|
Ф
|
0,002
|
000000000
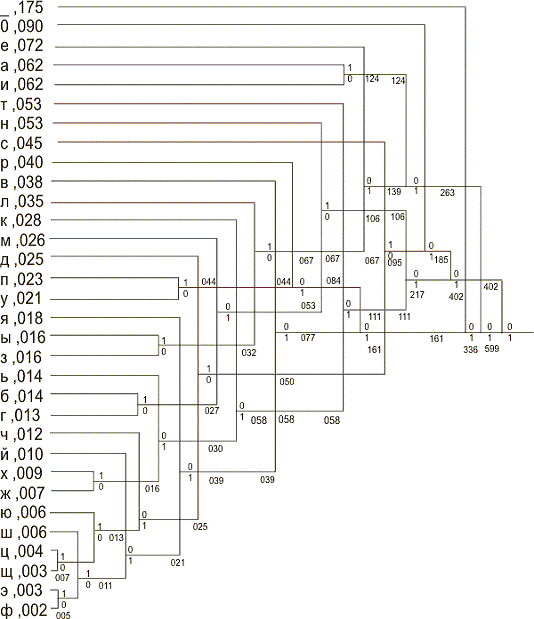
Рис. 3. Среднее число элементарных сигналов для передачи буквы при данном
методе кодирования равно 4,4
Метод
Шеннона-Фано
Данный метод выделяется своей простотой. Берутся исходные сообщения m(i)
и их вероятности появления P(m(i)). Сообщения упорядываются так, чтобы
вероятность i-го сообщения была не больше (i+1)-го. Этот список делится на две
группы с примерно равной интегральной вероятностью. Каждому сообщению из группы
1 присваивается 0 в качестве первой цифры кода. Сообщениям из второй группы
ставятся в соответствие коды, начинающиеся с 1. Каждая из этих групп делится на
две аналогичным образом и добавляется еще одна цифра кода. Процесс продолжается
до тех пор, пока не будут получены группы, содержащие лишь одно сообщение.
Каждому сообщению в результате будет присвоен код x c длиной -lg(P(x)). Это
справедливо, если возможно деление на подгруппы с совершенно равной суммарной
вероятностью. Если же это невозможно, некоторые коды будут иметь длину
-lg(P(x))+1. Алгоритм Шеннона-Фано не гарантирует оптимального кодирования.
Алгоритм
Зива-Лемпеля
В 1977 году Абрахам Лемпель и Якоб Зив предложили алгоритм сжатия данных,
названный позднее LZ77. Этот алгоритм используется в программах архивирования
текстов compress, lha, pkzip и arj. Модификация алгоритма LZ78 применяется для
сжатия двоичных данных. Эти модификации алгоритма защищены патентами США.
Алгоритм предполагает кодирование последовательности бит путем разбивки ее на
фразы с последующим кодированием этих фраз. Позднее появилась модификация
алгоритма LZ78 - Lempel-Ziv Welsh (использует словарь для байтов для потоков
октетов).
Суть алгоритма заключается в следующем:
Если в тексте встретится повторение строк символов, то повторные строки
заменяются ссылками (указателями) на исходную строку. Ссылка имеет формат
<префикс, расстояние, длина>. Префикс в этом случае равен 1. Поле
расстояние идентифицирует слово в словаре строк. Если строки в словаре нет,
генерируется код символ вида <префикс, символ>, где поле префикс =0, а
поле символ соответствует текущему символу исходного текста. Отсюда видно, что
префикс служит для разделения кодов указателя от кодов символ. Введение кодов
символ, позволяет оптимизировать словарь и поднять эффективность сжатия.
Главная алгоритмическая проблема здесь заключатся в оптимальном выборе строк,
так как это предполагает значительный объем переборов.
Рассмотрим пример с исходной последовательностью U=0010001101 (без
надежды получить реальное сжатие для столь ограниченного объема исходного
материала).
Введем обозначения:[n] - фраза с номером n.- результат сжатия.
Разложение исходной последовательности бит на фразы представлено в
таблице ниже.
|
N фразы
|
Значение
|
Формула
|
Исходная последовательность U
|
|
0
|
-
|
P[0]
|
0010001101
|
|
1
|
0
|
P[1]=P[0].0
|
0. 010001101
|
|
2
|
01
|
P[2]=P[1].1
|
0.01.0001101
|
|
3
|
010
|
P[3]=P[1].0
|
0. 01.00.01101
|
|
4
|
00
|
P[4]=P[2].1
|
0. 01.00.011.01
|
|
5
|
011
|
P[5]=P[1].1
|
0. 01.00. 011.01
|
[0] - пустая строка. Символом « . » (точка) обозначается операция
объединения (конкатенации).
Формируем пары строк, каждая из которых имеет вид (A.B). Каждая пара
образует новую фразу и содержит идентификатор предыдущей фразы и бит,
присоединяемый к этой фразе. Объединение всех этих пар представляет
окончательный результат сжатия С. P[1]=P[0].0 дает (00.0), P[2]=P[1].0 дает (01.0)
и т.д. Схема преобразования отражена в таблице ниже.
|
Формулы
|
P[1]=P[0].0
|
P[2]=P[1].1
|
P[3]=P[1].0
|
P[4]=P[2].1
|
P[5]=P[1].1
|
|
Пары
|
00.0=000
|
01.1=011
|
01.0=010
|
10.1=101
|
01.1=011
|
|
С
|
000.011.010.101.011 = 000011010101011
|
Все формулы, содержащие P[0] вовсе не дают сжатия. Очевидно, что С
длиннее U, но это получается для короткой исходной последовательности. В случае
материала большего объема будет получено реальное сжатие исходной
последовательности.
Локально
адаптивный алгоритм сжатия
Этот алгоритм используется для кодирования (L,I), где L строка длиной N,
а I - индекс. Это кодирование содержит в себе несколько этапов.
. Сначала кодируется каждый символ L с использованием локально
адаптивного алгоритма для каждого из символов индивидуально. Определяется вектор
целых чисел R[0],…,R[N-1], который представляет собой коды для символов
L[0],…,L[N-1]. Инициализируется список символов Y, который содержит в себе
каждый символ из алфавита Х только один раз. Для каждого i = 0,…,N-1
устанавливается R[i] равным числу символов, предшествующих символу L[i] из
списка Y. Взяв Y = [‘a’,’b’,’c’,’r’] в качестве исходного и L = ‘caraab’,
вычисляем вектор R: (2 1 3 1 0 3).
. Применяем алгоритм Хафмана или другой аналогичный алгоритм сжатия к
элементам R, рассматривая каждый элемент в качестве объекта для сжатия. В
результате получается код OUT и индекс I.
Рассмотрим процедуру декодирования полученного сжатого текста (OUT,I).
Здесь на основе (OUT,I) необходимо вычислить (L,I). Предполагается, что
список Y известен.
1. Сначала вычисляется вектор R, содержащий N чисел: (2 1 3 1 0 3).
2. Далее вычисляется строка L, содержащая N символов, что дает
значения R[0],…,R[N-1]. Если необходимо, инициализируется список Y, содержащий
символы алфавита X (как и при процедуре кодирования). Для каждого i = 0,…,N-1
последовательно устанавливается значение L[i], равное символу в положении R[i]
из списка Y (нумеруется, начиная с 0), затем символ сдвигается к началу Y.
Результирующая строка L представляет собой последнюю колонку матрицы M.
Результатом работы алгоритма будет (L,I). Взяв Y = [‘a’,’b’,’c’,’r’] вычисляем
строку L = ‘caraab’.
Наиболее важным фактором, определяющим скорость сжатия, является время,
необходимое для сортировки вращений во входном блоке. Наиболее быстрый способ
решения проблемы заключается в сортировке связанных строк по суффиксам.
Для того чтобы сжать строку S, сначала сформируем строку S’, которая
является объединением S c EOF, новым символом, который не встречается в S.
После этого используется стандартный алгоритм к строке S’. Так как EOF
отличается от прочих символов в S, суффиксы S’ сортируются в том же порядке,
как и вращения S’. Это может быть сделано путем построения дерева суффиксов,
которое может быть затем обойдено в лексикографическом порядке для сортировки
суффиксов. Для этой цели может быть использован алгоритм формирования дерева
суффиксов Мак-Крейгта. Его быстродействие составляет 40% от наиболее быстрой
методики в случае работы с текстами. Алгоритм работы с деревом суффиксов
требует более четырех слов на каждый исходный символ. Манбер и Майерс
предложили простой алгоритм сортировки суффиксов строки. Этот алгоритм требует
только двух слов на каждый входной символ. Алгоритм работает сначала с первыми
i символами суффикса а за тем, используя положения суффиксов в сортируемом
массиве, производит сортировку для первых 2i символов. К сожалению этот
алгоритм работает заметно медленнее.
Сжатие данных
с использованием преобразования Барроуза-Вилера
Майкл Барроуз и Давид Вилер (Burrows-Wheeler) в 1994 году предложили свой
алгоритм преобразования (BWT). Этот алгоритм работает с блоками данных и
обеспечивает эффективное сжатие без потери информации. В результате
преобразования блок данных имеет ту же длину, но другой порядок расположения
символов. Алгоритм тем эффективнее, чем больший блок данных преобразуется
(например, 256-512 Кбайт).
Последовательность S, содержащая N символов ({S(0),… S(N-1)}),
подвергается N циклическим сдвигам (вращениям), лексикографической сортировке,
а последний символ при каждом вращении извлекается. Из этих символов
формируется строка L, где i-ый символ является последним символом i-го
вращения. Кроме строки L создается индекс I исходной строки S в упорядоченном
списке вращений. Существует эффективный алгоритм восстановления исходной
последовательности символов S на основе строки L и индекса I. Процедура
сортировки объединяет результаты вращений с идентичными начальными символами.
Предполагается, что символы в S соответствуют алфавиту, содержащему K символов.
Для пояснения работы алгоритма возьмем последовательность S= “abraca”
(N=6), алфавит X = {‘a’,’b’,’c’,’r’}.
. Формируем матрицу из N*N элементов, чьи строки представляют собой
результаты циклического сдвига (вращений) исходной последовательности S,
отсортированных лексикографически. По крайней мере одна из строк M содержит
исходную последовательность S. Пусть I является индексом строки S. В
приведенном примере индекс I=1, а матрица M имеет вид:
|
Номер строки
|
|
|
0
|
aabrac
|
abraca
|
|
2
|
acaabr
|
|
3
|
bracaa
|
|
4
|
caabra
|
|
5
|
racaab
|
. Пусть строка L представляет собой последнюю колонку матрицы M с
символами L[0],…,L[N-1] (соответствуют M[0,N-1],…,M[N-1,N-1]). Формируем строку
последних символов вращений. Окончательный результат характеризуется (L,I). В
данном примере L=’caraab’, I =1.
Процедура декомпрессии использует L и I. Целью этой процедуры является
получение исходной последовательности из N символов (S).
. Сначала вычисляем первую колонку матрицы M (F). Это делается путем
сортировки символов строки L. Каждая колонка исходной матрицы M представляет
собой перестановки исходной последовательности S. Таким образом, первая колонка
F и L являются перестановками S. Так как строки в M упорядочены, размещение
символов в F также упорядочено. F=’aaabcr’.
. Рассматриваем ряды матрицы M, которые начинаются с заданного символа ch.
Строки матрицы М упорядочены лексикографически, поэтому строки, начинающиеся с
ch упорядочены аналогичным образом. Определим матрицу M’, которая получается из
строк матрицы M путем циклического сдвига на один символ вправо. Для каждого
i=0,…, N-1 и каждого j=0,…,N-1, M’[i,j] = m[i,(j-1) mod N]
В рассмотренном примере M и M’ имеют вид
|
Строка
|
M
|
M’
|
|
0
|
aabrac
|
caabra
|
|
1
|
abraca
|
aabraс
|
|
2
|
acaabr
|
racaab
|
|
3
|
bracaa
|
abraca
|
|
4
|
caabra
|
acaabr
|
|
5
|
racaab
|
bracaa
|
Подобно M каждая строка M’ является вращением S, и для каждой строки M
существует соответствующая строка M’. M’ получена из M так, что строки M’
упорядочены лексикографически, начиная со второго символа. Таким образом, если
мы рассмотрим только те строки M’, которые начинаются с заданного символа ch,
они должны следовать упорядоченным образом с учетом второго символа.
Следовательно, для любого заданного символа ch, строки M, которые начинаются с
ch, появляются в том же порядке что и в M’, начинающиеся с ch. В нашем примере
это видно на примере строк, начинающихся с ‘a’. Строки ‘aabrac’, ‘abraca’ и
‘acaabr’ имеют номера 0, 1 и 2 в M и 1, 3, 4 в M’.
Используя F и L, первые колонки M и M’ мы вычислим вектор Т, который
указывает на соответствие между строками двух матриц, с учетом того, что для
каждого j = 0,…,N-1 строки j M’ соответствуют строкам T[j] M.
Если L[j] является к-ым появлением ch в L, тогда T[j]=1, где F[i]
является к-ым появлением ch в F. Заметьте, что Т представляет соответствие один
в один между элементами F и элементами L, а F[T[j]] = L[j]. В нашем примере T
равно: (4 0 5 1 2 3).
. Теперь для каждого i = 0,…, N-1 символы L[i] и F[i] являются
соответственно последними и первыми символами строки i матрицы M. Так как
каждая строка является вращением S, символ L[i] является циклическим
предшественником символа F[i] в S. Из Т мы имеем F[T[j]] = L[j]. Подставляя i
=T[j], мы получаем символ L[T(j)], который циклически предшествует символу L[j]
в S.
Индекс I указывает на строку М, где записана строка S. Таким образом,
последний символ S равен L[I]. Мы используем вектор T для получения
предшественников каждого символа: для каждого i = 0,…,N-1 S[N-1-i] = L[Ti[I]],
где T0[x] =x, а Ti+1[x] = T[Ti[x]. Эта процедура позволяет восстановить
первоначальную последовательность символов S (‘abraca’).
Последовательность Ti[I] для i =0,…,N-1 не обязательно является
перестановкой чисел 0,…,N-1. Если исходная последовательность S является формой
Zp для некоторой подстановки Z и для некоторого p>1, тогда
последовательность Ti[I] для i = 0,…,N-1 будет также формой Z’p для некоторой
субпоследовательности Z’. Таким образом, если S = ‘cancan’, Z = ‘can’ и p=2,
последовательность Ti[I] для i = 0,…,N-1 будет [2,4,0,2,4,0].
Описанный выше алгоритм упорядочивает вращения исходной
последовательности символов S и формирует строку L, состоящую из последних
символов вращений. Для того, чтобы понять, почему такое упорядочение приводит к
более эффективному сжатию, рассмотрим воздействие на отдельную букву в обычном
слове английского текста.
Возьмем в качестве примера букву “t” в слове ‘the’ и предположим, что
исходная последовательность содержит много таких слов. Когда список вращений
упорядочен, все вращения, начинающиеся с ‘he’, будут взаимно упорядочены. Один
отрезок строки L будет содержать непропорционально большое число ‘t’,
перемешанных с другими символами, которые могут предшествовать ‘he’, такими как
пробел, ‘s’, ‘T’ и ‘S’.
Аналогичные аргументы могут быть использованы для всех символов всех
слов, таким образом, любая область строки L будет содержать большое число
некоторых символов. В результате вероятность того, что символ ‘ch’ встретится в
данной точке L, весьма велика, если ch встречается вблизи этой точки L, и мала
в противоположном случае. Это свойство способствует эффективной работе локально
адаптивных алгоритмов сжатия, где кодируется относительное положение идентичных
символов. В случае применения к строке L, такой кодировщик будет выдавать малые
числа, которые могут способствовать эффективной работе последующего
кодирования, например, посредством алгоритма Хафмана.
алгоритм
хафман сжатие данные
Используемая
литература
1. Ватолин
Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство
архиваторов, сжатие изображений и видео. - М.: ДИАЛОГ-МИФИ, 2002. - 384 с.
2. Вернер
М. Основы кодирования М.: Техносфера, 2004. - 288 с.
. Сэломон
Д. Сжатие данных, изображения и звука. М.: Техносфера, 2006. - 368 с.
4. Семенов Ю.А.
Образовательный сервер "Телекоммуникационные технологии". М.: 2004. URL:
<http://book.itep.ru> (дата обращения 16.04.2014)
Похожие работы на - Методы сжатия информации
|