|
Название
ПО
|
Возможность
подсчёта символов
|
Возможность
построения графиков
|
Возможность
сохранения графиков
|
Возможность
нахождения локальных максимумов
|
Возможность
сравнения профилей методом ЭССТ
|
Удобный
пользовательский интерфейс для быстрого решения поставленных задач
|
Бесплатный
продукт
|
|
CounterOf
Characters
|
+
|
-
|
-
|
-
|
-
|
-
|
+
|
|
HOROS
|
+
|
-
|
-
|
+
|
+
|
-
|
+
|
|
Graph
|
-
|
+
|
+
|
+
|
-
|
-
|
+
|
|
Advanced
Grapher
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
|
Trans
Counter
|
+
|
-
|
-
|
-
|
-
|
+
|
+
|
|
Mathcad
|
+
|
+
|
+
|
+
|
-
|
-
|
-
|
|
SciDAVis
|
-
|
+
|
+
|
+
|
-
|
+
|
+
|
|
Veusz
|
-
|
+
|
+
|
+
|
-
|
-
|
+
|
|
Microsoft
Mathematics 4.0
|
+
|
+
|
+
|
+
|
-
|
-
|
+
|
|
ESCT
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
Для достижения цели дипломной работы было
разработано ПО «ESCT», которое позволяет представлять текстовые исторические
источники в форме математических профилей, сохранять профили в файл,
осуществлять построение графических отображений этих профилей с возможностью
сохранения в графический файл, а также производить сравнительный анализ по
эмпирико-статистическому методу сравнения текстов.
.1 Функциональность программного
обеспечения «ESCT»
ПО «ESCT» обеспечивает выполнение следующих
функций:
чтение текста из текстового файла.txt
возможность разбиения текста на главы путём
создания пользователем опорных точек
поиск по тексту по ключевому слову
сохранение название главы, позиции в тексте и
соответствующего количества символов, отведённых на данный участок текста
сохранение структуры профиля текста в файл
формата .xml
чтение всей коллекции профилей из файла формата
.xml
построение графика профиля
сохранение графика в форматах .png , .jpeg, .jpg
и .bmp
поиск локальных максимумов профиля
сравнительный анализ двух профилей и вывод
результата
«ESCT» отвечает всему комплексу требований и
выполняет все функции, необходимые для проверки эффективности и
работоспособности метода независимым экспертом, а также для дальнейшего
использования этого метода с целью корректирования существующей хронологической
шкалы. Все промежуточные результаты анализа содержатся в отчете для того, чтобы
любой посторонний наблюдатель мог удостовериться в корректности выполняемой
работе и в отсутствии фальсификаций. Также сохранение профиля в графическом
виде даёт возможность опубликования промежуточного результата в научных
статьях.
.2 Входные и выходные данные программного
обеспечения «ESCT»
Входными данными ПО «ESCT» являются:
.Исторический документ в текстовом формате.txt
.База профилей исторических источников в формате
.xml
Выходными данные ПО «ESCT» являются:
.База профилей исторических источников в формате
.xml
.Профиль исторического источника, представленный
в графическом виде в форматах .png, .jpeg, .bmp
.3 Выбор средств разработки
Для реализации ПО «ESCT» выбраны программная
платформа.Net Framework, язык программирования C# и среда разработки Visual
Studio 2010 Ultimate. для хранения информации выбран XML, для создания
справочной системы help - ПО Dr.Explain.
2.3.1 Выбор программной платформы
В качестве программной платформы была выбрана
платформа.Net Framework, являющаяся продуктом компании Microsoft.
Выбор был сделан вследствие того, что
разрабатываемое ПО будет использовано на операционной системе Windows. Один из
основных принципов платформы.NET - ориентирование на системы, работающие под
управлением семейства операционных систем Microsoft Windows [8].
Также разрабатываемое ПО использует удобный
компонент для рисования графиков под.NET Framework - ZedGraph.
Одной из главных причин является тот факт, что
платформа.NET облегчает разработку пользовательского интерфейса приложения за
счет библиотеки классов Windows Forms, делающих его использование более
простым.
.3.2 Выбор языка программирования
В качестве языка программирования был выбран
язык программирования C#.
Выбор обоснован тем, что язык специально был
разработан для платформы Microsoft.NET Framework, и это является его очевидным
преимуществом перед остальными языками программирования.
Также язык хорошо документирован, активно
поддерживается и обладает широкой сферой применения. C# имеет возможность
привлечения сторонних разработчиков при разработке системы для программирования
узкоспециализированных задач [5].
Таким образом, C# - очень простой, удобный и
современный язык, по эффективности не уступающий C++, но существенно повышающий
продуктивность разработок. Данный язык является хорошим выбором для быстрого
конструирования различных компонентов - от высокоуровневой бизнес логики до
системных приложений, использующих низкоуровневый код [1].
.3.3 Выбор среды разработки
В качестве среды разработки была выбрана
интегрированная среда разработки Microsoft Visual Studio 2010.
Среда обладает рядом преимуществ. Отладка
выполнена так, что окно "Потоки" предоставляет возможности
фильтрации, поиска и расширения стека вызовов, а также группирования. Кроме
того, можно упорядочивать точки остановок, выполнять по ним поиск и совместно
использовать их с другими разработчиками.
Редактор кода облегчает чтение кода. Можно
масштабировать текст, нажав клавишу CTRL и вращая колесо мыши. Кроме того, если
щелкнуть символ в Visual C# или Visual Basic, автоматически будут выделены все
экземпляры этого символа. Поиск по мере ввода [6].
Функция "Перейти к" предоставляет
поддержку поиска по мере ввода для файлов, типов и элементов. Эта функция
позволяет использовать преимущества "Верблюжьего Регистра" и знаков
подчеркивания для сокращения текста поиска.
Иерархия вызовов устроена таким образом, что в
Visual C# и Visual C++ позволяет переходить от элемента как к вызывающему его,
так и к вызываемым им элемента. Это удобно при просмотре
объектно-ориентированного кода.
Функции в интерфейсе IDE, такие как добавление
ссылки и панель элементов, соответствуют версии.NET Framework, на которую
ориентируется проект. В результате типы, элементы и элементы управления из
сборок, созданных для предыдущих версий платформы.NET Framework, не появляются в
IntelliSense и создают фоновые ошибки компиляции. Например, если проект
ориентируется на.NET Framework 2.0 и используется функция языка, которую.NET
Framework 2.0 не поддерживает, например анонимный тип, то интерфейс IDE будет
помечать этот код как ошибочный.
В Visual Basic или Visual C# интерфейс IDE
теперь может создавать заглушки кода для новых типов и членов, исходя из их
использования, прежде чем они будут определены. В результате можно сначала
писать тесты, а затем создавать код, необходимый для компиляции этих тестов.
Кроме того, теперь IntelliSense предоставляет режим предложений, который
предотвращает автоматическое заполнение типа или элемента, который еще не был
определен.
Новые функции в языке C# упрощают
программирование с помощью интерфейсов API системы Microsoft Office. При
наличии именованных и дополнительных аргументов больше не нужно указывать
значения для каждого дополнительного параметра при вызове методов модели COM.
При наличии динамической поддержки можно ссылаться на любой объект, например на
возвращаемые значения из интерфейсов API модели COM или из динамических языков,
без использования явного приведения типов. Индексированные свойства и
необязательные модификаторы ref облегчают доступ к интерфейсам модели COM.
Кроме того, поддержка эквивалентности типов упрощает развертывание путем
включения типов из основных сборок взаимодействия (PIA) непосредственно в
нужную сборку [2].
Создание и использование текстовых шаблонов
возможны в любой версии Visual Studio без потребности в других компонентах. С
введением предварительно преобразованных текстовых шаблонов в Visual Studio
2010 создание всех типов текстовых файлов в приложении стало удобнее. Была
оптимизирована и поддержка создания кода за счет улучшения интеграции с
системой построений, так что созданный код остаётся актуальным независимо от
изменений в исходной модели.
В интерфейсе IDE можно найти и установить
расширения Visual Studio. Диспетчер расширений загружает и устанавливает
расширения, опубликованные в сообществе, с ресурса Visual Studio без
необходимости открывать браузер. Он также позволяет удалять, отключать или
повторно включать установленные расширения [4].
.3.4 Выбор XML для хранения данных
В ранних версиях программы сохранение данных
выполнялось двумя способами: в базу данных SQL и в специализированном
формате.esc , однако на практике ни одно из преимуществ такого способа хранения
информации не было актуальным. Сохраняемый файл не требовал никакой защиты, не
превышал объёма, влияющего на скорость работы ПО, а также обладал довольно
простой внутренней структурой [26]. Помимо этого, одним из ключевых требований
заказчика была возможность удобного чтения файла профилей текстовым редактором
[28].
Поэтому для сохранения массива профилей текстов
был выбран язык XML. Этот выбор был обусловлен несколькими причинами:
. XML файлы имеют текстовой формат, который
удобно читать и отслеживать;
. Свободен от требований на порядок расположения
атрибутов в элементах;
. XML основан на стандартах международного
уровня;
. Файлы XML легко конвертировать в другие
форматы, которые в дальнейшем будут использоваться при составлении отчётов и
статей;
. XML поддерживает Юникод [16];
Таким образом, для реализации поставленной
задачи сохранение коллекции профилей в формате файла XML является оптимальным
решением.
.3.5 Выбор программного обеспечения
для создания справочной системы
Для создания справочной системы была выбрана
программа Dr.Explain. Данное ПО:
Позволяет быстро и качественно создавать файлы
справки в форматах .rtf, .html, .chm и .pdf.
Имеет специализированный текстовый редактор с
большим количеством функций, ориентированных на создание файлов справки и
документации для ПО [17].
Обладает возможностью добавлять функции поиска и
индексации в on-line справки без использования программирования (PHP, ASP, и
т.д.) или баз данных на стороне сервера.
Имеет редактор аннотаций изображений для
быстрого создания пояснительных выносок на технических иллюстрациях и снимках
экрана [15].
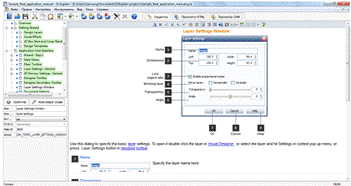
Рисунок 10 - Программа Dr.Explain
2.3.6 Выбор компонента ZedGraph для
построения графиков
Для построения и сохранения графиков был выбран
компонент ZedGraph.это библиотека классов и пользовательский элемент управления
под.NET Framework. Написан на языке C #, служит для рисования 2D графиков, линейных
и круговых диаграмм. Он имеет широкий спектр настроек, но большинство
параметров имеют значения по умолчанию для простоты использования [10].можно
адаптировать практически под любую задачу, связанную с построением,
масштабированием и сохранением графиков, благодаря наличию большого количества
методов, созданных для реализации огромного спектра задач.
Документация на русском языке практически
отсутствует, однако существует множество источников на иностранных языках, хотя
и в иностранных источниках редко появляется необходимость, потому что
функциональность и принцип работы большинства методов интуитивно понятен,
методы имеют характерное название и краткое описание в среде разработки.
Также необходимо отметить, что возможности
визуального отображения графиков практически ничем не ограничены. Есть
возможность изменять параметры точек, кривых, осей, названий, менять способ
отображения и настройки взаимодействия пользователя с панелями компонента.
На основании вышеперечисленных преимуществ,
ZedGraph был использован для построения и сохранения графиков в ПО «ESCT».
.4 Описание программных классов
программного обеспечения «ESCT»
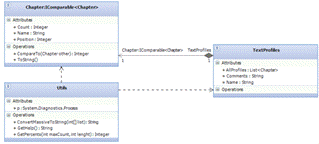
.4.1 Класс Chapter
Экземпляры класса Chapter служат для
представления глав текста, разделённого опорными точками.
Класс Chapter имеет следующие свойства:string
Name - имя главы, которое отображается в полях выбора опорных точек, а также на
графике профиля.int Position - позиция опорной точки, служащей конечной точкой
главы.int Count - количество символов текста, отведённое на данную главу.
Класс реализует интерфейс IComparable, поэтому у
него есть метод, который реализует сортировку экземпляров класса в коллекции по
возрастанию значения свойства Position.
Также класс имеет переопределённый метод
toString для отображения в списке опорных точек.
.4.2 Класс TextProfile
Класс служит для представления профиля текста и
имеет следующие свойства:string Name - имя профиля, которое отображается в
списке профилей, на графике профиля, а также в отчёте проведения анализа.string
PComment - комментарии, необходимые для того, чтобы пользователь мог отмечать,
какие участки вызвали у него затруднение и на что следует обратить внимание,
если результат анализа не будет однозначным.List<Chapter> AllProfiles -
коллекция всех опорных точек, на которые разделён текст. Необходима для
осуществления сравнения профилей.
.4.3 Класс Utils
Класс создан для реализации в нём
вспомогательных методов GetPercents, GetHelp и ConvertMassiveToString,
описанных в пункте Описание методов.
2.5 Структура XML документа,
содержащего базу данных профилей
Файл Profiles.XML содержит в себе коллекцию
объектов класса TextProfile, каждый из которых имеет следующую структуру:
В парном теге <Name> содержится имя
профиля, в <PComment> комментарии к профилю, в <AllProfiles>
содержатся все главы текста <Chapter>.
Каждая глава содержит теги <Name> - имя
главы, <Position> - позицию опорной точки и <Count> - количество
символов, отведённых на данную главу.
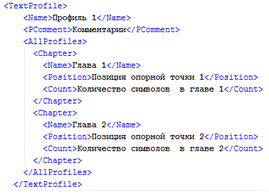
Рисунок 12 - структура профиля на XML
2.6 Описание процедур и функций
.6.1 Процедура openBase
Процедура openBase осуществляет загрузку всех
профилей в списки выбора профилей.
Сначала процедура создаёт объект reader -
экземпляр объекта System.Xml.Serialization.XmlSerializer, при помощи которого в
дальнейшем осуществляется чтение файла.
Далее создаётся поток для чтения файла формата
XML и записывает из него все находящиеся в нём экземпляры класса TextProfile в
коллекцию overview. Далее процедура закрывает файл, очищает поле отчёта
errorReport и записывает туда список всех загруженных профилей. Также список
всех профилей помещается в списки listProf и listProf.
Далее процедура помещает коллекцию overview в
startList, с которой далее будет происходить взаимодействие.
В случае неполадки, связанной с утерей или
некорректным форматом файла базы профилей, в поле отчёта выводится текст
возникшего исключения.
.6.2 Процедура addCh
Данная процедура осуществляет добавление опорной
точки в коллекцию опорных точек. Опорные точки необходимы, чтобы разделять
текст на главы.
Процедура создаёт экземпляр класса Chapter,
используя конструктор, помещает в него свойство Name из текстового поля
profileNameBox, при этом проверяя наличие на уже существующий объект с таким
именем. В случае конфликта имён, сообщение об ошибке выводится в поле отчёта.
Свойство Position класса Chapter устанавливается
из свойства SelectionStart текстового поля mainTextBox. Если значение свойства
Position численно равно значению другого экземпляра класса Chapter в коллекции,
то экземпляр не создаётся.
После занесения главы в коллекцию, коллекция
сортируется по возрастанию свойства Position при помощи метода Sort(). Это
необходимо для того, чтобы пользователь видел прямую последовательность глав
независимо от того, в каком порядке он ставил ту или иную опорную точку. Также
правильную последовательность в дальнейшем использует алгоритм нахождения
свойства Count. Значение является разностью настоящего значения Position с
соответствующим значением свойства предыдущего экземпляра.
Глава добавляется в список listProfiles при
помощи переопределённого метода toString класса Chapter.
.6.3 Процедура deleteCh
Процедура осуществляет удаление экземпляра
класса Chapter из общей коллекции экземпляров Chapters.
Процедура имеет входной параметр int index, в
котором передаётся порядковый номер элемента в списке, который нужно удалить.
Сначала создаётся временная коллекция tempList,
в которую поочерёдно помещаются все объекты из Chapters. Далее коллекция
Chapters очищается методом Clear, после чего в неё поочерёдно помещаются
экземпляры из коллекции tempList, за исключением того, чей порядковый номер
равен входному параметру index. Таким образом, в исходной коллекции остаются
все главы, кроме удалённой. Проводить сортировку коллекции не нужно, так как
порядок остаётся неизменным. При этом для каждого элемента новой коллекции
заново считается свойство Count, так как при удалении одной опорной точки,
фактически исчезает одна глава, размер следующей увеличивается на удалённую
величину.
Удаление элемента не осуществляется, если ни
один элемент не выбран.
.6.4 Процедура addProfile
Процедура создаёт профиль, помещает его в общую
коллекцию, добавляет в списки всех профилей и сохраняет в файл Profiles.XML.
В начале осуществляется проверка на совпадение
имени сохраняемого профиля с существующими именам в общей коллекции профилей.
Для этого используется логическая переменная dostup. Она принимает значение
true по умолчанию, и меняет его на false в случае совпадения имён.
Также осуществляется проверка на то, что поле
profileNameBox заполнено, а также что профиль содержит хотя бы одну главу. При
возникновении ошибок, соответствующее сообщение выводится в поле отчёта
errorReport.
Далее создаётся экземпляр toSave класса
TextProfile, который добавляется в общую коллекцию startList. Коллекция
сохраняется в файл Profiles.XML.
После этого в списки объектов ListBox listProf и
listProf1очищаются и заново заполняются всеми доступными профилями.
В случае возникновения ошибок записи, отчёт
помещается в текстовое поле отчёта errorReport.
.6.5 Процедура drawGraphic
Данная процедура осуществляет прорисовку графика
выбранного профиля, используя компонент ZedGraph.
Входные данные: объект GraphPane pane и int num.
В качество num передаётся значение выбранного
элемента списка профилей, в качестве pane - графическая панель того экземпляра
ZedGraph, в котором будет происходить построение графика.
Сначала панель очищается от ранее построенных
кривых методом Clear свойства CurveList. Это необходимо для того, чтобы новые
графики не строились на той же оси поверх предыдущего.
Свойствами XAxis.Title.Text и YAxis.Title.Text
объекта pane устанавливаются значения осей на ”Периоды” и ”Количество символов”
соответственно. Свойством Title.Text объекта pane устанавливается название
графика. Значение берётся из свойства Name объекта коллекции startList с
номером num.
Далее создается экземпляр объекта PointPairList
list, в который будут помещены точки графика. Для каждого элемента коллекции
глав, которая находится в свойстве AllProfiles объекта выбранной главы,
создаётся пара чисел x и y. x принимает значение c, которая изначально равна 0
,но возрастает в каждом цикле на 1, а y принимает значение свойства Count
выбранной главы. Таким образом, образуется коллекция точек, по которым в
дальнейшем строится график.
После этого процедура создаёт экземпляр объекта
LineItem myCurve и задаёт ему свойства отображения линий графика:- свойство
отображения точки;.Fill.Color - цвет заливки точки;.Fill.Type - FillType.Solid
- способ заливки точки;.Size - размер точки.
Это необходимо для того, чтобы пользователь
отчётливо видел опорные точки на графике в местах, в которых объёмы глав
примерно одинаковые.
Далее вызывается метод AxisChange, который
обновляет данные об осях.
На последнем этапе добавляются надписи названия
глав на оси X , для этого в цикле foreach для каждой главы создаётся экземпляр
объекта TextObj с текстом свойства Name текущей главы, и координатами (i,0)
,где i - счётчик цикла.
После того, как процедура отработала, для панели
вызывается метод Invalidate(), который обновляет панель и прорисовывает
созданные точки, соединённые кривыми.
.6.6 Процедура saveGraph
Процедура сохраняет график в графический файл
расширения .bmp, .jpeg или .png.
Входным параметром является панель GraphPane
pane того объекта ZedGraph, из панели которого необходимо сохранить график.
Сначала процедура создаёт диалоговое окно
SaveFileDialog dlg сохранения файла со свойство Filter которого принимает
значение "*.png|*.png|*.jpg; *.jpeg|*.jpg;*.jpeg|*.bmp|*.bmp|Все
файлы|*.*"
Методом GetImage объекта pane получается объект
Bitmap и помещается в переменную bmp. Далее для bmp вызывается метод Save с
двумя параметрами:
Свойство Filename объекта dlg, в котором
находится имя сохраняемого файла.
Свойства Png, Jpeg и Bmp объекта ImageFormat в
зависимости от выбора пользователя.
Если не был выбран пункт “Все файлы”, то
пользователь может ввести формат вручную, поэтому в таком случае метод Save
вызывается с единственным параметром dlg.FileName.
Если файл с названием сохраняемого файла уже существует,
пользователю предлагается заменить его.
Таким образом, осуществляется сохранение графика
в наиболее распространённых растровых графических форматах.
.6.7 Функция Analize
Функция осуществляет общий анализ профилей.
Находит все локальные максимумы профилей. Заполняет коллекции числовыми
разностями между локальными максимумами и передаёт их в функцию percentAnalize
для подсчёта процентного показателя взаимозависимости источников.
Сначала осуществляется проверка на корректность
выбора. Если не выбран ни один из профилей в обоих списках или в одном из
списков, а также если выбран один и тот же профиль в обоих списках. В этом
случае метод сообщит пользователю об ошибке, в которой будет сказано, что нужно
указать два разных профиля.
Далее функция создаёт временные объекты:
TextProfile pr1 =
startList[listProf.SelectedIndex];pr2 = startList[listProf2.SelectedIndex];
- профили текста, взятые из общей коллекции
профилей по индексу выбранных элементов listProf и listProf2 соответсвенно
List<Chapter> oper1 = pr1.AllProfiles;<Chapter>
oper2 = pr2.AllProfiles;
-временные коллекции всех глав, в которые
помещаются главы из выбранных профилей
List<int> opmas1 = new
List<int>();<int> opmas2 = new List<int>();
-коллекции, созданные для заполнения их
значениями локальных максимумов.
List<int> oplong1 = new
List<int>();<int> oplong2 = new List<int>();
-коллекции, созданные для заполнения их
значениями расстояний между локальными максимумами.s1 = "";s2 =
"";
строковые отображения коллекции расстояний между
локальными максимумами, которые в дальнейшем будут передаваться функции
percentAnalize в качестве входных параметров.
В поле отчёта помещается значение имени первого
профиля. После этого для каждой главы находится локальные максимумы по условию:
где a - значение текущего элемента коллекции,
a-1 и a+1 - значения предыдущего и последующего элемента соответственно.
Все эти числовые значения записываются в
коллекцию opmas1, а также в текстовое поле отчёта.
После этого осуществляется подсчёт расстояний
между локальными максимумами. Для этого из значения каждого максимума
вычитается значение предыдущего. Все расстояния заносятся в коллекцию
расстояний oplong1, а также в текстовое поле отчёта.
Далее строка s1 принимает значение коллекции
расстояний oplong1 в виде строки в форме чисел через точку, например,
”3.2.4.5.9.6.5.5.11.4”. Точки необходимы для разделения двухзначных чисел. На
практике такие числа появляются крайне редко, однако это может привести к
серьёзной ошибке, которая повлияет на результат анализа.
Все проделанные выше операции повторяются для
второго профиля с соответствующими объектами oper2, opmas2, oplong2 и s2.
Функция сравнивает коллекции расстояний по
количеству элементов. Это необходимо для того, чтобы передать в функцию
percentAnalize сначала строку, полученную из коллекции с большим количеством
символов, а затем с меньшим. Если количество элементов в обеих коллекциях
одинаковое, то порядок не имеет значения.
Последним этапом функция вызывает percentAnalize
с параметрами s1 и s2.
2.6.8 Процедура FindText
Осуществляет поиск слова или фразы в тексте
источника. Необходим в случае, если пользователь устанавливает опорные точки,
которые ранее были обозначены у него в бумажном варианте источника.
Входными данными являются строки part и text.
Для строки text применяется метод indexOf с
параметром part. Данная процедура возвращает число, которое помещается в
переменную index. Если index получает значение -1, то фрагмент в тексте не
встречается, и соответствующее сообщение выводится в поле отчёта. В противном
случае свойствам текстового поля SelectionStart и SelectionLength
устанавливаются значения index и part.Lenght соответственно, а также для него
вызывается метод Focus, чтобы перевести фокус на текстовое поле. Таким образом,
искомый участок текста находится и выделяется.
.6.9 Функция percentAnalize
Функция принимает коллекции глав двух профилей
oplong1 и oplong2, и строковые представления этих коллекций smalls и bigS
соответственно, и возвращает числовое значение maxCount от 0 до 100, характеризующее
процент взаимозависимости текстов, на основе которых были составлены эти
профили.
Если значение равно 100%, это означает что все
расстояния между локальными максимумами одинаковые и можно сделать вывод, что
профили полностью взаимозависимы.
Совпадение на 40-99% означает, что вероятность
взаимозависимости текстов, чьи профили подлежали анализу, очень велика, но в
силу тех или иных обстоятельств не все максимумы коррелировали. Это может быть
вызвано, в частности тем, что пользователь мог неправильно установить опорные
точки, тем самым некорректно разбить текст на главы. Ошибки эти иногда вызваны
субъективным характером разбиения на главы, так как в тексте не всегда явно
указано, в каком году было описано событие. Также причиной может быть то, что используется
не первоисточник, а более поздняя редакция, в которую были внесены изменения из
других источников. Тогда некоторые события получат более детальную окраску,
поэтому график профиля этого текста будет иметь другой вид.
Совпадения 40% и ниже можно считать
незначительными, и практически однозначно сделать вывод о том, что тексты
описывают разные исторические события. Сначала функция проверяет профили на
полное соответствие, для этого осуществляется поиск подстроки smallS в строке
bigS. В случае совпадения, функция возвращает значение 100. Далее функция
последовательно по убывающей начинает проверять, не содержится ли часть
расстояний между локальными максимумами одного профиля в другом профиле. Таким
образом, метод находит наибольшее количество совпадений расстояний между
локальными максимумами. Затем при помощи метода GetPercents переводит
полученный результат в проценты и помещает в переменную maxCount , которая
является выходным параметром функции.
.7 Описание методов.
.7.1 Метод ConvertMassiveToString
Метод, созданный для приведения массива int[] к
типу string таким образом, чтобы с ним мог корректно работать метод
percentAnalize.
Метод получает в качестве входного параметра
массив int[] и возвращает преобразованную строку.
.7.2 Метод GetPercents
Метод принимает значение количества
коррелирующих локальных максимумов и общего количества локальных максимумов int
maxCount и int lenght соответственно и возвращает результат в процентах.
2.7.3 Метод GetHelp
Открывает файл подсказки “help.chm”. Возвращает
сообщение об удачном открытии файла подсказки или сообщение об ошибке, если
файл уже открыт. Метод создаёт экземпляр System.Diagnostics.Process ,
проверяет, открыт ли файл с помощью метода HasExited, и в случае возврата
значения false , отправляет сообщение о том, что файл уже открыт, если только
файл подсказки не открыт впервые. Таким образом, пользователь не может открыть
несколько файлов помощи одновременно.
2.8 Порядок использования
программного обеспечения «ESCT»
Пользователь загружает исторический источник в
формате.txt в рабочую область, нажав кнопку ”Открыть текстовой файл”. После
загрузки в рабочей области отображается текст источника. Далее пользователь
начинает делить его на дискретные участки в зависимости от характера и объёма
текста, используя функциональность добавления опорных точек. Для каждой главы
пользователь задаёт имя и указывает позицию в тексте, которая разделяет текст
на участки. После того, как пользователь разделил текст на главы, он сохраняет
профиль в базу, предварительно указав имя профиля и при необходимости добавив
комментарии к тексту. Далее процесс работы происходит с профилями текстов.
Пользователь выбирает два профиля из коллекции профилей, и осуществляет
сравнение вышеописанным методом, нажав кнопку ”Провести анализ текстов”. В поле
отчёта записывается результат сравнения с указанием всех локальных максимумов,
расстояний и информация о взаимозависимости текстов, выраженная в процентах.
Эту информацию пользователь использует для написания отчётов или статей.
При необходимости, пользователь сохраняет
графики исследуемых профилей и добавляет их в отчёт в качестве иллюстраций.
2.9 Описание пользовательского
интерфейса программного обеспечения «ESCT»
.9.1 Общая информация
Пользовательский интерфейс осуществлён учитывая
все необходимые условия для работы с текстами по методу
эмпирико-статистического сравнения текстов. Он оформлен таким образом, чтобы
пользователю было удобно работать сразу с несколькими профилями, осуществляя
последовательный анализ одного профиля за другим.
Условно можно разделить его на две части:
а) участок для работы с главами,
б) участок для работы с профилями.
Однако, для полноценной работы необходимо, чтобы
оба участка находились на одной форме WindowsForms. Элементы расположены в том
порядке, в котором производится работа.
программный обеспечение text
comparison
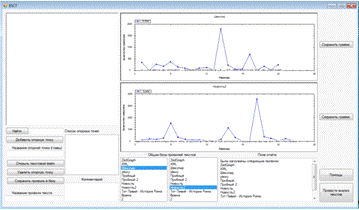
Рисунок 13 - Общий вид интерфейса «ESCT»
2.9.2 Участок работы с главами
Данный участок предназначен для разбиения текста
на главы, путём создания опорных точек, а также для сохранения профиля в общую
базу профилей.
Участок содержит следующие элементы:
Текстовое поле mainTextBox - экземпляр объекта
TextBox , служит для отображения тектса источника.
Кнопка поиска findButton - экземпляр объекта
Button, осуществляет поиск по ключевому слову в тексте поля mainTextBox
Текстовое поле findTextBox - экземпляр объекта
TextBox, создано для записи ключевого слова поиска.
Кнопка addButton - экземпляр объекта Button, по
нажатию осуществляется добавление новой опорной точки при выполнению описанных
условий.
Текстовое поле addTextBox - экземпляр объекта
TextBox , в которое записывается название добавляемой опорной точки.
Кнопка openButton - экземпляр объекта Button, по
нажатию открывается диалоговое окно открытия текстового файла, загружаемого в
mainTextBox
Кнопка removeButton - экземпляр объекта Button,
удаляет из списка выбранную опорную точку.
Кнопка saveButton - экземпляр объекта Button,
служит для сохранения профиля в общую базу профилей, находящуюся в XML-файле
при выполнении заданных условий. Текстовое поле profileNameBox - экземпляр
объекта TextBox, создано для записи имени сохраняемого в базу профиля.
Список listProfiles - экземпляр объекта ListBox,
служит для отображения всех опорных точек создаваемого профиля.
Текстовое поле comments - экземпляр объекта
TextBox , в которое записываются комментарии к профилю.
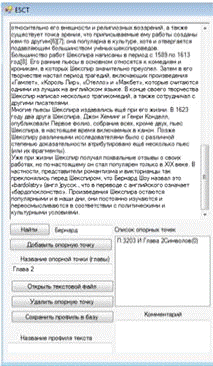
Рисунок 14 - Общий вид участка работы с главами
2.10 Описание работы элементов
участка работы с главами
.10.1 Текстовое поле mainTextBox
Поле создано для отображения текста
исторического источника и для дальнейшей работы с ним.
Текст можно открыть при помощи кнопки openButton
и выбора текстового файла, находящегося на компьютере, а также вставить из
буфера обмена.
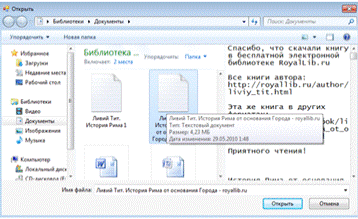
Рисунок 15 - Открытие текстового файла
2.10.2 Текстовое поле findTextBox и
кнопка findButton
Служит для поиска в тексте по ключевым словам.
При написании имени и нажатии кнопки Найти, находит и выделяет искомый участок
в тексте.

Рисунок 16 - Поиск в тексте по ключевым словам
2.10.3 Кнопка addButton, Текстовое
поле addTextBox
При написании имени опорной точки в поле
addTextBox и последующем нажатии кнопки addButton, создаётся новый экземпляр
опорной точки. Точка создаётся в том случае, если указано место в тексте, и
название точки, которое не совпадает с названием существующих точек.
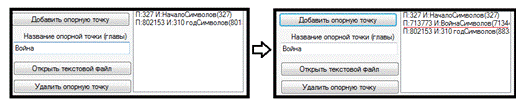
Рисунок 17 - Добавление опорной точки
При добавлении новой опорной точки автоматически
пересчитывается количество символов в каждой главе и список сортируется. Это
позволяет добавлять опорные точки в произвольном порядке, что значительно
облегчает процесс работы.
.10.4 Кнопка removeButton
При нажатии осуществляется удаление выбранной
опорной точки. При этом, как и в случае с добавлением, во всех точках коллекции
автоматически пересчитывается количество символов в каждой главе и список
сортируется.
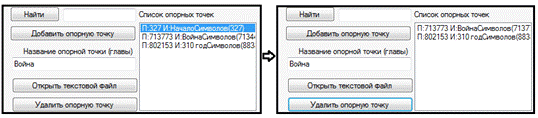
Рисунок 18 - Удаление опорной точки
.10.5 Кнопка saveButton, текстовые
поля comments и profileNameBox
Когда все опорные точки заполнены, профиль можно
сохранить в базу профилей. Для этого, необходимо указать его имя, а также
профиль должен содержать хотя бы одну опорную точку.
Если все условия выполнятся, профиль будет
успешно сохранён и сразу же отражён в списках выбора профилей listProf и
listProf1.
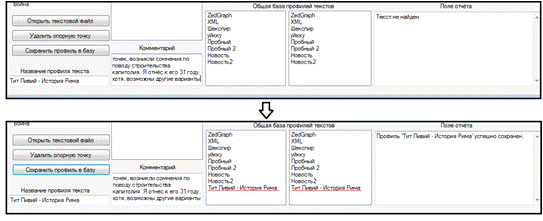
Рисунок 19 - Успешное сохранение профиля в базу
При возникновении конфликта имён или других
ошибках, соответствующие сообщения об ошибках будут описаны в поле отчёта.

Рисунок 20 - Сообщения об ошибках (а -
совпадение имён, б - нет опорных точек, в - поле имени не заполнено)
2.11 Участок работы с профилями
Данный участок пользовательского интерфейса
предназначен для выбора профилей из существующей базы профилей, построения
графиков, сохранение графиков в форматах .png, .jpg и .bmp, для проведения
анализа методом эмпирико-статистического сравнения текстов по принципу
корреляции локальных максимумов.
Участок содержит следующие элементы:
Два экземпляра панели объекта ZedGraph
graphControl и graphControl1, необходимые для построения графиков
Два элемента Button savePane1 и savePane2 ,
служат для сохранения графиков из соответствующих панелей graphControl и
graphControl1
Два экземпляра объекта ListBox listProf и
listProf2, необходимые для отображения общего списка профилей, находящихся в
базе.
Экземпляр объекта TextBox errorReport, в который
записываются сообщения об ошибках и результат анализа текстов.
Экземпляр объекта Button AnalysisButton, при
нажатии на который осуществляется анализ текста вышеописанным методом.
Экземпляр объекта Button helpButton, при нажатии
на который открывается файл подсказки help.chm
Поля listProf и listProf2 , а также поле отчёт
errorReport нужны и при работе с опорными точками. В ранних версиях программы
участки находились в разных формах, что затрудняло процесс работы. Поэтому в
ходе разработки программы оба участка были объединены в одну форму.
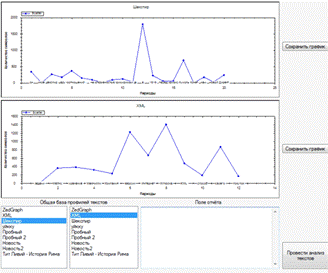
Рисунок 21 - Общий вид участка работы с
профилями
2.12 Описание работы элементов
участка работы с профилями
.12.1 Панели построения графиков
graphControl и graphControl
На панелях осуществляется прорисовка графиков
выбранных профилей, а также отображается название профиля и подпись всех
опорных точек, по которым строился график. График автоматически масштабируется,
исходя из количества максимальных значений на осях.
.12.2 Кнопки сохранения графиков
savePane1 и savePane2
По нажатию на кнопку ”Сохранит график”,
вызывается метод saveGraph, который открывает диалоговое окно сохранения файла
и осуществляет сохранение графика в виде изображения.
Рисунок 22 - Сохранение графика в файл
При возникновении конфликта имён, пользователю
предлагается заменить существующий файл.
Рисунок 23 - Замена существующего файла
Пользователю предоставляется возможность
сохранения файлов в трёх наиболее распространённых растровых графических
форматах для дальнейшего использования их пользователем в статьях в качестве
демонстрации.
2.12.3 Списки профилей listProf и
listProf2
Cписки служат для отображения всех профилей,
сохранённых в базе, для выбора профилей, построения графиков, а также для
проведения анализа.
При выборе одного из элементов списка, в
соответствующей панели объекта ZedGraph, выполняется метод drawGraph, тем самым
осуществляется построение графика выбранного профиля.
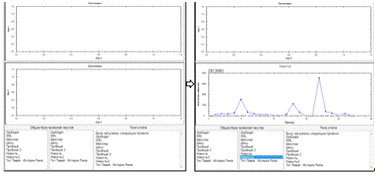
Рисунок 24 - Построение графика при выборе
профиля из списка
.12.4 Кнопка проведения анализа
AnalysisButton
При нажатии на кнопку запускается метод Analize,
в том случае если все условия были выполнены, то есть были выбраны два разных
профиля из списков listProf и listProf2.
В противном случае, пользователю сообщается об
ошибке.
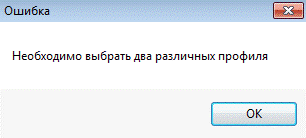
Рисунок 25 - Ошибка, возникающая при нарушении
условий
2.12.5 Текстовое поле errorReport
Поле служит для отображения сообщений об
ошибках, успешном выполнении действий, а также для вывода результатов.
Рисунок 26 - Отчет о загрузке профилей из базы.
При проведении анализа, в отчёт помещаются
следующие данные:
Название обоих сравниваемых профилей.
Названия всех опорных точек, в которых находятся
локальные максимумы.
Значения всех локальных максимумов.
Отрезок профиля, на котором локальные максимумы
коррелируют.
Значение взаимозависимости текстов, выраженное в
процентах.
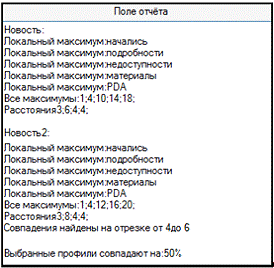
Рисунок 27 - Отчёт о проведении анализа
сравнения
Данные могут быть использованы в качестве
доказательства или опровержения работоспособности метода при публикации отчёта
о проделанном испытании метода.
.13 Описание справочной системы
пользователя
Для удобства использования «ESCT» была создана
справочная система пользователя help.chm, которая была выполнена при помощи
программы Dr.Explain.
Рисунок 28 - Общий вид справочной системы «ESCT»
Содержание справочной системы:
. Введение.
. Работа с текстом.
.1 Загрузка текста.
.2 Добавление опорных точек.
.3 Удаление опорных точки.
. Работа с профилями.
.1 Сохранение графиков.
.2 Сохранение профиля.
.3 Проведения анализа.
. Ошибки при работе с ПО.
Каждая страница содержит необходимую информацию
для работы с ПО «ESCT» и графические изображения элементов пользовательского
интерфейса с указателем на тот элемент, который необходим для текущей операции.
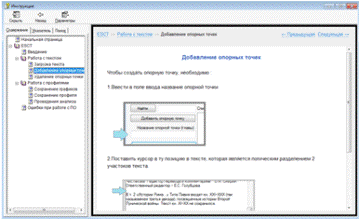
Рисунок 29 - Страница справочной системы
«Добавление опорных точек»
Также справочная система содержит встроенную
поисковую систему, которая осуществляет поиск по ключевому слову и отображает
все страницы, содержащие искомую информацию.
Рисунок 30 - Встроенная поисковая система
справочной системы
ГЛАВА 3. ТЕСТИРОВАНИЕ И ВНЕДРЕНИЕ
ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ «ESCT»В ОПЫТНУЮ ЭКСПЛУАТАЦИЮ
Для тестирования ПО «ESCT» проведено:
Сравнение результатов анализа текста при помощи
ПО «ESCT» и результата анализа, проведённого А.Т.Фоменко.
Сравнение результатов анализа зависимости двух
исторических источников при помощи ПО «ESCT» с результатом анализа сравнения
этих источников, проведённого А.Т.Фоменко.
На основе полученных результатов можно
установить, правильно ли выполняется алгоритм сравнения текстов методом
эмпирико-статистического анализа текстов.
Если в обоих случаях результат будет совпадать с
результатом, полученным автором метода, значит ПО работает корректно и его
можно вводить в опытную эксплуатацию.
Также, дальнейший анализ подтвердит корректность
работы метода, если результатом анализа будет корреляция максимумов заведомо
зависимых текстов и противоположный результат для заведомо независимых
источников.
.1 Сравнение результатов анализа
текста при помощи программного обеспечения «ESCT» с результатом анализа,
проведённого А.Т. Фоменко
Для проведения анализа была выбрана историческая
летопись “Повесть временных лет”. Общее количество символов - 364486.
Дискретным расстоянием был выбран временной отрезок в 5 лет.
Для сравнения был выбран участок текста,
описывающий события от 850 года до 1110 года.

Рисунок 31 - График профиля текста ”Повесть
временных лет”, полученный А.Т. Фоменко
Результаты анализа “Повесть временных лет”,
проведённого А.Т. Фоменко был взят из книги “ Истину можно вычислить.
Хронология глазами математики” [11].
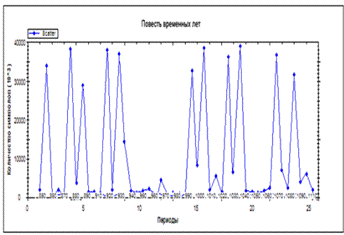
Рисунок 32 - график профиля текста ”Повесть
временных лет”, полученный при помощи «ESCT»
Результат анализа показал наличие следующих
локальных максимумов:
Таблица 3 - Сравнение локальных максимумов,
полученных при помощи ПО «ESCT» со значениями локальных максимумов, полученными
автором метода [15]
|
Локальные
максимумы, полученные А.Т. Фоменко
|
Локальные
максимумы, полученные при помощи ПО ESCT
|
|
855
|
855
|
|
865
|
865
|
|
875
|
875
|
|
885
|
885
|
|
915
|
915
|
|
930
|
930
|
|
955
|
955
|
|
995
|
995
|
|
1005
|
1005
|
|
1015
|
1015
|
|
1025
|
1025
|
|
1035
|
1035
|
|
1070
|
1070
|
|
1085
|
1085
|
|
1095
|
1095
|
Таким образом, все локальные максимумы,
полученные при помощи ПО «ESCT», совпадают с данными, полученными автором
метода.
На этом основании можно сделать вывод, что при
помощи ПО «ESCT» было корректно осуществлен поиск локальных максимумов и
построение графика исследуемого профиля.
3.2 Сравнение результатов анализа
зависимости двух исторических источников при помощи программного обеспечения
«ESCT» с результатом анализа сравнения этих источников, проведённого А.Т.
Фоменко
Для сравнения текстов были выбраны исторические
источники:
. Т. Ливий. - История Рима от основания города
[7].
. Ф. Грегоровиуса - История города Рима в
средние века [1].
Анализ, проведённый при помощи ПО «ESCT», показал
взаимозависимость этих исторических источников.
Дискретным расстоянием был выбран временной
отрезок в 5 лет.
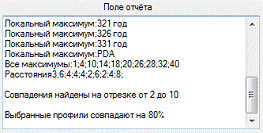
Рисунок 33 - Результат сравнения текстов Т.
Ливия и Ф. Григоровиуса при помощи «ESCT»
Анализ, проведённый А.Т. Фоменко, показал
аналогичный результат:
Проведённый анализ древних текстов показал, что
тексты, по-видимому, описывают одни и те же события, несмотря на существующий
сдвиг в традиционной хронологической шкале между этими событиями. Сдвиг
составляет порядка 1123 лет [11].
В этом случае также можно сделать вывод, что при
помощи ПО «ESCT» было корректно осуществлен поиск локальных максимумов и
построение графика исследуемого профиля.
3.3 Введение программного
обеспечения «ESCT» в опытную эксплуатацию
Заказчиком ПО является крупное закрытое
интернет-сообщество под названием «Общество скептиков», в которую входят
представители различных областей науки. Группа занимается проверкой
существующих научных и лженаучных теорий и методов. Результаты анализа публикуются
на различных Интернет-ресурсах.
Независимая проверка работоспособности метода
эмпирико-статистического сравнения текстов требует анализа большого количества
исторических источников: не менее 30-ти на каждый из двух групп текстов:
.Заведомо независимые источники.
.Заведомо зависимые источники.
В случае, если метод докажет свою
работоспособность на этих источниках, методом можно будет проводить анализ
источников, взаимозависимость которых не установлена.
При таком большом количестве материала, работая
без специального ПО, этот процесс может занять несколько месяцев или даже лет,
так как выполнение анализа первого профиля заняло 11 дней.
Хранение информации не было структурировано.
Текст был разделён на разные текстовые документы. Приходилось использовать
несколько программ, каждая из которых выполняла лишь маленькую часть задач.
Процесс оказался очень трудоёмким и занимал
много времени, вследствие чего появилась необходимость в разработке
программного обеспечения, адаптированного под поставленные задачи.
.4 Результаты использования
программного обеспечения «ESCT»
После введения ПО «ESCT» в опытную эксплуатацию,
заказчиком был выполнен анализ 7-ми исторических источников:
. Т. Ливий. - История Рима от основания города;
. Ф. Грегоровиуса - История города Рима в
средние века;
. Симеоновская летопись;
. Троицкая летопись;
. Пополь-Вух;
. Белорусско-литовская летопись;
. Степенная книга.
До применения ПО среднее время обработки текста
и составления профиля составляло около 5-9 дней (в зависимости от объёма и
сложности прочтения и установления точек разделения глав). Используя ПО «ESCT»,
за период в 29 дней был осуществлён анализ 7-ми исторических источников. То
есть, в среднем 2-3 дней на составление профиля.
Заметно был упрощён процесс работы с профилями и
процесс хранения общей базы профилей. Данные из XML файла легко конвертируются
в файлы необходимых форматов, сохраняются графики, на основе которых в
дальнейшем осуществляется публикация работы.
Таким образом, применение разработанного ПО
значительно ускорило и облегчило процесс анализа.
ЗАКЛЮЧЕНИЕ
В рамках дипломной работы были проанализированы
существующие программные решения на предмет наличия возможности проведения
независимой проверки эффективности эмпирико-статистического метода сравнения
текстов, а также выявлены их достоинства и недостатки.
На основании этого анализа была поставлена
задача реализации программного обеспечения, способного включить в себя все
необходимые функции, при помощи которых можно будет существенно ускорить и
упростить процесс проведения независимой проверки метода.
Разработаны и реализованы соответствующие
программные модули и интерфейс ПО «ESTC». Также были исследованы
эксплуатационные возможности разработанного ПО.
Вывод: В ходе выполнения выпускной
квалификационной работы была достигнута поставленная цель, а именно разработано
программное обеспечение для эмпирико-статистического сравнения текстов по
принципу корреляции локальных максимумов.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
1. Грегоровиус
Ф. История города Рима в Средние века (от V до XVI столетия) / Перевод с
немецкого М. Литвинова, В. Линде, В. Савина. - М.: Издательство АЛЬФА-КНИГА,
2008. - 1280 с.
2. Макки
Алекс Введение в.NET 4.0 и Visual Studio 2010 для профессионалов, Вильямс ISBN:
978-5-8459-1639-6, 2010. - 416с.
. Носовский
Г.В. Математико-статистические модели распределения информации в исторических
хрониках. Математические вопросы кибернетики/ Фоменко А.Т. - М., Наука,
физматлит. 1966, вып.6, с. 71-116.
. Нестор
Летописец - Повесть временных лет. Лаврентьевский список, исторический
источник.
. Павловская
Т.А. - C#. Программирование на языке высокого уровня, СПб.: Питер, 2009. - 432
с.
. Рихтер
Д.
- CLR via C#. Программирование на платформе Microsoft.NET
Framework 4.0 на языке C#, СПб Питер, - 928 с.
. Тит
Ливий - История Рима от основания города. Том I. Изд-во «Наука» М., 1989,
Перевод В.М. Смирина. Комментарий Н.Е. Боданской.
. Троелсен
Э. - С# 2008 и платформа.NET 3.5 Framework = Pro C# 2008 and the.NET 3.5
Framework. - 4-е изд. - М.: Вильямс, 2009. - С. 1368. - ISBN 978-5-8459-1589-4.
. Фоменко
А.Т. Методы статистического анализа нарративных текстов и приложения к
хронологии. (Распознавание и датировка зависимых текстов, статистическая
древняя хронология, статистика древних астрономических сообщений). - Москва,
изд-во МГУ, 1990. - 439 с.
. Фоменко
А.Т. Методика статистической обработки параллелей хронографических текстах и
глобальная хронологическая карта. - Исследование операций и АСУ. - Киев, изд-во
Киевского ун-та, 1983, вып.22, с.29-40. Объем 1 п.л.
. Фоменко
А.Т. Истину можно вычислить. Хронология глазами математики, Москва. АСТ,
Астрель, 2007, 475с.
. Фоменко
А.Т. Методы математического анализа исторических текстов: приложения к
хронологии: распознавание и датировка зависимых текстов, статистическая древняя
хронология, статистика древних астрономических сообщений, Наука, 1996, 475 с.
. Фоменко
А.Т. Новые методики хронологически правильного упорядочивания текстов и
приложения к задачам датировки древних событий - Исследование операций и АСУ.
Киев, изд-во Киевского ун-та, 1983, вып.21, с.40-59. Объем 1,5 п.л.
. Фоменко
А.Т. Методы статистического анализа исторических текстов, часть 1. Москва,
1999. - 446 с.
. Фоменко
А.Т. Числа против лжи (Математическое расследование прошлого). Критика
хронологии Скаллигера. Сдвиг дат и сокращение истории. Новая хронология,Том I,
АСТ, 2011. - 720 с.
. Фоменко
А.Т. Новая эмпирико-статистическая методика упорядочения текстов и приложения к
задачам датировки. - Доклады АН СССР, 1983, т.268, No.6, с.1322-1327. Объем 0,5
п.л.
17. Сайт
ИТ-группа «Два капитана» [Электронный ресурс] <http://grmm.ru/> (Дата
обращения: 14.03.2013).
. Сайт
«Новая Хронология» [Электронный ресурс] <http://chronologia.org/> (Дата
обращения: 12.03.2013).
. Сайт
«Alentum Software Ltd» [Электронный ресурс] <http://alentum.com> (Дата
обращения: 12.03.2013).
. Сайт
«Englishelp.ru» [Электронный ресурс] <http://englishelp.ru> (Дата
обращения: 14.03.2013).
. Сайт
«PRC Products» [Электронный ресурс] <http://ptc.com> (Дата обращения:
11.03.2013).
. Сайт
«SciDAVis» [Электронный ресурс] <http://scidavis.sourceforge.net/> (Дата
обращения: 14.03.2013).
. Сайт
«GNA Products» [Электронный ресурс] <http://home.gna.org> (Дата
обращения: 28.03.2013).
. Сайт
«Microsoft» [Электронный ресурс] <http://microsoft.com> (Дата обращения:
02.03.2013).
. Сайт
«Graphviz - Graph Visualization Software» [Электронный ресурс]
<http://graphviz.org/> (Дата обращения: 22.03.2013).
. Сайт
«Википедия» [Электронный ресурс] <http://ru.wikipedia.org> (Дата
обращения: 23.03.2013).
. Сайт
«DrexPlain» [Электронный ресурс] <http://drexplain.ru> (Дата обращения:
04.03.2013).
. Сайт
«XMLCON Products» [Электронный ресурс] <http://xmlcon.ru> (Дата
обращения: 12.03.2013).
. Сайт
«SForge» [Электронный ресурс] ресурсу <http://sourceforge.net> (Дата
обращения: 22.02.2013).
. Сайт
«Полезный Soft» [Электронный ресурс] <http://softsoft.ru> (Дата
обращения: 16.03.2013).