Алгоритмизация и языки программирования
Введение
Появление языков
программирования и основ программного обеспечения позволило расширить
образовательную сферу в Высших учебных заведениях в области информатики и
информационных технологий. В связи с этим перед
Вузами встает важная задача развития потенциала студентов в изучении курса
информатики.
В Ташкентском
государственном педагогическом университете им. Низами данная задача
реализуется на уроках информатики, на одном из важнейших предметов данного
курса - "Алгоритмизация и языки программирования", что в свою очередь
требует совершенствования учебного процесса в преподавании языков
программирования и последующей работы с ними.
Система и
методика обучения призвана обучить студента грамотно подходить к вопросам
создания программ, написанию кода для ее реализации, знаниям основ
программирования и отладки в случае неисправностей, а так же использованию
программ по назначению.
Целью данной
курсовой работы является рассмотрение и ознакомление с одним из наиболее
используемым языком программирования - С++ и то, как он используется в процессе
работы со строковыми типами данных и символами. Исходя из вышесказанной цели,
можно выделить частные задачи, поставленные в курсовой работе:
· Выявить
содержание теории о том, что представляют собой строковые типы данных и
символы, а именно их свойства и какие компоненты используются при работе с
ними.
· Изучить код
написания программ в режиме разработки консольного приложения в первой главе
курсовой работы.
· Разработать
приложение с использованием компонентов на форме и реализовать программу с
учетом задач и особенностей написания кода для них.
Объектом исследования в курсовой
работе является строковый тип данных, символы и текстовые файлы в языке С++.
Предметом курсовой работы являются
технологии создания программ, предназначенных для работы со строками и
текстовыми файлами.
Методологической основой
исследования в курсовой работе явились лекционные и практические занятия,
проводимые педагогом по предмету "Алгоритмизация и языки
программирования", материалы подобранные по теме урока и алгоритмы
реализации программ с учетом кода и принципов разработки. На уроках был записан
соответствующий лекционный материал по данной теме, который в свою очередь был
внесен в теоретическую часть курсовой работы.
язык программирование код консольный
Глава 1. Строки и символы в языке
программирования С++
.1 Массивы символов в С++
В стандарт С++ включена поддержка нескольких
наборов символов. Традиционный 8 битовый набор символов называется
"узкими" символами. Кроме того, включена поддержка 16 битовых
символов, которые называются "широкими". Для каждого из этих наборов
символов в библиотеке имеется своя совокупность функций.
Как и в ANSI С, для представления символьных
строк в С++ не существует специального строкового типа. Вместо этого строки в
С++ представляются как массивы элементов типа char, заканчивающиеся
терминатором строки - символом с нулевым значением ('\0'), Строки,
заканчивающиеся нуль-терминатором, часто называют ASCIIZ-строками. Символьные
строки состоят из набора символьных констант, заключенного в двойные кавычки:
"Это строка символов..."

При объявлении строкового массива необходимо
принимать во внимание наличие терминатора в конце строки, отводя тем самым под
строку на один байт больше:
// Объявление строки размером 10 символов,
// включая терминатор. Реальный размер
// строки: 9 символов + 1 терминаторbuffer[10];
Строковый массив может при объявлении
инициализировать начальным значением. При этом компилятор автоматически
вычисляет размер будущей строки и добавляет в конец нуль-терминатор:
// Объявление и инициализация строки:Wednesday[]
= "Среда";
// что равносильно:
char
Wednesday[] =
{'с','р','e','д','a','\0'};
В качестве оператора ввода при работе со
строками вместо оператора записи в "поток" лучше использовать функцию
get- line().
так как потоковый оператор ввода игнорирует вводимые пробелы, а кроме того,
может продолжить ввод элементов за пределами массива, если под строку отводится
меньше места, чем вводится символов. Функция getline()
принимает два параметра: первый аргумент указывает на строку, в которую
осуществляется ввод, а второй - число символов, подлежащих вводу.
В качестве примера возьмем объявления символьных
строк и использования функции ввода getline
().
#include <iostream.h>main()
{myString[4];" "Введите
строку: " " '\n';.getline (myString, 4);" "Вы ввели: "
" myString; 0;
}
Объявленная в начале программы строка myString
может принять только три значащих символа и будет завершена нуль-терминатором.
Все последующие символы, вводимые в этот строковый массив, будут отброшены. Как
видно из примера, при использовании функции getline
( ) вторым параметром следует указывать число, меньше или равное размеру
вводимой символьной строки. Большинство функций работы со строками содержится в
библиотеке string.h,
Основные функции работы с символьными массивами сведены в следующую таблицу.
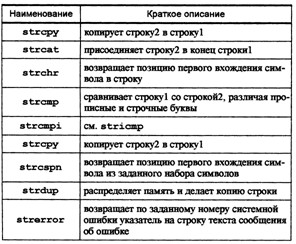
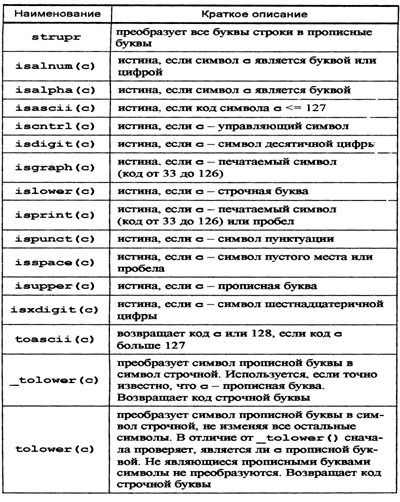

Определение длины строк очень часто при работе
со строками необходимо знать, сколько символов содержит строка. Для выяснения
информации о длине строки в заголовочном файле string.h описана функция
strlen(). Синтаксис этой
функции
имеет
вид:_t
strlen(const char* string)
Данная функция в качестве единственного
параметра принимает указатель на начало строки string, вычисляет количество
символов строки и возвращает полученное без знаковое целое число ( size__t ).
Функция sizeof() возвращает значение на единицу
меньше, чем отводится под массив по причине резервирования места для символа '
\0'. Следующий фрагмент демонстрирует использование функции strlen():
char
Str[] = "ABCDEFGHIJK";
unsigned
int i;-
strlen(Str);
Часто функция sizeof() используется при вводе
строк в качестве второго параметра конструкции cin.getline(), что делает код
более универсальным, так как не требуется явного указания числа вводимых
символов. Если теперь потребуется изменить размер символьного массива,
достаточно модифицировать лишь одно число при объявлении строки символов:
// Было:
// char myString[4];
// cin.getline(myString, 4);
// Стало:myString[20];.
getline (myString, sizeof (myString)) ;
1.2 Копирование и конкатенация строк
Значения строк могут копироваться из одной в
другую. Для этой цели используются ряд стандартных функций, описываемых ниже.
Функция strcpy() имеет
прототип:*
strcpy(char* strl, const char* str2)
и выполняет побайтное копирование символов из
строки, на которую указывает str2,
в строку по указателю strl.
Копирование прекращается только в случае достижения нуль-терминатора строки str2,
поэтому перед копированием необходимо удостовериться, что длина str2
меньше или равна длине strl.
В противном случае возможно возникновение ошибок, связанных с наложением
данных.
Например, следующий фрагмент копирует в строку Str
значение строки
"Проверка копирования":
char
Str[20];
strcpy(Str,
"Проверка копирования";
Можно производить копирование не всей строки, а
лишь отдельного ее фрагмента (до конца строки). При этом второй параметр
является указателем на некоторый элемент строкового массива. Например,
следующий фрагмент скопирует в str2
окончание строки str1:
char
strl[20] =
"Проверка копирования";
char str2[20];* ptr = strl;
+- = 9;
// ptr
теперь указывает на
// подстроку "копирования"
// в строке strl(str2, ptr);"
str2 " '\n';
Функция strncpy
( ) отличается от strcpy
( ) тем, что в ее параметрах добавляется еще один аргумент, указывающий
количество символов, не больше которого будет скопировано. Ее
синтаксис
имеет
вид:*
strncpy ( char* strl,const char* str2,__t
num )
Если длина strl
меньше длины str2,
происходит урезание символов:
char cLong [ ] * =
" 12345678901234567890123456789
";cShort [ ]="abcdef";(cShort, cLong, 4) ;" cShort "
'\n';
" cLong " f\n';
В результате будет выведено:
ef
То есть из строки cLong в строку cShort
скопировано четыре первых символа, затерев тем самым исходное значение начала
короткой строки.
Функция strdup ( ) в качестве параметра получает
указатель на строку-источник, осуществляет распределение памяти, копирует в
отведенную область строку и возвращает указатель на начало полученной
строки-копии. Синтаксис функции следующий:
char* strdup(const
char* source)
В следующем примере производится копирование
строки strl в строку str2:*
strl = "Процедура не найдена";
char* str2;" strdup (strl);
Конкатенация (или присоединение) строк довольно
часто используется для образования новой строки символов. Для этой операции
стандартная библиотека предлагает функции strcat()
и strncat().
В результате работы функции содержимое строки,
на которую указывает str2.
присоединяется к содержимому строки, на которую ссылается strl.
Возвращаемый функцией указатель str1
указывает на результирующую строку. При этом величина строкового массива strl
должна бьпъ достаточной для хранения объединенной строки. В следующем примере
строка str
инициализируется с помощью функции копирования strcpy()
и дополняется подстрокой, используя функцию strcat
( ):str[81];(str, "Для продолжения ");(str, "нажмите
клавишу");
Функция strncat () также осуществляет
конкатенацию строк, однако, присоединяет лишь указанное в третьем параметре
количество символов (беззнаковое целое):
char* strncat ( char* strl, const
char* str2, size_t num )
Функция возвращает указатель на начало сформированной
строки strl. Следующий пример производит конкатенацию строки strl с семью
первыми символами подстроки str2:strl[90] = "Для продолжения
";str2[30] = "нажмите клавишу";
strncat (strl, str2, 7);" strl
;
В результате будет выведена строка:
"Для продолжения нажмите".
1.3 Сравнение строк
Библиотека функций string.h предлагает к
использованию готовые функции, выполняющие сравнение строк Ниже приводятся
функции, выполняющие осимвольное сравнение двух строк.
Функция strcmp ( ) имеет
синтаксис
:strcmp (const char* strl, const char* str2)
Данная функция сравнивает строки strl и str2, не
различая
регистра символов. Возвращается одно из
следующих целочисленных значений
· ¦ <0 - если строка strl меньше,
чем str2;
· ¦ =0-еслистрокиэквивалентны;
· ¦ >0 - если строка strl больше,
чем str2.
Эта функция производит сравнение, различая
прописные и строчные буквы. Следующий пример иллюстрирует работу функции
strcmp():
char
strl [ ] = "Ошибка
открытия Базы";
char
str2 [ ] = "
Ошибка открытия Базы ";
int i;= strcmp (strl, str2);
В результате переменной i будет присвоено
положительное значение, так как строка из strl меньше, чем строка из str2, по
той причине, что прописные буквы имеют код символов меньше, чем те же символы в
нижнем регистре (слово "базы N в первом случае начинается со строчной
литеры, а во втором - с прописной).
Функция stricmp имеет
синтаксис:
int stricmp (const char* strl, const char* str2)
Данная функция сравнивает строки strl
и str2, не различая
регистра cимволов.
Возвращается одно из следующих целочисленных значений:
· ¦ <0 - если строка strl
меньше, чем str2;
· ¦ "о ~ если строки
эквивалентны;
· ¦ >O
- если строка strl больше, чем
str2.
Следующий фрагмент программы демонстрирует
применение функции stricmp
( ):
char strl [ ] ="Moon";str2
[ ]="MOON";i;= stricmp (strl, str2);
В данном случае переменной i
будет присвоено значение 0 (сигнализируя тем самым совпадение строк), так как strl
и str2 отличаются только
регистром.
Функция strncmp() производит сравнение
определенного числа первых символов двух строк. Регистр символов при этом
учитывается. Функция имеет следующий прототип:
int
strncmp (const
char* strl,
( const char* str2, size_t num )
Данная функция сравнивает num первых символов
двух строк, на которые указывают strl и str2, и возвращает одно из следующих
значений:
· ¦ <0 - если строка strl меньше,
чем str2;
· ¦ =0-еслистрокизквивалентны;
· ¦ >0-если строка str1
больше, чем в str2.
Пример использования функции strncmp ( ) .strl [
] = "Ошибка открытия базы";str2 [ ] = "Ошибка Открытия базы";
int i;= strncmp (strl, str2, 12);
В результате сравнения первых 12-ти символов
обеих строк переменная i получит положительное значение, так как подстроки
"Ошибка откры" и "Ошибка Откры" отличаются одним символом и
в первом случае код символа больше, чем во втором.
Функция strnicmp() производит сравнение
определенного числа первых символов двух строк, не обращая внимания на регистр
символов. Данная функция описана следующим образом:
int
strnicmp(const
char* strl,
const char*
str2, size_t
num)
Функция возвращает целочисленное значение
согласно следующему правилу:
· ¦ <0 - если строка strl меньше,
чем str2;
· ¦ =0 - если строки эквивалентны;
· ¦ >0 - если строка strl больше,
чем str2.
В следующем примере производится сравнение
заданного числа символов подстрок:
char strl [ ] = " Opening error
";str2 [ ] = "Opening Error...";i;= strnicmp (strl, str2, 13);
В результате переменной i будет присвоено
значение 0, так как первые 13 символов обеих подстрок отличаются только
регистром.
.4 Преобразование строк
Элементы символьных строк могут быть
преобразованы из одного регистра в другой. Для этого используются стандартные
функции _strlwr() и _strupr(). Следует отметить, что в некоторых версиях
компиляторов имена данных функций могут следовать без ведущего символа подчеркивания.
Фyнкция _strlwr ( ) принимает в качестве
параметра указатель на строку символов, гфеобразует эту строку к нижнему
регистру (строчные символы) и возвращает указатель на полученную строку. Данная
функция имеет следующий прототип:* _strlwr (char* str)
Следующий фрагмент показывает применение функции
_strlwr():
char str[] =
"ABRACADABRA";
_strlwr(str);
После вызова функции строка str
будет содержать значение "abracadabra".
Функция _strupr
() объявлена следующим образом:
char * _strupr
(char* str)
Данная функция преобразует строку символов, на
которую указывает str,
в прописные буквы (к верхнему регистру). В результате работы функции
возвращается указатель на полученную строку.
Следующий пример переводит символы заданной
строки в верхний регистр:
char str [ ] = "pacific
ocean";
_strupr(str); cout " str;
В результате будет выведено: PACIFIC OCEAN
Приведенные выше функции преобразования строк,
работая с указателями, преобразуют исходную строку, которая не всегда может
быть восстановлена, поэтому, если в дальнейшем коде программы потребуется
воспользоваться оригиналом символьной строки, перед использованием функций
_strlwr() и strupr () необходимо сделать копию их аргументов. На практике
довольно широко используются функции проверки принадлежности символов
какому-либо диапазону, такие как isalnum
( ), isalpha
( ), isascii
( ) , isdigit
( ) и т.д. объявленные в заголовочном файле ctype.h. Ниже рассматривается
пример использования этого вида функций.
#include <ctype.h>
#include
<iostream.h>main(void)
{str[4];
{" "Enter your age, please
¦ . . ";.getline(str, 4);(isalpha(str[O]))
{" "You entered a
letter,";" " try again\n"/;
}(iscntrl (str [O] ) )
{" "You entered a
control";" " symbol, try again\n";;
}( ispunct ( str[O] ) )
{(!isdigit ( str [ I ] ) );
{" "Your age is "
" str;
return 0;
}
}
}(true);
}
Здесь пользователю предлагается ввести свой
возраст. Функция cin.getline()
помещает в строку str
введенную последовательность (до трех) символов, после чего следует проверка
первого введенного элемента массива на принадлежность к буквенной, управляющей
последовательностей или символам пунктуации. Если результат соответствующей
проверки положительный, пользователю предлагается ввести данные повторно. В
противном случае все введенные элементы строки проверяются напринадлежность к
цифровому набору данных. Если хотя бы один из символов не удовлетворяет
проверяемому условию, цикл ввода повторяется сначала. После корректного ввода
данных на экран выводится сообщение о возрасте пользователя.
.5 Обращение строк
Функция обращения строки strrev ( ) меняет
порядок следования символов на обратный (реверс строки). Данная функция имеет
прототип:* strrev(char* str)
Следующий пример демонстрирует работу функции
strrev().
char str [ ] = "Привет";"
strrev (str) ;
В результате на экране будет выведена строка
"тевирП". Эта функция также преобразует строку-оригинал.
.6 Поиск символов
Одна из часто встречаемых задач при работе со
строками - поиск отдельного символа или даже группы символов. Библиотека
string.h предлагает следующий набор стандартных функций.
Функция нахождения символа в строке strchr()
имеет следующий прототип:
char* strchr (const char* string,
int с)
Данная функция производит поиск символа с в
строке string и в случае
успешного поиска возвращает указатель на место первого вхождения символа в
строку. Если указанный символ не найден, функция возвращает NULL. Поиск символа
осуществляется с начала строки.
Ниже рассматривается фрагмент, осуществляющий
поиск заданного символа в строке.
char str[ ] = "абвгдеёжзийк";*
pStr;
= strchr(str,
‘ж’);
В результате работы программы указатель pStr
будет указывать на подстроку "жзийк" в строке str.
Функция strrchr ( ) осуществляет поиск заданного
символа с конца строки. Она имеет следующий синтаксис:
char* strrchr(const
char* string,
int с)
Данная функция возвращает указатель на
последний, совпавший с заданным с, символ в строке string. Если символ не
найден, возвращается значение NULL.
В следующем примере производится поиск заданного
символа
с конца строки:str[] = "абвгдеёжзийк";
char* pStr;ш
strrchr(str, 'и');
Таким образом, указатель pStr будет указывать на
подстроку "ийк" в строке str.
Функция strspn ( ) проводит сравнение символов
одной строки с символами другой и возвращает позицию (начиная с нуля), в
которой строки перестают совпадать. Данная функция имеет следующий прототип:
size_t strspn ( const char* string,
const char* group )
Функция проверяет каждый символ строки string на
соответствие каждому из символов строки group. B результате работы функции
возвращается число совпавших символов.
Следующий пример демонстрирует использование
данной функции:str [ ] = "Загрузка параметров БД";
char substr [] = "Загрузка
параметррррр'\index=0;=
strspn ( str, substr ) ;" index;
На экран будет выведено число 17, так как
символы строки str и подстроки substr совпадают вплоть до 17-й позиции.
Приведенная функция различает регистр символов.
Функция strcpn
имеет синтаксис:
size_t
strcpn (const
char* strl,char*
str2)
Эта функция сопоставляет символы строки strl и
str2 и возвращает длину строки strl, не входящей в str2. Таким образом, можно
определить, в какой позиции происходит пересечение двух символьных массивов:
char str[ ] =
"abcdefghijk";index; = strcspn(str,
"elf");
Переменная index получит значение 4, так как в
этой позиции строки имеют первый общий элемент.
Функция strpbrk ( ) объявлена следующим образом:
char* strpbrk (const char* strl,
const char* str2)
Эта функция отыскивает место вхождения в строку
strl любого из символов строки str2. Если символы найдены, возвращается место
первого вхождения любого символа из str2 в строку strl. В противном случае
функция возвращает NULL.
Ниже иллюстрируется использование функции
strpbrk ( ):
char strl [ ]="abcdefghijk";str2
[ ] = "ecb";* ptr;= strpbrk(strl, str2);
cout " ptr " ' \n' ;
В результате будет выведена подстрока
"bcdefghijk". так как символ ‘b’
из строки str2 встречается в строке strl раньше других.
Поиск подстрок
При необходимости поиска в одной строке
последовательности символов, заданной в другом символьном массиве (подстроке,
лексеме), стандартная библиотека string.h предлагает воспользоваться одной из
следующих функций.
Функция strstr() описана следующим образом:
char* strstr (const char* str,
const char* substr)
Данная функция осуществляет сканирование строки
str и находит место первого вхождения подстроки substr в строку str. В случае
успешного поиска функция strstr возвращает указатель на первый символ строки
str, начиная с которого следует точное совпадение части str обязательно со всей
лексемой substr. Если подстрока substr не найдена в str, возвращается NULL.
Следующий пример показывает использование
функции strstr().strl[ ]="npoизводится поиск элемента";
char str2 [ ] = "поиск";*
ptr;= strstr(strl, str2);" ptr " '\n';
На экран будет выведено "поиск
элемента", так как подстрока, содержащаяся в str2, находится внутри строки
strl и функция strstr() установит указатель ptr на соответствующий элемент
символьного массива strl. Чтобы найти место последнего вхождения подстроки в
строку, можно воспользоваться следующим приемом: обе строки реверсируются с
помощью функции strrev(), а затем полученный результат анализируется в функции
strstr ( ).
Функция strtok ( ) имеет
синтаксис:*
strtok(char* str, const char* delim)
Эта функция выполняет поиск в строке str
подстроки, обрам-
обрамленной с обеих сторон любым
символом-разделителем из строки delim. В случае успешного поиска данная функция
обрезает строку str, помещая символ ' \0' в месте, где заканчивается найденная
лексема Таким образом, при повторном поиске лексемы в указанной строке stx
первым параметром следует указывать NULL. Так как strtok() модифицирует
строкуюригинал, рекомендуется предварительно сохранять копию последней.
Приведенный ниже пример иллюстрирует вышесказанное. Предположим, необходимо
разбить имеющееся в строковом массиве предложение по словам и вывести каждое из
них на экран.
#include <string.h>
#include <iostream.h>
main()
{
char
str [ ] = "Язык
программирования С++11;
char *Delimiters = "
.!?,;:\"'/0123456789 * 0#$%A&*O<>{}[]~+ -=";*ptr;=
strtok(str, Delimiters);(ptr)" ptr " '\n' ;(ptr)
{= strtok(NULL,
Delimiters);(ptr)" ptr " f \n' ;
}0;
В данной программе объявляется подлежащая
анализу строка str, подстрока, содержащая набор разделителей Delimiters и
указатель на символьный тип данных ptr. Вызов функции strtok(str, Delimiters)
сканирует строку str и как только в ней встретится любой символ, входящий в
подстроку Delimiters (в данном случае это символ пробела), указатель ptr станет
ссылаться на начало исходной строки до найденного символа. То есть ptr будет
содержать:
*ptr - "Язык".
Благодаря тому, что функция strtok ( ) помещает
в найденном месте нуль-терминатор (' \0')? исходная строка модифицируется.
Таким образом, массив символов str примет значение:
Осуществив проверку указателя ptr на
существование в операторе if (ptr), найденное слово выводится на экран. Далее в
цикле с помощью функции strtok() находится последний нуль-терминатор строки str:
ptr = strtok(NULL,
Delimiters);
что, фактически, соответствует локализации
следующего слова предложения, и найденная последовательность символов выводится
на экран.
.7 Функции преобразования типа
Функции преобразования данных довольно часто
используются, как следует из названия, для преобразования одного типа данных в
другой тип.
В приведенной ниже таблице перечислены основные
функции, их прототипы подключаются в заголовочном файле std2.ib.h.
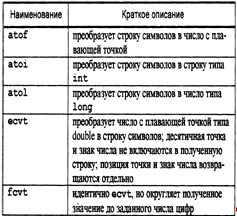

Чаще всего данные функции используются для
преобразования чисел, введенных в виде символьных строк, в числовое
представление, а также для выполнения определенных арифметических операций над
ними и обратное преобразование в строку символов.
2. Разработка приложения с использованием строк
и символов в языке программирования С++
.1 Создание приложения для выполнения
практической работы
Дан текстовый файл. Необходимо:
. Создать программу "Перевертыш".
. Удалить лишние пробелы из текста.
. Пронумеровать каждую строку текста.
. Определить есть ли в тексте пустые строки?
. Удалить пустые строки
. Подсчитать сколько слов в тексте.
. Определить какая самая длинная строка в
тексте.
. Определить какая самая короткая строка в
тексте.
. Объединить все строки текста.
. Определить сколько строк в тексте.
. Вставить вместо пробела ( _ ).
. Найти номер самой длинной строки текста.
. Заменить все слова текста на слово
"Котенок"..
.Подсчитать длину каждого слова в тексте.
. Удалить всю пунктуацию.
. Подсчитать длину каждой строки.
В данной главе курсовой работы подготовлены
вышеперечисленные задачи и способы их выполнения.
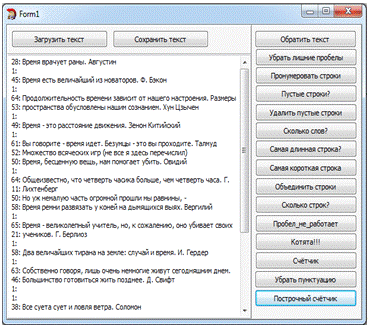
Следует учесть, что работа выполнялась на единой
форме, где размещены соответствующие кнопки выполняющие различные функции
программы, и поэтому был взят не единый код, а лишь его фрагменты.
Фрагмент кода, который описывается ниже,
используется для всех типов задач. Он представляет собой объявление таких
переменных, которые являются главными и будут использованы во всех задачах..
TForm1 *Form1;str;len, n;
//const char nl = Chr(10)+Chr(13);
Фрагмент кода
функцииswapch(AnsiString&
s, int a, int b){tmp =
s.SubString(a,1);.Delete(a,1);.Insert(s.SubString(b-1,1),a);
//str.SubString(i,1) =
str.SubString(len-i-2,1);.Delete(b,1);.Insert(tmp,b);
}
Фрагмент кода для загрузки текста из текстового
файла в поле Memo1:
{
Memo1->Lines->LoadFromFile("Ôàéë.txt");
n = Memo1->Lines->Count;=
"";= Memo1->Text;= str.Length();
//int i = str.Pos("\n");
//ShowMessage(str.SubString(i,4));
//ShowMessage(str);
}
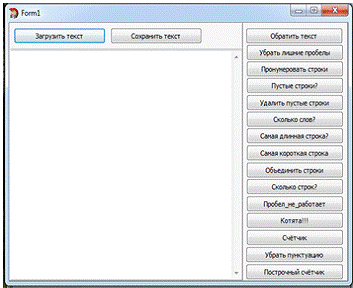
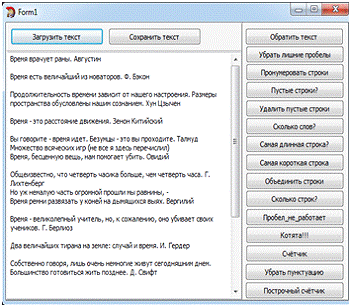
Задание №1.
Фрагмент кода для реализации программы
"Перевертыш". Свое название программа получила в связи с тем, что
слова из которых состоит текстовый файл, читаются справа налево (наоборот).
String tmp;(int i = 1; i <= len/2; i++) {=
str.SubString(i,1);(str,i,len-i+1);
//str.Delete(i,1);
//str.Insert(str.SubString(len-i,1),i);
//str.SubString(i,1) = str.SubString(len-i-2,1);
//str.Delete(len-i+1,1);
//str.Insert(tmp,len-i+1);
//ShowMessage(str);
//;str.SubString(len-i-2,1) = tmp;
}->Clear();->Text = str;= str.Length();
}
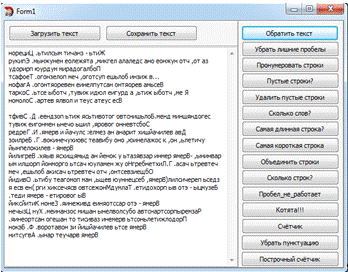
Задание №2.
Фрагмент кода для реализации программы
"Удаление лишних пробелов". Свое название программа получила в связи
с тем, что между словами могут образовываться лишние пробелы, которые
появляются во время ввода текста и его редактировании.
{
/*for (int i = 1; i <= len-1;
i++) {(int j = i+1; j <= len; i++) {
if (str.SubString(i,1).c_str() >
str.SubString(j,1).c_str()) {(str,i,j);
}
}
} */i;(i=str.Pos("
")){.Delete(i,1);
}= str.Length();->Clear();
Memo1->Text = str;
}
Задание №3. "Нумерация строк"
Фрагмент кода для реализации программы:
{j = 0;
//str = "1. " + str;tmp =
"";i;(i=str.Pos("\n")){++;= tmp+IntToStr(j)+".
"+str.SubString(1, i-1)+"\n";.Delete(1,i);
}++;= tmp + IntToStr(j)+".
"+str;= tmp;->Clear();->Text = str;= str.Length();
}

Задание №4. "Есть ли пустые строки?".
Фрагмент кода для реализации программы:
{(int i =
str.Pos("\n\r\n")) {
ShowMessage ("Ecть!");
}ShowMessage ("Нет!");
}
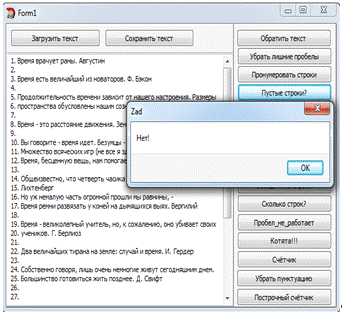
Задание №5. "Есть ли пустые строки?".
Фрагмент кода для реализации программы:
{
if (int i =
str.Pos("\r\n\r\n")) {
str.Delete(i,2);
Memo1->Text = str;
len = str.Length();(i =
str.Pos("\r\n\r\n")){
str.Delete(i,2);
Memo1->Text = str;
len = str.Length();
}
} else ShowMessage("Нет
пустых
строк!");
}
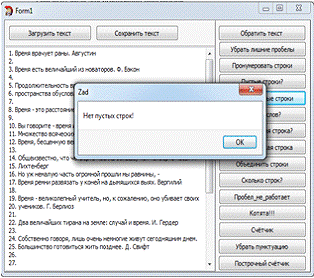
Задание №6. "Сколько слов?"
Фрагмент кода для реализации программы:
{AnsiString stmp = str;.Trim();j =
0, i;(i=stmp.Pos(" ")){.Delete(i,1);
}(i = stmp.Pos("\n\r\n")){
stmp.Delete(i,2);
}(i = stmp.Pos(" ")) {
j++;
stmp.Delete(i,1);
}(i = stmp.Pos("\r\n")) {
j++;
stmp.Delete(i,2);
}++;(IntToStr(j)+" слов(а)");
}
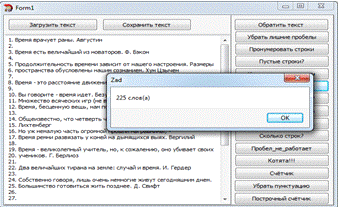
Задание №7. "Самая длинная строка"
Фрагмент кода для реализации программы:
{j = 0, jmax;tmp1, tmp2=str;i,lmax;=
0;.Trim();(i=tmp2.Pos("\r\n")){++;= tmp2.SubString(1,
i);.Delete(1,i);(tmp1.Length()>lmax) {
lmax = tmp1.Length();
jmax = j;
}
}("Строка № "+IntToStr(jmax));
}
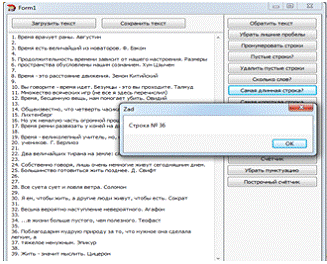
Задание №8. "Самая короткая строка"
Фрагмент кода для реализации программы:
{j = 0, jmin;tmp1, tmp2=str;i,lmin;=
999999;.Trim();(i=tmp2.Pos("\r\n")) {++;= tmp2.SubString(1,
i);.Delete(1,i);(tmp1.Length()<lmin) {
lmin = tmp1.Length();
jmin = j;
}
}("Строка
№ "+IntToStr(jmin));
}
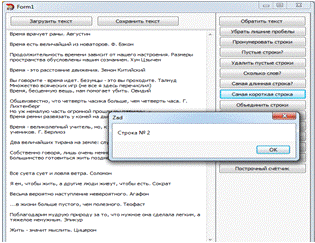
Задание №9. "Объединить строки"
Фрагмент кода для реализации программы:
{i;(i = str.Pos("\r\n")) {
str.Delete(i,2);
str.Insert(" ",i);
}= str.Length();->Clear();
Memo1->Text = str;
}
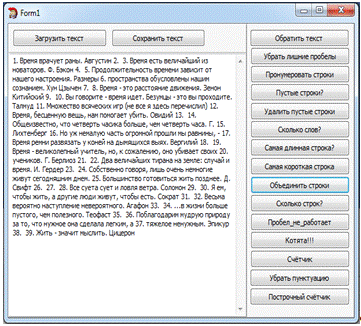
Задание №10. "Сколько строк?"
{
int i, j=0;
String tmp = str;
while
(i=tmp.Pos("\r\n")){++;.Delete(1,i);
}
j++;
ShowMessage(IntToStr(j)
+ " строк(и)");
}
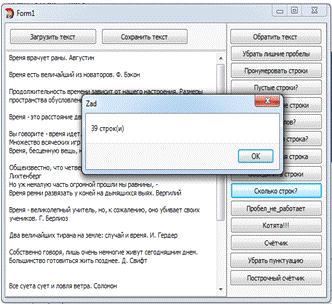
Задание №11. "Пробел не работает"
Фрагмент кода для реализации программы:
{
int
i;(i=str.Pos(" ")){.Delete(i,1);.Insert("_",i);
}=
str.Length();->Clear();
Memo1->Text = str;
}
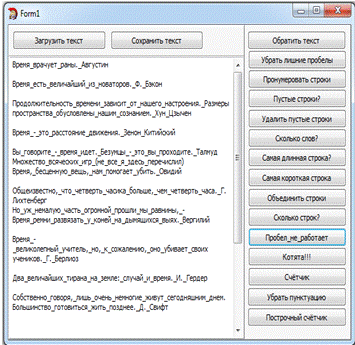
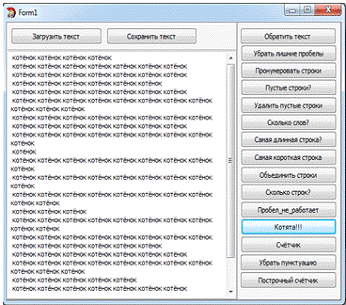
Задание №12. "Котята"
Фрагмент кода для реализации программы:
{j = 0;tmpline =
"", tmpword = "", tmp;i,k;(i=str.Pos("
")){.Delete(i,1);
}(i =
str.Pos("\n\r\n")){
str.Delete(i,2);
}(i=str.Pos("\r\n")){=
str.SubString(1, i-1);(k=tmpline.Pos(" ")) {
tmpword = tmpword +
" котёнок";
tmpline.Delete(1,k);
}= tmpword+ " котёнок";.Trim();=
tmp + tmpword+"\r\n";= "";.Delete(1, i+1);
}(k=str.Pos("
")) {
tmpword = tmpword +
" котёнок";
str.Delete(1,k);
}= tmpword+ " котёнок";.Trim();=
tmp + tmpword;= tmp;->Clear();->Text = str;
len = str.Length();
}
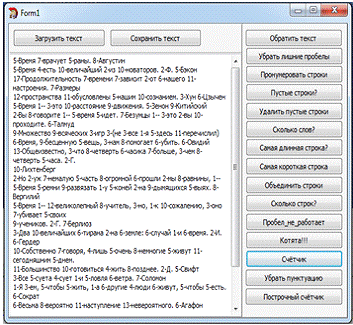
Задание №13. "Счетчик"
Фрагмент кода для реализации программы:
{j = 0;tmpline = "",
tmpword = "", tmp;i,k;(i=str.Pos(" ")){.Delete(i,1);
}(i = str.Pos("\n\r\n")){
str.Delete(i,2);
}(i=str.Pos("\r\n")){=
str.SubString(1, i-1);(k=tmpline.Pos(" ")) {
tmpword = tmpword +
IntToStr(k-1)+"-"+tmpline.SubString(1,k);
tmpline.Delete(1,k);
}=
tmpword+IntToStr(tmpline.Length())+"-"+tmpline;.Trim();= tmp +
tmpword+"\r\n";= "";.Delete(1, i+1);
}(k=str.Pos(" ")) {
tmpword = tmpword +
IntToStr(k-1)+"-"+str.SubString(1,k);
str.Delete(1,k);
}= tmpword+
IntToStr(str.Length())+"-"+str;.Trim();= tmp + tmpword;=
tmp;->Clear();->Text = str;
len = str.Length();
}
Задание №14. "Убрать пунктуацию"
Фрагмент кода для реализации программы:
{i;(i=str.Pos(".")) {
str.Delete(i,1);
}(i=str.Pos(",")) {
str.Delete(i,1);
}(i=str.Pos("?")) {
str.Delete(i,1);
}(i=str.Pos("!")) {
str.Delete(i,1);
}=
str.Length();->Clear();->Text = str;
}
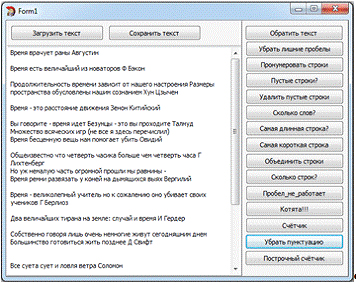
Задание №15. "Построчный счетчик"
Фрагмент кода для реализации программы:
{j = 0;tmp =
"";i;(i=str.Pos("\r\n")){= tmp+IntToStr(str.SubString(1,
i-1).Length())+": "+str.SubString(1, i+1);.Delete(1,i);
}++;= tmp +
IntToStr(str.Length())+": "+str;= tmp;->Clear();->Text = str;
len = str.Length();
}
Заключение
С++ предлагает богатую среду для
разработки программ, которая делает процесс программирования более
производительным и более эффективным.
Используя язык высокого уровня
можно писать программы для приложений любого типа и размера. Эта
профессиональная система программирования способна создать программы любого
уровня от простейших до наисложнейших.
В данной курсовой работе мы
совместили несколько задач и их решений на одной форме. В ходе выполнения
работы были задействованы большое количество различных источников, материалов
из учебных пособий и информация из интернета. Были продуманы создания таких
программ как "Котята" и "Перевертыш". Творческий подход
внес свою оригинальность в создании приложения.