Распределение задач с помощью нитей по процессорам вычислительной системы заданной структуры
Министерство
Образования и Науки Российской Федерации
«Московский
государственный технический университет имени Н. Э. Баумана»(МГТУ им. Н. Э.
Баумана)
Факультет
«Аэрокосмический»
Кафедра
«Компьютерные системы и сети»
РАСЧЕТНО-ПОЯСНИТЕЛЬНАЯ
ЗАПИСКА
на курсовую
работу
«Распределение
задач с помощью нитей по процессорам вычислительной системы заданной структуры»
по курсу
“Вычислительные системы”
Руководители, Шайхутдинов А.А.
Исполнители Башкин А.А.
Москва 2015
Содержание
Введение
Постановка задачи
Анализ исходных данных
Алгоритмы решения задачи
Алгоритм построения нитей для
графа решаемой задачи
Алгоритм уплотнения загрузки
процессоров
Алгоритм размещения
уплотненных нитей на узлах ВС
Описание разработанной
программы
Результат размещения уплотненных
нитей на узлах ВС
Заключение
Введение
Создание параллельных вычислительных систем (ВС) является одним из самых
перспективных направлений увеличения производительности вычислительных средств.
При решении задач распараллеливания существует два подхода.
. Имеется параллельная система, для которой необходимо подготовить
план и схему решения поставленной задачи, т. е. ответить на вопросы о том, в
какой последовательности будут выполняться программные модули и на каких
процессорах, как происходит обмен данными между процессорами, как
минимизировать время выполнения поставленной задачи.
. Имеется класс задач, для решения которых необходимо
спроектировать параллельную вычислительную систему, минимизирующую время
решения поставленной задачи при минимальных затратах на проектирование. При
создании параллельных ВС учитываются различные аспекты их эксплуатации, такие,
как множественность решаемых задач, частота их решения, требования к времени
решения и т. д., определяющие различные типы построения таких систем.
Перечислим эти типы в порядке возрастания сложности:
· однородные многомашинные вычислительные комплексы (ОМВК),
которые представляют собой сеть однотипных ЭВМ;
· неоднородные многомашинные вычислительные комплексы (НМВК),
которые представляют собой сеть разнотипных ЭВМ;
· однородные многопроцессорные вычислительные системы (ОМВС),
которые представляют собой ЭВМ с однотипными процессорами и общим полем
оперативной памяти или без него;
· неоднородные многопроцессорные вычислительные системы (НМВС),
которые представляют собой системы с разнотипными процессорами и общим полем
оперативной памяти или без него.
Постановка задачи
Цель работы - нахождение оптимального плана параллельного решения задачи
на ВС заданного типа.
Для заданной граф-схемы рассматриваемого алгоритма получить множества
нитей для каждого варианта решения задачи. Распределить их по узлам
рассматриваемой конфигурации вычислительной сети, используя распределенные
составные коммутаторы, определив при этом минимальное количество требуемых узлов.
Решение должно быть представлено в виде работающей программы со всеми
необходимыми пользовательскими интерфейсами и диаграммами полученных
результатов.
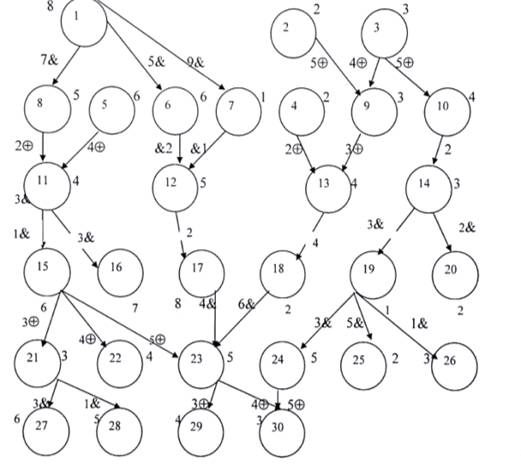
Рисунок 1. Граф-схема алгоритма. На дугах указаны логические функции
взаимодействия между дугами
Анализ исходных данных
Структура
решаемой задачи задана граф-схемой алгоритма (рис. 1). Для реализации
необходимо получить матрицу следования. Матрица следования - это матрица, в
которой i-й вершине графа ставится в соответствие i-й
столбец и строка матрицы следования, если существует информационная связь 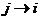 , то в матрице следования устанавливается значение
, то в матрице следования устанавливается значение 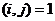 . Остальные элементы матрицы равны нулю. Граф-схема
алгоритма не должна содержать циклов (контуров), то есть главная диагональ
всегда должна содержать только нулевые элементы.
. Остальные элементы матрицы равны нулю. Граф-схема
алгоритма не должна содержать циклов (контуров), то есть главная диагональ
всегда должна содержать только нулевые элементы.
В
расширенной матрице следования также отражены веса вершин, для этого к матрице
справа пристраивается k столбцов, где k - размерность
вектора весов вершин. Вес вершины интерпретируется как время выполнения
оператора на процессоре заданного типа. В нашем задании веса вершин заданы в
столбце p и задают время решения оператора на процессоре
однородной вычислительной системы.
Кроме
того, в задании задан еще один столбец, позволяющий вычислить веса дуг,
соединяющих вершины графа. Веса дуг интерпретируются как время, затрачиваемое
на пересылку информации от одного оператора другому (при условии, что операторы
выполняются разными процессорами). Заданной матрице следования соответствует
граф, показанный на рисунке 1. Структура задачи, которую необходимо разместить
на узлах ВС соответствует этому графу.
ВС,
на узлах которой необходимо разместить решаемую задачу имеют структуру
гиперкуба. Структура ВС типа «Обобщенный nD-куб» описывается графом
вычислительный
нить процессор матрица
GS =(М, S*),
где
М - множество вычислительных модулей, определяемых вершинами графа, М ={mi}, i
= 0, … , N-1,  . По каждой координате j, j=1,…, n вводятся точки
NJ={0,1, ... , Nj-1}, где Nj - размерность куба по координате j. Множество
вершин графа ВС определяется декартовыми произведениями [N1]
. По каждой координате j, j=1,…, n вводятся точки
NJ={0,1, ... , Nj-1}, где Nj - размерность куба по координате j. Множество
вершин графа ВС определяется декартовыми произведениями [N1]  [N2] …[Nn], |N1|·|N2|·…·|Nn|=N. Две вершины соединяются
ребром, если декартовы произведения, определяющие эти вершины, отличаются друг
от друга на 1. Пример обобщенного гиперкуба представлен на Рисунке 2.
[N2] …[Nn], |N1|·|N2|·…·|Nn|=N. Две вершины соединяются
ребром, если декартовы произведения, определяющие эти вершины, отличаются друг
от друга на 1. Пример обобщенного гиперкуба представлен на Рисунке 2.
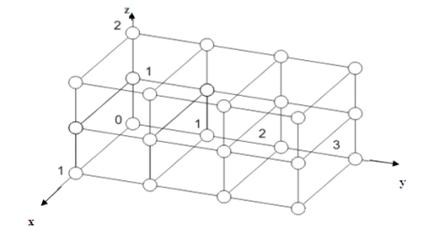
Рисунок
2. Схема представления обобщенного 3-х мерного гиперкуба 2х4х3
Алгоритмы решения задачи
Процесс поиска оптимального плана решения задачи с заданной структуры на
ВС распадается на несколько этапов: разбиение решаемой задачи на нити,
уплотнение построенных нитей, распределение уплотненных нитей по узлам
вычислительной сети. Разбиение задачи на нити заключается в выделении участков
в решаемой задаче, которые целесообразно выполнять на отдельном процессоре.
Нити должны строиться таким образом, чтобы выигрыш времени за счет выполнения
каждой нити на отдельном процессоре был максимальным.
Для
каждой построенной нити могут быть рассчитаны времена начала и окончания ее
выполнения. Нить может загружать процессор лишь часть времени решения задачи, в
этом случае целесообразно проверить, нельзя ли уплотнить график загрузки
процессора таким образом, чтобы в течение времени решения задачи он выполнил
операторы нескольких нитей. За счет такого уплотнения графика загрузки можно добиться
того, что число процессоров необходимое для решения задачи приблизится к нижней
оценке минимального числа процессоров 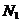 .
.
После
уплотнения необходимо назначить каждому (уплотненному) блоку нитей процессор,
на котором он будет выполняться. При назначении процессоров необходимо учесть
то, что нити должны иметь возможность передавать друг другу информацию. Для
того, чтобы время затрачиваемое на обмен информацией между нитями было
минимальным, необходимо, чтобы нити (имеющие потребность в обмене информацией)
располагались на смежных процессорах (то есть процессорах между которыми есть
связь).
Алгоритм построения нитей для графа решаемой задачи
Параллельное выполнение отдельных участков задачи приводит к тому, что
суммарное время, затрачиваемое на вычисления сокращается, однако при этом
возрастает время затрачиваемое на обмен данными между нитями. Время, которое
выполняется оператор на процессоре заданного типа, есть величина постоянная и
уменьшено быть не может, поэтому оптимальным будет такое разбиение задачи на
нити, при котором минимизируется время на пересылку данных между нитями.
Если два оператора выполняются на одном процессоре, то данные,
используемые ими, находятся в памяти этого процессора и пересылка данных не
требуется. Таким образом, выигрыш времени будет тем больше, чем больше времени
требуется на пересылку данных между этими операторами, если они выполняются на
разных процессорах.
Исходя из вышеизложенного, в одну нить следует объединять операторы,
связанные задающими связями с наибольшим весом. Перед тем как описать алгоритм
построения нитей для графа решаемой задачи введем несколько определений.
Сверткой
в вершине 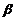 графа G, будем называть ситуацию, когда
графа G, будем называть ситуацию, когда 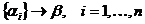 , то есть n вершин
, то есть n вершин 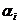 связано с вершиной , а
вершину - ядром свертки.
связано с вершиной , а
вершину - ядром свертки.
Разверткой
вершины графа G, будем называть ситуацию, когда вершина связана с n вершинами , то есть 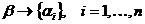 , а
вершину - ядром развертки.
, а
вершину - ядром развертки.
Теперь
рассмотрим алгоритм построения нитей (рисунок 3), его суть заключается в
следующем: выбирается одна из начальных вершин графа и из нее строится путь
наибольшей длины (под длиной пути понимаем сумму весов всех дуг, составляющих
путь), вершины графа, вошедшие в этот путь, составляют очередную нить. Вершины
и дуги, составившие нить удаляются из графа, при этом могут появиться связи не
имеющие начала или конца - это значит, что оператору из которого исходит связь
(или в который она входит) требуется осуществлять обмен информацией с
построенной нитью, чтобы учесть время затрачиваемое на это, вес дуги
прибавляется к весу оператора, после чего дуга удаляется. После этого вновь
выбирается очередная начальная вершина и строится новая нить, процесс
построения нитей заканчивается когда в графе не останется вершин.
Параллельно
с построением нитей строится таблица связей T, описывающая
какие нити обмениваются данными в ходе выполнения, эта таблица в последующем
используется при размещении нитей на узлах ВС.
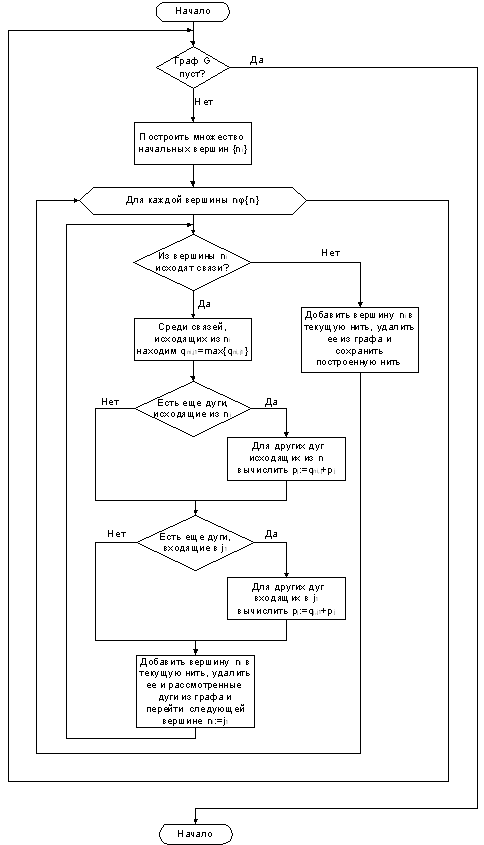
Рисунок
3. Схема алгоритма построения нитей для графа решаемой задачи
Для нитей может быть рассчитано время начала и окончания ее выполнения,
что будет использоваться в дальнейшем при уплотнении графика.
Алгоритм уплотнения загрузки процессоров
Для параллельного выполнения нитей построенных алгоритмом из предыдущего
раздела требуется, как правило, избыточное количество процессоров для решения
задачи, поэтому следует попытаться уменьшить требуемое количество процессоров
за счет уплотнения графика их загрузки. Другими словами, процессор будет
выполнять нить не все время решения задачи (об этом свидетельствуют времена начала
и завершения выполнения нитей), часть времени он будет простаивать, необходимо,
по возможности, скомпоновать нити так, чтобы они выполнялись на минимально
возможном количестве процессоров, и время простоя процессоров было как можно
меньше.
Предлагается решать эту задачу путем полного перебора всех возможных
вариантов компоновки нитей и на каждом шаге выбирать такую компоновку, при
которой минимизируется время простоя процессора. В качестве критерия для оценки
времени простоя будем использовать выражение:
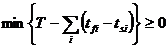 ,
,
где
T - заданное время выполнения задачи,  - множество времен окончания выполнения нитей,
- множество времен окончания выполнения нитей, 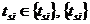 - множество времен начала выполнения нитей,
- множество времен начала выполнения нитей, 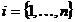 . Будем последовательно формировать все возможные
комбинации компоновки нитей и рассчитывать для каждой такой комбинации значение
критерия, минимальное значение критерия будет соответствовать оптимальной
комбинации. Комбинации будем формировать в естественном лексикографическом
порядке, то есть следующим образом:
. Будем последовательно формировать все возможные
комбинации компоновки нитей и рассчитывать для каждой такой комбинации значение
критерия, минимальное значение критерия будет соответствовать оптимальной
комбинации. Комбинации будем формировать в естественном лексикографическом
порядке, то есть следующим образом: 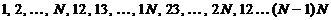 . Также
следует помнить, что времена выполнения нитей не должны пересекаться, для
упрощения проверки этого условия перед началом уплотнения отсортируем нити в
порядке не убывания времен начала выполнения
. Также
следует помнить, что времена выполнения нитей не должны пересекаться, для
упрощения проверки этого условия перед началом уплотнения отсортируем нити в
порядке не убывания времен начала выполнения 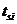 , и, в
дальнейшем будем проверять условие
, и, в
дальнейшем будем проверять условие 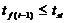 .
.
Следует
отметить, что не обязательно все нити удастся уплотнить, возможно, что для
некоторых нитей придется выделять отдельный процессор.
Алгоритм размещения уплотненных нитей на узлах ВС
Конечной задачей при написании параллельной программы является размещение
уплотненных нитей на заданную вычислительную систему. Здесь решается, какого
размера будет вычислительная система, как будут соединяться узлы вычислительной
системы между собой, и какое взаимное расположение они будут иметь относительно
друг друга.
На этом этапе учитываются особенности конкретной реализации
вычислительной системы и её особенности.
Изначально размерность вычислительной системы задать невозможно из-за
комплексных узлов, которые могут образоваться в ходе размещения уплотненных
нитей на узлы вычислительной системы. Комплексные узлы - это узлы
вычислительной системы, которые выполняют только транспортную функцию передачи
данных/управления от одного узла к другому. Они создаются в случае
невозможности соединения узлов непосредственно между собой. При этом считается,
что операция передачи данных/управления не занимает времени, соответственно
передача через комплексный узел не влияет на время начала работа следующей
нити. В общем виде алгоритм имеет следующий вид:
. Находится узел вычислительной системы, имеющий минимальное
расстояние до остальных узлов
. Находится уплотненная нить, имеющая максимальное количество
соединений с другими нитями (T)
. Найденная нить располагается в найденный узел
. В соседних узлах располагаются нити, связанные с расположенной
нитью T
. Если соединений с нитью T больше возможных соединений, чем в выбранной вычислительной
системе, либо нить уже расположена на другом узле, то создается один или более
комплексный узлов, через которое происходит соединение с нитью T
. После расположения всех соединенных с нитью T нитей, нить T считается рассмотренной, если она не была таковой ранее, и
из расположенных нитей выбирается нить, соединенная с T из нерассмотренных, у которой максимальное количество
соединений с другими нитями, и она является при рассмотрении новой нитью T.
. Если у выбранной нити T все нити, с которыми она соединена, рассмотрены и соединения с ними
построены, то нить считается рассмотренной, а нитью T назначается нить, от которой перешло рассмотрение на данную
нить и алгоритм повторяется с шага 6. Если же такой нити не существует, то
алгоритм переходит на шаг 9.
. Конец алгоритма - все уплотненные нити расположены и соединены
согласно исходным данным.
Описание разработанной программы
Для поиска оптимального плана решения задачи была разработана программа,
реализующая вышеописанные алгоритмы. Программа реализует следующие задачи:
построение исходного графа, построение матрицы следования, формирование нитей
для заданной задачи, подсчет времени начала и конца работы нити, уплотнение
загрузки процессоров, соединение уплотненных вычислителей между собой,
графическая визуализация соединения процессоров. На Рисунках 5-9 представлены
результаты работы программы.
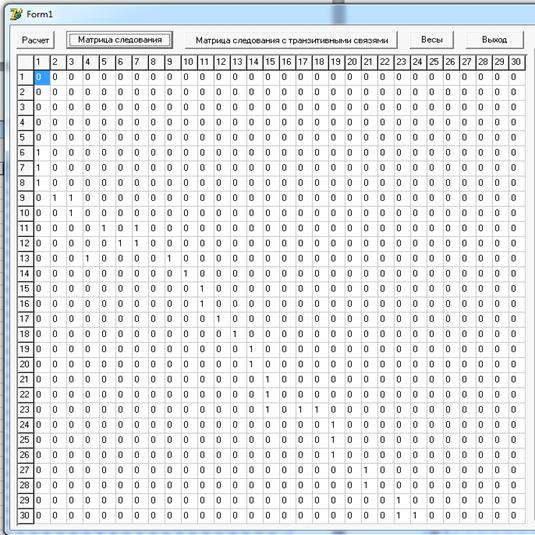
Рисунок 5. Матрица следования
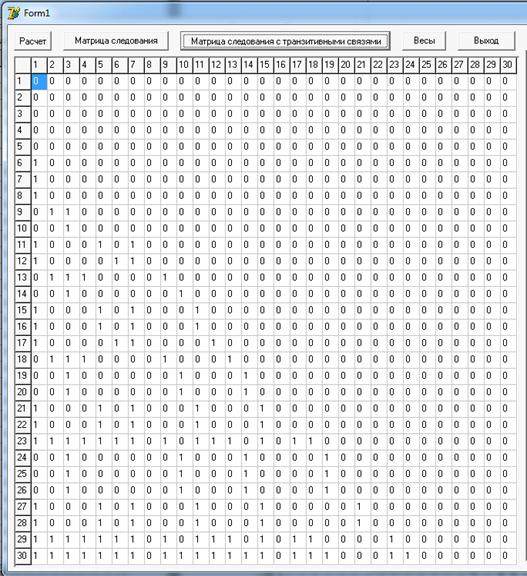
Рисунок 6. Транзитивная матрица следования
Рисунок 7. Матрица весов дуг


Рисунок 8. Остальные расчеты
Таблица 1. Временные диаграммы выполнения нитей процессорами
|
Time//proc
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
16
|
17
|
18
|
19
|
20
|
21
|
22
|
23
|
24
|
25
|
26
|
27
|
28
|
29
|
30
|
|
0
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
2
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
|
3
|
1
|
1
|
|
|
|
|
|
|
1
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
4
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5
|
|
|
|
|
|
|
|
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6
|
|
|
|
|
|
|
|
|
|
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
7
|
|
|
|
|
|
|
|
|
|
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8
|
|
|
|
|
|
|
|
|
|
|
|
1
|
1
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Результат размещения уплотненных нитей на узлах ВС
Используя алгоритм размещения уплотненных нитей и выданные программой
связи нитей между собой (графическое изображение которого представлено на рисунке
9), с учетом особенностей обобщенного гиперкуба получилось расположение,
представленное на рисунке 10.
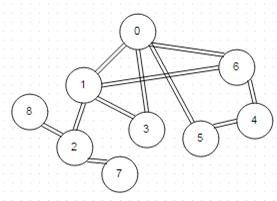
Рисунок 9. Графическое представление соединений уплотненных нитей
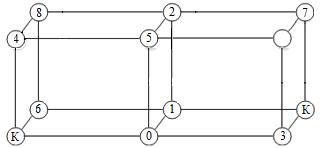
Рисунок 10. Расположение уплотненных нитей на ВС типа обобщенный гиперкуб
Заключение
В результате выполнения данной курсовой работы, была разработана
программа, определяющая оптимальный способ решения задачи на вычислительной
системе. Данная программа реализует алгоритмы разбиения задачи на множество
нитей, а также их компоновки и уплотнения.
Результатом выполнения данной программы, была проверка вышеописанных
алгоритмов на заданной задаче, и получение решения этой задачи на ВС типа
гиперкуб.
Список литературы
§ Ю.М.
Руденко Вычислительные системы: Методическме указания по выполнению курсовой
работы. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. - 12 с.
§ Ю.М.
Руденко Лабораторный практикум по организации параллельных вычислений:
Методические указания. - М.: Изд-во МГТУ им. Н.Э. Баумана, 2006 - 67с.
§ Ю.М.
Руденко Конспект лекций по курсу “Вычислительные системы”. МГТУ, 2007г.
§ Барский
А.Б. Параллельные процессоры в вычислительных системах. Планирование и
организация. - М.: Радио и связь, 1990. - 256 с.