Создание базы данных для электронного магазина с помощью 'Денвер'
Проектная
работа
Создание базы
данных для электронного магазина с помощью "Денвер"
Содержание
Введение
. Представление данных в памяти компьютера
.1 Типы и структуры данных
.2 Обобщенные структуры или модели данных
.3 Методы доступа к данным
. Физическая организация СУБД
.1 Архитектура "клиент-сервер"
.2 Обработка распределенных данных
.3 Структура сервера базы данных
. Создание базы данных с помощью "Денвер"
Заключение
Литература
Приложения
Введение
В последнее время большее внимание уделяется, продвижению своей продукции
или товара не на ограниченном участке территории, а большем, стараясь обхватить
большое количество территории и при удобном случае с выходом на внешний рынок.
В связи с этим, довольно сильно развивается интернет бизнес.
Для необоснованных затрат на транспортировку товара, в те районы, где он
может быть не востребован, служит Интернет магазин (сайт, где клиент может
произвести заказ, а так же, если продавец использует Интернет деньги, то сразу
оплатить его).
В связи с этим, для решения поставленной выше задачи, в данной работе
описывается пример создания базы данных для Интернет-магазина, занимающегося
реализацией компьютерной техники.
Цель проекта: создание базы данных для Интернет-магазина
Задачи работы:
· Определить понятие области базы данных;
· Рассмотреть этапы и способы создания базы данных;
· Обосновать выбор инструмента;
· Провести исследование средств MySql и phpMyAdmin;
. Представление данных в памяти компьютера
.1 Типы и
структуры данных
Данные, хранящиеся в памяти ЭВМ представляют собой совокупность нулей и
единиц (битов). Биты объединяются в последовательности: байты, слова и т.д.
Каждому участку оперативной памяти, который может вместить один байт или слово,
присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены - буквенными
или цифровыми, что означает то или иное число - все это определяется программой
обработки. Все данные необходимые для решения практических задач подразделяются
на несколько типов, причем понятие тип связывается не только с представлением
данных в адресном пространстве, но и со способом их обработки.
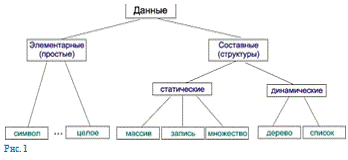
Любые данные могут быть отнесены к одному из двух типов: основному
(простому), форма представления которого определяется архитектурой ЭВМ, или сложному,
конструируемому пользователем для решения конкретных задач.
Данные простого типа это - символы, числа и т.п. элементы, дальнейшее
дробление которых не имеет смысла. Из элементарных данных формируются структуры
(сложные типы) данных.
Некоторые структуры:
Массив(функция с конечной областью определения) - простая совокупность
элементов данных одного типа, средство оперирования группой данных одного типа.
Отдельный элемент массива задается индексом. Массив может быть одномерным,
двумерным и т.д. Разновидностями одномерных массивов переменной длины являются
структуры типа кольцо, стек, очередь и двухсторонняя очередь.
Запись(декартово произведение) - совокупность элементов данных разного
типа. В простейшем случае запись содержит постоянное количество элементов,
которые называют полями. Совокупность записей одинаковой структуры называется
файлом. (Файлом называют также набор данных во внешней памяти, например, на
магнитном диске). Для того, чтобы иметь возможность извлекать из файла
отдельные записи, каждой записи присваивают уникальное имя или номер, которое
служит ее идентификатором и располагается в отдельном поле. Этот идентификатор
называют ключом.
Такие структуры данных как массив или запись занимают в памяти ЭВМ
постоянный объем, поэтому их называют статическими структурами. К статическим
структурам относится также множество. Имеется ряд структур, которые могут
изменять свою длину - так называемые динамические структуры. К ним относятся
дерево, список, ссылка.
Важной структурой, для размещения элементов которой требуется нелинейное
адресное пространство является дерево. Существует большое количество структур
данных, которые могут быть представлены как деревья. Это, например,
классификационные, иерархические, рекурсивные и др. структуры.
.2 Обобщенные
структуры или модели данных
Существует большое разнообразие сложных типов данных, но исследования,
проведенные на большом практическом материале, показали, что среди них можно
выделить несколько наиболее общих. Обобщенные структуры называют также моделями
данных, т.к. они отражают представление пользователя о данных реального мира.
Любая модель данных должна содержать три компоненты:
1. структура данных - описывает точку зрения пользователя на
представление данных.
2. набор допустимых операций, выполняемых на структуре данных.
Модель данных предполагает, как минимум, наличие языка определения данных
(ЯОД), описывающего структуру их хранения, и языка манипулирования данными
(ЯМД), включающего операции извлечения и модификации данных.
. ограничения целостности - механизм поддержания соответствия
данных предметной области на основе формально описанных правил.
В процессе исторического развития в СУБД использовалось следующие модели
данных:
· иерархическая
· сетевая
· реляционная
В последнее
время все большее значение приобретает объектно-ориентированный подход к
представлению данных.
.3 Методы
доступа к данным
Вопросы представления данных тесно связаны с операциями, при помощи
которых эти данные обрабатываются. К числу таких операций относятся: выборка,
изменение,включение и исключение данных. В основе всех перечисленных операций
лежит операция доступа, которую нельзя рассматривать независимо от способа
представления.
В задачах поиска предполагается, что все данные хранятся в памяти с
определенной идентификацией и, говоря о доступе, имеют в виду прежде всего
доступ к данным (называемым ключами), однозначно идентифицирующим связанные с
ними совокупности данных.
Пусть нам необходимо организовать доступ к файлу, содержащему набор
одинаковых записей, каждая из которых имеет уникальное значение ключевого поля.
Самый простой способ поиска - последовательно просматривать каждую запись в
файле до тех пор, пока не будет найдена та, значение ключа которой
удовлетворяет критерию поиска. Очевидно, этот способ весьма неэффективен,
поскольку записи в файле не упорядочены по значению ключевого поля. Сортировка
записей в файле также неприменима, поскольку требует еще больших затрат времени
и должна выполняться после каждого добавления записи. Поэтому, поступают
следующим образом - ключи вместе с указателями на соответствующие записи в
файле копируют в другую структуру, которая позволяет быстро выполнять операции
сортировки и поиска. При доступе к данным вначале в этой структуре находят
соответствующее значение ключа, а затем по хранящемуся вместе с ним указателю
получают запись из фала. Существуют два класса методов, реализующих доступ к
данным по ключу:
· методы поиска по дереву,
· методы хеширования.
2. Физическая
организация СУБД
.1 Архитектура
"клиент-сервер"
Как правило компьютеры и программы, входящие в состав информационной
системы, не являются равноправными. Некоторые из них владеют ресурсами
(файловая система, процессор, принтер, база данных и т.д.), другие имеют
возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий
ресурсом, называют сервером этого ресурса (файл-сервер, сервер базы данных,
вычислительный сервер...). Клиент и сервер какого-либо ресурса могут находится
как в рамках одной вычислительной системы, так и на различных компьютерах,
связанных сетью.
Основной принцип технологии "клиент-сервер" заключается в
разделении функций приложения на три группы:
· ввод и отображение данных (взаимодействие с пользователем);
· прикладные функции, характерные для данной предметной
области;
· функции управления ресурсами (файловой системой, базой даных
и т.д.)
Поэтому, в любом приложении выделяются следующие компоненты:
· компонент представления данных
· прикладной компонент
· компонент управления ресурсом
Связь между компонентами осуществляется по определенным правилам, которые
называют "протокол взаимодействия".
2.2 Обработка
распределенных данных
В современном бизнесе очень часто возникает необходимость предоставить
доступ к одним и тем же данным группам пользователей, территориально удаленным
друг от друга. В качестве примера можно привести банк, имеющий несколько
отделений. Эти отделения могут находиться в разных городах, странах или даже на
разных континентах, тем не менее необходимо организовать обработку финансовых
транзакций (перемещение денег по счетам) между отделениями. Результаты
финансовых операций должны быть видны одновременно во всех отделениях.
Сущесвтуют два подхода к организации обработки распределнных данных.
. технология распределенной базы данных Такая база включает
фрагменты данных, расположенные на различных узлах сети. С точки зрения
пользователей она выглядит так, как будто все данные хранятся в одном месте.
Естественно, такая схема предъявляет жесткие требования к производительности и
надежности каналов связи.
. технология тиражирования В этом случае в каждом узле сети
дублируются данные всех компьютеров. При этом:
· передаются только операции изменения данных, а не сами данные
· передача может быть асинхронной (неодновременной для разных
узлов)
· данные располагаются там, где обрабатываются
Это позволяет снизить требования к пропускной способности каналов связи,
более того при выходе из строя линии связи какого-либо компьютера, пользователи
других узлов могут продолжать работу. Однако при этом допускается неодинаковое
состояние базы данных для различных пользователей в один и тот же момент
времени. Следовательно, невозможно исключить конфликты между двумя копиями
одной и той же записи.
2.3 Структура сервера базы данных
В заключение рассмотрим физическую организацию сервера базы данных. Как
правило, он включает следующие компоненты:
· подсистема взаимодействия с клиентским приложением Данный
модуль отвечает за поддержание связи с клиентом. Как правило, механизм его
работы выглядит следующим образом. Подсистема взаимодействия
"прослушивает" сеть в ожидании клиентских запросов на установление
соединения. Когда такой запрос обнаруживается, порождается новый процесс,
который будет обеспечивать связь с данным клиентом. Клиенту сообщается
идентификатор данного процесса, в дальнейшем клиент передает свои запросы и
получает данные взаимодействуя с этим интерфейсным процессом. После того, как
клиент закрывает соединение, обслуживавший его процесс прекращается.
Характеристики интерфейсных процессов зависят от операционной системы, под
которой исполняется сервер базы данных.
· подсистема планирования выполнения запросов Данный модуль
должен составить такой план выполнения запроса, чтобы он был обработан наиболее
быстро. Для этого анализируются условия выборок и соединений, устанавливается
порядок их выполнения. Пусть, например, надо извлечь одного сотрудника из
списка работников, в качестве критерия поиска задаются его имя и фамилия.
Возможны два плана выполнения запроса: (1) вначале делается выборка всех
сотрудников с данным именем, из нее извлекаются записи, содержащие данную
фамилию; (2) - наоборот, вначале делается выборка по фамилии, затем по имени.
Поскольку множество имен, как правило, меньше множества фамилий, во втором
случае запрос будет обработан быстрее, т.к. на втором этапе здесь мы получим
меньшую выборку. Планировщики запросов ведущих СУБД отслеживают информацию о
распределении значений в таблицах. План выполнения запроса включается в его
откомпилированный код.
· подсистема выполнения транзакций Здесь выполняется
оптимизированный код запроса, обновляются индексы, выполняются в случае
необходимости триггеры и хранимые процедуры. Как правило, несколько запросов
могут исполняться параллельно, при этом обеспечивается необходимый уровень их
изоляции. Также ведется журнал транзакций, обеспечивается их завершение и корректный
откат.
· подсистема управления памятью Этот компонент отвечает за
считывание данных с диска в оперативную память, синхронизацию обновлений с
данными диске и т.д. Он может использовать файловые функции операционной
системы, но часто СУБД имеет свои собственные низкоуровневые средства доступа к
дискам.
3. Создание
базы данных с помощью "Денвер"
Денвер - это набор дистрибутивов и программная оболочка, используемые
Web-разработчиками (программистами и дизайнерами) для отладки сайтов на
локальной Windows-машине без необходимости выхода в Интернет. В состав базового
пакета Денвера входят:
· Apache 2 с поддержкой SSL и mod_rewrite;
· PHP5: выполняемые файлы, модуль для веб-сервера Apache,
дистрибутивный и адаптированный конфигурационный файл, библиотека GD, модули
поддержки MySQL и sqLite;
· MySQL5 с
поддержкой InnoDB, транзакций и русских кодировок (windows-1251). phpMyAdmin -
панель управления базой данных MySQL, а также скрипт, упрощающий добавление
нового пользователя MySQL
(MySQL использует собственный сервер баз данных для обеспечения безопасности);
· Отладочный эмулятор sendmail (/usr/sbin/sendmail), не
отправляющий письма, а записывающий их в директорию /tmp/!sendmail;
· Система автоматического поиска виртуальных хостов и
обновления системного файла hosts, а также конфигурации Apache. Благодаря ей
добавление нового виртуального хоста (или домена третьего уровня) заключается в
простом создании каталога в /home и перезапуске комплекса. Все изменения
вносятся в конфигурационные и системные файлы автоматически, но вы можете
управлять этим процессом при помощи механизма шаблонов хостов; Денвер является
бесплатным продуктом, поэтому его может использовать любой. Кроме того, на
сайте разработчиков доступны дополнения, расширяющие возможности базового комплекта.
Для начала необходимо иметь скаченный Денвер на компьютере. При его
запуске вы увидите окно (Рис.2), в котором необходимо будет указать директорию
файлов Денвера, затем выбрать метку виртуального диска.
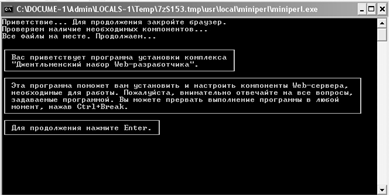
После установки комплекта, нужно проверить его работу. Для этого нужно в
браузере зайти на #"785743.files/image003.gif">
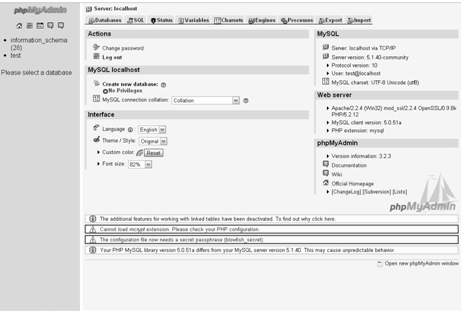
Для создания базы данных я использовал phpMyAdmin - систему управления
MySQL через Web-интерфейс. PhpMyAdmin (рис.4) можно запустить, выбрав
соответствующую гиперссылку в разделе утилиты на localhost.
данные память сервер денвер
Создав базу данных, можно приступить к созданию таблиц БД. Таблица, т.е.
структурированное вместилище данных, является основным понятием реляционных
баз. Прежде чем начать вводить данные в таблицу, мы должны определить ее
структуру.
Таблица содержит не только имена колонок, но и тип каждого поля, а также
возможные дополнительные сведения о полях. Тип данных поля определяет, какого
рода данные могут в нем содержаться. Типы данных SQL сходны с типами данных в
других языках программирования.дает возможность создавать таблицы двумя
способами:
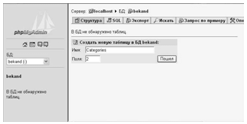
способ.
Можно использовать команду создать таблицу, указав ее название и число
полей (рис. 5).
Затем нужно описать каждое из полей (рис. 6).
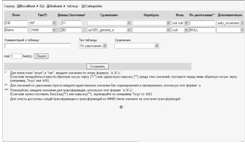
способ.
Можно создать таблицу, используя команду SQL CREATE TABLE, выбрав вкладку
SQL (приложение 1)
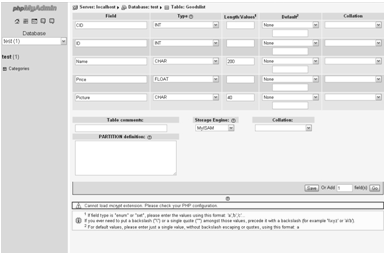
В итоге должна получиться таблица Goodslist с 5 полями CID (идентификатор
категории, в которой лежит товар), ID (идентификатор товара), Name
(наименование товара), Price (цена), Picture (имя файла-фотографии товара. Все
фотографии товаров закачиваются в директорию goods_pictures/ на сервере).
Таким же образом, создал еще три таблицы Categories, Orders, OrdererCarts. Далее необходимо заполнить эти таблицы. (приложение 2)Добавление данных
в таблицу является одной из наиболее простых операций SQL.
Заключение
В ходе работы была просмотрена область баз данных, были показаны этапы и
способы создания базы данных, проведено исследование инструментов Денвера.
Изучение проводилось путем практического изучения предмета и подбора
литературы.
Проект может быть доработан и использован в качестве основы на более
трудоемкий и объемный проект.
Полученные знания позволяют создавать базы данных для небольших
магазинов.
Литература
1. Алгоритмы и структуры данных. Н.Вирт.
"Мир",1989
. Алгоритмы обработки данных. М.Сибуя, Т.Ямамото.
"Мир",1986.
. Обзор нового и полезного софта -
http://www.programki.net
. Веб-сайт Мурманского Государственного Технического
Университета - http://www.mstu.edu.ru
. http://www.mysql.ru
. http://php-myadmin.ru
Приложение 1
CREATE TABLE `goodslist` (
`CID` INT( 11 ) NULL, `ID` INT( 11 ) NOT NULL auto_increment,
`Name` VARCHAR( 30 ) CHARACTER SET cp1251 COLLATE
cp1251_general_ci NULL, `Price` FLOAT NOT NULL ,
`Picture` VARCHAR( 40 ) CHARACTER SET cp1251 COLLATE
cp1251_general_ci NULL, PRIMARY KEY ( `ID` )
);
Приложение 2
INTO `categories` ( `CID` , `Name` ) VALUES
(1, ' Monitors'),
(2, ' Printers'),
(3, ' Noutbuki');INTO `goodslist` ( `CID` , `Name` , `Price`
) VALUES
(1, 'Sony MFM-HT205', 691),
(1, 'Samsung 214T', 707),
(2, 'Canon Laser Shot LBP-2900', 119),
(2, 'МФУ Samsung SCX-4200', 176),
(3, 'HP Pavilion 6550', 950);