Искусственные нейронные сети и генетические алгоритмы
Введение
экономический валютный курс
нейронный
С бурным развитием в 60-70х годах XX века вычислительных
информационных систем, ожидалось и скорейшее появление искусственного
интеллекта, способного заменить человека практически во всех сферах жизни. С
учетом того, как быстро ЭВМ могли производить сложные арифметические операции,
многие думали, что машины смогут легко справляться со всеми задачами,
повседневно выполняемыми головным мозгом человека. Но оказалось, что даже самые
простые операции, такие как распознавание и классификация образов, стали для
вычислительных машин непосильной задачей. Стандартные ЭВМ способны выполнять
лишь те команды, которые были в них прописаны разработчиками. Обработка же
информации человеческим мозгом существенно отличается от способа, применяемого
обычными вычислительными устройствами. Мозг можно представить, как очень
сложный, нелинейный компьютер способный параллельно выполнять огромное
количество операций.
Относительно недавно в мире
появились новые нестандартные методы вычислений, отличительной особенностью
которых является их способность менять внутренние параметры для нахождения
лучшего решения. С развитием генетики и накопления знаний о работе головного
мозга, стало возможным применение подходов в вычислениях, аналогичных тем, что
происходят в живой природе. Все эти технологии объединяются в литературе под
общим названием интеллектуальные вычисления (Computational intelligence) [3]. Одним из таких
видов решений задач выступает метод с применением модели с сетью нейронов. Развитие
искусственных нейронных сетей началось с 1943 г., когда Маккаллок и Питтс
предложили модель «порогового логического нейрона». Они показали, что любая
функция вычислимая с помощью классических методов, также может быть вычислена
при помощи нейронной сети [11]. Другим подклассом такого рода вычислений
являются модели генетических алгоритмов, основоположником которых в 1975 году
стал Дж. Холланд, который ввел в рассмотрение понятие репродуктивного плана
[9].
Одним из основных преимуществ
моделей интеллектуальных вычислений служит их способность к адаптации. Это
придает всем этим методам гибкость, так как при изменении условий, такие модели
будут искать новые решения. Традиционные же вычислительные алгоритмы, созданные
под конкретную среду, при изменении внешних условий не будут способны к поиску
других возможных вариантов. В качестве примера традиционных методов вычисления,
можно, например, рассматривать математические формулы. Обычно для описания
некоторого явления применяется конкретная математическая модель. Если условия
внешней среды поменяются, то для описания изменившегося явления, действовавшая
до этого формула, становится не подходящей. Модели же интеллектуальных
вычислений можно рассматривать как систему, постоянно подбирающую новую формулу
для описания внешне наблюдаемого явления.
В этой работе мы применим методы
интеллектуальных вычислений для построения прогноза валютного курса пары евро -
доллар на данных фондовых индексов S&P500 и DAX30. Здесь мы предполагаем, что предыдущая информация фондового
рынка, а также прошлая информация самого валютного курса может содержать в себе
сигналы о будущем изменении котировок валютной пары. Иными словами, мы хотим
найти зависимость валютного курса от динамики фондового рынка для построения
прогноза котировок пары евро - доллар. Эта связь может даже не быть постоянной
во времени. Модели интеллектуальных вычислений как раз могут справляться с
поиском сложных зависимостей в непостоянной среде. Поэтому когда между
переменными существует сложная зависимость, к тому же постоянно меняющаяся во
времени, применение метода интеллектуальных вычислений может быть полезнее
всего.
Предсказание будущей динамики курса
не является достаточно легкой задачей. Если бы участники рынка точно знали, как
будет изменяться соотношение валютной пары в каждый следующий момент времени,
они бы непрерывно могли увеличивать свой доход. Однако нет какого-нибудь
определенного подхода, гарантирующего нам постоянную прибыль.
Сейчас с все большим развитием
операционных мощностей, стало возможным реализация интеллектуальных вычислений.
Актуальность разработки системы прогнозирования валютного курса достаточно
очевидна. Если мы с большой вероятностью будем знать, как изменится курс в
каждый следующий момент времени, мы можем на этом построить прогноз и
обеспечить хорошую прибыль.
Для того чтобы построить
прогнозирующую модель, нам предварительно предстоит решить некоторые задачи.
Сначала мы рассмотрим, какие методы прогнозирования уже использовались на
валютном рынке. Узнаем эффективность их применения. Далее мы обсудим, почему
применение адаптивных алгоритмов наиболее подходят для этих целей.
Первой проблемой, с которой мы
столкнемся, будет выбор данных для прогнозирования. Здесь естественным
ограничением служат наши вычислительные ресурсы. Мы не можем реализовать такую
модель, в которой будут присутствовать всевозможные данные, которые по нашему
предположению могли бы влиять на котировки валютной пары. Существует множество
теорий, описывающих зависимость движения курса от определенных переменных. И на
этом этапе нам предстоит выбрать одну из этих концепций и реализовать ее в
нашей модели.
Второй задачей выступает определение
общей архитектуры искусственной нейронной сети для заданных входных и выходных
параметров. Хоть мы и будем разрабатывать модель с определенными входными
переменными, стоит заметить, что в последующем эту структуру можно будет
использовать и с другими значениями. Вообще, любые нейронные сети являются
универсальными. Одну и ту же архитектуру можно использовать для решения разного
рода задач. Единственное, что будет препятствовать нам в применимости к любым
моделям прогнозирования, это количество применяемых переменных. Так происходит
в силу того, что мы будем применять фиксированную архитектуру сети. Все нейроны
и связи между ними будут строго определены. Изменяться будут лишь синаптические
веса связей. Поэтому на этом этапе мы построим модель искусственных нейронных
сетей с определенной схемой связей нейронов в ней.
Третьей задачей, с которой нам стоит
разобраться, служит подбор весов синаптических связей сети. Для этой цели
обычно в практике искусственных нейронных сетей применяют метод обратного
распространения ошибки (этот метод хорошо описан в [5]). Но нам хотелось бы
получить несколько реализаций различных структур, наилучшим образом выполняющих
задачу прогнозирования курса. Поэтому при подборе весов мы используем еще один
подкласс интеллектуальных вычислений - генетические алгоритмы. Симбиоз
искусственной нейронной сети с генетическими алгоритмами уже был использован в
[1] для проектирования динамического колебательного звена второго порядка. В
этой работе была подтверждена высокая эффективность совместного применения
данных вычислительных подходов. Мы также попытаемся совместно использовать два
этих подхода, чтобы обеспечить высокую прогнозирующую способность модели, а
также для контроля внутренней структуры нейронной сети.
Одним из замечательных свойств
искусственной нейронной сети является то, что мы, не зная точную функциональную
зависимость переменных, можем предсказать их будущую динамику, опираясь на то,
как они изменялись в прошлом. Валютный рынок представляет собой сложную систему
с множеством взаимосвязанных частей. Для того чтобы делать прогнозы, нам
необходимо видеть всю картину целиком. Традиционно используемый аналитический
подход, при котором вся система делится на множество составляющих и
рассматривается отдельно, здесь не применим. Метод решения при помощи нейронной
сети кардинальным образом отличается от классического
интегрально-дифференциального способа. В традиционном подходе для того чтобы
оценить влияние одной из входных переменных на выходную, нужно проводить
следующие измерения. Необходимо последовательно изменять оцениваемый входной
параметр и наблюдать, каким образом изменилась выходная переменная. Оценив функцию
влияния каждой из переменных на выходной параметр, составляется общее уравнение
влияния входных переменных на выходную характеристику. При этом каждый из
коэффициентов оценивается отдельно при неизменном состоянии других
характеристик системы. Но эти же коэффициенты при другом наборе неизменных
характеристик, могли бы оказывать совсем иное воздействие на выходную функцию.
Другими словами, входные переменные могли быть взаимозависимы, и было бы
некорректно описывать систему формулой, не учитывающей эти связи. Поэтому при
выводе формул и вводится множество предположений об отсутствии между ними
зависимостей, либо о неизменности некоторых параметров. Конечно, в традиционных
интегрально-дифференциальных способах вычислений существуют и более
универсальные модели, учитывающие все возможные зависимости между
рассматриваемыми переменными. Но для описания такого сложного наблюдаемого
явления потребуется очень емкий математический аппарат. Для построения же
нейронной сети, нам не нужно знать функциональное описание, связывающее
выходную характеристику со всеми входными параметрами. Тем более, что нет
никакой гарантии того, что в следующий момент времени будет присутствовать
совсем другая зависимость. Именно когда не возможно одной функциональной формой
описать возможные зависимости функции от различных переменных и требуется метод
расчета с помощью интеллектуальных вычислений.
В [12] рассматриваются различные
подходы к прогнозированию движения на рынке. Применяются как базовые
эконометрические методы, так и интеллектуальные вычисления. Мы в данной
курсовой работе разработаем одну модель на базе синтеза искусственных нейронных
сетей и генетических алгоритмов и применим ее для оценки валютного курса.
1. Теоретические
аспекты движения валютного курса и интеллектуальных вычислительных технологий
Для построения модели нам нужно
будет выбрать одну теоретическую концепцию, которой мы будем придерживаться. В
зависимости от того, какие переменные мы будем подавать на вход, мы можем
проверять различные теоретические модели. Но при этом нужно также понимать, что
разные модели используют различные характеристики. И разработанная нами модель
будет универсальной только для тех теоретических подходов, в которых
используются такое же количество переменных, сколько будет входных значений
модели. Это связано с тем, что мы будем строить сеть с жестко заданной
структурой. Также нужно учесть и наши вычислительные возможности. Если мы
возьмем за основу подход, в котором фигурируют множество переменных, нужно
будет построить очень большую сеть с множеством связей. Поэтому нам необходимо
будет выбрать метод с небольшим количеством учитываемых значений и уже для этой
теоретической концепции строить систему прогнозирования.
1.1
Методы прогнозирования валютного курса
Для прогнозирования движения
валютного курса можно применять правила, основанные на фундаментальных законах.
Как правило, такие подходы достаточно хорошо теоретически обоснованы. Но, как
показывает опыт, в основном они плохо применимы для прогнозирования. Одним из
важных таких методов служит выполнение условия паритета процентных ставок. Он
характеризуется тем, что процентная ставка в одной стране должна равняться
процентной ставке в другой с поправкой на относительную разность ожидаемого и
текущего валютного курса первой экономики относительно второй и премию за риск
[4]:
r = r* + (E* - E)/E + ρ, (1)
где r - это процентная ставка в первой
экономике, r* - ставка во второй экономике, E - валюта первой страны, выраженная
в валюте второй, E* - ожидаемое значение валютного курса, ρ - премия за риск,
вкладывания средств в валюте второй страны относительно первой.
Казалось бы, что выполнение этого
условия достаточно логично. Если доходность облигаций в одной экономике
превышает доходность другой, то инвесторы, желая увеличить свое состояние,
будут стремиться вложить средства там, где процентные ставки с учетом премии за
риск будут выше. И чтобы устранить такую диспропорцию, рынок должен
скорректировать валютный курс этих стран соответствующим образом.
Существуют также, методы
технического анализа. Но весь арсенал правил, применяемый сторонниками этого
метода, представляется крайне субъективным. Особенно это касается в построении
тренда и различных фигур, применяемых для прогноза в техническом анализе. Также
личный опыт применения этого подхода показал явную неэффективность применения
стратегий этого метода.
Достаточно новым и интересным
направлением в этой сфере являются модели, основанные на поведенческих
характеристиках участников рынка. В отличие от двух предыдущих методов, такой
подход действительно дает хорошие результаты. Некоторый компромисс между
подходами, основанными на фундаментальном и техническом анализах, был найден в
модели, рассмотренной в статье [8], учитывающей поведенческие аспекты
участников рынка. В данной работе рынок формировался из двух типов участников.
Один тип формировал свои ожидания, основываясь на фундаментальном анализе
рынка. Второй тип предпочитал прогнозы, базирующиеся на техническом анализе. В
случае, когда одна из стратегий оказывалась более прибыльной, некоторая часть
участников, придерживавшихся противоположной стратегии, меняла ее. В процессе
взаимодействия этих агентов, была построена некоторая динамика валютного курса
достаточно схожая с той, которую мы наблюдаем на рынке. Но и эта модель имеет
свои недостатки в силу того, что используются множество различных
предположений, которые в действительности могут не выполняться.
Есть и более усовершенствованные
методы, учитывающие не только процентные ставки в двух странах, но и такие
показатели как уровни инфляций и отклонение реального от ожидаемого значения
выпуска рассматриваемых стран. Например, на базе такого подхода строится
модель, основанная на правиле Тейлора [13]. Данный метод мы не сможем применить
из-за очень большого количества используемых переменных. В принципе, мы вправе
построить очень большую нейронную сеть с множеством анализируемых переменных,
но вычислительная мощность обычного стационарного компьютера ограничивает нас в
построении такой сети. В книге [7] рассмотрена зависимость точности прогнозирования
нейронной сети в зависимости от количества скрытых слоев в ней. И как следует
из данной литературы, увеличение сложности сети не ведет к ее точности. Мы,
опять же из-за ограниченности ресурсов, применим простую нейронную сеть с одним
скрытым слоем. Наша главная задача в дипломной работе посмотреть применимость
интеллектуальных вычислений, а не оптимизация и нахождение структуры сети,
точно прогнозирующей по определенным входным параметрам некую величину. Поэтому
мы сами определим структуру сети. Тем более, что даже самая простая нейронная
сеть может определить сложные взаимосвязи между переменными. А построение
сложной сети не гарантирует пропорциональное улучшение прогнозирующей
способности модели. Напротив, усложнение структуры ведет лишь к тому, что сеть
будет искать очень сложную зависимость для того, чтобы описать процессы,
происходящие в обучающей выборке. Такая модель с большой вероятностью будет
выдавать неадекватный результат. Это связано с тем, что если количество
наблюдений будет меньше оптимального для данной нейронной сети, то сеть
построит очень сложную функциональную зависимость, правильно прогнозирующую
значение переменной на точках обучающей выборки, но в промежутках между этими
точками может быть совсем неправдоподобная функциональная зависимость. На рис.
1 показан эффект от увеличения количества нейронов в модели. Пунктирной линией
обазначена желаемая функция. Точки представляют собой обучающую выборку, на
которой осуществляется тренировка сети. Сплошная линия - это аппроксимирующая
функция, построенная нейронной сетью после обучения.
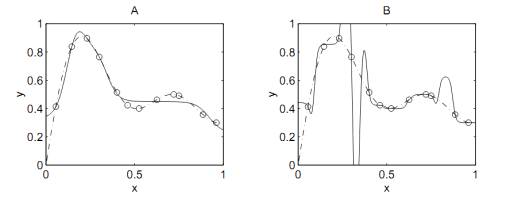
Рис. 1. Эффект увеличения количества
скрытых слоев нейронной сети.
Как видно из рисунка, усложнение
модели сети привело, к тому, что сеть нашла такую функциональную зависимость,
которая проходит через все точки тренировочной выборки. В то время как модель с
простой архитектурой сети подобрала функцию почти схожую с реальной. Повышение
точности не всегда является необходимым, так как с учетом анализируемых переменных
при одних и тех же входных данных на рынке могут быть разные выходные данные,
которые мы представляем для нейронной сети как истинные.
Достаточно интересным для нас было
бы проверить взаимосвязь фондового и валютного рынков. Могут ли события на
одном рынке вызвать изменения на другом? Данная концепция удовлетворяет нашему
техническому критерию минимальности количества входных используемых данных. Так
как для построения модели нам необходимо будет знать только значение котировок
индексов стран, валютную пару которых мы будем оценивать.
В данной работе мы отталкиваемся из
предпосылки связи фондового и валютного рынков. В ходе выполнения мы увидим,
существует ли действительно такая зависимость, и если да, то, как мы это можем
использовать.
Мы будем работать с валютным рынком,
так как этот рынок больше связан с макроэкономическими параметрами. В то же
время, если работать с фондовыми индексами, необходимо будет учитывать
разнородные новости по отраслям и крупным компаниям, входящим в индекс. Еще
необходимо учитывать, что для прогнозирования мы должны выбрать валютную пару
юрисдикций, целью центральных банков которых не является поддержание некоторого
валютного коридора относительно валюты других государств. Так как на динамику
валютного курса в этом случае будут больше влиять решения руководства ЦБ,
которые могут быть совсем не связаны с тем, что происходит на фондовых рынках.
Как известно, есть так называемая «три лемма центрального банка», по которому
ЦБ выбирает два из трех показателей, над которыми он будет вести контроль, но
соответственно, третья характеристика остается для ЦБ неконтролируемой. Это
такие показатели как: таргетирование инфляции, контроль уровня безработицы и
валютный курс. Странам с высоким внешнеторговым оборотом чаще необходим
контроль валютным курсом, так как от этого зависит выручка компаний страны.
Напротив, у большинства социально-развитых стран целью служит либо поддержание
низкого уровня безработицы (страны ЕС и Япония), либо таргетирование инфляции
(США), либо обе эти политики. В данной работе нас интересуют только те валютные
пары, над которыми ЦБ юрисдикций пар не ведут контроль. Именно поэтому мы взяли
пару евро - доллар.
1.2
Описание технологии интеллектуальных вычислений
Под термином «Computational intelligence» (интеллектуальные
вычисления) в англоязычной литературе понимается решения, полученные в
результате процесса обучения по доступным имеющимся данным вычислительной
системы [2]. В настоящее время широко применяются три основных подхода решения
задач таким способом. Это вычисления с помощью искусственных нейронных сетей,
применение, так называемых, генетических алгоритмов, а также использование
нечетких систем. Следует также заметить, что эти методы применяются не только
изолированно друг от друга, но и в разных комбинациях. Например, генетические
алгоритмы можно применять для подбора весов в нейронных сетях, а также для
формирования базы правил в нечетких системах. Именно один из таких симбиозов:
нейронная сеть с генетическим алгоритмом и будет построен в ходе выполнения данной
курсовой работы. Далее мы кратко ознакомимся с методами, основанными на
вычислениях с помощью нейронной сети и генетических алгоритмов отдельно.
Вычисления
с помощью искусственных нейронных сетей
В нейронной сети элементарной
вычислительной единицей является нейрон. Нейроны связаны между собой
синаптическими связями. Подобно мозгу, нейронная сеть может организовывать свою
структуру таким образом, чтобы выполнять конкретные задачи, будь то
распознавание образов или обработка сигналов. При этом нейронная сеть выполняет
эти действия намного быстрее обычных методик цифрового вычисления. Это
достигается благодаря распараллеливанию обработки информации. Также нейронная
сеть обладает способностью создавать обобщения. Обобщение - это способность
получать обоснованный результат на основании данных, которые не встречались в
процессе обучения.
В [5] дается следующее определение
нейронной сети:
«Нейронная сеть - это громадный
распределенный процессор, состоящий из элементарных единиц обработки
информации, накапливающих экспериментальные знания и предоставляющих их для
последующей обработки. Нейронная сеть сходна с мозгом с двух точек зрения.
Знания поступают в нейронную сеть из
окружающей среды и используются в процессе обучения
Для накопления знаний применяются
связи между нейронами, называемые синаптическими весами.»
Нейронные сети обладают множеством
уникальных замечательных свойств:
Нелинейность. Нейроны в сети могут
быть как линейными, так и нелинейными. А сама сеть, состоящая из множества
нелинейных нейронов, также будет нелинейной. Таким образом, такая система
способна учитывать очень сложные физические характеристики объекта. При этом,
вычисления происходят одновременно, начиная со всех входных нейронов. Это
значительно ускоряет скорость обработки данных.
Отображение входной информации в
выходную. Довольно часто в нейронных сетях прибегают к методу обучения с
учителем. В этом методе используется обучающее множество, состоящее из входных
сигналов и желаемого отклика на них. Цель нейронной сети настроить свои синаптические
веса таким образом, чтобы удовлетворять условию минимизации ошибки выхода и
желаемого отклика.
Адаптивность. Нейронные сети
обладают данным свойством, благодаря которому они могут изменять свои параметры
в меняющейся окружающей среде. Чем выше адаптивность системы, тем она лучше
ведет себя в быстро изменяющейся среде. Но, нужно учитывать и то, что если
адаптивность очень высока, а среда меняется более медленным образом, то такая
система будет быстро реагировать на посторонние шумы и постоянно перестраивать
свою структуру. Это плохо скажется на производительности модели. Поэтому
излишняя гибкость системы нам тоже не нужна. Поэтому при разработке нейронной
сети мы сталкиваемся с дилеммой стабильности - пластичности.
Очевидность ответа. При решении задачи
классификации образов нейронной сетью можно собирать информацию не только о
принадлежности к определенным классам, но и о достоверности решения. Исключая
таким образом маловероятные решения, мы увеличим производительность структуры.
Контекстная информация. В нейронной
сети знания хранятся в виде соответствующих функций активации нейронов. Любой
нейрон потенциально может быть зависим от других нейронов в сети. Поэтому само
существование структуры, основанной на нейронной сети, уже связано с наличием контекстной
информацией.
Отказоустойчивость. Повреждение
какого-нибудь нейрона или связи, не существенно повлияет на работоспособность
системы. Это связано с тем, что информация в нейронных сетях хранится не
локально в каждой связи, а распределена по всей структуре. И несущественные
повреждения не вызовут аварийных последствий. Будет наблюдаться лишь
незначительное снижение качества в долгосрочный период.
Масштабируемость. Как уже было
сказано, параллельное выполнение задачи ускоряет ее решение. Под масштабируемостью
понимается увеличение производительности при добавлении вычислительных
ресурсов.
Единообразие анализа и
проектирования. Одна и та же реализация нейронной сети может использоваться в
разных предметных областях. Поэтому одни и те же теории и алгоритмы можно
использовать для различных задач.
Аналогия с нейробиологией. Живым
подтверждением того, что отказоустойчивые параллельные вычислительные системы
физически реализуемы, являются животные и человек. Работа мозга у животных
достаточно хорошо и быстро справляется с множеством видов задач, порой никак не
осуществимых традиционными вычислительными способами.
Некоторые люди сравнивают нейронные
сети с нелинейной регрессией, способной описывать сложные функции высокого
порядка. Нелинейная регрессия способна воспроизводить ту динамику, которая
наблюдалась раньше. То есть, если у нас была некоторая синусоидальная
зависимость, и в данный момент времени мы находимся на какой-то ее части, то
лучший прогноз регрессии - это продолжение этой синусоиды. Нейронная же сеть, в
зависимости от ее структуры, к примеру, может настроить свои веса так, чтобы
выявить те факторы, из-за которых происходит это движение. И может случиться,
что формула изменения рынка не поменялась, а поменялось значение некоторой
переменной, из-за которого, к примеру, синусоида инвертировалась. Регрессия
будет продолжать строить первоначальную синусоиду. Так как в ней эта переменная
могла не учитываться из-за незначимости в целом. Хотя данная зависимость могла
фигурировать в обучающей выборке регрессии, из-за малой объясняющей способности
на всей выборке, эта переменная очень легко могла быть выкинута из
рассмотрения. Нейронная же сеть эволюционирует во времени. И если наблюдался
некий период, где переменная явным образом влияла на динамику, сеть должна была
поменять свои веса так, чтобы включить в рассмотрение этой характеристики
окружающей среды. Через некоторое время, когда события сложатся так, что
«дремавшая» до этого момента переменная вновь активизируется, нейронная сеть
может вспомнить свой «негативный» опыт обращения с этой характеристикой среды,
и предложить то решение, которое она находила в прошлом. В этом заключается
похожесть нейронной сети на мозг всех животных организмов. Конечно же, нет
гарантии того, что сеть непременно запомнит данное решение, и что в процессе
настройки связей данный опыт не будет потерян. Но, в итоге, в зависимости от
информационной емкости памяти сети и от того насколько сложным было обращение с
этой переменной для сети, найденное решение теоретически могло глубже сохраниться
в памяти. Под сложностью можно понимать, насколько дальше от текущей структуры
нужно было изменить связи в нейронной сети для нахождения решения поставленной
задачи.
Вычисления
с помощью генетических алгоритмов
Генетические алгоритмы призваны решать
оптимизационную задачу путем селекции особей. Каждая особь в популяции имеет
свою оригинальную последовательность генов в хромосоме. Основа генетических
алгоритмов заключаются в том, что с большой вероятностью наиболее
приспособленные особи принесут потомство, у которого признаки приспособленности
будут выражены еще сильней. Кроме того, в генетических алгоритмах действует
закон естественного отбора, заключающийся в удалении на каждом дискретном шаге
особей, наименее приспособленных к среде.
Рассмотрим более подробно процедуру
численной оптимизации при помощи методики селекции, представленной в [1]:
. Итак, обыкновенно
проектирование начинают с формирования в поисковом пространстве области
допустимых значений переменных и выбора в ней некоторых пробных точек (рис. 2).
Иными словами, первоначально всем особям популяции задается некоторые случайные
значения генотипов.
. Далее итеративно выполняют
следующие действия. Сначала при помощи математической модели устройства
производят отображение точек из поискового пространства на пространство
критериев. То есть декодируют информацию, заключенную в генотипах особей и
определяют фенотипические характеристики каждой из них. Мы сами определяем,
какие внешние фенотипические признаки особей каким образом будут закодированы в
их генотипах. На этом этапе мы производим обратную процедуру дешифрования этих
характеристик.
. Определив «внешние»
признаки закодированной информации в генотипах особей популяции, мы можем
задать некий критерий, по которому будем сравнивать особи между собой. А уже
получив параметр сравнения, мы можем производить отбор.
. Затем в соответствии с
выбранной поисковой стратегией осуществляются некоторые манипуляции с
координатами точек в пространстве переменных, завершающиеся генерацией
координат новых пробных точек (новых генотипов потомков).
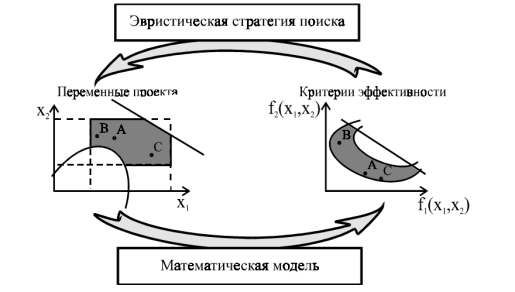
Рис. 2. Циклическая структура
процедуры численной оптимизации характеристик проекта
То есть, можно сказать, что вектор
переменных проектирования есть некий генотип особей. Применяя к этим генотипам
математическую модель, мы получаем ее внешние признаки, фенотип. И уже на
основе фенотипа, мы можем селекционировать популяцию по заданному критерию
эффективности. Из популяции отбираются особи, которые показали наилучшие
результаты для дальнейшего скрещивания. Особи же с наихудшими результатами на
данном дискретном промежутке времени отбрасываются из рассмотрения. Можно
сказать, что они вымирают. Таким образом, с помощью искусственного отбора, мы
реализуем эволюцию популяции и находим такую комбинацию генов, которые
наилучшим образом соответствуют нашему критерию эффективности.
Скрещивание родительских особей
можно рассматривать как некое преобразование их генов. С точки зрения
генетических алгоритмов это выглядит как простая манипуляция координатами в
пространстве переменных проектирования, в результате которой получаются новые
координаты. Эти координаты соответствуют генотипу потомков.
Но следует заметить, что выше
представленная модель ГА является прообразом гаплоидных организмов (бактерий,
водорослей и других примитивных существ). У гаплоидных особей есть один
существенный недостаток. При большом количестве итераций, мы найдем такую
комбинацию генов, которая наилучшим образом удовлетворяет текущему критерию
эффективности. Но при этом все особи будут генотипически схожими. А это
означает вырождаемость популяции. То есть, если условия среды вдруг внезапно
поменяются, мы не сможем ответить на это, найдя новых особей с подходящей
структурой генотипа. В случае вырожденности оставить в популяции только одного
победителя, а остальных сформировать произвольным образом мы тоже не сможем.
Потому что эта особь будет играть роль сверх индивида, и в скором времени
популяция вновь окажется состоящей из потомков, схожих на первоначальную особь.
Решить задачу с вырождаемостью
популяции нам поможет использование диплоидных особей. У диплоидных организмов
за один и тот же фенотипический признак отвечает комбинация материнских и
отцовских генов. В зависимости от доминантности-рецессивности того или иного
гена, особь может содержать оба признака, но внешне будет проявляться только
один из них.
Фенотипически схожие особи вовсе не
обязательно будут также схожи и внутренним устройством генотипа. Используя
диплоидную модель, мы можем поддерживать в популяции намного меньше особей, при
этом соблюдая генотипическое разнообразие в ней.
2. Построение
модели прогнозирования валютного курса
2.1 Применение
генетических алгоритмов для настройки архитектуры нейронных сетей
Как упоминалось выше, наша модель
будет представлять собой симбиоз искусственных нейронных сетей и генетических
алгоритмов. Мы будем применять эволюционную модель с хромосомами потомков для
подбора оптимальных синаптических весов в нейронных сетях. Обычно два этих
подхода применяют независимо друг от друга для решения различных классов задач.
Мы же объединим их и попробуем получить лучшее решение, используя преимущества
каждого из этих методов.
Изменение валютного курса
предположительного может зависеть от колебаний фондовых индексов. Если такая зависимость
присутствует, и она является нелинейной, тогда нейронные сети представляются
тем самым необходимым инструментом, позволяющим найти связь между показателями
и построить необходимый прогноз. Будем прогнозировать колебание пары курса евро
- доллар. На вход системы будем подавать 3 значения: индекс фондового рынка США
S&P500, индекс фондового рынка одной из
основных экономик ЕС - Германии DAX30, а также значение изменения валютного курса в предыдущем
периоде. Далее мы должны определить промежуточные слои нейронной сети. Мы можем
сами решать, сколько будет таких промежуточных слоев, нейронов в них, а также
структуру связей между ними. Другое дело, что веса связей будет подбирать уже
сама модель. В этой дипломной работе мы не задаемся вопросом, какой оптимальной
структурой должна обладать модель. Этот вопрос уже является другой большой
темой для исследований. Мы же примем структуру сети заданной.
За основу возьмем нейронную сеть на
основе радиально-базисных функций. За активационную функцию примем многомерную
функцию Гаусса, которая определяется следующим образом:
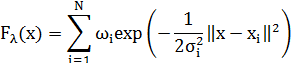
где 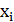 - центр активационной функции,
- центр активационной функции, 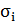 - ее ширина,
- ее ширина, 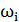 -
линейные веса.
-
линейные веса.
Рис. 3. Нейронная сеть
на основе радиальных базисных функций
Возьмем простую RBF-сеть с одним промежуточным слоем, характеризующейся параметрами
3-5-1. Здесь 3 - обозначает, что во входном слое будет 3 нейрона, 5 -
количество нейронов в скрытом слое, и 1 - то, что у сети будет один выходной
нейрон.
Область определения
любых активационных функций изменяется от 0 до1. Чем дальше сигнал, приходящий
от входного нейрона находится от центра активационной функции синаптической
связи, тем меньше влияние данных от этой переменной на нейрон скрытого слоя.
Второй параметр межнейронного соединения - ширина окна отвечает за калибровку
значений. Стандартный нейрон скрытого слоя представляет собой сумматор, в который
поступают сигналы от всех входных нейронов. При этом значение входного нейрона
может изменяться от 0 до 1. Следовательно, выход нейрона скрытого слоя может
изменяться от 0 до N, где N - о входных нейронов, соединенных с данным нейронгом скрытого
слоя. Далее выход нейрона скрытого слоя взвешивается на весовой коэффициент, и
в выходном нейроне происходит суммирование взвешенных значений выходов скрытых
нейронов.
То есть на скрытый слой
поступают числа от нуля до единицы от каждого входа сети.
Для настройки весов сети
будем применять так называемый метод «обучения с учителем». Суть такого подхода
заключается в том, что каждому набору входных переменных мы сопоставляем
желаемую функцию выхода сети. И при несовпадении выданного результата с
ожидаемым значением, вычисляется ошибка. В нашем случае желаемым выходом сети
будет доходность валютной пары за промежуток, следующий после того интервала
времени, из которого был взят набор входных характеристик. То есть на каждом
шагу вычисляется прогноз на один период вперед. Синаптические веса нейронной
сети перебираются до тех пор, пока суммарная ошибка на определенном интервале
времени не окажется ниже некоторого заданного уровня. Либо можно определить
количество итераций, после которого перебор весов будет прекращен.
Для оценки весов будем
использовать генетический алгоритм. Каждая особь будет содержать информацию о
структуре определенной нейронной сети. То есть ДНК индивидов в популяции будет
представлять из себя закодированную информацию о синаптических весах нейронной сети.
ДНК особей будет состоять из одной пары хромосом, в которых последовательно
будет содержаться информация о межнейронных связях всей нейронной сети (см.
рис. 4).
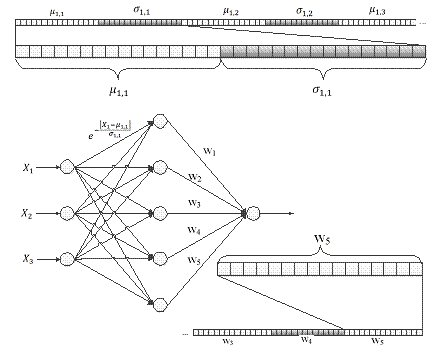
Рис. 4. Кодировка
параметров нейронной сети в хромосоме
Теперь нам нужно
определить какую именно информацию о весах мы будем кодировать. Для реализации
мы приняли нейронную сеть на основе радиационно-базисных функций. Чтобы задать
такого рода функцию, нам нужно знать два параметра: ширину активационной функции
и ее центр. Поэтому каждый фрагмент хромосомы, отвечающий за определенную связь
в нейронной сети должен содержать в себе информацию об этих двух значениях. Под
каждую переменную отведем по 32 бита (чтобы в дальнейшем можно было
воспользоваться стандартом кодирования чисел в двоичный код с плавающей
запятой, аналогичный тому, который обычно применяется в информационных
системах). Таким образом, для описания каждой нейронной связи нам потребуется
по 64 бита информации. Кроме того, нужно учесть, что связи, соединяющие
внутренние нейроны с выходным нейроном не используют активационную функцию, а
лишь содержат информацию о весе данных, поступающих по данной ветке. То есть
для кодирования этих связей нам понадобится не по 64, а всего по 32 разряда.
Тогда сама хромосома, которая будет содержать в себе информацию о связях между
тремя входными нейронами и 5 нейронами в скрытом слое (всего 15 связей), а
также данные о весах между 5 скрытыми и выходным нейроном (всего 5 связей)
будет содержать информацию о двадцати синаптических соединениях. Но не нужно
забывать, что такая бинарная строка, фактически, является фенотипом особи, то
есть внешним проявлением внутренней комбинации генов в диплоидном генотипе.
Далее произвольным
образом определим 20 особей. То есть задаем 40 бинарных строк со 1120 ячейками
в каждой (так как кодируется 15 межнейронных связей, каждая из которых требует
для кодировки 64 бит информации, и 5 связей, для которых необходимо 32 бита
информации). В каждой ячейке будет содержаться одна буква из алфавита {D, d, R, r}. После этого мы все
строки объединяем по две. Теперь каждая строка из пары будет представлять собой
одну из ветвей хромосомы.
Шаги, следующие после
инициализации популяции, будут итеративно повторяться много раз, характеризуя
собой эволюцию системы. Поэтому все последующие операции запишем в теле цикла
(см. рис. 5).
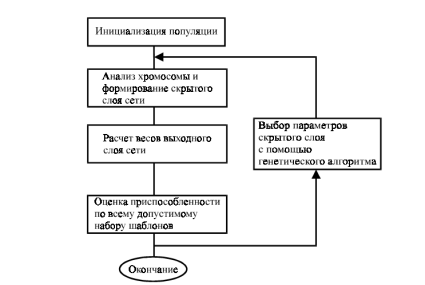
Рис. 5. Процедура
тренировки RBF-сети
В цикле мы сначала
занимаемся анализом хромосомы. То есть смотрим, каким фенотипическим признаком
будет обладать каждая особь по каждому признаку (1120 бит, кодирующих веса
межнейронных связей). Для определения фенотипического признака по каждому из
1120 разряду (нужно определить будет 0 или 1), воспользуемся решающим правилом
определения наследуемого признака (на основе доминантности-рецессивности гена),
приведенным выше.
Далее, получив все
признаки особи, подставляем ее значения в нейронную сеть. Для этого делим
полученную бинарную строку фенотипических признаков на 20 фрагментов для
определения информации по каждой из 20-ти связей. На этом этапе получаем массив
из тридцати пяти чисел в двоичном формате с плавающей запятой. Сначала будут
идти 15 пар чисел. В каждой паре первое число будет отвечать за ширину окна
активационной функции, второе число за ее центр.
Дисперсия σ
используется в функции активации 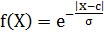 . Входными значениями X здесь служат индекс фондового рынка США S&P500, индекс фондового рынка Германии DAX30
и значение изменения валютного курса в предыдущем периоде.
. Входными значениями X здесь служат индекс фондового рынка США S&P500, индекс фондового рынка Германии DAX30
и значение изменения валютного курса в предыдущем периоде.
Таким образом, мы
построили архитектуру искусственной нейронной сети с настройкой синаптических
связей нейронов методом генетических алгоритмов, прогнозирующую значение
валютного курса на следующий период времени.
2.2 Анализ входных
данных и выбор технических параметров модели
Теперь разберемся с процессом
кодирования информации. Для простоты понимания, введем четырехбуквенный алфавит
{D, d, R, r}. Пусть латинские прописные буквы D и R будут отвечать за доминантный и
рецессивный признак гена «1», а малые d и r за доминантный и рецессивный признак «0» соответственно. Как и в
стандартной генетике, в случае нахождения на одной аллели доминантного и
рецессивного гена, у особи будут наблюдаться признаки доминантного гена. В
случае же, когда на обеих аллелях цепи будут либо только доминантные, либо
только рецессивные гены, мы введем следующие правила, по которым будем
определять, признак какого гена будет присутствовать у дочерней особи. В
принципе, все особи могут быть оценены по уровню приспособленности к среде.
Поэтому можно сказать, что одна из особей в родительской паре будет лучше
адаптирована, чем вторая. И поэтому, в случае неопределенности в паре
доминантных генов потомка мы будем наделять особь тем признака гена, который
принадлежал более приспособленному родителю. В паре же рецессивных генов,
выберем признак менее приспособленной особи. В реальности, конечно же, признаки
наследования определяются не так однозначно. Но мы сами вправе решать, как нам
осуществлять признаки наследования. И поэтому для упрощения мы возьмем такое
правило.
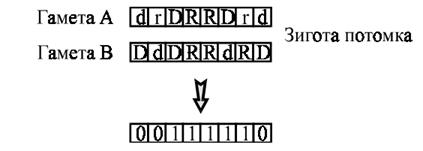
Рис. 6. Пример наследования
признаков в паре гомологичных генов
Чтобы представить ДНК в бинарном
виде, закодируем также символьные значения {D, R, d, r} в двоичный код. За
доминантную и рецессивную единицу будут отвечать последовательности 11 и 10
соответственно. А за доминантный и рецессивный нуль 00 и 01. Мы бы могли
воспользоваться предыдущим символьным кодированием. Но из-за того что мы хотим
представить информацию в виде последовательности нулей и единиц, нам придется
для определения полной характеристки гена использовать два бита вместо одного.
Такое преобразование удвоит длину ДНК.
Мы обсудили примеры проявления
генетических признаков. Теперь после того как мы определили, какой символ нуль
или единица проявится на том или ином участке цепи, нам нужно использовать это,
чтобы менять характеристики особи. Как мы помним, ДНК должна будет содержать
информацию о весовых коэффициентах нейронной сети. ДНК будет представлять из
себя последовательность закодированных чисел. Для определения одной нейронной
связи (для всех связей, кроме тех, которые соединяют скрытые нейроны с
выходными) нам понадобится пара чисел: одно число, характеризующее середину
окна активационной функции, второе ширину окна. В нашем случае три входных
нейрона будут соединены с пятью нейронами скрытого слоя. Таким образом, для
определения синаптических весов этих связей нам понадобятся пятнадцать пар
чисел. Мы построили простую нейронную сеть, поэтому далее сразу же после этого
будут идти пять связей, соединяющих выходной нейрон с пятью нейронами скрытого
слоя. Для определения одной связи этого типа нам понадобится лишь одно число, а
не два как в предыдущем случае, так как эти связи определяют лишь вес
информации, поступающей по каждой ветви.
Итак, мы выяснили, какую информацию
мы хотим закодировать в ДНК особей, сколько именно чисел, характеризующих
синаптические связи, нам понадобятся. Теперь определим, в какой
последовательности будут идти эти числа в цепочке ДНК особей. Сначала будут
идти 5 пар чисел, каждая одназначно характеризующая весовые коэффициенты
связей, соединяющих первый входной нейрон со всеми нейронами скрытого слоя.
Далее в ДНК будут следовать 5 пар чисел, содержащих информацию о всех связях со
вторым входным нейроном. И также, далее 5 пар с данными связей с третьим
входом. В конце цепочки ДНК будет содержаться информация о пяти нейронных
связях выходного нейрона с нейронами скрытого слоя.
Итак, ДНК будет представлять из себя
последовательность 35 чисел: по 5 пар чисел на каждую связь трех входных
нейронов с нейронами скрытого слоя и 5 чисел, представляющих связи между
нейронами скрытого слоя и выходным нейроном. Каждое число представим в двоичном
виде в формате с плавающей запятой.
В практических приложениях в
настоящее время стандартным представлением чисел в двоичном виде с плавающей
запятой является формат IEEE - 754.
В этом стандарте при представлении
числа в двоичном виде в формате с плавающей запятой используется следующая
форма записи:
*10e,
Ниже приведено описание, по которому
кодируются десятичные числа в двоичный формат.
Мы решили, что будем кодировать 35
чисел в двоичный вид по 32 бита каждый. В итоге, получается цепочка длиной в
1120 бит. Ранее мы узнали, чем диплоидные организмы лучше гаплоидных. Поэтому
воплотим в нашей модели эту идею.
Далее обсудим какой тип кодирования:
двоичный или код Грея лучше применять в алгоритме. В таблице 1 приведен пример
кодирования натуральных чисел двоичным кодом и кодом Грея.
Таблица 1. Представление натуральх чисел
в двоичном коде и коде Грея
|
Натуральное число
|
Двоичный код
|
Код Грея
|
|
0
|
000
|
000
|
|
1
|
001
|
001
|
|
2
|
010
|
011
|
|
3
|
011
|
010
|
|
4
|
100
|
110
|
|
5
|
101
|
111
|
|
6
|
110
|
101
|
|
7
|
111
|
100
|
Из таблицы видно, что близкие
значения цифр в двоичном коде могут кардинально отличаться в бинарном
представлении. Например, при переходе от 3 к 4, в двоичном коде все биты
поменялись на противоположные. А это означает, что 3 и 4 в таком пространстве
представления находятся максимально далеко друг от друга. В коде же Грея при
переходе к следующему значению может меняться только один бит. Поэтому близкие
значения чисел будут также похожи и в закодированном состоянии.
Теперь, когда мы выяснили как будем
шифровать и дешифровать информацию в генотипе особей, нужно перейти к
рассмотрению операторов, обеспечивающих способность популяции изменяться и
приспосабливаться к окружающей среде. Существует, так называемая триада
генетических операторов: мутация, инверсия и кроссовер. Применяя их, мы можем
обеспечивать передачу важных признаков потомству, а также поддерживать
эволюционно значимую изменчивость популяции. Нахождение отличных от
родительских фенотипических признаков будет представлять собой поисковую
способность ГА.
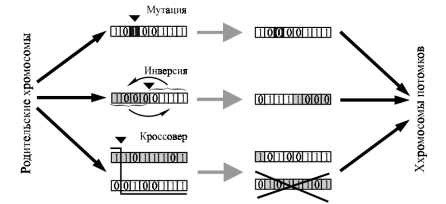
Рис. 7. Примеры выполнения
генетических операторов
Оператор мутации представляет собой
замену существующего гена в хромосоме на противоположное состояние. Мутация
гена может возникнуть абсолютно в любом месте цепи. В зависимости от того, в
каком разряде произошла мутация, потомок может оказаться в разной удаленности
от родителя в пространстве векторов переменных. Оператор инверсии приводит к
изменению порядка следования генов в хромосоме. Случайным образом определяется
место в цепочке генов, по которому будет осуществлена инверсия. Все гены в
подцепочке, которые располагались до этой точки, перемещаются в конец цепочки
(рис. 7). При этом первый ген этой подцепочки оказывается на том месте цепи,
которое было определено случайным образом, а порядок следования генов в
подцепочке остается прежним. Соответственно, вторая подцепочка генов
переносится в начало цепи. Мутация и инверсия могут произойти с любой
хромосомой любой особи популяции. Для реализации же третьего оператора -
кроссовера (также его называют кроссинговер), необходимы пара хромосом особи.
Кроме того, если первые два оператора могут произойти только с некоторой
априорно заданной вероятностью, то кроссовер применяется всегда при
формировании потомка. Суть оператора кроссовера заключается в том, что еще до
скрещивания в предварительной стадии формирования половых клеток родительских
особей (в биологии - в стадии мейоза клеток) в гомологичных парах хромосом
происходит их рекомбинация. В цепочке хромосомы выбирается некоторая случайная
точка, по которой происходит разрыв цепочки. Аналогично, в той же области
происходит разрыв гомологичной хромосомы. Затем эти части пары гомологичных
хромосом перекрестно соединяются друг с другом. В результате получается пара
цепочек, одна из которой будет хромосомой потомка. Вторая хромосома потомка
формируется от другой особи, хромосомы которой также предварительно
подвергаются операции кроссинговера.
Все три оператора являются важным
звеном в обеспечении популяционной изменчивости особей, а, следовательно, и
поисковых возможностей всего алгоритма. Изменяя ДНК особей, мы можем
сформировать потомков, с ранее не встречавшимися характеристиками. Как мы
помним, ДНК особи определяет весовые коэффициенты нейронной сети.
Следовательно, мы можем подобрать такую комбинацию весов, которая наилучшим
образом описывает связь между входными параметрами и выходным значением.
3.
Анализ выявленных проблем и способы улучшения модели
Из всех свойств нейронных сетей
можно выделить один большой недостаток, заключающийся в невозможности точно
предсказать, каким будет выход сети в следующий момент времени. В этом смысле
нейронная сеть похожа на черный ящик, преобразующий неким неизвестным нам
способом входные данные в выходные. И чем сложнее и запутаннее будет
архитектура сети, тем более непредсказуемым становится ее решение. С одной стороны
это и хорошо, так как система в принципе способна описать всевозможные
нелинейные взаимосвязи переменных. Но, нет гарантии того, что при одних и тех
же входных данных, выходные значения будут одинаковыми.
Еще одним существенным недостатком
является зависимость результата от обучения сети. Сеть ищет функциональную
зависимость тех данных, что была ей предложена на этапе обучения. Более того
результаты сети будут зависеть не только от того какого рода данные мы подавали
на вход, но и от последовательности их подачи и от частоты появления похожих
значений. В принципе, это не только недостаток нейронной сети. Формулы,
полученные интегрально-дифференциальными способами, и правильно работающие на
одном промежутке данных, могут совершенно не подходить для других данных.
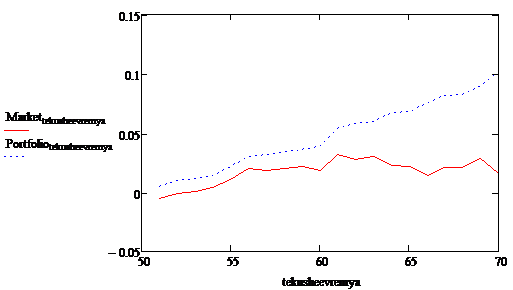
Синтез двух адаптивных методов
вычисления дал очень хорошие результаты (см. рис. 8). Накопленная доходность
инвестиционного портфеля, построенного на модели искусственных нейронных сетей
и генетических алгоритмов, значительно превысила значения суммарной доходности
рыночного портфеля. При этом рост портфеля наблюдался на всем промежутке
наблюдения, что говорит о хороших прогностических свойствах модели.
Улучшение работы системы мы видим в
том, что будут найдены модели-интерпретаторы, способные объяснять, почему
именно такое решение предлагает система и насколько уверенным можно быть в этом
случае.
Одной из основных причин, по которым
адаптивные алгоритмы до сих пор не имеют широкого применения, является то, что
у многих людей нет доверия к этим системам вычисления. Когда заранее известно,
что при нажатии кнопки машина выдаст строго определенный результат, существует
ощущение того, что человек управляет работой системы, возникает доверие к ней.
Если же система сама каким-либо образом преобразует данные, и выдает некий
результат, при этом ничем не поясненный, почему именно таким должно быть
решение, то веры в правильность вычислений нет. У человека нет возможности
контролировать процесс вычисления. Этот недостаток искусственных нейронных
сетей мы попытались смягчить, применив к оценке активационных функций
синаптических связей нейронов генетические алгоритмы. При таком подходе мы уже
имеем некоторое количество шаблонов сети, решающие задачу наиболее приближенно
к желаемому значению выхода. И мы можем проследить, каким образом происходит
эволюция структуры сети. Таким образом, «черный ящик» в виде искусственной
нейронной сети становится более «прозрачным». Ее можно косвенным образом
интерпретировать через эмпирически полученные структуры сети. Да, мы не сможем
дать точную функциональную зависимость характеристик среды. Но все же знание
того, какие структуры нейронной сети позволили получить желаемый отклик, уже
снимает ту неопределенность, связанную с настройкой весовых коэффициентов сети.
Еще один положительный результат
применения генетических алгоритмов к нейронной сети заключается в том, что мы
получаем множество различных реализаций модели, выполняющих требование
минимальности ошибки. В отличие от других применяемых методов, у нас будет не
одна, а целая группа различных нейронных сетей. При других методах, если
текущая структура оказалась неправильной (то есть решение попало в локальный
экстремум), то придется перестраивать всю модель. Наша же модель с
генетическими алгоритмами оперирует группой различных решений. И в случае если
на текущем шаге мы попадем в локальный экстремум, существует множество других
решений, которые вполне возможно могут оказаться глобальным экстремумом в
изменившихся условиях среды. К тому же не стоит забывать о том, что нам не
придется, в отличие от других способов настройки весов в нейронной сети, с нуля
перебирать множество комбинаций ее структуры, позабыв о других шаблонах также
неплохо выполнявших задачу минимизации ошибки.
Заключение
В ходе выполненной работы нам
удалось построить систему, прогнозирующую валютный курс. При этом мы применили
для этого метод, основанный на интеллектуальных расчетах. Рынок невозможно
представить как статическую машину с неизменными «правилами игры». Как раз,
наоборот, часто говорят о невозможности предсказания поведения рынка, о частой
смене настроения его участников. Наша система является достаточно гибкой, и при
изменении условий на рынке, она будет пытаться найти наилучшие решения в
измененной среде. Она в буквальном смысле будет адаптироваться в окружающем ее
мире. Это выгодно отличает ее от других способов решений. Во-первых, такие
решения достаточно сложно найти. Даже, применив очень много усилий, и найдя
решение, исследователям будет сложно его объяснить и заставить поверить
инвесторов в их эффективность. Ведь может оказаться так, что поведение на рынке
описывается какими-либо факторами, влияние которых в действительности
маловероятно. Во-вторых, если всем станет известно, по каким правилам нужно
действовать на рынке, то, все участники захотят использовать эти выводы. В
итоге, это приведет к тому, что рынок перестанет подчиняться тем законам,
которые были выведены исследователями. И для того, чтобы постоянно давать
правильный прогноз, нужно всякий раз находить новые законы изменения валютного
курса.
Наша же модель как раз и
предназначена для изменяющейся среды. Изменение генотипа связей будет постоянно
поддерживать эволюцию нейронных сетей. Для прогноза необходима всего одна
реализация структуры нейронной сети. А из-за того, что мы применили
генетические алгоритмы, у нас есть целая популяция различных сетей. Каждая
реализация нейронной сети имеет свои характеристики связей между нейронами, а
значит и свой метод прогнозирования. То есть, в работе мы описываем метод
«выращивания» таких искусственных нейронных сетей, каждая из которых выступает
в роли одной особи в популяции таких же систем. Здесь мы реализуем среди них
искусственный отбор. Главной движущей силой отбора является наилучшая
способность предсказывания нейронной сетью динамики валютного курса на основе
входных данных по динамике фондового рынка. И неважно как будет меняться
функция зависимости рынков между собой. Поиск наилучшей нейронной сети
осуществляется на основе случайного изменения генотипа особей, увеличивая тем
самым гибкость системы в динамической среде. При этом сохраняется
преемственность поколений. Так как особи, наилучшим образом соответствующие
правилам отбора, будут продолжать существование при условии того, что не
найдутся потомки, выполняющие эти правила лучше них.
Вычисления, основанные на нейронных
сетях, благодаря распараллеливанию обработки информации происходят быстрее. Это
обстоятельство добавляет преимущество использования таких технологий в системах
с большим объемом информации.
Следует еще раз обратить внимание на
то, что построенную архитектуру модели можно применять для различных входных
данных. Это делает нашу модель универсальной. Какие бы переменные мы не
подавали на вход, система будет искать наилучшую структуру прогнозирования.
Если же в действительности не существует зависимости между входными и выходными
данными, то такой прогноз, конечно же, будет плохим. Но большим достоинством
нейронных сетей является то, что они могут найти сложные, достаточно
неочевидные связи между характеристиками среды. Причем чем большую выборку
использовать для тренировки, тем более убедительным становится выявленная
сложная зависимость. Так как если данное явление систематически повторяется на
большом промежутке времени, то вероятнее всего данная тенденция действительно
присутствует на рынке.
В целом, наша модель, как система
для прогнозирования валютного курса, выполняет те цели, которые были поставлены
в ходе курсовой работы. Нужно заметить, что модель предназначена не только для
прогнозирования направления движения, но и значения, на которое изменится курс.
Информация о величине изменений может рассматриваться как мера уверенности
движения в данном направлении. Модель реагирует на происходящие изменения
среды, меняя свои внутренние характеристики. Это отвечает требованию гибкости
модели в динамической среде.
Недостатком является сложность
интерпретации полученной зависимости на рынке. Модель не выдает связи между
переменными в виде определенной функциональной формулы. Существуют лишь
некоторые закодированные значения весовых функций активации синаптических
связей нейронов, которые при подстановке в нейронную сеть дадут некий прогноз.
Еще одна слабая характеристика
построенной модели - это жестко заданная архитектура сети. Мы определили эту
структуру чисто интуитивно. При этом не существует каких-либо строгих правил
того, сколько нейронов нужно использовать, сколько скрытых слоев должно быть в
сети, каким образом нейроны должны быть связаны друг с другом. При возможности
улучшения модели путем изменения архитектуры сети, построенная нейронная сеть
уже не будет универсальной, так как для разных входных данных будет своя
оптимальная архитектура сети. И поиск оптимальной структуры, удовлетворяющей
новым условиям, таким как, например, быстродействие, либо простота находимой
функциональной зависимости, это уже другая системная задача, ответ, на который
среди исследователей интеллектуальных систем, пока еще не найден.
Вычисления, построенные на
адаптивных алгоритмах, являются новым подходом к решению различного рода задач.
У интеллектуальных вычислительных систем есть свои преимущества и недостатки по
сравнению с классическими способами вычислений. Но, совершенно очевидно, что
такого вида вычисления правомерно использовать в качестве равнозначных методов
расчета.