Разработка структуры данных и алгоритмов управления информационными ресурсами
Содержание
Введение
. Анализ требований к заданию
. Разработка структуры данных и алгоритмов управления
информационными ресурсами
. Разработка сайта информационной системы
. Руководства по работе с системой
.1 Руководство пользователя
4.2 Руководство администратора
Заключение
Список литературы
сайт булевой поиск алгоритм
Введение
Пополнение информационных ресурсов
Интернета происходит высокими темпами, и найти необходимую информацию
становиться всё труднее. Различные печатные справочники устаревают ещё до
выхода в свет. Единственным надёжным способом поиска информации является
использование различных поисковых систем, которые постоянно отслеживают
изменение информации в сети.
За время существования Интернета
предпринимались различные попытки организации поисковых средств. Многие из этих
попыток оказались неудачными, другие же привели к созданию удобных средств
поиска информации. Наиболее удачные проекты появились в последние пять лет.
Многие поисковые системы позволяют искать
информацию не только в Web-страницах, но и в группах новостей и хранилищах
файлов. Таким образом, в результате поиска вы можете найти сообщение в группе
новостей или какой-то файл. Поэтому чаще применяют вместо термина страница
более общий термин - документ. Под документом подразумеваются Web-страница,
сообщение или файл, содержащие различную информацию.
Процесс поиска довольно прост: задавая
ключевые слова, характерные для искомой информации, мы найдём нужный нам
документ. Вне зависимости от того, какой поисковой системой вы пользуетесь,
примерный алгоритм поиска информации практически одинаковый.
Темой курсовой работы является разработка сайта-каталога программного
обеспечения с поиском на основе булевой модели. Создаваемая поисковая система
будет хранить информацию о различных программных обеспечениях: все программы
будут классифицированы по видам разделам.
1. Анализ технического задания
Цель курсовой работы - разработать поисковую систему программного
обеспечения, имеющую web-интерфейс.
Во введении было показано, чем полезны поисковые системы для пользователя. В
соответствии с этим надо создать максимально удобный с подробной информацией
для пользователя сайт.
Для начала рассмотрим основные функции сайта, позволяющие
хранить информацию и производить поиск в ней.
- Добавление данных разных категорий -
разделов и сведений о программных продуктах;
- Автоматическое индексирование при
добавлении;
- Работа с логическими операторами
"И", "ИЛИ", "НЕ";
- Вывод поисковой информации.
В сайте необходимо реализовать поисковую систему.
Информационный поиск занимается представлением, хранением,
организацией и обеспечением доступа к информационным объектам. Представление и
организация информации должны предоставлять пользователю удобный доступ к
интересующей его информации. Основной целью системы ИП является получение
информации, которая может быть полезна и релевантна для пользователя, с
использованием его запроса.
Моделями информационного поиска являются булевая, вероятностная и
векторная. При выполнении курсовой работы используется булева модель.
Достоинства булевой модели:
· Логические выражения имеют точную
семантику;
· Используются структурированные запросы;
· Для опытных пользователей она
интуитивна;
· Простой и аккуратный формализм позволял
принять ее во многих ранних коммерческих библиографических системах;
Недостатки булевой модели:
· Не осуществляется ранжирование.
Стратегия поиска основана на двоичном критерии решения, т.е. документ
предполагается либо релевантным, либо нерелевантным;
· Не просто перевести информационное
требование в логическое выражение;
В рамках булевой модели документы и запросы представляются в виде
множества термов - ключевых слов и устойчивых словосочетаний. Каждый терм
представлен как булева переменная: 0 (терм из запроса не присутствует в
документе) или 1 (терм из запроса присутствует в документе). При этом весовые
значения терма в документе принимает лишь два значения:  .
.
В булевой модели запрос пользователя представляет собой логическое
выражение, в котором термы связываются логическими операторами конъюнкции  (AND, ˄) дизъюнкции (OR, ˅)
и отрицания (NOT, ¬). Известно, что любое логическое выражение можно
представить дизъюнкцией некоторых выражений, соединенных между собой операцией
конъюнкции (дизъюнктивной нормальной формой, ДНФ - dnf).
(AND, ˄) дизъюнкции (OR, ˅)
и отрицания (NOT, ¬). Известно, что любое логическое выражение можно
представить дизъюнкцией некоторых выражений, соединенных между собой операцией
конъюнкции (дизъюнктивной нормальной формой, ДНФ - dnf).
Поиск по слову в базе данных системы такой архитектуры осуществляется в
соответствии с алгоритмом:
. Происходит обращение к словарной таблице, по которой определяется,
входит ли слово в состав словаря базы данных, и если входит, то определяется
ссылка в инверсной таблице на цепочку появлений этого слова в документах.
. Происходит обращение к инверсной таблице, по которой определяются
номера документов, содержащих данное слово, и координаты всех вхождений слова в
текстах базы данных.
. По номеру документа происходит обращение к записи таблицы указателей
текстов. Каждая запись этого файла соответствует одному документу в базе
данных.
. По номеру документа происходит прямое обращение к фрагменту текстовой
таблицы - документу, после чего следует вывод найденного документа.
Приведенный алгоритм охватывает случай, когда запрос состоит из одного
слова. Если же в запрос входит не одно слово, а некоторая их комбинация, то в
результате выполнения поиска по каждому из этих слов запроса формируется массив
записей, которые соответствуют вхождению этого слова в базу данных. После
окончания формирования массивов результатов поиска происходит выявление
релевантных документов путем выполнения теоретико-множественных операций над
записями этих массивов в соответствии с правилами булевой логики.
В сайте производится расчет PageRank (далее просто PR) - числовой
величины - мера "важности" страницы в поисковой системе Google,
которая зависит от числа внешних ссылок на данную страницу и от их веса
(важности). Другими словами от количества и качества ссылающихся страниц. А
если говорить математическим языком, то PR это алгоритм расчёта авторитетности
страницы, используемый поисковой системой Google. PR не является основным, но
является одним из вспомогательных факторов при ранжировании сайтов в
результатах поиска.
Следует отметить, что при расчете PR Google учитывает не все ссылки, а
отфильтровывает ссылки с сайтов, специально предназначенных для скопления
ссылок. Некоторые ссылки могут не только не учитываться, но и отрицательно
сказаться на ранжировании ссылающегося сайта (такой эффект назвается поисковой
пессимизацией).
Существует множество способов повышения веса своих страниц, но главная
идея - это качественные ссылки с других сайтов. Для этого можно использовать
каталоги, социальные закладки, статьи, форумы, блоги и другие типы сайтов.
Для разработки web-сайта выбрана операционная система Windows 7. Поводом
для этого стала широкая распространенность этой операционной системы, наличие
большого количества прикладных программ необходимых для разработки сайта,
удобный графический интерфейс.
Выбор языка разметки документа и выбор технологии реализации запросов,
функций, сведем к выбору технологии РНР. РНР - язык описания сценариев,
выполняемых на сервере, встроенный в HTML. РНР обладает значительным набором функций и относительно большой
гибкостью. РНР-скрипт представляет собой обычный html-документ со вставками тэгов РНР - команд.
Возможно самая сильная и значимая возможность в РНР - уровень интеграции
с базами данных (Oracle, Sybase, mSQL, Informix, dBase). РНР - наиболее простой и удобный
язык для написания Web-страницы,
работающей с базой данных. При программировании на РНР наиболее часто
используется база данных MySQL,
которая характеризуется большой скоростью, устойчивостью и легкостью в
использовании. Краткий перечень возможностей MySQL:
)Поддерживается неограниченное количество пользователей, одновременно
работающих с базой данных.
)Количество строк в таблицах может достигать 50млн.
)Быстрое выполнение команд.
)Простая и эффективная система безопасности [3].
Так как выбрана технология построения Web-страниц (РНР), можно сделать некоторые дополнения о
дизайне сайта. Для того чтобы страницы отображались в одном стиле и были единым
целым, проще не описывать каждый стиль отображения на HTML, а подключить каскадную таблицу стилей. Каскадные
таблицы стилей, или CSS, позволяют
разделить смысловое содержимое страницы и его оформление. Стиль определяет
внешний вид документа HTML
при его отображении в окне браузера: шрифты и цвета заголовков разных уровней,
шрифт и разрядка основного текста, задаваемого в тэге абзаца и т.д. Таблица
стилей - это шаблон, который управляет форматированием тэгов HTML в Web-документе. Поэтому для упрощения и следования логике
разработки сайта целесообразно включить css-таблицы.
Для создания и редактирования сайта мною была использована версия HTML-редактора Dreamweaver
CS5.5.
Программное обеспечение Adobe Dreamweaver CS5.5 - передовое средство
разработки и редактирования веб-сайтов на базе отраслевых стандартов, которое
позволяет создавать проекты для настольных ПК, смартфонов, планшетов и других
устройств в визуальном режиме и с помощью кода. Богатый
инструментарий, открытость приложения для всевозможных настроек, удобный интерфейс
и другие особенности сделали Dreamweaver одним из наиболее популярных HTML-редакторов в мире. Недостатком считается добавление
"лишнего" кода.
Для отладки создаваемого сайта будем использовать
Denwer3_Base_2008, который использует Apache 2.2.4, PHP 5.2.4, phpMyAdmin 2.6.1
и MySQL 5.0.45.
После установки Денвера web-сервер
полностью готов к использованию. Для отладки сайта и дальнейшей работы с ним
нужно будет скопировать его в /home/localhost/www . Для того чтобы запустить его в браузере необходимо
набрать следующий URL-адрес: #"724318.files/image003.gif">
Рисунок 1 - Алгоритм индексации информации
Также необходимо продумать структуры базы данных и структуру
таблиц для поиска информации:
. Таблица Article_items - таблица, содержащая полное описание
программного обеспечения, включает следующие поля:
Section_id - id_раздела;
Content - текст статьи;
Id - id_статьи;
Caption - название статьи;
SITE_URL - официальный сайт программы;
2. Таблица INDEX_TABLE - хранит соответствие термов и
статей.
. Таблица ISPELL_AFFIX - содержит флаг правила, маску
окончания (регулярное выражение), окончание, вариант замены окончания.
. Таблица ISPELL_DICTIONARY - содержит слово в базовой форме и
флаги применяемых правил.
5. Таблица search_object содержит описание программного обеспечения:
Id - id_статьи
. Таблица Sections - содержит названия разделов и включает
следующие поля:
Title - название раздела;
Id - id_раздела;
7. Таблица STOP_WORDS - список стоп-слов;
8. Таблица TERMS
- хранит уникальные слова, которые встречаются
где-либо в содержимом сайта.
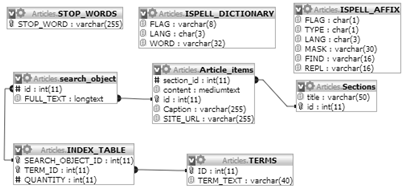
Рисунок 2 - Структура базы данных
Далее определимся со структурой сайта:
Сайт содержит несколько страниц, на главной - осуществляется
поиск, на других вкладки с разделами программного обеспечения.
3. Программная реализация
Программа реализована на языке программирования PHP. Функционал сайта разбит на модули, часть из которых
является страницами и помимо программного кода содержит код HTML-разметки.
Таблица 3.1 - Перечень программных модулей
|
Имя файла
|
Описание
|
|
index.php
|
Главная страница сайта;
функции отображения разделов и статей
|
|
find.php
|
Форма поиска по сайту и
отображения результатов поиска
|
|
AddArticle.php
|
Форма создания и
редактирования статьи
|
|
AddSection.php
|
Форма создания и
редактирования раздела
|
|
AdminLogin.php
|
Форма авторизации
администратора
|
|
includes\glob.php
|
Функции инициализации
подключения к базе данных; функции проверки авторизации
|
|
Includes\google_pr.php
|
Функция определения Google PageRank для заданной ссылки на сайт
|
|
includes\boolean_search.php
|
Функции булевого поиска;
функции работы со словарями ISpell; функции преобразования поисковых запросов
|
База данных реализована в СУБД MySQL. База данных хранит следующую информацию:
список разделов;
список статей (описаний спортивных Интернет-ресурсов);
словарь термов;
индексную таблицу;
словарь ISpell;
набор правил ISpell;
список стоп-слов;
Структура таблиц в базе данных приведена в таблицах 3.2-3.7.
Список статей и список разделов хранит основное содержимое сайта в том
виде, в котором оно было введено администратором при заполнении сайта.
Таблица 3.2 - Структура таблицы "Список разделов" в базе данных
|
Имя поля
|
Тип данных
|
|
Код раздела
|
Число
|
|
Наименование раздела
|
Текст
|
Таблица 3.3 - Структура таблицы "Список статей" в базе данных
|
Имя поля
|
Тип данных
|
|
Код статьи
|
Число
|
|
Код раздела
|
Число
|
|
Текст статьи
|
Текст
|
Словарь термов хранит уникальные слова, которые встречаются где-либо в
содержимом сайта. При хранении в словаре термов, все слова приводятся к базовой
форме.
Таблица 3.4 - Структура таблицы "Словарь термов" в базе данных
|
Имя поля
|
Тип данных
|
|
Код терма
|
Число
|
|
Текст терма
|
Текст
|
Индексная таблица хранит соответствие термов и статей. По индексной
таблице можно легко получить список термов, которые присутствуют в статье, или
же быстро проверить присутствует ли заданный терм в заданной статье.
Таблица 3.5 - Структура индексной таблицы в базе данных
|
Имя поля
|
Тип данных
|
|
Код терма
|
Число
|
Число
|
|
Количество повторений
|
Число
|
Словарь ISpell в исходном формате представляет
собой два текстовых файла: Ispell_dictionary (словарь) и ispell_affix
(набор правил). Для быстрой работы со словарями ISpell в рамках данного проекта, словарь и набор правил
преобразованы в таблицы в базе данных. Это позволяет быстро находить все
словоформы или приводить слово к исходной форме с помощью простейших SQL-запросов к БД.
Таблица 3.6 - Структура таблицы "Словарь ISpell" в базе данных
|
Имя поля
|
Тип данных
|
|
Слово в базовой форме
|
Текст
|
|
Флаги применяемых правил
|
Текст
|
Таблица 3.7 - Структура таблицы "Набор правил ISpell" в базе данных
|
Имя поля
|
Тип данных
|
|
Флаг правила
|
Символ
|
|
Маска окончания (регулярное
выражение)
|
Текст
|
|
Окончание
|
Текст
|
|
Вариант замены окончания
|
Текст
|
Для работы полнотекстового поиска, необходимо построение индекса статьи в
момент её добавления, а также перестроение индекса при любых изменениях статей.
Построение индекса включает в себя следующие шаги:
удаление старого индекса (удаление записей из индексной таблицы);
выделение уникальных слов из текста статьи и приведение их к базовой форме;
добавление слов в словарь термов;
добавление пар код_терма - код_статьи в индексную таблицу.
Описанные шаги реализованы в модуле boolean_search.php с помощью следующих функций:
Таблица 3.8 - Перечень функций, используемых при индексировании
|
Имя функции
|
Описание
|
Входные данные
|
Выходные данные
|
|
RebuildSearchIndex
|
Перестроение индекса по
заданной статье
|
Код статьи
|
нет
|
|
PrepareTextStep1
|
Приведение текста к
верхнему регистру, удаление коротких слов и лишних пробелов
|
Текст
|
Текст
|
|
PrepareTextGetBaseForms
|
Приведение всех слов текста
к базовой форме
|
Текст
|
Текст
|
|
GetQueryWords
|
Получение списка уникальных
слов из текста
|
Текст
|
Набор слов
|
|
CreateNewTerm
|
Поиск терма в словаре
термов или создание нового если не существует
|
Текст (одно слово)
|
Код терма
|
|
CreateIndexRecord
|
Создание записи в индексной
таблице
|
Код статьи; Код терма
|
нет
|
Форма поиска реализована в модуле find.php.
Данная форма осуществляет запрос текста для поиска, вызов необходимых функций
поиска и отображение результатов. Вся логика булевого поиска и работа с базой
данных реализована в модуле boolean_search.php. Перечень функций булевого поиска приведен в таблице
ниже.
Перечень функций используемых при булевом поиске
|
Имя функции
|
Описание
|
Входные данные
|
Выходные данные
|
|
PrepareTextStep1
|
Приведение текста поискового
запроса к верхнему регистру, удаление коротких слов и лишних пробелов
|
Текст
|
Текст
|
|
PrepareTextGetBaseForms
|
Приведение всех слов в
поисковом запросе к базовой форме
|
Текст
|
|
PrepareTextGetFindSQL
|
Формирование SQL-запроса
на выборку таблицы соответствия статей и термов
|
Текст запроса приведенный к
базовым формам
|
SQL-запрос
|
|
BooleanFindObjects
|
Выполнение поискового
запроса булевой модели поиска
|
Текст поискового запроса
|
Набор найденных статей
|
Релевантность статьи поисковому запросу рассчитывается по формуле:
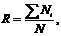
где  - количество повторений i-го слова поискового запроса в статье
- количество повторений i-го слова поискового запроса в статье
N -
общее количество слов в статье
Таким образом, релевантность статьи будет максимальна, если статья
целиком состоит из слов поискового запроса. Релевантность статьи будет нулевой,
если она не содержит ни одного слова из поискового запроса.
Код расчета релевантности статьи в %
//article_id - ID статьи в базе данных
//words - список слов поискового запроса, приведенных к базовой форме и к
верхнему регистру
function CalculateRelevance($search_object_id, $words)
{//получение общего количества проиндексированных слов в статье
$total_words_quantity=0;
$q=mysql_query("select sum(QUANTITY) from INDEX_TABLE
where SEARCH_OBJECT_ID = $search_object_id");
$row=mysql_fetch_row($q);($row)
$total_words_quantity=$row[0];($total_words_quantity==0) return 0;
//подсчет количества совпадающих слов
$match_words_quantity=0;
for($i=0; $i<count($words); $i++)
{//расчет релевантности в %
$relevance =
round($match_words_quantity/$total_words_quantity*100, 2);
return $relevance;
}
Определение Google Page Rank
Для определения рейтинга сайтов производителей программного обеспечения,
применяется метод Google Page Rank. Алгоритм определения PageRank является закрытой технологией Google. Тем не менее, данная компания
предоставляет всем желающим информацию о PageRank для любого интернет-ресурса.
Поскольку ссылающихся страниц может быть много, и общее количество страниц в
поисковой системе Google достаточно велико (около десятка биллионов штук) а
также их количество постоянно растет, то представлять вес страницы в абсолютных
значениях для вебмастеров было бы весьма неправильно. Для этого ввели понятие
TLPR -- ToolBar PageRank, который имеет значение от 0 до 10. Определение Google Page Rank с помощью сервисов Google реализовано следующим образом:
<? function StrToNum($Str, $Check, $Magic) {
$Int32Unit = 4294967296;
$length = strlen($Str);($i = 0; $i < $length; $i++) {
$Check *= $Magic;($Check >= $Int32Unit) {
$Check = ($Check - $Int32Unit * (int) ($Check / $Int32Unit));
$Check = ($Check < -2147483648) ? ($Check + $Int32Unit) :
$Check;
} $Check += ord($Str{$i});
} return $Check;
} function HashURL($String) {
$Check1 = StrToNum($String, 0x1505, 0x21);
$Check2 = StrToNum($String, 0, 0x1003F);
$Check1 >>= 2;
$Check1 = (($Check1 >> 4) & 0x3FFFFC0 ) | ($Check1
& 0x3F);
$Check1 = (($Check1 >> 4) & 0x3FFC00 ) | ($Check1
& 0x3FF);
$Check1 = (($Check1 >> 4) & 0x3C000 ) | ($Check1
& 0x3FFF);
$T1 = (((($Check1 & 0x3C0) << 4) | ($Check1 &
0x3C)) <<2 ) | ($Check2 & 0xF0F );
$T2 = (((($Check1 & 0xFFFFC000) << 4) | ($Check1
& 0x3C00)) << 0xA) | ($Check2 & 0xF0F0000 );($T1 | $T2);
} function CheckHash($Hashnum) {
$CheckByte = 0;
$Flag = 0;
$HashStr = sprintf('%u', $Hashnum) ;
$length = strlen($HashStr);($i = $length - 1; $i >= 0; $i
--) {
$Re = $HashStr{$i};(1 === ($Flag % 2)) {
$Re += $Re;
$Re = (int)($Re / 10) + ($Re % 10);
} $CheckByte += $Re;
$Flag ++;
} $CheckByte %= 10;(0 !== $CheckByte) {
$CheckByte = 10 - $CheckByte;(1 === ($Flag % 2) ) {(1 ===
($CheckByte % 2)) {
$CheckByte += 9;
} $CheckByte >>= 1;
} }'7'.$CheckByte.$HashStr;
} function getch($url) { return CheckHash(HashURL($url)); }
//получение Google PageRank для заданной ссылки
function UrlPR($url){
$ch = getch($url);
$main_url =
"#"724318.files/image007.gif">
Рисунок 3 - Главная страница сайта
Каталог программного обеспечения распределен по разделам.
Навигация по разделам осуществляется с помощью ссылок в верхней части
окна по вкладкам.
Рисунок 4 - Отображение ПО в разделе "Файлы и диски"
Для перехода на страницу поиска по сайту нужно перейти на вкладку
"Поиск по каталогу".
Далее в поле "Текст поиска" ввести поисковый запрос, например
"антивирус", при необходимости можно выбрать раздел, в котором будем
искать и нажать кнопку "Найти". Ниже будут отображены найденные ПО,
удовлетворяющие поисковому запросу (рис. 5).
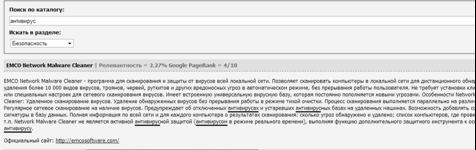
Рисунок 5 - Поиск по запросу
.2 Руководство администратора
1. Для того чтобы редактировать содержание сайта, необходимо выполнить
вход администратора. Для этого нажимаем ссылку "Редактировать
материал", и переходим на страницу авторизации администратора. Здесь
вводим соответствующие логин и пароль.

Рисунок 6 - Вход администратора
После входа администратором, напротив каждой статьи и каждого раздела
будут иконки:
[X] - удаление раздела; […] -
редактирование материала;

Рисунок 7 - Разделы после входа администратора
Рассмотрим добавление статьи в раздел "Офис", для этого
необходимо перейти по ссылке "Добавить статью".

Рисунок 8 - Добавление статьи в раздел
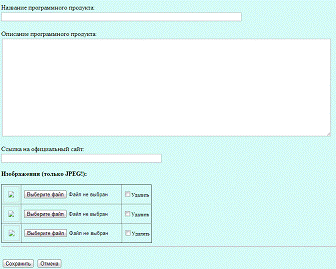
Рисунок 9 - Добавление статьи
Заключение
В результате выполнения курсовой работы была реализована поисковая
система программного обеспечения.
В курсовой работе проанализированы средства разработки, такие как
архитектура информационной системы, способы ее реализации, различные серверы и
системы управления базами данных, а также языки программирования. На основании
анализа технического задания произведено проектирование, а впоследствии и
реализация базы данных, а также администрирования системы в целом.
Информационная система реализована в виде интернет-сайта. Во время работы
над проектом проанализированы аналогичные сайты в сети Internet.
Поиск статей на сайте осуществляется на основе булевой системы поиска. В
модели были реализованы логические функции И, ИЛИ, НЕ. Результатом поиска
является список статей, отсортированные в порядке уменьшения релевантности.
Тестирование произведено на различных браузерах: Opera, Mozilla Firefox, Google Chrome. Тестирование информационной системы показало, что
вся информация, содержащаяся на сайте, отображается корректно, и правильно
выполняются все операции.
Разработанная информационная система отличается интуитивно понятным
интерфейсом, хорошо представленной и структурированной информацией, простотой и
удобством в эксплуатации.
Все требования, поставленные на начальном этапе разработки, были успешно
выполнены.
Список литературы
1. Береговой В.А., Крачун Г.П., Леонова Н.Г. Поиск
знаний в информационных сетях: базовые модели и технологии.
. Кириченко К.М., Герасимов М.Б. Обзор методов
кластеризации текстовых документов. матер.межд.конф. Диалог,2001
. Ланде Д.В. Поиск знаний в Интернет. Профессиональная
работа. М.: "Вильямс", 2005, 272 с.
. Фомин А.А. Управление информационными ресурсами.
Курс лекций
5. Программы, разработанные командой
SoftPortal//
[Электронный ресурс]. - Режим доступа:
http://www.softportal.com/screenshot-19646-prevent-restore.html
. Softline - каталог программного обеспечения //
[Электронный ресурс]. - Режим доступа:
http://store.softline.ru/subcategory/vosstanovlenie-dannih/
7. А.
В. Астрахов Научно-образовательный материал "Технология информационного
поиска", 2011// [Электронный ресурс]. - Режим доступа: http://do.gendocs.ru/docs/index-212707.html
8. Булевая модель поиска// [Электронный ресурс]. - Режим
доступа:
http://www.webground.su/services.php?param=book&part=chapter+2_1.htm
. Концепции информационного поиска// [Электронный
ресурс]. - Режим доступа:
http://knowledge.allbest.ru/programming/2c0b65625a3ac68b4d43a88421316c36_0.html