|
x
|
y
|
x2
|
y2
|
x • y
|
|
32
|
20
|
1024
|
400
|
640
|
|
30
|
24
|
900
|
576
|
720
|
|
36
|
28
|
1296
|
784
|
1008
|
|
40
|
30
|
1600
|
900
|
1200
|
|
41
|
31
|
1681
|
961
|
1271
|
|
47
|
33
|
2209
|
1089
|
1551
|
|
56
|
34
|
3136
|
1156
|
1904
|
|
54
|
37
|
2916
|
1369
|
1998
|
|
60
|
38
|
3600
|
1444
|
2280
|
|
55
|
40
|
3025
|
1600
|
2200
|
|
61
|
41
|
3721
|
1681
|
2501
|
|
67
|
43
|
4489
|
1849
|
2881
|
|
69
|
45
|
4761
|
2025
|
3105
|
|
76
|
48
|
5776
|
2304
|
3648
|
|
724
|
492
|
40134
|
18138
|
26907
|
. Параметры уравнения регрессии
Выборочные средние.
Выборочные дисперсии:
Среднеквадратическое отклонение
Коэффициент корреляции b можно находить по
формуле, не решая систему непосредственно:
Коэффициент корреляции
Рассчитываем показатель тесноты
связи. Таким показателем является выборочный линейный коэффициент корреляции,
который рассчитывается по формуле:
Линейный коэффициент корреляции
принимает значения от -1 до +1.
Связи между признаками могут быть
слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
.1 <rxy< 0.3:
слабая;
.3 <rxy< 0.5:
умеренная;
.5 <rxy< 0.7:
заметная;
.7 <rxy< 0.9:
высокая;
.9 <rxy< 1: весьма
высокая;
В нашем примере связь между признаком Y фактором
X весьма высокая и прямая. Кроме того, коэффициент линейной парной корреляции
может быть определен через коэффициент регрессии b:
Уравнение регрессии (оценка
уравнения регрессии).
Линейное уравнение регрессии имеет
вид y = 0.54 x + 7.04
Коэффициентам уравнения линейной
регрессии можно придать экономический смысл.
Коэффициент регрессии b = 0.54
показывает среднее изменение результативного показателя (в единицах измерения
у) с повышением или понижением величины фактора х на единицу его измерения. В
данном примере с увеличением на 1 единицу y повышается в среднем на 0.54.
Коэффициент a = 7.04 формально
показывает прогнозируемый уровень у, но только в том случае, если х=0 находится
близко с выборочными значениями.
Но если х=0 находится далеко от
выборочных значений х, то буквальная интерпретация может привести к неверным
результатам, и даже если линия регрессии довольно точно описывает значения
наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или
вправо.
Подставив в уравнение регрессии
соответствующие значения х, можно определить выровненные (предсказанные)
значения результативного показателя y (x) для каждого наблюдения.
Связь между у и х определяет знак
коэффициента регрессии b (если > 0 - прямая связь, иначе - обратная). В
нашем примере связь прямая.
Коэффициент детерминации.
Квадрат (множественного)
коэффициента корреляции называется коэффициентом детерминации, который
показывает долю вариации результативного признака, объясненную вариацией
факторного признака.
Чаще всего, давая интерпретацию
коэффициента детерминации, его выражают в процентах.2= 0.9692
= 0.9384
т.е. в 93.84 % случаев изменения х
приводят к изменению y. Другими словами - точность подбора уравнения регрессии
- высокая. Остальные 6.16 % изменения Y объясняются факторами, не учтенными в
модели (а также ошибками спецификации).
Таблица. Для оценки качества параметров
регрессии построим расчетную таблицу
|
x
|
y
|
y(x)
|
(yi-ycp)2
|
(y-y(x))2
|
|y - yx|:y
|
|
32
|
20
|
24.43
|
229.31
|
19.61
|
0.22
|
|
30
|
24
|
23.34
|
124.16
|
0.43
|
0.0275
|
|
36
|
28
|
26.6
|
51.02
|
1.95
|
0.0499
|
|
40
|
30
|
28.78
|
26.45
|
1.5
|
0.0408
|
|
41
|
31
|
29.32
|
17.16
|
2.82
|
0.0542
|
|
47
|
33
|
32.58
|
4.59
|
0.18
|
0.0127
|
|
56
|
34
|
37.47
|
1.31
|
12.06
|
0.1
|
|
54
|
37
|
36.39
|
3.45
|
0.38
|
0.0166
|
|
60
|
38
|
39.65
|
8.16
|
2.71
|
0.0433
|
|
55
|
40
|
36.93
|
23.59
|
9.43
|
0.0768
|
|
61
|
41
|
40.19
|
34.31
|
0.66
|
0.0198
|
|
67
|
43
|
43.45
|
61.73
|
0.2
|
0.0105
|
|
69
|
45
|
44.54
|
97.16
|
0.21
|
0.0103
|
|
76
|
48
|
48.34
|
165.31
|
0.12
|
0.00713
|
|
724
|
492
|
492
|
847.71
|
52.26
|
0.69
|
Значимость коэффициента корреляции.
Выдвигаем гипотезы:0: rxy
= 0, нет линейной взаимосвязи между переменными;1: rxy ≠
0, есть линейная взаимосвязь между переменными;
Для того чтобы при уровне значимости α
проверить нулевую гипотезу о равенстве нулю генерального коэффициента
корреляции нормальной двумерной случайной величины при конкурирующей гипотезе H1
≠ 0, надо вычислить наблюдаемое значение критерия (величина случайной
ошибки)
и по таблице критических точек
распределения Стьюдента, по заданному уровню значимости α и числу
степеней свободы k = n - 2 найти критическую точку tкрит
двусторонней критической области. Если tнабл<tкрит
оснований отвергнуть нулевую гипотезу. Если |tнабл| >tкрит
- нулевую гипотезу отвергают.
По таблице Стьюдента с уровнем
значимости α=0.05 и степенями
свободы k=12 находим tкрит:
крит (n-m-1;α/2) =
(12;0.025) = 2.179
где m = 1 - количество объясняющих
переменных.
Если |tнабл| >tкритич,
то полученное значение коэффициента корреляции признается значимым (нулевая
гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку |tнабл| >tкрит,
то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами,
коэффициент корреляции статистически - значим
В парной линейной регрессии t2r
= t2b и тогда проверка гипотез о значимости коэффициентов
регрессии и корреляции равносильна проверке гипотезы о существенности линейного
уравнения регрессии.
Интервальная оценка для коэффициента
корреляции (доверительный интервал).
Доверительный интервал для
коэффициента корреляции.
(0.813;1)
Индивидуальные доверительные
интервалы для Y при данном значении X.
(a + bxi ± ε)
где
крит (n-m-1;α/2) =
(12;0.025) = 2.179
Таблица
|
xi
|
y = 7.04 + 0.54xi
|
εi
|
ymin = y - εi
|
ymax = y + εi
|
|
32
|
24.43
|
5.01
|
19.41
|
29.44
|
|
30
|
23.34
|
5.08
|
18.26
|
28.42
|
|
36
|
26.6
|
4.9
|
21.7
|
31.51
|
|
40
|
28.78
|
4.82
|
23.96
|
33.59
|
|
41
|
29.32
|
4.8
|
24.52
|
34.12
|
|
47
|
32.58
|
4.73
|
27.86
|
37.31
|
|
56
|
37.47
|
4.72
|
32.75
|
42.19
|
|
54
|
36.39
|
4.71
|
31.67
|
41.1
|
|
60
|
39.65
|
4.76
|
34.88
|
44.41
|
|
55
|
36.93
|
4.72
|
32.21
|
41.64
|
|
61
|
4.78
|
35.41
|
44.97
|
|
67
|
43.45
|
4.89
|
38.56
|
48.34
|
|
69
|
44.54
|
4.94
|
39.59
|
49.48
|
С вероятностью 95% можно гарантировать, что
значения Y при неограниченно большом числе наблюдений не выйдет за пределы
найденных интервалов.
Проверка гипотез относительно коэффициентов
линейного уравнения регрессии.
) t-статистика. Критерий Стьюдента.
крит
(n-m-1;α/2)
= (12;0.025) = 2.179
Поскольку 13.51 > 2.179, то
статистическая значимость коэффициента регрессии b подтверждается (отвергаем
гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.27 > 2.179, то
статистическая значимость коэффициента регрессии a подтверждается (отвергаем
гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для
коэффициентов уравнения регрессии.
Определим доверительные интервалы
коэффициентов регрессии, которые с надежность 95% будут следующими:
(b - tкритSb;
b + tкритSb)
(0.54 - 2.179 • 0.0402; 0.54 + 2.179
• 0.0402)
(0.456;0.631)
С вероятностью 95% можно утверждать,
что значение данного параметра будут лежать в найденном интервале.
(a - tкритSa;
a + tкрит
Sa)
(7.036 - 2.179 • 2.15; 7.036 + 2.179
• 2.15)
(2.344;11.728)
С вероятностью 95% можно утверждать,
что значение данного параметра будут лежать в найденном интервале.
) F-статистика. Критерий Фишера.
где m - число факторов в модели.
Оценка статистической значимости парной линейной
регрессии производится по следующему алгоритму:
. Выдвигается нулевая гипотеза о том, что
уравнение в целом статистически незначимо: H0: R2=0 на
уровне значимости α.
2. Далее определяют фактическое значение
F-критерия:
где m=1 для парной регрессии.
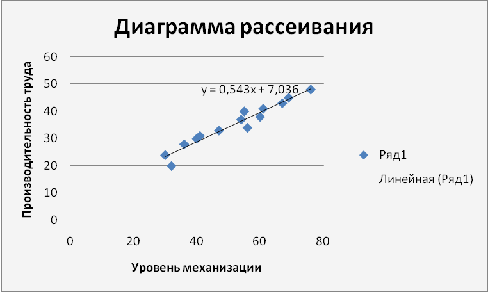
Задача 2
Исследуется зависимость
производительности труда (Yi) от уровня механизации работ
(Xi %) и
среднего возраста работников (Xi лет) по данным 14
промышленных предприятий (i - порядковый номер предприятия).
Статистические данные приведены в таблице .
Требуется:
) Вычислить ковариации и составить
ковариационную матрицу.
) Найти оценки параметров
множественной линейной регрессии и составить уравнение плоскости регрессии у = b0+b1x +b2x
) На уровне значимости а = 0,05
проверить гипотезу о согласии линейной множественной регрессии с результатом
наблюдений.
) С надежностью p = 0,95
найти доверительные интервалы для параметров множественной линейной регрессии.
2.1.
Таблица
|
i
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
|
X1i
|
32
|
30
|
36
|
40
|
41
|
4
|
56
|
54
|
60
|
55
|
61
|
67
|
69
|
76
|
|
X2i
|
33
|
31
|
41
|
39
|
46
|
43
|
34
|
38
|
42
|
35
|
39
|
44
|
40
|
41
|
|
Yi
|
20
|
24
|
28
|
30
|
31
|
33
|
34
|
37
|
38
|
40
|
41
|
43
|
45
|
48
|
Решение:
Определим вектор оценок коэффициентов регрессии.
Согласно методу наименьших квадратов, вектор s получается из выражения: s = (XTX)-1XTY
Таблица
|
1
|
32
|
33
|
|
1
|
30
|
31
|
|
1
|
36
|
41
|
|
1
|
40
|
39
|
|
1
|
41
|
46
|
|
1
|
47
|
43
|
|
1
|
56
|
34
|
|
1
|
54
|
38
|
|
1
|
60
|
42
|
|
1
|
55
|
35
|
|
1
|
61
|
39
|
|
1
|
67
|
44
|
|
1
|
69
|
40
|
|
1
|
76
|
41
|
Матрица Y
|
20
|
|
24
|
|
28
|
|
30
|
|
31
|
|
33
|
|
34
|
|
37
|
|
38
|
|
40
|
|
41
|
|
43
|
|
45
|
|
48
|
Таблица. Матрица XT
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
32
|
30
|
36
|
40
|
41
|
47
|
56
|
54
|
60
|
55
|
61
|
67
|
69
|
76
|
|
33
|
31
|
41
|
39
|
46
|
43
|
34
|
38
|
42
|
35
|
39
|
44
|
40
|
41
|
Умножаем матрицы, (XTX)
В матрице, (XTX) число
14, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма
произведений элементов 1-й строки матрицы XT и 1-го столбца матрицы
X
Умножаем матрицы, (XTY)
Таблица. Находим обратную матрицу (XTX)-1
|
6.168
|
-0.0023
|
-0.153
|
|
-0.0023
|
0.000427
|
-0.000508
|
|
-0.153
|
-0.000508
|
0.0046
|
Вектор оценок коэффициентов регрессии равен
Уравнение регрессии (оценка
уравнения регрессии)
= 1.74 + 0.53X1 + 0.16X2
Матрица парных коэффициентов
корреляции R.
Число наблюдений n = 14. Число
независимых переменных в модели равно 2, а число регрессоров с учетом
единичного вектора равно числу неизвестных коэффициентов. С учетом признака Y,
размерность матрицы становится равным 4. Матрица, независимых переменных Х
имеет размерность (14 х 4).
Таблица. Матрица, составленная из Y и X
|
1
|
20
|
32
|
33
|
|
1
|
24
|
30
|
31
|
|
1
|
28
|
36
|
41
|
|
1
|
30
|
40
|
39
|
|
1
|
31
|
41
|
46
|
|
1
|
33
|
47
|
43
|
|
1
|
34
|
56
|
34
|
|
1
|
37
|
54
|
38
|
|
1
|
38
|
60
|
42
|
|
1
|
40
|
55
|
35
|
|
1
|
41
|
61
|
39
|
|
1
|
43
|
67
|
44
|
|
1
|
45
|
69
|
40
|
|
1
|
48
|
76
|
41
|
Таблица. Транспонированная матрица.
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
1
|
|
20
|
24
|
28
|
30
|
31
|
33
|
34
|
37
|
38
|
40
|
41
|
43
|
45
|
48
|
|
32
|
30
|
36
|
40
|
41
|
47
|
56
|
54
|
60
|
55
|
61
|
67
|
69
|
76
|
|
33
|
31
|
41
|
39
|
46
|
43
|
34
|
38
|
42
|
35
|
39
|
44
|
40
|
41
|
Таблица. Матрица ATA.
|
14
|
492
|
724
|
546
|
|
492
|
18138
|
26907
|
19384
|
|
724
|
26907
|
28533
|
|
546
|
19384
|
28533
|
21544
|
Таблица. Полученная матрица имеет следующее
соответствие:
|
∑n
|
∑y
|
∑x1
|
∑x2
|
|
∑y
|
∑y2
|
∑x1 y
|
∑x2 y
|
|
∑x1
|
∑yx1
|
∑x12
|
∑x2 x1
|
|
∑x2
|
∑yx2
|
∑x1 x2
|
∑x22
|
Найдем парные коэффициенты корреляции.
Таблица
|
Признаки x и y
|
∑xi
|
∑yi∑xiyi
|
|
|
|
|
|
Для y и x1
|
724
|
51.714
|
492
|
35.143
|
26907
|
1921.929
|
|
Для y и x2
|
546
|
39
|
492
|
35.143
|
19384
|
1384.571
|
|
Для x1 и x2
|
546
|
39
|
724
|
51.714
|
28533
|
2038.071
|
Таблица
|
Признаки x и y
|
|
|
|
|
|
Для y и x1
|
192.347
|
60.551
|
13.869
|
7.781
|
|
Для y и x2
|
17.857
|
60.551
|
4.226
|
7.781
|
|
Для x1 и x2
|
17.857
|
192.347
|
4.226
|
13.869
|
уравнение линейный
регрессия
Таблица. Матрица парных коэффициентов корреляции
R:
|
-
|
y
|
x1
|
x2
|
|
y
|
1
|
0.969
|
0.426
|
|
x1
|
0.969
|
1
|
0.362
|
|
x2
|
0.426
|
0.362
|
1
|
Оценка дисперсии равна:
e2
= (Y - X*Y(X))T(Y - X*Y(X)) = 46.76
Несмещенная оценка дисперсии равна:
Оценка среднеквадратичного
отклонения (стандартная ошибка для оценки Y):
Найдем оценку ковариационной матрицы
вектора k = S2 • (XTX)-1
Дисперсии параметров модели
определяются соотношением S2i = Kii, т.е. это
элементы, лежащие на главной диагонали
Множественный коэффициент корреляции
(Индекс множественной корреляции).
Связь между признаком Y факторами X
сильная
Расчёт коэффициента корреляции
выполним, используя известные значения линейных коэффициентов парной корреляции
и β-коэффициентов.
Коэффициент детерминации
R2 = 0.945
Коэффициент детерминации.
2=
0.9722 = 0.945
Проверка гипотез относительно коэффициентов
уравнения регрессии (проверка значимости параметров множественного уравнения
регрессии).
Число v = n - m - 1 называется числом степеней
свободы. Считается, что при оценивании множественной линейной регрессии для
обеспечения статистической надежности требуется, чтобы число наблюдений, по
крайней мере, в 3 раза превосходило число оцениваемых параметров.
) t-статистика
табл
(n-m-1;α/2)
= (11;0.025) = 2.201
Находим стандартную ошибку
коэффициента регрессии b0:
Статистическая значимость
коэффициента регрессии b0 не подтверждается.
Находим стандартную ошибку
коэффициента регрессии b1:
Статистическая значимость
коэффициента регрессии b1 подтверждается.
Находим стандартную ошибку
коэффициента регрессии b2:
Статистическая значимость
коэффициента регрессии b2 не подтверждается.
Доверительный интервал для
коэффициентов уравнения регрессии.
Определим доверительные интервалы
коэффициентов регрессии, которые с надежность 95% будут следующими:
(bi
- tiSbi; bi + tiSbi)
b0: (1.74 - 2.201 • 5.12
; 1.74 + 2.201 • 5.12) = (-9.53;13.01)1: (0.53 - 2.201 • 0.0426 ;
0.53 + 2.201 • 0.0426) = (0.43;0.62)2: (0.16 - 2.201 • 0.14 ; 0.16 +
2.201 • 0.14) = (-0.15;0.47)
Задача 3
Исследуется зависимость себестоимости единицы
продукции (у тыс. р.) от объема произведенной продукции (х тыс. шт.) по данным
15 предприятий (г - порядковый номер предприятия). Статистические данные
приведены в таблице. Требуется:
) Построить диаграмму рассеяния. Убедиться, что
между себестоимостью и объемом произведенной продукции существует нелинейная
связь.
) Считая, что регрессия у по х представляется
многочленом второй степени, найти оценки параметров параболической регрессии и
составить уравнение линии регрессии.
) Построить кривую регрессии и нанести ее на
диаграмму рассеяния. 3.1.
Таблица
|
i
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
11
|
12
|
13
|
14
|
15
|
|
Xiг
|
2
|
3
|
4
|
4
|
5
|
6
|
6
|
6
|
7
|
8
|
9
|
10
|
12
|
13
|
14
|
|
Yi
|
8
|
10
|
7
|
6
|
5
|
5
|
4
|
3
|
4
|
5
|
3
|
2
|
1
|
1
|
2
|
С помощью средств MS
Excel нанесем точки
рассеивания на координатную плоскость. Анализируя, расположение точек на
диаграмме, можем утверждать наличие нелинейной связи между факторами.
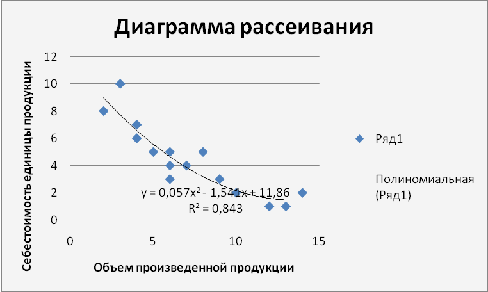
Составим уравнение регрессии 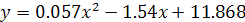
Задача 4
Поквартальная динамика объема
реализованной продукции (у млн. р.) объединения представлена в таблице.
Требуется:
) Оценить параметры линейного тренда
методом наименьших квадратов.
) На основании линейной модели
определить прогноз экономического показателя у в 4-ом квартале 99 года.
Таблица
|
1
KB.
98г.
|
2
кв. 98г.
|
3
кв. 98г.
|
4
кв. 98г.
|
1
KB.
99г.
|
2
кв. 99г.
|
3
кв. 99г.
|
|
yi
|
25
|
29
|
34
|
40
|
44
|
48
|
53
|
Решение:
Линейное уравнение тренда имеет вид y = a1t
+ a0
. Находим параметры уравнения методом наименьших
квадратов.
Система уравнений МНК:
0n
+ a1∑t = ∑y0∑t + a1∑t2
= ∑y • t
Таблица
|
t
|
y
|
t2
|
y2
|
t y
|
|
1
|
25
|
1
|
625
|
25
|
|
2
|
29
|
4
|
841
|
58
|
|
3
|
34
|
9
|
1156
|
102
|
|
4
|
40
|
16
|
1600
|
160
|
|
5
|
44
|
25
|
1936
|
220
|
|
6
|
48
|
36
|
2304
|
288
|
|
7
|
53
|
49
|
2809
|
371
|
|
28
|
273
|
140
|
11271
|
1224
|
Для наших данных система уравнений имеет вид:
a0 + 28a1 = 273
a0 + 140a1 = 1224
Из первого уравнения выражаем а0 и
подставим во второе уравнение
Получаем a0 = 20.143, a1 =
4.714
Уравнение тренда:= 4.714 t + 20.143
Эмпирические коэффициенты тренда a и b являются
лишь оценками теоретических коэффициентов βi,
а само уравнение отражает лишь общую тенденцию в поведении рассматриваемых
переменных.
Коэффициент тренда b = 4.714 показывает среднее
изменение результативного показателя (в единицах измерения у) с изменением
периода времени t на единицу его измерения. В данном примере с увеличением t на
1 единицу, y изменится в среднем на 4.714.
Однофакторный дисперсионный анализ.
Средние значения
Дисперсия
Среднеквадратическое отклонение
Для оценки качества параметров
уравнения построим расчетную таблицу (табл. 2)
Таблица
|
t
|
y
|
y(t)
|
(y-ycp)2
|
(y-y(t))2
|
(t-tp)2
|
|
1
|
25
|
24.86
|
196
|
0.0204
|
9
|
|
2
|
29
|
29.57
|
100
|
0.33
|
4
|
|
3
|
34
|
34.29
|
25
|
0.0816
|
1
|
|
4
|
40
|
39
|
1
|
1
|
0
|
|
5
|
44
|
43.71
|
25
|
0.0816
|
1
|
|
6
|
48
|
48.43
|
81
|
0.18
|
4
|
|
7
|
53
|
53.14
|
196
|
0.0204
|
9
|
|
|
273
|
624
|
1.71
|
28
|
. Анализ точности определения оценок параметров
уравнения тренда.
Стандартная ошибка уравнения.
где m = 1 - количество влияющих
факторов в модели тренда.
По таблице Стьюдента находим табл.табл
(n-m-1;α/2) = (5;0.025)
= 2.571
Рассчитаем границы интервала, в
котором будет сосредоточено 95% возможных значений Y при неограниченно большом
числе наблюдений и t = 0
(a + btp ± ε)
где
(0) = 4.714*0 + 20.143 = 20.143
(20.143 - 0.569 ; 20.143 - 0.569)
(19.574;20.712)
Интервальный прогноз.
Определим среднеквадратическую
ошибку прогнозируемого показателя.
= yn+L ± K
где
- период упреждения; уn+L
- точечный прогноз по модели на (n + L)-й момент времени; n - количество
наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого
показателя; Tтабл - табличное значение критерия Стьюдента для уровня
значимости α и для числа
степеней свободы, равного n-2.
По таблице Стьюдента находим Tтабл
табл (n-m-1;α/2) = (5;0.025)
= 2.571
Точечный прогноз, t = 8: y(8) = 4.71*8
+ 20.14 = 57.86
.86 - 1.97 = 55.89 ; 57.86 + 1.97 =
59.83
Интервальный прогноз:
= 8: (55.89;59.83)
уравнение линейный
регрессия
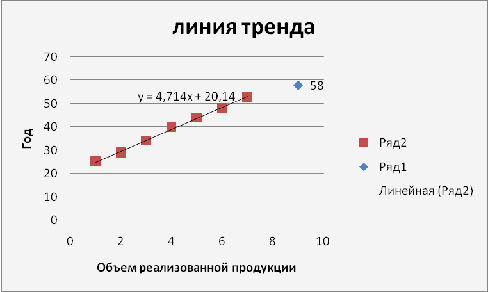
Диаграмма
1.