Базы данных и системы управления базами данных
Нижегородский
Государственный Университет им. Лобачевского
Специальность
«Финансы и кредит»
Курсовая работа
по предмету: «Информационные системы»
На тему
«Базы данных и системы управления
базами данных»
г. Кстово
2009 г.
Введение
База данных - это реализованная с помощью компьютера информационная
структура (модель), отражающая состояние объектов и их отношения.
Надо отметить, что база данных - это, собственно, хранилище информации и
не более того. Однако, работа с базами данных трудоемкая и утомительная. Для
создания, ведения и осуществления возможности коллективного пользования базами
данных используются программные средства, называемые системами управления
базами данных (СУБД).
Базы данных на ПК развивались по направлению от настольных (desktop), или
локальных приложений, когда реально с БД могло работать одно приложение, до
систем коллективного доступа к БД. Локальное приложение устанавливалось на
единичном ПК; там же располагалась и база данных (БД), с которой работало
данное приложение. Однако необходимость коллективной работы с одной и той же БД
повлекло за собой перенос БД на сервер. Приложение, работающее с БД,
располагалось также на сервере.
Для анализа свойств баз данных предлагается выделять характеристики
качества системы управления базой данных и содержащейся в ней информации.
Состав этих характеристик рекомендуется систематизировать на основе требований
международного стандарта ISO 9126.
Современные базы данных - один из тех объектов в сфере информатизации, от
которых иногда требуется особенно высокое качество и наличие возможности его
оценки.
Глава 1. Понятие, состав информационной системы
База данных - это реализованная с помощью компьютера информационная
структура (модель), отражающая состояние объектов и их отношения.
Базы данных - важнейшая составная часть информационных систем.
Информационные системы предназначены для хранения и обработки больших объемов
информации. Изначально такие системы существовали в письменном виде. Для этого
использовались различные картотеки, папки, журналы, библиотечные каталоги и
т.д. Любая информационная система должна выполнять три основные функции: ввод
данных, запросы по данным, составление отчетов.
Ввод данных. Система должна предоставлять возможность накапливания и
упорядочивания данных. Необходимо обеспечить просмотр этих данных, внесение в
них изменений и дополнений с тем, чтобы поддерживать актуальность информации.
Запросы по данным. В системе должна существовать возможность находить и
просматривать отдельные части накопленной информации.
Составление отчетов. Время от времени возникает необходимость обобщать и
анализировать большую группу данных (или даже все данные) информационной
системы, представляя ее в виде документа.
Обслуживание информационных систем, реализованных в письменном (бумажном)
виде, сопряжено со многими трудностями: чем больше информационная система, тем
больше бумаги (карточек) и места требуется для их хранения (в этом можно
убедиться на примере библиотеки); много времени тратится на поиск нужной
информации. Сложности возникают при обновлении, анализе и обработке данных.
Предположим мы хотим собрать информацию про альбомы музыкальных групп.
Пусть имеется информация о некоторых альбомах: 1965, Led Zeppelin 4, Lp, Help!,
Atlantic, 1971. Lp (England), EMI. 1970, Flash Gordon, Parlophone, 1980, Led Zeppelin 3,
Soundtrack, Lp, Atlantic. Этот список мало о чем говорит. Извлечь какую-либо информацию из этого
набора данных практически невозможно.
Представим данные в виде табл. 1.
Таблица 1. Информация об альбомах музыкальных групп
|
Название альбома
|
Год выпуска
|
Тип
|
Фирма альбома
|
|
Help!
|
1965
|
Lp (England)
|
Parlophone
|
|
Led Zeppelin 4
|
1971
|
Lp
|
Atlantic
|
|
Led Zeppelin 3
|
1970
|
Lp
|
Atlantic
|
|
Flash Gordon
|
1980
|
Soundtrack
|
EMI
|
Теперь воспринимать и использовать информацию стало гораздо удобнее.
Представленная таблица является информационной моделью. Объектами, отраженными
в этой модели, являются музыкальные альбомы (групп), причем все данные
взаимосвязаны.
.1 Виды структур данных
В информатике совокупность взаимосвязанных данных называется
информационной структурой, или структурой данных. В моём примере объектами
модели являются музыкальные альбомы. Свойства же этих объектов находятся в
столбцах таблицы (“Название альбома”, “Год выпуска”, “Тип альбома”, “Фирма”),
их называют атрибутами объектов. Таким образом, каждая строка таблицы - есть
совокупность атрибутов объекта. Такую строку называют записью, а столбец -
полем записи.
Помимо сведений, указанных в атрибутах, табличная организация данных
позволяет получить дополнительную информацию. К примеру, нетрудно узнать (в
предположении, что наша табл. заполнена данными):
• какая группа выпустила больше альбомов за определенный период;
• число альбомов данной группы;
• сколько имеется альбомов типа Soundtrack (музыка к фильму);
• какая фирма выпустила наибольшее число альбомов данной группы.
Табличная организация данных называется также реляционной. Кроме
табличной структуры данных существуют другие виды структурной организации
данных.
Для иерархических структур (рис. 1) характерна подчиненность объектов
нижнего уровня объектам верхнего уровня. Важно отметить, что в дереве, между
верхними и нижними объектами, задано отношение “один ко многим” (т.е. одной
группе соответствует много альбомов, одному альбому соответствует много песен).
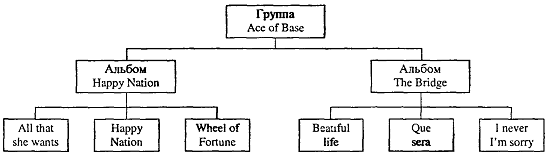
Рис. 1. Пример иерархической организации данных
Несмотря на то, что в атрибутах, описывающих песню, нет названия альбома,
глядя на дерево по линиям связи можно сказать, какая песня принадлежит альбому.
Благодаря линиям связи можно определить принадлежность альбома группе. Из
данной иерархической структуры можно узнать:
• в каком альбоме больше песен;
• число альбомов выпущенных группой;
• есть ли в альбомах одинаковые песни и т.д.
Сетевую структуру данных можно представить в виде схемы, рис. 2.
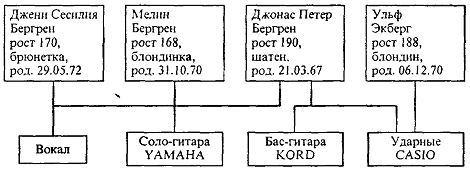
Рис. 2. Пример сетевой организации данных
Глядя на рис. 2, можно определить, какими инструментами владеет музыкант,
является ли он вокалистом. В этом случае есть два уровня взаимосвязанных объектов,
но отношение между ними “многие ко многим”.
Пусть в этой сетевой структуре данные о музыкантах и “инструментах”
состоят из следующих атрибутов: музыкант - ФИО, рост, цвет волос, время
рождения; инструмент- название инструмента, какой фирмой изготовлен инструмент.
Тогда схема позволяет ответить на следующие вопросы:
• гитары какой фирмы предпочитает большинство музыкантов;
• какой музыкант владеет наибольшим количеством инструментов и др.
Построение структуры данных происходит в следующем порядке:
• определяются объекты описания;
• определяются структуры этих объектов;
• строится конкретная информационная структура.
.2 Виды баз данных
Поскольку основу любой базы данных составляет информационная структура,
базы данных делят на три рассмотренные выше типа: табличные (реляционные),
сетевые, иерархические.
Опыт использования баз данных позволяет выделить общий набор их рабочих
характеристик:
• полнота - чем полнее база данных, тем вероятнее, что она содержит
нужную информацию (однако, не должно быть избыточной информации);
• правильная организация - чем лучше структурирована база данных, тем
легче в ней найти необходимые сведения;
• актуальность - любая база данных может быть точной и полной, если она
постоянно обновляется, т.е. необходимо, чтобы база данных в каждый момент
времени полностью соответствовала состоянию отображаемого ею объекта;
• удобство для использования - база данных должна быть проста и удобна в
использовании и иметь развитые методы доступа к любой части информации.
Соответственно возможностям организации реляционных, иерархических и
сетевых информационных структур, существуют и аналогичные виды баз данных. В
них данные представлены в формах, адекватных соответствующим структурам. Однако
иерархические и сетевые базы данных являются гораздо менее распространенными,
чем реляционные и не могут быть реализованы с помощью наиболее популярных СУБД,
входящих в состав программного обеспечения ЭВМ.
.3 Реляционные базы данных
Наиболее распространенными в практике являются реляционные базы данных.
Название “реляционная” (в переводе с английского relation - отношение) связано
с тем, что каждая запись в таблице содержит информацию, относящуюся только к
одному конкретному объекту.
Всякое отношение должно иметь свое имя. Пусть есть отношение с названием
“Альбомы группы”. В этом случае структура базы данных, состоящая из одной
таблицы, запишется так: Альбомы группы (название альбома, год выпуска, тип
альбома, фирма). Однако чаще база данных строится на основе нескольких таблиц,
связанных между собой через общие атрибуты. Пусть, например, в базе данных
“Рок-энциклопедия” содержатся две таблицы - 2 и 3.
Таблица 2. Музыкальные альбомы групп
|
Код альбома
|
Код группы
|
Название альбома
|
Год выпуска
|
Тип альбома
|
Фирма
|
|
25
|
1
|
Help!
|
1965
|
Lp (English)
|
Pariophone
|
|
36
|
2
|
Led Zeppelin 4
|
l97l
|
Lp
|
Atlantic
|
|
35
|
2
|
Led Zeppelin 4 -
|
1970
|
Lp
|
Atlantic
|
|
34
|
3
|
Flash Gordon
|
1980
|
Soundtrack
|
EMI
|
Таблица 3. Рок группы
|
Код группы
|
Название группы
|
Страна
|
Дата создания
|
Дата распада
|
|
1
|
The Bealles
|
Англия
|
1963
|
I970
|
|
2
|
Led Zeppelin 4
|
Англия
|
1989
|
-
|
|
3
|
Flash Gordon
|
Англия
|
199I
|
-
|
Эти две таблицы связаны между собой общим полем “Код группы”. Поле “Код
альбома” в таблице 2 создается для того, чтобы отличать альбомы друг от друга.
Это очень важно, так как в таблице могут находиться альбомы с одинаковыми
названиями.
Необходимость использования больше одной таблицы станет заметной, если
объединить эти таблицы в одну (табл. 4.).
Таблица 4. Объединение таблиц
|
Название группы
|
Страна
|
Дата создания
|
Название альбома
|
Год выпуска
|
Тип альбома
|
Фирма
|
|
The Beatles
|
Англия
|
1963
|
I970
|
With the Beatles
|
1963
|
Lp
|
Pariophone
|
|
The Beatles
|
Англия
|
1963
|
I970
|
Please, please me
|
1963
|
Lp
|
Pariophone
|
|
The Beatles
|
Англия
|
1963
|
I970
|
Rubber soul
|
1963
|
Lp
|
Pariophone
|
Из таблицы 4 видно, что при внесении в нее данных об альбомах
определенной группы каждый раз приходится дублировать информацию первых четырех
полей таблицы. Многократное сохранение в БД одних и тех же данных (название
группы, страна, дата создания, дата распада) приведет к неэффективному
использованию памяти, к тому же существенно возрастет вероятность ошибок при
вводе данных. Разбив же данные по таблицам, можно в значительной степени
избежать этих трудностей.
Через связь, определенную между этими таблицами, можно узнать
• сколько альбомов выпустила группа;
• в каком году было выпущено максимальное количество альбомов и т.п.
Реляционные базы данных удобны еще и тем, что для получения ответов на
различные запросы существует разработанный математический аппарат, который
называется исчислением отношений или реляционной алгеброй. Ответы на запросы
получаются путем “разрезания” и “склеивания” таблиц по строкам и столбцам. При
этом ясно, что ответы также будут иметь форму таблиц.
блокировка
база данные доступ
Глава 2. Системы управления базами данных (СУБД)
База данных предполагает наличие комплекса программных средств,
обслуживающих эту базу данных и позволяющих использовать содержащуюся в ней
информацию. Такие комплексы программ называют СУБД. СУБД - это программная
система, поддерживающая наполнение и манипулирование данными, представляющими
интерес для пользователей при решении прикладных задач. Иными словами, СУБД
является интерфейсом между базой данных и прикладными задачами.
В настоящее время выделяют пять уровней проблематики систем управления
базами данных:
• реляционные базы данных, 1970 - 90 гг.;
• объектно-ориентированные базы данных, 1980 - 90 гг.;
• интеллектуальные базы данных, 1985 - 90 гг.;
• распределенные базы данных, начало 1990 гг.;
• базы данных мультимедиа и виртуальной реальности настоящего времени.
Обычно современная СУБД содержит следующие компоненты:
· ядро,
которое отвечает за управление данными во внешней и оперативной памяти и
журнализацию <http://ru.wikipedia.org/wiki/%D0%96%D1%83%D1%80%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D0%B8%D0%B7%D0%BC%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B9>,
· процессор
языка базы данных, обеспечивающий оптимизацию запросов
<http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D1%82%D0%B8%D0%BC%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%BE%D0%B2_%D0%A1%D0%A3%D0%91%D0%94>
на извлечение и изменение данных и создание, как правило, машинно-независимого
исполняемого внутреннего кода,
· подсистему
поддержки времени исполнения, которая интерпретирует программы манипуляции
данными, создающие пользовательский интерфейс с СУБД,
· а
также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных
возможностей по обслуживанию информационной системы.
Архитектурно СУБД состоит из двух основных компонентов; языка описания
данных (ЯОД), позволяющего создать схему описания данных в базе, и языка
манипулирования данными (ЯМД), выполняющего операции с базой данных
(наполнение, обновление, удаление, выборку информации). Данные языки могут быть
реализованы в виде тренажеров или интерпретаторов. Помимо ЯОД и ЯМД к СУБД
следует отнести средства (или языки) подготовки отчетов (СПО), позволяющие
подготовить сводки (отчеты) на основе информации, найденной в базе данных, по
заданным формам.
Язык описания данных (ЯОД) - это язык высокого уровня декларативного
(непроцедурного) типа, предназначенный для формализованного описания типов
данных, их структур и взаимосвязей. Исходные тексты описания данных на этом
языке после трансляции отображаются в управляющие таблицы, задающие размещение
в памяти ЭВМ и связи между собой рассматриваемых данных. В соответствии с этими
описаниями СУБД находит в базе требуемые данные, правильно преобразует их и
передает, например, в прикладную программу пользователя, которой они
потребовались. При записи данных в базу СУБД по этим описаниям определяет место
в памяти ЭВМ, куда их требуется поместить, преобразует к заданному виду и
устанавливает необходимые связи.
Язык манипулирования данными (или язык запросов) представляет собой
систему команд, например, следующего типа:
• произвести выборку данного, значение, которого удовлетворяет заданным
условиям;
• произвести выборку всех данных определенного типа, значения которых
удовлетворяют заданным условиям;
• найти в базе позицию данного и поместить туда новое значение (или
удалить данное) и т.д.
Широкое распространение имеют СУБД для персональных компьютеров типа
DBASE (DBASE III, IV, FoxPro, Paradox), Clipper, Clarion. Эти СУБД ориентированы
на однопользовательский режим работы с базой данных и имеют очень ограниченные
возможности. Языки подобных СУБД представляют собой сочетание команд выборки,
организации диалога, генерации отчетов. В связи с развитием компьютерных сетей,
в которых персональные компьютеры выступают в качестве развитых
(интеллектуальных) терминалов, новые версии СУБД все в большей степени включают
в себя возможности описанного ниже языка манипулирования данными SQL.
В последнее время стали среди СУБД популярными ACCESS (входит в состав MS
Office), Lotus, Oracle.
2.1 Основные
функции СУБД
. управление данными - можно указать, кому разрешено знакомиться с
данными, корректировать их или добавлять новую информацию. Можно также
определять правила коллективного доступа, в том числе:
1.1
управление данными во внешней памяти
<http://ru.wikipedia.org/w/index.php?title=%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D1%8F%D1%8F_%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C&action=edit&redlink=1>
(на дисках);
.2
управление данными в оперативной памяти <http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%B0%D1%8F_%D0%BF%D0%B0%D0%BC%D1%8F%D1%82%D1%8C>
с использованием дискового кэша
<http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%81%D0%BA%D0%BE%D0%B2%D1%8B%D0%B9_%D0%BA%D1%8D%D1%88>;
. журнализация
изменений
<http://ru.wikipedia.org/wiki/%D0%96%D1%83%D1%80%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_%D0%B8%D0%B7%D0%BC%D0%B5%D0%BD%D0%B5%D0%BD%D0%B8%D0%B9>,
резервное копирование <http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B7%D0%B5%D1%80%D0%B2%D0%BD%D0%BE%D0%B5_%D0%BA%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5>
и восстановление базы данных
<http://ru.wikipedia.org/wiki/%D0%92%D0%BE%D1%81%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B1%D0%B0%D0%B7%D1%8B_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85>
после сбоев;
. поддержка
языков БД (язык определения данных, язык манипулирования данными);
. определение
данных - определить, какая именно информация будет храниться в базе данных,
задать свойства данных, их тип (например, число цифр или символов), а также
указать, как эти данные связаны между собой. В некоторых случаях есть
возможность задавать форматы и критерии проверки данных;
. обработка
данных - данные могут обрабатываться самыми различными способами. Можно
выбирать любые поля, фильтровать и сортировать данные. Можно объединять данные
с другой, связанной с ними, информацией и вычислять итоговые значения.
2.2
Классификация СУБД
Базы данных на ПК развивались по направлению от настольных (desktop), или
локальных приложений, когда реально с БД могло работать одно приложение, до
систем коллективного доступа к БД. Локальное приложение устанавливалось на
единичном ПК; там же располагалась и база данных (БД), с которой работало
данное приложение. Однако необходимость коллективной работы с одной и той же БД
повлекло за собой перенос БД на сервер. Приложение, работающее с БД,
располагалось также на сервере. Менее характерным был другой способ,
заключавшийся в хранении приложения, обращавшегося к БД, на конкретном
компьютере пользователей ("клиентов"). Были выпущены новые версии
локальных СУБД, которые позволяли создавать приложения, одновременно работающие
с одной БД на файловом сервере. Основной проблемой была явная или неявная
обработка транзакций и неизбежно встающая при коллективном доступе проблема
обеспечения смысловой и ссылочной целостности БД при одновременном изменении
одних и тех же данных.
По модели
данных
По типу управляемой базы данных СУБД разделяются на:
· Иерархические
<http://ru.wikipedia.org/wiki/%D0%98%D0%B5%D1%80%D0%B0%D1%80%D1%85%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>
· Сетевые
<http://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%82%D0%B5%D0%B2%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>
· Реляционные
<http://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>
· Объектно-реляционные
<http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D1%80%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>
· Объектно-ориентированные
<http://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>.
По
архитектуре организации хранения данных:
· локальные СУБД (все части локальной СУБД размещаются на одном
компьютере).
По способу
доступа к БД
· Файл-серверные
<http://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B9%D0%BB-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>.
В
файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере
<http://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%B9%D0%BB-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80>.
Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным
осуществляется через локальную сеть. Синхронизация чтений и обновлений
осуществляется посредством файловых блокировок. Преимуществом этой архитектуры
является низкая нагрузка на ЦП сервера, а недостатком - высокая загрузка
локальной сети.
На
данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access
<http://ru.wikipedia.org/wiki/Microsoft_Access>, Borland Paradox
<http://ru.wikipedia.org/w/index.php?title=Borland_Paradox&action=edit&redlink=1>.
· Клиент-серверные
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B8%D0%B5%D0%BD%D1%82-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94>.
Такие
СУБД состоят из клиентской части (которая входит в состав прикладной программы)
и сервера (см. Клиент-сервер
<http://ru.wikipedia.org/wiki/%D0%9A%D0%BB%D0%B8%D0%B5%D0%BD%D1%82-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80>).
Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение
доступа между пользователями и мало загружают сеть и клиентские машины. Сервер
является внешней по отношению к клиенту программой, и по надобности его можно
заменить другим. Недостаток клиент-серверных СУБД в самом факте существования
сервера (что плохо для локальных программ - в них удобнее встраиваемые СУБД) и
больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird
<http://ru.wikipedia.org/wiki/Firebird>, Interbase
<http://ru.wikipedia.org/wiki/Interbase>, IBM DB2
<http://ru.wikipedia.org/wiki/IBM_DB2>, MS SQL Server
<http://ru.wikipedia.org/wiki/MS_SQL_Server>, Sybase <http://ru.wikipedia.org/wiki/Sybase>,
Oracle <http://ru.wikipedia.org/wiki/Oracle_(%D0%A1%D0%A3%D0%91%D0%94)>,
PostgreSQL <http://ru.wikipedia.org/wiki/PostgreSQL>, MySQL
<http://ru.wikipedia.org/wiki/MySQL>, ЛИНТЕР
<http://ru.wikipedia.org/wiki/%D0%9B%D0%98%D0%9D%D0%A2%D0%95%D0%A0>.
· Встраиваемые
<http://ru.wikipedia.org/w/index.php?title=%D0%92%D1%81%D1%82%D1%80%D0%B0%D0%B8%D0%B2%D0%B0%D0%B5%D0%BC%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94&action=edit&redlink=1>.
Встраиваемая
СУБД - библиотека <http://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B0_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)>,
которая позволяет унифицированным образом хранить большие объёмы данных на
локальной машине. Доступ к данным может происходить через SQL
<http://ru.wikipedia.org/wiki/SQL> либо через особые функции СУБД.
Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки
сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими
объёмами данных (например, геоинформационные системы
<http://ru.wikipedia.org/wiki/%D0%93%D0%B5%D0%BE%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0>).
Примеры:
OpenEdge <http://ru.wikipedia.org/wiki/OpenEdge>, SQLite
<http://ru.wikipedia.org/wiki/SQLite>, BerkeleyDB
<http://ru.wikipedia.org/wiki/BerkeleyDB>, один из вариантов Firebird
<http://ru.wikipedia.org/wiki/Firebird>, один из вариантов MySQL
<http://ru.wikipedia.org/wiki/MySQL>, Sav Zigzag
<http://ru.wikipedia.org/wiki/Sav_Zigzag>, Microsoft SQL Server Compact
<http://ru.wikipedia.org/wiki/Microsoft_SQL_Server_Compact>, ЛИНТЕР
<http://ru.wikipedia.org/wiki/%D0%9B%D0%98%D0%9D%D0%A2%D0%95%D0%A0>.
Местоположение БД определяет так называемую архитектуру базы данных.
Имеются четыре разновидности архитектур баз данных:
локальные базы данных;
архитектура "файл-сервер";
архитектура "клиент-сервер";
многозвенная архитектура.
Использование той или иной архитектуры накладывает сильный отпечаток на
общую идеологию работы приложения и на программный код приложения. При работе с
локальными базами данных сами базы данных расположены на том же компьютере, что
и приложения, осуществляющие доступ к ним. Работа с базой данных происходит в
однопользовательском режиме. Приложение ответственно за поддержание целостности
базы и за выполнение запросов к базе данных.
При работе в архитектуре "файл-сервер" база данных и приложение
расположены на файловом сервере сети. Возможна многопользовательская работа с
одной и той же базой данных, когда каждый пользователь со своего компьютера
запускает приложение, расположенное на сетевом сервере. Тогда на компьютере
пользователя запускается копия приложения. По каждому запросу к базе данных из
приложения, данные из таблиц базы данных, перегоняются на компьютер
пользователя, независимо от того, сколько реально нужно данных для выполнения
запроса. После этого выполняется запрос.
Каждый пользователь имеет на своем компьютере локальную копию данных,
время от времени обновляемых из реальной базы данных, расположенной на сетевом
сервере. При этом изменения, которые каждый пользователь вносит в базу данных,
могут быть до определенного момента неизвестны другим пользователям, что делает
актуальной задачу систематического обновления данных на компьютере пользователя
из реальной базы данных. Другой актуальной задачей является блокирование
записей, которые изменяются одним из пользователей; это необходимо для того,
чтобы в это время другой пользователь не внес изменений в те же данные.
В архитектуре "файл-сервер" вся тяжесть выполнения запросов к
базе данных и управления целостностью базы данных ложится на приложение
пользователя. База данных на сервере является пассивным источником данных.
Кардинальных различий с точки зрения архитектуры между
однопользовательской архитектурой и архитектурой "файл-сервер" нет. И
в том, и в ином случае в качестве СУБД применяются так называемые
"персональные" (или "настольные", "локальные")
СУБД, такие как paradox, dbase и пр. Сама база данных в этом случае представляет
собой набор таблиц, индексных файлов, файлов полей комментариев (memo-полей) и
пр., хранящихся в одном каталоге на диске в виде отдельных файлов.
В ходе эксплуатации были выявлены общие недостатки файл-серверного
подхода при обеспечении многопользовательского доступа к базе данных:
Вся тяжесть вычислительной нагрузки при доступе к базе данных ложится на
приложение клиента, что является следствием принципа обработки информации в
системах "файл-сервер": при выдаче запроса на выборку информации из
таблицы вся таблица базы данных копируется на клиентское место, и выборка
осуществляется на клиентском месте. Локальные СУБД используют так называемый
"навигационный подход", ориентированный на работу с отдельными
записями.
Не оптимально расходуются ресурсы клиентского компьютера и сети;
например, если в результате запроса мы должны получить 2 записи из таблицы
объемом 10000 записей, все 10000 записей будут скопированы с файл-сервера на
клиентский компьютер; в результате возрастает сетевой трафик, и увеличиваются
требования к аппаратным мощностям пользовательского компьютера.
В базе данных на файл-сервере гораздо проще вносить изменения в отдельные
таблицы, минуя приложения, непосредственно из инструментальных средств
(например, из утилиты database desktop фирмы borland для файлов paradox или
dbase); подобная возможность облегчается тем обстоятельством, что, фактически,
у локальных СУБД база данных - понятие более логическое, чем физическое,
поскольку под базой данных понимается набор отдельных таблиц, сосуществующих в
едином каталоге на диске. Все это позволяет говорить о низком уровне
безопасности - как с точки зрения хищения и нанесения вреда, так и с точки
зрения внесения ошибочных изменений.
Недостаточно развитый аппарат транзакций для локальных СУБД служит
потенциальным источником ошибок как с точки зрения одновременного внесения
изменений в одну и ту же запись, так и с точки зрения отката результатов серий
объединенных по смыслу в единое целое операций над базой, когда некоторые из
них завершились успешно, а некоторые - нет; это может нарушать ссылочную и
смысловую целостность базы данных.
Недостатки настольных СУБД обычно проявляются не сразу, а лишь в процессе
длительной эксплуатации, когда объем хранимых данных и число пользователей
становятся достаточно велики - это приводит к снижению производительности
приложений, использующих такие СУБД.
Поскольку настольные СУБД не содержат специальных приложений и сервисов,
управляющих данными, а используются для этой цели файловые сервисы операционной
системы, вся реальная обработка данных в таких СУБД осуществляется в клиентском
приложении, и любые библиотеки доступа к данным в этом случае также находятся в
адресном пространстве клиентского приложения. Поэтому при выполнении запросов
данные, на основании которых выполняется такой запрос (это может быть одна или
несколько таблиц целиком, либо, если повезет, один или несколько индексов и
выбранные с их помощью части таблиц), должны быть доставлены в то же самое
адресное пространство клиентского приложения. Это и приводит к перегрузке сети
при увеличении числа пользователей и объема данных, а также грозит иными
неприятными последствиями, например разрушением индексов и таблиц. Недаром до
сих пор популярны утилиты для "ремонта" испорченных файлов настольных
СУБД.
Недостатки архитектуры "файл-сервер" решаются при переводе
приложений в архитектуру "клиент-сервер", которая знаменует собой
следующий этап в развитии СУБД.
Характерной особенностью архитектуры "клиент-сервер" является
перенос вычислительной нагрузки на сервер базы данных (sql-сервер) и
максимальная разгрузка приложения клиента от вычислительной работы, а также
существенное укрепление безопасности данных - как от злонамеренных, так и
просто ошибочных изменений.
БД в этом случае помещается на сетевом сервере, как и в архитектуре
"файл-сервер", однако прямого доступа к базе данных (БД) из
приложений не происходит. Функция прямого обращения к БД осуществляет
специальная управляющая программа - сервер БД (sql-сервер), поставляемый
разработчиком СУБД.
Архитектура "клиент-сервер" разделяет функции приложения
пользователя (называемого клиентом) и сервера.
Приложение-клиент формирует запрос к серверу, на котором расположена БД,
на структурном языке запросов sql, являющимся промышленным стандартом в мире
реляционных БД. Удаленный сервер принимает запрос и переадресует его
sql-серверу БД. sql-сервер - это специальная программа, управляющая удаленной
базой данных. sql-сервер обеспечивают интерпретацию запроса, его выполнение в
базе данных, формирование результата выполнения запроса и выдачу его
приложению-клиенту. При этом ресурсы клиентского компьютера не участвуют в
физическом выполнении запроса; клиентский компьютер лишь отсылает запрос к
серверной БД и получает результат, после чего интерпретирует его необходимым
образом и представляет пользователю.
Так как клиентскому приложению посылается результат выполнения запроса,
по сети "путешествуют" только те данные, которые необходимы клиенту.
В итоге снижается нагрузка на сеть. Поскольку выполнение запроса происходит там
же, где хранятся данные (на сервере), нет необходимости в пересылке больших
пакетов данных. Кроме того, sql-сервер, оптимизирует полученный запрос таким
образом, чтобы он был выполнен в минимальное время с наименьшими накладными
расходами. Всё это повышает быстродействие системы и снижает время ожидания
результата запроса.
При выполнении запросов сервером существенно повышается степень безопасности
данных, поскольку правила целостности данных определяются в базе данных на
сервере и являются едиными для всех приложений, использующих эту БД. Таким
образом, исключается возможность определения противоречивых правил поддержания
целостности. Мощный аппарат транзакций, поддерживаемый sql-серверами, позволяет
исключить одновременное изменение одних и тех же данных различными
пользователями и предоставляет возможность откатов к первоначальным значениям
при внесении в БД изменений, закончившихся аварийно.
Функциями приложения-клиента являются:
Посылка к серверу запросов;
Интерпретация результатов запросов, полученных от сервера, и
представление их пользователю в требуемой форме;
Реализация интерфейса пользователя.сервер должен быть загружен на момент
принятия запроса клиента.
Функциями сервера БД являются:
Прием запросов от приложений-клиентов, интерпретация запросов, выполнение
запросов в БД, отправка результата выполнения запроса приложению-клиенту;
Управление целостностью БД, обеспечение системы безопасности, блокировка
неверных действий приложений-клиентов;
Хранение бизнес-правил, часто используемых запросов в уже интерпретированном
виде;
Обеспечение одновременной безопасной от отказоустойчивой
многопользовательской работы с одними и теми же данными.
В архитектуре "клиент-сервер" используются так называемые
"удаленные" (или "промышленные") СУБД. Промышленными они
называются из-за того, что именно СУБД этого класса могут обеспечить работу
информационных систем масштаба среднего и крупного предприятия, организации,
банка. Локальные СУБД предназначены для однопользовательской работы или для
обеспечения работы информационных систем, рассчитанных на небольшие группы
пользователей.
К разряду промышленных СУБД принадлежат oracle, informix, sybase, ms sql
server, db2, interbase и ряд других.
Как правило, sql-сервер управляется отдельным сотрудником или группой
сотрудников (администраторы sql-сервера). Они управляют физическими
характеристиками баз данных, производят оптимизацию, настройку и
переопределение различных компонентов БД, создают новые БД, изменяют
существующие и т.д., а также выдают привилегии различным пользователям.
Кроме этого, существует отдельная категория сотрудников, называемых
администраторами баз данных. Как правило, это администраторы сервера,
разработчики БД или пользователи, имеющие привилегии на создание, изменение,
настройку оптимальных параметров отдельных серверных БД. Администраторы БД
также отвечают за предоставление прав на разноуровневый доступ к сопровождаемым
ими БД для других пользователей.
.3 Механизмы доступа
При выборе СУБД необходимо иметь представление, с помощью каких средств
разработки будет создаваться информационная система на основе данной СУБД, а
также о том, каким образом разработанные приложения будут манипулировать
данными. От того, правильно ли выбран механизм доступа к данным, зависит очень
многое, в частности производительность приложений, возможность применения тех
или иных функциональных особенностей данной СУБД, простота разработки
пользовательского интерфейса и ряд других факторов.
Существует несколько способов доступа к данным из средств разработки и
клиентских приложений.
Подавляющее большинство СУБД содержит в своем составе библиотеки,
предоставляющие специальный прикладной программный интерфейс (application
programming interface, api) для доступа к данным этой СУБД. Обычно такой
интерфейс представляет собой набор функций, вызываемых из клиентского
приложения. В случае настольных СУБД эти функции обеспечивают чтение/запись
файлов базы данных (БД), а в случае серверных СУБД инициируют передачу запросов
серверу баз данных и получение от сервера результатов выполнения запросов или
кодов ошибок, интерпретируемых клиентским приложением. Библиотеки, содержащие
api для доступа к данным серверной СУБД, обычно входят в состав ее клиентского
программного обеспечения, устанавливаемого на компьютерах, где функционируют
клиентские приложения.
В последнее время windows-версии клиентского программного обеспечения
наиболее популярных серверных СУБД, в частности microsoft sql server, oracle,
informix, содержат также СОМ-серверы, предоставляющие объекты для доступа к
данным и метаданным.
Использование клиентского api (или клиентских СОМ-объектов) является
наиболее очевидным способом манипуляции данными в приложении. Однако в этом
случае созданное приложение сможет использовать данные только СУБД этого
производителя, и замена ее на другую повлечет за собой переписывание
значительной части кода клиентского приложения - клиентские api, а объектные
модели не подчиняются никаким стандартам и различны для различных СУБД.
Другой способ манипуляции данными в приложении базируется на применении
универсальных механизмов доступа к данным. Универсальный механизм доступа к
данным обычно реализован в виде библиотек и дополнительных модулей, называемых
драйверами или провайдерами. Библиотеки содержат некий стандартный набор
функций или классов, нередко подчиняющийся той или иной спецификации.
Дополнительные модели, специфичные для той или иной СУБД, реализуют
непосредственное обращение к функциям клиентского api конкретных СУБД.
Отметим, что достоинством универсальных механизмов является возможность
применения одного и того же абстрактного api, а во многих случаях -
СОМ-серверов, компонентов, классов для доступа к различным типам СУБД. Поэтому
приложения, использующие универсальные механизмы доступа к данным, легко
модифицировать, если необходима смена СУБД.
Наиболее популярными среди универсальных механизмов доступа к данным
можно назвать следующие:
open database connectivity (odbc).db.data objects
(ado).database engine (bde).
Универсальные механизмы odbc, ole db и ado фирмы microsoft представляют
собой по существу промышленные стандарты. Что касается механизма доступа к
данным bde фирмы borland, то он так и не стал промышленным стандартом, однако
до недавнего времени применялся довольно широко, поскольку до выхода delphi 5
был практически единственным универсальным механизмом доступа к данным,
поддерживаемым средствами разработки borland на уровне компонентов и классов.
.4 Что такое sql?
часто называют языком эсперанто для СУБД. Действительно, в мире нет
другого языка для работы с базами данных (БД), который бы настолько широко
использовался в программах. Первый стандарт sql появился в 1986 г. и к
настоящему времени завоевал всеобщее признание. Его можно использовать даже при
работе с не реляционными СУБД. В отличие от других программных средств, таких,
как языки Си и Кобол, являющихся прерогативой программистов-профессионалов, sql
применяется специалистами из самых разных областей. Программисты,
администраторы СУБД, бизнес - аналитики - все они с успехом обрабатывают данные
с помощью sql. Знание этого языка полезно всем, кому приходится иметь дело с
БД.- это специализированный непроцедурный язык, позволяющий описывать данные,
осуществлять выборку и обработку информации из реляционных СУБД.
Специализированность означает, что sql предназначен лишь для работы с БД;
нельзя создать полноценную прикладную систему только средствами этого языка -
для этого потребуется использовать другие языки, в которые можно встраивать sql
- команды. Поэтому sql еще называют вспомогательным языковым средством для
обработки данных. Вспомогательный язык используется только в комплексе с
другими языками.
В прикладном языке общего назначения обычно имеются средства для создания
процедур, а в sql их нет. С его помощью нельзя указать, каким образом должна
выполняться некоторая задача, а можно лишь определить, в чем именно она
заключается. Другими словами, при работе с sql нас интересуют результаты, а не
процедуры для их получения. Иными словами, sql является непроцедурным языком.
Термин "непроцедурный" означает, что на этом языкек можно сформулировать,
что именно нужно сделать с данными, но нельзя проинструктировать, как это
следует сделать. В языке sql отсутствуют алгоритмические конструкции, такие как
метки, операторы цикла, условные переходы и т.п.
Наиболее существенным свойством sql является возможность доступа к
реляционным БД. Многие даже считают, что выражения "БД, обрабатываемая
средствами sql" и "реляционная БД" - синонимы. Предположим, что
имеется база данных, управляемая с помощью какой-либо СУБД. Для извлечения из
нее данных используется запрос, сформулированный на языке sql. СУБД
обрабатывает этот запрос, извлекает запрашиваемые данные и возвращает
их.позволяет не только извлекать данные, но и определять структуру данных,
добавлять и удалять данные, ограничивать или предоставлять доступ к данным, поддерживать
ссылочную целостность. sql сам по себе не является, ни СУБД, ни отдельным
продуктом. Это - язык, применяемый для взаимодействия с СУБД и являющийся в
определенном смысле ее неотъемлемой частью.
Глава 3. Анализ качества баз данных
Для анализа свойств баз данных предлагается выделять характеристики
качества системы управления базой данных и содержащейся в ней информации.
Состав этих характеристик рекомендуется систематизировать на основе требований
международного стандарта ISO 9126.
Современные базы данных - один из тех объектов в сфере информатизации, от
которых иногда требуется особенно высокое качество и наличие возможности его
оценки. Но что означает качество баз данных, какие требования следует
предъявлять к их качеству, какими характеристиками можно описывать качество,
как их оценивать и измерять? Для этого могут быть полезны методы и стандарты,
разработанные для анализа сложных программных средств.
При комплексном анализе качества баз данных не всегда удается четко
разделить требования и значения характеристик качества для каждого из этих
объектов. Одна СУБД может обрабатывать различные по структуре, составу и
содержанию данные, а одни и те же данные могут управляться различными СУБД. При
анализе качества баз данных целесообразно рассматривать два компонента: систему
программ управления данными и совокупность данных, упорядоченных по некоторым
правилам. Хотя эти компоненты тесно взаимодействуют при реализации конкретной
базы данных, первоначально они создаются независимо и могут рассматриваться в
своем жизненном цикле как два объекта, которые различаются:
- номенклатурой и содержанием показателей качества, определяющих их
назначение, функции и потребительские свойства;
технологией и средствами автоматизации разработки и обеспечения всего
жизненного цикла объекта;
категориями специалистов, обеспечивающих создание, эксплуатацию или
применение баз данных;
комплектами эксплуатационной и технологической документации,
поддерживающими жизненный цикл объекта.
Практически весь набор характеристик и атрибутов из стандарта ISO 9126
«Качество программных средств» в той или иной степени может использоваться в
составе требований к СУБД. Особенности состоят в изменении акцентов при их
выборе и упорядочении. Во всех случаях важнейшими характеристиками качества
СУБД являются требования к функциональной пригодности процессов формирования и
изменения информационного наполнения баз данных администраторами, а также
доступа к данным и представления результатов пользователям.
Различия требований к характеристикам качества привели к созданию
широкого спектра локальных, специализированных и распределенных СУБД. В
зависимости от области применения, приоритет при оценке качества может
отдаваться различным конструктивным характеристикам: надежности и защищенности
применения (финансовая сфера), удобству использования малоквалифицированными
пользователями (социальная сфера), эффективности использования ресурсов (сфера
материально-технического снабжения). Однако практически во всех случаях
сохраняется некоторая роль других конструктивных показателей качества - для
каждого из них необходимо оценивать его приоритет для конкретной сферы
применения, меры и шкалы необходимых и допустимых характеристик качества.
При разработке базы данных в техническом задании и спецификации на нее
должен формализоваться представительный набор функциональных требований к
качеству базы данных, адекватный ее назначению и области применения, а также
требованиям заказчика и потенциальных пользователей. Так же как для программных
систем, характеристики качества информации можно разделить на функциональные и
конструктивные. Их номенклатура, содержание и субхарактеристики базируются на
ISO 9126. Может быть заложена основа для стандартизированного формирования
требований к качеству баз данных и при изложении содержания характеристик
качества использованы номенклатура и описания характеристик, в которых объекты
для анализа качества - «программы», заменены термином и содержанием -
«информация баз данных». Однако номенклатура показателей качества не всегда
может ограничиваться только характеристиками информации в базе данных, а должна
включать ряд уточнений, отражающих комплексную эффективность и функциональную
пригодность ее применения в реальных условиях.
Функциональная пригодность информации базы данных может представлять
сложную проблему для измерения и оценки соответствия требованиям реальных
значений атрибутов качества. Особенно это актуально для больших распределенных
баз данных, в которых циркулирует разнообразная и сложная информация об
анализируемых объектах. Мерой качества функциональной пригодности может быть
степень покрытия целей, назначения и функций баз данных доступной пользователям
информацией. Как и для программных систем, для баз данных целесообразно
использовать группу субхарактеристик, определяющих функциональные, структурные
и эксплуатационные требования. На содержательном уровне функциональную
пригодность многих баз данных отражают:
Полнота накопленных описаний объектов - относительное число объектов или
документов, имеющихся в базе данных, к общему числу объектов по данной тематике
или по отношению к числу объектов в аналогичных базах данных.
Идентичность - относительное число описаний объектов, не содержащих
дефекты и ошибки, к общему числу документов об объектах в базах данных.
Актуальность - относительное число устаревших данных об объектах в базах
данных, к общему числу накопленных и обрабатываемых данных.
Разнообразие функций баз данных ограничивает возможность стандартизации
требований к ним только общими правилами их организации, структурирования и
документирования. Меры и шкалы качества функциональной пригодности столь же
разнообразны, насколько различаются назначения и специфика функций информации
баз данных, однако конструктивные характеристики могут быть в значительной
степени стандартизированы.
К конструктивным характеристикам качества информации можно отнести практически
все стандартизированные показатели качества, представленные в ISO 9126.
Требования к информации баз данных также должны содержать особенности
обеспечения ее надежности, эффективности использования ресурсов компьютера,
практичности, применимости, сопровождаемости и мобильности. Содержание и
атрибуты этих характеристик несколько отличаются от тех, которые применяются
для программ, однако их сущность целесообразно использовать. Меры и шкалы для
оценивания конструктивных характеристик, в значительной степени, могут
применяться те же, что при анализе качества программных средств.
Корректность или достоверность данных - это степень соответствия данных
об объектах в базах данных реальным объектам в данный момент времени,
определяющаяся изменениями самих объектов, некорректностями записей об их
состоянии или некорректностями расчетов их характеристик. Выбор и установку
требований к корректности данных можно оценивать по степени покрытия
накопленными, актуальными и достоверными данными состояния и изменения внешних
объектов, которые они отражают. Сюда же можно отнести и некоторые
объемно-временные характеристики сохраняемых и обрабатываемых данных:
Объем базы данных - относительное число записей описаний объектов или
документов, доступных для хранения и обработки, по сравнению с полным числом
реальных объектов во внешней среде.
Оперативность - степень соответствия динамики изменения данных состояниям
реальных объектов.
Глубина ретроспективы - интервал времени от даты выпуска и/или записи в
базу данных самого раннего документа до настоящего времени.
Динамичность - относительное число изменяемых описаний объектов к общему
числу записей в базе данных за некоторый интервал времени, определяемый
периодичностью издания версий базы.
Защищенность информации реализуется средствами СУБД в сочетании с
поддерживающими их средствами защиты данных. Цели, назначение и функции защиты
тесно связаны с особенностями функциональной пригодности каждой базы данных. В
распределенных базах данных показатели защищенности тесно связаны с
характеристиками целостности и отражают степень тождественности одинаковых
данных в памяти удаленных компонентов.
На практике способности защищать информацию баз данных от негативных
воздействий описываются обычно составом средств, используемых для защиты от
внешних и внутренних угроз. Однако есть попытки измерять и описывать качество
защищенности информации обобщенно, трудоемкостью и временем, необходимыми для
преодоления злоумышленниками системы защиты. Косвенным показателем ее качества
может служить относительная доля вычислительных ресурсов, используемых
непосредственно средствами защиты информации.
На практике основное внимание сосредоточено на защите от злоумышленных
разрушений, искажений и хищений информации баз данных. Основой такой защиты
является аудит санкционирования доступа, а также контроль организации и
эффективности ограничений доступа. В реальных базах данных возможны и не всегда
учитываются катастрофические последствия и аномалии информации, отражающиеся на
безопасности применения, при которых их источниками являются случайные,
непредсказуемые дестабилизирующие факторы. Качество защиты можно
характеризовать величиной предотвращенного ущерба, возможного при проявлении
дестабилизирующих факторов и реализации конкретных угроз безопасности, а также
средним временем между возможными проявлениями угроз, преодолевающих защиту
данных.
Надежность информации баз данных может основываться на применении понятий
и методов теории надежности, которая позволяет получить ряд четких, хорошо
измеряемых интегральных показателей. Надежная база данных, прежде всего, должна
обеспечивать низкую вероятность потери работоспособности. Быстрое реагирование
на потерю или искажение данных и восстановление их достоверности и
работоспособности за время меньшее, чем порог между сбоем и отказом,
обеспечивают высокую надежность.
Классификация сбоев и отказов по длительности восстановления приводит к
необходимости анализа динамических характеристик абонентов, являющихся
источниками и/или потребителями данных. Для любого потребителя информации
существует допустимое время отсутствия данных от базы данных, при котором их
значения, изменяясь по инерции, достигают предельного отклонения от того,
которое должно было быть рассчитано. Это допустимое отклонение результатов
после перерыва функционирования базы данных зависит, в основном, от
динамических характеристик источников и потребителей информации.
Используемость ресурсов (или ресурсная экономичность) в стандартах
отражается занятостью ресурсов центрального процессора, оперативной, внешней и
виртуальной памяти, каналов ввода-вывода, терминалов и каналов связи. В
зависимости от конкретных задач и особенностей базы данных при выборе атрибутов
качества может доминировать либо величина абсолютной занятости ресурсов
различных видов, либо относительная величина использования ресурсов каждого
вида при нормальном функционировании базы данных. Задача оценки и эффективного
использования вычислительных ресурсов сохраняет свою актуальность.
Практичность (применимость) - трудно формализуемое понятие, однако, в
итоге, значительно определяющее функциональную пригодность и полезность
применения базы данных для определенных пользователей. В эту группу показателей
входят субхарактеристики, с различных сторон отражающие функциональную
понятность, удобство освоения, системную эффективность и простоту использования
данных. Некоторые субхарактеристики можно оценивать экономическими показателями
- затратами труда и времени специалистов на реализацию определенных функций
взаимодействия с данными. В стандарте ISO 9126 для этой характеристики качества
предлагается наибольшее число атрибутов, подробно описывающих свойства
программных средств, которые так же могут быть полезны для оценки баз данных
заказчиками при их практическом выборе, освоении и применении. Оценки практичности
зависят не только от собственных характеристик баз данных, но также от
организации и адекватности документирования процессов их эксплуатации.
Понятность зависит от качества документации и субъективных впечатлений
потенциальных пользователей. Ее можно описать качественно четкостью
функциональной концепции, широтой демонстрационных возможностей, полнотой,
комплектностью и наглядностью представления в эксплуатационной документации
возможных функций и особенностей реализации данных. Она должна обеспечиваться
корректностью и полнотой описания исходной и результирующей информации, а также
всех деталей применения базы данных для пользователей.
Простота использования - возможность удобно и комфортно эксплуатировать
базу данных и манипулировать данными. Она соответствует управляемости,
устойчивости к дефектам данных и согласованности с ожиданиями и навыками
пользователей. Некоторые атрибуты этой субхарактеристики можно оценить
количественно путем измерения трудоемкости и длительности соответствующих процессов
подготовки и обучения квалифицированных пользователей.
Изучаемость может определяться трудоемкостью и длительностью подготовки
пользователя. Качество изучаемости зависит от внутренних свойств и сложности
структуры информации базы данных, а также от субъективных характеристик
квалификации конкретных пользователей. Изучаемость может также
характеризоваться объемом эксплуатационной документации или объемом и качеством
электронных учебников.
Сопровождаемость информации может отражаться удобством и эффективностью
исправления, усовершенствования или адаптации структуры и содержания описаний
данных в зависимости от изменений во внешней среде применения, а также в
требованиях и функциональных спецификациях заказчика. Обобщенно качество
сопровождаемости базы данных можно оценивать потребностью ресурсов для ее
обеспечения и для реализации. Возможные затраты ресурсов на развитие и
совершенствование качества базы данных зависят не только от внутренних свойств
данных, но также от запросов и потребностей пользователей и от готовности
заказчика и разработчика удовлетворить эти потребности. По объему
предполагаемых изменений, а также вновь вводимых в очередную версию данных с
учетом сложности и новизны их разработки могут быть оценены затраты на их
создание. Такой анализ может дать ориентиры для прогнозирования общих затрат на
сопровождение и для оценивания этой характеристики качества в конкретных
проектах. Совокупность субхарактеристик сопровождаемости программной системы,
представленная в стандарте ISO 9126, вполне применима для описания этого
качества баз данных, в основном, теми же организационно-технологическими
субхарактеристиками.
Анализируемость базы данных зависит от стройности архитектуры,
унифицированности интерфейсов, полноты и корректности технологической и эксплуатационной
документации. Изменяемость состоит в приспособленности структуры и содержания
данных к реализации специфицированных изменений и к управлению конфигурацией
данных. Изменяемость зависит не только от внутренних свойств базы данных, но
также от организации и инструментальной оснащенности процессов сопровождения и
конфигурационного управления, на которые ориентирована архитектура, внешние и
внутренние интерфейсы данных. Тестируемость зависит от величины области влияния
изменений, которые необходимо тестировать при модификациях структуры и
содержания данных, от сложности тестов для проверки их характеристик. Ее
атрибуты зависят от четкости правил структурного построения компонентов и базы
данных в целом, от унификации межмодульных и внешних интерфейсов, от полноты и
корректности технологической документации. Субхарактеристики изменяемости и
тестируемости данных доступны для количественных оценок по величине
трудоемкости и длительности реализации этих функций при типовых операциях с
данными при применении различных методов и средств автоматизации. Эти
экономические шкалы по существу (хотя и не явно) могут отражать также
анализируемость и стабильность, и применяться для интегрального оценивания
сопровождаемости в целом.
Мобильность баз данных, как и программ, можно характеризовать в основном
длительностью и трудоемкостью их инсталляции, адаптации и замещаемости при
переносе на иные аппаратные и операционные платформы. Информация о процессах,
происходящих во внешней среде, может иметь большие объемы и трудоемкость
первичного накопления и актуализации, что определяет необходимость ее
тщательного хранения и регламентированного изменения. Возможны ситуации, когда
подобные данные являются уникальными и невосстанавливаемыми. Однако первичные
аппаратная или операционная платформы, в которых они накапливались и
обрабатывались, может требовать расширения и замены. Формирование и заполнение
информацией баз данных достаточно сложный и трудоемкий процесс,
технико-экономические показатели которого сильно зависят от структуры, состава,
объема, связности и других характеристик исходной информации.
Однако часто возможность переноса при первичном формировании и наполнении
базы данных не предусматривается и проявляется после длительной эксплуатации.
Сложность, трудоемкость и длительность переноса в этом случае значительно
возрастают и требуют тщательного планирования и организации работ,
приближающихся к созданию новой базы данных. Одновременно должно быть
обеспечено сохранение или повышение качества ее функционирования на новой
платформе.
Для оценки качества и определения требований к мобильности базы данных
следует решать задачу сравнения достигаемого эффекта и затрат для методов
переноса или повторной разработки компонентов и наполнения базы данных в
конкретных условиях с учетом всех перечисленных факторов и затрат. Эти задачи
значительно упрощаются при одновременном сокращении затрат при применении
идеологии и концепции открытых компьютерных систем, поддержанных комплексом
международных стандартов POSIX, а также современных версий ОС и СУБД, как
стандартов де-факто.
Формализация характеристик качества информации баз данных, на основе
стандартов, разработанных для оценивания программных средств, открывает путь
для применения апробированных на комплексах программ методов систематизации,
определения и повышения их качества. Использование стандартизированных
характеристик качества информации баз данных позволяет упорядочить выбор
требований к ним и оценивание достигнутого качества. Это должно способствовать
повышению качества баз данных в целом, с учетом их программных и информационных
компонентов, возможности достоверного определения их реальных характеристик при
разработке, испытаниях и сертификации.
3.1 О надежности в терминах ISO 9126
Стандартом ISO 9126 рекомендуется анализировать и учитывать
надежностькомплексов программ четырьмя субхарактеристиками.
Завершенность - способность базы данных не попадать в состояния отказов
вследствие потерь, искажений, ошибок и дефектов в данных. На эту
субхарактеристику влияют потери работоспособности, которые могут быть
обусловлены не полным тестовым покрытием при испытаниях компонентов и системы в
целом, а также недостаточной завершенностью их тестирования и защищенностью от
искажений.
Устойчивость к дефектам и ошибкам - свойство базы данных автоматически
поддерживать заданный уровень качества данных в случаях проявления дефектов и
ошибок или нарушения установленного интерфейса с внешней средой. Для этого в
базу должна вводиться временная и информационная избыточность, реализующая
оперативное обнаружение дефектов и ошибок информации, их идентификацию и
автоматическое восстановление нормального функционирования. Относительная доля
вычислительных ресурсов, используемых непосредственно для быстрой ликвидации
последствий отказов и оперативного восстановления данных отражается на
повышении надежности и определяет значение устойчивости.
Восстанавливаемость - свойство базы данных в случае отказа возобновлять
требуемый уровень качества информации и корректировать поврежденные данные.
После отказа, база данных бывает неработоспособна в течение времени,
продолжительность которого определяется восстанавливаемостью ее данных. Для
этого необходимы вычислительные ресурсы и время на выявление неработоспособного
состояния, диагностику причин отказа, а также на реализацию процессов
восстановления. Основными показателями процесса восстановления данных являются
его длительность и вероятностный характер. Восстанавливаемость характеризуется
также полнотой восстановления нормального содержания.
Доступность (или готовность) - свойство базы данных быть в состоянии
полностью выполнять требуемую функцию в данный момент времени и при заданных
условиях ее использования. Внешне, доступность может оцениваться относительным
временем, в течение которого база данных находится в работоспособном состоянии,
в пропорции к общему времени ее применения. Обобщение характеристик отказов и
восстановления производится через коэффициент готовности, отражающий
вероятность работать с нормальными данными в произвольный момент времени. Нижние
границы шкал атрибутов надежности могут быть отражены значениям, при которых
резко уменьшается функциональная пригодность базы данных, а использование
конкретной базы данных становится неудобным и опасным.
Эффективность использования ресурсов компьютера при реальном
функционировании отражается временными характеристиками взаимодействия конечных
пользователей и администраторов баз данных. Эти характеристики зависят от
качества СУБД, а также от объема, структуры и показателей качества используемой
информации. Для баз данных важнейшим ресурсом является память компьютера,
занимаемая информацией, а также ее используемость. Эти показатели качества
влияют на время реакции системы на разные виды запросов пользователей и на
пропускную способность базы данных.
В стандарте ISO 9126 выделены две субхарактеристики качества, которые
рекомендуется описывать, в основном, количественными атрибутами, отражающими
динамику функционирования компонентов базы данных. Временная эффективность
определяется длительностью выполнения заданных функций и ожидания результатов в
средних и/или наихудших случаях, с учетом приоритетов задач. Она зависит от
объема, структуры и скорости обработки данных, влияющих непосредственно на
интервал времени завершения конкретного вычислительного процесса, и от
пропускной способности, т.е. от числа заданий, которые можно реализовать на
данном компьютере в заданном интервале времени. Она зависит также от
функционального содержания данных и конструктивной их реализации, тем самым
может рассматриваться как один из внутренних показателей качества.
Особенности и трудоемкость переноса зависят, прежде всего, от
характеристик совместимости архитектур и содержания переносимой между
платформами информации.
Форматная совместимость характеризуется степенью соответствия данных
требованиям стандартов на форматы представления данных для документальных,
фактографических, словарных и иных базах данных.
Лингвистическая совместимость определяется степенью использования в
рассматриваемых базах данных единых лингвистических средств (классификаторов,
рубрикаторов, словарей), формализованных соответствующими стандартами этих
платформ.
Физическая совместимость заключается в степени соответствия кодировки
информации одинаковым стандартам на машиночитаемые носители.
Глава 4. Тенденции в мире систем управления базами данных
Системы управления базами данных (СУБД) играют исключительную роль в
организации современных промышленных, инструментальных и исследовательских
информационных систем. Тематика СУБД поистине безгранична. В этой главе
описываются наиболее интересные направления исследований и разработок.
· Реляционные системы
Хотя многие полагают, что реляционные СУБД, являясь наиболее
распространенным современным аппаратом построения информационных систем, не
представляют уже интереса в научном отношении, остается еще много нерешенных
или решенных не полностью проблем. Об этом свидетельствует поток статей,
посвященных тематике чисто реляционных систем, а также активная деятельность
компаний-производителей коммерческих реляционных систем, стремящихся улучшать
свои продукты и придавать им новые качества.
Продолжающаяся работа исследователей затрагивают вопросы оптимизации
запросов, новых алгоритмов выполнения реляционных операций, оптимизации
структур хранения данных и другие аспекты, непосредственно определяющие
эффективность СУБД. Те же самые вопросы занимают и разработчиков коммерческих
СУБД, которые, кроме того озабочены и более прикладными проблемами. Рассмотрим
немного более подробно (но без технических деталей) существо некоторых из этих
вопросов и то, каким образом они решаются в наиболее развитых коммерческих
продуктах.
· Использование мультипроцессорных организаций
Уже довольно давно развитые коммерческие СУБД основываются на архитектуре
"клиент-сервер". При этой организации наиболее трудоемкие операции
над базами данных выполняются на выделенном компьютере-сервере, который должен
быть достаточно мощным и обладать соответствующим набором ресурсов основной и
внешней памяти. До поры серверная часть СУБД обладала простой организацией:
запросы, поступающие из клиентских частей системы, обрабатывались
последовательно с небольшой оптимизацией для совмещения процессорной работы с
работой устройств внешней памяти.
Однако с появлением на рынке мультипроцессорных симметричных аппаратных
архитектур, производители СУБД были вынуждены пересмотреть организацию своих
серверов, допустив в них внутреннюю параллельность. Естественно, это требует
очень основательного перепроектирования системы с ее существенным усложнением.
Заметим, что в большинстве случаев компании пошли на это после появления в ОС
UNIX механизма "легковесных" процессов (threads).
О серьезности этой работы говорит тот факт, что, например, в компании
Informix было образовано новое подразделение, занимающееся исключительно
вопросами распараллеливания работы серверов.
· Интеграция
Чтобы убедить новых потенциальных пользователей использовать новые
продукты, компании- производители должны обеспечить решение проблемы
использования старых баз данных. В принципе эта проблема является частным видом
проблемы включения в открытые системы компонентов, которые не были на это
рассчитаны с самого начала.
В большинстве случаев предлагаемые решения основываются на использовании
индустриальных стандартов распределенных объектных систем (например, стандарта
CORBA, разработанного OMG). Тем не менее, производители СУБД вынуждены решать
многочисленные проблемы для вхождения их систем в новые интегрированные среды.
· Базы сложных объектов, реляционная модель с отказом от первой
нормальной формы
Одним из основных положений реляционной модели данных является требование
нормализации отношений: поля кортежей могут содержать лишь атомарные значения.
Для традиционных приложений реляционных СУБД - банковских систем, систем
резервирования и т.д. - это вовсе не ограничение, а даже преимущество,
позволяющее проектировать экономные по памяти БД с предельно понятной
структурой. Запросы с соединениями в таких системах сравнительно редки, для
динамической поддержки целостности используются соответствующие средства SQL.
Однако с появлением эффективных реляционных СУБД их стали пытаться
использовать и в менее традиционных прикладных системах - САПР, системы
искусственного интеллекта и т.д. Такие системы обычно оперируют со сложно
структурированными объектами, для реконструкции которых из плоских таблиц
реляционной БД приходится выполнять запросы, почти всегда требующие соединения
отношений. В соответствии с требованиями разработчиков нетрадиционных
приложений появилось направление исследований баз сложных объектов. Это очень обширная
область исследований, в которой затрагиваются вопросы моделей данных, структур
данных, языков запросов, управления транзакциями, журнализации и т.д. Во многом
эта область соприкасается с областью объектно-ориентированных БД.
· Активные базы данных
По определению БД называется активной, если СУБД по отношению к ней
выполняет не только те действия, которые явно указывает пользователь, но и
дополнительные действия в соответствии с правилами, заложенными в саму БД.
Легко видеть, что основа этой идеи содержалась в языке SQL времени System
R. На самом деле, что есть определение триггера или условного воздействия как
не введение в БД правила, в соответствии с которым СУБД должна производить
дополнительные действия? Плохо лишь то, что на самом деле триггеры не были
полностью реализованы ни в одной из известных систем, даже и в System R. И это
не случайно, потому что реализация такого аппарата в СУБД очень сложна,
накладна и не полностью понятна.
· Дедуктивные базы данных
По определению, дедуктивная БД состоит из двух частей: экстенсиональной,
содержащей факты, и интенсиональной, содержащей правила для логического вывода
новых фактов на основе экстенсиональной части и запроса пользователя.
Легко видеть, что при таком общем определении SQL-ориентированную
реляционную СУБД можно отнести к дедуктивным системам. Действительно, что есть
определенные в схеме реляционной БД представления как не интенсиональная часть
БД.
Основным отличием реальной дедуктивной СУБД от реляционной является то,
что и правила интенсиональной части БД, и запросы пользователей могут содержать
рекурсию. Именно возможность рекурсии делает реализацию дедуктивной СУБД очень
сложной и во многих случаях эффективно неразрешимой проблемой.
Обычно языки запросов и определения интенсиональной части БД являются
логическими (поэтому дедуктивные БД часто называют логическими). Имеется прямая
связь дедуктивных БД с базами знаний (интенсиональную часть БД можно
рассматривать как БЗ). Более того, трудно провести грань между этими двумя
сущностями; по крайней мере, общего мнения по этому поводу не существует.
Какова же связь дедуктивных БД с реляционными СУБД, кроме того, что
реляционная БД является вырожденным частным случаем дедуктивной? Основным
является то, что для реализации дедуктивной СУБД обычно применяется реляционная
система. Такая система выступает в роли хранителя фактов и исполнителя
запросов, поступающих с уровня дедуктивной СУБД. Между прочим, такое
использование реляционных СУБД резко актуализирует задачу глобальной
оптимизации запросов.
При обычном применении реляционной СУБД запросы обычно поступают на
обработку по одному, поэтому нет повода для их глобальной (межзапросной)
оптимизации. Дедуктивная же СУБД при выполнении одного запроса пользователя в
общем случае генерирует пакет запросов к реляционной СУБД, которые могут
оптимизироваться совместно.
Конечно, в случае, когда набор правил дедуктивной БД становится велик, и
их невозможно разместить в оперативной памяти, возникает проблема управления их
хранением и доступом к ним во внешней памяти. Здесь опять же может быть
применена реляционная система, но уже не слишком эффективно. Требуются более
сложные структуры данных и другие условия выборки. Известны частные попытки
решить эту проблему, но общего решения пока нет.
· Темпоральные базы данных
Обычные БД хранят мгновенный снимок модели предметной области. Любое
изменение в момент времени t некоторого объекта приводит к недоступности
состояния этого объекта в предыдущий момент времени. Самое интересное, что на
самом деле в большинстве развитых СУБД предыдущее состояние объекта сохраняется
в журнале изменений, но возможности доступа со стороны пользователя нет.
Конечно, можно явно ввести в хранимые отношения явный временной атрибут и
поддерживать его значения на уровне приложений. Более того, в большинстве
случаев так и поступают. Недаром в стандарте SQL появились специальные типы
данных date и time. Но в таком подходе имеются несколько недостатков: СУБД не
знает семантики временного поля отношения и не может контролировать
корректность его значений; появляется дополнительная избыточность хранения
(предыдущее состояние объекта данных хранится и в основной БД, и в журнале
изменений); языки запросов реляционных СУБД не приспособлены для работы со
временем.
Существует отдельное направление исследований и разработок в области
темпоральных БД. В этой области исследуются вопросы моделирования данных, языки
запросов, организация данных во внешней памяти и т.д. Основной тезис
темпоральных систем состоит в том, что для любого объекта данных, созданного в
момент времени t1 и уничтоженного в момент времени t 2, в БД сохраняются (и
доступны пользователям) все его состояния во временном интервале [t1,t2].
Исследования и построения прототипов темпоральных СУБД обычно выполняются
на основе некоторой реляционной СУБД. Как и в случае дедуктивных БД
темпоральная СУБД - это надстройка над реляционной системой. Конечно, это не
лучший способ реализации с точки зрения эффективности, но он прост и позволяет
производить достаточно глубокие исследования.
Главными особенностями системы управления памятью в Postgres является,
во-первых, то, что в ней не ведется обычная журнализация изменений базы данных
и мгновенно обеспечивается корректное состояние базы данных после перевызова
системы с утратой состояния оперативной памяти. Во-вторых, система управления
памятью поддерживает исторические данные. Запросы могут содержать временные
характеристики интересующих объектов. Реализационно эти два аспекта связаны.
Основное решение состоит в том, что при модификациях кортежа изменения
производятся не на месте его хранения, а заводится новая запись, куда
помещаются измененные поля. Эта запись содержит, кроме того, данные,
характеризующие транзакцию, производившую изменения (в том числе и время ее
завершения), и подшивается в список к изменявшемуся кортежу. В системе
поддерживается уникальная идентификация транзакций и имеется специальная
таблица транзакций, хранящаяся в стабильной памяти. Таким образом, после сбоев
просто не следует обращать внимание на хвостовые записи списков, относящиеся к
незакончившимся транзакциям. Синхронизация поддерживается на основе обычного
двухфазного протокола захватов.
Отдельный компонент системы осуществляет архивизацию объектов базы
данных. Он производит сборку разросшихся списков изменявшихся кортежей и
записывает их в область архивного хранения. К этой области тоже могут
адресоваться запросы, но уже только на чтение.
Система была ориентирована на использование оптических дисков с разовой
записью и стабильной оперативной памяти (хотя бы небольшого объема). При
наличии таких технических средств она выигрывает по эффективности даже при
работе в традиционном режиме, по сравнению со схемой с журнализацией. Однако,
возможна работа и на традиционной аппаратуре, тогда эффективность системы
слегка уступает традиционным схемам.
Соответствующие возможности работы с историческими данными заложены в
язык Postquel (и в этом его главное отличие от последних вариантов Quel).
Возможна выборка информации, хранившейся в базе данных в указанное время, в
указанном временном интервале и т.д. Кроме того, имеется возможность создавать
версии отношений, и допускается их последующая модификация с учетом изменений
основных вариантов.
· Интегрированные или федеративные системы и мультибазы данных
Направление интегрированных или федеративных систем неоднородных БД и
мульти-БД появилось в связи с необходимостью комплексирования систем БД,
основанных на разных моделях данных и управляемых разными СУБД.
Основной задачей интеграции неоднородных БД является предоставление
пользователям интегрированной системы глобальной схемы БД, представленной в
некоторой модели данных, и автоматическое преобразование операторов
манипулирования БД глобального уровня в операторы, понятные соответствующим
локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются
реализации.
При строгой интеграции неоднородных БД локальные системы БД утрачивают
свою автономность. После включения локальной БД в федеративную систему все
дальнейшие действия с ней, включая администрирование, должны вестись на
глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать
локальную автономность, желая тем не менее иметь возможность работать со всеми
локальными СУБД на одном языке и формулировать запросы с одновременным
указанием разных локальных БД, развивается направление мульти-БД. В системах
мульти-БД не поддерживается глобальная схема интегрированной БД и применяются
специальные способы именования для доступа к объектам локальных БД. Как
правило, в таких системах на глобальном уровне допускается только выборка
данных. Это позволяет сохранить автономность локальных БД.
Как правило, интегрировать приходится неоднородные БД, распределенные в
вычислительной сети. Это в значительной степени усложняет реализацию.
Дополнительно к собственным проблемам интеграции приходится решать все
проблемы, присущие распределенным СУБД: управление глобальными транзакциями,
сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности.
Как правило, для внешнего представления интегрированных и мульти-БД используется
(иногда расширенная) реляционная модель данных. В последнее время все чаще
предлагается использовать объектно-ориентированные модели, но на практике пока
основой является реляционная модель. Поэтому, в частности, включение в
интегрированную систему локальной реляционной СУБД существенно проще и
эффективнее, чем включение СУБД, основанной на другой модели данных.
· Распределенные СУБД
В теоретическом плане распределенные СУБД составляют еще одно измерение в
пространстве исследований и разработок систем управления базами данных. В этих
системах приходится решать все задачи, свойственные централизованным СУБД, но,
как правило, в более сложных постановках. Кроме того, в распределенных системах
возникают и специфические проблемы, от решения которых во многом зависит
эффективность, надежность и доступность систем БД. В настоящее время
большинство распределенных СУБД базируется на реляционной модели данных и
рассчитано на использование в локальных сетях ЭВМ. Многие проблемы
распространяются и на распределенные СУБД в территориально разнесенных сетях, и
почти все проблемы сохраняются для распределенных СУБД, основанных на других
моделях данных.
· Синхронизация доступа к данным
В централизованных системах БД очень распространено использование
двухфазного протокола синхронизационных захватов объектов БД. В соответствии с
этим протоколом объект БД автоматически захватывается транзакцией в
соответствующем режиме при первом обращении, и все захваты данной транзакции
освобождаются только при ее завершении. В случае возникновения конфликта по
синхронизации транзакция блокируется, пока объект не будет освобожден.
Следование этому протоколу может привести к возникновению синхронизационного
тупика между двумя или более транзакциями. Задача СУБД - распознать появление тупика
и разрушить его путем отката одной или нескольких транзакций.
Распознавание тупиков сводится к обнаружению циклов в графе ожидания
транзакций, что является трудоемкой задачей даже в централизованных СУБД. В
распределенных системах решение этой задачи может потребовать неприемлемых
накладных расходов (хотя поиски алгоритмов с допустимыми затратами
продолжаются).
Поэтому более часто в распределенных системах применяются протоколы
синхронизации, основанные на временных метках. Это направление само по себе
очень широко, имеются разные варианты и даже комбинации с протоколом двухфазных
захватов, но основной проблемой реализации является отсутствие в распределенной
системе единого времени.
· Управление транзакциями
В истинно распределенной СУБД транзакции естественно утрачивают линейную
структуру. Распределенная транзакция в общем случае представляет собой дерево,
промежуточными узлами которого являются распределенные подтранзакции, а листья
соответствуют обычным линейным транзакциям локальных СУБД.
Основной проблемой управления транзакциями в этом случае является
корректное завершение (фиксация) распределенной транзакции. Классическим
решением является использование давно известного протокола двухфазной фиксации.
Однако прямое использование этого протокола порождает значительное число
служебных сообщений между составляющими распределенную систему локальными СУБД.
Большое число исследований посвящено поискам более экономичных протоколов.
· Поддержание копий данных в нескольких узлах сети
Основным накладным расходом при выполнении распределенного запроса
является пересылка данных между узлами сети. Одним из способов сокращения этого
накладного расхода является поддержание копий наиболее часто используемых
данных в нескольких узлах сети с учетом порождаемых этим дополнительных
накладных расходов по поддержанию согласованности копий при модификации данных.
Другим основанием для поддержания копий является увеличение уровня
доступности данных при выходе из строя узлов сети или коммуникационных линий,
вследствие чего утрачивается связность сети. Теоретически доступ к некоторому
объекту БД может продолжаться в любом разделе сети, содержащем его копию.
Однако приходится решать ту же проблему согласования копий при изменениях
объекта данных. Существует масса подходов к решению этой проблемы, от полного
разрешения любого доступа к любой копии объекта во всех разделах сети с
проведением сложной процедуры согласования копий после восстановления связности
сети, до разрешения модификации объекта только в одном разделе. Для обнаружения
этого раздела обычно применяются различные варианты алгоритма голосования.
· Фрагментация объектов БД
Альтернативный подход, обеспечивающий максимальное распараллеливание
выполнения запроса к БД, состоит в том, что отношение (если говорить в терминах
реляционной модели данных) разбивается на ряд вертикальных или горизонтальных
фрагментов, и эти фрагменты хранятся в разных узлах сети.
Понятно, что теоретически это может обеспечить убыстрение выполнения
запроса, затрагивающего фрагментированное отношение, но практически добиться
этого очень трудно. Основная проблема состоит в резком расширении пространства
поиска вариантов выполнения запросов, с которым должен работать оптимизатор
запросов.
Имеются предложения и исследования, связанные с комбинацией поддержания
копий и фрагментацией объектов БД. В этом случае поддерживаются копии
фрагментов, что, вообще говоря, решает обе задачи, но еще больше усложняет
реализацию.
· Алгоритмы выполнения реляционных операций
Даже если говорить только про реляционные распределенные СУБД, которые
наиболее развиты в теоретическом и практическом отношении, до сих пор
проводится масса исследований в области оптимизации алгоритмов выполнения
реляционных операций (главным образом, соединения удаленных отношений).
Таким образом, даже рассмотрев только небольшую часть проблем
распределенных систем, можно убедиться, что они нуждаются в большом количестве
исследований и экспериментов. Начавшийся в России переход к использованию
локальных сетей дает практическую возможность проведения таких работ.
Заключение
Базы данных - важнейшая составная часть информационных систем.
Информационные системы предназначены для хранения и обработки больших объемов
информации. Изначально такие системы существовали в письменном виде. Для этого
использовались различные картотеки, папки, журналы, библиотечные каталоги и
т.д. Любая информационная система должна выполнять три основные функции: ввод
данных, запросы по данным, составление отчетов.
При
комплексном анализе качества баз данных не всегда удается четко разделить
требования и значения характеристик качества для каждого из этих объектов. Одна
СУБД может обрабатывать различные по структуре, составу и содержанию данные, а
одни и те же данные могут управляться различными СУБД. При анализе качества баз
данных целесообразно рассматривать два компонента: систему программ управления
данными и совокупность данных, упорядоченных по некоторым правилам.
Список
используемой литературы
1. К.Дж. Дейт Введение в
системы баз данных = Introduction to Database Systems. - 8-е изд. - М.:
«Вильямс»
<http://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BB%D1%8C%D1%8F%D0%BC%D1%81_(%D0%B8%D0%B7%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D1%82%D0%B2%D0%BE)>,
2006. - С. 1328.
. Сергей Кузнецов
«Тенденции в мире систем управления базами данных»
. Леонтьев В.П.
Новейшая энциклопедия персонального компьютера 2003г. 5 изд., перераб. и доп. -
М.: ОЛМА-ПРЕСС, 2003г.