Сравнение возможностей OpenMP и TPL
Содержание
Глава 1. Аналитическая часть
.1 Описание предметной области
.1.1 Актуальность работы
.1.2 Предметная область
.2 Инструментарий параллельных вычислений
.2.1 OpenMP
.2.2 .Net TPL
.2.3 Использование OpenMP и библиотеки TPL для решения задач
.2.4 Сравнение возможностей OpenMP и TPL
.3 Линейная алгебра и параллельные вычисления
.3.1 Умножение матриц
.3.2 Возведение в степень
.3.3 Решение систем
.3.4 Решение систем с n правыми частями
.3.5 Детерминант матриц
.3.6 Работа со слабо заполненными матрицами
.4 Проблематика параллельных вычислений
Глава 2. Специальная часть
.1 Выбор программных средств
.2 Выбор средств разработки
.3 Математические методы и специальные алгоритмы решения
задачи. Оценка сложности алгоритма решения задачи
.3.1 Решение систем линейных уравнений
.3.2 Вычисление детерминанта
.3.3 Возведение матрицы в степень
Заключение
Глава 1. Аналитическая часть
.1 Описание предметной области
.1.1 Актуальность работы
Применение параллельных вычислительных систем является важным
направлением развития вычислительной техники. Это вызвано тем, что обычные
последовательные ЭВМ имеют ограничение максимально возможного быстродействия, а
также практически постоянным наличием вычислительных задач, для решения которых
возможностей существующих средств вычислительной техники всегда оказывается
недостаточно.
Проблема создания высокопроизводительных вычислительных систем относится
к числу наиболее сложных научно-технических задач современности. Ее разрешение
возможно только при всемерной концентрации усилий многих талантливых ученых и
конструкторов, предполагает использование всех последних достижений науки и
техники и требует значительных финансовых инвестиций. Тем не менее, достигнутые
в последнее время успехи в этой области впечатляют.
Организация параллельности вычислений, когда в один и тот же момент
выполняется одновременно несколько операций обработки данных, осуществляется, в
основном, за счет введения избыточности функциональных устройств
(многопроцессорности). В этом случае можно достичь ускорения процесса решения
вычислительной задачи, если осуществить разделение применяемого алгоритма на
информационно независимые части и организовать выполнение каждой части
вычислений на разных процессорах. Подобный подход позволяет выполнять
необходимые вычисления с меньшими затратами времени, и возможность получения
максимально-возможного ускорения ограничивается только числом имеющихся
процессоров и количеством "независимых" частей в выполняемых
вычислениях.
Однако следует отметить, что до сих пор применение параллелизма не
получило столь широкого распространения, как это ожидалось многими
исследователями. Одной из возможных причин подобной ситуации являлась до
недавнего времени высокая стоимость высокопроизводительных систем (приобрести
супер ЭВМ могли себе позволить только крупные компании и организации).
Современная тенденция построения параллельных вычислительных комплексов из
типовых конструктивных элементов (микропроцессоров, микросхем памяти,
коммуникационных устройств), массовый выпуск которых освоен промышленностью,
снизила влияние этого фактора, и в настоящий момент практически каждый
потребитель может иметь в своем распоряжении многопроцессорные вычислительные
системы достаточно высокой производительности. Наиболее кардинально ситуация
изменилась в сторону параллельных вычислений с появлением многоядерных
процессоров, которые, уже в 2006 году использовались более чем в 70%
компьютерных систем.
Другая основная причина сдерживания массового распространения
параллелизма состоит в том, что для проведения параллельных вычислений
необходимо "параллельное" обобщение традиционной - последовательной -
технологии решения задач на ЭВМ. Так, численные методы в случае
многопроцессорных систем должны проектироваться как системы параллельных и
взаимодействующих между собой процессов, допускающих исполнение на независимых
процессорах. Применяемые алгоритмические языки и системное программное
обеспечение должны обеспечивать создание параллельных программ, организовывать
синхронизацию и взаимоисключение асинхронных процессов и т.п.
Так же можно выделить следующий ряд общих проблем, возникающих при
использовании параллельных вычислительных систем:
· Потеря производительности при организации параллелизма - согласно
гипотезе Минского, ускорение, достигаемое при использовании параллельной
системы, пропорционально двоичному логарифму от числа процессоров (т.е. при
1000 процессорах возможное ускорение оказывается равным 10).
Подобная оценка ускорения справедлива при распараллеливании определенных
алгоритмов. Вместе с тем существует большое количество задач, при параллельном
решении которых достигается практически 100%-е использование всех имеющихся
процессоров параллельной вычислительной системы.
· Существование последовательных вычислений - в соответствии с законом
Амдаля ускорение процесса вычислений при использовании p процессоров
ограничивается величиной
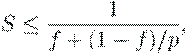
где f есть доля последовательных вычислений в применяемом алгоритме
обработки данных. К примеру, при наличии всего 10% последовательных команд в выполняемых
вычислениях эффект использования параллелизма не может превышать 10-кратного
ускорения обработки данных.
Данное замечание характеризует одну из самых серьезных проблем в области
параллельного программирования (алгоритмов без определенной доли последовательных
команд практически не существует). Однако часто доля последовательных действий
характеризует не возможность параллельного решения задач, а последовательные
свойства применяемых алгоритмов. Как результат, доля последовательных
вычислений может быть существенно снижена при выборе более подходящих для
распараллеливания алгоритмов.
· Зависимость эффективности параллелизма от учета характерных свойств
параллельных систем - в отличие от единственности классической схемы фон
Неймана последовательных ЭВМ, параллельные системы характеризуются существенным
разнообразием архитектурных принципов построения. Максимальный эффект от
параллелизма может быть получен только при полном использовании всех
особенностей аппаратуры; как результат, перенос параллельных алгоритмов и
программ между разными типами систем становится затруднительным (если вообще
возможен).
Однородность последовательных ЭВМ также является кажущейся, и эффективное
использование однопроцессорных компьютеров тоже требует учета свойств аппаратуры.
С другой стороны, при всем разнообразии архитектур параллельных систем, тем не
менее, существуют и определенные "устоявшиеся" способы обеспечения
параллелизма (конвейерные вычисления, многопроцессорные системы и т.п.). Кроме
того, инвариантность создаваемых параллельных программ может быть обеспечена и
при использовании типовых программных средств поддержки параллельных вычислений
(программных библиотек MPI, PVM и др.).
Если существующие программы обеспечивают решение поставленных задач, то,
конечно, переработка этих программ не является необходимой. Однако если
последовательные программы не позволяют получать решения задач за приемлемое
время или же возникает необходимость решения новых задач, то необходимостью
становится разработка нового программного обеспечения и эти программы могут
реализовываться для параллельного выполнения.
Проблема параллельных вычислений является чрезвычайно широкой областью
теоретических исследований и практически выполняемых работ и обычно
подразделяется на следующие направления деятельности:
• разработка параллельных вычислительных систем - обзор принципов
построения параллельных систем;
• анализ эффективности параллельных вычислений для оценки получаемого
ускорения вычислений и степени использования всех возможностей компьютерного
оборудования при параллельных способах решения задач. (анализ эффективности
организации процессов передачи данных как одной из важных составляющих
параллельных вычислений выполняется отдельно);
• формирование общих принципов разработки параллельных алгоритмов для
решения сложных вычислительно трудоемких задач;
• создание и развитие системного программного обеспечения для
параллельных вычислительных систем, программные реализации которого позволяют
разрабатывать параллельные программы и, кроме того, снизить в значительной
степени остроту важной проблемы параллельного программирования - обеспечение
мобильности (переносимости между разными вычислительными системами)
создаваемого прикладного программного обеспечения;
• создание и развитие параллельных алгоритмов для решения прикладных
задач в разных областях практических приложений.
Подводя итог всем перечисленным проблемам и замечаниям, можно заключить,
что параллельные вычисления являются перспективной и очень привлекательной
областью применения вычислительной техники и представляют собой сложную
научно-техническую область деятельности. Тем самым, знание современных
тенденций развития ЭВМ и аппаратных средств для достижения параллелизма, умение
разрабатывать модели, методы и программы параллельного решения задач обработки
данных следует отнести к числу важных квалификационных характеристик
современного специалиста по прикладной математике, информатике и вычислительной
технике.
.1.2 Предметная область
В данной дипломной работе мы проводим разработку приложения, позволяющего
провести сравнительный анализ инструментов параллелизма на примерах задач
линейной алгебры. Главными объектами анализа являются последовательные и
параллельные алгоритмы с применением соответствующих инструментов.
Для каждой задачи мы будем рассматривать идентичные алгоритмы, что бы
сравнение было максимально точным.
.2 Инструментарий параллельных вычислений
Количество ядер у процессоров растет год от года. Но многие программы до
сих пор умеют использовать только одно. Поэтому для разработки дипломной работы
мы выбрали такие среды разработки как Task Parallel
Library (.Net TPL) и инструментов Visual Studio, реализующих стандарт OpenMP.
.2.1 OpenMP
Одним из наиболее популярных средств программирования для компьютеров с
общей памятью, в настоящее время является технология OpenMP. За основу берётся последовательная программа, а для
создания её параллельной версии пользователю предоставляется набор директив,
функций и переменных окружения. Предполагается, что создаваемая параллельная
программа будет переносимой между различными компьютерами с разделяемой
памятью, поддерживающими OpenMP API.
Технология OpenMP нацелена на
то, чтобы пользователь имел один вариант программы для параллельного и
последовательного выполнения. Однако возможно создавать программы, которые
работают корректно только в параллельном режиме или дают в последовательном
режиме другой результат. Более того, из-за накопления ошибок округления
результат вычислений с использованием различного количества нитей может в
некоторых случаях различаться.
Разработкой стандарта занимается некоммерческая организация OpenMP ARB (Architecture Review Board) , в которую вошли представители
крупнейших компаний - разработчиков SMP-архитектур и программного обеспечения. OpenMP поддерживает работу с языками Фортран и Си/Cи++. Первая спецификация для языка
Фортран появилась в октябре 1997 года, а спецификация для языка Си/Cи++ - в октябре 1998 года. На данный
момент последняя официальная спецификация стандарта - OpenMP 3.0.
Интерфейс OpenMP задуман как
стандарт для программирования на масштабируемых SMP-системах (SSMP, ccNUMA и других) в модели общей памяти (shared memory model). В стандарт OpenMP входят спецификации набора директив компилятора,
вспомогательных функций и переменных среды. OpenMP реализует параллельные вычисления с помощью
многопоточности, в которой «главный» (master) поток создает набор «подчиненных» (slave) потоков, и задача распределяется между ними.
Предполагается, что потоки выполняются параллельно на машине с несколькими
процессорами, причём количество процессоров не обязательно должно быть больше
или равно количеству потоков. Примерами систем с общей памятью, масштабируемых
до большого числа процессоров, могут служить суперкомпьютеры Cray Origin2000
(до 128 процессоров), HP 9000 V-class (до 32 процессоров в одном узле, а в
конфигурации из 4 узлов - до 128 процессоров), Sun Starfire (до 64 процессоров).
Основные преимущества OpenMP:
o За счет идеи "инкрементального распараллеливания"
OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои
вычислительные программы с большими параллельными циклами. Разработчик не
создает новую параллельную программу, а просто последовательно добавляет в
текст последовательной программы OpenMP-директивы.
o При этом, OpenMP - достаточно гибкий механизм,
предоставляющий разработчику большие возможности контроля над поведением
параллельного приложения.
o Предполагается, что OpenMP-программа на однопроцессорной
платформе может быть использована в качестве последовательной программы, т.е.
нет необходимости поддерживать последовательную и параллельную версии.
Директивы OpenMP просто игнорируются последовательным компилятором, а для
вызова процедур OpenMP могут быть подставлены заглушки (stubs), текст которых
приведен в спецификациях.
o Одним из достоинств OpenMP его разработчики считают поддержку
так называемых "orphan" (оторванных) директив, то есть директивы
синхронизации и распределения работы могут не входить непосредственно в
лексический контекст параллельной области.
.2.2 Net TPL
Другим популярным средством параллельного программирования является
библиотека параллельных задач Task Parallel
Library (.Net TPL). Библиотека параллельных задач TPL - предоставляет такие императивные
методы, как Parallel.For, Parallel.Foreach и Parallel.Invoke для выполнения
параллельных вычислений. Вся работа по созданию и завершению потоков, в
зависимости от имеющихся процессоров выполняется библиотекой автоматически. Так
же библиотека представляет собой набор открытых типов и API-интерфейсов в
пространствах имен System.Threading и System.Threading.Tasks в .NET
Framework 4.
Основная цель TPL - повышение производительности труда разработчиков за
счет упрощения процедуры добавления параллелизма в приложения. TPL динамически
масштабирует степень параллелизма для наиболее эффективного использования всех
доступных процессоров. Кроме того, в библиотеке параллельных задач
осуществляется секционирование работы, планирование потоков в пуле ThreadPool,
поддержка отмены, управление состоянием и выполняются другие низкоуровневые
задачи. Используя библиотеку параллельных задач, можно повысить
производительность кода, сосредоточившись на работе, для которой предназначена
программа.
Начиная с .NET Framework 4 библиотека параллельных задач является
предпочтительным способом создания многопоточного и параллельного кода. Однако
не всякий код подходит для параллелизации; например, если цикл за каждую
итерацию выполняет небольшой объем работ или выполняется для небольшого числа
итераций, из-за дополнительной нагрузки, которую параллелизация оказывает на
систему, код может выполняться медленнее. Кроме того, параллелизация, как и
любой многопоточный код, усложняет выполнение программы. Хотя библиотека
параллельных задач упрощает многопоточные сценарии, рекомендуется иметь базовое
понимание понятий потоков, например блокировки, взаимоблокировки и состояния
гонки, чтобы эффективно использовать библиотеку параллельных задач.
· Одно из самых важных преимуществ этой библиотеки в том, что для создания
многопоточного кода требуется минимум изменений;
· Разработчик все еще должен сам явно разбить решение на
независимые задачи, которые могут выполняться параллельно, без ущерба для
логики, но оптимальным распределением этих задач по потокам уже занимается TPL;
· Эта библиотека усовершенствует многопоточное программирование
двумя основными способами. Во-первых, она упрощает создание и применение многих
потоков. И во-вторых, она позволяет автоматически использовать несколько
процессоров. TPL открывает возможности для автоматического масштабирования
приложений с целью эффективного использования ряда доступных процессоров.
Благодаря этим двум особенностям библиотеки TPL она рекомендуется в большинстве
случаев к применению для организации многопоточной обработки.
1.2.3 Использование OpenMP
и библиотеки TPL для решения задач
Основной причиной появления стандартов OpenMP и TPL,
служит возросшее значение параллелизма в современном программировании. В
настоящее время многоядерные процессоры уже стали обычным явлением. Кроме того,
постоянно растет потребность в повышении производительности программ. Все это,
в свою очередь, вызвало растущую потребность в механизме, который позволял бы с
выгодой использовать несколько процессов для повышения производительности программного
обеспечения.
Библиотека TPL определена в пространстве имен System.Threading.Tasks. Но
для работы с ней обычно требуется также включать в программу класс
System.Threading, поскольку он поддерживает синхронизацию и другие средства
многопоточной обработки, в том числе и те, что входят в класс Interlocked.
Применяя TPL, параллелизм в программу можно ввести двумя основными
способами. Первый из них называется параллелизмом данных. При таком подходе
одна операция над совокупностью данных разбивается на два параллельно
выполняемых потока или больше, в каждом из которых обрабатывается часть данных.
Так, если изменяется каждый элемент массива, то, применяя параллелизм данных,
можно организовать параллельную обработку разных областей массива в двух или
больше потоках. Нетрудно догадаться, что такие параллельно выполняющиеся
действия могут привести к значительному ускорению обработки данных по сравнению
с последовательным подходом.
Несмотря на то что параллелизм данных был всегда возможен и с помощью
класса Thread, построение масштабируемых решений средствами этого класса
требовало немало усилий и времени. Это положение изменилось с появлением
библиотеки TPL, с помощью которой масштабируемый параллелизм данных без особого
труда вводится в программу.
Второй способ ввода параллелизма называется параллелизмом задач. При
таком подходе две операции или больше выполняются параллельно. Следовательно,
параллелизм задач представляет собой разновидность параллелизма, который
достигался в прошлом средствами класса Thread. А к преимуществам, которые сулит
применение TPL, относится простота применения и возможность автоматически
масштабировать исполнение кода на несколько процессоров.
Библиотека TPL позволяет автоматически распределять нагрузку приложений
между доступными процессорами в динамическом режиме, используя пул потоков CLR.
Библиотека TPL занимается распределением работы, планированием потоков,
управлением состоянием и прочими низкоуровневыми деталями. В результате
появляется возможность максимизировать производительность приложений .NET. не
имея дела со сложностями прямой работы с потоками.
Существует основной подход, который является основой технологии OpenMP,
наиболее широко применяемой в настоящее время для организации параллельных
вычислений на многопроцессорных системах с общей памятью. В рамках данной
технологии директивы параллелизма используются для выделения в программе
параллельных областей (parallel regions), в которых последовательный
исполняемый код может быть разделен на несколько раздельных командных потоков
(threads). Далее эти потоки могут исполняться на разных процессорах
вычислительной системы. В результате такого подхода программа представляется в
виде набора последовательных (однопотоковых) и параллельных (многопотоковых)
участков программного кода. Подобный принцип организации параллелизма получил
наименование "вилочного" (fork-join) или пульсирующего параллелизма.
Идея технологии OpenMP состоит в следующем. За основу берется
последовательная программа, а для создания ее параллельной версии предоставляется
набор директив. Стандарт OpenMP разработан для языков Фортран, С и С++. Весь
текст программы разбивается на последовательные и параллельные области. В
начальный момент времени порождается нить-мастер или "основная" нить,
которая начинает выполнение программы со стартовой точки. При входе в
параллельную область порождаются дополнительные нити. После порождения каждая
нить получает свой уникальный номер, причем нить-мастер всегда имеет номер 0.
Все нити исполняют один и тот же код, соответствующий параллельной области. При
выходе из параллельной области основная нить дожидается завершения остальных
нитей, и дальнейшее выполнение программы продолжает только она. В параллельной
области все переменные программы разделяются на два класса: общие (SHARED) и
локальные (PRIVATE). Общая переменная всегда существует лишь в одном экземпляре
для всей программы и доступна всем нитям под одним и тем же именем. Объявление
локальной переменной вызывает порождение своего экземпляра данной переменной
для каждой нити. Изменение нитью значения своей локальной переменной не влияет
на изменение значения этой же локальной переменной в других нитях.
Все директивы OpenMP представлены в программе в виде комментариев и
начинаются, согласно синтаксису Фортран, на один из трех символов: !, C или *.
Для определения параллельных областей программы используется пара
директив
!$OMP PARALLEL
< параллельный код программы >
!$OMP END PARALLEL
Для выполнения кода, расположенного между данными директивами,
дополнительно порождается OMP_NUM_THREADS()-1 нитей. Процесс, выполнивший
данную директиву (нить-мастер), всегда получает номер 0. Все нити исполняют
код, заключенный между данными директивами. После END PARALLEL автоматически
происходит неявная синхронизация всех нитей, и как только все нити доходят до
этой точки, нить-мастер продолжает выполнение последующей части программы, а
остальные нити уничтожаются.
Все порожденные нити исполняют один и тот же код. Для распределения
работы между ними часто используется директива DO. Иными словами если в
последовательной программе встретился оператор цикла DO то, используя директивы
!$OMP DO
<do цикл>
!$OMP END DO
его можно распараллелить в параллельной части программы.
.2.4 Cравнение возможностей OpenMP и TPL
Для сравнения возможностей следует рассмотреть и сравнить некоторые
инструменты параллелизма OpenMP
и библиотеки TPL. При постоянном применении одной из
технологии и любого инструмента важно знать об особенностях, которые они могут
предоставить. Для использования данных инструментов в параллельном
программировании следует рассмотреть их с точки зрения следующих задач:
· Обработка исключений;
· Планирование вычислений;
· Управление циклом;
· Установка параметров вычислений.
Первой рассматриваемой задачей является обработка исключений. Очевидно,
что при работе приложений часто возникают исключительные ситуации, связанные с
какими-либо внешними или внутренними ошибками. Для повышения безопасности и
надежности кода и приложения в целом необходимо использовать механизм, который
позволяет обработать исключительную ситуацию, а не обрушить работу приложения.
В TPL основные функции представлены
классами Task и Parallel. Напомним, что класс Task представляет собой отдельную
асинхронную операцию - задачу, а класс Parallel - методы для итеративного и
функционального распараллеливания. При параллельном выполнении задач, в любой
из них может произойти исключительная ситуация. В TPL при появление такой ситуации возможна корректная
обработка.
Исключения в одном потоке не могут напрямую повлиять на работу других
потоков. При этом исключения могут появляться в двух и более потоках
одновременно. В TPL механизм
обработки исключений представлен следующим образом: в момент появления ошибки
возникает исключение, которое завершает поток и передается вверх по уровню.
Такая же ситуация происходит и в остальных потоках. После завершения всех задач
в TPL все исключения собираются в одно - AggregateException. Далее композитное исключение может
быть обработано после завершения параллельного блока кода. У класса AggregateException есть метод Handle, который позволяет обработать все включенные в него
исключения.
OpenMP
не предоставляет средств для внешних обработок исключений. Однако, внутри
параллельных регионов есть возможность использовать механизм исключений. При
этом на данный механизм налагаются жесткие ограничения. Все исключения не
должны покидать параллельный регион, который формируется директивами for и section. То есть, все исключения должны быть обработаны
именно в параллельном регионе. При выходе исключения за параллельный регион
может произойти сбой приложения. Если же есть необходимость во внешней передачи
сообщения об ошибке, то для этого следует применять другие механизмы.
Другим не менее важным механизмом является планирование вычислений. Под
планированием в нашем случае можно представить процесс распределения задач и
потоков. Так, распараллеливая цикл, его итерации можно объединить в группы и
задать выполнение каждой группы итераций определенному потоку.
В рассматриваемых инструментариях присутствует механизм планирования,
однако его реализации отличаются.
В TPL планирование и распределение
вычислений по потокам осуществляется автоматически. Стоит отметить тот факт,
что программист не может явно повлиять на этот процесс.
В OpenMP существует несколько стратегий
планирования:
· Static - групповое распределение вычислений. Есть
возможность явно указать размер группы. Группы распределяются по нитям от
нулевой и до последней, затем процесс повторяется опять же начиная с нулевой
нити.
· Dynamic - динамическое распределение вычислений с
определенным размером группы.
· Guided - динамическое распределение вычислений, при этом
размер группы вычислений постепенно уменьшается до некоторой заданной величины
прямо пропорционально количеству нераспределённых вычислений и обратно пропорционально
количеству нитей.
· Auto - стратегия распределения устанавливается
компилятором или во время выполнения.
· Runtime - стратегия распределения устанавливается во время
выполнения приложения.
Далее стоит рассмотреть возможности для управления циклом. При
использовании обычных циклов предоставляются два способа для управления
итерациями - пропуск итерации и прерывания цикла. Для этих целей определенны
такие ключевые слова как continue и break.
Для параллельных циклов пропуск итерации не является существенным,
поэтому реализации оператора continue не предусмотрено.
В TPL возможности для управления
итерациями цикла реализованы в классе ParallelLoopState. Для объектов этого класса определенны два метода - Break и Stop.
Метод Break позволяет прервать выполнение цикла
для всех итераций после текущей. При этом, если в какой-то момент времени в
одной из итераций вызван данный метод, то все запущенные итерации продолжат
свою работу, а далее будут выполнены только итерации с меньшим номером.
Метод Stop явно указывает на то, что в цикле должны быть завершены
выполняемые итерации, а оставшиеся итерации не должны быть запущены.не
предоставляет явных механизмов для управления итерациями. При этом
использование стандартных операторов завершения цикла запрещается.
Так же стоит рассмотреть оба инструментария с точки зрения возможности
установки дополнительных параметров. В OpenMP присутствуют методы для явного задания количества
нитей, порождаемых в параллельных регионах. В TPL такая возможность отсутствует.
Ниже в таблице приведено краткое сравнение инструментариев по
вышеперечисленным критериям.
|
|
Обработка исключений.
|
Планирование.
|
Управление циклом.
|
Установка параметров.
|
|
OpenMP
|
Только внутри параллельной области
|
Автоматически и вручную
|
Запрещено
|
Поддерживается
|
|
.Net TPL
|
Присутствует
|
Автоматически
|
Поддерживается
|
Отсутствует
|
.3 Линейная алгебра и параллельные вычисления
Линейная алгебра представляет собой раздел математики, который исследует
векторы, линейные и векторные пространства, линейные системы уравнений и
линейные отображения. Как дисциплина линейная алгебра является важным разделом
математики, поскольку векторные пространства широко встречаются в
программировании. Линейная алгебра хорошо подходит для проверки эффективности
распараллеливания систем при больших значениях n, а так же довольно легко распараллеливается.
В данной дипломной работе мы рассмотрим основные операции над матрицами и
их определителями:
· Умножение матриц;
· Возведение в степень;
· Решение систем;
· Детерминант матриц;
· Работа со слабо заполненными матрицами.
Дальше мы рассмотрим поставленные задачи.
.3.1 Умножение матриц
Произведением матрицы A = (aij) размера m×n и матрицы B = (bij) размера n×l называется матрица C = (cij) = A ·
B размера m×l, элементы которой определяются формулой:
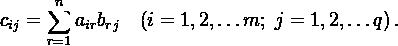
То, что матрица C является произведением матриц A и B, записывается в
виде C = A·B.
Заметим, что произведение матриц A и B определено только, если число
столбцов матрицы A равно числу строк матрицы B. Умножение матриц хорошо
подходит для её распараллеливания, так как элементы матрицы C можно вычислять независимо друг от
друга.
.3.2 Возведение в степень
Для любой квадратной матрицы  (n-ro порядка) определено
произведение
(n-ro порядка) определено
произведение  (матрицы
(матрицы 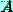 на себя). Поэтому можно говорить о целой неотрицательной
степени матрицы, определяя последовательно:
на себя). Поэтому можно говорить о целой неотрицательной
степени матрицы, определяя последовательно:
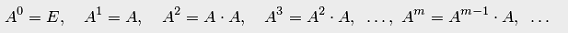
Заметим, что степени 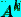 и
и 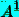 одной и той же матрицы
одной и той же матрицы 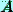 перестановочны.
перестановочны.
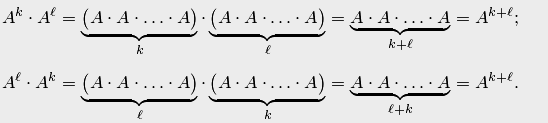
Поэтому справедливы обычные свойства степеней:
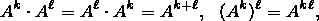 с натуральными показателями.
с натуральными показателями.
.3.3 Решение систем
Задача
о порядке перемножения матриц - классическая задача динамического
программирования, в которой дана последовательность матриц
<#"786178.files/image012.gif"> и требуется минимизировать количество скалярных
операций для вычисления их произведения. Матрицы предполагаются совместимыми по
отношению к матричному умножению (то есть количество столбцов 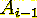 совпадает с количеством строк
совпадает с количеством строк 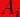 матрицы).
матрицы).
Произведение
матриц - ассоциативная <#"786178.files/image015.gif"> размерами соответственно 20×200,
200×10 и 10×100. Существует 2 способа их перемножения (расстановки
скобок):
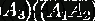 и
и 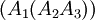 .
.
В
первом случае нам потребуется 20·200·10 + 20·10·100 = 60000 скалярных
умножений, а во втором случае 200·10·100 + 20·200·100 = 600000 умножений - как
мы видим разница довольно большая. Из этого сделаем вывод, и поэтому может быть
выгоднее потратить некоторое время на предобработку, решив, в каком порядке
лучше всего умножать, чем умножать сразу в лоб.
Таким
образом, даны n матриц:
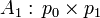 ,
, 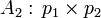 , …,
, …, 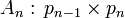 .
.
Требуется
определить, в каком порядке перемножать их, чтобы количество операций умножения
было минимальным.
.3.4
Решение систем с n правыми частями
Рассмотрим
систему m линейных алгебраических уравнений с n неизвестными,
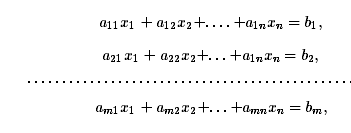
Матрицей
коэффициентов системы уравнений назовем матрицу
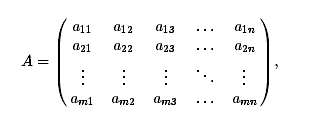
образуем
столбец правых частей системы
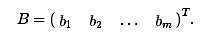
Решением
системы уравнений называют такой набор чисел x1,x2,...,xn, который при
подстановке в уравнения обращает все эти уравнения в равенства.
Система
уравнений называется однородной, если столбец правых частей нулевой. Если
столбец B ненулевой, система называется неоднородной. Так же система уравнений
может не иметь решений вообще.
Так
же для решений систем уравнений используют метод Гаусса.
Метод
Гаусса позволяет в рамках единого подхода построить решения произвольной
системы линейных алгебраических уравнений. Исходным является построение
расширенной матрицы, которая получается так:
К
матрице коэффициентов системы A добавляют справа столбец правых частей B. При
этом имеется естественное взаимно-однозначное соответствие. В каждой строке
расширенной матрицы отвечает уравнение системы.
Метод
Гаусса опирается на следующие простые соображения. Существуют преобразования
системы уравнений, которые не меняют набора решений системы. Перечислим эти
преобразования с указанием того, как они влияют на расширенную матрицу:
o Перестановка уравнений (перестановка строк расширенной
матрицы);
o Умножение уравнения на ненулевое число (умножение строки
расширенной матрицы на ненулевое число);
o Вычитание из одного уравнения другого, умноженного на
произвольное число (вычитание из строки расширенной матрицы другой строки,
умноженной на произвольное число);
o Перестановка двух неизвестных (с учетом необходимости обратной
замены переменных и перестановка столбцов расширенной матрицы).
Опишем теперь процедуру решения системы линейных уравнений с помощью
метода Гаусса. Она включает 2 шага: прямой и обратный.
. Прямой ход метода Гаусса. Выпишем расширенную матрицу системы
уравнений,
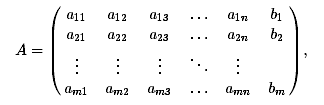
и найдем среди чисел aik число, отличное от 0. Перестановкой строк и
столбцов переместим это число в позицию (1,1),

Затем из второй, третьей и последующих строк вычитаем первую с подходящим
множителем, так, чтобы под числом a(1) появились нулевые элементы,

Затем в части матрицы, не включающей первую строку и последний столбец,
вновь ищем ненулевой элемент a(2) и, переставляя строки и столбцы, помещаем его
на позицию (2,2),
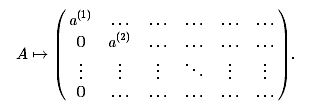
Вычитая вторую строку из всех последующих с подходящими множителями,
получаем 0 во всех элементах, стоящих под a(2),
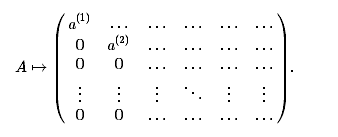
Затем в части матрицы, не включающей первую и вторую строки и последний
столбец, вновь ищем ненулевой элемент a(3) и, переставляя строки и столбцы,
помещаем его на позицию (3,3)и т.д. Продолжив нашу процедуру, мы преобразуем
исходную матрицу к матрице, имеющей "трапециевидную" форму: на
главной диагонали у такой матрицы стоят ненулевые элементы, а под главной
диагональю - нули. Наша процедура остановится, когда 1) мы дойдем до "дна"
матрицы, или 2) будет невозможно найти ненулевой элемент среди оставшихся
строк, т.е. оставшиеся строки содержат только нули (исключением может быть
последний столбец). На этом прямой ход метода Гаусса заканчивается. Его
результатом является преобразованная матрица.
. Обратный ход метода Гаусса. Рассмотрим внимательно построенную на
предыдущем шаге матрицу. Каждая строка построенной матрицы представляет
уравнение, которое однозначно по ней восстанавливается. Таким образом, следует
решить систему уравнений, соответствующую матрице, построенной в результате
прямого хода метода Гаусса. Возможны следующие ситуации:
а) Она содержит строки, состоящие из нулей, за исключением элементов
последнего столбца, которые не равны нулю,
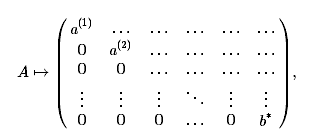
?≠0. Так же каждая такая строка матрицы соответствует уравнению, в
данном случае - уравнению с нулевыми коэффициентами, в правой части которого
стоит не ноль. Таким образом, в этом случае исходная система уравнений
несовместна.
б) Итоговая матрица содержит полностью нулевые строки. Такие строки
соответствуют тривиальному уравнению 0=0, их можно вычеркнуть. Далее, r, число
ненулевых элементов на главной диагонали равно рангу матрицы коэффициентов
исходной системы уравнений. При этом возможны 2 ситуации:
· r=n - ранг матрицы равен числу неизвестных. Это ситуация теоремы Крамера,
когда существует только одно решение системы уравнений. По построенной матрице
восстанавливают систему уравнений, которую решают снизу вверх . При этом на
каждом шаге уравнение тривиально.
· r<n. В этом случае следует неизвестные с номерами,
большими r, положить равными произвольным константам (т.е. написать равенства
xr+1=α,xr+2=β,...,xn=γ, причем α,β,...,γ могут принимать произвольные
значения), подставить эти значения в построенную систему уравнений и решать эти
уравнения снизу вверх . При этом мы получим набор решений, зависящий от n−r
свободных параметров - α,β,...,γ.
.3.5 Детерминант матриц
Для квадратной матрицы порядка n вводится важная для нее характеристика,
называемая детерминантом (иногда употребляется название определитель). Это
число, которое по определенному довольно сложному правилу сопоставляется
матрице. Для определителя матрицы A={Aik} применяют следующие обозначения:

где прямые скобки отличают определитель от матрицы (при обозначении
которой используют круглые скобки). Число n при этом называют также и порядком
определителя.
Про числа A11,A22,...,Ann говорят, что они стоят на главной диагонали
матрицы (и, соответственно, определителя).
Мы будем определять понятие определителя матрицы последовательно по
порядку n. Рассмотрим сначала матрицу порядка 1, которая содержит единственный
элемент (есть 1 строка и 1 столбец). Для такой матрицы определитель полагается
равным значению ее элемента.
Для матрицы порядка 2,
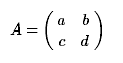
Детерминант задается соотношением:
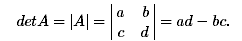
.3.6 Работа со слабо заполненными матрицами
Слабо заполненную матрицу будем хранить в виде массива из n элементов. В
зависимости от того, как мы хотим хранить матрицу - по строкам или по столбцам,
параметр n будет задавать число строк или число столбцов матрицы, и каждый
элемент массива задает соответственно строку или столбец слабо заполненной
матрицы. Каждый элемент этого массива представляет собой список структур.
Каждая структура хранит два числа - значение ненулевого элемента и его индекс в
строке, или в столбце.
Если перемножаемые матрицы A и B заполнены на 10%, то такое представление
матриц позволяет примерно в 5 раз сократить требуемую для их хранения память.
Существенно сократится и время умножения матриц, поскольку все действия будут
выполняться только над ненулевыми элементами.
Предположим, что нули равномерно распределены в слабо заполненной
матрице. Пусть p - вероятность того, что элемент такой матрицы не равен нулю, и
эта вероятность мала. Это значит, что для больших значений n произведение слабо
заполненных матриц этим свойством обладать не будет. Вероятность того, что
элемент матрицы C не равен нулю, можно посчитать по формуле:
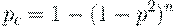
При n = 100 и p = 0,1 вероятность 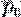 = 0,634, но при n = 1000 она
практически приближается к единице и равна 0,9999.
= 0,634, но при n = 1000 она
практически приближается к единице и равна 0,9999.
Ситуация меняется, если вероятность p является убывающей функцией от n.
Допустим, например, p = 1/n, тогда
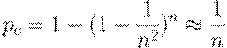
Учитывая оба этих соотношения, можно сформулировать следующее
утверждение:
Если при умножении слабо заполненных матриц A и B вероятность ненулевого
элемента p постоянна, то с ростом размера матриц n вероятность заполнения
результирующей матрицы C стремится к единице.
Если при умножении слабо заполненных матриц A и B вероятность ненулевого
элемента p зависит от n и равна 1/n, то результирующая матрица C также является
слабо заполненной с той же вероятностью заполнения, как и исходные матрицы 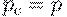 .
.
Подведем итог. Из утверждений следует, что разумно строить разные
алгоритмы, для случая, когда произведение умножаемых матриц является плотно
заполненной матрицей, и для случая, когда это произведение является слабо
заполненной матрицей.
1.4 Проблематика параллельных вычислений
Для параллельных вычислений свойственно более сложная архитектура
построения программ, чем для последовательных. Соответственно, при организации
вычислений приходится сталкиваться с такими трудностями как: доступ к ресурсам,
синхронизация выполнения, разделение работы.
К основным проблемам параллельных вычислений можно отнести следующие:
· Гонка данных;
· Взаимоблокировка;
· Синхронизация.
Под гонкой данных в параллельном программировании понимается такая
ситуация, когда два и более потока работают с общим ресурсом. Допустим, что из
нескольких потоков одновременно ведется запись в общую память. Тогда результат
такой операции непредсказуем, так как он будет определяться записью последнего
из потоков, при этом результаты операций из других потоков будут
проигнорированы и результат работы в целом будет некорректен.
Другой же не менее важной проблемой является синхронизация потоков
выполнения. При решении задач часто можно столкнуться с необходимостью ожидания
завершения какой-либо операций в одном или нескольких потоках, чтобы продолжить
выполнение в другом. Данная ситуация как раз и характеризует проблему
синхронизации.
Для решения вышеперечисленных проблем были созданы специальные механизмы
- средства синхронизации. К таким механизмам относятся:
· Мьютексы;
· Критические секции;
· Барьеры;
· Семафоры;
· Замки.
С решением вышеперечисленных проблем в параллельных вычислениях
появляется еще одна не менее важная ситуация, когда синхронизация и блокировка
доступа к ресурсам приводит к следующей проблеме - взаимоблокировке.
Взаимоблокировка может возникнуть, когда два и более потока пытаются получить
взаимоисключающий доступ к множественным общим ресурсам.
Для решения данной проблемы можно использовать как разграничение
блокировки доступа на чтение и на запись, а так же единовременную блокировку
всех общих ресурсов сразу.
Глава 2. Специальная часть
.1 Выбор
программных средств
Для разработки дипломного проекта необходимо определить средства
моделирования и разработки. К основным факторам выбора технологии
проектирования можно отнести следующие:
· Высокая производительность разработанного приложения;
· Быстрота разработки приложения;
· Низкие требования разработанного приложения к ресурсам
компьютера;
· Возможность разработки новых компонентов и инструментов
собственными средствами;
· Наращиваемость (за счет встраивания новых компонент);
· Удобная проработка иерархии объектов.
Исходя из выше перечисленных критериев, для проектирования информационной
подсистемы мы выбрали такие средства как Enterprise Architect 9 который будет
служить для создания моделей, выполнения анализа, документирования и
планирования изменения сложных бизнес-процессов и AllFusion Process Modeler ERwin 7 для разработки физической модели данных и базы
данных.Architect 9 - CASE-инструмент для проектирования и конструирования
программного обеспечения. EA поддерживает спецификацию UML 2.0, описывающую
визуальный язык, которым могут быть определены модели проекта.
Ключевые функций Enterprise Architect:
· Создание элементов UML-моделей широкого круга назначения;
·