Розробка програми обліку товарів в магазині
КАФЕДРА ІНФОРМАЦІЙНИХ
ТЕХНОЛОГІЙ
КУРСОВА РОБОТА
з дисципліни: Алгоритмізація
і програмування
на тему: Розробка програми
обліку товарів в магазині
Київ 2014
1. Мета курсової роботи
Закріпити теоретичні знання про статичні та динамічні
структури, організацію односпрямованих та двоспрямованих списків даних,
динамічний розподіл пам’яті та обробку файлів мови С++. Познайомитися з
методами, алгоритмами та прийомами програмування, що використовуються при
розробці інформаційно-управляючих систем. Набути практичного досвіду в аналізі
предметної області з метою виділення основних сутностей та їх моделювання,
постановки задачі, вибору методу реалізації та складання алгоритму. Оволодіти
практичними навичками розробки, тестування та налагодження програмного
забезпечення, створеного мовою високого рівня С++. Виконати розробку програми
обліку товарів для невеликого магазину, яка б забезпечувала наступні
можливості: додавання нового товару до списку, видалення товару зі списку,
пошук товару за кодом товару у списку, перегляд списку товарів, збереження
списку товарів у файл та отримання списку товарів із файлу, інтерфейс
користувача та відображення результатів на екрані. програма
автоматизація магазин інтерфейс
Вступ. Основні теоретичні відомості.
Структура даних - програмна одиниця, яка дозволяє зберігати
та обробляти множину логічно зв’язаних даних одного або різних типів в
обчислювальній техніці. В програмуванні та комп’ютерних науках структури даних
- це способи та методи організації даних. В мовах програмування часто разом зі
структурою даних часто пов'язується і специфічний перелік операцій, що можуть
бути виконаними над даними, організованими в ту чи іншу структуру.
Правильний підбір структур даних є надзвичайно важливим для
ефективного функціонування алгоритмів (програм) їх обробки. Правильно підібрані
і побудовані структури даних дозволяють оптимізувати час виконання програми та
використання пам'яті комп'ютера.
Підтримка базових структур даних, які використовуються в
програмуванні, входить в комплекти стандартних бібліотек С++.
Термін «структура даних» може мати декілька близьких, але тим
не менш відмінних значень:
· Абстрактний тип даних - тип даних,
який надає для роботи з елементами цього типу визначений набір функцій та
можливість створювати елементи цього типу з допомогою спеціальних функцій. Вся
внутрішня структура цього типу прихована від розробника програмного
забезпечення - у цьому суть абстракції. Різницю між абстрактними типами даних і
структурами даних, котрі реалізують абстрактні типи найкраще демонструвати на
прикладі: абстрактний тип даних «список» може бути реалізований за допомогою
масиву або лінійного списку, з використанням різних методів динамічного
виділення пам’яті. Однак, кожна реалізація
визначає один і той же набір функцій, який має працювати однаково (за
результатом, а не по швидкості) для усіх реалізацій.
· Реалізація якого-небудь абстрактного
типу даних.
· Екземпляр типу даних, наприклад,
лінійний односпрямований список, як структура даних, яка складається з
елементів одного типу,послідовно зв’язаних між собою за допомогою вказівників. Лінійний список зазвичай
визначається як абстрактний тип даних.
· В контексті функціонального
програмування - унікальна порція інформації, яка зберігається при змінах. Про
неї неформально говорять як про одну структуру даних, не дивлячись на можливу
наявність різних версій.
Структури даних формуються за допомогою типів даних, посилань
і операцій над ними у вибраній мові програмування (наприклад С++). Тип даних
визначає можливі значення змінних, констант, функцій і виразів, внутрішню форму
представлення даних в ЕОМ, операції і функції, які дозволено застосовувати до
величин, що належать даному типу. Фундаментальними блоками для більшості
структур даних в С++ є масиви, записи, розмічені об’єднання, посилання і
вказівники:
- Масив - структура (набір) одно типових компонентів
(елементів масиву), розташованих у пам’яті безпосередньо один за одним та об’єднаних одним єдиним ім’ям.
Доступ до кожного елементу здійснюється по індексу. Розмірність масиву -
кількість індексів необхідних для однозначного доступу до елементу. Фактично
багатовимірний масив - це одномірний масив одномірних масивів, кожний з яких, у
свою чергу, є масивом одномірних масивів, і т.д. Ім’я масиву є вказівником. Структура
масиву (кількість розмірностей і розмір) для кожної розмірності може бути
представлена одномірним масивом.
- Строки (рядки) - послідовність символів,
представлена масивом або вказівниками на змінні типу char. Для полегшення роботи зі строками в
С++ введено спеціальний клас «string», який дозволяє використовувати новий тип змінних
(динамічний масив символів), без початкового визначення розміру та надає
базовий набір основних функцій для роботи з даними такого типу.
Розмічені об’єднання забезпечують збереження значень,
які можуть відноситись до одного із множини іменованих варіантів, з різними
значеннями і типами. Що досить зручно для різнорідних даних, коли можливі різні
випадки, включаючи допустимі та помилкові; даних, типи яких відрізняються для
різних випадків; і в якості альтернативи ієрархії невеликих об’єктів. Дані, що зберігаються як значення, не являються фіксованими, вони
можуть бути одним з декількох визначених варіантів.
Посилання - це об’єкт, який вказує на певні дані,
але не зберігає їх. Посилання не являється вказівником - це просто інша назва
(псевдонім) для змінної, на яку воно ссилається. Посилання ініціалізується при
оголошені і не може бути змінено.
Вказівник - це змінна, яка представляє собою адресу
іншої змінної. Змінній типу вказівник можна присвоїти адресу будь-якої змінної,
тип якої співпадає з типом вказівника.
В С++ також використовуються поняття: об’єкт - деяка сутність
в ЕОМ, яка характеризується певним станом і поведінкою, має визначений набір
властивостей (атрибутів) та операцій над ними (методів), і екземпляр - певний
стан об’єкту. Наприклад, якщо об’єкт
- це лише тип даних, то сутності, що зберігають реальні дані і створені на
основі цього об’єкту, називаються його екземплярами.
Змінні і структури в мовах програмування, наприклад в С++, характеризуються
також розміром і методом виділення пам’яті для збереження даних. В С++ об’єкти (змінні, інші структури даних) можуть розміщуватись статично - під
час компіляції, або динамічно - під час виконання програми за допомогою виклику
функцій стандартних бібліотек. Процес зв’язування властивостей об’єкта
(змінної), не є одномоментним. Наприклад, зв’язування змінної з її типом завжди
відбувається при трансляції програми, а от зв’язування адресу пам’яті і
значення може відбуватися по різному:
· Глобальні (зовнішні) змінні розміщуються в загальному
сегменті даних і отримують у ньому свої адреси вже при трансляції. Аналогічно
відбувається їх ініціалізація (присвоєння значень).
· Локальні змінні розміщуються у стеку.
Оскільки дані в стеку адресуються відносно поточного положення вказівника
стеку, при трансляції визначається зміщення в поточному фреймі (кадрі) стеку,
сформованому при виклику функції. Відповідно, виділення пам’яті, розміщення
змінних і їх ініціалізація відбувається під час виконання при вході і функцію.
В С++ використовується ще одне поняття статичної змінної:
- Загалом звичайні типи змінних, незалежно від того
глобальними чи локальними вони є, являються статичними, оскільки тип змінної і
її розмірність визначаються при трансляції і в майбутньому не змінюються.
Кожний тип даних має фіксовану розмірність, а отже компілятор здійснює
статичний розподіл пам’яті, закріплюючи за кожною змінною адреси або зміщення у
відповідних сегментах пам’яті. У тому числі і локальні змінні, хоча вони
створюються в стеку при виконані програми, але їх кількість і розмірність не
може бути змінено.
Отже, загалом програма не може перевищити ліміт пам’яті, запланований при трансляції. В
іншому випадку їй знадобиться додаткова пам’ять, яка має виділятись при виконанні програми.
Тим не менш, при розробці багатьох програм розмірність
оброблюваних даних наперед не відома. У таких випадках, для статичних даних,
існує єдиний вихід - виділяти пам’ять по максимуму. Для вирішення таких проблем на рівні бібліотек С++
створено механізм породження і знищення змінних працюючою програмою. Такі
змінні називають динамічними, а область пам’яті, в якій вони створюються - динамічною або «кучою». Куча
організовується в одному або декількох сегментах пам’яті, які виділяються
програмі операційною системою. Основні властивості динамічних змінних:
· Створюються і знищуються програмою за
допомогою спеціальних операторів і функцій.
· Кількість змінних, інших структур
даних може змінюватись в процесі роботи програми.
· Не мають імені, доступ до даних
можливий лише за допомогою вказівників.
· Функція розміщення динамічної змінної
шукає у пам’яті необхідне місце для розміщення змінної і повертає вказівник
(адрес).
· Функція знищення динамічної змінної
отримує вказівник і знищує дані (звільняє пам’ять).
Окрім змінних динамічне виділення пам’яті може застосовуватися і для більш
складних структур даних. Та насправді можливість створити масив чи іншу
структуру даних заданого розміру не завжди дозволяє вирішити поставлену задачу.
Щоб в процесі виконання програми довільно додавати та
видаляти дані, потрібно більш гнучке представлення даних. В таких випадках
застосовують дані особливої структури, які представляють собою окремі елементи,
зв’язані за допомогою вказівників. Таким
чином створюється структурний елемент даних і вказівник (вказівники) на нього.
Кожний елемент динамічної структури даних (списку)
складається з даних та одного або декількох вказівників, які посилаються на
аналогічні елементи (вузли даних). Що дозволяє додавати в структуру нові дані
або видаляти існуючі, не чіпаючи при цьому інші елементи. До того ж структури
дозволяють організовувати дані так, щоб їх представлення в програмі було
максимально наближеним до реальності.
Для визначення останнього елементу в такій структурі
використовують нульові вказівники (NULL).
При додаванні нового вузла даних в таку структуру виділяється
новий блок пам’яті для збереження даних
(полів структури) і, за допомогою вказівників встановлюється зв’язок нового елементу з вже існуючими,
або присвоюємо вказівнику адресу, по якій розташована тільки-но створена
структура (вказівник на наступний елемент, якщо такий передбачено, при цьому
дорівнює NULL). В результаті при запуску
програми пам’ять виділяється лише на
вказівники, а решта пам’яті виділяється лише при
додаванні елементів. Якщо динамічні дані більше не потрібні, необхідно просто
звільнити пам’ять.
Елемент динамічної структури даних представляє собою
структуру (struct), яка містить щонайменше два
поля - для збереження даних і для вказівника. Поле даних може бути довільного
типу, у тому числі структурою.
Динамічні структури даних (списки) бувають лінійні і
нелінійні. У лінійних структурах дані зв’язуються в послідовний ланцюжок. До
лінійних динамічних структур відносять списки (односпрямовані, двоспрямовані,
кільцеві), стеки, черги (односпрямовані, двоспрямовані, черги з пріоритетами).
Організація нелінійних структур більш складна і представляється, як правило, у
вигляді дерева (кожний елемент має деяку кількість зв’язків), наприклад, у
бінарному дереві кожний елемент додатково має вказівник на лівий і правий
елемент.
Лінійний односпрямований список - динамічна структура даних,
кожний елемент котрої, за допомогою вказівника, зв’язаний з наступним елементом. Кожний
елемент списку має поле даних (простої або складної структури) і поле
вказівника на наступний елемент. Така структура зручна для швидкої вставки
елементів.
У двоспрямованому списку кожний елемент має поле даних і два
вказівника, де один вказівник зберігає адресу попереднього елементу, а другий -
наступного. Таким чином, для роботи з двоспрямованим списком використовують два
вказівники, котрі зберігають адреси початку і кінця списку:
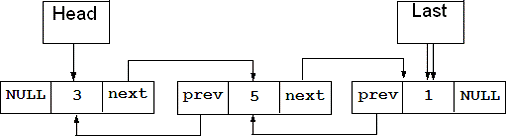
Для пустого списку обидва вказівники початку і кінця, так
само я і вказівник попереднього елементу для першого елементу і вказівник
наступного для останнього, дорівнюють NULL. Якщо
вказівник на останній елемент є вказівником на попередній елемент для першого
елементу списку, а вказівник наступного елементу для останнього вказує на
перший елемент списку, такий список називають циклічним. У циклічному списку
для єдиного елементу вказівники попереднього і наступного елементу будуть
вказувати на сам елемент. При роботі з таким списком кінець списку визначається
фактом повернення до початку.
Динамічні структури широко використовують як для більш
ефективної роботи з даними, розмір яких не відомий, так і для вирішення завдань
сортування. Сортування елементів зв’язаного списку виконується методом переміщення вказівників, а не
переміщенням елементів.
Оскільки динамічні структури даних як і решта змінних
зберігають дані лише доки працює програма, при створені програм роботи з даними
виникає необхідність використання файлів для збереження даних (інформації).
Файли дають можливість зчитувати та зберігати дані безпосередньо з/на
диску/диск. Існує два основних типи файлів: текстові і двійкові. Текстовими
називають файли, які складаються з будь-яких символів. Вони організовуються
строками, кожна з яких закінчується символом «кінця строки». Кінець файлу
помічається символом «кінець файлу». При запису інформації в текстовий файл всі
дані перетворюються в символьний тип і зберігаються у символьному типі.
Перегляд текстового файлу можна виконати у будь-якому текстовому редакторі. У
двійкових (бінарних) файлах інформація зчитується і записується у вигляді
блоків визначеного розміру, в яких можуть зберігатися дані будь-якого типу і
структури. В бінарному файлі дані представляються в такій самій формі, в якій
вони зберігаються у внутрішній пам’яті (основній/оперативній) ЕОМ. У текстовому файлі інформація (текстова)
представлена у вигляді кодів текстових символів, визначених кодовою таблицею (ASCII, Unicode). Так, ціле без знакове число
у текстовому і бінарному файлі буде представлене у різних формах. Наприклад
число 123 у текстовому файлі буде представлене побайтно (посимвольно): 00110001b (31h), 00110010b (32h),
00110011b (33h),
а в бінарному файлі: 01111011b, де b вказує на двійкову систему числення,
а h - на шістнадцятиричну.
Символи цифр в таблиці ASCII починаються зі зміщення 30h. Отже, у текстовому файлі n-знакове десяткове число займатиме n байтів, а в бінарному десь у два
рази менше. Хоча насправді, будь-який файл по своїй природі - двійковий
(бінарний), так як на фізичному рівні у пам’яті ЕОМ являє собою масив байтів.
Для роботи з файлами С++ підтримує множину функцій
стандартних бібліотек, які складають основу заготовочного файлу стандартної
бібліотеки <stdio.h>. У більшості випадків при роботі
зі списками в С++ для збереження/зчитування даних в/з файл/файлу зручно
використовувати спеціальні типи даних, які називаються потоками. С++ абстрагує
файлові операції, перетворюючи їх в операції з потоками байтів, які можуть бути
як потоками вводу так і потоками виводу. Для операцій з файлами існує три
класи: ifstream, ofstream и fstream. Ці класи є похідними від istream, ostream
и iostream. Оскільки останні, в свою чергу, є похідними від класу ios, класи
файлових потоків наслідують всі функціональні можливості батьківських (функції
і прапорці форматування, маніпулятори та інші). Для реалізації файлового
вводу-виводу потрібно включити у програму заголовочний файл fstream.h. Файловий потік повинен бути зв’язаний з файлом перш, ніж його буде
можливо використовувати. З іншого боку, передумовлені потоки можуть
використовуватися одразу після запуску програми, у конструкторах статичних
класів, які виконуються навіть раніше виклику функції main(). Файловий потік
можливо позиціонувати у довільну позицію в файлі. Для створення файлового
потоку ці класи передбачають наступні форми конструктора:
- створити потік, не зв’язуючи з файлом: ifstream(), ofstream(), fstream();
- створити потік, відкрити файл і зв’язати потік з
файлом: ifstream(constchar*name, ios::openmode mode=ios::in),
ofstream(constchar*name, ios::openmode mode=ios::outios::trunc);
fstream(constchar*name, ios::openmode mode = ios::in | ios::out), виводу, або
fstreamfs("FileName.dat"). Тут name - ім’я файлу, mode - режим відкриття
файлу. Параметр mode може приймати значення, наведені в таблиці:
Таблиця 1
|
Режим відкриття
|
Призначення
|
|
ios::in
|
Відкрити файл для читання
|
|
ios::out
|
Відкрити файл для запису
|
|
ios::ate
|
Початоко виводу- в кінець файлу
|
|
ios::app
|
Відкрити файл для додавання в кінець
|
|
ios::trunc
|
Видалитивміст файлу
|
|
ios::binary
|
Двійковий режим операцій
|
Режими відкриття файлу представляють собою бітові маски, тому
можливо задавати два чи більше режимів, об’єднуючи їх по бітах операцією «ИЛИ». За замовчуванням режим відкриття
файлу відповідає типу файлового потоку. В потоці вводу або виводу прапорець
режиму завжди встановлений неявно.
Файли, які відкриваються для виводу, створюються, якщо вони
не існують.
Якщо відкриття файлу закінчилось невдачею, об’єкт, який відповідає потоку, буде
повертати 0 (нуль).
Якщо при відкритті файлу не вказаний режим ios::binary, файл
відкривається в текстовому режимі і після того, як файл успішно відкритий для
виконання операцій вводу-виводу, можна використовувати оператори отримання і
вставки в потік. Для перевірки, на кінець файлу, можна використовувати функцію
ios::eof().
Контрольні питання.
1. Для яких цілей при розробці програмного забезпечення
використовується розгалужений алгоритм?
2. Що таке структура даних в обчислювальній техніці.
. Що означає структура даних в контексті
функціонального програмування?
. На що впливає вибір структури даних при створені
програмного забезпечення?
. За допомогою чого формуються структури даних?
. Що означає абстрактний тип даних?
. Що визначає тип даних?
. Які типи даних є фундаментальними блоками для
більшості структур даних в С++?
. Що представляє собою тип даних масив в С++?
. Що представляє собою тип даних строка (рядок) в
С++?
. Що представляє собою тип даних посилання С++?
. Що представляє собою тип даних вказівник С++?
. Що представляє собою тип даних структура С++?
. Чим характеризуються змінні і структури в мовах
програмування?
. У чому різниця між локальними і глобальними
змінними?
. Яким чином можна в С++ при створені програми
вирішити питання визначення змінних, якщо розмірність оброблюваних даних
наперед не відома?
. Поняття динамічного типу даних.
. Як називають область пам’яті, в якій створюються динамічні
змінні?
. Які основні властивості динамічних змінних?
. Як забезпечити в процесі виконання програми на мові
С++ можливість довільно додавати та видаляти дані?
. У чому різниця між односпрямованим і двоспрямованим
динамічним списком в С++?
. Для чого використовують роботу з файлами в
програмуванні?
. У чому різниця між бінарним і текстовим файлом?
Які можливості роботи з файлами існують в С++?
2. Хід проекту
.1 Постановка завдання. Опис структур даних та вмісту файлів
з вхідними / вихідними даними
Спроектувати програму автоматизації процесу обліку (поставки
та видачі) товарів для невеликого магазину, яка б забезпечувала наступні
можливості: створення списку товарів, додавання нового товару до списку, видалення
товару зі списку, пошук у списку товару за кодом товару, перегляд списку
товарів у двох напрямках, збереження списку товарів у файл та отримання списку
товарів із файлу, інтерфейс користувача та відображення результатів на екрані.
Кількість товарів на складі в магазині невідома і може змінюватись.
Для введення даних про кожний із товарів на складі в магазині
використаємо структуру, яка буде містити наступні елементи:
код товару,
назва товару,
дата надходження товару,
кількість товару.
Для вводу і обробки списку товарів в магазині використаємо
динамічний двоспрямований список з наступними елементами:
структура - дані кожного товару,
вказівник на наступний запис товару у списку,
вказівник на попередній запис товару у списку.
Для організації інтерфейсу користувача будемо використовувати
змінну цілого типу - номер обраного пункту меню.
Для роботи з двоспрямованим списком використаємо проміжні
змінні-вказівники.
Для збереження списку товарів будемо використовувати бінарний
файл «database.txt», який буде по замовчуванню зберігатись на диску «С:\» у
попередньо створеному каталозі «С:\1». Для збереження вхідних і вихідних даних
буде використовуватися один і той самий файл даних.
.2 Математична постановка основних задач
Таблиця 2
|
Вхідні данні
|
Дії
|
Вихідні дані
|
|
key - цілочисленого типу (початкова
ініціалізація key = -1), можливі значення для виконання
функцій - пункти меню (від 0 до 8).
|
Якщо key = 1, input_product(синонім
структури елементу); add_element_struct(вказівник
на список, вказівник структури елементу);
|
Новий товар додано
у список.
|
|
Якщоkey = 2, rus_code("Введите код товара для удаления: "); зчитування коду елементу;delete_product(список,
введений код елементу);rus_code("Для продолжения работы нажмите ENTER \n");
|
Товар із кодом «код
товару» видалено зі списку.
|
|
Якщо key = 3, rus_code("Список
товаров с начала \n");
show_list_head(список);
|
На екран виведено
список товарів з початку списку.
|
|
Якщоkey = 4, rus_code("Список
товаров с конца\n");
show_list_tail(список);
|
На екран виведено
список товарів з кінця списку.
|
|
Якщо key = 5, search_unit(список); rus_code("Нажмите любую клавишу для продолжения\n");
|
Знайдений елемент
виведено на екран.
|
|
Якщо key = 6, save_struct(список,1); rus_code("Список товаров дописан в файл\n")
|
Елемент дописано в
кінець файлу.
|
|
Якщо key = 7, save_struct(список,0); rus_code("Список товаров сохранен\n");
|
Весь список
збережено у файл.
|
|
Якщо key = 8, clear_struct(вказівник на список); read_database(вказівник на
список); rus_code("Список товаров
получен из файла\n")
|
Список загружено з
файлу.
|
|
Якщо key = 0, clear_struct(вказівник на список); rus_code("Пожалуйста,
нажмите любую клавишу для завершения\n");
|
Очищено список.
Попередження про завершення роботи.
|
|
Якщо key не приймає жодного з допустимих значень, clear_struct(вказівник на
структуру); cout<<"Error\n";
|
Повідомлення про
помилку.
|
|
Вказівник на буфер
приймання рядка
|
CharToOem(s,bufer)
(для перекодування використали функцію прототип з <windows.h>)
|
Перекодований рядок
|
|
&Ps (адреса
початку списка), D (вказівник елементу списка-структури)
|
sklads*Inc=new sklads; якщо список не порожній - додаємо
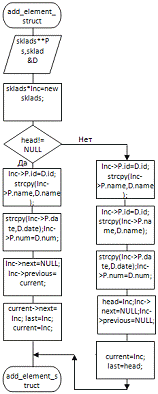
наступний елемент: Inc->P.id=D.id;strcpy(Inc->P.name,D.name);strcpy(Inc->P.date,D.date); Inc->P.num=D.num; і оновлюємо вказівники: Inc->next=NULL;Inc->previous=current; current->next=Inc; last=Inc; current=Inc; якщо список порожній - додаємо перший
елемент: Inc->P.id=D.id; strcpy(Inc->P.name,D.name); strcpy(Inc->P.date,D.date); Inc->P.num=D.num; і ініціалізуємо вказівники: head=Inc;Inc->next=NULL; Inc->previous=NULL;
current=Inc; last=head;
|
|
Ps (список),
delete_id (код товару для
видалення)
|
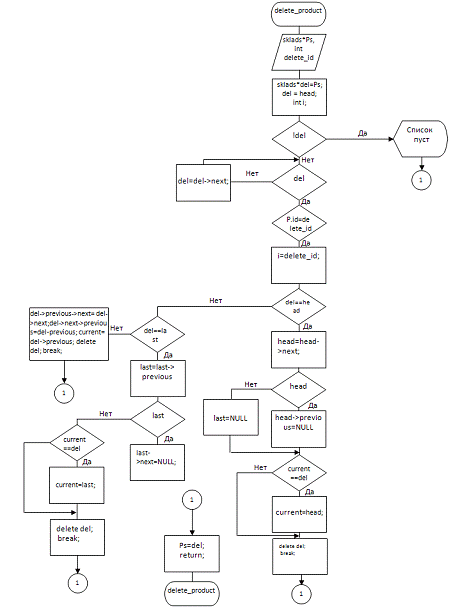
ініціалізація
вказівника на початок списку: sklads*del = Ps; del = head; якщо список
порожній - видаємо повідомлення і завершуємо функцію;доки список не скінчився
виконуємо пошук елементу, код якого дорівнює заданому (delete_id): якщо
елемент для видалення - перший елемент списку (del==head) - оновлюємо
вказівник на перший елемент (наступний елемент тепер перший) і видаляємо елемент:
head=head->next; if(head) head->previous=NULL; else last=NULL;
if(current==del) current=head; deletedel; break; якщо елемент для видалення
останній (del==last)- переміщуємо вказівник останнього елементу на
попередній: last=last->previous; if(last) last->next=NULL;
if(current==del) current=last; delete del; break; якщо елемент для видалення
в середині списку - переміщуємо вказівники (зв’язуємо попередній і наступний
елементи):
del->previous->next=del->next;del->next->previous=del->previous;
current=del->previous; delete del; break; якщо елемент не був елементом
для видалення, переходимо до наступного елементу: del=del->next;
|
Sklads: {Sklad
Previous Next}-1 … {Sklad Previous Next}-n
|
2.3 Характеристика системи програмування
Для розробки програмного забезпечення було використано
середовище розробки MS Visual Studio 2012.
Visual
Studio включає в себе редактор початкового програмного коду
з підтримкою технології IntelliSenseі можливістю найпростішої реорганізації
(рефакторингу) коду - тобто процес зміни внутрішньої структури програми, без
зміни її зовнішньої поведінки. Оскільки кожне перетворення незначне, легше
прослідкувати за його правильністю, и в той же час вся послідовність може
призвести до істотної перебудови програми та покращенню узгодженості і чіткості.
Вбудований відладчик може працювати як відладчик початкового програмного коду,
так і як відладчик машинного рівня. Решта інструментів включає в себе редактор
форм для спрощення створення графічного інтерфейсу, веб-редактор, дизайнер
класів і дизайнер схеми бази даних.Visual Studioдозволяє створювати і підключати сторонні доповнення
(плагіни) для розширення функціональності практично на кожному рівні, включаючи
додавання підтримки систем контролю версій початкового коду (наприклад,Subversion, Visual Source Safe), додавання нових наборів інструментів (наприклад, для візуального
проектування коду на предметно-орієнтовних мовах програмування (як варіант,
клієнт Team Explorer для роботи з Team Foundation Server).
Розробляти програму на C++ з допомогоюVisual
Studio 2012 можна тільки під Windows7 SP1 та Windows 8, хоча
останні оновлення дозволяють використовувати середу розробки і під Windows XP.
У Visual Studio 2012 повністю перероблено
інтерфейс з використанням Windows Presentation Foundation(WPF), впроваджено інструменти ASP.NET, присутня підтримка
динамічних розширень в мовах програмування C# і Visual Basic, використовуються нові шаблони
проектів, інструментарій документування тестових сценаріїв і велика кількість
нових бібліотек, що підтримуються у Windows 8, а також новий інструмент для
спільної розробки програм.
Щоб створити програму в Visual Studioвиконується наступний порядок дій:
1. MS Visual Studio 2012\MS Visual Studio 2012.exe натиснути Enter.
2. В меню Файл вибираємо пункт
«Создать» та натискаємо проект.
. У списку типів проектів Visual C++ вибираємо «Консольное приложение» та натискаємо «Пустой проект» і задаємо ім'я проекту, натискаємо «ОК».
. Для додавання в проект
файлу з програмним кодом послідовно обираємо пункти«Добавить» і «Создать элемент» та задаємо ім'я файлу.
. Вводимо програмний код.
. В меню «Построение» вибираємо «Построить решение», далі у вікні «Выходные данные»буде відображено інформацію про хід виконання та помилки.
Також можна використати кнопку F5 для запуску «Отладки».
. Далі необхідно вибрати меню
«Файл» - «Сохранить». При збереженні автоматично
виконується компіляція проекту.
.4 Опис динамічної структури даних, що використовується в КР,
та дій, що над нею виконуються
Дані організовано у вигляді двоспрямованого динамічного
списку, елементи якого у свою чергу є структурою фіксованої кількості полів для
збереження даних про кожний з товарів в магазині.
Для вводу даних про кожний із товарів в магазині створено
структуру sklad, яка містить наступні елементи: - код товару (ціле число),-
назва товару (64 символи),
date - дата надходження товару (64 символи),- кількість
товару (ціле число).
Оголошення структури:
struct sklad
{
int id;
char name[64];date[64]; num;
}.
Для вводу і обробки списку товарів в магазині створено динамічний
двоспрямований список sklads з наступними елементами:(для зручності
використаємо синонім «Р») - запис про товар у магазині (структура),
*next - вказівник на наступний товар у списку,
*previous - вказівник на попередній товар у списку.
Оголошення структури:
sklads
{P;sklads *next;sklads *previous;
}.
Структура sklad є елементом двоспрямованого динамічного
списку sklads.
Над даними виконуються наступні дії:
- введення даних про товар (заповнення структури sklad),
- додавання елементу списку (розширення структури
sklads - вказівники кожного елементу вказують на попередній і наступний
елементи),
- вивід товару (консольне відображення даних, які
зберігаються в полях структури sklad),
- вивід списку товарів з початку (консольне
відображення даних, які зберігаються в полях кожної структури sklad, включеної
до списку, відображення даних починається з першого елементу),
- вивід списку товарів з кінця (консольне
відображення даних, які зберігаються в полях кожної структури sklad, включеної
до списку, відображення даних починається з останнього елементу),
- видалення елементу списку(звуження структури sklads
- вказівники кожного елементу вказують на попередній і наступний елементи),
пошук елементу у списку (починаючи з початку списку
виконується пошук структури даних про товар, код якого дорівнює вказаному),
збереження списку товарів в файл (запис усіх
елементів списку у бінарний файл),
отримання списку товарів з файлу (зчитування усіх
елементів списку з ініціалізацією усіх вказівників),
очищення списку товарів (знищення динамічного
списку і усіх його елементів).
.5 Опис програмного інтерфейсу з користувачем
Інтерфейс користувача організовано за допомогою меню. При
запуску програми на екран виводиться:
Меню
1. Добавление записи о товаре
. Удаление товара со склада
. Показ списка товаров с начала
. Показ списка товаров с конца
. Поиск товара
. Добавление записи в файл
. Перезапись файла
. Вычитка списка из файла
Выход
Ваш выбор: __.
Вибір здійснюється вводом з клавіатури номеру обраного пункту
меню, без крапки.
Якщо введено номер одного з пунктів меню, виконується обрана
дія, якщо введено довільний (не припустимий) символ (набір символів), на екрані
відображається повідомлення: «Error», та при натисканні будь-якої клавіші
програма завершує роботу.
.6 Проектування схем алгоритмів згідно вимог
Таблиця 3
|
АМ функції
перекодування символів (російською)
|
АМ додавання товару
(елементу) у список
|
|
 АМ
функції вводу товару АМ
функції вводу товару
|
|
АМ функції видалення заданого (за кодом товару) товару
(елементу) із списку
АМ основної програми
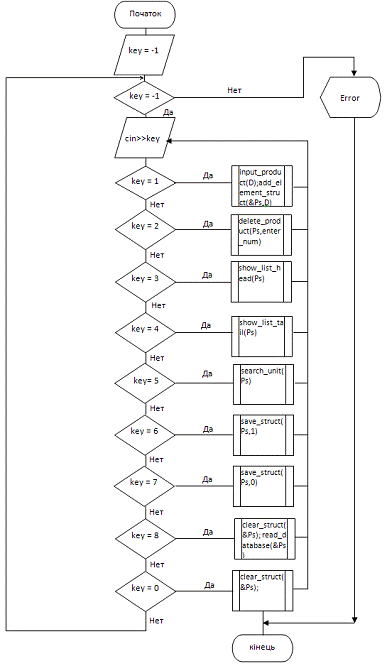
.7 Опис головної програми та опис програмних модулів
У головній програмі організовано підключення вбудованих
бібліотек і заголовних файлів, оголошення та, за необхідності, ініціалізацію
змінних, структур даних, функцій. Основний процес організації інтерфейсу
користувача та звернення до усіх функцій програми також організовано у головній
програмі. Головна програма складається з наступних блоків:
- блок підключення стандартних бібліотек прототипів
функцій С++;
- блок оголошення структури даних і динамічного
списку;
блок оголошення і ініціалізації
змінних-вказівників;
блок оголошення функцій;
блок основної програми:
оголошення змінних,
відображення інтерфейсу користувача (меню дій),
обробка результату вибору - виконання обраної дії, за
допомогою виклику функції.
Організоване, за допомогою оператору множинного вибору (case), меню користувача, дозволяє
обирати, яку дію потрібно виконати. Кожну дію в меню оформлено у вигляді
окремої функції, описаної у блоці функцій:
Таблиця 4
|
Назва і формат
виклику функції
|
Функціональне
призначення
|
Стислий опис
функціоналу
|
|
char bufer [255]; char*rus_code (char*s); rus_code(“Строка
виводу”)
|
Функція
перекодування (російською) символів, що знаходяться у буфері виводу.
Використовується для організації інтерфейсу користувача (виводу на екран
меню, повідомлень).
|
Використовуючи
функцію прототип <CharToOem> з бібліотеки <windows.h>, дозволяє
виводити на екран російські літери. Виконує перекодування символів з ANSI
коду ОС Windows в OEM код консолі Windows і повертає в
буфер перекодований рядок.
|
|
void
add_element_struct (sklads **Ps, sklad&D); add_element_struct (вказівник
на список, адреса елементу, який додається)
|
Функція додавання
елемента списку. Використовується для додавання елементу (товару), введеного
користувачем, або вичитаного з файлу даних, до динамічного списку.
|
Використовуючи
роботу з вказівниками додає передану у функцію структуру з параметрами
товару, заповнену у функції введення товару, до динамічного двоспрямованого списку,
вказівник на який передано вхідним параметром.
|
|
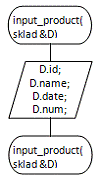
void input_product
(sklad&D); input_product (адреса структури елементу (товар))
|
Функція введення
товару. Використовується для запиту, зчитування і заповнення структури даних
про товар, який потрібно додати у список.
|
Використовуючи
класові об’єкти, створювані за допомогою заголовного файлу
бібліотеки <iostream>, - потоки вводу виводу, здійснює запит, отримання
даних про товар і заповнення структури даних товару (елементу списку).
|
|
void print_product
(sklad); print_product (структура елементу (товар))
|
Функція виводу
товару. Використовується для виводу елементу (товару) із списку,введеного
користувачем, або вичитаного з файлу даних.
|
Використовуючи
класові об’єкти, створювані за допомогою заголовного файлу бібліотеки
<iostream>, - потоки вводу виводу, здійснює вивід на екран даних з
полів структури елементу списку (товару), який передано вхідним параметром.
|
|
void show_list_head
(sklads*Ps);show_list_head (список)
|
Функція виводу
списку товарів з початку. Використовується для виводу на екран усіх структур
даних про товар, які є елементами динамічного списку, починаючи з першого
елементу списку.
|
Використовуючи
роботу з вказівниками та функцію виводу елементу, здійснює послідовний вивід
на екран даних з структури кожного елементу списку (товару), починаючи з
першого елементу списку. Список передано вхідним параметром.
|
|
void show_list_tail
(sklads*Ps); show_list_tail (список)
|
Функція виводу
списку товарів з кінця. Використовується для виводу на екран усіх структур даних
про товар, які є елементами динамічного списку, починаючи з останнього
елементу списку.
|
Використовуючи
роботу з вказівниками та функцію виводу елементу, здійснює послідовний вивід
на екран даних з структури кожного елементу списку (товару), починаючи з
останнього елементу списку. Список передано вхідним параметром.
|
|
void delete_product
(sklads*, int); delete_product (список, код товару)
|
Функція видалення
елементу (товару) із списку. Використовується для видалення із списку
елементу (структури товару), код якого дорівнює заданому (список і код
передаються вхідними параметрами).
|
Використовуючи
роботу з вказівниками, потоки вводу виводу, здійснює пошук у списку елементу
(товару), код якого дорівнює заданому та видалення знайденого товару
(елементу) зі списку, методом переміщення вказівників, та очищення пам’яті,
яку займав елемент. Якщо список пустий, або видалення виконано успішно,
відображаються відповідні повідомлення.
|
|
void search_unit
(sklads*Ps); search_unit (список)
|
Функція пошуку
елементу у списку. Використовується для пошуку у списку елементу (структури
товару), код товару якого дорівнює введеному користувачем.
|
Використовуючи
класові об’єкти, створювані за допомогою заголовного файлу
бібліотеки<iostream>, - потоки вводу виводу, здійснює запит і зчитування
коду товару, який потрібно знайти. Використовуючи роботу з вказівниками,
потоки вводу виводу та функцію виводу товару, здійснює пошук у списку
елементу (товару), код якого дорівнює заданому та вивід знайденого товару на
екран. Якщо список пустий, або товар по коду не знайдено, відображаються
відповідні повідомлення.
|
|
void save_struct
(sklads*,int); save_struct(список,1-додавання в кінець файлу/0 - перезапис
файлу);
|
Функція збереження
списку товарів в файл. Використовується для збереження списку в файл даних у
двох режимах: додавання списку в кінець файлу/перезапис файлу, в залежності
від заданого режиму (1або 0).
|
Використовуючи
об’єкти, створювані за допомогою заголовного файлу бібліотеки
<fstream>, організацію файлового потоку вводу, класові об’єкти,
створювані за допомогою заголовного файлу бібліотеки <iostream>, -
потоки вводу виводу, і роботу з вказівниками, здійснює збереження списку в
файл даних у двох режимах: додавання списку в кінець файлу/перезапис файлу, в
залежності від заданого режиму (1або 0). У разі виникнення помилок при роботі
з файлом користувачу надається повідомлення.
|
|
void read_database
(sklads**); read_database (вказівник на список)
|
Функція отримання
списку товарів з файлу. Використовується для вичитки списку із файлу даних в
структуру двоспрямованого списку.
|
Використовуючи
об’єкти, створювані за допомогою заголовного файлу бібліотеки
<fstream>, організацію файлового потоку вводу, класові об’єкти,
створювані за допомогою заголовного файлу бібліотеки <iostream>, -
потоки вводу виводу, і роботу з вказівниками, здійснює зчитування елементів
списку з файлу даних, додавання елементів в список з ініціалізацією
вказівників списку, шляхом виклику функції додавання елементу. У разі
виникнення помилок при роботі з файлом користувачу надається повідомлення.
|
|
void clear_struct
(sklads**); clear_struct (вказівник на список)
|
Функція очищення
списку товарів. Використовується для видалення всього списку, очищення пам’яті у
разі завершення роботи програми, або зчитування списку із файлу.
|
Використовуючи
роботу з вказівниками та класові об’єкти, створювані за допомогою заголовного
файлу бібліотеки <iostream>, - потоки вводу виводу, виконується
видалення кожного елементу та знищення вказівників списку, якщо список
пустий, користувачеві надається повідомлення.
|
2.8 Опис та обґрунтування тестових прикладів виконання
програми
При створені програми використовувався метод покрокової
розробки, оскільки цей метод дозволяє весь час контролювати управляючу та
інформаційну структуру алгоритмів. Враховуючи модульність організації програми,
для налагодження програми створювались функціональні тести для перевірки
базових функцій програми та перевірки коректності виконання програмних
переходів. Наведені у таблиці тести включають опис вхідних даних і опис
очікуваних результатів для кожного тесту.
Таблиця 5
|
Вхідні дані
|
Очікуваний
результат
|
|
ТЕСТ 1. Меню
інтерфейсу користувача
|
|
Виведення на екран
пунктів меню та запит вибору користувача.
|
На екрані
відображено меню та рядок вводу обраного пункту: 1. Добавление записи о товаре 2. Удаление товара со
склада 3. Показ списка товаров с начала 4. Показ списка товаров с конца 5.
Поиск товара 6. Добавление записи в файл 7. Перезапись файла 8. Вычитка
списка из файла 0. Выход Ваш выбор:
(cin>>key)
|
|
ТЕСТ 2. Зчитування
та обробка вибору користувача
|
|
key = -1
- початкове значення, cin>>key
|
key = 1- Додавання запису про товар: input_product(D);
add_element_struct(&Ps,D); key = 2- Видалення товару зі складу: delete_product(Ps,enter_num); вивід
повідомлення: "Для продолжения работы нажмите ENTER"; key = 3 - відображення списку товарів з початку:
вивід повідомлення: "Список товаров с начала"; show_list_head(Ps); key =4 - відображення списку товарів з кінця:
вивід повідомлення:"Список товаров с конца"; show_list_tail(Ps); key =5 - пошук товару за кодом: search_unit(Ps);
вивід повідомлення: "Нажмите любую клавишу для продолжения"; key = 6 - додавання списку в файл:
save_struct(Ps,1); вивід повідомлення: "Список товаров дописан в
файл"; key =7 - оновлення вмісту файлу:save_struct(Ps,0); вивід
повідомлення: "Список товаров сохранен "); key =8
- вичитка списку з файлу: clear_struct(&Ps); read_database(&Ps); key =0 - вивільнення пам’яті і
завершення програми: clear_struct(&Ps); повідомлення: "Пожалуйста,
нажмите любую клавишу для завершения"; при натискані кнопки - завершення
програми; keyне входить в область допустимих значень-вивільнення пам’яті і
переривання програми:clear_struct(&Ps); повідомлення: "Error".
|
.9
Аналіз отриманих результатів
Функціональність програми відповідає поставленій меті і
вимогам. Помилок в роботі програми не виявлено.
Результати проведених тестів:

Тестування можна вважати успішно завершеним.
Висновок
У залежності від поставленої задачі
алгоритм програми може бути лінійним чи розгалуженим. У більшості випадків
обчислювальні алгоритми - це розгалужені процеси. В мові Сі++ існує два
оператори розгалуження:
базовий (if... else);
вибору (switch case... case [ default ]).
Оператори розгалуження дозволяють
приймати рішення в ході обчислення про наступну дію в залежності від введених
даних, проміжних результатів, або вибору користувача.
Змінні і структури в С++, характеризуються у тому числі
розміром і методом виділення пам’яті для збереження даних. Змінні і структури в мовах програмування,
наприклад в С++, характеризуються також розміром і методом виділення пам’яті для збереження даних. Загалом
програма не може перевищити ліміт пам’яті, запланований для змінних при трансляції. В іншому випадку їй
знадобиться додаткова пам’ять, яка має виділятись при
виконанні програми. Якщо, при розробці програми, розмірність оброблюваних даних
наперед не відома, на рівні бібліотек С++ створено механізм породження і
знищення змінних працюючою програмою. Такі змінні називають динамічними, а
область пам’яті, в якій вони створюються
- динамічною або «кучою». Динамічне виділення пам’яті може застосовуватися і для більш складних структур даних.
Щоб в процесі виконання програми довільно додавати та видаляти
дані, потрібно більш гнучке представлення даних. В таких випадках застосовують
дані особливої структури, які представляють собою окремі елементи, зв’язані за допомогою вказівників. Таким
чином створюється структурний елемент даних і вказівник (вказівники) на нього.
Динамічні структури даних (списки) бувають лінійні і нелінійні. У лінійних
структурах дані зв’язуються в послідовний ланцюжок. До лінійних динамічних
структур відносять списки (односпрямовані, двоспрямовані, кільцеві), стеки,
черги (односпрямовані, двоспрямовані, черги з пріоритетами).
У двоспрямованому списку кожний елемент має поле даних і два
вказівника, де один вказівник зберігає адресу попереднього елементу, а другий -
наступного. Таким чином, для роботи з двоспрямованим списком використовують два
вказівники, котрі зберігають адреси початку і кінця списку. Для пустого списку
обидва вказівники початку і кінця, так само я і вказівник попереднього елементу
для першого елементу і вказівник наступного для останнього, дорівнюють NULL.
Оскільки динамічні структури даних як і решта змінних
зберігають дані лише доки працює програма, при створені програм роботи з даними
виникає необхідність використання файлів для збереження даних (інформації).
Файли дають можливість зчитувати та зберігати дані безпосередньо з/на
диску/диск. Існує два основних типи файлів: текстові і двійкові. Текстовими
називають файли, які складаються з будь-яких символів. Вони організовуються
строками, кожна з яких закінчується символом «кінця строки». У двійкових
(бінарних) файлах інформація зчитується і записується у вигляді блоків
визначеного розміру, в яких можуть зберігатися дані будь-якого типу і
структури.
У більшості випадків при роботі зі списками в С++ для
збереження/зчитування даних в/з файл/файлу зручно використовувати спеціальні
типи даних, які називаються потоками. С++ абстрагує файлові операції,
перетворюючи їх в операції з потоками байтів, які можуть бути як потоками вводу
так і потоками виводу. Для операцій з файлами існує три класи: ifstream,
ofstream и fstream. Ці класи є похідними від ifstream, ofstream и iostream.
Література
1. Глинський Я.М. С++ і С++Builder /
Я.М. Глинський, В.Э. Анохін, В.А Ряжський. - Львів: Деол, 2003. - 193 c.
. Керниган Б. Язык программирования Си. / Б. Керниган, Д.
Ритчию - М.: Вильямс, 2007. - 304 с.
3. Герберт Шилдт, Си полное руководство. / Ш. Герберт. - М.: Вильямс, 2010. - 704
с.
. Прата С. Язык программирования Си.
Лекции, упражнения. / С.
Прата. - М.: Вильямс, 2006. - 260
с.
. Хабібулін. І.Ш. Программирование
C++: Пер. з англ. - 3-е вид. - СПб.:
БХВ-Пітербург, 2006. - 512 с.
. Давидов В.Г. Программирование и основы алгоритмизации. 2-е вид., стер.-М.: Высш.шк.,2005.-447
с.