
|
0,46
|
66
|
28,80%
|
|
6
|
9,3
|
0,19
|
0,55
|
86
|
30,08%
|
|
7
|
10,1
|
0,24
|
0,66
|
118
|
45,53%
|
|
8
|
7,6
|
0,03
|
0,48
|
29
|
-37,98%
|
|
9
|
10,8
|
0,37
|
0,67
|
245
|
70,69%
|
|
10
|
10,3
|
0,27
|
0,65
|
130
|
1,78%
|
|
11
|
11,1
|
0,17
|
0,7
|
74
|
-17,48%
|
|
#
|
Рыночный граф
|
|
Ср. знач.
|
Плотность (θ = 0.5)
|
Кластеризация (θ = 0.5)
|
Макс. клика (θ = 0.5)
|
|
1
|
0,03
|
0,01
|
0,26
|
8
|
|
2
|
0,03
|
0,01
|
0,24
|
10
|
|
3
|
0,02
|
0,01
|
0,28
|
18
|
|
4
|
0,02
|
0,01
|
0,23
|
13
|
|
5
|
0,02
|
0,00
|
0,24
|
8
|
|
6
|
0,04
|
0,01
|
0,28
|
14
|
|
7
|
0,05
|
0,01
|
0,33
|
19
|
|
8
|
0,12
|
0,02
|
0,38
|
39
|
|
9
|
0,07
|
0,01
|
0,26
|
36
|
|
10
|
0,07
|
0,01
|
0,28
|
15
|
|
11
|
0,17
|
0,02
|
0,4
|
42
|
Таблица 24. Сводная таблица по результатам для рынка России
|
#
|
Граф доходностей
|
Динамика индекса MICEX
|
|
Ср. знач.
|
Плотность (θ = 15)
|
Кластеризация (θ = 15)
|
Макс. клика (θ = 15)
|
|
|
1
|
16,6
|
0,72
|
0,84
|
17
|
64,58%
|
|
2
|
12
|
0,29
|
0,66
|
12
|
34,16%
|
|
3
|
14,2
|
0,49
|
0,78
|
11
|
62,35%
|
|
4
|
15,6
|
0,63
|
0,87
|
27
|
5,71%
|
|
5
|
16,3
|
0,64
|
0,86
|
40
|
85,69%
|
|
6
|
13,4
|
0,42
|
0,75
|
36
|
59,40%
|
|
7
|
9,4
|
0,13
|
0,52
|
23
|
19,25%
|
|
8
|
5,7
|
0
|
0,06
|
5
|
-68,31%
|
|
9
|
15,2
|
0,57
|
0,8
|
92
|
123,58%
|
|
10
|
12,5
|
0,38
|
0,76
|
68
|
21,81%
|
|
11
|
8,9
|
0,05
|
0,42
|
15
|
-17,00%
|
|
#
|
Рыночный граф
|
|
Ср. знач.
|
Плотность (θ = 0.5)
|
Кластеризация (θ = 0.5)
|
Макс. клика (θ = 0.5)
|
|
1
|
0,27
|
0,27
|
0,55
|
9
|
|
2
|
0,17
|
0,17
|
0,42
|
11
|
|
3
|
0,02
|
0,02
|
0
|
2
|
|
4
|
0,14
|
0,14
|
0,47
|
11
|
|
5
|
0,04
|
0,04
|
0,23
|
10
|
|
6
|
0,03
|
0,03
|
0,2
|
12
|
|
7
|
0,02
|
0,02
|
0,15
|
12
|
|
8
|
0,14
|
0,14
|
0,44
|
31
|
|
9
|
0,02
|
0,02
|
0,19
|
15
|
|
10
|
0,02
|
0,02
|
0,22
|
13
|
|
11
|
0,04
|
0,04
|
0,25
|
21
|
Таблица 25. Сводная таблица по результатам для рынка Индии
|
#
|
Граф доходностей
|
Динамика индекса
|
|
Ср. знач.
|
Плотность (θ = 15)
|
Кластеризация (θ = 15)
|
Макс. клика (θ = 15)
|
BSE SENSEX
|
CNX NIFTY
|
|
1
|
14,1
|
0,4
|
0,61
|
12
|
-19,83%
|
н/д
|
|
2
|
0,16
|
0,65
|
43
|
6,71%
|
н/д
|
|
3
|
15,7
|
0,64
|
0,85
|
343
|
67,72%
|
н/д
|
|
4
|
11,2
|
0,31
|
0,64
|
254
|
14,02%
|
н/д
|
|
5
|
12,6
|
0,34
|
0,77
|
383
|
42,46%
|
н/д
|
|
6
|
9,9
|
0,19
|
0,63
|
260
|
48,09%
|
н/д
|
|
7
|
12
|
0,29
|
0,73
|
385
|
39,79%
|
н/д
|
|
8
|
9,6
|
0,05
|
0,59
|
98
|
-47,29%
|
-46,63%
|
|
9
|
13,9
|
0,6
|
0,81
|
891
|
65,54%
|
62,07%
|
|
10
|
11,9
|
0,27
|
0,76
|
438
|
18,81%
|
19,27%
|
|
11
|
10,5
|
0,08
|
0,66
|
125
|
-22,02%
|
-21,81%
|
|
#
|
Рыночный граф
|
|
Ср. знач.
|
Плотность (θ = 0.5)
|
Кластеризация (θ = 0.5)
|
Макс. клика (θ = 0.5)
|
|
1
|
0,21
|
0,16
|
0,57
|
8
|
|
2
|
0,11
|
0,01
|
0,26
|
20
|
|
3
|
0,09
|
0,00
|
0,18
|
22
|
|
4
|
0,1
|
0,01
|
0,25
|
59
|
|
5
|
0,1
|
0,01
|
0,14
|
138
|
|
6
|
0,13
|
0,02
|
0,3
|
224
|
|
7
|
0,08
|
0,01
|
0,2
|
290
|
|
8
|
0,2
|
0,02
|
0,34
|
103
|
|
9
|
0,14
|
0,01
|
0,18
|
51
|
|
10
|
0,09
|
0,00
|
0,12
|
16
|
|
11
|
0,13
|
0,00
|
0,16
|
56
|
Таблица 26. Сводная таблица по результатам для рынка Китая
|
#
|
Граф доходностей
|
Динамика индекса
|
|
Ср. знач.
|
Плотность (θ = 15)
|
Кластеризация (θ = 15)
|
Макс. клика (θ = 15)
|
SSE Composite
|
SZSE Component
|
|
1
|
14,4
|
0,47
|
0,81
|
273
|
-20,93%
|
-30,41%
|
|
2
|
13,5
|
0,33
|
0,76
|
170
|
-15,65%
|
-15,25%
|
|
3
|
15
|
0,58
|
0,83
|
382
|
9,53%
|
25,07%
|
|
4
|
14,9
|
0,57
|
0,82
|
379
|
-15,17%
|
-10,84%
|
|
5
|
15,1
|
0,59
|
0,82
|
352
|
-10,91%
|
-9,54%
|
|
6
|
19
|
0,93
|
0,96
|
915
|
104,71%
|
120,79%
|
|
7
|
19,2
|
0,87
|
0,93
|
1038
|
117,68%
|
169,28%
|
|
8
|
15,7
|
0,68
|
0,87
|
639
|
-60,44%
|
-55,74%
|
|
9
|
21,4
|
0,98
|
0,99
|
1453
|
54,27%
|
73,62%
|
|
10
|
18,4
|
0,88
|
0,94
|
1105
|
-7,07%
|
-1,20%
|
|
11
|
13,2
|
0,3
|
0,76
|
277
|
-23,12%
|
-28,82%
|
|
#
|
Рыночный граф
|
|
Ср. знач.
|
Плотность (θ = 0.5)
|
Кластеризация (θ = 0.5)
|
Макс. клика (θ = 0.5)
|
|
1
|
0,42
|
0,38
|
0,81
|
420
|
|
2
|
0,55
|
0,67
|
0,88
|
692
|
|
3
|
0,32
|
0,13
|
0,61
|
146
|
|
4
|
0,35
|
0,14
|
0,62
|
143
|
|
5
|
0,34
|
0,13
|
0,62
|
152
|
|
6
|
0,22
|
0,01
|
0,43
|
28
|
|
7
|
0,35
|
0,18
|
0,65
|
252
|
|
8
|
0,5
|
0,57
|
0,86
|
773
|
|
9
|
0,4
|
0,23
|
0,72
|
258
|
|
10
|
0,35
|
0,09
|
0,62
|
106
|
|
11
|
0,33
|
0,08
|
0,69
|
147
|
Если мы посмотрим, для каких периодов характерны наибольшие корреляции,
то увидим, что это периоды падения фондового рынка. С одной стороны, об этом
свидетельствует отрицательная динамика индекса, с другой - меньшие значения
меры близости в графе доходностей. Например, для всех стран наблюдается рост
связности во время кризиса 2008 г. Это подтверждает гипотезу о том, что
отрицательные доходности коррелируют сильнее, нежели положительные; в периоды
же экономического подъема акции движутся более разнонаправленно. В отличие от
корреляций Пирсона, динамика значений новой меры близости достоверно отражает
изменение возможностей по получению дохода на рынке.
Сравнение характеристик графа доходностей со значениями
индекса показывает, имеет место следующая закономерность. Увеличение темпов
роста индекса сопровождается ростом средних значений меры близости, и,
следовательно, плотности, коэффициентов кластеризации и размера максимальной
клики. И наоборот, замедление темпов роста или падение индекса сопровождается
снижением этих характеристик.
Однако, как мы можем видеть, динамика индекса не всегда
отражает состояние рынка в целом. Так, на рынке Китая в период 5 и на рынке
Бразилии в период 11, падение основных индексов сопровождалось ростом средних
значений. Для Индии в период 6 наоборот, индекс растет, но падает значение меры.
Таким образом, индекс отражает динамику именно тех акций,
которые участвуют в его расчете. Другие же акции рынка могут вести себя иначе.
Преимущество модели графа доходностей заключается в том, что она позволяет
оценить, насколько изменение индекса поддерживалось всеми акциями, торгующимися
на рынке.
Связи между динамикой индекса и коэффициентами корреляции не
наблюдается.
Таким образом, в ходе работы была изучена динамика
характеристик модели графа доходностей с новой мерой близости и модели
рыночного графа со стандартными корреляциями Пирсона; полученные результаты
были сравнены между собой, а также с динамикой другой характеристики доходности
рынка - значениями биржевых индексов.
Заключение
В представленной работе была изучена возможность применения
альтернативной меры близости для построения модели графа фондового рынка.
В ходе работы были реализованы алгоритмы, позволяющие строить
сетевые модели фондовых рынков, как с новой мерой близости, так и с
корреляциями Пирсона, и вычислять их структурные характеристики. В качестве
модельных данных были выбраны данные по рынкам стран БРИК с 2001 по 2011 гг.
Для изучения моделей в динамике, данный временной отрезок был разбит на 11
последовательных периодов. Для каждого из периодов с помощью написанных алгоритмов
были построены модели рынка и произведен расчет их характеристик.
Выводы
Основываясь на полученных результатах, можно сделать
следующие выводы.
. Модель рыночного графа, основанная на вычислении
корреляций между акциями, характеризует степень связности фондового рынка,
насколько согласованно меняются доходности акций. Эта модель может
использоваться для оценки возможностей по формированию диверсифицированного
портфеля и управления рисками, но не включает информацию об итоговой доходности
акций. В частности, было показано, что сильнее всего ценные бумаги коррелируют
в период падения, а инвестора в первую очередь интересуют те акции, которые
приносили доход.
. Использование новой меры близости позволяет
избавиться от недостатков оригинальной модели. Основные преимущества модели
графа доходностей: возможность интерпретации с экономической точки зрения, учет
реальной доходности акций, учет инфляции, использование точных значений вместо
выборочных корреляций, включение в рассмотрение акций с низкой ликвидностью.
Кроме того, переход от шкалы дней к шкале недель позволяет снизить влияние
волатильности рынка на качество получаемых результатов. Это позволяет
использовать новую модель при оценке возможностей по получению дохода на рынках
ценных бумаг.
. Преимущества модели графа доходностей видны также
при сравнении с другой характеристикой фондового рынка - биржевого индекса. В
отличие от индекса, новая мера близости позволяет не только судить о росте или
падении, но и о том, насколько этот рост поддерживался всеми акциями рынка. Для
ряда периодов было сделано наблюдение, что рост индекса не всегда сопровождался
ростом возможностей по получению дохода. То есть индекс отражает динамику лишь
тех акций, которые его образуют, а модель графа доходностей - динамику рынка в
целом.
. Анализ распределения степеней вершин свидетельствует
о том, что для определенных значений порога модель рыночного графа с новой
мерой близости имеет свойство степенного закона.
. Сравнительный анализ моделей для разных стран
позволяет сделать вывод о том, что наибольшей связностью, равно как и
наибольшей доходностью, обладает рынок Китая. Даже в периоды кризиса
возможности для получения дохода на этом рынке существенно выше, чем на рынках
других стран БРИК.
. Результаты расчетов структурных характеристик графа
доходностей говорят о том, что большие возможности инвесторам предоставляет
также фондовый рынок Индии, хотя он растет медленнее китайского.
. Для рынка ценных бумаг России среднее значение меры
близости в графе доходностей сравнимы со значениями для рынка Индии. Однако
большие колебания таких характеристик, как плотность ребер, коэффициент
кластеризации и размер максимальной клики говорят о том, что российский рынок
является достаточно рискованным и нестабильным.
. Наконец, фондовый рынок Бразилии характеризуется как
низкими корреляциями, так и низкими характеристиками графа доходностей. Таким
образом, возможности для получения инвестором одновременного дохода на этом
рынке сравнительно меньше, чем на рынках остальных стран БРИК.
Список литературы
1. Albert, R. Statistical mechanics of complex networks / R.
Albert, A.L. Barabási // Reviews of
modern physics. - 2002. - Vol. 74. - P. 47.
2. Barabási, A.L.
Emergence of scaling in random networks / A.L. Barabási, R. Albert // Science. - 1999. -
Vol. 286. - P. 509-512.
. Batsyn, M.V. Improvements to MCS algorithm for the
maximum clique problem / M.V. Batsyn, B.I. Goldengorin, E.V. Maslov, P.M.
Pardalos // Journal of Combinatorial Optimization. - 2014. - Vol. 27. - P.
397-416.
. Bautin, G.A. Simple measure of similarity for the market
graph construction / G.A. Bautin, V.A. Kalyagin, A.P. Koldanov, P.A. Koldanov,
P.M. Pardalos // Computational Management Science. - 2013. - Vol. 10. - P.
105-124.
. Boginski, V. Mining market data: a network approach / V.
Boginski, S. Butenko, P. M. Pardalos // Computers & Operations Research. -
2006. - Vol. 33. - P. 3171-3184.
. Boginski, V. On structural properties of the market graph
/ V. Boginski, S. Butenko, P. M. Pardalos // Innovations in financial and
economic networks. - Northampton: Edward Elgar Publishers, 2003. - P. 29-45.
. Boginski, V. Statistical analysis of financial networks /
V. Boginski, S. Butenko, P. M. Pardalos // Computational statistics & data
analysis. - 2005. - Vol. 48. - №. 2. - С. 431-443.
. Ebel, H. Scale-free topology of e-mail networks / H.
Ebel, L.I. Mielsch, S. Bornholdt // Physical review E. - 2002. - Vol. 66. - P.
1-4.
. Garey, M.R. Computers and intractability: a guide to the
theory of NP-completeness / M.R. Garey, D.S. Johnson. - New York: Freeman,
1979. - 338 p.
. Glotov, A.A. Market Graph Construction Using the
Performance Measure of Similarity / A.A. Glotov, V.A. Kalyagin, A.N. Vizgunov,
P.M. Pardalos // Models, Algorithms and Technologies for Network Analysis. -
Springer International Publishing, 2014. - P. 21-35.
. Huang, W.Q. A network analysis of the Chinese stock
market / W.Q. Huang, X.T. Zhuang, S. Yao // Physica A: Statistical Mechanics
and its Applications. - 2009. - Vol. 388. - P. 2956-2964.
. Jallo, D. Network-based representation of stock market
dynamics: an application to American and Swedish stock markets / D. Jallo, D.
Budai, V. Boginski, B.I. Goldengorin, P.M. Pardalos // Models, Algorithms, and
Technologies for Network Analysis. - Springer New York, 2013. - P. 93-106.
. Kim, H.J. Scale-free network in stock markets / H.J. Kim,
I.M. Kim, Y. Lee, B. Kahng // Journal-Korean Physical Society. - 2002. - Vol.
40. - P. 1105-1108.
. Mantegna, R.N. Hierarchical structure in financial
markets / R.N. Mantegna // The European Physical Journal B-Condensed Matter and
Complex Systems. - 1999. - Vol. 11. - P. 193-197.
. Mantegna, R.N. An Introduction to Econophysics:
Correlations and Complexity in Finance / R.N. Mantegna, H.E. Stanley. -
Cambridge: Cambridge University Press, 2000 - 154 p.
. Markowitz, H.M. Portfolio selection / H.M. Markowitz //
The journal of finance. - 1952. - Vol. 7. - P. 77-91.
. Mensi, W. Do global factors impact BRICS stock markets? A
quantile regression approach / W. Mensi, S. Hammoudeh, J.C. Reboredo, D.K.
Nguyen // Emerging Markets Review. - 2014. - Vol. 19. - P. 1-17.
. Milgram, S. The small world problem / S. Milgram //
Psychology today. - 1967. - Vol. 2. - P. 60-67.
. Newman, M.E.J. The structure and function of complex
networks / M.E.J. Newman, // SIAM review. - 2003. - Vol. 45. - P. 167-256.
. Onnela, J.P. Asset trees and asset graphs in financial
markets / J.P. Onnela, A. Chakraborti, K. Kaski, J. Kertesz, A. Kanto //
Physica Scripta. - 2003. - Vol. 106. - P. 48.
. Onnela, J.P. Clustering and information in correlation
based financial networks / J.P.
Onnela, K. Kaski, J. Kertész // The European Physical Journal
B-Condensed Matter and Complex Systems. - 2004. - Vol. 38. - P. 353-362.
. Onnela, J. P. Dynamic asset trees and Black Monday / J.P.
Onnela, A. Chakraborti, K. Kaski, J. Kertesz, A. Kanto // Physica A:
Statistical Mechanics and its Applications. - 2003. - Vol. 324. - P. 247-252.
. Samitas, A. Financial crises and stock market dependence
/ A. Samitas, D. Kenourgios, N. Paltalidis // European Financial Management
Association 16th Annual Meeting (EFMA). - Vienna, 2007. - P. 27-30.
. Sedgewick, R. Algorithms (4th Edition). / R. Sedgewick,
K. Wayne. - Princeton, 2011. - 992 p.
. Tumminello, M. A tool for filtering information in
complex systems / M. Tumminello, T. Aste, T. Di Matteo, R.N. Mantegna //
Proceedings of the National Academy of Sciences of the United States of
America. - 2005. - Vol. 102. - P. 10421-10426.
. Tumminello, M. Correlation based networks of equity
returns sampled at different time horizons / / M. Tumminello, T. Aste, T. Di
Matteo, R.N. Mantegna // The European Physical Journal B-Condensed Matter and
Complex Systems. - 2007. - Vol. 55. - P. 209-217.
. Tumminello, M. Correlation, hierarchies, and networks in
financial markets / M. Tumminello, F. Lillo, R.N. Mantegna // Journal of
Economic Behavior & Organization. - 2010. - Vol. 75. - P. 40-58.
. Vizgunov A.N. Comparative analysis of the BRIC countries
stock markets using network approach / A.N. Vizgunov, A.A. Glotov, P.M.
Pardalos // Models, Algorithms, and Technologies for Network Analysis. - New
York: Springer, 2013. - P. 191-201.
. Vizgunov, A.N. Network approach for the Russian stock
market / A.N. Vizgunov, B.I. Goldengorin, V.A. Kalyagin, A.P. Koldanov, P.A.
Koldanov, P.M. Pardalos // Computational Management Science. - 2014. - Vol. 11.
- P. 45-55.
. Wagner, A. The small world inside large metabolic
networks / A. Wagner, D.A. Fell // Proceedings of the Royal Society of London.
Series B: Biological Sciences. - 2001. - Vol. 268. - P. 1803-1810.
. Wang, X.F. Complex networks: small-world, scale-free and
beyond / X.F. Wang, G. Chen // Circuits and Systems Magazine, IEEE. - 2003. -
Vol. 3. - P. 6-20.
. Watts, D.J. Collective dynamics of ‘small-world’ networks
/ D.J.Watts, S.H. Strogatz // Nature. - 1998. - Vol. 393. - P. 440-442.
33. Берж,
К. Теория графов и ее применения / К.Берж. - М.: Издательство иностранной
литературы, 1962 - 320 с.
. Берзон,
Н.И. Фондовый рынок: Учебное пособие для вузов экономического профиля / Н.И.
Берзон, Е.А. Буянова, М.А. Кожевников, А.В. Чаленко. - М.: Вита-Пресс, 1998 -
400 с.
. Визгунов,
А.Н. Применение рыночных графов к анализу фондового рынка / А. Н. Визгунов, Б.
И. Гольденгорин, В.А. Замараев, В.А. Калягин, А. П. Колданов, П.А. Колданов,
П.М. Пардалос, //Журнал новой экономической ассоциации. - 2012. - №. 3. - С.
66-81.
. Визгунов,
А.Н. Сравнительный анализ фондового рынка России и стран БРИК на основе модели
графа рынка / А.Н. Визгунов, А.А. Глотов // XIV Апрельская международная
научная конференция по проблемам развития экономики и общества: в 4-х книгах.
Книга 4 / Отв. ред.: Е. Г. Ясин. - М.: Издательский дом НИУ ВШЭ, 2014. - С.
382-393.
. Гудман,
С. Введение в разработку и анализ алгоритмов / C. Гудман, С. Хидетниеми.
- М.: Мир, 1981 - 368 с.
. Евин,
И.А. Введение в теорию сложных сетей / И.А. Евин // Компьютерные исследования и
моделирование. - 2010. - №. 2. - P. 121-141.
. Ноздрев,
С.В. Современное состояние и тенденции развития международного рынка ценных
бумаг / С.В. Ноздрев. - М.: ИМЭМО РАН, 2012. - 100 с.
Приложения
Приложение 1
Программа для загрузки данных о котировках
import
java.io.FileOutputStream;java.io.IOException;java.net.MalformedURLException;java.net.URL;java.nio.channels.Channels;java.nio.channels.ReadableByteChannel;java.text.ParseException;java.text.SimpleDateFormat;java.util.Calendar;
/**
* Program to download historical quotes of a
stock or index from
* Yahoo! Finance.
*
* For more details, see
*
https://code.google.com/p/yahoo-finance-managed/wiki/csvHistQuotesDownload
*/class QuotesDownloader {
static final String INTERVAL_DAILY =
"d";static final String INTERVAL_WEEKLY = "w";static final
String INTERVAL_MONTHLY = "m";
/**
* Build URL for historical quotes download.
*
* @param id the ID of the stock or index
* @param fromDate the first date
* @param toDate the last date
* @return the URL for historical quotes download
* @throws MalformedURLException if URL is invalid
*/static final URL buildURL(String id, Calendar
fromDate,toDate, String interval) throws MalformedURLException {
// Starturl =
"http://ichart.yahoo.com/table.csv?s=";
// ID+= id;
// From Date+= "&a=" +
fromDate.get(Calendar.MONTH);+= "&b=" +
fromDate.get(Calendar.DAY_OF_MONTH);+= "&c=" +
fromDate.get(Calendar.YEAR);
// To Date+= "&d=" +
toDate.get(Calendar.MONTH);+= "&e=" +
toDate.get(Calendar.DAY_OF_MONTH);+= "&f=" +
toDate.get(Calendar.YEAR);
// Interval+= "&g=" + interval;
// Static part+= "&ignore=.csv";
new URL(url);
}
/**
* Download historical quotes of a stock or index.
*
* @param id the ID of the stock or index
* @param fromDate the first date
* @param toDate the last date
* @param interval the interval of the trading
periods
* @param dirName the directory to save the quotes
* @throws IOException if an I/O error occurs
*/static void download(String id, Calendar
fromDate,toDate, String interval, String dirName) IOException {url =
buildURL(id, fromDate, toDate, interval);.out.println(url);
rbc = Channels.newChannel(url.openStream());
outFile = dirName + "/" + id +
".csv";
fos = new
FileOutputStream(outFile);.getChannel().transferFrom(rbc, 0,
Long.MAX_VALUE);.close();.close();
}
/**
* The entry point to class & application.
*
* @param args the command-line arguments
* @throws IOException if an I/O error occurs
* @throws ParseException if an invalid date is
specified
*/static void main(String[] args) IOException,
ParseException {(args.length!= 5) {.err.println("Usage: QuotesDownloader
<id> <from_date> " +
"<to_date> <interval>
<dir>");.exit(1);
}
id = args[0];
sdf = new
SimpleDateFormat("dd.mm.yyyy");fromDate =
Calendar.getInstance();.setTime(sdf.parse(args[1]));toDate = Calendar.getInstance();.setTime(sdf.parse(args[2]));
interval = args[3];
dirPath = args[4];
download(id, fromDate, toDate, interval,
dirPath);
}
}
Приложение 2
Модуль для работы с базой данных котировок
import java.io.BufferedReader;java.io.File;java.io.FileInputStream;java.io.IOException;java.io.InputStreamReader;java.sql.Connection;java.sql.Date;java.sql.PreparedStatement;java.sql.ResultSet;java.sql.SQLException;java.text.ParseException;java.text.SimpleDateFormat;java.util.ArrayList;java.util.Calendar;java.util.GregorianCalendar;java.util.Locale;java.util.TreeMap;
oracle.jdbc.pool.OracleDataSource;
/**
* Database session handle.
*/class DatabaseSession {
static final String DRIVER =
"jdbc:oracle:thin";static final String HOSTNAME =
"127.0.0.1";static final String PORT = "1521";static final
String SERVICE = "XE";
static Connection conn;
static String readString(String message) throws
IOException {.out.print(message);br = new
BufferedReader(new(System.in));br.readLine();
}
void connect(String user, String password) throws
SQLException {
// Cannot access NLS files on my
machine.setDefault(Locale.ENGLISH);
ods = new OracleDataSource();url = DRIVER +
":" + user + "/" + password + "@" + HOSTNAME
+ ":" + PORT + ":" +
SERVICE;.setURL(url);= ods.getConnection();
}
/**
* Create a database session (silent version).
*
* @param user The username
* @param password The password
* @throws SQLException If a database access error
occurs
*/DatabaseSession(String user, String password)
SQLException {(user, password);
}
/**
* Create a database session. Prompt user for
login & password.
*
* @throws IOException If an I/O error occurs
* @throws SQLException If a database access error
occurs
*/DatabaseSession() throws IOException,
SQLException {user = readString("User: ");password =
readString("Password: ");(user,
password);.out.println("Connected!\n");
}
/**
* Select all trading days given a country and a
range of dates.
*
* @param country The country
* @param fromDate The start of the period
* @param toDate The end of the period
* @return A list of dates
* @throws SQLException If a database access error
occurs
*/ArrayList<Date> selectDates(String
country, Date fromDate, toDate) throws SQLException {<Date> dates = new
ArrayList<Date>();query = "SELECT DISTINCT qdate FROM Quotes WHERE
stock IN ("
+ " SELECT id FROM Stocks WHERE exchange IN
("
+ " SELECT id FROM Exchanges WHERE country =
("
+ " SELECT id FROM Countries "
+ " WHERE name =?"
+ " )"
+ " )"
+ ") "
+ "AND qdate BETWEEN? AND? "
+ "ORDER BY 1";stmt =
conn.prepareStatement(query);.setString(1, country);.setDate(2,
fromDate);.setDate(3, toDate);
rset =
stmt.executeQuery();(rset.next()).add(rset.getDate(1));
.close();dates;
}
/**
* Select all stocks for the given country that
traded at least
* <tt>minDays</tt> during the given
period.
*
* @param country The country
* @param fromDate The start of the period
* @param toDate The end of the period
* @param minDays The minimum number of trading
days for each stock
* @return List of stocks
* @throws SQLException If a database access error
occurs
*/ArrayList<Integer> selectStocks(String
country, Date fromDate,toDate, int minDays) throws SQLException
{<Integer> stocks = new ArrayList<Integer>();
query = "SELECT stock, COUNT(*) FROM Quotes
WHERE stock IN ("
+ " SELECT id FROM Stocks WHERE exchange IN
("
+ " SELECT id FROM Exchanges WHERE country =
("
+ " SELECT id FROM Countries "
+ " WHERE name =?"
+ " )"
+ " )"
+ ") "
+ "AND qdate BETWEEN? AND? "
+ "GROUP BY stock "
+ "HAVING (COUNT(*) >=?)";stmt =
conn.prepareStatement(query);.setString(1, country);.setDate(2,
fromDate);.setDate(3, toDate);.setInt(4, minDays);
ResultSet rset =
stmt.executeQuery();(rset.next()).add(rset.getInt(1));
.close();stocks;
}
/**
* Select all stocks for the given country that
traded in the given time
* period.
*
* @param country The country
* @param fromDate The start of the period
* @param toDate The end of the period
* @param minDays The minimum number of trading
days for each stock
* @return List of stocks
* @throws SQLException If a database access error
occurs
*/ArrayList<Integer> selectStocks(String
country, Date fromDate,toDate) throws SQLException {<Integer> stocks =
new ArrayList<Integer>();
query = "SELECT DISTINCT stock FROM Quotes
WHERE stock IN ("
+ " SELECT id FROM Stocks WHERE exchange IN
("
+ " SELECT id FROM Exchanges WHERE country =
("
+ " SELECT id FROM Countries "
+ " WHERE name =?"
+ " )"
+ " )"
+ ") "
+ "AND qdate BETWEEN? AND? ";stmt =
conn.prepareStatement(query);.setString(1, country);.setDate(2,
fromDate);.setDate(3, toDate);
rset =
stmt.executeQuery();(rset.next()).add(rset.getInt(1));
.close();stocks;
}
/**
* Close connection.
*
* @throws SQLException If a database access error
occurs
*/void close() throws SQLException {.close();
}
/**
* Get ID for the given exchange from the
Exchanges table.
*
* @param name The name of the exchange
* @return The exchange ID; null if there is no
matching entry in the
* database
* @throws SQLException If a database access error
occurs
*/Integer getExchangeID(String name) throws
SQLException {query = "SELECT id FROM Exchanges "
+ "WHERE short_name =?";stmt =
conn.prepareStatement(query);.setString(1, name);rset = stmt.executeQuery();id
= rset.next()? rset.getInt(1): null;.close();id;
}
/**
* Get ID for the given country from the Countries
table.
*
* @param name The name of the country
* @return The country ID; null if there is no
matching entry in the
* database
* @throws SQLException If a database access error
occurs
*/Integer getCountryID(String name) throws
SQLException {query = "SELECT id FROM Countries "
+ "WHERE name =?";stmt =
conn.prepareStatement(query);.setString(1, name);rset = stmt.executeQuery();id
= rset.next()? rset.getInt(1): null;.close();id;
}
/**
* Create entry for given stock symbol to the
Stocks table.
*
* @param exchangeID The exchange ID for this
stock
* @param symbol The stock symbol
* @return The auto-generated ID for this stock;
null if something
* went wrong
* @throws SQLException If a database access error
occurs
*/Integer insertStock(String symbol, int
exchangeID) SQLException {query = "INSERT INTO Stocks "
+
"VALUES(seq_stocks_id.nextval,?,?)";stmt =
conn.prepareStatement(query);.setString(1, symbol);.setInt(2,
exchangeID);.execute();.close();
= "SELECT seq_stocks_id.currval FROM
Dual";= conn.prepareStatement(query);rset = stmt.executeQuery();id =
rset.next()? rset.getInt(1): null;.close();id;
}
/**
* Select all quotes for the given stock.
*
* @param id The stock id
* @param fromDate The start of the period
* @param toDate The end of the period
* @return A list containing quotes information
* @throws SQLException If a database access error
occurs
* @see Quote
*/ArrayList<Quote> selectQuotes(int stock,
Date fromDate, toDate) throws SQLException {<Quote> quotes = new
ArrayList<Quote>();
query = "SELECT qdate, close "
+ "FROM Quotes WHERE stock =? "
+ "AND qdate BETWEEN? AND?"
+ "ORDER BY 1";stmt =
conn.prepareStatement(query);.setInt(1, stock);.setDate(2,
fromDate);.setDate(3, toDate);
rset = stmt.executeQuery();(rset.next()).add(new
Quote(rset.getDate(1), rset.getDouble(2)));
.close();quotes;
}
/**
* Read quotes from file and insert into the
database.
*
* @param file The file containing quotes data
* @param id The ID of the corresponding stock in
the database
* @throws IOException If an I/O error occurs
* @throws SQLException If a database access error
occurs
* @throws ParseException If the file contains
invalid data
*/void insertQuotes(File file, int id)
IOException, SQLException, ParseException {query = "INSERT INTO Quotes
VALUES (?,?,?,?)";stmt = conn.prepareStatement(query);
br = new BufferedReader(new (new (file)));
sdf = new
SimpleDateFormat("yyyy-MM-dd");
line = br.readLine(); // Skip the header((line =
br.readLine())!= null) {[] fields = line.split(",");(fields.length!=
7) {.close();new RuntimeException("Invalid file format");
}
.setInt(1, id);.setDate(2, new
Date(sdf.parse(fields[0]).getTime()));.setDouble(3,
Double.parseDouble(fields[4]));.setDouble(4, Double.parseDouble(fields[5]));
.execute();
}
.close();.close();
}
/**
* Read inflation values from file and insert into
the database.
*
* @param file The file containing inflation data
* @throws IOException If an I/O error occurs
* @throws SQLException If a database access error
occurs
*/void insertInflation(File file) throws
SQLException, IOException {br = new BufferedReader(new (new
FileInputStream(file)));
query = "INSERT INTO Inflation
VALUES(?,?,?,?,?)";stmt = conn.prepareStatement(query);
s;((s = br.readLine())!= null) {[] fields =
s.split(";");
year = Integer.parseInt(fields[1]);month =
Integer.parseInt(fields[2]);rate = Double.parseDouble(fields[3]);daysInMonth =
new GregorianCalendar(year, month-1, 1)
.getActualMaximum(Calendar.DAY_OF_MONTH);
.setInt(1, getCountryID(fields[0]));.setInt(2,
year);.setInt(3, month);.setDouble(4, rate);.setDouble(5, rate / daysInMonth);
.execute();
}
.close();.close();
}
TreeMap<Integer, double[]>
dailyInflation(String country)SQLException {<Integer, double[]> inflation
=TreeMap<Integer, double[]>();
query = "SELECT year, month, daily_rate
"
+ "FROM Inflation "
+ "WHERE country =? "
+ "ORDER BY year, month";
stmt = conn.prepareStatement(query);.setInt(1,
getCountryID(country));res = stmt.executeQuery();(res.next()) {year =
res.getInt(1);month = res.getInt(2);rate = res.getDouble(3);
(!inflation.containsKey(year)).put(year, new
double[12]);.get(year)[month - 1] = rate;
}
.close();inflation;
}
}
/**
* The class to represent a single quote entry.
*/Quote {
Date date;double close;
/**
* Construct a new quote object.
* @param date
* @param price
*/Quote(Date date, double close) {();.date =
date;.close = close;
}
/**
* Get the date.
* @return the date
*/Date getDate() {date;
}
/**
* Set date.
* @param date the date
*/void setDate(Date date) {.date = date;
}
/**
* Get the close price.
* @return the close price
*/double getClose() {close;
}
/**
* Set the close price.
* @param price the close price
*/void setClose(double close) {.close = close;
}
}
Приложение 3
Программа для импорта данных в базу
import
java.io.File;java.io.FileFilter;java.io.IOException;java.sql.SQLException;java.text.ParseException;
/**
* Program to import quotes to the Oracle XE
database.
* If no exchange name is specified, the program
will import stock quotes
* from each of the existing subdirectories.
*/class ImportQuotes {
static File dir;
static DatabaseSession db;
static void importAll() SQLException,
IOException, ParseException {directoryFilter = new FileFilter() {boolean
accept(File file) {file.isDirectory();
}
};(File subdir:
dir.listFiles(directoryFilter))(subdir);
}
static void importExchange(File exDirectory) SQLException, IOException,
ParseException {exchangeName = exDirectory.getName();
.out.println("Importing quotes for " +
exchangeName);
exchangeID = db.getExchangeID(exchangeName);(exchangeID
== null) {.err.println("Unknown exchange: " + exchangeName);.exit(1);
}
[] stockFiles = exDirectory.listFiles();(int i =
0; i < stockFiles.length; i++) {
// Remove extension to get the symbolfileName =
stockFiles[i].getName();symbol = fileName.substring(0,
fileName.lastIndexOf('.'));
.out.println("(" + (i + 1) +
"/" + stockFiles.length
+ ") " + symbol);
stockID = db.insertStock(symbol,
exchangeID);(stockID == null) {.err.println("Cannot insert symbol: "
+ symbol);.exit(1);
}
.insertQuotes(stockFiles[i], stockID);
}
}static void main(String[] args) SQLException,
IOException, ParseException {(args.length < 1) {.out.println("Usage:
java ImportQuotes <dir> " +
[<exchange>]");;
}
// Open directory= new File(args[0]);(!dir.exists())
{.err.println("No such directory: " + args[0]);.exit(1);
}(!dir.isDirectory()) {.err.println("Not a
directory: " + args[0]);.exit(1);
}
= new DatabaseSession();
(args.length < 2)();{exDirectory = new
File(dir.getAbsolutePath()
+ File.separator + args[1]);(!exDirectory.exists())
{.err.println("No such directory: "
+ exDirectory.toString());.exit(1);
}(!exDirectory.isDirectory())
{.err.println("Not a directory: "
+ exDirectory.toString());.exit(1);
}(exDirectory);
}
.close();
}
}
Приложение 4
Класс для представления модели графа доходностей
import
java.io.BufferedReader;java.io.File;java.io.FileInputStream;java.io.FileWriter;java.io.IOException;java.io.InputStreamReader;java.io.PrintWriter;java.sql.Date;java.util.ArrayList;
/**
* The performance matrix for the given country
and time period.
*/class PerformanceMatrix {
ArrayList<Integer> stocks;String
country;Date startDate;Date endDate;int[][] C;int N;
/**
* Create an initial matrix (with all zeros).
*
* @param country the country
* @param startDate the first date
* @param endDate the last date
* @param stocks the list of stock ID's
*/PerformanceMatrix(String country, Date
startDate, Date endDate,<Integer> stocks) {= new
int[stocks.size()][stocks.size()];.N = stocks.size();.country = country;.startDate
= startDate;.endDate = endDate;.stocks = stocks;
}
/**
* Get the country.
*
* @return the country
*/String getCountry() {country;
}
/**
* Get the first date.
*
* @return the first date
*/Date getStartDate() {startDate;
}
/**
* Get the last date.
*
* @return the last date
*/Date getEndDate() {endDate;
}
/**
* Read the matrix from a file.
* @param file the file
* @return the matrix
* @throws NumberFormatException if file is
invalid
* @throws IOException if an I/O error occurs
*/static PerformanceMatrix readFromFile(File
file) NumberFormatException, IOException {br = new
BufferedReader(InputStreamReader(new FileInputStream(file)));
// Read countrycountry = br.readLine();
// Read dates[] dates =
br.readLine().split(";");startDate = Date.valueOf(dates[0]);endDate =
Date.valueOf(dates[1]);
// Read stock listN =
Integer.parseInt(br.readLine());<Integer> stocks = new
ArrayList<Integer>(N);[] ids = br.readLine().split(";");(int i
= 0; i < ids.length; i++).add(i, Integer.parseInt(ids[i]));
m = new PerformanceMatrix(country, , endDate,
stocks);(int i = 0; i < (N - 1); i++) {[] correlations =
br.readLine().split(";");j = i + 1;(String Cij: correlations).set(i,
j++, Integer.parseInt(Cij));
}
.close();m;
}
/**
* Write the matrix to a file.
*
* @param file the file
* @throws IOException if an I/O error occurs
*/void dumpToFile(File file) throws IOException
{out = new PrintWriter(new FileWriter(file));
.println(country);.println(startDate +
";" + endDate);.println(stocks.size());
(int i = 0; i < stocks.size() - 1;
i++).print(stocks.get(i) + ";");.println(stocks.get(stocks.size() -
1));
(int i = 0; i < C.length; i++) {(int j = i +
1; j < C[i].length; j++) {.print(C[i][j]);(j < C[i].length -
1).print(";");
}.println();
}
.close();
}
/**
* Set the performance measure value <i>C(i,
j)</i>.
*
* @param i the first stock number
* @param j the second stock number
* @param c the value
*/void set(int i, int j, int c) {[i][j] = C[j][i]
= c;
}
/**
* Increment the performance measure value
<i>C(i, j)</i>.
*
* @param i the first stock number
* @param j the second stock number
*/void increment(int i, int j)
{[i][j]++;[j][i]++;
}
/**
* Get list of stocks.
*
* @return the list of stocks
*/ArrayList<Integer> getStocks() {stocks;
}
/**
* Performance distribution.
*
* @return the vector containing distribution
values
*/double[] distribution() {[] distr = new
double[53];(int i = 0; i < N; i++)(int j = i + 1; j < N;
j++)[C[i][j]]++;(int i = 0; i < 53; i++)[i] *= 2.0 / (N * (N - 1));distr;
}
/**
* Mean value.
*
* @return the mean performance value
*/double mean() {mean = 0;(int i = 0; i < N;
i++)(int j = i + 1; j < N; j++)+= C[i][j];*= 2.0 / (N * (N-1));mean;
}
/**
* Standard error.
*
* @return the standard error value for
performance
*/double stderr() {mean = mean();Var = 0.0;(int i
= 0; i < N; i++)(int j = i + 1; j < N; j++)+= (C[i][j] - mean) * (C[i][j]
- mean);*= 2.0 / (N * (N-1));Math.sqrt(Var);
}
/**
* Create an unweighted graph for given threshold.
*
* @param t the threshold value
* @return the corresponding graph
*/Graph graph(int t) {g = new Graph(N);(int i =
0; i < N; i++)(int j = i + 1; j < N; j++)(C[i][j] >= t).addEdge(i, j);
return g;
}
}
Приложение 5
Программа для построения модели графа доходностей
import java.io.File;java.io.IOException;java.sql.Date;java.sql.SQLException;java.text.ParseException;java.text.SimpleDateFormat;java.util.ArrayList;java.util.Calendar;java.util.HashMap;java.util.Iterator;java.util.TreeMap;
/**
* Program to calculate the stock market's
performance measure.
*
* The program will split the given time interval
in periods of length 52
* weeks using 1-week shifts. For each period the
performance matrix is
* calculated. Each matrix is saved in a separate
file in the specified
* directory.
*/class CalculatePerformance {
static final int PERIOD_LENGTH = 52;static final
int PERIOD_SHIFT = 1;static File dir;static DatabaseSession db;
private static boolean[] calculatePerformance(int
stock,<Week> weeks, double[] inflation) throws SQLException {
// Get quotesfirst = weeks.get(0).getStart();last
= weeks.get(weeks.size() - 1).getEnd();<Quote> quotes =
db.selectQuotes(stock, first, last);
<Quote> quoteIterator =
quotes.iterator();(!quoteIterator.hasNext()) {.err.println("No quotes for
" + stock + " in " + + " - " + last);
//System.exit(1);null;
}
// For each week, determine the last close
price[] prices = new double[weeks.size()];currWeek =
0;(quoteIterator.hasNext()) {q = quoteIterator.next();date = q.getDate();price
= q.getClose();
(weeks.get(currWeek).getEnd().compareTo(date)
< 0)++;[currWeek] = price;
}
// For each week, determine profitability[]
profitable = new boolean[weeks.size()];lastPrice = 0.0;(int i = 0; i <
weeks.size(); i++) {(prices[i] == 0.0); // no quotes for this week
(lastPrice == 0.0) // first time - always
profitable[i] = true;{R = (prices[i] - lastPrice) * 100.0 / lastPrice;[i] = R
> inflation[i];
}= prices[i];
}profitable;
}
static double[] getWeeklyInflation(String
country, <Week> weeks) throws SQLException {<Integer, double[]>
dailyInflation = .dailyInflation(country);
[] weeklyInflation = new
double[weeks.size()];(int i = 0; i < weeks.size(); i++) {w = weeks.get(i);
start =
Calendar.getInstance();.setTime(w.getStart());end =
Calendar.getInstance();.setTime(w.getEnd());
while (start.compareTo(end) <= 0) {[i] +=
dailyInflation.get(.get(Calendar.YEAR))[start.get(Calendar.MONTH)];.add(Calendar.DATE,
1);
}
}
weeklyInflation;
}
static void main(String[] args) throws
IOException, SQLException {(args.length!= 4) {.err.println("Usage: java
CalculateCorrelations <dir> " +
"<country> <first_date>
<last_date>");.exit(1);
}
// Open directory= new
File(args[0]);(!dir.exists()) {.mkdirs();
} else if (!dir.isDirectory())
{.err.println("Not a directory: " + args[0]);.exit(1);
}
country = args[1];
// Parse datessdf = new
SimpleDateFormat("yyyy-MM-dd");fromDate = null;{= new
Date(sdf.parse(args[2]).getTime());
} catch (ParseException e)
{.err.println("Invalid Date: " + args[2]);.exit(1);
}toDate = null;{= new Date(sdf.parse(args[3]).getTime());
} catch (ParseException e)
{.err.println("Invalid Date: " + args[3]);.exit(1);
}
= new DatabaseSession();
// Get all stocks<Integer> stocks =
db.selectStocks(country, fromDate, , 200);
// List all weeks<Week> weeks =
Week.listWeeks(fromDate, toDate);
// For each week compute inflation[] inflation =
getWeeklyInflation(country, weeks);
<Integer, boolean[]> performance =
HashMap<Integer, boolean[]>();(int i = 0; i < stocks.size(); i++)
{.out.println("Calculating performance (" + (i + 1) + "/"
+.size() + ")");.put(stocks.get(i), сalculatePerformance(.get(i), weeks,
inflation));
}
// For each period calculate C(i,j)count =
0;total = (weeks.size() - PERIOD_LENGTH) / PERIOD_SHIFT + 1;(int w = 0; w <=
(weeks.size()-PERIOD_LENGTH); w += PERIOD_SHIFT)
{++;.out.println("Generating file (" +
count + "/" ++ ")");
firstDate = weeks.get(w).getStart();lastDate =
weeks.get(w + PERIOD_LENGTH - 1).getEnd();
<Integer> ids = db.selectStocks(country,
firstDate,, 200);c = new PerformanceMatrix(country, , lastDate, ids);(int i =
0; i < ids.size(); i++)(int j = i + 1; j < ids.size(); j++)(int v = w; v
< w + PERIOD_LENGTH; v++)(performance.get(ids.get(i))[v] &&
.get(ids.get(j))[v]).increment(i, j);
// Write the matrix to filefileName =
dir.getAbsolutePath() + File.separator + + "_" + count +
".csv";.dumpToFile(new File(fileName));
}
.close();
}
}
/**
* Class for representing weeks.
*/Week {
final Date start;final Date end;
/**
* Create a week object.
*
* @param start the first date
* @param end the end date
*/Week(Date start, Date end) {.start = start;.end
= end;
}
/**
* Get the first day of the week.
*
* @return the first day of the week
*/Date getStart() {start;
}
/**
* Get the last day of the week.
*
* @return the last day of the week
*/Date getEnd() {end;
}
/**
* Create a list of all weeks in the given time
period.
*
* @param from the first date of the period
* @param to the last date of the period
* @return the list of weeks
*/static ArrayList<Week> listWeeks(Date
from, Date to) {<Week> weeks = new ArrayList<Week>();
cal =
Calendar.getInstance();.setTime(from);(cal.getTime().compareTo(to) <= 0)
{startDate = new Date(cal.getTime().getTime());dayOfWeek =
cal.get(Calendar.DAY_OF_WEEK);.add(Calendar.DATE, 8 -
dayOfWeek);(cal.getTime().compareTo(to) > 0);endDate = new
Date(cal.getTime().getTime());.add(Calendar.DATE, 1);.add(new Week(startDate,
endDate));
}weeks;
}
}
Приложение 6
Класс для представления невзвешенного графа
import
java.io.BufferedReader;java.io.File;java.io.FileInputStream;java.io.FileWriter;java.io.IOException;java.io.InputStreamReader;java.io.PrintWriter;java.util.LinkedList;
/**
* Class to represent graphs (unweighted).
*
* This implementation uses adjacency lists to
represent the graph, which
* may be inefficient for very dense graphs.
*/class Graph {
final int V;int E;LinkedList<Integer>[]
adj;
/**
* Construct a new graph with V vertices.
*
* @param V the number of vertices.
*/Graph(int V) {.V = V;.E = 0;=
(LinkedList<Integer>[]) new LinkedList[V];(int v = 0; v < V; v++)[v] =
new LinkedList<Integer>();
}
/**
* Read graph from file.
*
* @param f the file
* @throws NumberFormatException if the file
contains invalid data
* @throws IOException if an I/O error occurs
*/Graph(File f) throws NumberFormatException,
IOException {br = new BufferedReader(InputStreamReader(new
FileInputStream(f)));[] h = br.readLine().split(" ");
.V = Integer.parseInt(h[2]);=
(LinkedList<Integer>[]) new LinkedList[V];(int v = 0; v < V; v++)[v] =
new LinkedList<Integer>();
E = Integer.parseInt(h[3]);
(int i = 0; i < E; i++) {[] v =
br.readLine().split(" ");(Integer.parseInt(v[1])-1,
Integer.parseInt(v[2])-1);
}.close();
}
/**
* Dump this graph to a file (using the format
suitable for the MCS
* algorithm).
*
* @param file the file to read from
* @throws IOException if an I/O error occurs
*/void dump(File file) throws IOException {out =
new PrintWriter(new FileWriter(file));.println("p edge " + V + "
" + E);(int v = 0; v < V; v++) {(int w: adj(v))(w >
v).println("e " + (v + 1) + " " + (w + 1));
}.close();
}
/**
* Number of vertices.
*
* @return the number of vertices
*/int V() {V;
}
/**
* Number of edges.
*
* @return the number of edges
*/int E() {E;
}
/**
* Add a new edge between two vertices.
*
* @param v the one vertex
* @param w the other vertex
*/void addEdge(int v, int w)
{++;[v].add(w);[w].add(v);
}
/**
* Get list f vertices adjacent to v.
*
* @param v the vertex
* @return the list of adjacent vertices
*/LinkedList<Integer> adj(int v) {
return adj[v];
}
Приложение 7
Программы для расчета характеристик графа
import
java.io.File;java.io.FileOutputStream;java.io.IOException;java.io.PrintStream;java.util.LinkedList;
/**
* Compute the clustering coefficient.
*/Clustering {static double local(Graph g, int v)
{<Integer> N = g.adj(v);(N.size() < 2)0;count = 0;(int j: N) {(int k:
g.adj(j)) {(N.contains(k))++;
}
}(double) count / (N.size() * (N.size() - 1));
}
static double global(Graph g) {c = 0.0;(int v =
0; v < g.V(); v++)+= local(g, v);/= g.V();c;
}
}
/**
* Calculate the edge density.
*/EdgeDensity {static double density(Graph g)
{(double) g.E() * 2.0 / (g.V() * (g.V() - 1));
}
}
/**
* Calculate the degree distributon.
*/DegreeDistribution {static int[]
degreeDistribution(Graph g) {[] degree = new int[g.V()];(int v = 0; v <
g.V(); v++)[g.adj(v).size()]++;degree;
}
}