Использование индексов в базе данных
Министерство образования и науки РФ
Новосибирский государственный
университет экономики и управления
Кафедра экономической информатики
Учебная дисциплина: Базы данных
Тема контрольной (курсовой) работы: Использование Индексов в базе данных
Наименование специальности: Прикладная информатика (в экономике)
Выполнил: Остапенко М.В.
Проверил: Зав каф. ЭИ Пашков П.М.
Содержание
Введение
Индексирование в БД
Индекс. Создание индекса
Типы и виды индексов
Индексация
Структура индекса
Индексы для последовательных файлов
Методы доступа к файлам
Неупорядоченные файлы
Упорядоченные файлы
Хеширование. Типы хеширования
Связанная область переполнения
Многократное хеширование
Древовидные структуры
В-деревья
Структура В-дерева
Бинарное дерево
Древовидные структуры для многомерных данных
Деревья квадрантов
R-деревья
Заключение
Список используемой литературы
Приложения
Введение
Для того, чтобы найти необходимые нам данные в базе данных,
нам нужно понимать структуру поиска. В том, что базы данных надо индексировать
- не сомневается ни один здравомыслящий программист. Так как правильно
построенные индексы позволят нам найти нужную информацию "в одно
касание". Без индексации мы заставляем наши компьютеры искать нужную
информацию методом перебора, лишь потому, что они делают это быстро. Но это
если поиск нужно произвести в тысячах записей. А если речь пойдёт о миллионах?
На поиск необходимых данных уйдёт время. Поэтому базу данных необходимо
оптимизировать.
Целью данного реферата является знакомство с индексами,
которые хоть и не являются обязательным компонентом СУБД, но могут существенным
образом повысить ее производительность. Мы познакомимся с их структурой, целью
создания, а так же как, и с помощью чего создаются индексы.
Написание данного реферата я начала с определения перечня
необходимой литературы (см. Список литературы). Далее сформировала список
понятий, после чего они были занесены в таблицу понятий (см. Приложение 1).
Затем, при помощи ментальной карты структурировала и установила взаимосвязи
между терминами из таблицы понятий (см. Приложение 2). После этого, на основе
составленной ментальной карты создала структуру данной работы.
В первом пункте данного реферата более подробно описаны цели
и способы создания индексов, их типы и виды, а так же из первого пункта мы
узнаем, что такое индексирование и индексация, и какую роль они играют в БД. Во
втором пункте более детально рассмотрена структура индекса, описание моделей
конструирования индексов, а так же описание методов доступа к файлам и
хеширование. В третьем пункте имеется описание древовидной структуры,
поддерживающей иерархическое представление информации, приведены основные виды
древовидных индексов. В этом пункте также рассмотрено моделирование информации
с помощью древовидной структуры.
Индексирование
в БД
База данных - это единое, вместительное хранилище
разнообразных данных и описаний их структур. Хранимые данные организованы в
совместно используемый набор и логически связаны между собой. [1, с.13] Если
данных много, то найти нужную запись бывает очень трудно. Поиск данных
производится методом перебора, то есть просматриваются все записи таблицы от
первой записи до последней записи, что приводит к большим затратам времени,
чтобы облегчить поиск данных в таблице, используют индексы. [2, с.47]
Индекс. Создание
индекса
Индекс - структура данных определенного вида, которая
предназначена для ускорения поиска записей файла данных.
В простейшем варианте, индекс представляет собой файл, записи
которого содержат ключ (поле, содержащее одно или несколько атрибутов записи
файла данных и предназначенное для осуществления поиска записей по этому
критерию) и указатель (поле, содержащее адрес записи в файле данных). Поле
адреса заполняется СУБД. Записи индекса упорядочиваются по ключевому полю. Файл
данных, для которого существует индекс, называется индексированным, а поле
индексированного файла, значения которого используется в индексе, называется
индексным полем. Индекс можно создать как по одному полю, так и по нескольким
полям, причем не обязательно относящимся к первичному ключу. [3, c.110] На
рис.1 [3, c.110] изображена структура простого индекса.
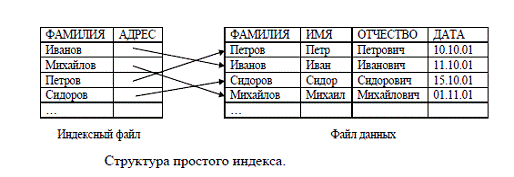
Рис. 1. Структура простого индекса
Далее мы рассмотрим, как и какими способами можно создать
индекс. Создать индекс можно двумя способами:
) С помощью команды:
ON < индексное выражение > ТО <
idx-файл>| TAG < имя тега>
[OF <cdx-файл>]
[FOR <условие>]
[COMPACT]
[DESCENDING]
[UNIQUE]
[ADDITIVE]
[NOOPTIMIZE]
Назначение опций:
<индексное выражение> - имя поля (или полей), по
значениям которого надо построить индекс. При построении сложного индекса имена
полей перечисляются через знак + (плюс). Если сложный индекс построен по:
• числовым полям, то индекс строится по сумме значений
полей;
• символьным полям, то индекс строится сначала по значению
первого поля, а при повторяющихся значениях первого поля - по значениям второго
поля; при повторяющихся значениях первого и второго полей - по значениям
третьего поля и т.д.;
• по полям разных типов, то сначала значения полей
приводят к одному типу, как правило символьному, а затем строят индекс
Длина индексного выражения не должна превышать 254
символа.
ТО <idx-файл> - указывается имя
одноиндексного файла.
TAG <имя тега> [OF <cdx-файл>] - указывается имя тега в
мультииндексном файле. Если используется опция [OF], то создаваемый тег
помешается в указанный мультииндексный файл, а если требуемый мультииндексный
файл отсутствует, то будет построен структурный мультииндексный файл. Если
опция [OF <cdx-файл>] опущена, то созданный тег будет помещен в
текущий мультииндексный файл.
FOR <условие> - устанавливает режим
отбора в индекс тех записей таблицы, которые удовлетворяют <условию>.
COMPACT - управляет созданием компактного одноиндексного
файла. В старших версиях FoxPro не используется.
DESCENDING - строит индекс по убыванию. По умолчанию
используется построение индекса по возрастанию (ASCENDING). Для
одноиндексных файлов можно построить индекс только по возрастанию. Если перед
использованием команды INDEX ON. подать команду SET COLLATE, то
можно построить одноиндексный файл по убыванию.
UNIQUE - строит уникальный индекс. Если индексное поле
(поля) содержит повторяющиеся значения, то в индекс попадает только одна первая
запись и остальные записи будут не доступны.
ADDITTVE - вновь создаваемый индексный файл не закрывает
уже открытые к этому моменту времени индексные файлы. Если опция опушена, то
вновь создаваемый индексный файл закрывает все ранее открытые индексные файлы.
NOOPTIMIZE - отключает использование технологии
Rashmore для ускоренного доступа к данным. [2, c.48]
) С помощью Главного меню
SQL Server автоматически создает индексы по всем первичным и
внешним ключам. Разработчик может также с помощью SQL Server создавать индексы
и по другим столбцам, которые часто фигурируют в предложениях WHERE или используются
для сортировки данных при последовательной обработке таблицы для запросов и
отчетов.
Чтобы создать индекс, щелкните правой кнопкой мыши на
таблице, содержащей столбец, который вы хотите индексировать, выберите All
Tasks (Все задачи), затем выберите Manage Indexes (Управление индексами).
Откроется диалоговое окно, изображенное в левой части рис.2. Щелкните на кнопке
New. (Новый.), и перед вами появится диалоговое окно, изображенное в правой
части рис.2. На этом рисунке разработчик создает индекс по столбцу Zip таблицы
CUSTOMER. Индекс, который называется CUSTOMER_Zip_Index, должен быть заполнен
на 80% и отнесен к группе файлов PRIMARY. Перегрузка оставляет пространство в
индексе открытым для вставок на всех уровнях, исключая самый нижний. Заполнение
характеризует объем пустого пространства, оставляемого на нижнем уровне
индекса.

Рис. 2. Создание индекса в графическом режиме [9]
В последнем диалоговом окне щелкните на кнопке Edit SQL.
(Редактировать SQL.), и вы увидите диалоговое окно, изображенное на рис.3. Оно
будет содержать текст SQL-оператора, введя который в окне анализатора запросов,
можно было бы создать тот же самый индекс.

Рис. 3. SQL-код, создающий индекс [9]
SQL Server поддерживает два вида индексов: кластеризованные и
некластеризованные. В кластеризованном индексе данные хранятся на нижнем уровне
и в том же порядке, что и сам индекс. В некластеризованном индексе нижний
уровень не содержит данных, но содержит указатели на данные. Поскольку строки
могут быть отсортированы только в одном физическом порядке за один раз, для
каждой таблицы допускается только один кластеризованный индекс.
Кластеризованные индексы обеспечивают более быстрое получение данных, чем некластеризованные.
Обычно они оказываются быстрее и при обновлении, но не в том случае, когда
много обновлений происходит в одном и том же месте в середине отношения. За
дальнейшей информацией обращайтесь к документации на SQL Server. [9 с.486]
Типы и виды индексов
Индексы можно классифицировать следующим образом:
) по виду используемых полей записи данных:
• первичный индекс -
индекс, построенный на основе поля первичного ключа данных. Такой индекс всегда
один, значение ключа индекса уникально; введение первичного индекса позволяет
хранить данные в неупорядоченном последовательном файле. В реляционной БД
каждая таблица может иметь только один первичный ключ. Внешних ключей у таблицы
может быть много и они могут иметь один из типов:
Ø Candidat - это кандидат в
первичный ключ или альтернативный ключ
Ø Unique (уникальный тип
индекса) - это тип индекса, который допускает повторяющиеся значения в поле, по
которому он построен, но на экран будет выводиться только одна первая запись из
группы записей с одинаковым значением индексного поля
Ø Regular (регулярный тип
индекса) - это тип индекса, который не накладывает никаких ограничений на
значения индексного поля и на вывод записей, на экран
Ø Primary - это один из
индексов, удовлетворяющий требованиям индекса типа Candidat может быть выбран в
качестве первичного ключа; [2, с.47]
• вторичный индекс -
индекс, построенный не по первичному ключу (см. рис.4) [6]. Позволяет ускорить
операции выборки для запросов, выполняющих фильтрацию не по полям первичного
ключа. Вторичных индексов может быть несколько (однако следует помнить, что чем
больше индексов у файла данных, тем медленнее вставка в него данных - вторичные
индексы должны строиться только для самых критичный и часто выполняемых
запросов); значения ключей в индексе могут повторяться;
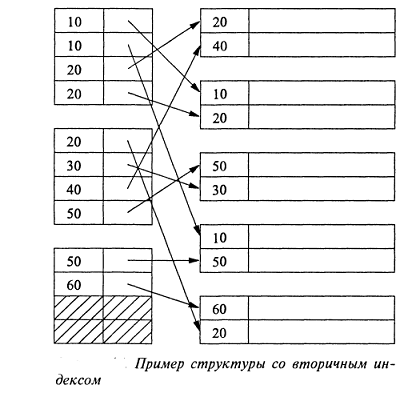
Рис. 4. Пример структуры с вторичным индексом
• индекс кластеризации.
Файл данных последовательно упорядочивается по неключевому полю, и на основе
этого неключевого поля формируется поле индексации, поэтому в файле может быть
несколько записей, соответствующих значению этого поля индексации. Неключевое
поле называется атрибутом кластеризации; [3, с.111]
• обращенный (inverted)
индекс - это индекс, который сочетает в себе все индексы и используется совместно
с промежуточным уровнем групп - сегментов указателей; [6, с.635] На рисунке 5
[9] показан поиск документов с помощью обращенного индекса.
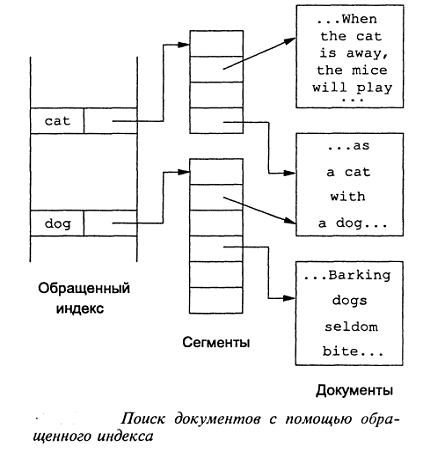
Рис. 5. Поиск документа с помощью
обращенного индекса
2) по числу используемых полей записи данных, а также в
зависимости от структуры и организации записи:
• несоставной - ключ
индекса состоит только из одного поля записи;
• составной - ключ индекса
состоит из нескольких полей записи, при этом сортировка ключа индекса
выполняется в следующем виде: основной порядок сортировки задает первое поле
ключа, дополнительный порядок сортировки (сортировка в группе) задает второе
поле ключа, и т.п.; составной индекс по полям записи (f1,f2,f3,…,fn) может
использоваться для поиска по полю f1 либо по комбинациям полей (f1, f2), (f1,
f2, f3), (f1, f2, f3, f4), …, (f1,f2,f3,…,fn-1), (f1,f2,f3,…,fn) - т.е. один
составной индекс может обслуживать ряд запросов, но поля, используемые при
этом, должны располагаться с начала ключа индекса (т.к. они зададут порядок
сортировки записей индекса) и без разрывов; [3, с.112]
• простой индекс - это
индекс, построенный по значениям одного поля;
• сложный индекс - это
индекс, построенный по значениям двух и более полей;
• интервальный индекс
[interval index] - это индекс, значения которого определяются некоторой
областью, например, диапазоном от 3 до 12;
3) по числу ссылок на данные:
• плотный - число индексных
записей равно числу записей данных, одна индексная запись ссылается только на
одну запись данных. На рисунке 6 [8] изображен пример плотного индекса;
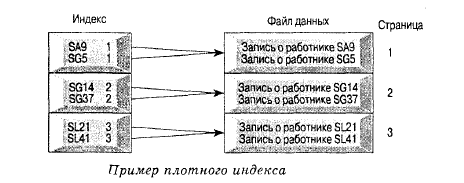
Рис. 6. Пример плотного индекса
• неплотный - число
индексных записей меньше числа записей данных, индекс указывает либо на первую
запись в определенной группе, либо на страницу с определенной группой записей
данных, записи данных при этом также должны быть упорядочены по некоторому
полю. Например, если список сотрудников упорядочен по фамилии, то можно
построить неплотный индекс, которых будет в качестве ключа содержать первую
букву фамилии, и этот индекс будет ссылаться на записи данных следующим
образом: "А" - > на первую фамилию в списке, начинающуюся на
"А", "Б" - > на первую фамилию в списке, начинающуюся на
"Б", и т.п. Поиск конкретного сотрудника по фамилии тогда можно
осуществить следующим образом:) найти букву, на которую начинается фамилия
сотрудника;
b) выполнить поиск фрагмента файла данных, отвечающего
за размещение фамилий начинающихся на данную букву, с использованием неплотного
индекса;) выполнить поиск в этом фрагменте файла данных (либо
последовательным перебором, либо используя упорядоченность по фамилии для
бинарного поиска).
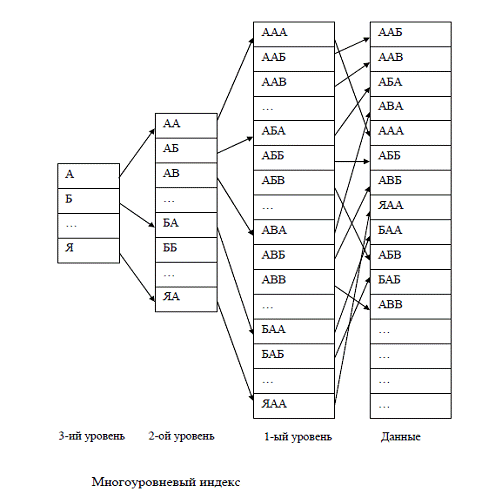
Рис. 7. Многоуровневый индекс [3, с.113]
) по числу уровней индекса:
· одноуровневый - индекс, который
непосредственно ссылается на данные, а не на другие индексные структуры;
· многоуровневый - индекс, состоящий из
нескольких индексных файлов, при этом только индекс первого уровня ссылается на
реальные данные (обычно это плотный индекс), а индексы более высоких уровней
ссылаются на предыдущие уровни (эти индексы обязательно неплотные). Структура
многоуровневого индекса за счет увеличения объема данных позволяет сократить
время поиска записей, т.к. данные уже разбиты на фрагменты, которые бы получались,
например, в результате бинарного поиска. Многоуровневый индекс вводится при
наличии в файле данных большого числа записей, обычно при условии, что бинарный
поиск в одноуровневом плотном индексе проводится за значительное число шагов.
Поиск данных в многоуровневом индексе начинается с самого верхнего уровня и
продолжается пока не будет достигнута запись данных, поиск ссылки на следующий
уровень на текущем уровне проводится методом двоичного поиска в определенном
диапазоне. На практике, число уровней многоуровневого индекса обычно не
превышает трех; [3, с.114]
· в зависимости от характера используемой
системы знаков:
· буквенный индекс [alphabetic code,
alphabetic notation] - индекс, использующий отдельные буквы или
сочетание букв алфавита;
· цифровой индекс [numerical code, numerical
notation] - индекс, использующий отдельные цифры, числа, сочетания цифр или их
комбинации;
· десятичный индекс [decimal code, decimal
classification code] - цифровой индекс, составленный на основе десятичной
системы счисления;
· алфавитно-цифровой индекс [alphanumeric
code] - смешанный индекс, состоящий из букв и цифр;
· смешанный индекс [mixed code, mixed
notation] - индекс, состоящий из разнородных знаков, например, из букв
различных алфавитов, букв и цифр и т.п.
) в зависимости от уровня приоритетности:
· гипериндекс [hyperindex] - высший уровень
индекса индексной организации баз данных, принятый в некоторых СУБД (наряду с
главным и нормальным индексами);
· главный (основной, первичный, старший)
индекс [master index, primary index, main subject code, main classification
number] - 1. Индекс высшего уровня в иерархической системе организации данных;
· 2. Индекс, отражающий главную тему
содержания индексируемого текста, документа и т.п. и относящийся к основной
принятой системе классификации;
· нормальный индекс [normal index] -
подмножество ключей базы данных, соответствующих конкретному значению поля,
объявленного дескриптором (признаком поиска). Используется в четырехуровневой
системе индексов СУБД, например, - ADABAS;
· вспомогательный (дополнительный) индекс
[additional index, auxiliary code, auxiliary classification number] - индекс,
являющийся дополнением к главному (основному) и отражающий дополнительные
признаки индексируемого текста, документа и т.п. или относящийся к вспомогательной
системе классификации;
6) в зависимости от характера индексируемых объектов
и/или назначения индекса различают:
· авторский знак [author mark, author
notation, author number] - индекс, обозначающий автора произведения,
используемый при расстановке и поиске книг в библиотеках;
· кеттерский знак [cutter number] -
авторский знак, определяемый по "Авторской таблице" Ч. Кеттера;
· расстановочный индекс [location mark,
location number] - индекс, используемый для расстановки и поиска книг,
документов и т.п. в библиотеке или фонде;
· каталожный индекс [catalog classification
mark, catalog classification number] - индекс, используемый для расстановки и
поиска карточек в каталоге;
· индекс каталога [catalog index] - старший
индекс в библиотечной организации данных;
· индекс массива [array index] - индекс,
присваиваемый массиву документов или данных для его идентификации;
· индекс файла [index number] - в некоторых
операционных системах (например, UNIX) номер индексного дескриптора файла и др.
[7]
Преимущество всех перечисленных выше типов и видов индексов в
том, что они значительно повышают производительность, и уменьшают скорость
поиска.
Основной недостаток использования индексов - замедление
обновления файла данных, т.к. при добавлении новой записи в файл данных
требуется обновление индекса, а индекс представляет собой упорядоченный
последовательный файл и обновляется медленно. [3]
Индексация
В указанных ниже определениях понятие "индексация"
никоим образом не обозначает процесс и его нельзя смешивать с понятием
"индексирование"!
ИНДЕКСАЦИЯ [subscripting, notation system, indexing] - 1.
Метод, обеспечивающий возможность обращения к элементу массива с помощью
указания массива и выражений, определяющих местоположение этого элемента в
массиве;
. Система (совокупность) индексов, используемая для
индексирования и соответствующая определенной системе классификации.
Различаются следующие виды индексации:
· кумулятивная индексация [cumulative
indexing] - индексация, предусматривающая присвоение одному адресу несколько
индексов;
· однорядная индексация [pure notation
system] - индексация, в которой использованы "однорядные" знаки:
буквы одного алфавита, цифры одной системы счисления и т.п.:
· одноуровневая индексация - индексация с
использованием одноуровневых индексов;
· многоуровневая индексация - индексация с
использованием многоуровневых индексов;
· смешанная индексация [mixed notation
system] - индексация, в которой использованы различные знаки: буквы, цифры и
т.п.
Есть несколько вариантов индексации файлов и ввода
документов. При ручной индексации оператор самостоятельно присваивает атрибуты
каждому документу. Операция отнимает существенное количество времени, но
позволяет избежать ошибок распознавания информации, при вводе атрибутов
написанных от руки. Автоматическая индексация документов проводится без участия
оператора (оператор делает только контрольную выборку случайных документов для
проверки качества распознавания информации). Позволяет быстро описывать
документы, значения атрибутов которых напечатаны на принтере (с полями,
заполненными от руки появляется большая вероятность ошибки OCR программы).
Структура
индекса
Индекс в базе данных аналогичен предметному указателю,
приведенному в конце книги. Это структура, связанная с файлом и предназначенная
для поиска информации по тому же принципу, что и предметный указатель в книге.
Индекс позволяет избежать проведения последовательного или пошагового
сканирования файла в поисках нужных данных. При использовании индексов в базе
данных искомым объектом может быть одна или несколько записей файла. Как и
предметный указатель данной книги, индекс базы данных упорядочен, и каждый
злемент индекса содержит название искомого объекта, а также один или несколько
указателей (идентификаторов записей) на место его расположения.
Структура индекса связана с определенным ключом поиска и
содержит записи, состоящие из ключевого значения и адреса логической записи в
файле, содержащей это ключевое значение. Файл, содержащий логические записи,
называется файлом данных, а файл, содержащий индексные записи, - индексным
файлом. Значения в индексном файле упорядочены по полю индексирования,
которое обычно строится на базе одного атрибута. [8, c.1019]
Индексы для
последовательных файлов
Одна из простейших индексных структур основывается на файле,
отсортированном по значениям атрибутов индекса. Подобный файл называют
последовательным (sequential file). Структура индекса для последовательного
файла особенно полезна в тех случаях, когда ключ поиска совпадает с первичным
ключом отношения. На рис. 8 [6] схематически изображено отношение,
представленное в виде последовательного файла.
Кортежи отношения, хранимого в форме последовательного файла,
отсортированы по значениям первичного ключа. Рисунок соответствует ситуации,
когда ключами являются целочисленные значения; здесь показаны только ключевые
поля и выдвинуто довольно нетипичное предположение о том, что каждый блок
способен содержать только две записи. Например, в первом блоке размешены записи
с ключами 10 и 20. Помимо того, в этом и многих других примерах в качестве
ключевых значений используются последовательные целые числа, кратные 10, хотя,
разумеется, на практике подобное требование не ставится - равно как и то, чтобы
в индексе и файле данных присутствовали все значения, кратные 10, из определенного
интервала.
На рис. 9 [6] изображены начальные блоки файла индекса для
последовательного файла, приведенного на рис. 8 [6]. Для удобства мы полагаем,
что значения ключей кратны 10, хотя на практике подобная закономерность
встречается, конечно, весьма редко. Мы подразумеваем также, что блоки
индексного файла содержат по четыре пары вида "ключ-указатель". Надо
сказать, что и эта гипотеза далека от реальности - в типичном дисковом блоке
могут уместиться сотни подобных пар.
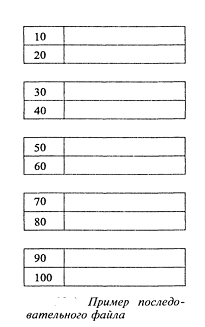
Рис. 8. Пример последовательного файла
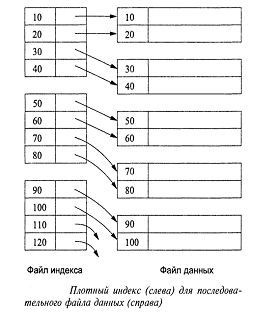
Рис. 9. Плотный индекс (слева) для последовательного файла
данных (справа)
Первый блок индекса содержит указатели на четыре начальные
записи данных, второй блок - на следующие четыре записи и т.д. На практике
иногда целесообразно заполнять блоки индексного файла не полностью.
Плотный индекс позволяет системе с успехом обрабатывать
запросы, в которых предполагается отыскание записей по заданному значению
ключа.
Система просматривает блоки индекса в поисках значения К
ключа, а затем, когда запись индекса с ключом К найдена, обращается по
указателю, адресующему запись данных с тем же ключевым значением.
На первый взгляд может показаться, что для отыскания записи
индекса с ключом К системе придется просмотреть каждый блок индекса (или в
среднем - половину блоков), но существует ряд факторов, которые дают
возможность значительно увеличить производительность операций поиска по
индексу.
1.
Размер
файла индекса обычно существенно меньше объема файла данных.
2.
Поскольку
ключи хранятся в упорядоченном виде, для отыскания значения К уместно
использовать алгоритм бинарного поиска. Если индекс содержит п блоков, системе
придется обратиться только к log2n из них.
3.
Индекс
может быть настолько мал, что его удастся целиком загрузить в оперативную
память и хранить здесь в течение такого промежутка времени, какой требуется; в
этом случае для отыскания ключа поиска К достаточно выполнить ряд операций в
оперативной памяти, не обращаясь к диску.
Если плотный индекс оказывается слишком большим, иногда
целесообразно воспользоваться схожей структурой разреженного индекса (sparse
index), позволяющей уменьшить размер файла ценой вероятного увеличения
промежутка времени, необходимого для отыскания записи по заданному значению
ключа.
Как показано на рис. 10 [6], разреженный индекс содержит
только по одному указателю на каждый блок файла данных, а ключами индекса
являются ключевые значения первых записей каждого блока данных.
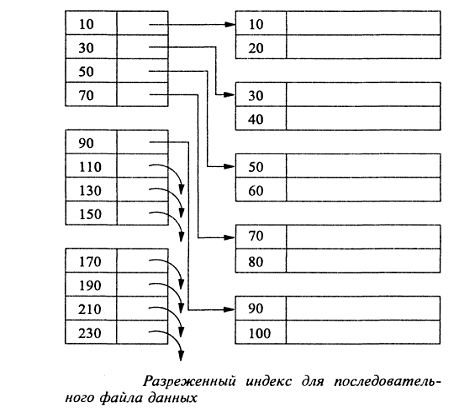
Рис. 10. Разреженный индекс для последовательного файла
На рис. 11, [6] показан вариант разреженного индекса для
файла данных. Этот индекс выглядит как обычно: он содержит пары
"ключ-указатель", соответствующие значениям ключа поиска первых
записей блоков данных.
Чтобы найти записи с заданным значением К ключа поиска в
такой структуре, необходимо отыскать элемент индекса (назовем его Е1)
с наибольшим номером, обладающий значением ключа, меньшим или равным К. Затем надлежит
перемещаться к началу индекса до тех пор, пока не будет достигнут первый
элемент индекса либо элемент Е2 со значением ключа, строго меньшим К
(в частном случае, когда Ех уже содержит значение ключа, строго
меньшее К, Е2 совпадает с Е1). Блоки данных, способные
содержать записи со значением К ключа поиска, адресуются элементами индекса с
номерами из интервала от Е2 до Е1 включительно.
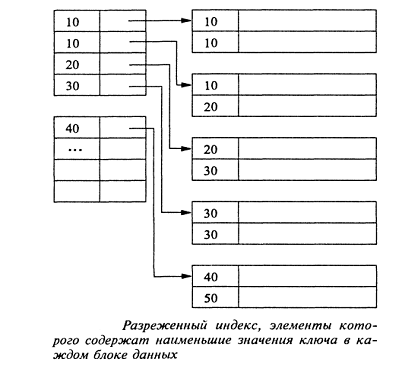
Рис. 11. Разреженный индекс, элементы которого содержат
наименьшие значения ключа в каждом блоке данных
На рис. 12 [6] перечислены все действия, предпринимаемые в
отношении файлов разреженных и плотных индексов при выполнении каждой из семи
различных операций над файлами данных - создания/удаления пустых блоков
переполнения или блоков последовательного файла, а также вставки, удаления и
перемещения записей. Мы полагаем, что создаваться или изыматься могут только
пустые блоки. В частности, если удалению подлежит блок, содержащий записи,
прежде всего следует "избавиться" от записей этого блока - либо
удалить их, либо перенести в другой блок.

Рис. 12. Как действия в отношении последовательного файла
данных влияют на файл индекса
Рассмотрим операцию удаления записи из блока
последовательного файла данных при наличии плотного индекса. Обратимся к
структуре, изображенной на рис. 9 (см. с. 15), и предположим, что удалению
подлежит запись с ключом 30. На рис. 13 [6] показан фрагмент той же структуры
после выполнения операции удаления.
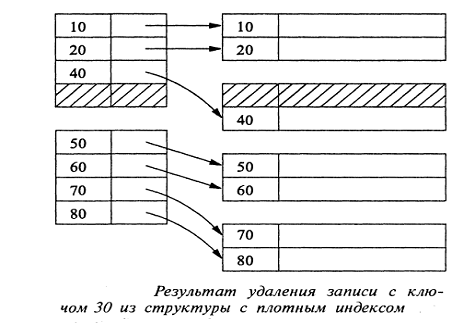
Рис. 13. Результат удаления записи с ключом 30 из структуры с
плотным индексом
Вначале из последовательного файла данных удаляется запись с
ключом 30. Вполне возможно существование внешних указателей, ссылающихся на
оставшуюся запись блока, и поэтому передвигать ее в начало блока
нецелесообразно - на месте удаленной записи система способна
"воздвигнуть" признак - "обелиск" (tombstone).
Далее из индекса изымается пара "ключ-указатель" со
значением ключа 30. Внешние указатели на записи индекса наверняка отсутствуют и
необходимости в использовании "обелиска" нет. Поэтому имеет смысл
переместить оставшиеся записи в блоке индекса на одну позицию
"вверх", чтобы консолидировать свободные участки внутри блока (если
их несколько) в единую более крупную область.
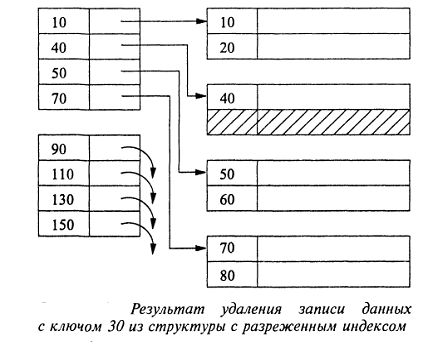
Рис. 14. Результат удаления записи данных с ключом 30 из
структуры с разреженным индексом, показанной на рис. 10
Результат удаления записи данных с ключом 30 схематически
изображен на рис. 14 [6]. После удаления записи с ключом 30 следующая запись
блока, обладающая ключом 40, смещена "вверх" с целью укрупнения
свободной области внутри блока. Поскольку запись с ключом 40 теперь занимает
первую позицию во втором блоке данных, необходимо обновить содержимое элемента
ключа, ссылающегося на этот блок. На рис.14 показано, что значение ключа,
которому отвечает указатель, адресующий второй блок данных, изменено с 30 на
40. [6]
Методы
доступа к файлам
Организация файла - физическое
распределение данных файла по записям и страницам на вторичном устройстве
хранения.
Существуют следующие основные типы
организации файлов.
§ Неупорядоченная
организация файла предусматривает произвольное неупорядоченное размещение
записей на диске.
§ Упорядоченная
(последовательная) организация предполагает размещение записей в соответствии
со значением указанного поля.
§ В хешированием файле
записи хранятся в соответствии со значением некоторой хеш-функции.
Для каждого типа организации файлов
используется соответствующий набор методов доступа.
Метод доступа - действия, выполняемые
при сохранении или извлечении записей из файла.
Поскольку некоторые методы доступа могут
применяться только к файлам с определенным типом организации (например, нельзя
применять индексный метод доступа к файлу, не имеющему индекса), термины
Организация файла и метод доступа часто рассматриваются как эквивалентные.
Дальше в этом приложении описаны основные типы структуры файлов и
соответствующие им методы доступа. В главе 16 представлена методология
физического проектирования базы данных для реляционных систем вместе с
рекомендациями по выбору наиболее подходящей структуры файлов и индексов.
Неупорядоченные
файлы
Неупорядоченный файл (который иногда
называют кучей) имеет простейшую структуру. Записи размещаются в файле в том
порядке, в котором они в него вставляются. Каждая новая запись помещается на
последнюю страницу файла, а если на последней странице для нее не хватает
места, то в файл добавляется новая страница. Это позволяет очень эффективно
выполнять операции вставки. Но поскольку файл подобного типа не обладает
никаким упорядочением по отношению к значениям полей, для доступа к его записям
требуется выполнять линейный поиск. При линейном поиске все страницы файла
последовательно считываются до тех пор, пока не будет найдена нужная запись.
Поэтому операции извлечения данных из неупорядоченных файлов, имеющих несколько
страниц, выполняются относительно медленно, за исключением тех случаев, когда
извлекаемые записи составляют значительную часть всех записей файла.
Для удаления записи сначала требуется
извлечь нужную страницу, потом удалить нужную запись, а после этого снова
сохранить страницу на диске. Поскольку пространство удаленных записей повторно
не используется, производительность работы по мере удаления записей
уменьшается. Это означает, что неупорядоченные файлы требуют периодической
реорганизации, которая должна выполняться администратором базы данных (АБД) с
целью освобождения неиспользуемого пространства, образовавшегося на месте
удаленных записей.
Неупорядоченные файлы лучше всех остальных
типов файлов подходят для выполнения массовой загрузки данных в таблицы,
поскольку записи всегда вставляются в конец файла, что исключает какие-либо
дополнительные действия по вычислению адреса страницы, в которую следует
поместить ту или иную запись.
Упорядоченные
файлы
Записи в файле можно отсортировать по
значениям одного или нескольких полей и таким образом образовать набор данных,
упорядоченный по некоторому ключу. Поле (или набор полей), по которому
сортируется файл, называется полем упорядочения. Если поле упорядочения
является также ключом доступа к файлу и поэтому гарантируется наличие в каждой
записи уникального значения этого поля, оно называется ключом упорядочения для
данного файла.
В общем случае бинарный поиск эффективнее
линейного, однако этот метод чаще применяется для поиска данных в первичной
(оперативной), а не во вторичной памяти (внешней).
Операции вставки и удаления записей в
отсортированном файле усложняются в связи с необходимостью поддерживать
установленный порядок записей. Для вставки новой записи нужно определить ее
расположение в указанном порядке, а затем найти свободное место для вставки.
Если на нужной странице достаточно места для размещения новой записи, то
потребуется переупорядочить записи только на этой странице, после чего вывести
ее на диск. Если же свободного места недостаточно, то потребуется переместить
одну или несколько записей на следующую страницу. На следующей странице также
может не оказаться достаточно свободного места, и из нее потребуется
переместить некоторые записи на следующую страницу и т.д.
Таким образом, вставка записи в начало
большого файла может оказаться очень длительной процедурой. Для решения этой
проблемы часто используется временный неотсортированный файл, который
называется файлом переполнения (overflow file) или файлом транзакции
(transaction file). При этом все операции вставки выполняются в файле
переполнения, содержимое которого периодически объединяется с основным
отсортированным файлом. Следовательно, операции вставки выполняются более
эффективно, но выполнение операций извлечения данных немного замедляется. Если
запись не найдена во время бинарного поиска в отсортированном файле, то
приходится выполнять линейный поиск в файле переполнения. И наоборот, при
удалении записи необходимо реорганизовать файл, чтобы удалить пустующие места.
Упорядоченные файлы редко используются для
хранения информации баз данных, за исключением тех случаев, когда для файла
организуется первичный индекс. [10]
Хеширование.
Типы хеширования
В хешированном файле записи необязательно должны записываться
в файл последовательно.
Вместо этого для вычисления адреса страницы, в которой должна
находиться та или иная запись, используется хеш-функция (hash function),
аргументами которой являются значения одного или нескольких полей этой записи.
Подобное поле называется полем перемешивания (hash field), а если поле
также является ключевым полем файла, то оно называется хеш-ключом (hash
key). Записи в хешированном файле произвольным образом распределены по всему
доступному для файла пространству. По этой причине хешированные файлы иногда
называют файлами с произвольной структурой (random file) или файлами
прямого доступа (direct file).
Хеш-функция выбирается таким образом, чтобы записи внутри
файла были распределены максимально равномерно. Один из методов построения
хеш-функции носит название свертка (folding) и основан на выполнении
некоторых арифметических действий над различными частями поля перемешивания.
При этом символьные строки преобразуются в целые числа с использованием
некоторой кодировки - на основе расположения букв в алфавите или ASCIl-кодов
символов. Например, можно преобразовать в целое число первых два символа поля
номера сотрудника (атрибут Sno), а затем сложить полученное значение с
остальной частью номера сотрудника. Вычисленная сумма используется в качестве
адреса дисковой страницы, на которой будет храниться данная запись. Более
популярный альтернативный метод основан на перемешивании на основе остатка
от деления (division-remainder). В этом методе используется функция МОО, на
вход которой передается значение поля. Функция делит полученное значение на
некоторое предопределенное целое число, после чего остаток от деления
использует в качестве адреса.
Проблема, связанная с использованием большинства хеш-функций,
заключается в том, что они не могут гарантировать уникальность вычисляемого
адреса, поскольку количество возможных значений поля перемешивания может быть
гораздо больше количества доступных для записей адресов. Каждый вычисленный
хеш-функцией адрес соответствует некоторой странице, или сегменту
(bucket), с несколькими ячейками - слотами, - предназначенными для
отдельных записей. В пределах одного сегмента записи размещаются в слотах в
порядке поступления. Тот случай, когда один и тот же адрес генерируется для
двух или более записей, называется конфликтом (collision), а подобные
записи - синонимами. В этой ситуации новую запись необходимо вставить в
другую позицию, поскольку место с вычисленным для нее хеш-адресом, уже занято.
Разрешение конфликтов усложняет сопровождение хешированных файлов и снижает
общую производительность их работы.
Для разрешения конфликтов можно использовать следующие
методы:
открытую адресацию;
несвязанную область переполнения;
связанную область переполнения;
многократное хеширование.
Открытая адресация
При возникновении конфликта система выполняет линейный поиск
первого доступного слота для вставки в него новой записи. После неудачного
поиска пустого слота в последнем сегменте поиск продолжается с первого
сегмента. При выборке записи используется тот же метод, который применялся при
сохранении записи, за исключением того, что запись в данном случае
рассматривается несуществующей, если до обнаружения искомой записи будет
обнаружен пустой слот. Например, рассмотрим тривиальную хеш-функцию на основе
остатка от деления по модулю 3 (МОD 3), как показано на рис.15 [8]. Каждый
сегмент обладает двумя слотами, поэтому записи о сотрудниках 'SG5' и 'SG14'
попадают в сегмент 2. При вставке записи 'SL41' хешфункция генерирует адрес,
соответствующий сегменту 2. Но в сегменте 2 нет свободных слотов, поэтому
следует найти первый свободный слот. Такой слот имеется лишь в сегменте 1,
который и будет найден после продолжения линейного поиска с начала файла и
безуспешного просмотра сегмента О.
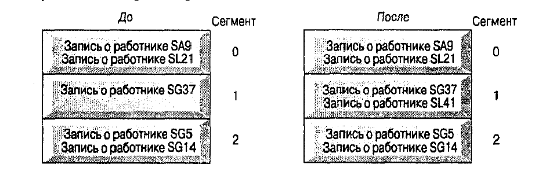
Рис.15. Разрешение конфликта с помощью открытой адресации
Несвязанная область переполнения
Вместо поиска пустого слота для разрешения конфликтов можно
использовать область переполнения, предназначенную для размещения записей,
которые не могут быть вставлены по вычисленному для них адресу перемешивания.
На рис.16 [8] показано, как в этом случае разрешается конфликтная ситуация,
представленная на рис.15. В данном случае вместо поиска свободного слота для
записи 'SL41' она сразу же помещается в область переполнения. На первый взгляд
может показаться, что этот подход не дает большого выигрыша в
производительности. Однако при более внимательном анализе обнаруживается. что
при использовании открытой адресации конфликты, устраненные с помощью первого
свободного слота, потенциально вызывают дополнительные конфликты с записями,
которые будут иметь хеш-значение, равное адресу этого раньше свободного слота.
Таким образом, количество конфликтов будет возрастать, а производительность -
падать. С другой стороны, если количество конфликтов можно свести к минимуму,
то линейный поиск в малой области переполнения будет выполняться достаточно
быстро.
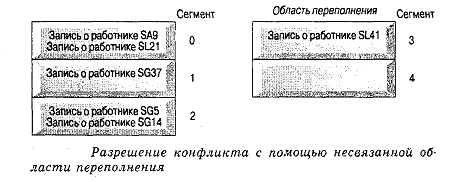
Рис. 16. Разрешение конфликта с помощью несвязанной области
переполнения
Связанная
область переполнения
Как и в предыдущем методе, в этом методе для разрешения
конфликтов с записями, которые не могут быть размещены в слоте с их адресом
перемешивания, используется область переполнения. Однако в данном методе
каждому сегменту выделяется дополнительное поле, которое иногда называется
указателем синонима. Оно определяет наличие конфликта и указывает страницу в
области переполнения, использованную для его разрешения.
Если указатель равен нулю, то никаких конфликтов нет. На
рис.17 сегмент 2 указывает на сегмент переполнения 3, а указатели синонима
сегментов 0 и 1 равны нулю, что означает, что в этих сегментах конфликтов нет.
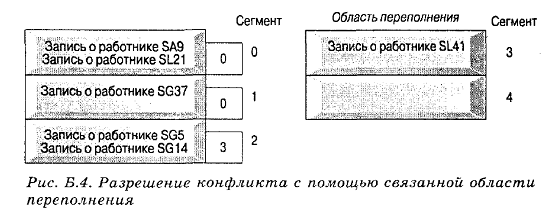
Рис.17. Разрешение конфликта с помощью связанной области
переполнения
Для более быстрого доступа к записи переполнения можно
использовать указатель синонима, который указывает на адрес слота внутри
области переполнения, а не на адрес сегмента. Записи внутри области
переполнения также имеют указатели синонима, которые содержат в области
переполнения адрес следующего синонима для такого же адреса, поэтому все
синонимы одного адреса могут быть извлечены с помощью цепочки указателей.
Многократное
хеширование
Альтернативный подход для разрешения конфликтов заключается в
применении второй функции хеширования, если первая функция приводит к
возникновению конфликта. Цель второй хеш-функции заключается в создании нового
адреса перемешивания, который позволил бы избежать конфликта. Вторая хеш-функция
обычно используется для размещения записей в области переполнения.
При работе с хешированными файлами запись может быть
достаточно эффективно найдена с помощью первой хеш-функции, а в случае
возникновения конфликта для определения ее адреса следует применить один из
перечисленных выше способов. Прежде чем обновить хешированную запись, ее
следует найти. Если обновляется значение поля, которое не является хеш-ключом,
то такое обновление может быть выполнено достаточно просто, причем обновленная
запись сохраняется в том же слоте. Но если обновляется значение хеш-ключа, то в
этом случае до размещения обновленной записи потребуется вычислить хеш-функцию.
Если при этом будет получено новое хеш-значение, то исходная запись должна быть
удалена из текущего слота и сохранена по вновь вычисленному адресу. [8]
Хеширование (hashing - перемешивание) - это технология
быстрого прямого доступа к физической записи на основе заданного значения поля
перемешивания (хеш-ключ).
Различают статическое и динамическое хеширование.
Для статического хеширования, размер хеш-файла задается один
раз при его создании и больше не изменяется (фиксируется пространство
хеш-адресов).
Для вычисления адреса страницы, на которой должна храниться
запись, используется хеш-функция, аргументами которой являются значения одного
или нескольких полей записи (хеш-ключ). Хеш-функция выбирается таким образом,
чтобы записи внутри файла были размещены максимально равномерно, но в
статических хеш-файлах все равно остается чистое место (чистые страницы, разбросанные
по всему файлу) под неиспользованные значения хеш-ключа.
Преимущество хеш-файлов - быстрый доступ к записям по
известному значению хеш-ключа, который осуществляется в два этапа:
вычисление адреса страницы с помощью хеш-функции и известного
хеш-ключа;
извлечение данной страницы и последовательный поиск в ней
заданной записи.
К недостаткам статических хеш-файлов относят следующие:
• физическая последовательность записей в файле почти
всегда отличается от логической последовательности, последовательный перебор
записей фактически не имеет смысла;
• между записями в файле могут быть чистые промежутки
- зависит от выбора хеш-функции;
• возникновение коллизий - ситуаций, когда записи
имеют одинаковые хеш-адреса и не вмешаются на адресуемую страницу.
Динамическое хеширование позволяет динамическое изменение
размера хеш-файла при добавлении в него записей. Кроме того, динамическое
хеширование исключает коллизии. Основной принцип динамического хеширования
заключается в рассмотрении хеш-адреса, как битовой последовательности и
распределение записей на страницах на основе прогрессивной оцифровки этой
последовательности.
Один из типов динамического хеширования называется
расширяемое хеширование (см. рис.18). Основные принципы расширяемого
хеширования:
) В результате вычисления хеш-функции h для поля k записи r
будет получен псевдоключ s. Псевдоключ используется не как адрес, а как
косвенный указатель на место хранения записей.
) Хеш-файл имеет каталог, имеющий глубину каталога d и
содержащий 2d указателей на страницы данных.
) Если старшие d бит псевдоключа рассматривать как двоичное
число b, то i-ый указатель в каталоге (1≤ i ≤2d) будет
относиться к странице, на которой хранятся записи b=i-1
) Каждая страница данных имеет заголовок с указанием
локальной глубины (p < d) этой страницы (локальная глубина показывает,
сколько указателей каталога могут на нее ссылаться - 2d-p
указателей). [3]
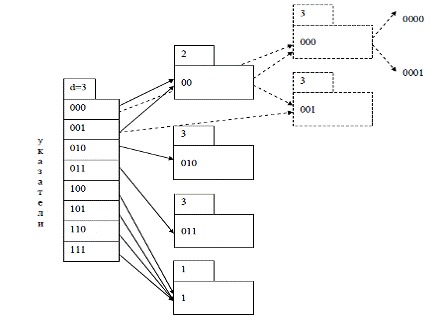
Рис. 18. Расширяемое хеширование
Следует отметить, однако, что хорошей хеш-функцией является
такая функция, которая минимизирует коллизии и распределяет записи равномерно
по всей таблице. Поэтому и желательно иметь массив с размером больше, чем число
реальных записей. Чем больше диапазон хеш-функции, тем менее вероятно, что два
ключа дадут одинаковое значение хеш-функции. Конечно, при этом возникает
компромисс между временем и пространством. Наличие пустых мест в массиве
неэффективно с точки зрения использования пространства, но при этом уменьшается
необходимость разрешения коллизий при хешировании, что, следовательно, является
более эффективным в смысле временных затрат.
Алгоритм, который позволяет распределять в таблице записи,
конкурирующие с другими записями в одну ячейку хеш-таблицы, называется методом разрешения
коллизий (collision resolution).
Древовидные
структуры
Основной структурой, поддерживающей иерархическое
представление информации, является дерево. Для моделирования информации с
помощью древовидной структуры зачастую используется обобщенное дерево (general.
tree), которое схематично изображено на рис. 19 [8]. На этом рисунке Показано
абстрактное представление данной структуры, состоящей из узлов (nodes),
соединенных связями, которые называются дугами (arcs) или ребрами (edge). Самый
верхний узел называется корневым узлом (root node). Он может иметь нуль или
несколько дочерних узлов (child nodes), которые, в свою очередь, также могут
иметь нуль или несколько дочерних узлов. В результате подобная структура может
быть определена рекурсивно. Все узлы дерева, за исключением корня, должны иметь
родительский узел. Любая часть дерева, исходящая из одного узла (помимо корня
дерева), называется поддеревом (subtree). С практической точки зрения, каждый
узел может быть представлен либо в виде некоторого типа записи, где каждая
связь является встроенным указателем (или адресом), либо с помощью некоторого
физического упорядочения записей.
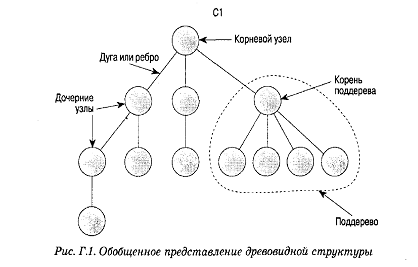
Рис. 19. Обобщенное представление древовидной структуры
Узлы представляют интересующие нас объекты, а связи между
ними определяются самим расположением узлов и ребер, которые, соединяя узлы,
образуют эту древовидную структуру. Объекты могут иметь одинаковый тип. [8]
В-деревья
Хотя многоуровневые индексы считаются неплохим инструментом
ускорения процессов обработки запросов, существует более общая, гибкая и
эффективная разновидность структур, находящих самое широкое применение в
коммерческих СУБД. Речь идет о семействе структур, называемых В-деревьями
(B-tree); наиболее распространенный вариант В-дерева известен как В+-дерево
(B+-tree). Основные особенности В-деревьев таковы:
·
автоматическая
поддержка необходимого количества уровней индексации, отвечающего размеру
индексируемого файла данных;
·
эффективное
управление размером свободных областей внутри блоков (уровень заполнения блоков
колеблется от 50% до 100%) и исключение потребности в использовании блоков
переполнения.
Ниже мы будем обсуждать такие характеристики В-деревьев,
которые полностью справедливы для В+ - деревьев. Сведения о
В-деревьях иных типов вынесены в упражнения.
Структура
В-дерева
Как следует из названия структуры В-дерева, ее блоки
организованы в виде древовидного графа (tree-like graph). В-дерево является
сбалансированным (balanced) - в том смысле, что длины всех путей от корневой
(root) вершины до любой из вершин-листьев (leaves) равны. Типичное
В-дерево содержит три уровня: корневую вершину, промежуточные вершины и листья,
- хотя способно включать и произвольное количество уровней. Чтобы получить
начальное представление о В-деревьях, взгляните на рис.20 и 21 [6], описывающие
отдельные вершины, и на рис.22 [6], изображающий небольшое полное В-дерево.
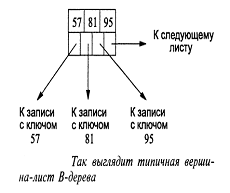
Рис. 20. Вершина-лист В-дерева
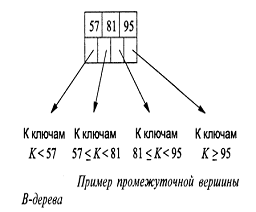
Рис. 21. Пример промежуточной вершины В-дерева
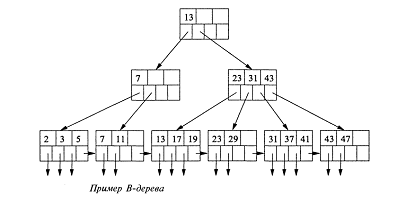
Рис.22. Пример В-дерева
Каждому В-древовидному индексу поставлен в соответствие
параметр п, определяющий свойства компоновки блоков В-дерева. Каждый блок
обладает пространством, достаточным для размещения п значений ключа поиска и п
+ 1 указателей. Блок В-дерева по существу схож с индексными блоками, за
исключением того, что наряду с п парами вида "ключ-указатель" он
содержит дополнительный, п + 1-й, указатель. Величина п выбирается таким
образом, чтобы обеспечить возможность хранения в блоке п + 1 указателей и n
ключевых значений. [6]
Бинарное
дерево
Специальным приложением концепции индексов, или
инвертированных списков, являются бинарные деревья - многоуровневые индексы,
предоставляющие возможность как последовательной, так и прямой обработки
записей. Благодаря особенностям своей структуры они также обеспечивают
определенное повышение эффективности обработки.
Бинарное дерево - это индекс, состоящий из двух частей:
последовательного набора (sequence set) и индексного набора (index set). (Эти
термины используются в документации компании IBM, описывающей структуру
VSAM-файла. Вам могут встретиться другие, синонимичные термины.) Последовательный
набор представляет собой индекс, содержащий указатели на все записи в файле.
Этот индекс физически упорядочен, обычно по значению первичного ключа. Такая
структура позволяет обращаться к записям последовательно, считывая один за
другим адреса записей из последовательного набора н по ним считывая сами
записи.
Индексный набор - это индекс, указывающий на группу записей в
последовательном наборе. Эта структура обеспечивает быстрый доступ к записям о
файле, и именно в индексном наборе и заключается уникальность бинарных
деревьев.
Пример бинарного дерева изображен на рис.23 [9], а конкретный
экземпляр этой структуры показан на рис.24 [9]. Обратите внимание, что нижняя
строчка на рис.23 - последовательный набор - представляет собой обычный индекс.
Он содержит указатель на каждую запись в файле (хотя для краткости данные и
адреса записей были опущены). Также заметьте, что элементы последовательного
набора сгруппированы по три. Записи в каждой группе физически упорядочены, и
каждая группа связана со следующей посредством связного списка, как можно
видеть на рис.24.
Взгляните на индексный набор на рис.23. Верхняя запись
содержит дна значения.45 и 77. Следуя левой линии связи (к записи с
относительным номером 2), мы можем обратиться к записям, значения ключей которых
меньше или равны 45; следуя средней линии связи, мы можем обратиться к записям,
значения ключей которых больше 45 и меньше или равны 77; наконец, следуя правой
линии связи (к записи с относительным номером 4), мы можем обратиться к
записям, значения ключей которых больше 77.
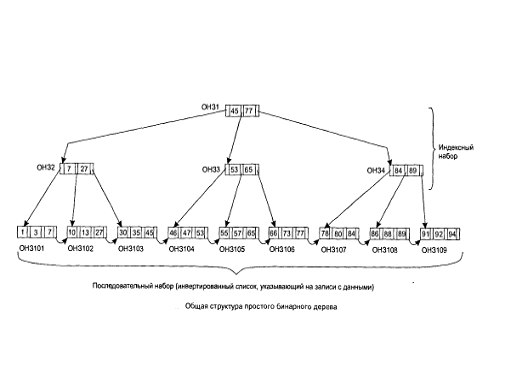
Рис.23. Общая структура простого бинарного дерева
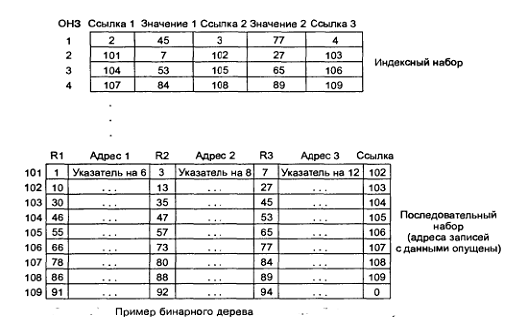
Рис. 24. Пример бинарного дерева, со структурой,
соответствующей рисунку 23
Аналогичным образом, на следующем уровне имеется три значения
и три указателя на каждый элемент индекса. Всякий раз, когда мы спускаемся на
уровень ниже, мы сужаем область своего поиска. Например, если от верхней записи
мы проследуем по левой линии связи, а от следующего уровня - по правой линии,
мы сможем обратиться ко всем записям, значения ключей которых больше 27, но
меньше или равны 45. На первом уровне мы исключили все записи, значения ключей
которых больше 45.
Бинарные деревья по определению являются сбалансированными.
Это значит, что все записи находятся на одинаковом расстоянии от верхней записи
индексного набора. Это свойство бинарных деревьев обусловливает их
эффективность, хотя алгоритмы вставки и удаления записей оказываются сложнее,
чем для обычных деревьев (которые могут быть несбалансированными), поскольку
для того, чтобы при этих операциях сохранить все записи на одинаковом
расстоянии, может потребоваться модификация нескольких записей. [9]
Древовидные
структуры для многомерных данных
Теперь рассмотрим ряд индексных структур,
особенно полезных при обработке запросов в диапазонах значении и поиске
объектов, ближайших по отношению к заданному:
1)
индексы
с несколькими ключами (multiple-key indexes);
2)
kd-деревья
(kd-trees);
3)
деревья
квадрантов (quad trees);
4)
R-деревья
(R-trееs).
Три первые структуры предназначены для представления множеств
точек. R-дерсвья обычно используются с целью описания множеств областей
пространства, хотя находят применение и для отображения множеств точек.
Индексы с несколькими ключами
Предположим, что схема отношения содержит атрибуты,
представляющие значения координат элементов данных многомерного пространства, и
необходимо обеспечить эффективную поддержку запросов в диапазонах значений
(range queries) координат либо процедур поиска объектов, наиболее близких к
заданному (nearesl-neighbor search). Одно из простых решений связано с
использованием индекса индексов или, говоря в более общем смысле, древовидной
схемы, в которой вершины каждого уровня являются индексами для определенного
атрибута.
Основная идея проиллюстрирована на рис. 25 [6] на примере
двух атрибутов. "Корнем дерева" служит индекс для первого атрибута. В
подобной роли может выступать индекс любого из традиционных типов, таких как
В-дерево или хеш-таблица-Индекс связывает значение ключа поиска (содержимое
компонента первого атрибута) с указателем на некоторый индекс для другого
атрибута. Если V - содержимое компонента первого атрибута, отыскав элемент со
значением V ключа поиска в первом индексе и проследовав в "направлении"
указателя, связанного с этим элементом, мы "придем" к индексу,
представляющему подмножество точек, первые координаты которых равны V, а вторые
содержат произвольные значения.
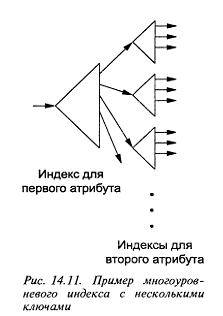
Рис. 25. Пример многоуровнего индекса с несколькими ключами
kd-деревья
kd-дерево (kd-tree или k-dimensional search Iree) -
это структура, служащая для представления информации в оперативной памяти и
обобщающая модель бинарных деревьев поиска на случаи многомерных данных.
Вначале мы обсудим основные характеристики схемы kd-дсрева, а затем расскажем
об особенностях ее реализации в контексте модели блоковых вторичных хранилищ
данных, kd-дерево представляет собой бинарное дерево, с корневой и
промежуточными вершинами которого ассоциированы атрибут а, представляющий
некоторую размерность данных, и определенное значение V этого атрибута,
расщепляющее множество точек данных на два подмножества: точкам одного
подмножества отвечают значения атрибута я, меньшие V, a точкам другого -
значения а, равные или большие V. Атрибуты в пределах одного уровня
дерева одинаковы, а в соседних уровнях - различны: при движении от корневой
вершины дерева "вниз" по уровням промежуточных вершин все
атрибуты-размерности циклически замешают друг друга.
В классическом kd-дереве, как и в дереве бинарного поиска, с
вершинами связаны точки данных. Мы, однако, незначительно изменим схему таким
образом, чтобы адаптировать ее к особенностям модели блокового хранилища
данных:
1) каждой промежуточной
вершине поставлены в соответствие некоторый атрибут, конкретное
"разделяющее" значение этого атрибута и указатели-дуги, адресующие
левую и правую дочерние вершины;
2) листья дерева
представляют блоки, способные содержать такое количество записей, какое
обусловлено физическим объемом блока.
Деревья квадрантов
В дереве квадрантов (quad tree) каждая промежуточная вершина
соответствует определенному квадранту пространства данных - прямоугольной
двумерной области либо k-мерному параллелепипеду, если количество измерений
равно k. Как и при рассмотрении всех остальных структур данных, описываемых в
этой главе, мы сосредоточим внимание на случае двух измерений. Если количество
точек, принадлежащих квадранту, ниже допустимого максимума, квадрант следует
воспринимать как вершину-лист дерева, представляемую соответствующим блоком.
Если же, напротив, количество точек слишком велико, квадрант интерпретируется
как промежуточная (вначале - корневая) вершина с четырьмя дочерними вершинами,
отвечающими частным квадрантам.
R-деревья
дерево (R-lree, или region tree - дерево областей) - это
структура данных, наследующая многие свойства модели В-дерева в применении к
многомерной информации. Напомним, что вершина В-дерева содержит подмножество
значений ключа, делящих числовую ось на сегменты. Каждая точка оси может принадлежать
только одному сегменту. Отыскание заданной точки в В-дереве труда не
составляет: так как точка расположена на оси, представляемой вершиной В-дерева,
мы можем определить единственный сегмент (дочернюю вершину), которые позволят
сузить область поиска и в конце концов либо найти точку, либо убедиться, что ее
не существует.дерево, с другой стороны, представляет информацию в виде 2 - или
А-мсрных областей данных (data regions). Корневая (или промежуточная) вершина
R-дерева соответствует некоторой внутренней области (interior region), или
просто "области", которая обычно не является областью данных. Вообще
говоря, область может иметь любую форму, хотя на практике, как правило,
используются области прямоугольных или иных простых форм. Вершина R-дерева
вместо ключевых значений содержит подобласти (subregions), описывающие
содержимое дочерних вершин. [6]
индекс база хеширование файл
Заключение
Само по себе, построение таблиц и обращение к их содержимому
- настолько простая и понятная вещь, что многие, освоив основные приемы,
попросту перестают изучать синтаксис построения и оптимизации таблиц более
глубоко.
А между тем, одна только индексация таблиц порой поднимает
производительность в несколько раз.
В данном реферате рассмотрены все типы и виды индексов, а так
же приведены примеры и способы создания индексов в SQL и определение индексации
было изложено, но постараюсь ещё раз на простом примере объяснить, что такое
индексация и для чего она нужна.
Вспомните любую публичную библиотеку. Пусть детскую или даже
школьную. Помните зал со стеллажами книг? И даже если вы были очень давно в
библиотеке, вы прекрасно знаете, что все книги в этом уважаемом заведении
расставлены не просто так, не в порядке их поступления в библиотеку (как
поступают данные в базу), а по каким-то правилам. Обычно, книги разносят по
темам, авторам и по алфавиту.
Я думаю, излишне объяснять, зачем все это делается, и почему
библиотекари так ревностно следят за порядком размещения книг на стеллажах. Но
обратите ваше внимание на сравнительную эффективность поиска в такой
структурированной системе, которой, кстати, обычно пренебрегают при построении
и использовании компьютерных баз данных.
Предположим, вы в библиотеке ищите книгу "Как выращивать
цветы в сухой местности". Если вы начнете просто перебирать все книги в
библиотеке, то у вас на это уйдет не один день или даже не один месяц, если это
крупная библиотека.
Но если вы знаете автора или год или тему книги, то, подойдя
к соответствующим стеллажам, вы найдете издание за несколько минут, а то и секунд.
Как, собственно, это и бывает в библиотеке.
То же самое происходит и с нашей базой данных, когда мы её
индексируем. С помощью индексов мы ускоряем работу нашего компьютера, не
заставляя его перебирать все данные в нашей базе, а всего-навсего обращаться к
нужным данным. Полагаю, что польза индексации очевидна.
Список
используемой литературы
1. Малыхина
М.П. Базы
данных: основы, проектирование, использование. - Спб.: БХВ - Петербург, 2004. -
528с.: ил.
2. Иштерякова,
Т.И. Базы
данных: Курс лекций/ Т.И. Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009. - 133с.:
ил.
3. Калабухов
Е.В. Базы
данных, знаний, и экспертные системы: Курс лекций - Минск: БГУИР, 2007. -
290с.: ил.
4. Хомоненко
А.Д. Базы
данных. Учебник для высших учебных заведений, под редакцией проф. Санкт
Петербург, Корона, 2004г. - 726с.: ил.
5. Саймон
А.Р. Стратегические
технологии баз данных: менеджмент на 2000 год: Пер. с англ. / Под ред. И с
предисл. М.Р. Когаловского. - М.: Финансы и статистика, 1999.
6. Гарсиа-Молина
Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс - М.: Вильямс, 2003. - 1088
с.: ил. - Парал. тит. англ.
7. Dmitry. Burmistrov
<http://wiki.auditory.ru/%D0%A3%D1%87%D0%B0%D1%81%D1%82%D0%BD%D0%B8%D0%BA:Dmitry.Burmistrov>,
Иван Игнатьев <http://wiki.auditory.ru/%D0%A3%D1%87%D0%B0%D1%81%D1%82%D0%BD%D0%B8%D0%BA:Ivan.Ignatyev>.
Индексирование в базах данных [Электронный ресурс] // База знаний кафедры ИКТ
<http://wiki.auditory.ru/%D0%94%D0%BE%D0%B1%D1%80%D0%BE_%D0%BF%D0%BE%D0%B6%D0%B0%D0%BB%D0%BE%D0%B2%D0%B0%D1%82%D1%8C_%D0%B2_%D0%B1%D0%B0%D0%B7%D1%83_%D0%B7%D0%BD%D0%B0%D0%BD%D0%B8%D0%B9_%D0%BA%D0%B0%D1%84%D0%B5%D0%B4%D1%80%D1%8B_%D0%98%D0%9A%D0%A2%21>:
[сайт]. [2009]. URL: http://wiki. auditory.ru/%D0%91%D0%94:
%D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,09 <http://wiki.auditory.ru/%D0%91%D0%94:%D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,09>
(дата обращения 29.03.2012).
8. Коннолли,
Томас, Бегг, Каролин. Базы
данных. Проектирование, реализация, сопровождение. Теория и практика.3-е изд.:
Пер. с англ. - М.: "Вильямс", 2003. - 1440с.: ил. - Парал. тит. англ.
9. Кренке Д. Теория построения баз данных.8-е изд., Спб.: Питер,
2003. - 800с.: ил.
10. Диго С.М., Базы данных: проектирование и использование: Учебник.
- М.: Финансы и статистика, 2005. - 592с.: ил.
Приложения
Приложение 1
Таблица понятий
|
№
|
Понятие (термин)
|
Определение
|
Источник
|
|
1
|
База данных
|
это именованная совокупность данных, отражающая
состояние объектов и их отношений в рассматриваемой предметной области, или
иначе БД - это совокупность взаимосвязанных данных при такой минимальной
избыточности, которая допускает их использование оптимальным образом для
одного или нескольких приложений в определенной предметной области. БД
состоит из множества связанных файлов.
|
Малыхина М.П. Базы данных: основы,
проектирование, использование. - Спб.: БХВ - Петербург, 2004.
|
|
2
|
Индексированный файл
|
это основной файл, содержащий данные отношения,
для которого создан индексный файл
|
Малыхина М.П. Базы данных: основы,
проектирование, использование. - Спб.: БХВ - Петербург, 2004.
|
|
3
|
Индексный файл
|
это файл особого типа, в котором каждая запись
состоит из двух значений: данных и указателя
|
Малыхина М.П. Базы данных: основы,
проектирование, использование. - Спб.: БХВ - Петербург, 2004.
|
|
4
|
Индекс [index]
|
это структура данных, отображающая значения
поискового ключа в адреса объектов поиска; это специальные структуры данных,
создаваемые для повышения производительности базы данных
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
Крёнке Д. Теория и практика построения баз данных.9-е изд. - Спб.: Питер,
2005.
|
|
5
|
Вторичный индекс [secondary index]
|
это индекс по вторичному ключу; это индекс,
построенный не по первичному ключу, позволяет ускорить операции выборки для
запросов, выполняющих фильтрацию не по полям первичного ключа
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
Калабухов Е.В. Базы данных, знаний, и экспертные системы: Курс лекций -
Минск: БГУИР, 2007.
|
|
6
|
Главный индекс [master index]
|
это индекс высшего уровня в иерархии индексной
организации данных
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
|
|
7
|
В-дерево
|
это дерево, которое содержит три уровня:
корневую вершину, промежуточные вершины и листья, хотя способно включать в
себя и произвольное количество уровней
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
8
|
Бинарное дерево
|
это индекс, состоящий из двух частей:
последовательного набора (sequence set) и индексного набора (index set)
|
Крёнке Д. Теория и практика построения баз
данных.9-е изд. - Спб.: Питер, 2005.
|
|
9
|
Последовательный набор
|
представляет собой индекс, содержащий указатели
на все записи в файле. Этот индекс физически упорядочен, обычно по назначению
первичного ключа.
|
Крёнке Д. Теория и практика построения баз
данных.9-е изд. - Спб.: Питер, 2005.
|
|
10
|
Индексный набор
|
это иерархический индекс для последовательного
набора
|
Крёнке Д. Теория и практика построения баз
данных.9-е изд. - Спб.: Питер, 2005.
|
|
11
|
Индекс дорожек [traks index]
|
это область индексно-последовательного файла,
представляющая собой низший уровень системы его индексов и содержащая таблицу
адресов дорожек цилиндра и максимальных значений ключей записей, размещенных
на этих дорожках
|
|
12
|
одноуровневый индекс
|
это индекс, который непосредственно ссылается
на данные, а не на другие индексные структуры
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
13
|
Многоуровневый индекс [multilevel index]
|
это структура в виде сбалансированного дерева,
имеющая два уровня иерархии или более. Корень такого дерева - главный индекс
(индекс высшего уровня)
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
|
|
14
|
Первичный индекс [primary index]
|
это ведущий индекс, индекс по первичному ключу;
это поле или группа полей, однозначно определяющих запись, т.е. значения
первичного индекса уникальны
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И. Иштерякова - Оренбург: ГОУ
ВПО ОГУ, 2009.
|
|
15
|
Составной индекс [concatenated]
|
это индекс, аргументом которого является
комбинация значений атрибутов
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
|
|
16
|
Индексация [indexing, subscriping]
|
это метод, обеспечивающий возможность обращения
к элементу массива с помощью указания массива и выражений, определяющих
местоположение этого элемента в массиве
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
|
|
17
|
Индексирование [indexing]
|
1. Использование индексов в базе данных.2.
Процесс описания содержания документов и запросов в терминах информационно-поискового
языка; назначение документу набора ключевых слов, отражающих его смысловое
содержание
|
Марков А.С., Лисовский К.Ю. Базы данных.
Введение в теорию и методологию: Учебник. - М.: Финансы и статистика, 2004.
|
|
18
|
Индексы в виде В-деревьев
|
Представляют собой эффективный доступ для
запросов диапазонов значений, за исключением случаев, когда количество
подходящих строк становится слишком большим.
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
19
|
Индексы в виде битовых отображений
|
Предположим, что в индексированной таблице Т
содержится n строк. Тогда индекс в виде битового отображения для столбца С
таблицы Т будет содержать вектор из n бит для каждого значения в домене
столбца С и установленный бит будет соответствовать строке R, если в её
столбце С будет содержаться соответствующее значение.
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
20
|
Кэш-индексы
|
это индексы, которые эффективны для доступа к
конкретным строкам, а не к диапазонам.
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
21
|
Мультитабличные индексы
|
это индексы, которые позволяют повысить
производительность операции соединения и ускорить проверку ограничений
целостности для нескольких таблиц. По существу элемент мультитабличного индекса
содержит указатели на строки в нескольких таблицах вместо простых указателей
на строки в одной таблице
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
22
|
Булевы индексы (индексы выражений)
|
Булев индекс указывает, для каких строк
определенной таблицы определенное логическое выражение будет истинным
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
23
|
Функциональные индексы
|
функциональные индексы индексируют строки
таблицы не на основе значений в этих строках, а на основе результата
применения к этим значениям некоторой функции
|
К. Дж. Дейт. Введение в системы баз данных = An
Introduction to Data base systems - 7 издание: Пер. С англ. - М: Издательский
дом "Вильямс", 2001
|
|
24
|
Гибридная индексная структура
|
это структура, в которой дерево индекса
разбивается на несколько поддеревьев, а доступ управляется некоторой хеш-функцией
|
Саймон А.Р. Стратегические технологии баз
данных: менеджмент на 2000 год: Пер. с англ. / Под ред. И с предисл. М.Р.
Когаловского. - М.: Финансы и статистика, 1999
|
|
25
|
Простой индекс
|
это индекс, построенный по значениям одного
поля
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
26
|
Сложный индекс
|
это индекс, построенный по значениям двух и
более полей
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
27
|
Candidat
|
это кандидат в первичный ключ или
альтернативный ключ
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
28
|
Unique (уникальный тип индекса)
|
это тип индекса, который допускает
повторяющиеся значения в поле, по которому он построен, но на экран будет
выводиться только одна первая запись из группы записей с одинаковым значением
индексного поля
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
29
|
Regular (регулярный тип индекса)
|
это тип индекса, который не накладывает никаких
ограничений на значения индексного поля и на вывод записей на экран
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
30
|
Primary
|
это один из индексов, удовлетворяющий
требованиям индекса типа Candidat может быть выбран в качестве первичного
ключа
|
Базы данных. Учебник для высших учебных
заведений, под редакцией проф.А.Д. Хомоненко, Санкт Петербург, Корона, 2004г.
|
|
31
|
Одноиндексный файл
|
это индексный файл, который хранит только один
индекс
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
32
|
Мультииндексные файлы
|
это индексные файлы, которые хранят много
индексов
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
33
|
Тег
|
это каждый индекс, который хранится в
мультииндексном файле
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
34
|
Структурный мультииндексный файл
|
это индексный файл, который имеет одинаковое
имя с таблицей, которой он принадлежит
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
35
|
Индексное выражение
|
это имя поля (или полей), по значениям которого
надо построить индекс
|
Иштерякова, Т.И. Базы данных: Курс лекций/ Т.И.
Иштерякова - Оренбург: ГОУ ВПО ОГУ, 2009.
|
|
36
|
Несоставной индекс
|
это индекс, в котором ключ состоит только из
одного поля записи
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
37
|
Плотный индекс
|
это индекс, в котором число индексных записей
равно числу записей данных, одна индексная запись ссылается только на одну
запись данных
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
38
|
Неплотный индекс
|
это индекс, в котором число индексных записей
меньше числа записей данных, индекс указывает либо на первую запись в
определенной группе, либо на страницу с определенной группой записей данных
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
39
|
Индекс кластеризации
|
это индекс, в котром файл данных
последовательно упорядочивается по неключевому полю, и на основе этого
неключевого поля формируется поле индексации, поэтому в файле может быть
несколько записей, соответствующих значению этого поля индексации. Неключевое
поле называется атрибутом кластеризации.
|
Российский новый университет - РосНОУ. Базы
Данных. Индексирование. http://rosnoun. narod.ru/bd/17. htm
|
|
40
|
индексированно - последовательные файлы
|
это отсортированные файлы данных с первичным
индексом
|
Российский новый университет - РосНОУ. Базы
Данных. Индексирование. http://rosnoun. narod.ru/bd/17. htm
|
|
41
|
иерархия узлов
|
это иерархия, в которой каждый узел, за
исключением корня (root), имеет родительский (parent) узел, а также один,
несколько или ни одного дочернего (child) узла
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,09
|
|
42
|
Глубина дерева
|
это максимальное количество уровней между корнем
и листом
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,10
|
|
43
|
Степень (degree) (или порядок (order)) дерева
|
это максимально допустимое количество дочерних
узлов для каждого родительского узла
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,11
|
|
44
|
Структурный индексный файл
|
это индексный файл, который обеспечивает
реализацию всех индексов одной таблицы и имеет имя, совпадающее с именем
самой таблицы, и расширение CDX
|
Базы данных. Учебник для высших учебных
заведений, под редакцией проф.А.Д. Хомоненко, Санкт Петербург, Корона, 2004г.
|
|
45
|
Ключ поиска (search key)
|
1. это поля, на основе значений которых индекс
конструируется; 2. это атрибуты, заданные значения которых используются в
качестве критерия поиска (с применением индекса) определенных групп кортежей
отношений
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
46
|
Плотная индексная структура (dense)
|
это индексная структура, где каждой записи
файла данных отвечает определенный элемент файла индекса
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
47
|
Разреженная индексная структура (sparse)
|
это структура, в которой файл индекса содержит
указатели только на некоторые записи файла данных
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
48
|
Последовательный файл
|
это файл, отсортированный по значениям
атрибутов индекса
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
49
|
Разреженные индексы (sparse index)
|
это индексы, которые хранят по одному ключевому
элементу для каждого блока файла данных
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
50
|
Хеш-таблицы (hash tables)
|
это первичные индексы, в которых ключ поиска
определяет сегмент (bucket), которому принадлежит определенная запись
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
51
|
Хеш-функция (hash function)
|
это функция, принимающая в качестве параметра
значение ключа поиска (в данном случае уместно называть его хеш-ключом) и
вычисляющая число в интервале от 0 до В-1, где В-количество сегментов
(buckets)
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
52
|
Обращенный (inverted) индекс
|
это индекс, который сочетает в себе все индексы
и используется совместно с промежуточным уровнем групп - сегментов указателей
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
53
|
Сбалансированное (balancer) В-дерево
|
это В-дерево, в котором длины всех путей от
корневой (root) вершины до любой из вершин-листьев (leaves) равны
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
54
|
Хеширование (hashing - перемешивание)
|
это технология быстрого прямого доступа к
физической записи на основе заданного значения поля перемешивания (хеш-ключ)
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
55
|
Статическое хеширование
|
это размер хеш-файла задается один раз при его
создании и больше не изменяется (фиксируется пространство хеш-адресов)
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
56
|
Динамическое хеширование
|
позволяет динамическое изменение размера
хеш-файла при добавлении в него записей
|
Калабухов Е.В. Базы данных, знаний, и
экспертные системы: Курс лекций - Минск: БГУИР, 2007.
|
|
57
|
Точечный индекс (bitmap index) для некоторого
поля F
|
это коллекция битовых векторов длины n, по
одному на каждое возможное значение поля F
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
58
|
Cеточные файлы (grid files)
|
это многомерная версия хеш-таблиц
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
59
|
Раздельные хеш-функции (partioned hash
functions)
|
это альтернативный способ реализации механизма
хеш-таблиц в применении к многомерным данным
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
60
|
Индексы с несколькими ключами (multiple-key
index)
|
это структуры, в которых индексные значения
одного кдюча связаны со значениями ключа индексов следующего уровня и т.д.
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
61
|
kd-деревья (kd-trees)
|
это обобщение модели В-дерева в приложении к
множествам точек
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
62
|
Деревья квадрантов (quad trees)
|
это деревья, каждая дочерняя вершина которых
представляет один из квадрантов площади, описываемой родительской вершиной
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
63
|
R-деревья (R-trees)
|
это обобщение модели В-дерева для представления
множеств областей пространства
|
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы
баз данных. Полный курс - М.: Вильямс, 2003.
|
|
64
|
Хеш-ключ
|
это поле, являющееся ключевым полем файла
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,09
|
|
65
|
Поле хеширования (hash field)
|
это поле, значения которого являются
параметрами хеш-функции
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,10
|
|
66
|
Метод доступа
|
это действия, выполняемые при сохранении или
извлечении записей из файла
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,11
|
|
67
|
Организация файла
|
это физическое распределение данных файла по
записям и страницам на вторичном устройстве хранения
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,12
|
|
68
|
Неупорядоченные файлы
|
это файл, в котором записи размещаются в том
порядке, в котором они в него вставляются
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,13
|
|
69
|
Упорядоченные файлы
|
это файл, записи в котором можно отсортировать
по значениям одного или нескольких полей и таким образом образовать набор
данных, упорядоченный по некоторому ключу
|
База знаний кафедры ИКТ http://wiki.
auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,14
|
|
70
|
Буквенный индекс [alphabetic code, alphabetic
notation]
|
это индекс, использующий отдельные буквы или сочетание
букв алфавита
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
71
|
Цифровой индекс [numerical code, numerical
notation]
|
это индекс, использующий отдельные цифры,
числа, сочетания цифр или их комбинации
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
72
|
Десятичный индекс [decimal code, decimal
classification code]
|
это цифровой индекс, составленный на основе
десятичной системы счисления
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
73
|
Алфавитно-цифровой индекс [alphanumeric code]
|
это смешанный индекс, состоящий из букв и цифр
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
74
|
Смешанный индекс [mixed code, mixed notation]
|
это индекс, состоящий из разнородных знаков,
например, из букв различных алфавитов, букв и цифр и т.п.
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
75
|
Интервальный индекс [interval index]
|
это индекс, значения которого определяются
некоторой областью, например, диапазоном от 3 до 12
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
76
|
Гипериндекс [hyperindex]
|
это высший уровень индекса индексной
организации баз данных, принятый в некоторых СУБД (наряду с главным и
нормальным индексами)
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
77
|
Нормальный индекс [normal index]
|
это подмножество ключей базы данных,
соответствующих конкретному значению поля, объявленного дескриптором
(признаком поиска). Используется в четырехуровневой системе индексов СУБД,
например, - ADABAS
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
78
|
Вспомогательный (дополнительный) индекс
[additional index, auxiliary code, auxiliary classification number]
|
это индекс, являющийся дополнением к главному
(основному) и отражающий дополнительные признаки индексируемого текста,
документа и т.п. или относящийся к вспомогательной системе классификации
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
79
|
Авторский знак [author mark, author notation,
author number]
|
это индекс, обозначающий автора произведения,
используемый при расстановке и поиске книг в библиотеках
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
80
|
Кеттерский знак [cutter number]
|
это авторский знак, определяемый по
"Авторской таблице" Ч. Кеттера
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
81
|
Расстановочный индекс [location mark, location
number]
|
это индекс, используемый для расстановки и
поиска книг, документов и т.п. в библиотеке или фонде
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
82
|
Каталожный индекс [catalog classification mark,
catalog classification number]
|
это индекс, используемый для расстановки и
поиска карточек в каталоге
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
83
|
Индекс каталога [catalog index]
|
это старший индекс в библиотечной организации
данных
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
84
|
Индекс массива [array index]
|
это индекс, присваиваемый массиву документов
или данных для его идентификации
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
85
|
Индекс файла [index number]
|
это в некоторых операционных системах
(например, UNIX) номер индексного дескриптора файла и др.
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
86
|
Кумулятивная индексация [cumulative indexing]
|
это индексация, предусматривающая присвоение
одному адресу несколько индексов
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
87
|
Однорядная индексация [pure notation system]
|
это индексация, в которой использованы т. н.
"однорядные" знаки: буквы одного алфавита, цифры одной системы
счисления и т.п.
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
88
|
Одноуровневая индексация
|
это индексация с использованием одноуровневых
индексов
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
89
|
Многоуровневая индексация
|
это индексация с использованием многоуровневых
индексов
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
90
|
Смешанная индексация [mixed notation system]
|
это индексация, в которой использованы
различные знаки: буквы, цифры и т.п.
|
ИНДЕКСИРОВАНИЕ И КОДИРОВАНИЕ ДАННЫХ http://www.gpntb.ru/win/book/1/Doc18.html
|
|
91
|
свертка (folding)
|
это один из методов создания хеш-функции,
основан на выполнении некоторых арифметических действий над различными
частями поля хеширования
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,12
|
|
92
|
Хеширование с применением остатка от деления
|
это метод, в котором используется функция MOD,
которой передается значение поля
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,13
|
|
93
|
Расширяемое хеширование
|
Этот метод предусматривает изменение размеров
блоков по мере роста базы данных, но это компенсируется оптимальным
использованием места
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,15
|
|
94
|
Метод цепочек
|
это самый очевидный путь решения проблемы. В
случае, когда элемент таблицы с индексом, который вернула хеш-функция, уже
занят, к нему присоединяется связный список
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,16
|
|
95
|
Открытая адресация
|
это путь решения проблемы, который заключается
в формулировании правила, согласно которому по данному ключу определяется
пробная последовательность, т.е. последовательность позиций таблицы, которые
должны быть просмотрены при вставке или поиске ключа K
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,17
|
|
96
|
Линейная адресация
|
это простейшая схема открытой адресации,
известная как линейная адресация (линейное исследование, linear probing)
использует циклическую последовательность проверок h (K), h (K - 1), …, 0, M
- 1, M - 2, …, h (K) + 1 и описывается следующим алгоритмом. Он выполняет
поиск ключа K в таблице из M элементов. Если таблица не полна, а ключ
отсутствует, он добавляется
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,18
|
|
97
|
Квадратичная и произвольная адресация
|
Вместо постоянного изменения на единицу, как в
случае с линейной адресацией, можно воспользоваться следующей формулой: h = h
+ a2, где a - это номер попытки
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,
19
|
|
98
|
Адресация с двойным хешированием
|
Этот алгоритм выбора цепочки очень похож на
алгоритм для линейной адресации, но он проверяет таблицу несколько иначе, используя
две хеш - функции h1 (K) и h2 (K). Последняя должна порождать значения в
интервале от 1 до M - 1, взаимно простые с М
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,
20
|
|
99
|
Хеширование паролей
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,21
|
|
100
|
Коллизия (collision)
|
это такая ситуация, в которой предположим, что
существуют два различных ключа k1 и k2 (k1 k2) такие, что h (k1) =h (k2).
Когда запись с ключом k1 вводится в таблицу, она вставляется в позицию с
индексом h (k1). Но когда хешируется ключ k2, получаемая позиция является той
же позицией, в которой хранится запись с ключом k1. Ясно, что две записи не
могут занимать одну и ту же позицию.
|
База знаний кафедры ИКТ http://wiki.
Auditory.ru/%D0%91%D0%94: %D0%9B%D0%B5%D0%BA%D1%86%D0%B8%D1%8F_%E2%84%9608,22
|