Комп'ютерна система штучного інтелекту 'Неокогнітрон'
Міністерство
освіти і науки України
Тернопільський
національний технічний університет імені Івана Пулюя
Кафедра
комп’ютерних систем та мереж
РЕФЕРАТ
з дисципліни
"Комп'ютерні системи штучного інтелекту"
на тему
Неокогнітрон
Тернопіль - 2013
Зміст
Вступ
1. Введення в процедуру зворотного
поширення
2. Навчальний алгоритм зворотного поширення
2.1 Мережеві конфігурації
.2 Нейрон
.3 Багатошарова мережа
3. Огляд навчання
.1 Прохід вперед
3.2 Зворотний прохід
.3 Налаштування ваги прихованого прошарку
.4 Додавання нейронного зміщення
.5 Імпульс
4. Подальші алгоритмічні розробки
5. Застосування
6. Застереження
.1 Параліч мережі
.2 Локальні мінімуми
.3 Розмір кроку
Висновки
Література
зворотній
поширення алгоритм нейрон
Вступ
Довгий час не існувало теоретично обґрунтованого алгоритму
для навчання багатошарових штучних нейронних мереж. А оскільки можливості
представлення з допомогою одношарових нейронних мереж виявилися досить
обмеженими, то і вся область загалом прийшла в занепад.
Розробка алгоритму зворотного поширення зіграла важливу роль
у відродженні інтересу до штучних нейронних мереж. Зворотне поширення - це
систематичний метод для навчання багатошарових штучних нейронних мереж. Він має
солідне математичне обґрунтування. Незважаючи на деякі обмеження, процедура
зворотного поширення сильно розширила область проблем, в яких можуть бути
використані штучні нейронні мережі, і переконливо продемонструвала свою
потужність.
1.
Введення в процедуру зворотного поширення
Цікава історія розробки процедури. У було дано ясний і повний
опис процедури. Але як тільки ця робота була опублікована, виявилося, що вона
була передбачена в . А незабаром з'ясувалося, що ще раніше метод був описаний
в. Автори роботи зекономили б свої зусилля, знай вони про роботу. Хоч подібне
дублювання є звичайним явищем для кожної наукової області, в штучних нейронних
мережах стан з цим набагато серйозніше через граничний характер самого предмета
дослідження. Дослідження по нейронних мережах публікуються в таких різних
книгах і журналах, що навіть самому кваліфікованому досліднику потрібні значні
зусилля, щоб бути обізнаним про всі важливі роботи в цій області.
2.
Навчальний алгоритм зворотного поширення
2.1 Мережеві
конфігурації
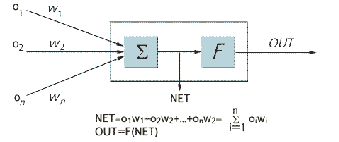
Рисунок 1 - Штучний нейрон з активаційною функцією
2.2 Нейрон
На рисунку 1 показаний нейрон, що використовується як
основний будівельний блок в мережах зворотного поширення. Подається множина
входів, що йдуть або ззовні, або від попереднього прошарку. Кожний з них
перемножується з вагою, і добутки підсумовуються. Ця сума, що позначається NET,
повинна бути обчислена для кожного нейрона мережі. Після того, як величина NET
обчислена, вона модифікується за допомогою активаційний функції і виходить
сигнал OUT.
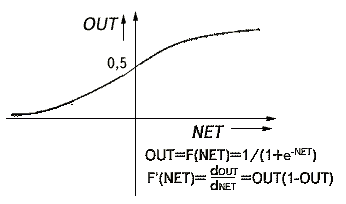
Рисунок 2 - Сигмоїдальна активаційна функція
На рисунку 2 показана активаційна функція, що переважно
використовується для зворотного поширення.
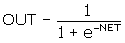 . (1)
. (1)
Як показує рівняння (2), ця функція, звана сигмоїдоюдосить
зручна, оскільки має просту похідну, що використовується при реалізації
алгоритму зворотного поширення.
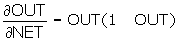 .(2)
.(2)
Сигмоїда, яка іноді називається також логістичною або стискаючою
функцією, звужує діапазон зміни так, що значення OUT лежить між
нулем і одиницею. Як вказувалося вище, багатошарові нейронні мережі мають
більшу потужність, ніж одношарові, тільки у разі наявності нелінійності.
Стискаюча функція забезпечує необхідну нелінійність.
Насправді є багато функцій, які могли б бути використані. Для
алгоритму зворотного поширення потрібно лише, щоб функція була всюди
диференцьована. Сигмоїда задовольняє цій вимозі. Її додаткова перевага
складається в автоматичному контролі посилення. Для слабких сигналів (величина NET
близька до нуля) крива вхід-вихід має сильний нахил, що дає велике підсилення.
Коли величина сигналу стає більшою, підсилення падає. Таким чином, великі
сигнали сприймаються мережею без насичення, а слабкі сигнали проходять по
мережі без надмірного ослаблення.
2.3
Багатошарова мережа
На рисунку 3 зображена багатошарова мережа, яка може
навчатися за допомогою процедури зворотного поширення. (Для ясності малюнок
спрощений.) Перший прошарок нейронів (сполучений з входами) служить лише як розподільні
точки, підсумовування входів тут не проводиться. Вхідний сигнал просто
проходить через них до ваги на їх виходах. А кожний нейрон подальших прошарків
видає сигнали NET і OUT, як описане вище.
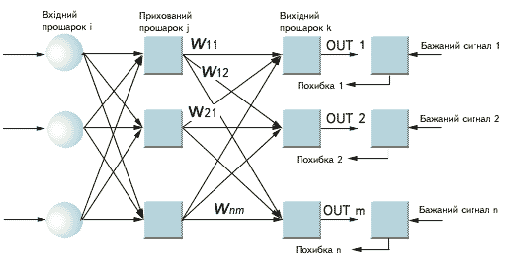
Рисунок 3 - Двошарова мережа зворотного поширення (e -
бажаний сигнал)
У літературі немає однієї думки відносно того, як рахувати
число прошарків в таких мережах. Одні автори використовують число прошарків
нейронів (включаючи вхідний прошарок, що не підсумовує), інші - число прошарків
ваг. Оскільки останнє визначення функціонально описове, то воно буде
використовуватися протягом книги. Згідно з цим визначенням, мережа на рис. 3.3
розглядається як двошарова. Нейрон об'єднаний з множиною ваг, приєднаної до
його входу. Таким чином, ваги першого прошарку закінчуються на нейронах першого
прошарку. Вхід розподільчого прошарку вважається нульовим прошарком.
Процедура зворотного поширення застосовна до мереж з
будь-яким числом прошарків. Однак для того, щоб продемонструвати алгоритм,
досить двох прошарків. Зараз будуть розглядатися лише мережі прямої дії, хоч
зворотне поширення застосовується і до мереж із зворотними зв'язками. Ці
випадки будуть розглянуті в даному розділі пізніше.
3.
Огляд навчання
Метою навчання мережі є таке налаштування її ваг, щоб добуток
з деякою множиною входів приводив до необхідної множини виходів. Скорочено ці
множини входів і виходів будуть називатися векторами. При навчанні
передбачається, що для кожного вхідного вектора існує парний йому цільовий вектор,
що задає необхідний вихід. Разом вони називаються навчальною парою. Як
правило, мережа навчається на багатьох парах. Наприклад, вхідна частина
навчальної пари може складатися з набору нулів і одиниць, що представляє
двійковий образ деякої букви алфавіту. На рис. 3.4 показана множина входів для
букви "А", нанесеної на сітці. Якщо через квадрат проходить лінія, то
відповідний нейронний вхід рівний одиниці, в іншому випадку він рівний нулю.
Вихід може бути числом, що представляє букву "А", або іншим набором з
нулів і одиниць, який може бути використаний для отримання вихідного образу.
При необхідності розпізнавати за допомогою мережі всі букви алфавіту, було б
потрібно 26 навчальних пар. Така група навчальних пар називається навчальною
множиною.
Перед початком навчання всім вагам повинні бути надані
невеликі початкові значення, вибрані випадковим чином. Це гарантує, що в мережі
не станеться насичення великими значеннями ваги, і запобігає ряду інших
патологічних випадків. Наприклад, якщо всім вагам надати однакові початкові
значення, а для необхідного функціонування потрібні нерівні значення, то мережа
не зможе навчитися.
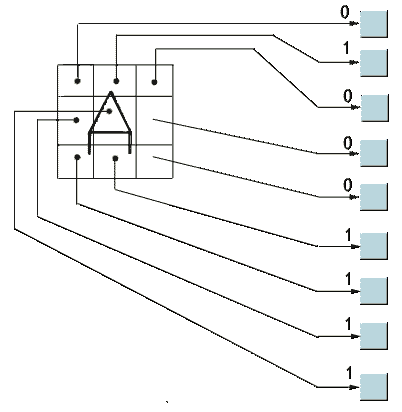
Рисунок 4 - Розпізнавання зображення
Навчання мережі зворотного поширення вимагає виконання наступних
операцій:
1. Вибрати чергову навчальну пару з навчальної множини;
подати вхідний вектор на вхід мережі.
2. Обчислити вихід мережі.
. Обчислити різницю між виходом мережі і необхідним
виходом (цільовим вектором навчальної пари).
. Скорегувати ваги мережі так, щоб мінімізувати
похибку.
. Повторити кроки з 1 по 4 для кожного вектора
навчальної множини доти, поки похибка на всій множини не досягне прийнятного
рівня.
Операції, що виконуються на кроках 1 і 2, схожі з тими, які
виконуються при функціонуванні вже навченої мережі, тобто подається вхідний
вектор і обчислюється поточний вихід. Обчислення виконуються пошарово. На рис.
3.3 спочатку обчислюються виходи нейронів прошарку j, потім вони
використовуються як входи прошарку k, обчислюються виходи нейронів прошарку
k, які і утворюють вихідний вектор мережі.
На кроці 3 кожний з виходів мережі, які на рис. 3.3 позначені
OUT, віднімається з відповідної компоненти цільового вектора, щоб
отримати похибку. Ця похибка використовується на кроці 4 для корекції ваги мережі,
причому знак і величина змін ваги визначаються алгоритмом навчання (див.
нижче).
Після достатнього числа повторень цих чотирьох кроків різниця
між дійсними виходами і цільовими виходами повинна зменшитись до прийнятної
величини, при цьому кажуть, що мережа навчилася. Тепер мережа використовується
для розпізнавання і ваги не змінюються.
На кроки 1 і 2 можна дивитися як на "прохід
вперед", оскільки сигнал розповсюджується по мережі від входу до виходу.
Кроки 3, 4 складають "зворотний прохід", що тут обчислюється сигнал
похибки розповсюджується зворотно по мережі і використовується для налаштування
ваг. Ці два проходи тепер будуть деталізовані і виражені в математичній формі.
3.1 Прохід вперед
Кроки 1 і 2 можуть бути виражені у векторній формі таким чином:
подається вхідний вектор Х і на виході продукується вектор Y.
Векторна пари вхід-мета Х і Т береться з навчальної множини.
Обчислення проводяться над вектором X, щоб отримати вихідний вектор Y.
Як ми бачили, обчислення в багатошарових мережах виконуються
прошарок за прошарком, починаючи з найближчого до входу прошарку. Величина NET
кожного нейрона першого прошарку обчислюється як зважена сума входів нейрона.
Активаційна функція F "стискає" NET і дає величину OUT
для кожного нейрона в цьому прошарку. Коли множина виходів прошарку отримана,
вона є вхідною множиною для наступного прошарку. Процес повторюється прошарок
за прошарком, поки не буде отримана заключна множина виходів мережі.
Цей процес може бути виражений в стислій формі за допомогою
векторної нотації. Ваги між нейронами можуть розглядатися як матриця W.
Наприклад, вага від нейрона 8 в прошарку 2 до нейрона 5 прошарку 3 позначається
w8,5. Тоді NET-вектор прошарку Nможе бути
виражений не як сума добутків, а як добуток Хі W. В векторному
позначенні N = XW. Покомпонентне застосування функції F до NET-вектора
N продукує вихідний вектор О. Таким чином, для даного прошарку
обчислювальний процес описується наступним виразом:
О = F(XW). (3)
Вихідний вектор одного прошарку є вхідним вектором для
наступного, тому обчислення виходів останнього прошарку вимагає застосування
рівняння (3) до кожного прошарку від входу мережі до її виходу.
3.2 Зворотний прохід
Налаштування ваг вихідного прошарку. Оскільки для кожного нейрона
вихідного прошарку задане цільове значення, то налаштування ваг легко
здійснюється з використанням модифікованого дельта-правила з розділу 2.
Внутрішні прошарки називають "прихованими прошарками", для їх виходів
немає цільових значень для порівняння. Тому навчання ускладнюється.
На рисунку 5 показаний процес навчання для однієї ваги від
нейрона р в прихованому прошарку j до нейрона q у
вихідному прошарку k. Вихід нейрона прошарку k, віднімаючись з
цільового значення (Target), дає сигнал похибки. Він множиться на
похідну стискаючої функції [OUT(1 - OUT)], обчислену для цього
нейрона в прошарку k, даючи, таким чином, величину d.
d = OUT(1 - OUT)(Target - OUT) (4)
Потім d множиться на величину OUT нейрона j,
з якого отримують поточні ваги. Це в свою чергу множиться на коефіцієнт
швидкості навчання h(переважно від 0,01 до 1,0), і результат додається
до ваги. Така ж процедура виконується для кожної ваги від нейрона прихованого
прошарку до нейрона у вихідному прошарку.
Наступні рівняння ілюструють це обчислення:
Dwpq,k = h dq,k OUT (5)
wpq,k(n+1) = wpq,k(n) + Dwpq,k(6)
де wpq, k(n) - величина
ваги від нейрона р в прихованому прошарку до нейрона q у
вихідному прошарку на кроці n (до корекції); зазначимо, що індекс k
відноситься до прошарку, в якому закінчується дана вага, тобто, згідно з
прийнятому в цій книзі узгодженні, з якою він об'єднаний; wpq,
k(n+1) - величина ваги на кроці n+ 1 (після корекції);dq,k
величина d для нейрона q, у вихідному прошарку k; OUTp,
j величина OUT для нейрона р в прихованому прошарку j.
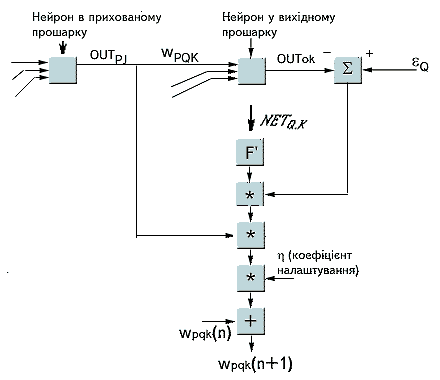
Рисунок 5 - Налаштування ваги у вихідному прошарку
3.3 Налаштування ваги прихованого прошарку
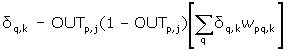 (7)
(7)
Коли значення d отримано, ваги, підтримуючі перший
прихований рівень, можуть бути скореговані за допомогою рівнянь (5) і (6), де
індекси модифікуються у відповідності з прошарком.
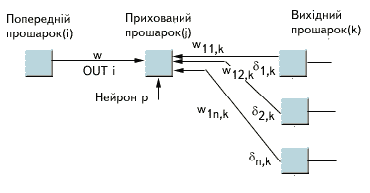
Рисунок 6 - Налаштування ваги в прихованому прошарку
Для кожного нейрона в даному прихованому прошарку повинне
бути обчислено d і налаштовані всі ваги, асоційовані з цим прошарком.
Цей процес повторюється прошарок за прошарком у напрямі до входу, поки всі ваги
не будуть скоректовані.
За допомогою векторних позначень операція зворотного
поширення похибки може бути записана значно компактніше. Визначимо множину
величин d вихідного прошарку через Dk і множину ваг
вихідного прошарку як масив Wk. Щоб отримати Dj,d
- вектор вихідного прошарку, досить наступних двох операцій:
1. Помножити про-вектор вихідного прошарку Dk
на транспоновану матрицю ваги W'k, що з'єднує прихований
рівень з вихідним рівнем.
2. Помножити кожну компоненту отриманого добутку на
похідну стискаючої функції відповідного нейрона в прихованому прошарку.
У символьному записі
Dj = DkW'k $[0j $(I-0j)],
(8)
де оператор $ в даній книзі означає покомпонентне вироблення
векторів, Оj - вихідний вектор прошарку j і I -
вектор, всі компоненти якого рівні 1.
3.4 Додавання нейронного зміщення
У багатьох випадках бажано наділяти кожний нейрон навчальним
зміщенням. Це дозволяє зсувати початок відліку логістичної функції, даючи
ефект, аналогічний налаштуванню порога перцептроного нейрона, і приводить до
прискорення процесу навчання. Ця можливість може бути легко введена в
навчальний алгоритм за допомогою ваги, що додається до кожного нейрона,
приєднаної до +1. Ця вага навчається так само, як і всі інші ваги, за винятком того,
що сигнал, що подається на нього завжди рівний +1, а не виходу нейрона
попереднього прошарку.
3.5 Імпульс
У роботі [7] описаний метод прискорення навчання для
алгоритму зворотного поширення, що збільшує також стійкість процесу. Цей метод,
названий імпульсом, полягає в додаванні до корекції ваги члена, пропорційного
величині попередньої зміни ваги. Як тільки відбувається корекція, вона
"запам'ятовується" і служить для модифікації всіх подальших корекцій.
Рівняння корекції модифікуються таким чином:
pq,k(n+1)= h dq,k OUTp,j +
a Dwpq,k(n) (9)
wpq,k(n+1) = wpq,k(n) +
Dwpq,k(n+1)(10)
де a - коефіцієнт імпульсу, звичайно встановлюється біля 0,9.
Використовуючи метод імпульсу, мережа прагне йти по дну
вузьких ярів поверхні похибки (якщо такі є), а не рухатися від схилу до схилу.
Цей метод, мабуть, добре працює на деяких задачах, але дає слабкий або навіть
негативний ефект на інших.
У роботі [8] описаний схожий метод, заснований на
експонентному згладжуванні, який може мати перевагу в ряді застосувань.
Dwpq,k(n+1)= (1- a ) dq,k OUTp,j
+ a Dwpq,k(n) (11)
Обчислюється зміна ваг,
wpq,k(n+1) = wpq,k(n) +
hDwpq,k(n+1), (12)
де a коефіцієнт згладжування, в діапазоні від 0,0 до 1,0.
Якщо a рівне 1,0, то нова корекція ігнорується і повторюється попередня. У області
між 0 і 1 корекція ваги згладжується величиною, пропорційною a. Як і раніше, h
є коефіцієнтом швидкості навчання, що служить для управління середньою
величиною зміни ваги.
4.
Подальші алгоритмічні розробки
Багатьма дослідниками були запропоновані поліпшення і
узагальнення описаного вище основного алгоритму зворотного поширення.
Література в цій області дуже широка, щоб її можна було тут охопити. Крім того,
зараз ще дуже рано давати остаточні оцінки. Деякі з цих підходів можуть
виявитися дійсно фундаментальними, інші ж згодом зникнуть. Деякі з найбільш
багатообіцяючих розробок обговорюються в цьому розділі.
У [5] описаний метод прискорення збіжності алгоритму
зворотного поширення. Названий зворотним поширенням другого порядку, він
використовує другі похідні для більш точної оцінки необхідної корекції ваги. У
[5] показано, що цей алгоритм оптимальний в тому значенні, що неможливо
поліпшити оцінку, використовуючи похідні більш високого порядку. Метод вимагає
додаткових обчислень в порівнянні із зворотним поширенням першого порядку, і
необхідні подальші експерименти для доведення виправданості цих витрат.
У [9] описаний цікавий метод поліпшення характеристик
навчання мереж зворотного поширення. У роботі вказується, що загальноприйнятий
від 0 до 1 динамічний діапазон входів і виходів прихованих нейронів
неоптимальний. Оскільки величина корекції ваги Dwpq,k
пропорційна вихідному рівню нейрона, що породжує OUTp, j, то
нульовий рівень веде до того, що вага не змінюється. При двійкових вхідних
векторах половина входів в середньому буде рівна нулю, і ваги, з якими вони
пов'язані, не будуть навчатися! Рішення складається в приведенні входів до
значень ±Ѕ і додаванні зміщення до стискаючої функції, щоб вона також приймала
значення ±Ѕ. Нова стискаюча функція виглядає таким чином:
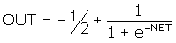 (13)
(13)
За допомогою таких простих засобів час збіжності скорочується
в середньому від 30 до 50%. Це є одним з прикладів практичної модифікації,
істотно поліпшуючої характеристику алгоритму.
У [6] і [1] описана методика застосування зворотного
поширення до мереж із зворотними зв'язками, тобто до таких мереж, в яких виходи
подаються через зворотний зв'язок на входи. Як показано в цих роботах, навчання
в подібних системах може бути дуже швидким і критерії стійкості легко задовольняються.
5.
Застосування
Зворотне поширення було використане в широкій сфері
прикладних досліджень. Деякі з них описуються тут, щоб продемонструвати
потужність цього методу.
Фірма NEC в Японії оголосила недавно, що зворотне поширення
було нею використане для візуального розпізнавання букв, причому точність
перевищила 99%. Це поліпшення було досягнуте за допомогою комбінації звичайних
алгоритмів з мережею зворотного поширення, що забезпечує додаткову перевірку.
У роботі [8] досягнуть вражаючий успіх з Net-Talk, системою,
яка перетворює друкарський англійський текст у високоякісну мову. Магнітофонний
запис процесу навчання сильно нагадує звуки дитини на різних етапах навчання
мови.
У [2] зворотне поширення використовувалося в машинному
розпізнаванні рукописних англійських слів. Букви, нормалізовані за розміром,
наносилися на сітку, і бралися проекції ліній, що перетинають квадрати сітки.
Ці проекції служили входами для мережі зворотного поширення. Повідомлялося про
точність 99,7% при використанні словникового фільтра.
У [3] повідомлялося про успішне застосування зворотного
поширення до стиснення зображень, коли образи представлялися одним бітом на
піксель, що було восьмиразовим поліпшенням в порівнянні з вхідними даними.
6.
Застереження
Незважаючи на численні успішні застосування зворотного
поширення, воно не є панацеєю. Більше всього прикрощів приносить невизначено
довгий процес навчання. У складних задачах для навчання мережі можуть бути
потрібні дні або навіть тижні, вона може і взагалі не навчитися. Тривалий час
навчання може бути результатом неоптимального вибору довжини кроку. Невдачі в
навчанні звичайно виникають по двох причинах: паралічу мережі і попадання в
локальний мінімум.
6.1
Параліч мережі
У процесі навчання мережі значення ваги можуть внаслідок
корекції стати дуже великими величинами. Це може привести до того, що всі або
більшість нейронів будуть функціонувати при дуже великих значеннях OUT, в
області, де похідна стискаючої функції дуже мала. Оскільки що зворотно поширена
в процесі навчання похибка пропорційна цієї похідній, то процес навчання може
практично завмерти. У теоретичному відношенні ця проблема погано вивчена.
Звичайно цього уникають зменшенням розміру кроку h, але це збільшує час
навчання. Для запобігання від параліча або для відновлення після нього
використовувалися різні эвристики, але поки що вони можуть розглядатися лише як
експериментальні.
6.2 Локальні
мінімуми
Зворотне поширення використовує різновид градієнтного спуску,
тобто здійснює спуск вниз по поверхні похибки, безперервно налаштовуючи ваги в
напрямі до мінімуму. Поверхня похибки складної мережі сильно порізана і
складається з горбів, долин, складок і ярів в просторі високої розмірності.
Мережа може попасти в локальний мінімум (неглибоку долину), коли поряд є набагато
більш глибоких мінімумів. У точці локального мінімуму всі напрями ведуть
догори, і мережа нездатна з нього вибратися. Статистичні методи навчання можуть
допомогти уникнути цієї пастки, але вони повільні. У [10] запропонований метод,
що об'єднує статистичні методи машини Коши з градієнтним спуском зворотного
поширення і що приводить до системи, яка знаходить глобальний мінімум,
зберігаючи високу швидкість зворотного поширення. Це обговорюється в розділі 5.
6.3
Розмір кроку
Уважний розбір доказу збіжності в [7] показує, що корекції
ваги передбачаються нескінченно малими. Ясно, що це нездійсненне на практиці,
оскільки веде до нескінченного часу навчання. Розмір кроку повинен братися
кінцевим, і в цьому питанні доводиться спиратися тільки на досвід. Якщо розмір
кроку дуже малий, то збіжність дуже повільна, якщо ж дуже великий, то може
виникнути параліч або постійна нестійкість. У [11] описаний адаптивний алгоритм
вибору кроку, автоматично корегуючий розмір кроку в процесі навчання.
Висновки
Якщо мережа вчиться розпізнавати букви, то немає значення
вчити "Б", якщо при цьому забувається "А". Процес навчання
повинен бути таким, щоб мережа навчалася на всій навчальній множини без
пропусків того, що вже вивчено. У доказі збіжності ця умова виконана, але потрібно
також, щоб мережі пред'являлися всі вектори навчальної множини раніше, ніж
виконується корекція ваги. Необхідні зміни ваги повинні обчислюватися на всій
множини, а це вимагає додаткової пам'яті; після ряду таких навчальних циклів
ваги зійдуться до мінімальної похибки. Цей метод може виявитися некорисним,
якщо мережа знаходиться в зовнішньому середовищі, що постійно змінюється, так
що другий раз один і той же вектор може вже не повторитися. У цьому випадку
процес навчання може ніколи не зійтися, безцільно блукаючи. У цьому значенні
зворотне поширення не схоже на біологічні системи. Невідповідність (серед
інших) привела до системи ART, що належить Гроссбергу.
Література
В даному рефераті було використано матеріал з книги
американського автора Ф.Уосермана "Нейрокомп’терна техніка: Теорія і
практика"