|
mn-1
Одной из используемых моделей данных в дисперсионном анализе является
двухфакторная модель. Она состоит в учёте систематических (первый фактор) и
случайных (второй фактор) ошибок в определении измеряемых параметров.
Пусть с помощью методов 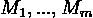 производится измерение нескольких параметров, чьи точные
значения - производится измерение нескольких параметров, чьи точные
значения - 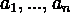 . В таком случае, результаты измерений различных величин
различными методами можно представить как: . В таком случае, результаты измерений различных величин
различными методами можно представить как:
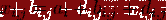 , ,
где:
 - результат измерения - результат измерения  -го параметра по методу -го параметра по методу  ; ;
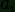 - точное значение -го параметра; - точное значение -го параметра;
 - систематическая ошибка измерения -го параметра по методу - систематическая ошибка измерения -го параметра по методу  ; ;
 - случайная ошибка измерения -го параметра по методу - случайная ошибка измерения -го параметра по методу  . .
Тогда дисперсии случайных величин ,  , ,  , ,  , где: , где:
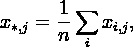
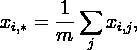

выражаются как:
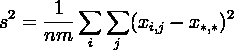
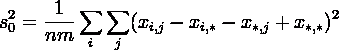
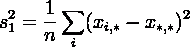
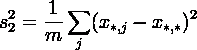
и удовлетворяют тождеству:
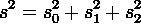
Двухфакторная схема позволяет лишь обнаружить систематические
расхождения, но непригодна для их численной оценки с последующим исключением из
результатов наблюдений. Эта цель может быть достигнута только при многократных
измерениях (то есть при повторных использованиях указанной схемы над данными
повторных экспериментов).
1.4
Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между
многофакторным и однофакторным дисперсионным анализом нет. Многофакторный
анализ не меняет общую логику дисперсионного анализа, а лишь несколько
усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из
факторов по отдельности, следует оценивать и их совместное действие. Таким
образом, то новое, что вносит в анализ данных многофакторный дисперсионный
анализ, касается в основном возможности оценить межфакторное взаимодействие.
Тем не менее, по-прежнему остается возможность оценивать влияние каждого
фактора в отдельности. В этом смысле процедура многофакторного дисперсионного
анализа (в варианте ее компьютерного использования) более экономична, поскольку
всего за один запуск решает сразу две задачи: оценивается влияние каждого из
факторов и их взаимодействие.
Данные, подвергаемые многофакторному дисперсионному
анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в рассматриваемой задаче о качестве
различных m партий изделия изготавливались на
разных t станках и требуется выяснить,
имеются ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к задаче
двухфакторного дисперсионного анализа.
В таблице 2 представлен общий вид вычисления значений,
с помощью дисперсионного анализа.
Таблица 2: Базовая таблица многофакторного
дисперсионного анализа
|
Компоненты дисперсии
|
Сумма квадратов
|
Число степеней свободы
|
Средние квадраты
|
|
Межгрупповая (фактор А)
|
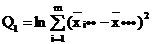 m-1 m-1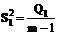
|
|
|
|
Межгрупповая (фактор B)
|
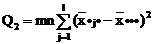 l-1 l-1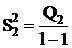
|
|
|
|
Взаимодействие
|
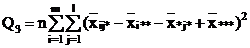 (m-1)(l-1) (m-1)(l-1)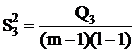
|
|
|
|
Остаточная
|
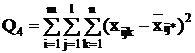 mln - ml mln - ml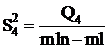
|
|
|
|
Общая
|
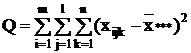 mln - 1 mln - 1
|
|
|
дисперсионный анализ нормативный
отклонение
Проверка
нулевых гипотез HA, HB, HAB об отсутствии
влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB
осуществляется сравнением отношений 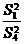 , , 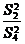 , , 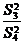 (для модели
I с фиксированными уровнями факторов) или отношений (для модели
I с фиксированными уровнями факторов) или отношений 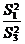 , , 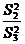 , (для случайной модели II) с соответствующими
табличными значениями F - критерия Фишера - Снедекора. Для смешанной модели III
проверка гипотез относительно факторов с фиксированными уровнями производится
также как и в модели II, а факторов со случайными уровнями - как в модели I. , (для случайной модели II) с соответствующими
табличными значениями F - критерия Фишера - Снедекора. Для смешанной модели III
проверка гипотез относительно факторов с фиксированными уровнями производится
также как и в модели II, а факторов со случайными уровнями - как в модели I.
Если
n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть
проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а
с ней и средний квадрат 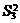 , так как в этом случае не может быть речи о
взаимодействии факторов. , так как в этом случае не может быть речи о
взаимодействии факторов.
С
точки зрения техники вычислений для нахождения сумм квадратов Q1, Q2, Q3, Q4, Q
целесообразнее использовать формулы:
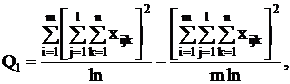
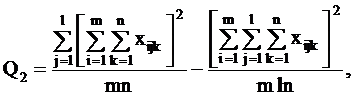
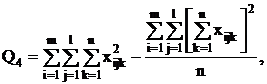
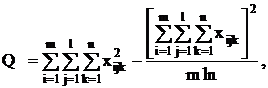
Q3 = Q - Q1 - Q2 - Q4.
отклонение
от основных предпосылок дисперсионного анализа - нормальности распределения исследуемой
переменной и равенства дисперсий в ячейках (если оно не чрезмерное) - не
сказывается существенно на результатах дисперсионного анализа при равном числе
наблюдений в ячейках, но может быть очень чувствительно при неравном их числе.
Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность
аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с
равным числом наблюдений в ячейках, а если встречаются недостающие данные, то
возмещать их средними значениями других наблюдений в ячейках. При этом, однако,
искусственно введенные недостающие данные не следует учитывать при подсчете
числа степеней свободы.
2. Практическая часть
.1 Решение
задач двухфакторного дисперсионного анализ без повторений
Microsoft Excel располагает
функцией: Двухфакторный дисперсионный анализ без повторений, которая
используется для выявления факта влияния контролируемых факторов А и В
на результативный признак на основе выборочных данных, причем каждому уровню
факторов А и В соответствует только одна выборка. Для вызова этой
функции необходимо на панели меню выбрать команду Сервис - Анализ
данных. На экране раскроется окно Анализ данных, в котором следует
выбрать значение Двухфакторный дисперсионный анализ без повторений и
щелкнуть на кнопке ОК. В результате на экране раскроется диалоговое
окно, показанное на рисунке 1.
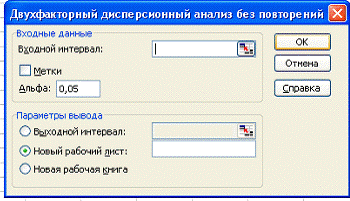
Рис. 1: диалоговое окно функции
В диалоговом окне задаются следующие параметры.
. В поле Входной материал вводится ссылка на диапазон ячеек,
содержащий анализируемые данные.
. Флажок опции Метки устанавливается в том случае, если
первая строка во входном диапазоне содержит заголовки столбцов. Если заголовки
отсутствуют, флажок следует сбросить. В этом случае для данных выходного
диапазона будут автоматически созданы стандартные названия.
. В поле Альфа вводится принятый уровень значимости α, соответствующий вероятности
возникновения ошибки первого рода.
. Переключатель в группе Параметры вывода может быть
установлен в одно из трех положений: Выходной интервал, Новый рабочий
лист или Новая рабочая книга.
Пример
Рассмотрим использование функции Двухфакторный дисперсионный анализ
без повторений на следующем примере.
На рисунке. 2 представлены данные об урожайности (ц/га) четырех сортов
пшеницы (четыре уровня фактора А), достигнутой при использовании пяти типов
удобрений (пять уровней фактора В). Данные получены на 20 участках одинакового
размера и аналогичного почвенного покрова. Необходимо определить, влияет ли
сорт и тип удобрения на урожайность пшеницы.
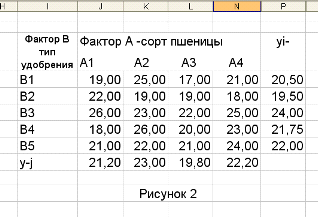
Рис. 2: данные об урожайности
Результаты двухфакторного дисперсионного анализа с помощью функции Двухфакторный
дисперсионный анализ без повторений представлены на рисунке 3.
Как видно по результатам, расчетное значение величины F-статистики для фактора А (тип
удобрения) FА=l,67,
а критическая область образуется правосторонним интервалом (3,49; +∞).
Так как FА=l,67
не попадает в критическую область, гипотезу НА: a1 = a2 + … = ak принимаем, т.е. считаем, что в этом
эксперименте тип удобрения не оказал влияния на урожайность.
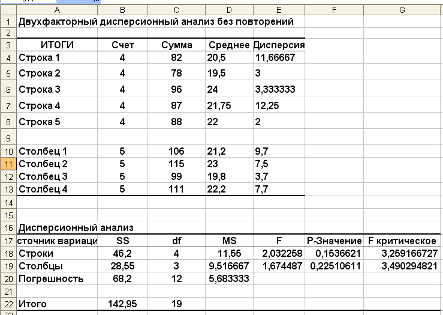
Рис. 3: Результаты двухфакторного дисперсионного анализа
Расчетное значение величины F-статистики для фактора В (сорт пшеницы) FВ =2,03, а критическая область образуется правосторонним
интервалом (3,259;+∞).
также принимаем, т.е. считаем, что в данном эксперименте сорт пшеницы
также не оказал влияния на урожайность.
2.2
Решение задач двухфакторного дисперсионного анализа c повторениями
Microsoft Excel располагает
функцией: Двухфакторный дисперсионный анализ с повторениями, которая
также используется для выявления факта влияния контролируемых факторов А и В на
результативный признак на основе выборочных данных, однако каждому уровню одного
из факторов А (или В) соответствует более одной выборки данных.
Рассмотрим использование функции Двухфакторный дисперсионный анализ с
повторениями на следующем примере.
Пример
В таблице. 3 приведены суточные привесы (г) собранных для исследования 18
поросят в зависимости от метода удержания поросят (фактор А) и качества их
кормления (фактор В).
Таблица 3: суточные привесы собранных для исследования 18 поросят
|
Количество голов в группе
(фактор А)
|
Содержание протеина в
корме, г (фактор В)
|
|
В1=80
|
В2=100
|
|
А1-30
|
530, 540, 550
|
600, 620, 580
|
|
А2=100
|
490, 510, 520
|
550, 540, 560
|
|
А3=300
|
430, 420, 450
|
470, 460, 430
|
Необходимо оценить существенность (достоверность) влияния каждого фактора
и их взаимодействия на суточный привес поросят.
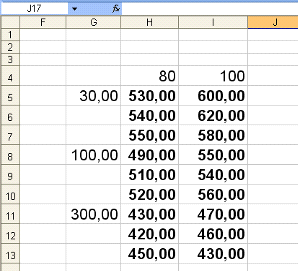
Рис. 4: Порядок ввода данных
На рисунке 4 порядок ввода данных на рабочий лист табличного процессора Microsoft Excel.
Для вызова необходимой функции необходимо на панели меню выбрать команду Сервис
- Анализ данных. На экране раскроется диалоговое окно Анализ данных,
в котором следует выбрать значение: Двухфакторный дисперсионный анализ с
повторениями и щелкнуть на кнопке ОК. В результате на экране
раскроется диалоговое окно Двухфакторный дисперсионный анализ с повторениями,
показанное на рисунке 5.
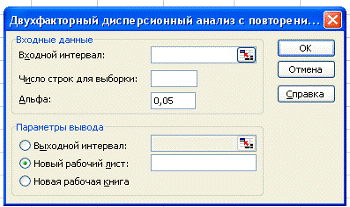
Рис. 5: Диалоговое окно функции
В этом диалоговом окне задаются следующие параметры.
. В поле Входной интервал вводится ссылка на диапазон ячеек,
содержащий анализируемые данные. Необходимо выделить ячейки от G 4 до I 13.
. В поле Число строк для выборки определяется число
выборок, которое приходится на каждый уровень одного из факторов. Каждый
уровень фактора должен содержать одно и то же количество выборок (строк
таблицы). В нашем случае число строк равно трем.
. В поле Альфа вводится принятое значение уровня значимости α, которое равно вероятности
возникновения ошибки первого рода.
. Переключатель в группе Параметры вывода может быть установлен в
одно из трех положений: Выходной интервал, Новый рабочий лист или
Новая рабочая книга.
Результаты двухфакторного дисперсионного анализа с помощью функции
Двухфакторный дисперсионный анализ с повторениями представлены на рисунке 6.
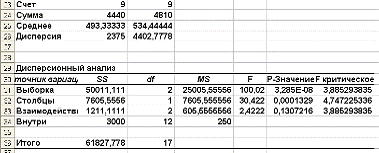
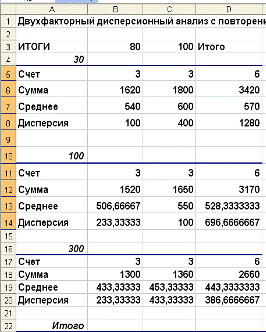
Рис. 6: Результаты двухфакторного дисперсионного анализа
Очевидно, данные факторы имеют фиксированные уровни, т.е. мы находимся в
рамках модели I. Поэтому для проверки существенности
влияния факторов А, В и их взаимодействия АВ необходимо найти отношения
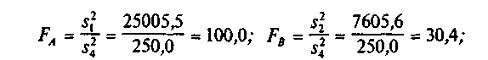
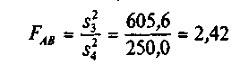
и
сравнить их с табличными значениями соответственно 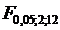 :=3,88; :=3,88; 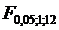 =: =4,75;
=3,88. Так как =: =4,75;
=3,88. Так как 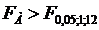 и и 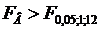 то влияние метода содержания поросят (фактора А) и
качества их кормления (фактора В) является существенным. В силу того что то влияние метода содержания поросят (фактора А) и
качества их кормления (фактора В) является существенным. В силу того что 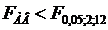 взаимодействие указанных факторов незначимо (на
5%-ном уровне). взаимодействие указанных факторов незначимо (на
5%-ном уровне).
2.3
Решение задач однофакторного дисперсионного анализа
Три группы продавцов продавали штучный товар,
расфасованный в различные упаковки. После окончания срока распродажи был
произведен тестовый контроль над случайно отобранными продавцами из каждой
группы. Были получены следующие результаты:
|
Номер группы
|
Число продаж, которые
сделали продавцы, 
|
Общее количество продаж
|
Количество продавцов, nk
|
|
1
|
1 3 2 1 0 2 1
|
10
|
7
|
|
2
|
2 3 2 1 4 - -
|
12
|
5
|
|
3
|
4 5 3 - - - -
|
12
|
3
|
Если число выборок m=3, число продаж во всех выборках
n=15, то:
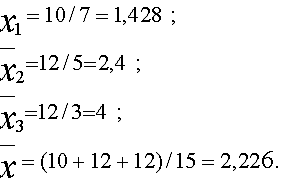
Если
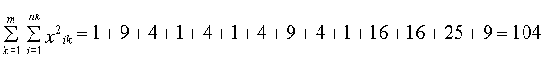 , ,
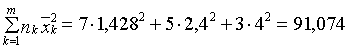 , ,
тогда
Q=104-15·2,226 2=26,93 ,
Q1=91,074-15·2,226 2=14,01,
Q2=Q-Q1=26,93-14,01=12,92.
Вычислим критерий Фишера
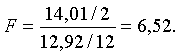
Сравнивая это значение с табличным F > F0,05;2;12 =3,885,
делаем вывод, что упаковка влияет на количество распродаж.
Вывод
В результате проделанной работы я выяснила следующее.
Анализ производится следующим образом:
. Группируют совокупность наблюдений по факторному признаку
. Находят среднее значение результата и дисперсию по каждой
группе.
. Определяют общую дисперсию и вычисляют, какая доля ее зависит от
условий, общих для всех групп, какая - от исследуемого фактора, а какая - от
случайных причин.
. С помощью специального критерия определяют, насколько
существенны различия между группами наблюдений и, следовательно, можно ли
считать ощутимым влияние тех или иных факторов.
Существует две модели дисперсионного анализа:
· с фиксированными уровнями факторов,
· со случайными факторами.
В зависимости от количества факторов, определяющих вариацию
результативного признака, дисперсионный анализ подразделяют на однофакторный и
многофакторный.
Основными схемами организации исходных данных с двумя и более факторами
являются:
· перекрестная классификация, которая характерная для моделей с
фиксированными уровнями факторов
· иерархическая (гнездовая) классификация, характерная для
моделей со случайными факторами.
В основе дисперсионного анализа лежит разделение дисперсии на части или
компоненты. Внутригрупповая дисперсия объясняет влияние неучтенных при
группировке факторов, а межгрупповая дисперсия объясняет влияние факторов
группировки на среднее значение по группе.
Однофакторный дисперсионный анализ используется для сравнения средних
значений для трех и более выборок.
Недостаток: невозможно выделить те выборки, которые отличаются от других.
Для этой цели необходимо использовать метод Шеффе или проводить парные сравнения
выборок.
Многофакторный дисперсионный анализ, помимо функций однофакторного
дисперсионного анализа, оценивает межфакторное взаимодействие.
Список используемой литературы
1. Орлов А.И. «Математика случая: Вероятность и статистика -
основные факты» Учебное пособие. - М.: МЗ-Пресс, 2004. - 110 с.
2. Ветров А.А., Ломовацкий Г.И. - «Дисперсионный анализ
в экономике» 1975. 120 с
. Шеффе Г. «Дисперсионный анализ» - М.: Наука, 1980.
-512 c.
. http://bono-esse.ru/blizzard/Medstat/Statan/stat_da.html
. http://dic.academic.ru
Похожие работы на - Применение методов дисперсионного анализа в экономике
|