Виды выборок. Регрессионная модель и функция регрессии
Содержание
1. Что такое генеральная совокупность и выборка. Какие виды
выборок вы знаете
Практическое задание 1.1
Практическое задание 1.2
. Что такое регрессионная модель и функция регрессии.
Перечислите этапы регрессионного анализа
Практическое задание 2.1
Список использованных источников
выборка статистика инфляция регрессионный
1. Что такое генеральная совокупность и выборка. Какие виды выборок вы
знаете
Статистическое исследование может осуществляться по данным несплошного
наблюдения, основная цель которого состоит в получении характеристик изучаемой
совокупности по обследованной ее части.
Одним из наиболее распространенных в статистике методов, применяющих
несплошное наблюдение, является выборочный метод.
Под выборочным понимается метод статистического исследования, при котором
обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее
части на основе положений случайного отбора.
При выборочном методе обследованию подвергается сравнительно небольшая
часть всей изучаемой совокупности (обычно до 5-10%, реже до 15-25%). При этом
подлежащая изучению статистическая совокупность, из которой производится отбор
части единиц, называется генеральной совокупностью.
Отобранная из генеральной совокупности некоторая часть единиц,
подвергающаяся обследованию, называется выборочной совокупностью или просто
выборкой.
Выборка может быть:
) собственно-случайная;
) механическая;
) типическая;
) серийная;
) комбинированная.
Собственно-случайная выборка состоит в том, что выборочная совокупность
образуется в результате случайного (непреднамеренного) отбора отдельных единиц
из генеральной совокупности. При этом количество отобранных в выборочную
совокупность единиц обычно определяется исходя из принятой доли выборки.
Механическая выборка состоит в том, что отбор единиц в выборочную
совокупность производится из генеральной совокупности, разбитой на равные
интервалы (группы). При этом размер интервала в генеральной совокупности равен
обратной величине доли выборки.
Важной особенностью механической выборки является то, что формирование
выборочной совокупности можно осуществить, не прибегая к составлению списков.
На практике часто используют тот порядок, в котором фактически размещаются
единицы генеральной совокупности. Например, последовательность выхода готовых
изделий с конвейера или поточной линии, порядок размещения единиц партии товара
при хранении, транспортировке, реализации и т.д.
При типической выборке генеральная совокупность вначале расчленяется на
однородные типические группы. Затем из каждой типической группы
собственно-случайной или механической выборкой производится индивидуальный
отбор единиц в выборочную совокупность.
Типическая выборка обычно применяется при изучении сложных статистических
совокупностей. Например, при выборочном обследовании производительности труда
работников торговли, состоящих из отдельных групп по квалификации. Важной
особенностью типической выборки является то, что она дает более точные
результаты по сравнению с другими способами отбора единиц в выборочную
совокупность.
Если в выборку попадают не отдельные единицы совокупности, а целые серии,
такая выборка называется серийная.
Серийный отбор применяется редко, т.к. дает высокую ошибку выборки.
Комбинированная выборка предполагает использование нескольких способов
выборки. Можно комбинировать, например, серийную выборку и случайную. В этом
случае, разбив генеральную совокупность на серии (группы) и отобрав нужное
число серий, производят случайную выборку единиц в серии. Можно комбинировать
типическую и серийную выборку.
Практическое задание 1.1
Приведена статистика темпа инфляции за 10 лет.
Необходимо:
Построить эмпирическую функцию распределения
Найти средние несмещенные оценки среднего темпа инфляции, дисперсии и
среднего квадратичного отклонения
Определить доверительные интервалы для вычисленных величин.
|
№
|
Данные статистики.
|
|
1
|
2,5
|
3,2
|
5,1
|
1,8
|
-0,6
|
0,7
|
2,1
|
2,7
|
4,1
|
3,5
|
Выполнение задания
Данные в выборке представлены случайно, поэтому целесообразно упорядочить
их, выполнив сортировку.
|
№
|
Данные статистики.
|
|
1
|
-0,6
|
0,7
|
1,8
|
2,1
|
2,5
|
2,7
|
3,2
|
3,5
|
4,1
|
5,1
|
Определим размах выборки как разность между наибольшим и наименьшим
элементами.= 5,1 - (-0,6) = 5,7
Построим
частотную таблицу. Зададим количество интервалов, например, 5 и определим длину
интервала 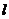 =
=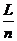 , где n -
число интервалов; в данном случае
, где n -
число интервалов; в данном случае 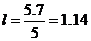 Построим
таблицу. Границы интервалов определяются формулой: bi = bi-1 +
.
Построим
таблицу. Границы интервалов определяются формулой: bi = bi-1 +
.
|
Размах
|
5,7
|
Число интервалов
|
5
|
|
Длина интервала
|
1,14
|
|
|
|
|
Таблица интервалов
|
|
№
|
1
|
2
|
3
|
4
|
5
|
6
|
|
граница
|
-0,6
|
0,54
|
1,68
|
2,82
|
3,96
|
5,1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
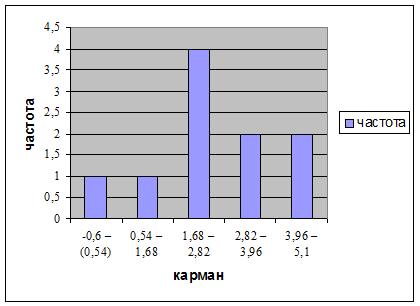
Карман
|
частота
|
|
-0,6 - (0,54)
|
1
|
|
0,54 - 1,68
|
1
|
|
1,68 - 2,82
|
4
|
|
2,82 - 3,96
|
2
|
|
3,96 - 5,1
|
2
|
Воспользуемся инструментом EXCEL / Гистограмма.
Щелкнув в роле диаграммы правой клавишей выберем в контекстном меню
команду / Добавить линию тренда / вид полиномиальный / параметры (вывод
уравнения тренда.
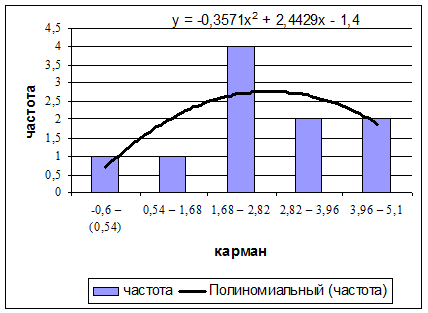
Уравнение тренда - есть приближенная функция распределения частот.
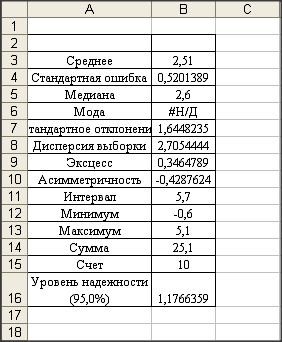
Основными статистическими моментами являются: среднее значение, медиана,
мода, дисперсия, стандартное отклонение.
Для вычисления используем статистические функции: СРЗНАЧ, ДИСП,
СТАНДОТКЛОН по выборке.
Для данного примера
|
СРЗНАЧ
|
2,510
|
|
ДИСП
|
2,705
|
|
СТАНДОТКЛОН
|
1,645
|
Можно воспользоваться инструментом описательная статистика / Сервис /
анализ данных / описательная статистика.
· доверительный интервал для среднего определяется -
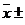
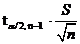 ,
,
где S - выборочное среднеквадратичное отклонение (корень из выборочной
дисперсии;
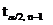 -
значение обратного распределения Стьюдента (функция СТЬЮРАСПОБР).
-
значение обратного распределения Стьюдента (функция СТЬЮРАСПОБР).
= 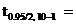 0,7455
0,7455

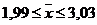
· Доверительный
интервал значений дисперсии оценивается по формуле 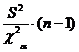 .
.
Значение ч2 вычисляются использованием функции ХИ2ОБР.
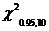 = 3,9403
= 3,9403
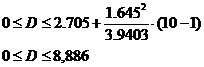
Практическое задание 1.2
При выборочном обследовании торговых предприятий района оценивалась
величина запаса (в днях оборота).
Общее количество торговых предприятий района N = 40 и объем выборки n = 4.
По результатам выборочного обследования требуется:
1. Оценить средний запас и построить для него доверительный интервал
при уровне надежности p =
0,9.
2. Определить представительный объем выборки nв на уровне надежности p = 0,95 и допустимой относительной погрешности E = 0,05 в
оценке среднего запаса.
. По данной выборке оценить уровень надежности p для интервала с
погрешностью E, не превышающей 0,1.
|
№
|
Запасы на обследуемых предприятиях
|
|
x1
|
x2
|
x3
|
x4
|
|
1
|
120
|
90
|
110
|
160
|
Выполнение задания
|
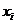 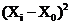
|
|
|
1
|
120
|
0
|
|
2
|
90
|
900
|
|
3
|
110
|
100
|
|
4
|
160
|
1600
|
|
Сумма
|
|
2600
|
Средний
запас в обследованных предприятиях: 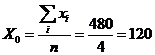
Или
с помощью функции СРЗНАЧ: X0=120 дн.
Выборочная дисперсия:
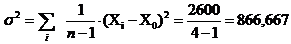
Или с помощью функции ДИСП: s2 = 866,667
Стандартное отклонение: s = 29,439
1. Предельная ошибка выборки для среднего значения при бесповторном
отборе вычисляется по формуле:
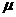 = t
= t 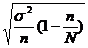
где
t - коэффициент доверия (при вероятности 0,9 он равен
1,64, определяется по таблицам интегралов вероятности),
у2
- выборочная дисперсия; n - численность выборки;
Дх
- предельная ошибка выборочной средней.

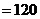 -
выборочная средняя.
-
выборочная средняя.
у = 29,439 - выборочное среднеквадратическое отклонение.
Подставляем рассчитанные значения в формулу предельной ошибки -
= t = 1,64  дн.
дн.
Далее рассчитаем возможные значения среднего значения запаса в
генеральной совокупности;
- Дх ≤
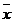 ≤ + Дх,
≤ + Дх,
где
х - выборочная средняя,
-
генеральная средняя.
-
22,901 ≤ ≤ 120 + 22,901
,099
≤ ≤ 142,901
Таким образом, с вероятностью 0,9 можно утверждать, что средний запас в
генеральной совокупности будет не меньше 97 и не больше 143 дн.
Вычисляем
среднюю ошибку выборки: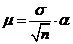 , где б =
, где б = 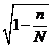
.
Если допустимая относительная погрешность Е=0,05 в оценке среднего запаса, то 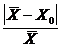 £ E
£ E
Тогда
предельная погрешность Д = Е* X0= 0,05*120 = 6
Представительный
объем выборки nB на уровне надежности р=0,95 найдем по формуле для
бесповторной выборки:
nв = 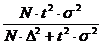 ,
,
Получаем
t=1,96в= 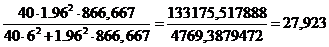
или,
округляя, nв=28
.
Если погрешность Е не превышает 0,1, то предельная погрешность:
Д=Е*X0=0,1*120=12
Тогда
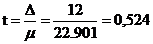 ;
;
уровень
надежности будет равен значению - р=0,4.
2. Что такое регрессионная модель и функция регрессии. Перечислите этапы
регрессионного анализа
Исследование связей в условиях массового наблюдения и действия случайных
факторов осуществляется, как правило, с помощью экономико-статистических
моделей. В широком смысле модель - это аналог, условный образ (изображение,
описание, схема, чертёж и т.п.) какого-либо объекта, процесса или события,
приближенно воссоздающий «оригинал».
Модель представляет собой логическое или математическое описание
компонентов и функций, отображающих существенные свойства моделируемого объекта
или процесса, даёт возможность установить основные закономерности изменения
оригинала. В модели оперируют показателями, исчисленными для качественно
однородных массовых явлений (совокупностей). Выражение и модели в виде
функциональных уравнений используют для расчёта средних значений моделируемого
показателя по набору заданных величин и для выявления степени влияния на него
отдельных факторов.
По количеству включаемых факторов модели могут быть однофакторными и
многофакторными (два и более факторов).
Функция регрессии - это модель вида
у = f (x),
где у - зависимая переменная (результативный признак);
х - независимая, или объясняющая, переменная (признак-фактор).
Линия регрессии - график функции у = f (x).
Виды регрессий:
1)
гиперболическая - регрессия равносторонней гиперболы: у = а + 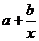 ;
;
)
линейная - регрессия, применяемая в статистике в виде четкой экономической
интерпретации ее параметров: у = 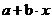 ;
;
)
логарифмически линейная - регрессия вида: 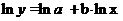
)
множественная - регрессия между переменными у и х1, х2...xm, т. е. модель вида: у = f(х1, х2...xm), где у - зависимая переменная (результативный признак), х1,
х2...xm - независимые, объясняющие переменные
(признаки-факторы);
)
нелинейная - регрессия, нелинейная относительно включенных в анализ объясняющих
переменных, но линейная по оцениваемым параметрам; или регрессия, нелинейная по
оцениваемым параметрам.
)
обратная - регрессия, приводимая к линейному виду, реализованная в стандартных
пакетах прикладных программ вида: у = 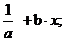
)
парная - регрессия между двумя переменными у и x, т. е, модель
вида: у = f (x), где у - зависимая переменная (результативный
признак), x - независимая, объясняющая переменная (признак -
фактор).
Этапы корреляционно-регрессионного анализа:
1. Предварительный (априорный) анализ. Он дает неплохие результаты
если проводится достаточно квалифицированным исследователем.
2. Сбор информации и ее первичная обработка.
. Построение модели (уравнения регрессии). Как правило, эту
процедуру выполняют на ПК, используя стандартные программы.
. Оценка тесноты связей признаков, оценка уравнения регрессии и
анализ модели.
. Прогнозирование развития анализируемой системы по уравнению
регрессии.
На первом этапе формулируется задача исследования,
определяется методика измерения показателей или сбора информации, определяется
число факторов, исключаются дублирующие факторы или связанные в
жестко-детерминированную систему.
На
втором этапе анализируется объем единиц: совокупность должна быть достаточно
большой по числу единиц и наблюдений (N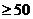 ), число
факторов “n” должно соответствовать количеству наблюдений “N”. Данные должны
быть количественно и качественно однородны.
), число
факторов “n” должно соответствовать количеству наблюдений “N”. Данные должны
быть количественно и качественно однородны.
На
третьем этапе определяется форма связи и тип аналитической функции (парабола,
гипербола, прямая) и находятся ее параметры.
На
четвертом этапе оценивается достоверность всех характеристик корреляционной
связи и уравнения регрессии используя критерий достоверности Фишера или
Стьюдента, производится экономико-технологический анализ параметров.
На
пятом этапе осуществляется прогноз возможных значений результата по лучшим
значениям факторных признаков, включенных в модель. Здесь выбираются наилучшие
и наихудшие значения факторов и результата.
Практическое задание 2.1
В результате наблюдений за спросом на некий товар и ростом его цены
сделана выборка.
Необходимо:
. Построить корреляционное поле
2. Вычислить коэффициент корреляции и проверить его значимость
. Построить регрессионную модель.
. Проверить значимость модели
. Проверить статистическую значимость коэффициентов модели.
Исходные данные для задания 2.1
|
№
|
Исходные данные
|
|
1
|
Х
|
4,4
|
12,9
|
5,5
|
15,5
|
13,9
|
15,3
|
14,2
|
11,2
|
5,5
|
10,8
|
|
У
|
2,6
|
10,9
|
6,2
|
16
|
16,1
|
14,7
|
11,1
|
12,7
|
6,2
|
8,4
|
Выполнение задания
. Создадим на рабочем листе таблицу и заполним данными первые два
столбца.
|
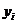 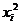 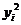 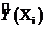
|
|
|
|
|
|
1
|
4,4
|
2,6
|
19,36
|
6,76
|
4,0906
|
|
2
|
12,9
|
10,9
|
166,41
|
118,81
|
12,4334
|
|
3
|
5,5
|
6,2
|
30,25
|
38,44
|
5,1703
|
|
4
|
15,5
|
16
|
240,25
|
256
|
14,9853
|
|
5
|
13,9
|
16,1
|
193,21
|
259,21
|
13,4149
|
|
6
|
15,3
|
14,7
|
234,09
|
216,09
|
14,7890
|
|
7
|
14,2
|
11,1
|
201,64
|
123,21
|
13,7093
|
|
8
|
11,2
|
12,7
|
125,44
|
161,29
|
10,7648
|
|
9
|
5,5
|
6,2
|
30,25
|
38,44
|
5,1703
|
|
10
|
10,8
|
8,4
|
116,64
|
70,56
|
10,3722
|
|
сумма
|
109,2
|
104,9
|
1357,54
|
1288,81
|
104,9
|
. Вычислим коэффициент корреляции с использованием статистической функции
КОРРЕЛ.
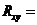 0,9187.
0,9187.
.
Проверим значимость коэффициента, выдвинув две гипотезы:
Н0:
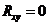 и связи нет, альтернативная Н1:
и связи нет, альтернативная Н1: 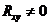 и связь имеется.
и связь имеется.
Вычислим
выражение
Т=
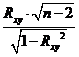
Для
n=10, получим Т=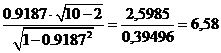
Вычислим
значение статистической функции СТЬЮДРАСПОБР.
При
уровне значимости 0,1 (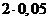 ) и степенях свободы 8.
) и степенях свободы 8.
Получим
tстьюд=3,3555, т.к. модуль Т≥ tстьюд, принимается
гипотеза о значимости и наличии связи.
3. Так как элементы выборки взяты случайно, проведем сортировку пар
значений, ключевое поле столбец Х и построим диаграмму поля наблюдений.
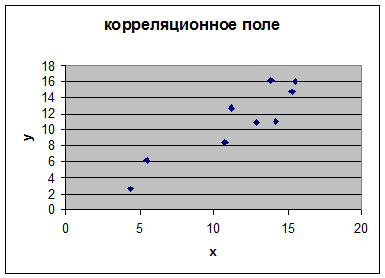
. Для переменных X, Y вычислить средние, дисперсии и стандартное
отклонение используя соответствующие статистические функции
5. Вычислим параметры модели, используя функцию ЛИНЕЙН.
Уравнение
регрессии: У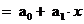
|
параметры регрессии
|
0,981499431
|
-0,2279738
|
У
= 0,9815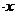 - 0,22797
- 0,22797
.
Вычислим и поместим в четвертый столбец величину значений регрессии .
Для
этого используйте процедуру задания формулы, в которой используются абсолютные
ссылки на адреса параметров регрессии, вычисленные в п.5. и относительный адрес
переменной Xi второй столбец.
.
На график корреляционного поля нанесем график регрессии и точку средних
значений переменных (использованием контекстного меню диаграммы исходные данные
/ ряд / добавить)
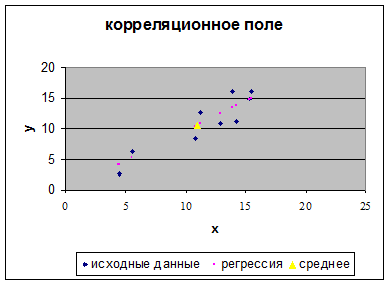
. Выполним оценку адекватности модели для этого оценим две суммы
квадратов
Qe
=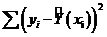 и Qr =
и Qr =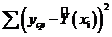 ,
,
где
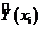 - значения регрессии, Ср = 10,49 - среднее
значение наблюдений у.
- значения регрессии, Ср = 10,49 - среднее
значение наблюдений у.
Для
вычисления используем математическую функцию СУММКВ.
|
|
4,4
|
2,6
|
4,0906
|
2,2220
|
40,9520
|
|
2
|
12,9
|
10,9
|
12,4334
|
2,3512
|
3,7767
|
|
3
|
5,5
|
6,2
|
5,1703
|
1,0603
|
28,2995
|
|
4
|
15,5
|
16
|
14,9853
|
1,0297
|
20,2074
|
|
5
|
13,9
|
16,1
|
13,4149
|
7,2099
|
8,5549
|
|
6
|
15,3
|
14,7
|
14,7890
|
0,0079
|
18,4811
|
|
7
|
14,2
|
11,1
|
13,7093
|
6,8085
|
10,3640
|
|
8
|
11,2
|
12,7
|
10,7648
|
3,7449
|
0,0755
|
|
9
|
5,5
|
6,2
|
5,1703
|
1,0603
|
28,2995
|
|
10
|
10,8
|
8,4
|
10,3722
|
3,8897
|
0,0139
|
|
сумма
|
-
|
104,9
|
104,9
|
29,3845
|
159,0245
|
. Вычислим коэффициент детерминации -
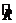 = 1-
= 1-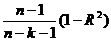 ,
,
где
k - число параметров регрессии, исключая свободный член, т.е. 1,
2 =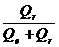 (коэффициент детерминации для n≥20)
(коэффициент детерминации для n≥20)
2 =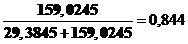
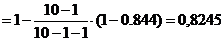
Коэффициент детерминации показывает, что модель работает на 82,45%, а
17,55% приходится на неучтенные факторы.
. Оценим параметры регрессии.
Вычислим остаточную дисперсию
S2
=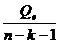
S2
= 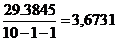
Для
простой линейной регрессии мерой служат величины:
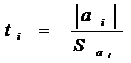
где аi - параметр регрессии,
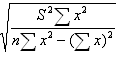
Sа1
=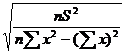
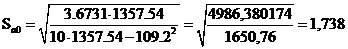
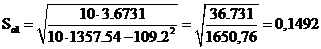
Если
величина 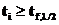 ,где
,где 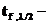 значение
Стьюдента при числе степеней свободы f =n-k-1 и л=0,05 (функция СТЬЮДРАСПОБР),
параметр значим, иначе его не учитывают.
значение
Стьюдента при числе степеней свободы f =n-k-1 и л=0,05 (функция СТЬЮДРАСПОБР),
параметр значим, иначе его не учитывают.
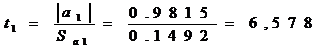
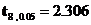 .
следовательно, коэффициент регрессии
.
следовательно, коэффициент регрессии 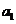 значим.
значим.
Доверительный
интервал параметра регрессии равен - 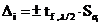
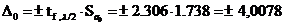
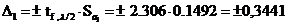
Тогда доверительный интервал для а0:
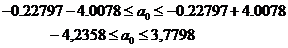
Тогда
доверительный интервал для а1:
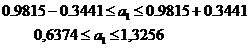
Аналогичные
результаты можно получить, используя надстройку MS Excel Пакет анализа (команда
Сервис\ Анализ данных\ Регрессия).
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,9187
|
|
|
|
|
|
R-квадрат
|
0,8440
|
|
|
|
|
|
Нормированный R-квадрат
|
0,8245
|
|
|
|
|
|
Стандартная ошибка
|
1,9165
|
|
|
|
|
|
Наблюдения
|
10,0000
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
Регрессия
|
1,0000
|
159,0245
|
159,0245
|
43,2948
|
0,0002
|
|
Остаток
|
8,0000
|
29,3845
|
3,6731
|
|
|
|
Итого
|
9,0000
|
188,4090
|
|
|
|
|
|
|
|
|
|
|
|
|
Коэффициенты регрессии
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-0,2280
|
1,7380
|
-0,1312
|
0,8989
|
-4,2358
|
3,7798
|
|
Переменная X
|
0,9815
|
0,1492
|
6,5799
|
0,0002
|
0,6375
|
1,3255
|
|
|
|
2,306
|
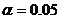
|
|
|
Столбец «Коэффициенты регрессии» содержит численные значения
коэффициентов регрессии. Названия строк показывают, с каким регрессором связаны
рассчитанные параметры. Строка У-пересечение не связана ни с одним параметром.
Это свободный коэффициент.
Качество полученной модели можно проанализировать с помощью данных в
столбцах
· Стандартная ошибка;
· t-статистика;
· Р-значение.
В ячейку после t-статистика запишем формулу = СТЬЮДРАСПОБР(0,05;10-8-1)
для расчета критической точки распределения Стьюдента. Получили 2,306.
В
ячейке после P-Значение - уровень значимости - . Нижние
95%, Верхние 95% - доверительные интервалы для коэффициентов регрессии.
Было
получено уравнение регрессии: У = 0,9815 - 0,2280
Анализ полученных результатов:
· Стандартная ошибка > стандартной ошибки коэффициентов
· Fнабл > Fкрит, регрессия значима. Значимость F < 0,05.
· |tстатистика| > tкр
· P-значение < 0,05
Используем F-статистику: FРАСПОБР
(0,05;1;10) = 0,828.
Поскольку Fнабл. = 43,3> Fкрит. =0,828, то построенная модель статистически значима.
Значимость F (=0,0002) < 0,05.
P-значения
коэффициента при х < 0,05
Модель статистически значима.
Список использованных источников
1. Бородич С.А. Эконометрика. - Минск: Новое знание,
2001.
. Магнус Я.Р. Эконометрика. Начальный курс - М.: Дело,
1997.
. Тюрин Ю.Н. Обработка статистических данных на ПЭВМ -
М.: Финансы и статистика, 1994.