Применение дисперсионного анализа в статистических исследованиях
РЕФЕРАТ
факторный статистический дисперсионный беларусь
Курсовая работа содержит листов, рисунков, таблиц, источников литературы.
Основные понятия: факторный анализ, фактор, дисперсионный анализ,
гипотеза, дисперсия, модель, метод.
Целью работы является ознакомление с дисперсионным анализом и апробация
его основных положений на статистических данных, собранных по Республике
Беларусь.
Основные результаты работы: изучены основные положения факторного анализа
и типы факторов; изучены основные положения и модели дисперсионного анализа;
изучена роль и место дисперсионного анализа при статистических исследованиях;
проведен дисперсионный анализ при исследовании социально-экономических
показателей по Республике Беларусь.
ВВЕДЕНИЕ
Все явления и процессы хозяйственной деятельности предприятий находятся
во взаимосвязи и взаимообусловленности. Одни из них непосредственно связаны
между собой, другие косвенно. Отсюда важным методологическим вопросом в
экономическом анализе является изучение и измерение влияния факторов на
величину исследуемых экономических показателей.
Дисперсионный анализ - статистический метод, позволяющий анализировать
влияние различных факторов на исследуемую переменную. Метод был разработан
биологом Р. Фишером в 1925 году и применялся первоначально для оценки
экспериментов в растениеводстве. В дальнейшем выяснилась общенаучная значимость
дисперсионного анализа для экспериментов в психологии, педагогике, медицине и
др.
Целью дисперсионного анализа является проверка значимости различия между
средними с помощью сравнения дисперсий. Дисперсию измеряемого признака
разлагают на независимые слагаемые, каждое из которых характеризует влияние
того или иного фактора или их взаимодействия. Последующее сравнение таких
слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их
комбинации [7].
При истинности нулевой гипотезы (о равенстве средних в нескольких группах
наблюдений, выбранных из генеральной совокупности), оценка дисперсии, связанной
с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой
дисперсии.
При проведении исследования рынка часто встает вопрос о сопоставимости
результатов. Например, проводя опросы по поводу потребления какого-либо товара
в различных регионах страны, необходимо сделать выводы, насколько данные опроса
отличаются или не отличаются друг от друга. Сопоставлять отдельные показатели
не имеет смысла и поэтому процедура сравнения и последующей оценки производится
по некоторым усредненным значениям и отклонениям от этой усредненной оценки.
Изучается вариация признака. За меру вариации может быть принята дисперсия.
Дисперсия σ2
- мера вариации, определяемая как средняя из отклонений признака, возведенных в
квадрат.
На практике часто возникают задачи более общего характера - задачи
проверки существенности различий средних выборочных нескольких совокупностей.
Например, требуется оценить влияние различного сырья на качество производимой
продукции, решить задачу о влиянии количества удобрений на урожайность с/х
продукции.
Иногда дисперсионный анализ применяется, чтобы установить однородность
нескольких совокупностей (дисперсии этих совокупностей одинаковы по
предположению; если дисперсионный анализ покажет, что и математические ожидания
одинаковы, то в этом смысле совокупности однородны). Однородные же совокупности
можно объединить в одну и тем самым получить о ней более полную информацию,
следовательно, и более надежные выводы [2].
Целью работы является ознакомление с дисперсионным анализом и апробация
его основных положений на статистических данных, собранных по Республике
Беларусь.
Предполагается решение следующих задач:
изучение основных положений факторного анализа и типов факторов;
изучение основных положений и моделей дисперсионного анализа;
изучение роли и места дисперсионного анализа при статистических
исследованиях;
практическое применение дисперсионного анализа при исследовании
социально-экономических показателей по Республике Беларусь.
1. Факторный
анализ и его особенности
1.1 Понятие,
типы и задачи факторного анализа
Под факторным анализом понимается методика комплексного и системного
изучения и измерения воздействия факторов на величину результативных
показателей.
Различают следующие типы факторного анализа:
детерминированный и стохастический;
прямой и обратный;
одноступенчатый и многоступенчатый;
статический и динамичный;
ретроспективный и перспективный (прогнозный).
Детерминированный факторный анализ представляет собой методику
исследования влияния факторов, связь которых с результативным показателем носит
функциональный характер, т.е. когда результативный показатель представлен в
виде произведения, частного или алгебраической суммы факторов.
Стохастический анализ представляет собой методику исследования факторов,
связь которых с результативным показателем в отличие от функциональной является
неполной, вероятностной (корреляционной). Если при функциональной (полной)
зависимости с изменением аргумента всегда происходит соответствующее изменение
функции, то при корреляционной связи изменение аргумента может дать несколько
значений прироста функции в зависимости от сочетания других факторов,
определяющих данный показатель. Например, производительность труда при одном и
том же уровне фондовооруженности может быть неодинаковой на разных предприятиях
[11].
При прямом факторном анализе исследование ведется дедуктивным способом -
от общего к частному. Обратный факторный анализ осуществляет исследование
причинно-следственных связей способом логичной индукции - от частных, отдельных
факторов к обобщающим.
Факторный анализ может быть одноступенчатым и многоступенчатым. Первый
тип используется для исследования факторов только одного уровня (одной ступени)
подчинения без их детализации на составные части. При многоступенчатом
факторном анализе проводится детализация факторов на составные элементы с целью
изучения их поведения.
Необходимо различать также статический и динамический факторный анализ.
Первый вид применяется при изучении влияния факторов на результативные
показатели на соответствующую дату. Другой вид представляет собой методику
исследования причинно-следственных связей в динамике.
Факторный анализ может быть ретроспективным, который изучает причины
прироста результативных показателей за прошлые периоды, и перспективным,
который исследует поведение факторов и результативных показателей в перспективе.
Основными задачами факторного анализа являются следующие:
. Отбор факторов, определяющих исследуемые результативные показатели.
. Классификация и систематизация факторов с целью обеспечения
комплексного и системного подхода к исследованию их влияния на результаты
хозяйственной деятельности.
. Определение формы зависимости между факторами и результативным
показателем.
. Моделирование взаимосвязей между результативным и факторными
показателями.
. Расчет влияния факторов и оценка роли каждого из них в изменении
величины результативного показателя.
. Работа с факторной моделью.
Отбор факторов для анализа того или другого показателя осуществляется на
основе теоретических и практических знаний, приобретенных в этой отрасли. При
этом обычно исходят из принципа: чем больший комплекс факторов исследуется, тем
точнее будут результаты анализа.
Важным методологическим вопросом в факторном анализе является определение
формы зависимости между факторами и результативными показателями:
функциональная она или стохастическая, прямая или обратная, прямолинейная или
криволинейная. Здесь используется теоретический и практический опыт, а также
способы сравнения параллельных и динамичных рядов, аналитических группировок
исходной информации, графический и др.
1.2
Классификация факторов
Классификация факторов представляет собой распределение их по группам в
зависимости от общих признаков. Она позволяет глубже разобраться в причинах
изменения исследуемых явлений, точнее оценить место и роль каждого фактора в
формировании величины результативных показателей.
Исследуемые в анализе факторы могут быть классифицированы по разным
признакам (рисунок 1.1).
По своей природе факторы подразделяются на природно-климатические,
социально-экономические и производственно-экономические. Природно-климатические
факторы оказывают большое влияние на результаты деятельности в сельском
хозяйстве, в добывающей промышленности, лесном хозяйстве и других отраслях.
Учет их влияния позволяет точнее оценить результаты работы субъектов
хозяйствования.
К социально-экономическим факторам относятся жилищные условия работников,
организация культурно-массовой, спортивной и оздоровительной работы на
предприятии, общий уровень культуры и образования кадров и др. Они способствуют
более полному использованию производственных ресурсов предприятия и повышению
эффективности его работы.
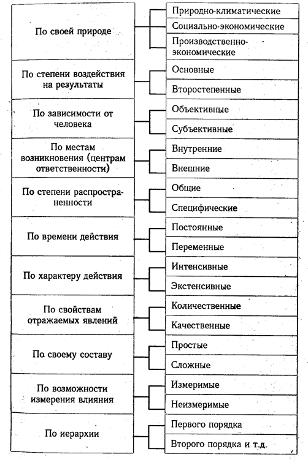
Рисунок
1.1 - Классификация факторов
Примечание
- Источник: [11]
Производственно-экономические
факторы определяют полноту и эффективность использования производственных
ресурсов предприятия и конечные результаты его деятельности.
По
степени воздействия на результаты хозяйственной деятельности факторы делятся на
основные и второстепенные. К основным относятся факторы, которые оказывают
решающее воздействие на результативный показатель. Второстепенными считаются
те, которые не оказывают решающего воздействия на результаты хозяйственной
деятельности в сложившихся условиях. Здесь необходимо заметить, что один и тот
же фактор в зависимости от обстоятельств может быть и основным, и
второстепенным. Умение выделить из разнообразия факторов главные, определяющие
обеспечивает правильность выводов по результатам анализа.
Большое
значение при исследовании экономических явлений и процессов и оценке
результатов деятельности предприятий имеет классификация факторов на внутренние
и внешние, то есть на факторы, которые зависят и не зависят от деятельности
данного предприятия. Основное внимание при анализе должно уделяться
исследованию внутренних факторов, на которые предприятие может воздействовать.
Вместе
с тем во многих случаях при развитых производственных связях и отношениях на
результаты работы каждого предприятия в значительной степени оказывает влияние
деятельность других предприятий, например, равномерность и своевременность
поставок сырья, материалов, их качество, стоимость, конъюнктура рынка,
инфляционные процессы и др. Нередко на результатах работы предприятий
отражаются перемены в области специализации и производственной кооперации. Эти
факторы являются внешними. Они не характеризуют усилия данного коллектива, но
их исследование позволяет точнее определить степень воздействия внутренних
причин и тем самым более полно выявить внутренние резервы производства.
Для
правильной оценки деятельности предприятий факторы необходимо подразделять на
объективные и субъективные Объективные, например стихийное бедствие, не зависят
от воли и желаний людей. В отличие от объективных субъективные причины зависят
от деятельности юридических и физических лиц.
По
степени распространенности факторы делятся на общие и специфические. К общим
относятся факторы, которые действуют во всех отраслях экономики. Специфическими
являются те, которые действуют в условиях отдельной отрасли экономики или
предприятия. Такое деление факторов позволяет полнее учесть особенности
отдельных предприятий, отраслей производства и сделать более точную оценку их
деятельности.
По
сроку воздействия на результаты хозяйственной деятельности различают факторы
постоянные и переменные. Постоянные факторы оказывают влияние на изучаемое
явление беспрерывно, на протяжении всего времени. Воздействие же переменных
факторов проявляется периодически, например, освоение новой техники, новых
видов продукции, новой технологии производства и т.д.
Большое
значение для оценки деятельности предприятий имеет деление факторов по
характеру их действия на интенсивные и экстенсивные. К экстенсивным относятся
факторы, которые связаны с количественным, а не с качественным приростом
результативного показателя, например, увеличение объема производства продукции
путем расширения посевной площади, увеличения поголовья скота, количества
рабочих и т.д. Интенсивные факторы характеризуют степень усилия, напряженности
труда в процессе производства, например, повышение урожайности
сельскохозяйственных культур, продуктивности животных, уровня
производительности труда.
Если
при анализе ставится цель измерить влияние каждого фактора на результаты
хозяйственной деятельности, то их разделяют на количественные и качественные,
сложные и простые, прямые и косвенные, измеримые и неизмеримые.
Количественными
считаются факторы, которые выражают количественную определенность явлений
(количество рабочих, оборудования, сырья и т.д.). Качественные факторы
определяют внутренние качества, признаки и особенности изучаемых объектов
(производительность труда, качество продукции, плодородие почвы и т.д.).
Большинство
изучаемых факторов по своему составу являются сложными, состоят из нескольких
элементов. Однако есть и такие, которые не раскладываются на составные части. В
связи с этим факторы делятся на сложные (комплексные) и простые (элементные).
Примером сложного фактора является производительность труда, а простого -
количество рабочих дней в отчетном периоде.
Как
уже указывалось, одни факторы оказывают непосредственное влияние на
результативный показатель, другие - косвенное. По уровню соподчиненности
(иерархии) различают факторы первого, второго, третьего и последующих уровней
подчинения. К факторам первого уровня относятся те, которые непосредственно
влияют на результативный показатель. Факторы, которые определяют результативный
показатель косвенно, при помощи факторов первого уровня, называются факторами
второго уровня и т.д. На рисунке 1.2 показано, что факторами первого уровня
являются среднегодовая численность рабочих и среднегодовая выработка продукции
одним рабочим. Количество отработанных дней одним рабочим и среднедневная
выработка - факторы второго уровня относительно валовой продукции. К факторам
же третьего уровня относятся продолжительность рабочего дня и среднечасовая
выработка.
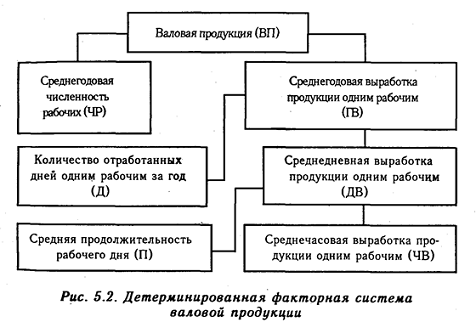
Рисунок
1.2 - Детерминированная факторная система валовой продукции Примечание -
Источник: [11]
Воздействие
отдельных факторов на результативный показатель может быть определено
количественно. Вместе с тем имеется целый ряд факторов, влияние которых на
результаты деятельности предприятий не поддается непосредственному измерению,
например, обеспеченность персонала жильем, детскими учреждениями, уровень
подготовки кадров и др.
1.3
Систематизация факторов
Системный подход вызывает необходимость взаимосвязанного изучения
факторов с учетом их внутренних и внешних связей, взаимодействия и
соподчиненности, что достигается с помощью систематизации.
Одним из способов систематизации факторов является создание детерминированных
факторных систем. Создать факторную систему - значит представить изучаемое
явление в виде алгебраической суммы, частного или произведения нескольких
факторов, определяющих его величину и находящихся с ним в функциональной
зависимости [4].
Большое значение в исследовании стохастических взаимосвязей имеет
структурно-логический анализ связи между изучаемыми показателями. Он позволяет
установить наличие или отсутствие причинно-следственных связей между
исследуемыми показателями, изучить направление связи, форму зависимости и т.д.,
что очень важно при определении степени их влияния на изучаемое явление и при
обобщении результатов анализа.
Анализ структуры связи изучаемых показателей осуществляется с помощью
построения структурно-логической блок-схемы, которая позволяет установить
наличие и направление связи не только между изучаемыми факторами и
результативным показателем, но и между самими факторами. Построив блок-схему,
можно увидеть, что среди изучаемых факторов имеются такие, которые более или менее
непосредственно воздействуют на результативный показатель, и такие, которые
воздействуют не столько на результативный показатель, сколько друг на друга.
Например, на рисунке 1.3 показана связь между себестоимостью единицы
продукции растениеводства и такими факторами, как урожайность культур,
производительность труда, количество внесенного удобрения, качество семян,
степень механизации производства.
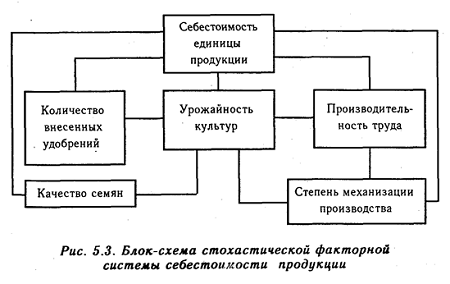
Рисунок
1.3 - Блок-схема стохастической факторной системы себестоимости продукции
Примечание - Источник: [11]
Прежде
всего, необходимо установить наличие и направление связи между себестоимостью
продукции и каждым фактором. Безусловно, между ними существует тесная связь.
Непосредственное влияние на себестоимость продукции оказывает в данном примере
только урожайность культур. Все остальные факторы влияют на себестоимость
продукции не только прямо, но и косвенно, через урожайность культур и
производительность труда. Например, количество внесенных удобрений в почву
содействует повышению урожайности культур, что при прочих одинаковых условиях
обусловливает снижение себестоимости единицы продукции. Однако необходимо
учитывать и то, что увеличение количества внесенных удобрений приводит к росту
суммы затрат на гектар посева. И если сумма затрат возрастает более высокими
темпами, чем урожайность, то себестоимость продукции будет не снижаться, а
повышаться. Значит, связь между этими двумя показателями может быть и прямой, и
обратной. Аналогично влияет на себестоимость продукции и качество семян.
Приобретение элитных, высококачественных семян вызывает рост суммы затрат. Если
они возрастают в большей степени, чем урожайность от применения более
высококачественных семян, то себестоимость продукции будет увеличиваться, и
наоборот.
Степень
механизации производства влияет на себестоимость продукции и прямо, и косвенно.
Повышение уровня механизации вызывает рост затрат на содержание основных
средств производства. Однако при этом увеличивается производительность труда,
растет урожайность, что содействует снижению себестоимости продукции.
Исследование
взаимосвязей между факторами показывает, что из всех изучаемых факторов
отсутствует причинно-следственная связь между качеством семян, количеством
удобрений и механизацией производства. Отсутствует также непосредственная
обратная зависимость данных показателей от уровня урожайности культуры. Все
остальные факторы прямо или косвенно влияют друг на друга.
Таким
образом, систематизация факторов позволяет более глубоко изучить взаимосвязь
факторов при формировании величины изучаемого показателя, что имеет очень
важное значение на следующих этапах анализа, особенно на этапе моделирования
исследуемых показателей.
1.3
Детерминированное моделирование и преобразование факторных систем
Одной из задач факторного анализа является моделирование взаимосвязей
между результативными показателями и факторами, которые определяют их величину.
Моделирование - это один из важнейших методов научного познания, с
помощью которого создается модель (условный образ) объекта исследования.
Сущность его заключается в том, что взаимосвязь исследуемого показателя с
факторными передается в форме конкретного математического уравнения.
В факторном анализе различают модели детерминированные (функциональные) и
стохастические (корреляционные). С помощью детерминированных факторных моделей
исследуется функциональная связь между результативным показателем (функцией) и
факторами (аргументами).
При моделировании детерминированных факторных систем необходимо выполнять
ряд требований:
. Факторы, включаемые в модель, и сами модели должны иметь определенно
выраженный характер, реально существовать, а не быть придуманными абстрактными
величинами или явлениями.
. Факторы, которые входят в систему, должны быть не только необходимыми
элементами формулы, но и находиться в причинно-следственной связи с изучаемыми
показателями. Иначе говоря, построенная факторная система должна иметь
познавательную ценность. Факторные модели, которые отражают
причинно-следственные отношения между показателями, имеют значительно большее
познавательное значение, чем модели, созданные при помощи приемов
математической абстракции. Последнее можно проиллюстрировать следующим образом.
Возьмем две модели:
)ВП=ЧРхГВ;
)ГВ=ВП/ЧР,
где ВП - валовая продукция предприятия;
ЧР - численность работников на предприятии;
ГВ - среднегодовая выработка продукции одним работником.
В первой системе факторы находятся в причинной связи с результативным
показателем, а во второй - в математическом соотношении. Значит, вторая модель,
построенная на математических зависимостях, имеет меньшее познавательное
значение, чем первая.
. Все показатели факторной модели должны быть количественно измеримыми,
т.е. должны иметь единицу измерения и необходимую информационную
обеспеченность.
. Факторная модель должна обеспечивать возможность измерения влияния
отдельных факторов, это значит, что в ней должна учитываться соразмерность
изменений результативного и факторных показателей, а сумма влияния отдельных
факторов должна равняться общему приросту результативного показателя.
В детерминированном анализе выделяют следующие типы наиболее часто
встречающихся факторных моделей [6, 8].
. Аддитивные модели:
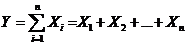 (1.1)
(1.1)
Они
используются в тех случаях, когда результативный показатель представляет собой
алгебраическую сумму нескольких факторных показателей.
.
Мультипликативные модели:
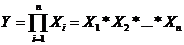 (1.2)
(1.2)
Этот
тип моделей применяется тогда, когда результативный показатель представляет
собой произведение нескольких факторов.
.
Кратные модели:
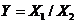 (1.3)
(1.3)
Они
применяются тогда, когда результативный показатель получают делением одного
факторного показателя на величину другого.
.
Смешанные (комбинированные) модели - это сочетание в различных комбинациях
предыдущих моделей:
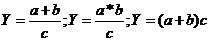 и т.д. (1.4)
и т.д. (1.4)
Моделирование
мультипликативных факторных систем осуществляется путем последовательного
расчленения факторов исходной системы на факторы-сомножители. Например, при
исследовании процесса формирования объема производства продукции можно
применять такие детерминированные модели, как:
ВП
= ЧР*ГВ = ЧР*Д*ДВ = ЧР*Д*П*ЧВ
Эти
модели отражают процесс детализации исходной факторной системы
мультипликативного вида и расширения ее за счет расчленения на сомножители
комплексных факторов. Степень детализации и расширения модели зависит от цели
исследования, а также от возможностей детализации и формализации показателей в
пределах установленных правил.
Аналогичным
образом осуществляется моделирование аддитивных факторных систем за счет
расчленения одного или нескольких факторных показателей на составные элементы.
Как
известно, объем реализации продукции равен:
РП
= VBП - VИ,
где
VBП - объем производства; И - объем внутрихозяйственного использования
продукции.
В
хозяйстве продукция использовалась в качестве семян (С) и кормов (К). Тогда
приведенную исходную модель можно записать следующим образом:
РП
= VBП - (С + К).
К
классу кратных моделей применяют следующие способы их преобразования:
удлинения, формального разложения, расширения и сокращения.
Первый
метод предусматривает удлинение числителя исходной модели путем замены одного
или нескольких факторов на сумму однородных показателей. Например,
себестоимость единицы продукции можно представить в качестве функции двух
факторов: изменения суммы затрат (3) и объема выпуска продукции (VBП). Исходная
модель этой факторной системы будет иметь вид
С
= З/VВП
Если
общую сумму затрат (3) заменить отдельными их элементами, такими, как
заработная плата (3П), сырье и материалы (СМ), амортизация основных средств
(А), накладные расходы (HP) и др., то детерминированная факторная модель будет
иметь вид аддитивной модели с новым набором факторов:
С
= ЗП/VВП+СМ/VВП+А/VВП+НР/VВП=Х1 + Х2 + Х3 + Х4
где
Х1 - трудоемкость продукции;
Х2
- материалоемкость продукции;
Х3
- фондоемкость продукции;
Х4
- уровень накладных расходов.
Способ
формального разложения факторной системы предусматривает удлинение знаменателя
исходной факторной модели путем замены одного или нескольких факторов на сумму
или произведение однородных показателей. Если В = L+М+N+Р,то
Y = А/В = А/(L+M+N+P)
На
практике такое разложение встречается довольно часто. Например, при анализе
показателя рентабельности производства (R):
R=П/З
где
П - сумма прибыли от реализации продукции;
-
сумма затрат на производство и реализацию продукции.
Если
сумму затрат заменить на отдельные ее элементы, конечная модель в результате
преобразования приобретет следующий вид:
R=П/(ЗП+СМ+А+НР)
Метод
расширения предусматривает расширение исходной факторной модели за счет
умножения числителя и знаменателя дроби на один или несколько новых
показателей. Например, если в исходную модель Y=A/B ввести новый показатель с,
то модель примет вид
=A/B
= А*С/В*С = А/С*С/В = Х1 + Х2
В
результате получилась конечная мультипликативная модель в виде произведения
нового набора факторов.
Этот
способ моделирования очень широко применяется в анализе. Например,
среднегодовую выработку продукции одним работником можно записать таким
образом: ГВ = ВП/ЧР. Если ввести такой показатель, как количество отработанных
дней всеми работниками (D), то получим следующую модель годовой выработки:
ГВ=ВП*D/ЧР*D
= ВП/D*D/ЧР = ДВ*Д
где
ДВ - среднедневная выработка;
Д
- количество отработанных дней одним работником.
Способ
сокращения представляет собой создание новой факторной модели путем деления
числителя и знаменателя дроби на один и тот же показатель
=A/B
= А:С/В:С = Х1 / Х2
В
результате получилась более содержательная модель, которая имеет большую
познавательную ценность, так как учитывает причинно-следственные связи между
показателями.
Таким
образом, результативные показатели могут быть разложены на составные элементы
(факторы) различными способами и представлены в виде различных типов
детерминированных моделей. Выбор способа моделирования зависит от объекта
исследования, поставленной цели, а также от профессиональных знаний и навыков
исследователя.
2.
Дисперсионный анализ
2.1 Основные
понятия дисперсионного анализа
В процессе наблюдения за исследуемым объектом качественные факторы
произвольно или заданным образом изменяются. Конкретная реализация фактора
(например, определенный температурный режим, выбранное оборудование или
материал) называется уровнем фактора или способом обработки. Модель
дисперсионного анализа с фиксированными уровнями факторов называют моделью I,
модель со случайными факторами - моделью II. Благодаря варьированию фактора
можно исследовать его влияние на величину отклика.
В зависимости от количества факторов, определяющих вариацию
результативного признака, дисперсионный анализ подразделяют на однофакторный и
многофакторный.
Основными схемами организации исходных данных с двумя и более факторами
являются:
перекрестная классификация, характерная для моделей I, в которых каждый
уровень одного фактора сочетается при планировании эксперимента с каждой
градацией другого фактора;
иерархическая (гнездовая) классификация, характерная для модели II, в
которой каждому случайному, наудачу выбранному значению одного фактора
соответствует свое подмножество значений второго фактора.
Если одновременно исследуется зависимость отклика от качественных и
количественных факторов, т.е. факторов смешанной природы, то используется
ковариационный анализ [5].
При обработке данных эксперимента наиболее разработанными и поэтому
распространенными считаются две модели. Их различие обусловлено спецификой
планирования самого эксперимента. В модели дисперсионного анализа с
фиксированными эффектами исследователь намеренно устанавливает строго
определенные уровни изучаемого фактора. Термин «фиксированный эффект» в данном
контексте имеет тот смысл, что самим исследователем фиксируется количество
уровней фактора и различия между ними. При повторении эксперимента он или
другой исследователь выберет те же самые уровни фактора. В модели со случайными
эффектами уровни значения фактора выбираются исследователем случайно из
широкого диапазона значений фактора, и при повторных экспериментах,
естественно, этот диапазон будет другим.
Таким образом, данные модели отличаются между собой способом выбора
уровней фактора, что, очевидно, в первую очередь влияет на возможность
обобщения полученных экспериментальных результатов. Для дисперсионного анализа
однофакторных экспериментов различие этих двух моделей не столь существенно,
однако в многофакторном дисперсионном анализе оно может оказаться весьма
важным.
При проведении дисперсионного анализа должны выполняться следующие
статистические допущения: независимо от уровня фактора величины отклика имеют
нормальный закон распределения и одинаковую дисперсию. Такое равенство
дисперсий называется гомогенностью. Таким образом, изменение способа обработки
сказывается лишь на положении случайной величины отклика, которое
характеризуется средним значением или медианой.
Говорят, что техника дисперсионного анализа является
"робастной". Этот термин, используемый статистиками, означает, что
данные допущения могут быть в некоторой степени нарушены, но, несмотря на это,
технику можно использовать.
При неизвестном законе распределения величин отклика используют
непараметрические (чаще всего ранговые) методы анализа.
В
основе дисперсионного анализа лежит разделение дисперсии на части или
компоненты. Вариацию, обусловленную влиянием фактора, положенного в основу
группировки, характеризует межгрупповая дисперсия σ2. Она
является мерой вариации частных средних по группам 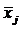 вокруг общей средней
вокруг общей средней 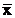 и
определяется по формуле 2.1:
и
определяется по формуле 2.1:
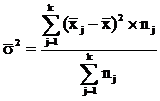 , (2.1)
, (2.1)
где k - число групп;
nj - число единиц в j-ой группе;
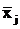 - частная
средняя по j-ой группе;
- частная
средняя по j-ой группе;
- общая
средняя по совокупности единиц.
Вариацию, обусловленную влиянием прочих факторов, характеризует в каждой
группе внутригрупповая дисперсия σj2 (формула 2.2).
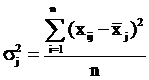 . (2.2)
. (2.2)
Между
общей дисперсией σ02, внутригрупповой дисперсией σ2 и
межгрупповой дисперсией 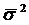 существует соотношение 2.3:
существует соотношение 2.3:
σ02 = 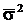 + σ2.
(2.3)
+ σ2.
(2.3)
Внутригрупповая
дисперсия объясняет влияние неучтенных при группировке факторов, а межгрупповая
дисперсия объясняет влияние факторов группировки на среднее значение по группе
[3].
2.2
Однофакторный дисперсионный анализ
Однофакторная дисперсионная
модель имеет вид 2.4:
xij = μ + Fj + εij, (2.4)
где хij - значение
исследуемой переменой, полученной на i-м уровне фактора (i=1,2,...,т) c j-м порядковым
номером (j=1,2,...,n);
Fi - эффект,
обусловленный влиянием i-го уровня фактора;
εij - случайная компонента,
или возмущение, вызванное влиянием неконтролируемых факторов, т.е. вариацией
переменой внутри отдельного уровня.
Основные предпосылки
дисперсионного анализа [5]:
- математическое ожидание
возмущения εij равно нулю для
любых i, т.е.
M(εij) = 0; (2.5)
- возмущения εij взаимно
независимы;
дисперсия переменной xij (или
возмущения εij) постоянна
длялюбых i, j, т.е.
D(εij) = σ2; (2.6)
переменная xij (или
возмущение εij) имеет
нормальный законраспределения N(0;σ2).
Влияние уровней фактора может
быть как фиксированным или систематическим (модель I), так и
случайным (модель II).
Пусть, например, необходимо
выяснить, имеются ли существенные различия между партиями изделий по некоторому
показателю качества, т.е. проверить влияние на качество одного фактора - партии
изделий. Если включить в исследование все партии сырья, то влияние уровня
такого фактора систематическое (модель I), а полученные
выводы применимы только к тем отдельным партиям, которые привлекались при
исследовании. Если же включить только отобранную случайно часть партий, то
влияние фактора случайное (модель II). В многофакторных комплексах
возможна смешанная модель III, в которой одни факторы имеют
случайные уровни, а другие - фиксированные.
Пусть имеется m партий
изделий. Из каждой партии отобрано соответственно n1, n2, …, nm изделий (для
простоты полагается, что n1=n2=...=nm=n). Значения
показателя качества этих изделий представлены в матрице наблюдений:
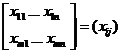 (i = 1,2, …, m; j = 1,2, …, n).
(i = 1,2, …, m; j = 1,2, …, n).
Если полагать, что элементы строк матрицы наблюдений - это численные значения случайных
величин Х1,Х2,...,Хm, выражающих качество изделий и
имеющих нормальный
закон распределения с математическими ожиданиями соответственно a1,а2,...,аm
и одинаковыми дисперсиями σ2, то данная задача
сводится к проверке нулевой гипотезы Н0:
a1=a2 =...= аm, осуществляемой в дисперсионном анализе.
Усреднение по какому-либо индексу обозначено звездочкой (или точкой) вместо индекса,
тогда средний показатель качества изделий i-й партии, или групповая средняя для i-го уровня фактора, примет вид:
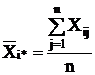 , (2.6)
, (2.6)
где
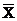 i* - среднее значение по
столбцам;
i* - среднее значение по
столбцам;
ij - элемент матрицы наблюдений;
n - объем
выборки.
А общая средняя:
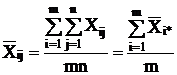 . (2.7)
. (2.7)
Сумма квадратов отклонений наблюдений хij от общей средней ** выглядит так:
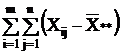 2=
2=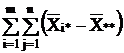 2+
2+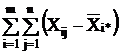 2+
2+
+2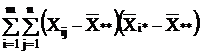 2.
(2.8)
2.
(2.8)
или
Q = Q1 + Q2 + Q3.
Последнее слагаемое равно нулю
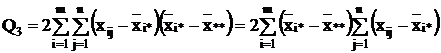 =0. (2.9)
=0. (2.9)
так как сумма отклонений значений переменной от ее
средней равна нулю, т.е.
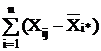 2=0.
2=0.
Первое слагаемое можно записать в виде:
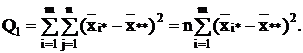
В результате получается тождество:
Q = Q1 + Q2, (2.10)
где 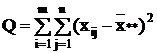 - общая, или полная, сумма квадратов отклонений;
- общая, или полная, сумма квадратов отклонений;
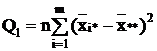 - сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная)
сумма квадратов
отклонений;
- сумма квадратов отклонений групповых средних от общей средней, или межгрупповая (факторная)
сумма квадратов
отклонений;
 - сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая
(остаточная) сумма квадратов отклонений.
- сумма квадратов отклонений наблюдений от групповых средних, или внутригрупповая
(остаточная) сумма квадратов отклонений.
В
разложении (2.10) заключена основная идея дисперсионного анализа. Применительно к
рассматриваемой задаче равенство
(2.10) показывает, что общая вариация
показателя качества, измеренная суммой Q, складывается из двух компонент - Q1 и Q2, характеризующих изменчивость этого показателя между партиями (Q1) и изменчивость внутри партий (Q2), характеризующих одинаковую для всех партий вариацию под
воздействием неучтенных факторов.
В дисперсионном анализе анализируются не сами суммы квадратов отклонений, а так называемые средние квадраты,
являющиеся несмещенными оценками
соответствующих дисперсий, которые получаются делением сумм квадратов отклонений на соответствующее число степеней
свободы [3].
Число степеней свободы определяется как общее число наблюдений минус
число связывающих их уравнений. Поэтому для среднего квадрата s12, являющегося несмещенной оценкой межгрупповой
дисперсии, число степеней свободы k1=m-1, так как при его расчете
используются m групповых средних, связанных между собой
одним уравнением (2.7). А для среднего квадрата s22, являющегося несмещенной
оценкой внутригрупповой дисперсии, число степеней свободы k2=mn-m, т.к. при ее расчете используются все mn наблюдений, связанных между собой m уравнениями (2.6).
Таким образом:
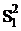 = Q1/(m-1),
= Q1/(m-1),
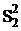 = Q2/(mn-m).
= Q2/(mn-m).
Если найти математические ожидания средних квадратов и , подставить в их формулы
выражение xij (2.4) через параметры модели,
то получится:
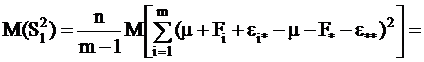

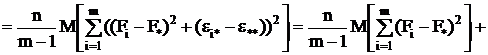
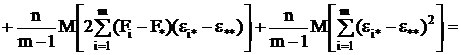
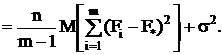 (2.11)
(2.11)
т.к. с учетом свойств математического ожидания
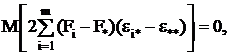 а
а
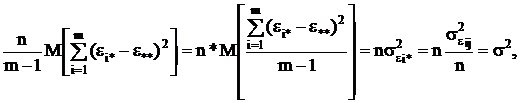
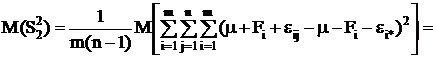
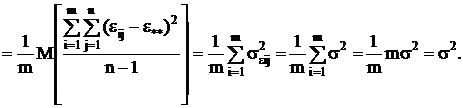 (2.12)
(2.12)
Для модели I с фиксированными уровнями фактора
Fi(i=1,2,...,m) - величины неслучайные,
поэтому
M(S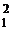 ) =
) =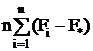 2 /(m-1) +σ2.
2 /(m-1) +σ2.
Гипотеза H0
примет вид Fi = F*(i = 1,2,...,m), т.е. влияние всех уровней фактора одно и то же. В случае
справедливости этой
гипотезы
M(S)= M(S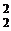 )= σ2.
)= σ2.
Для случайной модели II слагаемое Fi в выражении (2.4) - величина случайная.
Обозначая ее дисперсией
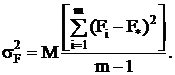
получим
из (2.11)
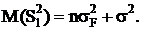 (2.13)
(2.13)
и,
как и в модели I M(S)= σ2.
В таблице 2.1 представлен общий вид вычисления
значений, с помощью дисперсионного анализа.
Таблица 2.1 - Базовая таблица дисперсионного анализа
|
Компоненты дисперсии
|
Сумма квадратов
|
Число степеней свободы
|
Средний квадрат
|
Математическое ожидание
среднего квадрата
|
|
Межгрупповая
|
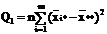
|
m-1
|
= Q1/(m-1)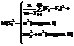
|
|
|
Внутригрупповая
|
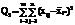
|
mn-m
|
= Q2/(mn-m)M(S)= σ2
|
|
|
Общая
|
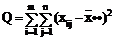
|
mn-1
|
|
|
Примечание - Источник: [5]
Гипотеза H0 примет вид σF2 =0. В случае
справедливости этой гипотезы
M(S)= M(S)= σ2.
В
случае однофакторного комплекса как для модели I, так и модели II
средние квадраты S2 и S2, являются несмещенными и независимыми оценками одной
и той же дисперсии σ2.
Следовательно, проверка нулевой гипотезы H0 свелась к проверке существенности различия
несмещенных выборочных оценок S и S дисперсии σ2.
Гипотеза H0
отвергается, если фактически вычисленное значение статистики F = S/S больше критического Fα:K1:K2, определенного
на уровне значимости α при числе степеней свободы k1=m-1 и k2=mn-m,
и принимается, если F < Fα:K1:K2 .
F-
распределение Фишера (для x > 0) имеет следующую функцию плотности (для 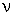 = 1, 2, ...;
= 1, 2, ...; 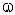 = 1, 2,
...):
= 1, 2,
...):
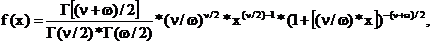
где
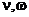 - степени свободы;
- степени свободы;
Г
- гамма-функция.
Применительно к данной задаче опровержение гипотезы H0 означает наличие существенных различий в качестве
изделий различных партий на рассматриваемом
уровне значимости.
Для вычисления сумм квадратов Q1, Q2, Q часто бывает
удобно использовать следующие формулы:
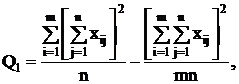 (2.14)
(2.14)
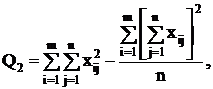 (2.15)
(2.15)
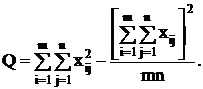 (2.16)
(2.16)
т.е. сами средние, вообще говоря,
находить не обязательно.
Таким образом, процедура однофакторного дисперсионного
анализа состоит в проверке гипотезы H0 о том, что
имеется одна группа однородных экспериментальных данных против альтернативы о
том, что таких групп больше, чем одна. Под однородностью понимается
одинаковость средних значений и дисперсий в любом подмножестве данных. При этом
дисперсии могут быть как известны, так и неизвестны заранее. Если имеются
основания полагать, что известная или неизвестная дисперсия измерений одинакова
по всей совокупности данных, то задача однофакторного дисперсионного анализа
сводится к исследованию значимости различия средних в группах данных [5].
2.3 Многофакторный
дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы
между многофакторным и однофакторным дисперсионным анализом нет. Многофакторный
анализ не меняет общую логику дисперсионного анализа, а лишь несколько
усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из
факторов по отдельности, следует оценивать и их совместное действие. Таким
образом, то новое, что вносит в анализ данных многофакторный дисперсионный
анализ, касается в основном возможности оценить межфакторное взаимодействие.
Тем не менее, по-прежнему остается возможность оценивать влияние каждого
фактора в отдельности. В этом смысле процедура многофакторного дисперсионного
анализа (в варианте ее компьютерного использования) несомненно, более экономична,
поскольку всего за один запуск решает сразу две задачи: оценивается влияние
каждого из факторов и их взаимодействие [3].
Общая схема двухфакторного эксперимента, данные
которого обрабатываются дисперсионным анализом имеет вид (рисунок 2.1):
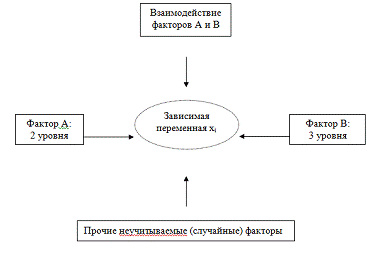
Рисунок 2.1 - Схема двухфакторного эксперимента
Примечание - Источник: [5]
Данные, подвергаемые многофакторному дисперсионному
анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в
рассматриваемой задаче о качестве различных m партий изделия
изготавливались на разных t станках и требуется выяснить, имеются
ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к
задаче двухфакторного дисперсионного анализа.
Все данные представлены в таблице
2.2, в которой по строкам - уровни Ai фактора А, по
столбцам - уровни Bj фактора В, а в соответствующих ячейках,
таблицы находятся значения показателя качества изделий xijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 2.2 - Показатели качества
изделий
|
B1
|
B2
|
…
|
Bj
|
…
|
Bl
|
|
A1
|
x11l,…,x11k
|
x12l,…,x12k
|
…
|
x1jl,…,x1jk
|
…
|
x1ll,…,x1lk
|
|
A2
|
x21l,…,x21k
|
x22l,…,x22k
|
…
|
x2jl,…,x2jk
|
…
|
x2ll,…,x2lk
|
|
…
|
…
|
…
|
…
|
…
|
…
|
…
|
|
Ai
|
xi1l,…,xi1k
|
xi2l,…,xi2k
|
…
|
xijl,…,xijk
|
…
|
xjll,…,xjlk
|
|
…
|
…
|
…
|
…
|
…
|
…
|
…
|
|
Am
|
xm1l,…,xm1k
|
xm2l,…,xm2k
|
…
|
xmjl,…,xmjk
|
…
|
xmll,…,xmlk
|
Примечание - Источник: [5]
Двухфакторная дисперсионная модель имеет вид:
xijk=μ+Fi+Gj+Iij+εijk, (2.17)
где xijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
Fi - эффект, обусловленный влиянием i-го уровня фактора А;
Gj - эффект, обусловленный влиянием j-го уровня фактора В;
Iij - эффект, обусловленный
взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке
ij от суммы первых трех слагаемых в
модели;
εijk - возмущение, обусловленное
вариацией переменной внутри отдельной ячейки.
Предполагается, что εijk имеет нормальный закон распределения
N(0; с2), а все математические ожидания F*, G*, Ii*, I*j равны нулю.
Групповые средние находятся по формулам:
в ячейке:
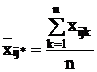 ,
,
по
строке:
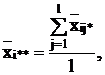
по
столбцу:
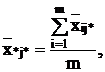
общая
средняя:
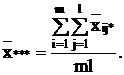
В таблице 2.3 представлен общий вид вычисления
значений, с помощью дисперсионного анализа.
Таблица
2.3 - Базовая таблица дисперсионного анализа
|
Компоненты дисперсии
|
Сумма квадратов
|
Число степеней свободы
|
Средние квадраты
|
|
Межгрупповая (фактор А)
|
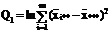 m-1 m-1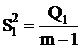
|
|
|
|
Межгрупповая (фактор B)
|
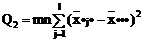 l-1 l-1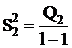
|
|
|
|
Взаимодействие
|
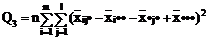 (m-1)(l-1) (m-1)(l-1)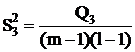
|
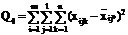 mln - ml mln - ml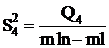
|
|
|
|
Общая
|
 mln - 1 mln - 1
|
|
|
Примечание - Источник: [5]
Проверка нулевых гипотез HA, HB, HAB об отсутствии влияния на
рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется
сравнением отношений 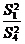 ,
, 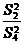 ,
, 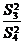 (для модели I с фиксированными
уровнями факторов) или отношений
(для модели I с фиксированными
уровнями факторов) или отношений 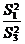 ,
, 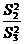 , (для случайной модели II) с соответствующими
табличными значениями F - критерия Фишера - Снедекора. Для смешанной модели III проверка гипотез
относительно факторов с фиксированными уровнями производится также как и в
модели II, а факторов со случайными уровнями - как в модели I.
, (для случайной модели II) с соответствующими
табличными значениями F - критерия Фишера - Снедекора. Для смешанной модели III проверка гипотез
относительно факторов с фиксированными уровнями производится также как и в
модели II, а факторов со случайными уровнями - как в модели I.
Если n=1, т.е. при одном наблюдении в ячейке, то не все
нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов
отклонений, а с ней и средний квадрат 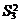 , так как в этом случае не может быть речи о
взаимодействии факторов.
, так как в этом случае не может быть речи о
взаимодействии факторов.
С
точки зрения техники вычислений для нахождения сумм квадратов Q1, Q2, Q3, Q4, Q
целесообразнее использовать формулы:
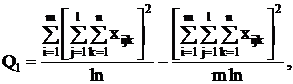
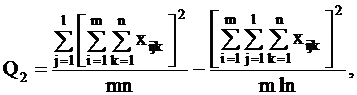
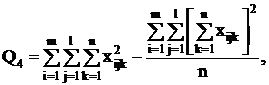
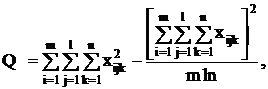
Q3 = Q - Q1 - Q2 - Q4.
Отклонение от основных предпосылок дисперсионного анализа - нормальности распределения
исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) - не
сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в
ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках
резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему
с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их
средними значениями
других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие
данные не следует учитывать при подсчете числа степеней свободы.
3.
Дисперсионный анализ в контексте статистических методов
Статистические методы анализа - это методология измерения результатов
деятельности человека, то есть перевода качественных характеристик в
количественные.
Основные этапы при проведении статистического анализа:
-
содержательный анализ <#"824305.files/image080.gif">
Примечание - Источник: [5]
К большинству сложных систем применим принцип Парето, согласно которому
20 % факторов определяют свойства системы на 80 %. Поэтому первоочередной
задачей исследователя имитационной модели является отсеивание несущественных
факторов, позволяющее уменьшить размерность задачи оптимизации модели.
Анализ дисперсии оценивает отклонение наблюдений от общего среднего.
Затем вариация разбивается на части, каждая из которых имеет свою причину.
Остаточная часть вариации, которую не удается связать с условиями эксперимента,
считается его случайной ошибкой. Для подтверждения значимости используется
специальный тест - F-статистика.
Дисперсионный анализ определяет, есть ли эффект. Регрессионный анализ
позволяет прогнозировать отклик (значение целевой функции) в некоторой точке
пространства параметров. Непосредственной задачей регрессионного анализа
является оценка коэффициентов регрессии.
Слишком большая размерность выборок затрудняет проведение статистических
анализов, поэтому имеет смысл уменьшить размер выборки.
Применив дисперсионный анализ можно выявить значимость влияния различных
факторов на исследуемую переменную. Если влияние фактора окажется
несущественным, то этот фактор можно исключить из дальнейшей обработки.
3.1 Методы
факторного анализа
Факторный анализ включает совокупность методов, которые на основе реально
существующих связей признаков (или объектов) позволяют выявлять латентные
обобщающие характеристики организационной структуры и механизма развития
изучаемых явлений и процессов.
Понятие латентности в определении ключевое. Оно означает неявность
характеристик, раскрываемых при помощи методов факторного анализа. Вначале имеется
дело с набором элементарных признаков Xj, их взаимодействие предполагает наличие определенных
причин, особенных условий, т.е. существование некоторых скрытых факторов.
Последние устанавливаются в результате обобщения элементарных признаков и
выступают как интегрированные характеристики, или признаки, но более высокого
уровня. Естественно, что коррелировать могут не только тривиальные признаки Xj, но и сами наблюдаемые объекты Ni поэтому поиск латентных факторов
теоретически возможен как по признаковым, так и по объектным данным.
Если объекты характеризуются достаточно большим числом элементарных
признаков (m > 3), то логично и другое
предположение - о существовании плотных скоплений точек (признаков) в
пространстве n объектов. При этом новые оси обобщают
уже не признаки Xj, а объекты ni, соответственно и латентные факторы Fr
будут распознаны по составу наблюдаемых объектов:
Fr = c1n1 + c2n2 + ... + cNnN,
где ci - вес объекта ni в факторе Fr.
В зависимости от того, какой из рассмотренных выше тип корреляционной
связи - элементарных признаков или наблюдаемых объектов - исследуется в
факторном анализе, различают R и Q - технические приемы обработки данных.
Название R-техники носит объемный анализ данных по m признакам, в
результате него получают r линейных комбинаций (групп) признаков: Fr=f(Xj),
(r=1..m). Анализ по данным о близости (связи) n наблюдаемых объектов называется
Q-техникой и позволяет определять r линейных комбинаций (групп) объектов: F=f(ni), (i = l .. N).
Набор методов факторного анализа в настоящее время достаточно велик,
насчитывает десятки различных подходов и приемов обработки данных. Чтобы в
исследованиях ориентироваться на правильный выбор методов, необходимо
представлять их особенности. Разделим все методы факторного анализа на несколько
классификационных групп [5]:
Метод главных компонент. Строго говоря, его не относят к факторному
анализу, хотя он имеет с ним много общего. Специфическим является, во-первых,
то, что в ходе вычислительных процедур одновременно получают все главные компоненты
и их число первоначально равно числу элементарных признаков. Во-вторых,
постулируется возможность полного разложения дисперсии элементарных признаков,
другими словами, ее полное объяснение через латентные факторы (обобщенные
признаки).
Методы факторного анализа. Дисперсия элементарных признаков здесь
объясняется не в полном объеме, признается, что часть дисперсии остается
нераспознанной как характерность. Факторы обычно выделяются последовательно:
первый, объясняющий наибольшую долю вариации элементарных признаков, затем
второй, объясняющий меньшую, вторую после первого латентного фактора часть
дисперсии, третий и т.д. Процесс выделения факторов может быть прерван на любом
шаге, если принято решение о достаточности доли объясненной дисперсии элементарных
признаков или с учетом интерпретируемости латентных факторов.
Методы факторного анализа целесообразно разделить дополнительно на два
класса: упрощенные и современные аппроксимирующие методы. Простые методы
факторного анализа в основном связаны с начальными теоретическими разработками.
Они имеют ограниченные возможности в выделении латентных факторов и
аппроксимации факторных решений. К ним относятся:
однофакторная модель. Она позволяет выделить только один генеральный
латентный и один характерный факторы. Для возможно существующих других
латентных факторов делается предположение об их незначимости;
бифакторная модель. Допускает влияние на вариацию элементарных признаков
не одного, а нескольких латентных факторов (обычно двух) и одного характерного
фактора;
центроидный метод. В нем корреляции между переменными рассматриваются как
пучок векторов, а латентный фактор геометрически представляется как
уравновешивающий вектор, проходящий через центр этого пучка. Метод позволяет
выделять несколько латентных и характерные факторы, впервые появляется
возможность соотносить факторное решение с исходными данными, т.е. в простейшем
виде решать задачу аппроксимации.
Современные аппроксимирующие методы часто предполагают, что первое,
приближенное решение уже найдено каким либо из способов, последующими шагами
это решение оптимизируется. Методы отличаются сложностью вычислений. К этим
методам относятся:
групповой метод. Решение базируется на предварительно отобранных
каким-либо образом группах элементарных признаков;
метод главных факторов. Наиболее близок методу главных компонент, отличие
заключается в предположении о существовании характерностей;
метод максимального правдоподобия, минимальных остатков, а-факторного
анализа канонического факторного анализа, все оптимизирующие.
Эти методы позволяют последовательно улучшить предварительно найденные
решения на основе использования статистических приемов оценивания случайной
величины или статистических критериев, предполагают большой объем трудоемких
вычислений. Наиболее перспективным и удобным для работы в этой группе
признается метод максимального правдоподобия.
Основной задачей, которую решают разнообразными методами факторного
анализа, включая и метод главных компонент, является сжатие информации, переход
от множества значений по m
элементарным признакам с объемом информации n х m к
ограниченному множеству элементов матрицы факторного отображения (m х r) или матрицы значений латентных факторов для каждого
наблюдаемого объекта размерностью n х r, причем обычно r < m.
Методы факторного анализа позволяют также визуализировать структуру
изучаемых явлений и процессов, а это значит определять их состояние и
прогнозировать развитие. Наконец, данные факторного анализа дают основания для
идентификации объекта, т.е. решения задачи распознавания образа.
Методы факторного анализа обладают свойствами, весьма привлекательными
для их использования в составе других статистических методов, наиболее часто в
корреляционно-регрессионном анализе, кластерном анализе, многомерном
шкалировании и др.
3.2 Парная
регрессия. Вероятностная природа регрессионных моделей
Если рассмотреть задачу анализа расходов на питание в группах с
одинаковыми доходами, например в $10.000(x), то это детерминированная величина.
А вот Y - доля этих денег, затрачиваемая на питание - случайна и может меняться
от года к году. Поэтому для каждого i-го индивида:
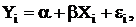
где
εi -
случайная ошибка;
α и β
- константы (теоретически), хотя могут
меняться от модели к модели.
Предпосылки
для парной регрессии:
X
и Y связаны линейно;
Х
- неслучайная переменная с фиксированными значениями;
- ε - ошибки нормально распределены N(0,σ2);
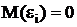 ;
;
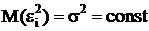 .
.
На
рисунке 3.1 представлена модель парной регрессии.
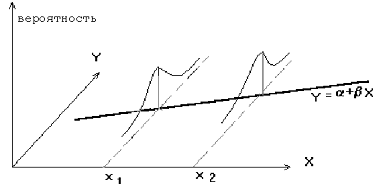
Рисунок
3.1 - Модель парной регрессии
Примечание
- Источник: [3]
Эти
предпосылки описывают классическую линейную регрессионную модель.
Если
ошибка имеет ненулевое среднее, исходная модель будет эквивалентна новой модели
и другим свободным членом, но с нулевым средним для ошибки.
Если
выполняются предпосылки, то МНК оценки 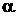 и
и 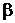 являются эффективными линейными несмещенными оценками
являются эффективными линейными несмещенными оценками
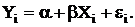
Если
обозначить:
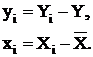
то
что математическое ожидание и дисперсии коэффициентов и будут
следующие:
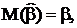
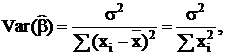
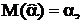
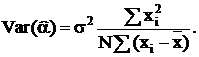
Ковариация
коэффициентов:

Если
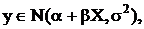 то и распределены тоже нормально:
то и распределены тоже нормально:
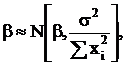

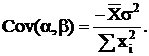
Отсюда
следует, что:
Вариация
β
полностью определяется вариацией ε;
-
Чем выше дисперсия X - тем лучше оценка β.
Полная
дисперсия определяется по формуле:
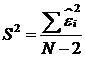
Дисперсия
отклонений в таком виде - несмещенная оценка и называется стандартной ошибкой
регрессии. N-2 - может быть интерпретировано как число степеней свободы.
Анализ
отклонений от линии регрессии может представить полезную меру того, насколько
оцененная регрессия отражает реальные данные. Хорошая регрессия та, которая
объясняет значительную долю дисперсии Y и наоборот плохая регрессия не
отслеживает большую часть колебаний исходных данных. Интуитивно ясно, что
всякая дополнительная информация позволит улучшить модель, то есть уменьшить
необъясненную долю вариации Y. Для анализа регрессионной модели проводят
разложение дисперсии на составляющие, определяют коэффициент детерминации R2.
Отношение
двух дисперсий распределено по F-распределению, т. е. если проверить на
статистическую значимость отличия дисперсии модели от дисперсии остатков, можно
сделать вывод о значимости R2.
Проверка
гипотезы о равенстве дисперсий этих двух выборок:

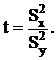
Если
гипотеза Н0 (о равенстве дисперсий нескольких выборок) верна, t
имеет F-распределение с (m1,m2)=(n1-1,n2-1)
степенями свободы.
Посчитав
F - отношение как отношение двух дисперсий и сравнив его с табличным значением,
можно сделать вывод о статистической значимости R2 [7].
4. Применение
дисперсионного анализа в статистических исследованиях
С помощью дисперсионного анализа исследуют влияние одной или нескольких
независимых переменных на одну зависимую переменную (одномерный анализ) или на
несколько зависимых переменных (многомерный анализ). В обычном случае
независимые переменные принимают только дискретные значения (и относятся к
номинальной или порядковой шкале); в этой ситуации также говорят о факторном
анализе. Если же независимые переменные принадлежат к интервальной шкале или к
шкале отношений, то их называют ковариациями, а соответствующий анализ -
ковариационным.
Применим для исследования пакет прикладных программ SPSS.
В рамках SPSS предлагается выполнение дисперсионного анализа в рамках
двух подходов [1]:
при помощи традиционного "классического" метода по Фишеру
(Fisher);
при помощи нового метода "обобщенной линейной модели".
Первый подход сводится к разложению по методу наименьших квадратов (МНК);
в однофакторном случае совокупная дисперсия всех наблюдаемых значений
раскладывается на дисперсию внутри отдельных групп и дисперсию между группами.
В основе обобщенной линейной модели напротив, лежит, корреляционный или
регрессионный анализ.
Дисперсионный анализ может быть вызван посредством выбора меню Analyze
(Анализ) General Linear Model (Общая линейная модель). Можно провести
одномерный дисперсионный анализ (Univariate...), многомерный дисперсионный
анализ (Multivariate...), многомерный дисперсионный анализ с учетом повторных
измерений (Repeated Measures...). И, наконец, в данном меню имеется один пункт
для расчёта компонентов дисперсии (Variance Components...).
Возможно также проведение дисперсионного анализа по традиционному
"классическому" методу Фишера. Однако такой анализ выполним только за
счёт использования программного синтаксиса (процедура ANOVA).
4.1
Статистическое исследование удельного веса мужчин по областям Республики
Беларусь с помощью одномерного дисперсионного анализа
Одномерный дисперсионный анализ исследует влияние одной или нескольких
независимых переменных на одну зависимую. Одномерный дисперсионный анализ может
быть однофакторным (one-way ANOVA) или многофакторным (n-way ANOVA). В первом
случае есть только одна независимая переменная; во втором - несколько.
Необходимо отметить, что для проведения одномерного дисперсионного
анализа на практике (в исследованиях социально-экономических процессов)
существует одно весьма существенное ограничение. При увеличении количества
факторов (то есть независимых переменных) в модели сложность интерпретации
результатов расчета возрастает многократно. Так, однофакторный анализ является
наиболее простым. Мультифакторные модели в большинстве своем могут успешно
интерпретироваться только квалифицированными исследователями.
Исследуем зависимость между процентным соотношением мужчин (ud_ves_M)
среди населения Беларуси и областью (obl). Переменная obl представлена категориями (1 - Брестская, 2 - Витебска,
3 - Гомельская, 4 - Гродненская, 5 - Минская, 6 - Могилевская). Проведем
однофакторный одномерный дисперсионный анализ и установим, насколько значимо
различается удельный вес мужчин в каждой области. Данные взяты из [10].
В качестве зависимой переменной в дисперсионном анализе выступает
основание сегментирования по группам, то есть та переменная, которая и
определяет различия между категориями независимой переменной. В область для
независимых переменных Fixed Factor(s) поместим obl. Фиксированными факторами
называют переменные, уровни которых охватывают все возможные состояния этой
переменной. Случайные факторы представляют переменные, уровни которых
охватывают лишь часть из всего многообразия возможных состояний.
Модель дисперсионного анализа - это математическое соотношение, в котором
каждая переменная представлена в виде суммы среднего значения и ошибки. В
полнофакторной модели среднее значение каждого наблюдения представлено в виде
генерального среднего и суммы вклада всех главных "эффектов"
(факторов влияния), помимо которых производится также расчёт всех
взаимодействий между факторами.
Установить равенство/неравенство дисперсий позволяет тест Levene. В общем
случае мы не знаем, равны ли дисперсии и, соответственно, какую группу
статистических тестов следует использовать. Поэтому рекомендуется сразу вывести
тесты для равных и неравных дисперсий, чтобы сократить количество итераций при
проведении дисперсионного анализа. Ограничимся наиболее популярным и
универсальным тестом Scheffe для равных дисперсий и тестом Tamhane’s T2 - для
неравных дисперсий [9].
Первой практически значимой таблицей является результат теста на
равенство дисперсий зависимой и независимых переменных Levene’s Test of
Equality of Error Variances (рисунок 4.1). В столбце Sig. данной таблицы
содержится единственное интересующее нас значение - это статистическая
значимость тестовой статистики F. Если значение в данном столбце показывает
незначимость F - значит, дисперсии равны, и в дальнейшем мы будем анализировать
результаты расчета теста Scheffe (предполагающего равенство дисперсий).
В противном случае, если F-статистика значима, - дисперсии не равны, и
при анализе различий между группами следует использовать тест Tamhane’s T2
(предполагающий неравенство дисперсий). Как вы видите на рисунке, статистика F
значима (Sig. = 0,034) - и, следовательно, можно сделать вывод о неравенстве
дисперсий.
Рисунок
4.1 - Таблица Levene’s Test of Equality
of Error Variances
|
Levene's Test
of Equality of Error Variancesa
|
|
Dependent
Variable:ud_ves_M
|
|
|
F
|
df1
|
df2
|
Sig.
|
|
2,647
|
5
|
48
|
,034
|
|
Tests the null
hypothesis that the error variance of the dependent variable is equal across
groups.
|
|
a. Design: Intercept + obl
|
|
Примечание - Источник: [собственная разработка]
Следующая таблица - это Tests of Between-Subjects Effects (рисунок
4.2). Данная таблица является центральной в выводимых результатах
дисперсионного анализа и показывает наличие/отсутствие значимых различий между
категориями исследуемых переменных. Первое, на что следует обратить внимание
при анализе описываемой таблицы, - это величина R2, отражающая долю
совокупной дисперсии в зависимой переменной. Другими словами, это та часть
вариации зависимой переменной, которую можно объяснить на основании независимой
переменной. В данном случае величина R2 достаточно велика,
следовательно, около 80% вариации зависимой переменной можно объяснить
независимой переменной.
Рисунок
4.2 - Таблица Tests of Between-Subjects
Effects
|
Tests of
Between-Subjects Effects
|
|
Dependent
Variable:ud_ves_M
|
|
|
|
|
|
Source
|
Type III Sum of
Squares
|
df
|
Mean Square
|
F
|
Sig.
|
|
Corrected Model
|
5,166a
|
5
|
1,033
|
39,639
|
,000
|
|
Intercept
|
118816,463
|
1
|
118816,463
|
4,559E6
|
,000
|
|
obl
|
5,166
|
5
|
1,033
|
39,639
|
,000
|
|
Error
|
1,251
|
48
|
,026
|
|
|
|
Total
|
118822,880
|
54
|
|
|
|
|
Corrected Total
|
6,417
|
53
|
|
|
|
|
a. R Squared =
,805 (Adjusted R Squared = ,785)
|
|
|
Второе, на что обращают внимание исследователи при интерпретации таблицы
Tests of Between-Subjects Effects, - это собственно значимость различия между
группами независимой переменной. Этот вывод следует из значения на пересечении
строки, содержащей соответствующую независимую переменную, и столбца Sig. Как
вы видите на рисунке, имеет место статистически высоко значимое различие между
различными областями по удельному весу мужчин (значимость F-статистики у
переменной obl < 0,00).
После того как мы установили наличие статистически значимого различия
между областями, необходимо определить, какие из 6 имеющихся групп отличаются
от остальных и каким образом (в большую или в меньшую сторону). Сделаем это при
помощи таблицы Multiple Comparisons, представленной на рисунке 4.3. При
интерпретации данной таблицы прежде всего вспомним результаты теста Levene.
Так, в нашем случае на основании данного теста дисперсии оказались неравными, и
поэтому в данной таблице мы будем рассматривать только ту ее часть, в которой
приведены расчеты по методу Tamhane.
|
Multiple Comparisons
|
|
Dependent
Variable:ud_ves_M
|
|
|
|
|
|
(I) obl
|
(J) obl
|
Mean Difference (I-J)
|
Std. Error
|
Sig.
|
95% Confidence Interval
|
|
|
|
|
|
|
Lower Bound
|
Upper Bound
|
|
Tamhane
|
1
|
2
|
,6333*
|
,03287
|
,000
|
,5169
|
,7498
|
|
|
3
|
,7222*
|
,03287
|
,000
|
,6058
|
,8387
|
|
|
4
|
,2444*
|
,05720
|
,015
|
,0384
|
,4504
|
|
|
5
|
-,1111
|
,11811
|
,999
|
-,5774
|
,3552
|
|
|
6
|
,1333*
|
,03287
|
,019
|
,0169
|
,2498
|
|
2
|
1
|
-,6333*
|
,03287
|
,000
|
-,7498
|
-,5169
|
|
|
3
|
,0889*
|
,02485
|
,037
|
,0036
|
,1742
|
|
|
4
|
-,3889*
|
,05300
|
,000
|
-,5913
|
-,1865
|
|
|
5
|
-,7444*
|
,11614
|
,003
|
-1,2133
|
-,2756
|
|
|
6
|
-,5000*
|
,02485
|
,000
|
-,5853
|
-,4147
|
|
3
|
1
|
-,7222*
|
,03287
|
,000
|
-,8387
|
-,6058
|
|
|
2
|
-,0889*
|
,02485
|
,037
|
-,1742
|
-,0036
|
|
|
4
|
-,4778*
|
,05300
|
,000
|
-,6802
|
-,2754
|
|
|
5
|
-,8333*
|
,11614
|
,001
|
-1,3021
|
-,3645
|
|
|
6
|
-,5889*
|
,02485
|
,000
|
-,6742
|
-,5036
|
|
4
|
1
|
-,2444*
|
,05720
|
,015
|
-,4504
|
-,0384
|
|
|
2
|
,3889*
|
,05300
|
,000
|
,1865
|
,5913
|
|
|
3
|
,4778*
|
,05300
|
,000
|
,2754
|
,6802
|
|
|
5
|
-,3556
|
,12522
|
,217
|
-,8215
|
,1103
|
|
|
6
|
-,1111
|
,05300
|
,621
|
-,3135
|
,0913
|
|
5
|
1
|
,1111
|
,11811
|
,999
|
-,3552
|
,5774
|
|
|
2
|
,7444*
|
,11614
|
,003
|
,2756
|
1,2133
|
|
|
3
|
,8333*
|
,11614
|
,001
|
,3645
|
1,3021
|
|
|
4
|
,3556
|
,12522
|
,217
|
-,1103
|
,8215
|
|
|
6
|
,2444
|
,11614
|
,646
|
-,2244
|
,7133
|
|
6
|
1
|
-,1333*
|
,03287
|
,019
|
-,2498
|
-,0169
|
|
|
2
|
,5000*
|
,02485
|
,000
|
,4147
|
,5853
|
|
|
3
|
,5889*
|
,02485
|
,000
|
,5036
|
,6742
|
|
|
4
|
,1111
|
,05300
|
,621
|
-,0913
|
,3135
|
-,2444
|
,11614
|
,646
|
-,7133
|
,2244
|
|
Based on
observed means. The error term is Mean Square(Error) = ,026.
|
|
|
|
|
*. The mean
difference is significant at the ,05 level.
|
|
|
|
Рисунок 4.3 - Таблица Multiple Comparisons
Примечание - Источник: [собственная разработка]
Итак, в первой части таблицы мы видим сравнение различий между каждой из
6 областей с остальными областями. На основе этих данных и определяются та или
те группы, которые значимо отличаются от других. Так, из столбца Sig. (статистическая
значимость) мы видим, что только вторая и третья группы статистически значимо
отличаются от всех остальных. Остальные целевые группы не отличаются друг от
друга. При этом из столбца Mean Difference можно видеть, насколько отличается
среднее значение той или иной группы от среднего значения других групп
(звездочками отмечены значимые различия при 95%-ном доверительном уровне).
Также из рассматриваемой таблицы можно сделать вывод о направлении
различия между выделенными категориями. Так, в нашем случае мы можем заключить,
что в Витебской и Гомельской областях удельный вес мужчин ниже, чем в других
областях.
Рассмотрим таблицу Homogeneous Subsets (рисунок 4.4).
|
ud_ves_M
|
|
obl
|
N
|
Subset
|
|
|
|
1
|
2
|
3
|
|
Scheffea
|
3
|
9
|
46,4556
|
|
|
|
2
|
9
|
46,5444
|
|
|
|
4
|
9
|
|
46,9333
|
|
|
6
|
9
|
|
47,0444
|
47,0444
|
|
1
|
9
|
|
47,1778
|
47,1778
|
|
5
|
9
|
|
|
47,2889
|
|
Sig.
|
|
,926
|
,086
|
,086
|
|
The error term
is Mean Square(Error) = ,026.
|
|
a. Uses Harmonic
Mean Sample Size = 9,000.
|
|
Рисунок 4.4 - Таблица Homogeneous Subsets
Примечание - Источник: [собственная разработка]
В этой таблице представлена однозначная картина различий между группами
независимой переменной. Здесь все группы разделены на три категории на
основании различий в удельном весе мужчин. В первую категорию входит целевая
группа из Гомельской и Витебской областей; во вторую - Брестская, Гродненская и
Могилевская, в третью - Могилевская, Брестская, Минская. Если бы оказалось, что
статистически значимых различий в удельном весе мужчин в различных областях не
наблюдается, все группы независимой переменной были бы отнесены к одной
категории (Subset был бы только 1).
4.2
Статистическое исследование удельного веса занятых на предприятиях
государственной формы собственности по областям Республики Беларусь с помощью
двухфакторного дисперсионного анализа
Рассмотрим теперь ситуацию, когда необходимо исследовать сразу две
независимые переменные (и взаимодействия между ними), то есть выполнить
двухфакторный одномерный дисперсионный анализ.
Исходные данные останутся такими же, как в предыдущем случае, однако
теперь мы будем устанавливать различие в занятых на предприятиях
государственной формы собственности в зависимости от области и удельного веса
мужчин. Переменная ud_ves_f_sob будет представлена тремя группами - 1 - до 50%, 2 -
от 50% до 60%, 3 - больше 60%.
При проведении многофакторного анализа (двухфакторной и более) зададим
исследование всех возможных взаимодействий между независимыми переменными (в
нашем случае будет установлено различие не только между областями и удельным
весом мужчин, но и на основе взаимодействия). В диалоговом окне Options
необходимо добавить переменную ud_ves_M, а также ее взаимодействие с переменной - ud_ves_M * obl, что позволит вывести средние
значения по каждой группе при определении направления различия между ними.
Тест Левене на равенство дисперсий показывает, значимый результат со
значением вероятности ошибки р = 0,009. Это означает, что отсутствует
однородность дисперсий между группами, которая наряду с нормальным
распределением значений выборки, является основной предпосылкой для возможности
проведения дисперсионного анализа (рисунок 4.5).
|
Levene's Test of
Equality of Error Variancesa
|
|
Dependent
Variable:ud_ves_f_sob
|
|
F
|
df1
|
df2
|
Sig.
|
|
53,651
|
16
|
37
|
,000
|
|
Tests the null
hypothesis that the error variance of the dependent variable is equal across
groups.
|
|
a. Design:
Intercept + obl + ud_ves_M + obl * ud_ves_M
|
Рисунок
4.5 - Таблица Levene’s Test of Equality
of Error Variances
Примечание - Источник: [собственная разработка]
В таблице Tests of Between-Subjects Effects появились результаты расчета
значимости F-статистики для переменной ud_ves_M, а также для взаимодействия ud_ves_M * obl. Как видно из рисунка 4.6, удельный
вес мужчин оказывает воздействие на количество занятых на предприятиях
государственной формы собственности. Однако совместное воздействие переменных ud_ves_M * obl не является статистически значимым.
При этом, несмотря на неравенство дисперсий, переменная obl оказывает значимое влияние на зависимую
переменную (Sig. = 0,000), то удельный вес занятых на предприятиях
государственной формы собственности разнится по областям.
Необходимо также отметить, что доля совокупной дисперсии в зависимой
переменной, объясняемая построенной моделью, несколько высока (R2 =
0,764).
|
Tests of
Between-Subjects Effects
|
|
Dependent
Variable:ud_ves_f_sob
|
|
|
|
|
Source
|
Type III Sum of
Squares
|
df
|
Mean Square
|
F
|
Sig.
|
|
Corrected Model
|
14,170a
|
16
|
,886
|
7,504
|
,000
|
|
Intercept
|
118,734
|
1
|
118,734
|
1,006E3
|
,000
|
|
obl
|
5,666
|
4
|
1,417
|
12,003
|
,000
|
|
ud_ves_M
|
5,035
|
9
|
,559
|
4,741
|
,000
|
|
obl * ud_ves_M
|
,216
|
2
|
,108
|
,913
|
,410
|
|
Error
|
4,367
|
37
|
,118
|
|
|
|
Total
|
215,000
|
54
|
|
|
|
|
Corrected Total
|
18,537
|
53
|
|
|
|
|
a. R Squared =
,764 (Adjusted R Squared = ,663)
|
|
|
Рисунок
4.6 - Таблица Tests of Between-Subjects
Effects
Примечание - Источник: [собственная разработка]
В таблице Homogeneous Subsets (рисунок 4.7) представлена однозначная
картина различий между группами независимой переменной. Здесь все группы
разделены на три категории на основании различий в удельном весе занятых на
предприятиях государственной формы собственности. В первую категорию входит
целевая группа из Гродненской и Брестской областей; во вторую - Брестская и
Минская, в третью - Минская, Витебская, Могилевская и Гомельская.
|
ud_ves_f_sob
|
|
obl
|
N
|
Subset
|
|
|
|
1
|
2
|
3
|
|
Scheffea
|
4
|
9
|
1,2222
|
|
|
|
1
|
9
|
1,5556
|
1,5556
|
|
|
5
|
9
|
|
1,8889
|
1,8889
|
|
2
|
9
|
|
|
2,2222
|
|
6
|
9
|
|
|
2,2222
|
|
3
|
9
|
|
|
2,3333
|
|
Sig.
|
|
,525
|
,525
|
,212
|
|
The error term
is Mean Square(Error) = ,118.
|
|
a. Uses Harmonic
Mean Sample Size = 9,000.
|
|
Рисунок 4.7 - Таблица Tests of Between-Subjects Effects
Примечание - Источник: [собственная разработка]
Завершают вывод результатов двухфакторного анализа таблицы с расчетами
апостериорных тестов (рисунок 4.8).
|
Multiple Comparisons
|
|
Dependent
Variable:ud_ves_f_sob
|
|
|
|
|
|
(I) obl
|
(J) obl
|
Mean Difference (I-J)
|
Std. Error
|
Sig.
|
95% Confidence Interval
|
|
|
|
|
|
|
Lower Bound
|
Upper Bound
|
|
Tamhane
|
1
|
2
|
-,6667
|
,22906
|
,146
|
-1,4572
|
,1239
|
|
|
3
|
-,7778
|
,24216
|
,079
|
-1,6095
|
,0540
|
|
|
4
|
,3333
|
,22906
|
,934
|
-,4572
|
1,1239
|
|
|
5
|
-,3333
|
,20787
|
,880
|
-1,0697
|
,4030
|
|
|
6
|
-,6667
|
,22906
|
,146
|
-1,4572
|
,1239
|
|
2
|
1
|
,6667
|
,22906
|
,146
|
-,1239
|
1,4572
|
|
|
3
|
-,1111
|
,22222
|
1,000
|
-,8760
|
,6538
|
|
|
4
|
1,0000*
|
,20787
|
,003
|
,2864
|
1,7136
|
|
|
5
|
,3333
|
,18426
|
,760
|
-,3073
|
,9739
|
|
|
6
|
,0000
|
,20787
|
1,000
|
-,7136
|
,7136
|
|
3
|
1
|
,7778
|
,24216
|
,079
|
-,0540
|
1,6095
|
|
|
2
|
,1111
|
,22222
|
1,000
|
-,6538
|
,8760
|
|
|
4
|
1,1111*
|
,22222
|
,002
|
,3462
|
1,8760
|
|
|
5
|
,4444
|
,20031
|
,488
|
-,2608
|
1,1497
|
|
|
6
|
,1111
|
,22222
|
1,000
|
-,6538
|
,8760
|
|
4
|
1
|
-,3333
|
,22906
|
,934
|
-1,1239
|
,4572
|
|
|
2
|
-1,0000*
|
,20787
|
,003
|
-1,7136
|
-,2864
|
|
|
3
|
-1,1111*
|
,22222
|
,002
|
-1,8760
|
-,3462
|
|
|
5
|
-,6667*
|
,18426
|
,038
|
-1,3073
|
-,0261
|
|
|
6
|
-1,0000*
|
,20787
|
,003
|
-1,7136
|
-,2864
|
|
5
|
1
|
,3333
|
,20787
|
,880
|
-,4030
|
1,0697
|
|
|
2
|
-,3333
|
,18426
|
,760
|
-,9739
|
,3073
|
|
|
3
|
-,4444
|
,20031
|
,488
|
-1,1497
|
,2608
|
|
|
4
|
,6667*
|
,18426
|
,038
|
,0261
|
1,3073
|
|
|
6
|
-,3333
|
,18426
|
,760
|
-,9739
|
,3073
|
|
6
|
1
|
,6667
|
,22906
|
,146
|
-,1239
|
1,4572
|
|
|
2
|
,0000
|
,20787
|
1,000
|
-,7136
|
,7136
|
|
|
3
|
-,1111
|
,22222
|
1,000
|
-,8760
|
,6538
|
|
|
4
|
1,0000*
|
,20787
|
,003
|
,2864
|
1,7136
|
|
|
5
|
,18426
|
,760
|
-,3073
|
,9739
|
|
Based on
observed means. The error term is Mean Square(Error) = ,118.
|
|
|
|
|
*. The mean
difference is significant at the ,05 level.
|
|
|
|
Рисунок
4.8 - Таблица Tests of Between-Subjects
Effects
Примечание - Источник: [собственная разработка]
Переменная obl и в этом
случае оказывает ощутимое влияние на зависимую переменную. Видим, что
значительно отличаются результаты анализа по Гродненской области, в которой
меньше всего населения занято на предприятиях государственной формы
собственности.
ЗАКЛЮЧЕНИЕ
Стохастическое моделирование факторных систем взаимосвязей отдельных
сторон хозяйственной деятельности строится на обобщении закономерностей
варьирования значений экономических показателей - количественных характеристик
факторов и результатов хозяйственной деятельности. Количественные параметры
связи выявляются на основе сопоставления значений изучаемых показателей в
совокупности хозяйственных объектов или периодов.
В стохастическом анализе, где сама модель составляется на основе
совокупности эмпирических данных, предпосылкой получения реальной модели
является совпадение количественных характеристик связей в разрезе всех исходных
наблюдений. Это означает, что варьирование значений показателей должно
происходить в пределах однозначной определенности качественной стороны явлений,
характеристиками которых являются моделируемые экономические показатели (в
пределах варьирования не должно происходить качественного скачка в характере
отражаемого явления).
Современные приложения дисперсионного анализа охватывают широкий круг
задач экономики и трактуются обычно в терминах статистической теории выявления
систематических различий между результатами непосредственных измерений,
выполненных при тех или иных меняющихся условиях.
Благодаря автоматизации дисперсионного анализа исследователь может
проводить различные статистические исследования с применение ЭВМ, затрачивая
при этом меньше времени и усилий на расчеты данных. В настоящее время
существует множество пакетов прикладных программ, в которых реализован аппарат
дисперсионного анализа.
Применяя пакет SPSS для проведения дисперсионного анализа на
статистических данных по Республике Беларусь, были получены следующие
результаты.
При анализе колебания показателя удельного веса мужчин по областям
Республики Беларусь, было выявлено неравенство дисперсий исследуемого
показателя по областям (значимость F-статистики у переменной obl < 0,00). Дальнейшие результаты
подтвердили вывод о том, что в Витебской и Гомельской областях удельный вес
мужчин ниже, чем в других областях.
При анализе удельного веса занятых на предприятиях государственной формы
собственности снова была выявлена неоднородность дисперсий. Переменная obl и в этом случае оказывает ощутимое
влияние на зависимую переменную. Видим, что значительно отличаются результаты
анализа по Гродненской области, в которой меньше всего населения занято на
предприятиях государственной формы собственности.
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1 Бююль, А. SPSS:
искусство обработки информации. Анализ статистических данных и восстановления
скрытых закономерностей. Пер с нем./ А. Бююль, П. Цефель. - СПб.: ООО
«ДмаСофтЮП», 2005. - 608 с.
Гмурман, В.Е. Теория вероятностей и математическая
статистика. /В.Е. Гмурман. - М.: Высшая школа, 2003. - 523 с.
Гусев, А.Н. Дисперсионный анализ в экспериментальной
психологии. / А.Н. Гусев. - М.: Учебно-методический коллектор «Психология»,
2000. - 136 с.
Канке, А.А. Кошевая, И.П. Анализ финансово-хозяйственной
деятельности предприятия: учебное пособие./ А.А.Канке. - М.: Инфра-М, 2007. -
288 с.
Ким, Дж.-О., Мьюллер, Ч.У. и др. Факторный, дискриминантный и
кластерный анализ. / Дж.-О. Ким. - М.: Финансы и статистика, 1989. - 215 с.
Комплексный экономический анализ хозяйственной деятельности:
Учебное пособие / А.И.Алексеева, Ю.В.Васильев, А.В., Малеева, Л.И.Ушвицкий. -
М.: Финансы и статистика, 2006. - 672с.
Кремер, Н.Ш. Теория вероятности и математическая статистика /
Н.Ш. Кремер. - М.: Юнити - Дана, 2002. - 343с.
Лысенко, Д.В. Комплексный экономический анализ хозяйственной
деятельности: учебник для вузов / Д.В. Лысенко. - М.: Инфра-М, 2008. - 320 с.
Наследов, А.Д. SPSS:
компьютерный анализ данных в психологии и социальных науках/ А.Д. Наследов. -
СПб.: Питер, 2005. - 416 с.
Регионы Республики Беларусь. Статистический сборник. /
Министерство статистики и анализа Республики Беларусь; редкол.: В.И. Зиновский
[и др.] - Мн.: Министерство статистики и анализа Республики Беларусь, 2011. -
810 с.
Савицкая, Г.В. Анализ хозяйственной деятельности предприятия:
учебник. / Г.В. Савицкая. - М.: Инфра-М, 2009. - 536 с.