Оценка посещаемости сайтов
Министерство
образования и науки Российской Федерации
ФЕДЕРАЛЬНОЕ
ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ
УЧРЕЖДЕНИЕ
ВЫСШЕГО
ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
"ОРЕНБУРГСКИЙ
ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ"
Математический
факультет
Кафедра
математического обеспечения информационных систем
ОТЧЕТ
ПО
ПРОИЗВОДСТВЕННОЙ ПРАКТИКЕ
на тему:
"Оценка посещаемости сайтов"
ГОУ ОГУ
010503.65.5011.13 ОО
Руководитель:
Татжибаева О.А.
Исполнитель:
студентка гр. 09МОС
Филимонова А.Н..
Оренбург
2014
Содержание
Введение
Цели и задачи
. Анализ систем статистики сайтов
.1 Факторы, учитываемые при оценке посещаемости сайта
.2 Счетчики посещаемости
.3 Наиболее популярные счетчики
. Методы оценки и прогноза
.1 Анали существующих решений
.2. Задачи корреляционно-регрессионного анализа
.2.1 Корреляция случайных величин
.2.2 Линейная регрессия
.3 Проверка адекватности моделей
. Оценка посещаемости сайта skalyariya.ru
.1 Факторы формирующие моделируемое явление
.2 Анализ матрицы коэффициентов парных корреляций
.3 Построение уравнения регрессии
.4 Вывод
Заключение
Литература
статистика сайт посещаемость счетчик
Введение
В Интернет существует не одна система для ведения статистики посещений.
За последнее время системы статистики "выросли" из обычных счетчиков
посещений, и уже не ограничивается только подсчетом количества посещений.
Современные статистические системы позволяют провести достаточно
содержательный анализ сайтов. Например, позволяют более объективно оценивать не
только источники посетителей, но и качество аудитории, поведение конкретного
посетителя на сайте, его переходы по страницам, время пребывания на сайте и
многое другое. С другой стороны такие системы помогают определить конкретную
цель, например, конечной целью работы многих сайтов должно быть существование
обратной связи с пользователем. В интернет-магазине это может быть сделанный
заказ, на другом сайте - звонок менеджеру и т.д. Такая аналитика позволит найти
в сайте узкое место и доработать его.
Оценивая статистику сайта можно также делать прогнозы посещаемости сайта.
Если определить, какие факторы напрямую влияют на число посетителей, то можно в
десятки, а то и сотни раз увеличить аудиторию сайта. Для некоторых сайтов это
количество иллюстраций, для других количество товара, для третьих скорость
загрузки, и таких факторов достаточно много. Главное правильно оценить все
имеющиеся статистические данные, сделать выводы и умело ими воспользоваться.
Цели и задачи
Цель:
Оценить посещаемость сайта
Задачи:
· Проанализировать факторы, влияющие на посещаемость сайта
· Проанализировать методы оценки посещаемости сайта
· Построить модель оценки посещаемости сайта
1. Анализ
систем статистики сайтов
1.1 Факторы,
учитываемые при оценке посещаемости сайта
Развитие сайта, его продвижение в поисковых системах - это процесс,
который непременно нуждается в постоянном контроле, оценке и анализе со стороны
вебмастера. Можно самостоятельно исследовать логи сайта, но проще и зачастую
эффективней - обратиться к показаниям счетчика учета посещаемости
интернет-ресурса. На сегодняшний день существует множество счетчиков учета
посещаемости сайтов. Все счетчики обладают схожим базовым функционалом и
отслеживают следующие факторы посещаемости:
· Трафик
Количество посетителей сайта - наиболее простой для оценки измеримый
параметр успешности ресурса. Оценивая динамику прироста трафика, можно сделать
первоначальные выводы о ходе рекламной/SEO кампании. Количественный показатель трафика - только
первичный критерий оценки.
· Глубина просмотра страниц
Определяется соотношением количества просмотров страниц сайта к
количеству посетителей. Чем больше глубина просмотра, тем интереснее для
посетителей интернет-ресурс. Минимальная глубина просмотра может
свидетельствовать об ошибках рекламной кампании, проблемах с юзабилити сайта,
недостаточной надежности хостинга.
· Количество новых и постоянных посетителей сайта
Счетчик учета посещаемости отслеживает не только количественные, но и
качественные показатели. С его помощью можно определить, насколько лояльна
аудитория к сайту, вызывает ли интернет-ресурс желание повторного посещения.
Анализ данных показателей поможет сделать выводы о необходимости (или ее
отсутствии) принятия дополнительных мер по превращению случайных гостей в
постоянных посетителей.
· География и демография аудитории
Немаловажный параметр, особенно, если вы владелец коммерческого сайта,
интернет-магазина. Представьте, что сайт занимаетеся онлайн-продажами цветочных
горшков в Санкт-Петербурге, на сайт идет постоянный приток посетителей, но
уровень конвертации посетителей в клиентов чрезвычайно низок. Оценивая
географические и демографические параметры аудитории сайта, можно с удивлением
обнаружить, что большинство посетителей - мужчины младше 18-ти лет из Москвы.
Стоит сделать вывод о нерелевантности контента сайта и принять решение о его
скорейшей реорганизации.
С учетом региональной выдачи Яндекса "географический" раздел
счетчика посещаемости поможет сделать заключение о высоком/низком рейтинге
сайта в определенном регионе.
· Точки входа и выхода
Страницы сайта, с которых начинают его просмотр посетители, очень важны
для понимания качества и релевантности трафика. В идеале эти страницы входа
должны соответствовать плану рекламной кампании и приводить посетителя к
необходимой цели (получению нужной информации, клику на рекламный баннер, заполнению
анкеты, совершению покупки)..
· Источники трафика
Благодаря статистическим данным об источниках трафика можно узнать,
откуда посетители пришли на данный сайт. На основе полученной информации можно
сделать выводы об эффективности того или иного метода продвижения - SEO, рекламные баннеры, каталоги и проч.
· Поисковые фразы
Чаще всего посетителей на сайт приводят именно поисковые системы. При
помощи анализа поисковых фраз, по которым приходят к посетители, задавшие тот
или иной запрос в поисковой строке Яндекса и Гугла, можно определить наиболее
актуальные для сайта ключевые слова. Кроме того, именно поисковые фразы дадут
больше всего информации о качестве трафика (владельца магазина электроники не
должен радовать приток посетителей, запрашивающих у Яндекса "фильм
"Электроник").
1.2 Счетчики
посещаемости
По обработке посещаемости сайта счетчики делятся:
Счетчик, стоящий на отдельно взятой странице. Как правило, этой страницей
является самая посещаемая - главная страница сайта. Т.к. большинство пользователей
начинают свое посещение именно с главной страницы - по такому счетчику можно
оценить и посещаемость сервера в целом. Хотя, следует иметь ввиду, что часть
пользователей может начинать посещение сайта сразу с внутренней страницы и не
подниматься вверх на главную. Они будут не учтены, что вызовет погрешность в
расчетах.
Счетчики, размещаемые на всех страницах сайта. В этом случае получается
гораздо более репрезентативная картина. Посещаемость определяется по всем
страницам. Имеется возможность определить и проанализировать:
· наиболее популярные маршруты по серверу;
· точки входа и выхода посетителей;
· наиболее популярные разделы сервера;
· глубину интереса посетителей, т.е. сколько в среднем страниц
читается, сколько времени проводят на сайте и т.д.
По идентификации уникального пользователя счетчики делятся:
Счетчики, ориентирующиеся на IP-адреса. Как мы говорили это не самый
точный метод определения уникального пользователя. Этот же принцип используется
при анализе логов сайта.
Счетчики, ориентирующиеся на cookies. Более точный способ. Соответственно
счетчики, его использующие, уже сразу дают фору лог-файлам.
Также счетчики делятся на независимые (внешние) - расположенные на
отдельных серверах и предоставляющие подсчет как бесплатный сервис, и
внутренние - программа, обслуживающая счетчик, расположена непосредственно на
сайте.
Помимо этого, часто, счетчики одновременно являются и рейтингами. Это
позволяет достаточно точно сравнивать посещаемость и охват сайтов
веб-издателей, участвующих в одном и том же рейтинге.
Существует два основных критерия оценки счетчиков. Первый - это,
безусловно, надежность системы и точность подсчета. Второй - как много данных
они собирают, насколько детально предоставляются отчеты и т.д.
1.3 Наиболее
популярные счетчики
На сегодняшний день в российском Интернете существует множество
статистических сервисов, каждый из которых имеет свои особенности. Также
существуют зарубежные счетчики, но их применение в российских условиях
ограничено недостатком знаний о российских поисковых системах и отсутствием
возможности определения географии посетителя с точностью до региона.
Рамблер (#"773488.files/image001.gif">
Рисунок 1- Классификация моделей и методов оценки прогнозирования.
Одним из наиболее важных классификационных признаков методов
прогнозирования является степень формализации, которая достаточно полно
охватывает прогностические методы. Формализованные методы используются в том
случае, когда информация об объекте прогнозирования носит в основном
количественный характер, а влияние различных факторов можно описать с помощью
математических формул.
Эти методы делятся на две самостоятельные группы: методы прогнозной
экстраполяции и методы моделирования.
В практике прогнозирования экономических процессов преобладающими, по
крайней мере, до последнего времени, являются статистические модели
экстраполяционного метода. Это вызвано, главным образом, тем, что
статистические методы опираются на аппарат анализа, развитие и практика
применения которого имеют достаточно длительную историю. Мировая практика
обладает обширным материалом в области перспективного анализа, и уже сейчас
очевидно, что успешность прогнозов, получаемых на основе статистических
моделей, существенно зависит от анализа эмпирических данных, от того, насколько
такой анализ сможет выявить и обобщить закономерности поведения изучаемых
процессов во времени.
.2 Задачи
корреляционно-регрессионного анализа
В статистике показатели, характеризующие социально-экономические явления,
могут быть связаны либо корреляционной зависимостью, либо быть независимыми.
Корреляционная зависимость является частным случаем стохастической зависимости,
при которой изменение значений факторных признаков (х 1 х2
..., хn ) влечет за собой изменение среднего
значения результативного признака. Корреляционная зависимость исследуется с
помощью методов корреляционного и регрессионного анализов.
Корреляционный анализ - метод,
позволяющий обнаружить зависимость между несколькими случайными величинами.
Корреляционный анализ, как и другие статистические методы, основан на
использовании вероятностных моделей, описывающих поведение исследуемых
признаков в некоторой генеральной совокупности, из которой получены
экспериментальные значения xi и yi.
Методами корреляционного анализа решаются следующие задачи:
1) Взаимосвязь. Есть ли взаимосвязь между параметрами?
) Прогнозирование. Если известно поведение одного
параметра, то можно предсказать поведение другого параметра, коррелирующего с
первым.
) Классификация и идентификация объектов.
Корреляционный анализ помогает подобрать набор независимых признаков для
классификации.
Регрессионный анализ заключается в определении аналитического выражения
связи в виде уравнения регрессии.
Целью регрессионного анализа является оценка функциональной зависимости
условного среднего значения результативного признака (У) от факторных (х1.
Х2...,
хn).
Основные задачи регрессионного анализа следующие:
) определения вида и формы зависимости;
) оценка параметров уравнения регрессии;
) проверка значимости уравнения регрессии;
) проверка значимости отдельных коэффициентов уравнения;
) построение интервальных оценок коэффициентов;
) исследование характеристик точности модели;
) построение точечных и интервальных прогнозов результирующей
переменной.
Регрессионный анализ очень тесно связан с корреляционным анализом. В
корреляционном анализе исследуется направление и теснота связи между
количественными переменными. В регрессионном анализе исследуется форма
зависимости между количественными переменными. Т.е. фактически оба метода
изучают одну и ту же взаимосвязь, но с разных сторон, и дополняют друг друга.
На практике корреляционный анализ выполняется перед регрессионным анализом.
После доказательства наличия взаимосвязи методом корреляционного анализа можно
выразить форму этой связи с помощью регрессионного анализа. Пользуясь методами корреляционно-регрессионного анализа,
аналитики измеряют тесноту связей показателей с помощью коэффициента
корреляции. При этом обнаруживаются связи, различные по силе (сильные, слабые,
умеренные и др.) и различные по направлению (прямые, обратные). Если связи
окажутся существенными, то целесообразно будет найти их математическое выражение
в виде регрессионной модели и оценить статистическую значимость модели.
2.2.1
Корреляция случайных величин
Прямое токование термина корреляция - стохастическая, вероятная,
возможная связь между двумя (парная) или несколькими (множественная) случайными
величинами. Для числовой оценки возможной связи между двумя случайными
величинами: Y(со средним My и среднеквадратичным отклонением Sy) и - X (со средним Mx и среднеквадратичным отклонением Sx) принято использовать так называемый
коэффициент корреляции
xy=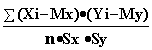 .
.
Этот коэффициент может принимать значения от -1 до +1 - в зависимости от
тесноты связи между данными случайными величинами. Если коэффициент корреляции
равен нулю, то X и Y называют некоррелированными. Считать
их независимыми обычно нет оснований - оказывается, что существуют такие, как
правило - нелинейные связи величин, при которых Rxy = 0, хотя величины зависят друг от
друга. Обратное всегда верно - если величины независимы, то Rxy = 0. Но, если модуль Rxy = 1, то есть все основания
предполагать наличие линейной связи между Y и X.
Именно поэтому часто говорят о линейной корреляции при использовании такого
способа оценки связи между случайными величинами. В отдельных случаях
приходится решать вопрос о связях нескольких (более 2) случайных величин или
вопрос о множественной корреляции. Можно найти парные коэффициенты корреляции Rxy, Rxz, Ryz по приведенной выше формуле. В
случаях множественного корреляционного анализа иногда требуется отыскивать т.
н. частные коэффициенты корреляции - например, оценка виляния Z на связь между X и Y производится с помощью коэффициента
Rxy.z =
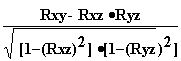
И, наконец, связь между данной случайной величиной и совокупностью
остальных определяют коэффициенты множественной корреляции Rx.yz, Ry.zx, Rz.xy, формулы для вычисления которых
построены по тем же принципам - учету связи одной из величин со всеми
остальными в совокупности.
2.2.2
Линейная регрессия
В тех случаях, когда из природы процессов в модели или из данных
наблюдений над ней следует вывод о нормальном законе распределения двух
случайных велечин - Y и X, из которых одна является
независимой, т. е. Y является
функцией X, то возникает соблазн определить
такую зависимость "формально", аналитически.
В случае успеха будет намного проще вести моделирование. Конечно,
наиболее заманчивой является перспектива линейной зависимости типа
= a + b·X .
Подобная задача носит название задачи регрессионного анализа.
Изучение связи между тремя и более связанными между собой признаками
носит название множественной (многофакторной) регрессии. При исследовании
зависимостей методами множественной регрессии задача формулируется так же, как
и при использовании парной регрессии. Построение моделей множественной
регрессии включает несколько этапов:
• выбор формы связи (уравнения регрессии):
• отбор факторных признаков:
• обеспечение достаточного объема совокупности для получения несмещенных
оценок.
Наиболее приемлемым способом определения вида исходного уравнения
регрессии является метод перебора различных уравнений.
Сущность данного метода заключается в том, что большое число уравнений
(моделей) регрессии, отобранных для описания связей какого-либо
социально-экономического явления или процесса, реализуется на ЭВМ с помощью
специально разработанного алгоритма перебора с последующей статистической
проверкой, главным образом на основе t-крнтерия Стьюдeнта и
F-критерия Фишера. Способ перебора
является достаточно трудоемким и связан с большим объемом вычислительных работ.
Практика построения многофакторных моделей взаимосвязи показывает, что все
реально существующие зависимости между социально-экономическими явлениями можно
описать, используя пять типов моделей:
1.
линейная:
Y=A0+A1X1+….AkXk
2.
степенная
3.
показательная
4.
параболическая
5.
гиперболическая
Основное значение имеют линейные модели в силу простоты и логичности их
экономической интерпретации. Нелинейные формы зависимости приводятся к линейным
путем линеаризации.
Важным этапом построения уже выбранного уравнения множественной регрессии
являются отбор и последующее включение факторных признаков. Сложность
формирования уравнения множественной регрессии заключается в том, что почти все
факторные признаки находятся в зависимости один от другого. Проблема
размерности модели связи, т. е. определение оптимального числа факторных
признаков, является одной из основных проблем построения множественного
уравнения регрессии. С одной стороны, чем больше факторных признаков включено в
уравнение, тем оно лучше описывает явление. Однако модель размерностью 100 и
более факторных признаков сложно реализуема и требует больших затрат машинного
времени. Сокращение размерности модели за счет исключения второстепенных,
экономически и статистически несущественных факторов способствует простоте и качеству
ее реализации. В то же время построение модели регрессии малой размерности
может привести к тому, что такая модель будет недостаточно адекватна
исследуемым явлениям и процессам. Проблема отбора факторных признаков для
построения моделей взаимосвязи может быть решена на основе эвристических или
многомерных статистических методов анализа.
Наиболее приемлемым способом отбора факторных признаков является шаговая
регрессия (шаговый регрессионный анализ). Сущность метода шаговой регрессии
заключается в последовательном включении факторов в уравнение регрессии и
последующей проверке их значимости. Факторы поочередно вводятся в уравнение так
называемым "прямым методом". При проверке значимости введенного
фактора определяется, насколько уменьшается сумма квадратов остатков и
увеличивается величина множественного коэффициента корреляции. одновременно
используется и обратный метод, т.е. исключение факторов, ставших незначимыми на
основе t-критерия Стьюдента. Фактор является
незначимым, если его включение в уравнение регрессии только изменяет значение
коэффициентов регрессии, не уменьшая суммы квадратов остатков и не увеличивая
их значения. Если при включении в модель соответствующего факторного признака
величина множественного коэффициента корреляции увеличивается, а коэффициент
регрессии не изменяется (или меняется несущественно), то данный признак
существен и его включение в уравнение регрессии необходимо.
Качество уравнения регрессии зависит от степени достоверности и
надежности исходных данных и объема совокупности. Исследователь должен
стремиться к увеличению числа наблюдений, так как большой объем наблюдений
является одной из предпосылок построения адекватных статистических моделей.
Аналитическая форма выражения связи результативного признака и ряда
факторных называется многофакторным (множественным) уравнением регрессии, или
моделью связи.
Уравнение линейной множественной регрессии имеет вид:
=A0+A1X1+….AkXk
Коэффициенты Аn
вычисляются при помощи систем нормальных уравнений.
Общий вид нормальных уравнений для расчета коэффициентов регрессии:
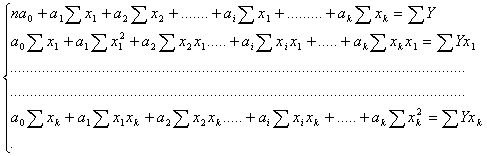
2.3 Проверка
адекватности моделей
Проверка адекватности моделей, построенных на основе уравнений регрессии,
начинается с проверки значимости каждого коэффициента регрессии.
Значимость коэффициентов регрессии осуществляется с помощью
t-критерия
Стьюдента:
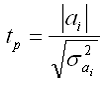
- дисперсия коэффициента регрессии.
Параметр модели признается статистически значимым, если tp>tкр
Наиболее сложным в этом выражении является определение дисперсии, которая
может быть рассчитана двояким способом.
Наиболее простой способ, выработанный методикой экспериментирования,
заключается в том, что величина дисперсии коэффициента регрессии может быть
приближенно определена по выражению:
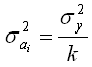
дисперсия результативного признака:
k -
число факторных признаков в уравнении.
Интерпретация моделей регрессии осуществляется методами той отрасли
знаний, к которой относятся исследуемые явления. Но всякая интерпретация
начинается со статистической оценки уравнения регрессии в целом и оценки
значимости входящих в модель факторных признаков, т. е. с выяснения, как они
влияют на величину результативного признака. Чем больше величина коэффициента
регрессии, тем значительнее влияние данного признака на моделируемый. Особое
значение при этом имеет знак перед коэффициентом регрессии. Знаки коэффициентов
регрессии говорят о характере влияния на результативный признак. Если факторный
признак имеет знак плюс, то с увеличением данного фактора результативный
признак возрастает; если факторный признак со знаком минус, то с его увеличением
результативный признак уменьшается. Интерпретация этих знаков полностью
определяется социально-экономическим содержанием моделируемого
(результативного) признака. Если его величина изменяется в сторону увеличения,
то плюсовые знаки факторных признаков имеют положительное влияние. При
изменении результативного призна-л-1 в сторону снижения положительное значение
имеют минусовые знаки факторных признаков. Если экономическая теория
подсказывает, что факторный признак должен иметь положительное значение, а он
со знаком минус, то необходимо проверить расчеты параметров уравнения
регрессии. Такое явление чаще всего бывает в силу допущенных ошибок при
решении. Однако следует иметь в виду, что при анализе совокупного влияния
факторов, при наличии взаимосвязей между ними характер их влияния может
меняться. Для того чтобы быть уверенным, что факторный признак изменил знак
влияния, необходима тщательная проверка решения данной модели, так как часто
знаки могут меняться в силу допустимых ошибок при сборе или обработке
информации.
При адекватности уравнения регрессии исследуемому процессу возможны
следующие варианты.
. Построенная модель на основе ее проверки по F-критерию Фишера в целом адекватна, и все коэффициенты
регрессии значимы. Такая модель может быть использована для принятия решений к
осуществлению прогнозов.
. Модель по F-критерию Фишера
адекватна, но часть коэффициентов регрессии незначима. В этом случае модель
пригодна для принятия некоторых решений, но не для производства прогнозов.
. Модель по F-критерию Фишера
адекватна, но все коэффициенты регрессии незначимы. Поэтому модель полностью
считается неадекватной. на ее основе не принимаются решения и не осуществляются
прогнозы.
3. Оценка
посещаемости сайта skalyariya.ru
Объектом исследования является совокупность наблюдений за посещаемостью WEB сайта skalyariya.ru. Тематика сайта
- это описание содержания аквариумных рыб, уход ха ними, а также продажа
комплектующих для аквариумов. Сайт предлагает посетителям продажу необходимого
инвентаря и рыб разной среды содержания. База редких рыб пополняется ежедневно.
Моделируемым показателем является N- количество человек в день посетивших сайт.
3.1 Факторы
формирующие моделируемое явление
Отбор факторов для модели осуществляется в два этапа. На первом идет анализ,
по результатам которого исследователь делает вывод о необходимости рассмотрения
тех или иных явлений в качестве переменных, определяющих закономерности
развития исследуемого процесса, на втором - состав предварительно отобранных
факторов уточняется непосредственно по результатам статистического анализа. Полученные данные с помощью программы наблюдения за
компьютерной сетью (Net Medic, Net lab) являются не совсем точными, но довольно близки к
реальным и по этому будем считать, что они дают представление о характере
процесса. Из совокупности этих факторов отберем следующие: Зависимый фактор: N- количество человек в день посетивших
сайт. Для модели в
абсолютных показателях
Независимые факторы: P - Загруженность внутренней сети (чел/день)
S - Cкорость обмена данными в сети
Кбит/сек
V -
Кол-во в продаже видов редких рыб на текущий день
B -
Количество "Баннеров" - рекламных ссылок на исследуемый сайт.
Данные представлены в таблице 2.
Таблица 2
|
№ Объекта наблюдения
|
N Кол-во человек в день
|
P Загруженность внутренней сети (чел/ден)
|
S Скорость обмена данными в сети Кбит/сек
|
V Кол-во в продаже видов редких рыб на текущий день
|
B Кол-во баннеров
|
|
1
|
11
|
651
|
2627
|
165
|
4
|
|
2
|
18
|
1046
|
3045
|
400
|
4
|
|
3
|
19
|
944
|
2554
|
312
|
5
|
|
4
|
11
|
1084
|
4089
|
341
|
4
|
|
5
|
15
|
1260
|
6417
|
496
|
7
|
|
6
|
10
|
1212
|
4845
|
264
|
8
|
|
7
|
12
|
254
|
923
|
78
|
1
|
|
8
|
14
|
1795
|
9602
|
599
|
13
|
|
9
|
9
|
2851
|
12542
|
12
|
|
10
|
15
|
1156
|
6718
|
461
|
9
|
.2 Анализ
матрицы коэффициентов парных корреляций
Таблица 3
|
№ фактора
|
N
|
P
|
S
|
V
|
B
|
|
N
|
1.00
|
-0.22
|
-0.06
|
0.44
|
0.12
|
|
P
|
-0.22
|
1.00
|
0.91
|
0.68
|
0.74
|
|
S
|
-0.06
|
0.91
|
1.00
|
0.86
|
0.91
|
|
V
|
0.44
|
0.68
|
0.86
|
1.00
|
0.85
|
|
B
|
0.12
|
0.74
|
0.91
|
0.85
|
1.00
|
Из таблицы 3 определяются тесно коррелирующие факторы. Налицо
мультиколлениарность факторов P и S ( 0.91 ). Оставим только один фактор
P. И действительно если скорость в
сети высокая то она может без значительных задержек во времени обработать
значительное кол-во запросов от пользователей, значит, чем больше скорость в
сети, тем больше в ней пользователей. Тем загруженее сеть.
3.3
Построение уравнения регрессии
Найдем искомое уравнение множественной регрессии, исключив из расчетов,
как указывалось выше, факторы S -
скорость сети (чел/день )
Путем перебора возможных комбинаций оставшихся факторных признаков
получим следующую модель:
Функция N = +12.567-0.005*P+0.018*V
Оценки коэффициентов линейной регрессии
|
№
|
Значение
|
Дисперсия
|
Среднеквадратическое отклонение
|
Значение tрасч
|
|
1
|
12.57
|
2.54
|
1.59
|
7.88
|
|
2
|
-0.01
|
0
|
0
|
-3.60
|
|
3
|
0.02
|
0
|
0
|
4.07
|
Критические значения t-pаспpеделения пpи 8 степенях свободы имеют
следующие значения:
вероятность t-значение
0.950 1.863
0.990 2.887
В данной модели |tрасч
|> tкритич у всех коэффициентов регрессии
значит можно утверждать, что модель является адекватной моделируемому явлению,
т.е. гипотеза о значимости уравнения не отвергается, о чем говорят также данные
выдаваемые компьютером:
Характеристики остатков
Среднее значение...................………….. -0.000
Оценка дисперсии...................…………. 3.6
Оценка приведенной дисперсии......…. 4.95
Средний модуль остатков...........……… 1.391
Относительная ошибка аппроксимации. 9.898
Критерий Дарбина-Уотсона...........……. 1.536
Коэффициент детерминации...........…… 0.690
F - значение ( n1 = 3, n2 = 8).………. 143
Гипотеза о значимости уравнения не отвергается с вероятностью 0.950
3.4 Вывод
При увеличении количества вид редких рыб , количество посетивших сайт
людей будет увеличиваться . Это означает что в настоящий момент сайт не
полностью удовлетворяет запросы пользователей, и необходимо увеличить
количество видов..
При увеличении загруженности внутренней сети в которой расположен сервер
содержащий исследуемый сайт количество людей посетивших сайт будет уменьшатся
из-за снижения скорости доступа к нему а также из-за возможных перегрузках в
узлах сети, в связи с чем сервер содержащий сайт может не отвечать на запросы
пользователей. Также с перегрузкой связаны различные сбои в работе системы, что
отрицательно сказывается на работе сайта. Коэффициент детерминации у линейной
модели - 0.69. Это означает, что факторы, вошедшие в модель объясняют изменение
количества посетивших сайт людей на 69%. Следовательно значения полученные с
помощью линейной модели близки к фактическим.
Заключение
Всесторонний
анализ темы практической работы показал, что посещаемость сайта относится к
проблемам, решающимся как в социально- экономическом моделировании. Модель
решения относится к статистическим методам, а для учета факторов влияющих на
посещаемость сайта необходимы специальные программные средства. В данной работе
были рассмотрены следующие вопросы: факторы, влияющие на посещаемость сайта;
методы оценки и прогнозирования посещаемости сайта, а также было построено
линейное уравнение регрессии. По совокупности всех рассмотренных задач была
реализована цель, заключающаяся в оценки посещаемости сайта.
Литература
. Google Analytics: профессиональный анализ
посещаемости веб-сайтов.: Пер. с англ. - М.: ООО "И.Д. Вильяме",
2009. - 400 с.: ил. - Парал. тит. англ.
. Теория статистики : учеб. для вузов / под ред. Р. А.
Шмойловой. - М. : Финансы и статистика, 1996. - 464 с.
. Компьютеры, сети, Интернет:Энцикорпедия.2-е изд./Под
общей ред. Ю.Н. Новикова.-СПб.: Питер, 2003.-832 с.: ил.
. Статистическое моделирование и прогнозирование : учеб. пособие для вузов / под ред. А. Г. Гранберга. - М. :
Финансы и статистика, 1990. - 382 с. : ил. - Библиогр.: с. 374-377. - ISBN 5-279-00307-7.
. Статистические методы прогнозирования : учеб.-практ. пособие / Т. А. Дуброва. - М. : [Б. и.], 1998.
- 92 с. - (Система дистанционного образования) - ISBN 5-7764-0064-3.