Технология параллельного программирования OpenMP
Содержание
Введение
Описание
технологии OpenMP
Инструментарий
OpenMP
Структура
OpenMP
Компиляция
OpenMP программы
Применение
OpenMP
Средства
отладки
Анализ
эффективности
Заключение
Список
литературы
Введение
Современные технологии параллельные технологии
отличаются друг от друга не столько языками программирования, сколько
архитектурными подходами к построению параллельных систем.
К примеру, некоторые технологии предлагают
построение параллельных программ на основе нескольких компьютеров, а другие же
позволяют работать на одной машине с несколькими процессорами.
Довольно давно используются системы на базе
нескольких компьютеров, они относятся к системам распределённых вычислений.
Самый яркий пример распределённых вычислений это MPI(Message
Passing Interface(интерфейс для передачи сообщений))является наиболее
распространённым стандартом интерфейса обмена данными в параллельном
программировании, существуют его реализации для большого числа компьютерных
платформ. MPI предоставляет программисту единый механизм взаимодействия ветвей
внутри параллельного приложения независимо от машинной архитектуры
(однопроцессорные/многопроцессорные с общей/раздельной памятью), взаимного
расположения ветвей (на одном процессоре или на разных).[8]
Системы параллельного программирования для
работы на одном компьютере, начали свое развитие относительно недавно. Ведь при
разработке приложений перед разработчиком стает вопрос, как повысить
быстродействие с ресурсами которые имеются под рукой, а именно использованием
нескольких ядер компьютера, и к программисту на помощь приходит API
Open MP.
Разработанная в 1997 году технология OpenMP позволяет в максимальной степени
эффективно реализовать возможности многопроцессорных вычислительных систем с
общей памятью, обеспечивая использование общих данных для параллельно
выполняемых потоков без каких-либо трудоемких межпроцессорных передач
сообщений.
Основные этапы исследования:
а) Изучение
средств распараллеливания, предоставляемых технологиями OpenMP.
б) Изучение
синтаксиса и семантики функций технологии OpenMP
на языке программирования Visual
C++.
в) Практическое
применение полученных знаний.
г) Проектирование
интерфейса пользователя для взаимодействия с программой.
д) Отладка
и тестирование программ.
е) Сравнительный
анализ и оценка производительности данного алгоритма.
Ожидается, что будет проведение изучения
технологии OpenMP,
распараллеленная последовательная программа с использованием технологии OpenMP,
построение интерфейса пользователя для взаимодействия с программой, проведение
сравнительной оценки и анализа.
Описание технологии OpenMP
Так что же такое OpenMP
и с чем его едят. Технология OpenMP
(Open Multi-Processing) это наиболее популярная и используемая сегодня
технология распараллеливания. За основу берётся последовательная программа, а
для его распараллеливания используется набор директив компилятора, переменные
окружения и библиотечные процедуры, которые предназначены для программирования
многопоточных приложений на многопроцессорных системах с общей памятью
(SMP-системах).
Рисунок 1. SMP
система
· Все процессоры имеют доступ к любой
точке памяти с одинаковой скоростью.
· Процессоры подключены к памяти либо
с помощью общей шины, либо с помощью crossbar-коммутатора.
· Аппаратно поддерживается
когерентность кэшей.
Стандарт Open MP был основан на языке Fortran в
1997 г., но позднее в 1998 г. включил в себя и языки C/C++.
На данный момент уже доступна версия 4.0 , но во время выполнения курсовой
работы использовалась версия 2.0, так как новый стандарт на данный момент
поддерживается только компилятором Intel.
Разработкой OpenMP занимается ARB(Architecture
Review Board),
это некоммерческая организация, в ёё состав входят крупнейшие разработчики SMP-архитектур
и ПО.
Программа, созданная с применением технологии OpenMP,
состоит из последовательных (однопоточных) и параллельных (многопоточных)
участков. В OpenMP
используется модель распараллеливания « Ветвление - Слияние». Вначале иметься
только единственный поток его называют начальным потоком или ещё основной
нитью(Master
thread, здесь threard
это легковесные процессы). Как только поток встречает параллельную конструкцию
в коде программы, он создает группу потоков и становится главным потоком. В
созданной группе все потоки, включая главный, выполняют код программы. После выполнения
параллельной конструкции в коде, работу продолжает только главный поток.
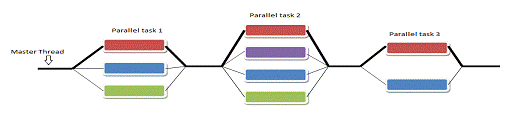
Рисунок 2. Модель
распараллеливания « Ветвление - Слияние».
Число потоков выполняющие параллельную часть
можно контролировать по разному, можно использовать OMP_NUM_THREADS или вызвать
процедуру omp_set_num_threads()
Память в OpenMP
разделяется на: локальную и общую память. Локальная память доступна только для
одной нити, а общая, для нескольких.
Опишем основные возможности и положительные
качества технологии распараллеливания OpenMP:
1. В OpenMP
дается возможность реализовать максимально эффективно многопроцессорные
вычислительные системы с общей памятью, позволяя использовать общие данные для
параллельно выполняемых потоков, без каких либо затруднений для межпроцессорных
передач данных.
. В OpenMP
дается возможность инкрементной (поэтапной) разработки параллельных программ.
Это значит, что на ранних этапах разработки мы уже можем получить параллельную
программу, достигается это благодаря директивам OpenMP,
они могут добавляться в последовательную программу поэтапно.
. В OpenMP
снижена вероятность возникновения проблем при переносе параллельных программ
между разными компьютерами. Программа, написанная на языке C
или Fortran
с использованием технологии OpenMP,
будет выполняться для разных вычислительных систем с общей памятью.
. В OpenMP
простой набор директив для изучения. И разработка сравнительно простых
параллельных программ не требует больших усилий, иногда достаточно добавить
пару директив в последовательную программу. Но не стоит забывать, что при
разработке сложных программ требуется соответствующие знания.
Инструментарий
Рассмотрим инструмент, который понадобиться нам
для работы. А потребуется нам Visual Studio, в курсовой работе использовалось VS
Express 2013.
Как уже говорилось ранее, одним из достоинств
технологии OpenMP является
то, что последовательную программу можно распараллелить без существенной
модификации. Достигается это расстановкой директив. На практике же нам приходиться
менять и код программы, но этих изменений намного меньше, чем, например в MPI.
Всё это означает, что для распараллелирования
последовательной программы на языке C/С++
нам достаточно включить в проект поддержку пакета OpenMP.
В Visual
Studio после создания
проекта, нужно во вкладке «Отладка» зайти в «Свойства проекта». Далее выбираем C/C++/
Язык. Выставляем в графе «Конфигурация» - «Активная (debug)»,
а в «Платформа» - «Активная(Win32)»
как показано на рисунке 3.

Рисунок 3. Выбор конфигураций и платформ, для
которых мы устанавливаем параметры.
Поддержка OpenMP
включается, как показано на рисунке 4.
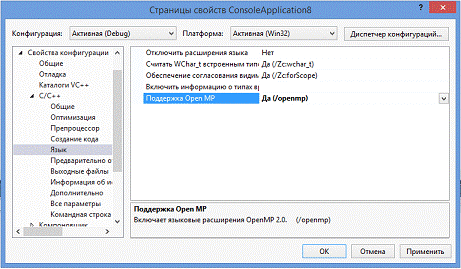
Рисунок 4. Поддержка OpenMP
включена.
Возможностей Visual
Studio Express
2013 хватает для того, чтобы мы могли разрабатывать параллельные программы с
применением технологии OpenMP.
Однако для полноценной работы следует иметь Intel® Parallel Studio. Его будем
использовать для поиска параллельных ошибок в создаваемом коде. Данный дистрибутив
можно скачать с официального сайта[12].
Структура OpenMP
Кратко рассмотрим структуру OpenMP.
В составе OpenMP можно
выделить:
· Директивы
· Функции
· Переменные окружения
Директивы.
В общем виде формат директив можно представить в
виде:
#pragma omp <Имя директивы>
[<параметр>[[,] <параметр>]…]
Где #pragma omp <Имя директивы> это
фиксированная часть, а параметром может быть хоть сколько угодно.
Основные директивы:
· parallel - используется для
выделения параллельной области
· for - используется для
автоматического распараллеливания циклов
Приведем общий вид для этих двух директив:
#pragma omp parallel[<параметр>[[,]
<параметр>]…]
<код программы>
#pragma omp for[<параметр>[[,]
<параметр>]…]
<Цикл for>
Основные функции:
· omp_get_thread_num() - узнать номер
текущей нити (все нити нумеруются с 0).
· Функции управления свойствами
параллельных областей:
(1) omp_set_nested(true|false),
(2)omp_set_dynamic(true|false)
Переменные окружения:
· OMP_DYNAMIC - значение говорит о
том, разрешено ли программе менять количество процессов динамически.
· OMP_NUM_THREADS - количество
процессов в параллельной области по умолчанию, и пр.
Компиляция OpenMP
программы
Для использования OpenMP нужно скомпилировать
программу компилятором, поддерживающим OpenMP, с указанием соответствующего
ключа. В курсовой использовался компилятор от компании Microsoft
Visual Studio 2013 C++
Компилятор интерпретирует директивы OpenMP и
создаёт параллельный код. При использовании компиляторов, не поддерживающих
OpenMP, директивы OpenMP игнорируются без дополнительных сообщений. Компилятор
с поддержкой OpenMP определяет макрос_OPENMP, который может использоваться для
условной компиляции отдельных блоков, характерных для параллельной версии
программы. Этот макрос определён в формате yyyymm, где yyyy и mm - цифры года и
месяца, когда был принят поддерживаемый стандарт OpenMP.[9]
|
Производитель
|
Компилятор
|
Ключ
компиляции
|
|
IBM
|
XL
C/C++ / Fortran
|
-qsmp
=
omp
|
|
Intel
|
C/C++
/ Fortran
|
-openmp
/Qopenmp
|
|
Microsoft
|
Visual
Studio 2013 C++
|
/openmp
|
|
Portland
Group
|
C/C++
/ Fortran
|
-mp
|
|
Sun
Microsystems
|
C/C++
/ Fortran
|
-xopenmp
|
|
GNU
|
gcc
|
-fopenmp
|
Таблица 1 с ключами компиляции.
Применение OpenMP
После проведения исследования на основе
полученных знаний, реализуем три примера: сортировка массива, умножение матриц,
вычисление числа π. Реализация
будет вестись на Visual
Studio 2013 на языке
программирования C++.
Пример 1. С сортировкой массива по возрастанию.
Используем 2 сортировки: быструю и пузырьковую. Массив содержит 100000
элементов, которые создаются случайным образом.
Практическая реализация:
#define M 100000
#define N
100000a[M]; buble(int a[], int n) // Функция
сортировки пузырьковым методом
{(int i = 1; i <
n; ++i)(int j = 0; j < n - i; ++j)(a[j] > a[j + 1])
{temp = a[j];[j] =
a[j + 1];[j + 1] = temp;
}
}
void qsort(int b, int e) // Функция сортировки быстрым методом
{begin = b, end =
e;point = a[(b + e) / 2];(b < e){(a[b] < point) b++;(a[e] > point)
e--;(b <= e)
{ int swap =
a[b];[b] = a[e];[e] = swap;++;-;
}
}(b < end) qsоrt(b,
end);(begin < e) qsоrt(begin, e);
}main(int argc,
char* argv[])
{_t
t1;(time(0));(int i = 0; i < M; ++i)
{[i] = rand() % N;
}=
clock();_set_num_threads(2);
#pragma omp
parallel firstprivate(a)
{(omp_get_thread_num()
== 1)
{buble(a, M);=
clock() - t1;<< (float)t1 / CLOCKS_PER_SEC << ” Buble sort \n ”;
}(omp_get_thread_num()
== 0)
{
qsort(0, M - 1);=
clock() - t1;<< (float)t1 / CLOCKS_PER_SEC << ” Quick sort\n ”;
}
}0;
}
Пример демонстрируется применение таких
конструкций, как omp_set_num_threads
он используется для задавания количество нитей для выполнения параллельной
области; omp_get_thread_num()
используется для определения номера нити. Распараллеливание начинается с
конструкции #pragma omp parallel , для которого firstprivate(a)
является параметром порождающий локальную копию в каждой нити.
Пример 2.
Умножение квадратных матриц размером 1024х1024.
Матрицы заполняются случайными значениями. Время будет замеряться основным
вычислительным блоком не включающий начальную инициализацию.
Практическая реализация:
#include <stdio.h>
#include
<omp.h>
#include<iostream>
#define N
1024A[N][N], B[N][N], P[N][N];main()
{i, j, m;time1,
time2; //временные интервалы (i = 0; i < N; i++){ // инициализация
и заполнение матриц
for (j = 0; j <
N; j++){[i][j] = B[i][j] = rand() % N;
}
time1 = omp_get_wtime(); // Замеряем время начала работы
#pragma omp
parallel for shared (A, B, P) private (i, j, m) (i = 0; i < N; i++){(j = 0;
j < N; j++){[i][j] = 0.0;(int m = 0; m < N; m++)
P[i][j] = A[i][m] *
B[m][j];
}
}2 = omp_get_wtime(); // Замеряем время конца работы
std::cout <<”
Time =” << time2 - time1;
}
Директива parallel for
имеет параметры shared()
и private(). Shared()
задает переменные (A, B, P)
общими, а private()
задает переменные, которые содержаться в нем, как частные. После
вычислительного блока замеряем время конца работы и выводим время.
Пример 3.
Рассчитаем приблизительное значение числа пи.
Для расчета будем использовать формулу 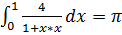 .
Мы можем рассматривать интеграл как сумму прямоугольников
.
Мы можем рассматривать интеграл как сумму прямоугольников 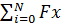 i▲x
≈π.
Где каждый прямоугольник имеет ширину ▲x
и высоту F(xi)
в середине интервала.
i▲x
≈π.
Где каждый прямоугольник имеет ширину ▲x
и высоту F(xi)
в середине интервала.
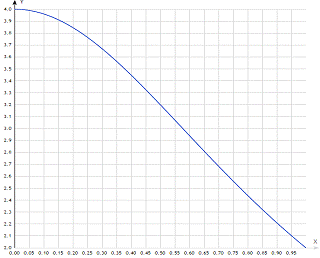
Рисунок 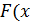 )=
)=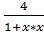
Практическая реализация
n = 100, i;
double рi, h, sum, х;= 1.0 /
(double)n;= 0.0;
#pragma omp
parallel default (none) private (i,х) shared (n,h) reduction(+:sum)
{
#pragma omp for
schedule (static)(i = 1; i <= n; i++)
{
х = h * ((double)i - 0.5);
+= (4.0 / (1.0 + х*х));
}
}
рi = h * sum;
printf(“pi about
%.16f”, рi);
return 0;
}
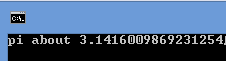
Результат работы 3 примера.
В 3 примере используется опции директивы parallel:
default (none) - это означает, что все переменные в параллельной области
будут назначены явно, reduction(+:sum) - задаёт оператор и список общих
переменных. А в конструкции #pragma omp for schedule (static),
с помощью schedule директивы for, задается, как
будет происходить распределение итераций, в данном случае итерации будут
раздаваться поровну.
Рассмотрение средств отладки
Для отладки трех программ применялись встроенные
средства Microsoft Visual2013. Основным же средством отладки являлась Intel
Parallel
Studio XE
2015 Professional.
Для работы использовались Intel
Inspector
XE 2015 и Intel
VTune Amplifier
XE 2015. Intel
Inspector
XE 2015 это утилита
для тестирования программы на наличие утечек памяти, проверки потоков на
состояние гонки и взаимных блокировок. Intel
VTune Amplifier XE
2015 применяется для анализа производительности программ, т.е. для оценки
временных затрат участков кода и тем самым позволяет находить узкие по
производительности места.
Отладка программ, осуществлялась с
использованием утилиты Intel Inspector XE 2015. Проверялись:
неинициализированные переменные, конфликт доступа к данным, утечка памяти. В
результате отладки во всех 3 программах, во второй был найден конфликт доступа
к данным, проблема была решена после применением параметров shared()
и private(), в двух других
ошибок не было выявлено.
Анализ эффективности
Тестирование проводилось на примерах сортировки
матриц и их умножения, так же использовались данные от NAS Division и NASA Arms
Research Center. Ниже приведена таблица для первого и второго примера.
|
Количество
ядер
|
2
|
4
|
6
|
8
|
|
Быстрая
сортировка
|
0,031
|
0,030
|
0,016
|
0,020
|
|
Пузырьковая
|
47,299
|
28,487
|
28,405
|
30,210
|
Таблица 2, для примера 1.
Как видно по таблице 2 с увеличением количества
ядер, время работы на выполнение сортировок уменьшается.
|
1024х1024
|
1680х1680
|
1800х1800
|
|
С
технологией OpenMP
|
54,5235
|
59,8104
|
69,7429
|
|
Без
OpenMP
|
118,071
|
128,584
|
137,494
|
Таблица 3, для примера 2.
Таблица 3 дает понимание того, как влияет
технология OpenMP на скорость
вычислений.
Далее приведём некоторые пояснения:
|
Аббревиатура
|
Обозначение
|
|
BT
|
|
CG
|
Оценка
наибольшего собственного значения симметричной разреженной матрицы
|
|
EP
|
Генерация
пар случайных чисел Гаусса
|
|
FT
|
Быстрое
преобразование Фурье, 3D спектральный метод
|
|
IS
|
Параллельная
сортировка
|
|
LU
|
3D
Навье-Стокс, метод верхней релаксации
|
|
MG
|
3D
уравнение Пуассона, метод Multigrid
|
|
SP
|
3D Навье-Стокс,
Beam-Warning approximate factorization
|
Таблица 4.
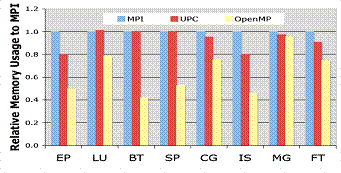
Рисунок 5.
the Effect of Different Programming
Models Upon Performance and Memory Usage on Cray XT5 Platforms [10]
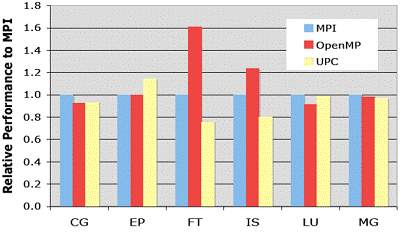
Рисунок 6.
the Effect of Different Programming
Models Upon Performance and Memory Usage on Cray XT5 Platforms [10]
Как видно OpenMP
является хорошим инструментом распараллеливания, это достигается за счет того,
что реализовано инкрементное распараллеливание, имеет очень гибкий механизм для
контроля разработчику над параллельной программой, так же в OpenMP
простой набор директив для изучения и применения, которые, могут в случаи
ненадобности, игнорироваться компилятором без вреда для работы программы.
Заключение
Во время курсовой работы были изучены технологии
параллельного программирования, в частности OpenMP.
Изучены методы работы с OpenMP,
изучены директивы, компиляторы, которые поддерживают OpenMP.
Были применены на практике, знания, которые были получены в ходе изучения
технологии, для решения практических задач.
Проведён сравнительный анализ из полученных
тестовых данных.
параллельное программирование
интерфейс
Список литературы
1) Антонов
А.С. Параллельное программирование с использованием технологии OpenMp. - М.:
Изд-во МГУ, 2009. - 77 с
2) Малышкин
В.Э. Параллельное программирование мультикомпьютеров, Новосибирск, 2006. - 452
с
3) Бахтин
А.В. Технология параллельного программирования OpenMP, Москва, 2012. - 125 с
4) Воеводин
В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.:
БХВ-Петербург,
2002.
5) Chandra,
R., Dagum, L., Kohr, D., Maydan, D., McDonald, J., and Melon, R.(2000).
Parallell Programming in OpenMP. San-Francisco, CA: Morgan Kaufmann Publishers.
6) Quinn,
M. J. (2004). Parallel Programming in C with MPI and OpenMP. - New York, NY:
McGraw-Hill.
7) Гергель
В.П. Параллельное программирование с использованием, Новосибирск, 2007. - 33с
8) Параллельные
заметки. URL: http://habrahabr.ru/company/intel/blog/82486
9) Лабораторная
работа. Компиляция и запуск программ. URL:http://gigabaza.ru/doc/106635.html
10) OpenMP
Compilers. - URL: http://openmp.org/wp/openmp-compilers/
11) Analyzing
the Effect of Different Programming Models Upon Performance and Memory Usage on
Cray XT5 Platforms
12) URL:
https://www.nersc.gov/assets/NERSC-Staff-Publications/2010/Cug2010Shan.pdf
13) Дистрибутив
Intel Parallel Studio XE 2015. URL: https://software.intel.com/en-us/intel-parallel-studio-xe