|
P1
|
P2
|
A
|
|
0
|
0
|
0
|
|
0
|
1
|
1
|
|
1
|
0
|
1
|
|
1
|
1
|
0
|
Что же подразумевается под "линейной неотделимостью" множеств?
Чтобы ответить на этот вопрос, изобразим множество выходных значений в
пространстве входов (см. рисунок 9.10), следуя следующему правилу: сочетания
входов P1 и P2, при которых выход A обращается в нуль, обозначаются кружком, а
те, при которых A обращается в единицу - крестиком.
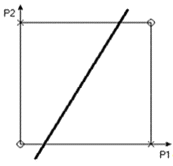
Рисунок 9.10. Состояния логического элемента "исключающее ИЛИ"
Наша цель - провести границу, отделяющую множество нулей от множества
крестиков. Из построенной картины на рисунке 9.10 видно, что невозможно
провести прямую линию, которая бы отделила нули от единиц. Именно в этом смысле
множество нулей линейно неотделимо от множества единиц, и персептроны,
рассмотренные ранее, в принципе, не могут решить рассматриваемую задачу.
Если же использовать персептроны со специальными нелинейными функциями
активации, например, сигмоидными, то решение задачи возможно.
Выберем персептрон с двумя нейронами скрытого слоя, у которых функции
активации сигмоидные, и одним выходным нейроном с линейной функцией активации
(см. рисунок 9.11). В качестве функции ошибки укажем MSE (Mean Square Error -
средний квадрат ошибки). Напомним, что функция ошибки устанавливается в окне
"Создание сети" после выбора типа сети.

Рисунок 9.11 Сеть для решения задачи "исключающего ИЛИ"
Инициализируем сеть, нажав кнопку Initialize Weights на вкладке
Initialize, после чего обучим, указав в качестве входных значений
сформированную ранее переменную data1, в качестве целей - новый вектор,
соответствующий желаемым выходам. В процессе обучения сеть не может обеспечить
точного решения, то есть свести ошибку к нулю. Однако получается приближение,
которое можно наблюдать по кривой обучения на рисунке 9.12.
Следует отметить, что данная кривая может менять свою форму от
эксперимента к эксперименту, но, в случае успешного обучения, характер функции
будет монотонно убывающим.
В результате обучения, ошибка была минимизирована до весьма малого
значения, которое практически можно считать равным нулю.
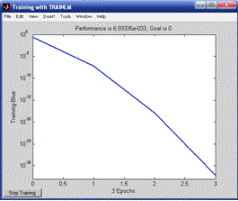
Рисунок 9.12. Кривая обучения в задаче "исключающего ИЛИ"
Задача синтеза элемента "исключающего ИЛИ" является также
примером задачи классификации. Она отражает общий подход к решению подобного
рода задач.
Контрольные
вопросы:
1. Как задать входные и целевые вектора
. Как создать нейронную сеть
. Какую нейронную сеть использовали
. За какое время нейронная сеть достигла цели
нейронний
сеть генетический алгоритм
Лабораторная работа № 10
Создание нейронной сети, выполняющей различные функции
Одним из
самых замечательных свойств нейронных сетей является способность
аппроксимировать и, более того, быть универсальными аппроксиматорами.
Сказанное
означает, что с помощью нейронных цепей можно аппроксимировать сколь угодно точно
непрерывные функции многих переменных.
Задание 1.
Необходимо выполнить аппроксимацию функции следующего вида
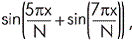
где x € 1÷N, а N - число точек функции.
Заготовим целевые данные, введя в поле "Значение" (Value) окна
создания новых данных выражение:
(5*pi*[1:100]/100+sin(7*pi*[1:100]/100)).
Эта кривая представляет собой отрезок периодического колебания с частотой
5p/N, модулированного по фазе гармоническим колебанием с частотой 7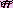 N (см. рис. 10.1).
N (см. рис. 10.1).
Теперь заготовим набор обучающих данных (1, 2, 3, …, 100), задав их
выражением: 1:100.
Выберем персептрон (Feed-Forward Back Propa-gation) c тринадцатью
сигмоидными (TANSIG) нейронами скрытого слоя и одним линейным (PURELIN)
нейроном выходного слоя.
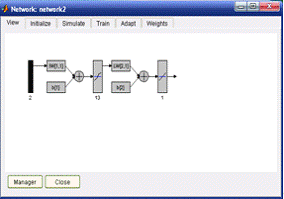
Рисунок 10.1 Архитектура сети для решения задачи аппроксимации
Обучение будем производить, используя алгоритм Левенберга-Маркардта
(Levenberg-Mar-quardt), который реализует функция TRAINLM. Функция ошибки - MSE.
Полученная сеть имеет вид (см. рисунок 10.2).
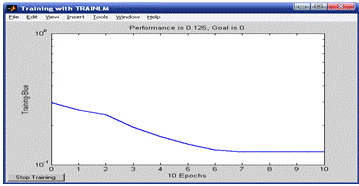
Рисунок 10.2. Кривая обучения в задаче аппроксимации
Теперь приступаем к обучению. Для этого необходимо указать, какие наборы
данных должны использоваться в качестве обучающих и целевых, затем провести
обучение (см. Рис. 10.2). Рисунок 10.3 иллюстрирует разницу между целевыми
данными и полученной аппроксимирующей кривой.
Из рисунков 10.2 и 10.3 видно, насколько уменьшилась ошибка аппроксимации
за 100 эпох обучения. Форма кривой обучения на последних эпохах говорит также о
том, что точность приближения может быть повышена.
Одной из популярных областей применения нейронных сетей является
распознавание образов. Аппроксимационные возможности NN играют здесь
первостепенную роль.
Задание - 2. Необходимо построить и обучить нейронную сеть для решения
задачи распознавания цифр. Цель этой лабораторной работы - показать общий
подход к решению задач распознавания образов. Поэтому, чтобы не загромождать
изложение техническими деталями, обозначим лишь ключевые моменты, полагая, что
на данном этапе студент готов самостоятельно произвести соответствующие
действия с NNTool.
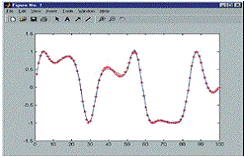
Рисунок 10.3 Красная кривая - целевые данные, синяя кривая -
аппроксимирующая функция
Система, которую предстоит синтезировать с помощью нейронной сети, будет
обучена воспринимать символы, близкие к шаблонным (см. рисунок 10.4).
Рисунок 10.4 Монохромное изображение исходных данных
Наборы исходных данных (не путать с целевыми данными) можно как загружать
из файлов изображений, так и создавать непосредственно в MATLAB. Рисунок 10.5
иллюстрирует содержимое массива исходных данных.

Рисунок 10.5 Графическое представление массива исходных данных
Получим обучающие данные, наложив шум на набор исходных данных (см.
рисунок 10.6).

Рисунок 10.6. Обучающие данные
В задачах классификации, к которым относится данный пример, количество выходов
сети соответствует числу разделяемых сетью классов. Этот факт должен быть учтён
при выборе архитектуры сети и на этапе формирования целевых данных.
Сеть классификации даёт наибольшее значение на выходе, который
соответствует подходящему классу. При хорошо сконструированной и обученной NN
значения других выходов будут заметно меньше.
Для решения этой задачи выбрана сеть Feed-forward backprop с пятью
сигмоидными нейронами первого слоя и пятью линейными нейронами второго слоя.
Алгоритм обучения - Левенберга-Маркардта. С такой конфигурацией сеть после
восьми эпох обучения дала ошибку порядка 10-30.Чтобы удостовериться в
правдивости результата, мы прогнали сеть на заготовленном контрольном
множестве. Сеть безукоризненно разделила и новую выборку зашумлённых символов.
Отметим, что уже сейчас успешно разрабатываются разнообразные системы
распознавания образов (визуальных, звуковых), базирующиеся на нейронных сетях.
Примером могут послужить программы распознавания сканированного текста. Они
достаточно широко распространены среди обладателей оптических сканеров и в
реальном масштабе времени справляются с поставленными задачами.
Задание-3. Создать нейронную сеть, выполняющую задачу импорта-экспорта
данных. На практике часто приходится пере носить данные с одного компьютера на
другой или пользоваться внешними, по отношению к NNTool, средствами обработки
данных. В связи с этим возникает необходимость сохранения результатов работы и
загрузки данных. Не менее важен обмен данными между NNTool и MATLAB, поскольку
пространства их переменных не пересекаются.
Эти задачи решают средства импорта-экспорта и загрузки-сохранения данных.
Доступ к ним осуществляется через главное окно NNTool (см. Рис. Л8.1)
посредством кнопок Import и Export.
Импорт. Источником служит переменная в рабочем пространстве MATLAB, а
пунктом назначения - переменная в рабочем пространстве NNTool. Нажав кнопку
Import, попадаём в окно "Импорта-за-грузки данных" (Import or Load to
Network/Data Manager). По умолчанию здесь установлена опция загрузки из рабочего
пространства MATLAB, поэтому в центре окна появляется список принадлежащих ему
переменных.
Выбрав мышью нужную переменную в поле "Выбор переменной"
(Select a Variable), - ей можно задать произвольное имя в поле "Имя"
(Name), под которым она будет скопирована в NNTool.
Когда переменная выделена, NNTool анализирует её тип и делает доступными
для выбора те "Категории данных" (Import As), которые поддерживаются.
Указав одну из них, следует нажать кнопку "Импортировать"
(Import), чтобы завершить копирование. После того, как все действия успешно
проведены, имя импортируемой переменной появится в одном из списков главного
окна NNTool.
Загрузка из файла. Здесь источник - файл. При этом важно, чтобы его
формат поддерживался NNTool. В подходящем формате хранятся так называемые
MAT-файлы. Они содержат бинарные данные и позволяют MATLAB сохранять переменные
любых поддерживаемых типов и размерностей. Такие файлы могут создаваться,
например, в процессе работы с NNTool. Чтобы загрузить переменные из MAT-файла в
NNTool, необходимо открыть окно импорта, нажав кнопку "Import"
главного окна NNTool. Затем следует отметить опцию "Загрузить из
файла" (Load from disk file) и, нажав "Обзор" (Browse), открыть
файл с данными, хранящимися в формате MAT-файлов.
Чаще всего, это файлы с расширением MAT. В результате, список в окне
импорта заполнится именами переменных, сохранённых в указанном MAT-файле.
Дальнейшая последовательность действий полностью совпадает с описанной в пункте
Импорт (см. рис. 10.7).
Экспорт. Эта функция копирует заданные переменные из NNTool в рабочее
пространство MATLAB. Она доступна по нажатию кнопки Export главного окна
NNTool. В окне экспорта единым списком перечислены переменные всех категорий,
представленных в NNTool.
Здесь необходимо выделить те из них, которые подлежат экспорту, и нажать
Export. Теперь выделенные переменные скопированы в рабочее пространство MATLAB.
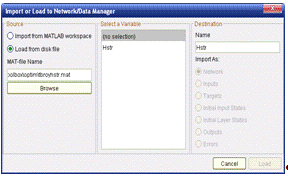
Рисунок 10.7.
Окно импорта и загрузки данных из MAT-файла
Сохранение в
файле. В целом, процедура схожа с экспортом, за одним исключением: отметив
переменные, следует нажать кнопку "Сохранить" (Save). Тогда появится
окно, в котором можно задать имя файла. Его можно указать без расширения - по
умолчанию NNTool прикрепит расширение MAT. Это связано с тем, что NNTool
сохраняет данные только в формате MAT-файлов (см. рисунок 10.8).
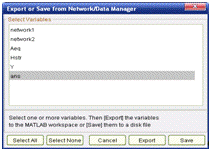
Рисунок 10.8 Окно экспорта и сохранения данных в MAT-файле
Мы рассмотрели простейшие задачи синтеза цепей и обработки сигналов, для
решения которых применялись наиболее популярные нейронные сети прямого
распространения. На самом деле, NNTool позволяет решать значительно более
широкий круг задач, предоставляя возможность использовать сети разнообразных
архитектур, с памятью и без, с обратными связями и без таковых. При этом
следует иметь ввиду, что успех во многом зависит от понимания поведения
конструируемых сетей и их аппроксимационных возможностей.
Контрольные вопросы:
. Как задали входные данные для аппроксимации
. Какое количество слоев в нейронной сети для аппроксимации
. Сколько нейронов в слое для аппроксимации
. Опишите процесс экспорта и импорта файлов
Лабораторные работы №11
«Создание однонаправленной сети»
Цель занятия - продемонстрировать основные этапы реализации
нейронно-сетевого подхода для решения конкретной задачи. Можно выделить 4
основных этапа:
Задание:
. Подготовка данных для тренировки сети.
. Создание сети.
. Обучение сети.
. Тестирование сети.
. Моделирование сети. (Использование сети для решения поставленной
задачи.)
. Необходимо изменить значения параметров С, A и S.
В качестве примера рассмотрим следующую задачу: Задан массив, состоящий
из нескольких значений функции (S>0) на интервале (0,1). Создать нейронную
сеть такую, что при вводе этих значений на входы сети на выходах получались бы
значения параметров С, A и S.
Подготовка данных для обучения сети. В первую очередь необходимо
определиться с размерностью входного массива. Выберем количество значений
функции равным N=21, т.е. в качестве входных векторов массива используем
значения функции y в точках х=0.05; …1.0. Для обучения сети необходимо
сформировать массив входных векторов для различных наборов параметров С, A и S.
Каждый набор этих параметров является вектором-эталоном для соответствующего
входного вектора.
Для подготовки входного и эталонного массивов воспользуемся следующим
алгоритмом. Выбираем случайным образом значения компонент вектора - эталона С,A
S и вычисляем компоненты соответствующего входного вектора. Повторяем эту
процедуру М раз и получаем массив входных векторов в виде матрицы размерностью
NxM и массив векторов - эталонов в виде матрицы размерностью в нашем случае
3хМ. Полученные массивы мы можем использовать для обучения сети.
Прежде чем приступать к формированию обучающих массивов необходимо
определиться с некоторыми свойствами массивов.
Диапазон изменения параметров С, A, S. Выберем диапазоны изменения
параметров C, A, S равными (0, 1, 1). Значения, близкие к 0 и сам 0 исключим в
связи с тем, что функция не определена при S=0. Второе ограничение связано с
тем, что при использовании типичных передаточных функций желательно, чтобы
компоненты входных и выходных векторов не выходили за пределы диапазона (-1,
1). В дальнейшем мы познакомимся с методами нормировки, которые позволяют
обойти это ограничение.
Количество входных и эталонных векторов выберем равным М=100. Этого
достаточно для обучения, а процесс обучения не займет много времени. Тестовые
массивы и эталоны подготовим с помощью программы mas1: % формирование входных
массивов (входной массив P) и (эталоны T):
P=zeros(100,21);=zeros(3,100);=0:5.e-2:1;i=1:100=0.9*rand+0.1;=0.9*rand+0.1;=0.9*rand+0.1;
(1,i)=c;(2,i)=a;(3,i)=s;(i,:)=c*exp(-((x-a).^2/s));;
P=P'.
С помощью этой программы формируется матрица P из M=100 входных
векторов-столбцов, каждый из которых сформирован из 21 точки исходной функции
со случайно выбранными значениями параметров C,A,S, и матрица T эталонов из 100
эталонных векторов-столбцов, каждый из которых сформирован из 3 соответствующих
эталонных значений. Матрицы P и T будут использованы при обучении сети. Следует
отметить, что при каждом новом запуске этой программы будут формироваться
массивы с новыми значениями компонентов векторов, как входных, так и эталонных.
Создание сети. Вообще, выбор архитектуры сети для решения конкретной задачи
основывается на опыте разработчика. Поэтому предложенная ниже архитектура сети
является одним вариантом из множества возможных конфигураций. Для решения
поставленной задачи сформируем трехслойную сеть обратного распространения,
включающую 21 нейрон во входном слое (по числу компонент входного вектора) с
передаточной функцией logsig, 15 нейронов во втором слое с передаточной
функцией logsig и 3 нейрона в выходном слое (по числу компонентов выходного
вектора) с передаточной функцией purelin. При этом в качестве обучающего
алгоритма выбран алгоритм Levenberg-Marquardt (trainlm). Этот алгоритм
обеспечивает быстрое обучение, но требует много ресурсов. В случае, если для
реализации этого алгоритма не хватит оперативной памяти, можно использовать
другие алгоритмы (trainbfg, trainrp, trainscg, traincgb, traincgf,
traincgp,trainoss,traingdx). По умолчанию используется trainlm. Указанная сеть
формируется с помощью процедуры:
net=newff(minmax(P),[21,15,3],{'logsig' 'logsig'
'purelin'},'trainlm');
Первый аргумент - матрица Mx2 минимальных и максимальных значений
компонент входных векторов вычисляется с помощью процедуры minmax. Результатом
выполнения процедуры newff является объект - нейронная сеть net заданной
конфигурации. Сеть можно сохранить на диске в виде mat. файла с помощью команды
save и загрузить снова с помощью команды load. Более подробную информацию о
процедуре можно получить, воспользо-вавшись командой help. Обучение сети.
Следующий шаг - обучение созданной сети. Перед обучением необходимо задать параметры
обучения. Задаем функцию оценки функционирования sse.
.performFcn='sse';
В этом случае в качестве оценки вычисляется сумма квадратичных отклонений
выходов сети от эталонов. Задаем критерий окончания обучения значение
отклонения, при котором обучение будет считаться законченным:
.trainParam.goal=0.01;
Задаем максимальное количество циклов обучения. После того, ка будет
выполнено это количество циклов, обучение будет завершено:
.trainParam.epochs=1000;
Теперь можно начинать обучение: net,tr]=train(net,P,T).
Процесс обучения иллюстрируется графиком зависимости оценки
функционирования от номера цикла обучения (см. рисунок 11.1).
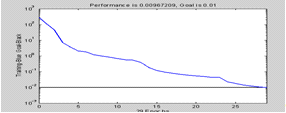
Рисунок 11.1. Результаты обучения
Таким образом, обучение сети окончено. Теперь эту сеть можно сохранить в
файле nn1.mat: save nn1 net;
Тестирование сети. Перед тем, как воспользоваться нейронной сетью,
необходимо исследовать степень достоверности результатов вычислений сети на
тестовом массиве входных векторов. В качестве тестового массива необходимо
использовать массив, компоненты которого отличаются от компонентов массива,
использованного для обучения. В нашем случае для получения тестового массива
достаточно воспользоваться еще раз программой mas1.
Для оценки достоверности результатов работы сети можно воспользоваться
результатами регрессионного анализа, полученными при сравнении эталонных
значений со значениями, полученными на выходе сети, когда на вход поданы
входные векторы тестового массива. В среде MATLAB для этого можно
воспользоваться функцией postreg. Следующий набор команд иллюстрирует описанную
процедуру:
>> mas1 - создание тестового массива P;
>> y=sim(net,P) - обработка тестового массива;
>> [m,b,r]=postreg(y(1,:),T(1,:)) - регрессионный анализ
результатов обработки.
Сравнение компонентов С эталонных векторов с соответствующими
компонентами выходных векторов сети. На рисунке 11.2 видно, что все точки легли
на прямую - это говорит о правильной работе сети на тестовом массиве
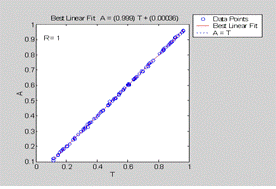
Рисунок 11.2. Сравнение компонентов С эталонных векторов с
соответствующими компонентами выходных векторов сети
>> [m,b,r]=postreg(y(2,:),T(2,:));
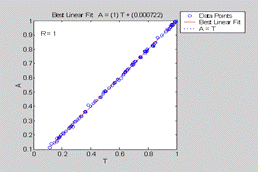
Рисунок 11.3 Сравнение компонентов А эталонных векторов с
соответствующими компонентами выходных векторов сети
>> [m,b,r]=postreg(y(3,:),T(3,:));
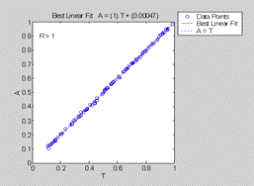
Рисунок 11.4 Сравнение компонентов S эталонных векторов с соответствующими компонентами выходных
векторов сети
Как видно из рисунков 11.2-11.4, наша сеть отлично решает поставленную
задачу для всех трех выходных параметров. Сохраним обученную сеть net на диске
в файл nn1.mat save nn1 net
Моделирование сети. (Использование сети для решения поставленной задачи.
Для того, чтобы применить обученную сеть для обработки данных, необходимо
воспользоваться функцией sim:
=sim(net, p);
где p - набор входных векторов, Y - результат анализа в виде набора
выходных векторов. Например, пусть
С=0.2, A=0.8, S=0.7, тогда=0.2*exp(-((x-0.8).^2/0.7)).
Подставив этот входной вектор в качестве аргумента функции sim:
Y=sim(net,p), получим:
Y= 0.2048 (C)
.8150 (A)
.7048 (S)
Что весьма близко к правильному результату (0.2; 0.8; 07).
Контрольные вопросы:
. Каким образом выбираем значения компонент вектора - эталона С, A S
. Из какого количества столбцов формируются матрицы P и Т
. Какие параметры использовали для обучения сети
. Какой массив использовали в качестве тестового массива
Лабораторная работа №12
Сравнительный анализ моделей управления, созданных с помощью нечеткого
алгоритма и нейронной сети
Цель: Провести сравнительный анализ нечеткой логики и нейронной сети на
примере печи кипящего слоя и выяснить, какая из систем лучше. (Вывод
обязателен)
Система управления процессом обжига цинковых концентратов в печи кипящего
слоя. Если процесс стабилизации температуры и подсистемы оптимального
управления хорошо описываются с помощью традиционного математического описания,
то процесс гидродинамики кипящего слоя из-за своей сложности трудно поддается
математической обработке. Поэтому предлагается создать гибридную систему
управления с использованием как традиционных подходов регулятор и подсистема
оптимального управления, так и методов искусственного интеллекта (подсистема
управления манометрическим режимом).
Система управления процессом обжига (см. рисунок 13.1) состоит из
регулятора температуры, подсистемы оптимального управления кинетикой химических
реакций и подсистемы управления манометрическим режимом кипящего слоя.
Технологической задачей процесса обжига цинковых концентратов является перевод
сульфидного цинка, в структурно свободную окись и частично в сульфат, которые
легко перерабатываются при выщелачивании и дают максимальное извлечение цинка,
за минимальный промежуток времени и с наименьшими затратами.
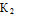

Рисунок 13.1 Структура гибридной системы управления процессом обжига
цинковых огарков в печи кипящего слоя
Задание. В связи с тем, что подсистема оптимального управления процессом
основана на достаточно точном математическом описании кинетики обжига и
известных алгоритмах оптимизации в работе требуется исследовать алгоритм
управления для интеллектуальной подсистемы управления манометрическим режимом в
печи кипящего слоя. Необходимо исследовать модели управления гидродинамикой
кипящего слоя, основанных на нечетких алгоритмах и нейронных сетях и сравнить
их.
Используя знания в области ведения процесса обжига в печи кипящего слоя
(КС) предлагаются следующие 10 правил нечетких продукций:
ПРАВИЛО-1: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя
средняя» И «разрежение под сводом среднее» ТО «расход воздуха средний»
ПРАВИЛО-2: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя
средняя» И «разрежение под сводом высокое» ТО «расход воздуха высокий»
ПРАВИЛО-3: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя низкая»
И «разрежение под сводом среднее» ТО «расход воздуха средний»
ПРАВИЛО-4: ЕСЛИ «упругость дутья низкая» И «высота кипящего слоя средняя»
И «разрежение под сводом среднее» ТО «расход воздуха средний»
ПРАВИЛО-5: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя
высокая» И «разрежение под сводом низкое» ТО «расход воздуха низкий»
ПРАВИЛО-6: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя низкая»
И «разрежение под сводом высокое» ТО «расход воздуха высокий»
ПРАВИЛО-7: ЕСЛИ «упругость дутья низкая» И «высота кипящего слоя средняя»
И «разрежение под сводом высокое» ТО «расход воздуха высокий»
ПРАВИЛО-8: ЕСЛИ «упругость дутья высокая» И «высота кипящего слоя средняя»
И «разрежение под сводом высокое» ТО «расход воздуха высокий»
ПРАВИЛО-9: ЕСЛИ «упругость дутья высокая» И «высота кипящего слоя
высокая» И «разрежение под сводом высокое» ТО «расход воздуха средний»
ПРАВИЛО-10: ЕСЛИ «упругость дутья средняя» И «высота кипящего слоя
средняя» И «разрежение под сводом высокое» ТО «расход воздуха высокий»
Исследование нечеткой модели управления. Для исследования этой модели
надо нормировать значения используемых переменных для работы интеллектуальной
подсистемы по следующей формуле:
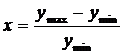
где
уmin - минимальное значение; уmax - максимальное значение; х - преобразованное
значение;
После
проведения операции нормирования все переменные будут изменятся от 0 до1. В
качестве терм-множества для трех входных лингвистических переменных
используется множество {«низкий», «средний», «высокий»}, которое записывается в
символическом виде {nizkoe, srednee, visokoe}. В качестве терм-множества выходной лингвистической
переменной используется множество {«низкий», «средний», «высокий»}, которое
записывается в символическом виде {nizkoe, srednee, visokoe}
(см. рисунок 13.2).
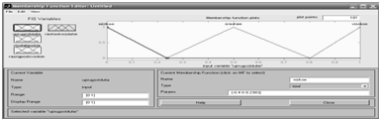
Рисунок
13.2 Графический интерфейс редактора функций принадлежности после задания
первой входной переменной
В
редакторе FIS определяем три входные переменные с именами «упругость дутья»
(uprugostdutya), высота кипящего слоя (vysotakipsloya) и разрежение под сводом
(razrigpodsvodom) и одну выходную переменную с именем расход
воздуха (rashodvozduha).
Зададим
10 правил для разрабатываемой системы нечеткого вывода (см. рисунок 13.3).
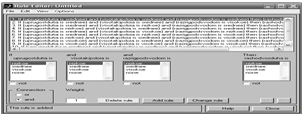
Рисунок 13.3 Графический интерфейс редактора правил после задания базы
правил для данной системы нечеткого вывода
Теперь можно выполнить оценку построенной системы нечеткого вывода для
задачи автоматического управления расходом воздуха. Для этого откроем программу
просмотра правил системы Matlab и введем значения входных переменных для
частного случая, когда упругость дутья равна 0.5, высота кипящего слоя 0.5 и
разрежение под сводом 0.5. Процедура нечеткого вывода выдает в результате
значение выходной переменной «расход воздуха», равное 0,526 (см. рисунок 13.4).
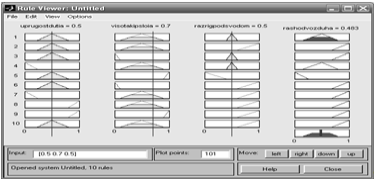
Рисунок 13.4. Графический интерфейс программы просмотра правил после
выполнения процедуры нечеткого вывода
Данное значение соответствует высокому расходу воздуха.
Также если значения входных переменных будут определяться как «не очень
низкая» или «не очень высокая», которые мы не определяли в правилах, результат
соответствует тому значению выходной переменной, которая на практике ведения
процесса бывает в таких случаях.
А теперь решим задачу синтеза интеллектуальной подсистемы с
использованием нейронных сетей.
Для чего составим таблицу истинности обучения нейронной сети
Таблица 13.1 Таблица истинности для обучения нейронной сети
|
№
|
Входные данные
|
Цель обучения
|
|
Упругость дутья
|
Высота кипящего слоя
|
Разряжение под сводом
|
Расход воздуха
|
|
0.5
|
0.5
|
0.5
|
0.5
|
|
0.5
|
0.5
|
1
|
1
|
|
0.5
|
0
|
0.5
|
1
|
|
0
|
0.5
|
0.5
|
0.5
|
|
0.5
|
1
|
0
|
0
|
|
0.5
|
0
|
1
|
1
|
|
0
|
0.5
|
1
|
1
|
|
1
|
0.5
|
1
|
1
|
|
1
|
1
|
1
|
1
|
|
0.5
|
0.5
|
1
|
1
|
Для обучения нейронной сети вводим данные из таблицы 13.1, а затем
создаем нейронную сеть. В поле (см. рисунок 13.5) входные данные указываем
заранее созданные данные, задаем тип нейронной сети, выберем персептрон
(Feed-Forward Back Propa-gation) c 10 сигмоидными (TANSIG) нейронами скрытого
слоя и одним линейным (PURELIN) нейроном выходного слоя.
Обучение будем производить, используя алгоритм Левенберга-Маркардта
(Levenberg-Mar-quardt), который реализует функция TRAINLM. Функция ошибки -
MSE, число слоев соответственно равно 2.
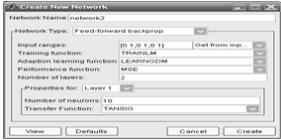
Рисунок 13.5. Создание нейронной сети
Теперь необходимо обучить сеть для ее дальнейшего применения, задаем
входные и целевые данные, затем указываем параметры обучения, программа покажет
прогресс и итог обучения как показано на рисунке 13.6.
Сравним результаты моделирования полученных данных нейронной сети и
нечеткой модели. Результаты показали: нейронные сети и нечеткие модели подходят
для внедрения в данную систему управления, но чтобы выяснить какие все-таки
лучше надо провести сравнение.
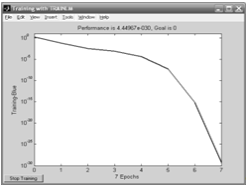
Рисунок 13.6. Итог обучения
Таким образом, мы обучили нейронную сеть и создали нечеткую модель, и
теперь необходимо провести сравнительный анализ результатов расчета по этим
двум моделям и запишем их в таблицу 13.2.
Таблица 13.2
Таблица сопоставления ответов нейронной сети и нечеткой логики
|
№
|
Нейронная сеть
|
Нечеткая логика
|
Правильный ответ
|
|
|
|
0.5
|
|
|
|
0
|
|
|
|
0.25
|
|
|
|
0.75
|
|
|
|
1
|
|
|
|
0.7
|
|
|
|
0.6
|
|
|
|
0.25
|
|
|
|
0.6
|
|
|
|
0.55
|
|
|
|
0.45
|
|
|
|
0.4
|
|
|
|
0.6
|
|
|
|
0.4
|
|
|
|
0.77
|
|
|
|
0.8
|
|
|
|
0.45
|
|
|
|
0.35
|
|
|
|
0.15
|
|
|
|
0.07
|
|
|
|
0.4
|
|
|
|
0.2
|
|
|
|
0
|
|
|
|
0
|
|
|
|
1
|
|
|
|
1
|
|
|
|
0.85
|
|
|
|
0.75
|
|
|
|
1
|
|
|
|
1
|
|
|
|
0.85
|
|
|
|
0.6
|
|
|
|
1
|
Теперь зададим в качестве входных данных величины из заданного нами
интервала, и посмотрим, как будет реагировать нейронная сеть и нечеткая логика
(см. таблицу 13.3).
Таблица 13.3 Таблица ответов нейронной сети и нечеткой логики при входных
переменных из заданного интервала
|
№
|
Заданные переменые
|
Ответы
|
Интервал правильных ответов
|
|
|
Нейронная сеть
|
Нечеткая логика
|
|
|
1
|
[0 0 0,15]
|
|
|
(1-0.75)
|
|
2
|
[1 1 0,5]
|
|
|
(0-0.75)
|
|
3
|
[0,62 0 1]
|
|
|
(0.5-1)
|
|
4
|
[0 0,38 0]
|
|
|
(0.1-0.75)
|
|
5
|
[0,62 0,25 0,84]
|
|
|
(0.25-1)
|
Теперь необходимо проанализировать таблицу 13.3 и сделать заключение о
том, какая из моделей (ЭС или НС) более точно описывает поведение данной
системы.
Контрольные вопросы:
. Сколько правил, по вашему мнению, необходимо добавить для получения
более гибкого анализа системы
. Какой показатель сильнее всего влияет на расход воздуха
. В чем преимущества и недостатки нечеткой логики
4. В
чем преимущества и недостатки нейронной сети
Лабораторная работа №13
Создание экспертной модели управления с использованием метода
планирования эксперимента
Применительно к процессу Ванюкова при безокислительной плавке сульфидного
сырья физико-химические и гидродинамические модели не созданы по ряду
объективных причин. Несмотря на это, процессы функционируют и успешно
управляются операторами, осуществляющими выбор управляющих воздействий на
основании опыта, т.е. неформализованной модели процесса, существующей в их
сознании. Таким образом, при исследовании указанных процессов возникает
необходимость учета качественной информации, которая зачастую является
определяющей, хотя и не поддается точному описанию, т.е. является нечеткой по
своей сути.
В связи с этим возникает задача построения управляющей модели в нечеткой
среде на основе знаний технологов о моделируемом процессе с использованием
лингвистических переменных (ЛП). Эксперту удобнее всего представлять свои
знания в виде причинно-следственных связей «Если …, то …». Так, например,
эксперт описывает свои действия при управлении: «Если влажность концентрата
высокая, то увеличить общее дутье или уменьшить скорость подачи шихты».
Понятие ЛП дает подходящее средство для описания различных процессов, в частности
интеллектуальной деятельности человека. Для логико-лингвистического описания
поведения системы будем считать причины входными параметрами, а следствия -
выходными. например, влажность концентрата станет ЛП, если она ассоциируется с
терм- множеством значений: низкая, ниже средней, средняя, выше средней,
высокая.
Лингвистические переменные могут использоваться при опросе эксперта на
основании теории планирования эксперимента в качестве входных (Хi) и выходных (Yj) переменных и параметров управления с
дальнейшей аппроксимацией результатов аналитической функцией в виде полинома
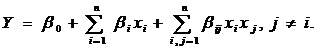
При
применении значений ЛП в качестве точек факторного пространства,
характеризующих процесс, поведение исследуемой системы описывается экспертом на
естественном (или близком к нему) языке. Это делает ЛП наиболее адекватным
средством представления экспертных знаний, так как переход от словесных оценок
к числовым не вызывает затруднений по любой из шкал.
Множество
пар «ситуация-действие» задается в вершинах гиперкуба по методам планирования
эксперимента. Алгоритм построения управляющей модели приведен на рисунке 14.1.
Для реализации данной схемы необходимо использовать методы теории нечетких
множеств и теории планирования эксперимента, элементы которых приведены ниже.
Элементы
теории планирования экспериментов. Под экспериментом будем понимать
совокупность операций совершаемых над объектом исследования с целью получения
информации о его свойствах. Важнейшей задачей методов обработки полученной в
ходе эксперимента информации является задача построения математической модели
изучаемого явления, процесса, объекта. Ее можно использовать и при анализе
процессов и при проектировании объектов. Можно получить хорошо аппроксимирующую
математическую модель, если целенаправленно применяется активный эксперимент.
Другой задачей обработки полученной в ходе эксперимента информации является
задача оптимизации, т.е. нахождения такой комбинации влияющих независимых
переменных, при которой выбранный показатель оптимальности принимает
экстремальное значение.
Опыт
- это отдельная экспериментальная часть. План эксперимента - совокупность
данных определяющих число, условия и порядок проведения опытов. Планирование
эксперимента - выбор плана эксперимента, удовлетворяющего заданным требованиям,
совокупность действий направленных на разработку стратегии экспериментирования
(от получения априорной информации до получения работоспособной математической
модели или определения оптимальных условий). Это целенаправленное управление
экспериментом, реализуемое в условиях неполного знания механизма изучаемого
явления. Цель планирования эксперимента - нахождение таких условий и правил
проведения опытов при которых удается получить надежную и достоверную
информацию об объекте с наименьшей затратой труда, а также представить эту
информацию в компактной форме с количественной оценкой точности.
Пусть
интересующее нас свойство (Y) объекта зависит от нескольких независимых переменных
(X1, X2,,…, Xn) и мы хотим выяснить характер этой зависимости - Y=F(X1, X2,,…,
Xn), о которой мы имеем лишь общее представление.
Величина Y - называется «отклик», а сама зависимость Y=F(X1, X2,,…,
Xn) - «функция отклика».
Регрессионный
анализ функции отклика предназначен для получения ее математической модели в виде
уравнения регрессии
Y=F(X1 , X2,,…, Xn;B1,B2,,…,Bm)+e,
где
B1,B2,,…,Bm - некоторые коэффициенты; e - погрешность.
Функция
отклика может быть выражена через кодированные факторы Y= f(x1, …
,xn) и записана в полиномиальном виде
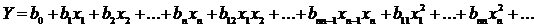
Очевидно,
что Bi≠bi ,но
Y=F(X1, …
, Xi, … , Xn) = f(x1 , … , xi , … , xn).
Для
полинома, записанного в кодированных факторах, степень влияния факторов или их
сочетаний на функцию отклика определяется величиной их коэффициента bi.
Для полинома в именованных факторах величина коэффициента Bi
еще не может быть записана более компактной форме
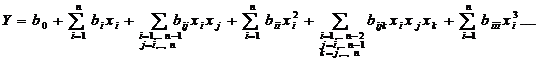 .
.
При
определении общего числа членов степенного ряда количество парных сочетаний для
n факторов в полиноме, тройных сочетаний, i-ых
сочетаний (Cin) при n>i находится по соотношению
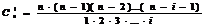 .
.
Например,
для набора четырех чисел (n=4) - 1, 2, 3, 4 число тройных сочетаний составляет
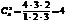 - 123,
134, 124, 234.
- 123,
134, 124, 234.
Если
считать, что существует фактор х0 всегда равный 1, то
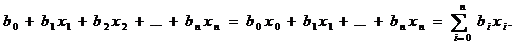
Если
дополнительно все двойные, тройные и т.д. сочетания факторов, а также квадраты
факторов и все соответствующие и коэффициенты обозначить через xi и bi ,
для i=n+1, ... , m, то степенной ряд можно
записать в виде
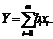
Здесь
m+1 общее число рассматриваемых членов степенного ряда.
Для
линейного полинома с учетом всех возможных сочетаний факторов

Полный
квадратичный полином выглядит следующим образом:
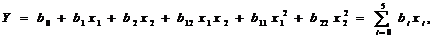
где
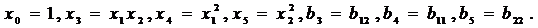
Матричные
преобразования при обработке результатов эксперимента. При матичной записи
результатов различных N опытов для полиномиального представления результата
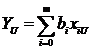
будем
иметь в виде
Y=X∙B
где
x - матрица сочетаний факторов
X= 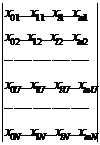
N строк и m+1
столбец
Здесь
0,1, … ,i, … , m - номера членов уравнения; I, … , U, …
, N… - номера опытов. Матрица Х элементы x0U=1, U=1,…,
N, то матрицу Х можно записать
Х=
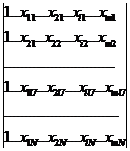 .
.
матрица
столбец результатов опыта,
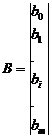 -
матрица столбец коэффициента полинома.
-
матрица столбец коэффициента полинома.
Домножим
левую и правую части этого равнения на одну и ту же матрицу Xt -
транспонированную матрицу Х
Xt∙X∙B=Xt∙Y.
Транспонированная
матрица - это матрица, у которой по отношению к исходной матрице столбцы и
строки поменяны местами.
Xt=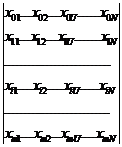
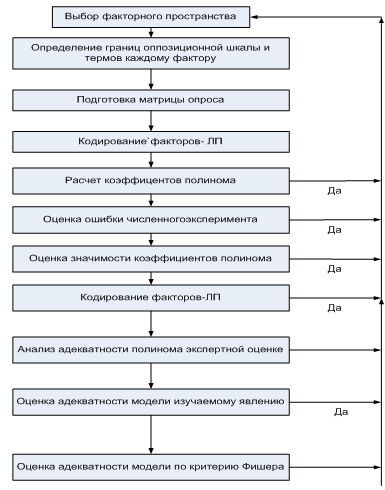
Рисунок
14. Алгоритм построения управляющей модели
m+1
строка и N столбцов.
C=Xt∙X матрица, получившаяся в результате произведения
траспонированной матрицы на исходную. Она является квадратной матрицей,
содержащей m+1 строку и m+1 столбец.
C∙B=Xt∙Y.
Для того чтобы получить в общем виде матрицу-столбец коэффициентов В
необходимо домножить обе части последнего матричного уравнения слева на матрицу
С-1 - матрицу обратную матрице С.
C-1∙C∙B=C-1∙Xt∙Y.
Обратная матрица строится так (используется процедура обращения матрицы),
что при умножении ее на исходную матрицу получается единичная матрица - Е, у
которой на главной диагонали расположены 1, а вне ее - 0.
С-1∙С=Е=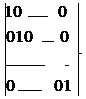
Окончательная
в общем виде матрица-столбец коэффициентов полинома
B=C-1∙Xt∙Y.
Рассмотрим
в качестве простого примера полином в виде
YU=b0x0+b1xU; x0=1; U=1,…, N;
формируемого по результатам N опытов
X=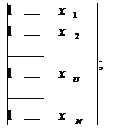 Y=
Y= B=
B= Xt=
Xt=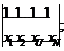 =Xt∙X=
=Xt∙X=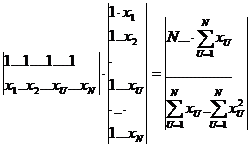 ;∙B=
;∙B=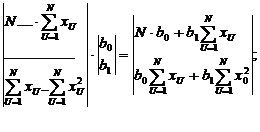 ∙Y=
∙Y=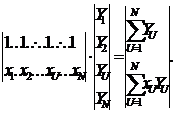 ∙B=Xt∙Y;
∙B=Xt∙Y;
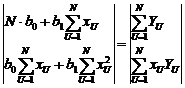 или
или 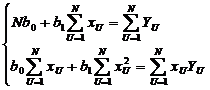
Откуда решение системы относительно коэффициентов b0 и b1
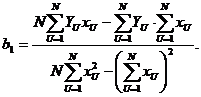
Этот
результат полностью совпадет с соотношениями для такого же полинома при
использовании метода наименьших квадрантов, где используется численный
показатель минимальности суммы квадрантов отклонений во всех N
опытах. Следовательно, построенный таким образом полином будет проходить самым
ближайшим образом к результатам эксперимента.
Существуют
несколько видов планирования эксперимента:
ортогональное
планирование эксперимента;
планы
полного факторного эксперимента 2n (планы ПФЭ 2n );
планы
дробного факторного эксперимента (планы ДФЭ);
насыщенные
планы первого порядка;
планы
второго порядка;
ортогональный
центрально-композиционный план второго порядка;
рототабельные
планы;
рототабельный
ортогональный центрально-композиционный план;
планы
второго порядка с единичной областью планирования;
рототабельный
план на основе правильного многоугольника n=2.
Разработка
алгоритма нечеткого управления плавкой в ПВ
При
построениях управляющей модели процессом безокислительной плавки медного
концентрата цеха разделения файнштейна (ЦРФ) в качестве экспертов выступали
квалифицированные операторы и технологи.
В
результате их опроса были выявлены следующие переменные, используемые при
управлении процессом:
Х1
- скорость загрузки концентрата;
Х2
- соотношение дутье-загрузка, нм3/т;
Х3
- обогащение дутья кислородом, %;
Х4
- влажность концентрата;
Х5
- разность температур воды на входе и выходе, 0С.
В
качестве выходного параметра была выбрана уставка скорости загрузки Y,
т/ч.
План
опроса представлял собой набор продукционных правил типа «ситуация-действие».
Была реализована матрица полного факторного эксперимента типа 25. Ситуация
задавались в следующей форме: «если Х1 - низкая, Х2 - высокое, Х3 - низкое,Х4 -
высокая, Х5 - высокая, то Y - ? »
Числовые
значения Y представлены в виде унимодальных нечетких чисел (L-R).
Лингвистическая переменная Y - скорость загрузки концентрата.
Математической
обработкой результатов опроса по матрице планирования получена следующая
зависимость:
Y=16,06+1,63Х1+4,5Х2+4Х5-1,81Х1
Х2+1 Х1Х3+2,06 Х2Х4-2 Х3 Х5+0,69 Х4 Х5 (1)
Таблица
13.4 Матрица полного факторного эксперимента типа 25
|
N
|
Загрузка Х1
|
Дутье Х2
|
Кислород в КВС Х3
|
Влажность концентрата Х4
|
Температура воды Х5
|
Скорость загрузки Y
|
|
1
|
-1
|
-1
|
-1
|
-1
|
1
|
Средняя - выше средней
|
|
2
|
1
|
-1
|
-1
|
-1
|
-1
|
Ниже средней - средняя
|
|
3
|
-1
|
1
|
-1
|
-1
|
-1
|
Средняя
|
|
4
|
1
|
1
|
-1
|
-1
|
1
|
Выше средней
|
|
5
|
-1
|
-1
|
1
|
-1
|
-1
|
Ниже средней
|
|
6
|
1
|
-1
|
1
|
-1
|
1
|
Средняя - выше средней
|
|
7
|
-1
|
1
|
1
|
-1
|
1
|
Выше средней
|
|
8
|
1
|
1
|
1
|
-1
|
-1
|
Средняя
|
|
9
|
-1
|
-1
|
-1
|
1
|
-1
|
Низкая
|
|
10
|
1
|
-1
|
-1
|
1
|
1
|
Выше средней
|
|
11
|
-1
|
1
|
-1
|
1
|
1
|
Высокая
|
|
12
|
1
|
1
|
-1
|
1
|
-1
|
Средняя
|
|
13
|
-1
|
-1
|
1
|
1
|
1
|
Ниже средней
|
|
14
|
1
|
- 1
|
1
|
1
|
-1
|
Ниже средней- средняя
|
|
15
|
-1
|
1
|
1
|
1
|
-1
|
Средняя
|
|
16
|
1
|
1
|
1
|
1
|
1
|
Высокая
|
Здесь приведены только значимые коэффициенты полинома. ошибка при уровне
значимости 0,05 составила s{bi}=0,06. Коэффициентами при
квадратичных членах в указанном полиноме можно пренебречь, так как
b0 - Y0<s{bi}.
Анализ проведения графиков расхода концентрата, расчетных по уравнению
(1) и фактических, показывает высокую степень адекватности модели процессу
управления им оператором, наблюдающиеся различия в загрузках не противоречат
практике ведения процесса, что было подтверждено экспертами-технологами. Таким
образом, прогностические возможности полученного полинома весьма высоки и
данная модель может быть рекомендована к внедрению в виде советчика оператору.
Важно отметить следующие особенности предлагаемого метода. Полученная
модель несет дополнительную и эвристическую информацию, позволяющую судить о
логике оператора-технолога при управлении процессом. Известно, что эксперт
способен оперировать с небольшим количеством входных переменных, но, как видно
из уравнения (1), количество линеаризованных (нелинейных) значимых
коэффициентов существенно превышает указанный верхний предел. Следовательно,
эксперт не в состоянии их формализовать при описании своей понятийной модели,
используемой при выборе управляющего воздействия. Другими словами, только
предлагаемым расчетным путем удается оценить влияние неформализованных
переменных, интуитивно учитываемых экспертом, и выявить их смысл. Например,
переменная Х3 (содержание кислорода в кислородно-воздушной смеси (КВС)) в линейном
виде оказывает незначимое воздействие на изменение загрузки, но ее влияние
происходит через парные взаимодействия с разностью температур охлаждающего
контура (Х3 Х5 ) и загрузкой концентрата ЦРФ (Х1 Х3).
Значимость взаимодействия такого типа, по видимому, следует отнести к
процессам, происходящим в подсознании эксперта на уровне интуиции. Таким
образом, можно полагать, что разработанный метод позволяет количественно
оценить кроме входных еще и «интуитивную составляющую», существенно влияющую на
выбор управляющего воздействия. По методу построения управляющих моделей
металлургических процессов на основе оценки качественной информации, полученной
от оператора-технолога, построена управляющая модель процесса плавки
концентрата ЦРФ в ПВ.
АСУТП, использующая эту модель как базу знаний, в принципе способна вести
процесс на уровне оператора-технолога.
Опыт технолога-эксперта, зафиксированный в виде полиномиальной модели,
может быть тиражирован для управления аналогичными агрегатами либо в качестве
базы знаний на тренажере для обучения операторов.
Контрольные вопросы:
. Расскажите алгоритм построения управляющей модели
. Какова цель планирования эксперимента
. Какой анализ функции отклика предназначен для получения ее
математической модели в виде уравнения регрессии
. Сколько входных и выходных показателей и как они влияют друг на друга
Лабораторная работа №14.
Лабораторная работа №15
Исследование генетического алгоритма поиска экстремума
целевой функции
Генетический алгоритм - это простая модель эволюции в природе,
реализованная в виде компьютерной программы. В нем используются как аналог
механизма генетического наследования, так и аналог естественного отбора. При
этом сохраняется биологическая терминология в упрощенном виде
Моделирование генетического наследования Таблица15.1
|
Хромосома
|
Вектор (последовательность) из нулей и единиц. Каждая
позиция (бит) называется геном.
|
|
Индивидуум = генетический код
|
Набор хромосом = вариант решения задачи.
|
|
Кроссовер
|
Операция, при которой две хромосомы обмениваются своими
частями.
|
|
Мутация
|
Cлучайное изменение одной или нескольких позиций в
хромосоме.
|
Чтобы смоделировать эволюционный процесс, сгенерируем вначале случайную
популяцию - несколько индивидуумов со случайным набором хромосом (числовых
векторов). Генетический алгоритм имитирует эволюцию этой популяции как
циклический процесс скрещивания индивидуумов и смены поколений (см. рисунок
15.1).
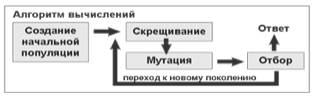
Рисунок 15.1. Принцип построения генетического алгоритма
Жизненный цикл популяции - это несколько случайных скрещиваний
(посредством кроссовера) и мутаций, в результате которых к популяции
добавляется какое-то количество новых индивидуумов. Отбор в генетическом
алгоритме - это процесс формирования новой популяции из старой, после чего старая
популяция погибает. После отбора к новой популяции опять применяются операции
кроссовера и мутации, затем опять происходит отбор, и так далее.
Связь отбора в генетическом алгоритме и в природе Таблица15.2
|
Приспособленность индивидуума
|
Значение целевой функции на этом индивидууме.
|
|
Выживание наиболее приспособленных
|
Популяция следующего поколения формируется в соответствии с
целевой функцией. Чем приспособление индивидуум, тем больше вероятность его
участия в кроссовере, т.е. размножении.
|
Генетические Алгоритмы (ГА) - адаптивные методы поиска, которые в
последнее время часто используются для решения задач функциональной
оптимизации. Они основаны на генетических процессах биологических организмов:
биологические популяции развиваются в течение нескольких поколений, подчиняясь
законам естественного отбора и по принципу "выживает наиболее
приспособленный" (survival of the fittest), открытому Чарльзом Дарвином.
Подражая этому процессу, генетические алгоритмы способны "развивать"
решения реальных задач, если те соответствующим образом закодированы. Например,
ГА могут использоваться, чтобы проектировать структуры моста, для поиска
максимального отношения прочности/веса, или определять наименее расточительное
размещение для нарезки форм из ткани. Они могут также использоваться для
интерактивного управления процессом, например на химическом заводе, или
балансировании загрузки на многопроцессорном компьютере.
В природе особи в популяции конкурируют друг с другом за различные
ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного
вида часто конкурируют за привлечение брачного партнера. Те особи, которые
наиболее приспособлены к окружающим условиям, будут иметь относительно больше
шансов воспроизвести потомков. Слабо приспособленные особи либо совсем не
произведут потомства, либо их потомство будет очень немногочисленным. Это
означает, что гены от высоко адаптированных или приспособленных особей будут
распространятся в увеличивающемся количестве потомков на каждом последующем
поколении. Комбинация хороших характеристик от различных родителей иногда может
приводить к появлению "суперприспособленного" потомка, чья
приспособленность больше, чем приспособленность любого из его родителя. Таким
образом, вид развивается, лучше и лучше приспосабливаясь к среде обитания.
ГА используют прямую аналогию с таким механизмом. Они работают с
совокупностью "особей" - популяцией, каждая из которых представляет
возможное решение данной проблемы. Каждая особь оценивается мерой ее
"приспособленности" согласно тому, насколько "хорошо"
соответствующее ей решение задачи. Например, мерой приспособленности могло бы
быть отношение силы/веса для данного проекта моста. (В природе это эквивалентно
оценке того, насколько эффективен организм при конкуренции за ресурсы.)
Наиболее приспособленные особи получают возможность "воспроизводить"
потомство с помощью "перекрестного скрещивания" с другими особями
популяции. Это приводит к появлению новых особей, которые сочетают в себе
некоторые характеристики, наследуемые ими от родителей. Наименее
приспособленные особи с меньшей вероятностью смогут воспроизвести потомков, так
что те свойства, которыми они обладали, будут постепенно исчезать из популяции
в процессе эволюции.
Так и воспроизводится вся новая популяция допустимых решений, выбирая
лучших представителей предыдущего поколения, скрещивая их и получая множество
новых особей. Это новое поколение содержит более высокое соотношение
характеристик, которыми обладают хорошие члены предыдущего поколения. Таким
образом, из поколения в поколение, хорошие характеристики распространяются по
всей популяции. Скрещивание наиболее приспособленных особей приводит к тому,
что исследуются наиболее перспективные участки пространства поиска. В конечном
итоге, популяция будет сходиться к оптимальному решению задачи.
Цель: Используя программу генетического алгоритма, исследуйте скорость
его сходимости и точность поиска для различных функций
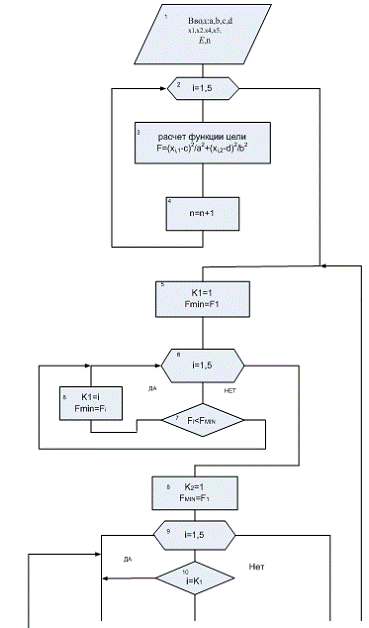
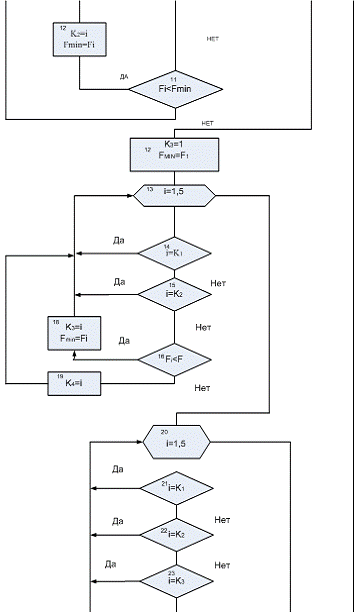
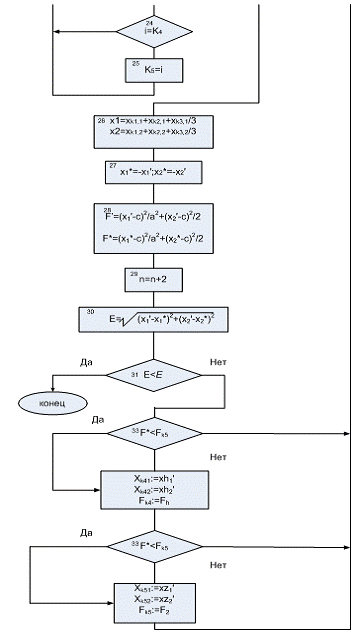
Алгоритм нахождения экстремума целевой функции с помощью генетического
алгоритма
Вводятся исходные данные, x(i) количество входных переменных x(i) -k,
величина шага-h, заданной точности поиска-ε,
значения величины
изменения аргумента при нахождения частных производных-dx, счетчик шагов в начальный момент должен быть равен единице
(n=1), так как до начала итерационных
процедур требуется один раз рассчитать функцию цели-Fц0=GZnкр,
Для удобства исследования генетического алгоритма
необходимо написать программу, в которой можно было бы менять функции не
создавая заново саму программу. Эта программа является в некотором роде универсальной,
поэтому для ее создания взят более простой пример и на его основе проведен
сравнительный анализ с другой программой нахождения экстремума, а также
исследование генетического алгоритма на решение других задач, более сложных для
классических методов нахождения экстремума. В описанной ниже программе взята
некоторая область, описанная уравнением окружности, в этой области взяли
начальную популяцию из пяти точек из них определили три наиболее близкие к
точке экстремума, определили потомка этих точек (середину треугольника), затем
провели мутацию этой точки, мутация - нескольких видов, так как
основополагающем фактором в нахождении точки экстремума и является мутирование
потомка (т.е. выброс точки за треугольник). Виды мутации:
умножение координат потомка на 2;
замена координат потомка оси абцисc на оси ординат;
умножение координат потомка на отрицательные числа;
умножение координат потомка на числа полученных от генератора
случайных чисел.
В данный алгоритм разработан для пяти точек координаты, которых равны
следующим значениям (7;8); (2,5;7); (-3; -5); (-2;-1); (3,5;-1,5). Значение
даны в виде матрицы
Задание:
· Изменить целевую функцию на функцию Оврага Розенброка
· Поменять значения координат для 5 точек, а также значения
коэффициентов;
· Повысить или понизить число итерации;
Контрольные вопросы:
. Как производится естественный отбор в природе?
. Что такое генетический алгоритм?
. Как используется процедура мутации в генетическом алгоритме?
. Какова скорость сходимости Вашего алгоритма?
. Какова точность поиска Вашего алгоритма?