Системы программирования
ФГАОУ ВПО
«Северо-Восточный Федеральный университет имени М.К. Аммосова»
Курсовая работа
Системы программирования
Выполнила:
студент ИМИ группы ПМ12-2
Дмитриева
Екатерина Александровна
Проверил:
Антонов Михаил Юрьевич
Якутск 2014г
Общая
характеристика работы
Объект исследования:
1) Microsoft Visual C++;
2) ArgoUML;
3) LEX и YACC;
4) Intel Parallel Studio XE;
5) Intel C++ Studio XE;
6) MMX/SSE;
7) Microsoft Visual Studio;
8) Intel Parallel Studio XE;
9) Github;
10) Bitbucket.
Цель работы:
1) подготовить место для выполнения работы и подготовить программу,
выводящую на экран сообщение “Hello World!”;
) построить диаграммы;
) узнать про компиляторов, изучить входные и выходные файлы;
) Разработать лексический анализатор для языка программирования с
использованием ПО LEX;
) Приобрести лицензию Studio XE для Linux или С++ Studio для Win;
) Кратко описать расширений MMX/SSE;
) Написать программу умножения матриц, с замером времени на
операцию.
) Сравнить компиляторы msvs/gcc с компилятором intel;
) Сделать анализ и обзор технологии GIT;
) Зарегистрироваться и создать свой репозиторий.
Задачи:
) Ознакомиться с программой;
2) Подготовить место для выполнения работы;
) Разбор программы;
) Сделать реферат для выполнения домашней работы №3;
) Разработать лексический анализатор для языка программирования с
использованием LEX;
) Описать описание продуктов VTune Amplifier, Composer, Inspector;
) Приобрести лицензию Studio XE;
) Описать расширения MMX/SSE, узнать какие языки реализуют
автоматическое управление освобождением динамической памяти;
) Установить Intel Parallel Studio XE;
10) Сравнить репозитории github и bit bucket.
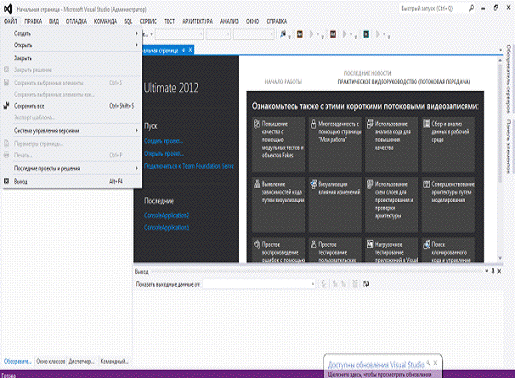
Введение
Я буду работать на программе Microsoft Visual C++ 2008. Для
написания программы на C++
нужно создать проект. Для этого нужно выбрать соответствующую ссылку на
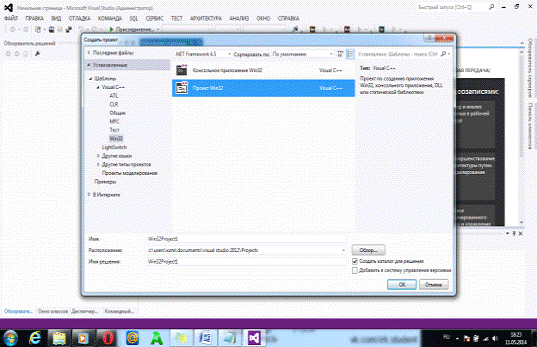
стартовой странице (“New Project”). В
появившемся окне нужно выбрать тип проекта (Win 32 Console Application), и
задать его имя и расположение, после чего нажать кнопку “OK”.
Теперь нужно определить свойства проекта. Для этого в появившемся окне
нажать “Next”, и в появившемся после этого
установить флаг “Empty Project” и нажать “Finish”.
Создастся пустой проект и откроется в обозревателе проектов (Solution Explorer). Для добавления в проект файлов,
содержащих текст программы, нужно щелкнуть правой кнопкой мыши по заголовку
проекта и в появившемся окне контекстном меню выбрать пункт Add, и затем New Item и в окне задать тип добавляемого файла (C++ File(.cpp))
и его имя. После этого нужно выбрать Add, и создается указанный файл, добавляется в проект и открывается в
редакторе.
Для запуска программы нужно воспользоваться меню “Debug”, пункт “Start without debugging” и нажать “Yes”. Программа компилируется, компонуется,
если нет ошибок, запускается, для чего открывается новое текстовое окно
терминала. После завершения работы программы выдается сообщение “Press any key to continue…”, после нажатия любой клавиши окно
закроется.
Замечание: если программа запущена, то перекомпилировать её невозможно -
нужно сначала дождаться завершения работы программы или принудительно закрыть
её, и только потом компилировать новую версию.
Также, для каждой программы нужно создавать свой проект. Для этого после
завершения работы над программой нужно закрыть проект, выбрав пункт “Close solution” меню “File”, и затем создать для следующей программы новый
проект.
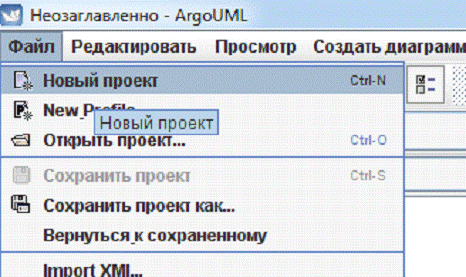
Для выполнения домашней работы №2, я буду работать в ArgoUML, т.к. это бесплатное программное
обеспечение.
Чтобы построить диаграммы нужно создать новый проект.
Рисунок
Унифицированный язык моделирования (Unified Modeling Language - UML) это
язык для специфицирования, визуализации, конструирования и документирования
программных систем, а так же бизнес моделей и прочих не программных систем.
Диаграмма вариантов использования (use case diagram).
Этот вид диаграмм позволяет создать список операций, которые выполняет
система. Часто этот вид диаграмм называют диаграммой функций, потому что на
основе набора таких диаграмм создается список требований к системе и
определяется множество выполняемых системой функций.
Диаграммы вариантов использования описывают функциональное назначение
системы или то, что система должна делать. Разработка диаграммы преследует
следующие цели:
· определить общие границы и контекст моделируемой предметной
области;
· сформулировать общие требования к функциональному поведению
проектируемой системы;
· разработать исходную концептуальную модель системы для ее
последующей детализации в форме логических и физических моделей;
· подготовить исходную документацию для взаимодействия
разработчиков системы с ее заказчиками и пользователями.
Суть диаграммы вариантов использования состоит в следующем. Проектируемая
система представляется в виде множества сущностей или актеров,
взаимодействующих с системой с помощью вариантов использования. При этом
актером (actor) или действующим лицом называется любая сущность,
взаимодействующая с системой извне. Это может быть человек, техническое
устройство, программа или любая другая система, которая может служить
источником воздействия на моделируемую систему так, как определит сам
разработчик. Вариант использования служит для описания сервисов, которые
система предоставляет актеру.
Диаграмма классов (class diagram).
Диаграмма классов (class diagram) служит для представления статической
структуры модели системы в терминологии классов объектно-ориентированного
программирования. Класс (class) в языке UML служит для обозначения множества
объектов, которые обладают одинаковой структурой, поведением и отношениями с
объектами других классов.
Диаграмма состояний (statechart diagram).
Диаграммы состояний чаще всего используются для описания поведения
отдельных объектов, но также могут быть применены для спецификации
функциональности других компонентов моделей, таких как варианты использования,
актеры, подсистемы, операции и методы. Понятие состояния (state) является
фундаментальным не только в метамодели языка UML, но и в прикладном системном
анализе. Вся концепция динамической системы основывается на понятии состояния.
Семантика же состояния в языке UML имеет ряд специфических особенностей.
Диаграмма деятельности (activity diagram).
Данный тип диаграмм может использоваться и для отражения состояний
моделируемого объекта, однако, основное назначение Activity diagram в том,
чтобы отражать бизнес-процессы объекта. Этот тип диаграмм позволяет показать не
только последовательность процессов, но и ветвление и даже синхронизацию
процессов.
Диаграмма последовательности (sequence diagram).
На диаграмме последовательности изображаются только те объекты, которые
непосредственно участвуют во взаимодействии. Ключевым моментом для диаграмм
последовательности является динамика взаимодействия объектов во времени.
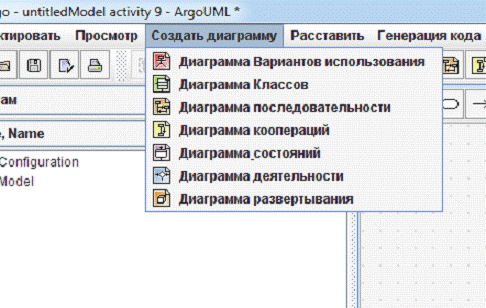
Чтобы выбрать диаграммы нажимаем вкладку «Создать диаграммы».
Компилятор - это программа, которая считывает текст программы, написанной
на одном языке - исходном, и транслирует (переводит) его в эквивалентный текст
на другом языке - целевом. Одним из важных моментов трансляции является
сообщение пользователю о наличии ошибок в исходной программе.
Компиляторы составляют существенную часть программного обеспечения ЭВМ.
Это связано с тем, что языки высокого уровня стали основным средством
разработки программ. Только очень незначительная часть программного
обеспечения, требующая особой эффективности, программируется с помощью
ассемблеров. В настоящее время распространено довольно много языков
программирования.
С другой стороны, постоянно растущая потребность в новых компиляторах
связана с бурным развитием архитектур ЭВМ. Это развитие идет по различным
направлениям. Совершенствуются старые архитектуры как в концептуальном
отношении, так и по отдельным, конкретным линиям.
Наконец, бурно развиваются различные параллельные архитектуры. Среди них
отметим векторные, многопроцессорные, с широким командным словом (вариантом
которых являются суперскалярные ЭВМ).
Основные понятия и определения:
· Транслятор - программа, которая переводит программу, написанную на одном
языке, в эквивалентную ей программу, написанную на другом языке.
· Компилятор - транслятор с языка высокого уровня на машинный
язык или язык ассемблера.
· Ассемблер - транслятор с языка Ассемблера на машинный язык.
· Интерпретатор - программа, которая принимает исходную программу
и выполняет ее, не создавая программы на другом языке.
· Макропроцессор (препроцессор - для компиляторов) - программа,
которая принимает исходную программу, как текст и выполняет в нем замены
определенных символов на подстроки. Макропроцессор обрабатывает программу до
трансляции. Любой язык обязательно подчиняется определенным правилам, которые
определяют его синтаксис и семантику.
· Синтаксис - это совокупность правил, определяющих допустимые
конструкции языка, т. е. его форму.
· Семантика - это совокупность правил, определяющих логическое
соответствие между элементами и значением синтаксически корректных предложений,
т. е. содержание языка.
Этапы процесса компиляции
Процесс компиляции предполагает распознавание конструкций исходного языка
(анализ) и сопоставление каждой правильной конструкции семантически
эквивалентной конструкций другого языка (синтез). Он включает несколько этапов:
· лексический анализ;
· синтаксический анализ;
· семантический анализ;
· распределение памяти;
· генерация и оптимизация объектного кода.
Lex
- программа для генерации лексических анализаторов
<#"870790.files/image003.gif">
Рисунок 1
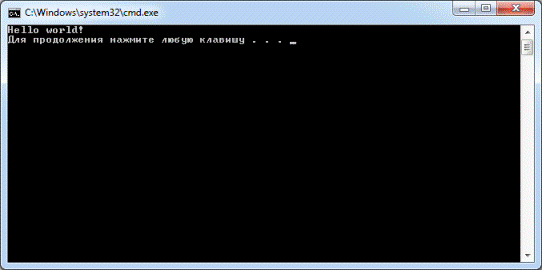
Рисунок 2
Глава 2.
Домашняя работа №2
Построение UML диаграммы
Диаграмму вариантов использования я построила только действия со стороны
человека.
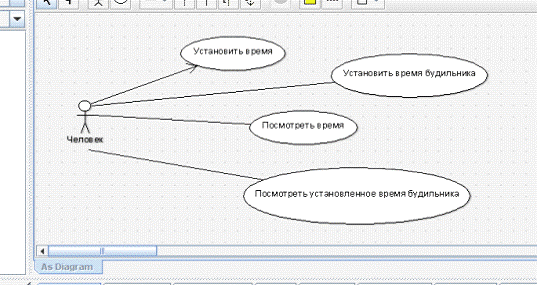
Рисунок 1.
Диаграмму состояний я сделала так (рисунок 2):
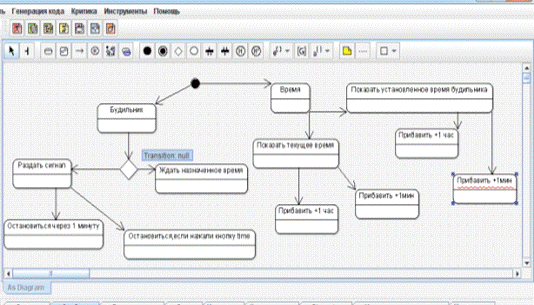
Рисунок 2.
Диаграмма деятельности (Рисунок 3):
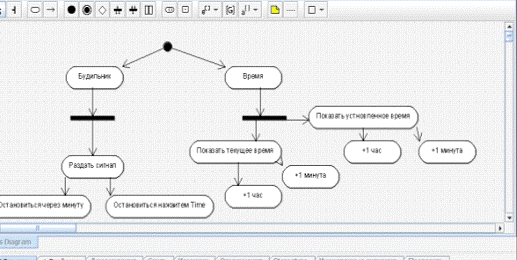
Рисунок 3
Диаграмма классов (рисунок 4)
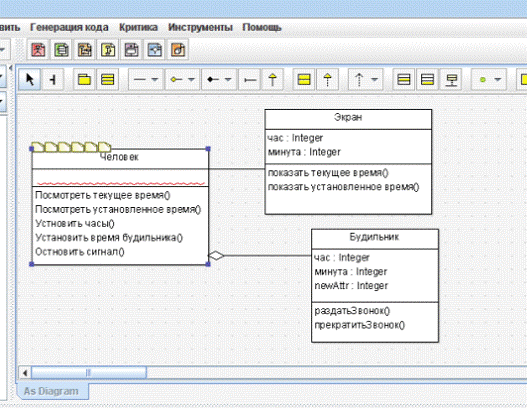
Рисунок 4.
Диаграмма последовательности (Рисунок 5):
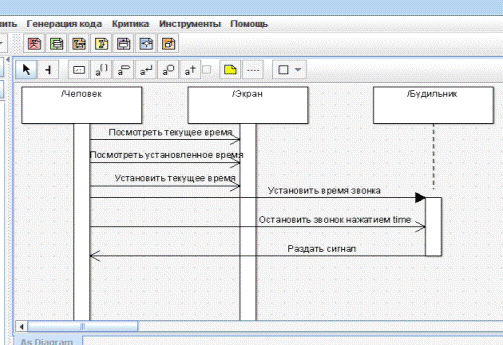
Рисунок 5
Глава 3.
Домашняя работа №3
Компиляторы компиляторов. Лексический анализатор LEX и синтаксический анализатор YACC
Структура компилятора
Обобщенная структура компилятора и основные фазы компиляции показаны на
рисунок 1.
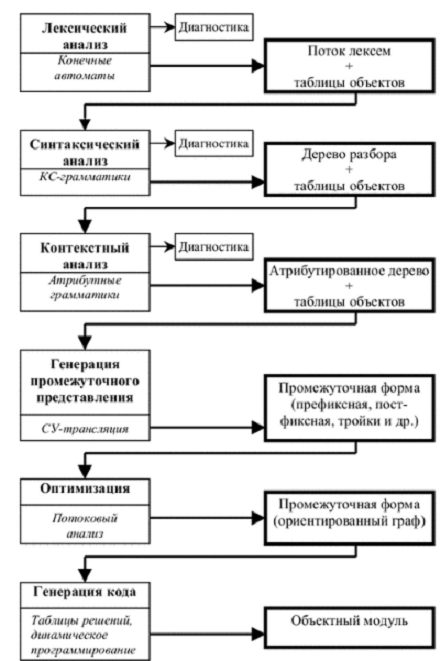
Рисунок 1.
Лексический анализ.
Основная задача лексического анализа - разбить входной текст, состоящий
из последовательности одиночных символов, на последовательность слов, или
лексем, т.е. выделить эти слова из непрерывной последовательности символов. Все
символы входной последовательности с этой точки зрения разделяются на символы,
принадлежащие каким-либо лексемам, и символы, разделяющие лексемы
(разделители). В некоторых случаях между лексемами может и не быть разделителей.
С другой стороны, в некоторых языках лексемы могут содержать незначащие символы
(например, символ пробела в Фортране). В Си разделительное значение
символов-разделителей может блокироваться («\» в конце строки внутри
"...").
С точки зрения дальнейших фаз анализа лексический анализатор выдает
информацию двух сортов: для синтаксического анализатора, работающего вслед за
лексическим существенна информация о последовательности классов лексем,
ограничителей и ключевых слов, а для контекстного анализа, работающего вслед за
синтаксическим, важна информация о конкретных значениях отдельных лексем
(идентификаторов, чисел и т.д.).
Лексический анализатор может быть как самостоятельной фазой трансляции,
так и подпрограммой, работающей по принципу «дай лексему». В первом случае
(рис. 1, а) выходом анализатора является файл лексем, во втором (рис. 1, б)
лексема выдается при каждом обращении к анализатору (при этом, как правило,
признак класса лексемы возвращается как результат функции «лексический
анализатор», а значение лексемы передается через глобальную переменную). С
точки зрения обработки значений лексем, анализатор может либо просто выдавать
значение каждой лексемы, и в этом случае построение таблиц объектов
(идентификаторов, строк, чисел и т.д.) переносится на более поздние фазы, либо
он может самостоятельно строить таблицы объектов. В этом случае в качестве
значения лексемы выдается указатель на вход в соответствующую таблицу.
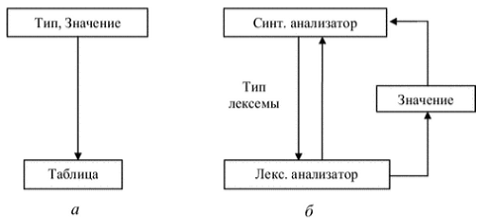
Рисунок 1
Работа лексического анализатора задается некоторым конечным автоматом.
Однако, непосредственное описание конечного автомата неудобно с практической
точки зрения. Поэтому для задания лексического анализатора, как правило,
используется либо регулярное выражение, либо праволинейная грамматика. Все три
формализма (конечных автоматов, регулярных выражений и праволинейных грамматик)
имеют одинаковую выразительную мощность. В частности, по регулярному выражению
или праволинейной грамматике можно сконструировать конечный автомат,
распознающий тот же язык.
Построение лексических анализаторов
При построении лексических анализаторов конечные автоматы используют для
распознавания лексем второго типа (базовых понятий языка). Эти понятия можно
описать в рамках самых простых, регулярных грамматик и предложить для них
эффективную технику разбора. Отделение сканера от синтаксического анализатора
позволяет также сократить время распознавания лексем, так как при этом
появляется возможность использования оптимизированных ассемблерных команд,
специально предназначенных для сканирования строк.
Алфавит автомата лексического анализатора - все множество однобайтовых
(ANSI) или двухбайтовых (Unicode) символов. При записи правил обычно
используются обобщающие нетерминалы вида «Буквы», «Цифры». В процессе
распознавания может формироваться описываемый объект, например, литерал или
идентификатор.
Пример: Распознаватель целых чисел. Синтаксическая диаграмма синтаксиса
языка описывается синтаксической диаграммой (рис 2).
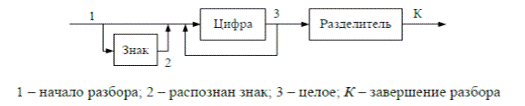
Рисунок 2
По диаграмме строим таблицу переходов (рис. 3), обозначая состояние
ошибки символом «E». В таблице переходов указываем подпрограммы обработки,
которые должны быть выполнены при осуществлении указанного перехода. При
выполнении этих подпрограмм формируются указанные значения.

Рисунок 3.
а) Подпрограммы обработки:: Инициализация: Целое := 0; Знак_числа := «+».
А1: Знак_числа := Знак
А2: Целое := Целое*10 + Цифра
А3: Если Знак_числа = «-» то Целое := -Целое Все-если
б) Диагностические сообщения:
Д1: «Строка не является десятичным числом»;
Д2: «Два знака рядом»;
Д3: «В строке отсутствуют цифры»;
Д4: «В строке встречаются недопустимые символы»
Обозначим: S - строка на входе автомата; Ind - номер очередного символа;
q - текущее состояние автомата; Table - таблица, учитывающая символы завершения
и другие символы.
Тогда алгоритм сканера-распознавателя можно представить следующим
образом.
:= 1:= 1
Выполнить А0
Цикл-пока q ¹≠ «Е» и q ¹≠ «К»
Если
S[Ind] = «+» или S[Ind] = «-»,
то j := 1
иначе Если S[Ind] ³ ≥«0» и S[Ind] ≤«9»,
то j := 2,
иначе j := 3
Все-если
Все-если
Выполнить Ai := Table [q, j]. A():= Table [q, j]:= Ind +1
Все-цикл
Если q = «К»
то Выполнить А3
Вывести сообщение «Это число»
иначе Вывести сообщение Дi
Все-если
Синтаксический анализатор
YACC -
компьютерная программа, служащая стандартным генератором синтаксических
анализаторов (парсеров) в Unix-системах. Название является акронимом «Yet
Another Compiler Compiler» («ещё один компилятор компиляторов»). Yacc
генерирует парсер на основе аналитической грамматики, описанной в нотации BNF
(форма Бэкуса-Наура) или контекстно-свободной грамматики. На выходе yacc
выдаётся код парсера на языке программирования Си.
Yacc
отображает файл спецификаций в процедуру на языке C, которая разбирает входной
текст в соответствии с заданной спецификацией. Алгоритм же самого разбора
относительно прост, знание его облегчит понимание механизма нейтрализации
ошибок и обработки неоднозначностей.
Построение синтаксических анализаторов.
Синтаксические анализаторы регулярных языков на вход получают строку
лексем. Пример. Синтаксический анализатор списка описания целых скаляров,
массивов и функций (упрощенный вариант), например: int xaf, y22[5], zrr[2][4],
re[N], fun(), *g;
После лексического анализа входная строка представлена в алфавите:-
идентификатор; N - целочисленная константа; служебные символы: ≪[ ] ( ) , ; *».
Функцию переходов зададим синтаксической диаграммой (рис. 4).

Рисунок 4.
По диаграмме построим таблицу автомата (рис. 5).
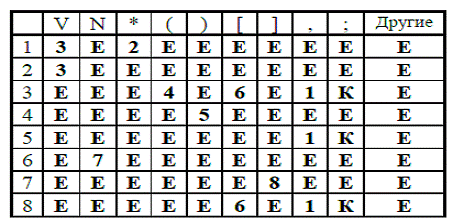
Рисунок 5.
Алгоритм распознавателя:
:= 1:= 1
Цикл-пока q ¹≠ «Е» и q ¹ ≠«К»
q := Table [q, Pos(S[Ind], «VN*()[];»)] := Ind +1
Все-цикл
Если q = «К»
то Выполнить А3
Вывести сообщение «Это число»
иначе Вывести сообщение Дi
Все-если
Глава 4.
Домашняя работа №4
Описание лексики LEX
для языка Си
Генерируется программа lex.yy.c. Будучи загруженной с библиотекой, она для каждой
распознанной цепочки выполняет соответствующие С-операторы, а остальные фрагменты
входного файла копирует в выходной файл без изменений.
Разрабатываемый язык относится к разделу Си подобных языков, код
регистрозависим. Правильная программа на данном языке представляет собой
непустой список функций. Точкой входа в программу считается функция с название main. Функция состоит из имени функции,
списка параметров и тела. Тело функции является набором операторов. Операторы
разграничиваются с помощью разделителя “;”. Операторы объединяются в блоки с
помощью фигурных скобок.
Обозначения:
[ ] - необязательная часть
… - часть, повторяющаяся произвольное количество раз
< > - описание конструкции
<Б>|<Ц>|<пБ>|<пЦ>|<пБЦ> - буква | цифра |
последовательность букв | последовательность цифр | последовательность букв
и/или цифр или пусто
<И> - <имя объекта>
<В> - <выражение>
<ЛВ> - <ЛогическоеВыражение>
<ОБ> - <ОператорИлиБлок> (<О> - одиночный оператор)
<К> - <константа>
Язык различает следующие типы данных:
|
Название типа
|
Псевдонимы типа
|
|
number
|
|
|
real
|
|
|
char
|
chara, charac, charact, character,
character
|
|
bool
|
|
|
data
|
|
Основными конструкциями языка являются:
|
Завершение функции и возврат значения
|
return <значение>
|
|
Cоздание/уничтожение экземпляров объектов
|
create, kill
|
|
Оператор присваивания
|
<И><=
<В> ;
|
|
Условный оператор
|
when <ЛВ> then <ОБ> [else <ОБ>];
|
|
Переключатель
|
with <В> {?<К>:<ОБ> …}
|
|
Оператор цикла
|
repeat <ОБ> when <ЛВ>
|
|
Вызов функции
|
<ИМЯ_ФУНКЦИИ>(<ПАРАМЕТРЫ>)
|
Используемые арифметические операторы:
|
+сложение
|
|
|
-
|
вычитание
|
|
/
|
деление
|
|
*
|
умножение
|
|
%
|
остаток от деления
|
Операторы сравнения:
|
==
|
равенство
|
|
<
|
меньше
|
|
>
|
больше
|
|
=<
|
меньше-равно
|
|
=>
|
больше-равно
|
|
<>
|
неравенство
|
Логические операторы:
|
!
|
Инверсия
|
|
^
|
Кольцевая сумма
|
|
|
|
Побитовое сложение
|
|
&
|
Побитовое умножение
|
|
||
|
Или
|
|
&&
|
И
|
Константы могут быть целыми, вещественными, символьными (с экранированием
служебных символов).
Незначащие символы - символы языка, разбивающие текст программы на
лексемы: символ пробела, перевода строки, табуляции и возврата каретки.
Комментарии - не оказывают влияние на код программы и используются только
для удобства программиста. Комментарии могут быть двух видов:
строчные:
· //<произвольный набор символов>\r\n (занимают одну
строку);
блочные:
· /*<произвольный набор символов>*/(могут занимать любое
число строк). Вложенные блочные комментарии не поддерживаются.
Идентификаторы и объекты могут определяться в любом месте программы,
причем идентификаторы и имена объектов объявление вне объявления функций
являются глобальными, например:
i;check(numbers j)
{
return
(i+j);
}
Язык является объектно-ориентированным. Объекты определяются следующей
конструкцией:
{
<тип> <имя идентификатора>;
<тип> <имя метода>(<список параметров>);
}
Точка входа в программу определяется функцией main0.
В ходе выполнения лабораторных работ была разработана система регулярных
выражений, а также классы и действия для расширения лексического акцептора, до
анализатора.
|
Имя автомата
|
Имя группы слов
|
Регулярное выражение
|
Действие
|
Примечание
|
|
main
|
brakes
|
[(){}]
|
tables.processBraket(Lexem);
|
Скобки
|
|
main
|
charSt
|
[']
|
ignoreLastWord=true;stack.push(lexAcceptor);lexAcceptor=lexAcceptors[findAutomat("CharB")];
|
Обнаружен символ
|
|
main
|
conditionOper
|
[<>=]+
|
tables.processOperator(Lexem);
|
Операторы сравнения, присваивания
|
|
main
|
fifth
|
[0-4]+"#5"
|
tables.base5ToBase10(Lexem);
tables.processConst(Lexem, typeInt);
|
пятеричка
|
|
main
|
float
|
([0-9]+[.][0-9]*)|([0-9]*[.][0-9]+)
|
tables.processConst(Lexem, typeDouble);
|
десятичное
|
|
main
|
id
|
[a-zA-Z]+[0-9]
|
tables.processIdent(Lexem, -1);
|
идентификатор
|
|
main
|
int
|
[0-9]+
|
tables.processConst(Lexem, typeInt);
|
целое
|
|
main
|
keyword
|
([a-zA-Z]+)|([?:])
|
ti.put(0,"keyword");tables.CheckForAlias(Lexem);tables.processKeyword(Lexem);
ti.put(Lexem.groupIndex, Lexem.textOfWord);
|
|
|
main
|
logicalOper
|
[&|^!]+
|
tables.processLogicalOper(Lexem);
|
Логические операторы
|
|
main
|
separator
|
[,;.]
|
|
|
|
main
|
sign
|
[-+*/%]
|
|
Знаки операций
|
|
main
|
space
|
[ \n\r\t]+
|
ignoreLastWord = true;
tables.debugGroupWordEndln(Lexem);
|
|
|
CharB
|
char
|
other
|
lexAcceptor=lexAcceptors[findAutomat("CharE")];tables.processConst(Lexem,
typeChar);
|
Символ!
|
|
CharB
|
ekr
|
[\\]
|
ignoreLastWord=true;lexAcceptor=lexAcceptors[findAutomat("CharEk")];
|
Символ экранируется!
|
|
CharB
|
empty
|
[']
|
Lexem.groupIndex=codeCharError;
ti.put(0,"char error");
|
Пустой символ, не верно!
|
|
CharEk
|
CharError1
|
other
|
Lexem.groupIndex=codeCharError;ti.put(0,"char
error");
|
|
CharEk
|
char
|
[\\nt0']
|
lexAcceptor=lexAcceptors[findAutomat("CharE")];
Lexem.textOfWord=new
StringBuffer("\\"+Lexem.textOfWord.toString());tables.processConst(Lexem,
typeChar);
|
Список экранируемых символов
|
|
CharE
|
CharError2
|
other
|
Lexem.groupIndex=codeCharError;ti.put(0,"char
error");
|
Неверный конец символа
|
|
CharE
|
Exit
|
[']
|
ignoreLastWord=true;lexAcceptor=(fAutomat)stack.pop();
|
Конец символа
|
Краткое описание функций интерфейсного класса
|
void CheckForAlias(lexem Lex)
|
Служебная функция для замены псевдонимов типов (boole, boolea, boolean -> bool и т.д.)
|
|
public boolean isBoolConst(lexem
Lex)
|
Служебная функция для разрешения конфликта пересечения
групп ключевых слов и булевских констант
|
|
public int isKeyWord(lexem Lex)
|
Служебная функция проверки на принадлежность к ключевым
словам
|
|
public int processIdent(lexem Lex,
int type)
|
Функция обработки идентификаторов и занесения их в таблицу
при необходимости
|
|
public int processConst(lexem Lex,
int type)
|
Функция обработки констант и занесения их в таблицу при
необходимости
|
|
public int processKeyword(lexem
Lex)
|
Функция обработки ключевых слов и занесения их в таблицу
при необходимости
|
|
public int processOperator(lexem
Lex)
|
Функция обработки операторов сравнения и присваивания
(разрешение конфликтов)
|
|
public int processLogicalOper(lexem
Lex)
|
Функция обработки логических операторов (разрешение
конфликтов)
|
|
public void base5ToBase10(lexem
Lex)
|
Служебная функция перевода из системы счисления по
основанию 5 в систему счисления по основанию 10
|
|
public String getIdentTable()
public String getConstTable() public String getKeywordTable()
|
Служебные функции для вывода таблиц
|
|
public void
debugGroupWordFill(lexem Lex) public void debugGroupWordEndln(lexem Lex) public String debugGroupWordGet()
|
Служебные функции для построения отладочного представления
программы в виде токенов (групп слова, индекс слова)
|
|
determinateGroupIndex
|
Функция, создающая ассоциативный массив имен групп слов и
индексов этих групп
|
|
debugGroupName
|
Служебная функция для вывода таблице построенной на основе
массива соответствия имен и индексов групп
|
Встроенные переменные:
1) yytext[] - одномерный массив (последовательность символов),
содержащий фрагмент входного текста, удовлетворяющего регулярному выражению и
распознанного данным правилом;
2) yyleng - целая переменная, значение которой равно количеству
символов, помещенных в массив yytext.
Встроенные переменные позволяют определить конкретную последовательность
символов, распознанных данным правилом. При применении правила анализатор lex автоматически заполняет значениями
встроенные переменные. Эти значения можно использовать в действии примененного
правила.
Пример правила:
[a-z]+ printf(“%s”,yytext);
Регулярное выражение правила определяет бесконечное множество
последовательностей символов, состоящих из букв латинского алфавита. Данное
правило применяется, когда из входного потока символов поступает конкретная
последовательность символов, удовлетворяющих его регулярному выражению.
Оператор языка С printf выводит в
выходной поток эту последовательность символов.
Встроенные функции:
1) yymore(). В обычной ситуации содержимое yytext обновляется всякий
раз, когда производится применение некоторого правила. Иногда возникает
необходимость добавить к текущему содержимому yytext цепочку символов,
распознанных следующим правилом;
2) yymore() вызывает переход анализатора к применению следующего
правила. Входная последовательность символов, распознанная следующим правилом,
будет добавлена в массив yytext, а значение переменной yyleng будет равно суммарному количеству символов,
распознанными этими правилами;
3) yyless(n). Оставляет в
массиве yytext первые n
символов, а остальные возвращает во входной поток. Переменная yyleng принимает значение n. Лексический анализатор будет читать
возвращенные символы для распознавания следующей лексемы. Использование yyless(n) позволяет посмотреть правый контекст.
4) input(). Выбирает из входного потока очередной символ и возвращает его в
качестве своего значения. Возвращает ноль при обнаружении конца входного
потока;
5) output(c). Записывает
символ с в выходной поток;
6) unput(c) Помещает символ с во входной поток;
7) yywrap(). Автоматически вызывается при обнаружении конца входного
потока. Если возвращает значение 1, то лексический анализатор завершает свою
работу, если 0 - входной поток продолжается текстом нового файла. По умолчанию yywrap возвращает 1. Если имеется
необходимость продолжить ввод данных из другого источника, пользователь должен
написать свою версию функции yywrap(),
которая организует новый входной поток и возвратит 0.
Пример входного файла:
%%
\"[^"]* { if( yytext[yyleng - 1] == '\\')
yymore();
{ /* здесь должна быть часть программы, обрабатывающая и закрывающую
кавычку */ }
}
Входной файл генератора lex
содержит одно правило.
Анализатор распознает строки символов, заключенные в двойные кавычки,
причем символ двойная кавычка внутри этой строки может изображаться с
предшествующей косой чертой.
Анализатор должен распознавать кавычку, ограничивающую строку, и кавычку,
являющуюся частью строки, когда она изображена как \".
Допустим, на вход поступает строка "абв\"эюя".
Сначала будет распознана цепочка "абв\ и, так как последним символом
в этой цепочке будет символ "\", выполнится вызов yymore().
В результате повторного применения правила к цепочке "абв\ будет
добавлено "эюя, и в yytext мы получим: "абв\"эюя, что и
требовалось.
Встроенные макрооперации
· ECHO - эквивалентно printf(“%s”,yytext); . Печать в выходной поток содержимого массива yytext.
· BEGIN st - перевод анализатора в состояние с именем st.
· BEGIN 0 - перевод анализатора в начальное состояние.
· REJECT - переход к следующему альтернативному правилу.
Последовательность символов, распознанная данным правилом, возвращается во
входной поток, затем производится применение альтернативного правила.
Альтернативные правила.
Регулярное выражение, входящее в правило, определяет множество
последовательностей символов.
Два правила считаются альтернативными, если определяемые ими два
множества последовательностей символов имеют непустое пересечение, либо
существуют такие две последовательности из этих множеств, начальные части которых
совпадают.
Примеры альтернативных правил:
) Регулярное выражение
SWITCH
- определяет единственную последовательность символов SWITCH, а регулярное
выражение;
[A-Z]+ - определяет бесконечное множество последовательностей
символов, в том числе и SWITCH.
) Регулярное выражение
INT -
определяют последовательность INT,
которая является подпоследовательностью последовательности INTEGER,
определяемой регулярным выражением
INTEGER
) Регулярное выражение
AC+ -
определяет множество, являющееся пересечением множеств, определяемых
выражениями
[BC]+
A[CD]+
В лексическом анализаторе каждый входной символ учитывается один раз.
Поэтому в ситуации, когда возможно применение нескольких правил,
действует следующая стратегия:
1) Выбирается правило, определяющее самую длинную последовательность
входных символов;
2) Если таких правил оказывается несколько, выбирается то из них,
которое текстуально стоит раньше других.
Если требуется несколько раз обработать один и тот же фрагмент входной
цепочки символов, то можно воспользоваться функцией yyless или макрооператором REJECT.
Пример 1 (Предположим, что мы хотим подсчитать все вхождения цепочек she
и he во входном тексте.
Для этого я могла бы написать следующий входной файл для lex):
%{int s=0,h=0;%}
%%{ s++;(1); }h++;
Пример2:
%%
[jJ][aA][nN][uU][aA][rR][yY] printf("Январь");
[fF][eE][bB][rR][uU][aA][rR][yY] printf("Февраль");
[mM][aA][rR][cC][hH] printf("Март");
[aA][pP][rR][iI][lL] printf("Апрель");
[mM][aA][yY] printf("Май");
[jJ][uU][nN][eE] printf("Июнь");
[jJ][uU][lL][yY] printf("Июль");
[aA][uU][gG][uU][sS][tT] printf("Август");
[sS][eE][pP][tT][eE][mM][bB][eE][rR] printf("Сентябрь");
[oO][cC][tT][oO][bB][eE][rR] printf("Октябрь");
[nN][oO][vV][eE][mM][bB][eE][rR] printf("Ноябрь");
[dD][eE][cC][eE][mM][bB][eE][rR] printf("Декабрь");
Генератор построит конечный автомат, который распознает английские
наименования месяцев и выводит русские значения найденных английских слов.
Все другие последовательности входных символов без изменений копируются в
выходной поток.
Глава 5. Домашняя
работа №5
Описание продуктов
Приобретение лицензии Studio XE для Linux или С++ Studio для Win
Intel Parallel Composer- это не просто компилятор С++ от Intel. Он уже
проинтегрирован в Visual Studio вместе с библиотекой производительности IPP и
параллельной библиотекой TBB, что значительно облегчает процесс разработки
параллельного кода для новичков, т.е. тех, кто еще не пользовался продуктами
Intel, такими, например, как Compiler Pro, и только собирается попробовать
улучшить производительность своих приложений с помощью технологий Intel.
Наличие сразу нескольких компонент в пакете позволит сразу же начать
оптимизировать свою программу с использованием параллельных технологий, которые
содержит Composer:
Вычислительные примитивы, реализованные в виде функций в библиотеке IPP,
гарантируют высокую производительность алгоритмов на платформах Intel;
Поддержка компилятором элементов стандарта С++ 0х облегчит кодирование
программистам.Parallel Inspector
Это самый востребованный и ожидаемый инструмент на сегодняшний день, так
как он помогает избавиться от ошибок в многопоточной программе на этапе
верификации, повышая корректность и стабильность ее исполнения. Inspector
применяется не только командами тестировщиков (QA team). Нормальная инженерная
практика предполагает проверку программы на наличие ошибок и самим
разработчиком, хотя бы на уровне юнит-тестов (unit tests).
Я разберу, какие ошибки помогает обнаружить Parallel Inspector.
Инструмент адресует два класса ошибок: ошибки многопоточности и ошибки работы с
памятью, причем анализ для каждого класса запускается отдельно. Последний класс
ошибок хорошо известен программистам, которые до последнего времени
использовали различные инструменты, чтобы найти утечки памяти, нарушение
целостности стека или доступ по несуществующим адресам. Второй класс ошибок
связан с многопоточной природой программ. Они неизбежно возникают при
разработке параллельных приложений, и их чрезвычайно сложно отловить, особенно
если они проявляются нерегулярно и только при совпадении определенных условий.
Пример ошибок памяти:
// Запись по недействительному адресу освобожденной памяти
char *pStr = (char*) malloc(20);(pStr);(pStr, "my
string"); // Ошибка!
// Попытка чтения неинициализированной памяти* pStr = (char*)
malloc(20);c = pStr[0]; // Ошибка!
// Функция освобождения памяти не соответствует функции выделения
char *s = (char*)malloc(5);s;// Ошибка!
// Выход за пределы стекаstackUnderrun()
{array[10];(array, "my string");len =
strlen(array);(array[len] != "Z") // Ошибка!-;
}
Ошибки многопоточности:
Наиболее распространенные ошибки многопоточности - это «гонки» (Data
Races), или конкурирующий доступ потоков к разделяемым данным, и
взаимоблокировки (Deadlocks), когда, захватив неправильно расставленные объекты
синхронизации, потоки самозаблокировались и не могут продолжить свое
выполнение.
Пример ошибки, которая рано или поздно приведет к «зависанию» программы,
представлена в примере ниже.
// Поток A захватывает критическую секцию L1, затем ожидает критическую
секцию L2WINAPI
threadA(LPVOID arg)
{(&L1);(&L2);(data1, data2);(&L2);(&L1);
return(0);
}
// Поток В захватывает критическую секцию L2, затем ожидает секцию L1WINAPI threadB(LPVOID arg)
{(&L2);(&L1);(data2, data1) ;(&L1);(&L2);(0);
}Parallel Amplifier
Профилировщик производительности предназначен для того, чтобы выяснить,
насколько эффективно используется мультипроцессорная платформа приложением, и
где находятся те узкие места в программе, которые мешают ей масштабироваться и
увеличивать производительность с ростом вычислительных ядер в системе.
Методология профилировки приложения проста: необходимо ответить себе на три
основных вопроса, каждый из которых соответствует своему типу анализа и
отражает суть, место и причины проблем с производительностью.анализ. «На что
моя программа тратит вычислительное время процессора?» Нам необходимо знать те
места в программе, Hotspot-функции, где больше всего тратится вычислительных
ресурсов при исполнении, а также тот путь, по которому мы в эти места попали,
т.е. стэк вызовов.анализ. «Почему моя программа плохо параллелится?» Бывает,
что независимо от того, насколько продвинута параллельная инфраструктура
приложения, ожидаемый прирост производительности при переходе, например от
4-ядерной системе к 8-ядерной так и не достигается. Поэтому тут нужна оценка
эффективности параллельного кода, которая дала бы представление о том, на
сколько полно используются ресурсы микропроцессора.& Wait - анализ. «Где
моя программа простаивает в ожидании синхронизации или операции ввода-вывода?»
Поняв, что наша программа плохо масштабируется, мы хотим найти, где именно и
какие именно объекты синхронизации стали на пути к хорошей параллельности.
Программа на данный момент находится в стадии альфа тестирования и не
входит в комплект Intel
Parallel Studio, поэтому полный обзор до релиза приложения делать некорректно.
Я зарегистрировалась и получила код. Скачала Intel Parallel Studio XE 2013.
Глава 6.
Домашняя работа №6
Расширения MMX/SSE. Общее представление о SSE
обеспечивает инструкции для управления кэшированием всей MMX технологии и
32-битных типов данных. Эти инструкции включают возможность записи данных в
память без “засорения” кэша промежуточный буфер с быстрым доступом, и
возможность упреждающей выборки кода/данных до их использования.
Потоковое Расширение SIMD обеспечивает следующие новые возможности при
программировании оборудования IA архитектура Intel (Intel architecture):
· Восемь SIMD-регистров с плавающей точкой (XMM0 - XMM7);
· Тип данных SIMD (упакованные числа одинарной точности с
плавающей точкой) - 128-бит;
· Набор команд SSE.регистры с плавающей точкойсодержит восемь
128-разрядных регистров общего назначения, каждый из них может быть напрямую
адресован. Так как эти регистры новые, то для использования нуждаются в
поддержке операционной системы.регистры с плавающей точкой содержат упакованные
128-разрядные данные. Команды SSE обращается к SIMD-регистрам с плавающей
точкой, используя регистровые имена XMM0 и до XMM7 . SIMD-регистры с плавающей
точкой могут быть использованы для вычислений над данными; но не могут быть
использованы для адресации памяти. Адресация выполняется с помощью определенных
в IA режимов адресации и регистров общего назначения (EAX, EBX, ECX, EDX, EBP,
ESI, EDI и ESP).
Если произошло исчезновение порядка (underflow), а поле flush-to-zero (FZ
бит 15) регистра MXCSR установлено в 1, то процессор выполняет следующие
действия:
· возвращает нулевое значение в качестве результата, присваивая
ему знак истинного результата;
· устанавливает в 1 биты 4 и 5 регистра MXCSR (флаги
обнаружения исключений исчезновения порядка и неточного результата).
Указанные действия выполняются в том случае, если исключение underflow
маскировано (бит 11 регистра MXCSR установлен в 1). При таком режиме увеличивается
скорость работы программ, в которых часто происходит исчезновение порядка
результата. Достигается это ценой снижения точности вычислений. Переход от
операций MMX к операциям с плавающей точкой требует запуска команды EMMS. Но
так как SIMD-регистры с плавающей точкой являются отдельным регистровым файлом,
то команды MMX и команды с плавающей точкой могут быть смешаны с командами SSE
без выполнения специальных инструкций, таких как EMMS.
Тип данных SIMD с плавающей точкой
Основной тип данных SSE это 128-разрядное значение, содержащее четыре
последовательно расположенных (“упакованных”) 32-разрядных числа одинарной
точности с плавающей точкой (single-precision floating-point (SPFP)) .
Данный формат сохранен и в процессорах, начиная с Pentium III, но для упакованных
чисел с плавающей точкой используется представление в 32-разрядном формате с
одинарной точностью. Поэтому в отдельных случаях результаты вычислений с
плавающей точкой в архитектуре х87 могут отличаться от результатов таких же
вычислений, использующих новые SSE SPFP-команды.
Новые команды SIMD над целыми могут работать над типами данных состоящих
из упакованных байт, слов или двойных слов. Новые команды предварительной
выборки работают над данными размер, которых от 32 байт и выше.
Команды SSE копирует упакованные типы данных (данные одинарной точности с
плавающей точкой - двойные слова) из памяти в 64-битные или 128-битные блоки.
Однако, при вычислении арифметических или логических операций над упакованными
данными, SSE работает параллельно над каждым двойным словом, заключенным в SIMD
регистре с плавающей точкой.
Модель выполнения SIMD
Так как потоковое расширение SSE поддерживает операции над упакованными
типами данных одинарной точности с плавающей точкой, и дополнительные SIMD
команды над целыми, поддерживаются операции над упакованными типами данных
(байт, слово или двойное слово).
Этот подход был выбран, потому что большинство приложений обработки
мультимедиа имеют следующие характеристики:
· существенна параллельность;
· широкий динамический уровень, отсюда базированы на переменных
с плавающей точкой;
· регулярная и повторяющая выборка шаблонов из памяти;
· локализированные повторяющие операции выполняемые над
данными;
· независимый процесс управления данными.
Формат данных в памяти
В SSE вводиться новый упакованный 128-разрядный тип данных, который
состоит из четырех чисел одинарной точности с плавающей точкой. Бит 0 это
наименьше значащий - бит (LSB), и бит 127 это наибольше значащий - бит (MSB).
Байты в новом формате данных имеют последовательные адреса памяти. Порядок как
всегда немного странный, то есть байты с меньшими адресами имеют меньшее
значение, чем байты со старшими адресами.
Команды Потокового Расширения SIMD
Потоковое Расширение SIMD состоит из 70 команд, сгруппированных в следующие
категории:
· Команды копирования данных;
· Арифметические команды;
· Команды сравнения;
· Команды преобразования типов данных;
· Логические команды;
· Дополнительные целочисленные SIMD-команды;
· Команды перестановки;
· Команды управления состоянием;
· Команды управления кэшированием
Глава 7.
Домашняя работа №7
Написать программу умножения матриц, с замером времени на операцию.
Сравнить компиляторы msvs/gcc с компилятором intel.
Глава 8.
Домашняя работа №8
Технология GIT. Сравнение
репозиториев gihub/bit bucket
Сравнение репозиториев github и bitbucket
Bitbucket
<#"870790.files/image018.gif">
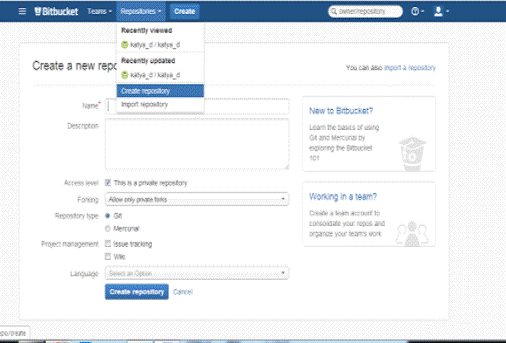
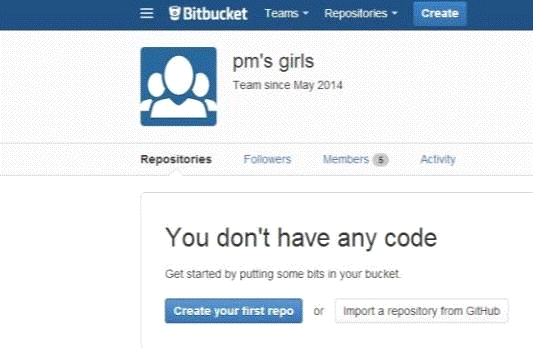
Создать репозиторий.
Для создания команды нужно было разделиться по группам. В нашей группе
есть Жиркова Сардаана, Григорьева Сардаана, Стручкова Катя, Иванова Арина и я.
Для того чтобы создать команду нужно нажать на вкладку teams.
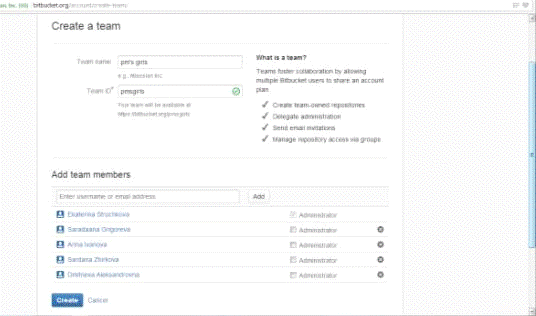
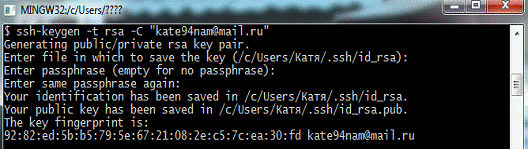
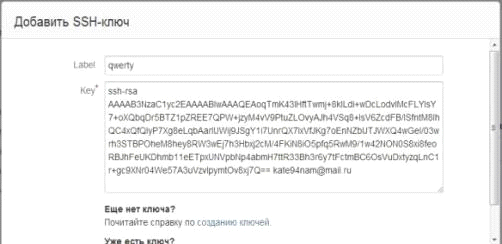
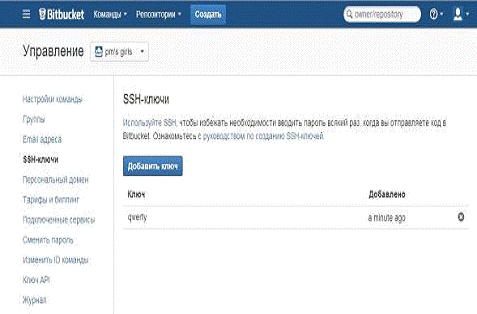
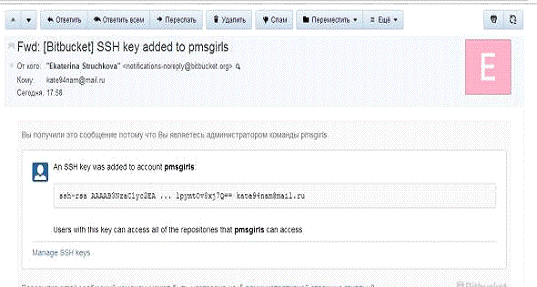
На этом базовая настройка Bitbucket окончена и можно приступать к работе
над кодом.