Сравнение и анализ методов сортировки массивов
РЕФЕРАТ
с., 7 рис., 3 библ., 1 прил.
МАССИВ, МЕТОД, АЛГОРИТМ, ШАБЛОН.
Целью работы является исследование и сравнение методов сортировки
массивов в среде Visual Studio.
Разработанная программа позволяет сравнить методы сортировки массивов.
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
. ПОСТАНОВКА ЗАДАЧИ
.1 Цель и задачи работы
.2 Обоснование выбора средства программирования
.3 Входная и выходная информация
.4 Требования к аппаратному обеспечению
.5 Требования к программному обеспечению
. СВЕДЕНИЯ ИЗ ТЕОРИИ
. анализ метода поиска
в строке по алгоритму боуера-мура
. РЕЗУЛЬТАТ АНАЛИЗА
. ОПИСАНИЕ ПРОГРАММЫ
.1 Функциональное назначение
.2 Глобальные переменные и константы
. РУКОВОДСТВО ПОЛЬЗОВАТЕЛЯ
ЗАКЛЮЧЕНИЕ
ЛИТЕРАТУРА
ПРИЛОЖЕНИЕ А
ПРИЛОЖЕНИЕ Б
ВВЕДЕНИЕ
В последнее время резко возрос интерес к программированию. Это связано с
развитием и внедрением в повседневную жизнь информационно - коммуникационных
технологий. Если человек имеет дело с компьютером, то рано или поздно у него
возникает желание, а иногда и необходимость, программировать.
Среди пользователей персональных компьютеров в настоящее время наиболее
популярно семейство операционных систем Windows и естественно, что тот, кто собирается
программировать, стремится писать программы, которые будут работать в этих
системах.
Бурное развитие вычислительной техники, потребность в эффективных
средствах разработки программного обеспечения привели к появлению систем
программирования, ориентированных на так называемую "быструю
разработку", среди которых можно выделить Visual Studio. В основе систем быстрой разработки (RAD-систем, Rapid Application Development - среда быстрой разработки
приложений) лежит технология визуального проектирования и событийного
программирования, суть которой заключается в том, что среда разработки берет на
себя большую часть рутинной работы, оставляя программисту работу по
конструированию диалоговых окон и функций обработки событий.
Программировать на C#
можно как в среде Windows, так и в DOS, причем для каждой из операционных
систем существует довольно большое количество средств разработки: от
компилятора, работающего в режиме командной строки DOS, до мощной интерактивной среды разработки.
1/
ПОСТАНОВКА ЗАДАЧИ
1.1 Цель и задачи работы
Исследовать и сравнить методы сортировки массивов.
Задачи курсовой работы:
изучить основные методы сортировки массивов;
разработать алгоритм решения задачи;
определить более эффективный метод;
осуществить программную реализацию и протестировать разработанное
приложение.
1.2 Обоснование выбора средства программирования
Для написания программы была выбрана среда программирования Visual Studio 2012 и язык программирования C#. Данная среда, помимо того, что является самой популярной в
своём роде, отличается надёжностью и эффективностью. К тому же Visual Studio является программным продуктом корпорации Microsoft (которая и разработала C#), что означает полную поддержку
всех возможностей языка.
1.3 Входная и выходная информация
Входными данными для программы являются:
цифры.
Выходными данными являются результаты сортировки массива.
1.4 Требования к аппаратному обеспечению
Для стабильного функционирования программы необходим компьютер фирмы IBM или совместимый с ним, с объёмом
оперативной памяти не менее 256 Мб. Данный объём является довольно большим для
программы своего рода, но вызвано это тем, что определённый процент использует
платформа .NetFramework, без которой не будет работать ни Visual Studio, ни сама программа, а связанно это с идеологией
платформы .NET.
.5 Требования к программному обеспечению
программирование visual studio поиск
Для функционирования данного программного продукта на компьютере должна
быть установлена операционная система Windows XP, или более
поздняя версия. Это связано так же с .NET.
. СВЕДЕНИЯ ИЗ ТЕОРИИ
Главное требование при разработке алгоритмов сортировки массивов -
экономное использование доступной оперативной памяти. Это означает, что
перестановки, с помощью которых упорядочиваются элементы, должны выполняться на
месте, то есть не требуя дополнительной временной памяти, так что методы,
которые требуют копирования элементов из массива a в массив-результат b, не представляют интереса. Ограничив таким образом выбор методов,
попробуем классифицировать их в соответствии с эффективностью, то есть временем
работы. Хорошая мера эффективности - число необходимых сравнений ключей С, а
также число перестановок элементов М. Эти величины являются функциями числа
сортируемых элементов n.
Хотя хорошие алгоритмы сортировки требуют порядка n*log(n) сравнений, мы сначала рассмотрим
несколько простых и очевидных методов, которые называются простыми и требуют
порядка n^2 сравнений ключей.
Простая сортировка вставками.
Этот метод часто используется игроками в карты. Элементы мысленно
разделяются на последовательность-приемник a0 … ai-1 и
последовательность-источник ai … ai-1.На каждом шаге, начиная с i = 1 и, затем увеличивая i на единицу, в
последовательности-источнике берётся i-й элемент и ставится в правильную позицию в
последовательности-приемнике. В табл. 2.1 работа сортировки вставки показана на
примере восьми взятых наугад чисел.
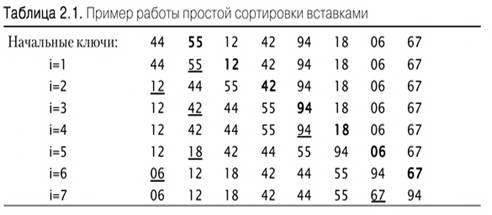
При поиске правильной позиции для элемента удобно чередовать сравнения и
пересылки, то есть позволять значению х «просеиваться» вниз, при этом
сравниваем х со следующим aj, а
затем вставляем х, либо передвигаем aj вправо и переходим влево. Заметим, что есть два разных условия, которые
могут вызывать прекращение процесса просеивания:
. У элемента aj
ключ оказался меньше, чем ключ х.
. Обнаружен левый конец последовательности-приемника.
Простая сортировка выбором
Данный метод основан на следующей схеме:
1. Выберем элемент с наименьшим ключом.
2. Переставим его с первым элементом а(0)
. Повторим эти операции с остальными n-1 элементами, затем с n-2
элементами, пока не останется только один - наибольший элемент.
Проиллюстрируем метод на той же последовательности из восьми ключей, что
и табл. 2.1:
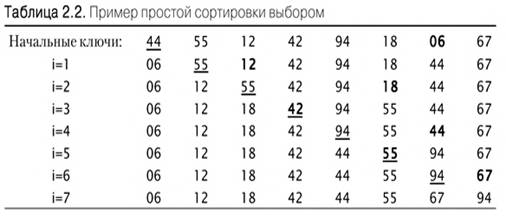
Этот момент можно назвать простой сортировкой выбором. В некотором смысле
он противоположен простой сортировке вставками: в последней на каждом шаге,
чтобы найти позицию вставки, рассматривается очередной элемент
массива-источника и все элементы массива-приемника; в простой сортировке
выбором просматривается весь массив-источник, чтобы найти один элемент с
наименьшим ключом, который должен быть вставлен в массив-приемник.
Быстрая сортировка
Построение быстрой сортировки исходит из того, что для достижения
максимальной эффективности желательно выполнять обмены между максимально
удалёнными позициями. Пусть даны n элементов, расставленных в обратном порядке.
Можно отсортировать их всего за n/2 обменов, сначала взяв крайние левый и
правый элементы и постепенно продвигая внутрь массива с обеих сторон.
Естественно, такая процедура сработает, только если заранее известно, что
элементы стоят в обратном порядке.
3. Анализ методов сортировки массивов
.1 Анализ простой сортировки вставками
Число сравнений ключей в i-ом
просеивании Ci не больше i-1, как минимум равно 1 и - предполагая, что все перестановки
n ключей равновероятны, - в среднем
равно i/2. Число Mi пересылок равно Ci+1. Поэтому полные числа сравнений и пересылок равны:
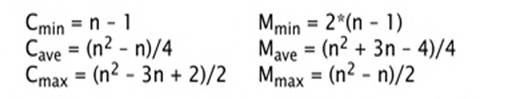
Минимальные значения получаются, когда элементы изначально упорядочены;
наихудший случай имеет место, когда элементы изначально стоят в обратном
порядке. В этом смысле сортировка вставками ведет себя вполне естественно. Ясно
также, что представленный алгоритм является устойчивой сортировкой:
относительный порядок элементов с равным ключами не нарушается.
Очевидно, число С сравнений ключей не зависит от начального порядка
ключей. В этом смысле можно сказать, что этот метод ведёт себя не так
естественно, как метод простых вставок. Получаем:
С=(n^2-n)/2
Число М пересылок не меньше, чем
(min)=3*(n-1)
для изначально упорядоченных ключей, и не больше, чем
(max)=n^2/+3(n-1),
если изначально ключи стояли в обратном порядке. Чтобы определить M(avg),
будем рассуждать так: алгоритм просматривает массив, сравнивая каждый элемент с
наименьшим значением, найденным до сих пор, и если элемент оказывается меньше,
чем этот минимум, выполняется присваивание. Вероятность, что второй элемент
меньше, чем первый , равна ½; такова же и вероятность присваивания
минимуму нового значения. Вероятность того, что третий элемент окажется меньше,
чем первые два, равна 1/3, а вероятность того, что четвёртый окажется
наименьшим, равна ¼ , и т. д. Поэтому полное среднее число
пересылок равно H(n-1), где H(n)-n-ое гармоническое число
(n)=1+1/2+1/3+...+1/n
(n) можно представить как
(n)=ln(n)+g+1/2n-1/12n^2+...
где g=0.577216... - константа Эйлера. Для достаточно больших n можно
отбросить дробные члены и получить приближенное среднее число присваиваний на
i-м проходе в виде
(i) = ln(i)+g+1
Тогда среднее число пересылок M(avg) в сортировке выбором равно сумме
величин Fi c i, пробегающим от 1 до n:
M(avg)=n*(g+1)+(Si: 1<=i<=n: ln(i))
Аппроксимируя дискретную сумму интегралом
(1:n) ln(x) dx = n*ln(n)-n+1
получаем приближенное выражение
(avg) = n * (ln(n)+g)
Можно заключить, что в общем случае простая сортировка выбором
предпочтительней простой сортировки вставками, хотя если ключами изначально
упорядочены или почти упорядочены, простые вставки работают немного быстрее.
.3 Анализ быстрой сортировки
Чтобы изучить эффективность сортировки, нужно сначала исследовать
поведение процесса разделения. После выбора разделяющего значения х
просматривается весь массив. Поэтому выполняется в точности n сравнений. Число
обменов может быть определено с помощью следующего вероятностного рассуждения.
Если положение разделяющего значения фиксировано и соответствующее
значение индекса равно u, то среднее число операций обмена равно числу
элементов в левой части сегмента, а именно u, умноженному на вероятность того,
что элемент попал на своё место путём обмена. Обмен произошёл, если элемент
принадлежал правой части; вероятность этого равна (n-u)/n. Поэтому среднее
число обменов равно среднему этих значений по всем возможным значениям u:
M = [su; 0<=u<=n-1 : u*(n-u)]/n^2
= n*(n-1)/2n-(2n^2 - 3n + 1)/6n
= (n-1/n)/6
Если нам сильно везёт и в качестве границы всегда удаётся выбрать
медиану, то каждый процесс разделения разбивает массив пополам, и число
необходимых для сортировки проходов равно log(n). Тогда полное число сравнений
равно n*log(n), а полное число обменов - n*log(n)/6.
Разумеется, нельзя ожидать, что с выбором медианы всегда будет так везти,
ведь вероятность этого всего 1/n. Но удивительно то, что средняя эффективность
алгоритма быстрой сортировки хуже оптимального случая только на множитель
2*ln(2), если разделяющее значение выбирается в массиве случайно.
Однако и у алгоритма быстрой сортировки есть свои подводные камни. Прежде
всего, при малых n его производительность не более чем удовлетворительна, как и
для всех эффективных методов. Но его преимущество над другими эффективными
методами заключается в лёгкости подключения какого-нибудь метода для обработки
коротких сегментов. Это особенно важно для рекурсивной версии алгоритма. Однако
ещё остаётся проблема наихудшего случая. Как поведёт себя метод быстрой
сортировки тогда. Увы, ответ неутешителен, и здесь выявляется главная слабость
этого алгоритма. Например, рассмотрим неудачный случай, когда каждый раз в
качестве разделяющего значения x выбирается наибольшее значение в разделяемом
сегменте. Тогда каждый шаг разбивает сегмент из n элементов на левую часть из
n-1 элементов и правую из единственного элемента. Как следствие нужно сделать n
разделений вместо log(n), и поведение в худшем случае оказывается порядка n^2.
Очевидно, что ключевым шагом здесь является выбор разделяющего значения
х. В приведённом варианте алгоритма на эту роль выбирается средний элемент. Но
с равным успехом можно выбрать первый или последний элемент. В этих случаях
наихудший вариант поведения будет иметь место для изначально упорядоченного
массива; то есть алгоритм быстрой сортировки явно «не любит» лёгкие задачки и
предпочитает беспорядочные наборы значений. При выборе среднего элемента это
странное свойство алгоритма быстрой сортировки не так очевидно, так как изначально
упорядоченный массив оказывается наилучшим случаем. На самом деле если
выбирается средний элемент, то и производительность в среднем оказывается
немного лучшей. Хоор предложил выбирать х случайным образом или брать медиану
небольшой выборки из, скажем, трёх ключей [2.10] и [2.11]. Такая
предосторожность вряд ли ухудшит среднюю производительность алгоритма, но она
сильно ухудшает его поведение в наихудшем случае. Во всяком случае, ясно, что
сортировка с помощью алгоритма быстрой сортировки немного похожа на
тотализатор, и пользователь должен чётко понимать, какой проигрыш он может себе
позволить, если удача от него отвернётся.
Отсюда можно извлечь важный урок для программиста. Каковы последствия
поведения алгоритма быстрой сортировки в наихудшем случае, указанном выше? Мы
уже знаем, что в такой ситуации каждое разделение даёт правый сегмент,
состоящий из единственного элемента, и запрос на сортировку этого сегмента
сохраняется на стеке для выполнения в будущем. Следовательно, максимальное
число таких запросов и, следовательно, необходимый размер стека равны n.
Конечно, это совершенно неприемлемо.(Заметим, что дело обстоит ещё хуже в
рекурсивной версии, так как вычислительная система, допускающая рекурсивные
вызовы процедур, должна автоматически сохранять значения локальных переменных и
параметров всех активаций процедур, и для этого будет использоваться скрытый
стек.) Выход здесь в том, чтобы сохранять на стеке запрос на обработку более
длинной части, а к обработке короткой части приступать немедленно. Тогда размер
стека М можно ограничить величиной log(n).
4. РЕЗУЛЬТАТ АНАЛИЗА
) метод сортировки простым выбором
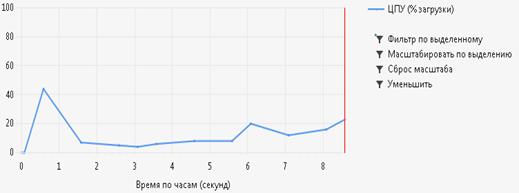
Рисунок 4.1 (анализ метода сортировки простым выбором)
) метод сортировки простыми вставками
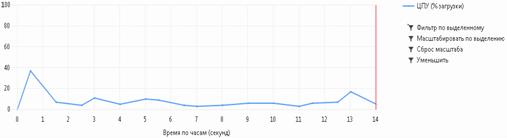
Рисунок 4.2 (анализ метода сортировки простыми вставками)
) метод быстрой сортировки
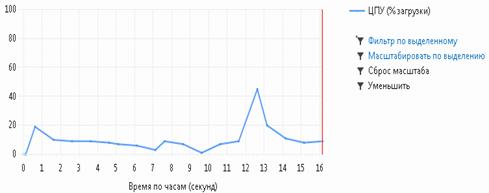
Рисунок 4.3 (анализ метода быстрой сортировки)
Как видно из рисунков 4.1 - 4.3 самым эффективным является метод быстрой
сортировки.
. ОПИСАНИЕ ПРОГРАММЫ
5.1 Функциональное назначение
Данная программа предназначена для сортировки массива методом прямого
выбора, прямыми вставками и быстрой сортировкой.
5.2 Глобальные переменные и константы
· Form1 - главное окно программы;
· Prostymi_Vstavkami - функция сортировки массива
простыми вставками;
· ProstoiVybor - функция сортировки массива простым
выбором;
· quikSortirovka - функция
быстрой сортировки массива;
. РУКОВОДСТВО ПОЛЬЗОВАТЕЛЯ
Запускаемым файлом программы является файл - "Сортировка.exe".
После запуска программы, необходимо ввести размер массива.(рис. 6.1)
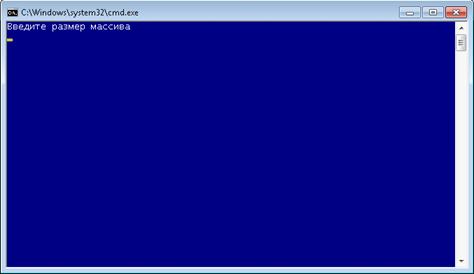
Рисунок 6.1 (работа программы)
Затем ввести элементы массива, которые должны являться цифрами, и
отделяться друг от друга пробелами.(рисунок 6.2)
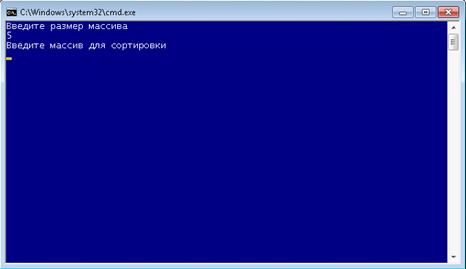
Рисунок 6.2 (работа программы)
Затем необходимо выбрать метод сортировки, нажав на 1, 2 или 3.(рисунок
6.3)
- сортировка простым выбором.
- сортировка простыми вставками.
- быстрая сортировка.
Рисунок 6.3 (работа программы)
Далее показывается результат работы программы. (рисунок 6.4).
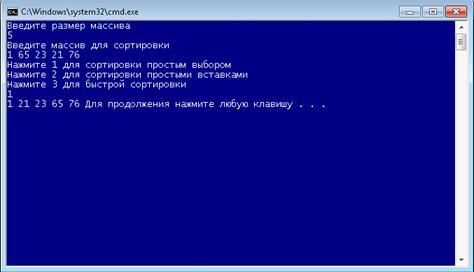
Рисунок 6.4 (работа программы)
ЗАКЛЮЧЕНИЕ
В данной курсовой работе был проведён анализ методов сортировки массива,
таких как:
прямым выбором;
прямыми вставками;
Изученные методы поиска дают возможность применять их для решения
подобных задач. В ходе выполнения данной курсовой работы были изучены и
закреплены алгоритмы сортировки массива. Была построена блок-схема, которая
помогла корректно составить программный код. В процессе создания программы был
получен опыт по работе в среде программирования Microsoft Visual Studio 2012.
Проведенный анализ программы при помощи инструмента Visual Studio Profiler наглядным образом показывает нам,
что алгоритм быстрой сортировки массива является более быстрым, чем предыдущие
способы.
Все задачи, сформулированные в данной курсовой работе, выполнены в полном
объеме.
ЛИТЕРАТУРА
1. Лойко
В.И. Структуры и алгоритмы обработки данных. Учебное пособие для вузов. -
Краснодар: КубГАУ. 2000.
. Шилд
Г. C# 4.0. Полное руководство. - М.:
Издательский дом "Вильямс", 2011.
. Хейлсбрерг
А. и др. Язык программирования C#. -
СПб. : Питер, 2012.
4. Материалы сайта www.intuit.ru <http://www.intuit.ru>
. Вирт Н. Алгоритмы и
структуры данных (Классика программирования) Москва 2010.
Приложение А
Листинг исходного текста программы
using System;
using
System.Collections.Generic;System.Linq;System.Text;System.Threading.Tasks;Курсовая
{Program
{void quickSort(int[] a, int l, int r)
{temp;x = a[l + (r - l) / 2];
//запись эквивалентна (l+r)/2,
//но не вызвает переполнения на больших данных
int i = l;j = r;
//код в while обычно выносят в процедуру particle
while (i <= j)
{(a[i] < x) i++;(a[j] > x) j--;(i
<= j)
{= a[i];[i] = a[j];[j] = temp;++;-;
}
}(i < r)(a, i, r);(l < j)(a, l, j);
}int[] quikSortirovka(int size, int[] a)
{(a, 0, size - 1);a;
}int[] ProstoiVybor(int size, int[] a)
{temp;(int i = 0; i < size; i++)
{
// Найдем минимальный элемент на
// промежутке индексов [i; size);
// изначально его индекс равен iminValueIndex = i;
// Переберем оставшиеся элементы промежутка(int j = i +
1; j < size; j++)
{
// Если элемент в позиции j меньше
// элемента в позиции minValueIndex, то
// необходимо обновить значение индекса
if (a[j] < a[minValueIndex])
{= j;
}
}
// Меняем текущий элемент с минимальным
temp = a[i];[i] =
a[minValueIndex];[minValueIndex] = temp;
}a;
}void Prostymi_Vstavkami(int size, int[] a)
{
//выполнение сортировки(int i = 0; i <
size; i++)
{temp = a[i]; //запомним i-ый элемент
int j = i - 1;//будем идти начиная с i-1 элемента
while (j >= 0 && a[j] > temp)
// пока не достигли начала массива
// или не нашли элемент больше i-1-го
// который храниться в переменной temp
{[j + 1] = a[j];
//проталкиваем элемент вверх-;
}[j + 1] = temp;
// возвращаем i-1 элемент
}
}void Main(string[] args)
{
// Считываем размер массива,
// который необходимо
отсортироватьsize;.Write("Введите размер массива" + "\n");
size = Convert.ToInt32(Console.ReadLine());
// Динамически выделяем память под
// хранение массива размера size
int[] a = new int[size];
//считываем строку.Write("Введите массив для
сортировки" + "\n");
string str = Console.ReadLine();
//разбиваем по пробелам[] mas = str.Split('
');
{[i] = int.Parse(mas[i]);
}.Write("Нажмите 1 для сортировки простым
выбором" + '\n');.Write("Нажмите 2 для сортировки простыми
вставками" + '\n');.Write("Нажмите 3 для быстрой сортировки" +
'\n');
int s =
Convert.ToInt32(Console.ReadLine());(s)
{1: ProstoiVybor(size, a);;2:
Prostymi_Vstavkami(size, a);;3: quikSortirovka(size, a);;
}
// Выводим отсортированный массив(int i =
0; i < size; i++)
{.Write(a[i]);.Write(' ');
}
}
}
}
Приложение Б.
Блок-схема алгоритма
Main
да
нет
да
нет
да
нет
Рисунок 5
ProstoiVybor(int size, int[] a)
Рисунок
6
Prostymi_Vstavkami(int size, int[] a)
Рисунок
7
quickSort(int[] a, int l, int r)
Рисунок 8