Разработка компонентов системы удаленного доступа и управления распределенными вычислительными ресурсами
Федеральное агентство по образованию
Государственное образовательное
учреждение высшего профессионального образования
Кемеровский государственный
университет
Математический факультет
Кафедра ЮНЕСКО по Новым
информационным технологиям
Специальность 010503 -
«Математическое обеспечение и администрирование информационных систем»
ДИПЛОМНАЯ РАБОТА
Тема:
Разработка компонентов системы
удаленного доступа и управления распределенными вычислительными ресурсами
Выполнил студент 5 курса
Окулов Николай Николаевич
Руководитель: К.Е. Афанасьев
д-р физ.-мат. наук, профессор
Кемерово 2014
СОДЕРЖАНИЕ
ВВЕДЕНИЕ
Обзор систем
управления вычислительными ресурсами
Требования к
системе УД и УРВР
Архитектура
системы УД и УРВР
Структура
пользовательских данных
Система УД к
ВР
Принцип
работы пакета KemsuWebмодель базы данных системы УД и УРВР
ГЛАВА 1.
РАЗРАБОТКА КОМПОНЕНТА «ИНТЕРФЕЙС АДМИНИСТРАТОРА» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
.1
Определение функций администратора
.2
Моделирование администраторской части системы УД к ВР
.3 Требования
к компоненту «Интерфейс администратора»
.4 Описание
web-форм и их реализация
.5 Описание
пакета p_admin
ГЛАВА 2.
РАЗРАБОТКА КОМПОНЕНТА «ИНТЕРФЕЙС КЛИЕНТА» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
.1
Определение функций клиента
.2
Моделирование клиентской части системы УД к ВР
.3 Требования
к компоненту «Интерфейс клиента»
.4 Описание
web-форм и их реализация
.6 Описание
пакета p_client
ГЛАВА 3.
РАЗРАБОТКА КОМПОНЕНТА «ВИРТУАЛЬНАЯ ЛАБОРАТОРИЯ» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
.2
Определение функций
.3
Моделирование
.4 Требования
к компоненту «Виртуальная лаборатория»
.5 Описание
web-форм и их реализация
.6 Описание
пакета p_virtlab
ЗАКЛЮЧЕНИЕ
СПИСОК
ЛИТЕРАТУРЫ
СПИСОК
СОКРАЩЕНИЙ
ПРИЛОЖЕНИЯ
ВВЕДЕНИЕ
В настоящее время вычислительные системы кластерного типа получают все
большее распространение. Это обусловлено различными факторами, главным из
которых является насущная потребность в решении актуальных задач
фундаментальной и прикладной науки, для анализа и исследования которых
производительности существующих средств вычислительной техники оказывается
недостаточно. [18]challenges - это фундаментальные научные или инженерные
задачи с широкой областью применения, эффективное решение которых возможно
только с использованием мощных (суперкомпьютерных) вычислительных ресурсов.
Вот лишь некоторые области, где возникают задачи подобного рода:
предсказания погоды, климата и глобальных изменений в атмосфере, гидро- и
газодинамика, науки о материалах, разведка нефти и газа, управляемый
термоядерный синтез, генетика человека и многие другие области. [20]
С аппаратной точки зрения кластер представляет собой набор серийно
выпускаемых ЭВМ (вычислительных узлов), объединенных сетью передачи данных. С
точки зрения программного обеспечения кластер является единой виртуальной
машиной, имеющей несколько процессоров и распределенную память.
Производительность кластера определяется производительностью его узлов и
характеристиками среды передачи данных. Мощные вычислительные узлы и
низколатентная сеть с высокой скоростью передачи данных дают
производительность, сравнимую с заводскими многопроцессорными машинами, при
этом удельная стоимость MFLOPS
у кластеров в среднем ниже, чем у заводских ЭВМ параллельной архитектуры.
Рост популярности кластерных решений в научной и академической среде
привел к появлению практически в каждом ВУЗе страны набора кластеров, как
высокопроизводительных для научных расчетов, так и относительно
низкопроизводительных для обучения студентов и отладки программ. [21]
Однако при развертывании систем такого рода возникает ряд проблем.
Заметное место в этом ряду занимает проблема эффективного управления
кластерными системами. Для того чтобы распределенная вычислительная система
успешно функционировала, необходимо, по крайней мере, реализовать систему
распределения задач по доступным вычислительным ресурсам (систему доступа),
обеспечивающую планирование выполнения задач на кластерах (диспетчер заданий) и
мониторинг состояния вычислительных ресурсов. В случае отсутствия систем такого
рода возможны конфликты в процессе запроса вычислительных мощностей во время
проведения экспериментов, что приведет к падению общей производительности
системы. Таким образом, разработка программных систем, решающих эти задачи,
является необходимым условием успешного развития вычислительных систем
рассматриваемого класса. [18]
Многие организации, а особенно университеты, имеют несколько компьютерных
классов, на базе каждого из которых легко может быть организован однородный
кластер. Так, например, в ЦНИТ КемГУ организован распределенный вычислительный
ресурс на базе уже существующих учебных компьютерных классов, включенных в
единую университетскую сеть. [21]
При поддержке аналитической ведомственной целевой программы «Развитие
научного потенциала высшей школы (2006-2014 годы)» в КемГУ был создан
информационно-вычислительный портал для организации учебной и научной
деятельности ВУЗа, одной из подсистем которого является система УД и УРВР.
Обзор
систем управления вычислительными ресурсами
Современные программные пакеты системного уровня, предназначенные для
поддержки параллельных вычислений на кластерах, либо обеспечивают запуск
пользовательских задач, либо предоставляют возможность мониторинга состояния
вычислительных узлов. Ни один из известных пакетов не даёт пользователю
взаимосвязанной и согласованной информации о динамических характеристиках
выполнения его задачи на кластере, не позволяет провести содержательный анализ
эффективности работы его программы.
В настоящее время наиболее развиты и представляют интерес несколько
систем управления прохождением заданиями. Сделаем их краткий обзор. [11]
Load Leveler
Данная система разработана и поддерживается компанией IBM. Это
стандартная система управления прохождением заданиями для мейнфреймов под
управлением ОС AIX. В данной системе поддерживается детальное описание
ресурсов, необходимых для задачи. По этому описанию система пытается найти
наилучший из доступных компьютеров для запуска.
Единицей измерения вычислительных ресурсов в Load Leveler является
компьютер. Это не обязательно должен быть физически один компьютер, это может
быть очередь NQS (Network Queue System), обслуживающая вычислительный
кластер.Leveler изначально ориентирована на однопроцессорные задачи, но в настоящее
время поддерживает и параллельные среды. Однако набор их весьма невелик и
ограничивается IBM Parallel Environment Library (POE/MPI/LAPI) 2.4.0, Parallel Virtual Machine (PVM)
3.3 (на архитектуре RS6K architecture) и Parallel Virtual Machine (PVM)
3.3.11+ (на архитектуре SP2MPI).
Важной особенностью Load Leveler является поддержка контрольных точек,
как для последовательных, так и для параллельных приложений. Система активно
используется во всём мире. Например, под её управлением работает комплекс Regatta,
установленный на факультете ВМиК МГУ им. М.В. Ломоносова в Москве.
Condor
Изначальное предназначение системы Condor - использование времени простоя
компьютеров для счёта задач. В обычном режиме компьютер может использоваться
как рабочая станция, а когда пользователь не работает за компьютером, Condor
запускает на нём задачи. Эта система была разработана в 1988 году и продолжает
активно развиваться.
Кроме однопроцессорных заданий поддерживаются и параллельные, однако их
круг ограничен приложениями PVM и приложениями MPI, использующими библиотеку
mpich, причём только определённые версии (последняя версия mpich-1.2.6 не
поддерживается).
Система Condor поддерживает механизм контрольных точек, но только для
последовательных задач. Создание и восстановление контрольных точек происходит
прозрачно для программы. Таким образом, если вычислительные ресурсы компьютера
надо вернуть до того, как программа завершилась, Condor может сделать
контрольную точку в программе, завершить её и запустить из этой контрольной точки
позднее на этом или другом компьютере. Condor позволяет сконфигурировать
очередь таким образом, чтобы контрольные точки автоматически создавались через
заданные интервалы времени. Программа также может использовать контрольные
точки явно, вызывая соответствующие подпрограммы.
OpenPBS (TorquePBS)
OpenPBS
- одна из самых популярных систем на сегодняшний день. К сожалению, сейчас
проект OpenPBS заморожен и не развивается, хотя есть его коммерческая версия
OpenPBS Pro, которая развивается и поддерживается. Существует новый проект,
основанный на OpenPBS - TorquePBS, который унаследовал от предшественника все
достоинства, но и большинство недостатков.
По умолчанию, OpenPBS не имеет поддержки параллельных программ, но,
используя дополнительные средства, такую поддержку можно организовать. Для
запуска программы необходимо написать специальный командный файл, описывающий
необходимые ресурсы и строку запуска программы. По информации из этого файла
OpenPBS осуществляет планирование запуска программы.
Одним из важных недостатков OpenPBS является отсутствие контроля над
запущенными программами. Неудачное завершение программы может остаться
незамеченным системой, а оставшиеся от неудачного запуска процессы могут
оставаться на рабочих узлах и затруднять работу других программ. А также,
пользователь может напрямую запустить параллельную программу в обход системы,
что может привести к затруднению работы программ. В случае сбоя вычислительного
узла, система не исключает его из рабочего поля и продолжает распределять на
него задачи.
Queue
Интерфейс к системе представляет собой расширенную замену стандартного
сервиса rsh. Задачи, запущенные через Queue, запускаются на том вычислительном
узле, который наименее загружен в данный момент. Загруженность узла
определяется по количеству запущенных на нём задач. Таким образом, Queue
осуществляет балансировку загрузки вычислительных узлов кластера. Запуск
параллельных задач возможен при условии, что запуск процессов задачи
осуществляется с помощью rsh (как сделано в реализации mpich_p4).
Система Queue не предоставляет возможности отложить запуск задачи до
момента освобождения необходимых ресурсов, а также просмотра состояния и
управления уже запущенными задачами.
Система управления прохождением задач в системе МВС-1000/М
Эта система разработана в Институте прикладной математики им. М.В.
Келдыша РАН специально для суперкомпьютера МВС-1000/М коллективом в составе:
Баранов А.В., Лацис А.О., Храмцов М.Ю., Шарф С.В. Данная система сразу была
ориентирована на запуск параллельных задач на больших кластерных установках и
гарантированное освобождение вычислительных узлов по окончании работы задач.
Постановка задачи в очередь осуществляется с помощью написания своего
командного файла, в котором описываются необходимые ресурсы. Планировщик,
поддерживаемый этой системой, принимает во внимание не только заказанные для
задачи ресурсы, но и время, которое пользователь уже потратил на счёт. Если
пользователь превысил заданный порог отведённого ему времени, то приоритет его
задач понижается. Таких порогов может быть задано несколько. Алгоритм
планирования не может быть изменён без внесения правок в код системы.
Схема запуска задач предполагает, что каждый процесс будет запущен
командой rsh. Данное ограничение может быть снято путём запуска задачи-пустышки
и реализации своей схемы запуска вручную. В этом случае система управления
заданиями не может контролировать задачу. Важной особенностью системы является
её корректное поведение, в случае отказа одного или нескольких вычислительных
узлов. Система успешно функционирует на суперкомпьютере МВС-1000/М.
NQS/NQE
NQS (Network Queue System) - это одна из самых старых систем управления
прохождением заданиями. Программа запускается через специальный командный файл,
в котором могут быть описаны необходимые программе ресурсы и строка запуска
программы. Описание ресурсов также может быть сделано через ключи командной
строки.
Система поддерживает базовые операции с заданиями (блокировка, отмена,
получение статуса задания, состояния очереди), а также ограничения для
запущенных задач в терминах операционной системы (размер занимаемой памяти,
размер core-файла и т.п.). Указанные ограничения не принимаются в расчёт при
планировании задач.
В NQS не предусмотрена поддержка параллельных задач. Проект не
развивается с 1992 года.
Для работы с несколькими очередями NQS применяется система NQE (Network
Queue Envinronment), которая может выбирать, в какую очередь посылать запрос.
Проект NQE поддерживался компанией Silicon Graphics, но с 1993 года не
развивается.
DQS
Система DQS во многом аналогична NQS, но имеет возможность учитывать
ограничения, указанные в скрипте при добавлении задачи в очередь. Параллельные
задачи не поддерживаются. Проект не развивается с 1996 года. Существовала
коммерческая реализация DQS - Codine. Однако последний проект в данный момент
закрыт и не поддерживается.
LSF
Наверное, самая развитая в рассматриваемой области система. К сожалению,
полной документации по ней нет в открытом доступе, т.к. эта система является
коммерческой. LSF разработана в компании Platform. Поддерживаются как обычные,
так и параллельные приложения. Система может управлять несколькими кластерами
одновременно.
Важными качествами LSF являются поддержка внешних модулей для
планирования задач, контроль исполнения задач (гарантированное удаление задачи
после неудачного завершения).
Разработки систем удаленного доступа и управления ВР ведутся во многих
организациях (в том числе - ВУЗах), но эти системы, как правило, ориентированы
на распределение задач между узлами одного кластера.
Требования
к системе УД и УРВР
Разработка любой информационной системы (ИС) начинается с определения
требований к системе, описания ее функций. Есть общий набор требований,
предъявляемых ко всем современным ИС, к которым относятся надежность системы,
обеспечение целостности обрабатываемых данных, доступность (высокая степень
готовности), конфиденциальность данных, эффективность и удобство использования.
Но помимо общих, существуют еще и частные требования, связанные со спецификой
работы системы, которые определяют выбор архитектуры и структуры ИС. [21]
Исходя из анализа предметной области и опроса потенциальных
пользователей, были сформированы следующие требования к системе:
— обеспечить пользователю удобный графический интерфейс для
работы с системой в удаленном режиме;
— следить за состоянием доступных вычислительных ресурсов;
— принимать от пользователей файлы с расчетными программами и
начальными данными, компилировать их на кластере, ставить в очередь на запуск;
— поддерживать набор очередей программ для запуска и оптимизировать
последовательность запуска программ для наиболее эффективного использования
доступных вычислительных ресурсов;
— сообщать пользователю информацию о состоянии его расчетов (в
очереди, выполняется, выполнен);
— передавать пользователю файлы с результатами работы его
программ;
— ограничивать доступ пользователей к расчетам других
пользователей.
На основе этих требований были определены задачи, которые и должна решать
создаваемая система:
— хранение файлов расчетных программ пользователей ИС (далее
«программ») в виде исходного и/или бинарного кода, файлов начальных данных,
результатов и другой информации, необходимой для проведения научных расчетов;
— хранение и сопровождение информации (метаданных) о файлах и
других объектах пользователей;
— передача файлов с кодами программ, начальными данными или
результатами между пользовательским приложением и хранилищем данных;
— создание, удаление и управление пользователем своими
объектами (файлами, расчетами);
— хранение информации о доступных вычислительных ресурсах;
— отслеживание состояния доступных удаленных вычислительных
ресурсов;
— отслеживание состояния расчетных программ на удаленных
вычислительных ресурсах;
— передача файлов между хранилищем и удаленными вычислительными
ресурсами;
— передача команд на удаленные вычислительные ресурсы;
— определение очередности запуска программ в случае
существования конкуренции за вычислительные ресурсы. [21]
Архитектура
системы УД и УРВР
Система УД и УРВР построена по трехзвенной архитектуре «клиент - сервер -
удаленный агент». В состав серверной части входят: сервер приложений, сервер
баз данных и сервер управления кластерами (менеджер вычислительных ресурсов).
Общая структура системы приведена на рисунке 1.

Рисунок 1 - Структура системы УД и УРВР
Так как система является частью информационно-вычислительного портала
КемГУ, то пользователь взаимодействует с системой посредством web-браузера. В
качестве хранилища данных выступает СУБД Oracle, а связующим звеном браузера
пользователя и хранилища является web-сервер приложений Tomcat, который
осуществляет динамическую генерацию страниц с использованием пакета KemsuWeb.
Такая архитектура позволяет работать с системой из любой точки, имеющей выход в
Интернет, а также обеспечивает независимость от платформы и минимальные
системные требования к аппаратному обеспечению пользователя. Менеджер
вычислительных ресурсов обеспечивает передачу агентам, размещенным на
вычислительных кластерах, файлов из хранилища и запросов на генерацию
исполняемого кода и выполнение расчетов, а также осуществляет прием результатов
расчетов и размещение их в хранилище данных. [21]
Взаимодействие менеджера вычислительных ресурсов с базой данных
осуществляется через прикладной интерфейс OCCI (Oracle C++ Call Interface) -
низкоуровневый интерфейс, предназначенный для выполнения операций с базой
данных Oracle (например, для входа в систему, разбора и исполнения
SQL-предложений, получения записей и т.д.). [24]
Структура
пользовательских данных
Хранилище данных содержит файлы и метаинформацию, необходимую для
организации проведения расчетов. Структура пользовательских объектов в системе
представлена на рисунке 2. Основным пользовательским объектом в системе
является проект, который содержит make-файл и исходный код программы, создаваемый
системой, исполняемый код и наборы начальных данных, из которых формируются
серии расчетов. Для каждого расчета, после его обработки на вычислительном
кластере, в хранилище размещаются файлы с результатами расчетов.
Основными объектами, которые обрабатываются системой, являются:
— расчет - совокупность выполняемого кода программы и начальных
данных;
— задание - совокупность расчета и параметров его запуска:
выбранный кластер, количество процессоров, время старта.
Основной семантической единицей, с которой работает сервер, является
задание. Для пользователя же задание является лишь малой частью проекта,
который имеет следующую структуру:
Проект:
— файл исходного кода (1 .. *);
— make-файл (0 .. 1);
— параметры:
— архитектура вычислительной системы (1);
— операционная система (1);
— параллельная библиотека (1);
— компилятор (1);
— исполняемый файл (0 .. 1) или файл ошибки компиляции (0 ..
1);
— серия (1 .. *):
- подсерия (0 .. *):
— расчет (0 .. *):
- файл начальных данных (0 .. *);
- задание (0 .. *):
— файл промежуточного результата (0 .. *);
— файл ошибки (0 .. 1) или файл результата (0 .. 1);
- расчет (0 .. *):
- файл начальных данных (0 .. *);
- задание (0 .. *):
— файл промежуточного результата (0 .. *);
— файл ошибки (0 .. 1) или файл результата (0 .. 1).
Проект содержит не менее одного файла исходного кода, make-файл, исполняемый файл или файл с
текстом ошибки компиляции, в случае, если проект не компилировался или
компиляция завершилась неудачно. Параметры компиляции выбираются так, чтобы
соответствовать доступным вычислительным ресурсам. В проекте расчеты
размещаются по сериям, которые имеют иерархическую структуру. В каждой серии
может быть множество подсерий, содержащих свои расчеты, а также само множество
расчетов. Расчет, в свою очередь, содержит файлы начальных данных, файлы
результатов программы или файлы с текстом ошибки, в случае, если программа
завершилась некорректно. Диаграмма состояний проекта представлена на рисунке 3.

Рисунок 2 - Структура пользовательских данных в хранилище
Состояния задания на запуск разделяются на 4 основные группы:
— Начальные состояния, связанные с ожиданием на сервере (New, Scheduled, Wait, NewBlocked, ScheduledBlocked, WaitBlocked);
— Состояния, связанные с обработкой на кластере (например, WaitOnCluster, ProcessingOnCluster);
— Состояния, связанные с созданием результата (например, DoneOnCluster, ResultCreated, DoneWithErrorOnCluster, RunErrorCreated);
— Терминальные («тупиковые») состояния (DeleteOnServerError, GetResultErrorOnCluster
и др.).
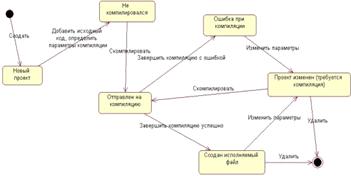
Рисунок 3 - Диаграмма состояний проекта
Сначала задание обрабатывается на сервере, далее передается для обработки
на кластер, а затем происходит получение результата работы программы с кластера
и процесс формирования результата в базе данных. Расчетная программа может
завершиться либо успешно (в этом случае в БД генерируется объект типа
«результат»), либо завершиться с ошибкой (текстовый файл с ошибкой также
размещается в БД). В случае ошибки при создании результата в БД, задание может
попасть в одно из терминальных состояний. Такие состояния обрабатываются
вручную администратором. Из ряда состояний задача может быть удалена.
Основные этапы жизненного цикла задания на компиляцию аналогичны заданию
на запуск.
Диаграммы состояний заданий на запуск и на компиляцию представлены на
рисунках 4 и 5 соответственно.
Система УД
к ВР
Система УД к ВР является интерфейсом системы УД и УРВР, т.е. клиентской
частью данной системы. Система УД к ВР построена по трехзвенной архитектуре
«клиент - сервер приложений - сервер баз данных» (рисунок 6) и взаимодействует
с системой УРВР на уровне общей базы данных.

Рисунок 6 - Структура системы УД к ВР
Функции системы удаленного доступа сводятся к управлению объектами в базе
данных системы УД и УРВР. Уровень привилегий пользователя портала определяет
его права на манипулирование объектами в базе данных: обычный пользователь
может управлять лишь своими объектами, в то время как администратор системы
имеет доступ к ряду пользовательских и общесистемным объектам.
С помощью клиентского приложения (web-браузера) пользователь
просматривает текущее состояние объектов в базе данных и может создавать новые
объекты, изменять параметры уже существующих и удалять объекты, вызывая
процедуры, хранимые на сервере баз данных.

Рисунок 4 - Диаграмма состояний задания на запуск
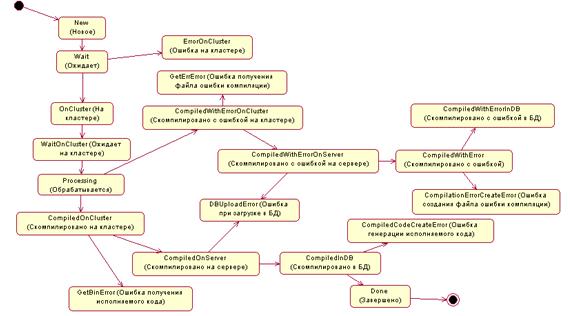
Рисунок 5 - Диаграмма состояний задания на компиляцию
В зависимости от привилегий пользователя, интерфейс может быть двух
типов: интерфейс клиента и интерфейс администратора.
Принцип
работы пакета KemsuWeb
Логика приложения реализуется на сервере приложений и сервере баз данных.
В качестве сервера приложений используется Apache Tomcat, предназначенный для реализации технологии Java Servlets и выполняющий функции web-сервера. В качестве системы
управления базой данных был использован Oracle 10 DataBase Server. В качестве
клиента к системе используется стандартный web-браузер, обмен данными проходит по стандартным
сетевым протоколам в среде Intranet/Internet.
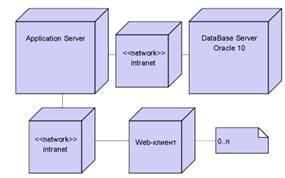
Рисунок 7 - Архитектура системы на физическом уровне
Логика приложения на стороне сервера базы данных реализована в виде
набора пакетов: для функциональных блоков создаются пакеты для осуществления
операций с данными, обеспечивающие манипуляцию необходимыми данными путем
вызова хранимых процедур. Для реализации пакетов используется язык PL/SQL. Для реализации web-интерфейса используются технологии J2EE и XML.
На сервере приложений Apache Tomcat использована
библиотека KemsuWeb, которая обеспечивает единую среду
для создания приложений, основанных на трехуровневой архитектуре в среде Internet за счет адаптеров, которые
удовлетворяют различные потребности разработчика: в операциях с Oracle, в защите информации, в управлении
ходом приложения. Пакет разработан в ЦНИТ КемГУ. [9]
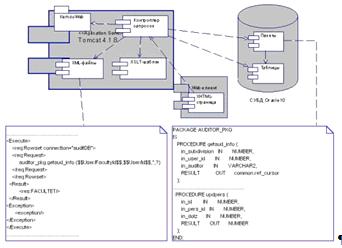
Рисунок 8 - Архитектура реализации
Разработчик
создает XSLT-шаблоны оформления интерфейса пользователя и XML-файлы,
в которых описывается вызов хранимых процедур и обработка полученных
результатов с использованием специальных "команд", которые
описываются элементами из пространства имен "res=<#"868430.files/image009.jpg">
Рисунок
9 - Архитектура web-интерфейса
ER-модель базы данных системы УД и УРВР
ER-модель
базы данных системы УД и УРВР содержит 37 сущностей с общим количеством
атрибутов свыше 200. Полная ER-модель
базы данных приведена на рисунке 10. Далее приведено краткое описание основных
сущностей ER-модели:
T_PROJECT - содержит информацию о пользовательских проектах.
T_SERIES - содержит информацию о сериях расчетов.
T_CALCULATION - содержит информацию о расчетах.
T_TASK - содержит информацию о заданиях на запуск.
T_COMPILATION_TASK - содержит информацию о заданиях на компиляцию.
T_CALCULATOR - содержит информацию о вычислительных ресурсах (кластерах).
T_RESULT - содержит информацию о файлах результатов заданий.
T_RUN_ERROR - содержит информацию о файлах
ошибок.
T_SOURCE_CODE - содержит информацию о файлах
исходных кодов программ.
T_INPUT_DATA - содержит информацию о файлах
начальных данных расчетов.
T_USER - содержит информацию о пользователях системы.
T_USERS_GROUP - содержит информацию о группах
пользователей.
T_ACCESS - содержит информацию о правах доступа пользователей к вычислительным
ресурсам (кластерам).
T_GROUP_ACCESS - содержит информацию о правах
доступа групп пользователей к вычислительным ресурсам (кластерам).
T_LOG
- содержит информацию о всех событиях в системе.
T_FILE - содержит пользовательские файлы всех типов и информацию о них.
Целью данной работы является разработка и реализация компонентов
«Интерфейс администратора», «Интерфейс клиента» и «Виртуальная лаборатория»
системы УД и УРВР. В соответствии с целью работы были поставлены следующие
задачи:
- изучить пакет KemsuWeb и освоить
необходимые программные средства и языки (HTML, XML, PL/SQL, JavaScript);
- изучить архитектуру и принципы функционирования системы УД и
УРВР; определить требования к разрабатываемым компонентам;
- построить модели разрабатываемых компонентов системы;
- реализовать компоненты.

Рисунок 10 - ER-модель БД
системы УД и УРВР
В главе 1 описаны основные этапы процесса разработки компонента
«Интерфейс администратора» системы УД и УРВР, приведены модели, поясняющие
механизм работы компонента, а также даны описания web-форм и пакета p_admin, содержащего
процедуры и функции, необходимые для реализации компонента.
В главе 2 описаны основные этапы процесса разработки компонента
«Интерфейс клиента» системы УД и УРВР, приведены модели, поясняющие механизм
работы компонента, а также даны описания web-форм и пакета p_client,
содержащего процедуры и функции, необходимые для реализации компонента.
В главе 3 описаны основные этапы процесса разработки компонента
«Виртуальная лаборатория» системы УД и УРВР, приведены модели, поясняющие
механизм работы компонента, а также даны описания web-форм и пакета p_virtlab,
содержащего процедуры и функции, необходимые для реализации компонента.
ГЛАВА 1.
РАЗРАБОТКА КОМПОНЕНТА «ИНТЕРФЕЙС АДМИНИСТРАТОРА» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
1.1
Определение функций администратора
Любая сложная информационная система нуждается в администрировании. Для
осуществления функций по администрированию системы УД и УРВР понадобилась
реализация отдельного компонента «Интерфейс администратора». Администратор
отвечает за работоспособность системы в целом. Для этого он наделен
соответствующими возможностями по управлению объектами БД системы УД и УРВР.
Были определены следующие функции администратора системы УД и УРВР:
- Управление кластерами:
- Просмотреть список вычислительных ресурсов (кластеров), подключенных к
системе;
- Добавить кластер в систему (добавить информацию о новом
кластере);
- Удалить кластер из системы;
- Заблокировать кластер (в случае временной неисправности);
- Изменить атрибуты кластера;
- Перезагрузить кластер;
- Управление очередью заданий:
- Просмотреть очередь заданий;
- Заблокировать задание;
- Удалить задание (с отправкой клиенту промежуточных
результатов или без);
- Изменить приоритет задания;
- Просмотр и анализ статистики использования системы:
- Просмотреть журнал
событий;
- Просмотреть общую статистику использования системы;
- Просмотреть статистику по определенному кластеру;
- Просмотреть статистику по определенному пользователю;
- Управление пользователями и группами:
- Просмотреть списки пользователей и групп;
- Назначить (изменить) права на доступ пользователей к
кластерам;
- Назначить (изменить) права на доступ групп пользователей к
кластерам;
- Назначить (изменить) атрибуты пользователей, (в том числе,
принадлежность группам и приоритеты).
1.2
Моделирование администраторской части системы УД к ВР
Для формализации механизма функционирования данного компонента системы
были составлены следующие диаграммы:
— Диаграмма вариантов использования;
— Диаграмма связей между web-формами.
Диаграмма вариантов использования для администратора системы УД и УРВР
представлена на рисунке 11.
Управлять кластерами. Администратор должен иметь возможность
просматривать список кластеров в системе, добавлять в систему новые кластеры,
блокировать/разблокировать (при неисправностях или профилактических работах на
кластере), перезагружать и удалять кластеры, а также изменять их атрибуты.
Управлять очередью заданий. Администратор должен иметь возможность
просматривать очередь заданий, блокировать и разблокировать задания, изменять
приоритет заданий, а также удалять задания (например, при подозрении на
«зависание»). Доступность этих операций определяется статусом задания. В
зависимости от статуса удаляемого задания в некоторых случаях клиенту могут
прийти промежуточные результаты.
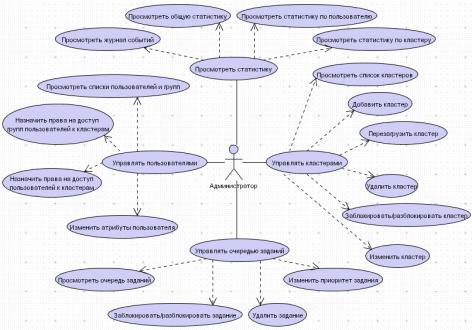
Рисунок 11 - Диаграмма вариантов использования (администратор)
Просмотреть статистику. Администратор должен иметь возможность
просматривать статистику использования системы (для оценки эффективности ее
работы), включая просмотр общей статистики, статистики по определенному
кластеру и по определенному пользователю, а также просмотр журнала событий,
произошедших в системе.
Управлять пользователями. Администратор должен иметь возможность
просматривать списки пользователей и групп, назначать пользователям и группам
права на доступ к кластерам, а также изменять атрибуты пользователей (например,
добавлять пользователя в группу или исключать из нее, назначать (изменять)
приоритеты).
На рисунке 12 представлена диаграмма связей между web-формами интерфейса администратора.
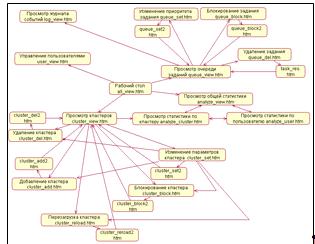
Рисунок 12 - Диаграмма связей между web-формами интерфейса администратора
1.3
Требования к компоненту «Интерфейс администратора»
Функциональные требования:
— Реализация основных функций администратора в соответствии с
пунктом 1.1.
Требования к прикладному ПО:
— Доступ к системе должен осуществляться в удаленном режиме
посредством web-браузера.
Системные требования:
— Для обеспечения интеграции с системой УД и УРВР, компонент
должен строиться на основе СУБД Oracle,
сервера приложений Tomcat и пакета KemsuWeb.
Требования к web-интерфейсу:
— Наличие кнопок навигации по формам (перехода на родительские
формы);
— Отображение всей необходимой информации об объектах;
— Генерация предупреждений при удалении объектов;
— Наличие возможностей сортировки и фильтрации отображаемой
информации.
1.4
Описание web-форм и
их реализация
В соответствии пунктом 1.3, были определены необходимые для компонента
«Интерфейс администратора» web-формы и их содержание. Реализация web-форм показана на рисунках.
Функции управления кластерами
1. Форма «Рабочий стол администратора» (рисунок 13). На данной форме
расположены ссылки на группы функций (разделы) с описанием доступных действий в
данном разделе. При нажатии на ссылку, осуществляется переход на
соответствующую форму.
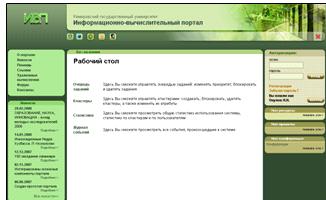
Рисунок 13 - Рабочий стол администратора (all_view.htm)
2. Форма просмотра состояния кластеров (рисунок 14). На данной форме
отображается список кластеров в системе, а также некоторые их атрибуты, такие
как: идентификатор кластера, название, описание, архитектура, операционная
система, количество процессоров (общее и доступное), максимальное количество
задач, количество запущенных задач, статус, состояние, объем памяти (общий и
доступный). Доступны операции изменения параметров кластера,
блокирования/разблокирования, удаления, перезагрузки кластера, добавления
нового кластера, а также просмотра статистики по кластеру. При выборе
определенной операции, осуществляется переход на соответствующую ей web-форму.

Рисунок 14 - Просмотр состояния кластеров (cluster_view.htm)
3. Форма добавления кластера (рисунок 15). На данной форме можно задать
основные атрибуты нового кластера, такие как: название, описание, архитектура,
операционная система, количество процессоров, максимальное количество задач,
статус, объем памяти. Значения атрибутов «Архитектура» и «ОС» задаются с
помощью выпадающих списков, содержимое которых формируется запросом к БД. При
нажатии на кнопку «Добавить», информация о новом кластере заносится в базу
данных, и осуществляется переход на форму просмотра состояния кластеров.
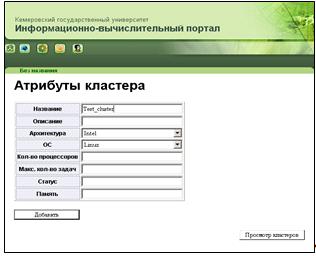
Рисунок 15 - Добавление кластера (cluster_add.htm)
4. Форма изменения параметров кластера (рисунок 16). Данная форма позволяет
изменить основные атрибуты выбранного кластера, такие как: название, описание,
архитектура, операционная система, количество процессоров, максимальное
количество задач, статус, объем памяти. Значения атрибутов «Архитектура» и «ОС»
задаются с помощью выпадающих списков, содержимое которых формируется запросом
к БД. При нажатии на кнопку «Применить изменения», обновленная информация
заносится в базу данных, и осуществляется переход на форму просмотра состояния
кластеров. Доступны операции блокирования/разблокирования, удаления,
перезагрузки кластера, а также просмотра статистики по кластеру. При выборе
определенной операции, осуществляется переход на соответствующую ей web-форму. Для удобства работы, на этой
форме отображается список заданий, выполняемых на изменяемом кластере, и
доступных операций с ними, а также полная информация о заданиях. Имеются
возможности сортировки и фильтрации заданий по любому атрибуту.
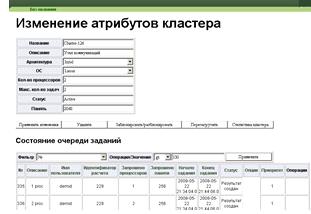
Рисунок 16 - Изменение параметров кластера (cluster_set.htm)
5. Форма блокирования кластера (рисунок 17). На данной форме можно
заблокировать/разблокировать кластер. Отображаются основные атрибуты выбранного
кластера и список выполняемых на нем заданий. Для удобства работы, на этой
форме отображается список заданий, выполняемых на блокируемом кластере, и
доступных операций с ними, а также полная информация о заданиях. Имеются
возможности сортировки и фильтрации заданий по любому атрибуту. При нажатии
кнопки «Заблокировать» или кнопки «Разблокировать», изменяется статус
выбранного кластера, и осуществляется переход на форму просмотра состояния
кластеров. Доступна операция просмотра статистики по кластеру.
6. Форма удаления кластера (рисунок 18). Данная форма позволяет
удалить кластер. Отображаются основные атрибуты выбранного кластера и список
выполняемых на нем заданий. Для удобства работы, на этой форме отображается
список заданий, выполняемых на удаляемом кластере, и доступных операций с ними,
а также полная информация о заданиях. Имеются возможности сортировки и
фильтрации заданий по любому атрибуту. При нажатии на кнопку «Удалить»,
информация о данном кластере удаляется из базы данных, и осуществляется переход
на форму просмотра состояния кластеров. Доступна операция просмотра статистики
по кластеру.
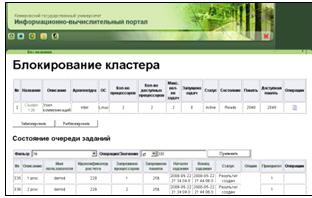
Рисунок 17 - Блокирование кластера (cluster_block.htm)
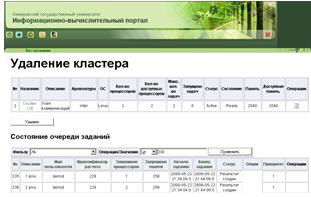
Рисунок 18 - Удаление кластера (cluster_del.htm)
7. Форма перезагрузки кластера (рисунок 19). На данной форме можно
перезагрузить кластер. Отображаются основные атрибуты выбранного кластера и
список выполняемых на нем заданий. Для удобства работы, на этой форме
отображается список заданий, выполняемых на перезагружаемом кластере, и
доступных операций с ними, а также полная информация о заданиях. Имеются
возможности сортировки и фильтрации заданий по любому атрибуту. При нажатии на
кнопку «Перезагрузить», в БД происходит изменение статуса кластера, вследствие
чего, на кластер должна отправляться команда на перезагрузку. В настоящее время
данная функция не поддерживается системой УД и УРВР. Доступна операция
просмотра статистики по кластеру.
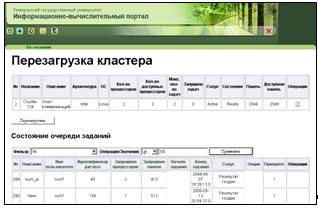
Рисунок 19 - Перезагрузка кластера (cluster_reload.htm)
Функции управления очередью заданий
8. Форма просмотра очереди заданий (рисунок 20). Данная форма позволяет
просмотреть список заданий в системе, а также их основные параметры, такие как:
идентификатор задачи, название, описание, идентификатор пользователя,
идентификатор расчета, идентификатор кластера, требуемые количество
процессоров, объем памяти, время запуска и окончания обсчета задания, его
статус и приоритет. Для обеспечения удобства просмотра, предусмотрены
возможности фильтрации и сортировки заданий по любому параметру. В зависимости
от статуса задания, доступны определенные операции, такие как: изменение
приоритета задания, блокирование, удаление задания (с отправкой клиенту
промежуточных результатов или без).

Рисунок 20 - Просмотр очереди заданий (queue_view.htm)
9. Форма изменения приоритета задания (рисунок 21). На данной форме можно
изменить приоритет задания. Отображаются основные атрибуты выбранного задания.
При нажатии на кнопку «Применить изменения», обновленная информация заносится в
базу данных, и осуществляется переход на форму просмотра очереди заданий.
Данная операция доступна, если задание находится либо в состоянии «Поставлено в
очередь», либо в состоянии «Ожидает».

Рисунок 21 - Изменение приоритета задания (queue_set.htm)
10. Форма блокирования задания (рисунок 22). Данная форма позволяет
заблокировать/разблокировать задание. Отображаются его основные атрибуты. При
нажатии кнопки «Заблокировать» или кнопки «Разблокировать», соответственным
образом изменяется статус выбранного задания, и осуществляется переход на форму
просмотра очереди заданий. Данная операция доступна, если задание находится в
одном из следующих состояний: «Новое», «Поставлено в очередь», «Ожидает» или
«Заблокировано» (т.е. до того, как задание было запущено на кластере).

Рисунок 22 - Блокирование задания (queue_block.htm)
11. Форма удаления задания (рисунок 23). На данной форме можно удалить
задание. Отображаются основные атрибуты выбранного задания. При нажатии на
кнопку «Удалить», задание помечается на удаление, и осуществляется переход на
форму просмотра очереди заданий. В связи с использованием информации о заданиях
для сбора статистики и расчета приоритетов пользователей, задания физически не удаляются
из базы данных. Данная операция доступна, если задание находится в одном из
состояний, связанных с ожиданием на сервере или обработкой на кластере.
Функции просмотра статистики использования системы
12. Форма просмотра журналов (рисунок 24). Данная форма позволяет
просмотреть список событий, произошедших в системе, с указанием даты, времени и
типа события. Для обеспечения удобства просмотра, предусмотрены возможности
сортировки по любому атрибуту и фильтрации записей по категории, дате и
идентификатору события.
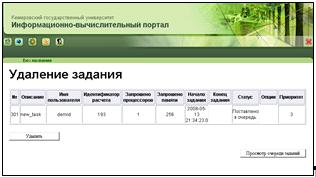
Рисунок 23 - Удаление задания (queue_del.htm)
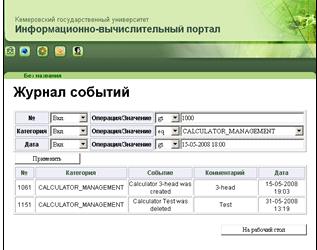
Рисунок 24 - Просмотр журнала событий (log_view.htm)
13. Форма просмотра общей статистики использования системы. На данной
форме отображаются характеристики системы в целом, такие как: количество
запущенных заданий, число созданных проектов и расчетов, число скомпилированных
проектов, общее время выполнения заданий и среднее время, потраченное на
задание, количество заданий, завершенных успешно/неудачно и др. Статистика
предоставляется за любой выбранный период функционирования системы, по
умолчанию - за последнюю неделю. Форма находится в разработке.
14. Форма просмотра статистики по кластеру. Данная форма предоставляет
подробную информацию об использовании конкретных кластеров системы. Здесь
отображаются основные характеристики использования ВР. Форма находится в
разработке.
. Форма просмотра статистики по пользователю. Данная форма
предоставляет подробную информацию об активности конкретных пользователей
системы. Здесь отображаются основные характеристики использования системы.
Форма находится в разработке.
Функции управления пользователями
16. Форма управления пользователями. На данной форме будут доступны
функции: просмотра списков пользователей и групп, назначения пользователям и
группам прав на доступ к кластерам и изменения атрибутов пользователей, в
частности, принадлежности группам. При реализации этих функций, будут
производиться манипуляции с данными в таблицах T_ACCESS, T_GROUP_ACCESS,
T_USER и T_USER_GROUP. Форма находится в разработке.
На всех формах есть кнопки для перехода на родительскую форму (например,
кнопка «Рабочий стол» на форме просмотра состояния кластеров). Кроме того, при
удалении кластеров или заданий, выдается предупреждение, и требуется
подтверждение операции (во избежание случайного удаления).
Для обеспечения работы функций интерфейса администратора, также был
реализован ряд web-форм
служебного назначения, посредством которых происходит вызов хранимых в БД
процедур и функций из пакета p_admin.
Список служебных форм:
- cluster_add2.htm - вызывает функцию добавления нового
кластера;
- cluster_block2.htm - вызывает функции
блокирования/разблокирования кластера;
- cluster_del2.htm - вызывает функцию удаления
кластера;
- cluster_reload2.htm - вызывает функцию перезагрузки
кластера;
- cluster_set2.htm - вызывает функцию изменения
параметров кластера;
- queue_block2.htm - вызывает функцию блокирования
задания;
- queue_set2.htm - вызывает функцию изменения приоритета
задания;
- queue_del2.htm - вызывает функцию физического
удаления задания;
- task_res.htm - вызывает функции удаления задания
и получения промежуточных результатов.
1.5
Описание пакета p_admin
Для реализации функций администратора в базе данных был написан пакет p_admin. Сейчас он содержит 20 процедур и функций,
использующихся в администраторской части.
Состав пакета p_admin:
cluster_add
- процедура добавления кластера;
Входные параметры:
- in_name (VARCHAR2) - имя кластера,
- in_description (VARCHAR2) - описание кластера,
in_arch_id (NUMBER) -
идентификатор архитектуры кластера,
- in_os_id (NUMBER) -
идентификатор операционной системы кластера,
- in_proc_num (NUMBER)
- число процессоров в кластере,
- in_max_task (NUMBER)
- максимальное число заданий, обрабатываемых кластером одновременно,
- in_status (VARCHAR2) - статус кластера,
in_mem (NUMBER) - объем памяти кластера;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
cluster_block -
процедура для блокирования или разблокирования кластера;
Входные параметры:
- in_id (NUMBER) - идентификатор кластера;
- in_action (NUMBER) - код операции (блокировать или разблокировать);
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
cluster_del
- процедура удаления кластера;
Входной параметр:
- in_id (NUMBER) - идентификатор кластера;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
cluster_set
- процедура изменения параметров кластера;
Входные параметры:
- in_id (NUMBER) - идентификатор кластера,
- in_name (VARCHAR2) - имя кластера,
- in_description (VARCHAR2) - описание кластера,
in_arch_id (NUMBER) -
идентификатор архитектуры кластера,
- in_os_id (NUMBER) -
идентификатор операционной системы кластера,
- in_proc_num (NUMBER)
- число процессоров в кластере,
- in_max_task (NUMBER)
- максимальное число заданий, обрабатываемых кластером одновременно,
- in_status (VARCHAR2) - статус кластера,
in_mem (NUMBER) - объем памяти кластера;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
log_sort -
процедура для просмотра журнала событий с возможностями сортировки и фильтрации
по идентификатору, дате и категории события;
Входные параметры:
- in_sort (VARCHAR2) - имя атрибута, по которому будет выполняться
сортировка,
- in_prdk (VARCHAR2) - показатель направления сортировки (asc/desc),
- in_fltr_id (VARCHAR2) -
показатель применения фильтрации событий по идентификатору,
- in_fltr_class (VARCHAR2)
- показатель применения фильтрации событий по категории,
- in_fltr_date (VARCHAR2)
- показатель применения фильтрации событий по времени происхождения,
- in_op_id (VARCHAR2) -
название операции сравнения при фильтрации событий по идентификатору,
- in_op_class (VARCHAR2)
- название операции сравнения при фильтрации событий по категории,
- in_op_date (VARCHAR2)
- название операции сравнения при фильтрации событий по времени происхождения,
- in_value_id (VARCHAR2) -
сравниваемое значение при фильтрации событий по идентификатору,
- in_value_class (VARCHAR2)
- сравниваемое значение при фильтрации событий по категории,
- in_value_date (VARCHAR2)
- сравниваемое значение при фильтрации событий по времени происхождения;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список событий и сопутствующую
информацию.
queue_block - процедура для блокирования или разблокирования задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
queue_del -
процедура физического удаления задания;
Входной параметр:
- in_id (NUMBER) - идентификатор задания;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
queue_set -
процедура изменения приоритета задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания,
- in_rank (NUMBER) - значение приоритета задания;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
queue_op_SetRank (NUMBER) - функция, определяющая доступность операции
изменения приоритета задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания.
queue_op_Block (NUMBER) - функция, определяющая доступность операции
блокирования задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания.
queue_op_UnBlock (NUMBER) - функция, определяющая доступность операции
разблокирования задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания.
queue_op_GetRes (NUMBER) - функция, определяющая доступность операции
получения промежуточных результатов вычислений;
Входные параметры:
- in_id (NUMBER) - идентификатор задания.
queue_op_Del (NUMBER) - функция, определяющая доступность операции
удаления задания;
Входные параметры:
- in_id (NUMBER) - идентификатор задания.
queue_sort -
процедура для просмотра очереди заданий с возможностями сортировки и фильтрации
по нескольким атрибутам.
Входные параметры:
- in_sort (VARCHAR2) - имя атрибута, по которому будет выполняться
сортировка,
- in_prdk (VARCHAR2) - показатель направления сортировки (asc/desc),
- in_filter (VARCHAR2) - имя поля, по которому будет выполняться
фильтрация заданий,
- in_op (VARCHAR2) - название операции сравнения при фильтрации
заданий,
- in_value (VARCHAR2) - сравниваемое значение при фильтрации заданий;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список заданий и сопутствующую
информацию.
task_res -
процедура для удаления задания с получением промежуточных результатов или без;
Входные параметры:
- in_id (NUMBER) - идентификатор кластера;
- in_action (NUMBER) - код операции (забирать промежуточные результаты
или нет);
Выходной параметр:
- out_res (NUMBER) - показатель успешности выполнения процедуры.
cluster_access (NUMBER) - функция проверки прав доступа
пользователя к кластеру;
Входные параметры:
- in_user_id - идентификатор пользователя,
- in_cluster_id - идентификатор кластера.
Следующие функции находятся в разработке:
cluster_reload -
процедура перезагрузки кластера;
Входной параметр:
- in_id (NUMBER) - идентификатор кластера;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
analyze_general -
процедура для вывода общей статистики использования системы за указанный период
времени.
Входные параметры:
- in_start_time (VARCHAR2)
- дата начала обзора статистики,
- in_finish_time (VARCHAR2)
- дата окончания обзора статистики;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий статистическую информацию:
список характеристик системы и их значения за указанный период времени.
analyze_cluster -
процедура для вывода статистической информации по использованию определенного
кластера за указанный период времени.
Входные параметры:
- in_start_time (VARCHAR2)
- дата начала обзора статистики,
- in_finish_time (VARCHAR2)
- дата окончания обзора статистики,
- in_cluster_id (NUMBER) - идентификатор кластера;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий статистическую информацию по
заданному кластеру: список характеристик и их значения за указанный период
времени.
analyze_user -
процедура для вывода статистической информации по использованию системы
определенным пользователем за указанный период времени.
Входные параметры:
- in_start_time (VARCHAR2)
- дата начала обзора статистики,
- in_finish_time (VARCHAR2)
- дата окончания обзора статистики,
- in_user_id (NUMBER) -
идентификатор пользователя;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий статистическую информацию по
заданному пользователю: список характеристик и их значения за указанный период
времени.
ГЛАВА 2.
РАЗРАБОТКА КОМПОНЕНТА «ИНТЕРФЕЙС КЛИЕНТА» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
В рамках проекта (РНП.3.2.3.4256): «Создание типового
информационно-вычислительного портала для организации учебной и научной
деятельности ВУЗа» аналитической ведомственной целевой программы «Развитие
научного потенциала высшей школы (2006-2014 годы)» в 2006-2007 годах был
реализован прототип клиентского интерфейса системы УД и УРВР, в котором были
заложены базовые функции. В ходе выполнения данной работы, этот прототип был
адаптирован к измененной структуре данных системы, а также была существенно
расширена его функциональность.
2.1
Определение функций клиента
Были определены следующие функции клиента системы УД и УРВР:
- Управление проектами:
- Просмотреть список своих проектов;
- Создать проект;
- Добавить (удалить) файлы проекта:
— make-файл;
— файлы исходного кода;
- Изменить параметры проекта (компилятор, ОС, архитектура);
- Отправить проект на компиляцию;
- Удалить проект;
- Работа с очередью заданий:
- Просмотреть список своих заданий;
- Создать задание;
- Получить промежуточные результаты вычислений;
- Удалить задание;
- Управление сериями и расчетами:
- Создать серию (подсерию) расчетов;
- Создать расчет;
- Просмотреть дерево серий и расчетов;
- Удалить расчет;
- Удалить серию расчетов;
- Работа с результатами вычислений:
- Просмотреть файлы результатов/ошибок расчета;
- Просмотреть файлы результатов/ошибок всех расчетов в заданной
серии, включая ее подсерии;
- Удалить файлы.
2.2
Моделирование клиентской части системы УД к ВР
Для формализации механизма функционирования данного компонента системы,
были составлены следующие диаграммы:
— Диаграмма вариантов использования;
— Диаграмма последовательности действий;
— Диаграмма связей между web-формами.
Диаграмма вариантов использования для клиента системы УД и УРВР
представлена на рисунке 25.
Управлять проектами. Клиент должен иметь возможность просматривать список
своих проектов, создавать и удалять проекты, добавлять (удалять) make-файлы и файлы исходного кода,
компилировать проекты, изменять их атрибуты, такие как: компилятор,
вычислительная архитектура и операционная система.
Управлять сериями и расчетами. Клиент должен иметь возможность
просматривать дерево серий и расчетов, создавать и удалять серии (подсерии) и
расчеты, добавлять и удалять файлы данных.
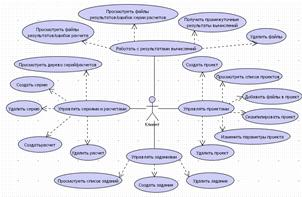
Рисунок 25 - Диаграмма вариантов использования (клиент)
Управлять заданиями. Клиент должен иметь возможность просматривать список
своих заданий, создавать и удалять задания, получать промежуточные результаты
выполнения задания.
Работать с результатами вычислений. Клиент должен иметь возможность
просматривать файлы результатов и ошибок для расчета, а также для всех расчетов
серии (включая ее подсерии), а также удалять файлы результатов и ошибок.
Диаграмма последовательности действий (рисунок 26) описывает типовой
сценарий работы клиента с системой УД и УРВР.
На рисунке 27 представлена диаграмма связей между формами интерфейса клиента.
.3
Требования к компоненту «Интерфейс клиента»
Функциональные требования:
— Реализация функций клиента в соответствии с пунктом 2.1.
Требования к прикладному ПО:
— Доступ к системе должен осуществляться в удаленном режиме
посредством web-браузера.
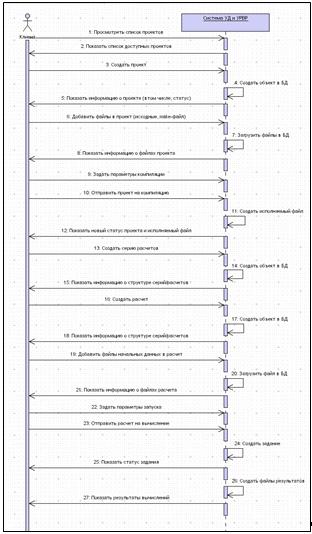
Рисунок 26 - Диаграмма последовательности действий (клиент)
интерфейс удаленный вычислительный распределительный
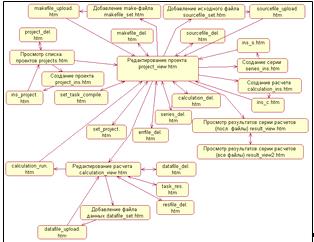
Рисунок 27 - Диаграмма связей между web-формами интерфейса клиента
Системные требования:
— Для обеспечения интеграции с системой УД и УРВР, компонент
должен строиться на основе СУБД Oracle,
сервера приложений Tomcat и пакета KemsuWeb.
Требования к web-интерфейсу:
— Наличие кнопок навигации по формам (перехода на родительские
формы);
— Отображение всей необходимой информации об объектах;
— Генерация предупреждений при удалении объектов;
— Наличие возможностей сортировки и фильтрации отображаемой
информации.
Требования к защите информации:
— Система должна предусматривать разграничение возможностей
манипулирования информационными объектами в зависимости от уровня привилегий
пользователя.
.4
Описание web-форм и
их реализация
В соответствии пунктом 2.3, были определены необходимые для компонента
«Интерфейс клиента» web-формы и их содержание. Реализация web-форм показана на рисунках.
1. Форма просмотра списка клиентских проектов (рисунок 28). На данной
форме отображается список проектов клиента с описанием и указанием статуса и
даты последней модификации. Доступны операции редактирования и удаления
проекта, а также создания проекта (кнопка «Создать проект»).
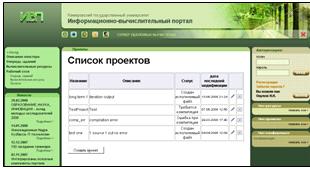
Рисунок 28 - Просмотр списка проектов (projects.htm)
2. Форма создания проекта (рисунок 29). На данной форме можно задать
основные атрибуты нового проекта, такие как: название, описание, компилятор,
вычислительная и параллельная архитектуры, операционная система. Значения
атрибутов «Компилятор», «Операционная система», «Вычислительная архитектура» и
«Параллельная архитектура» задаются с помощью выпадающих списков, содержимое
которых формируется запросом к БД. При нажатии на кнопку «Добавить проект»,
информация о новом проекте заносится в базу данных, и осуществляется переход на
форму просмотра списка проектов.
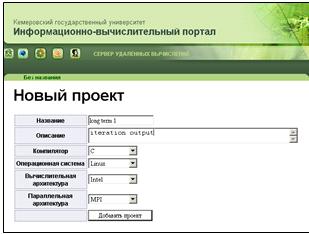
Рисунок 29 - Создание проекта (project_ins.htm)
3. Форма редактирования проекта (рисунок 30). На данной форме
отображается полная информация о проекте: идентификатор, название, описание,
дата модификации и статус текущего проекта. Далее показаны основные параметры
проекта, такие как: компилятор, вычислительная и параллельная архитектуры и
операционная система. Их можно изменить с помощью кнопки «Изменить параметры
проекта». Затем следует блок управления файлами проекта. В нем отображаются
относящиеся к проекту файлы исходного кода и make-файл, а также кнопки для добавления файлов и
компиляции проекта. В случае ошибки при компиляции, отображается файл ошибки и
сопутствующая информация. Далее показывается дерево серий и расчетов с
указанием их названия и описания, а также кнопки для создания и удаления серий
(подсерий) и расчетов, редактирования расчетов и просмотра файлов результатов и
ошибок всех расчетов серии.
. Форма создания серии расчетов (рисунок 31). На данной форме можно
задать название и описание новой серии расчетов. При нажатии на кнопку «Создать
серию», информация о новой серии расчетов заносится в базу данных, и
осуществляется переход на форму редактирования родительского проекта.

Рисунок 30 - Редактирование проекта (project_view.htm)
5. Форма создания расчета (рисунок 32). На данной форме можно задать
название и описание нового расчета. При нажатии на кнопку «Создать расчет»,
информация о новом расчете заносится в базу данных, и осуществляется переход на
форму редактирования родительского проекта.
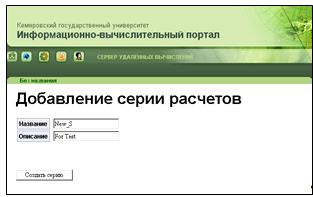
Рисунок 31 - Создание серии расчетов (series_ins.htm)
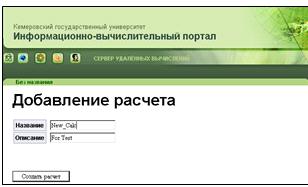
Рисунок 32 - Создание расчета (calculation_ins.htm)
6. Форма редактирования расчета (рисунок 33). На данной форме
отображается основная информация о расчете: идентификатор, название, описание,
дата модификации и статус текущего расчета. Далее показан список файлов данных
для этого расчета с указанием имени, размера и даты модификации каждого файла.
Доступны операции просмотра, редактирования, удаления файлов, а также
добавления файлов данных. В блоке «Просмотр заданий» показаны все задания,
относящиеся к данному расчету, а также подробная информация о каждом задании. В
зависимости от текущего статуса задания, доступны определенные операции, такие
как: блокирование, получение промежуточных результатов и удаление задания (с
получением промежуточных результатов или без). Далее расположена таблица файлов
результатов и ошибок для данного расчета, в которой представлена полная
информация о каждом файле. Доступна операция удаления файла. Затем следует блок
постановки расчета в очередь на вычисление, где представлены поля для выбора
кластера, определения описания задания, требуемого количества процессоров,
объема оперативной памяти и времени запуска (возможны варианты немедленного или
отложенного запуска). В поле «Параметры командной строки» задаются специальные
опции запуска. При нажатии на кнопку «Поставить в очередь», в БД формируется задание,
и осуществляется переход на форму редактирования родительского проекта.
7. Формы добавления исходного, make-файла и файла данных (рисунок 34). На данных формах
(их вид одинаков) присутствует поле для ввода полного пути к загружаемому
файлу, а также кнопка «Обзор» (для поиска файла с помощью диалогового окна
«Выбор файла»). При нажатии на кнопку «Загрузить», происходит загрузка
выбранного файла в БД, и осуществляется переход на форму редактирования
родительского проекта (при загрузке файла данных - на форму редактирования
расчета).

Рисунок 34 - Добавление исходного файла (sourcefile_set.htm)
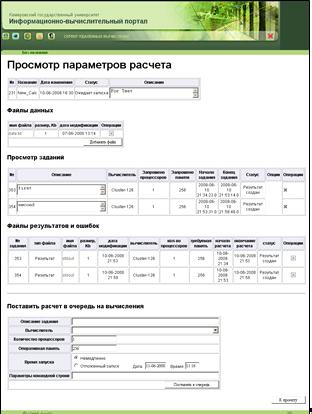
Рисунок 33 - Редактирование расчета (calculation_view.htm)
8. Формы просмотра файлов результатов серии расчетов (рисунок 35). На
данных формах отображаются файлы результатов и ошибок, относящиеся ко всем
расчетам выбранной серии, а также основные атрибуты этих файлов: идентификатор
расчета, название файла, его размер, дата модификации, идентификаторы серии и
файла результата, имя кластера, количество процессоров, объем памяти, время
начала и окончания расчета и статус. По умолчанию показываются только последние
полученные файлы результатов и ошибок по каждому расчету (форма result_view.htm),
но по кнопке «Просмотреть все файлы» можно перейти на просмотр полного списка
файлов (форма result_view2.htm).
По кнопке «Просмотреть последние файлы» происходит обратный переход. Также
доступна операция удаления файла.

Рисунок 35 - Просмотр файлов результатов серии расчетов (result_view.htm)
На всех формах есть кнопки для перехода на родительскую форму (например,
кнопка «К проекту» на форме редактирования расчета). Кроме того, при удалении
любого объекта (проект, серия, расчет, задание, файл любого типа), выдается
предупреждение и требуется подтверждение операции (во избежание случайного
удаления).
Для обеспечения работы функций интерфейса клиента, также был реализован
ряд web-форм служебного назначения,
посредством которых происходит вызов хранимых в БД процедур и функций из
пакетов p_admin и p_client.
Список служебных форм:
— calculation_del - вызывает функцию удаления расчета;
— errfile_del -
вызывает функцию удаления файла ошибки;
— resfile_del -
вызывает функцию удаления файла результата;
— project_del -
вызывает функцию удаления проекта;
— series_del -
вызывает функцию удаления серии расчетов;
— task_res -
вызывает функции удаления задания и получения промежуточных результатов
вычислений;
— calculation_run - вызывает функцию постановки расчета в очередь
заданий;
— datafile_del - вызывает функцию удаления файла данных;
— datafile_upload - вызывает функцию загрузки файла данных в БД;
— makefile_del - вызывает функцию удаления make-файла;
— makefile_upload - вызывает функцию загрузки make-файла в БД;
— sourcefile_del - вызывает функцию удаления исходного файла;
— sourcefile_upload - вызывает функцию загрузки файла исходного кода;
— ins_project
- вызывает функцию добавления нового проекта;
— ins_s -
вызывает функцию добавления новой серии расчетов;
— ins_c -
вызывает функцию добавления нового расчета;
— set_project
- вызывает функцию изменения параметров проекта;
— set_task_compile - вызывает функцию отправки проекта
на компиляцию;
— set_compiler, set_parallel, set_architecture, set_os - необходимы для отображения параметров (компилятор,
параллельная и вычислительная архитектуры, операционная система) проекта.
2.6
Описание пакета p_client
Для реализации функций клиента, используются хранимые процедуры и функции
из пакетов p_client и p_admin. На данный момент в этих пакетах
содержится 40 процедур и функций, относящихся к клиентской части системы УД к ВР.
Состав пакета p_client:
getMake_File_Info - процедура для вывода информации о make-файле проекта;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию о make-файле проекта.
getSource_File_Info - процедура для вывода информации об
исходных файлах проекта;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список исходных файлов и сопутствующую
информацию.
getCalculation_Data_Info - процедура для вывода информации о
файлах данных, относящихся к расчету;
Входной параметр:
- in_calculation_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию о файлах данных,
относящихся к расчету.
getSeries_Info -
процедура для вывода списка расчетов, входящих в серию;
Входной параметр:
- in_series_id (NUMBER) - идентификатор серии;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список расчетов, входящих в
серию, и сопутствующую информацию.
getExe_File_Info - процедура для выдачи информации об
исполняемом файле проекта;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию об исполняемом файле
проекта.
getProject_Info -
процедура для вывода подробной информации о проекте;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий подробную информацию о проекте.
get_Status_Msg (VARCHAR2) - функция, возвращающая статус проекта;
Входной параметр:
- in_status_id (NUMBER) - идентификатор статуса.
get_Calculation_Status_Msg (VARCHAR2) - функция, возвращающая статус расчета;
Входной параметр:
- in_status_id (NUMBER) - идентификатор статуса.
set_File -
процедура для определения параметров файла при загрузке в БД (имеет специальный
вид для интеграции с KemsuWeb);
Входные параметры:
- in_id (NUMBER) - идентификатор проекта;
- in_file_name (VARCHAR2) - имя файла;
Выходные параметры:
- out_id (NUMBER) - идентификатор файла в таблице, в которую он
помещается;
- out_table_name (VARCHAR2)
- имя таблицы, в которую помещается файл;
- out_id_field (VARCHAR2)
- имя атрибута, являющегося первичным ключом в таблице, в которую помещается
файл;
- out_file_field (VARCHAR2)
- имя атрибута для хранения тела файла в таблице, в которую помещается файл.
get_File -
процедура для получения файла из БД (имеет специальный вид для интеграции с KemsuWeb);
Входной параметр:
- in_id (NUMBER) - идентификатор проекта;
Выходные параметры:
- out_table_name (VARCHAR2)
- имя таблицы, в которую помещается файл;
- out_id_field (VARCHAR2)
- имя атрибута, являющегося первичным ключом в таблице, в которую помещается файл;
- out_file_field (VARCHAR2)
- имя атрибута для хранения тела файла в таблице, в которую помещается файл;
- out_file_name (VARCHAR2) - имя файла.
insMake_File -
процедура занесения в БД информации о новом make-файле;
Входные параметры:
- in_project_id (NUMBER) - идентификатор проекта;
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор записи о файле).
insSource_File -
процедура занесения в БД информации о новом исходном файле;
Входные параметры:
- in_project_id (NUMBER) - идентификатор проекта;
- in_file_id (NUMBER) - идентификатор файла;
in_user_id (NUMBER) -
идентификатор пользователя;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор записи о файле).
insInput_File -
процедура занесения в БД информации о новом файле данных;
Входные параметры:
- in_id (NUMBER) - идентификатор проекта;
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор записи о файле).
delSource_File -
процедура удаления исходного файла;
Входные параметры:
- in _id (NUMBER) - идентификатор файла в таблице T_SOURCE_CODE;
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор записи о файле).
delInput_File -
процедура удаления файла данных;
Входные параметры:
- in
_id (NUMBER) - идентификатор файла в таблице T_INPUT_DATA;
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор записи о файле).
delRes_File -
процедура удаления файла результатов;
Входной параметр:
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры.
ins_Series -
процедура добавления новой серии расчетов;
Входные параметры:
- in_parent_id (NUMBER) -
идентификатор родительской серии;
- in_project_id (NUMBER) - идентификатор проекта;
in_c_name (VARCHAR2) - название серии;
in_c_description (VARCHAR2) - описание серии;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор серии).
ins_Project -
процедура добавления нового проекта;
Входные параметры:
- in_user_id (NUMBER) -
идентификатор пользователя;
- in_compiler_id (NUMBER) -
идентификатор компилятора;
- in_os_id (NUMBER) -
идентификатор операционной системы;
- in_architecture_id (NUMBER) -
идентификатор вычислительной архитектуры;
- in_parallel_soft_id (NUMBER) - идентификатор параллельной
архитектуры;
- in_name (VARCHAR2) - название проекта;
- in_description (VARCHAR2) - описание проекта;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор проекта).
upd_Project -
процедура изменения атрибутов проекта;
Входные параметры:
- in
_id (NUMBER) - идентификатор проекта;
- in_compiler_id (NUMBER) -
идентификатор компилятора;
- in_os_id (NUMBER) - идентификатор
операционной системы;
- in_architecture_id (NUMBER) -
идентификатор вычислительной архитектуры;
- in_parallel_soft_id (NUMBER) - идентификатор параллельной
архитектуры;
- in_description (VARCHAR2) - описание проекта;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор проекта).
ins_Calculation - процедура добавления нового расчета;
Входные параметры:
- in_user_id (NUMBER) -
идентификатор пользователя;
- in_series_id (NUMBER) - идентификатор серии;
in_name (VARCHAR2) - название расчета;
in_description (VARCHAR2) - описание расчета;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор расчета).
set_Task_Compile - процедура отправки проекта на
компиляцию;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры.
set_Calculation_Run -
процедура отправки расчета на выполнение (данная функция формирует задание);
Входные параметры:
- in_calculation_id (NUMBER) - идентификатор расчета;
- in_calculator_id (NUMBER) - идентификатор кластера;
in_proc_req (NUMBER)
- запрашиваемое количество процессоров;
- in_ram_req (NUMBER)
- запрашиваемый объем памяти;
- in_start_time_req (VARCHAR2) - запрашиваемое время постановки
задания в очередь;
- in_start_time_req_date (VARCHAR2) - дата;
in_start_time_req_time (VARCHAR2) - время;
in_options (VARCHAR2) - строка опций запуска;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры.
getCalculatorForRun - процедура вывода списка кластеров, способных
выполнить расчет;
Входной параметр:
- in_calculation_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список кластеров, способных
выполнить расчет, и сопутствующую информацию.
Состав пакета p_admin:
getSeries_Result_Info - процедура вывода информации о
последних файлах результатов для каждого расчета серии;
Входной параметр:
- in_id (NUMBER) - идентификатор серии расчетов;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список файлов результатов и
сопутствующую информацию.
getSeries_Result_Info2 - процедура вывода информации обо всех файлах
результатов для каждого расчета серии;
Входной параметр:
- in_id (NUMBER) - идентификатор серии расчетов;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список файлов результатов и
сопутствующую информацию.
getProject_Error_Info - процедура для вывода информации о
файле ошибки компиляции проекта;
Входной параметр:
- in_file_id (NUMBER) -
идентификатор файла ошибки компиляции;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию о файле ошибки
компиляции проекта.
getCalculation_ResErr_Info - процедура вывода информации обо
всех файлах результатов и ошибок для расчета;
Входной параметр:
- in_calculation_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список файлов результатов и
ошибок и сопутствующую информацию.
delErr_File -
процедура удаления файла ошибки;
Входной параметр:
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры.
delMake_File -
процедура удаления make-файла;
Входной параметр:
- in_file_id (NUMBER) - идентификатор файла;
Выходной параметр:
- out_res (NUMBER) - показатель успешности выполнения процедуры.
project_del -
процедура удаления проекта;
Входной параметр:
- in_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
series_del -
процедура удаления серии расчетов;
Входной параметр:
- in_id (NUMBER) - идентификатор серии;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
calculation_del -
процедура удаления расчета;
Входной параметр:
- in_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_res (VARCHAR2) - показатель успешности выполнения процедуры.
getTasksForCalc - процедура вывода информации обо всех заданиях для
данного расчета;
Входной параметр:
- in_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список заданий и сопутствующую
информацию.
task_res -
процедура для удаления задания с забором промежуточных результатов или без;
Входные параметры:
- in_id (NUMBER) - идентификатор кластера;
- in_action (NUMBER) - код операции (забирать промежуточные результаты
или нет);
Выходной параметр:
- out_res (NUMBER) - показатель успешности выполнения процедуры.
Следующие процедуры на данный момент не используются, но могут
понадобиться при дальнейшем развитии системы:
getQueue_by_Id - процедура для просмотра списка
заданий пользователя;
Входной параметр:
- in_id (NUMBER) - идентификатор пользователя;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список заданий и сопутствующую
информацию.
getCompilation_Error_Info - процедура для вывода информации о
файле ошибки компиляции проекта;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию о файле ошибки
компиляции проекта.
getCalculation_Info -
процедура для вывода информации о состоянии расчета и относящихся к нему
файлах;
Входной параметр:
- in_calculation_id (NUMBER) - идентификатор расчета;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий информацию о состоянии расчета,
список относящихся к нему файлов данных и результатов и сопутствующую
информацию.
upd_Series -
процедура изменения названия/описания серии расчетов;
Входные параметры:
- in_id (NUMBER) - идентификатор серии;
- in_project_id (NUMBER) - идентификатор проекта;
in_c_name (VARCHAR2) - название серии;
in_c_description (VARCHAR2) - описание серии;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры
(идентификатор серии).
set_Series_Run - процедура отправки на выполнение
всех расчетов серии;
Входные параметры:
- in_series_id (NUMBER) - идентификатор серии;
- in_calculator_id (NUMBER) - идентификатор кластера;
in_proc_req (NUMBER)
- запрашиваемое количество процессоров;
- in_ram_req (NUMBER)
- запрашиваемый объем памяти;
- in_start_time_req (VARCHAR2) - запрашиваемое время постановки
задания в очередь;
- in_start_time_req_date (VARCHAR2) - дата;
in_start_time_req_time (VARCHAR2) - время;
in_options (VARCHAR2) - строка опций запуска;
Выходной параметр:
- out_id (NUMBER) - показатель успешности выполнения процедуры.
getCalculatorForCompile - процедура вывода списка кластеров, способных
выполнить компиляцию проекта;
Входной параметр:
- in_project_id (NUMBER) - идентификатор проекта;
Выходной параметр:
- out_queue (REF CURSOR) - курсор, содержащий список кластеров, способных
выполнить компиляцию проекта, и сопутствующую информацию.
ГЛАВА 3.
РАЗРАБОТКА КОМПОНЕНТА «ВИРТУАЛЬНАЯ ЛАБОРАТОРИЯ» СИСТЕМЫ УДАЛЕННОГО ДОСТУПА К
ВЫЧИСЛИТЕЛЬНЫМ РЕСУРСАМ
Федеральным агентством по образованию было поручено КемГУ выполнение
работ по проекту (РНП.3.2.3.13048): «Создание системы научно-методического
обеспечения образовательными ресурсами учебных заведений для подготовки
специалистов по высокопроизводительным распределенным вычислениям».
Данный проект нацелен на разработку системы научно-методического
обеспечения образовательных программ подготовки студентов и повышения
квалификации профессорско-преподавательского состава по высокопроизводительным
вычислениям.
Техническая ценность результатов выполнения проекта заключается в
доведении созданных моделей системы поддержки учебного процесса до реализации,
интеграция в существующий информационно-вычислительный портал Кемеровского
государственного университета.
Создание информационной системы поддержки учебного процесса с
возможностью проведения виртуальных практикумов является актуальной задачей
информационного обеспечения учебно-научного процесса. [21]
Одной из частей данной системы является компонент «Виртуальная
лаборатория» системы УД и УРВР.
.1 Описание компонента «Виртуальная лаборатория»
Цель разработки
Организация виртуального лабораторного практикума с использованием
высокопроизводительных вычислительных ресурсов в удаленном режиме в рамках
курсов по ВПВ.
Задачи системы
- Предоставление преподавателю механизма для формирования лабораторного
задания в рамках курса по ВПВ, предусматривающего исследование поведения
определенного численного алгоритма на вычислительных ресурсах кластерной
архитектуры (например, зависимость эффективности алгоритма от количества
процессоров и параметров задачи);
- Предоставление пользователю возможности просмотра текста
лабораторной работы, а также выполнения задания и просмотра результатов для
проведения анализа.
Архитектура
Поскольку «Виртуальная лаборатория» является частью системы УД к ВР, то
строится по той же архитектуре, что и другие ее компоненты, и интегрирована в
схему БД системы УД и УРВР.
«Виртуальная лаборатория» взаимодействует с системой поддержки учебного
процесса (СПУП), являющейся частью портала КемГУ:
- Назначение преподавателем лабораторных работ студентам посредством СПУП;
-