Работа с текстурной памятью
Московский авиационный институт
(национальный исследовательский университет)
Кафедра вычислительной математики и программирования
Спецкурс "Параллельное программирование"
Лабораторная работа
Работа с текстурной памятью
Выполнил: Федотова С.В.
Группа: 18-2012, вариант 17
Преподаватель: Семенов С.А.
Москва, 2014
Оглавление
видеокарта текстурный память программа
1. Постановка
задачи
. Описание
решения
.1 Текстурная
память
.2 Линейная
текстурная память
.3 CudaArray
текстурная память
. Основные
моменты кода
. Результат
работы программ
Выводы
Приложения
1. Постановка
задачи
Выполнить параллельные вычисления на видеокарте с использованием
текстурной памяти. Рассмотреть специфические особенности по ее адресации,
видах, чтении и записи данных.
2. Описание
решения
.1 Текстурная
память
Текстурная память располагается в DRAM графического процессора, но в
отличие от глобальной памяти имеет кэш, ускоряющий доступ к данным.
Несмотря на то, что существуют дополнительные стадии конвейера (преобразование
адресов, фильтрация, преобразование данных), которые снижают скорость первого
обращения, текстурную память разумно использовать в следующих случаях:
- объем данных не влезает в shared память;
- паттерн доступа хаотичный;
- данные переиспользуются разными потоками.
Для использования текстурной памяти необходимо задать объявление текстуры
как глобальную переменную:
texture < type, dim, tex_type> g_TexRef;
§ type - тип хранимых переменных;
§ dim - размерность текстуры (1, 2, 3);
§ tex_type - тип возвращаемых значений:
- cudaReadModeNormalizedFloat;
- cudaReadModeElementType.
Кроме того, для более полного использования возможностей текстурной
памяти можно задать описание канала:
struct cudaChannelFormatDesc {int x, y, z, w;
enum cudaChannelFormatKind f;};
Задает формат возвращаемого значения;
§ int x, y, z, w; - число [0,32] проекция исходного значения по битам
§ cudaChannelFormatKind - тип возвращаемого значения:
- cudaChannelFormatKindSigned - знаковые;
- intocudaChannelFormatKindUnsigned - беззнаковые ;
- intocudaChannelFormatKindFloat - float.
В CUDA существуют два типа текстур линейная и cudaArray:
|
Линейная
|
cudaArray
|
|
Можно использовать обычную глобальную память. Ограничения: · только для одномерных массивов; · нет фильтрации; · доступ по целочисленным
координатам; · обращение
по адресу вне допустимого диапазона возвращает ноль. Доступ: tex1Dfetch(tex,
int)
|
Позволяет организовывать данные в1D/ 2D/3D массивы данных
вида: ·
1/2/4 компонентные
векторы; · 8/16/32 bit
signed/unsigned integers; · 32 bit float; · 16
bit float (driver API). Доступ по семейству функций: tex1D() / tex2D() /
tex3D()
|
2.2 Линейная
текстурная память
Линейная текстурная память не обладает никакими особыми свойствами кроме
кэша, однако уже этого иногда достаточно для значительного ускорения работы
программы. Как уже сказано выше, линейная текстурная память хранится в обычной
глобальной памяти и не требует особых функций копирования. Для включения
возможностей линейной текстурной памяти требуется "привязать" обычный
массив в глобальной памяти к объявленной текстуре.
Привязывание линейного массива:(size_t shift, texref tex,&src, size_t
size));
- shift - смещение при привязки к массиву (к одному массиву
можно привязать несколько тектсур)
- tex - объявленная текстура
- src - массив в глобальной памяти, к которому привязывается
текстура
- size - размер привязываемой области в байтах
Привязывание "двумерного массива" (в глобальной памяти он все
равно хранится как линейный, и обращение к нему идет по одной координате):
cudaBindTexture2D(size_t shift, texref tex, &src,
&channelDesc, int width, int height, int pitch);
- shift - смещение при привязке к массиву (к одному массиву
можно привязать несколько текстур);
- tex - объявленная текстура;
- src - массив в глобальной памяти, к которому привязывается
текстура;
- channelDesc - описание канала;
- width - ширина двумерного массива;
- height - высота двумерного массива;
- pitch - смещение каждой строки.
После окончания работы с текстурой её надо "отвязать":(texref
tex);
Все вышеприведенные функции вызываются с хоста. На устройстве
используется функция, которая достает значение из текстуры:
tex1Dfetch(texRef tex, int index);
- tex - объявленная текстура;
- index - индекс вынимаемого значения в линейном массиве.
В качестве входного демонстрационного примера в Лабораторной работе №4
создан проект LR4_1, в котором одномерный массив тестовых данных загружается в
текстурную память, и ядро GPU вычисляет произведение элемента массива на его
индекс, заполняя выходной одномерный массив.
2.3 CudaArray
текстурная память
В качестве основы для такого типа памяти выступает специальный контейнер
cudaArray, который является черным ящиком для приложений. Использование
cudaArray обосновано тогда, когда мы хотим создать двух или трехмерную
структуру, или нас важны преобразования, которые графический процессор может
совершать аппаратно с исходными данными:
§ Нормализация координат (перевод [W, H] => [0,1]).
- Clamp - координата обрезается по границе;
- Wrap - координата заворачивается.
§ Фильтрация (при обращении по float координате):
- Point - возвращается ближайшее заданное значение;
- Linear - производится билинейная интерполяция.
Для использования cudaArray текстурной памяти требуется объявить
переменную-указатель на cudaArray:* a;
Затем необходимо выделить память под данные на видеокарте:
cudaMallocArray(struct cudaArray **arrayPtr, const struct
cudaChannelFormatDesc *channelDesc, size_t width, size_t height);
- arrayPtr - указатель на cudaArray;
- channelDesc - описание канала;
- width - ширина массива;
- height - высота массива.
Затем скопировать в выделенную память данные:
cudaMemcpyToArray(struct cudaArray * dst, size_t wOffset,
size_t hOffset, const void * src, size_t count, enum cudaMemcpyKind kind);
- arrayPtr - указатель на cudaArray;
- wOffset - смещение по горизонтали при привязке к массиву;
- hOffset - смещение по вертикали при привязке к массиву;
- src - массив в памяти хоста, к который копируется;
- count - размер данных в байтах;
- kind - направление копирования.
После того как данные скопированы, можно осуществлять привязку cudaArray
массива к текстуре:
cudaBindTextureToArray(const struct textureReference *tex,
const struct cudaArray *array, const struct cudaChannelFormatDesc *desc);
- tex - объявленная текстура;
- array - массив в cudaArray, к которому привязывается
текстура;
- channelDesc - описание канала.
На устройстве используются функции, которые достают значение из текстуры:
tex1D (texRef tex, float x);
- tex - объявленная текстура;
- x - индекс вынимаемого значения в линейном массиве.
tex2D (texRef tex, float x, float y);
- tex - объявленная текстура;
- x, y - индексы вынимаемого значения в двухмерном массиве.
tex3D (texRef tex, float x, float y, float z);
- tex - объявленная текстура;
- x, y, z - индексы вынимаемого значения в трехмерном массиве.
После использования необходимо отвязать текстуру точно так же как и
линейную.
В Лабораторной работе №4 создан проект LR4_2, в котором одномерный массив
тестовых данных загружается в двумерную cudaArray текстурную память. На видеокарте
осуществляется билинейная интерполяция массива данных. Рассмотрено два варианта
передачи массива: с целочисленными и нормализованными координатами. В случае
нормализации в программе также предусматривается возможность использования двух
режимов адресации в текстурную память: Clamp и Warp. Исполняемое окно проекта
демонстрирует результат обработки данных при параллельных вычислениях для
наглядного отображения свойств исследуемых режимов работы с текстурной памятью
видеокарты.
3. Основные
моменты кода
Проект LR4_1. Алгоритм выполнения:
. Объявляется ссылка на линейную текстуру.
. Массив a[] заполняется одним и тем же значением PI.
. Резервируется область глобальной памяти графической карты.
. Копируются данные на устройство.
. Ссылка линейной текстуры привязывается к области памяти с
загруженным массивом данных.
. Запускаются потоки параллельного вычисления на видеокарте, в
которых каждый поток умножает исходное значение элемента массива из текстуры на
его индекс и записывает полученный результат в элемент массива, предназначенный
для обмена с хостом, с этим же индексом.
. Синхронизируем программу, дожидаясь окончания работы всех
потоков.
. Освобождаем ресурсы проекта.
|
Файл kernel.cu, проект LR4_1
|
|
... #define
nThreads 128 // Number of threads per block texture<float,
cudaTextureType1D, cudaReadModeElementType> g_TexRef; __global__ void
kernel(float *data) { int idx= blockIdx.x* blockDim.x+ threadIdx.x; data
[idx] = tex1Dfetch ( g_TexRef, idx )*idx; if (idx >=100) return;
printf("%d\t %.2f\t %.2f\n", idx, tex1Dfetch(g_TexRef, idx),
data[idx] ); } void main() { ... for (int i=0;i<nBlocks*nThreads;i++)
a[i]=PI; cudaMalloc((void**)&devX, nBlocks*nThreads * sizeof(float)
); cudaMemcpy( devX, a, nBlocks*nThreads*sizeof(float), cudaMemcpyHostToDevice);
cudaBindTexture( (size_t)0, &g_TexRef, devX, &g_TexRef.channelDesc,
(size_t)(nBlocks*nThreads*sizeof(float)) );
kernel<<<nBlocks,nThreads>>>( devX );
cudaDeviceSynchronize(); cudaUnbindTexture ( &g_TexRef ); cudaFree (
devX ); system("pause"); }
|
Проект LR4_2. Для оценки правильности работы программы в одном проекте
объединена работа с текстурами в двух режимах: целочисленном и нормализованном.
Алгоритм выполнения:
. Объявляются ссылки на двумерные cudaArray-текстуры и формат
текстурных каналов.
. Задается тестовый массив a[].
. Резервируется область глобальной памяти графической карты под
линейные массивы обмена данными между устройством и хостом.
. Резервируется область глобальной памяти графической карты под
двумерные массивы cudaArray-текстур.
. Копируются данные с хоста в текстурные области на устройстве.
. Устанавливаются режимы фильтрации на устройстве для возвращаемой
выборки из текстур. Дополнительно выбираются режимы адресации для
нормализованных координат: Clamp, в случае, когда координата обрезается по
границе, или Wrap (координата заворачивается).
. Ссылки текстур привязываются к области памяти с загруженным
массивом данных.
. Запускаются потоки параллельного вычисления на видеокарте, в
которых каждый поток возвращает хосту значение элемента массива, полученное в
результате фильтрации (ближайшее заданное или билинейная интерполяция) и
заданного режима адресации.
. Синхронизируем программу, дожидаясь окончания работы всех
потоков.
. Освобождаем ресурсы проекта.
Пример кода для случая задания целочисленных координат:
|
Файл kernel.cu, проект LR4_2
|
|
...
texture<float, 2, cudaReadModeElementType> g_TexRef2;
cudaChannelFormatDesc Desc2 =
cudaCreateChannelDesc(32,0,0,0,cudaChannelFormatKindFloat); __global__ void
Kernel2(float *c2) { int index = blockIdx.x * blockDim.x + threadIdx.x; int
i = index + blockIdx.y*gridDim.x * blockDim.x; c2 [i] = tex2D(g_TexRef2,
index, blockIdx.y); } int main(int argc, char* argv[]) { ... // задаем тестовый массив а for
(int i = 0; i<numItems; i++)a[i]=i; //for (int i = 0; i<numItems; i++)
a[i]=(float)(double(rand()) / RAND_MAX * 100); float * a = new float
[numItems]; // выделяем память под массивы a, c2 float * c2 = new float
[numItems]; float * cDev2 = NULL; //создаем указатель на массивы для
памяти ГП cudaMalloc(&cDev2, size); // выделяем память в ГП под массив
cudaArray * aca2 = NULL; // создаем указатель на cuda-массив int
nBlocksX = 2; int nBlocksY = 1; cudaMallocArray(&aca2, &Desc2,
nBlocksX*nThreads, nBlocksY); // копируем данные из памяти хоста в
2D-cuda массив на устройство cudaMemcpyToArray(aca2,0,0, a, size,
cudaMemcpyHostToDevice); // устанавливаем режим фильтрации: // выборка
текстуры вернет интерполяцию из значений четырех соседних точек 2D
поверхности g_TexRef2.filterMode = cudaFilterModeLinear; // выборка текстуры
вернет ближайшее заданное значение из значений четырех соседних точек 2D
поверхности //g_TexRef2.filterMode = cudaFilterModePoint; //привязываем
текстурную ссылку к CUDA-массиву в ГП cudaBindTextureToArray(g_TexRef2,aca2);
dim3 threads = dim3( nThreads ); dim3 blocks = dim3( nBlocksX, nBlocksY );
Kernel2<<<blocks, threads>>> (cDev2);
cudaThreadSynchronize(); //Копируем массив c2 из памяти ГП в память ЦП cudaMemcpy((void
*) c2, cDev2, size, cudaMemcpyDeviceToHost); ... cudaFree ( cDev2);
//освобождаем память массивов в ГП cudaUnbindTexture ( &g_TexRef2 );
//Отмена привязки текстур ГП и текстурных ссылок delete [] a; //освобождаем
память массивов в ЦП delete [] c2; ... }
|
Пример кода для случая задания нормализованных координат:
|
Файл kernel.cu, проект LR4_2
|
|
...
texture<float, 2, cudaReadModeElementType> g_TexRef;
cudaChannelFormatDesc Desc =
cudaCreateChannelDesc(32,0,0,0,cudaChannelFormatKindFloat); __global__ void
Kernel (float * c, int width, int height) { // вычисление нормализованных текстурных координат
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x; unsigned int y =
blockIdx.y * blockDim.y + threadIdx.y; float u = x / (float) width; float v
= y / (float) height; // запись в глобальную память int i = y*width + x; c[i]
=tex2D(g_TexRef, u,v); } int main(int argc, char* argv[]) { ... size_t size
= numItems * sizeof(float); //сколько занимают элементы в байтах float
* a = new float [numItems]; // выделяем память под массивы a, c
float * c = new float [numItems]; // задаем тестовый массив а for
(int i = 0; i<numItems; i++)a[i]=i; //for (int i = 0; i<numItems; i++)
a[i]=(float)(double(rand()) / RAND_MAX * 100); //создаем
указатель на массивы для памяти ГП float * cDev = NULL; // выделяем память
в ГП под массив cudaMalloc(&cDev, size); // создаем указатель на
cuda-массив cudaArray * aca = NULL; int width = nThreads; int
height = numBloks; cudaMallocArray(&aca, &Desc,width,height); // копируем данные
из памяти хоста в 2D-cuda массив на устройство cudaMemcpyToArray(aca,0,0,
a, size, cudaMemcpyHostToDevice); //g_TexRef.addressMode[0] =
cudaAddressModeClamp; //g_TexRef.addressMode[1] = cudaAddressModeClamp;
g_TexRef.addressMode[0] = cudaAddressModeWrap; g_TexRef.addressMode[1] =
cudaAddressModeWrap; g_TexRef.normalized = true; // устанавливаем режим
фильтрации: // выборка текстуры вернет интерполяцию из значений четырех
соседних точек 2D поверхности g_TexRef.filterMode = cudaFilterModeLinear;
// выборка текстуры вернет ближайшее заданное значение из значений четырех
соседних точек 2D поверхности //g_TexRef.filterMode = cudaFilterModePoint;
//привязываем текстурную ссылку к CUDA-массиву в ГП cudaBindTextureToArray(g_TexRef,
aca, Desc); dim3 dimBlock(16, 2); int kx = width + dimBlock.x; unsigned int
kxx = (unsigned int)(kx -1); int ky = height + dimBlock.y; unsigned int kyy
= (unsigned int)(ky -1); dim3 dimGrid( kxx/dimBlock.x, kyy /dimBlock.y);
Kernel<<<dimGrid, dimBlock>>> (cDev, width, height); cudaThreadSynchronize();
//Копируем массив с c2 из памяти ГП в память ЦП cudaMemcpy((void
*) c, cDev, size, cudaMemcpyDeviceToHost); ... //освобождаем память массивов
в ГП cudaFree ( cDev); //Отмена привязки текстур ГП и текстурных ссылок
cudaUnbindTexture ( &g_TexRef ); //освобождаем память массивов в ЦП
delete [] a; delete [] c; ... }
|
4. Результат
работы программ
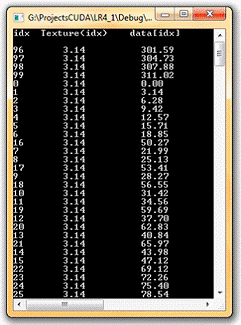
Рис. 1. Окно вывода консольного приложения LR4_1
Проект LR4_2. Пример 1 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode = cudaFilterModePoint;_TexRef.addressMode[0]
= cudaAddressModeClamp;_TexRef.addressMode[1] = cudaAddressModeClamp;
g_TexRef2.filterMode = cudaFilterModePoint;
Массив входных данных упорядоченный.
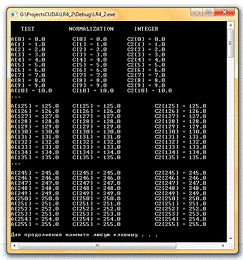
Рис. 2. Окно вывода консольного приложения LR4_2. Пример 1.
Проект LR4_2. Пример 2 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModePoint;_TexRef.addressMode[0] = cudaAddressModeClamp;_TexRef.addressMode[1]
= cudaAddressModeClamp;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModePoint;
Массив входных данных случайный.

Рис. 3. Окно вывода консольного приложения LR4_2. Пример 2.
Проект LR4_2. Пример 3 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModePoint;_TexRef.addressMode[0] = cudaAddressModeWrap;
g_TexRef.addressMode[1] = cudaAddressModeWrap;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModePoint;
Массив входных данных упорядоченный.
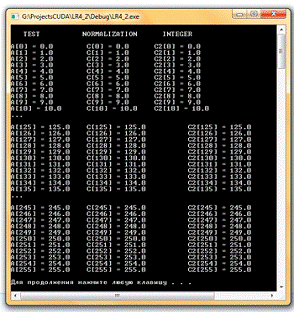
Рис. 4. Окно вывода консольного приложения LR4_2. Пример 3.
Проект LR4_2. Пример 4 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModePoint;_TexRef.addressMode[0] = cudaAddressModeWrap;
g_TexRef.addressMode[1] = cudaAddressModeWrap;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModePoint;
Массив входных данных случайный.
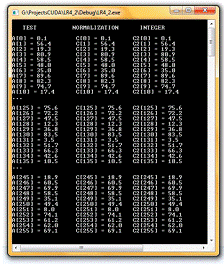
Рис. 5. Окно вывода консольного приложения LR4_2. Пример 4.
Проект LR4_2. Пример 5 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode = cudaFilterModeLinear;_TexRef.addressMode[0]
= cudaAddressModeClamp;_TexRef.addressMode[1] = cudaAddressModeClamp;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModeLinear;
Массив входных данных упорядоченный.
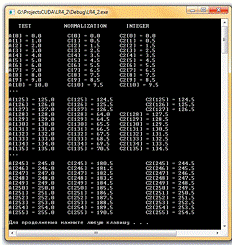
Рис. 6. Окно вывода консольного приложения LR4_2. Пример 5.
Проект LR4_2. Пример 6 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModeLinear;_TexRef.addressMode[0] = cudaAddressModeClamp;_TexRef.addressMode[1]
= cudaAddressModeClamp;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModeLinear;
Массив входных данных случайный.
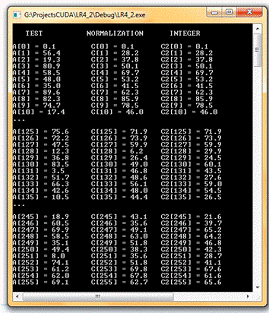
Рис. 7. Окно вывода консольного приложения LR4_2. Пример 6.
Проект LR4_2. Пример 7 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModeLinear;_TexRef.addressMode[0] =
cudaAddressModeWrap;_TexRef.addressMode[1] = cudaAddressModeWrap;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModeLinear;
Массив входных данных упорядоченный.
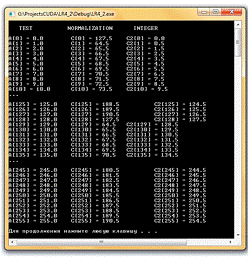
Рис. 8. Окно вывода консольного приложения LR4_2. Пример 7.
Проект LR4_2. Пример 8 - заданы следующие стартовые параметры:
- нормализованные координаты
g_TexRef.filterMode =
cudaFilterModeLinear;_TexRef.addressMode[0] =
cudaAddressModeWrap;_TexRef.addressMode[1] = cudaAddressModeWrap;
- целочисленные координаты
g_TexRef2.filterMode = cudaFilterModeLinear;
Массив входных данных случайный.

Рис. 9. Окно вывода консольного приложения LR4_2. Пример 8.
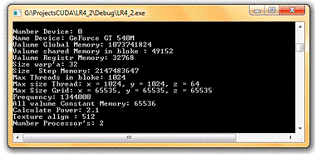
Рис. 10. Окно вывода консольного приложения LR4_2. Параметры видеокарты.
Выводы
В Лабораторной работе проведен анализ работы параллельных вычислений на
видеокарте GeForce GT 540M с использованием текстурной памяти. Рассматривались
специфические особенности по ее адресации, видах, чтении и записи данных.
Из проводимых исследований, при использовании в программе целочисленных
или нормализованных координат, в сравнении видно:
. При режиме фильтрации cudaFilterModePoint значения входных данных не
изменяются при обоих способах задания координат текстуры. Способ задания
тестового массива (случайный или упорядоченный) не влияет на результат (Примеры
1-4).
. При режиме фильтрации cudaFilterModeLinear значения входных данных
изменяются.
|
Целочисленные координаты
|
Нормализованные координаты
|
Случайный
|
Упорядоченный
|
Случайный
|
|
Clamp
|
близко верный на всем тестовом массиве
|
средняя погрешность
|
близко верный на всем тестовом массиве, совпадают с
целочисленными координатами
|
средняя погрешность, выше, чем у целочисленных координат
|
|
Warp
|
близко верный на всем тестовом массиве
|
высокая погрешность
|
близко верный на всем тестовом массиве, совпадают с
целочисленными координатами, но с эффектом заворачивания
|
высокая погрешность, выше, чем у целочисленных координат
|
Таким образом, видно, что билинейная интерполяция от входных данных дает
приближенные значения, уровень погрешности которых растет при уменьшении
упорядочивания набора данных. Выборка из текстуры по нормализованным
координатам увеличивает погрешность, особенно при Warp-преобразовании. Кроме
того необходимо знать и учитывать эффект заворачивания, если текстурная память
использует нормализованные координаты для своей адресации.
Приложения
Код программы
|
Файл kernel.cu, проект LR4_1
|
|
#include
"cuda.h" #include "cuda_runtime.h" #include
<iostream> #include <vector> #include <cstdio> using
namespace std; #define PI 3.1415926536 #define nBlocks 1 // Number of thread
blocks #define nThreads 128 // Number of threads per block texture<float,
cudaTextureType1D, cudaReadModeElementType> g_TexRef; __global__ void
kernel(float *data) { int idx= blockIdx.x* blockDim.x+ threadIdx.x; data
[idx] = tex1Dfetch ( g_TexRef, idx )*idx; if (idx >=100) return;
printf("%d\t %.2f\t %.2f\n", idx, tex1Dfetch(g_TexRef, idx),
data[idx] ); } void main() { cout<<"idx Texture(idx)
data[idx]\n"<<endl; float a[nBlocks*nThreads]; float *devX = NULL;
for (int i=0;i<nBlocks*nThreads;i++) a[i]=PI;
cudaMalloc((void**)&devX, nBlocks*nThreads * sizeof(float) ); cudaMemcpy(
devX, a, nBlocks*nThreads*sizeof(float), cudaMemcpyHostToDevice);
cudaBindTexture( (size_t)0, &g_TexRef, devX, &g_TexRef.channelDesc,
(size_t)(nBlocks*nThreads*sizeof(float)) );
kernel<<<nBlocks,nThreads>>>( devX );
cudaDeviceSynchronize(); cudaUnbindTexture ( &g_TexRef ); cudaFree ( devX
); system("pause");
}
|
Код программы
|
Файл kernel.cu, проект LR4_2
|
|
#include
"cuda.h" #include "cuda_runtime.h" #include
<stdlib.h> #include <stdio.h> #include <time.h> #include
<fstream> #include <iostream> #define numBloks 2 #define nThreads
128 texture<float, 2, cudaReadModeElementType> g_TexRef;
texture<float, 2, cudaReadModeElementType> g_TexRef2;
cudaChannelFormatDesc Desc =
cudaCreateChannelDesc(32,0,0,0,cudaChannelFormatKindFloat);
cudaChannelFormatDesc Desc2 =
cudaCreateChannelDesc(32,0,0,0,cudaChannelFormatKindFloat); __global__ void
Kernel (float * c, int width, int height) { // вычисление нормализованных текстурных координат
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x; unsigned int y =
blockIdx.y * blockDim.y + threadIdx.y; float u = x / (float) width; float v =
y / (float) height; // запись в глобальную память int i = y*width + x; c[i]
=tex2D(g_TexRef, u,v);
//printf("c[%d]=%.2f\tx=%d\ty=%d\tu=%f\tv=%f\t\n\n",i,c[i],x,y,u,v);
} __global__ void Kernel2(float *c2) { int index = blockIdx.x * blockDim.x +
threadIdx.x; int i = index + blockIdx.y*gridDim.x * blockDim.x; c2 [i] =
tex2D(g_TexRef2, index, blockIdx.y); } int main(int argc, char* argv[]) {
const unsigned int numItems = nThreads*numBloks; //число элементов в массивах a, c,
c2 size_t size = numItems * sizeof(float); //сколько занимают элементы в байтахfloat *
a = new float [numItems]; // выделяем память под массивы a, c, c2 float *
c = new float [numItems]; float * c2 = new float [numItems]; // задаем тестовый массив а for
(int i = 0; i<numItems; i++)a[i]=i; //for (int i = 0; i<numItems; i++)
a[i]=(float)(double(rand()) / RAND_MAX * 100); //создаем указатель на массивы для
памяти ГП float * cDev = NULL; float * cDev2 = NULL; // выделяем память
в ГП под массив cudaMalloc(&cDev, size); cudaMalloc(&cDev2,
size); //
создаем указатель на cuda-массив cudaArray * aca = NULL; cudaArray
* aca2 = NULL; int width = nThreads; int height = numBloks;
cudaMallocArray(&aca, &Desc,width,height); int nBlocksX = 2; int
nBlocksY = 1; cudaMallocArray(&aca2,
&Desc2,nBlocksX*nThreads,nBlocksY); // копируем данные из памяти хоста в
2D-cuda массив на устройство cudaMemcpyToArray(aca,0,0, a, size,
cudaMemcpyHostToDevice); cudaMemcpyToArray(aca2,0,0, a, size,
cudaMemcpyHostToDevice); //g_TexRef.addressMode[0] = cudaAddressModeClamp;
//g_TexRef.addressMode[1] = cudaAddressModeClamp; //g_TexRef.addressMode[0] =
cudaAddressModeWrap; //g_TexRef.addressMode[1] = cudaAddressModeWrap; g_TexRef.normalized
= true; // устанавливаем режим фильтрации: // выборка текстуры вернет
интерполяцию из значений четырех соседних точек 2D поверхности g_TexRef.filterMode
= cudaFilterModeLinear; // выборка текстуры вернет ближайшее заданное
значение из значений четырех соседних точек 2D поверхности //g_TexRef.filterMode
= cudaFilterModePoint; //g_TexRef2.filterMode = cudaFilterModePoint;
g_TexRef2.filterMode = cudaFilterModeLinear; //привязываем текстурную ссылку к CUDA-массиву в ГП
cudaBindTextureToArray(g_TexRef,aca,Desc);
cudaBindTextureToArray(g_TexRef2,aca2); dim3 dimBlock(16, 2); int kx = width
+ dimBlock.x; unsigned int kxx = (unsigned int)(kx -1); int ky = height +
dimBlock.y; unsigned int kyy = (unsigned int)(ky -1); dim3 dimGrid(
kxx/dimBlock.x, kyy /dimBlock.y); Kernel<<<dimGrid,
dimBlock>>> (cDev, width, height); cudaThreadSynchronize(); dim3
threads = dim3( nThreads ); dim3 blocks = dim3( nBlocksX, nBlocksY );
Kernel2<<<blocks, threads>>> (cDev2);
cudaThreadSynchronize(); //Копируем массив с c2 из памяти ГП в память ЦП cudaMemcpy((void
*) c, cDev, size, cudaMemcpyDeviceToHost); cudaMemcpy((void *) c2, cDev2,
size, cudaMemcpyDeviceToHost); //выводим результат printf("\n
TEST NORMALIZATION INTEGER\n\n"); for (int i = 0; i<numItems; i++) {
printf("A[%d] = %.1f\t C[%d] = %.1f\t C2[%d] = %.1f\n ", i, a[i],i,
c[i],i, c2[i]); } //освобождаем память массивов в ГП cudaFree ( cDev);
cudaFree ( cDev2); //Отмена привязки текстур ГП и текстурных ссылок cudaUnbindTexture
( &g_TexRef ); cudaUnbindTexture ( &g_TexRef2 ); //освобождаем
память массивов в ЦП delete [] a; delete [] c; delete [] c2; int
deviceCount; cudaGetDeviceCount(&deviceCount); for(int device = 0; device
< deviceCount; device++) { cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device); printf("\n\nNumber
Device: %d\n",device); printf("Name Device: %s\n",
deviceProp.name); printf("Valume Global Memory: %d\n",
deviceProp.totalGlobalMem); printf("Valume shared Memory in bloke :
%d\n", deviceProp.sharedMemPerBlock); printf("Valume Registr
Memory: %d\n", deviceProp.regsPerBlock); printf("Size warp'a:
%d\n", deviceProp.warpSize); printf("Size Step Memory: %d\n",
deviceProp.memPitch); printf("Max Threads in bloke: %d\n",
deviceProp.maxThreadsPerBlock); printf("Max size Thread: x = %d, y =
%d, z = %d\n", deviceProp.maxThreadsDim[0],
deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]); printf("Max
Size Grid: x = %d, y = %d, z = %d\n", deviceProp.maxGridSize[0],
deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);
printf("Frequency: %d\n", deviceProp.clockRate); printf("All
valume Constant Memory: %d\n", deviceProp.totalConstMem); printf("Calculate
Power: %d.%d\n", deviceProp.major, deviceProp.minor);
printf("Texture align : %d\n", deviceProp.textureAlignment);
printf("Number Processor's: %d\n", deviceProp.multiProcessorCount);
} printf("\n"); system("pause"); return 0; }
|