Динамічні структури даних
Міністерство
освіти і науки України
Національний
університет „ Львівська політехніка ”
Кафедра
ЕОМ
Розрахункова
робота на тему
"
Динамічні структури даних "
з
дисципліни
"
Обчислювальний практикум "
Варіант
№7
Козак Н.Б.
Львів
ТЕОРЕТИЧНА ЧАСТИНА
Абстрактний тип даних (АТД, ADT)
Абстрактний тип даних - математична модель із
сукупністю операторів, визначених в рамках цієї моделі. Простим прикладом
можуть служити множини цілих чисел з операторами об’єднання, перетину та
різниці множин. В моделі АТД оператори можуть мати операндами не лише дані,
визначені цим АТД, але і дані інших типів: стандартних типів, визначених мовою
програмування чи визначених в інших АТД.
АТД можна розглядати як узагальнення простих
типів даних. Він інкапсулює типи даних в тому сенсі, що визначення типу і всі
оператори, виконувані над даними цього типу, поміщаються в один розділ
програми. Якщо необхідно змінити реалізацію АТД, ми знаємо, де знайти і що
змінити в одному невеликому розділі програми.
Термін «реалізація АТД» передбачає наступне:
переведення в оператори мови програмування оголошень, що визначають змінні
цього абстрактного типу даних, плюс процедури для кожного оператора,
виконуваного над об’єктами АТД. Реалізація залежить від структури даних, що
представляє АТД. Кожна з них будується на основі базових типів даних
застосовуваної мови програмування, використовуючи доступі засоби
структурування.
Різницяміжабстрактними типами даних і
структурами даних, які реалізують абстрактні типи, можна пояснити на наступному
прикладі. Абстрактний тип данихсписок може бути реалізований за допомогою
масиву або лінійного списку, з використанням різних методів динамічного
виділення пам'яті. Однак кожна реалізація визначає один і той же набір функцій,
який повинен працювати однаково (по результату, а не по швидкості) для всіх
реалізацій.
Абстрактнітипиданихдозволяютьдосягтимодульності
програмнихпродуктів і матикількаальтернативнихвзаємозаміннихреалізаційокремого
модуля.
Стек (Stack)
З англ. stack - стопка - структура даних, в якій
доступ до елементів організований за принципом LIFO (англ. last in - firstout ,
"Останнім прийшов - першим вийшов"). Найчастіше принцип роботи стека
порівнюють зі стопкою тарілок: щоб взяти другу зверху, потрібно зняти верхню. В
цифровому обчислювальному комплексі стек називається магазином - по аналогії з
магазином у вогнепальній зброї (стрільба почнеться з патрона, зарядженого
останнім).
Таблиця 1.2.1. Основні операції над стеком
|
Операція
|
Дія
|
|
empty()
|
Повертає true, якщо стек порожній, і false у
противному випадку
|
|
sіze()
|
Повертає розмір стека
|
|
pop()
|
Видаляє вершину стека
|
|
top()
|
Повертає значення вершини стека
|
|
push(T item)
|
Додає новий елемент у стек, де Т - тип даних
стека
|
|
swap(stack& x)
|
Обмінюється вмістом двох стеків
|
Черга (Queue)
Черга(queue) - впорядкований контейнер
елементів, в якому додавання нового здійснюється в кінець (чи як його ще
називають «хвіст» (tail, rear)) і видалення елементів здійснюється з іншого
боку, тобто початку (голови (head, front)). Як тільки елемент встане в чергу,
він опиняється в її кінці і прямує до голови, очікуючи видалення елемента, що
стоїть перед ним.Такий принцип ще називають «Перший прийшов - перший пішов»
(FiFo - first-infirstout).
Найпростішим прикладом черги є звичайна
«людська» черга, в якій ми опиняємось практично кожен день. Ми стоїмо на касі в
супермаркеті, в черзі за кавою, чекаємо потрібного сеансу в кінотеатрі тощо.
Черга (як структура даних) є обмежена тим, що є
лише один вхід і один вихід з неї. Не можна просто взяти та зайти в середину
черги чи покинути її, не дочекавшись потрібного часу, щоб дістатись до її
голови.
Перевагою такої структури для зберігання даних
можна вважати її динамічність - обмежується тільки об’ємом пам’яті. Недоліком -
складну процедуру пошуку і додавання елементів при великих об’ємах даних, що
зберігаються.
Таблиця 1.3.1. Основні операції над чергою
|
Операція
|
Дія
|
|
empty()
|
Повертає true, якщо черга порожня, і false у
противному випадку
|
|
sіze()
|
Повертає розмір черги
|
|
front()
|
Повертає значенняпершого елементу
|
|
back()
|
Повертає значення останнього елементу
|
|
pop()
|
Видаляє елемент із черги, але не повертає його
значення
|
|
push(T item)
|
Додає новий елемент у чергу
|
|
swap(queue& x)
|
Обмінюється вмістом двох стеків
|
Дек - особливий вид черги. Дек (від англ. deque
- doubleendedqueue, тобто черга із двома кінцями) - це така послідовність, у
якій як додавання, так і вилучення елементів може здійснюватися з кожного із
двох кінців. Окремий випадок дека - дек з обмеженим входом і дек з обмеженим
виходом. Логічна й фізична структури дека аналогічні логічній і фізичній
структурі кільцевої FіFO-черги. Однак, стосовно до дека доцільно про лівий і
правий кінці. Динамічна реалізація дека є об'єднанням стека і черги.
Прикладом дека може бути, наприклад, якийсь
термінал, у який вводяться команди, кожна з яких виконується якийсь час. Якщо
ввести наступну команду, не дочекавшись, поки закінчиться виконання
попередньої, то вона встане в чергу й почне виконуватися, як тільки звільниться
термінал. Це FІFO черга. Якщо ж додатково ввести операцію скасування останньої введеної
команди, то отримаємо дек. Дек підтримує роботу з літератором, відповідно є
доступ до будь-якого його елемента.
Таблиця 1.3.2. Основні операції над деком
|
Операція
|
Дія
|
|
empty()
|
Повертає true, якщо дек порожній, і false у
противному випадку
|
|
sіze()
|
Повертає розмір деку
|
|
front()
|
Повертає значенняпершого елементу
|
|
back()
|
Повертає значенняостаннього елементу
|
|
pop_front()
|
Видаляє перший елемент
|
|
pop_back()
|
Видаляє останній елемент
|
|
push_front(T item)
|
Додає новий елемент в початок деки
|
|
push_back(T item)
|
Додає новий елемент в кінець деки
|
Список (List)
Лінійний список - це скінчена послідовність
однотипних елементів (вузлів), можливо, з повтореннями. Список розташовується в
пам'яті довільним чином. Кожний вузол однонаправленого лінійного зв'язаного
списку містить вказівник на наступний вузол списку, що дозволяє переміщатися
вперед по списку. Кожний вузол двонаправленоголінійного зв'язаного списку
містить вказівники на попередній і наступний вузли списку, що дозволяє
переміщатися по списку вперед та назад.
Вставка і видалення вузлів списку реалізовані
ефективно: змінюються тільки вказівники. З іншого боку, довільний доступ до
вузлів списку підтримується погано: щоб прийти до певного вузла списку, треба
відвідати всі попередні вузли. Крім того, на відміну від стеків або черг,
додатково витрачається пам'ять під один або два вказівники на кожний елемент
списку.
Список росте дуже просто: додавання кожного
нового елемента приводить до того, що вказівники на попередній і наступний
вузли списку, між якими вставляється новий вузол, міняють свої значення. У
новому елементі таким вказівникам присвоюється значення адрес сусідніх
елементів. Список використовує тільки такий об'єм пам'яті, який потрібний для
наявної кількості елементів. Підтримується робота з ітератором.
Таблиця 1.4.1. Основні операції над списком
|
Операція
|
Дія
|
|
empty()
|
Повертає true, якщо список порожній, і false у
противному випадку
|
|
sіze()
|
Повертає розмір списку
|
|
front()
|
Повертає значенняпершого елементу
|
|
back()
|
Повертає значенняостаннього елементу
|
|
pop_front()
|
Видаляє перший елемент
|
|
pop_back()
|
Видаляє останній елемент
|
|
push_front(T item)
|
Додає новий елемент в початок деки
|
|
push_back(T item)
|
Додає новий елемент в кінець деки
|
|
insert(it pos, T item)
|
Вставляє елемент в позицію/проміжок, задані
ітератором (itpos)
|
|
erase(it pos, T item)
|
Видаляє елемент(и) з позиції/проміжку, заданої
ітератором (itpos)
|
Таблиця 1.4.1. Основні операції над списком
Дерево (Tree)
Дерево - в інформатиці та програмуванні одна з
найпоширеніших структур даних. Формально дерево визначається як скінченна
множина Т з однієї або більше вершин (вузлів, nodes), яке задовольняє наступним
вимогам:
існує один виокремлений вузол - корінь (root)
дерева
інші вузли (за виключенням кореня) розподілені
серед m ≥ 0 непересічних множинT1.Tm і кожна з цих множин в свою чергу є
деревом. Дерева T1.Tm мають назву піддерев (subtrees) даного кореня.
З цього визначення випливає, що кожна вершина є
в свою чергу коренем деякого піддерева. Кількість піддерев вершини має назву
ступеня (degree) цієї вершини. Вершина ступеню нуль має назву кінцевої
(terminal) або листа (leaf). Некінцева вершина також має назву вершини
розгалуження (branchnode). Нехай x - довільна вершина дерева з коренем r. Тоді
існує єдиний шлях з r до x. Усі вершини на цьому шляху називаються предками
(ancestors) x; якщо деяка вершина y є предком x, то x називається нащадком
(descendant) y. Нащадки та предки вершини x, що не співпадають з нею самою,
називаються власними нащадками та предками. Кожну вершину x, в свою чергу,
можна розглядати як корень деякого піддерево, елементами якого є
вершини-нащадки x. Якщо вершини x є предком y та не існує вершин поміж ними
(тобто x та y з'єднані одним ребром), а також існують предки для x (тобто x не
є коренем), то вершина x називається батьком (parent) до y, а y - сином (child)
x. Коренева вершина єдина не має батьків. Вершини, що мають спільного батька,
називаються братами (siblings). Вершини, що мають нащадків, називаються
внутрішніми (internal). Глибиною вершини x називається довжина шляху від кореня
до цієї вершини. Максимальна глибина вершин дерева називається висотою.
Важливим окремим випадком кореневих дерев є
бінарні дерева, які широко застосовуються в програмуванні і визначаються як
множина вершин, яка має виокремлений корінь та два піддерева (праве та ліве),
що не перетинаються, або є пустою множиною вершин (на відміну від звичайного
дерева, яке не може бути пустим).
Важливими операціями на деревах є:
обхід вершин в різному порядку
перенумерація вершин
пошук елемента
додавання елемента у визначене місце в дереві
видалення елемента
видалення цілого фрагмента дерева
додавання цілого фрагмента дерева
знаходження кореня для будь-якої вершини
Найбільшого розповсюдження ці структури даних
набули в тих задачах, де необхідне маніпулювання з ієрархічними даними,
ефективний пошук в даних, їхнє структуроване зберігання та модифікація.
В програмуванні бінарне дерево - дерево, в якому
кожна вершина має не більше двох синів. Зазвичай такі сини називаються правим
та лівим. На базі бінарних дерев будуються такі структури, як бінарні дерева
пошуку та бінарні купи.
Різновиди бінарних дерев :
Повне (закінчене) бінарне дерево - таке бінарне
дерево, в якому кожна вершина має нуль або двох синів.
Ідеальне бінарне дерево -- це таке повне бінарне
дерево, в якому листя (вершини без синів) лежать на однаковій глибині (відстані
від кореня).
Бінарне дерево на кожному n-му рівні має від 1
до 2n вершин.
Часто виникає необхідність обійти усі вершини
дерева для аналізу інформації, що в них знаходиться. Існують декілька порядків
такого обходу, кожний з яких має певні властивості, важливі в тих чи інших
алгоритмах: прямий (preorder), симетричний (simetric) та зворотній (postorder).
Бінарне дерево пошуку:
Бінáрнедéревопóшуку
(англ. binarysearchtree, BST) в інформатиці - бінарне дерево, в якому кожній
вершині xспівставлене певне значення val[x].При
цьомутакізначенняповиннізадовольнятиумовівпорядкованості:
нехай x - довільнавершина бінарного дерева
пошуку;
якщо вершина y знаходиться в
лівоміпіддеревівершини x, то val[y] ≤ val[x];
якщо у знаходиться у правому піддереві x, то
val[y] ≥ val[x].
Такеструктуруваннядозволяєнадрукуватиусізначення
у зростаючому порядку за допомогою простого алгоритма центрованого обходу
дерева. Бінарні дерева пошукунабагатоефективніші в операціяхпошуку,
аніжлінійніструктури, в якихвитрати часу на пошукпропорційні O(n), де n --
розмірмасивуданих, тоді як в повномубінарномудеревіцей час пропорційний в
середньому O(log2n) або O(h), де h - висота дерева (хочагарантувати, що h не
перевищує log2n можналише для збалансованих дерев, які є ефективнішими на
пошукових алгоритмах, аніжпростібінарні дерева пошуку).
ПОБУДОВА АТД
Абстрактний тип даних «Стек»
Змоделювати АТД «Стек». Оформити АТД у вигляді
класу. Переписати основні операції роботи з АТД і продемонструвати їх
застосування при додаванні та вилученні елементів з АТД.
Я вирішив реалізувати стек на основі статичного
масиву з такими методами : перевірка на порожній вміст, повернення розміру,
виштовхування, зштовхування, повернення верхнього елементу, друк вмісту стеку.
Реалізація стеку
-Stack.h--
#include<iostream>;
{:array[20];iterator;:(){
iterator = -1; };empty();size() { return iterator + 1;
};pop();top();push(int);show();
~Stack() {};
};
--Stack.cpp--
#include"Stack.h"::
empty(void)
{(iterator==-1);;
}:: pop(void)
{(iterator!=-1)-;
}:: top(void)
{(iterator!=-1)array[iterator];
}:: push(inta)
{++;[iterator]=a;
}:: show(void)
{(iterator!=-1)
{i=iterator;(i!=-1)
{<<array[i]<<"
";-;
}
}<<"Stack
empty"<<endl;
}
Тестова програма
#include"Stack.h"
void main()
{;[10] = { 2, 2, 4,
5, 7, 6, 8, 9, 4, 3 };<<"Your array: ";(int
i=0;i<10;i++)<<ar[i]<<" ";<<endl;(int
i=0;i<10;i++)
{<<"Element:"
<<ar[i] <<endl;<<"Stack
now:";(ar[i]%2==0).push(ar[i]);.pop();
st.show();
}
}
Результат тестування
Як бачимо на рис. 1, парні елементи заносяться у
стек, непарні - видаляють вершину стека. Відповідно зміни відображені на
рисунку нижче :

Рис..1. Результат виконання
тестової програми
Абстрактний тип даних «Черга»
Змоделювати АТД «Queue». Оформити АТД у вигляді
класу. Переписати основні операції роботи з АТД і продемонструвати їх
застосування при додаванні та вилученні елементів з АТД.
Я реалізував чергу на основі
двохзв’язних вузлів з наступними методами: додавання та видалення елементів,
повернення першого та останнього елементів, розміру, перевірки її на порожність
та виведення вмісту черги.
Реалізація черги
--queue.h--
#include<iostream>;
{:(){cout<<"Queueempty"<<endl;}
};
{;* next;* prev;
};
{:* front;* rear;;:()
{= NULL;= NULL;= 0;
}()
{(isEmpty())();
//
Deletethefrontnodeandfixthelinks* tmp = front;(front->next != NULL)
{=
front->next;>prev = NULL;
}= NULL;-;;
}(intelement)
{
// Create a
newnode* tmp = newNode();>data = element;>next = NULL;>prev =
NULL;(isEmpty())= rear = tmp;
{
//
Appendtothelistandfixlinks>next = tmp;>prev = rear;= tmp;
}++;
}()
{(isEmpty())();front->data;
}()
{(isEmpty())();rear->data;
}(){returncount;}(){returncount
== 0 ? true : false;}()
{* p =
front;(isEmpty());(int i = 0; i <count; i++)
{<<
p->data<<" ";= p->next;
}<<endl;
}
~Queue()
{;;
}
};
Тестова програма
#include"queue.h"
#include<math.h>()
{(LC_ALL,
"Ukrainian");;k;<<"Вводьте елементи, якi бажаєте внести в чергу"<<endl;<<"Додатнє число додається в чергу, вiд'ємне вилучає елемент"<<endl;
cout<<"Введiть -999
для завершення введення"<<endl;
do
{>> k;(k ==
-999)break;(k >= 0)
{.Push(k);<<"Додаємо:
"<< k <<endl;.ShowQueue();
}
{(!test.isEmpty())
{<<"Вилучаємо
"<<test.Front() <<endl;.Pop();.ShowQueue();
}();
}
} while (k !=
-999);("pause");
}
Результат тестування
Як бачимо з рис.2, додатні елементи заносяться у
чергу, від’ємні елементи - вилучають перший елемент із черги. Динаміку вмісту
показано на цьому ж рисунку.
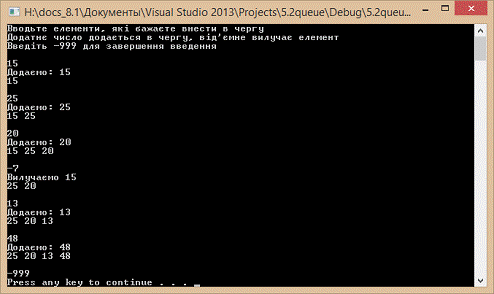
Рис. 2. Результат виконання тестової програми
Абстрактний тип даних «Список»
Змоделювати АТД «Список». Оформити АТД у вигляді
класу. Переписати основні операції роботи з АТД і продемонструвати їх
застосування при додаванні та вилученні елементів з АТД.
Я реалізував однозв’язний список на базі
однозв’язних вузлів (кожен з яких містить вказівник лише на наступний елемент
списку) та написав для нього наступні методи : додавання в початок, кінець
списку та в певну позицію, пошук вузла за значенням, «інверсія» та друк списку.
Реалізація списку
-List.h--
#include<iostream>std;
{:
{
int value; // певна
інформативна частина* next; // вказівник на наступну структуру-вузол у списку
};* head = NULL; // вказівник
на голову списку
public:addToBegin(intv)
{* n =
newNode;>value = v;>next = head;= n;
}addToEnd(intv)
{* n;(!head)
{=
newNode;>value = v;>next = NULL;;
}
{=
head;(n->next)= n->next;* newNode = newNode;>value = v;>next =
NULL;>next = newNode;;
}
}deleteNode(Node *
n)
{<<"Видаляємо елемент
"<<n->value << endl;* k = head;(head == n)
{;= NULL;;
}(k->next != n)=
k->next;>next = n->next;;
}insert(constintv,
Node * n)
{* newNode =
newNode;>value = v;>next = n->next;>next = newNode;
}* find(constintv)
{* n = head;(n)
{(n->value ==
v)n;= n->next;
};
}Show()
{<<"Список зараз :
";*n = head;(n != NULL)
{<<
n->value <<" ";= n->next;
}<< endl;
}reverse()
{<<"Iнверсiя списку:
";*temp, *tmp, *var;= head;= NULL;(temp != NULL)
{= var;= temp;=
temp->next;>next = tmp;
}= var;
}
};
Тестова програма
void main()
{(LC_ALL,
"Ukrainian");list;N, p;<<"Введiть число
N"<< endl;>> N;<<"Введiть
"<< N <<" елементiв"<< endl;(int i = 0; i < N; i++)
{>>
p;.addToEnd(p);.Show();
}.deleteNode(list.find(10));.deleteNode(list.find(25));.Show();.reverse();.Show();("pause");
}
Результат тестування
На рисунку 3. показано динаміку вмісту списку
при внесенні до нього елемента. Як бачимо, елемент додається у кінець списку.
Результат виконання методів видалення елементів та інвертування списку також
продемонстровано на даному рисунку.
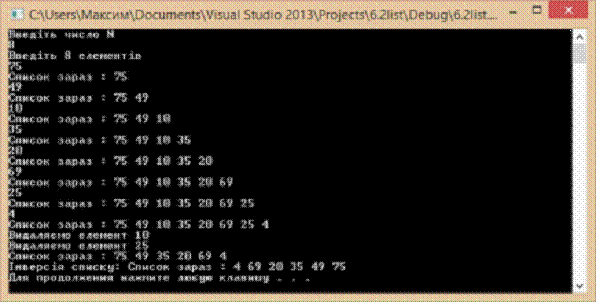
Рис.3. Результат виконання тестової програми
Абстрактний тип даних «Дерево»
Змоделювати АТД «Дерево». Оформити АТД у вигляді
класу. Переписати основні операції роботи з АТД і продемонструвати їх
застосування при додаванні та вилученні елементів з АТД.
Я реалізував дерево на основі вузлів, кожен з
яких містить поле для значення вузла, вказівник на ліве та праве піддерева та
написав наступні методи для нього: додавання та видалення елемента, видалення
дерева цілком, перевірка на пустоту, повернення кореня та методи обходу дерева
в трьох варіантах.
Реалізація дерева
-Tree.h--
#include<iostream>std;
{:{data;*left;*right;
};*p;k;*root;:()
{root = NULL; }
~Tree() { clear();
}* getRoot() { return root; }isEmpty() const { return root == NULL;
}addNode(intd)
{* t =
newNode;*parent;>data = d;>left = NULL;>right = NULL;=
NULL;(isEmpty())= t;
{*current;=
root;(current)
{=
current;((t->data) > (current->data))= current->right;=
current->left;
}(t->data <
parent->data)>left = t;>right = t;
}
}clear() {
recursive_delete(root); }recursive_delete(Node* node)
{(node != NULL)
{_delete(node->left);_delete(node->right);(node);
}
}deleteNode(Node*
node)
{;= NULL;
}printInOrder()
{<<"Inorder:
";(root);<< endl;
}inorder(Node* p)
{(p != NULL)
{(p->left)(p->left);<<"
"<<p->data <<" ";(p->right)(p->right);
};
}printPostOrder()
{<<"Postorder:
";(root);<< endl;
}postorder(Node* p)
{(p != NULL)
{(p->left)
postorder(p->left);(p->right) postorder(p->right);<<"
"<<p->data <<" ";
};
}printPreOrder()
{<<"Preorder:
";(root);<< endl;
}preorder(Node* p)
{(p != NULL)
{<<"
"<<p->data <<" ";(p->left)
preorder(p->left);(p->right) preorder(p->right);
};
}
};print(Tree&k)
{.printPreOrder();.printInOrder();.printPostOrder();
}create(Tree&k)
{x;<<"type
10 elements"<< endl;(int i = 0; i <10; i++)
{>>
x;.addNode(x);
}
}
Тестова програма
#include"Tree.h"
void main()
{(LC_ALL,
"Ukrainian");t1;(t1);(t1);
}
Результат тестування
На основі введених десяти чисел програма
побудувала дерево та здійснила обхід у трьох напрямах, що показано на рис.
4.Вхідні дані взяті з книгиХ. М., П. Дж. Дейтела.
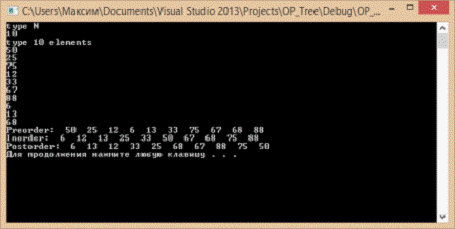
Рис. 4. Результат виконання тестової програми
ЗАСТОСУВАННЯ АТД
Завдання 1
Написати програму синтаксичного аналізу
відповідностей відкриваючих і закриваючих дужок в арифметичному виразі, що має
три набори дужок "(" i ")", "<" i
">", "[" i "]". Роздрукувати таблицю
відповідностей дужок, причому в таблиці повинно бути зазначено, для яких дужок
відсутні парні їм дужки. Для ідентифікації дужок використати їх порядкові
номери у виразі.
Приклад: Для арифметичного виразу:
2 3 4 5 6
(a+b1)/2+6.5]*{4.8+sin(x)
має бути виведена таблиця виду:
Дужки
відкриваюча закриваюча
-
Прочерки в таблиці означають відсутність
відповідної дужки
Опис алгоритму
Користувач вводить вираз. Для завершення
введення виразу потрібно натиснути клавішу Enter. Потім ми проходимо по всьому
рядку, якщо зустрічається відкриваюча дужка то ми заштовхуємо її в стек . Якщо
закриваюча дужка(і стек не порожні) і якщо тип відкриваючої і закриваючої дужки
співпадає то виводим ці дужки і видаляємо їх з стеку, а у випадку коли стек був
порожній то на місце відкриваючої дужки ставим прочерк, виводимо закриваючу
дужку і встановлюємо що балансу дужок немає.
Якщо після того як ми ввели у стек всі
закриваючі дужки і вивели їх на екран а стек залишився не порожнім то на екран
виводиться повідомлення що переважає кількість відкриваючих дужок. Після цього
виводимо ці дужки і на місце закриваючих дужок ставимо прочерк. А якщо
кількість закриваючих і відкриваючих дужок співпадає то програма завершує своє виконання
і на екран виводиться повідомлення що баланс дужок було дотримано.
Результат виконання програми
На рис.5 показано, як програма перевіряє тип
дужки у виразі та виводить результат.
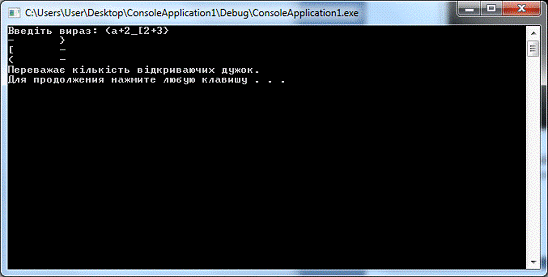
Рис.5. Результат виконання тестової програми
Блок-схема алгоритму
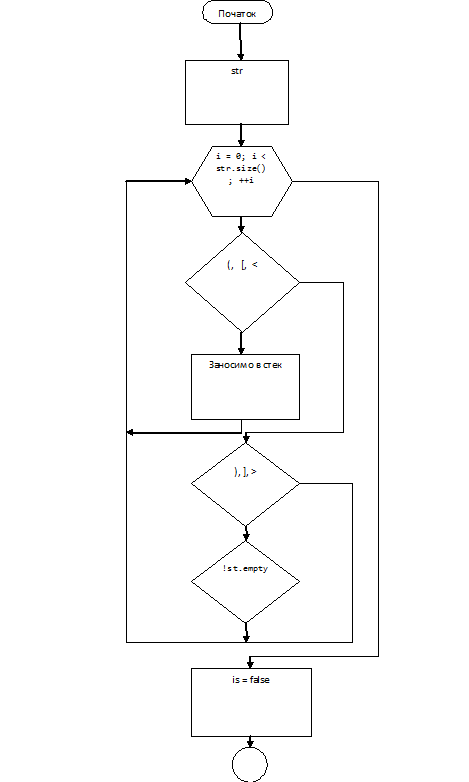
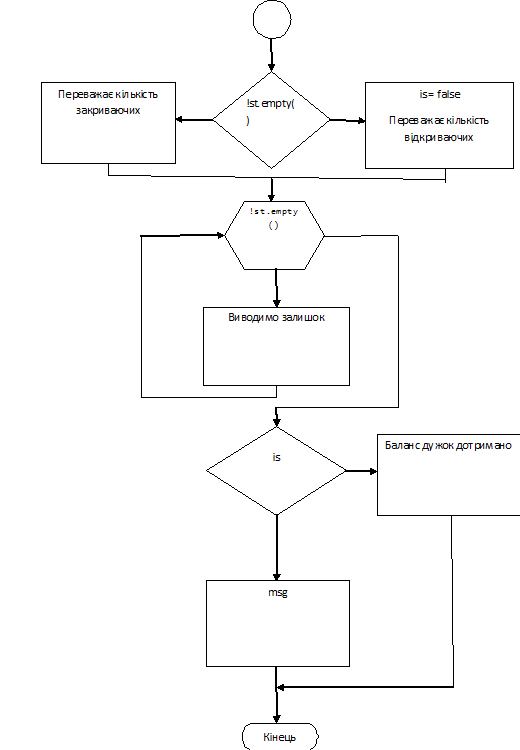 Рис.6.Блок-схема алгоритму
вирішення завдання
Рис.6.Блок-схема алгоритму
вирішення завдання
Дано позначення двох полів шахівниці
(наприклад, A5 і C2). Знайти мінімальне число ходів, які потрібні шаховому
коневі для переходу з першого поля на друге.
Вказівки до розв’язання задачі: Ідея
рішення ґрунтується на використанні черги. Спочатку в чергу міститься елемент,
що визначає вихідне положення шахового коня, а відповідна клітка поля
позначається як така, яку відвідали.
На кожному з наступних кроків
алгоритму (поки черга не порожня або не позначена кінцева клітка) виконуються
наступні дії.
Із черги вилучається черговий
елемент, що визначає деяку позицію (x,y).
Знаходяться клітки в межах поля, які
досяжні з (x,y) одним ходом шахового коня, і які ще не позначені.
Елементи, що відповідають знайденим
кліткам, додаються в чергу, а клітки позначаються як такі, яких відвідали.
При цьому спочатку всі клітки
повинні бути непозначені, а мітку бажано ставити таку, щоб можна було відновити
шлях між полями. Для цього мітку поля можна визначити як позицію поля, з якої
вона була позначена.
Опис алгоритму
Програма зчитує файл. За допомогою
функції NumberOfRows рахує кількість рядків і відповідне виділяє 1/3 к-ті
рядків для масивів структур buy i sell. Якщо перший символ рядка “Z”, то
обраховується загальна вартість закупленої партії і елемент масиву заноситься
до черги типу buy; якщо ж “P”, то множник збільшення ціни збільшується на 0,2
(20%), обраховується ціна, по якій був проданий товар, а також, за допомогою
функції DigSymb, - кількість товару, проданого з кожної партії. Якщо кількість
купленого товару менша, ніж кількість проданого, то сума, на яку були продані
товари з кожної партії буде рівна к-ті куплених товарів, помножених на їх ціну,
інакше к-ті проданих товарів, помножених на їх ціну, і в обох випадках показник
загальної кількості проданих товарів збільшується на відповідну величину.
Загальна сума грошей, отриманих за продані товари збільшується на суму, на яку
були продані товари з кожної партії, обчислюється сума отриманого прибутку і
цей елемент заноситься до черги sell.
Результат виконання програми
Результат виконання даної програми
показаний на рисунку нижче (Рис.7). Як бачимо програма шукає найкоротший шлях
між двома полями шахівниці.
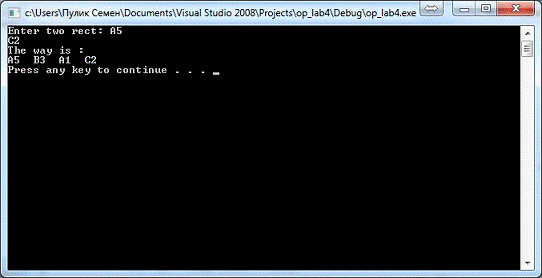
Рис. 7. Результат виконання програми
Блок-схема алгоритму
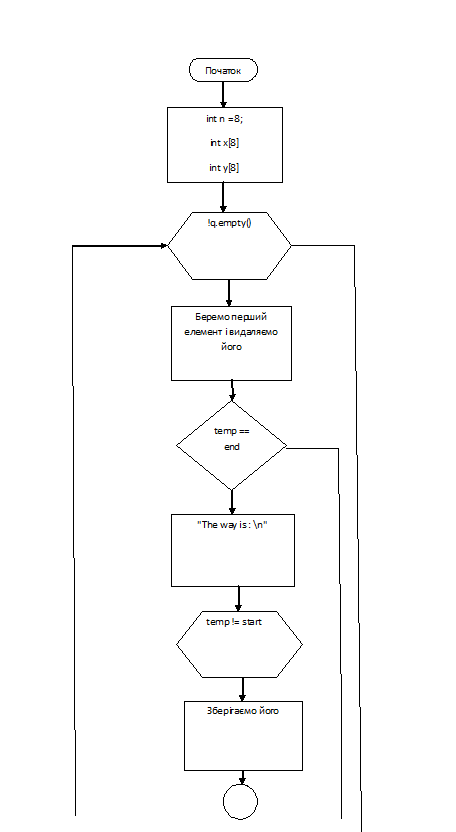
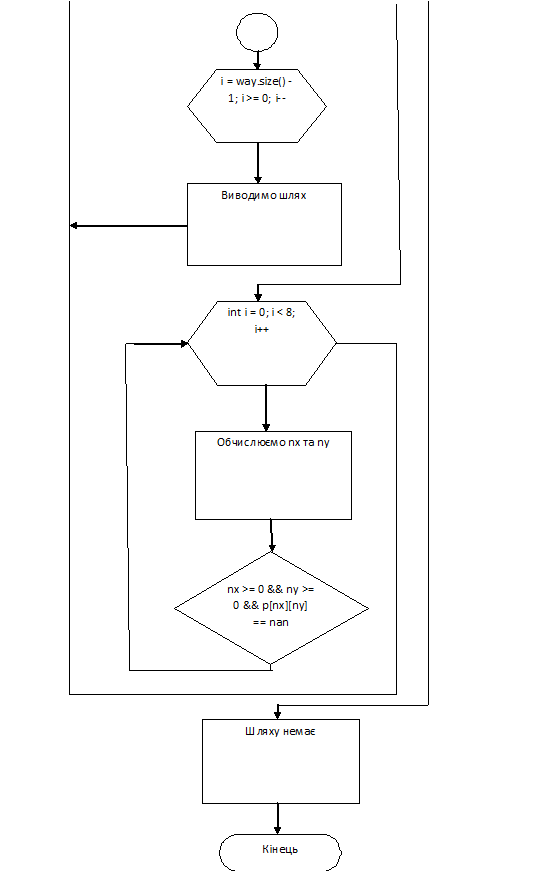
Рис.8. Блок-схема алгоритму
вирішення завдання
Завдання 3
Написати програму для роботи з розрідженими
матрицями, представленими у вигляді зв’язаних списків:
Додавання двох матриць.
Опис алгоритму
Створюються дві матриці.розмір матриці задається
в самому коді програми,в даному випадку наша матриця розміру 5:4. Далі
відбуваєть занулення всіх елементів кожної матриці а деяким окремим елементам
надається якесь значення. Сьворюємо об’єкти R_Matrix.R_Matrix::AddR_Matrix -
функція яка додає дві матриці.вона проходить по всій матриці і ненульові
координати заносить в список._Matrix res-функція яка виводить результат
додавання двох матриць.R_Matrix::Check-функція яка шукає потрібну нам координату
в списку для додавання.
Спочатку на екран виводяться дві матриці а потім
результат додавання матриць.
Результат виконання програми
Із скріншота нижче (рис. 9), маємо результат
додавання матриці:
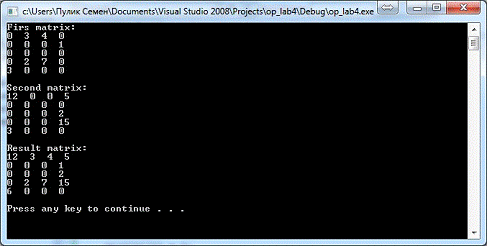
Рис. 9. Результат виконання програми
Блок-схема алгоритму
Рис. 10. Блок-схема алгоритму
розв’язання задачі
Завдання 4
кісточок доміно за правилами гри викладаються в
прямий ланцюжок, починаючи з кісточки, обраної довільним чином, в обидва кінці
доти, поки це можливо. Змоделювати гру в доміно і написати програму
а) побудови самого довгого ланцюжка;
б) знаходження такого варіанта викладання
кісточок, при якому до моменту, коли ланцюжок не можна далі продовжити,
"на руках" залишиться максимальне число очок.
Приклад: Вхідні дані Результат = 5 5
2 56:62:21:13:36
3
6
6
6
Опис алгоритму
Користувач вводить послідовність. Далі за
допомогою кількох функцій будується послідовність коли послідовність побудована
ми перевертаємо фішки та знову будуємо послідовність.функція яке перевертає
фішки.функція яка додає нову фішку до послідовності.функція яка перевіряє чи
можливе продовження побудови послідовності.функція яка визначає суму на фішках
які невикористані.
На екран виводиться максимальна довжина
послідовності фішок та максимальна сума на фішках які залишаються після
побудови послідовності.
Результат виконання програми
Як видно із скріншота (рис.11), послідовність
успішно побудована.
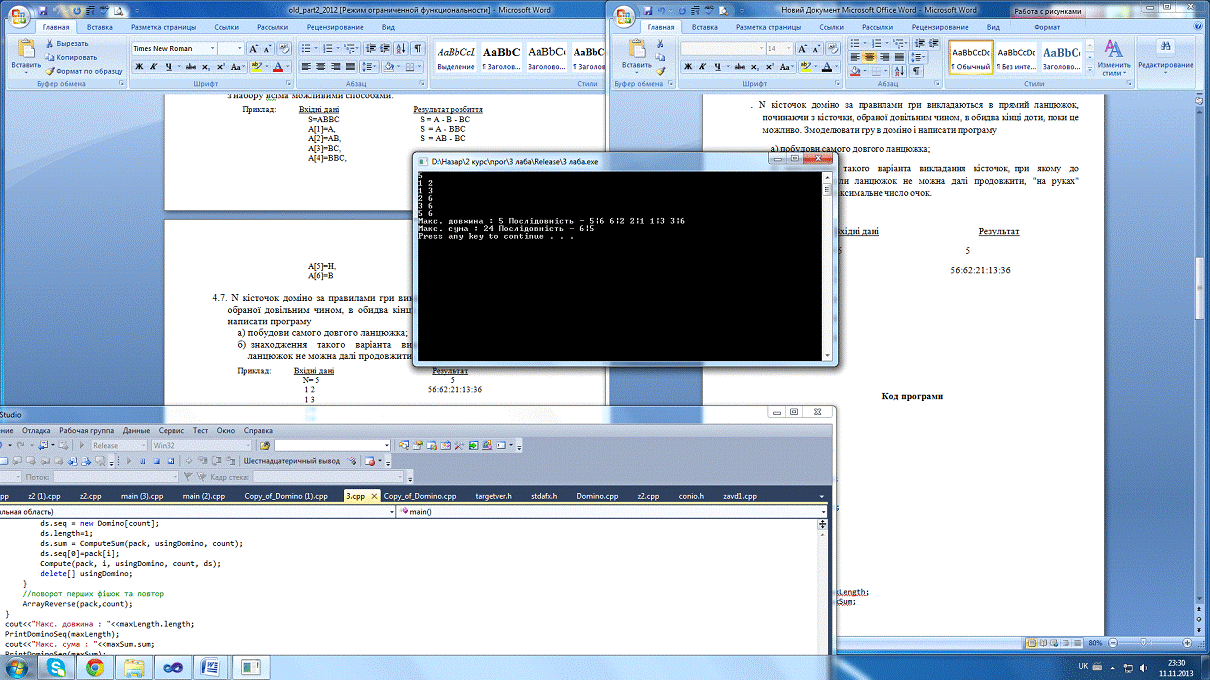
Рис. 11. Результат виконання програми
Блок-схема алгоритму
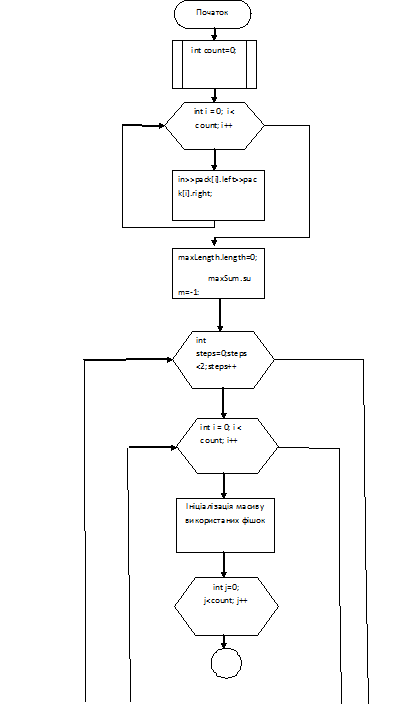
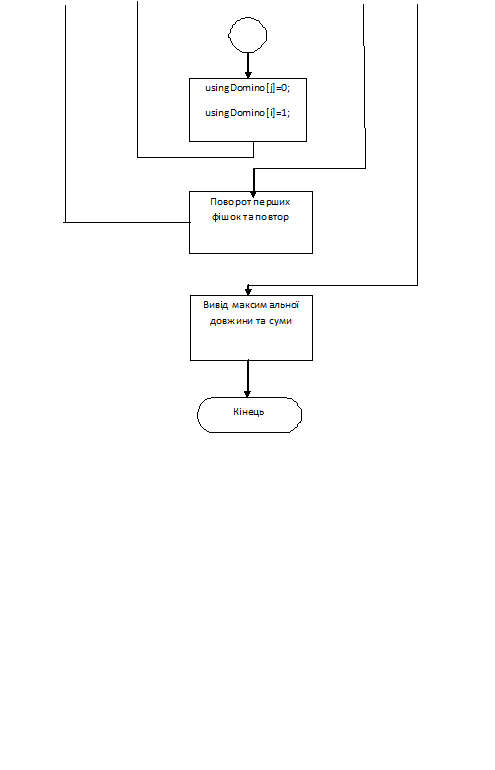
Рис. 12. Блок-схема алгоритму
розв’язання задачі
стек список програма
дані
ВИСНОВКИ
Виконуючи дану розрахункову роботу, я
ознайомився із динамічними структурами даних, зокрема стеком, чергою, списком
та деревом, удосконалив свої знання щодо створення та написання алгоритмів,
навчився реалізовувати основні методи даних АТД, застосовувати їх до
розв’язання різноманітних задач.
СПИСОК ЛІТЕРАТУРИ
Х.
М. Дейтел, П. Дж. Дейтел Как программировать на С++: Пятое издание. Пер. с
англ. - М.: ООО «Бином-Пресс», 2008 г. - 1456 с.: ил.
Cormen
T. H., C. E. Leiserson, R. L. Rivest and C. Stein, Introduction to Algorithms,
Second Edition, Prentice Hall of India Pvt. Ltd., New Delhi, 2003.N.,
GraphTheorywithApplication to Engineering and Computer Science, Prentice Hall
of India Pvt. Ltd., New Delhi, 2000.E., S. Sahni and S. Rajasekaran, Computer
Algorithms, Galgotia Publications Pvt. Ltd., New Delhi, 2004.D. E., The Art of
Computer Programming (Volume 1): Fundamental Algorithms, Third Edition,
Addition Wesley: An Imprint of Pearson Education, Delhi, 2002.
Седжвик
Роберт,Фундаментальные алгоритмы на С++. Анализ/Структуры
данных/Сортировка/Поиск, 2001.
ГОСТ
19.701-90://interactivepython.org/runestone/static/pythonds/index.html#basic-data-structures
Лисак
Т.А., Методичні вказівки до лабораторної роботи "Структура даних
"БІНАРНЕ ДЕРЕВО ПОШУКУ"" з дисципліни «Програмування. Частина
IIІ»для підготовки студентів напрямку 6.0915 “Комп’ютерна інженерія”/
Львів: Видавництво НУ “Львівська політехніка”, 2010 - 16 с.
ДОДАТОК А. КОД ПРОГРАМИ ДО ЗАВДАННЯ 1
#include
<iostream>
#include
<string>
#include
"stack.h"namespace std;main()
{(0,
"Ukr");str;<< "Введiть вираз: ";>> str; is = true;<char> st; (unsigned i
= 0; i < str.size(); ++i)
{(str[i] == '(' ||
str[i] == '[' || str[i] == '<')
{.push(str[i]); ;
}(str[i] == ')' ||
str[i] == ']' || str[i] == '>')
{(!st.empty()){(
(str[i] == ')' && st.top() == '(') || (str[i] == '>' &&
st.top() == '<') || (str[i] == ']' && st.top() == '['))
{<< st.top()
<< '\t' << str[i] << endl; .pop();}
{<<
"-\t" << str[i] << endl; = false;
}
}
{<<
"-\t" << str[i] << endl; = false;
}
}
}msg;(!st.empty())
{= false;= "Переважає кiлькiсть вiдкриваючих дужок.\n";
}= "Переважає кiлькiсть закриваючих дужок.\n";(!st.empty())
{<< st.top()
<< '\t' << "-\n"; .pop();
}(is)<<"Баланс дужок дотримано.\n";<<
msg;("pause");
return 0;
}
ДОДАТОК Б. КОД ПРОГРАМИ ДО ЗАВДАННЯ 2
#include <iostream>
#include <vector>
#include <limits>
#include <string>
#include <algorithm>
#include <queue>namespace
std;main(){ n = 8;
//cin >> n;x[8] = {1, 1, -1,
-1, 2, 2, -2, -2};y[8] = {2, -2, 2, -2, 1, -1, 1, -1};<pair<int, int>
> q;<int, int> start, end, temp, nan = make_pair(-1, -1);<vector
<pair<int, int> > > p(n, vector <pair<int, int> >
(n, nan));<< "Enter two rect: ";ch1, ch2;>> ch1 >>
start.second >> ch2 >> end.second;.first = ch1 - 'A';.first = ch2 -
'A';.push(start);[start.first][start.second] = start;(!q.empty()) {=
q.front();.pop();(temp == end) {<< "The way is : \n";<pair
<int, int> > way;(temp != start) {.push_back(temp);=
p[temp.first][temp.second];
}.push_back(start);(int i =
way.size() - 1; i >= 0; i--) {<< (char) (way[i].first + 'A') <<
way[i].second << " ";
}<<
endl;("pause");0;
}(int i = 0; i < 8; i++) {nx =
temp.first + x[i];ny = temp.second + y[i];(nx >= 0 && ny >= 0
&& nx < n && ny < n && p[nx][ny] == nan)
{[nx][ny] = temp;.push(make_pair(nx, ny));
}
}
}<< "No
way";<< endl;
system("pause");0;
}
ДОДАТОК В. КОД ПРОГРАМИ ДО ЗАВДАННЯ 3
#include <iostream>
#include <list>namespace
std;int UserType; data
{val;i;j;
};R_Matrix
{:<data> lst; rows;
columns;Check(const unsigned i, const unsigned j) const; :_Matrix();
_Matrix(UserType **mtr, const unsigned columns, const unsigned rows);
_Matrix(const R_Matrix &mtr);
~R_Matrix(); AddR_Matrix(UserType
**mtr, const unsigned columns, const unsigned rows); _Matrix operator+(const
R_Matrix &mtr); operator=(const R_Matrix &mtr); ostream &
operator<<(ostream & os, const R_Matrix &mtr);
};_Matrix::R_Matrix()
{>rows = 0;>columns = 0;
}_Matrix::R_Matrix(UserType **mtr,
const unsigned columns, const unsigned rows)
{>rows = rows;>columns =
columns;dt;(unsigned i = 0; i < this->columns; ++i) (unsigned j = 0; j
< this->rows; ++j)
{(mtr[i][j])
{.i = i;.j = j;.val =
mtr[i][j];.push_back(dt);
}
}
}_Matrix::R_Matrix(const R_Matrix
&mtr)
{>lst = mtr.lst; >columns =
mtr.columns;>rows = mtr.rows;
}_Matrix::~R_Matrix()
{
}R_Matrix::AddR_Matrix(UserType
**mtr, const unsigned columns, const unsigned rows)
{>rows = rows; >columns =
columns;dt;(unsigned i = 0; i < this->columns; ++i) (unsigned j = 0; j
< this->rows; ++j)
{(mtr[i][j])
{.i = i;.j = j;.val =
mtr[i][j];.push_back(dt);
}
}true;
}R_Matrix::Check(const unsigned i,
const unsigned j) const
{<data>::const_iterator c_itr;
(c_itr = this->lst.cbegin(); c_itr != this->lst.cend(); c_itr++) списку
{( (*c_itr).i == i &&
(*c_itr).j == j) true;
}false;
}_Matrix R_Matrix::operator+(const
R_Matrix &mtr)
{_Matrix res(*this);
<data>::const_iterator c_itr; (c_itr = mtr.lst.cbegin(); c_itr !=
mtr.lst.cend(); c_itr++)
{(Check( (*c_itr).i, (*c_itr).j))
(list<data>::iterator itr = res.lst.begin(); itr != res.lst.end(); itr++)
{( (*itr).i == (*c_itr).i &&
(*itr).j == (*c_itr).j)
{
(*itr).val += (*c_itr).val;
}
}
{dt;dt.i = c_itr->i;.j =
c_itr->j;.val = c_itr->val;.lst.push_back(dt);
}
}res;
}R_Matrix::operator=(const R_Matrix
&mtr)
{>lst = mtr.lst; >columns =
mtr.columns;>rows = mtr.rows;
}& operator<<(ostream
& os, const R_Matrix &mtr)
{(unsigned i = 0; i <
mtr.columns; ++i)
{(unsigned j = 0; j < mtr.rows;
++j)
{(! mtr.Check(i, j)) <<
"0 ";
{(list<data>::const_iterator
c_itr = mtr.lst.cbegin(); c_itr != mtr.lst.cend(); c_itr++)
{(i == c_itr->i && j ==
c_itr->j) << c_itr->val << " ";
}
}<< endl;
}os;
}main()
{unsigned n = 5;unsigned m =
4;**mtr1; **mtr2;
#pragma region= new
UserType*[n];mtr2 = new UserType*[n];(int i = 0; i < n; ++i)
{[i] = new UserType[m];[i] = new UserType[m];
}
#pragma endregion
#pragma region (int i = 0; i < n;
++i) (int j = 0; j < m; ++j)
{[i][j] = 0;[i][j] = 0;
}[0][2] = 4;[0][1] = 3;[1][3] =
1;[3][2] = 7;[4][0] = 3;[3][1] = 2;
[0][0] = 12;[0][3] = 5;[2][3] =
2;[3][3] = 15;[4][0] = 3;
#pragma endregion_Matrix
r_mtr1(mtr1, n, m); _Matrix r_mtr2;_mtr2.AddR_Matrix(mtr2, n, m);_Matrix res;=
r_mtr1 + r_mtr2; << "Firs matrix: " << endl <<
r_mtr1 << endl; << "Second matrix: " << endl
<< r_mtr2 << endl;<< "Result matrix: " <<
endl << res << endl;
system("pause");0;
}
ДОДАТОК Г. КОД ПРОГРАМИ ДО ЗАВДАННЯ 4
#include <iostream>
#include <string>namespace
std;Domino{left,right;
};DominoSeq{* seq;count;length;sum;
};DominoSeq maxLength;
static DominoSeq maxSum;
//ф-ція визначення суми на фішках, що не використані
int ComputeSum(Domino* pack, int*
usingDomino, int count){sum=0;(int i = 0; i < count; i++)
{(usingDomino[i]==0)+=pack[i].left +
pack[i].right;
}sum;
}PrintDominoSeq(DominoSeq
ds){<<" Послiдовнiсть
- ";(int i = 0; i<ds.length; i++)<<ds.seq[i].left<<"|"<<ds.seq[i].right<<"
";
cout<<endl;
}
//ф-ції перевірки та додання нової фішки до
послідовності
int TryAppend(Domino a, Domino
b){(a.right==b.left || a.right == b.right)1;0;
}Append(Domino* pack, int a, int b,
int* usingDomino, DominoSeq &ds){(pack[a].right == pack[b].right){tmp =
pack[b].left;[b].left = pack[b].right;[b].right = tmp;
}.seq[ds.length++]=pack[b];[b]=1;
}
//перевірка
можливості
продовженняCanContinue(Domino*
pack, int startDominoIndex, int* usingDomino, int count){(int i=0; i<count;
i++)(usingDomino[i]!=1 && i!=startDominoIndex &&
TryAppend(pack[startDominoIndex],pack[i]))1;0;
}Compute(Domino* pack, int
startDominoIndex, int* usingDomino, int count, DominoSeq &ds){(int j=0;
j<count; j++){(!CanContinue(pack, startDominoIndex, usingDomino, count)){(ds.length>maxLength.length)=ds;.sum=ComputeSum(pack,usingDomino,count);(ds.sum>maxSum.sum)=ds;
}(j==startDominoIndex);(usingDomino[j]!=1
&& TryAppend(pack[startDominoIndex],pack[j])){* tmpUsingDomino = new
int[count];(tmpUsingDomino,usingDomino,count*sizeof(int));* tmpDominoPack = new
Domino[count];//так як
фішки
можуть
обертатися
(2|3 -> 3|2) потрібно
зберігати
проміжні
масивии
фішок(tmpDominoPack,pack,count*sizeof(Domino));tmpDS;.count
= count;.length = ds.length;.seq = new Domino[count];//зберігання
поточної
послідовності
фішок(tmpDS.seq,ds.seq,count*sizeof(Domino));(tmpDominoPack,
startDominoIndex, j, tmpUsingDomino, tmpDS);(tmpDominoPack, j, tmpUsingDomino,
count, tmpDS);
}
}
}ArrayReverse(Domino* pack, int
count){ //поворот масиву
фішок(int
i = 0; i < count; i++)
{tmp = pack[i].left;[i].left =
pack[i].right;[i].right = tmp;
}
}main()
{(0,".1251");count=0;>>count;*
pack = new Domino[count];(int i = 0; i < count;
i++)>>pack[i].left>>pack[i].right;.length=0;.sum=-1;(int
steps=0;steps<2;steps++){(int i = 0; i < count; i++)
{
//ініціалізація
масиву
використаних
фішок*
usingDomino = new int[count];(int j=0; j<count; j++) [j]=0;[i]=1;
//-----ds;.count=count;.seq = new
Domino[count];.length=1;.sum = ComputeSum(pack, usingDomino, count);.seq[0]=pack[i];(pack,
i, usingDomino, count, ds);
delete[] usingDomino;
}
//поворот перших фішок та повтор(pack,count);
}<<"Макс. довжина :
"<<maxLength.length;
PrintDominoSeq(maxLength);<<"Макс.
сума
: "<<maxSum.sum;(maxSum);[] pack;("pause");
return 0;
}