Фиктивные переменные. Динамические эконометрические модели
Контрольная работа
Фиктивные переменные. Динамические
эконометрические модели
1. Необходимость использования фиктивных переменных
До сих пор рассматривались модели, в которых все объясняющие переменные
были количественными переменными (производительность труда, себестоимость,
доход и т.п.). На практике часто возникает необходимость исследования влияния
качественных признаков, имеющих два или несколько уровней. К числу таких
признаков можно отнести: пол (мужской, женский), образование (начальное,
среднее, высшее), фактор сезонности (зима, весна, лето, осень) и т.п.
Качественные признаки могут существенно влиять на структуру линейных
связей и приводить к скачкообразному изменению параметров регрессионной модели.
В этом случае говорят об исследовании регрессионных моделей с переменной
структурой или о построении регрессионных моделей по неоднородным данным.
Например, необходимо изучить зависимость размера з/п Y не только от количественных факторов
х1,…,хр, но и от качественного признака Z1 (например, пола). Можно получить оценки регрессионной
модели

для
каждого уровня качественного признака, а затем изучать различия между ними.
Другой подход позволяет оценивать влияние количественных переменных и
качественных признаков по одному уравнению регрессии. Он связан с введением
фиктивных переменных (структурных переменных).
В
качестве фиктивных переменных обычно используют булевы переменные, принимающие
лишь значения «0» и «1».
В
этом случае первоначальная регрессионная модель з/п примет вид
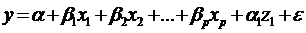 , где
, где 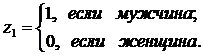
Таким
образом, принимая эту модель, считается, что з/п у мужчин на 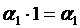 выше, чем у женщин. Проверка гипотезы
выше, чем у женщин. Проверка гипотезы
Н0: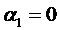 может установить существенность влияния фактора «пол»
на размер з/п. Следует отметить, что в принципе качественное различие можно
формализовать с помощью любой переменной, принимающей два разных значения, не
обязательно «0» или «1». Однако, в эконометрической практике почти всегда
используются фиктивные переменные типа «0-1», так как при этом интерпретация
полученных результатов выглядит наиболее просто. Если качественный признак
имеет k уровней, то можно ввести дискретную переменную,
принимающую k значений. Однако так не поступают из-за трудности
содержательной интерпретации, а вводят (k-1) бинарную
переменную. Например, для учета фактора образования можно ввести k = 3
- 1 = 2 бинарные переменные z21 и z22:
может установить существенность влияния фактора «пол»
на размер з/п. Следует отметить, что в принципе качественное различие можно
формализовать с помощью любой переменной, принимающей два разных значения, не
обязательно «0» или «1». Однако, в эконометрической практике почти всегда
используются фиктивные переменные типа «0-1», так как при этом интерпретация
полученных результатов выглядит наиболее просто. Если качественный признак
имеет k уровней, то можно ввести дискретную переменную,
принимающую k значений. Однако так не поступают из-за трудности
содержательной интерпретации, а вводят (k-1) бинарную
переменную. Например, для учета фактора образования можно ввести k = 3
- 1 = 2 бинарные переменные z21 и z22:
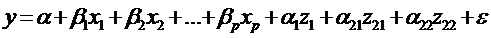 ,
,
где
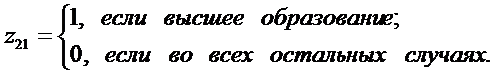
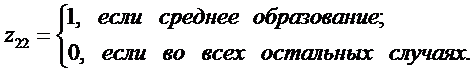
Третьей
переменной не требуется, так как если работник имеет начальное образование, то z21 =
z22 = 0. Более того, z23 вводить
нельзя, так как для любого работника z21 + z22 + z23 =
1, и
получался бы столбец в матрице Х из 1 (т.е., уже два таких столбца). И ХТХ была
бы вырожденной, следовательно, невозможно получить оценки коэффициентов. Такая
ситуация получила название «ловушки». Чтобы избежать её, число вводимых
бинарных переменных должно быть на 1 меньше числа уровней качественного
признака.
Название
«фиктивной» переменной не совсем удачно, так как все процедуры регрессионного
анализа (оценка параметров модели, проверка значимости коэффициентов и т.п.)
проводятся при включении фиктивных переменных так же, как и количественных
переменных. «Фиктивность» состоит только в том, что они количественным образом
описывают качественный признак.
.
Модели ANOVA и ANCOVA
Значит,
кроме моделей, содержащих только количественные объясняющие переменные, в
регрессионном анализе рассматривают также модели, содержащие лишь качественные
переменные, либо те и другие одновременно. Регрессионные модели, содержащие
лишь качественные объясняющие переменные, называются ANOVA - моделями
(моделями дисперсионного анализа). Например, пусть Y - начальная
з/п,
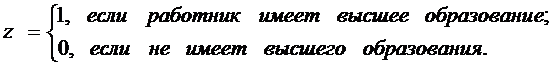
Зависимость
можно описать моделью парной регрессии
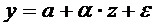 ,
очевидно,
,
очевидно,
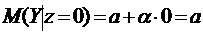 ,
, 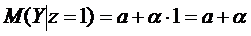
При
этом коэффициент 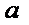 определяет среднюю начальную з/п при отсутствии в.о.
Коэффициент
определяет среднюю начальную з/п при отсутствии в.о.
Коэффициент 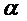 указывает, на какую величину отличаются средние
начальные з/п при наличии и при отсутствии в.о. Проверяя статистическую
значимость коэффициента
указывает, на какую величину отличаются средние
начальные з/п при наличии и при отсутствии в.о. Проверяя статистическую
значимость коэффициента 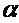 с помощью t - статистики, либо значимость
коэффициента детерминации R2 с помощью F - статистики, можно определить,
влияет или нет наличие высшего образования на начальную з/п. Модели, в которых
объясняющие переменные носят как количественный, так и качественный характер,
называют ANCOVA - моделями (моделями ковариационного анализа).
с помощью t - статистики, либо значимость
коэффициента детерминации R2 с помощью F - статистики, можно определить,
влияет или нет наличие высшего образования на начальную з/п. Модели, в которых
объясняющие переменные носят как количественный, так и качественный характер,
называют ANCOVA - моделями (моделями ковариационного анализа).
Рассмотрим
простейшую ANCOVA - модель с одной количественной и одной качественной
переменной, имеющей 2 уровня
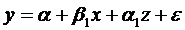
где
Y - з/п сотрудника фирмы, х - стаж, z -
пол, т.е.

Ожидаемое
значение з/п при х годах трудового стажа будет:
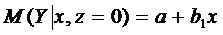 -для
женщин,
-для
женщин,
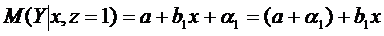 - для
мужчин.
- для
мужчин.
З/п
является линейной функцией стажа, причем для мужчин и женщин з/п меняется с
одним и тем же коэффициентом 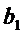 .
Отличаются только свободные члены. Проверив с помощью t - статистики
значимость коэффициентов
.
Отличаются только свободные члены. Проверив с помощью t - статистики
значимость коэффициентов 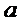 и
и 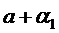 , можно
определить, имеет ли место в фирме дискриминация по половому признаку. При
, можно
определить, имеет ли место в фирме дискриминация по половому признаку. При 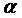 > 0 она будет в пользу мужчин, при
> 0 она будет в пользу мужчин, при 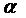 < 0 - в пользу женщин. Пример. Исследуется
эффективность лекарств у в зависимости от возраста пациента х. При этом
сравнивается эффективность лекарств а и b.
< 0 - в пользу женщин. Пример. Исследуется
эффективность лекарств у в зависимости от возраста пациента х. При этом
сравнивается эффективность лекарств а и b.
|
лекарство
|
y
|
x
|
z
|
zx
|
|
a
|
54
|
69
|
0
|
0
|
|
b
|
30
|
48
|
1
|
48
|
|
a
|
58
|
73
|
0
|
0
|
|
b
|
66
|
64
|
1
|
64
|
|
b
|
67
|
60
|
1
|
60
|
|
a
|
64
|
62
|
0
|
0
|
|
a
|
67
|
70
|
0
|
0
|
|
a
|
33
|
52
|
0
|
0
|
|
a
|
33
|
63
|
0
|
0
|
|
b
|
42
|
48
|
1
|
48
|
|
b
|
33
|
46
|
1
|
46
|
|
a
|
28
|
55
|
0
|
0
|
|
b
|
30
|
40
|
1
|
40
|
|
b
|
23
|
41
|
1
|
41
|
|
a
|
21
|
55
|
0
|
0
|
|
b
|
43
|
45
|
1
|
45
|
|
a
|
38
|
58
|
0
|
0
|
|
b
|
43
|
58
|
1
|
58
|
|
a
|
43
|
64
|
0
|
0
|
|
b
|
45
|
55
|
1
|
55
|
|
b
|
48
|
57
|
1
|
57
|
|
a
|
48
|
63
|
0
|
0
|
|
a
|
53
|
60
|
0
|
0
|
|
b
|
58
|
62
|
1
|
62
|
Решение
Вводится фиктивная переменная z:
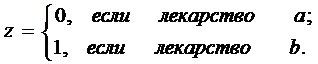
Возможен
один из трех вариантов: 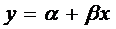 ,
, 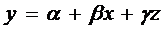 или
или 
Какой
из вариантов предпочтительнее?
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,690350892
|
|
|
|
|
|
|
R-квадрат
|
0,476584354
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,452792733
|
|
|
|
|
|
|
Стандартная ошибка
|
10,42269343
|
|
|
|
|
|
|
Наблюдения
|
24
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
2176,084158
|
2176,084158
|
20,03160557
|
0,000188762
|
|
|
Остаток
|
22
|
2389,915842
|
108,6325383
|
|
|
|
|
Итого
|
23
|
4566
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-17,86138614
|
14,09491696
|
-1,267221807
|
0,218326504
|
-47,09245468
|
11,3696824
|
|
x
|
1,094059406
|
0,24444605
|
4,47566817
|
0,000188762
|
0,587109328
|
1,601009484
|
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,818778974
|
|
|
|
|
|
|
R-квадрат
|
0,670399008
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,639008438
|
|
|
|
|
|
|
Стандартная ошибка
|
8,465498967
|
|
|
|
|
|
|
Наблюдения
|
24
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
2
|
3061,041872
|
1530,520936
|
21,35670027
|
8,68719E-06
|
|
|
Остаток
|
21
|
1504,958128
|
71,66467277
|
|
|
|
|
Итого
|
23
|
4566
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-53,19211823
|
15,23631493
|
-3,491140638
|
0,00217736
|
-84,87776958
|
-21,50646687
|
|
x
|
1,583743842
|
0,242565436
|
6,529140623
|
1,81395E-06
|
1,079301405
|
2,08818628
|
|
z
|
14,83743842
|
4,222311121
|
3,514056164
|
0,002062797
|
6,056661791
|
23,61821506
|
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,820613512
|
|
|
|
|
|
|
R-квадрат
|
0,673406536
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,624417516
|
|
|
|
|
|
|
Стандартная ошибка
|
8,634887835
|
|
|
|
|
|
|
Наблюдения
|
24
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
3
|
3074,774242
|
1024,924747
|
13,74607086
|
4,28274E-05
|
|
|
Остаток
|
20
|
1491,225758
|
74,56128792
|
|
|
|
|
Итого
|
23
|
4566
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-61,67248908
|
25,13975551
|
-2,453185715
|
0,02345824
|
-114,1131
|
-9,231878171
|
|
x
|
1,720524017
|
0,403481811
|
4,264192264
|
0,00037931
|
0,87887571
|
2,562172325
|
|
z
|
27,60406803
|
30,05830936
|
0,918350653
|
0,369378456
|
-35,0964664
|
90,30460246
|
|
zx
|
-0,219208228
|
0,510788146
|
-0,429156843
|
0,672396526
|
-1,284693626
|
0,84627717
|
Вывод
Значения фиктивной переменной можно изменять на противоположные. Суть
модели от этого не меняется. У коэффициента изменится знак. Значение
качественной переменной, для которой принимается Z = 0, называют базовым или сравнительным. Выбор базового
значения обычно диктуется целями исследования, но может быть и произвольным.
Коэффициент
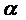 иногда называют дифференциальным коэффициентом
свободного члена, так как он показывает, на какую величину отличается свободный
член модели при значении фиктивной переменной, равной 1, от свободного члена
модели при базовом значении фиктивной переменной.
иногда называют дифференциальным коэффициентом
свободного члена, так как он показывает, на какую величину отличается свободный
член модели при значении фиктивной переменной, равной 1, от свободного члена
модели при базовом значении фиктивной переменной.
Рассмотрим
модель с двумя объясняющими переменными, одна из которых количественная, другая
- качественная, имеющая 3 альтернативы. Например, расходы на содержание ребенка
могут быть связаны с доходами и возрастом ребёнка: дошкольный, младший школьный
и старший школьный. Модель будет иметь вид:
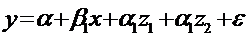
где
Y - расходы, х - доходы, 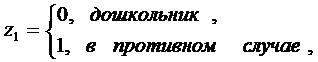

Получим
следующие зависимости:
Средний
расход на дошкольника
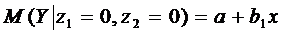 ;
;
Средний
расход на младшего школьника:
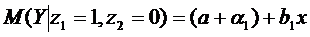 ;
;
Средний
расход на старшего школьника:
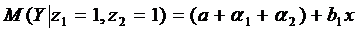 ;
;
Чтобы
учесть сезонные колебания аналогично можно вводить фиктивные переменные,
например,
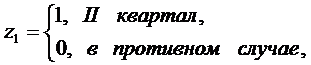
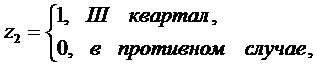
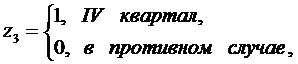
3.
Сравнение двух регрессий. Тест Чоу.
В
рассматриваемых примерах предполагалось, что изменение значения качественного
фактора влияет лишь на изменение свободного члена. В более сложных моделях
может быть отражено влияние качественного фактора на сами параметры при
переменных. Например, можно предположить, что до некоторого года в стране
обменный курс валют был фиксированным, а затем плавающим. Или налог на ввозимые
автомобили был одним, а затем он существенно изменился. Зависимость может быть
выражена так:
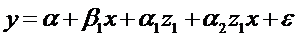 ,
,
где
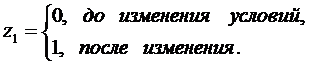
Тогда
ожидаемое значение Y определяется следующим образом:
 и
и 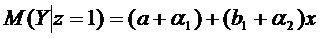 .
.
Фиктивная
переменная z1 в уравнении используется как в аддитивном виде (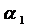 z1), так и в
мультипликативном (
z1), так и в
мультипликативном (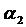 z1x),
что позволяет фактически разбивать рассматриваемую зависимость на две части,
связанные с периодом изменения качественного фактора. Имеет ли смысл разбивать
выборку на части или в этом нет необходимости можно решить с помощью теста Чоу.
Задача может быть и противоположной: можно ли объединить две выборки в одну и
рассматривать единую модель (без качественного фактора).
z1x),
что позволяет фактически разбивать рассматриваемую зависимость на две части,
связанные с периодом изменения качественного фактора. Имеет ли смысл разбивать
выборку на части или в этом нет необходимости можно решить с помощью теста Чоу.
Задача может быть и противоположной: можно ли объединить две выборки в одну и
рассматривать единую модель (без качественного фактора).
Суть
теста Чоу состоит в следующем. Пусть выборка имеет объем n, и
есть основание предполагать, что целесообразно разбить её на две объёмами n1 и n2: n1 + n2 = n.
Строят уравнение общей регрессии и уравнение регрессий по каждой подвыборке.
Обозначим
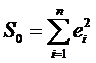 ,
, 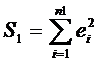 ,
, 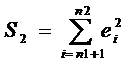 .
.
Очевидно,
что 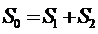 возможно лишь при совпадении коэффициентов регрессии
для всех трех уравнений. Чем сильнее различие в поведении Y для
двух подвыборок, тем больше S0 будет превосходить S1 + S2.
Тогда S0 - (S1 + S2) может быть интерпретирована как улучшение качества
модели при разбиении. Следовательно, дробь (S0 - (S1 + S2))/(p+1)
определяет оценку уменьшения дисперсии регрессии. Проверку проводят с помощью
критерия Фишера
возможно лишь при совпадении коэффициентов регрессии
для всех трех уравнений. Чем сильнее различие в поведении Y для
двух подвыборок, тем больше S0 будет превосходить S1 + S2.
Тогда S0 - (S1 + S2) может быть интерпретирована как улучшение качества
модели при разбиении. Следовательно, дробь (S0 - (S1 + S2))/(p+1)
определяет оценку уменьшения дисперсии регрессии. Проверку проводят с помощью
критерия Фишера
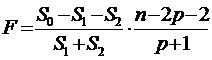
(здесь
n-2p-2 и р+1 - число степеней свободы необъясненной и
объясненной дисперсий).
Если
F > Fкр(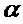 , р+1, n-2p-2),
то разбиение целесообразно. Это означает необходимость введения в уравнение
регрессии соответствующей фиктивной переменной.
, р+1, n-2p-2),
то разбиение целесообразно. Это означает необходимость введения в уравнение
регрессии соответствующей фиктивной переменной.
Если
F < Fкр, то различие между S0 и S1 + S2
статистически незначимо и нет смысла разбивать уравнение регрессии на части.
Пример.
Рассматривая зависимость между доходом Х и сбережениями Y за
20 лет, обнаружено изменение экономической ситуации на 12-м году наблюдений.
Построить
общее уравнение регрессии для всего интервала наблюдений, а также уравнение
регрессии, учитывающее изменение ситуации. Проверить с помощью теста Чоу
необходимость разбиения интервала наблюдений на два подынтервала.
|
год
|
Y
|
X
|
Z
|
|
75
|
4,7
|
100
|
0
|
|
76
|
6,1
|
105
|
0
|
|
77
|
6,5
|
108
|
0
|
|
78
|
6,8
|
111
|
0
|
|
79
|
5,2
|
115
|
0
|
|
80
|
6,5
|
122
|
0
|
|
81
|
7,5
|
128
|
0
|
|
82
|
8
|
135
|
0
|
|
83
|
9
|
143
|
0
|
|
84
|
9,1
|
142
|
0
|
|
85
|
8,7
|
147
|
0
|
|
86
|
12
|
155
|
1
|
|
87
|
16,2
|
167
|
1
|
|
88
|
18,5
|
177
|
1
|
|
89
|
18
|
188
|
1
|
|
90
|
17,6
|
195
|
1
|
|
91
|
20
|
210
|
1
|
|
92
|
23
|
226
|
1
|
|
93
|
22,5
|
238
|
1
|
|
94
|
24,3
|
255
|
1
|
) строим уравнение для всего интервала.
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,975998
|
|
|
|
|
|
|
R-квадрат
|
0,952571
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,949936
|
|
|
|
|
|
|
Стандартная ошибка
|
1,500972
|
|
|
|
|
|
|
Наблюдения
|
20
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
814,4655
|
814,4655
|
361,5159
|
2,3E-13
|
|
|
Остаток
|
18
|
40,55252
|
2,252918
|
|
|
|
|
Итого
|
19
|
855,018
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-9,56407
|
1,208504
|
-7,91397
|
2,86E-07
|
-12,103
|
-7,02509
|
|
X
|
0,1394
|
0,007332
|
19,01357
|
2,3E-13
|
0,123997
|
0,154804
|
) строим уравнение множественной регрессии с фиктивной переменной
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,989934
|
|
|
|
|
|
|
R-квадрат
|
0,979969
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,977612
|
|
|
|
|
|
|
Стандартная ошибка
|
1,00373
|
|
|
|
|
|
|
Наблюдения
|
20
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
2
|
837,8909
|
418,9455
|
415,8374
|
3,67E-15
|
|
|
Остаток
|
17
|
17,12706
|
1,007474
|
|
|
|
|
Итого
|
19
|
855,018
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-5,43851
|
1,176906
|
-4,62103
|
0,000244
|
-7,92157
|
-2,95546
|
|
X
|
0,101714
|
0,009226
|
11,02452
|
3,64E-09
|
0,082248
|
0,121179
|
|
Z
|
4,093698
|
0,848963
|
4,821998
|
0,000159
|
2,302542
|
5,884853
|
) строим уравнение парной регрессии для данных до 86 года
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Множественный R
|
0,91651
|
|
|
|
|
|
|
R-квадрат
|
0,83999
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,822211
|
|
|
|
|
|
|
Стандартная ошибка
|
0,62994
|
|
|
|
|
|
|
Наблюдения
|
11
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
18,74858
|
18,74858
|
47,24651
|
7,28E-05
|
|
|
Остаток
|
9
|
3,571422
|
0,396825
|
|
|
|
|
Итого
|
10
|
22,32
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-3,00135
|
1,481807
|
-2,02546
|
0,073471
|
-6,35343
|
0,350733
|
|
X
|
0,081943
|
0,011921
|
6,87361
|
7,28E-05
|
0,054975
|
0,108911
|
) Парная регрессия для интервала с 86 по 94 годы
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,946876
|
|
|
|
|
|
|
R-квадрат
|
0,896574
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,881799
|
|
|
|
|
|
|
Стандартная ошибка
|
1,316233
|
|
|
|
|
|
|
Наблюдения
|
9
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
105,1283
|
105,1283
|
60,68116
|
0,000108
|
|
|
Остаток
|
7
|
12,12729
|
1,73247
|
|
|
|
|
Итого
|
8
|
117,2556
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-2,5731
|
2,819436
|
-0,91263
|
0,391785
|
-9,24001
|
4,093808
|
|
Переменная X 1
|
0,107818
|
0,013841
|
7,789811
|
0,000108
|
0,075089
|
0,140546
|
). Применим тест Чоу.
0 = 855,018; S1 = 22,32; S2 = 117,256; n = 20;
p = 1;
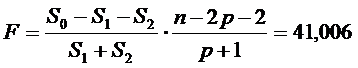
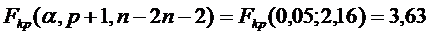
Так
как F > Fkp, то разбиение целесообразно, т.е. целесообразно
использование фиктивной переменной.
.
Фиктивная зависимая переменная
Иногда
фиктивные переменные могут быть использованы для объяснения поведения зависимой
переменной. Например, если исследовать зависимость наличия автомобиля от
дохода, пола и т.п., то зависимая переменная имеет два возможных значения: 0 -
нет машины, 1 - есть.
Если
для моделей такого типа использовать обыкновенный МНК, то оценки не будут
обладать свойствами наилучших линейных несмещенных оценок. Для определения
коэффициентов используют другие методы (например, взвешенный МНК).
Модель
LPM.
Рассмотрим
модель, в которой зависимая переменная - фиктивная переменная. Объясняющие
переменные могут быть и качественными, и количественными. Например, анализ
наличия работы у субъекта в зависимости от возраста, образования, семейного
положения, доходов остальных членов семьи и т.д. Или, исследование торгового
баланса (отрицательный или положительный). Пусть
авторегрессионый
модель койка фиктивный
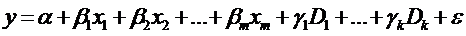 , (*)
, (*)
где
y - результат сдачи экзамена в ГАИ с 1-й попытки, x1-
количество часов вождения в автошколе, x2 - средний
процент выпускников, сдающих экзамен с 1-й попытки, D1-
использование компьютерной методики обучения:
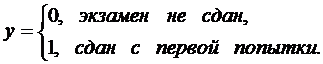
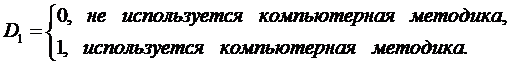
Получим
модель
 .
.
Модели
такого вида называют линейными вероятностными моделями (LPM).
Применимость
МНК к таким моделям имеет определенные ограничения:
. Случайные
отклонения 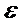 в таких моделях не являются нормальными случайными
величинами. Скорее всего, они имеют биномиальное распределение (при
в таких моделях не являются нормальными случайными
величинами. Скорее всего, они имеют биномиальное распределение (при 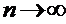 оно сходится к нормальному закону).
оно сходится к нормальному закону).
. Случайные
отклонения не обладают свойством постоянства дисперсии (гомоскедастичности).
. Использование
модели (*) может привести к тому, что некоторые уi будут либо
меньше нуля, либо больше 1.
. Применение
модели LPM затруднено с содержательной точки зрения (увеличение x на
1 ед. приводит к изменению y на величину 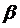 вне зависимости
от конкретного значения x и т.п.).
вне зависимости
от конкретного значения x и т.п.).
Поэтому, непосредственное использование МНК в модели LPM приводит к
серьезным погрешностям и необоснованным выводам, его использование не
рекомендуется.
Пример.
Исследуется вопрос о наличии собственного дома Y (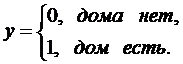 ) в зависимости от совокупного дохода семьи Х по
выборке объема 40.
) в зависимости от совокупного дохода семьи Х по
выборке объема 40.
|
семья
|
y
|
x
|
|
|
|
|
|
|
|
|
|
1
|
0
|
10
|
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
|
2
|
20
|
|
|
|
|
|
|
|
|
|
3
|
1
|
22
|
|
Регрессионная статистика
|
|
|
|
|
|
|
4
|
0
|
18
|
|
Множественный R
|
0,72763199
|
|
|
|
|
|
|
5
|
0
|
9
|
|
R-квадрат
|
0,52944831
|
|
|
|
|
|
|
6
|
0
|
15
|
|
Нормированный R-квадрат
|
0,51706537
|
|
|
|
|
|
|
7
|
1
|
25
|
|
Стандартная ошибка
|
0,35013012
|
|
|
|
|
|
|
8
|
1
|
30
|
|
Наблюдения
|
40
|
|
|
|
|
|
|
9
|
1
|
40
|
|
|
|
|
|
|
|
|
|
10
|
0
|
16
|
|
Дисперсионный анализ
|
|
|
|
|
|
|
|
11
|
0
|
12
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
12
|
0
|
8
|
|
Регрессия
|
1
|
5,241538247
|
5,241538247
|
42,75627105
|
1,04143E-07
|
|
|
13
|
1
|
20
|
|
Остаток
|
38
|
4,658461753
|
0,122591099
|
|
|
|
|
14
|
0
|
19
|
|
Итого
|
39
|
9,9
|
|
|
|
|
|
15
|
1
|
30
|
|
|
|
|
|
|
|
|
|
16
|
1
|
50
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
17
|
1
|
37
|
|
Y-пересечение
|
-0,1694268
|
0,123166627
|
-1,37559031
|
0,17700343
|
-0,418764617
|
0,079911
|
|
18
|
1
|
28
|
|
x
|
0,03022802
|
0,00462285
|
6,538827957
|
1,04143E-07
|
0,020869548
|
0,0395865
|
|
19
|
1
|
45
|
|
|
|
|
|
|
|
|
|
20
|
1
|
38
|
|
|
|
|
|
|
|
|
|
21
|
1
|
30
|
|
Оценим LPM модель, её
качество и вероятность того, что при доходе, равном 18, семья имеет доход.
|
|
22
|
0
|
12
|
|
|
|
|
|
|
|
|
|
23
|
0
|
16
|
|
|
|
|
|
|
|
|
|
24
|
1
|
27
|
|
P (Y=1 / X=18) =
|
0,3746775
|
|
|
|
|
|
|
25
|
0
|
19
|
|
|
|
|
|
|
|
|
|
26
|
0
|
15
|
|
|
|
|
|
|
|
|
|
27
|
1
|
32
|
|
|
|
|
|
|
|
|
|
28
|
0
|
18
|
|
|
|
|
|
|
|
|
|
29
|
1
|
43
|
|
|
|
|
|
|
|
|
|
30
|
0
|
13
|
|
|
|
|
|
|
|
|
|
31
|
1
|
22
|
|
|
|
|
|
|
|
|
|
32
|
0
|
14
|
|
|
|
|
|
|
|
|
|
33
|
0
|
10
|
|
|
|
|
|
|
|
|
|
34
|
0
|
17
|
|
|
|
|
|
|
|
|
|
35
|
1
|
36
|
|
|
|
|
|
|
|
|
|
36
|
1
|
45
|
|
|
|
|
|
|
|
|
|
37
|
0
|
14
|
|
|
|
|
|
|
|
|
|
38
|
1
|
2
|
|
|
|
|
|
|
|
|
|
39
|
1
|
41
|
|
|
|
|
|
|
|
|
|
40
|
1
|
34
|
|
|
|
|
|
|
|
|
Logit
модель.
Для
преодоления недостатков LPM-моделей необходимо использовать такие модели, в
которых не будут, по крайней мере, нарушаться неравенства 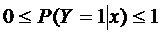 , и зависимость между
, и зависимость между 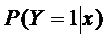 и
х не будет линейной, а будет удовлетворять закону убывающей эффективности.
и
х не будет линейной, а будет удовлетворять закону убывающей эффективности.
Поясним
суть logit модели. По модели LPM
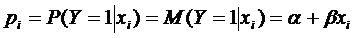 (для
одной переменной)
(для
одной переменной)
Представим
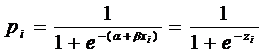
где
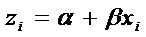 .
.
Здесь
можно заметить, что при 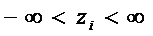 , неравенство
, неравенство 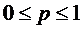 не
нарушается никогда. Формула зависимости pi от xi не
является линейной. Однако, pi не является линейной функцией от параметров и
не
нарушается никогда. Формула зависимости pi от xi не
является линейной. Однако, pi не является линейной функцией от параметров и 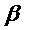 . Это
значит, что для их определения неприменим МНК. Преодолеем эту проблему.
. Это
значит, что для их определения неприменим МНК. Преодолеем эту проблему.
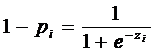
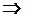
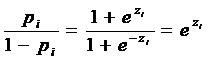 .
.
Отношение
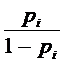 является отношением вероятностей, характеризующим во
сколько раз
является отношением вероятностей, характеризующим во
сколько раз 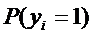 больше, чем
больше, чем 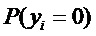 .
Прологарифмировав, получим
.
Прологарифмировав, получим
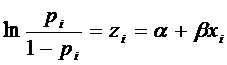 . (**)
. (**)
Модель
(**) называют logit моделью, она напоминает полулогарифмическую модель.
Однако, для её построения невозможно использовать обычный МНК, так как не
неизвестными являются значения
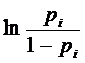
Поэтому
предварительно необходимо определить pi. Если имеется выборка по
сгруппированным данным, то 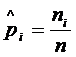 (относительная
частота). В случае несгруппированных данных для определения pi
используют метод максимального правдоподобия. И в этом случае использование
обычного МНК нецелесообразно в силу проблемы гетероскедастичности. Поэтому при
расчетах коэффициентов обычно применяют ВМНК, устраняющий этот недостаток.
(относительная
частота). В случае несгруппированных данных для определения pi
используют метод максимального правдоподобия. И в этом случае использование
обычного МНК нецелесообразно в силу проблемы гетероскедастичности. Поэтому при
расчетах коэффициентов обычно применяют ВМНК, устраняющий этот недостаток.
Пример.
В таблице представлены данные о количестве семей N, имеющих
определенный уровень дохода Х, и количестве семей n, имеющих
частные дома.
Оценить
logit модель по МНК. Оценить logit модель по
ВМНК, учитывая при этом, что дисперсии отклонений оцениваются по следующей
формуле
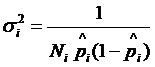 ;
;  .
.
Сравните
качество построенных регрессий.
Составим
таблицу
|
Xi
|
N
|
n
|
pi
|
Zi
|
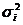 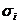 a'X'Z' a'X'Z'
|
|
|
|
|
|
10
|
35
|
5
|
0,142857
|
-1,79176
|
0,233333
|
0,483046
|
2,070197
|
20,70197
|
-3,70929
|
|
15
|
45
|
10
|
0,222222
|
-1,25276
|
0,128571
|
0,358569
|
2,788867
|
41,833
|
-3,49379
|
|
20
|
60
|
18
|
0,3
|
-0,8473
|
0,079365
|
0,281718
|
3,549648
|
70,99296
|
-3,00761
|
|
25
|
80
|
30
|
0,375
|
-0,51083
|
0,053333
|
0,23094
|
4,330127
|
108,2532
|
-2,21194
|
|
30
|
100
|
45
|
0,45
|
-0,20067
|
0,040404
|
0,201008
|
4,974937
|
149,2481
|
-0,99832
|
|
35
|
130
|
60
|
0,461538
|
-0,15415
|
0,030952
|
0,175933
|
5,683986
|
198,9395
|
-0,87619
|
|
40
|
90
|
55
|
0,611111
|
0,451985
|
0,046753
|
0,216225
|
4,624812
|
184,9925
|
2,090346
|
|
45
|
65
|
45
|
0,692308
|
0,81093
|
0,072222
|
0,268742
|
3,721042
|
167,4469
|
3,017505
|
|
50
|
50
|
38
|
0,76
|
1,15268
|
0,109649
|
0,331133
|
3,019934
|
150,9967
|
3,481016
|
|
55
|
30
|
24
|
0,8
|
1,386294
|
0,208333
|
0,456435
|
2,19089
|
120,499
|
3,037219
|
|
60
|
15
|
13
|
0,866667
|
1,871802
|
0,576923
|
0,759555
|
1,316561
|
78,99367
|
2,464342
|
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,9956
|
|
|
|
|
|
|
R-квадрат
|
0,99122
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,990244
|
|
|
|
|
|
|
Стандартная ошибка
|
0,114177
|
|
|
|
|
|
|
Наблюдения
|
11
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
1
|
13,24509
|
13,24509
|
1016,002
|
1,45E-10
|
|
|
Остаток
|
9
|
0,117328
|
0,013036
|
|
|
|
|
Итого
|
10
|
13,36241
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
-2,34572
|
0,08362
|
-28,0521
|
4,52E-10
|
-2,53488
|
-2,15655
|
|
Xi
|
0,0694
|
0,002177
|
1,45E-10
|
0,064475
|
0,074326
|
|
ВЫВОД ИТОГОВ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Регрессионная статистика
|
|
|
|
|
|
|
Множественный R
|
0,985839
|
|
|
|
|
|
|
R-квадрат
|
0,971879
|
|
|
|
|
|
|
Нормированный R-квадрат
|
0,857643
|
|
|
|
|
|
|
Стандартная ошибка
|
0,507898
|
|
|
|
|
|
|
Наблюдения
|
11
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дисперсионный анализ
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость F
|
|
|
Регрессия
|
2
|
80,23657
|
40,11829
|
155,5212
|
3,95E-07
|
|
|
Остаток
|
9
|
2,321642
|
0,25796
|
|
|
|
|
Итого
|
11
|
82,55822
|
|
|
|
|
|
Коэффициенты
|
Стандартная ошибка
|
t-статистика
|
P-Значение
|
Нижние 95%
|
Верхние 95%
|
|
Y-пересечение
|
0
|
#Н/Д
|
#Н/Д
|
#Н/Д
|
#Н/Д
|
#Н/Д
|
|
a'
|
-2,28664
|
0,134015
|
-17,0626
|
3,67E-08
|
-2,5898
|
-1,98348
|
|
X'
|
0,067203
|
0,003817
|
17,6074
|
2,78E-08
|
0,058569
|
0,075837
|
. Общая характеристика ДЭМ
К динамическим эконометрическим моделям (ДЭМ) относят модели, которые в
данный момент времени учитывают значения входящих в нее переменных, относящихся
к текущему и к предыдущему моментам времени.
Например
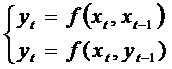 ДЭМ, а
ДЭМ, а 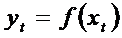 не является ДЭМ.
не является ДЭМ.
Можно
выделить два основных типа ДЭМ:
1. К моделям первого типа относятся модели авторегрессии и модели с
распределенным лагом, в которых лаговые значения переменных (переменных,
относящихся к предыдущим моментам времени) непосредственно включены в модель.
Модели авторегрессии - это ДЭМ, в которых в качестве факторных переменных
содержатся лаговые значения результативной переменной. Например
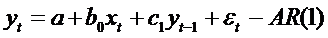 -
марковский случайный процесс;
-
марковский случайный процесс;
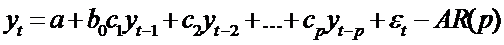 -
авторегрессионная модель порядка р.
-
авторегрессионная модель порядка р.
Модели с распределенным лагом - это ДЭМ, в которых содержатся не только
текущие, но и лаговые значения факторных переменных. Например

.
Модели второго типа учитывают динамическую информацию в неявном виде. Они
включают переменные, характеризующие ожидаемый или желаемый уровень
признака-результата или одного из факторов в момент времени t.
Этот уровень считается неизвестным и определяется с учетом информации в
предыдущий момент времени t-1. В зависимости от способа определения ожидаемых
значений показателей различают модели: адаптивных ожиданий, частичной
корректировки и рациональных ожиданий. Оценка параметров этих моделей сводится
к оценке параметров моделей авторегрессии.
.
Оценка моделей с лагами в независимых переменных. Преобразование Койка
Оценка моделей с распределенным лагом во многом зависит от того, конечное
или бесконечное число лагов она содержит:
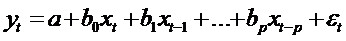 ,
,
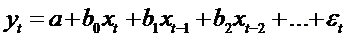 .
.
В
обеих моделях коэффициенты 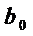 называются
краткосрочными мультипликатором, так как он характеризует изменение среднего
значения Y под воздействием единичного изменения переменной X в
тот же момент времени.
называются
краткосрочными мультипликатором, так как он характеризует изменение среднего
значения Y под воздействием единичного изменения переменной X в
тот же момент времени.
Сумму
всех коэффициентов
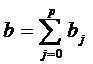
называют
долгосрочным мультипликатором, так как она характеризует изменение Y под
воздействием единичного изменения переменной X в каждом из
рассматриваемых временных периодов.
Любую
сумму коэффициентов
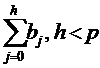
называют
промежуточным мультипликатором.
Модель
с конечным числом лагов оценивается сведением ее к уравнению множественной
регрессии.
Полагают
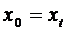 ,
, 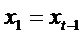 , ... ,
, ... , 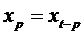 и получают уравнение
и получают уравнение 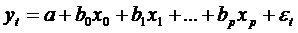
Для
оценки моделей с бесконечным числом лагов разработано несколько методов.
Преобразование
Койка
Метод Койка обычно применяют, если в моделях с распределенным лагом
величина максимального лага p
бесконечна. Предполагается, что коэффициенты при лаговых значениях объясняющей
переменной убывают в геометрической прогрессии. Если имеется одна объясняющая
переменная, то модель имеет вид
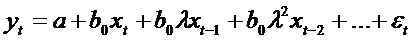
где
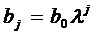 ,
, 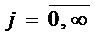 ,
, 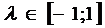 . В модели всего три параметра:
. В модели всего три параметра: 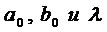 . Для их оценивания нельзя использовать обычный МНК,
так как:
. Для их оценивания нельзя использовать обычный МНК,
так как:
1) возникает проблема мультиколлинеарности;
2) из
полученных оценок МНК не удается вывести 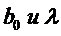 (не
однозначность).
(не
однозначность).
Для
оценки параметров 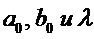 можно использовать два метода: нелинейный МНК и
преобразование Койка.
можно использовать два метода: нелинейный МНК и
преобразование Койка.
Суть
нелинейного МНК. Параметру 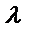 присваивают
последовательно все значения из интервала (0,1) с шагом, например, 0,01;
0,001;... . Для каждого значения
присваивают
последовательно все значения из интервала (0,1) с шагом, например, 0,01;
0,001;... . Для каждого значения 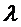 рассчитывается
переменная
рассчитывается
переменная 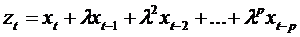 с таким значением р, при котором дальнейшие лаговые
значения х не оказывают существенного воздействия на z.
с таким значением р, при котором дальнейшие лаговые
значения х не оказывают существенного воздействия на z.
С
помощью обычного МНК оценивается уравнение регрессии: 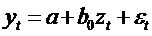 . Из всех возможных значений
. Из всех возможных значений 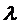 выбирается то, при котором коэффициент детерминации
выбирается то, при котором коэффициент детерминации 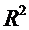 будет наибольшим.
будет наибольшим.
Суть
метода Койка. Если выражение 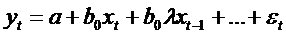 выполняется
для периода t, то оно должно выполняться и для периода (t-1):
выполняется
для периода t, то оно должно выполняться и для периода (t-1):
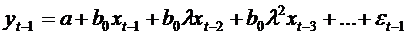
 и вычтем из предыдущего, получим:
и вычтем из предыдущего, получим:
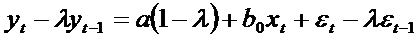 или
или
 .
.
Полученная модель относится к моделям авторегрессии. Эта форма позволяет
анализировать краткосрочные и долгосрочные динамические свойства модели.
В
краткосрочном аспекте (в текущем периоде) значение 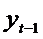 нужно рассматривать как фиксированное. Воздействие х
на у характеризует коэффициент
нужно рассматривать как фиксированное. Воздействие х
на у характеризует коэффициент 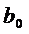 .
.
В
долгосрочном периоде (без учета 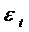 ) если
) если 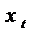 стремится к некоторому равновесному значению
стремится к некоторому равновесному значению 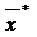 , то
, то 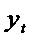 и
и 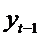 будут также стремиться к равновесному уровню
будут также стремиться к равновесному уровню 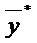 , определяемому как:
, определяемому как: 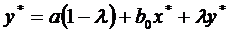 ,
из которого
,
из которого 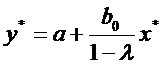 .
.
Таким
образом, долгосрочное воздействие х на у отражается коэффициентом 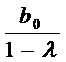 . Если
. Если 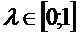 , то этот
коэффициент превысит
, то этот
коэффициент превысит  , то есть долгосрочное воздействие оказывается сильнее
краткосрочного.
, то есть долгосрочное воздействие оказывается сильнее
краткосрочного.
Модель
преобразования Койка привлекательна с практической точки зрения, так как
оценивание парной регрессии с помощью МНК позволяет получить оценки 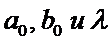 . Метод Койка требует гораздо меньше усилий, чем
нелинейный МНК. Однако его применение сопряжено с одной проблемой - нарушение
одной из предпосылок МНК: объясняющая переменная
. Метод Койка требует гораздо меньше усилий, чем
нелинейный МНК. Однако его применение сопряжено с одной проблемой - нарушение
одной из предпосылок МНК: объясняющая переменная 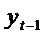 частично
зависит от
частично
зависит от 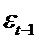 и поэтому коррелирует с одной из случайных
составляющих (
и поэтому коррелирует с одной из случайных
составляющих (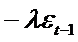 ). В итоге оценки МНК оказываются смещенными и
несостоятельными.
). В итоге оценки МНК оказываются смещенными и
несостоятельными.
. Авторегрессионые модели: модель адаптивных ожиданий и частичной
корректировки. Метод инструментальных переменных
При построении моделей авторегрессии
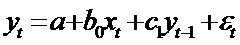
возникает
проблема: нарушается предпосылка линейной регрессионной модели об отсутствии
связи между признаком и случайной составляющей. В модели авторегрессии признак 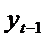 связан с
связан с 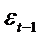 . Поэтому
применение обычного МНК для оценки параметров уравнения регрессии приводит к
получению смещенной оценки параметра при переменной
. Поэтому
применение обычного МНК для оценки параметров уравнения регрессии приводит к
получению смещенной оценки параметра при переменной 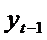 . Для оценки параметров уравнения может быть
использован метод инструментальных переменных. Суть его состоит в следующем.
. Для оценки параметров уравнения может быть
использован метод инструментальных переменных. Суть его состоит в следующем.
Переменную
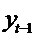 из правой части уравнения, для которой нарушается
предпосылка МНК, заменяют на новую переменную, удовлетворяющую следующим
требованиям:
из правой части уравнения, для которой нарушается
предпосылка МНК, заменяют на новую переменную, удовлетворяющую следующим
требованиям:
)
она должна тесно коррелировать с 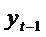 ;
;
)
она не должна коррелировать со случайной составляющей  .
.
Затем оценивать регрессию с новой инструментальной переменной с помощью
обычного МНК.
Рассмотрим
один из методов получения инструментальной переменной. Так как 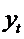 зависит от
зависит от 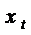 , можно
предположить, что
, можно
предположить, что  зависит также от
зависит также от 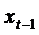 , то есть
, то есть
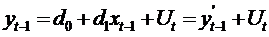 . Оценка
. Оценка 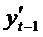 может
быть найдена с помощью обычного МНК. Новая переменная
может
быть найдена с помощью обычного МНК. Новая переменная 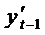 тесно коррелирует с
тесно коррелирует с 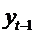 и не
коррелирует с
и не
коррелирует с 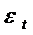 , то есть может служить инструментальной переменной.
, то есть может служить инструментальной переменной.
В
результате модель авторегрессии примет вид
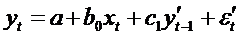
где
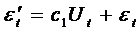 .
.
Оценки
параметров данной модели находят обычным МНК. Полученные оценки являются
искомыми оценками модели авторегрессии.
Замечание:
реализация метода инструментальных переменных осложняется появлением
мультиколлинеарности факторов в модели: функциональная связь 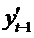 с
с 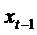 приводит
к высокой корреляционной связи между
приводит
к высокой корреляционной связи между 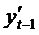 и
и 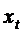 . В некоторых случаях эту проблему можно решить
включением в модель фактора времени t.
. В некоторых случаях эту проблему можно решить
включением в модель фактора времени t.
Модель
адаптивных ожиданий
Модель
адаптивных ожиданий учитывает желаемое (ожидаемое) значение факторного признака
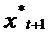 . Например, ожидаемое в будущем значение курса доллара
. Например, ожидаемое в будущем значение курса доллара
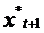 влияет на наши инвестиции в текущем периоде
влияет на наши инвестиции в текущем периоде 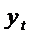 .
.
В
общем виде модель адаптивных ожиданий можно записать так:
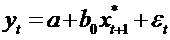 .
.
Механизм
формирования ожиданий в модели следующий
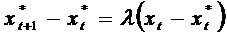 ,
,  или
или 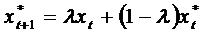
То
есть значение переменной, ожидаемой в следующий период 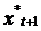 , формирующееся как среднее арифметическое взвешенное
ее реального и ожидаемого значений в текущем периоде. Чем больше величина
, формирующееся как среднее арифметическое взвешенное
ее реального и ожидаемого значений в текущем периоде. Чем больше величина 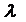 , тем быстрее ожидаемое значение адаптируется
предыдущим реальным значениям. Чем меньше
, тем быстрее ожидаемое значение адаптируется
предыдущим реальным значениям. Чем меньше 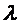 , тем
ожидаемое значение в будущем
, тем
ожидаемое значение в будущем 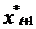 ближе к
ожидаемому значению предыдущего периода
ближе к
ожидаемому значению предыдущего периода 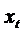 .
Использовать обычный МНК нельзя, так как модель содержит ожидаемое значение
факторной переменной. Для оценки параметров модель преобразовывают.
.
Использовать обычный МНК нельзя, так как модель содержит ожидаемое значение
факторной переменной. Для оценки параметров модель преобразовывают.
Подставим
в модель 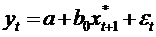 вместо
вместо 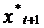
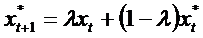 :
:
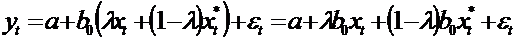 .
.
Аналогично,
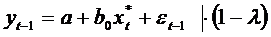
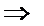
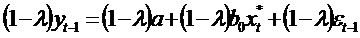 . Вычтем
почленно.
. Вычтем
почленно.
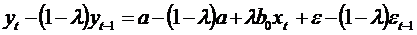 или
или
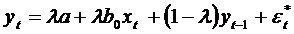
где
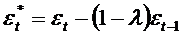 .
.
Полученная
модель включает только фактические значения переменных, поэтому ее параметры
можно определить обычным МНК, а затем перейти к исходной модели.
Модель
частичной корректировки
Модель
частичной корректировки учитывает желаемое (ожидаемое) значение результативного
признака 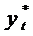 . В общем виде модель можно записать так
. В общем виде модель можно записать так
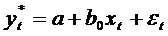 .
.
В
таких моделях предполагается, что фактическое приращение зависимой переменной 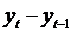 пропорционально разнице между ее желаемым уровнем и
фактическим значением в предыдущий период
пропорционально разнице между ее желаемым уровнем и
фактическим значением в предыдущий период 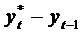 :
:
 ,
, 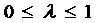 или
или
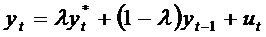
То
есть 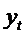 получается как среднее арифметическое взвешенное
желаемого уровня
получается как среднее арифметическое взвешенное
желаемого уровня 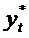 и фактического значения этой переменной в предыдущий
период
и фактического значения этой переменной в предыдущий
период 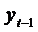 . Чем больше
. Чем больше 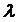 , тем
быстрее происходит процесс корректировки. Если
, тем
быстрее происходит процесс корректировки. Если 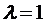 , то
, то 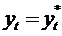 и полная корректировка происходит за 1 период.
и полная корректировка происходит за 1 период.
Если
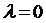 , то корректировки не происходит совсем.
, то корректировки не происходит совсем.
Аналогично
получим:
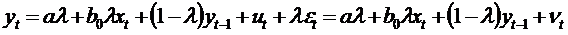 ,
, 
Параметры
преобразованного уравнения регрессии 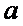 ,
, 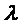 ,
, 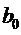 могут
быть оценены с помощью обычного МНК.
могут
быть оценены с помощью обычного МНК.
.
Полиномиально распределенные лаги Алмон
Лаги
Алмон используют для описания модели с распределенным лагом:
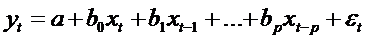 ,
,
имеющей
полиномиальную структуру лага и конечную величину лага р. Суть метода Алмон
состоит в следующем:
.
Формализуют зависимость коэффициентов 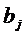 от
величины лага
от
величины лага 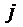 . Модель зависимости представляет собой полином:
. Модель зависимости представляет собой полином:
· 1й степени 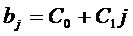 ;
;
· 2й степени 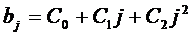
· 3й степени 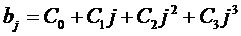
· k-степени 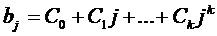
2.
Каждый коэффициент модели - 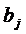 можно
выразить следующим образом:
можно
выразить следующим образом:
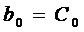
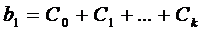
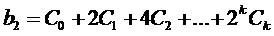
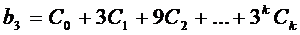 и
т.д.
и
т.д.
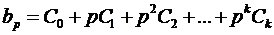
Подставим
эти соотношения для 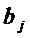 в модель и получим:
в модель и получим:
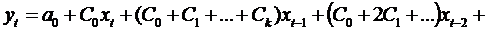
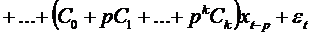 .
.
.
Перегруппируем слагаемые:
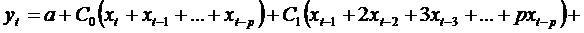
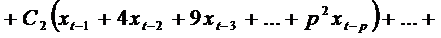
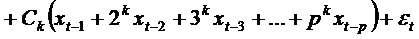 .
.
Обозначим
слагаемые в скобках при коэффициентах 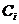 как
новые переменные
как
новые переменные
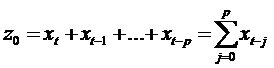
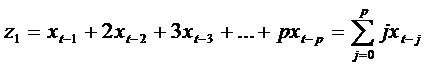
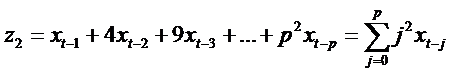
............................................................................

Модель
примет вид
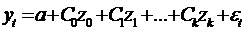
.
Определим параметры новой модели с помощью обычного МНК. Затем от параметров 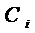 перейдем к параметрам
перейдем к параметрам 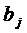 ,
используя соотношения на 1-ом шаге.
,
используя соотношения на 1-ом шаге.
Применение
метода сопряжено с рядом проблем:
а)
определение максимального лага с использованием показателей тесноты связи: 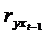 ,
,  , ...;
, ...;
б)
определение степени полинома (обычно 2, 3). Степень должна быть на 1 меньше
числа экстремумов в структуре лага;
в)
мультиколлинеарность.
Литература
1. Айвазян
С.А., Иванова С.С. Эконометрика. Краткий курс: учеб. пособие / С.А. Айвазян,
С.С. Иванова. - М.: Маркет ДС, 2007. - 104 с.
. Прикладная
статистика. Основы эконометрики: Учебник для вузов: В 2 т. 2-у изд., испр. - Т.
2: Айвазян С.А. Основы эконометрики. - М.: ЮНИТИ-ДАНА, 2009. - 432 с.
. Симчера
В.М. Методы многомерного анализа статистических данных: учеб. пособие. - М.:
Финансы и статистика, 2008. - 400 с.
. Чураков
Е.П. Прогнозирование эконометрических временных рядов: учеб. пособие / Е.П.
Чураков. - М.: Финансы и статистика, 2008. - 208 с.
.
Эконометрика: учеб. / под ред. д-ра экон. наук, проф. В.С. Мхитаряна. - М.:
Проспект, 2008. - 384 с.
.
Эконометрика: учеб. / под ред. И.И. Елисеевой М.: Проспект, 2009. - 288 с.
.
Эконометрика: Учебник/И.И. Елисеева, С.В. Курышева, Т.В. Костеева и др., Под
ред. И.И. Елисеевой. - 2-е изд., перераб. и доп. - М.: Финансы и статистика,
2006. - 576 с.