|
Направление
|
Old Bottom. Balance
|
New Current. Balance
|
New Pivot. Balance
|
|
Левый или Правый
|
0
|
0
|
0
|
|
Правый
|
+1
|
0
|
-1
|
|
Правый
|
-1
|
+1
|
0
|
|
Левый
|
+1
|
-1
|
0
|
|
Левый
|
-1
|
0
|
+1
|
Оценка эффективности
Г.М. Адельсон-Вельский и Е.М. Ландис доказали теорему,
согласно которой высота АВЛ-дерева с N внутренними вершинами заключена между
log2 (N+1) и 1.4404*log2 (N+2) - 0.328, то есть высота АВЛ-дерева никогда не
превысит высоту идеально сбалансированного дерева более, чем на 45%. Для
больших N имеет место оценка 1.04*log2 (N). Таким образом, выполнение основных
операций 1 - 3 требует порядка log2 (N) сравнений. Экспериментально выяснено,
что одна балансировка приходится на каждые два включения и на каждые пять
исключений.
1.3 Обходы
бинарных деревьев
Существует достаточно много алгоритмов работы с древовидными
структурами, в которых часто встречается понятие обхода (traversing) дерева или
"прохода" по дереву. При таком методе исследования дерева каждый узел
посещается только один раз, а полный обход задает линейное упорядочивание
узлов, что позволяет упростить алгоритм, так как при этом можно использовать
понятие "следующий" узел. т.е. узел стоящий после данного при
выбранном порядке обхода.
Существует несколько принципиально разных способов обхода
дерева:
Обход в прямом порядке
Каждый узел посещается до того, как посещены его
потомки.
Для корня дерева рекурсивно вызывается следующая процедура:
Посетить узел
Обойти левое поддерево
Обойти правое поддерево
Примеры использования обхода:
· решение задачи методом
деления на части
· разузлование сверху
· стратегия "разделяй
и властвуй" (Сортировка Фон Hеймана, быстрая сортировка, одновременное
нахождение максимума и минимума последовательности чисел, умножение длинных
чисел).
1.4
Сортировка пузырьком
Расположим массив сверху вниз, от нулевого элемента - к
последнему.
Идея метода: шаг сортировки состоит в проходе снизу вверх по
массиву. По пути просматриваются пары соседних элементов. Если элементы
некоторой пары находятся в неправильном порядке, то меняем их местами.
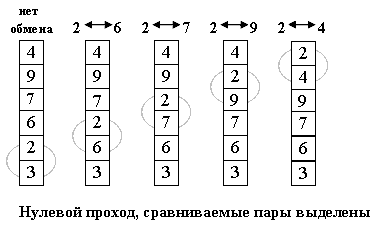
После нулевого прохода по массиву "вверху" оказывается
самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий
проход делается до второго сверху элемента, таким образом второй по величине
элемент поднимается на правильную позицию.
Делаем проходы по все уменьшающейся нижней части массива до тех
пор, пока в ней не останется только один элемент. На этом сортировка
заканчивается, так как последовательность упорядочена по возрастанию.

<class T>
void bubbleSort (T a [], long size) {i,
j;x;(i=0; i < size; i++) { // i - номер прохода
for (j = size-1; j > i; j--) { // внутренний цикл прохода
if (a [j-1] > a [j]) {=a [j-1]; a [j-1]
=a [j]; a [j] =x;
}
}
}
}
Среднее число сравнений и обменов имеют квадратичный порядок
роста: Theta (n2), отсюда можно заключить, что алгоритм пузырька
очень медленен и малоэффективен.
Тем не менее, у него есть громадный плюс: он прост и его можно
по-всякому улучшать.
1.5 Алгоритм
Боуера и Мура (БМ)
Алгоритм Бойера-Мура, разработанный двумя учеными - Бойером
(Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди
алгоритмов общего назначения, предназначенных для поиска подстроки в строке.
Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой
мы будем понимать всю последовательность символов текста. Собственно говоря,
речь не обязательно должна идти именно о тексте. В общем случае строка - это
любая последовательность байтов. Поиск подстроки в строке осуществляется по
заданному образцу, т.е. некоторой последовательности байтов, длина
которой не превышает длину строки. Наша задача заключается в том, чтобы
определить, содержит ли строка заданный образец.
Простейший вариант алгоритма Бойера-Мура состоит из следующих
шагов. На первом шаге мы строим таблицу смещений для искомого образца. Процесс
построения таблицы будет описан ниже. Далее мы совмещаем начало строки и
образца и начинаем проверку с последнего символа образца. Если последний символ
образца и соответствующий ему при наложении символ строки не совпадают, образец
сдвигается относительно строки на величину, полученную из таблицы смещений, и
снова проводится сравнение, начиная с последнего символа образца. Если же
символы совпадают, производится сравнение предпоследнего символа образца и т.д.
Если все символы образца совпали с наложенными символами строки, значит мы
нашли подстроку и поиск окончен. Если же какой-то (не последний) символ образца
не совпадает с соответствующим символом строки, мы сдвигаем образец на один
символ вправо и снова начинаем проверку с последнего символа. Весь алгоритм
выполняется до тех пор, пока либо не будет найдено вхождение искомого образца,
либо не будет достигнут конец строки.
Величина сдвига в случае несовпадения последнего символа
вычисляется исходя из следующих соображений: сдвиг образца должен быть
минимальным, таким, чтобы не пропустить вхождение образца в строке. Если данный
символ строки встречается в образце, мы смещаем образец таким образом, чтобы
символ строки совпал с самым правым вхождением этого символа в образце. Если же
образец вообще не содержит этого символа, мы сдвигаем образец на величину,
равную его длине, так что первый символ образца накладывается на следующий за
проверявшимся символ строки.
Величина смещения для каждого символа образца зависит только
от порядка символов в образце, поэтому смещения удобно вычислить заранее и
хранить в виде одномерного массива, где каждому символу алфавита соответствует
смещение относительно последнего символа образца. Поясним все вышесказанное на
простом примере. Пусть у нас есть набор символов из пяти символов: a, b, c, d,
e и мы хотим найти вхождение образца "abbad" в строке
"abeccacbadbabbad”. Следующие схемы иллюстрируют все этапы выполнения
алгоритма:
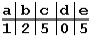
Таблица смещений для образца "abbad”.
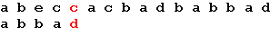
Начало поиска. Последний символ образца не совпадает с наложенным
символом строки. Сдвигаем образец вправо на 5 позиций:
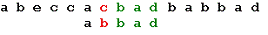
Три символа образца совпали, а четвертый - нет. Сдвигаем образец
вправо на одну позицию:
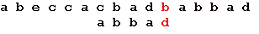
Последний символ снова не совпадает с символом строки. В
соответствии с таблицей смещений сдвигаем образец на 2 позиции:

Еще раз сдвигаем образец на 2 позиции:
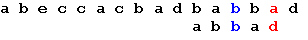
Теперь, в соответствии с таблицей, сдвигаем образец на одну
позицию, и получаем искомое вхождение образца:
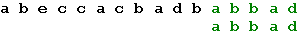
1.6 Линейный
однонаправленный список
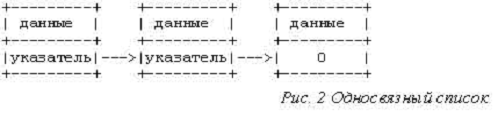
В односвязном списке каждый элемент информации содержит
ссылку на следующий элемент списка. Каждый элемент данных обычно представляет
собой структуру, которая состоит из информационных полей и указателя связи.
Концептуально односвязный список выглядит так, как показано на рис.2.
Существует два основных способа построения односвязного
списка. Первый способ - помещать новые элементы в конец списка. Второй -
вставлять элементы в определенные позиции списка, например, в порядке
возрастания. От способа построения списка зависит алгоритм функции добавления
элемента. Давайте начнем с более простого способа создания списка путем
помещения элементов в конец.
Как правило, элементы связанного списка являются структурами,
так как, помимо данных, они содержат ссылку на следующий элемент. Поэтому
необходимо определить структуру, которая будет использоваться в последующих
примерах. Поскольку списки рассылки обычно хранятся в связанных списках,
хорошим выбором будет структура, описывающая почтовый адрес. Ее описание показано ниже:
struct address {name [40];street [40];city
[20];state [3];zip [11];
struct address *next; /* ссылка на следующий адрес */
} info;
Приведенная ниже функция slstore () создает односвязный
список путем помещения каждого очередного элемента в конец списка. В качестве
параметров ей передаются указатель на структуру типа address, содержащую новую
запись, и указатель на последний элемент списка. Если список пуст, указатель на
последний элемент должен быть равен нулю.
void slstore (struct address *i,address **last)
{(! *last) *last = i; /* первый элемент в списке */(*last) -
>next = i;>next = NULL;
*last = i;
}
Несмотря на то, что созданный с помощью функции slstore ()
список можно отсортировать отдельной операцией уже после его создания, легче
сразу создавать упорядоченный список, вставляя каждый новый элемент в нужное
место в последовательности. Кроме того, если список уже отсортирован, имеет
смысл поддерживать его упорядоченность, вставляя новые элементы в
соответствующие позиции. Для вставки элемента таким способом требуется
последовательно просматривать список до тех пор, пока не будет найдено место
нового элемента, затем вставить в найденную позицию новую запись и
переустановить ссылки.
При вставке элемента в односвязный список может возникнуть
одна из трех ситуаций: элемент становится первым, элемент вставляется между
двумя другими, элемент становится последним. На рис.3 показана схема изменения
ссылок в каждом случае.
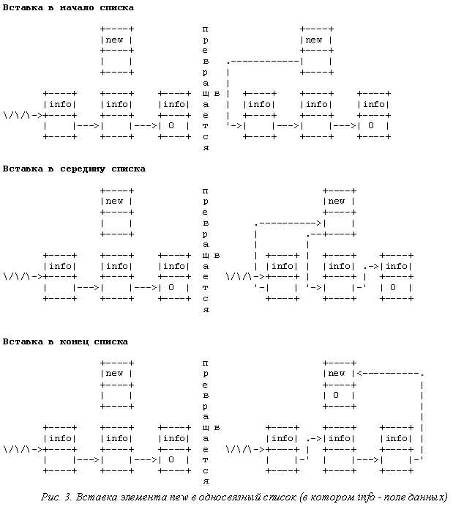
Следует помнить, что при вставке элемента в начало (первую
позицию) списка необходимо также изменить адрес входа в список где-то в другом
месте программы. Чтобы избежать этих сложностей, можно в качестве первого
элемента списка хранить служебный сторожевой элемент. В случае
упорядоченного списка необходимо выбрать некоторое специальное значение,
которое всегда будет первым в списке, чтобы начальный элемент оставался
неизменным. Недостатком данного метода является довольно большой расход памяти
на хранение сторожевого элемента, но обычно это не столь важно.
Следующая функция, sls_store (), вставляет структуры типа
address в список рассылки, упорядочивая его по возрастанию значений в поле
name. Функция принимает указатели на указатели на первый и последний элементы
списка, а также указатель на вставляемый элемент. Поскольку первый или
последний элементы списка могут измениться, функция sls_store () при
необходимости автоматически обновляет указатели на начало и конец списка. При
первом вызове данной функции указатели first и last должны быть равны нулю.
/* Вставка в упорядоченный односвязный список. */sls_store
(struct address *i, /* новый элемент */address
**start, /* начало списка */address
**last) /* конец списка */
{address *old, *p;= *start;
if (! *last) { /* первый элемент в списке */
i->next = NULL;
*last = i;
*start = i;;
}= NULL;(p) {(strcmp (p->name, i->name)
<0) {= p;= p->next;
}{(old) { /* вставка в середину */
old->next = i;>next = p;
return;
}>next = p; /* вставка в начало */
*start = i;;
}
}
(*last) - >next = i; /* вставка в конец */>next =
NULL;
*last = i;
}
Последовательный перебор элементов связанного списка
осуществляется очень просто: начать с начала и следовать указателям. Обычно
фрагмент кода перебора настолько мал, что его вставляют в другую процедуру -
например, функцию поиска, удаления или отображения содержимого. Так,
приведенная ниже функция выводит на экран все имена из списка рассылки:
void display (struct address *start)
{(start) {("%s\n", start->name);
start = start->next;
}
}
При вызове функции display () параметр start должен быть
указателем на первую структуру в списке. После этого функция переходит к
следующему элементу, на который указывает указатель в поле next. Процесс
прекращается, когда next равно нулю.
Для получения элемента из списка нужно просто пройти по
цепочке ссылок. Ниже приведен пример функции поиска по содержимому поля name:
struct address *search (struct address *start,
char *n)
{(start) {(! strcmp (n, start->name)) return
start;= start->next;
}NULL; /* подходящий элемент не найден */
}
Поскольку функция search () возвращает указатель на элемент
списка, содержащий искомое имя, возвращаемый тип описан как указатель на
структуру address. При отсутствии в списке подходящих элементов возвращается
нуль (NULL).
Удаление элемента из односвязного списка выполняется просто.
Так же, как и при вставке, возможны три случая: удаление первого элемента,
удаление элемента в середине, удаление последнего элемента. На рис.4 показаны
все три операции.
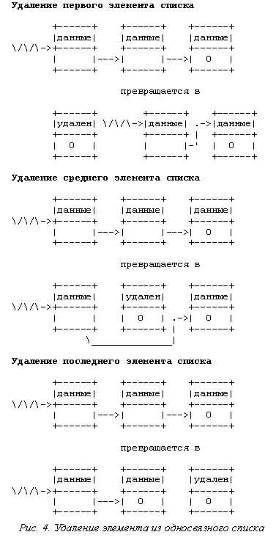
Ниже приведена функция, удаляющая заданный элемент из списка
структур address.
void sldelete (address *p, /* предыдущий элемент */address *i,
/* удаляемый элемент */address
**start, /* начало списка */address
**last) /* конец списка */
{(p) p->next = i->next;*start = i->next;(i==*last
&& p) *last = p;
}
Функции sldelete () необходимо передавать указатели на
удаляемый элемент, предшествующий удаляемому, а также на первый и последний
элементы. При удалении первого элемента указатель на предшествующий элемент
должен быть равен нулю (NULL). Данная функция автоматически обновляет указатели
start и last, если один из них ссылается на удаляемый элемент.
У односвязных списков есть один большой недостаток:
односвязный список невозможно прочитать в обратном направлении. По этой причине
обычно применяются двусвязные списки.
4. Описание
программы
Программа состоит из нескольких файлов исходных текстов
программ.
Все функции описаны в хедер файлах. Их предназначение:
Parserlib. h - функции-парсеры для проверки валидности данных;
Registration. h - Работа с односвязным списком,
функциональность: регистрация вселения/выселения постояльца
hastable. h - Работа с хеш-таблицей
функциональность: работа с информацией о постояльцах
avl. h - работа с АВЛ-деревом
функциональность: работа с гостиничными номерами
Программа обладает простым, интуитивным интерфейсом, не
требующим специального курса обучения.
Исходные тексты программы:
Avl. h
/**********************************************
работа с АВЛ-деревом
функциональность: работа с гостиничными номерами
***********************************************/
// структура нодаNODE
{Number [5]; // номер гостиничного номераCountBads; //
количество спальных местCountRooms; // количество комнатCountFreeBads; //
количество оставшихся свободных местtoilet; // наличие санузлаequipment [1000];
// оборудование номераFlag;NODE *Left_Child;NODE *Right_Child;
};convertnum (char *); // вспомогательная функция для
получения номера гостиничного номера без префикса в виде intNODE * Binary_Tree
(char *, int, int, char, char *, struct NODE *, int *); // Добавление элемента
в деревоNODE * Balance_Right_Heavy (struct NODE *, int *); // перебалансировка
дерева при удалении узлаNODE * Balance_Left_Heavy (struct NODE *, int *); //
перебалансировка дерева при удалении узлаNODE * Delete_Element (struct NODE *,
int, int *, int *); // удаление узла из дереваDeleteAllAVL (struct NODE **); //
удаление всего дереваOutput (struct NODE *); // вывод дерева на
экранboyer_moore (char *, char *); // функция поиска подстроки по алгоритму
Боуера-Мураfindequip (struct NODE *, char *, int *); // ищем номера по
фрагментам оборудованияfind_hotel_room (struct NODE *, char *, struct element
*, struct NodeHash **, int *); // поиск по № гостиничного номера (с
использованием дерева, хеш-таблицы и тд)find_numbers (struct NODE *, char *,
int *, int *, int); // проверка наличия гостиничного номера в базе (поиск
номера в дереве)printsk (char *,.);
avl. cpp
#define _CRT_SECURE_NO_WARNINGS
#include<string. h>
#include<conio. h>
#include<windows. h>
#include "avl. h"
#include "hashtable. h"
#include "registration. h"
# define T 1
// ----------------------------------------
/*вспомогательная функция для получения номера гостиничного
номера без префикса в виде int*/convertnum (char *Number)
{tmp [3];[0] =* (Number+1);[1] =* (Number+2);[2] =*
(Number+3);atoi (tmp);
}
// ----------------------------------------
/* Добавление элемента в дерево */NODE * Binary_Tree (char
*Number, int CountBads, int CountRooms, char toilet, char *equipment, struct
NODE *Parent, int *H)
{NODE *Node1;NODE *Node2;
// если дерево пусто(! Parent)
{= (struct NODE *) malloc (sizeof (struct
NODE));(Parent->Number,Number);>Number [4]
='\0';>CountBads=CountBads;>CountFreeBads=CountBads;>CountRooms=CountRooms;>toilet=toilet;(Parent->equipment,equipment);>Left_Child
= NULL;>Right_Child = NULL;>Flag = 0;
*H = T;(Parent);
}(convertnum (Number) == convertnum (Parent->Number))
{("Невозможно добавление двух номеров с одинаковыми
номерами!");
_getch ();(Parent);
}(convertnum (Number) < convertnum (Parent->Number))
{>Left_Child = Binary_Tree (Number,CountBads, CountRooms,
toilet,equipment, Parent->Left_Child, H);(*H)
/* Левая ветвь стала выше */(Parent->Flag)
{1:
/* Right heavy */>Flag = 0;
*H = F;;0:
/* Balanced tree */>Flag = - 1;;- 1:
/* Left heavy */= Parent->Left_Child;(Node1->Flag == -
1)
{
// printf ("\n Left to Left
Rotation\n");>Left_Child = Node1->Right_Child;->Right_Child =
Parent;>Flag = 0;= Node1;
}
{
// printf ("\n Left to right rotation\n");=
Node1->Right_Child;->Right_Child = Node2->Left_Child;->Left_Child =
Node1;>Left_Child = Node2->Right_Child;->Right_Child =
Parent;(Node2->Flag == - 1)>Flag = 1;>Flag = 0;(Node2->Flag ==
1)->Flag = - 1;->Flag = 0;= Node2;
}>Flag = 0;
*H = F;
}
}(convertnum (Number) > convertnum (Parent->Number))
{>Right_Child = Binary_Tree (Number, CountBads,
CountRooms, toilet,equipment, Parent->Right_Child, H);(*H)
/* Правая ветвь стала выше */(Parent->Flag)
{- 1:
/* Left heavy */>Flag = 0;
*H = F;;0:
/* Balanced tree */>Flag = 1;;1:
/* Right heavy */= Parent->Right_Child;(Node1->Flag ==
1)
{
// printf ("\n Right to Right
Rotation\n");>Right_Child = Node1->Left_Child;->Left_Child =
Parent;>Flag = 0;= Node1;
}
{
// printf ("\n Right to Left Rotation\n");=
Node1->Left_Child;->Left_Child = Node2->Right_Child;->Right_Child =
Node1;>Right_Child = Node2->Left_Child;->Left_Child =
Parent;(Node2->Flag == 1)>Flag = - 1;>Flag = 0;(Node2->Flag == -
1)->Flag = 1;->Flag = 0;= Node2;
}>Flag = 0;
*H = F;
}
}(Parent);
}
// ----------------------------------------
/* Balancing Right Heavy */NODE * Balance_Right_Heavy (struct
NODE *Parent, int *H)
{NODE *Node1, *Node2;(Parent->Flag)
{- 1:>Flag = 0;;0:>Flag = 1;
*H = F;;1:
/* Rebalance */= Parent->Right_Child;(Node1->Flag >=
0)
{
// printf ("\n Right to Right
Rotation\n");>Right_Child = Node1->Left_Child;->Left_Child =
Parent;(Node1->Flag == 0)
{>Flag = 1;->Flag = - 1;
*H = F;
}>Flag = Node1->Flag = 0;= Node1;
}
{
// printf ("\n Right to Left Rotation\n");=
Node1->Left_Child;->Left_Child = Node2->Right_Child;->Right_Child =
Node1;>Right_Child = Node2->Left_Child;->Left_Child =
Parent;(Node2->Flag == 1)>Flag = - 1;>Flag = 0;(Node2->Flag == -
1)->Flag = 1;->Flag = 0;= Node2;->Flag = 0;
}
}(Parent);
}
// ----------------------------------------
/* Balancing Left Heavy */NODE * Balance_Left_Heavy (struct
NODE *Parent, int *H)
{NODE *Node1, *Node2;(Parent->Flag)
{1:>Flag = 0;;0:>Flag = - 1;
*H = F;;- 1:
/* Rebalance */= Parent->Left_Child;(Node1->Flag <=
0)
{
// printf ("\n Left to Left
Rotation\n");>Left_Child = Node1->Right_Child;->Right_Child =
Parent;(Node1->Flag == 0)
{>Flag = - 1;->Flag = 1;
*H = F;
}>Flag = Node1->Flag = 0;= Node1;
}
{
// printf ("\n Left to Right Rotation\n");=
Node1->Right_Child;->Right_Child = Node2->Left_Child;->Left_Child =
Node1;>Left_Child = Node2->Right_Child;->Right_Child =
Parent;(Node2->Flag == - 1)>Flag = 1;>Flag = 0;(Node2->Flag ==
1)->Flag = - 1;->Flag = 0;= Node2;->Flag = 0;
}
}(Parent);
}
// ----------------------------------------
/* Перемещаем ноду с найденым ключом с последним правым
ключем левого ребенка */NODE * Delete (struct NODE *R, struct NODE *Temp, int
*H)
{NODE *Dnode = R;(R->Right_Child! = NULL)
{>Right_Child = Delete (R->Right_Child, Temp, H);(*H)=
Balance_Left_Heavy (R, H);
}
{= R;(Temp->Number,R->Number);=
R->Left_Child;(Dnode);
*H = T;
}(R);
}
// ----------------------------------------
/* Удаление элемента из дерева */NODE * Delete_Element
(struct NODE *Parent, int Number, int *H, int *status)
{NODE *Temp;(! Parent)
{("\n База пуста или номер не найден!");(Parent);
}
{(Number < convertnum (Parent->Number))
{>Left_Child = Delete_Element (Parent->Left_Child,
Number, H, status);(*H)= Balance_Right_Heavy (Parent, H);
}if (Number > convertnum (Parent->Number))
{>Right_Child = Delete_Element (Parent->Right_Child,
Number, H, status);(*H)= Balance_Left_Heavy (Parent, H);
}
{= Parent;(Temp->Right_Child == NULL)
{= Temp->Left_Child;
*H = T;(Temp);
*status=1;
}if (Temp->Left_Child == NULL)
{= Temp->Right_Child;
*H = T;(Temp);
*status=1;
}
{>Left_Child = Delete (Temp->Left_Child, Temp, H);(*H)=
Balance_Right_Heavy (Parent, H);
*status=1;
}
}
}(Parent);
}
// ----------------------------------------
/*удаление всего дерева*/DeleteAllAVL (struct NODE **Parent)
{NODE *t = *Parent;(t! = NULL)
{(&t->Left_Child);(&t->Right_Child);(t);
}
}
// ----------------------------------------
/* Вывод дерева */Output (struct NODE *Tree)
{(Tree)
{(Tree->Left_Child);("\n№ гостиничного номера: %s
\nКоличество мест: %i \nКоличество комнат: %i \nНаличие санузла: %c
\nОборудование: %s\n\n", Tree->Number, Tree->CountBads,
Tree->CountRooms,
Tree->toilet,Tree->equipment);(Tree->Right_Child);
}
}
// ----------------------------------------
/*функция поиска подстроки по алгоритму
Боуера-Мура*/boyer_moore (char * haystack, char * needle)
{i, j, k;needle_table [256];needle_len = strlen
(needle);haystack_len = strlen (haystack);*tmp= (char*) malloc
(haystack_len*sizeof (char));(tmp,haystack);(needle_len <= haystack_len)
{(i = 0; i < 256; i++)_table [i] = needle_len;(i = 1; i
< needle_len; i++)_table [needle [i]] = needle_len-i;= needle_len;= i;( (j
> 0) && (i <= haystack_len))
{= needle_len;= i;( (j > 0) && (tmp [k-1] ==
needle [j-1]))
{-;-;
}+= needle_table [tmp [i]];
}(k > haystack_len - needle_len)0;k + 1;
}0;
}
// ----------------------------------------
/*поиск № по номеру гостиничного номера*/find_hotel_room
(struct NODE *Tree, char *Number, struct element *pbegin, struct NodeHash
**hashtable, int *status)
{element *pv=pbegin;hashkey;NodeHash *tmp;(Tree)
{_hotel_room (Tree->Left_Child, Number, pbegin, hashtable,
status);_hotel_room (Tree->Right_Child, Number, pbegin, hashtable,
status);(strcmp (Tree->Number,Number) ==0)
{
*status=1;("\n№ гостиничного номера: %s \nКоличество
мест: %i \nКоличество комнат: %i \nНаличие санузла: %c \nОборудование:
%s\n\n", Tree->Number, Tree->CountBads, Tree->CountRooms,
Tree->toilet,Tree->equipment);(pv! =0)
{(strcmp (pv->Number,Number) ==0)
{("\nНомер паспорта заселенного постояльца: %s",
pv->passport);=hash (pv->passport);=* (hashtable+hashkey);(tmp! =0)
{(strcmp (tmp->passport,pv->passport) ==0)("\nФИО:
%s",tmp->fio);=tmp->next;
}
}=pv->next;
}
}
}
}
// ----------------------------------------
/*ищем номера по фрагментам оборудования*/findequip (struct
NODE *Tree, char *equip, int *status)
{(Tree)
{(boyer_moore (Tree->equipment, equip))
{("\n№ гостиничного номера: %s \nКоличество мест: %i
\nКоличество комнат: %i \nНаличие санузла: %c \nОборудование: %s\n\n",
Tree->Number, Tree->CountBads, Tree->CountRooms,
Tree->toilet,Tree->equipment);
*status=1;
}(Tree->Left_Child, equip, status);(Tree->Right_Child,
equip, status);
}
}
// ----------------------------------------
/*проверка наличия гостиничного номера в базе (поиск номера в
дереве)
и вычисляем количество оставшихся свободных мест в
номере*/find_numbers (struct NODE *Tree, char *Number, int *status, int
*CountFreeBads, int key)
{(Tree)
{(strcmp (Tree->Number,Number) ==0)
{
*status=1;(key==0)
*CountFreeBads=-- (Tree->CountFreeBads);if
(Tree->CountFreeBads==-1) *CountFreeBads=++ (++ (Tree->CountFreeBads));;
}_numbers (Tree->Left_Child, Number, status,
CountFreeBads, key);_numbers (Tree->Right_Child, Number, status,
CountFreeBads, key);
}
}
Hastable. h
/**********************************************
Работа с хеш-таблицей
функциональность: работа с информацией о постояльцах
***********************************************/
// структура элемента хеш-таблицыNodeHash{passport [12];fio
[100];birthdayyear;adress [300];target [300];NodeHash *next;
};hash (char *); // вычисление хеш-функцииadd_hash_element
(struct NodeHash **, struct NodeHash *, int); // добавление элемента в
хеш-таблицуdel_hash_element (struct NodeHash **,char *, int); // удаление
элемента из хеш-таблицыview_hash_elements (struct NodeHash **); // просмотр
всех элементов хеш-таблицыclear_hash_table (struct NodeHash **); // очистка
хеш-таблицыfindfio_hash_table (struct NodeHash **,char *); // поиск в
хеш-таблице по ФИОfindpassport_hash_table (struct NodeHash **, char *, struct
element *); // поиск в хеш-таблице по паспорту и вывод результатов по таблице и
спискуfind_repeats (struct NodeHash **, int, char *); // поиск совпадений
номеров паспортов в таблице при попытке добавить нового постояльцаprintsk (char
*,.);
hashtable. cpp
#define _CRT_SECURE_NO_WARNINGS
#include<string. h>
#include<stdlib. h>
#include "hashtable. h"
#include "registration. h"
// -----------------------------------------
/*вычисление хеш-функции (метод деления) */hash (char
*passport)
{intpas,k=0;tmp [10];(int i=0; i<11; i++)(i==4) continue;
{tmp [k] =* (passport+i);++;
}=atoi (tmp);(intpas % 97);
}
// -----------------------------------------
/* Добавление нового элемента в хеш таблицу. */add_hash_element
(struct NodeHash **hashtable, struct NodeHash *pv, int hashkey)
{( (* (hashtable+hashkey)) - >birthdayyear==0) // если по
данному ключу элементов нет
{( (* (hashtable+hashkey)) - >adress,pv->adress);
(* (hashtable+hashkey)) - >birthdayyear=pv->birthdayyear;(
(* (hashtable+hashkey)) - >fio,pv->fio);( (* (hashtable+hashkey)) -
>passport,pv->passport);( (* (hashtable+hashkey)) -
>target,pv->target);
(* (hashtable+hashkey)) - >next=0;
}// добавляем в начало списка
{*hashtableitem;= (* (hashtable+hashkey));
(* (hashtable+hashkey)) =pv;>next=hashtableitem;
}
}
// -----------------------------------------
/* Удаление элемента из хеш-таблицы. */del_hash_element
(struct NodeHash **hashtable, char *passport, int hashkey)
{level=0;*p,*p1,*p2;= (* (hashtable+hashkey));(p! =0)
{(strcmp (p->passport,passport) ==0) // проверяем
совпадение заданного ключа и значения в таблице
{( (level==0) && (p->next==0)) // первый и
единственный элемент
{( (* (hashtable+hashkey)) - >adress,"\0");
(* (hashtable+hashkey)) - >birthdayyear=0;( (*
(hashtable+hashkey)) - >fio,"\0");
(* (hashtable+hashkey)) - >next=0;( (*
(hashtable+hashkey)) - >passport,"0000-000000");( (*
(hashtable+hashkey)) - >target,"\0");
}if ( (level! =0) && (p->next==0)) // последний
элемент
{(p);->next=0;
}if ( (level==0) && (p->next! =0)) // первый
элемент
{=p;=p->next;(p2);
}if ( (level! =0) && (p->next! =0)) // в середине
списка
{->next=p->next;(p);
}("\nУдаление завершено. ");;
}=p;=p->next;++;
}("\nПостояльца с таким паспортом не найдено!");
}
// -----------------------------------------
/* Просмотр элементов хеш-таблицы */view_hash_elements
(struct NodeHash **hashtable)
{*p;count=0;(int i=0; i<97; i++)
{=* (hashtable+i);(strcmp
(p->passport,"0000-000000")! =0)
{("№ паспорта: %s\nФИО: %s\nГод рождения: %i\nАдрес:
%s\nЦель прибытия:
%s\n\n",p->passport,p->fio,p->birthdayyear,p->adress,p->target);++;(p->next==0)
break;=p->next;
}
}(count==0) printsk ("\nДанные отсутсвуют");
}
// -----------------------------------------
/* Очистка хеш-таблицы */clear_hash_table (struct NodeHash
**hashtable)
{*p,*p1,*p2;level=0;(int i=0; i<97; i++)
{= (* (hashtable+i));=0;(p->next==0 &&
p->birthdayyear! =0) // если элемент единственный
{(p->adress,"\0");>birthdayyear=0;(p->fio,"\0");(p->passport,"0000-000000");(p->target,"\0");;
}
{=p->next;(p2! =0)
{(level==0)
{(p->adress,"\0");>birthdayyear=0;(p->fio,"\0");(p->passport,"0000-000000");(p->target,"\0");>next=0;++;
}
{=p2;=p2->next;(p1);++;
}
}
}
}
}
// -----------------------------------------
/* Поиск в хеш-таблице по фио */findfio_hash_table (struct
NodeHash **hashtable,char *fio)
{*p;count=0;(int i=0; i<97; i++)
{= (* (hashtable+i));(strcmp
(p->passport,"0000-000000")! =0)
{(strcmp (p->fio,fio) ==0)
{("№ паспорта: %s\nФИО:
%s\n\n",p->passport,p->fio);++;
}(p->next==0);=p->next;
}
}(count==0) printsk ("Совпадений не найдено. ");
}
// -----------------------------------------
/* поиск в хеш-таблице и списке по паспорту
*/findpassport_hash_table (struct NodeHash **hashtable, char *passport, struct
element *pbegin)
{*p;element *pv=pbegin;count=0;(int i=0; i<97; i++)
{= (* (hashtable+i));(strcmp
(p->passport,"0000-000000")! =0)
{(strcmp (p->passport,passport) ==0)
{("№ паспорта: %s\nФИО: %s\nГод рождения: %i\nАдрес:
%s\nЦель прибытия: %s\n\n",p->passport,p->fio,p->birthdayyear,p->adress,p->target);++;
}(p->next==0);=p->next;
}
}(count==0)
{("Совпадений не найдено. ");;
}(strcmp ( (pbegin) - >startdate,"00.00.0000")
==0)
{("Нет заселенных зарегистрированных постояльцев.
");;
}(pv! =0)
{(strcmp (pv->passport,passport) ==0)("\nКлиент
зарегистрирован в номере: %s", pv->Number);
(pv) = (pv) - >next;
}
}
// -----------------------------------------
/* Поиск совпадений введенного паспорта и паспортов в
хеш-таблице */find_repeats (struct NodeHash **hashtable, int hashkey, char
*passport)
{NodeHash *tmp=* (hashtable+hashkey);(tmp! =0)
{(strcmp (tmp->passport,passport) ==0)1;=tmp->next;
}0;
}
Parserlib. h
/**********************************************
функции-парсеры для проверки валидности данных
***********************************************/pars_passport
(char *); // проверка корректности номера паспортаpars_fio (char *); //
проверка корректности ФИОpars_year (int); // проверка возрастаpars_number (char
*); // проверка номера гостиничного номераpars_num (char *); // проверка, что
все символы лежат в диапазоне 0.9pars_bool (char *); // проверка
y/n/yes/nopars_date (char *); // проверка датыprintsk (char *,.);
parserlib. cpp
#include "parserlib. h"
#include <string. h>
// ----------------------------------------
/*проверка корректности номера паспорта*/pars_passport (char
*passport)
{(strcmp (passport,"0000-000000") ==0)
{("\nНевозможный номер паспорта!");1;
}( (* (passport+4)! ='-') | (strlen (passport)! =11) |
(strlen (passport) ==0))
{("\nНекорректный формат паспорта");1;
}(int i=0; i<11; i++)(i==4) continue;if (! (* (passport+i)
>='0' && * (passport+i) <='9'))
{("\nНекорректный формат паспорта");1;
}0;
}
// ----------------------------------------
/*проверка корректности введенного ФИО*/pars_fio (char *fio)
{(strlen (fio) ==0)1;(int i=0; i<100; i++)
{(i==strlen (fio)) break;( ( (* (fio+i) >='A' && *
(fio+i) <='z')) || (* (fio+i) ==' ') || (* (fio+i) =='-') || (* (fio+i)
=='\''));
{("\nНекорректный ввод ФИО");1;
}
}0;
}
// -----------------------------------------
/* Проверка корректности введенного года рождения */pars_year
(int year)
{(year<=1900 || year>=2010)
{("\nНевозможный возраст!");1;
}0;
}
// ----------------------------------------
/*проверка корректности введенного номера гостиничного
номера*/pars_number (char *number)
{(strlen (number)! =4)
{("\nНекорректный номер");1;
}(*number! ='l' && *number! ='p' && *number!
='o' && *number! ='m')
{("\nНекорректный тип номера");1;
}(int i=1; i<4; i++)( (* (number+i) >='0') &&
(* (number+i) <='9'));
{("\nНекорректный номер");1;
}0;
}
// ----------------------------------------
/*проверка корректности введенного числа*/pars_num (char
*number)
{(strlen (number) ==0)1;(unsigned int i=0; i<strlen
(number); i++)
{( (* (number+i) >='0') && (* (number+i)
<='9'));
{("\nНекорректный ввод");1;
}
}0;
}
// ----------------------------------------
/*проверка корректности yes/no/y/n*/pars_bool (char *letter)
{(strlen (letter) ==0)1;(strcmp (letter,"y")! =0
&& strcmp (letter,"n")! =0 && strcmp
(letter,"yes") && strcmp (letter,"no"))
{("Неверный ввод");1;
}0;
}
// ----------------------------------------
/*проверка корректности введенной даты*/pars_date (char
*date)
{countpoints=0;(strlen (date) ==0)1;(strlen (date)! =10)
{("\nНекорректный ввод");1;
}(unsigned int i=0; i<strlen (date); i++)
{( (* (date+i) >='0') && (* (date+i) <='9') ||
* (date+i) == '. ')
{(* (date+i) =='. ') countpoints++;;
}
{("\nНекорректный ввод");1;
}
}(countpoints>2)
{("\nНекорректный ввод");1;
}(* (date+2)! ='. ' && * (date+5)! ='. ')
{("\nНекорректный ввод");1;
}0;
}
Registration. h
Работа с односвязным списком,
функциональность: регистрация вселения/выселения постояльца
***********************************************/
/*структура элемента списка*/element
{passport [12]; // № паспортаNumber [5]; // № гостиничного
номераstartdate [11]; // даты заезда и выезда в формате dd. mm. yyyyenddate
[11];element *next;
};element * create (void); // инициализирование ноды
спискаadd_registration (struct element **, char *, char *, char *, char *); //
добавление элемента в список (вселение постояльца)del_registration (struct NODE
*, struct element **, char *, char *); // удаление элемента из списка
(выселение постояльца)bubble_sort (struct element **); // сортировка
пузырькомcheck_registration (struct element *, char *, char *); // проверка на
двойную регистрацию одного постояльца в один номерcheck_reg (struct element *,
char *); // проверка на попытку удалить зарегистрированного постояльца из
базыfind_number (struct element *, char *); // проверка заселенности
номераprintsk (char *,.);
registration. cpp
#define _CRT_SECURE_NO_WARNINGS
#include<string. h>
#include<windows. h>
#include<stdio. h>
#include<conio. h>
#include "registration. h"
#include "avl. h"
// -----------------------------------------
/* Добавление нового элемента в список. */add_registration
(struct element **pbegin, char *passport, char *Number, char *startdate, char
*enddate)
{element *tmp=*pbegin;
/* Создание первого элемента в списке. */(strcmp ( (*pbegin)
- >passport,"ffff-ffffff") == 0)
{( (*pbegin) - >passport,passport);( (*pbegin) -
>Number,Number);( (*pbegin) - >startdate,startdate);( (*pbegin) -
>enddate,enddate);;
}
// /---------------------------------element *pv = new struct
element; // Создаем новый элемент(pv->passport,passport); // заполняем поля
информацией(pv->Number,Number);(pv->startdate,startdate);(pv->enddate,enddate);>next
= 0;
/* Вставка в конец списка. */(tmp->next!
=0)=tmp->next;>next = pv;;
}
// ---------------------------------------
/* Создание пустого списка. */element * create (void)
{element *pv = new struct
element;(pv->passport,"ffff-ffffff");(pv->Number,"l000");(pv->startdate,"00.00.0000");(pv->enddate,"00.00.0000");>next
= 0;pv;
}
// ---------------------------------------
/*Удаление элемента списка*/del_registration (struct NODE
*Tree, struct element **pbegin, char *passport, char *number)
{element *pv=*pbegin,*tmp,*prev=*pbegin;CountFreeBads,
status;(pv! =0)
{( (strcmp (pv->passport,passport) ==0) && (strcmp
(pv->Number,number) ==0))
{_numbers (Tree, number, &status, &CountFreeBads, 1);
// увеличиваем кол-во свободных мест в номере( (*pbegin) - >next==0) // если
элемент в списке единственный
{(pv->passport,"ffff-ffffff");(pv->Number,"l000");(pv->startdate,"00.00.0000");(pv->enddate,"00.00.0000");("\nok");
_getch ();;
}if (pv->next==0) // если элемент списка последний
{>next=0;(pv);("\nok");
_getch ();;
}if (pv== (*pbegin)) // удаление первого элемента
{= (*pbegin);
(*pbegin) = (*pbegin) - >next;(tmp);("\nok");;
}// удаление из середины
{=pv;>next=pv->next;(tmp);("\nok");
_getch ();;
}
}=pv;=pv->next;
}("\nДанные введены неправильно или такой записи
нет!");
_getch ();
}
// ---------------------------------------
/*Сортировка списка пузырьком*/bubble_sort (struct element
**pbegin)
{status=1;replace=0;i=1;element
*pv=*pbegin,*tmp,*prev=*pbegin, *next= (*pbegin) - >next;(pv! =0)
{++;=pv->next;
}++;(status==1)
{=*pbegin;= (*pbegin) - >next;=0;-;=1;(i<replace)
{(convertnum (pv->Number) >convertnum
(next->Number))
{>next=next->next;>next=pv;=next;=pv;=tmp;=1;
}(i==1)
*pbegin=pv;>next=pv;=pv;=pv->next;=next->next;++;
}
}
}
// ---------------------------------------
/*проверка зарегистрирован ли клиент уже в этом
номере*/check_registration (struct element *pbegin, char *passport, char
*number)
{element *pv=pbegin;( (pv)! =0)
{(strcmp (pv->passport,passport) ==0 && (strcmp
(pv->Number,number) ==0))
{("Нельзя заселить одного и того же постояльца в один
номер дважды");1;
}=pv->next;
}0;
}
// ---------------------------------------
/*проверка на попытку удалить зарегистрированного постояльца
из базы*/check_reg (struct element *pbegin, char *passport)
{element *pv=pbegin;( (pv)! =0)
{(strcmp (pv->passport,passport) ==0)1;=pv->next;
}0;
}
// ---------------------------------------
/*проверка, есть ли зарегистрированный постоялец по
запросу*/find_number (struct element *pbegin, char *number)
{element *pv=pbegin;(pv! =0)
{(convertnum (pv->Number) ==atoi (number))1;=pv->next;
}0;
}
Main. cpp
/**********************************************
КУРСОВАЯ РАБОТА ПО ПРЕДМЕТУ "САОД" 2 КУРС 4 СЕМЕСТР
НА ТЕМУ: "РЕГИСТРАЦИЯ ПОСТОЯЛЬЦЕВ В ГОСТИНИЦЕ"
**********************************************/
# define _CRT_SECURE_NO_WARNINGS
# include<stdio. h>
# include<conio. h>
# include<windows. h>
# include "avl. h"
# include "hashtable. h"
# include "registration. h"
# include "parserlib. h"
// ----------------------------------------
/* Преобразования кодовой таблицы для Windows */printsk (char
*format,.)
{buf [1000];_list ptr;(format, buf);_start (ptr,
format);(buf, ptr);
}
// ----------------------------------------
/*меню*/menu ()
{("Регистрация постояльцев в
гостинице\n");("\nВыберите действие: \n");("1. Регистрация
нового постояльца\n");("2. Удаление данных о
постояльце\n");("3. Просмотр всех зарегистрированных
постояльцев\n");("4. Очистка данных о постояльцах\n");("5.
Поиск постояльца по № паспорта\n");("6. Поиск постояльца по
ФИО\n");("7. Добавление нового гостиничного номера
\n");("8. Удаление сведений о гостиничном номере \n");("9.
Просмотр всех имеющихся гостиничных номеров \n");("10. Очистка данных
о гостиничных номерах\n");("11. Поиск гостиничного номера по '№
гостиничного номера'\n");("12. Поиск гостиничного номера по
оборудованию\n");("13. Регистрация вселения
постояльца\n");("14. Регистрация выселения
постояльца\n");("0. Выход\n");
}main ()
{H, choice, step =
0;CountBads;CountFreeBads=-1;CountRooms;status=0;status2;Number2;startdate
[11];enddate [11];toilet;tmp [4];Number [4];pass [12];equipment [1000];equip
[1000];NODE *Tree = (struct NODE *) malloc (sizeof (struct NODE));=
NULL;element *pbegin = create ();
/*******************************
инициализируем хеш-таблицу
********************************/hashkey=0;**hashtable=
(NodeHash**) malloc (97*sizeof (NodeHash*));(int i=0; i<97; i++)
{[i] = (NodeHash*) malloc (sizeof (NodeHash));(hashtable [i]
- >adress,"\0");[i] - >birthdayyear=0;(hashtable [i] -
>fio,"\0");[i] - >next=0;(hashtable [i] - >passport,"0000-000000");(hashtable
[i] - >target,"\0");
}
{("cls");();(stdin);=-1;("%i",
&choice);(choice == 1)
{NodeHash *pv = new struct NodeHash;("cls");
{("\nВведите № паспорта:
");(stdin);("%s",&pv->passport);
}while (pars_passport (pv->passport));=hash
(pv->passport);(find_repeats (hashtable,hashkey,pv->passport))
{("\nНевозможно зарегистрировать двух постояльцев с
одинаковыми паспортами!");
_getch ();;
}{("\nВведите ФИО: ");(stdin);(pv->fio);
}while (pars_fio (pv->fio));{("\nВведите год
рождения: ");(stdin);("%i",&pv->birthdayyear);
}while (pars_year (pv->birthdayyear));("\nВведите
адрес: ");(stdin);(pv->adress);("\nВведите цель прибытия:
");(stdin);(pv->target);_hash_element (hashtable, pv,
hashkey);("\nРегистрация завершена. ");
_getch ();;
}(choice == 2)
{("cls");{("\nВведите № паспорта:
");(stdin);("%s",&pass);
}while (pars_passport (pass));(check_reg (pbegin,pass))
{("\nНельзя удалить заселенного постояльца");
_getch ();;
}=hash (pass);_hash_element (hashtable,pass,hashkey);
_getch ();;
}(choice == 3)
{("cls");("Список постояльцев:
\n");_hash_elements (hashtable);
_getch ();;
}(choice == 4)
{("cls");("Очистка данных о
постояльцах");(strcmp (pbegin->passport,"ffff-ffffff")! =0)
{("\nБаза зарегистрированных постояльцев не пуста!
\nОчистка данных о постояльцах невозможна!");
_getch ();;
}_hash_table (hashtable);("\nok");
_getch ();;
}(choice == 5)
{("cls");{("\nВведите № паспорта для поиска:
");(stdin);("%s",&pass);
}while (pars_passport (pass));_hash_table (hashtable,pass,
pbegin);
_getch ();;
}(choice == 6)
{fio [100];("cls");{("\nВведите ФИО для
поиска: ");(stdin);(fio);
}while (pars_fio (fio));_hash_table (hashtable,fio);
_getch ();;
}(choice == 7)
{
{("\nВведите № гостиничного
номера\nl-люкс\np-полюлюкс\no-одноместный\nm-многоместный\n: > ");(stdin);("%s",
&Number);
}while (pars_number (Number));(*Number=='o') // если выбран
одноместный номер, то количество комнат и мест равно 1 по
умолчанию=CountBads=1;
{
{(stdin);("\nВведите количество мест:
");("%s",&tmp);
}while (pars_num (tmp));=atoi (tmp);
{(stdin);("\nВведите количество комнат:
");("%s",&tmp);
}while (pars_num (tmp));=atoi (tmp);
}
{(stdin);("\nНаличие санузла (y/n):
");("%s",&tmp);
}while (pars_bool (tmp));=tmp
[0];(stdin);("\nОборудование: ");(equipment);(stdin);= Binary_Tree
(Number, CountBads, CountRooms, toilet,equipment, Tree, &H);;
}(choice == 8)
{("cls");{("\nВведите номер гостиничного
номера для удаления (без типа): ");(stdin);("%s", &tmp);
}while (pars_num (tmp));(find_number (pbegin, tmp))
{("\nНельзя удалить номер, когда в нем зарегистрирован
(ы) постоялец (ы)");
_getch ();;
}=atoi (tmp);=0;= Delete_Element (Tree, Number2, &H,
&status);(status==1)("\n Запись удалена\n");
_getch ();;
}(choice == 9)
{("cls");("\nИнформация о гостиничных номерах:
\n");(! Tree)
{("\nБаза пуста!");
_getch ();;
}(Tree);
_getch ();("cls");;
}(choice == 10)
{("cls");(strcmp
(pbegin->passport,"ffff-ffffff")! =0)
{("\nНельзя очистить базу номеров, когда в них
зарегистрированы постояльцы");
_getch ();;
}(&Tree);
// Tree=NULL;(Tree);("\nОчистка базы завершена\n");
_getch ();("cls");;
}(choice == 11)
{("cls");{("\nВведите № гостиничного номера:
");(stdin);(Number);
}while (pars_number (Number));=0;("Информация о номере:
");_hotel_room (Tree, Number, pbegin, hashtable,&status);(!
status)("информация не найдена");
_getch ();;
}(choice == 12)
{("cls");("Введите необходимое оборудование:
");(stdin);(equip);=0;("Найденные номера: ");(Tree, equip,
&status);(status==0)("Ничего не найдено");
_getch ();("cls");;
}(choice == 13)
{("cls");("Регистрация вселения постояльца
\n");{("\nВведите № паспорта: ");(stdin);("%s",
&pass);(strcmp (pass,"esc") ==0) break; // для выхода из ввода
паспорта=0;=hash (pass);(pars_passport (pass))
{=0;;
}if (! find_repeats (hashtable,hashkey, pass))
{("Клиента нет в базе! Сначало зарегистрируйте
постояльца, потом заселяйте! \nДля выхода из ввода наберите esc");=0;
}status=1;
}while (! status);(status==0) continue; // прерывание
регистрации
{=0;("\nВведите № гостиничного номера:
");(stdin);(Number);(strcmp (Number,"esc") ==0) break; // для
выхода из ввода гостиничного номера=0;(pars_number (Number))
{=0;;
}_numbers (Tree, Number, &status2, &CountFreeBads,
0);(! status2)
{("Номера нет в базе! Сначало добавьте гостиничный
номер! \nДля выхода из ввода наберите esc");=0;;
}if (CountFreeBads<0)
{("В этом номере мест нет. \nДля выхода из ввода
наберите esc");=0;;
}if (check_registration (pbegin, pass, Number))=0;status=1;
}while (! status);(status==0)
{_numbers (Tree, Number, &status2, &CountFreeBads,
1);; // прерывание регистрации
}
{("\nВведите дату заселения:
");(stdin);(startdate);
}while (pars_date (startdate));
{(stdin);("\nВведите дату выселения:
");(stdin);(enddate);
}while (pars_date (enddate));_registration (&pbegin,
pass, Number,startdate,enddate);_sort (&pbegin);("\nok");
_getch ();("cls");;
}(choice == 14)
{("cls");("Регистрация выселения постояльца
\n");(strcmp ( (pbegin) - >startdate,"00.00.0000") ==0)
{("Нет зарегистрированных клиентов. ");
_getch ();;
}
{("Введите № паспорта: ");(stdin);(pass);
}while (pars_passport (pass));
{("Введите номер в котором зарегистрирован постоялец:
");(stdin);(Number);
}while (pars_number (Number));_registration (Tree,
&pbegin,pass,Number);;
}(choice == 0)(1);
}(1);
}
5.
Тестирование программы
Главное окно программы
Регистрация нового постояльца
Просмотр всех зарегистрированных постояльцев

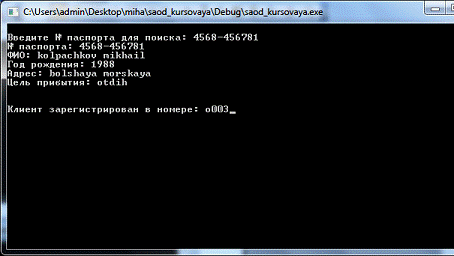
Поиск по номеру паспорта
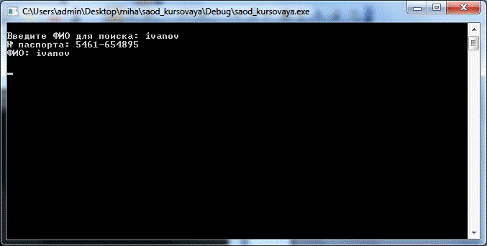
Поиск по ФИО
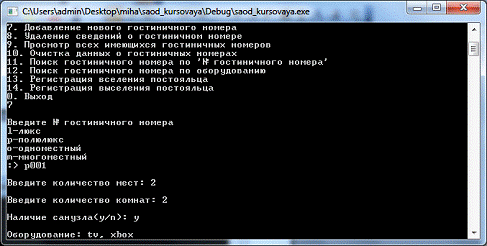
Регистрация нового номера
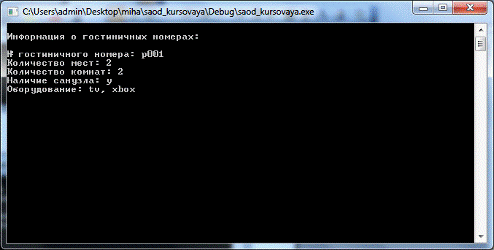
Все гостиничные номера
Поиск номеров по фрагментам оборудования
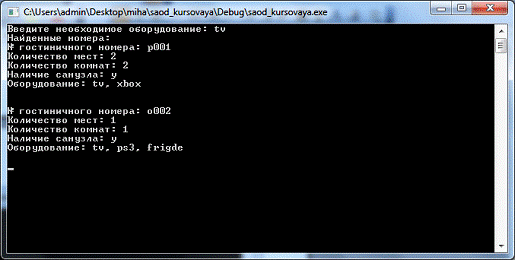
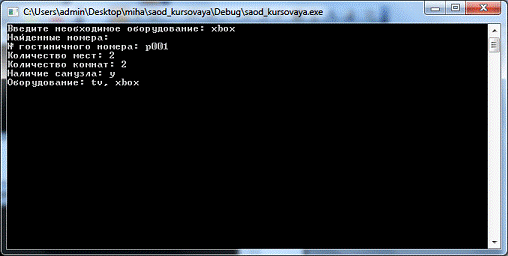
Регистрация вселения постояльца
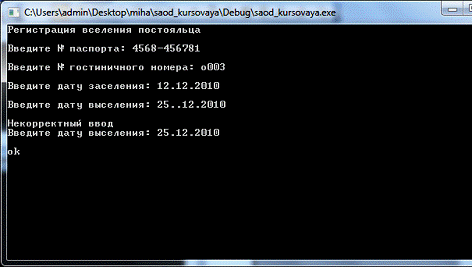
Регистрация выселения постояльца
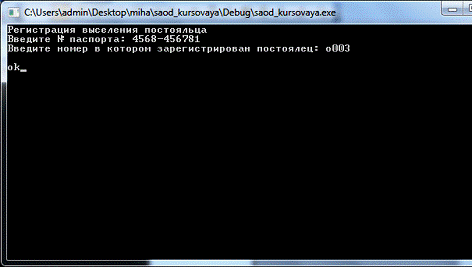
Заключение
В процессе выполнения данной курсовой работы я изучил
структуры данных и алгоритмы их обработки, а также получил практические навыки
их использования при разработке программ.
В курсовом проекте реализована информационная система
регистрации постояльцев в гостинице.
Для организации данных использовались такие структуры данных,
как хеш-таблицы, АВЛ-деревья, односвязные списки. Трудностей во время
выполнения не возникло.
Список
использованной литературы
1. Кормен,
Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Алгоритмы: построение и анализ =
Introduction to Algorithms / Под ред. И.В. Красикова. - 2-е изд. - М.: Вильямс,
2005. - 1296 с. - ISBN 5-8459-0857-4
2. Вирт
Н. Алгоритмы и структуры данных. М.: Мир, 1989.
. Вирт
H. Алгоритмы + структуры данных = программы. - М.: Мир, 1985. - 406 с.
. М.
Сибуя, Т. Ямомото. Алгоритмы обработки данных. - М.: "Мир", 1986.